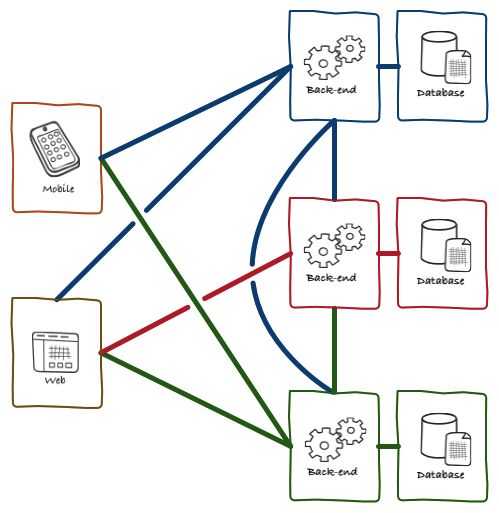
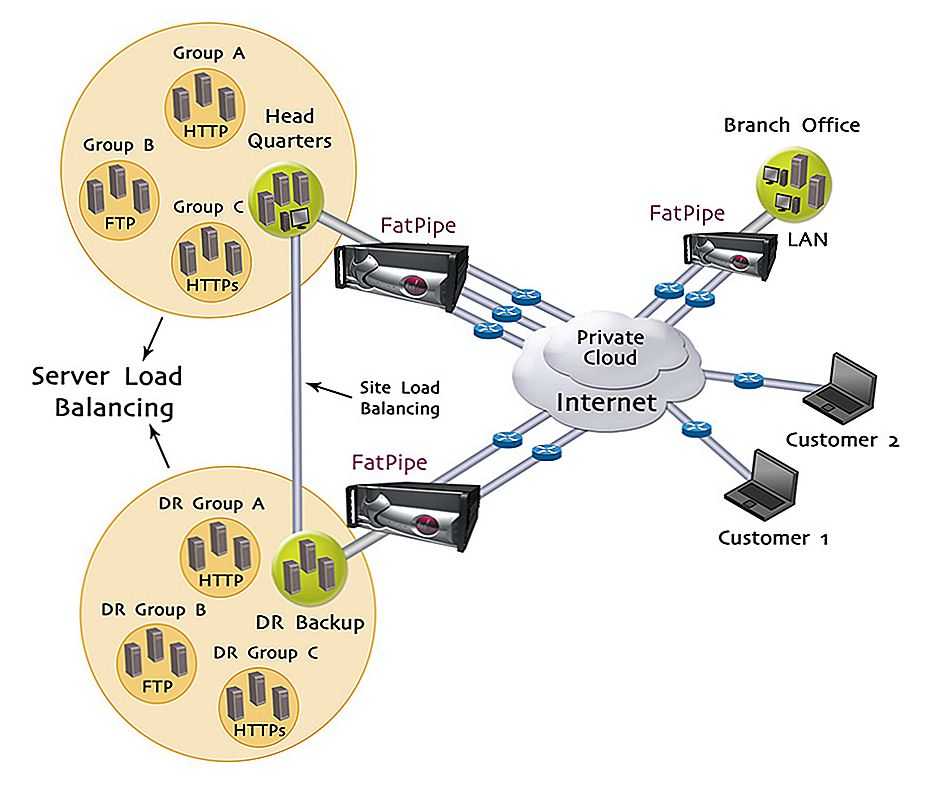
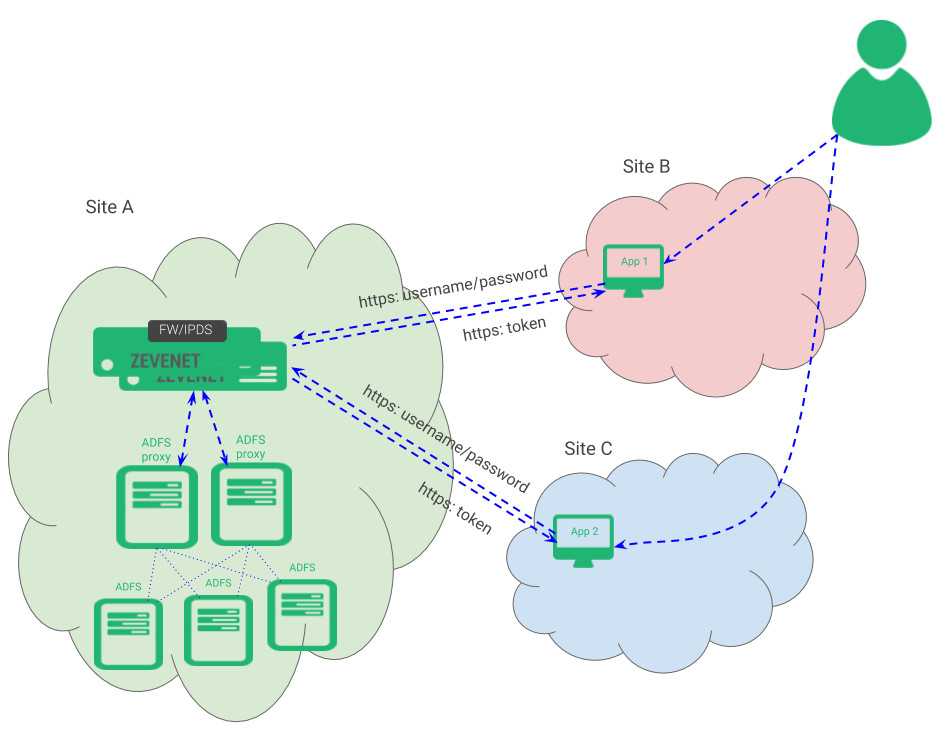
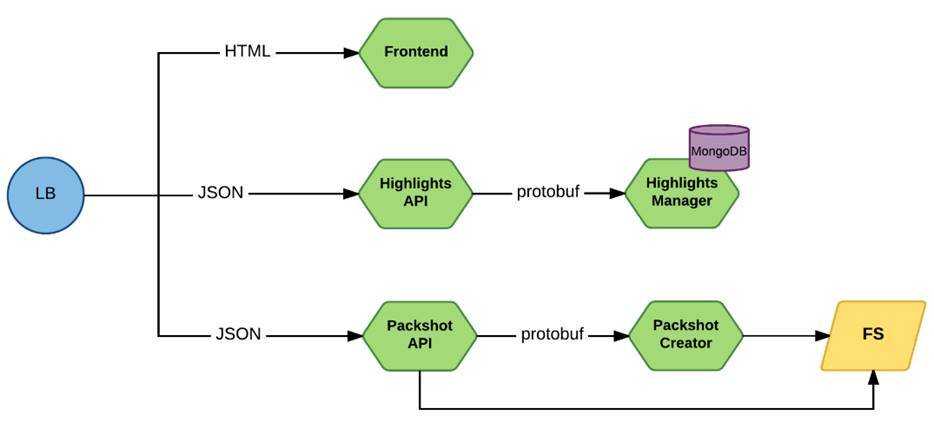
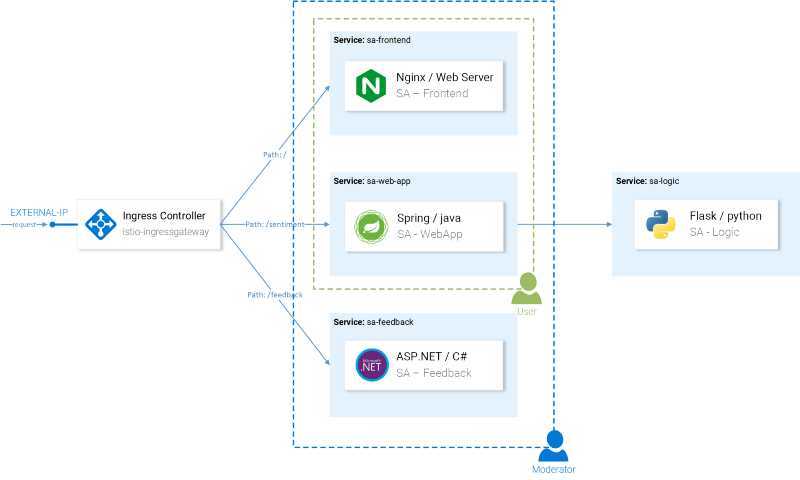
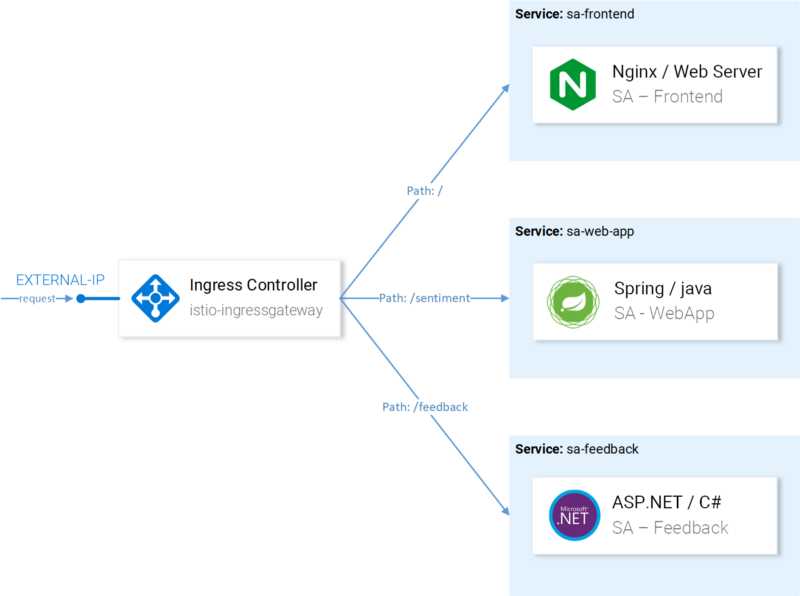
Шаг 2. Создание образа для двух контейнеризованных веб-служб IIS
На этом этапе мы создадим образ контейнеров для двух простых веб-приложений на базе IIS. Позже мы будем использовать эти изображения для создания двух служб докеров.
Примечание. Выполните инструкции в этом разделе на одном из узлов контейнера, которые вы намереваетесь использовать в качестве swarm.
Построение общего образа веб-сервера IIS
На моем личном репо GitHub я сделал простой файл Dockerfile, который можно использовать для создания образа веб-сервера IIS. Dockerfile просто включает роль веб-сервера IIS в контейнере microsoft/windowsservercore. Загрузите файл Dockerfile отсюда и сохраните его в каком-либо месте (например, C:\temp\iis) на одной из хост-машин, которые вы планируете использовать в качестве узла swarm. С этого места создайте образ, используя следующую команду:
C:\temp\iis> docker build -t iis-web.
| 1 | C\temp\iis>docker build-tiis-web. |
(Необязательно) Убедитесь, что готов образ веб-сервера IIS
Сначала запустите контейнер:
C:\temp> docker run -it -p 80:80 iis-web
| 1 | C\temp>docker run-it-p8080iis-web |
Затем используйте команду docker, чтобы убедиться, что контейнер работает. Запишите его идентификатор. Идентификатором вашего контейнера является значение В следующей команде.
Получить IP-адрес контейнера:
C:\temp>docker exec <code></code> ipconfig
| 1 | C\temp>docker exec<code></code>ipconfig |
Теперь откройте браузер на своем контейнере и введите IP-адрес вашего контейнера в адресную строку. Должна появиться страница подтверждения, указывающая на успешное выполнение роли веб-сервера IIS в контейнере.
Сборка двух пользовательских образов веб-сервера IIS
На этом этапе мы заменим страницу проверки IIS, которую мы видели выше, с пользовательскими HTML-страницами — двумя разными образами, соответствующими двум различным образам веб-контейнера. На более позднем этапе мы будем использовать наш контейнер NGINX для балансировки нагрузки между экземплярами этих двух образов. Поскольку образы будут отличаться, мы легко увидим балансировку нагрузки в действии, поскольку она переключает между содержимым, которое обслуживается контейнерами, которые мы определим на этом этапе.
Сначала создайте на хост-компьютере простой файл с именем index_1.html. В файла любой текст. Например, файл index_1.html может выглядеть так:
Теперь создайте второй файл index_2.html. Опять же, в файла любой текст. Например, файл index_2.html может выглядеть так:
Теперь мы будем использовать эти HTML документы для создания двух пользовательских образов веб-сервисов.
Если созданный экземпляр контейнера iis-web еще не запущен, запустите новый, затем получите идентификатор контейнера, используя:
C:\temp> docker exec ipconfig
| 1 | C\temp>docker exec ipconfig |
Теперь скопируйте файл index_1.html со своего хоста на экземпляр контейнера IIS, который запущен, используя следующую команду:
C:\temp> docker cp index_1.html : C:\inetpub\wwwroot\index.html
| 1 | C\temp>docker cp index_1.htmlC\inetpub\wwwroot\index.html |
Затем остановите и зафиксируйте контейнер в его текущем состоянии. Это создаст образ контейнера для первой веб-службы. Давайте назовем это первый образ, «web_1».
C:\> docker stop
C:\> docker commit web_1
|
1 |
C\>docker stop C\>docker commit web_1 |
Теперь запустите контейнер снова и повторите предыдущие шаги, чтобы создать второй образ веб-службы, на этот раз используя файл index_2.html. Сделайте это, используя следующие команды:
C:\> docker start
C:\> docker cp index_2.html :C:\inetpub\wwwroot\index.html
C:\> docker stop
C:\> docker commit web_2

|
1 |
C\>docker start C\>docker cp index_2.htmlC\inetpub\wwwroot\index.html C\>docker stop C\>docker commit web_2 |
Теперь вы создали образы для двух уникальных веб-сервисов; Если вы просматриваете образ Докера на вашем хосте, запустив , вы должны увидеть, что у вас есть два новых образа контейнера — «web_1» и «web_2».
Поместите образ контейнера IIS на все ваши хосты swarm
Для выполнения этого вам понадобятся пользовательские образы веб-контейнера, которые вы только что создали, на всех хост-машинах, которые вы намереваетесь использовать в качестве узлов swarm. У вас есть два способа получить образ на дополнительные машины:
Вариант 1. Повторите описанные выше шаги, чтобы создать контейнеры «web_1» и «web_2» на втором узле.Вариант 2 : вставьте образ в ваш репозиторий в Docker Hub, затем подтяните их на дополнительные хосты.
Example of TCP and UDP Load-Balancing Configuration
This is a configuration example of TCP and UDP load balancing with NGINX:
In this example, all TCP and UDP proxy‑related functionality is configured inside the
block, just as settings for HTTP requests are configured in the
block.
There are two named
blocks, each containing three servers that host the same content as one another. In the
for each server, the server name is followed by the obligatory port number. Connections are distributed among the servers according to the
load‑balancing method: a connection goes to the server with the fewest number of active connections.
The three
blocks define three virtual servers:
-
The first server listens on port 12345 and proxies all TCP connections to the stream_backend group of upstream servers. Note that the
directive defined in the context of the module must not contain a protocol.Two optional timeout parameters are specified: the
directive sets the timeout required for establishing a connection with a server in the stream_backend group. The
directive sets a timeout used after proxying to one of the servers in the stream_backend group has started. -
The second server listens on port 53 and proxies all UDP datagrams (the parameter to the directive) to an upstream group called dns_servers. If the parameter is not specified, the socket listens for TCP connections.
-
The third virtual server listens on port 12346 and proxies TCP connections to backend4.example.com, which can resolve to several IP addresses that are load balanced with the Round Robin method.
Метод балансировки
Рассмотрим способы балансировки, которые можно использовать в NGINX:
- Round Robin.
- Hash.
- IP Hash.
- Least Connections.
- Random.
- Least Time (только в платной версии NGINX).
Настройка метода балансировки выполняется в директиве upstream. Синтаксис:
YAML
upstream <название апстрима> {
<метод балансировки>
…
}
|
1 |
upstream<названиеапстрима>{ <методбалансировки> … } |
Round Robin
Веб-сервер будет передавать запросы бэкендам по очереди с учетом их весов. Данный метод является методом по умолчанию и его указывать в конфигурационном файле не нужно.
Hash
Данный метод определяет контрольную сумму на основе переменных веб-сервера и ассоциирует каждый полученный результат с конкретным бэкендом. Пример настройки:
YAML
upstream test_backend {
hash $scheme$request_uri;
server 192.168.10.10;
server 192.168.10.11;
server 192.168.10.12;
}
|
1 |
upstreamtest_backend{ hash$scheme$request_uri; server192.168.10.10; server192.168.10.11; server192.168.10.12; } |
* это самый распространенный пример настройки hash — с использованием переменных $scheme (http или https) и $request_uri. При данной настройке каждый конкретный URL будет ассоциирован с конкретным сервером.
IP Hash
Ассоциация выполняется исходя из IP-адреса клиента и только для HTTP-запросов. Таким образом, для каждого посетителя устанавливается связь с одним и тем же сервером. Это, так называемый, Sticky Session метод.
Для адресов IPv4 учитываются только первые 3 октета — это позволяет поддерживать одинаковые соединения с клиентами, чьи адреса меняются (получение динамических адресов от DHCP провайдера). Для адресов IPv6 учитывается адрес целиком.
Пример настройки:
YAML
upstream test_backend {
ip_hash;
server 192.168.10.10;
server 192.168.10.11;
server 192.168.10.12;
}
|
1 |
upstreamtest_backend{ ip_hash; server192.168.10.10; server192.168.10.11; server192.168.10.12; } |
Least Connections
NGINX определяет, с каким бэкендом меньше всего соединений в данный момент и перенаправляет запрос на него (с учетом весов).
Настройка выполняется с помощью опции least_conn:
YAML
upstream test_backend {
least_conn;
server 192.168.10.10;
server 192.168.10.11;
server 192.168.10.12;
}
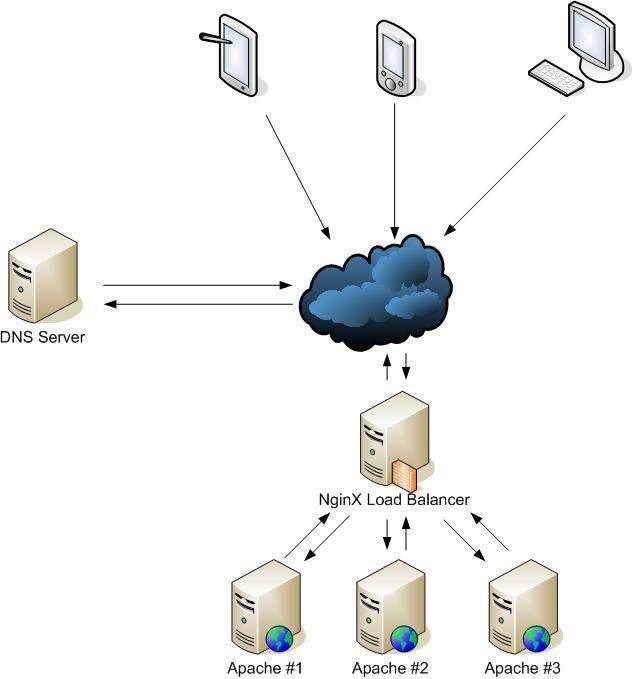
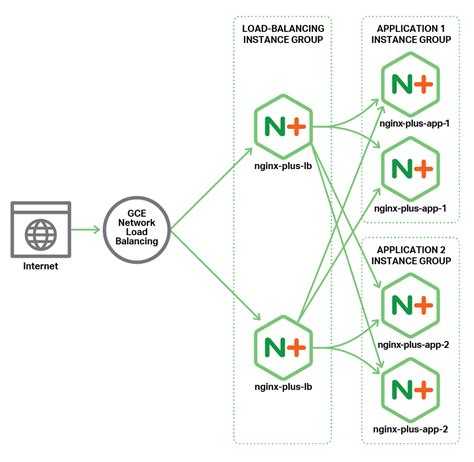
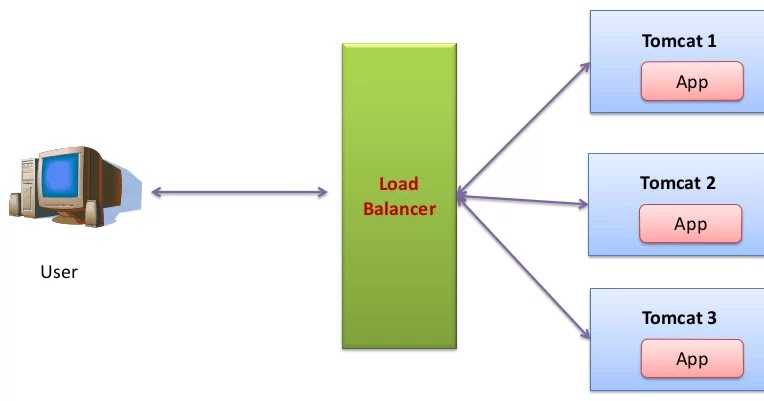
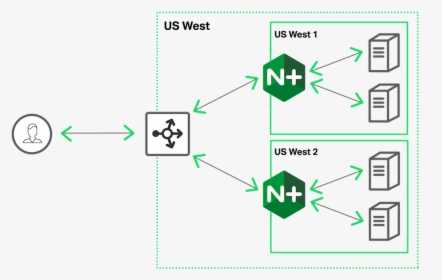
|
1 |
upstreamtest_backend{ least_conn; server192.168.10.10; server192.168.10.11; server192.168.10.12; } |
Random
Запросы передаются случайным образом (но с учетом весов). Дополнительно можно указать опцию two — если она задана, то NGINX сначала выберет 2 сервера случайным образом, затем на основе дополнительных параметров отдаст предпочтение одному из них. Это следующие параметры:
- least_conn — исходя из числа активных подключений.
