
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
# zabbix_agent -t service_state service_state
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Введение
Сразу хочу предупредить, что моя информация это только мой личный опыт, результат моих мыслей и способностей по решению конкретных задач. Он не претендует на истину, а скорее всего нуждается в дополнении.
Как я уже сказал, статья с мониторингом web сайта актуальна и по сей день, хотя писалась для старой версии заббикса. Ни в одном из вышедших обновлений с тех пор модуль, отвечающий за мониторинг сайта, не менялся. Все осталось точно таким же, как и было. Сегодня я хочу дополнить статью некоторой информацией, плюс поделиться своими триггерами и советами по мониторингу времени отклика сайта.
Я обратил внимание на этот параметр не случайно. Последнее время поисковые системы стали внимательно относиться к времени отклика сервера с сайтом
Первым об этом заявил гугл еще несколько лет назад. В его инструменте PageSpeed Insights давно присутствует тест на время отклика сервера. Если он отвечает медленнее, чем 200 мс, то вы получаете предупреждение и рекомендации по устранению данного недостатка сервера. Некоторое время назад яндекс в вебмастере стал тоже указывать на высокое время отклика сайта, если таковое замечает.
Так что тема времени ответа сервера на сегодняшний день очень актуальна. Отдельно нужно рассматривать настройку веб сервера для уменьшения отклика. Возможно, я соберусь и напишу свои рекомендации на этот счет. А пока настроим мониторинг времени отклика сайта.
Введение
Я давно знаком с видеонаблюдением Линия. Она популярна, функциональна, стоит не очень дорого, ставится без проблем на любую версию Windows. Настроить и ввести в эксплуатацию такую систему нет никаких проблем. Мне нужно было настроить мониторинг этой системы, установленной на Windows 7.
С базовыми метриками нет никаких проблем — ставим сам zabbix сервер, , настраиваем мониторинг дисков. Дальше нужно было подумать, как мониторить сами камеры.
Первое, что приходит в голову — icmp проверки по ip. У такого подхода есть 2 минуса:
- Камера может пинговаться, но при этом реально не выдавать картинку на сервер.
- Камеры могут быть в разных сетях, к которым может не быть доступа с сервера мониторинга.
Гораздо удобнее было бы получать всю необходимую информацию по камерам с самого сервера Линии. Стал копать в этом направлении и вот что нашел.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
А что там с JMX обнаружением?
JMX обнаружение появилось в Zabbix одновременно с появлением нативной поддержки мониторинга Java приложений через JMX. За эту функцию отвечает недокументированный (на тот момент) ключ jmx.discovery. В документации о нём не было ни слова, потому что это была ещё очень сырая функция:
- В таком обнаружении нет особого смысла, потому что нет никаких возможностей для фильтрации. А вряд ли кому-то требуется обнаруживать все существующие JMX-объекты.
- Это очень медленное решение, т.к. здесь выполняется по одному запросу на каждый MBean, а их может быть довольно много. Очень вероятно, что такая проверка просто отвалится по таймауту.
- В таком виде можно создать лишь одно правило обнаружения в рамках хоста, что весьма печально, потому что на практике хотелось бы создавать множество правил (банально могут отличаться типы данных для разных атрибутов).
В Zabbix 3.4 появилась возможность фильтрации, что сразу решает многие проблемы.
Новая проверка выглядит так:
И позволяет указать, требуется ли обнаружение MBean’ов или их атрибутов, а также по какому шаблону их искать.
Давайте попробуем её в деле! Замониторим, к примеру, сборщики мусора. Известно, что их имена могут различаться в зависимости от того, с какими параметрами запущена JVM. А значит мы не можем задать статичные имена и ключи для элементов данных — это работёнка как раз для jmx.discovery.Документация описывает нам четыре примера использования:
| Ключ | Описание |
|---|---|
| Получение всех JMX MBean атрибутов | |
| Получение всех JMX MBeans | |
| Получение всех атрибутов сборщика мусора | |
| Получение всех сборщиков мусора |
Первые два варианта мы использовать не будем, т.к. это не очень хорошо с точки зрения производительности. Посмотрим, что возвращают нам два последних.
Для этой цели мы можем просто создать item с нужным нам ключом и текстовым типом данных. Но это не очень удобно. Во-первых, вывод будет неформатированным и ненаглядным. Во-вторых, чтобы изменить запрос, нам всякий раз придётся изменять ключ item’а и какое-то время ждать обновления данных.
