
Введение
Рассказываю подробно, что я хочу получить в конце статьи. В стандартном шаблоне Zabbix для Linux есть несколько триггеров. Они могут немного отличаться в названиях, в зависимости от версии шаблона, но смысл один и тот же:
- High CPU utilization
- Load average is too high
- Too many processes on hostname
Я хочу получить информацию о запущенных процессах на хосте в момент срабатывания триггера. Это позволит мне спокойно посмотреть, что создает нагрузку, когда у меня будет возможность. Мне не придется идти руками в консоль хоста и пытаться ловить момент, когда опять появится нагрузка.
В дефолтной конфигурации у Zabbix нет готовых инструментов, чтобы реализовать желаемое. Вы можете настроить мониторинг процесса или группы процессов в Zabbix. Но это не то, что нужно. Можно настроить автообнаружение всех процессов и мониторить их. Чаще всего это тоже не нужно, а подобный мониторинг будет генерировать большую нагрузку и сохранять кучу данных в базу. Особенно если на сервере регулярно запущено несколько сотен процессов.
Моя задача посмотреть на список процессов именно в момент нагрузки. Более того, мне даже не нужны все процессы, достаточно первой десятки самых активных, нагружающих больше всего систему. Я буду реализовывать этот мониторинг следующим образом:
- Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
- Разрешаю на zabbix agent запуск внешних команд.
- Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
Приступаем к реализации задуманного. Я буду настраивать описанную схему на Zabbix Server версии 5.2. Если у вас его нет, читайте мою статью по установке и настройке zabbix. В качестве подопытной системы будет выступать Centos. Так же предлагаю мои статьи по ее установке и предварительной настройке.
Сразу же сделаю важное замечание. Все, что написано далее, полностью придумано и реализовано мной
Это не самый оптимальный вариант решения задачи, но лично я ничего лучше, удобнее, проще придумать не смог. Если вы знаете, как сделать то же самое лучше, поделитесь информацией. С удовольствием ознакомлюсь с ней.
Как организовать слежение за компьютером
Нам нужна программа шпион NeoSpy. Заходим на сайт http://ru.neospy.net/download/ и скачиваем программу. Сохраняем файл например на рабочий стол, сейчас будем устанавливать.
Еще хочу сразу написать о цене и о специальном предложении. Значит программа платная, но не дорогая. В зависимости от версии, цена от 490 р. и до 1280 рублей. Купить можно на странице http://ru.neospy.net/buy/. Но можно бесплатно протестировать программу, на протяжении 60 минут и с некоторыми урезанными функциями. Этого хватит, для того, для того, что бы понять нужна вам NeoSpy, или нет.
У меня для вас есть подарок :).
Установка NeoSpy
Запускаем скачанный нами файл “neospy.exe”. Нажимаем “Далее”.
Читаем о возможностях программы и еще раз нажимаем “Далее”.
Читаем и принимаем лицензионное соглашение, нажимаем “Далее”.
Теперь нам нужно выбрать тип установки. Есть Администраторская и Скрытая установка.
Администраторская – выбирайте, если не нужно прятать программу. Ее можно будет запустить с ярлыка на рабочем столе, в меню Пуск и т. д. Если вы хотите следить за компьютером, то лучше выберите скрытую установку.
Скрытая установка – при выборе этого пункта, программу можно будет запустить только нажав “Пуск”, “Выполнить” и введя команду neospy.
Определитесь и нажмите “Установить”.
Ждем пока NeoSpy установиться, в процессе установки нужно будет ответить на два вопроса, нажимайте “Да”. По завершению установки нажмите “Заверено”. Программа запуститься сама.
Настройка и запуск слежения за компьютером
Программа очень простая, за что разработчикам огромное спасибо. Нажатием всего на одну кнопку, можно запустить слежение, включить скрытый режим и остановить слежение за компьютером.
Чуть ниже есть три кнопки, для просмотра результатов слежения.
Допустим нам нужно проследить, какие сайты посещает ребенок. Нажимаем кнопку “Запустить слежение” и для того, что бы скрыть программу, сделать ее невидимой, нажимаем “Скрытый режим”.
Программа полностью пропадет, но будет следить за компьютером. А вы можете заниматься своими делами.
Просмотр результатов наблюдения за компьютером
Для того, что бы остановить слежение, и посмотреть результаты, нужно:
В Windows XP: “Пуск”, “Выполнить”.
В Windows 7: “Пуск”, “Все программы”, “Стандартные”, “Выполнить”.
Вводим команду neospy.
Откроется окно с программой, нажмите на “Остановить слежение”. Теперь можно приступить к просмотру результатов слежения. Нажмите на кнопку с соответствующим способом просмотра результатов.
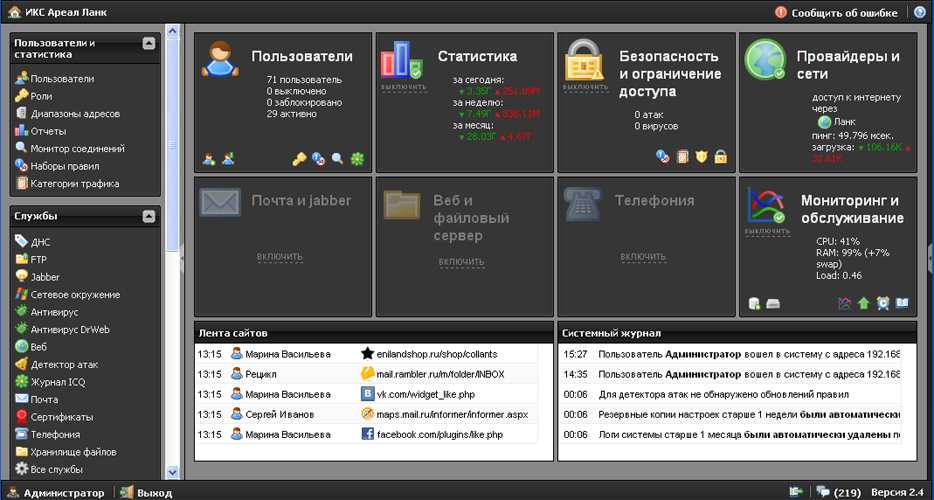
Я например выбрал “Отчет по категориям”. Затем выбираем запись которую хотим просмотреть.
Дальше уже просто смотрим, что делали на вашем компьютере. Можно переходит на разные вкладки. Например клавиатура, скриншоты и т. д.
Собственно все. Вот так просто, можно узнать, что делают на вашем компьютере во время вашего отсутствия, какие сайты посещают ваши дети, и чем в рабочее время занимаются ваши сотрудники. Если вы хотите только защитить детей от не совсем детских сайтов, то рекомендую вам программу “Интернет Шериф”, которая сделает блокировку сайтов, нежелательных сайтов для вашего ребенка.
Думаю, что в этой статье вы получили ответы на свои вопросы, а программа NeoSpy поможет защитить ваших детей от ненужной информации, которой сейчас в сети очень много. Удачи!
#10. Sensu
Ключевые особенности:
- Sensu – это инструмент для мониторинга событий с открытым исходным кодом.
- Sensu контролирует серверы, службы, работоспособность приложений, сеть.
- Инструмент мониторинга Sensu использует стороннюю интеграцию.
- Инструмент мониторинга Sensu использует агент sensu для проверки операционной системы и показателей.
- Мы можем контролировать облачную инфраструктуру с помощью инструмента мониторинга sensu.
- Sensu написан на Ruby.
Преимущества:
- Инструмент мониторинга Sensu является портативным.
- Простота использования
- Инструмент для мониторинга Sensu быстрый.
см. также:
Показания состояния жестких дисков
Для получения температуры дисков воспользуемся утилитой hddtemp. Если ее нет, ставим:
Работать вообще просто: для получения температуры ей указывается устройство, и с параметром -n не будет лишних данных:
Для получения данных со SMART воспользуемся smartmontools
Для использования надо указать на какой диск смотреть, и ключ -a, иначе будет выведена просто короткая справка о диске.Утилита вываливает целую гору информации, несколько экранов. Не буду приводить тут скриншоты, слишком много. Из всей этой кучи надо выделить интересующие показатели. Я для себя выделил эти:
-
Raw_Read_Error_Rate — количество ошибок чтения. Ненулевые значения уже требуют внимания, а большие говорят о скором выходе диска из строя. В интернетах пишут, что у некоторых моделей большое значение в этом поле является нормальным. В общем случае значение должно быть равно нулю. А поскольку мы все таки мониторим, нас будет волновать увеличение этого числа;
-
Reallocated_Sector_Ct — количество перераспределённых секторов. Большое значение говорит о большом количестве ошибок диска;
-
Seek_Error_Rate — количество ошибок позиционирования. Большое значение говорит о плохом состоянии диска;
-
Spin_Retry_Count — количество попыток повторной раскрутки. Большое значение говорит о плохом состоянии диска;
-
Reallocated_Event_Count — количество операций перераспределения секторов;
-
Offline_Uncorrectable — количество неисправных секторов. Большое значение говорит о повреждённой поверхности.
Чтобы их вытащить из ответа утилиты, можно воспользоваться удобной функцией — вывод значений в формате json. Для этого к строке запуска добавляем параметр -j, вот так:
В ответ получим длинный json, для удобства анализа сохраняем в файл. Вот мой. Ваш, скорее всего будет несколько иным. В этом внушительном файле надо глазами или иным образом получить json xpath к интересующим параметрам.
Получив xpath, выделяем конкретную цифру с помощью той же утилиты jq, вот так (в конце в комментарии имя параметра):
Кроме того, есть такой ответ на вопрос типа «ты нормально скажи — здоров ты или нет» — запустив утилиту с параметром -H, можно получить суммарный вывод о здоровье диска. У режима тоже есть параметр -j, выводящий структурированный json.
Также выделям его из json:
Лучшее для отслеживания времени и лёгкого управления проектами: DeskTime Pro
DeskTime представляет собой доступное и простое приложение для отслеживания времени и проектов плюс производительности. Функциональность и отчёты простые по сравнению с другими инструментами, но есть много вариантов настроек.

Плюсы
- Отслеживание приложений и URL
- Кастомные отчёты
- Интеграция с календарём Google и Outlook
- Мобильные приложения
- Метрики производительности
- Управление проектами и задачами
- Отслеживание времени
Минусы
- Нет отслеживания ключевых слов
- Нет записи нажатий клавиш
- Отсутствуют автоматические оповещения
- Нет отслеживания документов и файлов
- Ограниченные отчёты
- Экспорт только XLS, нет CSV
Учет расходных материалов принтеров
На следующем этапе настройки мониторинга и учета принтеров, нам нужно добавить расходные материалы. Логика работы программы такая:
- Ищем и добавляем принтеры.
- Создаем склад и добавляем на него расходные материалы.
- Устанавливаем расходные материалы в принтеры.
- Ведем учет расходных материалов.
Сначала добавим хотя бы один склад. У меня структура компании состоит из трех филиалов. Склад добавлю в офис и назову его «Комната сисадмина»
Склад добавили. Идем теперь в Расходные материалы и добавляем новые расходники. В списке для добавления расходных материалов будут только те, что подходят к добавленным вами принтерам. Это весьма удобно. У меня все принтеры были определены, так что с расходниками никаких хлопот не было — добавил все из готового списка.
После того, как добавили все необходимые расходники для принтеров, можно идти обратно в список оборудования и устанавливать расходники в принтеры и МФУ. Для этого выбираем нужный принтер, переходим на вкладку Установки РМ и добавляем расходник. Это могут быть не только картриджи, но и прочее оборудование — барабан, ёмкость для отработанного тонера и др.
Интуитивно не очень понятный интерфейс. Вам нужно стрелочками добавить по одному расходнику со склада на принтер. После того, как картриджи будут установлены, начинается контроль за их ресурсом и за количеством оставшихся страниц, которые смогут быть напечатаны с этого картриджа. Если для данного принтера не задействован мониторинг, то первое время данные по остаткам не будут отображаться, пока не накопится статистика установок картриджей. На скриншоте ниже показан вариант, когда мониторинг задействован – сразу отобразились реальные остатки тонера и страниц. Но остаток дней, на которые хватит этого картриджа, посчитан, исходя из даты установки и он не актуальный – дату установки желательно указывать как можно ближе к реальной.
Программа поддерживает кучу всевозможных параметров для расходных материалов:
- Серийный номер и штрихкод.
- Стоимость покупки или заправки.
- Дату покупки, установки, перемещения между складами, списание.
- Программа автоматически определяет к каким устройствам подходит данный расходник, показывает сколько у вас всего таких устройств.
В общем, когда вы все настроите и добавите, приведете информацию в программе к реальному положению дел на складе, следить за устройствами и расходными материалами будет очень удобно. Программа может отслеживать оставшийся ресурс картриджей и отправлять информацию на почту. Настраивается это в Сервис -> Настройки -> Служба уведомлений.
Если вам нужно заправить картридж, вы просто из принтера его переводите в ремонт, а потом из ремонта отправляете обратно на склад. Он туда приходит заправленным. Дальше его можно снова устанавливать в устройство. Таким образом, вы всегда будете знать, сколько раз уже заправляли картридж, чтобы понимать, когда его нужно выкинуть. Это удобно.
Контроль компьютерных классов
LanAgent поможет в организации учебного процесса. Он позволяет увидеть, что именно студенты или школьники делают на компьютерах. Заняты ли они выполнением учебных заданий или вместо
этого играют в онлайн игры или лазят по сомнительным сайтам.
Преподаватель может вывести на своем мониторе экраны всех учеников и наблюдать за ними в реальном времени. Просмотреть подробнее любой экран,
принять выполненное учеником задание. Либо взять управление компьютером и что-то продемонстрировать.
Набор автоматических правил поможет вовремя среагировать и пресечь нарушения. Правила блокировок позволят ограничить круг программ и сайтов, которые студенты могут открыть.
- Блокировка запуска нежелательных программ и сайтов
- Онлайн-мониторинг неограниченного количества компьютеров
- блокировка подключения съемных носителей
- Анализ посещения web сайтов
- Обнаружение нарушения учебной дисциплины
Ручное управление блокировками
По умолчанию в качестве Decision применяется ban на 4 часа. Изменить эти параметры можно в файле /etc/crowdsec/profiles.yaml. В настоящий момент, как я понял, доступны 2 действия:
- Ban
- Captcha
Как настроить последнюю, я не разбирался. А вообще интересная штука. Надо бы потестировать.
Разблокировать вручную конкретный ip можно следующей командой:
# cscli decisions delete --ip 10.20.1.16
Так же можно разом удалить все баны:
# cscli decisions delete --all
Можно вручную кого-то забанить:
# cscli decisions add --ip 10.20.1.16 --reason "web bruteforce" --type ban
Помимо ip адресов можно банить сразу подсети. Синтаксис точно такой же, только вместо конкретного ip указывается подсеть со своей маской. В целом, тут функционал аналогичен Fail2ban.
