
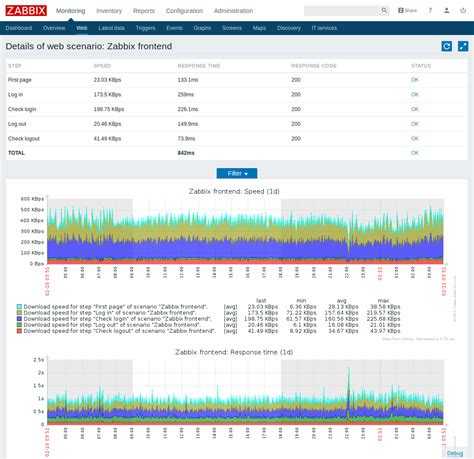
Настройка мониторинга репликации mysql на zabbix server
Здесь все как обычно. Скачиваем шаблон mysql-slave.xml импортируем его на сервер. Для этого идем в Configuration -> Templates и нажимаем Import:
Выбираем скачанный шаблон и жмем Import:
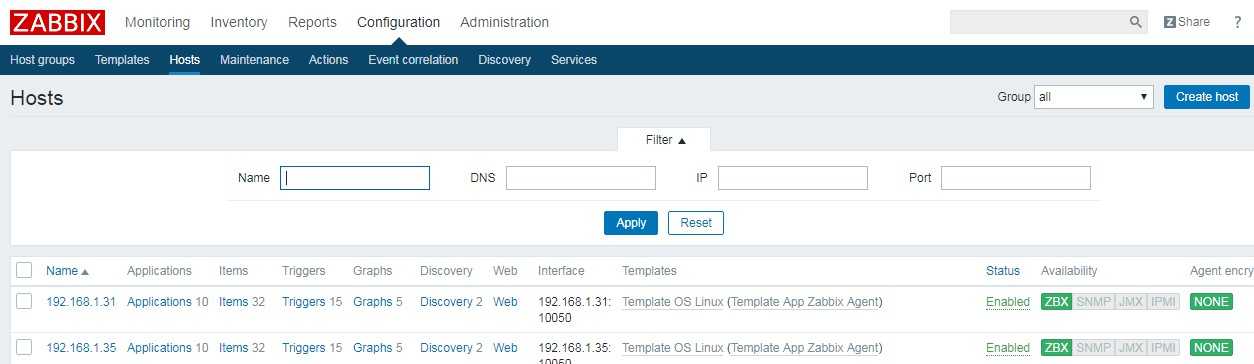
Дальше отправляемся к списку хостов в Configuration -> Hosts, выбираем нужный хост и назначаем ему новый шаблон:
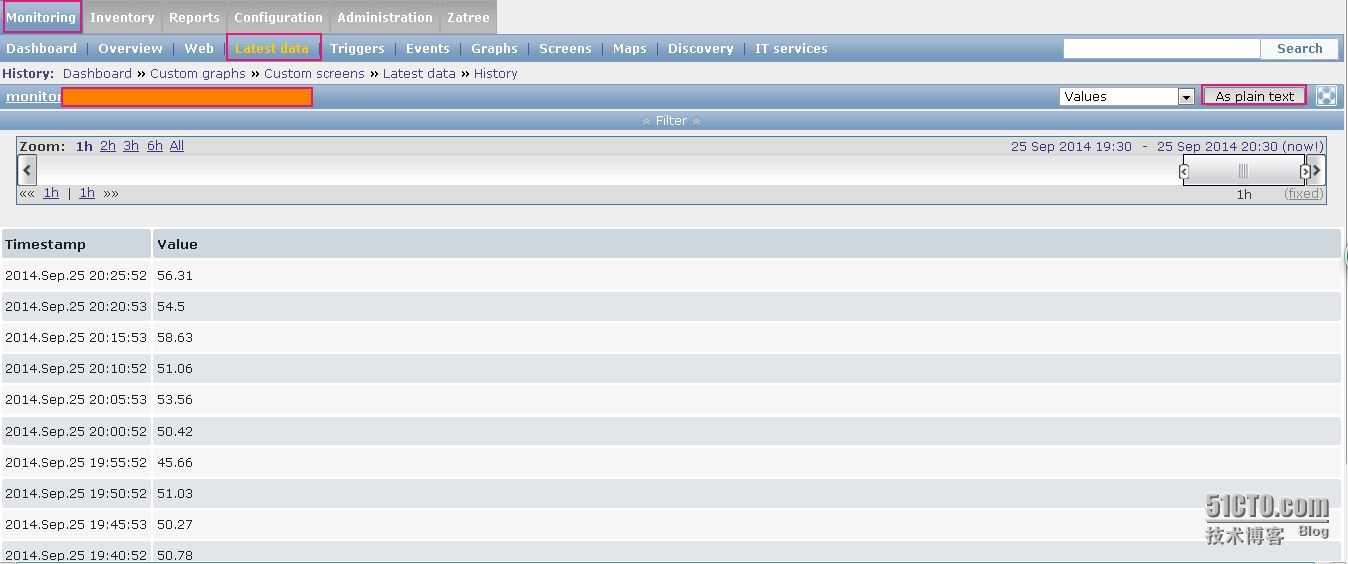
Жмем Update для применения настроек. Ждем несколько минут и идем проверять поступление новых данных репликации mysql. Открываем Monitoring -> Latest Data, настраиваем фильтр и проверяем значения:
В данном случае мы видим, что значение Seconds Behind Master = 0, отставания от мастера нет. Два других значения равны единице, это значит, что наш скрипт проверки состояния репликации получает статусы Slave_IO_Running и Slave_SQL_Running равные Yes и поэтому возвращает значения 1. То есть наша репликация работает в штатном режиме, все в порядке.
Установка Zabbix Agent на Linux
Если вы хотите установить zabbix-agent на сам сервер мониторинга, то ничего делать не надо, кроме самой установки. Для других систем необходимо подключить репозитории заббикса, которые мы использовали во время установки сервера. Можете посмотреть их в соответствующих разделах для своей системы.
Установка zabbix agent в Centos:
# yum install zabbix-agent
Тоже самое в Ubuntu/Debian:
# apt install zabbix-agent
Для работы с сервером, который установлен локально на этой же машине, больше никаких настроек не надо делать. Если же вы будете устанавливать zabbix agent на другую машину, то в файле конфигурации агента /etc/zabbix/zabbix_agentd.conf нужно будет задать следующие параметры:
# mcedit /etc/zabbix/zabbix_agentd.conf
Server=192.168.13.117 ServerActive=192.168.13.117 Hostname=srv10 # имя вашего узла мониторинга, которое будет указано на сервере zabbix, Zabbix server если это сам сервер заббикса
Запускаем агент и добавляем в автозагрузку:
# systemctl start zabbix-agent # systemctl enable zabbix-agent
Проверяем лог файл.
