
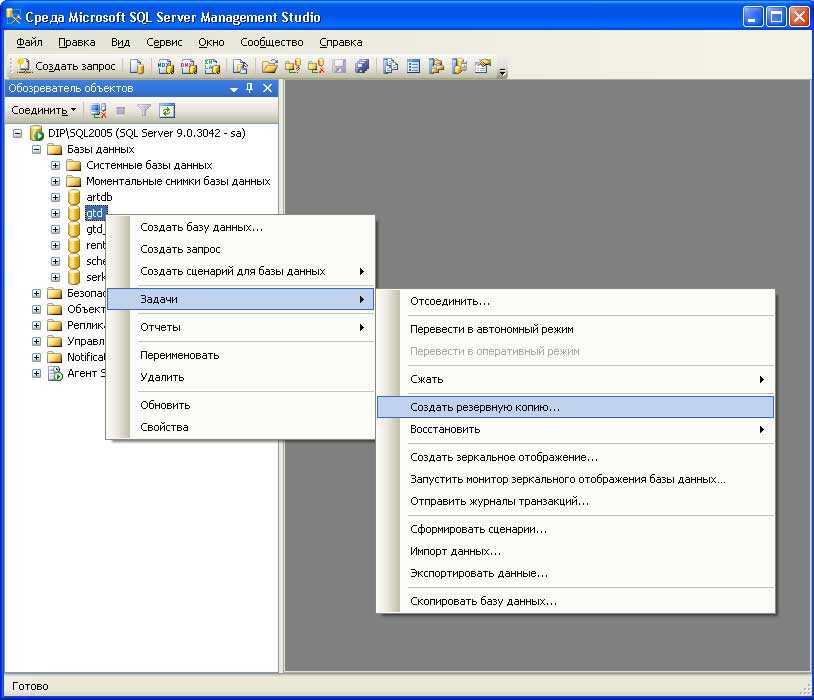
Проверка дампа mysql
То, что вы сделали дамп базы совсем не значит, что он завершился успешно. Он может быть прерван по какой-то причине. Причем, он год может выполняться успешно, а в какой-то момент начнет давать сбой в самом конце выгрузки. Если никак не отслеживаете ситуацию, можете это не заметить, а потом получить неконсистентную (битую) выгрузку.
Я делаю следующую проверку дампа сразу после его создания, чтобы не тащить на сервер бэкапов битый архив. Если дамп прошел успешно, то в первой строке дампа будет примерно такая строка:
-- MySQL dump 10.13 Distrib 5.7.33-36, for Linux (x86_64)
У вас может отличаться версия сервера, но начало будет одинаковое — двойное тире и слово Mysql. В конце дампа будет следующая строка:
-- Dump completed on 2021-07-11 20:21:06
Эти две строки я и буду проверять в скрипте, который будет делать дамп в автоматическом режиме. Результат проверки бэкапа я буду записывать в лог файл, а заодно и вывод утилиты mysqldump, чтобы в случае какой-то ошибки, я смог его проанализировать.
#!/bin/bash
#ключи mysqldump
OPTS="-v --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob"
#файл дампа
FNAME="/mnt/backup/`date +%Y-%m-%d_%H-%M`_dbname.sql"
#лог результатов проверки дампа
LOG="/var/log/mysql/backup.log"
#лог вывода mysqldump
MLOG="/var/log/mysql"
#формат даты
DATA=`date +%Y-%m-%d_%H-%M`
#делаем дамп базы и записываем вывод в лог
/usr/bin/mysqldump ${OPTS} --databases dbname -u'root' -p'password' > ${FNAME} 2>> ${MLOG}/${DATA}-mysqldump.log
#сжимаем лог
/usr/bin/gzip ${MLOG}/${DATA}-mysqldump.log
#проверяем первую и последнюю строки дампа
BEGIN=`head -n 1 ${FNAME} | grep ^'-- MySQL dump' | wc -l`
END=`tail -n 1 ${FNAME} | grep ^'-- Dump completed' | wc -l`
#если обе строки верны, то пишем в лог ОК и сжимаем дамп
if ;then
if ;then
echo `date +%F_%H-%M` ${FNAME} is OK >> $LOG
/usr/bin/gzip ${FNAME}
else
echo `date +%F_%H-%M` ${FNAME} is corrupted >> $LOG
/usr/bin/rm ${FNAME}
fi
else
echo `date +%F_%H-%M` ${FNAME} is corrupted >> $LOG
/usr/bin/rm ${FNAME}
fi
#если дамп не проходит проверки, удаляем его и пишем в лог corrupted
#удаляем бэкапы и логи старше суток.
find /mnt/backup -type f -mmin +1440 -exec rm -rf {} \;
find /var/log/mysql/*mysqldump* -type f -mmin +1440 -exec rm -rf {} \;
Я скрипт прокомментировал, так что добавить особо нечего. Делаем дамп, проверяем первую и последнюю строки. Результат проверки пишем в лог файл, за которым далее будем наблюдать с помощью Zabbix.
Восстановления базы из дампа
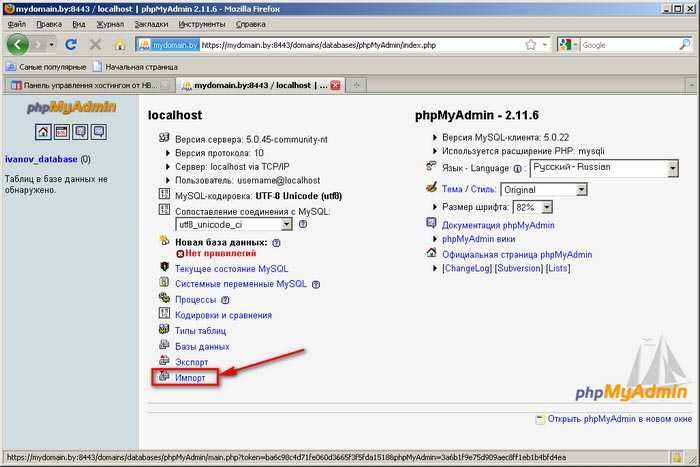
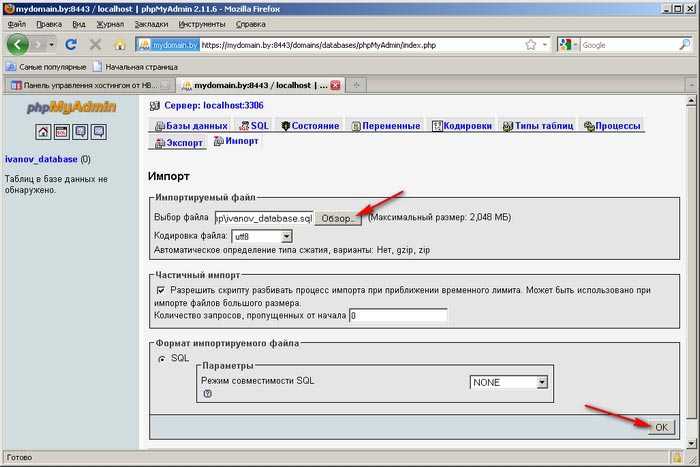
Через phpMyAdmin
В основном, пользователи работают с MySQL через панель phpMyAdmin, поэтому ниже приведен наиболее простой способ сделать восстановление из бэкапа вручную. Чтобы восстановить базу из дампа, нужно выполнить несколько действий:
Как увеличить объем импортируемых баз данных
К сожалению, описанный выше способ восстановить базу данных MySQL подходит в основном для небольших баз данных. Ведь в phpMyAdmin «из коробки» установлены ограничения на максимальный размер загружаемых файлов на сервер в 2 Мб.