#9. Netdata
Ключевые особенности:
Netdata – это распределенный мониторинг производительности и работоспособности систем.
Используя Netdata, мы можем отслеживать:
- Сервер
- Системные приложения
- Контейнеры
- Веб-приложения
- Виртуальные машины
- Базы данных
- Устройства IOT.
Мы можем контролировать 1000 устройств с помощью Netdata.
Нам нужно будет установить плагин python для мониторинга баз данных PostgreSQL.
Преимущества:
- Netdata представляет собой инструмент мониторинга с открытым исходным кодом.
- Netdata также может контролировать определенные устройства SNMP.
- Netdata имеет хорошие интерактивные веб-дашборды.
- Netdata работает быстро и эффективно.
- Netdata имеет открытый исходный код и не зависит от платформы.
- Использование ОЗУ, мониторинг оптимизации ядра становится очень простым с помощью Netdata.
см. также:
#1 CleverControl: Удаленный контроль над всеми видами деятельности пользователей ПК
Программа подойдет тем, кто хочет быть в курсе всех действий каждого сотрудника, не только для учета рабочего времени, но и в целях повышения информационной безопасности предприятия. Благодаря широкому функционалу, приложение позволяет повысить продуктивность команды, выявить лентяев, а также предотвратить утечку информации и расследовать неправомерные действия коллег.
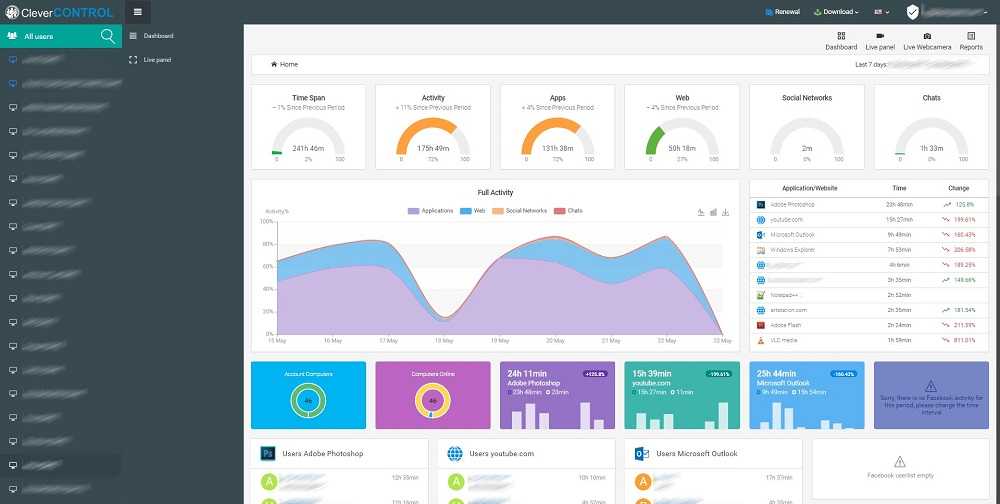
Возможности CleverControl
Непрерывная запись экрана (программа ведет постоянную запись экрана целевого ПК, записывая все действия сотрудника на рабочем месте);
Кейлоггер;
Контроль чатов в мессенджерах (полезная функция, если у вас есть подозрения, что сотрудник слишком много времени тратит на общение с коллегами вместо выполнения рабочих задач);
Запись поисковых запросов и посещенных сайтов;
Запись с микрофона и веб-камеры;
Мониторинг USB, SD, HDD для предотвращения утечки корпоративных данных;
Контроль активных приложений (программа показывает, в каких приложениях сотрудник проводит больше всего времени в рабочие часы, и позволяет выявить приложения, отвлекающие внимание сотрудника).
Удаленные настройки (все настройки программы можно изменять удаленно из веб-аккаунта);
Скрытый режим (программа записывает данные незаметно для сотрудника, не отвлекая его от рабочих задач).
Достоинства CleverControl
- Возможность следить за сотрудниками удаленно, без доступа к их компьютерам;
- Широкий функционал, нацеленный на решение сразу нескольких проблем (снижение продуктивности, утечка информации, учет рабочего времени);
- Удобный личный кабинет, показывающий статистику продуктивности как каждого сотрудника отдельно, так и всего коллектива.
Недостатки
В условиях «удаленки» вряд ли кто-то из сотрудников согласится установить программу, отслеживающую все действия пользователя, на свой ПК, поэтому CleverControl стоит устанавливать на рабочий компьютер, а сотруднику следует использовать программы для удаленного контроля рабочим столом (например, Team Viewer). Таким образом, коллеги не будут переживать за свои личные данные, а программа начнет запись активности сотрудника, как только он подключиться к рабочему ПК из дома.
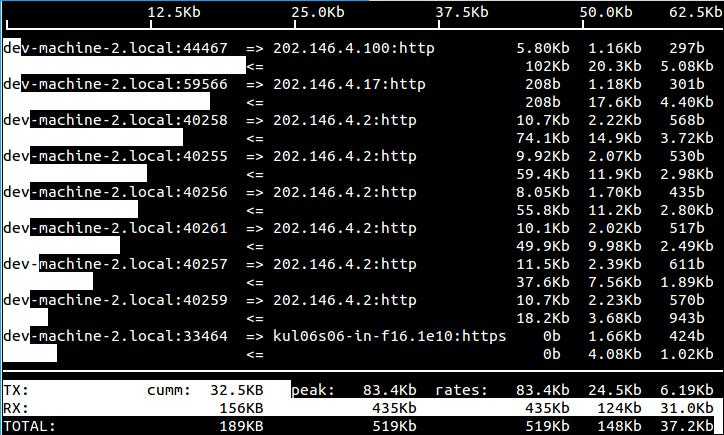
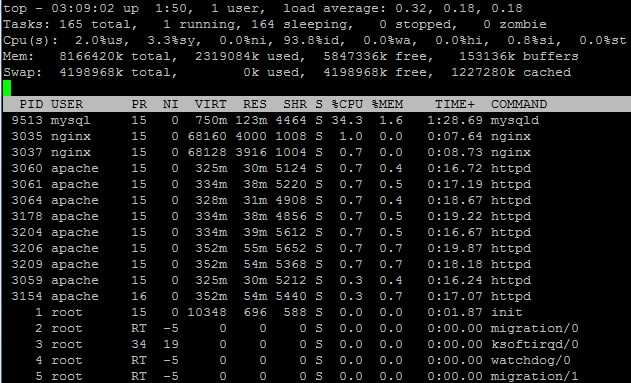
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
# zabbix_agentd -t proc.num proc.num
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных срабатываем.
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Настройка Сервера
Консоль Администратора можно запустить через ярлык, расположенный на рабочем столе, или через группу программы в меню Пуск.