- least_time=header (только в платной версии) — на основе времени ответа (расчет по заголовку).
- least_time=last_byte (только в платной версии) — на основе времени ответа (расчет по полной отдаче страницы).
Пример настройки:
YAML
upstream test_backend {
random two least_conn;
server 192.168.10.10;
server 192.168.10.11;
server 192.168.10.12;
}
|
1 |
upstreamtest_backend{ randomtwoleast_conn; server192.168.10.10; server192.168.10.11; server192.168.10.12; } |
Least Time
Данная опция будет работать только в NGINX Plus. Балансировка выполняется исходя из времени ответа сервера. Предпочтение отдается тому, кто отвечает быстрее.
Опция для указания данного метода — least_time. Также необходимо указать, что мы считаем ответом — получение заголовка (header) или когда страница возвращается целиком (last_byte).
Пример 1:
YAML
upstream test_backend {
least_time header;
server 192.168.10.10;
server 192.168.10.11;
server 192.168.10.12;
}
|
1 |
upstreamtest_backend{ least_timeheader; server192.168.10.10; server192.168.10.11; server192.168.10.12; } |
* в данном примере мы будем делать расчет исходя из того, как быстро мы получаем в ответ заголовки.
Пример 2:
YAML
upstream test_backend {
least_time last_byte;
server 192.168.10.10;
server 192.168.10.11;
server 192.168.10.12;
}
|
1 |
upstreamtest_backend{ least_timelast_byte; server192.168.10.10; server192.168.10.11; server192.168.10.12; } |
* в данном примере мы будем делать расчет исходя из того, как быстро мы получаем в ответ целую страницу.
Health checks
Это ни в коем случае не дает никаких гарантий.
Health checks: с точки зрения бэкенда
- Проверить готовность к работе всех нижележащих подсистем, от которых зависит работа бэкенда: установлено нужное количество соединений с базой данных, в пуле есть свободные коннекты и т.д., и т.п.
- На Health checks URL можно повесить свою логику, если используемый балансировщик не особо интеллектуальный (допустим, вы берете Load Balancer у хостера). Сервер может запоминать, что «за последнюю минуту я отдал столько-то ошибок — наверное, я какой-нибудь „неправильный“ сервер, и последующие 2 минуты я буду отвечать „пятисоткой“ на Health checks. Таким образом сам себя забаню!» Это иногда очень спасает, когда у вас неконтролируемый Load Balancer.
- Как правило, интервал проверки около секунды, и нужно, чтобы Health check handler не убил ваш сервер. Он должен быть легким.
Health checks: имплементации
- Request;
- Timeout на него;
- Interval, через который мы делаем проверки. У навороченных прокси есть jitter, то есть некая рандомизация для того, чтобы все Health checks не приходили на бэкенд одномоментно, и не убивали его.
- Unhealthy threshold — порог, сколько должно пройти неудачных Health checks, чтобы сервис пометить, как Unhealthy.
- Healthy threshold — наоборот, сколько удачных попыток должно пройти, чтобы сервер вернуть в строй.
- Дополнительная логика. Вы можете разбирать Check status + body и пр.
Envoypanic mode.
Требования
Все команды нужно запускать с правами root или sudo. Подробнее об этом можно прочитать в этом руководстве.
Кроме того, могут оказаться полезными следующие руководства:
- Установка LAMP stack на Ubuntu 14.04
- Установка нескольких SSL-сертификатов на один IP с помощью Nginx
- Балансировка нагрузки Nginx
В целом, стек LAMP не является обязательным, но далее он будет использован в качестве примера.
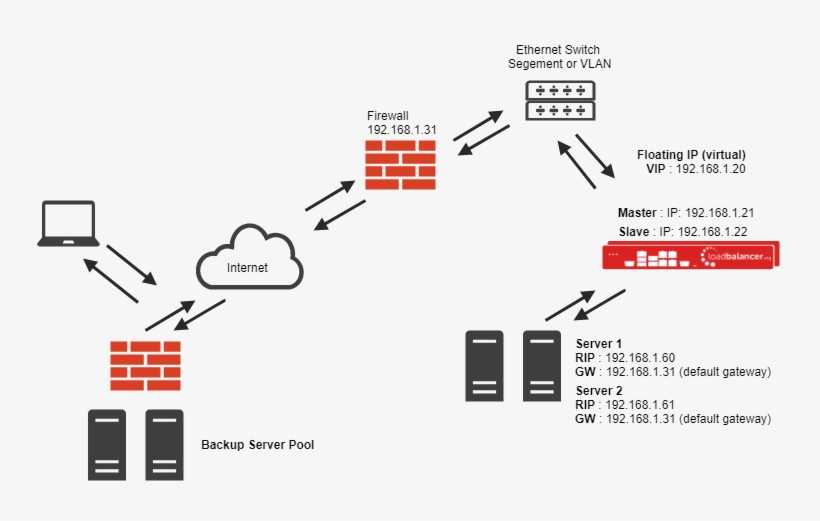
Подготовка серверов
В данном руководстве будет использовано три облачных сервера:
Сервер 1 (фронт-энд)
- Ubuntu 14.04
- Имя хоста: loadbalancer
- IP-адрес: 10.130.227.33
Сервер 2 (бэкэнд)
- Ubuntu 14.04
- Имя хоста: web1
- IP-адрес: 10.130.227.11
Сервер 3 (бэкэнд)
- Ubuntu 14.04
- Имя хоста: web2
- IP-адрес: 10.130.227.22
Условное доменное имя – example.com.
Кроме того, на всех серверах нужно включить поддержку частной сети.
Обновите программы на всех серверах:
Перезапустите каждый сервер, чтобы активировать обновления
Это очень важно, так как для работы понадобится последняя версия OpenSSL
Далее нужно будет создать для домена новый виртуальный хост Nginx с модулем upstream.
Если веб-сервер Nginx не был установлен на облачный сервер ранее, установите его при помощи команды:
На серверах бэкэнда обновите репозитории и установите Apache:
Также на эти серверы нужно установить PHP:
Примечание: Более подробную информацию по установке этих программ можно найти здесь.