Чтобы обойти дефолтные ограничения phpMyAdmin, нужно увеличить размер разрешенных к загрузке файлов. Это можно сделать как в настройках самой программы, так и на стороне сайта/сервера.
Во втором случае (в файлах php.ini /.htaccess) потребуется увеличить значения по умолчанию ряда опций, влияющих на загрузку:
- upload_max_filesize («максимальный размер загружаемого файла»). Первоначальное значение: «2Mб».
- post_max_size («максимальный размер POST-запросов»). Значение параметра должно быть больше, чем у «upload_max_filesize».
- max_execution_time («время исполнения скрипта»). Чтобы снять ограничения с параметра, ему нужно присвоить значение «0».
- max_input_time («время обработки входящих запросов»).
Способы увеличения лимитов на исполнение php-скриптов
- В настройках конфигурационного файла phpMyAdmin (config.inc.php). В файл нужно добавить строки:
$ cfg = './upload';
После чего добавить туда же переменную, снимающую ограничения со времени исполнения скриптов (после загрузки базы данных ее лучше убрать):
$ cfg = 0;
- В пользовательском файле сайта (php.ini), где хранятся настройки исполнения php-скриптов. Файл «php.ini» можно найти, если открыть в браузере ранее добавленный (в корень сайта) php-файл. Например, ввести запрос вида «https://mysitename.com/myphpinfo.php», где «mysitename.com» — имя сайта, а «myphpinfo.php» — название php-файла. В открывшемся окне нужно найти параметры «Loaded Configuration File» или «Configuration File (php.ini) Path», где и будет указан путь к «php.ini».
Добавляем в конце файла строки:
post_max_size = 500M upload_max_filesize = 400M max_execution_time = 3000 max_input_time = 6000
- В конфигурационном файле сервера (.htaccess), отвечающем, в том числе, за настройку обработки файлов на определенном сайте. Чтобы изменения сработали для всех файлов сайта, «.htaccess» должен обязательно находится в его корневой папке.
Добавляем в файл строки:
php_value post_max_size 500M php_value upload_max_filesize 400M php_value max_execution_time 3000 php_value max_input_time 6000
Очистка и уменьшение mysql базы zabbix
Начнем с очистки базы данных zabbix от ненужных данных. Рассмотрим по пунктам в той последовательности, в которой это нужно делать.
- Первым делом надо внимательно просмотреть все используемые шаблоны и отключить там все, что вам не нужно. Например, если вам не нужен мониторинг сетевых соединений windows, обязательно отключите автообнаружение сетевых интерфейсов. Оно само по себе находит десятки виртуальных соединений, которые возвращают нули при опросе и не представляют никакой ценности. Тем не менее, все эти данные собираются и хранятся, создавая лишнюю нагрузку. Если же вам нужен мониторинг сети в windows, зайдите в каждый хост и отключите руками лишние адаптеры, которые будут найдены. Этим вы существенно уменьшите нагрузку. По моему опыту, в стандартных шаблонах windows мониторинг всех сетевых интерфейсов дает примерно 2/3 всей нагрузки этих шаблонов.
- Отредактируйте в используемых стандартных шаблонах время опроса и хранения данных. Возможно вам не нужна та частота опроса и время хранения, которые заданы. Там достаточно большие интервалы хранения. Чаще всего их можно уменьшить. В целом, не забывайте в своих шаблонах ставить адекватные реальной необходимости параметры. Не нужно хранить годами информацию, которая теряет актуальность уже через неделю.
- После отключения лишних элементов в шаблонах, нужно очистить базу данных от значений неактивных итемов. По-умолчанию, они там остаются. Можно их очистить через web интерфейс, но это плохая идея, так как неудобно и очень долго. Чаще всего попытки очистить 50-100 элементов за раз будут сопровождаться ошибками таймаута или зависанием web интерфейса. Далее расскажу, как это сделать эффективнее.
Для очистки базы данных zabbix от значений неактивных итемов, можно воспользоваться следующими запросами. Запускать их можно как в консоли mysql сервера (максимально быстрый вариант), так и в phpmyadmin, кому как удобнее.
Данными запросами можно прикинуть, сколько данных будет очищено:
SELECT count(itemid) AS history FROM history WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_uint FROM history_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_str FROM history_str WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_text FROM history_text WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_log FROM history_log WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS trends FROM trends WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS trends_uint FROM trends_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
Если запросы нормально отрабатывают и возвращают счетчик данных, которые будут удалены, дальше можете их удалять из базы следующими sql запросами.
DELETE FROM history WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_str WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_text WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_log WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM trends WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM trends_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
Данными запросами вы очистите базу данных zabbix от значений неактивных элементов данных. Но реально размер базы данных у вас не уменьшится, потому что в дефолтной настройке базы данных используется формат innodb. Все данные хранятся в файле ibdata1, который автоматически не очищается после удаления данных из базы.
Администрировать такую базу неудобно. Нужно как минимум настроить хранение каждой таблицы в отдельном файле. Этим мы далее и займемся, а заодно обновим сервер базы данных до свежей версии mariadb и реально очистим базу, уменьшив ее размер.
Решение
Существует несколько способов восстановить MySQL:
I. Принудительное восстановление InnoDB
Остановите mysqld и сохраните резервную копию всех файлов, расположенных в папке /var/lib/mysql/:
Добавьте опцию innodb_force_recovery в раздел в /etc/my.cnf. Эта опция позволит вам запустить mysqld и создать дамп базы данных.
ПРИМЕЧАНИЕ. Вы можете увеличить эту опцию до 5 или 6 — пока не получите оптимальный дамп.
Запустите службу mysqld:
Создайте дамп всех баз данных:
Если при создании дампа возникла следующая ошибка:
увеличьте значение innodb_force_recovery и повторите попытку. Если вы не можете создать дамп баз данных, попробуйте использовать способ II (скопировать содержимое таблицы) или III (восстановить из резервной копии).
Остановите mysqld и удалите поврежденные данные:
Удалите опцию innodb_force_recovery из файла /etc/my.cnf и запустите mysqld:
В результате этого будет восстановлена главная база данных «mysql» и движок баз данных InnoDB.
Восстановите базы данных из дампа:
II. Копирование содержимого таблицы
Остановите mysqld и сохраните резервную копию всех файлов, расположенных в папке /var/lib/mysql/:
Добавьте опцию innodb_force_recovery в раздел в /etc/my.cnf. Эта опция позволит вам запустить mysqld и создать дамп базы данных.
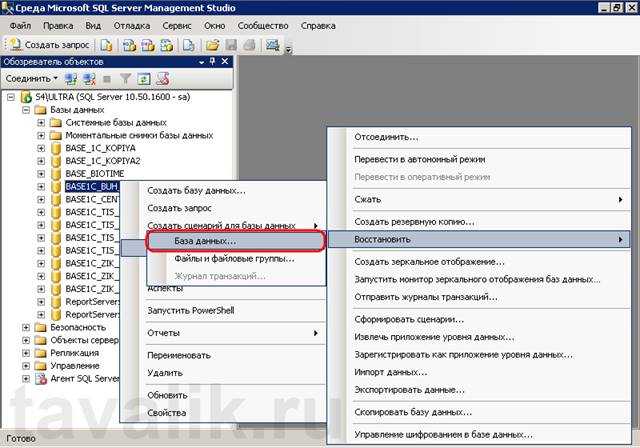
Попробуйте создать копию:
Если получилось, удалите поврежденную таблицу и присвойте ее имя новой.