Состояние системы
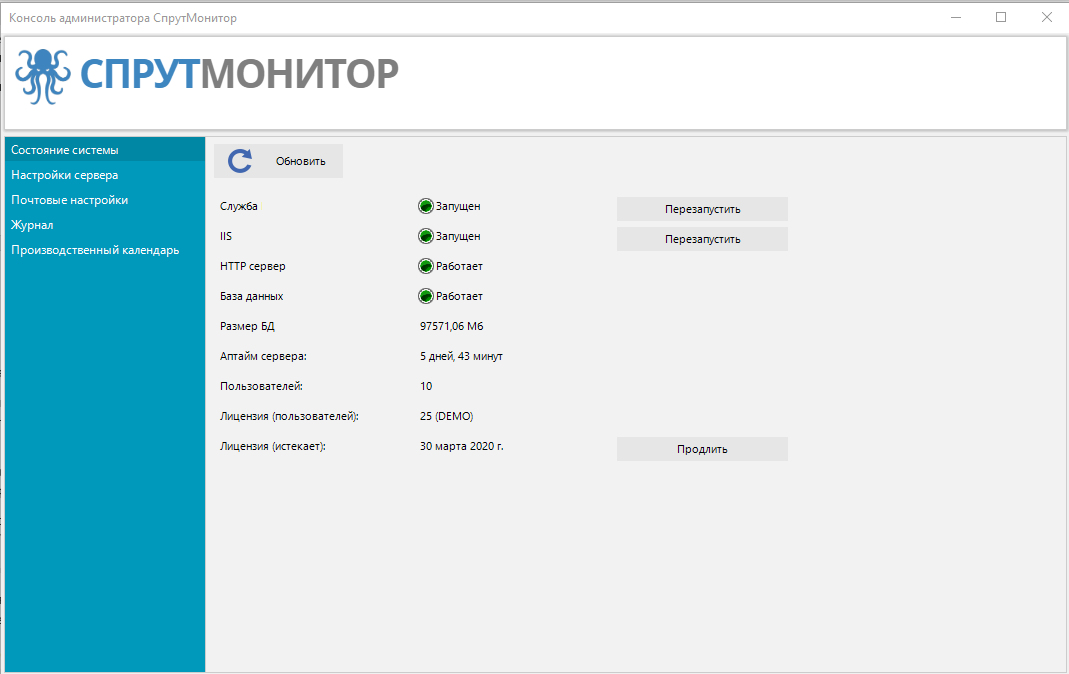
Показывает состояние основных компонентов СпрутМонитор, статистическую информацию и информацию о лицензии. После первой установки время запуска HTTP сервера может составлять до 1 минуты.
СпрутМонитор лицензируется по количеству пользователей, на компьютерах которых установлены Грабберы. Заблокировать ненужных пользователей можно из окна Вьюера, вкладка Пользователи.
Служба СпрутМонитор проводит периодическую чистку БД. Так, по умолчанию бинарная информация (скриншоты, вебкамшоты, файлы) хранится в БД 7 дней, текстовая информация — 30 дней. Управлять временем хранения можно из окна Вьюера, вкладка . Для получения более подробной информации обратитесь к руководству пользователя СпрутМонитор.
Настройки сервера
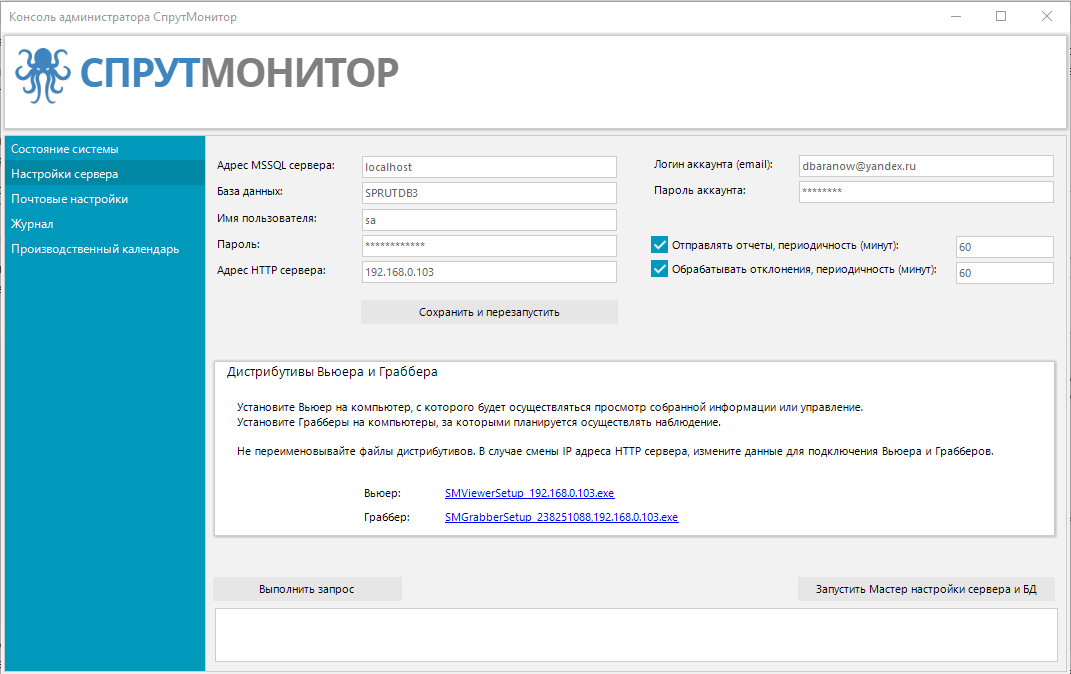
На этой вкладе вы можете изменять параметры подключения к базе данных, данные аккаунта СпрутМонитор, и т.п. Эти изменения требуют обязательного перезапуска Службы и Сервера.
Также на этой вкладке вы можете получить дистрибутивы Вьюера и Граббера для установки на компьютеры сотрудников/руководителей (см. и ).
Внимание: не переименовывайте файлы инсталляторов. Эта информация используется для автоматической установки и настройки
Почтовые настройки
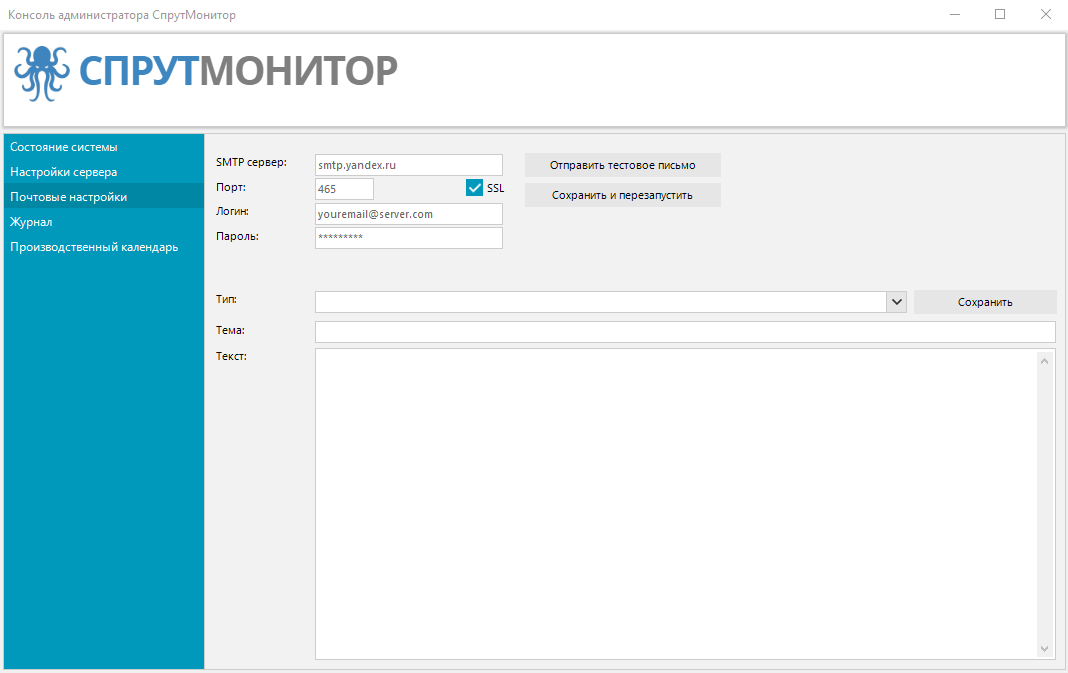
СпрутМонитор имеет развитую систему уведомлений. На почтовый адрес, указанный в (Вьюер), будут приходить оповещения о нарушениях (рисках), отчеты и проч. Для их отправки необходимо заполнить данные SMTP сервера.
Эта операция требует перезапуска Службы СпрутМонитор.
Проблемы, которые мы можем найти на ПК с Linux
Это один из самых распространенных сбоев, который может привести к тому, что с течением времени дисководы постепенно становятся медленнее. Среди наиболее распространенных симптомов в этом смысле мы можем обнаружить себя медленно, ошибки чтения, блокировки и т. Д. Во многих случаях эти проблемы, о которых мы говорим, могут быть связаны с тем, что у нас хранится слишком много информации.
Это, как вы понимаете, программы мы ежедневно используем наши фотографии, видео и т. д. Как бы то ни было, жесткие диски часто выходят из строя и повреждаются при использовании. Однако до достижения критической точки мы можем принять определенные меры, например, сделать резервную копию. Для этого, прежде чем мы сможем использовать определенные команды и инструменты, которые помогают нам узнать состояние жесткого диска.
С другой стороны, также интересно знать, что время от времени важно знать статус установленного RAM. И это так, как это происходит с компьютерами на базе Windows системе, пользователи Linux должны наблюдать за этим компонентом конкретно
Стоит упомянуть, что мы можем найти несколько сценариев, в которых оперативная память может начать выходить из строя. Это то, что, как могло быть иначе, напрямую повлияет на результативность команды в целом. Вот почему интересно узнать, исправна ли оперативная память компьютера, в чем мы также поможем вам.
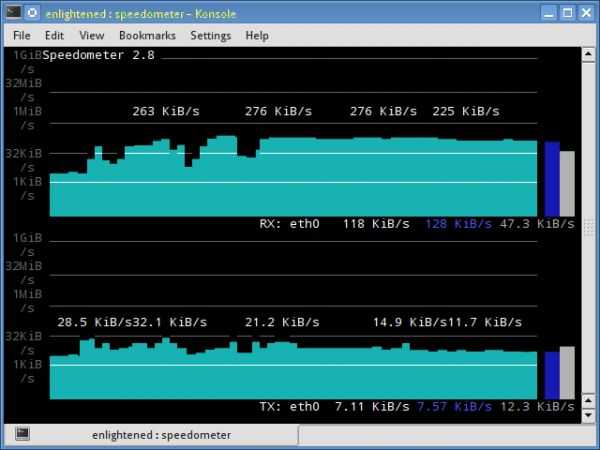
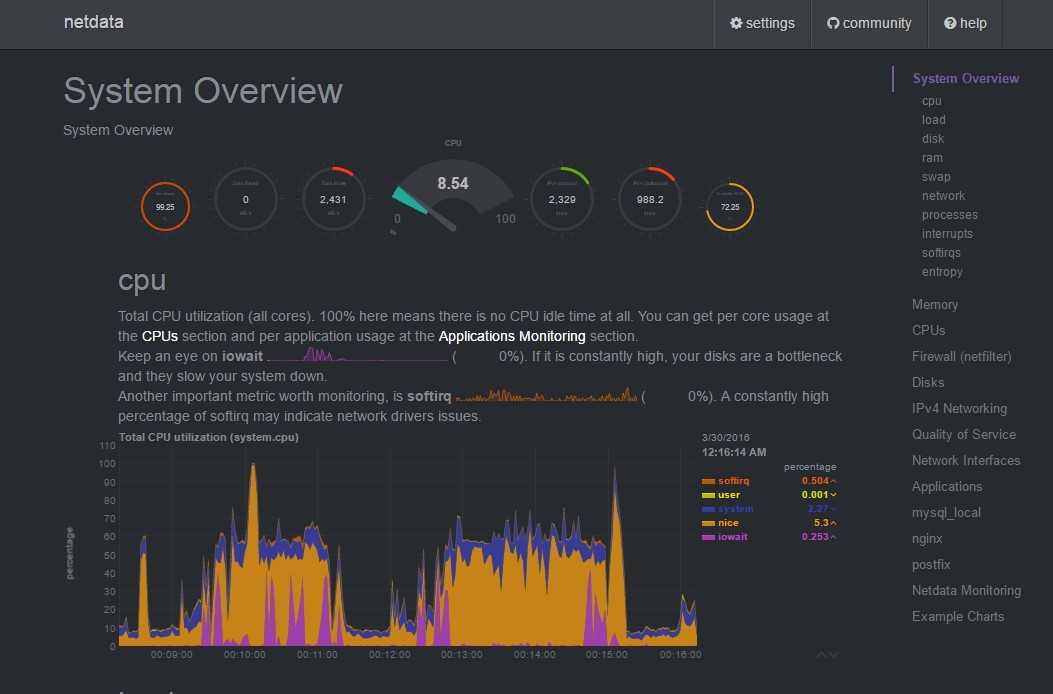

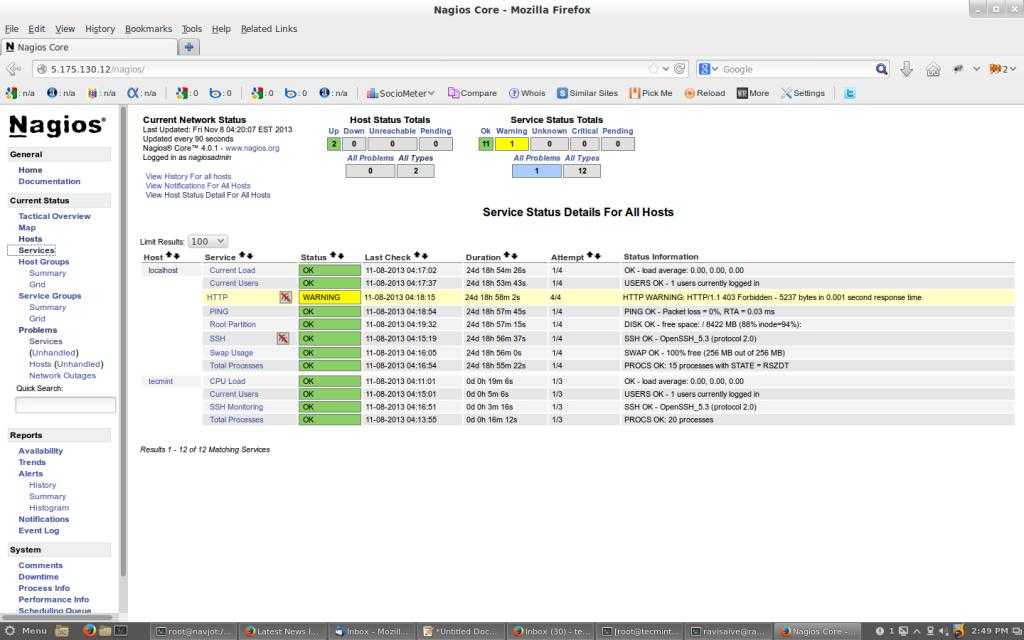
Показания системных датчиков
Для получения встроенных датчиков воспользуемся утилитой sensors
Если она не установлена, поставим ее:
Сначала надо найти все имеющиеся датчики. Запускаем команду и отвечаем y на все вопросы. После этого можно поглядеть что получилось:
Надо отметить, что лично у меня sensors стал выводить все найденные датчики только после перезагрузки. Может какой то баг, не знаю.
Надо бы как то формализовать вывод. К счастью у sensors есть удобный режим вывода в json, и можно скрыть название адаптора. выдаст длинный json. Вот мой, например.
Ну вот, с этим работать удобнее. Для передачи показаний дальше надо разобрать данные. Для разбора json прямо в консоли есть шикарнейшая утилита — jp. Если она не установлена — для ubuntu она есть в пакетах:
Определяем xpath нужного параметра. Можно глазами, можно с помощью например этого удобного онлайн-инструмента.
Теперь прямо одной строкой можно получить интересующие нас данные. Я хочу сохранять температуру процессора, одного ядра хватит, частоту вращения кулера, и еще какой то третий сенсор temp3, который показался мне подходящим для косвенной оценки температуры внутри корпуса:
Контроль печати на принтерах
мониторинг печати документов
Функция мониторинг принтеров в сети программы LanAgent позволяет легко просмотреть объемы печати документов в организации. Какие принтеры более
всего загружены. Кто из сотрудников печатает больше всего. В том числе и использование принтеров не по назначению. Например, печать на оборудовании
с дорогими расходниками черновиков.
Наши преимущества:
- Подсчет печати за выбранный период, например, за месяц. Так можно определить расходы компании на печать и оптимизировать их.
- Сохранение изображения напечатанных документов для контроля нецелевой печати
Kickidler
Программное обеспечение, в котором функция кейлоггера связана с записью видео. Историю посещений пользователя и набор определенных клавиш администратор может просмотреть в отчете. Собранную информацию независимо от формы (текст, видео о все нарушения трудового распорядка) можно посмотреть на временной шкале. Такой способ позволяет выяснить чем работник занимался в определенный момент времени.
Основной функцией утилиты является предотвращение утечки информации и контроль использования конфиденциальных данных. Программное обеспечение работает на персональных компьютерах с различными ОС: Windows, Linux и MAC OS. Для компаний, в которых трудятся до 6 человек работает бесплатная версия.
Удаление Граббера
Удаление вручную:
Запустите файл “unins000.exe” из папки “C:\Program Files (x86)\SPMClient\”
Скрытое удаление:
Используйте параметры /SILENT или /VERYSILENT
Используйте параметр /PIN= для передачи Пин-кода для удаления (Пин-код находится в Вьюере, вкладка Пользователи)
Удаленное удаление:
Для удаления с помощью PsExec, команда будет выглядеть следующим образом:
psexec.exe [C:\Program Files (x86)\SPMClient\unins000.exe /VERYSILENT /PIN=код]
Несмотря на отсутствие Граббера в списке Установленных программ, незаметно удалить его для владельца аккаунта невозможно: помимо необходимости наличия прав Администратора, каждая попытка удаления будет отображена на вкладке Рисков в окне Вьюера СпрутМонитор, а также будет отправлено соответствующее уведомление.
18. Nagios – Мониторинг сети/сервера
Nagios – мощная система мониторинга, которая даёт возможность сетевому/системному администраторы выявить и разрешить проблемы с сервером до того, как они доставят серьёзные проблемы. С системой Nagios, администраторы могут следить за удалёнными Linux, Windows, свичерами, роутерами и принтерами в одном окне. Она показывает критические предупреждения и даёт знать, если что-то пошло не так в вашей сети/сервере, что является предпосылкой для начала процессов исправления до того, как проблема по-настоящему проявила себя.
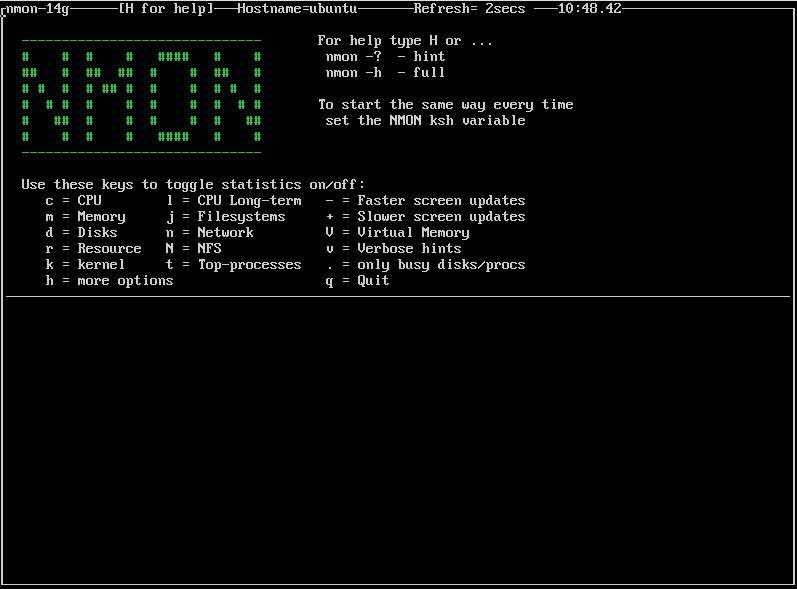
19. Nmon: Производительность системы Linux
Nmon – инструмент контроля производительности, который используется для наблюдения за всеми ресурсами Linux, к которым относится центральный процессор, память, использование диска, сеть, топ процессов, NFS, ядро и многое другое. Этот инструмент поставляется с двумя режимами: Online Mode и Capture Mode.
Online Mode используется для мониторинга в реальном времени, а Capture Mode сохраняет вывод в формате CSV для последующей обработки.
nmon
#4. Nagios Core
Ключевые особенности:
- Nagios используется для непрерывного мониторинга серверов, сети, приложений, бизнес-процессов и инфраструктуры.
- Nagios – это масштабируемый, управляемый и безопасный инструмент для мониторинга серверов.
- Nagios обнаруживает сетевые ошибки, сбои сервера и автоматически отправляет предупреждения.
- В Nagios возникшие проблемы также могут быть исправлены автоматически.
- Nagios использует результаты от плагинов для определения текущего статуса хостов и сервисов в вашей сети.
Преимущества:
- Nagios построен на архитектуре сервер/агенты, которая упрощает взаимодействие с серверами.
- С Nagios может быть выполнено быстрое обнаружение сбоев сервера и сетевых протоколов.
- В Nagios доступно 3500 различных дополнений для мониторинга ваших серверов.
- Использование Nagios экономит наше время, так как мониторинг всего осуществляется на одной платформе.