# cat /var/log/zabbix/zabbix_agentd.log 14154:20181004:201307.800 Starting Zabbix Agent . Zabbix 4.0.0 (revision 85308). 14154:20181004:201307.800 **** Enabled features **** 14154:20181004:201307.800 IPv6 support: YES 14154:20181004:201307.800 TLS support: YES 14154:20181004:201307.800 ************************** 14154:20181004:201307.800 using configuration file: /etc/zabbix/zabbix_agentd.conf 14154:20181004:201307.800 agent #0 started 14157:20181004:201307.801 agent #3 started 14159:20181004:201307.802 agent #5 started 14155:20181004:201307.804 agent #1 started 14158:20181004:201307.806 agent #4 started 14156:20181004:201307.810 agent #2 started
Все в порядке. Идем в веб интерфейс и проверяем поступление данных. Для этого идем в раздел Мониторинг -> Последние данные. Указываем в разделе Узлы сети Zabbix Server и ждем поступления первых данных. Они должны пойти через 2-3 минуты после запуска агента.
Теперь попробуем остановить агент и проверить, придет ли уведомление на почту. Идем в консоль и выключаем агента:
# systemctl stop zabbix-agent
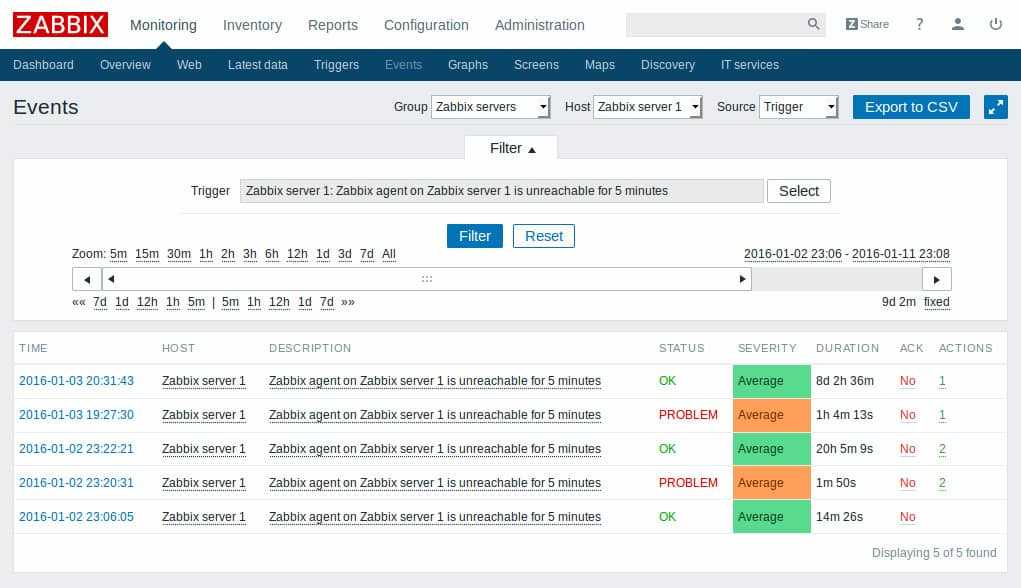
Ждем минимум 5 минут. Именно такой интервал указан по-умолчанию для срабатывания триггера на недоступность агента. После этого проверяем главную панель, виджет Проблемы.
Настройка мониторинга
Объекты мониторинга в систему вы можете добавлять как вручную, так и автоматически. Причем ручной ввод возможен как по ip адресам, так и по DNS или Netbios именам.
Далее я просканирую локальную сеть и добавлю найденные объекты автоматически. Для этого идем в Client и выбираем там установленный ранее сервер. После этого нажимаем Сканирование сети.
У меня он нашел все, что было доступно по сети — 2 windows сервера, 2 linux сервера и 2 микротика. Последних он никак не пометил, а вот первых двух определил, кто есть кто. Обнаружил открытые порты управления rdp, ssh и некоторые другие. Вы можете сразу же вручную переименовать те устройства, что обнаружены по ip адресам.
Для того, чтобы добавить информацию с узла в систему мониторинга, надо указать учетные данные для подключения. Для этого выбираем найденный хост, жмем правую кнопку мышки и выбираем раздел Задать пароли для раздела аналитика.
В зависимости от того, какая операционная система на сервере, надо будет указать либо WMI, либо SSH пользователя. После этого данные начнут поступать на сервер, и их можно будет анализировать. Чтобы получить актуальную инфомрацию, нужно будет подождать несколько минут после добавления учетных данных.
Если вы используете нестандартные порты на своих устройствах, то это не проблема. Изменить их можно, открыв на редактирование объект мониторинга, во вкладке порты.
Я не буду подробно останавливаться на собираемых метриках, так как этот вопрос внимательно рассмотрел в статье. С тех пор существенных изменений в этой части программы не было, кроме того, что появилась возможность мониторить linux машины.
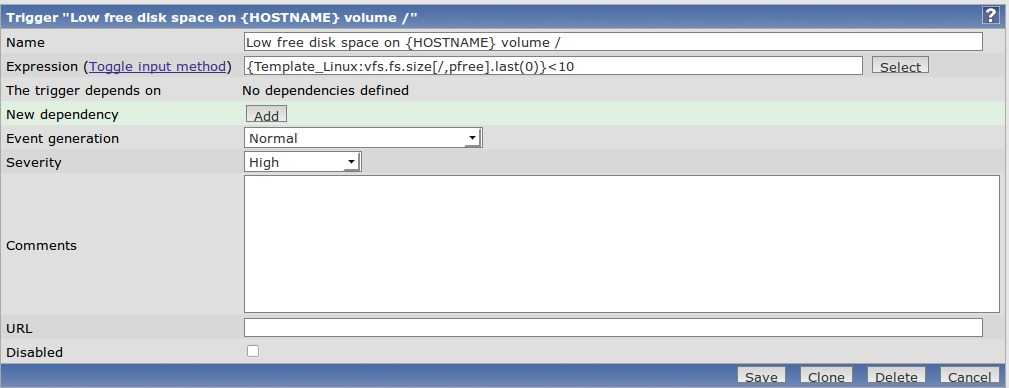
Так же из нововведений — возможность настраивать пороги срабатывания триггеров. Например, вы можете указать, что предупреждение об окончании свободного места на диске будет приходить, когда останется свободных 5%. Причем настройки могут наследоваться от группы хостов, от самого хоста, либо настраиваться для каждого диска в отдельности. То же самое с остальными метриками.
