
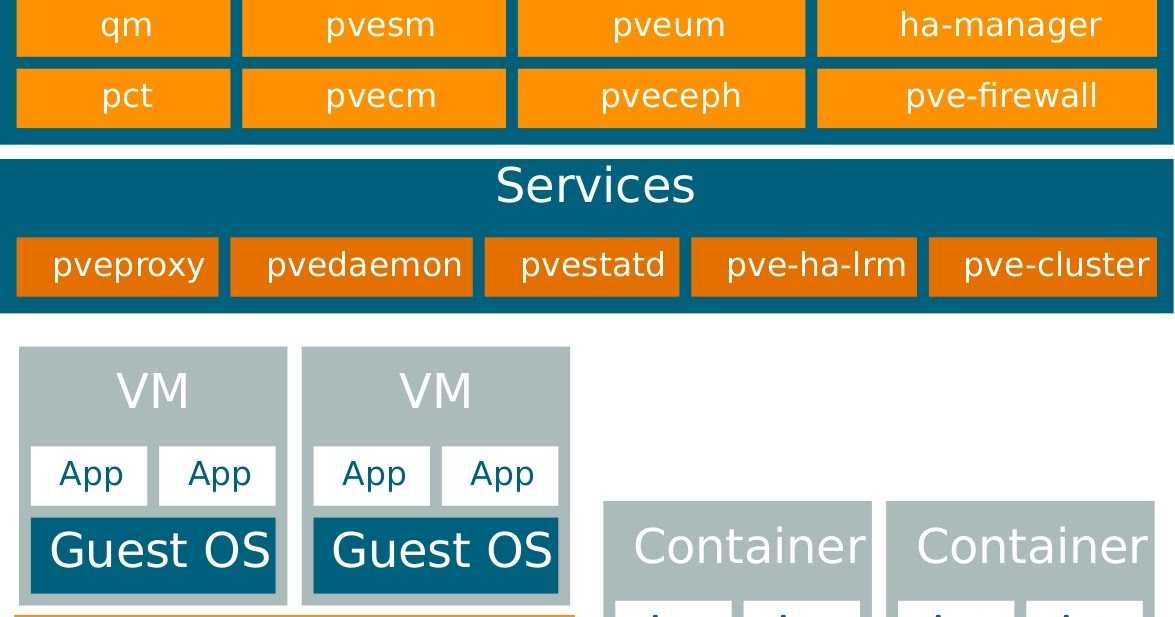
Конфигурация сети
Мы покажем, как настроить доступ к виртуальным машинам с помощью настройки DHCP и конфигурации сетевого моста vmbr0. Перед этим требуется получить отдельный MAC-адрес для IP-адреса виртуальной машины. Вы можете получить отдельный MAC-адрес только для одного IP-адреса. Вы не можете использовать несколько IP-адресов на одной виртуальной машине. Переадресация пакетов между интерфейсами (IP-пересылка) в хост-системе должна быть включена. Для того чтобы пересылка была включена автоматически, после перезагрузки необходимо внести соответствующие изменения в файл /etc/sysctl.conf
Обратите внимание, что перенаправление по умолчанию отключено
sysctl -w net.ipv4.ip_forward = 1
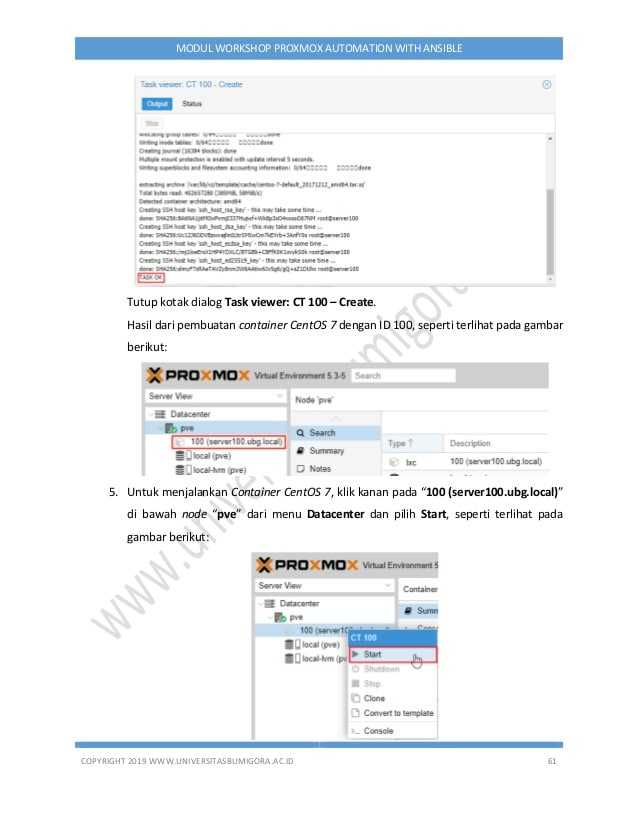
Далее настраиваем сетевой мост. Это можно сделать либо в графическом интерфейсе, либо в консоли. Если вы хотите настроить сетевой мост vmbr0 через графический интерфейс, вам необходимо перейти на вкладку Система -> Сеть. И выбрать Создать — Linux Bridge:
В поле Порты сетевого моста нужно добавить доступное сетевое устройство. В результате вы получаете такие сетевые настройки:
Если вы хотите настроить или проверить настройки сети через консоль, вам нужно перейти и отредактировать / etc / network / interfaces:
Если вы вносите изменения в этот файл, вам нужно применить настройки:
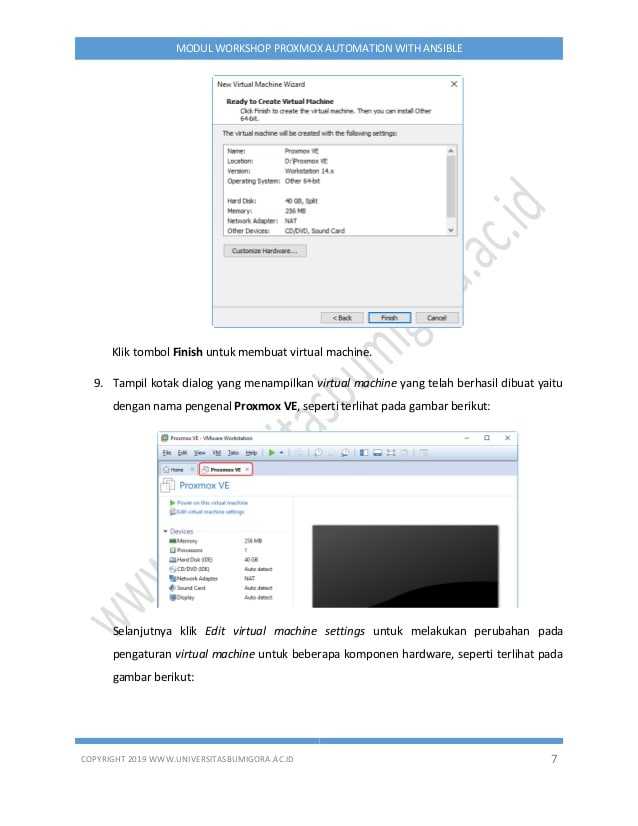
service networking restart
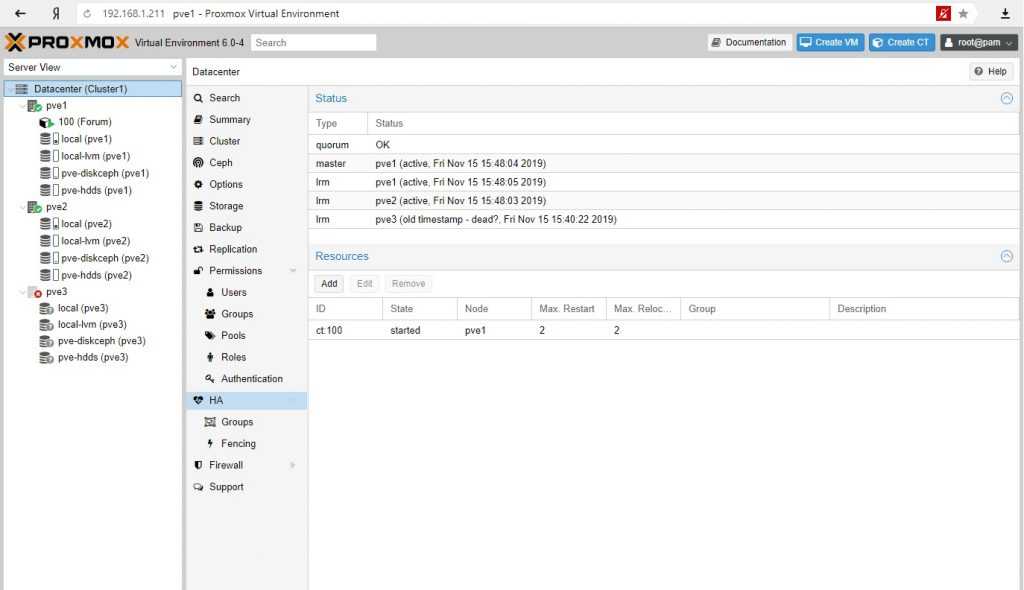
Ручное перемещение виртуальной машины
Представим ситуацию, что у нас произошел сбой одного из узлов кластера, но при этом виртуальная машина не переехала на рабочую ноду. Например, если сервер был отправлен в перезагрузку, но не смог корректно загрузиться. В консоли управления нет возможности мигрировать виртуалку с неработающего сервера. Поэтому нам понадобиться командная строка.
И так, открываем SSH-консоль сервера, на любой работающем сервере Proxmox. Переходим в каталог qemu-server той ноды, которая не работает:
cd /etc/pve/nodes/pve1/qemu-server
* мы предполагаем, что у нас вышел из строя сервер pve1.
Смотрим содержимое каталога:
ls
Мы должны увидеть конфигурационные файлы запущенных виртуальных машин, например:
100.conf
* в нашем примере у нас запущена только одна виртуальная машина с идентификатором 100.
mv 100.conf ../../pve2/qemu-server/
* где pve2 — имя второй ноды, на которой мы запустим виртуальный сервер.
Командой:
qm list
… проверяем, что виртуальная машина появилась в системе. В противном случае, перезапускаем службы:
systemctl restart pvestatd
systemctl restart pvedaemon
systemctl restart pve-cluster
Сбрасываем состояние для HA:
ha-manager set vm:100 —state disabled
ha-manager set vm:100 —state started
* в данном примере мы сбросили состояние для виртуальной машины с идентификатором 100. Если это не сделать, то при запуске виртуалки ничего не будет происходить.
После виртуальную машину можно запустить:
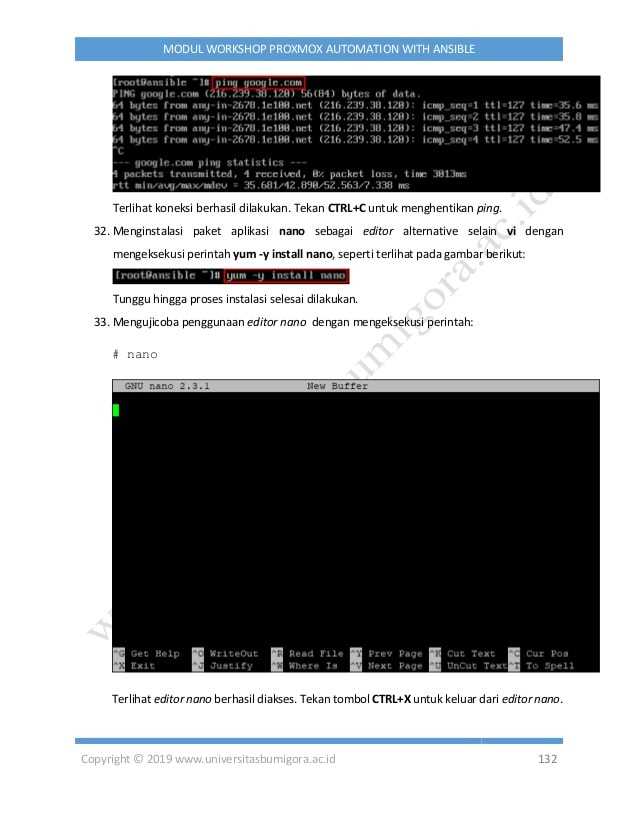
qm start 100
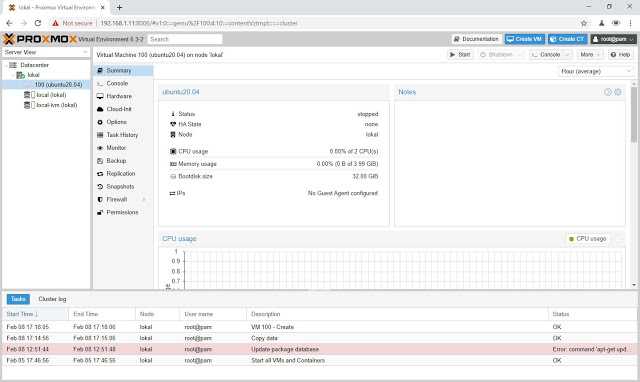
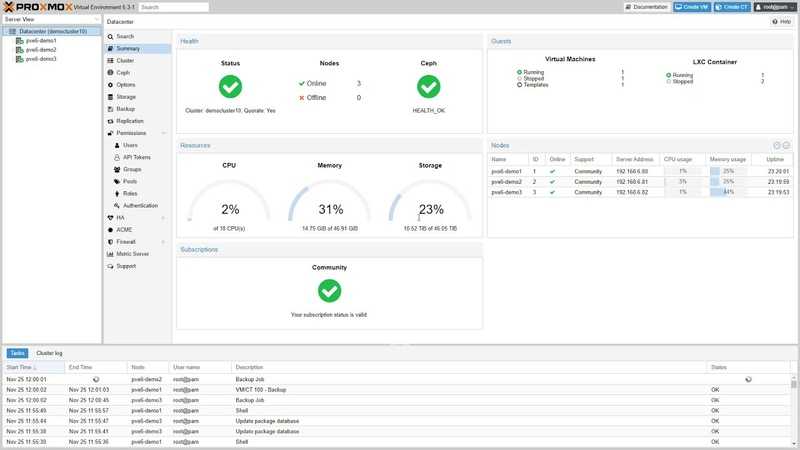
WEB-интерфейс гипервизора Proxmox VE
https://xxx.xxx.xx.xx:8006/
Аутентифицировавших польхователем root вместо окна приветствия мы увидим следующее предупреждение:
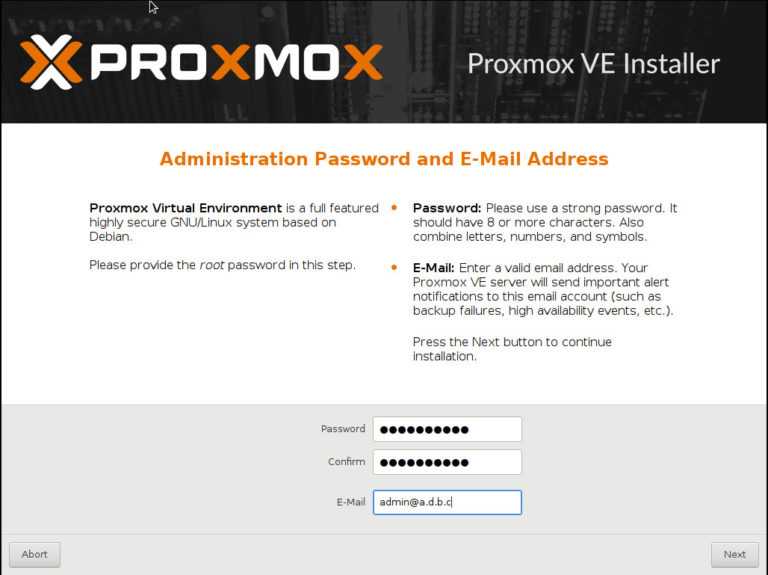
Proxmox VE является программным обеспечением с открытым исходным кодом, он бесплатен и поставляется под лицензией GNU GPL\GNU AGPL. Однако поддержка Enterprise версии платная. Если вы не желаете покупать лицензию, необходимо изменить репозиторий обновлений:

~# mcedit /etc/apt/sources.list.d/pve-enterprise.list
В нем необходимо закомментировать репозиторий pve-enterprise и добавить репозиторий pve-no-subscription:
#deb https://enterprise.proxmox.com/debian/pve buster pve-enterprise
deb https://download.proxmox.com/debian/pve buster pve-no-subscription
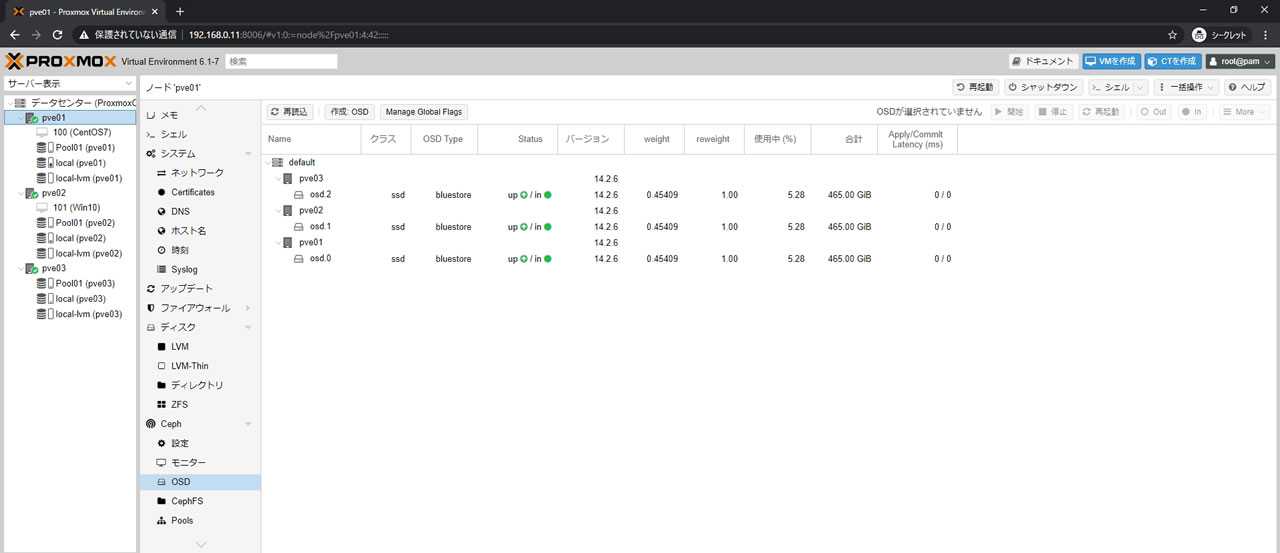
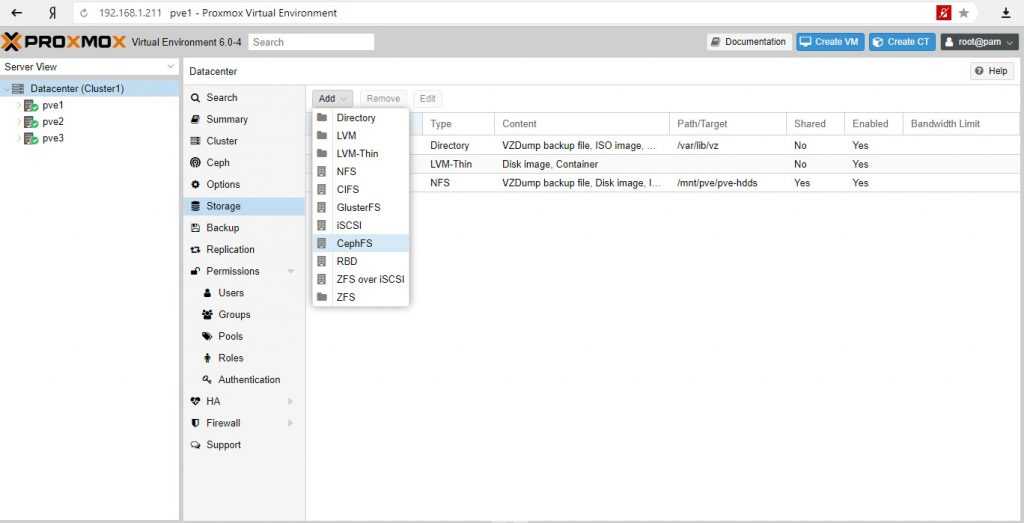
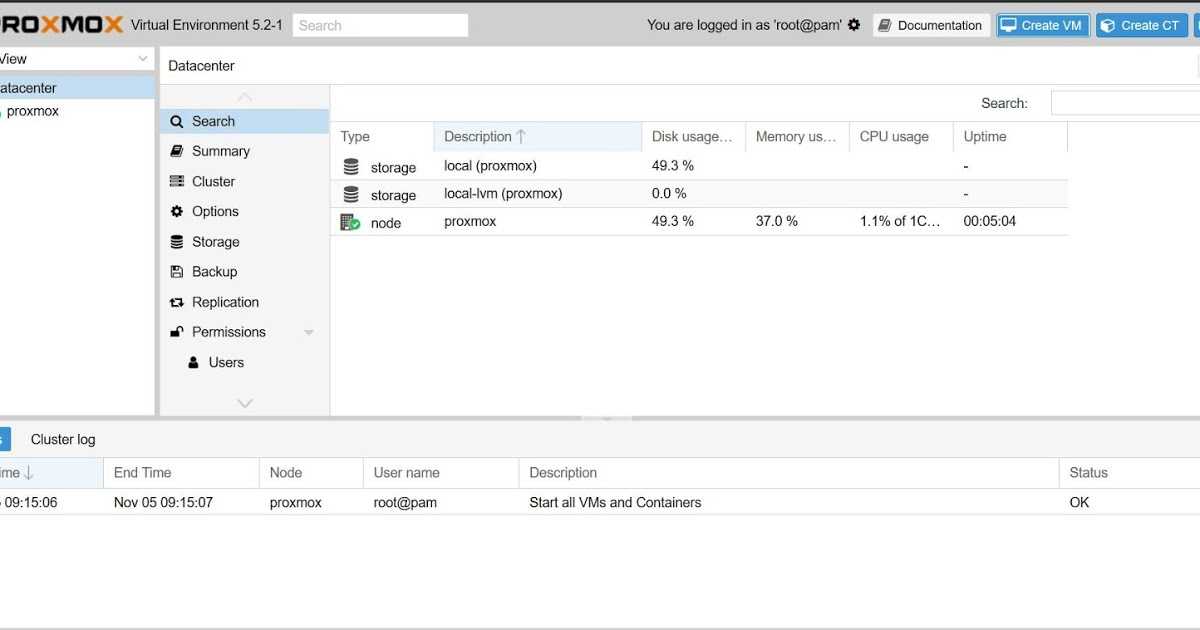
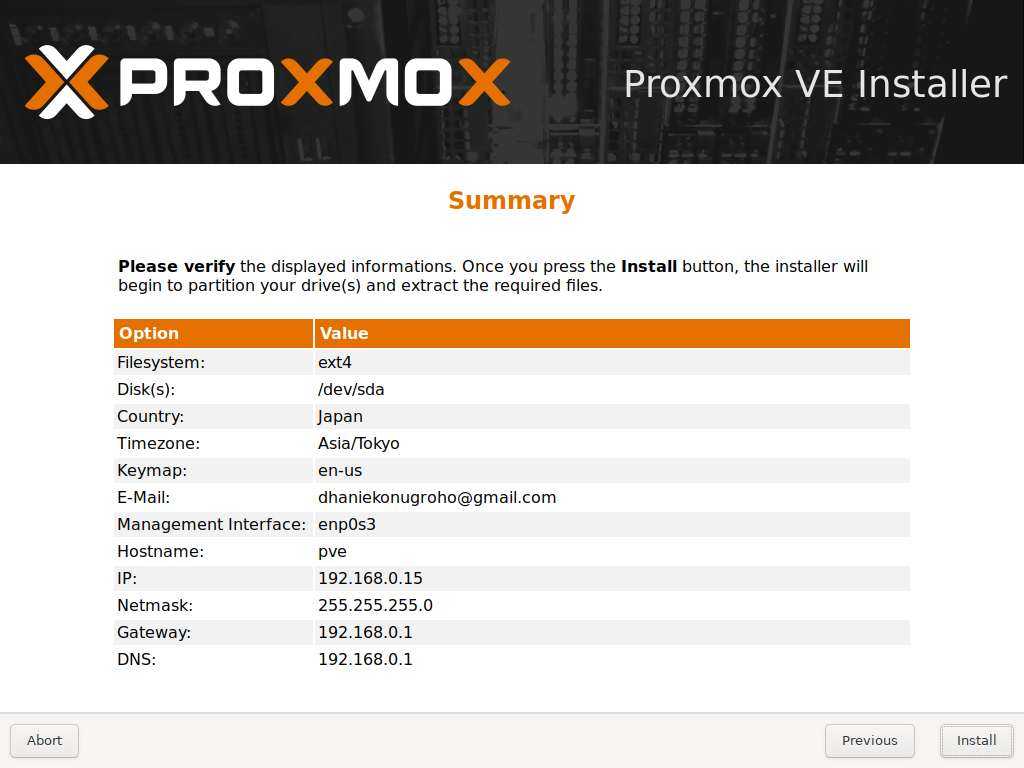
Теперь приступим к настройке хранилища. Для этого нам необходимо перейти в пункт меню «Datacenter» — «Storage» и нажать «Add», выбрав тип хранилища «Directory». Сюда мы добавим наш примонтированый каталог data, который мы создали на нашем программном raid, и на котором у нас будут размещены гостевые виртуальные машины.
Настройка сети. Для функционирования обычно используют три режима: Bridge, Routed и NAT. Bridge — при этом режиме, гостевые VM находятся в одной подсети с гипервизором и используют ip адреса этой подсети. Routed — при этом режиме, одна из виртуальных машин настроена как шлюз, для выхода в сеть интернет. NAT — виртуальные машины имеют собственную подсеть, однако во внешнюю выходят через NAT, который настроен на гипервизоре.
В этом примере мы используем режим Brige. Для этого необходимо перейти в раздел «Datacenter» — «your_Node» — «System» — «Network» и нажать «Create», выбрав режим «Linux Brige»
Создание виртуальной машины
Базовая настройка закончена — можно опробовать наш гипервизор в деле.
В правой верхней части панели управления кликаем по Создать VM:
В открывшемся окне снизу сразу ставим галочку Расширенный:
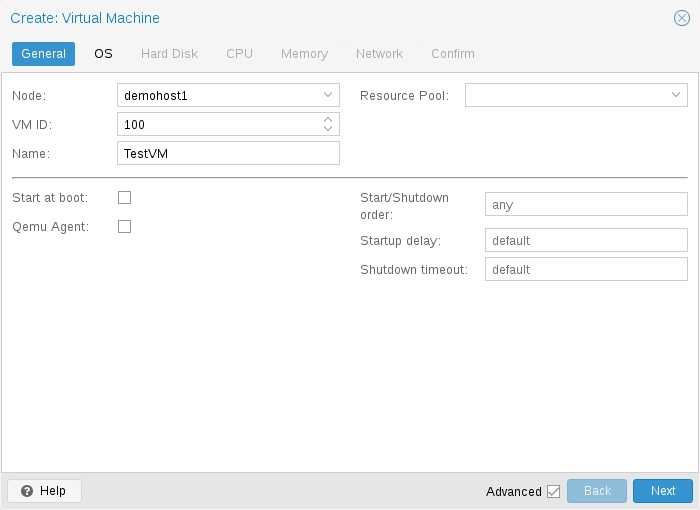
Задаем имя виртуальной машине и ставим галочку Запуск при загрузке (если хотим, чтобы виртуалка запускалась автоматически с сервером PVE):
* в данном примере мы задали имя FS. При желании, также можно изменить VM ID, но он проставляется автоматически и имеет правильное значение.
Выбираем загруженный нами ISO-образ, с которого будем ставить операционную систему, задаем тип гостевой операционной системы и ее версию:
* в данном примере мы будем устанавливать Linux Ubuntu. Среди списка операционных систем также доступны Microsoft Windows, Solaris и Other.
На вкладке Система можно оставить все значения по умолчанию:
* в некоторых случаях, необходимо выбрать другую видеокарту (при установке систем с GUI), а также особый вариант БИОС.
Задаем размер жесткого диска:
* 16 Гб для Ubuntu достаточно, однако, для наших задач расчет должен быть индивидуальным для каждой создаваемой виртуальной машины.
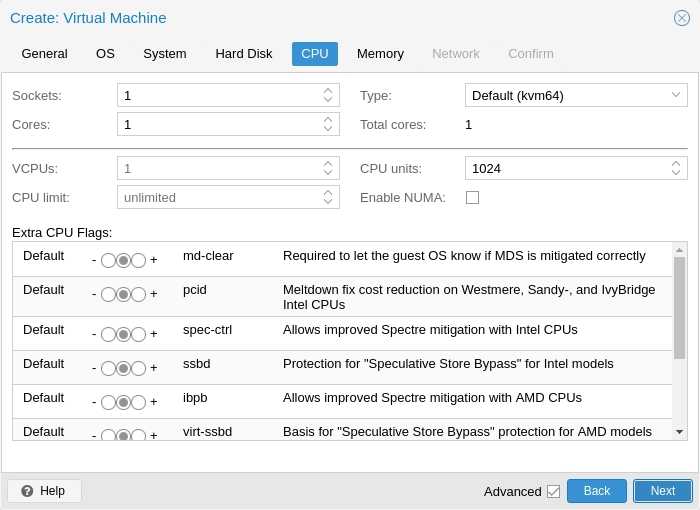
Мы можем задать количество процессоров и ядер:
* в данном примере мы создаем виртуалку с 2 процессорами, каждый из который с 2 ядрами, итого, 4. Для ненагруженных систем можно оставить значение по умолчанию.
Выделяем память:
* наша Ubuntu будет работать с 2 Гб оперативной памяти.
Выбираем созданный нами бридж — либо для получения прямого адреса из сети, либо для NAT:
* в данном примере, мы указали vmbr0 для подключения к сети напрямую.
Ставим галочку, чтобы виртуальная машина сразу запустилась после создания:
… и нажимаем Готово. Ждем окончания процесса и переходим к консоли:

Мы должны увидеть загрузку с ISO-образа.
Начало работы
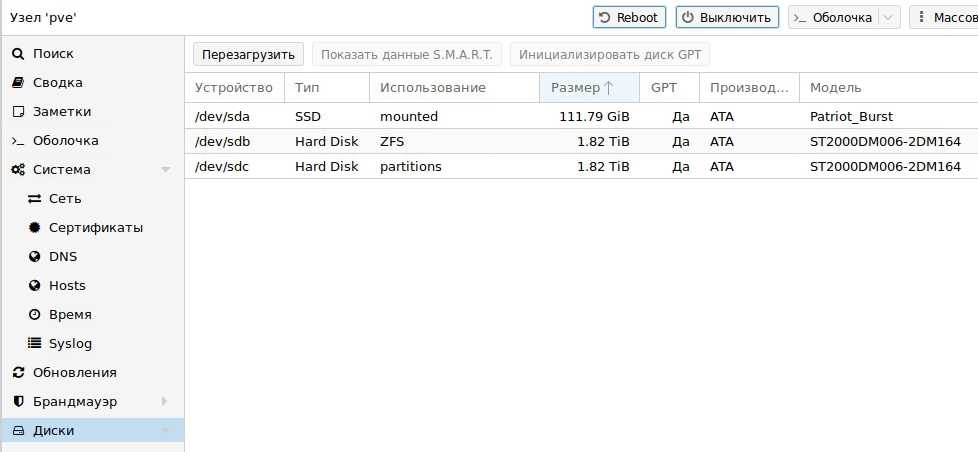
Настроить дисковые накопители
/dev/sda/dev/sdb/dev/sdbext4
- Размечаем диск, создавая новый раздел:
- Нажимаем клавишу o или g (разметить диск в MBR или GPT).
- Далее нажимаем клавишу n (создать новый раздел).
- И наконец w (для сохранения изменений).
- Создаем файловую систему ext4:
- Создаем директорию, куда будем монтировать раздел:
- Открываем конфигурационный файл на редактирование:
- Добавляем туда новую строку:
- После внесения изменений сохраняем их сочетанием клавиш Ctrl + X, отвечая Y на вопрос редактора.
- Для проверки, что все работает, отправляем сервер в перезагрузку:
- После перезагрузки проверяем смонтированные разделы:
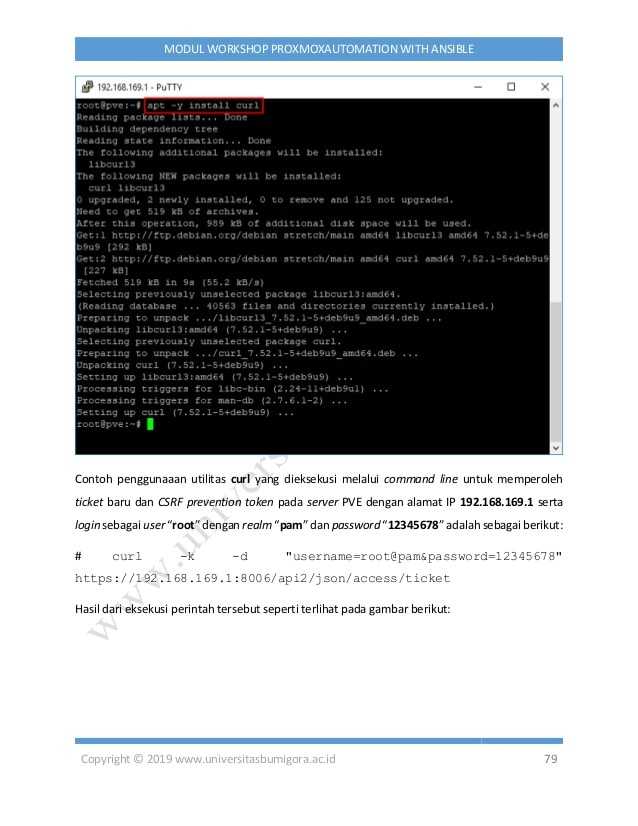
/dev/sdb1/mnt/storage
Добавить новое хранилище в Proxmox
ДатацентрХранилищеДобавитьДиректория
- ID — название будущего хранилища;
- Директория — /mnt/storage;
- Содержимое — выделяем все варианты (поочередно щелкая на каждом варианте).
Добавить
Создать виртуальную машину
- Определяемся с версией операционной системы.
- Заранее закачиваем ISO-образ.
- Выбираем в меню Хранилище только что созданное хранилище.
- Нажимаем Содержимое ➝ Загрузить.
- Выбираем из списка ISO-образ и подтверждаем выбор нажатием кнопки Загрузить.
- Нажимаем Создать VM.
- Заполняем поочередно параметры: Имя ➝ ISO-Image ➝ Размер и тип жесткого диска ➝ Количество процессоров ➝ Объем оперативной памяти ➝ Сетевой адаптер.
- Выбрав все желаемые параметры нажимаем Завершить. Созданная машина будет отображена в меню панели управления.
- Выбираем ее и нажимаем Запуск.
- Переходим в пункт Консоль и выполняем установку операционной системы точно таким же образом, как и на обычный физический сервер.
Настроить автозапуск
- Щелкаем по названию нужной машины.
- Выбираем вкладку Опции ➝ Запуск при загрузке.
- Ставим галочку напротив одноименной надписи.
Start/Shutdown order
Режимы архивирования
Proxmox предлагает на выбор системному администратору три метода резервного копирования. С помощью них можно решить требуемую задачу, определив приоритет между необходимостью простоя и надежностью сделанной резервной копии:
- Режим Snapshot (Снимок). Этот режим можно еще назвать как Live backup, поскольку для его использования не требуется останавливать работу виртуальной машины. Использование этого механизма не прерывает работу VM, но имеет два очень серьезных недостатка — могут возникать проблемы из-за блокировок файлов операционной системой и самая низкая скорость создания. Резервные копии, созданные этим методом, надо всегда проверять в тестовой среде. В противном случае есть риск, что при необходимости экстренного восстановления, они могут дать сбой.
- Режим Suspend (Приостановка). Виртуальная машина временно «замораживает» свое состояние, до окончания процесса резервного копирования. Содержимое оперативной памяти не стирается, что позволяет продолжить работу ровно с той точки, на которой работа была приостановлена. Разумеется, это вызывает простой сервера на время копирования информации, зато нет необходимости выключения/включения виртуальной машины, что достаточно критично для некоторых сервисов. Особенно, если запуск части сервисов не является автоматическим. Тем не менее такие резервные копии также следует разворачивать в тестовой среде для проверки.
- Режим Stop (Остановка). Самый надежный способ резервного копирования, но требующий полного выключения виртуальной машины. Отправляется команда на штатное выключение, после остановки выполняется резервное копирование и затем отдается команда на включение виртуальной машины. Количество ошибок при таком подходе минимально и чаще всего сводится к нулю. Резервные копии, созданные таким способом, практически всегда разворачиваются корректно.
Первый способ(его я использовал, когда не знал о втором)))
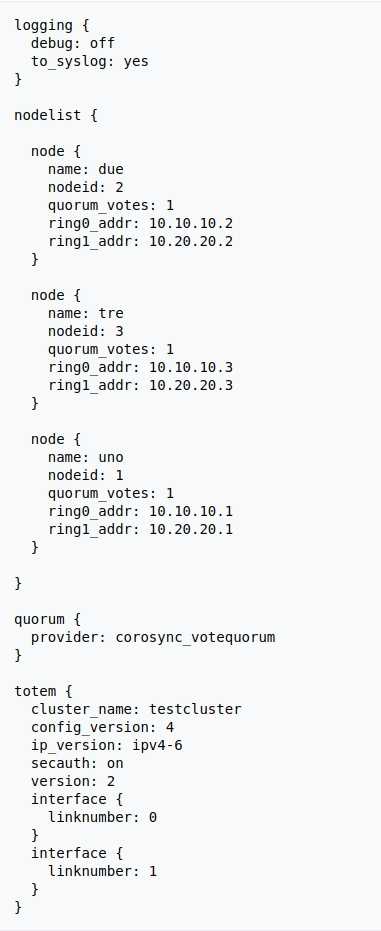
Не буду рассказывать на сколько и каких «граблей» пришлось наступить(с линуксом я знаком очень поверхностно), выложу содержимое файла /etc/network/interfaces. При этой конфигурации всё, вроде как, заработало.
Shell
# Создаем объединение физических сетевых интерфейсов
auto bond0
iface bond0 inet manual
slaves enp4s0f0 enp4s0f1
bond_miimon 100
bond_mode 802.3ad
bond_xmit_hash_policy layer2+3
# Добавляем VLAN100
auto bond0.100
iface bond0.100 inet manual
vlan-raw-device bond0
# Добавляем VLAN150
auto bond0.150
iface bond0.150 inet manual
vlan-raw-device bond0
# Создаем бридж VLAN150(его используем для подключения ВМ к VLAN150)
auto vmbr150
iface vmbr150 inet manual
address 0.0.0.0
netmask 0.0.0.0
bridge_ports bond0.150
bridge_stp off
bridge_fd 0
# Создаем бридж VLAN100(его используем для подключения ВМ к VLAN100. Также он служит для интерфейса управления ноды.)
auto vmbr100
iface vmbr100 inet static
address 192.168.102.63
netmask 255.255.252.0
gateway 192.168.102.251
bridge_stp off
bridge_ports bond0.100
bridge_fd 0
auto vmbr0
iface vmbr0 inet manual
bridge_ports bond0
bridge_stp off
bridge_fd 0
bridge_vlan_aware yes
|
1 |
# Создаем объединение физических сетевых интерфейсов auto bond0 iface bond0 inet manual slaves enp4s0f0 enp4s0f1 bond_miimon100 bond_mode802.3ad bond_xmit_hash_policy layer2+3 auto bond0.100 iface bond0.100inet manual vlan-raw-device bond0 auto bond0.150 iface bond0.150inet manual vlan-raw-device bond0 auto vmbr150 iface vmbr150 inet manual address0.0.0.0 netmask0.0.0.0 bridge_ports bond0.150 bridge_stp off bridge_fd auto vmbr100 iface vmbr100 inet static address192.168.102.63 netmask255.255.252.0 gateway192.168.102.251 bridge_stp off bridge_ports bond0.100 bridge_fd auto vmbr0 iface vmbr0 inet manual bridge_ports bond0 bridge_stp off bridge_fd bridge_vlan_aware yes |
В данном конфиге используются сети с VLAN ID 100 и 150. Если нужно добавить еще какие то, добавляем в файл:
Shell
auto bond0.<VLAN ID>
iface bond0.<VLAN ID> inet manual
vlan-raw-device bond0
|
1 |
auto bond0.<VLAN ID> iface bond0.<VLAN ID>inet manual vlan-raw-device bond0 |
и
Shell
auto vmbr<VLAN ID>
iface vmbr<VLAN ID> inet manual
address 0.0.0.0
netmask 0.0.0.0
bridge_ports bond0.<VLAN ID>
bridge_stp off
bridge_fd 0
|
1 |
auto vmbr<VLAN ID> iface vmbr<VLAN ID>inet manual address0.0.0.0 netmask0.0.0.0 bridge_ports bond0.<VLAN ID> bridge_stp off bridge_fd |
После редактирования файла /etc/network/interfaces не забудьте перезапустить службу /etc/init.d/networking restart(иногда нужно и перезагрузить хост).
В веб-интерфейсе это выглядит примерно так(добавлены еще несколько VLAN, которые не указаны в примере):
P.S. После экспериментов выяснилось, что bonde_mode 802.3ad не обеспечивает отказоустойчивость, в связи с чем она была заменена на bond_mode balance-xor
Форматы виртуальных накопителей
Расскажем подробнее об используемых в Proxmox форматах накопителей:
-
RAW. Самый понятный и простой формат. Это файл с данными жесткого диска «байт в байт» без сжатия или оптимизации. Это очень удобный формат, поскольку его легко смонтировать стандартной командой mount в любой linux-системе. Более того это самый быстрый «тип» накопителя, так как гипервизору не нужно его никак обрабатывать.
Серьезным недостатком этого формата является то, что сколько Вы выделили места для виртуальной машины, ровно столько места на жестком диске и будет занимать файл в формате RAW (вне зависимости от реально занятого места внутри виртуальной машины).
-
QEMU image format (qcow2). Пожалуй, самый универсальный формат для выполнения любых задач. Его преимущество в том, что файл с данными будет содержать только реально занятое место внутри виртуальной машины. Например, если было выделено 40 Гб места, а реально было занято только 2 Гб, то все остальное место будет доступно для других VM. Это очень актуально в условиях экономии дискового пространства.
Небольшим минусом работы с этим форматом является следующее: чтобы примонтировать такой образ в любой другой системе, потребуется вначале загрузить , а также использовать утилиту qemu-nbd, которая позволит операционной системе обращаться к файлу как к обычному блочному устройству. После этого образ станет доступен для монтирования, разбиения на разделы, осуществления проверки файловой системы и прочих операций.
Следует помнить, что все операции ввода-вывода при использовании этого формата программно обрабатываются, что влечет за собой замедление при активной работе с дисковой подсистемой. Если стоит задача развернуть на сервере базу данных, то лучше выбрать формат RAW.
-
VMware image format (vmdk). Этот формат является «родным» для гипервизора VMware vSphere и был включен в Proxmox для совместимости. Он позволяет выполнить миграцию виртуальной машины VMware в инфраструктуру Proxmox.
Использование vmdk на постоянной основе не рекомендуется, данный формат самый медленный в Proxmox, поэтому он годится лишь для выполнения миграции, не более. Вероятно в обозримом будущем этот недостаток будет устранен.
DRBDmanage и Linstor
Во первых стоит еще раз упомянуть про DRBDmanage, который очень неплохо интегрируется в Proxmox. LINBIT предоставляет готовый плагин DRBDmanage для Proxmox который позволяет использовать все его функции прямо из интерфейса Proxmox.
Выглядит это и правда потрясающе, но к сожалению имеет некоторые минусы.
- Во первых захаркоженные названия томов, LVM-группа или ZFS-пул обязательно должен иметь название .
- Невозможность использования более одного пула на ноду
- В силу специфики решения сontroller volume может находиться только на обычном LVM и никак иначе
- Переодические глюки dbus, который тесно используется DRBDmanage для взаимодействия с нодами.
В результате чего, LINBIT было принято решение заменить всю сложную логику DRBDmanage на простое приложение, которое связывается с нодами используя обычное tcp-соединение и работает безо всякой там магии. Так появился Linstor.
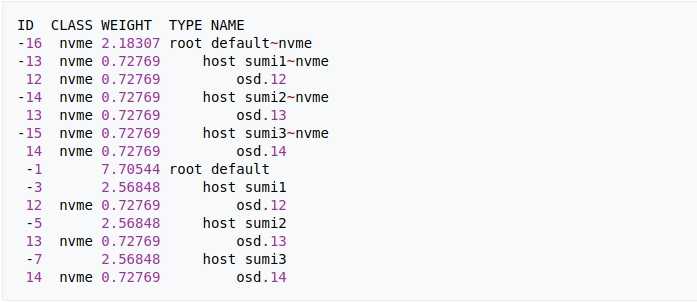
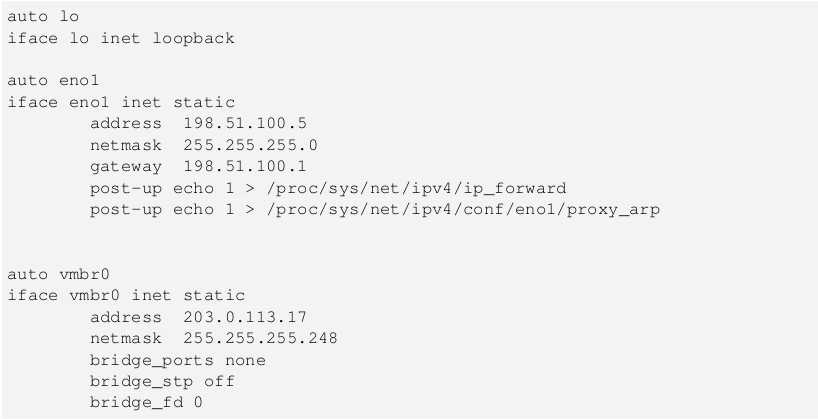
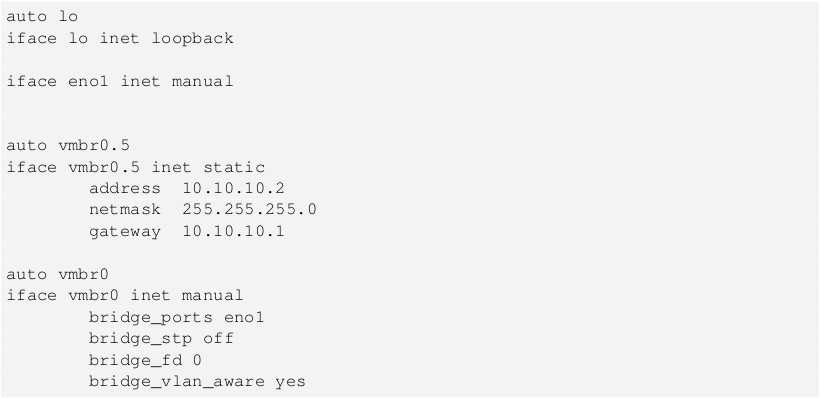
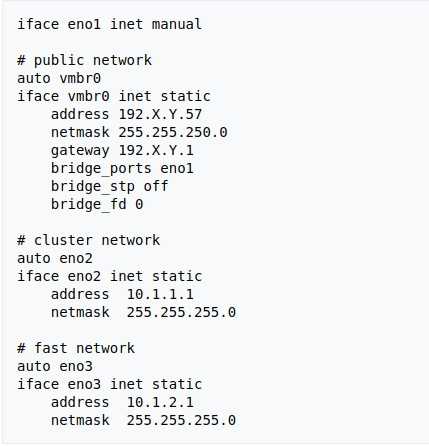
Linstor и правда работает очень хорошо. К сожалению разработчики выбрали java как основной язык для написания Linstor-server, но пусть это не пугает вас, так как Linstor сам по себе занимается только распределением конфигов DRBD и нарезкой LVM/ZFS разделов на нодах.
iSCSI и LVM
Подобным образом внутри контейнера может быть настроен и обычный tgt-демон, iSCSI будет выдавать значительно бОльшую производительность для операций ввода-вывода, а контейнер будет работать более гладко ввиду того tgt-сервер работает полностью в пространстве пользователя.
Как правило экспортируемый LUN нарезается на много кусочков с помощью LVM. Однако есть несколько ньюансов которые стоит учесть, например: каким образом обеспечены блокировоки LVM для совместного использования экспортированной группы на нескольких хостах.
Пожалуй эти и другие ньюансы я опишу в следующей статье.
UPD: Хочется добавить что помимо NFS-Kernel-Server существует ещё — сервер, который полностью работает в user-space.
На данный момент я бы советовал использовать именно его, т.к. с ним ваш контейнер больше никогда не подвиснет в неизвестном состоянии.
Установка всё также проста:
Но конфигурация немного отличается, экспорт нужно описать в
Затем выполнить:
Сетевой Bridge для kvm
Настройка сети для виртуальных машин kvm может быть настроена различными способами. Я как минимум 3 наиболее популярных знаю:
- Виртуальные машины выходят во внешний мир через сам хост kvm, на котором настроен NAT. Этот вариант вам будет доступен сразу после установки kvm. Ничего дополнительно настраивать не надо, так как сетевой бридж для этого virbr0 уже будет добавлен в систему. А в правилах iptables будет добавлен MASQUERADE для NAT.
- Одна из виртуальных машин превращается в шлюз и через нее осуществляется доступ во внешний мир для всех виртуальных машин. Наиболее гибкий способ управления сетью для vm, но в то же время требует больше времени на настройку и набор знаний по работе с сетями.
- Для виртуальных машин kvm создается отдельный сетевой бридж во внешнюю сеть. Они напрямую получают в нее сетевой доступ.
Последний вариант наиболее простой и удобный, поэтому настроим сеть для виртуальных машин таким образом. Для этого нам нужно установить дополнительный пакет на host.
sudo apt install bridge-utils
Теперь на хосте приводим сетевые настройки в /etc/netplan к следующему виду.
network:
ethernets:
ens18:
dhcp4: false
dhcp6: false
version: 2
bridges:
br0:
macaddress: 16:76:1a:3b:be:03
interfaces:
- ens18
dhcp4: true
dhcp6: false
parameters:
stp: true
forward-delay: 4
Здесь будьте очень внимательны. Не выполняйте изменения сетевых настроек, не имея прямого доступа к консоли сервера. Очень высок шанс того, что что-то пойдет не так и вы потеряете удаленный доступ к серверу.
В предложенном наборе правил netplan у меня один сетевой интерфейс на хосте гипервизора — ens18. Он изначально получал настройки по dhcp. Мы добавили новый сетевой бридж br0, в него добавили интерфейс ens18. Так же мы указали, что br0 будет получать сетевые настройки по dhcp. Я указал mac адрес для того, чтобы он не менялся после перезагрузки. Такое может происходить. Адрес можно указать любой, не принципиально. Я сделал похожий на адрес физического сетевого интерфейса.
Теперь надо применить новые настройки.
sudo netplan apply
Сразу после этого вы потеряете доступ к серверу по старому адресу. Интерфейс ens18 перейдет в состав bridge br0 и потеряет свои настройки. А в это время бридж br0 получит новые сетевые настройки по dhcp. IP адрес будет отличаться от того, что был перед этим на интерфейсе ens18. Чтобы снова подключиться удаленно к гипервизору kvm, вам надо будет пойти на dhcp сервер и посмотреть, какой новый ip адрес ему назначен.
Если у вас нет dhcp сервера или вы просто желаете вручную указать сетевые настройки, то сделать это можно следующим образом.
network:
ethernets:
ens18:
dhcp4: false
dhcp6: false
version: 2
bridges:
br0:
macaddress: 16:76:1a:3b:be:03
interfaces:
- ens18
addresses:
- 192.168.25.2/24
gateway4: 192.168.25.1
nameservers:
addresses:
- 192.168.25.1
- 77.88.8.1
dhcp4: false
dhcp6: false
parameters:
stp: true
forward-delay: 4
В этом случае после применения новых настроек, гипервизор kvm будет доступен по адресу 192.168.25.2.
Обращайте внимание на все отступы в конфигурационном файле netplan. Они важны
В случае ошибок, настройки сети применены не будут. Иногда эта тема очень напрягает, так как не получается сразу понять, где именно в отступах ошибка. В этом плане yaml файл для настроек сети гипервизора как-то не очень удобен.
Далее еще один важный момент. Чтобы наш kvm хост мог осуществлять транзит пакетов через себя, надо это явно разрешить в sysctl. Добавляем в /etc/sysctl.d/99-sysctl.conf новый параметр. Он там уже есть, надо только снять пометку комментария.
net.ipv4.ip_forward=1
Применяем новую настройку ядра.
sudo sysctl -p /etc/sysctl.d/99-sysctl.conf net.ipv4.ip_forward = 1
С настройкой сети гипервизора мы закончили. На данном этапе я рекомендую перезагрузить сервер и убедиться, что все настройки корректно восстанавливаются после перезагрузки.
Установка Proxmox VE на Debian 10 Buster
В статьях на различных порталах в Интернете можно прочитать, что VPS и VDS не имеют разницы, просто различные аббревиатуры одного и того же. Однако, с моей точки зрения, есть существенное различие в предложениях провайдеров – виртуальный хост приобретён в аренду или реальный сервер в стойке.
Чтобы проверить, можно ли полноценно использовать виртуализацию Proxmox VE в облаке или на реальном хосте, в Debian 10 Buster, подключаемся к консоли сервера по ssh, в моем случае с помощью Putty RUS и вводим:
Если виртуализация поддерживается процессором хоста, то результат работы не пустой, а несколько строк:
Обновление системы Debian 10 Buster
Обновите Debian 10 Buster до актуальной и перезагрузите по выполнении:
После перезагрузки установите необходимые пакеты:
Настройка файла /etc/hosts
Для нормальной установки Proxmox VE в Debian 10 в файле /etc/hosts должно быть указано краткое и доменное имя хоста. У VDS или VPS файл /etc/hosts обычно уже настроен, но проверить не мешает. Должно выглядеть так, как на скриншоте:
В моем случае указаны имена для адреса 127.0.0.1 localhost. Перед строкой 127.0.0.1 с именем хоста pve-test необходимо поставить знак #, чтобы закомментировать эту строку, иначе Proxmox VE установится некорректно. Это локальные адреса и внешние адреса для разрешения имени и адреса хоста.


192.168.0.166 IP-адрес для сетевой карты, по которому я подключаюсь к Debian 10 Buster. Ниже указаны адреса IPV6 и ещё ниже я указал самые быстрые адреса репозиториев Debian.org именно с моей локации, что позволило мне существенно ускорить загрузку пакетов при обновлении Debian 10 Buster. Вам это делать необязательно.
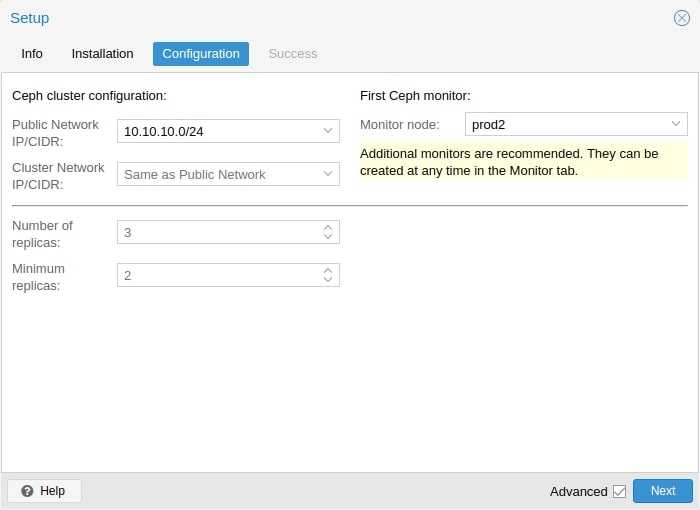
Отказоустойчивый кластер
Настроим автоматический перезапуск виртуальных машин на рабочих нодах, если выйдет из строя сервер.