см. также:
Заключение
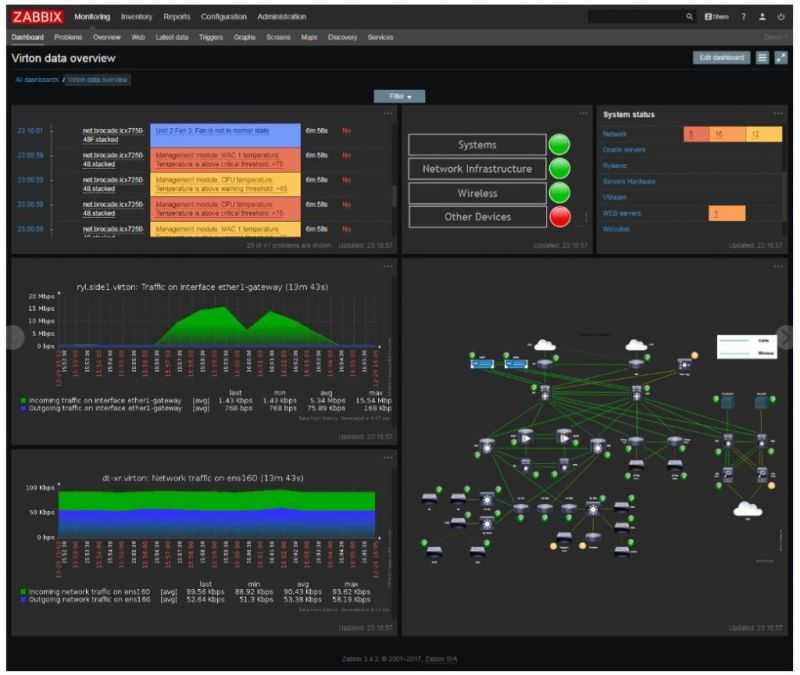
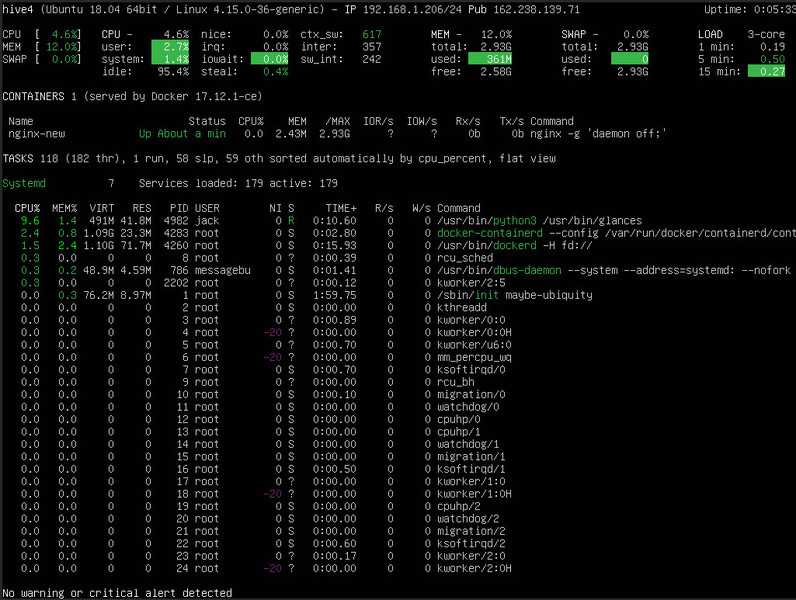
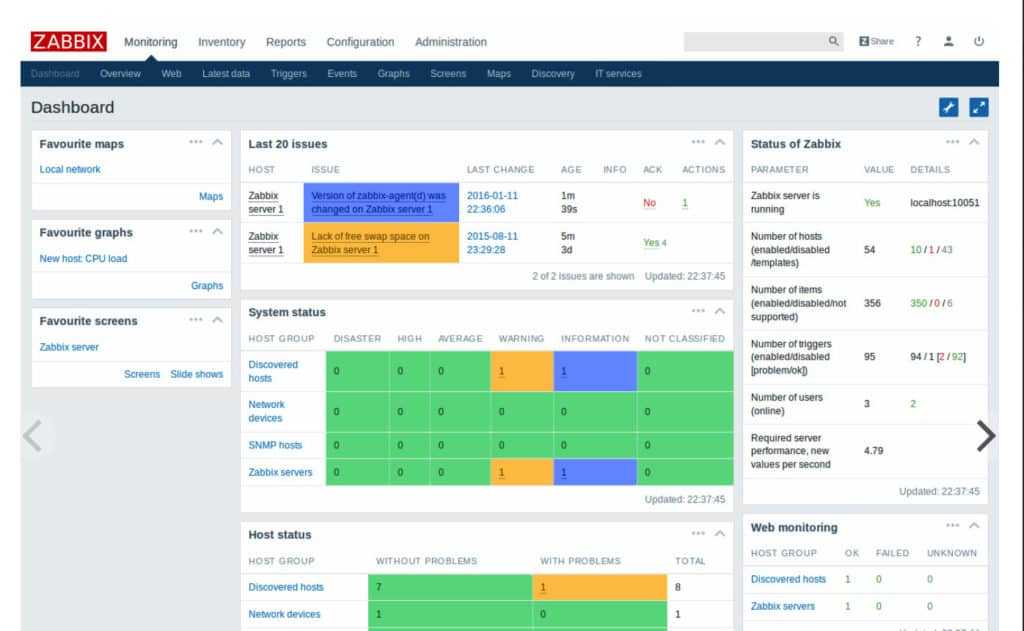
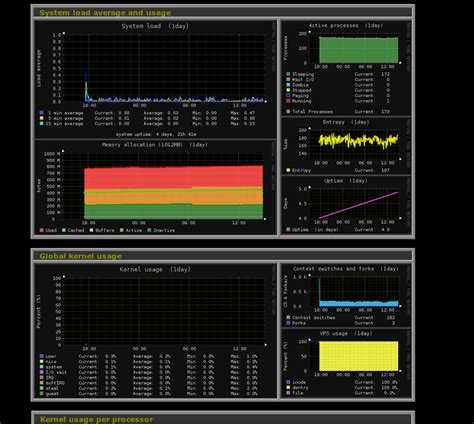
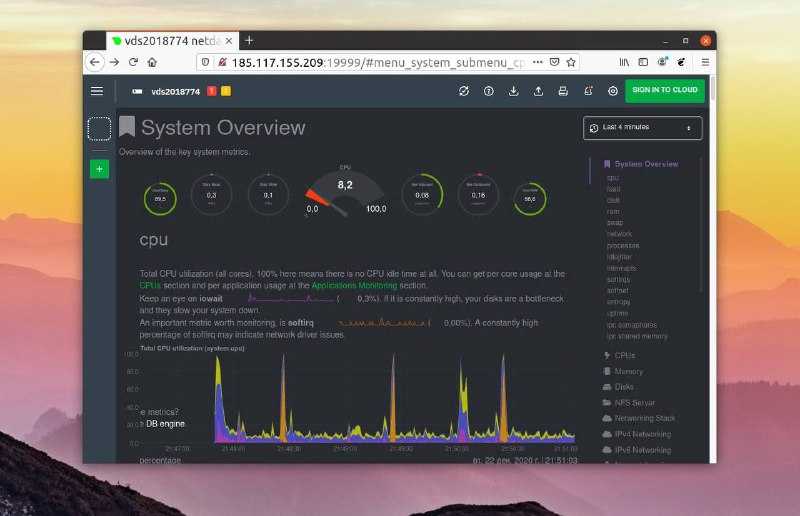
Вот такую реализацию я придумал, когда потребовалось решить задачу. Один сервер постоянно донимал оповещениями по ночам. Нужно было понять, что его дергает в это время. Жаль, что у Zabbix из коробки нет реализации подобного информирования. Помню лет 5 назад был бесплатный тариф у мониторинга NewRelic. Можно было поставить агент мониторинга на сервер и потом смотреть очень удобные отчеты в веб интерфейсе. Никаких настроек не нужно было, все работало из коробки. Там были отражены все запущенные процессы на сервере на временном ряду со всеми остальными метриками. Это было очень удобно. Я нигде в бесплатном софте не видел такой реализации. Это примерно вот так выглядело.