Это не наш путь. Давайте лучше сделаем что-то вроде zabbix_get, только вместо агента будем обращаться к Java Gateway. Для этого немного доработаем предложенный в этой заметке скрипт под новый API: добавим jmx_endpoint в запрос и поправим удаление заголовка из ответа:
Теперь мы с лёгкостью можем посмотреть, что возвращает нам шлюз в ответ на наши запросы:
То что нужно!
Если бы нам требовалась, допустим, всего пара метрик, то мы могли бы обнаружить все gc и создать на каждую метрику по прототипу.
Создаём правило обнаружения
Ищем MBean’ы (кстати, обратите внимание, что везде используется кастомный JMX endpoint).
Создаём прототипы на каждую интересующую нас метрику. В имени элемента данных и его ключе мы можем использовать любые макросы, которые видели в JSON’е.
Кстати, о макросах. При обнаружении MBean’ов макросы генерируются динамически на основе свойств MBean’ов (таких как type и name).
Но, допустим, мы хотим создать все доступные числовые метрики по сборщикам мусора.
- Тогда мы создадим правило обнаружения атрибутов с фильтром по типу данных.
- И всего лишь один прототип:
Вот таким нехитрым образом можно замониторить любое Java приложение. Дерзайте! 
Получение доступа к API Яндекс
Вам нужно будет заполнить несколько обязательных полей:
- Название приложения.
- В качестве платформы указать Веб-сервисы.
- Callback URI установить — https://oauth.yandex.ru/verification_code.
- В Доступах указать: Яндекс.Метрика, Получение статистики, чтение параметров своих и доверенных счетчиков.
Все остальное можно не указывать. Вы должны получить ID приложения и Пароль.
После разрешения, вы получите токен, с помощью которого можно подключаться к api.
Используя этот токен, можно получать данные из Метрики через API. Для примера зайдем на сервер мониторинга и через консоль запросим данные о посещаемости сайта. Для этого нам нужно узнать номер его id в метрике. Можно это сделать прямо в ней же.
Далее формируем запрос через curl с указанием токена в header.
# curl --header "Authorization: OAuth AgAAaaaaaaaaaaaDDDDDDDDDddd" --header "Content-Type: application/x-yametrika+json" -X GET "https://api-merika.yandex.ru/stat/v1/data?&ids=23506456&metrics=ym:s:users,ym:s:visits,ym:s:pageviews&dimensions=&date1=today&pretty=true"
В данном запросе я указал:
- AgAAAAAAGk3WAAaaYZaUSgzNyU7uvqAKCGwDSro — токен;
- ids=23506456 — id сайта в метрике;
- metrics=ym:s:users,ym:s:visits,ym:s:pageviews — запрошенные метрики — пользователи, визиты, просмотры страниц;
- date1=today — дата, сегодняшний день в данном случае;
- pretty=true — вывести в формате удобочитаемого json.
Получили ответ в виде подробного json. Он отлично подходит для zabbix, так как последний умеет из коробки парсить json. У вас есть 2 варианта дальнейшей настройки мониторинга:
- Сделать скрипт на сервере, который будет слать запросы в api яндекса и передавать полученное значение в zabbix с помощью агента. Плюс решения в том, что нагрузка на сервер мониторинга минимальная. Неудобство в том, что нужно куда-то добавлять скрипт.
- Слать запросы к api напрямую с zabbix сервера с помощью HTTP Агента. И сразу там же парсить полученный ответ. Плюс этого подхода в том, что все настройки хранятся в шаблоне и легко сохраняются или переносятся через экспорт шаблона. Минус в том, что все вычисления и запросы выполняются самим заббиксом.
Я обычно иду по второму пути, потому что так удобнее.
В таком виде это можно отправлять в Zabbix, чем мы далее и займемся.
Проверка работы
Для проверки работы мониторинга за временем, достаточно на каком-то сервере установить время с отставанием или опережением более чем на 60 секунд. После этого подождать 3 неудачные проверки.
