
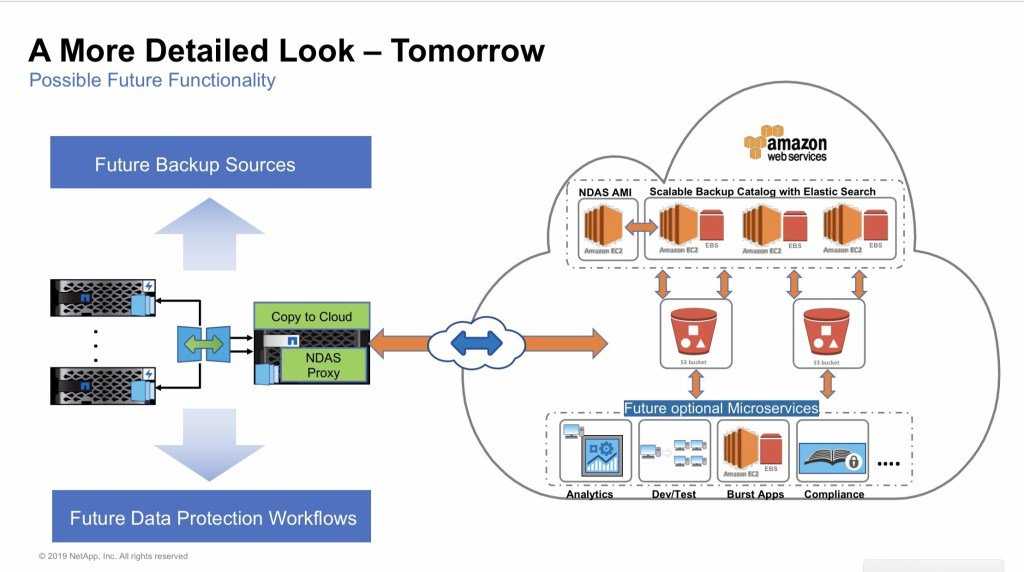
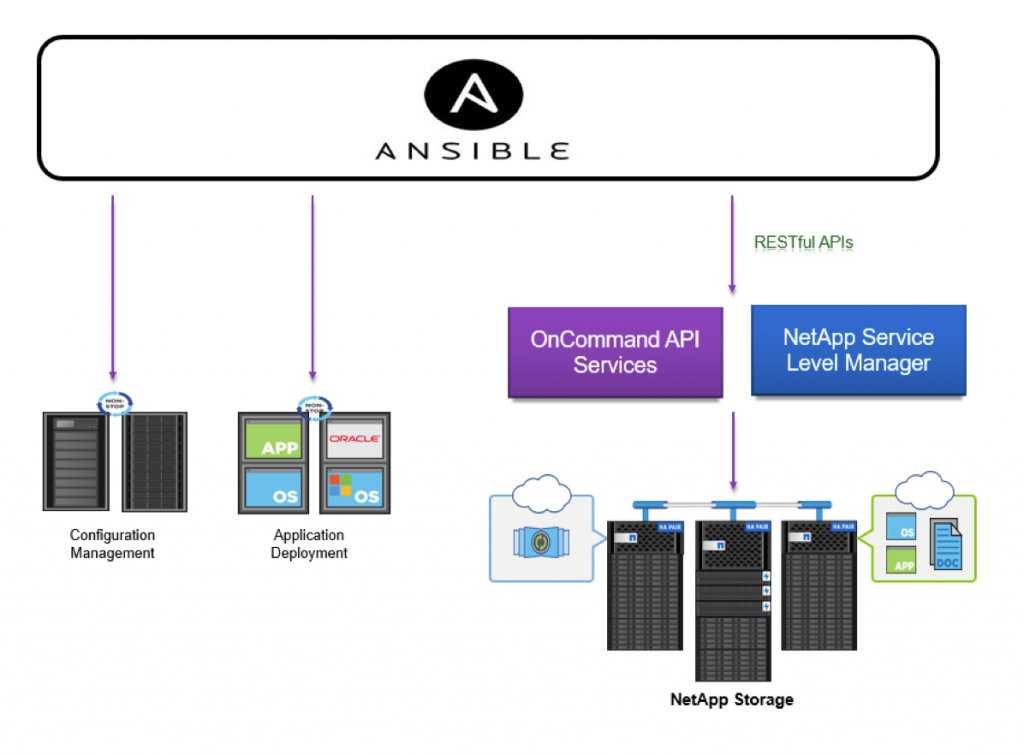
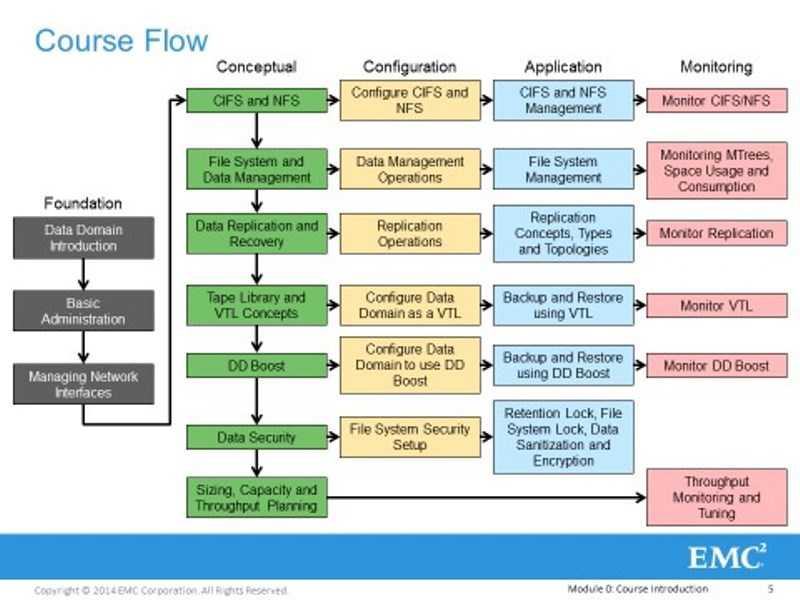
Введение
Начнем создание дашборда с самого сложного — настройки гео карты запросов. На официальном сайте есть подробный мануал на тему создания GeoIP карты. В нем вроде бы все понятно. Никаких особых настроек не требуется. Все работает из коробки. Но у меня никак не хотело работать все то, что там описано. Пришлось прилично поковыряться с elasticsearch и его шаблонами, чтобы разобраться в чем причина.
Все дело в том, что описанный в инструкции способ работает из коробки, только если вы используете стандартный шаблон для индексов в формате logstash-*. Скорее всего у вас будет много разных шаблонов и индексов после того, как вы запустите систему в промышленную эксплуатацию.
Основная сложность тут в том, что для работы geoip карты вам нужны в шаблоне поля с типом geo_point. После создания индекса, тип полей уже нельзя поменять. То есть просто преобразовать данные на основе ip в координаты не сложно, это умеет делать модуль geoip в logstash. Но вот дальше вы никак не превратите координаты в виде числа в geo_point данные. Нужно в самом начале создать шаблон с такими полями.
Надеюсь понятно объяснил  Если не понятно сразу, то сообразите дальше по ходу моего рассказа. Я сам пока разобрался в этой кухне, прилично поковырялся и нагуглился.
Если не понятно сразу, то сообразите дальше по ходу моего рассказа. Я сам пока разобрался в этой кухне, прилично поковырялся и нагуглился.
В дальнейшем я буду считать, что ваш elasticsearch и kibana настроены примерно как у меня в инструкции. Фильтр logstash, отвечающий за обработку логов nginx выглядит следующим образом:
if == "nginx-ext-access" {
grok {
match =>
overwrite =>
}
mutate {
convert =>
convert =>
convert =>
}
geoip {
source => "clientip"
target => "geoip"
add_tag =>
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
remove_field =>
}
useragent {
source => "agent"
}
}
И вот так логи уходят в elasticsearch
if == "nginx-ext-access" {
elasticsearch {
hosts => "localhost:9200"
index => "nginx-ext-%{+YYYY.MM.dd}"
}
}
Напоследок о мониторинге
Чтобы всё это работало так, как задумывалось, мы мониторим следующее:
- Каждая дата-нода сообщает в наше облако, что она есть, и на ней находятся такие-то шарды. Когда мы где-то что-то тушим, кластер через 2-3 секунды рапортует, что в центре А мы потушили ноду 2, 3, и 4 — это означает, что в других дата-центрах мы ни в коем случае не можем тушить те ноды, на которых остались шарды в единственном экземпляре.
- Зная характер поведения мастера, мы очень внимательно смотрим на количество pending-задач. Потому что даже одна зависшая задача, если вовремя не оттаймаутится, теоретически в какой-то экстренной ситуации способна стать той причиной, по которой у нас не отработает, допустим, промоушен replica-шарда в primary, из-за чего встанет индексация.
- Также мы очень пристально смотрим на задержки garbage collector, потому что у нас с этим уже были большие сложности при оптимизации.
- Реджекты по тредам, чтобы понимать заранее, где находится «бутылочное горло».
- Ну и стандартные метрики, типа heap, RAM и I/O.
При построении мониторинга обязательно надо учитывать особенности Thread Pool в Elasticsearch. Документация Elasticsearch описывает возможности настройки и дефолтные значения для поиска, индексации, но полностью умалчивает о thread_pool.management.Эти треды обрабатывают, в частности, запросы типа _cat/shards и другие аналогичные, которые удобно использовать при написании мониторинга. Чем больше кластер, тем больше таких запросов выполняется в единицу времени, а вышеупомянутый thread_pool.management мало того, что не представлен в официальной документации, так ещё и лимитирован по дефолту 5 тредами, что очень быстро утилизируется, после чего мониторинг перестаёт работать корректно.
Что хочется сказать в заключение: у нас получилось! Мы сумели дать нашим программистам и разработчикам инструмент, который практически в любой ситуации способен быстро и достоверно предоставить информацию о происходящем на продакшене.
Да, это получилось довольно-таки сложно, но, тем не менее, наши хотелки удалось уложить в уже существующие продукты, которые при этом не пришлось патчить и переписывать под себя.
Changing Index Settings
---
# Remember, leave a key empty if there is no value. None will be a string, not a Python "NoneType"
actions:
1:
action: index_settings
description: >-
Set Monitoring and watcher indices older than 1 day to be read only (block writes)
options:
disable_action: False
index_settings:
index:
blocks:
write: True
ignore_unavailable: False
preserve_existing: False
filters:
- filtertype: pattern
kind: regex
value: '^\.(monitoring-es-6-|monitoring-kibana-6-|monitoring-logstash-6-|watcher-history-6-).*$'
exclude:
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 1
curator --config ./curator_cluster_config.yml readOnly1DayOldUselessIndices.yml --dry-run
2017-10-03 16:39:10,237 INFO Preparing Action ID: 1, "index_settings"
2017-10-03 16:39:10,602 INFO Trying Action ID: 1, "index_settings": Set Monitoring ES indices older than 1 day to be read only (block writes)
2017-10-03 16:39:11,075 INFO DRY-RUN MODE. No changes will be made.
2017-10-03 16:39:11,075 INFO (CLOSED) indices may be shown that may not be acted on by action "indexsettings".
2017-10-03 16:39:11,075 INFO DRY-RUN: indexsettings: .monitoring-es-6-2017.10.02 with arguments: {'index': {'blocks': {'write': True}}}
2017-10-03 16:39:11,075 INFO DRY-RUN: indexsettings: .monitoring-kibana-6-2017.10.02 with arguments: {'index': {'blocks': {'write': True}}}
2017-10-03 16:39:11,075 INFO Action ID: 1, "index_settings" completed.
2017-10-03 16:39:11,075 INFO Job completed.
Анализ текстовых полей
Elasticsearch предоставляет большие возможности для полнотекстового поиска. Он может учитывать словоформы, пропускать стоп-слова, использовать морфологию языка. Для этого на этапе формирования маппинга нужно указать правильный анализатор для текстовых полей, которые этого требуют. Эти настройки также указываются в утилите администратора.
Анализатор включает в себя три этапа: преобразование отдельных символов, разбиение символов на токены и обработка этих токенов. В нашем случае фильтрация символов не требуется. В качестве токенизатора используем стандартный, который из коробки работает для большинства случаев. Ключевым звеном анализатора русского языка является официальный плагин analysis-morphology. Он предоставляет фильтр токенов, который позволяет искать с учетом словоформ. Также мы приводим все слова к нижнему регистру и используем свой набор стоп-слов.
Настройки для файлов
В Elasticsearch версии 5.0 появилась новая сущность — узел Ingest. Такие узлы используются для обработки документов перед их индексированием. Для этого нужно создать конвейер (pipeline) и добавить в него процессоры (processor). Любой из ваших узлов может использоваться как ingest. Или же можно выделить под первичную обработку отдельный узел.
Многие документы нашей системы содержат текстовые файлы. Полнотекстовый поиск должен уметь работать по их содержимому. Для реализации этого мы использовали плагин Ingest Attachment, в котором применяется недавно появившаяся технология конвейера. Определим процессор, который для каждого файла документа применяет процессор, доступный благодаря плагину. Суть этого процессора в том, чтобы из Base64 строки извлекать текст в отдельное поле. Все, что нам останется: во время индексирования получить Base64 строку по файлу и попасть в маппинг. В процессоре укажем, в каком поле содержится файл (Field) и в куда нужно поместить текст (TargetFiled). Настройка IndexedCharacters ограничивает длину обрабатываемого файла (-1 снимает ограничения).
Removing time-series indices
number of reasonsElasticSearch indices teamplatesaliases.watcher-history.monitoring-*Delete IndicesYYYY.MM.DDdelete3DaysOldUselessIndices.yml
---
# Remember, leave a key empty if there is no value. None will be a string, not a Python "NoneType"
actions:
1:
action: delete_indices
description: >-
"Delete indices older than 3 days (based on index name), for .watcher-history-
or .monitoring-es-6- or .monitoring-kibana-6- or .monitoring-logstash-6-
prefixed indices. Ignore the error if the filter does not result in an
actionable list of indices (ignore_empty_list) and exit cleanly."
options:
timeout_override: 300
continue_if_exception: True
ignore_empty_list: True
disable_action: False
filters:
- filtertype: pattern
kind: regex
value: '^\.(monitoring-es-6-|monitoring-kibana-6-|monitoring-logstash-6-|watcher-history-6-).*$'
exclude:
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 3
curator --config ./curator_cluster_config.yml ./delete3DaysOldUselessIndices.yml --dry-run 2017-10-04 12:15:38,544 INFO Preparing Action ID: 1, "delete_indices" 2017-10-04 12:15:38,900 INFO Trying Action ID: 1, "delete_indices": "Delete indices older than 1 day (based on index name), for .watcher-history- or .monitoring-es-6- or .monitoring-kibana-6- or .monitoring-logstash-6- prefixed indices. Ignore the error if the filter does not result in an actionable list of indices (ignore_empty_list) and exit cleanly." 2017-10-04 12:15:39,351 INFO DRY-RUN MODE. No changes will be made. 2017-10-04 12:15:39,351 INFO (CLOSED) indices may be shown that may not be acted on by action "delete_indices". 2017-10-04 12:15:39,351 INFO Action ID: 1, "delete_indices" completed. 2017-10-04 12:15:39,352 INFO Job completed.
—dry-run
Индексирование
Задача сервиса — непрерывно извлекать новые объекты из очереди и индексировать соответствующие документы. В этом процессе мы используем не объектную модель NEST, а низкоуровневую библиотеку ElasticsearchNet. Она предоставляет интерфейс взаимодействия с базой данных через JSON. Объекты формируем динамически обходом в глубину иерархической структуры документа. Для этого используется всем известная библиотека NewtonsoftJson.
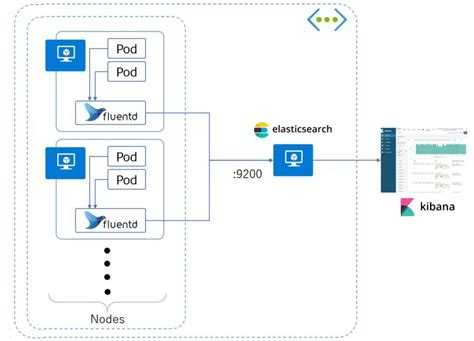
Индексирование реализовано многопоточно с параллельной обработкой каждого документа. Процесс формирования JSON занимает на порядок больше времени, чем его индексирование. Поэтому используется API для индексирования отдельных документов, а не Bulk API, при котором за один вызов в ES загружается массив документов. В таком случае индексирование бы происходило со скоростью формирования JSON для самого большого документа.
Индексирование файлов
Файлы индексируются вместе с остальными данными как часть JSON-объекта. Всё, что для это нужно — преобразовать поток байтов в Base64 строку. Это делается средствами стандартной библиотеки. Кроме того, необходимо, чтобы файлы попали под определение процессора. Иначе магии не произойдет, и они так и останутся обычной Base64 строкой. Чтобы при индексировании использовать конвейер, изменим вызов метода.
Настраиваем шифрование между узлами Elasticsearch
Следующим шагом необходимо настроить шифрование трафика между узлами Elasticsearch. Для этого выполняем несколько шагов:
Создаем CA (Certificate Authority) для кластера Elasticsearch:
Во время генерации корневого сертификата можно задать имя PKCS#12 файла, по умолчанию это и пароль к нему.
Для получения сертификата и ключа в PEM формате укажите ключ . На выходе будет ZIP архив с и файлами.
С помощью ключа можно указать каталог для создаваемого файла.
Ключ указывает путь к корневому сертификату CA в формате PKCS#12. Если сертификат и ключ были получены в PEM формате, то необходимо использовать ключи и соответственно.
Ключи и добавляют проверку по имени узла и IP адресу и являются опциональными. Если вы указываете их, то укажите эти параметры для каждого узла.
Где:
— включаем TLS/SSL
— режим проверки сертификатов. — проверка не выполняется, — выполняется проверка сертификата без проверки имени узла и IP адреса, — проверка сертификата, а также имени узла и адреса указанных в сертификате.
— путь к файлу с сертификатом и ключем узла.
— путь к доверенному сертификату (CA).
Для PKCS#12 формата:
Для PEM сертификата:
Чтобы запустить Elasticsearch с keystore, на который установлен пароль, необходимо передать этот пароль Elasticsearch. Это делается с помощью файла на который будет ссылаться переменная . После запуска файл можно удалить, но при каждом последующим запуске файл необходимо создавать.
Перезапускаем Elasticsearch
В логах Elasticsearch должны появится записи о создании кластера:
Если обратиться к API, то будет ошибка «missing authentication credentials for REST request». С момента включения функций безопасности для обращения к кластер необходимо пройти аутентификацию.
Смотрим полученные данные в Kibana
Открываем Kibana, в верхнем левом углу нажимаем меню и в секции выбираем . Далее слева выбираем и нажимаем кнопку . В поле описываем шаблон , в который попадут все индексы, начинающиеся с logstash.
Создание шаблона индекса
Жмем и выбираем поле , чтобы иметь возможность фильтровать данные по дате и времени. После жмем :
Выбор Time field
После создания шаблона индексов Kibana покажет информацию об имеющихся полях, типе данных и возможности делать агрегацию по этим полям.
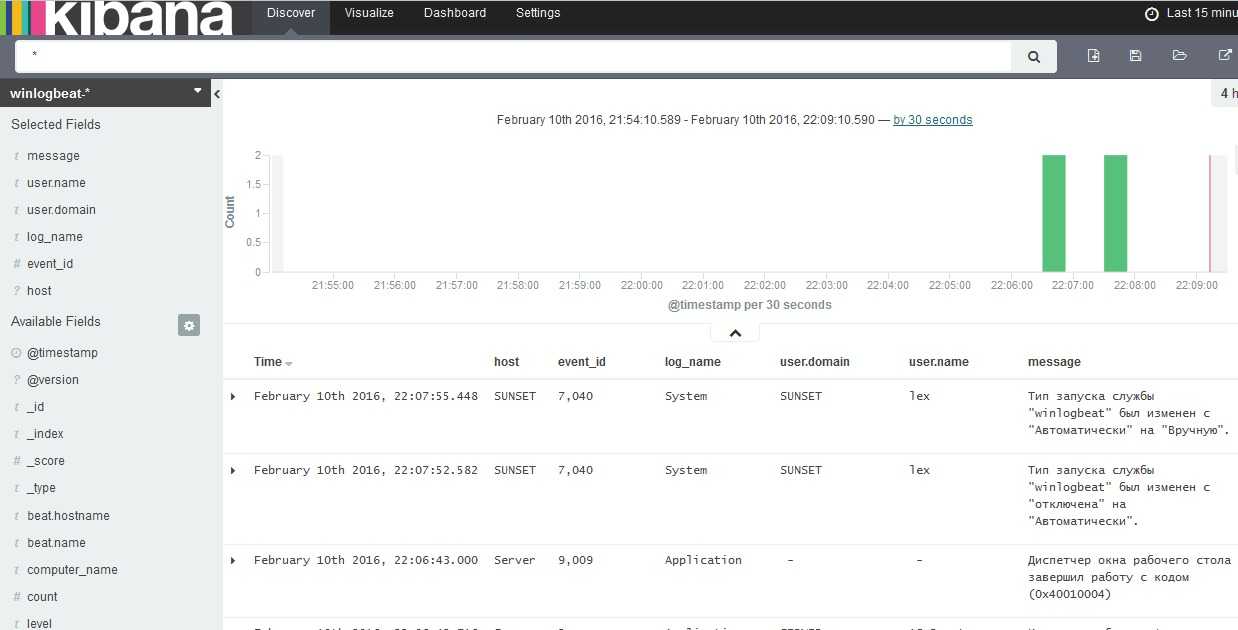
Чтобы посмотреть полученные данные на основе созданного шаблона нажимаем меню и в секции выбираем .
Kibana Discover
В правой части экрана можно выбрать интервал в рамках которого отображать данные.
Выбор временного интервала
В левой часте экрана можно выбрать шаблон индекса или поля для отображения из списка . При нажатии на доступные поля можно получить топ-5 значений.
Шаблон индекса и доступные поля
Для фильтрации данных можно использовать . Запрос пишется в поле . Запросы можно сохранять, чтобы использовать их в будущем.
Фильтрация данных с помощью KQL
Для визуализации полученных данных нажимаем меню и в секции выбираем . Нажав , откроется окно с перечнем доступных типов визуализации.


Типы визуализации Kibana
Для примера выбираем , чтобы построить круговую диаграмму. В качестве источника данных выбираем шаблон индексов . В правой части в секции жмем , далее — . Тип агрегации выбираем , поле . Жмем в правом нижнем углу и получаем готовую диаграмму. В секции можно добавить отображение данных или изменить вид диаграммы.
Круговая диаграмма
Чтобы посмотреть данные в Elasticsearch необходимо сделать запрос к любому узлу кластера. Добавление параметра позволяет отобразить данные в читабельном виде. По умолчанию вывод состоит из 10 записей, чтобы увеличить это количество необходимо использовать параметр :
Заключение
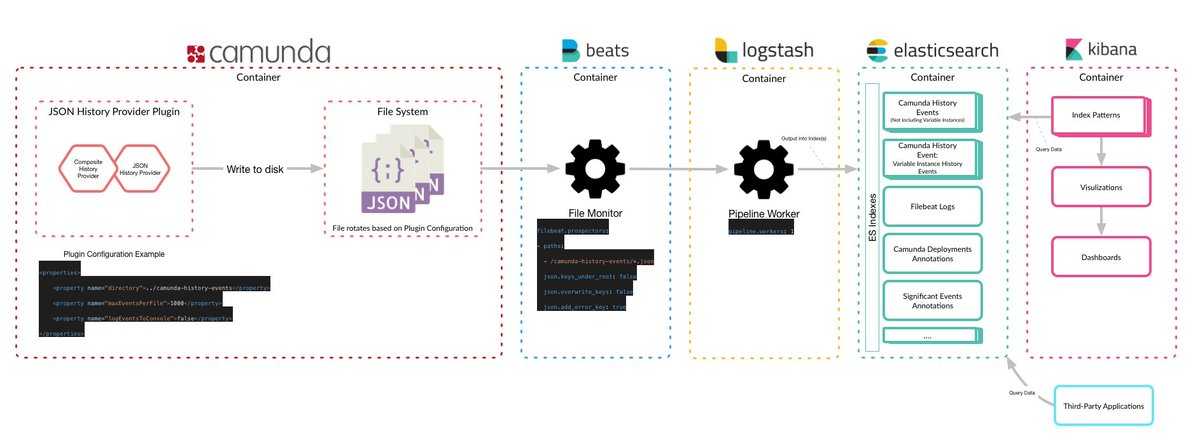
В рамках этой статьи была рассмотрена процедура установки и настройки Kibana и Logstash, настройка балансировки трафика между Kibana и Elasticsearch и работа нескольких экземпляров Kibana. Собрали первые данные с помощью Logstash, посмотрели на данные с помощью и построили первую визуализацию.
Прежде чем углубляться в изучение плагинов Logstash, сбор данных с помощью Beats, визуализацию и анализ данных в Kibana, необходимо уделить внимание очень важному вопросу безопасности кластера. Об этом также постоянно намекает Kibana, выдавая сообщение
Теме безопасности будет посвящена следующая статья данного цикла.
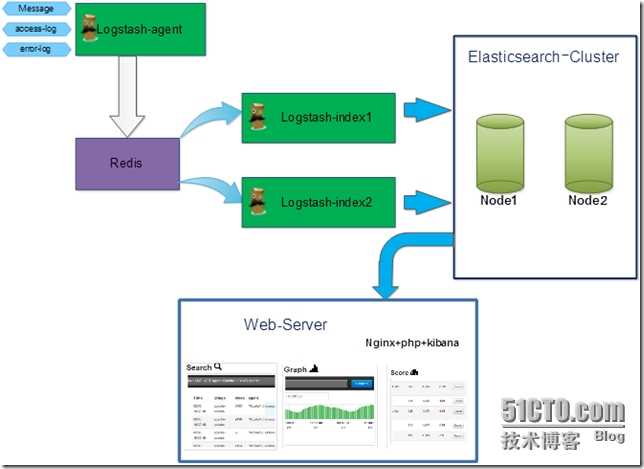
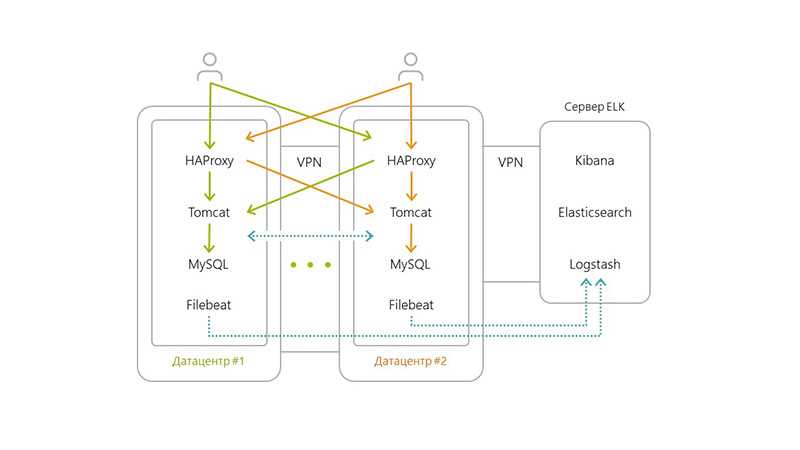
Коллектор
Теперь рассмотрим, что происходит на коллекторе.
Стрим поступает на TCP сокет коллектора и начинает процесс маршрутизации (фильтрации), и проходит следующий воркфлоу.
Попадает на цепочку docker_before — данная цепочка предназначена для переопределения тегов входящих логов от Docker контейнеров. Каждый контейнер имеет дополнительные атрибуты, такие как “attrs.service” и “attrs.container_name”. Переопределение тега происходит на основании “attrs.service”, например nginx. Все остальное, например, нам нет необходимости собирать логи с контейнера mongodb, все что нам нужно это убрать его из цепочки определения сервиса и он просто упадет в null. Выглядит вот так:
<match docker.logs.**>@type rewrite_tag_filter <rule> key $ pattern ^nginx$ tag docker.nginx </rule></match><match docker.logs.**>@type null</match>
Далее, выполняется маршрутизация (фильтрация) на основании переопределенного тега “docker.nginx” и попадает в следующий конфиг файл.
Nginx_common — данная цепочка выполняет разбивку логов на error и access на основании JSON поля “stream” и переопределяет тэги на “docker.nginx.stdout” и “docker.nginx.stderr”. Дальнейшее продвижение лога происходит на основании уже переопределенных тэгов.


<match docker.nginx>@type rewrite_tag_filter <rule> key stream pattern /stdout/ tag docker.nginx.stdout </rule> <rule> key stream pattern /stderr/ tag docker.nginx.stderr </rule></match>
Далее происходит матчинг по тэгу “docker.nginx.stdout” и применяет к нему парсер с определенным форматом.
<filter docker.nginx.stdout>@type parser key_name log reserve_data true time_parse true format /^\\s"(?<request_host>.*)"\s"(?<remote_host>.*)"\s"(?<status>\d{3})"\s"(?<request_time>\d+.\d+)"\s"(?<upstream_response_time>.*)"\s"(?<bytes_sent>.*)"\s"(?<method>\w{3,7})\s(?<request_uri>.*)\s(?<http_version>.*)"\s"(?<http_referer>.*)"\s"(?<http_user_agent>.*)"/ time_format %d/%b/%Y:%H:%M:%S %z</filter>
Далее модифицирует поле upstream_response_time (мы переопределяем значения некоторых полей (mapping)в Elasticsearch индексе для корректного поиска и фильтрации), чтобы поле содержало только цифирные значения, а не прочерки, если значение отсутствует.
<filter docker.nginx.stdout>@type record_transformer enable_ruby true auto_typecast true <record> upstream_response_time ${record == '-' ? -1.000 : record} </record></filter>
Далее добавляем GeoIP данные, такие как “country_code”, “country_name”, “city” и “geoip_hash”.
Запуск кластера Elasticsearch
Теперь все готово для того, чтобы запустить узлы Elasticsearch и убедиться, что они взаимодействуют друг с другом как кластер.
На каждом сервере выполните следующую команду:
sudo service elasticsearch start
Если все настроено правильно, кластер Elasticsearch должен запуститься. Чтобы убедиться, что все работает корректно, запросите Elasticsearch с любого из узлов:
curl -XGET 'http://localhost:9200/_cluster/state?pretty'
Ответ должен вернуть информацию о кластере и его узлах:
{
"cluster_name" : "my-cluster",
"compressed_size_in_bytes" : 351,
"version" : 4,
"state_uuid" : "3LSnpinFQbCDHnsFv-Z8nw",
"master_node" : "IwEK2o1-Ss6mtx50MripkA",
"blocks" : { },
"nodes" : {
"IwEK2o1-Ss6mtx50MripkA" : {
"name" : "es-node-2",
"ephemeral_id" : "x9kUrr0yRh--3G0ckESsEA",
"transport_address" : "172.31.50.123:9300",
"attributes" : { }
},
"txM57a42Q0Ggayo4g7-pSg" : {
"name" : "es-node-1",
"ephemeral_id" : "Q370o4FLQ4yKPX4_rOIlYQ",
"transport_address" : "172.31.62.172:9300",
"attributes" : { }
},
"6YNZvQW6QYO-DX31uIvaBg" : {
"name" : "es-node-3",
"ephemeral_id" : "mH034-P0Sku6Vr1DXBOQ5A",
"transport_address" : "172.31.52.220:9300",
"attributes" : { }
}
},
…
Индексы
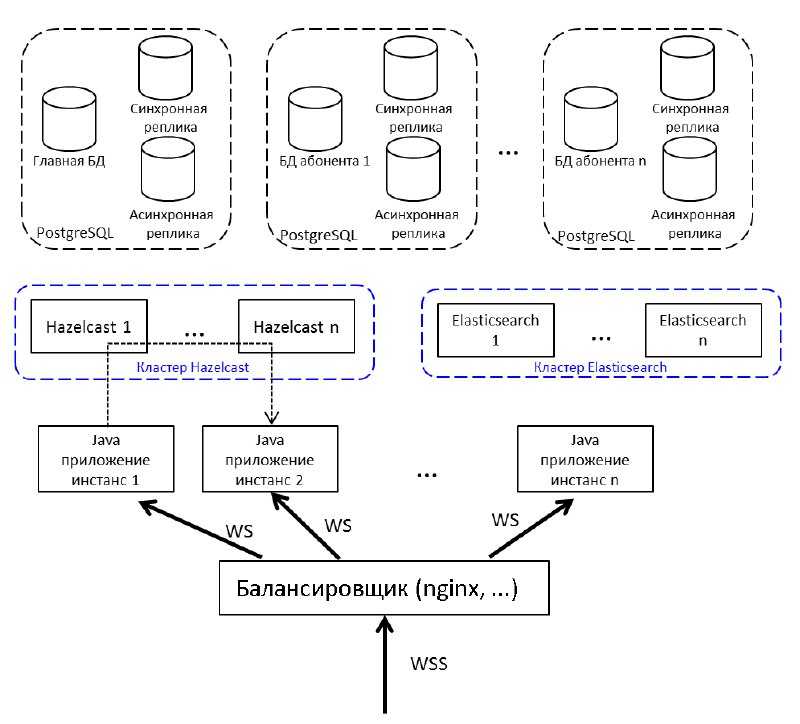
Возвращаясь к архитектуре системы, я бы хотел детальнее остановиться на том, как мы строили модель индексов, чтобы всё это работало корректно.
На приведённой ранее схеме это самый нижний уровень: Elasticsearch data nodes.
Индекс — это большая виртуальная сущность, состоящая из шардов Elasticsearch. Сам по себе каждый из шардов является ни чем иным, как Lucene index. А каждый Lucene index, в свою очередь, состоит и одного или более сегментов.
При проектировании мы прикидывали, что для обеспечения требования по скорости чтения на большом объёме данных нам необходимо равномерно «размазать» эти данные по дата-нодам.
Это вылилось в то, что количество шардов на индекс (с репликами) у нас должно быть строго равно количеству дата-нод. Во-первых, для того, чтобы обеспечить replication factor, равный двум (то есть мы можем потерять половину кластера). А, во-вторых, для того, чтобы запросы на чтение и запись обрабатывать, как минимум, на половине кластера.
Время хранения мы определили сперва как 30 дней.
Распределение шардов можно представить графически следующим образом:
Весь тёмно-серый прямоугольник целиком — это индекс. Левый красный квадрат в нём — это primary-шард, первый в индексе. А голубой квадрат — это replica-шард. Они находятся в разных дата-центрах.
Когда мы добавляем ещё один шард, он попадает в третий дата-центр. И, в конце концов, мы получаем вот такую структуру, которая обеспечивает возможность потери ДЦ без потери консистентности данных:
Ротацию индексов, т.е. создание нового индекса и удаление наиболее старого, мы сделали равной 48 часов (по паттерну использования индекса: по последним 48 часам ищут чаще всего).
Такой интервал ротации индексов связан со следующими причинами:
Когда на конкретную дата-ноду прилетает поисковый запрос, то, с точки зрения перформанса выгодней, когда опрашивается один шард, если его размер сопоставим с размером хипа ноды. Это позволяет держать “горячую” часть индекса в хипе и быстро к ней обращаться. Когда “горячих частей” становится много, то деградирует скорость поиска по индексу.
Когда нода начинает выполнять поисковой запрос на одном шарде, она выделяет кол-во тредов, равное количеству гипертрединговых ядер физической машины. Если поисковый запрос затрагивает большое кол-во шардов, то кол-во тредов растёт пропорционально. Это плохо отражается на скорости поиска и негативно сказывается на индексации новых данных.
Чтобы обеспечить необходимый latency поиска, мы решили использовать SSD. Для быстрой обработки запросов машины, на которых размещались эти контейнеры, должны были обладать по меньшей мере 56 ядрами. Цифра в 56 выбрана как условно-достаточная величина, определяющая количество тредов, которые будет порождать Elasticsearch в процессе работы. В Elasitcsearch многие параметры thread pool напрямую зависят от количества доступных ядер, что в свою очередь прямо влияет на необходимое кол-во нод в кластере по принципу «меньше ядер — больше нод».
В итоге у нас получилось, что в среднем шард весит где-то 20 гигабайт, и на 1 индекс приходится 360 шардов. Соответственно, если мы их ротируем раз в 48 часов, то у нас их 15 штук. Каждый индекс вмещает в себя данные за 2 дня.