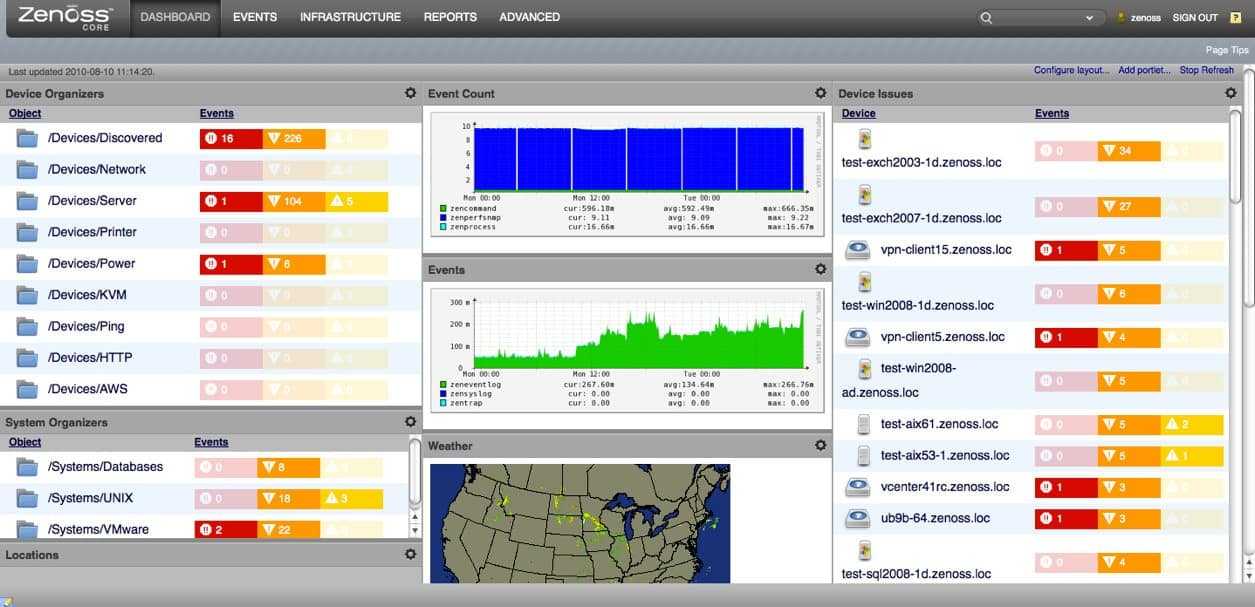
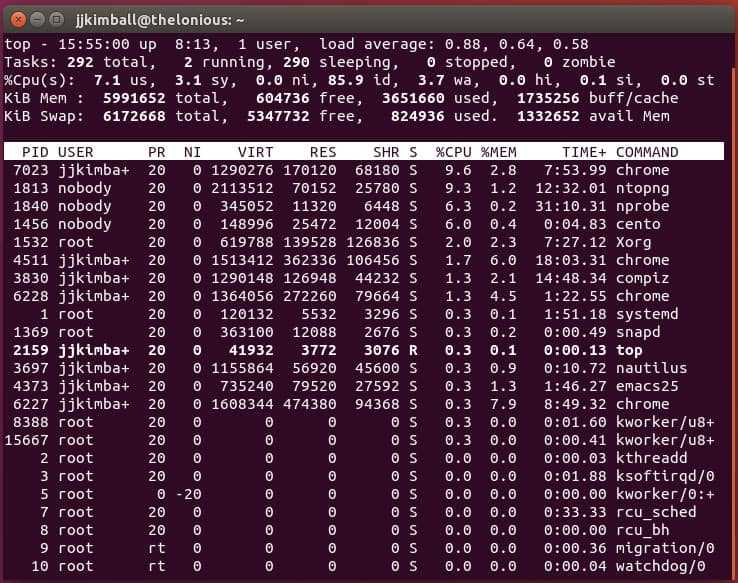
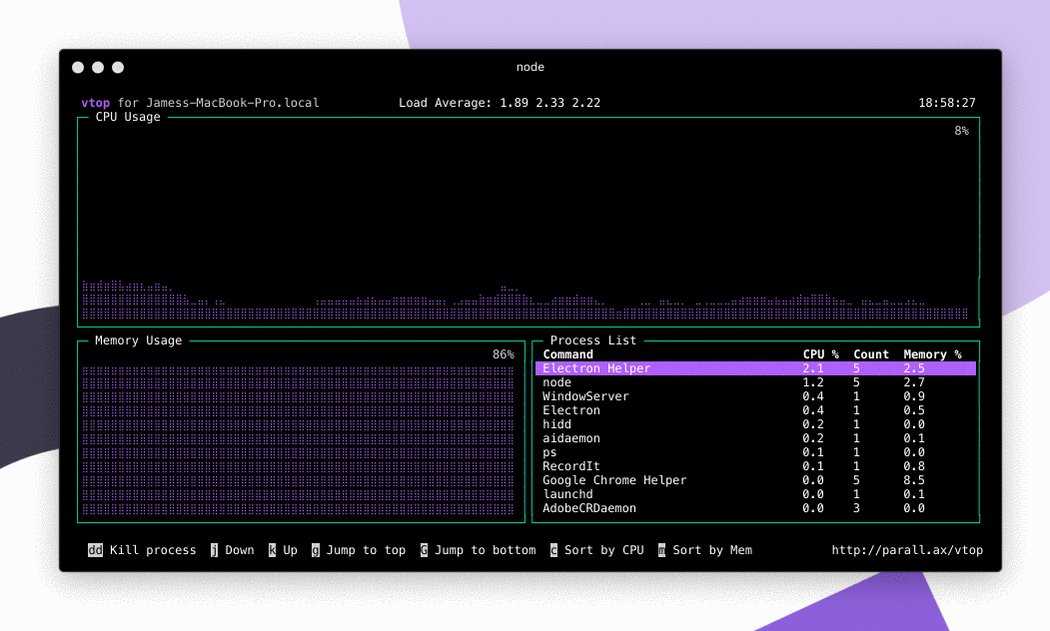
Кстати, в первоначальной версии действия я просто отправлял список процессов на почту. Мне показалось это удобным. Можно было сразу же в почте, в соседнем письме с триггером, посмотреть список процессов. Но потом решил, что удобнее все же хранить историю в одном месте на сервере и настроил сбор данных туда. Хотя можно делать и то, и другое. Например, в действии можно указать другую команду к исполнению:
# ps aux --sort=-pcpu,+pmem | awk 'NR<=10' | mail -s "Process List" zabbix@mail.ru
И вам на почту придет список запущенных процессов после активации триггера.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Заключение
На этом заканчиваю обзорную статью про Helm. Это мощный и достаточно сложный инструмент, если писать чарты к нему самостоятельно. Я постарался просто показать, как с ним работать и быстро устанавливать программы в Kubernetes. С помощью Helm этот процесс значительно упрощается. Можно в несколько команд, к примеру, на всем кластере развернуть мониторинг. Об этом я расскажу в следующих статьях более подробно.
Напоминаю, что данная статья является частью единого цикла про Kubernetes.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .