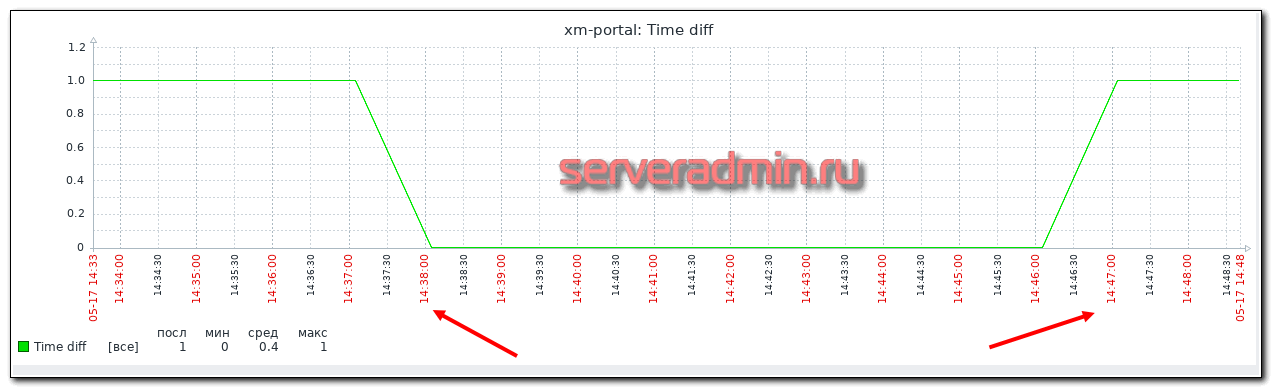
После этого сработает триггер.

Как видно по графику, 3 неверных значения пришли к 14:40, в этот момент сработал триггер. В 14:47 проверка вернула значение 1 и триггер перешл в состояние РЕШЕНО. В это время я сначала остановил ntpd, потом задал неправильное время командой:
# date +%T -s "14:35:13"
Этим я создал отставание на полторы минуты. Подождал несколько минут, потом обратно запустил службу ntpd и дождался, когда она проведет синхронизацию.
Дополнительные материалы по Zabbix
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Оповещение о недоступности сайта
Давайте настроим уведомления о проблемах на сайте. Я предлагаю 2 типа оповещения:
- О низкой скорости доступа к сайту.
- О недоступности сайта вообще.
Идем, как обычно в исходный шаблон, на вкладку Triggers и добавляем новый.
Я предлагаю вот такое условие срабатывания для определения недоступности сайта. Если среднее значение 3-х последних проверок больше, либо равно единице, то срабатывает оповещение о недоступности сайта.
Когда идет 0 во всех проверках, все в порядке. Триггер сработает только если все 3 последних проверки не равны нулю. В моем примере Failed step может принимать значение либо 0, либо 1, где 1 это номер сбойного шага. Если у вас шагов несколько, то сбойным может оказаться второй шаг или третий шаг. То есть значение может быть больше 1. Но в любом случае, если последние 3 значения подряд строго не 0, то идет срабатывание триггера. Операция восстановления очень простая. Если последняя проверка без ошибки, то есть код равен 0, то считаем, что сайт уже работает.
Чтобы проверить работу триггера, достаточно на zabbix server в файл /etc/hosts добавить строку:
127.0.0.1 github.com
и подождать 3 минуты, чтобы получились 3 неудачных проверки. После этого вам должно было отправиться уведомление о недоступности сайта. Я получил вот такое:
Дальше делаем проверку времени ответа сервера. Тут каждый волен настраивать так, как ему кажется более правильным и удобным. Я использую такую схему. Беру среднее время отклика сайта и умножаю его на 3. Далее смотрю последние 7 проверок. Если в 5 проверках среди этих семи были значения выше, чем утроенное среднее время отклика, то считаю, что сайт тормозит и надо слать уведомление. Немного замороченно, но на практике такая схема у меня себя хорошо зарекомендовала без ложных срабатываний. При этом, если возникают реальные проблемы, я их вижу. Рисуем триггер.
Условие восстановления — в последних трех запросах два и более были быстрее, чем утроенное среднее время доступа. Текст выражений для копирования:
{Sites Monitoring:web.test.time.count(#7,1.5,"ge")}>4
{Sites Monitoring:web.test.time.count(#3,1.5,"lt")}>1
В выражении 1.5 это время отклика в секундах. Именно в таком виде оно попадает в zabbix сервер. Проверить можно в Latest Data.
В завершении оставляю свой шаблон, который создал для написания статьи. Можете копированием и редактированием приспособить его для своих сайтов. Это быстрее, чем составлять с нуля. Шаблон экспортирован с версии zabbix 4.0 — sites_monitoring.xml
Вот и все, мониторинг веб сайта работает, авторизация проверяется, оповещение о недоступности сайта настроено. Для полноты картины можно создать Screen или Dashboard с выводом всех необходимых параметров на один экран. Его настройки уже будут зависеть от конкретной ситуации и тех данных, которыми вы располагаете. К примеру, если у вас настроен мониторинг веб сервера, то можно разместить рядом графики его загрузки и параметры доступа к сайту. Туда же можно добавить загрузку самого сервера по процессору и памяти и вывести график использования сетевого интерфейса.
В этом плане Zabbix очень гибок и позволяет настроить все на любой вкус и под любые требования.
Более подробно о мониторинге за временем отклика сайта читайте в отдельной статье на этот счет. Там описана теория процесса и практические рекомендации, вместе с готовым триггером.
Модуль мониторинга PostgreSQL в составе Zabbix Agent 2
Для соединения с PostgreSQL используется быстрый и популярный драйвер pgx (PG driver and toolkit for Go).
Пока мы используем два интерфейса: Exporter, вызывающий обработчик по ключу, и Configurator Zabbix Agent 2, который считывает и проверяет параметры соединения с сервером, заданные в конфигурационном файле.
Мы постарались оптимизировать работу СУБД, группируя метрики и используя обработчик (handler) для метрик и групп метрик, а также используя группы метрик в JSON как зависимые переменные (dependency items), и низкоуровневое обнаружение (discovery rules).
Основные возможности
- сохранение постоянного соединения с PostgreSQL между проверками;
- поддержка гибких интервалов опроса;
- совместимость с версиями PostgreSQL, начиная с 10, и Zabbix Server, начиная с версии 4.4;
- возможность подключения и мониторинга нескольких инстансов PostgreSQL одновременно благодаря тому, что Zabbix Agent 2 позволяет создавать несколько сессий.
Уровни параметров подключения к PostgreSQL
Всего доступны три уровня параметров подключения к PostgreSQL, т. е. задач и настроек:
- Global,
- Sessions,
- Macros.
-
Параметры Global задаются на уровне агента, параметры Session и Macros определяют параметры подключения базе.
-
Параметры подключения к PostgreSQL — Sessions задаются в файле zabbix_agent2.conf.
Параметры подключения к PostgreSQL — Sessions
- После ключевого слова Sessions указывается уникальное имя сессии, которое должно быть указано в ключе (шаблоне).
- Параметры URI и UserName обязательны для каждой сессии.
- Если имя базы не задано, используется общее по умолчанию имя базы для всех сессий для PostgreSQL, которое также задается в конфигурационном файле.
- Параметры подключения к PostgreSQL — Macros задаются в ключе метрики в шаблоне (аналогично способу, использованному в Zabbix Agent 1), т. е. создаются в шаблоне и далее указываются как параметры в ключе. При этом последовательность макросов фиксирована, т. е., например, URI всегда указывается на первом месте.
Параметры подключения к PostgreSQL — Macros
Модуль мониторинга PostgreSQL включает уже более 95 метрик, которые позволяют охватить довольно широкий объем параметров PostgreSQL, включая:
- количество соединений,
- объем баз данных,
- архивация wal-файлов,
- контрольные точки,
- количество «раздувшихся» таблиц,
- статус репликации,
- отставание реплики.
Метрики PostgreSQL не информативны без параметров операционной системы. Но Zabbix Agent 2 уже умеет собирать параметры операционной системы, поэтому для получения полной картины просто подключаем к узлу сети необходимые шаблоны.
Обработчик (handler)
Обработчик (handler) — основная единица модуля, в которой выполняется сам запрос и которая позволяет получать метрики.
Чтобы получить простую метрику:
- Создаем файл для получения новой метрики:
zabbix/src/go/plugins/postgres/handler_uptime.go
- Подключаем пакет и указываем уникальный ключ (ключи) метрик:
- Создаем обработчик (handler) с запросом, т. е. инициируем переменную, в которой будет результат:
- Выполняем запрос:
Необходимо проверить запрос на предмет ошибок, после чего результат будет подхвачен процессом Zabbix Agent 2.
- Регистрируем ключ новой метрики:
После регистрации метрики можно пересобирать агент с новой метрикой.
Модуль доступен, начиная с Zabbix 5.0 на сайте https://www.zabbix.com/download. В этой версии Zabbix параметры задаются отдельно через host и port. В версии Zabbix 5.0.2, которая скоро выйдет, параметры подключения будут скомпонованы в один URI.
Спасибо за внимание!
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
# zabbix_agentd -t proc.num proc.num
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных срабатываем.
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.