Для настройки отказоустойчивости (High Availability или HA) нам нужно:
- Минимум 3 ноды в кластере. Сам кластер может состоять из двух нод и более, но для точного определения живых/не живых узлов нужно большинство голосов (кворумов), то есть на стороне рабочих нод должно быть больше одного голоса. Это необходимо для того, чтобы избежать ситуации 2-я активными узлами, когда связь между серверами прерывается и каждый из них считает себя единственным рабочим и начинает запускать у себя все виртуальные машины. Именно по этой причине HA требует 3 узла и выше.
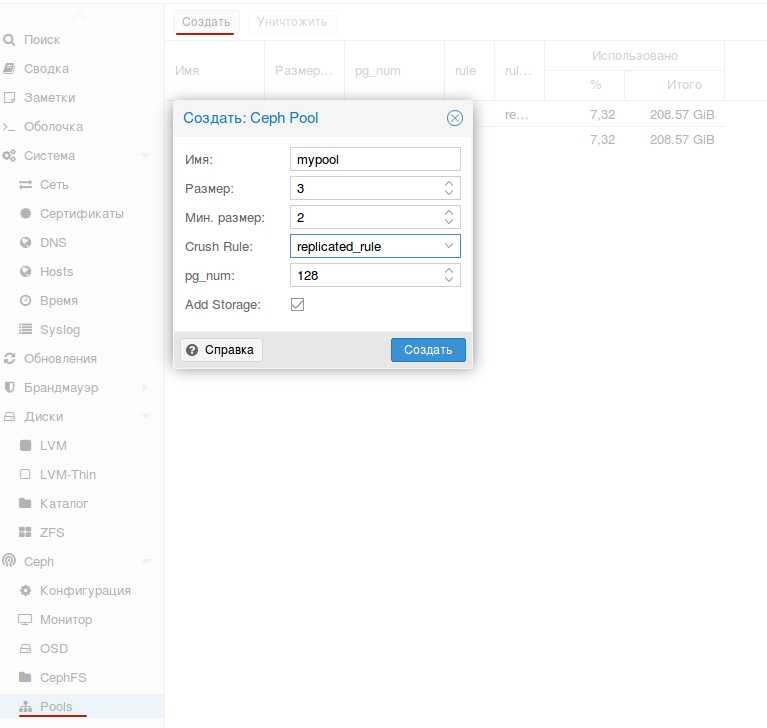
- Общее хранилище для виртуальных машин. Все ноды кластера должны быть подключены к общей системе хранения данных — это может быть СХД, подключенная по FC или iSCSI, NFS или распределенное хранилище Ceph или GlusterFS.
1. Подготовка кластера
Процесс добавления 3-о узла аналогичен процессу, — на одной из нод, уже работающей в кластере, мы копируем данные присоединения; в панели управления третьего сервера переходим к настройке кластера и присоединяем узел.
2. Добавление хранилища
Подробное описание процесса настройки самого хранилища выходит за рамки данной инструкции. В данном примере мы разберем пример и использованием СХД, подключенное по iSCSI.
Если наша СХД настроена на проверку инициаторов, на каждой ноде смотрим командой:
cat /etc/iscsi/initiatorname.iscsi
… IQN инициаторов. Пример ответа:
…
InitiatorName=iqn.1993-08.org.debian:01:4640b8a1c6f
* где iqn.1993-08.org.debian:01:4640b8a1c6f — IQN, который нужно добавить в настройках СХД.
После настройки СХД, в панели управления Proxmox переходим в Датацентр — Хранилище. Кликаем Добавить и выбираем тип (в нашем случае, iSCSI):
В открывшемся окне указываем настройки для подключения к хранилке:
* где ID — произвольный идентификатор для удобства; Portal — адрес, по которому iSCSI отдает диски; Target — идентификатор таргета, по которому СХД отдает нужный нам LUN.
Нажимаем добавить, немного ждем — на всех хостах кластера должно появиться хранилище с указанным идентификатором. Чтобы использовать его для хранения виртуальных машин, еще раз добавляем хранилище, только выбираем LVM:
Задаем настройки для тома LVM:
* где было настроено:
- ID — произвольный идентификатор. Будет служить как имя хранилища.
- Основное хранилище — выбираем добавленное устройство iSCSI.
- Основное том — выбираем LUN, который анонсируется таргетом.
- Группа томов — указываем название для группы томов. В данном примере указано таким же, как ID.
- Общедоступно — ставим галочку, чтобы устройство было доступно для всех нод нашего кластера.
Нажимаем Добавить — мы должны увидеть новое устройство для хранения виртуальных машин.
Для продолжения настройки отказоустойчивого кластера создаем виртуальную машину на общем хранилище.
3. Настройка отказоустойчивости
Создание группы
Для начала, определяется с необходимостью групп. Они нужны в случае, если у нас в кластере много серверов, но мы хотим перемещать виртуальную машину между определенными нодами. Если нам нужны группы, переходим в Датацентр — HA — Группы. Кликаем по кнопке Создать:
Вносим настройки для группы и выбираем галочками участников группы:
* где:
- ID — название для группы.
- restricted — определяет жесткое требование перемещения виртуальной машины внутри группы. Если в составе группы не окажется рабочих серверов, то виртуальная машина будет выключена.
- nofailback — в случае восстановления ноды, виртуальная машина не будет на нее возвращена, если галочка установлена.
Также мы можем задать приоритеты для серверов, если отдаем каким-то из них предпочтение.
Нажимаем OK — группа должна появиться в общем списке.
Настраиваем отказоустойчивость для виртуальной машины
Переходим в Датацентр — HA. Кликаем по кнопке Добавить:
В открывшемся окне выбираем виртуальную машину и группу:
… и нажимаем Добавить.




4. Проверка отказоустойчивости
После выполнения всех действий, необходимо проверить, что наша отказоустойчивость работает. Для чистоты эксперимента, можно выключиться сервер, на котором создана виртуальная машина, добавленная в HA.
Важно учесть, что перезагрузка ноды не приведет к перемещению виртуальной машины. В данном случае кластер отправляет сигнал, что он скоро будет доступен, а ресурсы, добавленные в HA останутся на своих местах
Для выключения ноды можно ввести команду:
systemctl poweroff
Виртуальная машина должна переместиться в течение 1 — 2 минут.
Настройка DRBD
Ну хорошо, с идеей разобрались теперь перейдем к реализации.
По умолчанию в комплекте с ядром Linux поставляется модуль восьмой версии drbd, к сожалению он нам не подходит и нам необходимо установить модуль девятой версии.
Подключим репозиторий LINBIT и установим все необходимое:
- — заголовки ядра необходимые для сборки модуля
- — модуль ядра в формате DKMS
- — основные утилиты для управления DRBD
- — интерактивный инструмент, как top только для DRBD
После установки модуля проверим, все ли в порядке с ним:
Если вы увидите в выводе команды восьмую версию значит что-то пошло не так и загружен in-tree модуль ядра. Проверьте что-бы разобраться в чем причина.
Каждая нода у нас будет иметь одно и тоже drbd-устройство запущенное поверх обычных разделов. Для начала нам нужно подготовить этот раздел под drbd на каждой ноде.
В качестве такого раздела может выступать любое блочное устройство, это может быть lvm, zvol, раздел диска или весь диск целиком. В этой статье я буду использовать отдельный nvme диск с разделом под drbd:
Стоит заметить, что имена устройств имеют свойство иногда меняться, так что лучше сразу взять за привычку использовать постоянный симлинк на устройство.
Найти такой симлинк для можно таким образом:
Опишем наш ресурс на всех трех нодах:
Желательно для синхронизации drbd использовать отдельную сеть.
Теперь создадим метаданные для drbd и запустим его:
Повторим эти действия на всех трех нодах и проверим состояние:
Сейчас наш диск Inconsistent на всех трех нодах, это потому, что drbd не знает какой диск должен быть взят в качестве оригинала. Мы должны пометить один из них как Primary, что бы его состояние синхронизировалось на остальные ноды:
Сразу после этого начнется синхронизация:
Нам не обязательно дожидаться ее окончания и мы можем параллельно выполнять дальнейшие шаги. Их можно выполнять на любой ноде, вне зависимости от ее текущего состояния локального диска в DRBD. Все запросы будут автоматически перенаправлены на устройство с UpToDate состоянием.
Стоит не забыть активировать автозапуск drbd-сервиса на нодах:





