
Введение
Я уже много раз использовал внешние скрипты и UserParameter для мониторинга в zabbix. Не буду подробно на этом останавливаться. Приведу список своих материалов по этой теме:
- Мониторинг информации из текстовых файлов
- Следим за временем делегирования домена в zabbix
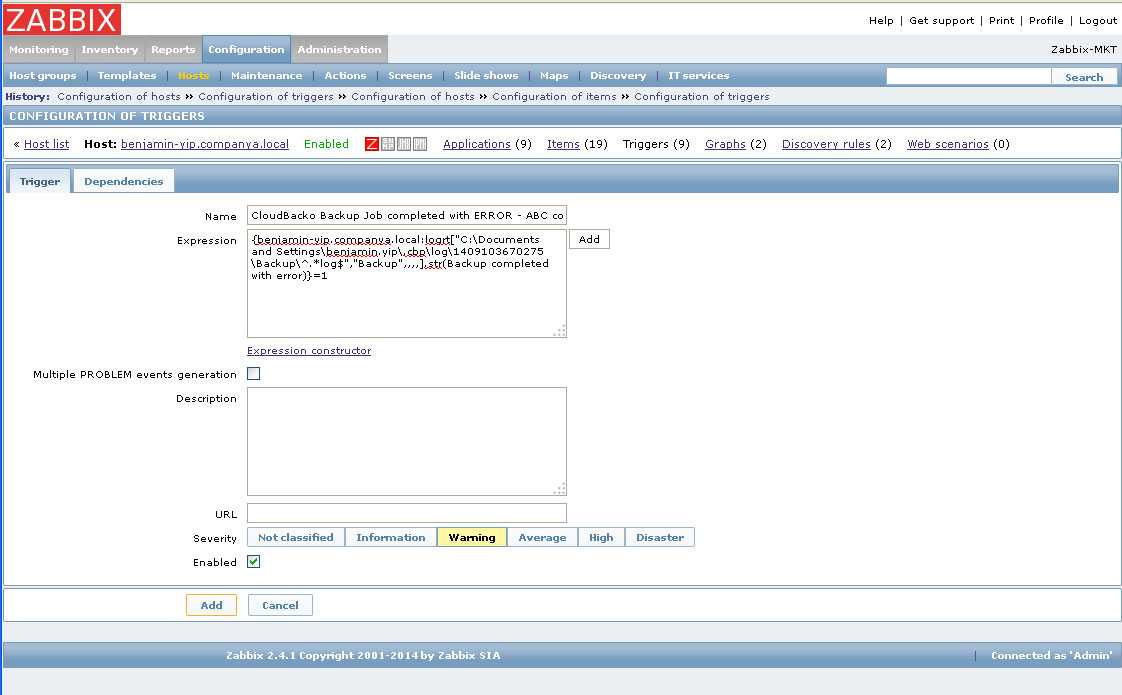
- Мониторинг бэкапов
- Статус транков в астериск
- Мониторинг рейда mdadm
- Наблюдение за mysql репликацией с помощью заббикс
- Состояние веб сервера nginx и php-fpm
- Мониторинг температуры windows сервера
Использовать будем такой же подход. У нас будет 2 скрипта. Первый будет собирать информацию о размерах папок с файлами, второй будет передавать сформированные данные в заббикс. Делать все будем раз в сутки, чаще нет смысла, так как у меня бэкапы выполняются с суточным интервалом. Сами бэкапы представляют из себя не отдельные файлы-архивы, а папки. Настроено все примерно так же, как в статье про настройку backup с помощью rsync.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Введение
Все будет сделано очень просто. Я буду мониторить системный log файл, который содержит информацию о ssh подключениях. В rpm дистрибутивах, в частности, в Centos это /var/log/secure. В deb дистрибутивах Debian/Ubuntu это /var/log/auth.log.
Вначале у меня была идея хранить полностью этот лог в zabbix для разбора каких-то инцидентов на сервере. Это может быть актуально, если у вас нет централизованного сбора логов в каком-то отдельном месте. Потом передумал, так как если у вас используется стандартный ssh порт 22, то лог подключений по ssh будет огромного размера. Хранить его полностью в zabbix — забивать понапрасну базу данных. В итоге решил хранить только информацию об успешных авторизациях.
Если сервером управляете только вы, то отправлять оповещения об успешных авторизациях, скорее всего нет смысла. Если несколько человек, то можно настроить проверку подключений кого-то конкретного, либо всех пользователей. Это уже на ваше усмотрение. Я в конце приведу готовый шаблон.
Все будет сделано с использованием штатного функционала zabbix. На хостах не нужно ничего настраивать, кроме выдачи прав на чтение к лог-файлу группе zabbix. Так что придется немного пожертвовать локальной политикой безопасности. По-умолчанию, системный лог не может читать никто, кроме рута. Исправляем это в Centos:
# chgrp zabbix /var/log/secure # chmod 640 /var/log/secure
и то же самое делаем в Debian/Ubuntu
# chgrp zabbix /var/log/auth.log # chmod 640 /var/log/auth.log
На хосте все готово. Все остальное делаем на сервере мониторинга.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
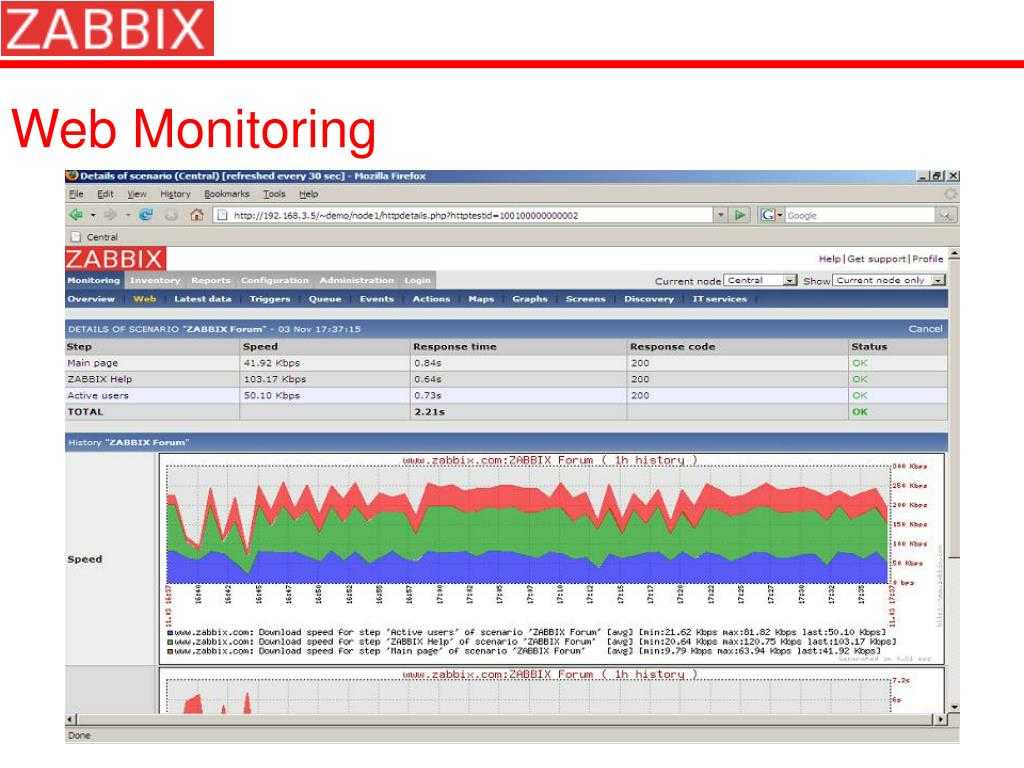
Оповещение о недоступности сайта
Давайте настроим уведомления о проблемах на сайте. Я предлагаю 2 типа оповещения:
- О низкой скорости доступа к сайту.
- О недоступности сайта вообще.
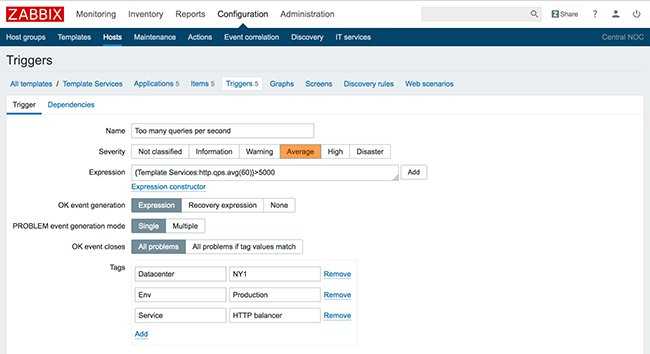
Идем, как обычно в исходный шаблон, на вкладку Triggers и добавляем новый.
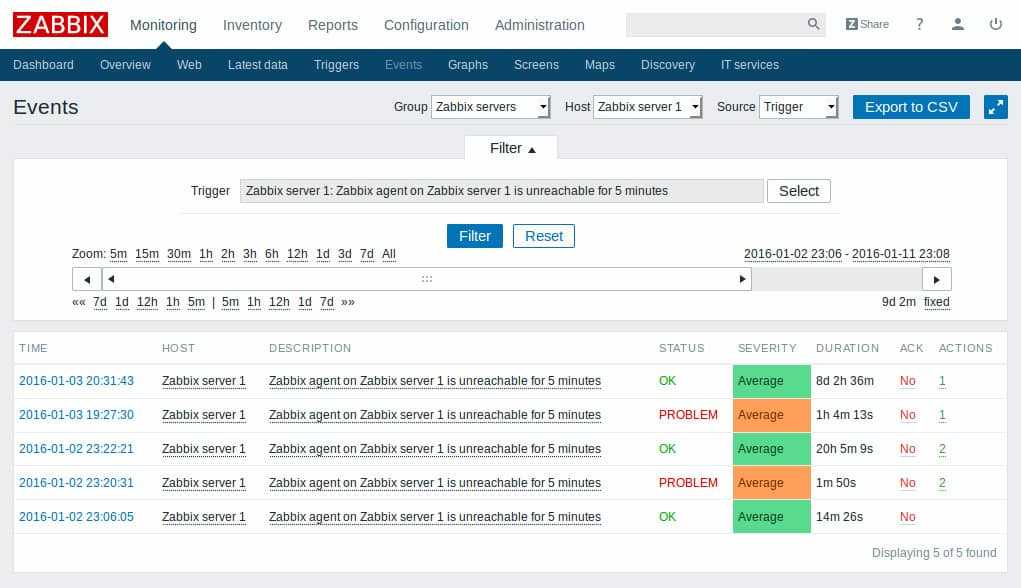
Я предлагаю вот такое условие срабатывания для определения недоступности сайта. Если среднее значение 3-х последних проверок больше, либо равно единице, то срабатывает оповещение о недоступности сайта.
Когда идет 0 во всех проверках, все в порядке. Триггер сработает только если все 3 последних проверки не равны нулю. В моем примере Failed step может принимать значение либо 0, либо 1, где 1 это номер сбойного шага. Если у вас шагов несколько, то сбойным может оказаться второй шаг или третий шаг. То есть значение может быть больше 1. Но в любом случае, если последние 3 значения подряд строго не 0, то идет срабатывание триггера. Операция восстановления очень простая. Если последняя проверка без ошибки, то есть код равен 0, то считаем, что сайт уже работает.
Чтобы проверить работу триггера, достаточно на zabbix server в файл /etc/hosts добавить строку:
127.0.0.1 github.com
и подождать 3 минуты, чтобы получились 3 неудачных проверки. После этого вам должно было отправиться уведомление о недоступности сайта. Я получил вот такое:
Дальше делаем проверку времени ответа сервера. Тут каждый волен настраивать так, как ему кажется более правильным и удобным. Я использую такую схему. Беру среднее время отклика сайта и умножаю его на 3. Далее смотрю последние 7 проверок. Если в 5 проверках среди этих семи были значения выше, чем утроенное среднее время отклика, то считаю, что сайт тормозит и надо слать уведомление. Немного замороченно, но на практике такая схема у меня себя хорошо зарекомендовала без ложных срабатываний. При этом, если возникают реальные проблемы, я их вижу. Рисуем триггер.
Условие восстановления — в последних трех запросах два и более были быстрее, чем утроенное среднее время доступа. Текст выражений для копирования:
{Sites Monitoring:web.test.time.count(#7,1.5,"ge")}>4
{Sites Monitoring:web.test.time.count(#3,1.5,"lt")}>1
В выражении 1.5 это время отклика в секундах. Именно в таком виде оно попадает в zabbix сервер. Проверить можно в Latest Data.
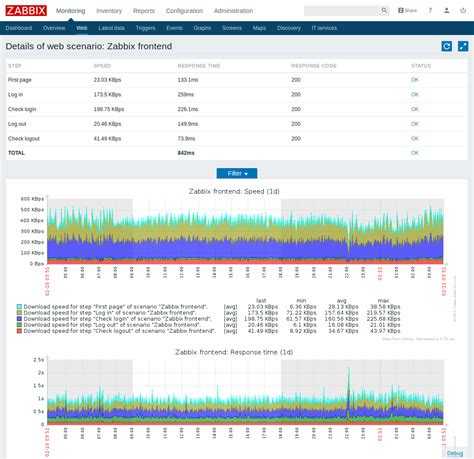
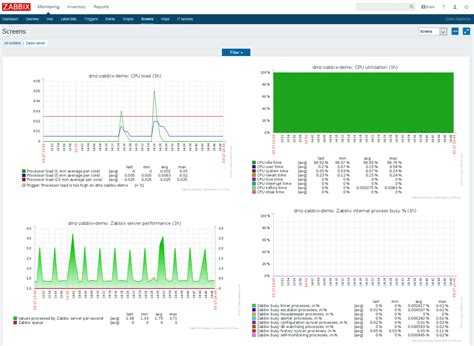
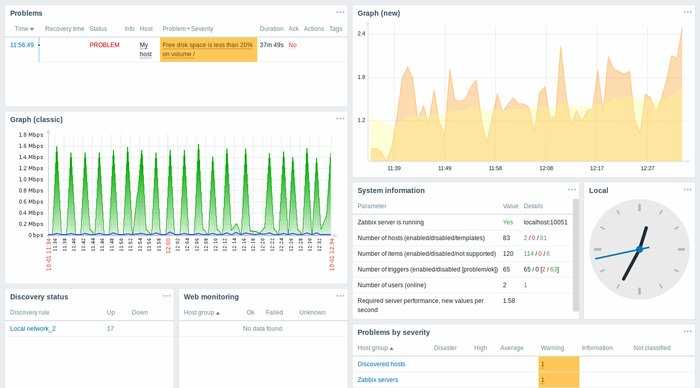
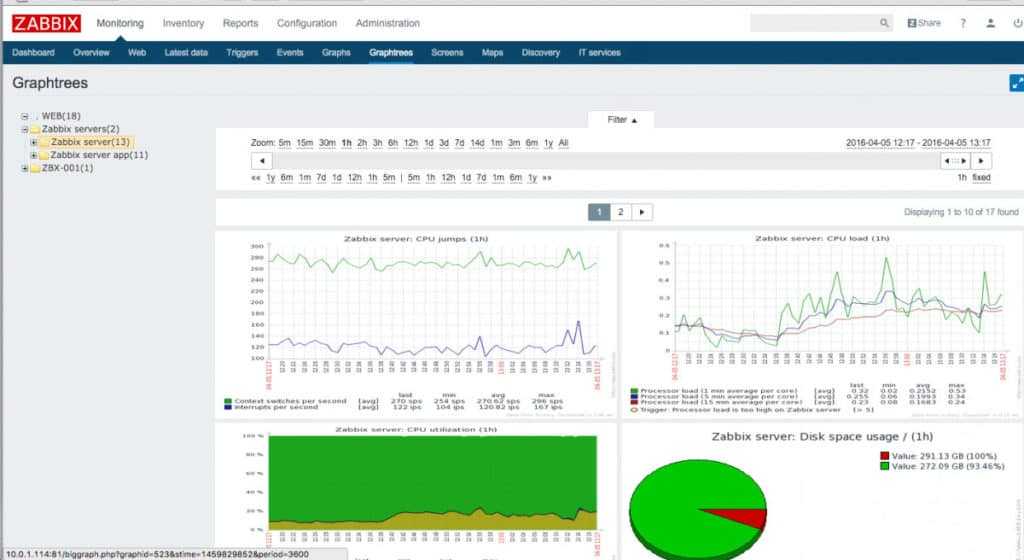
В завершении оставляю свой шаблон, который создал для написания статьи. Можете копированием и редактированием приспособить его для своих сайтов. Это быстрее, чем составлять с нуля. Шаблон экспортирован с версии zabbix 4.0 — sites_monitoring.xml
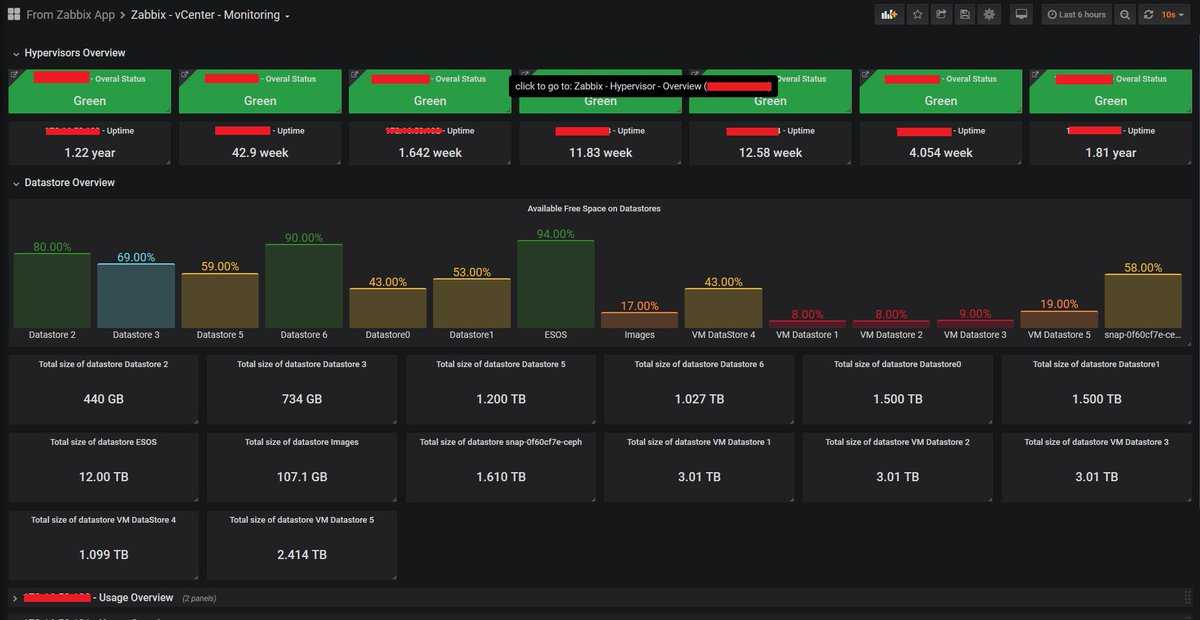
Вот и все, мониторинг веб сайта работает, авторизация проверяется, оповещение о недоступности сайта настроено. Для полноты картины можно создать Screen или Dashboard с выводом всех необходимых параметров на один экран. Его настройки уже будут зависеть от конкретной ситуации и тех данных, которыми вы располагаете. К примеру, если у вас настроен мониторинг веб сервера, то можно разместить рядом графики его загрузки и параметры доступа к сайту. Туда же можно добавить загрузку самого сервера по процессору и памяти и вывести график использования сетевого интерфейса.
В этом плане Zabbix очень гибок и позволяет настроить все на любой вкус и под любые требования.
Более подробно о мониторинге за временем отклика сайта читайте в отдельной статье на этот счет. Там описана теория процесса и практические рекомендации, вместе с готовым триггером.
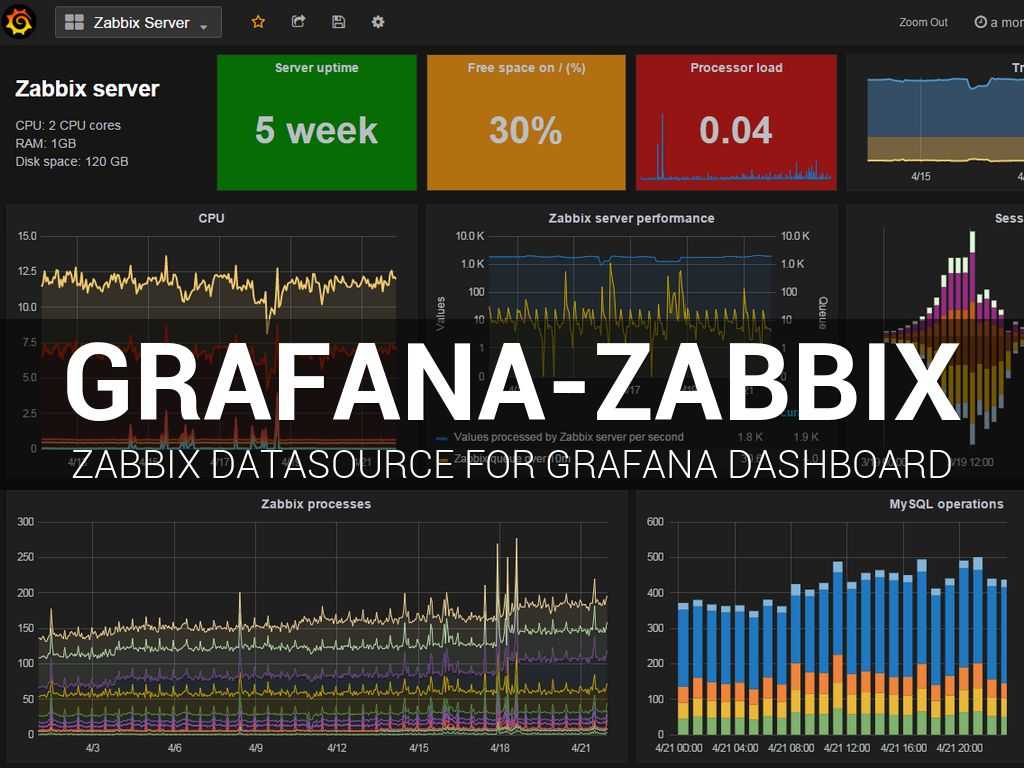
Grafana
Но на этом мы не остановились и подключили к Zabbix-у дашборды на основе Grafana. Это кроссплатформенное программное обеспечение с открытым исходным кодом для аналитики и интерактивной визуализации отчетов. Благо эти проекты (Grafana и Zabbix) очень хорошо дружат и настраиваются из коробки.
И после этого мы стали для всех штамповать удобные дашборды, т.к. в графане это делается очень просто и получается красиво.
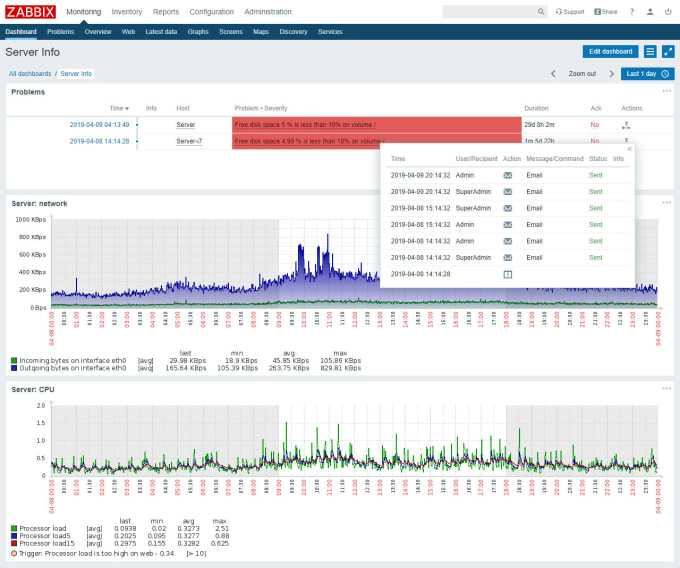
На слайде показан пример дашборда по сравнению производительности сотрудников 15 точек для территориального директора.
Далее показан дашборд для мониторинга состояния на торговой точке, показывающий ситуацию по персоналу, выполнению плана, производительность, претензии.
Если этот дашборд прокрутить вниз, можно увидеть графики по времени отдачи кухни и времени доставки.
Обратите внимание, что на графиках в графане можно оставлять комментарии, чтобы позже не вспоминать, что случилось на точке, и почему у них были такие показатели. Получив такие дашборды, операционный отдел уже хлопал стоя
Получив такие дашборды, операционный отдел уже хлопал стоя.
Скрипты по сбору информации о размере бэкапов
Первый скрипт будет проверять размер каталогов и записывать результат в текстовый файл. Сначала я собирал размер в байтах, потом решил скриптом преобразовывать в гигабайты, но через некоторое время нашел способ в заббиксе преобразовывать размер из байтов в гигабайты и снова стал в заббикс передавать только байты. Так оказалось удобнее всего. Создаем папку для скриптов и кладем туда сам скрипт:
# mkdir /etc/zabbix/scripts # mcedit /etc/zabbix/scripts/size-backup-dir.sh
#!/bin/bash
# Файл с информацией о размере папок
logfile=/etc/zabbix/scripts/size-log.txt
# Удаляем файл предыдущей работы скрипта
rm $logfile
# Определяем размер папки
size_1c=`du -s /mnt/data/backup/1c | awk '{print $1}'`
# Записываем результат в текстовый файл
echo 1c $size_1c >> $logfile
Если у вас несколько папок с бэкапами, добавляете их все в скрипт. Можно автоматизировать этот процесс, задать переменные с названиями папок с бэкапами и в цикле их перебирать, но у меня это не получилось, так как пути сильно разные. Пришлось все в ручную добавлять. Я привожу пример с одной папкой. Остальные по аналогии добавляете, не забывая изменять имена переменных, в которые передается размер директории.
Результатом работы скрипта будет файл следующего содержания:
# cat size-log.txt 1c 41374052
| 1с | имя бэкапа |
|
41374052 |
размер бэкапа в байтах |
Необходимо добавить этот скрипт в крон и выполнять раз в сутки. Находите конфиг крона в вашей системе и добавляете туда:
30 15 * * * /etc/zabbix/scripts/size-backup-dir.sh
Время выбираете на свое усмотрение. В данном случае у меня отдельный сервер для бэкапов, его можно днем напрячь, когда он простаивает.
Дальше рисуем скрипт, который будет передавать данные в заббикс:
# mcedit /etc/zabbix/scripts/send-zabbix-size.sh
#!/bin/bash cat /etc/zabbix/scripts/size-log.txt | grep $1 | cut -d " " -f 2
Проверяем его работу следующим образом:
# ./send-zabbix-size.sh 1c 41374052
На выходе просто цифра с размером, которая уходит на сервер заббикса. То, что нужно
Важно не забыть один момент, иначе ничего не зааработает. Скрипту нужно назначить владельца zabbix, чтобы агент мог его запускать:
# chown zabbix. /etc/zabbix/scripts/send-zabbix-size.sh
Если этого не сделать, получите ошибку в логе агента:
sh: 1: /etc/zabbix/scripts/send-zabbix-size.sh: Permission denied
Дополнительные материалы по Zabbix
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.

Проверьте себя на вступительном тесте и смотрите программу детальнее по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Оповещения в Telegram
Соответственно из этих метрик мы сделали оповещения через Telegram – в СушиВок для оперативной информации используется именно Telegram, а не почта. Причем, в Zabbix оповещения для Telegram настраиваются «из коробки».
В оповещениях операционный отдел просил указывать всю информацию о точке – количество поваров, сумма чеков, количество чеков в комплектации и т.д., чтобы можно было полностью понимать, какая ситуация на точке была во время сбоя. Из-за этого в выражении триггера и нужны были эти лишние всегда истинные неравенства. Но при большом объёме срабатывающих триггеров из-за всей этой информации сообщения стали не читаемы – получалось полотно из слов.
Поэтому я воспользовался советом Родислава Гандапаса из книги «К выступлению готов», где он при подготовке к выступлениям на карточках рекомендует использовать пиктограммы, т.к. они быстрее читаются при беглом взгляде.
Так в наших оповещениях появились:
-
ножи – это кухня;
-
черепашки – это доставка;
-
огоньки – если проблема не закрыта больше 10 мин.
Операционный отдел был очень доволен данными оповещениями.
Создание скрипта для мониторинга mysql репликации
Теперь создадим скрипт для мониторинга. Скачиваем его отсюда mysql-slave.sh и вставляем содержимое в папку /etc/zabbix/scripts:
# mcedit /etc/zabbix/scripts/mysql-slave.sh # chown zabbix:zabbix /etc/zabbix/scripts/mysql-slave.sh # chmod 550 /etc/zabbix/scripts/mysql-slave.sh
Проверяем его работу:
/etc/zabbix/scripts/mysql-slave.sh Master_Host zabbix parol
Скрипт должен вернуть в консоль имя мастера.
Если вы будете проверять работу скрипта от пользователя root, обязательно удалите временный файл из папки /tmp, который создает скрипт. Если этого не сделать, то потом заббикс не сможет его прочитать, так как ему не хватит для этого прав.
Данный скрипт анализирует вывод show slave status\G и парсит 3 необходимых нам значения. Он передает агенту информацию о задержке репликации через параметр Seconds_Behind_Master и анализирует значения Slave_IO_Running и Slave_SQL_Running. Если их значения равны Yes, он передает агенту 1, если там что-то другое то 0.
Вопросы
-
В последней версии Zabbix они не обещают решить проблему «девяти метрик»?
-
Когда я смотрел выступление разработчиков, которые рассказывали про возможности, которые они собираются включить в Zabbix версии 5.0, там ничего такого не было
-
Если не секрет, расскажите какие-нибудь кейсы с использованием интересных метрик и реакцию на них?
-
У нас, если при обмене данными накапливается большая очередь, и не отправляются данные больше 30 минут, всем программистам из Zabbix на почту рассылается сообщение, что очередь встала.
-
Расскажите про структуру сети Zabbix, сколько у вас серверов, есть ли прокси?
-
У нас используется один сервер Zabbix. На сервере 1С никакие вспомогательные прокси-серверы не разворачиваются – у нас центральный Zabbix сам запрашивает все данные, и этот обмен происходит с помощью веб-сервисов.
-
Метрики считывает 1С регламентным заданием или Zabbix периодически JSON запрашивает?
-
Когда вы настраиваете метрику в Zabbix, там очень гибко настраивается время опрашивания, вплоть до того, что ты можешь запрашивать эту метрику только по будням с 9 до 10, чтобы лишний раз не дергать 1С. И Zabbix каждый раз отправляет родительский JSON со списком метрик и GUID-ами узлов, которые хочет получить. И в ответ получает полный JSON с данными. А уже зависимые метрики разбирают этот JSON и получают из него элементы данных. Поэтому, отвечая на вопрос – никаких регламентных заданий. Это зло.
-
По поводу множества запросов в разные 1С. Вы говорите, что они легко подключаются. Как реализовано внедрение вашей подсистемы в эти базы?
-
-
Мы делали расширение 1С, чтобы можно было его подключать в несколько конфигураций.
-
Будет ли выложена эта публикация?
-
Собирались опубликовать. Выложу с инструкцией.
-
При онлайн-мониторинге и большом количестве метрик есть ли деградация производительности 1С?
-
Да, один раз было такое. Архитектурно немного некорректно сделано то, что в одной базе может быть 100 точек. И по сути, если метрика запрашивается каждую минуту, то каждую минуту запрашивается сто раз по количеству узлов. Но по-другому в той архитектуре, которую мы задумали, не сделать. Но даже при больших нагрузках все равно отрабатывало. Бывало, что, если метрика раз в минуту запрашивается, бывают пропуски, а потом все нормально идет подряд. Поэтому некритично. Когда мы все это архитектурно задумывали, мы сначала под этот проект хотели сделать отдельную базу SQL, но нам это не понадобилось
-
А вы не думали про такую модель, как выгрузка этой информации из 1С? Это как раз к этим регламентных заданиям. Когда вы архитектурное решение проектировали, вы не думали о том, что пусть 1С куда-нибудь «плюет» в RabbitMQ или еще какую-нибудь очередь, а Zabbix уже из нее получает?
-
По поводу RabbitMQ я пока не понял до конца всех плюсов – наверное, у нас нет таких объемов. Честно говоря, я против регламентов. У нас получилось очень гибко, и за счет этой гибкости очень легко настраиваются все эти метрики, триггеры без доработки конфигурации. Не хочется делать какие-то регламенты, потому что их потом придется дописывать дополнительно.
-
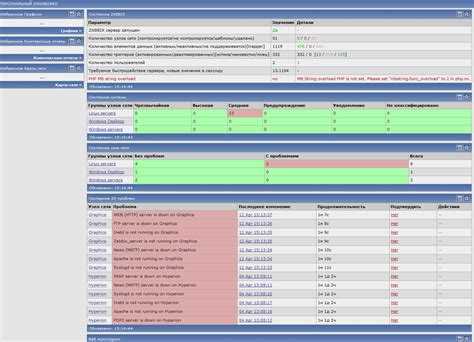
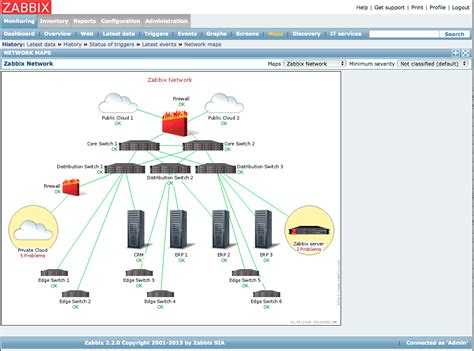
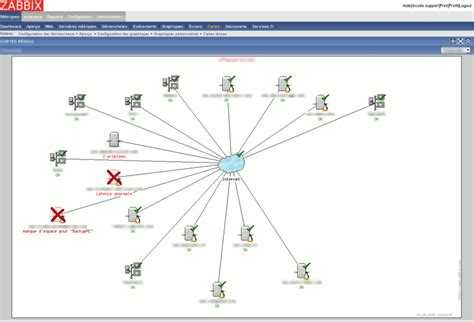
В PRTG есть карты (maps) – это такое поле x на y в графическом виде, куда можно вытащить любые сенсоры. Очень удобно – все разноцветное. Есть ли такое в Zabbix?
-
Это скорее вопрос к Grafana. В Zabbix есть графики, но они слишком упрощенные. Grafana в этом плане гораздо интереснее. Там есть различное представление отображаемой информации – не только графики. Там есть спидометры, индикаторы и т.д. Очень большое количество дашбордов, на любой вкус можно найти.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Saint Petersburg.Online. Больше статей можно прочитать здесь.
JavaScript и Duktape
Почему были выбраны именно JavaScript и Duktape? Рассматривались различные варианты языков и движков:
- Lua – Lua 5.1
- Lua – LuaJIT
- Javascript – Duktape
- Javascript – JerryScript
- Embedded Python
- Embedded Perl
Основными критериями выбора были распространенность, простота интеграции движка в продукт, низкое потребление ресурсов и общая производительность движка, и безопасность внедрения кода на этом языке в мониторинг. По совокупности показателей победил JavaScript на движке Duktape.
Критерии выбора и performance testing
Особенности Duktape:
— Стандарт ECMAScript E5/E5.1
— Модули Zabbix для Duktape:
- Zabbix.log() — позволяет вписать непосредственно в лог Zabbix Server сообщения с различным уровень детализации, что обеспечивает возможность сопоставлять ошибки, например, в Webhook с состоянием сервера.
- CurlHttpRequest() — позволяет делать HTTP-запросы в сеть, на чем основано применение Webhook.
- atob() и btoa() — позволяет кодировать и декодировать строки в формат Base64.
ПРИМЕЧАНИЕ. Duktape соответствует стандартам ACME. В Zabbix используется версия скрипта 2015 года. Последующие изменения незначительны, поэтому их можно игнорировать.
Может лучше на практике?
Нет ничего проще  Давайте для примера попробуем настроить мониторинг JBoss EAP 6.4.
Давайте для примера попробуем настроить мониторинг JBoss EAP 6.4.
Для начала сделаем несколько предположений:
- Вы уже установили Zabbix 3.4 и Zabbix Java Gateway. Если еще нет, то вы можете сделать это в соответствии с документацией Zabbix.
- Zabbix Server и Java Gateway с префиксом /usr/local/.
- JBoss уже установлен в /opt/jboss-eap-6.4/ и запускается в standalone режиме.
- Для простоты эксперимента будем считать, что все эти компоненты работают на одной и той же машине.
- Firewall и SELinux отключены (или настроены соответствующим образом, но это выходит за рамки статьи).
Сделаем несколько простых настроек в zabbix_server.conf:
И в конфиге zabbix_java/settings.sh (или zabbix_java_gateway.conf):
Проверьте, что JBoss слушает свой стандартный management port:
Теперь давайте создадим в Zabbix хост с JMX интерфейсом 127.0.0.1:9999.
Если мы сейчас просто возьмём стандартный шаблон «Template App Generic Java JMX» и прилинкуем его к хосту, то наверняка получим ошибку:
Java Gateway сообщает нам, что по указанному endpoint отвечает совсем не RMI. Хорошо, мы уже знаем, что эта версия JBoss использует протокол JBoss Remoting вместо RMI, и нам нужно лишь начать стучаться в правильный endpoint.
Давайте сделаем Full Clone шаблона «Template App Generic Java JMX» и назовём его «Template App Generic Java JMX-remoting». Выделим все элементы данных внутри этого шаблона и выполним операцию Mass update для параметра JMX endpoint. Пропишем такой URL:
Обновим конфигурационный кэш:
И снова ошибка.
Что на этот раз?
“Unsupported protocol: remoting-jmx” означает, что Java Gateway не умеет работать с указанным протоколом. Что ж, давайте его научим. В этом нам поможет совет из статьи «JBoss EAP 6 monitoring using remoting-jmx and Zabbix».
Создадим файл ~/needed_modules.txt со следующим содержимым:
Выполним команду:
Таким образом, Java Gateway будет иметь все необходимые модули для работы с jmx-remoting. Остаётся лишь перезапустить Java Gateway, немного подождать и, если вы всё сделали правильно, увидеть, что заветные данные начали поступать в Zabbix:
Подготовка zabbix agent
Мониторинг значений SMART жесткого диска будет выполняться с помощью smartmontools. Установить их можно следующей командой для CentOS:
# yum install smartmontools
Либо аналогично в Debian/Ubuntu
# apt install smartmontools
Далее нам понадобится скрипт на perl для автообнаружения дисков и вывода информации о них в JSON формате, который понимает заббикс. Создадим такой скрипт.
# mcedit /etc/zabbix/scripts/smartctl-disks-discovery.pl
#!/usr/bin/perl
#must be run as root
$first = 1;
print "{\n";
print "\t\"data\":[\n\n";
for (`ls -l /dev/disk/by-id/ | cut -d"/" -f3 | sort -n | uniq -w 3`)
{
#DISK LOOP
$smart_avail=0;
$smart_enabled=0;
$smart_enable_tried=0;
#next when total 0 at output
if ($_ eq "total 0\n")
{
next;
}
print "\t,\n" if not $first;
$first = 0;
$disk =$_;
chomp($disk);
#SMART STATUS LOOP
foreach(`smartctl -i /dev/$disk | grep SMART`)
{
$line=$_;
# if SMART available -> continue
if ($line = /Available/){
$smart_avail=1;
next;
}
#if SMART is disabled then try to enable it (also offline tests etc)
if ($line = /Disabled/ & $smart_enable_tried == 0){
foreach(`smartctl -i /dev/$disk -s on -o on -S on | grep SMART`) {
if (/SMART Enabled/){
$smart_enabled=1;
next;
}
}
$smart_enable_tried=1;
}
if ($line = /Enabled/){
$smart_enabled=1;
}
}
print "\t{\n";
print "\t\t\"{#DISKNAME}\":\"$disk\",\n";
print "\t\t\"{#SMART_ENABLED}\":\"$smart_enabled\"\n";
print "\t}\n";
}
print "\n\t]\n";
print "}\n";
Сохраняем скрипт и делаем исполняемым.
# chmod u+x smartctl-disks-discovery.pl
Выполняем скрипт и проверяем вывод. Должно быть примерно так с двумя дисками.
{
"data":
}
В данном случае у меня 2 физических диска — sda и sdb. Их мы и будем мониторить.
Настроим разрешение для пользователя zabbix на запуск этого скрипта, а заодно и smartctl, который нам понадобится дальше. Для этого запускаем утилиту для редактирования /etc/sudoers.
# visudo
Добавляем в самый конец еще одну строку:
zabbix ALL=(ALL) NOPASSWD:/usr/sbin/smartctl,/etc/zabbix/scripts/smartctl-disks-discovery.pl
Сохраняем, выходим Это если вы умеете работать с vi. Если нет, то загуглите, как работать с этим редактором. Именно он запускается командой visudo.
Проверим, что пользователь zabbix нормально исполняет скрипт.
# chown zabbix:zabbix /etc/zabbix/scripts/smartctl-disks-discovery.pl # sudo -u zabbix sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Вывод должен быть такой же, как от root. Если вам не хочется разбираться с этими разрешениями, либо что-то не получается, можете просто запустить zabbix-agent от пользователя root и проверить работу в таком режиме. Сделать это не трудно, данный параметр закомментирован в конфигурации агента. Вам достаточно просто снять комментарий и перезапустить агент.
После настройки скрипта автообнаружения, добавим необходимые UserParameters для мониторинга SMART. Для этого создадим отдельный конфигурационный файл. Для версии 3.2 и ниже он будет выглядеть вот так.
# mcedit /etc/zabbix/zabbix_agentd.d/smart.conf
UserParameter=uHDD,sudo smartctl -A /dev/$1| grep -i "$2"| tail -1| cut -c 88-|cut -f1 -d' ' UserParameter=uHDD.model.,sudo smartctl -i /dev/$1 |grep -i "Device Model"| cut -f2 -d: |tr -d " " UserParameter=uHDD.sn.,sudo smartctl -i /dev/$1 |grep -i "Serial Number"| cut -f2 -d: |tr -d " " UserParameter=uHDD.health.,sudo smartctl -H /dev/$1 |grep -i "test"| cut -f2 -d: |tr -d " " UserParameter=uHDD.errorlog.,sudo smartctl -l error /dev/$1 |grep -i "ATA Error Count"| cut -f2 -d: |tr -d " " UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Версия настроек для агента 3.4
UserParameter=uHDD.A,sudo smartctl -A /dev/$1 UserParameter=uHDD.i,sudo smartctl -i /dev/$1 UserParameter=uHDD.health,sudo smartctl -H /dev/$1 || true UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Сохраняем файл и перезапускаем zabbix-agent.
# systemctl restart zabbix-agent
Проверяем, как наш агент будет отдавать данные. Ключ uHDD.discovery будет одинаковый для обоих версий агента.
# zabbix_agentd -t uHDD.discovery
Вы должны увидеть полный JSON вывод с информацией о ваших диска. Теперь посмотрим, как передаются информация о smart. Запросим температуру дисков для версии 3.2.
# zabbix_agentd -t uHDD uHDD
Все в порядке. Можете погонять еще какие-нибудь параметры из смарта, но скорее всего все будет работать, если хотя бы один параметр работает. На этом настройка на агенте закончена, переходим к настройке сервера мониторинга.
Я ничего не понял. JMX, RMI, JNDI? WTF?
Хорошо-хорошо, давайте немного разберёмся, как всё это работает.JMX (Java Management Extensions) — технология Java, предназначенная для мониторинга и управления (в т.ч. удалённо) различными объектами (ресурсами): приложениями, устройствами, сетями — лишь бы этот объект был написан на Java.
Эти ресурсы называются MBeans (ManagedBeans). Каждый такой объект реализует определённый интерфейс, через который можно получить доступ к значениям атрибутов этого объекта, а также вызвать его методы и получать уведомления (если приложение зарегистрирует соответствующие “слушающие” MBean’ы).

MBeans регистрируются на MBean Server — реестре объектов. Любой зарегистрированный объект становится доступным для приложений (точнее, становится доступным его интерфейс).
Доступ к ресурсам осуществляется при помощи JMX-коннекторов, которые делают MBean Server доступным для JMX-клиентов. JMX-коннектор состоит из клиента и сервера. Коннектор-сервер соединяется с MBean-сервером и слушает запросы соединений от клиентов. Коннектор-клиент обычно находится на другой JVM, а чаще всего вообще на другой машине по отношению к коннектор-серверу.
JMX API имеет стандартный протокол подключения, основанный на Remote Method Invocation (RMI). Этот протокол позволяет JMX-клиенту удалённо получить доступ к MBean’ам на MBean-сервере. Кроме штатного RMI существуют и другие протоколы: JMXMP, JBoss Remoting, Hessian, Burlap, и даже HTTP и SNMP.
Используя интерфейс MBean’а клиент может получать различные метрики этого объекта, а также вызывать публичные методы.
Схематично взаимодействие компонентов можно изобразить так:
Любое приложение на платформе Java SE “из коробки” имеет возможности для его мониторинга: RMI коннектор автоматически делает доступным ваше Java приложение для удалённого управления и мониторинга. Достаточно лишь запустить приложение с нужными параметрами, и JMX-клиенты (а Zabbix Java Gateway — это JMX-клиент) уже смогут подключаться к нему удалённо и получать нужные метрики.
Чтобы указать JMX-клиенту конкретное приложение, к которому вы хотите подключиться, используется специальный адрес, который называется JMX endpoint (он же JMXServiceURL). Если говорить строже, то это адрес коннектор-сервера JMX API. Формат этого адреса определяется RFC 2609 и RFC 3111. В общем случае он выглядит так:
Где «service:jmx:» — константа.
protocol — это транспортный протокол (один из многих: RMI, JMXMP, etc), используемый для подключения к коннектор-серверу.sap — адрес, по которому коннектор-сервер может быть найден. Задаётся в таком формате (это подмножество синтаксиса, определённого в RFC 2609):
host — ipv4 адрес хоста (или ipv6, заключённый в квадратные скобки) и необязательный (в зависимости от протокола) номер порта.url-path — необязательный URL (обязательность зависит от протокола).
Лучше всего разобраться с этим на примере. Часто можно встретить такой JMX endpoint, вид которого некоторых может ввести в ступор:
Но на самом деле не всё так страшно.host — это целевой хост, где запущено наше приложение.port1 — это порт RMI-сервера, к которому мы хотим подключиться.
а port2 — это порт RMI registry (каталог, где регистрируются RMI-серверы). По умолчанию: 1099.
Если знать о том, что RMI-реестр выдаёт адрес и порт RMI-сервера по запросу клиента, то становится понятно, что первая часть здесь лишняя. Таким образом адрес можно сократить до такого вида:url-path часть означает буквально следующее: возьми ту часть URL, которая следует сразу за /jndi/ и выполни по этому адресу JNDI-запрос в RMI registry, чтобы получить информацию об RMI-сервере. Реестр вернёт в ответ его хост и порт.
Следует отметить, что порт в таком случае генерируется случайным образом и могут возникнуть проблемы с настройкой файрвола. В таких случаях и записи JMX endpoint’а, потому что он позволяет явно указать порт.
Если вам хотелось бы глубже разобраться в JMX, то рекомендуем обратиться к официальной документации Oracle.
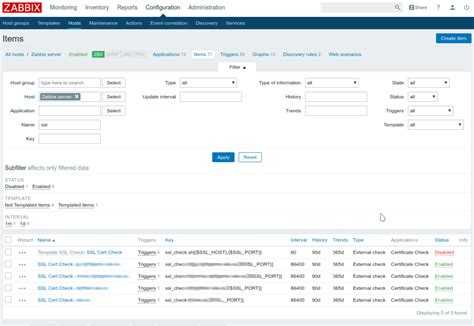
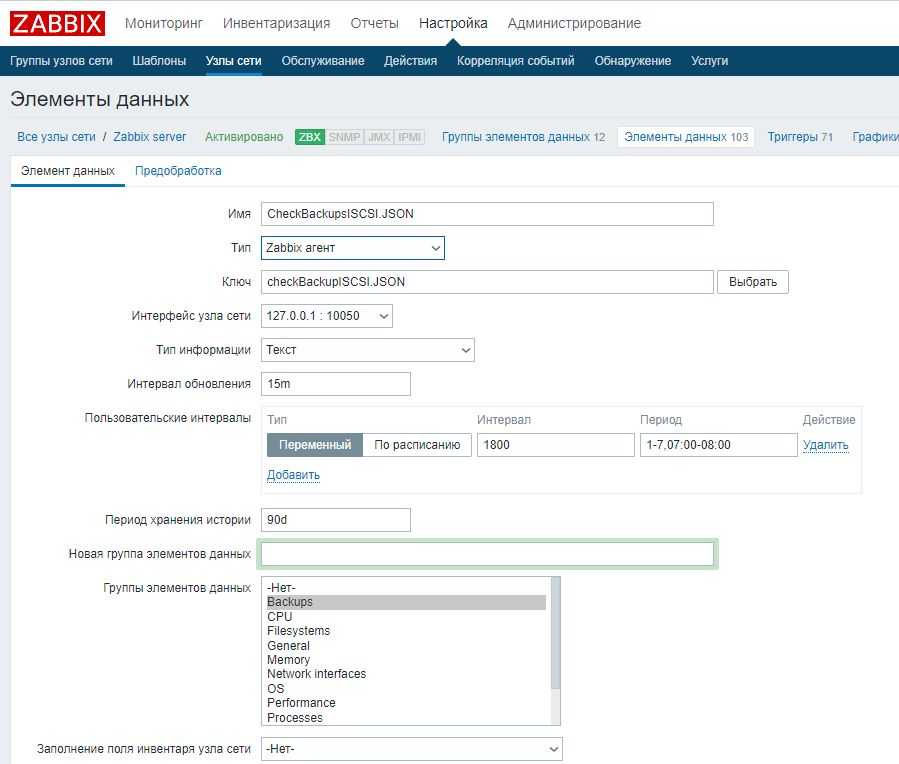
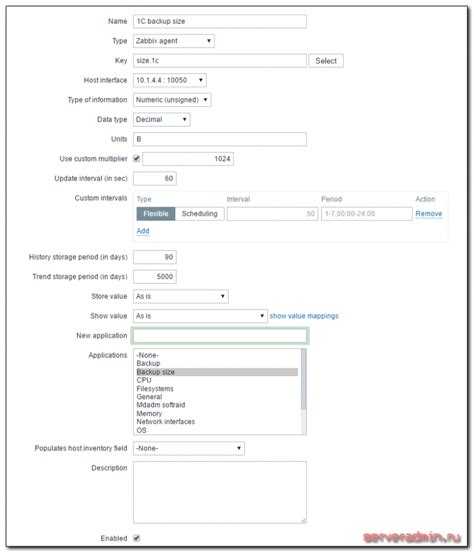
Добавляем новый итем на сервер мониторинга zabbix
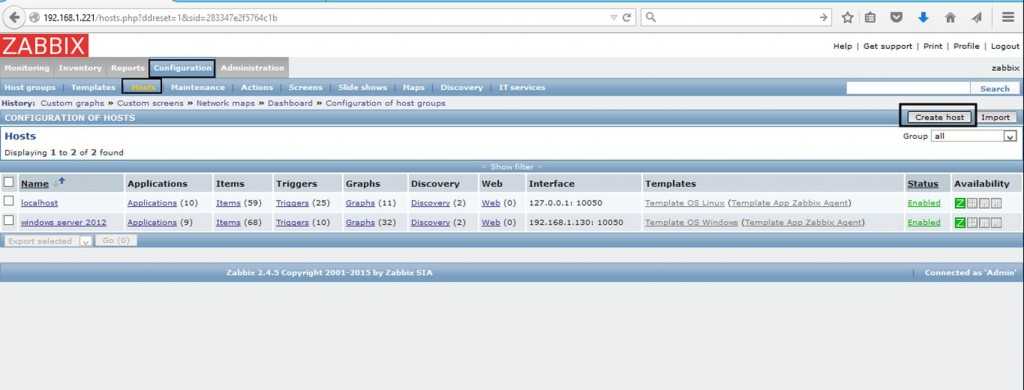
Кратко расскажу, что делать на сервере. Раньше я уже неоднократно рассматривал этот момент, поэтому не буду на нем подробно останавливаться. Больше информации можете получить в предыдущих статьях, которые я привел в самом начале. Идем в веб интерфейс. Выбираем хост, на котором мы только что настраивали агент, заходим в список итемов и добавляем новый:
| Name | Произвольное имя итема. |
| Key | Название ключа, должно быть точно таким же, как в UserParameter в агенте. |
| Update interval | Время обновления, в данном случае раз в минуту для отладки, потом рекомендую ставить раз в сутки. |
| Units | Единица измерения, в данном случае байты. |
| Use custom multiplier | Пользовательский множитель для корректного перевода в гигабайты |
Сохраняем новый итем и ждем поступления данных. В случае указания большого интервала обновления, к примеру, раз в сутки, я не знаю, когда заббикс первый раз проведет опрос. Будет здорово, если кто-нибудь подскажет. Меня всегда интересовал этот момент. Во время отладки я ставлю маленький интервал обновления, например минуту или две. После того, как убеждаюсь, что все работает корректно, изменяют интервал на необходимый.
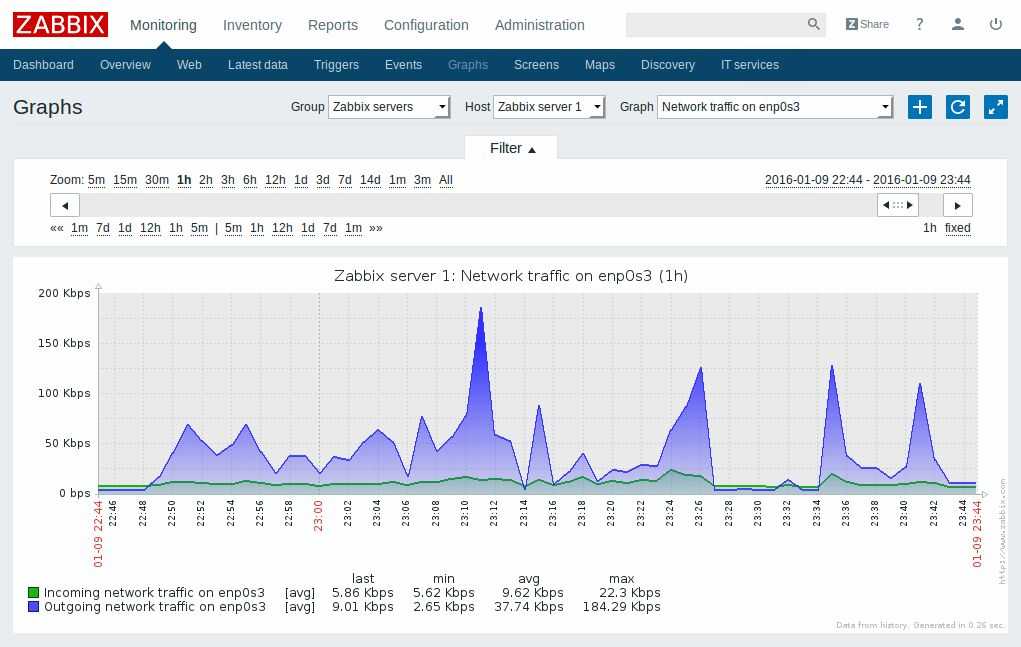
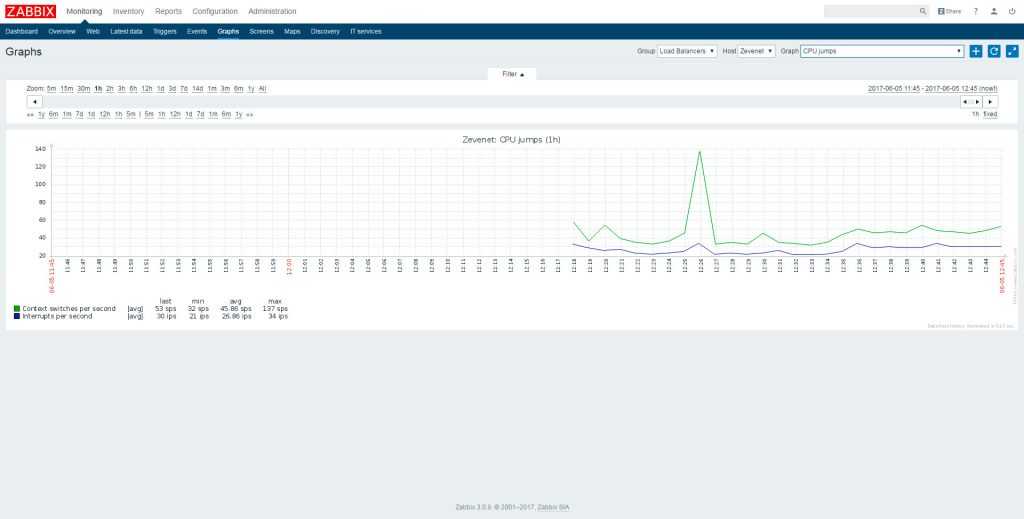
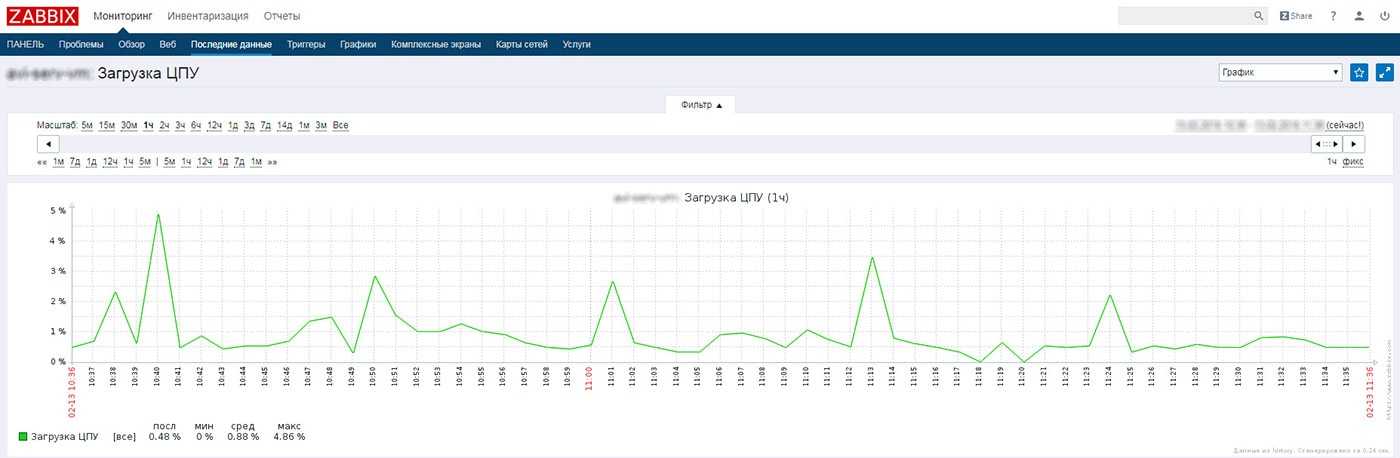
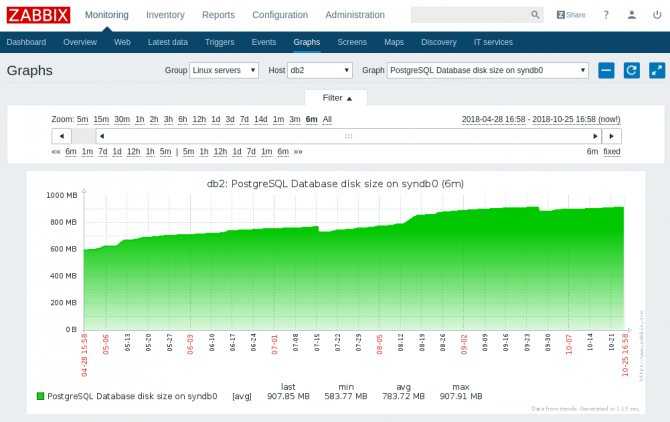
Смотреть результат следует, как обычно, в Latest data. Там же можно и график посмотреть, когда накопятся данные для него. Для более наглядных и красивых графиков, необходимо будет их вручную создать в конструкторе графиков конкретного хоста. Лично мне достатчно информации из последних данных.
Заключение
Данный функционал можно использовать не только для мониторинга бэкапов, но и других актуальных данных. Например, какая-то программа должна выгружать данные с определенной периодичностью. Мы можем следить за тем, как она это делает. В данной статье мы рассмотрели несколько параметров, по которым заббикс может анализировать файлы и каталоги. Но таких возможностей много. Он может, к примеру, проверять конкретный размер файла и предупреждать, если он сильно меньше или больше предыдущей версии. Настраивается это примерно так же, как здесь.
If you liked my post, feel free to subscribe to my rss feeds





