Prometheus short overview
Prometheus is an open-source monitoring system providing a powerful query language, storage, and visualization features for its users. It collects real-time metrics and records them in a time-series database. Prometheus provides a multidimensional data model that allows defining metrics by name and/or tags to identify them as part of a unique time series. It is written in Go and licensed under the Apache 2 License, with source code available on GitHub. As an open-source project, Prometheus has broad community support and therefore it has a range of client libraries that enable simple interaction with it. Also, Prometheus has native support from services like Docker and Kubernetes.
Деплой Thanos
Мы начнем с развертывания Thanos Sidecar в тех же кластерах Kubernetes, которые мы используем для пользовательских приложений, Prometheus и Grafana.
Есть много способов установки Prometheus, но я предпочитаю использовать Prometheus-Operator, который предоставляет настройки для мониторинга сервисов и развертываний Kubernetes, а также для управления экземплярами Prometheus.
Самый простой способ установки Prometheus-Operator — это использовать его Helm чарт, у которого есть встроенная поддержка высокой доступности, Thanos Sidecar и множество преднастроенных алертов для мониторинга кластерных виртуальных машин, инфраструктуры Kubernetes и ваших приложений.
Перед развертыванием Thanos Sidecar нам нужен Kubernetes Secret с информацией о том, как подключиться к облачному хранилищу.
Для демонстрации я буду использовать Microsoft Azure.
Создайте account для blob-хранилища:
Затем создайте папку (она же container) для метрик:
Получите ключи от хранилища:
Создайте файл с настройками хранилища (thanos-storage-config.yaml):
Создайте Kubernetes Secret:
Создайте файл prometheus-operator-values.yaml, в котором переопределите настройки по умолчанию для Prometheus-Operator.
И деплой:
Теперь у вас должен быть высокодоступный Prometheus вместе с Thanos Sidecar, который загружает ваши метрики в Azure Blob Storage с неограниченным сроком хранения.
Для того чтобы Thanos Store Gateway предоставить доступ к Thanos Sidecar, нужно выставить его наружу через Ingress. Я использую Nginx Ingress Controller, но вы можете использовать любой другой Ingress Controller, который поддерживает gRPC (возможно, Envoy будет лучшим вариантом).
Для защищенного соединения между Thanos Store Gateway и Thanos Sidecar мы будем использовать mutual TLS. То есть клиент будет аутентифицировать сервер и наоборот.
Если у вас есть .pfx-файл, то вы можете извлечь из него закрытый, открытый ключ и сертификат с помощью openssl:
Создайте из этого два Kubernetes Secrets.
Убедитесь, что у вас есть домен, который резолвится в ваш кластер Kubernetes, и создайте два поддомена, которые будут использоваться для маршрутизации к каждому из Thaos SideCar:
Теперь мы можем создать правила Ingress (измените имя хоста):
Теперь у нас есть защищенный доступ к Thanos Sidecars снаружи кластера!
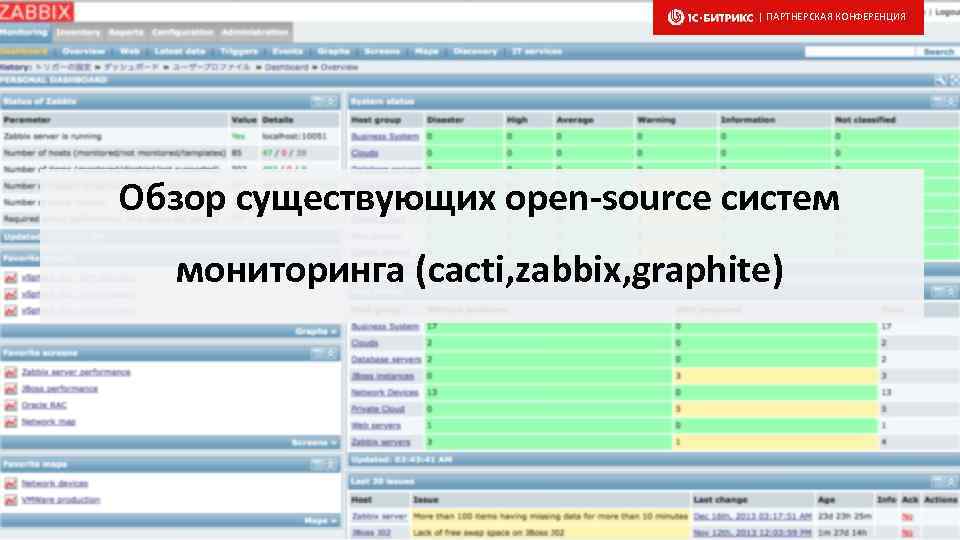
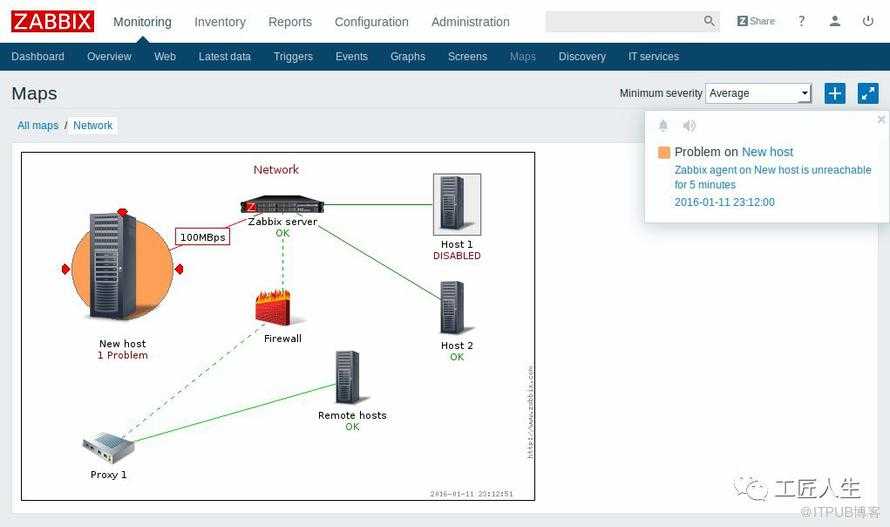
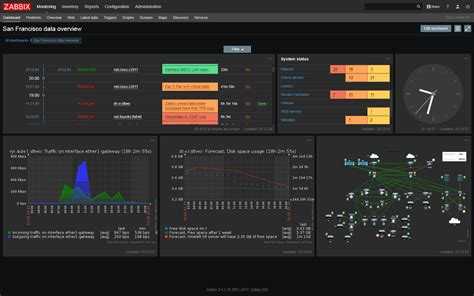
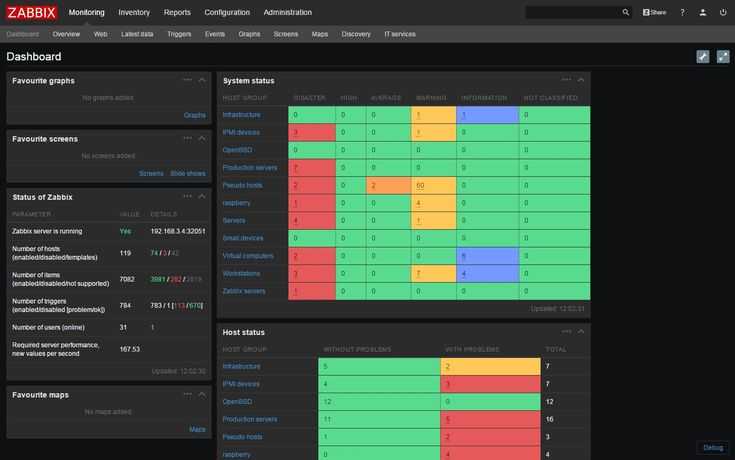
Zabbix способен объять всю инфраструктуру
Zabbix можно считать системой мониторинга общего назначения, на которую можно замкнуть всю инфраструктуру. Например, настроить мониторинг ssl сертификатов и время делегирования домена. Недавно я решал задачу мониторинга промышленных контроллеров, которые отдают данные по протоколу ModBus. Заббикс его поддерживает после установки дополнительного модуля. Как такие вещи сделать в Prometheus, я даже не представляю.