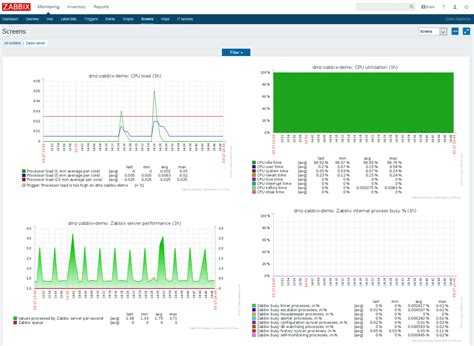
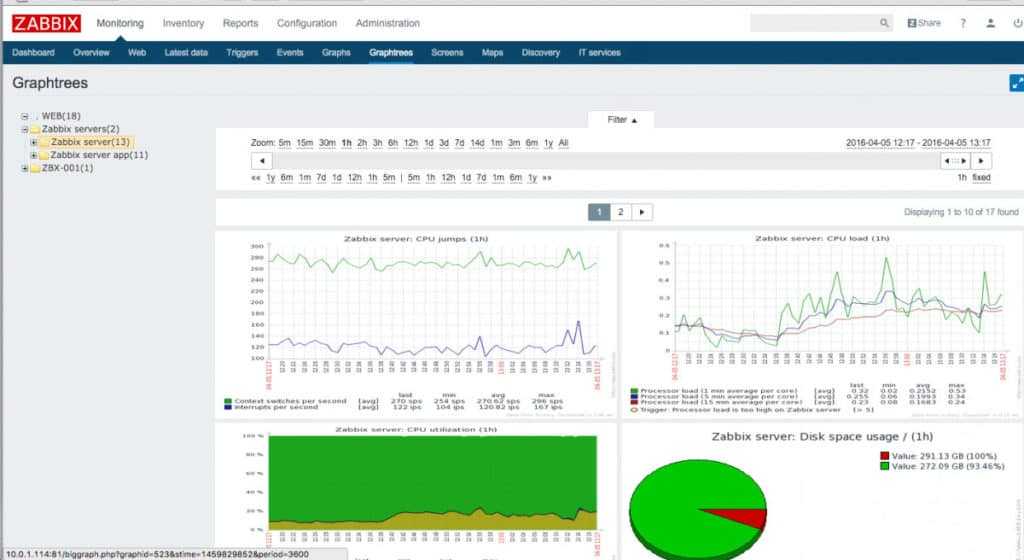
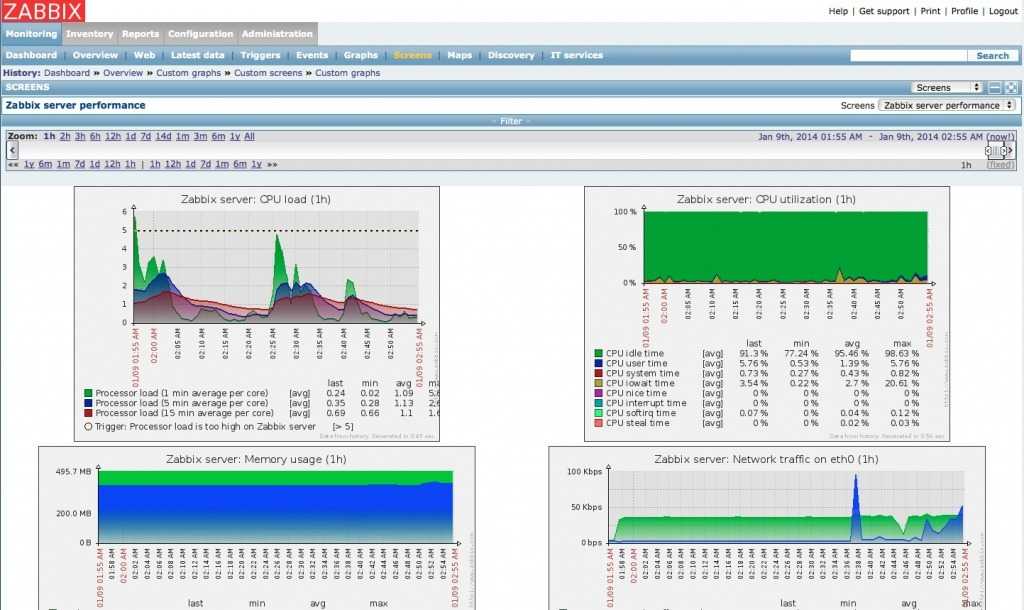
Как и в любой системе мониторинга вы сможете посмотреть исторические данные по каждому хосту, чтобы оценить динамику потребления ресурсов. С помощью этой информации, к примеру, можно прикинуть, когда закончится место на диске. Выглядит историческая информация примерно так.
Первый шаг миграции
Для начала, как и в любом другом мануале по миграции Zabbix, разделим файл schema.sql, расположенный в директории database/postgresql исходников zabbix, на 2 части:
в одной у нас будут CREATE, в другой ALTER.
На выходе имеем 2 файла: create.sql, alter.sql
Применим файл create.sql к нашей БД:
Подготовим файл для pgloader — zabbix.load.config
Обратите внимание на строку
с ее помощью мы пропускаем таблицы истории
Запустим миграцию:
Ждем буквально минуту, проверяем, что ошибок при миграции нет (символ галки во втором столбце):
Применим файл alter.sql к нашей БД:
Полагаю, важно, что в файле alter.sql нет никаких упоминаний таблиц trend и history. По крайней мере в версии 4.0 именно так обстоят дела
Наверное, при ином раскладе были бы проблемы, т.к. в существующих в сети мануалах по миграции данные сначала загружаются в БД, а потом применяется alter.sql
Удалим пакеты Zabbix, связанные с MySQL и заменим их теми, что нужны для PostgreSQL. На этот раз я приведу примеры для CentOS 7, чтобы было понятно, какие пакеты нам нужны:
А лучше смотрите официальную документацию по установке для вашей ОС:https://www.zabbix.com/documentation/4.0/manual/installation/install_from_packages
Сбросим настройки Web интерфейса Zabbix, чтобы заново пройти его настройку:
Укажем часовой пояс в файле:
Настроим новый zabbix_server.conf: укажем нужные значения в директивах DBHost, DBPort, DBUser, DBName, DBPassword.
Настала пора запустить наш Zabbix Server!
Идем по адресу web-интерфейса zabbix (http(s)://ip/zabbix), проходим по шагам мастера.
После настройки web-интерфейса вы увидите, что все ваши узлы, шаблоны, группы и т.п. будут на месте. Не будет только исторических данных. Вы можете в этом убедиться, посмотрев любые графики за прошлые периоды — там пусто.