III. Восстановление таблицы InnoDB
Восстановление таблиц InnoDB необходимо в случае возникновения следующей ошибки
Или при попытке сделать дамп через mysqldump
Внимание! До начала любых действий рекомендуем создать резервную копию файлов базы!
Для того чтобы восстановить таблицы InnoDB, нам нужно узнать:
узнать структуру таблиц
иметь файлы с данными (имеется ввиду файлы на уровне файловой системы)
Таблица InnoDB на уровне файловой системы состоит из двух фалов:
файл .frm хранит в себе структуру таблицы;
файл .ibd собственно данные
План восстановления:
выяснить структуру поврежденной таблицы;
создать новую базу;
создать в новой базе таблицу нужной структуры;
скопировать данные в новую таблицу из старой;
если данные окажутся поврежденными, можно попробовать восстановить их используя утилиту innochecksum
Применяем утилиту чтения структуры таблицы:
Также желательно узнать кодировку старой базы:
Создаем новую базу:
Создаем таблицу по выводу утилиты чтения структуры поврежденной таблицы:
Далее копируем данные. Очищаем автоматически созданный файл:
Копируем файл с данными с поврежденной таблицы:
Импортируем данные:
Проверяем корректность чтения данных:
Далее можно импортировать восстановленную таблицу или базу целиком.
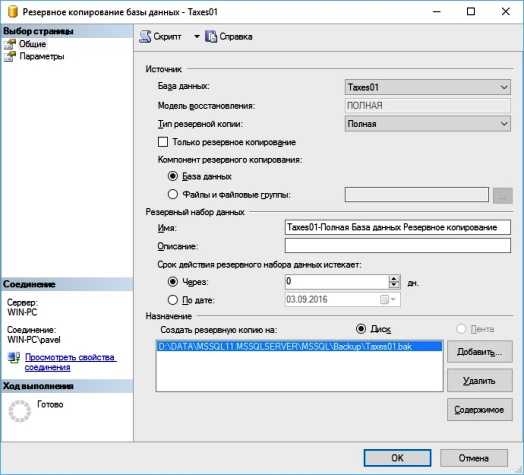
Часть 1: Резервное копирование базы данных
Для выполнения резервного копирования, вам понадобится инструмент под названием mysqldump. Он включен в MySQL, так что нет никакой необходимости устанавливать что-либо еще. Эта утилита упрощает процесс и позволяет четыре важных типа резервного копирования, которые данное руководство будет охватывать: одной базы данных, нескольких баз данных, общесистемные и уровня таблицы.
Резервное копирование одной базы данных
Предположим, что одна база данных – andreyex – необходимо резервное копирование. Это можно сделать следующим образом :
mysqldump -u root -p andreyex > andreyex_backup.sql
В этом примере, единая резервная копия базы данных andreyex в файл с именем andreyex.sql
Имя файла имеет важное значение; пользователь (и пароль) необходим для резервного копирования в Mysqldump. Вам будет предложено ввести пароль пользователя после выполнения команды
мульти-копии базы данных
Резервное копирование с несколькими базами данных позволит вам создавать резервные копии нескольких баз данных в одном файле .sql. Здесь мы хотим создать резервную копию нескольких баз данных.
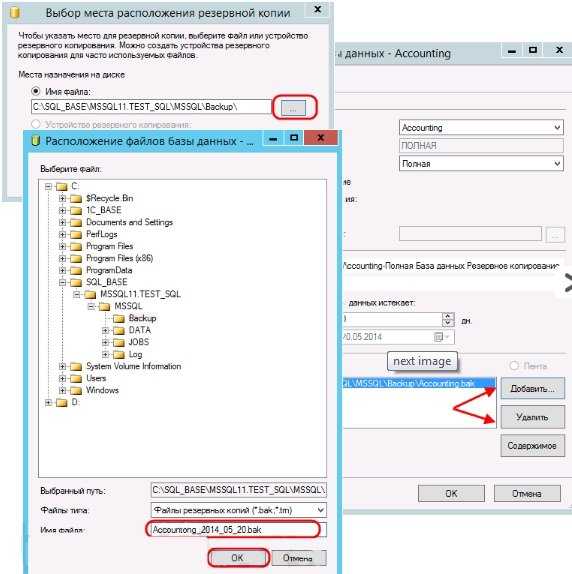
mysqldump -u root -p --databases andreyex username customer > 3databases_backup.sql
Как вы можете видеть, каждое имя базы данных должны быть разделено пробелом. Все остальное работает как можно было бы ожидать от единой резервной копии базы данных.
Общесистемные резервные копии
Периодические резервные копии базы данных всей вашей системы имеют первостепенное значение. Они гарантируют, что все может быть восстановлено в случае отказа диска или других неприятностей. В то время как они могут занять больше времени, чтобы выполнить, команда на самом деле проще, чем другие.
mysqldump -u root -p --all-databases > all_andreyex_databases.sql
Таблица резервных копий на уровне
В этом примере база данных andreyex содержит таблицу с именем customer_records. Необходимо указать как базу данных, где находится таблицы и имя таблицы.
mysqldump -u root -p andreyex customer_table > andreyex_customer_table.sql
Команда запросит у вас пароль суперпользователя, а затем таблица customer_records будут сохранена в файле andreyex.sql.
Установка
Установка XtraBackup из репозитория apt Percona.
Выполните последовательно следующие команды:
2. После установки выполните команду
Так как, важно убедиться, что утилита корректно работает на сервере. В результате на экране отобразится что-то подобное:
xtrabackup: recognized server arguments: — datadir=/var/lib/mysql — tmpdir=/tmp — server-id=1 — logbin=/var/log/mysql/mysql-bin.log — innodbbufferpoolsize=16384M — innodbfilepertable=1 — innodbflushmethod=Odirect — innodbflushlogattrxcommit=0xtrabackup version 2.4.20 based on MySQL server 5.7.26 Linux (x8664) (revision id: c8b4056)
Синтаксис и базовая команда
Создание дампа выполняется из командной строки Linux или Microsoft. Общий синтаксис:
mysqldump -p <база> > <в какой файл сделать дамп>
Пример базовой команды для резервирования базы:
mysqldump -v -uroot -p base > /tmp/dump.sql
* в данном примере мы создадим резервную копию базы base и поместим его в папку /tmp, назвав сам файл dump.sql. Подключение к базе происходит от пользователя root. Это самый простой пример создания дампа MySQL.
Базовые параметры команды mysqldump:
| Параметр | Описание |
|---|---|
| -u | Учетная запись, от которой выполняется резервное копирование. Необходимо, чтобы у пользователя были соответствующие права. |
| -p | Пароль учетной записи. Его можно ввести в команде, например -p12345 (для скрипта) или оставить -p (безопаснее). |
* полный перечень параметров смотрите в официальном руководстве.