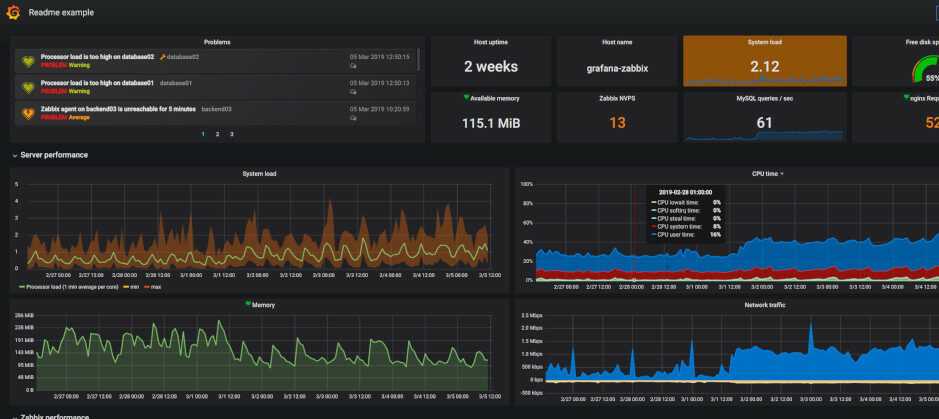
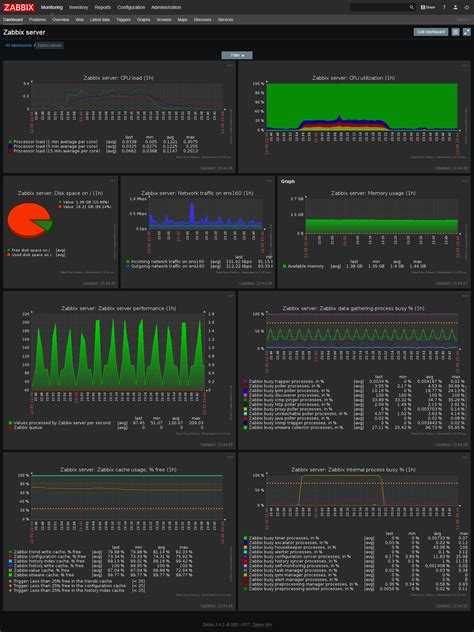
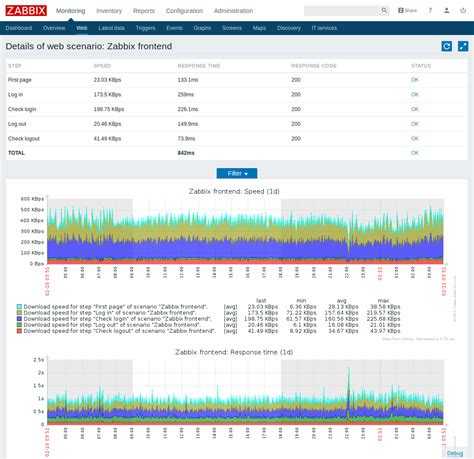
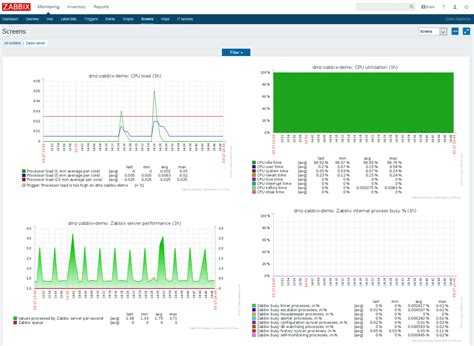
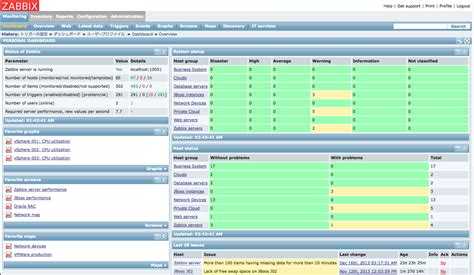
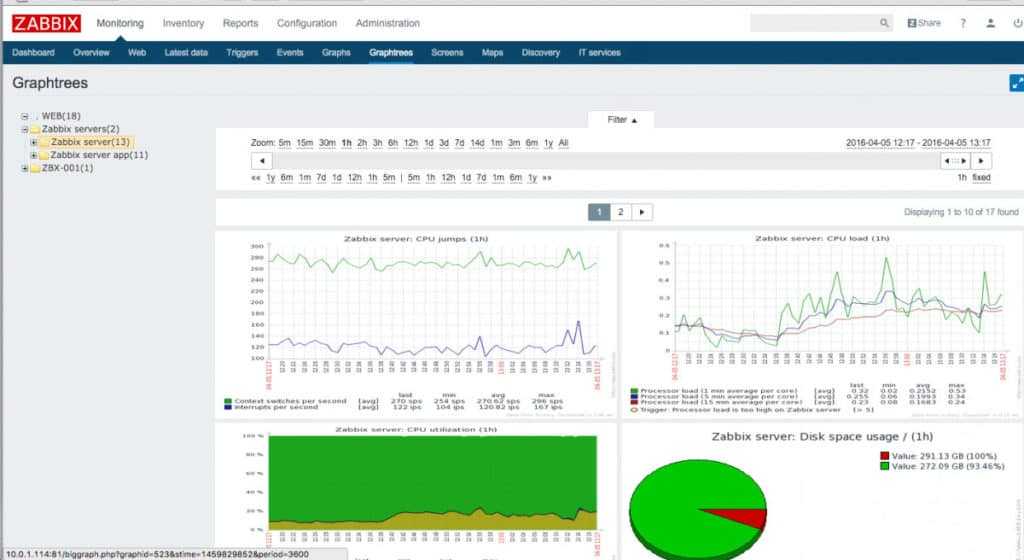
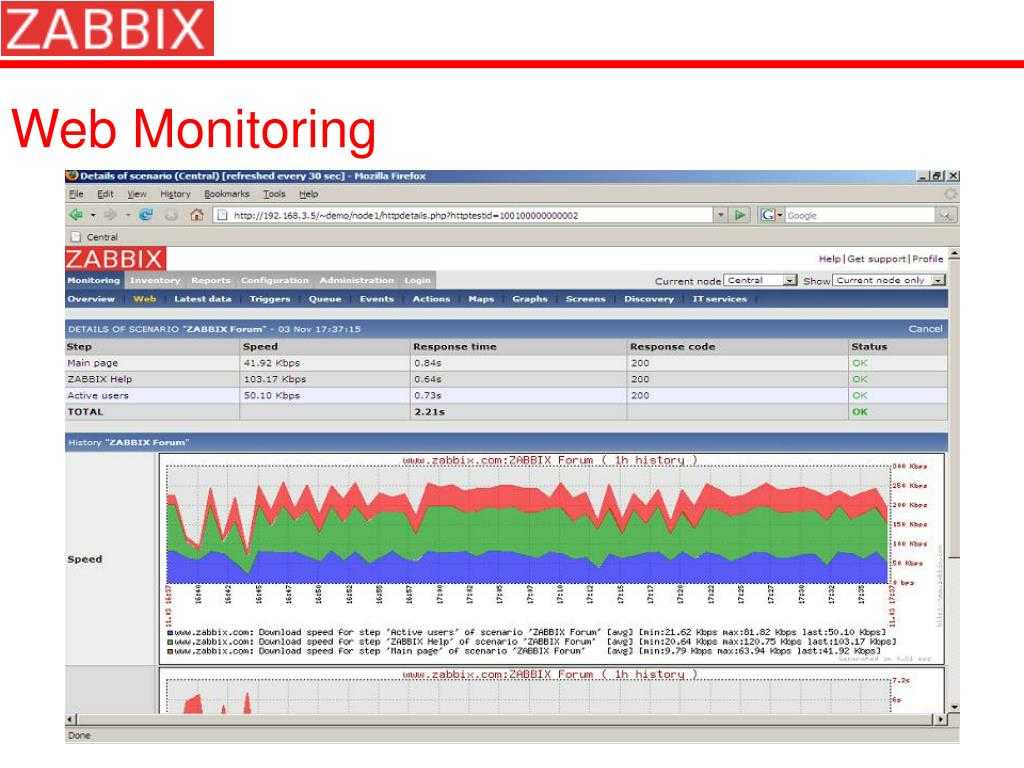
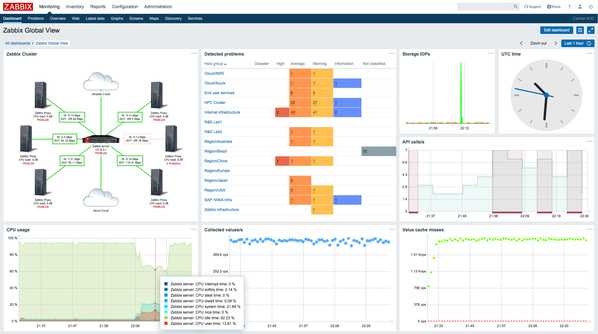
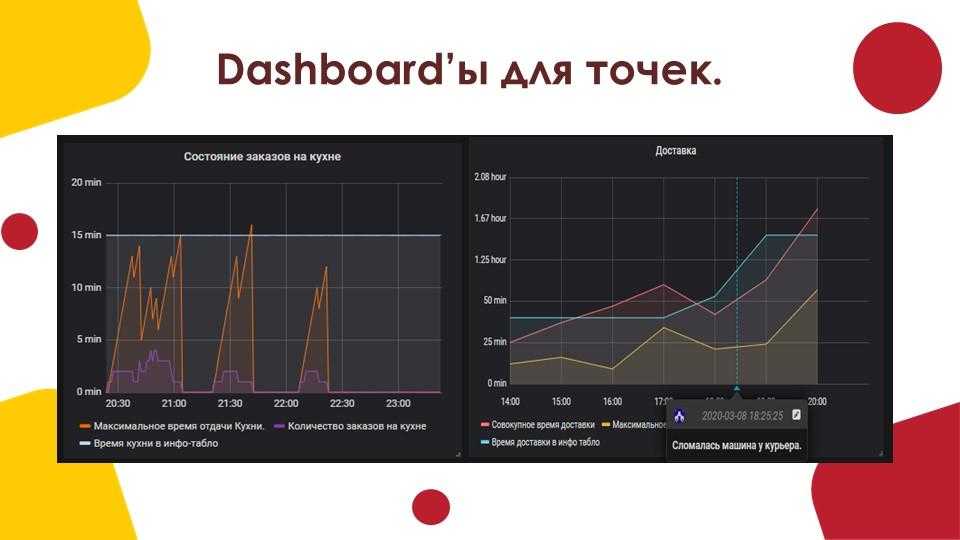
Таким образом, у вас есть универсальная система мониторинга, которая объединяет в себе вообще всю инфраструктуру. Плюс, можно сразу подключить какие-то внешние метрики через API удаленных систем. У Prometheus все же более узкая специализация под конкретные задачи.
Операционная система
- количество доступной памяти в %;
- активность использования swap: vmstat swapin, swapout;
- количество доступных inode и свободного места на файловой системе в %
- средняя загрузка;
- количество соединений в состоянии tw;
- заполненность таблицы conntrack;
- качество работы сети можно мониторить с помощью утилиты ss, пакетом iproute2 — получать из её вывода показатель RTT-соединений и группировать по dest-порту.
Также на уровне операционной системы у нас появляется такая сущность, как процессы
Важно выделить в системе набор процессов, которые играют важную роль в её работе. Если, к примеру, у вас есть несколько pgpool, то необходимо собирать информацию по каждому из них
Набор метрик следующий:
- CPU;
- память — в первую очередь, резидентная;
- IO — желательно в IOPS;
- FileFd — открытые и лимит;
- существенные отказы страницы — так вы сможете понять, какой процесс свапается.
Весь мониторинг у нас развернут в Docker, для сбора данных метрик мы используем Сadvisor. На остальных машинах применяем process-exporter.
Conclusion
Now you know how to use Prometheus, and I hope you will be able to configure it on your own. If this is something completely new here, you should re-watch the video and try to create the same items, the same low-level discovery rules like those described here.
Also, check out our official documentation and read about Low-level discovery and Prometheus checks. You will find examples, explanations of preprocessing parameters, patterns, and output, as well as similarities and differences between the PromQL and Zabbix Prometheus preprocessing syntax. You can read about output in JSON format and check examples on mapping LLD macros — basically about anything you have read in this article.
I do suggest that you use low-level discovery. It will be more complicated to configure rather than a normal item, but it will make more sense. If something changes on the device, the LLD rule will discover the changes based on item prototypes, and new items will be created based on item prototypes, and you will have full monitoring of your environment.
If something is still unclear, if something is not working in Zabbix or in the front-end configuration for LLD, and you cannot find answers in the documentation or in other sources, don’t hesitate and ask the questions in the comments.
Меркурий 236
добрые людирешениеммодуль
UserParameter
UserParameterZabbix trapperВнешние проверки
Настроим получение наших метрик счетчика
- Тип: Зависимый элемент данных
- Основной элемент данных: mercury-get
jsonpath.com
- Тип: Зависимый элемент данных
- Основной элемент данных: mercury-get
- будем использовать нотацию с квадратными скобками, так как в пути JSON есть дефис
- препроцессинг может быть многошаговым, например здесь результата первого шага умножим на 1000, чтобы получить Вт*ч из кВт*ч
Что получилось
здесь
- переиспользовали хорошую программку и не тратили время на написание своей реализации сбора данных по протоколу Меркурий
- UserParameter остался, но схлопнулся до простого вызова. По сути можно даже использовать
- cкрипты-обертки тоже не писали. Всё распарсили через JSON path в шаблоне
- cчетчик не мучали сильно, один запрос – все нужные нам данные разом.
DevOps
Со всеми этими экспортерами для разных систем, баз данных и серверов очевидно, что Prometheus предназначен, в основном, для сферы DevOps.
Мы знаем, что в этой сфере множество конкурирующих поставщиков и персонализированных решений.
Prometheus идеально подходит для DevOps.
Для настройки и запуска экземпляров почти не требуется усилий, и можно легко активировать и настроить любой вспомогательный инструмент.
Благодаря обнаружению целевых объектов — например, через файловый экспортер, —это отличное решение для стеков, где широко используются контейнеры и распределенные архитектуры.
В среде, где экземпляры то и дело создаются и удаляются, ни один стек DevOps не обойдется без обнаружения сервисов.
2. Здравоохранение
Сегодня решения для мониторинга нужны не только в ИТ. Они используются и в крупных отраслях, которые предоставляют гибкие и масштабируемые архитектуры для здравоохранения.
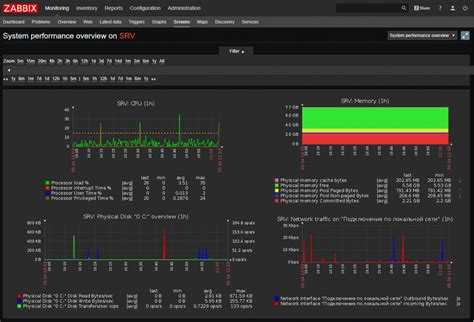
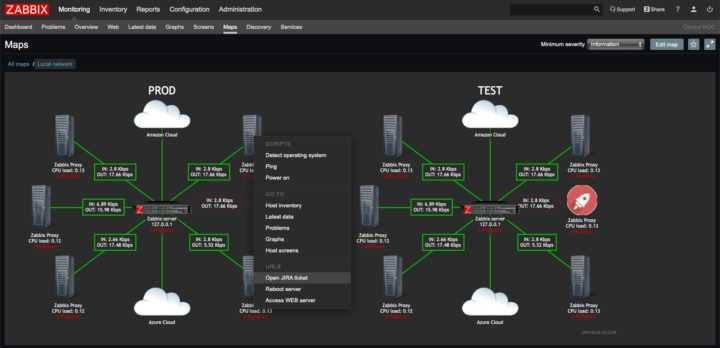
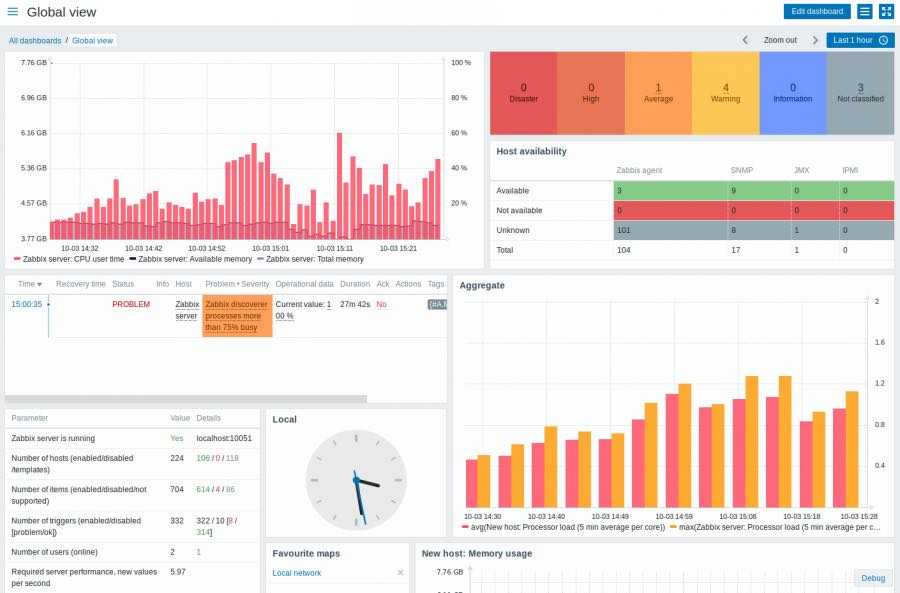
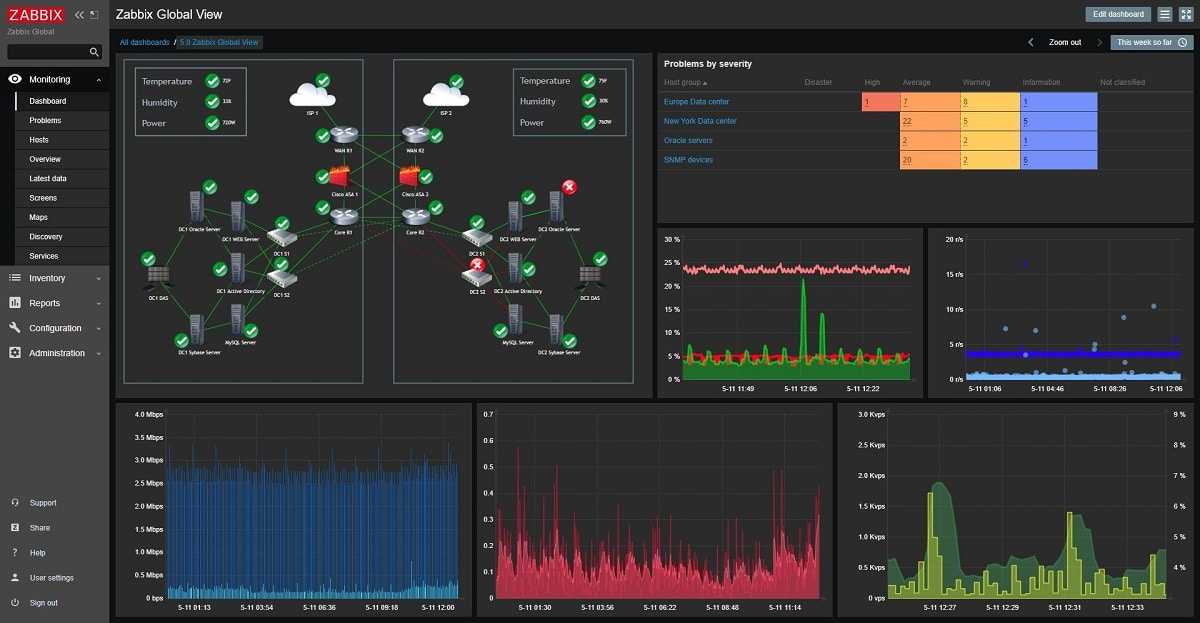
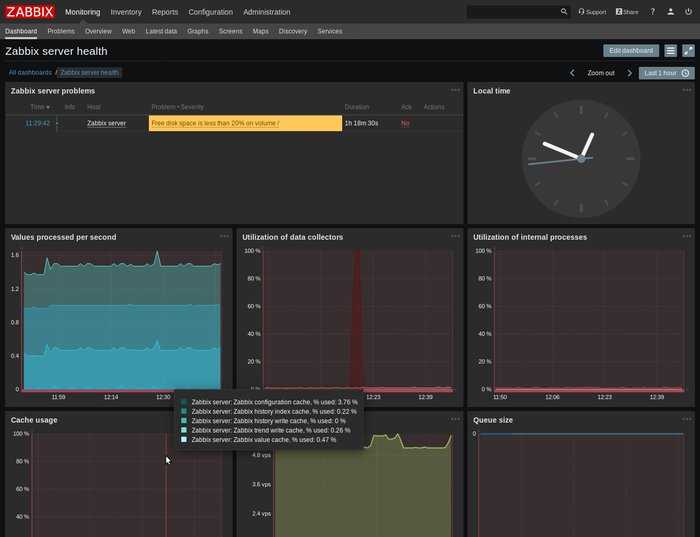
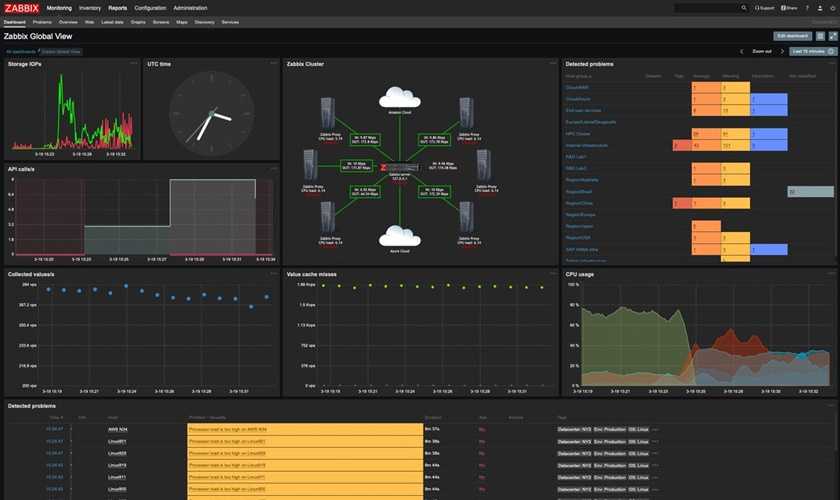
Спрос растет, и ИТ-архитектуры обязаны ему соответствовать. Если у вас нет надежного инструмента для мониторинга всей инфраструктуры, вы рискуете столкнуться с серьезными перебоями в обслуживании. Уж в сфере здравоохранения такую опасность точно надо свести к минимуму.
3. Финансовые услуги
Последний пример приводился на конференции InfoQ, где обсуждалось использование Prometheus в финансовых учреждениях.
Джейми Кристиан (Jamie Christian) и Алан Стрейдер (Alan Strader) показывали, как они используют Prometheus для мониторинга своей инфраструктуры в Northern Trust. Очень содержательно, советую посмотреть.
Долгосрочное хранение данных
Изначально Prometheus был рассчитан на краткосрочное (неделя-две) хранение метрик и работы с ними. У него для этого есть TSDB, отлично оптимизированная под временные ряды и добавление данные по модели pull. То есть это продукт для оперативного мониторинга. Если вы хотите хранить исторические данные месяцы и годы, вам придется искать какое-то отдельное решение для этого. Они существуют, их относительно много, но придется отдельно потрудиться, чтобы выбрать что-то подходящее и настроить.
В Zabbix с этим проще. Он изначально рассчитан на долгосрочное хранение. Конечно, там есть свои сложности с высокой нагрузкой на базу (это его узкое место, так как там честный SQL) и долгосрочным хранением больших объемов. Но тем не менее, эти вопросы прорабатываются и развиваются. К примеру, 5-я версия Zabbix поддерживает в качестве базы данных PostgreSQL + TimescaleDB.
Определение подхода к мониторингу
Нам хотелось декомпозировать задачу и тем самым систематизировать подход к мониторингу.
Для этого я разделил нашу систему на следующие уровни:
- «железо» и VMS;
- операционная система;
- системные сервисы, стек ПО;
- приложение;
- бизнес-логика.
Чем удобен такой подход:
- мы знаем, кто ответственен за работу каждого из уровней и, исходя из этого, можем высылать алертов;
- мы можем использовать структуру при подавлении алертов — было бы странно отсылать алерт о недоступности базы данных, когда в целом виртуальная машина недоступна.
Так как наша задача выявлять нарушения в работе системы, мы должны на каждом уровне выделить некий набор метрик, на которые стоит обращать внимание при написании правил алертинга. Далее пройдемся по уровням «VMS», «Операционная система» и «Системные сервисы, стек ПО»
Прометей против InfluxDB: Обзор
Prometheus — это база данных, оптимизированная для данных временных рядов и идеальный способ хранения показателей мониторинга. Prometheus выпустила Cloud Native Computing Foundation (CNCF), что означает отличную интеграцию с другими компонентами CNCF. Он имеет встроенное обнаружение сервисов, что упрощает его использование в высокодинамичных средах. В отличие от традиционных инструментов мониторинга, Prometheus использует модель извлечения, которая позволяет лучше масштабироваться. Для доступа к данным Prometheus предлагает гибкий язык запросов под названием PromQL.
Сравнение высокого уровня: Прометей против InfluxDB
| Характерная черта | Прометей | InfluxDB |
| Что это | Полностью интегрированная СУБД временных рядов и система мониторинга | База данных временных рядов |
| Что оно делает | Сбор, хранение, запросы, построение графиков и оповещение на основе данных временных рядов; предоставляет конечные точки API для данных, которые он хранит | Хранит числовые данные временных рядов |
| Реализовано на | Go | Go |
| Типы данных обрабатываются | Числовой | Числовой |
| Год выпуска | 2012 г. | 2013 |
| Веб-сайт | prometheus.io | https://github.com/influxdata/influxdb |
| Техническая документация | prometheus.io/docs | https://v2.docs.influxdata.com/v2.0/ |
| API и методы доступа | RESTful HTTP и JSON | HTTP, TCP и UDP API |
| Поддержка XML? | Да (можно импортировать) | Нет |
| Серверные операционные системы | Linux, Windows | Linux, macOS |
| Поддерживаемые языки программирования | .NET, C ++, Go, Haskell, Java, JavaScript (Node.js), Python, Ruby | C ++, Erlang, Elixir, Go, Haskell, Java, JavaScript, LISP, MATLAB, .Net, Perl, PHP, Python, R, Ruby, Rust, Scala |
| Разбиение поддерживается? | Да, шардинг | Да, шардинг |
| Репликация поддерживается? | Да, по федерации | Да, возможно несколько методов |
| Сбор данных | Активный или Pull(настраивается) | Push или Pull |
Prometheus
Мы выбрали Prometheus, исходя из трех основных показателей:
- Огромное количество доступных метрик. В нашем случае их 60 тысяч. Конечно, стоит отметить, что подавляющее большинство из них мы не используем (наверно, около 95%). С другой стороны, они все относительно дешевы. Для нас эта другая крайность, по сравнению с ранее использовавшейся Icinga. В ней добавление метрик доставляло особую боль: имеющиеся доставались дорого (достаточно посмотреть на исходники любого плагина). Любой плагин представлял собой скрипт на Bash или Python, запуск которых недешёвый с точки зрения потребляемых ресурсов.
- Эта система потребляет относительно небольшое количество ресурсов. На все наши метрики хватает 600 Мб оперативной памяти, 15% одного ядра и пару десятков IOPS. Конечно, приходится запускать экспортёры метрик, но все они написаны на Go и тоже не отличаются прожорливостью. Не думаю, что в современных реалиях это проблема.