Теперь можно проследить, что данные от ваших проверок начали поступать на сервер, что ошибок в логах нет, что ложные срабатывания триггеров отсутствуют. Как только вы поняли, что ситуация под контролем, можете включить оповещения, отключенные на этапе подготовки.
Можно немного выдохнуть — мониторинг опять заработал.
Второй шаг миграции
Теперь надо просто запустить миграцию истории, но чтобы этот процесс не сильно нагружал СУБД.
Так думал я, но все оказалось интереснее.
Перед вторым шагом миграции я решил создать в моем тестовом окружении нагрузку на Zabbix сервер. В тестовом окружении отсутствовали Zabbix прокси (это логично, так как мои основные прокси с тестовым сервером работать не намерены), так что нагрузку я решил создавать на самом сервере. Для этого с помощью API я создал около 200 хостов и попросил Zabbix сервер совершать проверки icmp и web checks к этим хостам каждую секунду. Получил около 1000 NVPS.
Очереди не росли, Zabbix server и PostgreSQL легко справлялись с такой нагрузкой.
Пора мигрировать историю.
Подготовим файл zabbix.load.data для pgloader:
Обратите внимание на строки:
говорит о том, что при начале миграции не будут очищены все мигрируемые таблицы. Ведь в истории уже появляются данные, так как мониторинг запущен.
говорит о том, что мигрировать в этот раз будут только таблицы истории.
Запускаем миграцию
Миграция истории началась, процесс этот может быть долгим. В моем случае при размере базы около 150 Гб и не самом сильном железе миграция истории занимает 4-5 часов.
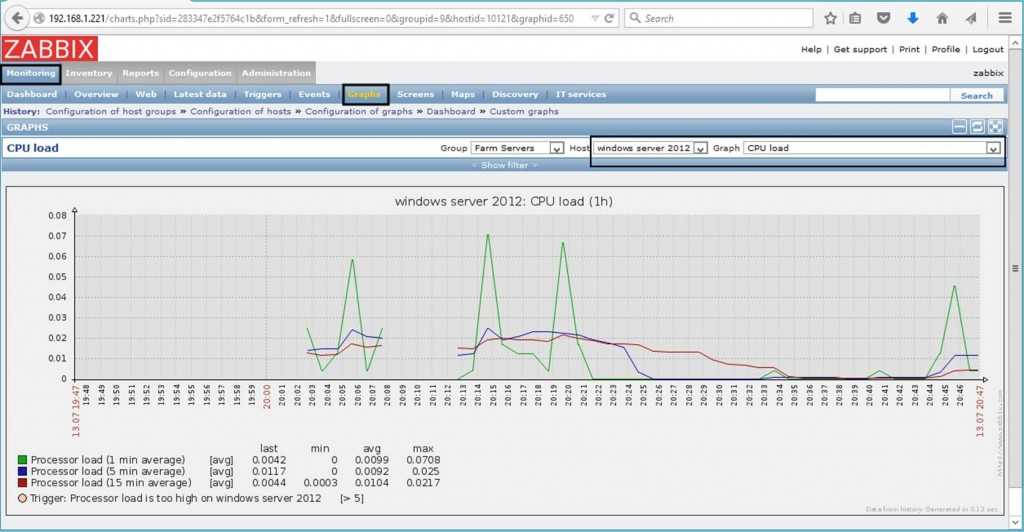
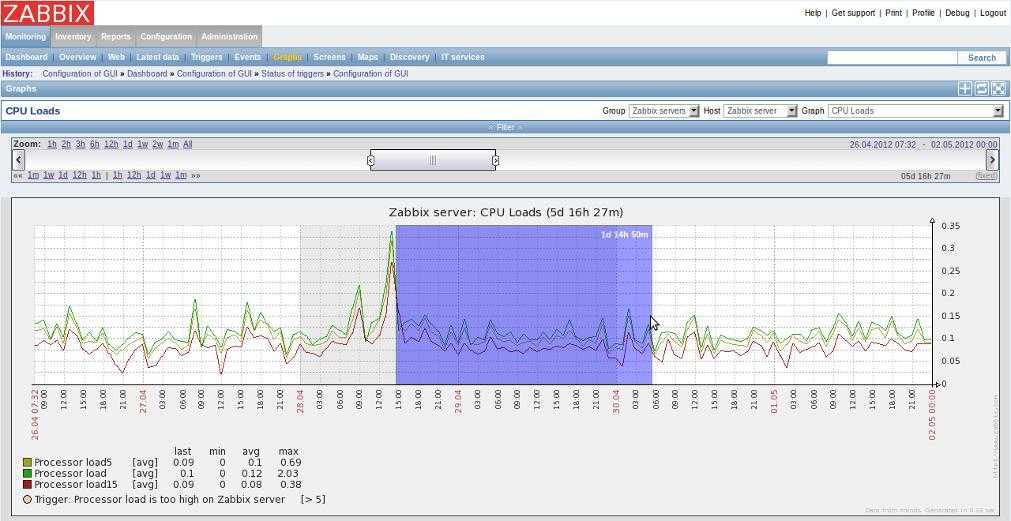
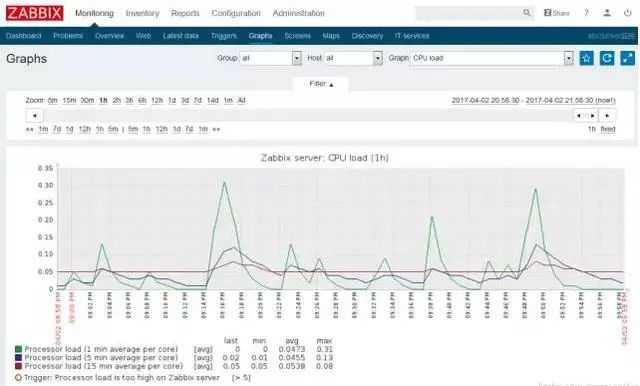
Поначалу все шло хорошо. Потом я обнаружил, что загрузка CPU на PostgreSQL сервере растет линейно, и со временем ресурсов для нормальной работы уже не хватало (на графике load average на 1 ядро):
В логи Zabbix сервера сплошным полотном начали сыпаться медленные запросы SELECT. Как я понял, для того, чтобы совершить web check, нужно для начала сделать SELECT.
![Zabbix настройка мониторинга сети и оборудования [айти бубен]](https://tehnikaarenda.ru/wp-content/uploads/1/a/a/1aa4b74f40188008c3509461f632e20f.jpeg)
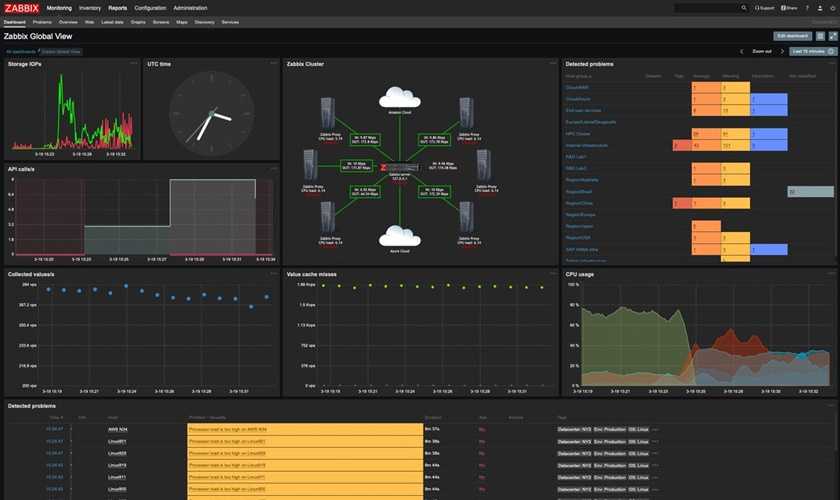
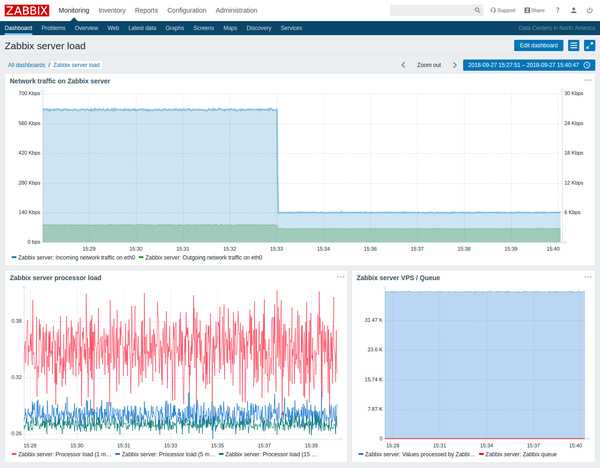
Я попробовал снизить интенсивность миграции. Для этого изменил следующие параметры в файле zabbix.load.data:
Но с такими настройками не поменялось ничего, кроме скорости миграции. Нагрузка росла также линейно со временем.
Ну не зря же я обвесил PostgreSQL мониторингом. Изучаю его показатели и вижу, что линейный рост нагрузки явно совпадал с продолжительностью транзакции, которую создал pgloader:
А также с количеством tuples, которые возвращала PostgreSQL клиентам в ответ на их запросы:
Идем в интернет, ищем информацию о том, как ведет себя PostgreSQL при длинных транзакциях. И находим вот такой замечательный доклад с конференции HighLoad:https://www.youtube.com/watch?v=3h48iowNbwo
Советую посмотреть доклад, но если вкратце, то при наличии длинной транзакции в PostgreSQL не срабатывает механизм внутристраничной очистки (single-page cleanup). И это приводит к росту тех самых возвращаемых tuple. СУБД приходится разбираться, какой tuple ей нужен, что ведет к росту загрузки CPU.
Я проверил мою ситуацию — действительно, достаточно открыть транзакцию, создать в ней таблицу, а затем НЕ закрыть транзакцию:
У спустя некоторое время видим рост загрузки CPU:
Падение загрузки в конце графика — это закрытая вручную транзакция.
Видимо, с этой особенностью придется мириться. Что можно сделать? Например, мигрировать историю отдельно, тренды отдельно, чтобы хоть немного уменьшить продолжительность транзакции.
Но это не всё. У меня все таки получилось сделать так, чтобы эта особенность PostgreSQL не мешала.
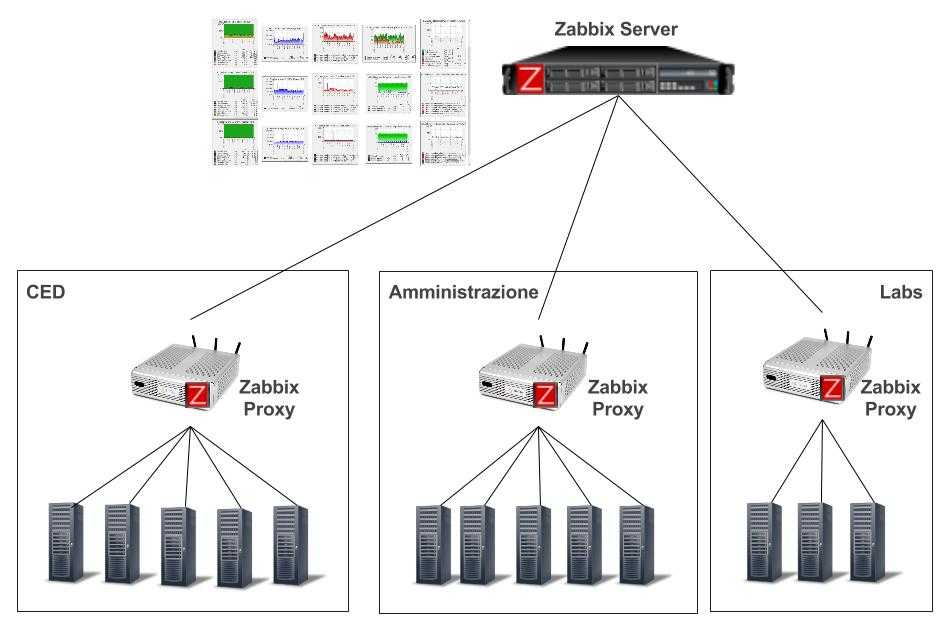
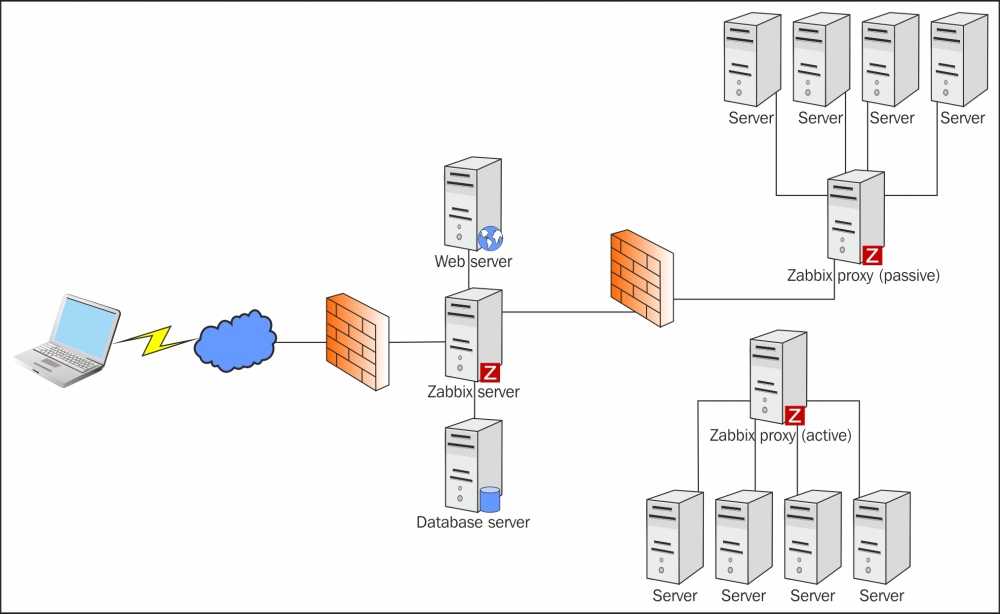
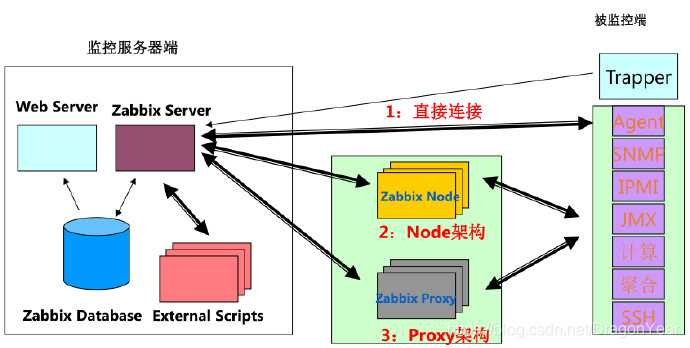
Немного о моей реальной инсталляции Zabbix. На ней почти все задачи сбора данных делегированы на Zabbix прокси. Сервер занимается лишь приемом данных и всякими триггерами/препроцессингом. Но как я написал выше, на тестовой инсталляции все проверки исполнял сам сервер.
Я вынес все задачи сбора данных на прокси в тестовой инсталляции, сильно снизив нагрузку на Zabbix Server и PostgreSQL. И оказалось, что это помогло! После этого никакая длинная транзакция не создавала сверхвысокой нагрузки на CPU, не мешала мониторингу нормально работать. Ну либо по какой-то причине внутристраничная очистка PostgreSQL при таком сценарии заработала. Может быть знатоки PostgreSQL подскажут?
Подготовка к обновлению
Важная информация перед обновлением. Версия 5.2 без длительной поддержки. Через пол года к ней перестанут выходить обновления, так что вам обязательно придется обновляться на следующую версию. Если для вас не критичны нововведения этого релиза, пропускайте его и ждите новой LTS версии.
Если у вас версия ниже 5.0, то предварительно обновите ее до указанной. У меня есть цикл статей на тему обновления Zabbix:
- 2.4 до 3.0
- 3.0 до 3.2
- 3.2 до 3.4
- 3.4 до 4.0
- 4.0 до 4.2
- 4.2 до 4.4
- 4.4 до 5.0
Перед обновлением, сделаем на всякий случай бэкап базы данных. Для этого предварительно остановим сервер с агентом.
У меня что-то активно писалось в базу, поэтому сервер выключался долго. Я проверил лог zabbix-server, чтобы убедиться в корректном выключении. Там все нормально было, сервер штатно завершил работу, дописав то, что у него там накопилось. Так что бэкапим.
| zabbix | название базы данных заббикса |
| -uzabbix | ключ -u и дальше имя пользователя базы данных |
| -p’password’ | ключ -p и дальше пароль пользователя бд, если в пароле есть спецсимволы, экранируйте их одиночными кавычками |
На всякий случай сохраним php скрипты админки, чтобы можно было оперативно запустить старую версию в случае нештатной ситуации. Хотя лично я сделал снепшот виртуалки перед обновлением, чтобы откатиться назад в случае проблем.
Centos 7
Подключаем репозиторий версии zabbix 5.0:
# rpm -Uvh https://repo.zabbix.com/zabbix/5.2/rhel/7/x86_64/zabbix-release-5.2-1.el7.noarch.rpm
Centos 8
# rpm -Uvh https://repo.zabbix.com/zabbix/5.2/rhel/8/x86_64/zabbix-release-5.2-1.el8.noarch.rpmСтарый репозиторий от версии 4.4 будет автоматически удален.
Очищаем и пересоздаем кэш yum:
Удаляем пакет текущего репозитория:
Подключаем новый:
Обновляем информацию о репозиториях:
Удаляем пакет текущего репозитория:
Подключаем новый:
Обновляем информацию о репозиториях:
Ubuntu 20
Удаляем пакет текущего репозитория:
Подключаем новый:
Обновляем информацию о репозиториях:
Если у вас другие версии систем, то простой найдите ссылки пакетов под свою версию в официальном репозитории — https://repo.zabbix.com/zabbix/5.2/ Дальнейшее обновление не будет отличаться от текущего.
К обновлению подготовились, можно приступать.
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
# zabbix_agentd -t proc.num proc.num
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных срабатываем.
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Проверка отправки списка процессов
Теперь проверим, как все это будет работать. Для этого идем на целевой сервер и нагружаем его чем-нибудь. Я для примера запустил в двух разных консолях по команде:
# cat /dev/zero | bzip2 -c > /dev/null # md5sum /dev/urandom
Они достаточно быстро нагрузили единственное ядро тестового сервера, так что оставалось только подождать активации триггера. Через 5 минут это случилось.
Иду в раздел Последние данные и вижу там список процессов, которые нагрузили мой сервер.
Что мне в итоге и требовалось. Теперь нет нужды каким-то образом проверять, что конкретно нагружает сервер. В момент пиковой нагрузки я получу список запущенных процессов в отдельный айтем. Для полного списка процессов все делается по аналогии.
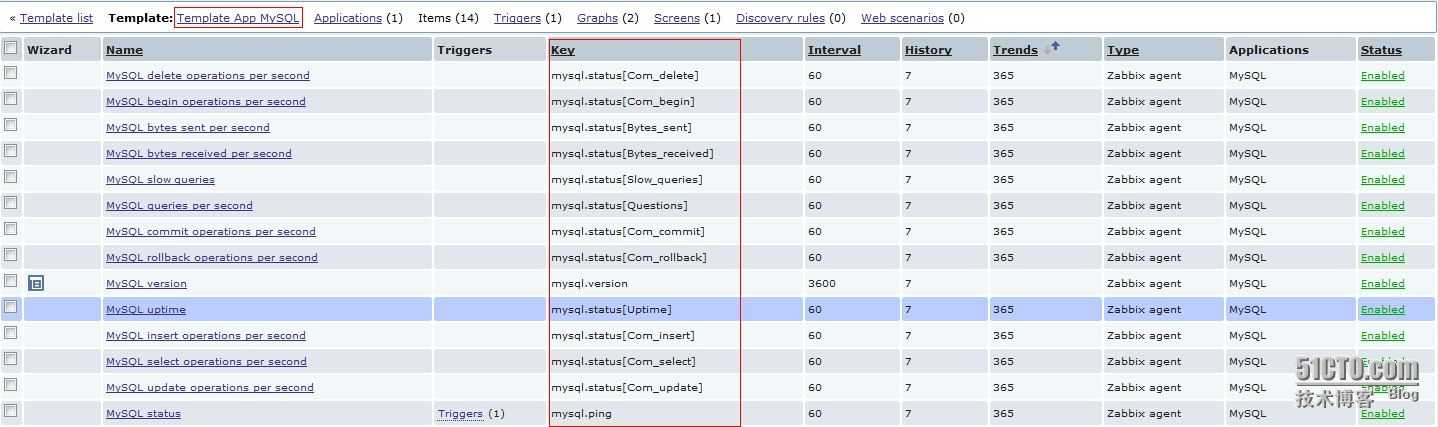
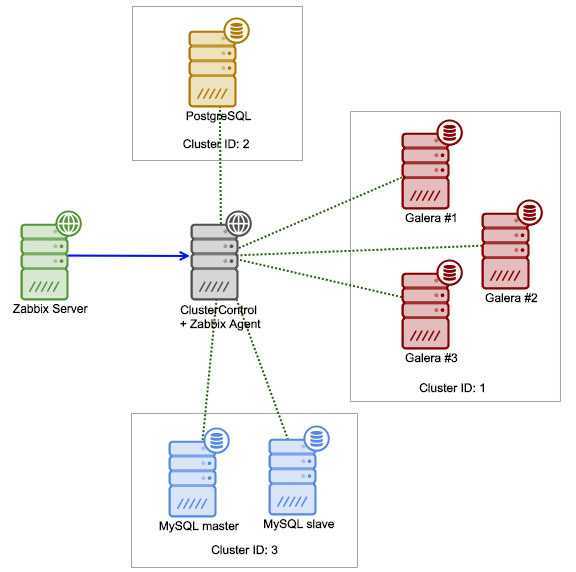
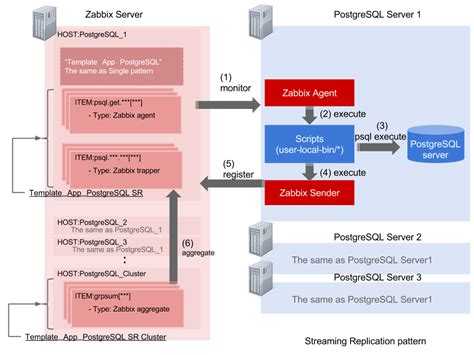
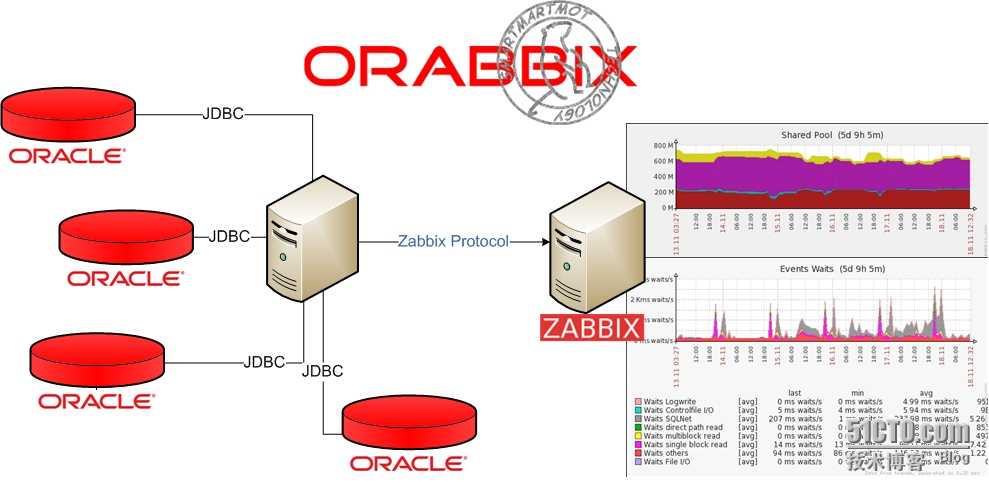
Настройка мониторинга MySQL в ZABBIX
Создаем каталог для скриптов, если его все ещё у вас нет. Сразу назначаем права и меняем владельца:
root@debian7:~# mkdir -m 750 /usr/local/etc/zabbix_agent_scripts
root@debian7:~# chown root:zabbix /usr/local/etc/zabbix_agent_scripts
Создаем скрипт:
root@debian7:~# nano /usr/local/etc/zabbix_agent_scripts/mysql-stats.sh
Со следующим содержанием:
Изменим владельца скрипта и сделаем его исполняемым для владельца и группы, назначив соответствующие права:
root@debian7:~# chown root:zabbix /usr/local/etc/zabbix_agent_scripts/mysql-stats.sh
root@debian7:~# chmod 550 /usr/local/etc/zabbix_agent_scripts/mysql-stats.sh
Далее необходимо создать пользователя в MySQL.
root@debian7:~# mysql -u root -p
mysql> grant usage on *.* to ‘zabbix’@’localhost’ identified by ‘your-password’ ;
mysql> flush privileges;
mysql> quit;
Следующий шаг будет создание каталога для пользовательских параметров. В принципе вы можете добавлять эти параметры в самом конце конфигурационного файла zabbix-агента, но грамотней будет в этом же конфиге определить внешний путь для дополнительных параметров, что я и сделал. Создаем каталог и сразу назначаем ему права и меняем владельца:
root@debian7:~# mkdir -m 750 /usr/local/etc/zabbix_agent_configs
root@debian7:~# chown root:zabbix /usr/local/etc/zabbix_agent_configs
Далее открываем конфигурационный файл zabbix-агента, ищем параметр «Include» (необходимо его раскомментировать), его значением будет определенный выше путь для дополнительных конфигурационных файлов.
root@debian7:~# nano /usr/local/etc/zabbix_agentd.confInclude=/usr/local/etc/zabbix_agent_configs/
Создаем файл с дополнительными пользовательскими параметрами, выставляем ему необходимые права и меняем владельца:
root@debian7:~# nano /usr/local/etc/zabbix_agent_configs/mysql.conf
UserParameter=mysql-stats,/usr/local/etc/zabbix_agent_scripts/mysql-stats.sh «none» «$1» user-name user-pass
Надо отметить, что в файле необходимо прописать в открытом виде имя пользователя и пароль, так что позаботьтесь о безопасности, не назначая дополнительных прав пользователю.
![Zabbix настройка мониторинга сети и оборудования [айти бубен]](https://tehnikaarenda.ru/wp-content/uploads/6/5/c/65c4572be83e7a4fc3b4b939849b006b.jpeg)
root@debian7:~# chown root:zabbix /usr/local/etc/zabbix_agent_configs/mysql.conf
root@debian7:~# chmod 550 /usr/local/etc/zabbix_agent_configs/mysql.conf
Перезапускаем агента:
root@debian7:~# service zabbix-agent restart
Остается импортировать новый шаблон на zabbix-сервер. Скачать готовый шаблон для мониторинга MySQL можно тут: Шаблон для мониторинга MySQL Stats (agent)
Для надежности проверим как отдаются данные:
root@debian7:~# zabbix_get -s 127.0.0.1 -k mysql-stats
Вместо «127.0.0.1» вставьте адрес вашего сервера с MySQL.
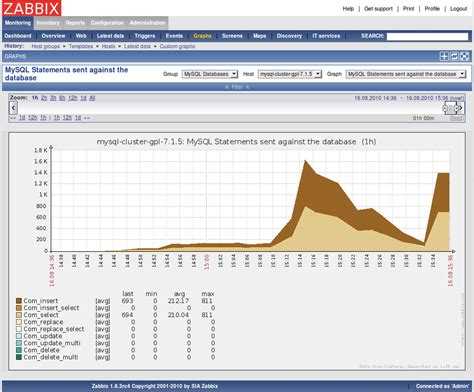
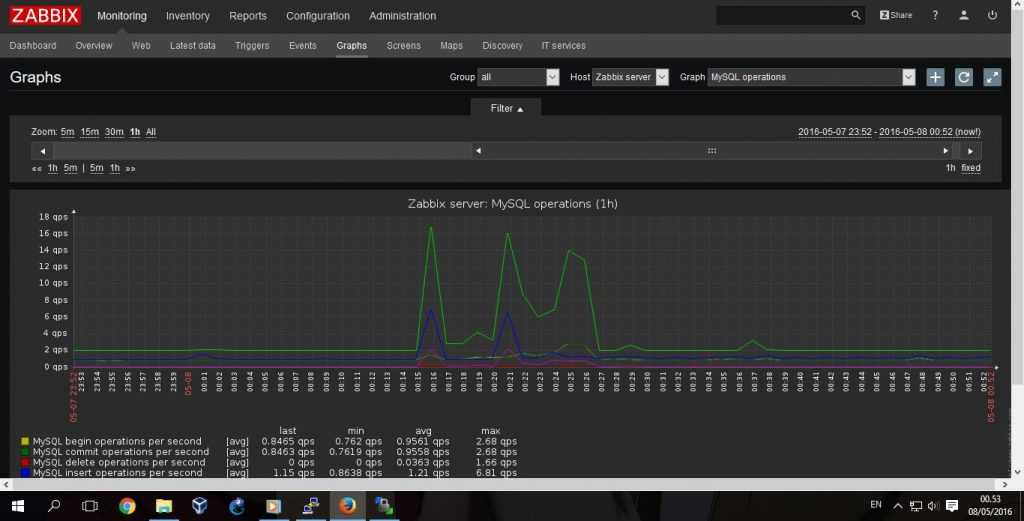
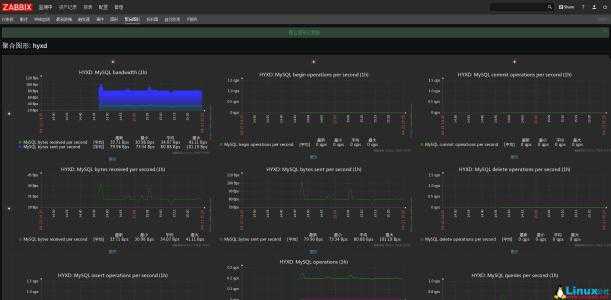
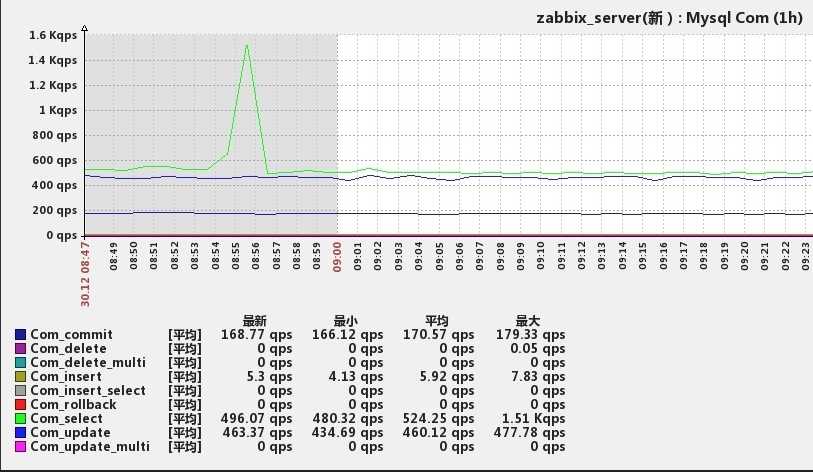
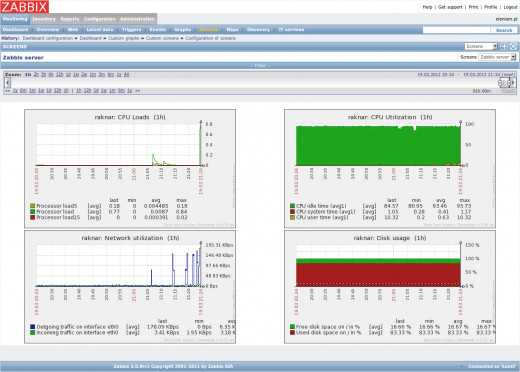
Настройка завершена. Ниже небольшой пример поступающих данных:
Вопрос анализа данных в этой статье не рассматривается, т.к. он упирается в комплексное отслеживания совокупности зависящих друг от друга параметров, которые нельзя рассматривать по-одному.
Notes:
- CREATE USER Syntax
comments powered by HyperComments