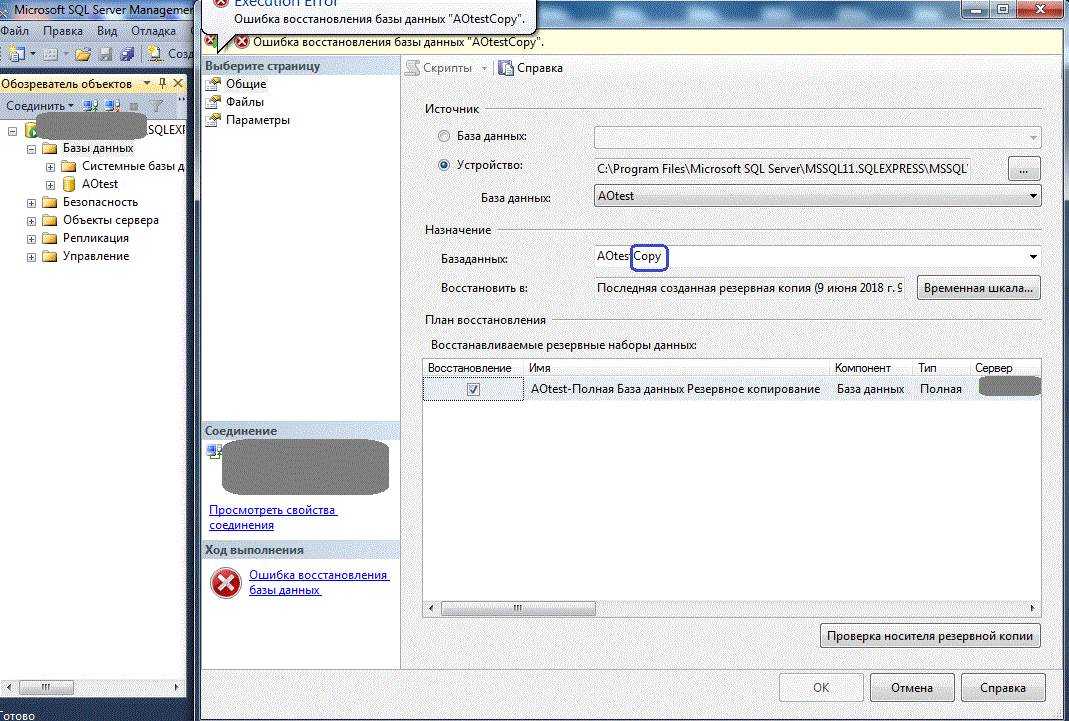
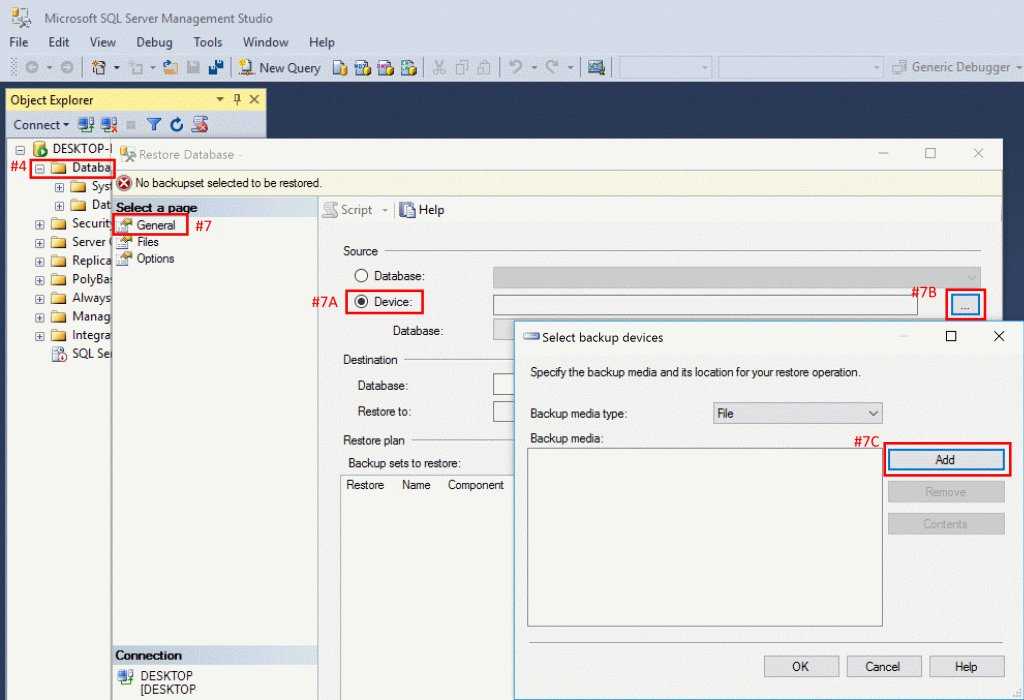
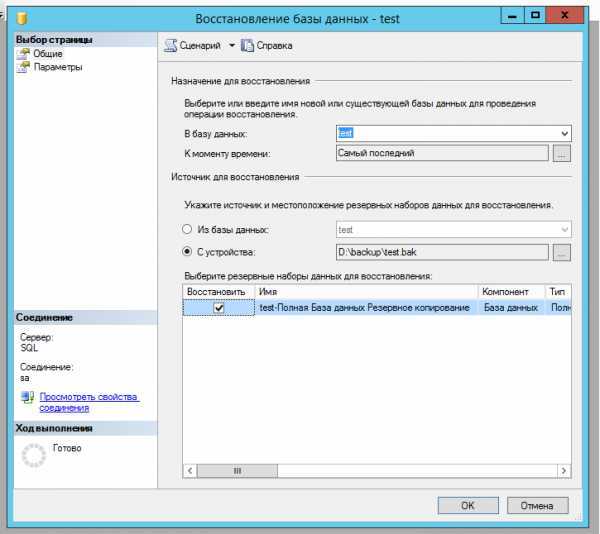
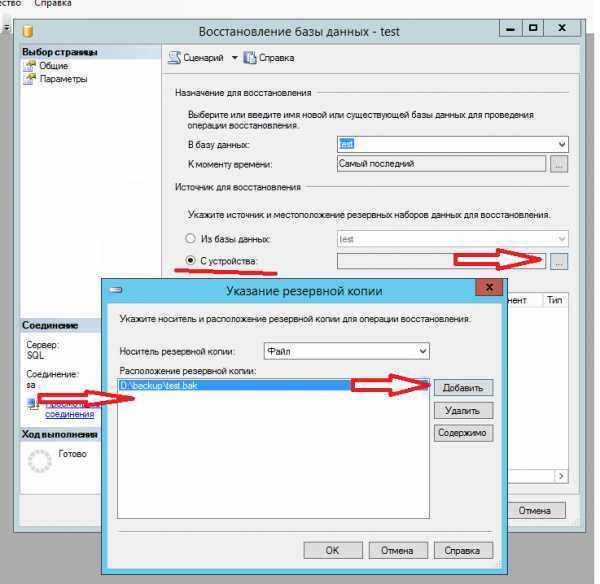
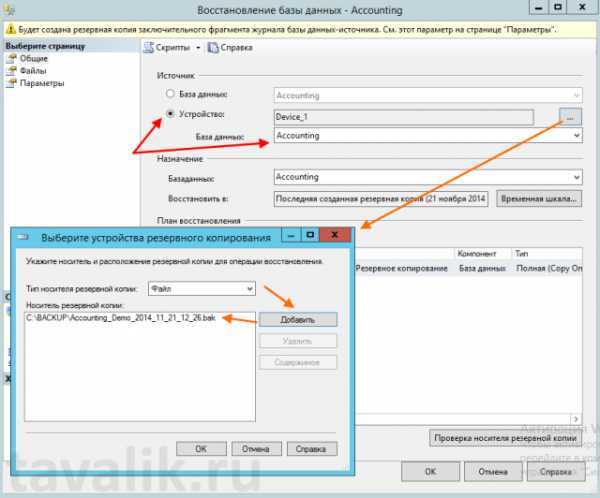
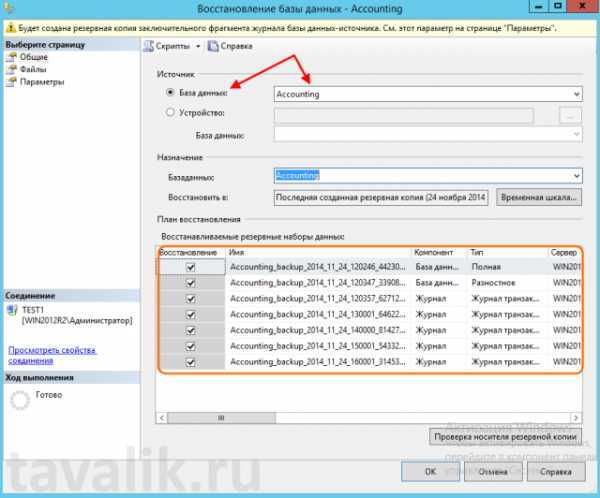
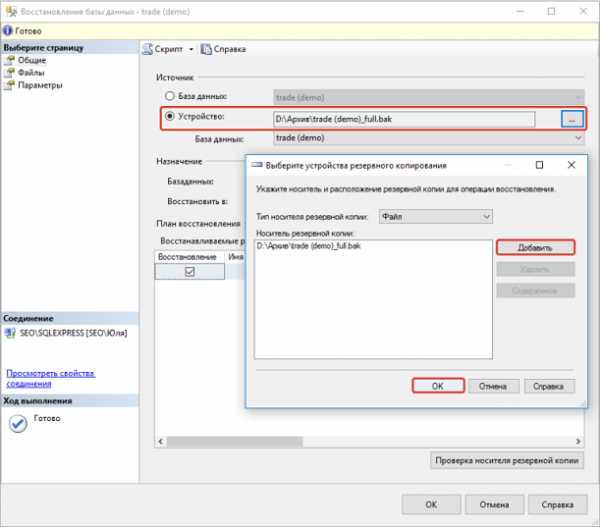
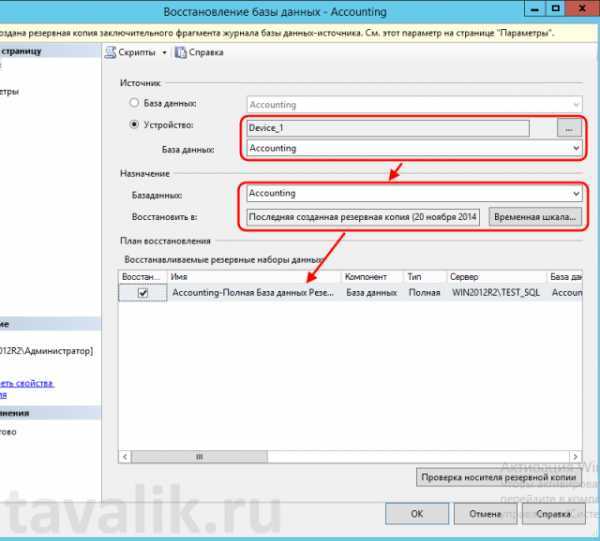
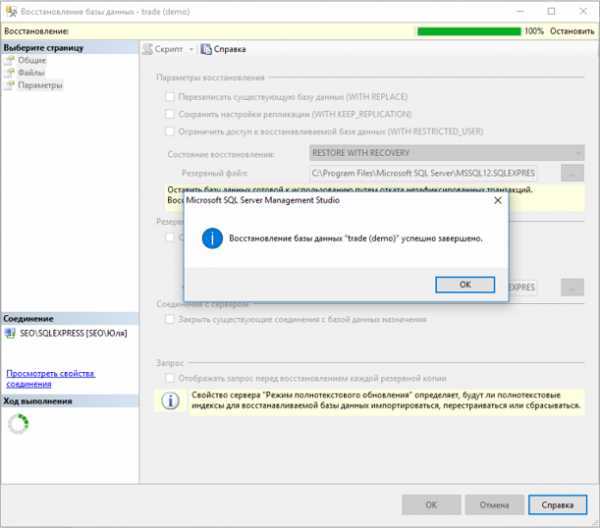
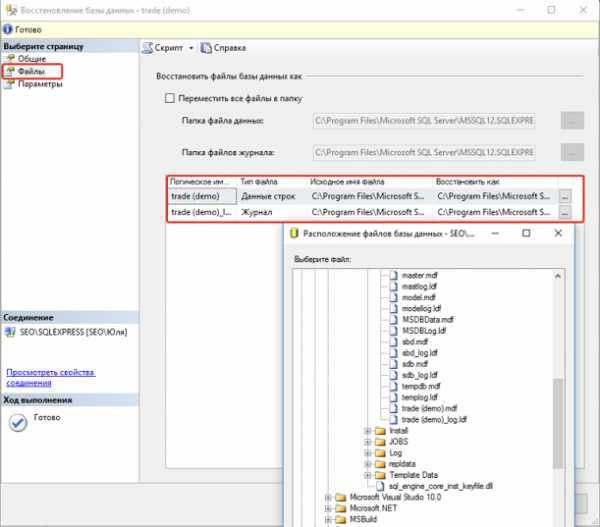
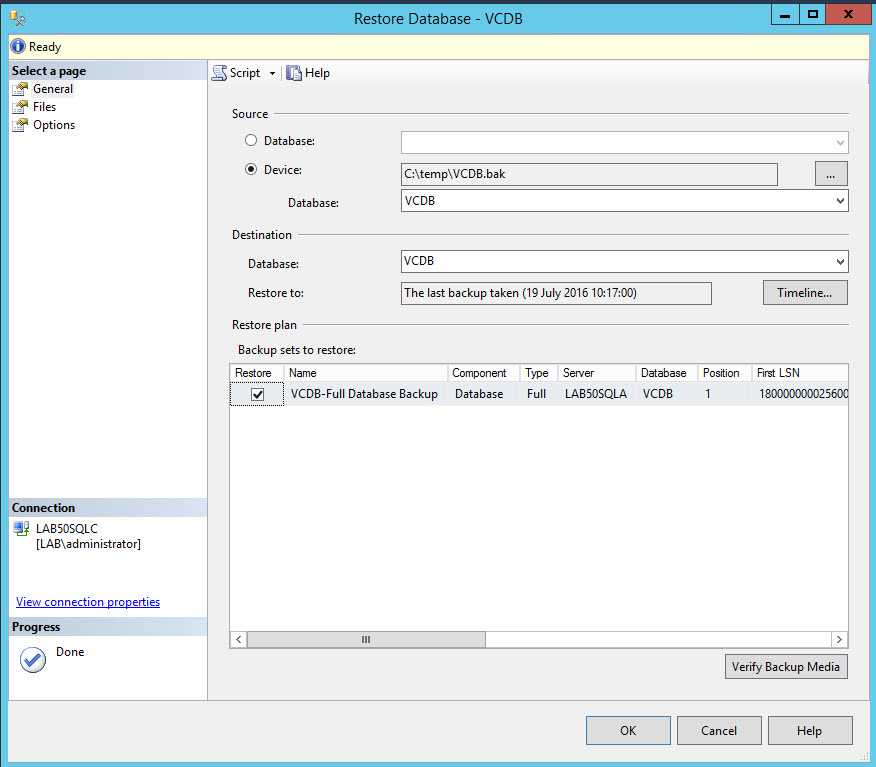
Восстановление базы данных
В следующем примере sqlcmd подключается к локальному экземпляру SQL Server и восстанавливает базу данных demodb
Обратите внимание на то, что используется параметр для обеспечения дополнительного восстановления резервных копий файлов журнала. Если вы не планируете восстанавливать дополнительные файлы журналов, удалите параметр
Совет
Если вы случайно используете параметр NORECOVERY, но у вас нет дополнительных резервных копий файлов журнала, выполните команду без дополнительных параметров. При этом восстановление завершается, а база данных остается в рабочем состоянии.