- Даёт возможность перехода в Kubernetes. Учитывая планы заказчика — выбор очевиден.
About MetricFire
MetricFire provides a wide range of monitoring services, through their platform built on the open source Prometheus, Graphite, and Grafana. MetricFire’s Hosted Prometheus absorbs all the advantages of the usual Prometheus, and also solves all its shortcomings to provide a full-fledged monitoring system.
MetricFire provides long term data storage of Prometheus time series data and ensures redundancy of data by creating three copies of everything automatically. The visualization is provided by Grafana, where your data will be visualized on beautiful real-time dashboards. MetricFire can run on-premises or on the cloud and offers a whole suite of support options such as alerting design, analytics, and so on.
The context
For my new mission, I had to maintain a monitoring tool called Centreon and I almost immediately disliked it. In its OSS version, you go a clunky interface, even a fresh install is not properly working, the synchronization system with the broker is awkward and not automatic. I also had permanent issues with the communication system.
Since we are in 2019 and we are talking about DevOps, automation and REST API, I thought we could do better. Last year, I have been working with AppManager from ManageEngine and was quite happy though it is pretty expensive.
For this new mission, the expectations are lower and the budget is lower too. Therefore I decided to set my interest on the open-source/freemium alternatives.
My own preferences have already discarded :
- Icinga : OK it’s Nagios in better, but it’s still Nagios
- Shinken : I used it 6 years ago, was happy with it, but now it’s time of something better
- Centreon : Never, not ANYMORE
- : I like the concept but I feel that it is going to be a nightmare to set in production with its relatively small community.
My interest will be the fight between :
| Prometheus + Grafana | Zabbix |
I will check especially the following aspects of these software :
- UI discovery
- Adding a host
- Testing the host connectivity
- Handling SNMP
- Alerts and notification
- Adding a host through REST API.
Рассказ про то, как работает Prometheus:
- Collector ходит в таргеты и забирает метрики с лейблами (обогащает их).
- И сохраняет их в TSDB. Каждый scrape период, например каждые 60 секунд.
- Если приложение не умеет нативно отдавать Prometheus метрики, нужно использовать экпортеры. Обычно их запускают в одном поде, т.н. sidecar.
- TSDB — БД временных рядов. Есть параметр сколько по времени хранить (но нет лимитам по размеру), 1–2 байта на измерение, нет кластеризации, репликации. Но можно сделать несколько Prometheus.
- БД Хорошо оптимизирована, оптимально использует дисковое IO.
- Из коробки поддерживает Service Discovery(SD), ходит в API кубера и забирает.
- Уникальный идентификатор — неймспейс+название группы+название пода Перед группой подов обычно есть балансер.
Настройки Prometheus задаются в Yaml файле в секции scrape_configs в виде job_name. Их может быть несколько.
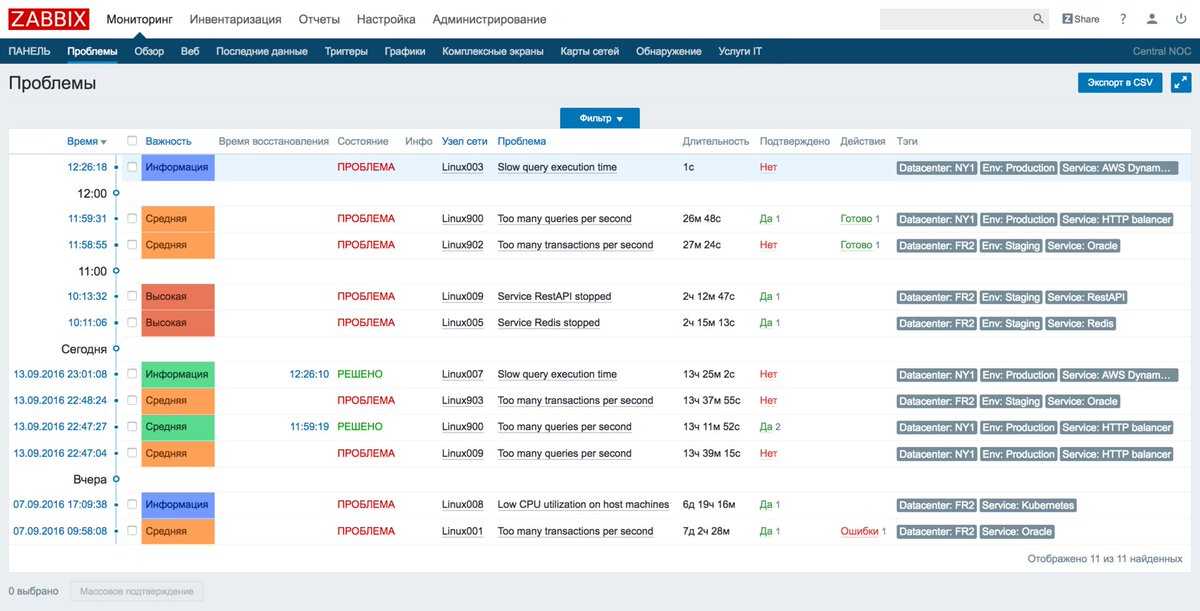
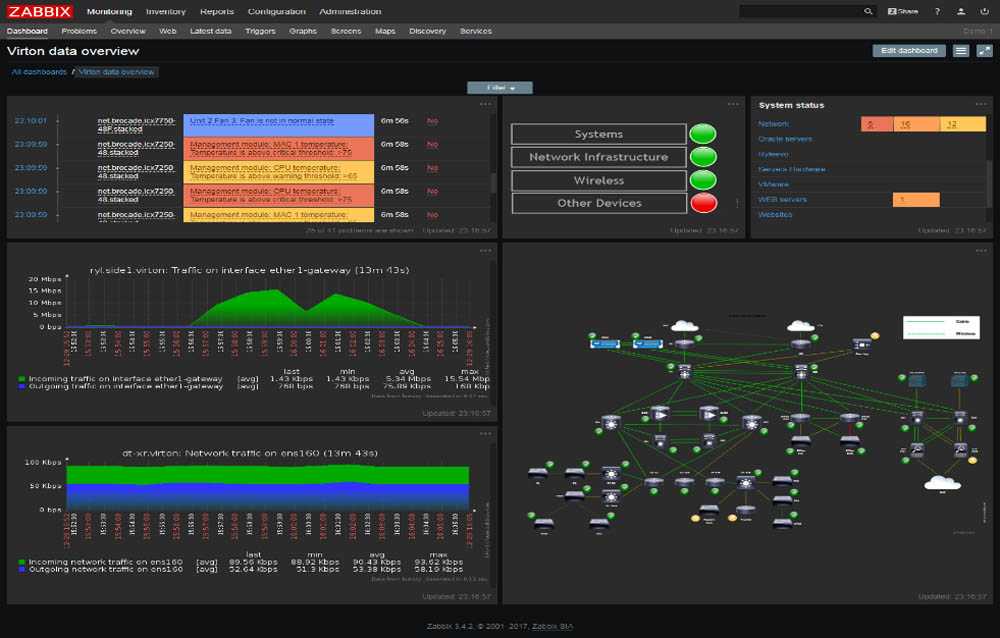
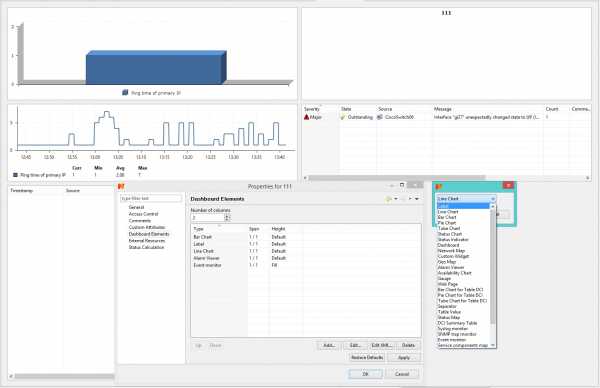
Introduction
For a successful business, you need to introduce an effective monitoring system covering all areas of your business and infrastructure — servers, databases, services, overall traffic, and even revenue collected. The users of this monitoring system can be system administrators, software engineers, information engineers, as well as all sorts of analysts. A modern efficient monitoring system should provide services for the collection of metrics, their storage, calculations/projections, visualizations, and alerting. Finding a tool that can achieve all of these things is a pretty big challenge.
In this article, we will consider two major service providers: Prometheus and Zabbix. Both Prometheus and Zabbix are great tools for monitoring time-series, where Zabbix is the older-generation tool and Prometheus is cutting edge. Both tools are open source with hosted options available.
For ease-of-use and budget friendly solutions, MetricFire’s Hosted Prometheus solution is the fastest way to get your infrastructure monitoring up and running in a scalable way. You can use Hosted Prometheus with minimal configuration to gain in-depth insight into your environments. If you would like to learn more about it, book a demowith MetricFire orsign on to the free trial today.
О проекте
Проект — одна из крупнейших в стране программ лояльности. Мы помогаем розничным сетям увеличивать частоту продаж за счёт различных маркетинговых инструментов вроде бонусных карт. В общей сложности в проект входят 14 приложений, которые работают на десяти серверах.
В процессе ведения собеседований я неоднократно замечал, что админы далеко не всегда правильно подходят к мониторингу веб-приложений: до сих пор многие останавливаются на метриках операционной системы, изредка мониторят сервисы.
В моём случаем прежде в основе системы мониторинга заказчика лежала Icinga. Она никак не решала указанные выше задачи. Часто клиент сам сообщал нам о проблемах и не реже нам просто не хватало данных, чтобы докопаться до причины.
Кроме того, было чёткое понимание бесперспективности её дальнейшего развития. Я думаю, те кто знаком с Icinga меня поймут. Итак, мы решили полностью переработать систему мониторинга веб-приложений на проекте.
Disclaimer
Это длинная запись с большим количеством картинок и ещё большим количеством текста. Здесь вы не найдёте однозначного ответа на простые вопросы наподобие «что лучше», но информацию для ответа на эти вопросы, основываясь на вашем опыте и желаниях. Я рассматриваю условия работы в Linux и слежения за Linux-хостами, поэтому поддержка системой разных платформ в расчёт не принималась. Также за условие принималось требование возможности следить за тысячами машин и тысячами сервисов.
По моему мнению, только Zabbix и Icinga 2 являются достаточно зрелыми для использования в «энтерпрайзе», главный вопрос, который должен задать себе тот, кто выбирает систему — какая философия мониторинга ему ближе, поскольку обе они позволяют получить один и тот же результат, используя совершенно разные подходы.
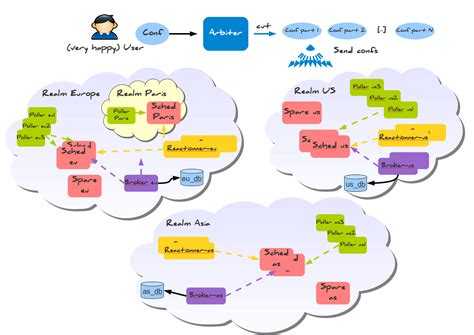
Thanos
Thanos — это проект с открытым исходным кодом, на основе которого можно построить высокодоступную систему сбора метрик с неограниченным размером хранилища, бесшовно интегрирующуюся с существующими экземплярами Prometheus.
Для хранения исторических данных Thanos использует формат хранения Prometheus и может хранить метрики в любом объектном хранилище. Кроме того, он обеспечивает global view для всех экземпляров Prometheus.
Основные компоненты Thanos:
-
Sidecar. Подключается к Prometheus и использует его для запросов в реальном времени через Query Gateway и/или загружает его данные в облачное хранилище для длительного хранения.
-
Query Gateway. Реализует Prometheus API для агрегирования данных из нижележащих компонент (таких как Sidecar или Store Gateway).
-
Store Gateway. Предоставляет доступ к содержимому облачного хранилища.
-
Compactor. Делает уплотнение и даунсэмплинг (downsampling) данных в облачном хранилище.
-
Receiver. Получает данные из remote-write WAL Prometheus, предоставляет их и/или загружает в облачное хранилище.
-
Ruler. Вычисляет recording rules и alerting rules для данных в Thanos.
В этой статье мы сосредоточимся на первых трех компонентах.
Теория
Prometheus сам собирает все данные с целевого объекта, для этого есть разные способы:
- Приложение может быть написано так, что само отдает метрики в нужном формате.
- Используются готовые экспортеры. Например, есть экспортеры для MySQL, Nginx или машины с GNU/Linux.
- Pushgateway. Применяется, когда нет возможности использовать Pull-запросы для снятия метрик стандартными средствами. Применяется, например, при выполнении задач в crontab.
Так как приём и обработка данных происходит в самом Prometheus, он является центральным звеном всей схемы мониторинга, где происходит вся настройка
Формат получаемых метрик в Prometheus — ключ-значение, это важно запомнить
Из дополнительных инструментов присутствуют:
- Alertmanager – для оповещения, его данная статья не коснётся.
- Data visualization – простой способ визуализации из коробки, из внешних можно использовать Grafana.
- Service discovery – динамическое обнаружение сервисов, также в данной статье не рассматривается.
А также присутствует PromQL – собственный язык запросов для извлечения метрик из базы данных.
Sensu
Sensu — фреймворк для мониторинга (или платформа, как они сами о себе говорят), но не готовая система мониторинга.
Её сильные стороны включают:
- Интеграция с Puppet \ Chef — определяйте, что проверять, и куда отправлять уведомления прямо в вашей системе управления конфигурацией
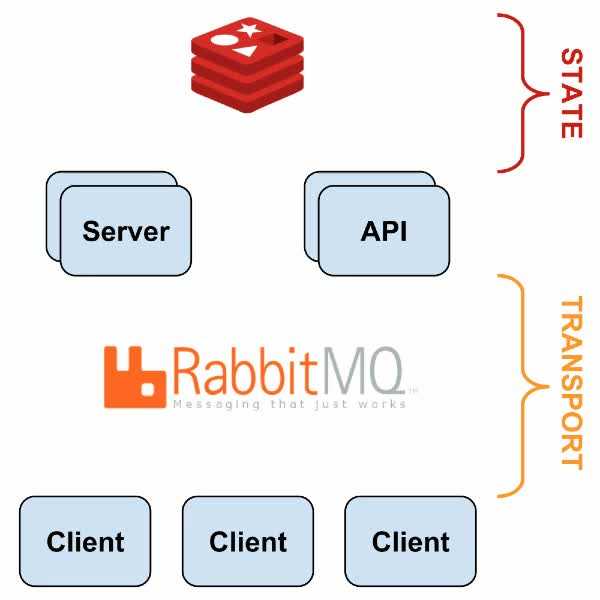
- Использование имеющихся технических решений там, где это возможно, вместо изобретения велосипедов (Redis, RabbitMQ)
Sensu вытягивает события из очереди и выполняет на них обработчики, вот и всё. Обработчики (Handlers) могут посылать сообщения, выполнять что-то на сервере, или делать что угодно ещё, чему вы их научите.
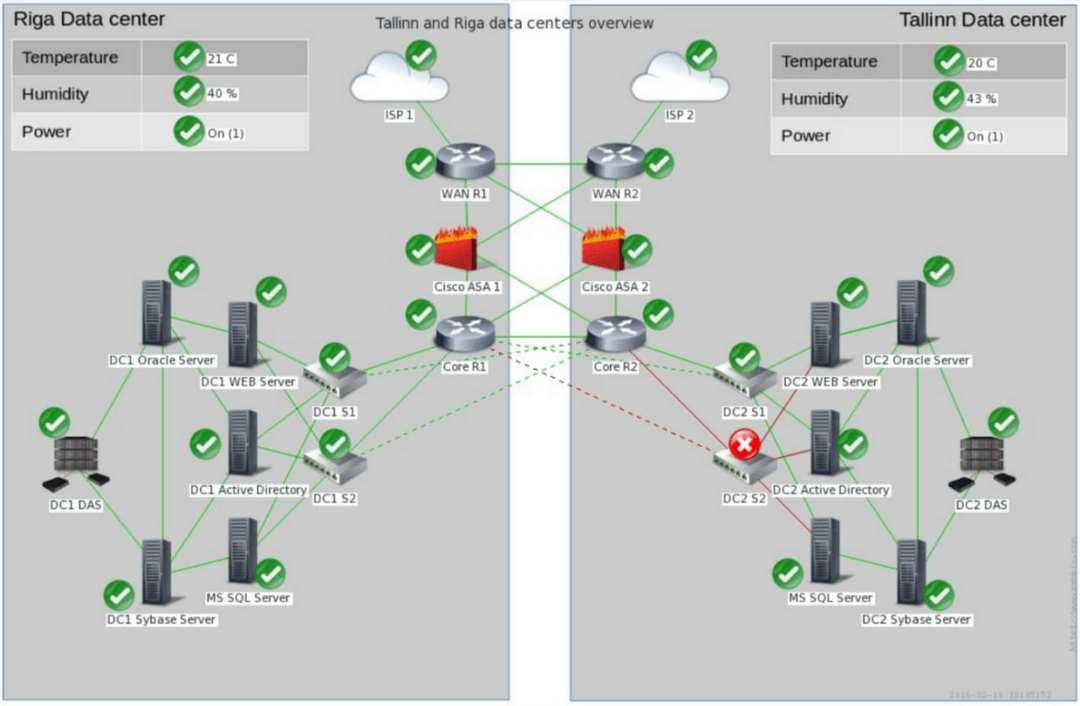
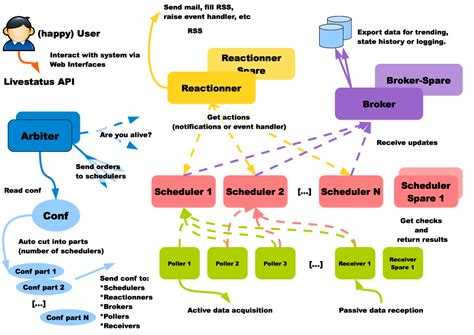
Масштабируемость
Sensu имеет гибкую архитектуру, поскольку каждый компонент может быть продублирован и заменён несколькими путями. Пример простой отказоустойчивой системы описан в следующей презентации; вот общая схема:
С HAProxy и Redis-sentinel вы можете построить систему, в которой, при наличии хотя бы одной живой машины каждого типа (Sensu API, Sensu Dashboard, RabbitMQ, Redis) мониторинг будет продолжать работать без какого-либо ручного вмешательства.
Встроенная (Puppet, Chef, EC2?!) но только в платной версии, что плохо, особенно если у вас тысячи серверов и вы не хотите платить за что-то, имеющее бесплатные аналоги.
Логирование действий
Встроенное, однако только в платной редакции.
UI
Интерфейс по-умолчанию для Sensu, Uchiwa, имеет много ограничений. Он выглядит слишком простым для окружения с тысячами хостов, которые имеют большой разброс по ролям. Платная версия имеет свой собственный дашборд, однако он не сильно отличается от бесплатной редакции, и только добавляет несколько выключенных из-коробки возможностей открытой версии.
Недостатки
- Отсутствие исторической информации и очень ограниченные возможности создания проверок, основанной на ней;
- Подход «сделай сам» — нет готового мониторинга, который можно было бы включить для вашей системы сразу после установки;
- Агрегирование событий нетривиально;
-
Замудрёная отправка сообщений, что страшно (потому что это та часть системы, которая должна быть самой простой и надёжной)— неправда, я получил неправильное впечатление от документации, спасибо x70b1 за разъяснение; - Путь «мы не хотим изобретать колесо» имеет свои ограничения, которые могут быть вам знакомы, если вы когда-либо использовали подобные системы (в моём случае, это была система мониторинга Prometheus, которая оставляла ряд функций на откуп пользователю, например, авторизацию\аутентификацию\идентификацию).
Ссылки
Sensu — What I’ve LearntMOTD integrationIcinga 2
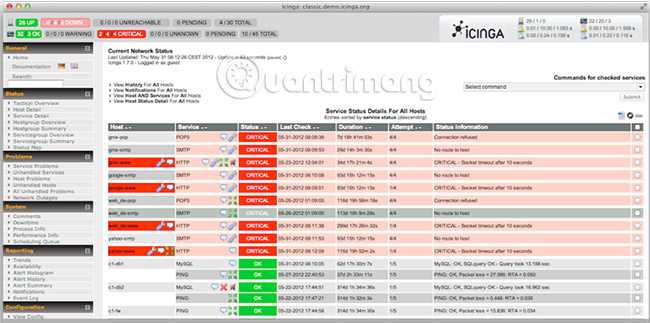
Icinga это форк Nagios’а, во второй версии переписанный с нуля. В отличии от Shinken, этот живой, часто обновляющийся проект.
Масштабируемость
Общая архитектура:
Icinga 2 имеет хорошо продуманную схему распределённого мониторинга. Единственный минус, который я обнаружил при поднятии тестового кластера — сложная изначальная настройка даже самой простейшей распределённой схемы.
Интеграция довольно хороша, вот две презентации по теме:
https://youtube.com/watch?v=lLsPwI-6UII
Логирование действий
Как я обнаружил, логирование действий представлено в модуле director. Встроенной поддержки аудита в IcingaWeb2 в данный момент нет.
UI
IcingaWeb2 выглядит неплохим UI с большим количеством дополнений под разные нужды. Из того, что я видел, он выглядит самым гибким и расширяемым, в то же время из коробки поддерживая все возможности, которые вы можете ожидать.
Недостатки
Единственным недостатком, который я встретил, является сложность изначальной настройки. Непросто понять взгляд Icinga на мониторинг, если вы до этого использовали что-то совершенно иное, как, в моём случае, Zabbix.