Общие сведения о резервных копиях файлов
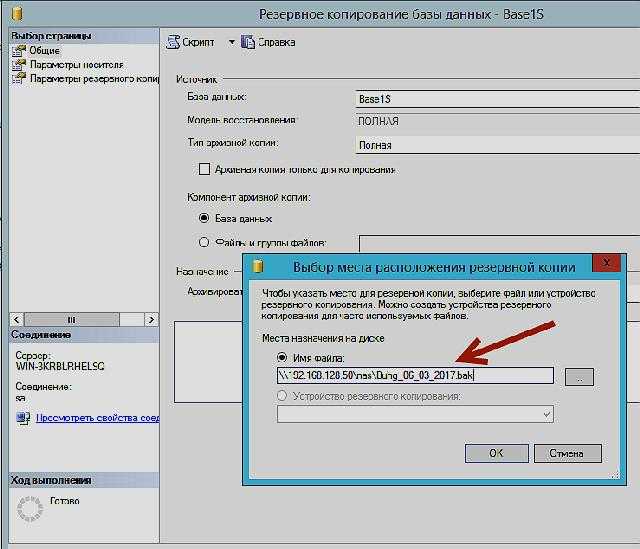
Полное резервное копирование позволяет сохранить все данные, содержащиеся в одной или нескольких файлах или файловых группах. По умолчанию резервные копии файлов содержат достаточное количество записей журнала для наката файла в конце операции резервного копирования файлов.
Создать резервную копию файла или файловой группы, доступную только для чтения, одинаковую для каждой модели восстановления. При модели полного восстановления полный набор резервных копий файлов совместно с количеством резервных копий журнала, достаточным для охвата всех резервных копий файлов, эквивалентен полной резервной копии базы данных.
Одновременно может выполняться лишь одна операция резервного копирования файлов. Можно создать резервные копии нескольких файлов за одну операцию, но это может увеличить время восстановления, если нужно восстановить всего один файл. Причина этого заключается в необходимости считывания всей резервной копии в поиске нужного файла.
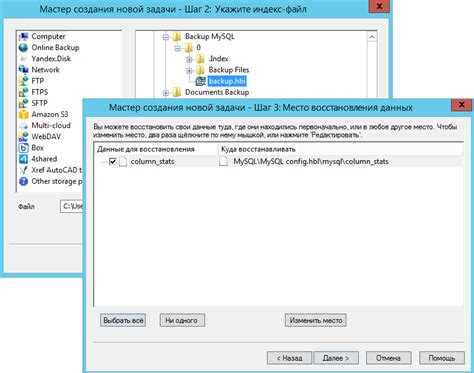
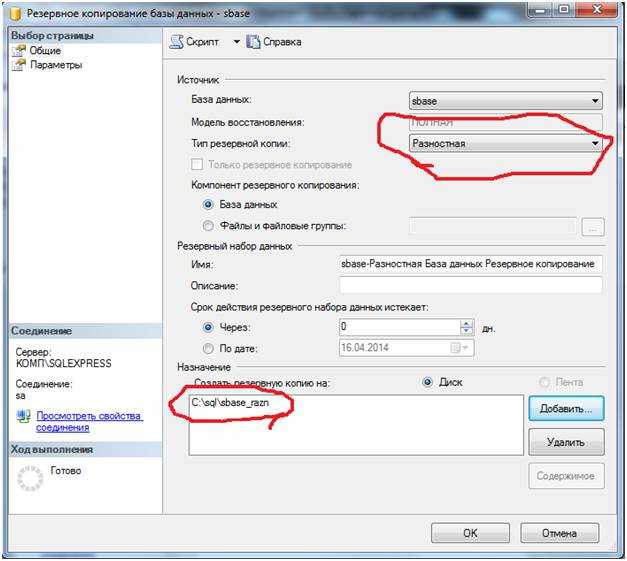
Примечание
Отдельные файлы могут быть восстановлены из резервной копии базы данных, однако поиск и восстановление файла из резервной копии базы данных займет больше времени, чем из резервной копии файла.
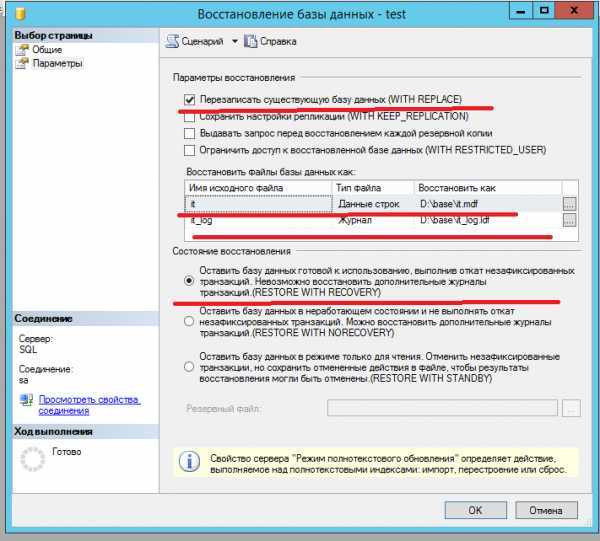
Резервные копии файлов и простая модель восстановления
В простой модели восстановления резервные копии файлов для чтения и записи должны создаваться вместе. Это гарантирует восстановление базы данных до согласованного момента времени. Вместо того чтобы указывать каждый файл или файловую группу для чтения и записи, воспользуйтесь параметром READ_WRITE_FILEGROUPS. Этот параметр создает резервные копии всех файловых групп, доступных для чтения и записи, в базе данных. С помощью параметра READ_WRITE_FILEGROUPS создаются так называемой частичной резервной копией. Дополнительные сведения см. в разделе Частичные резервные копии (SQL Server).
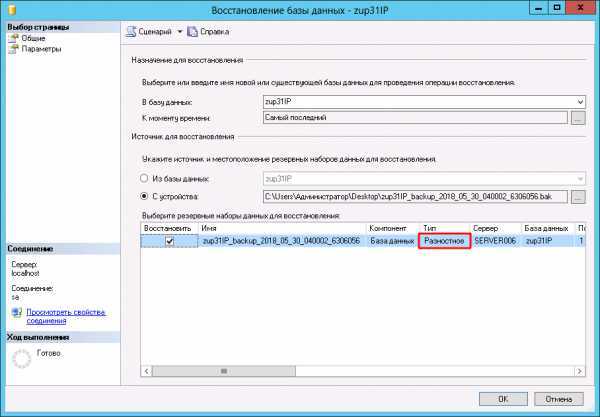
Резервные копии файлов и модель полного восстановления
В модели полного восстановления необходимо выполнять резервное копирование журналов транзакций отдельно от остальной части стратегии резервирования данных. Полный набор резервных копий файлов вместе с резервными копиями журналов, которых достаточно для охвата всех резервных копий файлов с момента первого копирования, эквивалентен полной резервной копии базы данных.
Восстановить базу данных лишь из файла и резервных копий журналов может оказаться сложно. Поэтому лучше выполнить полное резервное копирование базы данных, а затем начать резервное копирование журнала, чем сразу создавать резервную копию файлов. На следующем рисунке показана стратегия, согласно которой создается полная резервная копия базы данных (за время t1) вскоре после создания базы данных (за время t0). Эта первая резервная копия базы данных позволяет начать резервное копирование журнала транзакций. Резервное копирование журнала транзакций запланировано через определенные промежутки времени. Резервные копии файлов создаются через некоторый интервал времени, оптимально соответствующий требованиям предприятия. На данном рисунке показана каждая из четырех файловых групп, резервное копирование которых происходит одновременно. Порядок, в котором оно производится (группы A, C, B, A), отражает требования предприятия к базе данных.
Примечание
При использовании модели полного восстановления необходимо выполнить накат всех журналов транзакций во время восстановления резервной копии файла для записи и чтения, чтобы обеспечить согласованность состояния файла с остальной частью базы данных. Чтобы избежать необходимости наката большого количества резервных копий журналов транзакций, следует чаще создавать разностные резервные копии файлов. Дополнительные сведения см. в разделе Разностные резервные копии (SQL Server).
Настройка mysqldump
Как я уже сказал, бэкап базы данных mysql я буду делать с помощью mysqldump. В общем случае выполнить его проще простого. Вот пример команды, которая сделает дамп базы данных:
# mysqldump --databases dbname -u'root' -p'password' > dbname.sql
Отдельно отмечу, что использовать выгрузку сырых данных из базы в виде текстового дампа имеет смысл для не очень больших баз. Думаю, что для баз размером до 10-15 Гб это можно делать. Сжатые дампы будут весить 500-1000 Мб. Если базы больше, лучше использовать другие способы. Например, бинарный бэкап с помощью Percona XtraBackup.
Мы выгрузили дамп базы dbname в отдельный файл. Дальше его можно сжать и отправить на сервер бэкапов. Но, как это обычно бывает, везде есть куча нюансов. Дефолтные настройки mysqldump очень часто не подходят. Например, наиболее распространенная проблема — блокировка таблиц во врем дампа с дефолтными настройками. Если в базу активно идёт запись, а тут вы запускаете mysqldump и блокируете таблицы, возникают проблемы с записью.
Все параметры mysqldump можно посмотреть в документации — https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html. Если вы не указываете никакие дополнительные ключи, то по умолчанию используется ключ —opt, который включает в себя следующие параметры:
- —add-drop-table — в дампе перед каждым созданием таблицы добавляется строка с её удалением. То есть при заливке дампа сначала удаляется таблица, потом создается пустая и в неё заливаются данные из дампа. И так для всех таблиц.
- —add-locks — в дампе в строке перед созданием таблицы ставится команда на ее блокировку, а после окончания заливки данных блокировка снимается. Это позволяет гарантировать успешную запись данных в таблицу при загрузке дампа.
- —create-options — в дамп добавляются команды на создание таблиц.
- —disable-keys — в дамп добавляются параметры, отключающие создание индексов рядом с каждой командой insert. Это позволяет ускорить загрузку дампа, а индексы создаются, когда все строки будут добавлены.
- —extended-insert — используется особый синтаксис multiple-row для команд insert.
- —lock-tables — блокировка таблиц перед созданием дампа. Этот параметр частенько мешает в движке innodb и его лучше не использовать (параметр, а не движок).
- —quick — ускоренный механизм получения строк таблицы.
- —set-charset — добавляет в дамп информацию о кодировках.
В целом, все дефолтные параметры можно считать полезными и удобными, кроме блокировки таблиц. Для дампа innodb баз, а это самый популярный движок хранения данных в mysql, рекомендуется не использовать lock-tables, а вместо этого включать механизм single-transaction. С этим параметром для обеспечения целостности данных в дампе используется не механизм блокировок, а учёт транзакций.
Я не буду сейчас подробно останавливаться на теории, так как все эти параметры очень хорошо описаны в документации. Можете сами зайти и почитать. Показываю свой набор ключей для создания дампов баз данных mysql с помощью mysqldump.
# mysqldump --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob --databases dbname -u'root' -p'password' > dbname.sql
Это мой универсальный набор параметров mysqldump, которые я обычно использую, когда делаю выгрузку базы данных mysql. В целом, тут почти дефолтные настройки, только убраны блокировки, добавлены транзакции и некоторые другие сущности mysql типа events, triggers и т.д.
Обновление статистики и реиндексация в postgresql
С бэкапами разобрались, теперь настроим регламентные операции на уровне субд, чтобы поддерживать быстродействие базы данных. Тут особых комментариев не будет, в интернете очень много информации на тему регламентных заданий для баз 1С. Я просто приведу пример того, как это выглядит в postgresql.
Выполняем очистку и анализ базы данных 1С:
# vacuumdb --full --analyze --username postgres --dbname base1c
Реиндексация таблиц базы данных:
# reindexdb --username postgres --dbname base1c
Завернем все это в скрипт с логированием времени выполнения команд:
# cat /root/bin/service-sql.sh
#!/bin/sh # Записываем информацию в лог echo "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuum base1c" >> /var/log/postgresql/service.log # Выполняем очистку и анализ базы данных /usr/bin/vacuumdb --full --analyze --username postgres --dbname base1c echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuum base1c" >> /var/log/postgresql/service.log sleep 2 echo "`date +"%Y-%m-%d_%H-%M-%S"` Start reindex base1c" >> /var/log/postgresql/service.log # Переиндексирвоать базу /usr/bin/reindexdb --username postgres --dbname base1c echo "`date +"%Y-%m-%d_%H-%M-%S"` End reindex base1c" >> /var/log/postgresql/service.log
Сохраняем скрипт и добавляем в планировщик. Хотя я для удобства сделал еще один скрипт, который объединяет бэкап и обслуживание и уже его добавил в cron:
# cat all-sql.sh
#!/bin/sh /root/bin/backup-sql.sh sleep 2 /root/bin/service-sql.sh
Добавялем в /etc/crontab:
# Бэкап и обслуживание БД 1 3 * * * root /root/bin/all-sql.sh
Проверяем лог файл и наличие бэкапа. Не забывайте делать проверочное регулярное восстановление бд из архива.
Описанные выше операции очистки и переиндексации можно делать в ручном режиме в программе под windows — pgAdmin. Рекомендую ее установить на всякий случай. Достаточно удобно и быстро можно посмотреть информацию или выполнить какие-то операции с базой данных посгрес.
Решение:
Для решения этой задачи существуют специальные инструменты.
mysqldump, mysqlhotcopy
Все СУБД имеют в своем составе собственные средства для получения резервной копии (дампа) базы данных. Это mysqldump для mysql, pg_dump для postgresql и т.п.
В качестве одного из возможного варианта решения этой задачи мы рекомендуем использовать утилиту mysqlhotcopy.
Утилита mysqlhotcopy представляет собой Perl-сценарий, использующий SQL-команды LOCK TABLES, FLUSH TABLES и Unix-утилиты cp или scp для быстрого получения резервной копии базы данных.
Подробности по ссылкам внизу статьи.
Еще более проработанное решение — утилита AutoMySQLBackup
AutoMySQLBackup
AutoMySQLBackup с базовой конфигурации может создавать ежедневные, еженедельные и ежемесячные резервные копии баз данных MySQL с одного или нескольких серверов MySQL.
Прочие функции:
- Уведомление по электронной почте
- Сжатие и шифрование копий
- Управление правилами ротации
- Инкрементальные резервные копии
Порядок установки в CentOS:
Например:
mkdir ~/tmp1 cd ~/tmp1 wget http://downloads.sourceforge.net/project/automysqlbackup/AutoMySQLBackup/AutoMySQLBackup%20VER%203.0/automysqlbackup-v3.0_rc6.tar.gz tar -xzf automysqlbackup-v3.0_rc6.tar.gz ./install.sh
Порядок установки в Debian / Ubuntu:
Пакет automysqlbackup есть в репозиториях debian и усттановка производится командой:
apt-get install automysqlbackup
Для настройки можно использовать глобальный файл параметров (/etc/automysqlbackup/automysqlbackup.conf) или создать отдельный конфиг для каждого задания, например — /etc/automysqlbackup/myserver.conf
2. Откройте в любимом текстовом редакторе файл /etc/automysqlbackup/myserver.conf, раскомментруйте и укажите необходимые вам параметры.
Наиболее важные — имя, пароль и где хранить архивы:
CONFIG_mysql_dump_username='root' CONFIG_mysql_dump_password='mega_password' CONFIG_backup_dir='/var/backup/db' CONFIG_mail_address='webmaster@mydomain.com'
Каждый параметр описан в конфигурационном файле, изучите его не спеша.
Большинство параметров закомментировано символом #. Если вас устраивает значение по умолчанию оставьте параметр как есть, если нужно изменить значение, то нужно убрать # и задать желаемое значение.
Уделите внимание разделу «Rotation Settings» в конфигурационном файле если у вас особые правила ротации бэкапов.
Глобальные параметры automysqlbackup в Debian находятся в файле /etc/default/automysqlbackup
Запуск automysqlbackup
Если просто выполнить команду automysqlbackup, то он будет выполнена с параметрами из файла /etc/automysqlbackup/automysqlbackup.conf
Если вы создали для каждой базы данных отдельный конфиг, то можно выполнить команду с указанием конкретного конфига:
automysqlbackup -c /etc/automysqlbackup/myserver.conf
Для выполнения в фоновом режиме, что подходит для заданий cron лучше использовать:
automysqlbackup -bc /etc/automysqlbackup/myserver.conf
Пример задания для cron (делать бэкап ежедневно в 4:22):
22 4 * * * root /usr/local/bin/automysqlbackup -bc /etc/automysqlbackup/myserver.conf
Убедитесь, что путь к исполняемому файлу у вас именно такой
Восстановление базы данных
Если база данных удалена, то создайте новую. Пример команды создания базы данных.
mysqladmin -u USER -pPASSWORD create NEWDATABASE
Выберите нужный файл и декопрессируйте его и загрузите в базу данных. В зависимости от выбранного в конфиге automysqlbackup архиватора (компрессора) используйте соответствующую утилиту — gunzip для file.gz (или bunzip2 для file.bz2)
Это можно сделать одной командной конструкцией:
Для архивов gzip:
gunzip < /path/to/backupfile.sql.gz | mysql -u USER -pPASSWORD DATABASE
или так
zcat /path/to/backupfile.sql.gz | mysql -u USER -pPASSWORD DATABASE
Для архивов bzip2
bunzip2 < /path/to/backupfile.sql.bz2 | mysql -u USER -pPASSWORD DATABASE
или так
bzcat /path/to/backupfile.sql.bz2 | mysql -u USER -pPASSWORD DATABASE
Установка Percona XtraBackup
С установкой XtraBackup нет никаких проблем и нюансов. Под все популярные дистрибутивы есть готовые пакеты в официальном репозитории. Подключаем его в Centos.
# yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
Дальше ставим нужную нам версию программы. Самую последнюю 8.0:
# yum install percona-xtrabackup-80
или 2.4
# yum install percona-xtrabackup-24
Обращаю внимание, что если на сервере с установленным bitrixenv установить просто пакет xtrabackup, без указания версии, будет установлена версия 2.3, которая не работает с уставленным там же по дефолту сервером mysql 5.7. Устанавливаем в Debian/Ubuntu:
Устанавливаем в Debian/Ubuntu:
# wget https://repo.percona.com/apt/percona-release_latest.$(lsb_release -sc)_all.deb # dpkg -i percona-release_latest.$(lsb_release -sc)_all.deb
И сам пакет:
# apt update && apt install percona-xtrabackup-80
Полный бэкап Mysql сервера
Итак, база данных у нас работает, утилиту для бэкапа мы установили. Давайте теперь сделаем полный backup всех баз данных нашего сервера mysql.

# xtrabackup --backup --user=root --password='R(zDXcVUmI[zwx%aNBTN' --target-dir=/root/backupdb/full
| backup | инициируем процедуру бэкапа |
| user=root | пользователь mysql |
| password=’R(zDXcVUmI[zwx%aNBTN’ | пароль пользователя, взятый в одинарные кавычки |
| target-dir=/root/backupdb/full | директория для создания полного бэкапа mysql |
В дальнейших примерах я не буду указывать пользователя и пароль, чтобы упростить команды. Эти данные я указал в файле ~/.my.cnf.
user=root password='R(zDXcVUmI[zwx%aNBTN'
Мы сделали полный архив всего mysql сервера. В таком виде данные не консистентны, так как они могли меняться во время архивации. Если восстановить их как есть, сервер mysql не запустится. Будет ругаться на поврежденные данные. Чтобы восстановить целостность данных, необходимо выполнить еще одну команду.
# xtrabackup --prepare --target-dir=/root/backupdb/full
После этого бэкап будет полностью работоспособен и готов к восстановлению. Я обычно выполняю эту команду сразу же после бэкапа, но это не всегда возможно. К примеру, если вы захотите его сразу же сжать.
# xtrabackup --backup --compress --target-dir=/root/backupdb/full
В таком случае его сначала нужно будет распаковать, а потом подготовить. Делать это не обязательно сразу. Можно хранить бэкапы не подготовленными, а готовить только перед восстановлением, если это случится. Распаковывается бэкап следующим образом.
# xtrabackup --decompress --target-dir=/root/backupdb/full
Для того, чтобы команда decompress отработала без ошибки:
sh: qpress: command not found cat: write error: Broken pipe Error: decrypt and decompress thread 0 failed.
Необходимо установить пакет qpress.
# yum install qpress
Он есть в репозитории percona. После этого распаковка пройдет штатно.
Лично я не вижу большого смысла использовать ключи compress и decompress. Можно сделать полный бэкап, подготовить его, а потом сжать тем же gzip.
# tar -czvf /root/backupdb/full.tar.gz -C /root/backupdb full
На выходе получите тот же архив, только сжат лучше и нет необходимости ставить дополнительный софт. Gzip и tar обычно есть во всех дистрибутивах. К тому же архив в виде единого файла проще и быстрее передать на сервер бэкапов и там хранить.
В завершении раздела про полный backup, предлагаю простенький скрипт для автоматизации процесса через cron — mysql-full-backup.sh.
#!/bin/bash DATA=`date +%Y-%m-%d` mkdir -p /root/backupdb/$DATA xtrabackup --backup --target-dir=/root/backupdb/$DATA/full xtrabackup --prepare --target-dir=/root/backupdb/$DATA/full tar -czvf /root/backupdb/$DATA/full.tar.gz -C /root/backupdb/$DATA full rm -rf /root/backupdb/$DATA/full
При выполнении этого скрипта раз в день, вы будете иметь отдельные папки с именем в виде даты, а внутри полный бэкап. Дальше мы в эти же папки будем класть инкрементные бэкапы. Но обо всем по порядку.