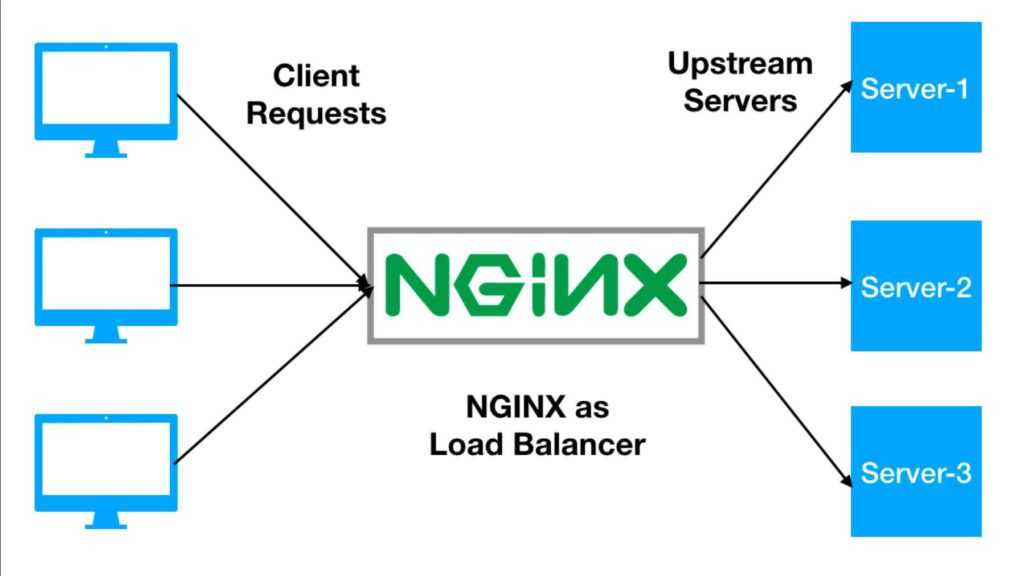
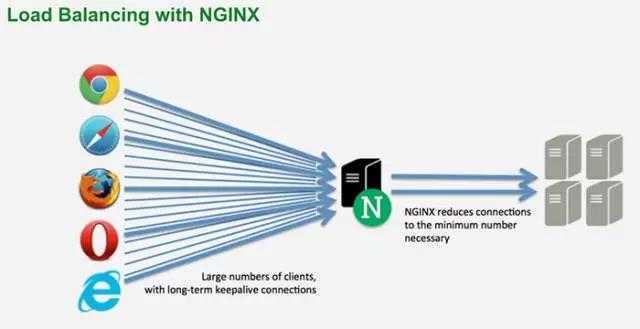
Advantages of load balancing
Load balancing is an excellent way to scale out your application and increase its performance and redundancy. Nginx, a popular web server software, can be configured as a simple yet powerful load balancer to improve your servers resource availability and efficiency.


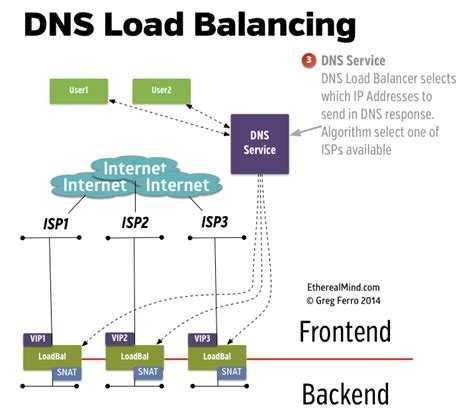
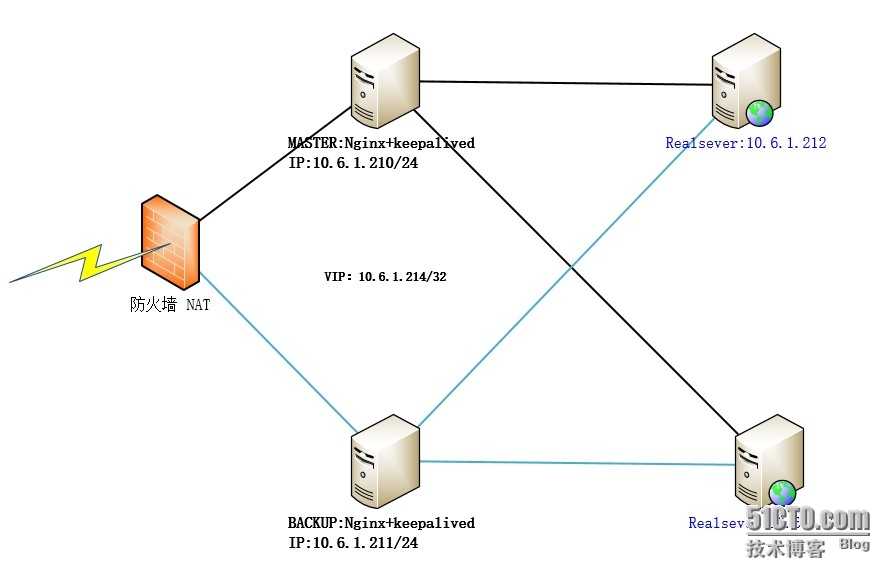
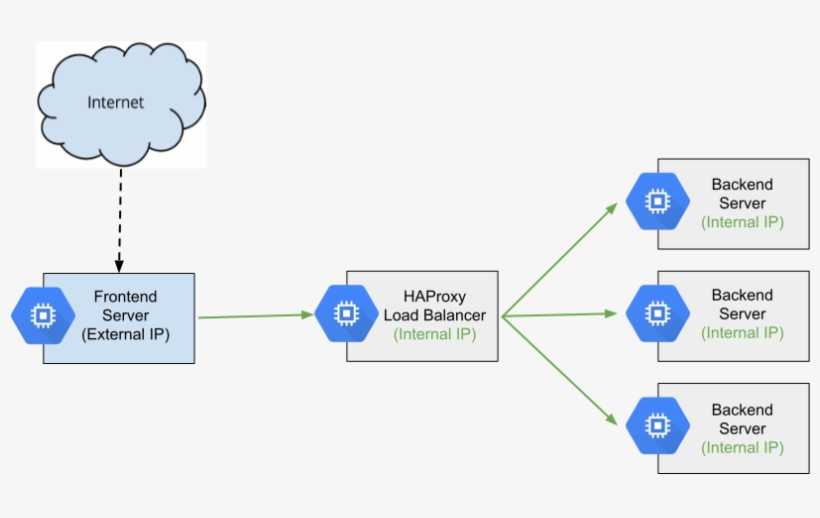
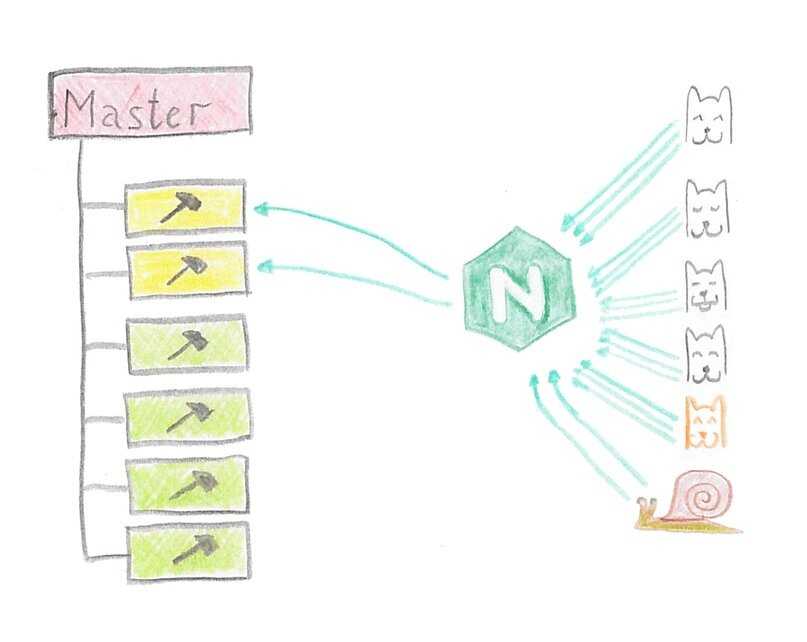
How does Nginx work? Nginx acts as a single entry point to a distributed web application working on multiple separate servers.
This guide describes the advantages of load balancing. Learn how to set up load balancing with nginx for your cloud servers.
As a prerequisite, you’ll need to have at least two hosts with a web server software installed and configured to see the benefit of the load balancer. If you already have one web host set up, duplicate it by creating a custom image and deploy it onto a new server at your UpCloud control panel.
Proxying HTTP Traffic to a Group of Servers
To start using NGINX Plus or NGINX Open Source to load balance HTTP traffic to a group of servers, first you need to define the group with the
directive. The directive is placed in the
context.
Servers in the group are configured using the [https://nginx.org/en/docs/http/ngx_http_upstream_module.html#server) directive (not to be confused with the block that defines a virtual server running on NGINX). For example, the following configuration defines a group named backend and consists of three server configurations (which may resolve in more than three actual servers):
To pass requests to a server group, the name of the group is specified in the
directive (or the
,
,
, or
directives for those protocols.) In the next example, a virtual server running on NGINX passes all requests to the backend upstream group defined in the previous example:
The following example combines the two snippets above and shows how to proxy HTTP requests to the backend server group. The group consists of three servers, two of them running instances of the same application while the third is a backup server. Because no load‑balancing algorithm is specified in the block, NGINX uses the default algorithm, Round Robin:
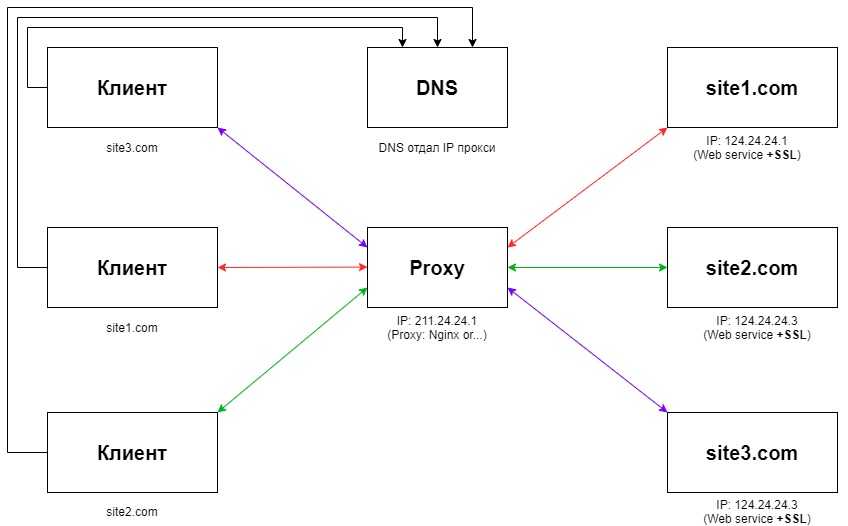
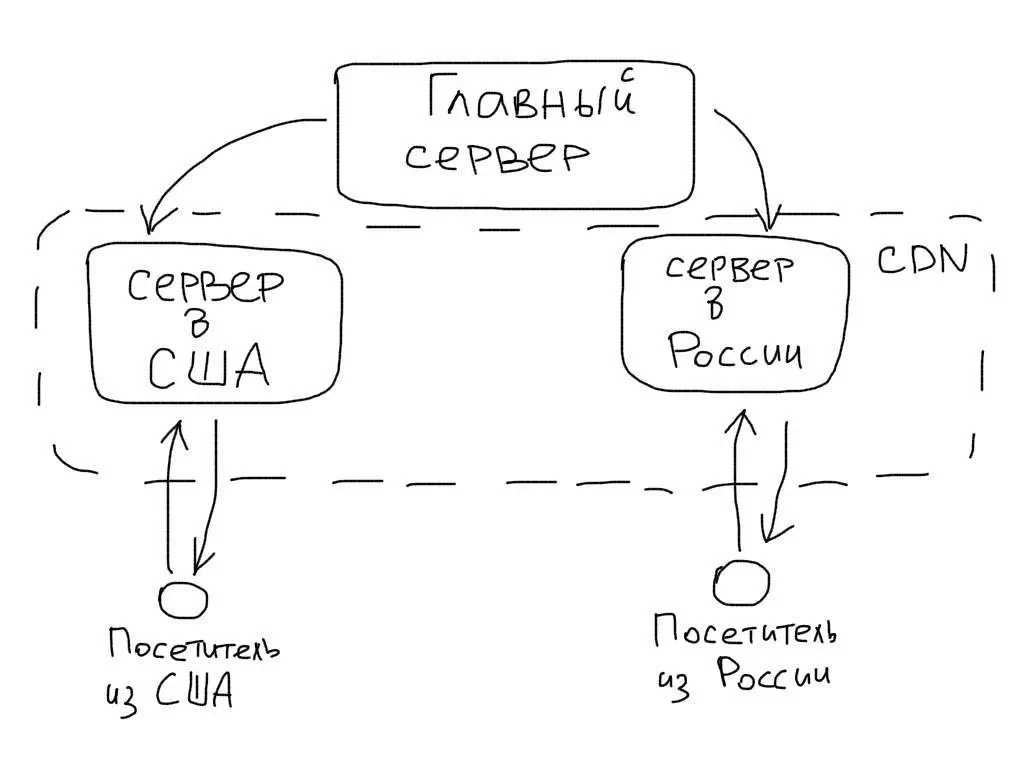
Балансировка нагрузки Nginx
Балансировка нагрузки Nginx означает, что когда прокси-сервер разрешает настраиваемое доменное имя для нескольких указанных IP-адресов, восходящий поток используется для обеспечения того, чтобы пользователи могли нормально обращаться к каждому IP-адресу через прокси-сервер.
тестирование
После агента
После использования прокси он будет преобразован в IP-адрес, указанный прокси-сервером.
нота:Nginx не поддерживает https прокси, только http прокси, новая версия Nginx может прокси tcp.
Если команда недоступна на сервере, установите ее вручную:
грамматика:Dig
HTTP протокол передачи гипертекста (HyperText Transfer Protocol) является наиболее широко используемым сетевым протоколом в Интернете.HTTPS (полное название: протокол передачи гипертекста по протоколу Secure Socket Layer) — это канал HTTP, предназначенный для обеспечения безопасности, иными словами, это защищенная версия HTTP. Протокол HTTPS — это сетевой протокол, построенный по протоколу SSL + HTTP, который может выполнять зашифрованную передачу и аутентификацию личности, чем протокол HTTP.Номер порта по умолчанию для HTTP — 80, а номер порта для HTTPS — 443.TCP (протокол управления передачей) — это ориентированный на соединение, надежный и основанный на байтах протокол связи транспортного уровня, определенный в RFC 793 IETF. Слушайте порт 80 по умолчанию.
Тестирование конфигурации
Теперь пора проверить, правильно ли работает наша установка. Введите IP-адрес системы балансировки нагрузки в веб-браузере (в нашем случае это 10.0.12.10) и постоянно обновляйте страницу 2–4 раза, чтобы убедиться, что балансировщик нагрузки HAProxy работает правильно. Вы должны увидеть разные IP-адреса или любой текст, который вы ввели в файл index.html, когда продолжите обновлять страницу несколько раз.
Другой способ проверки – отключить один веб-сервер и проверить, обслуживает ли другой веб-сервер запросы.
На этом пока все! Попробуйте поэкспериментировать с HAProxy, чтобы узнать больше о том, как он работает. Например, вы можете попробовать:
- Интеграция другого веб-сервера рядом с nginx.
- Изменение алгоритма балансировки нагрузки на другой, кроме циклического.
- Настройка проверки работоспособности HAProxy, чтобы определить, работает ли внутренний сервер.
- Применение липких сеансов для подключения пользователя к одному и тому же внутреннему серверу.
- Использование статистики HAProxy для получения информации о трафике на серверах.
HAProxy имеет обширную документацию, доступную как для версии сообщества HAProxy, так и для версии HAProxy для предприятий . Изучите эту документацию, чтобы получить больше информации о повышении производительности и надежности вашей серверной среды.
Это руководство было успешно выполнено в Debian 10 (Buster). Попробуйте установить HAProxy на другие дистрибутивы на основе Debian, такие как Ubuntu, Linux Mint и т. д. Пожалуйста, не забудьте поделиться этим руководством с другими.
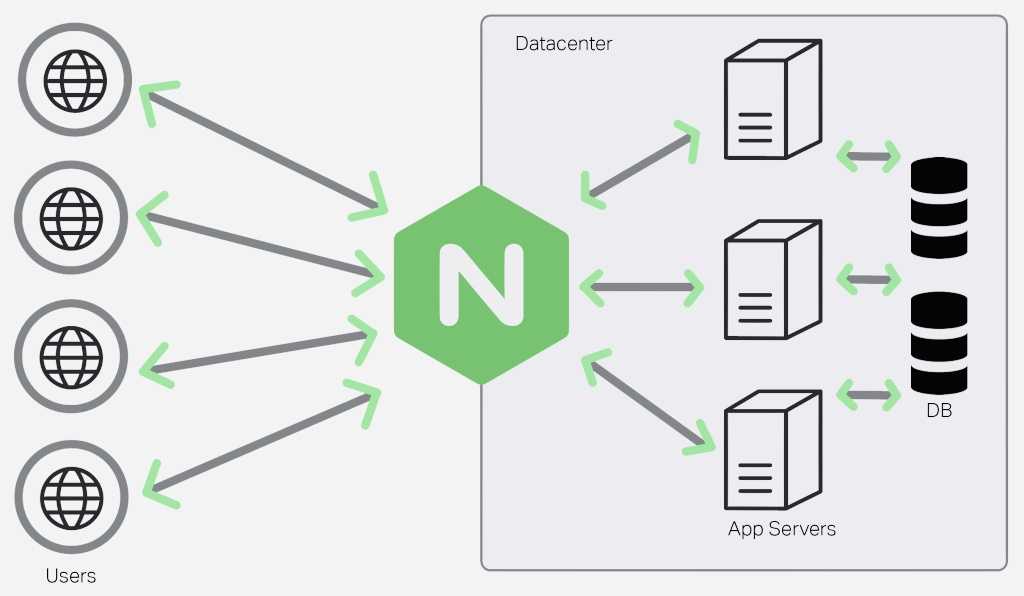
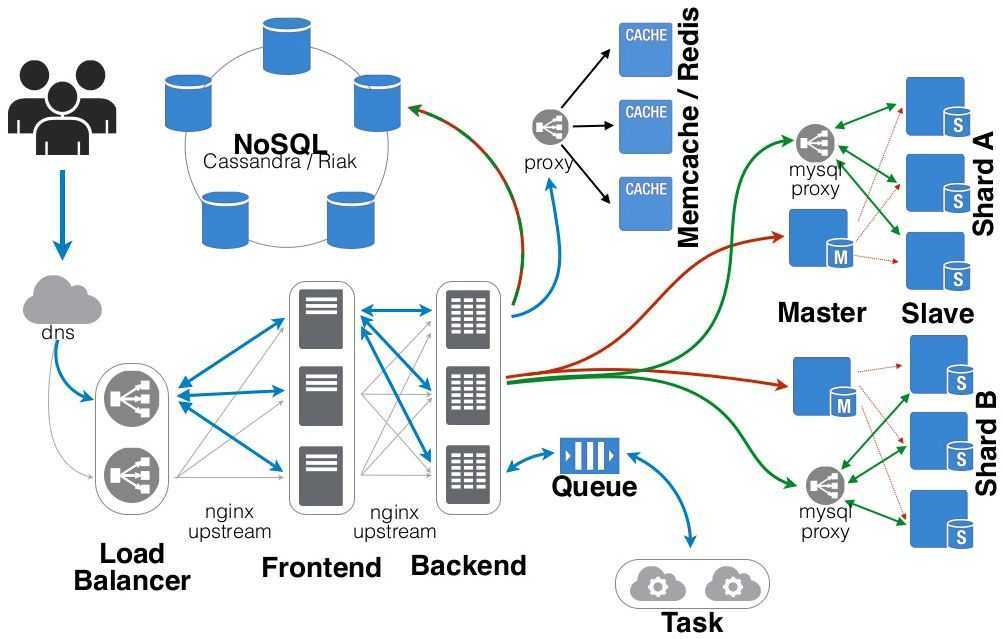
Как работает балансировка нагрузки NGINX
Основной принцип балансировки нагрузки заключается в том, что он находится между пользователем и набором серверов и передает запросы на них. Обычно это делается с двумя или более серверами, чтобы трафик было легче распределить между ними.
Большая часть конфигурации происходит в том, как NGINX выбирает сервер для маршрутизации. По умолчанию используется циклический перебор, который будет отправлять запросы на каждый сервер по порядку, обеспечивая равномерное распределение нагрузки.
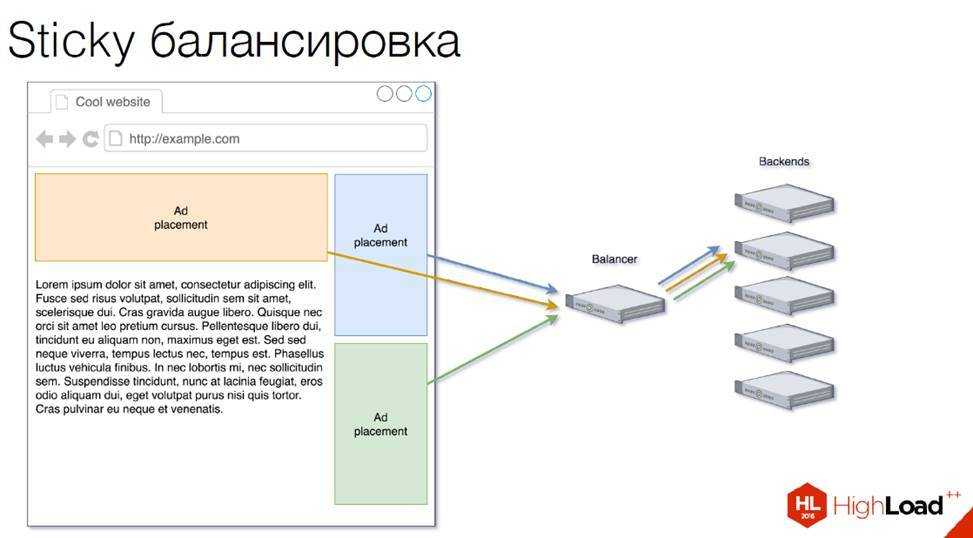
Однако это не всегда так просто. Многие веб-приложения требуют некоторой формы постоянство сеансаЭто означает, что пользователь должен обращаться к одному и тому же серверу в течение всего сеанса. Например, корзина покупок может храниться локально на одном сервере приложений, и если пользователь переключает серверы в середине сеанса, приложение может отключиться. Конечно, многие из этих сценариев могут быть исправлены с помощью лучшей инфраструктуры приложений и централизованных хранилищ данных, но многим людям требуется постоянство сеансов.
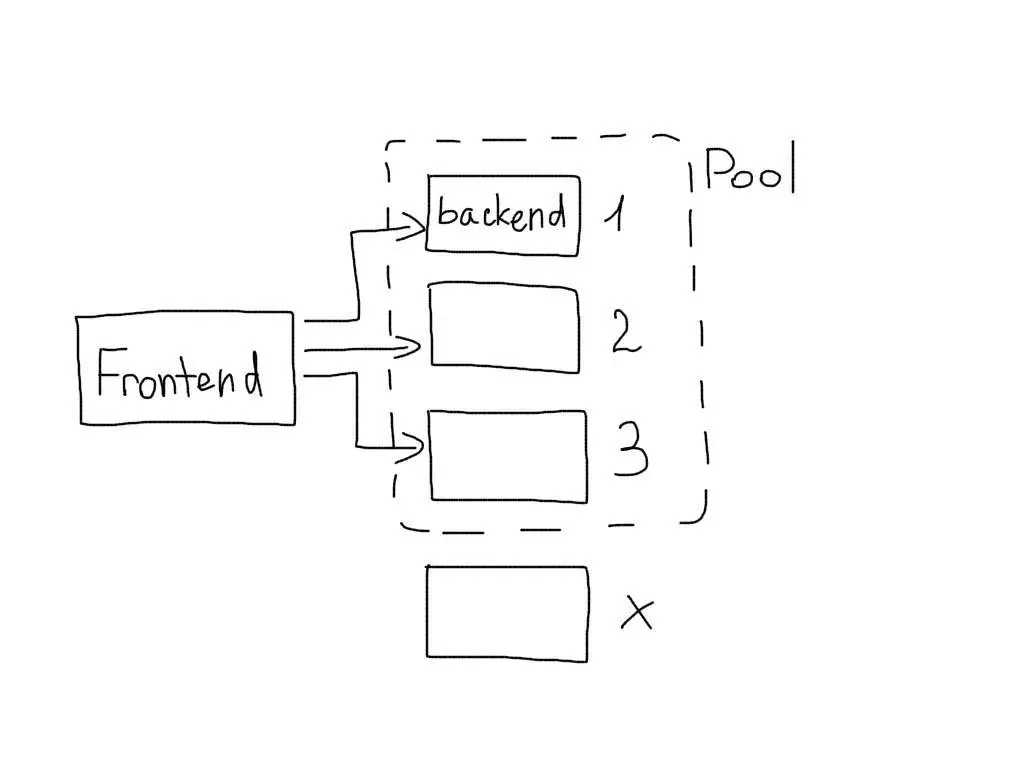
В NGINX набор серверов, на которые вы маршрутизируете, называется вверх по течениюи настроен как перечисляемый список адресов:
upstream backend {
server backend1.example.com weight=5;
server backend2.example.com;
}
Эти вверх по течению есть много вариантов; здесь мы установили вес, который будет отдавать приоритет этому серверу чаще (особенно полезно, если у вас разные размеры). Вы также можете установить максимальное количество подключений и различные таймауты. Если вы используете NGINX PlusВы также можете настроить проверку работоспособности, чтобы соединения не перенаправлялись на нездоровые серверы.
Самая основная форма сохранения сеанса — использование хэша IP. NGINX будет использовать IP для идентификации пользователей, а затем убедиться, что эти пользователи не переключают серверы в середине сеанса:
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
}
IP-хеш требуется для приложений на основе сокетов и всего, что требует постоянного хранения. Если вы не хотите использовать IP-адрес, вы можете настроить этот хеш:
upstream backend {
hash $scheme$request_uri consistent;
server backend1.example.com;
server backend2.example.com;
}
Если вам не нужен какой-либо тип сохранения сеанса, вы можете сделать циклический выбор немного более разумным, выбрав, какой сервер имеет наименьшее количество подключений:
upstream backend {
least_conn;
server backend1.example.com;
server backend2.example.com;
}
Или, в зависимости от того, какой из них в данный момент отвечает быстрее всего:
upstream backend {
least_time (header | last_byte);
server backend1.example.com;
server backend2.example.com;
}
, но IP-хеширование будет работать для большинства приложений.
Retries
Пользовательский запрос — святое, расшибись, но ответь
Мы хотим любой ценой ответить пользователю, пользователь — самое важное.
Лучше ответить ошибкой, чем перегруз серверов.
Целостность данных (при неидемпотентных запросах), то есть нельзя повторять определенные типы запросов.. Истина, как обычно, где-то между — Transport error
Истина, как обычно, где-то между — Transport error
- nginx: errors + timeout (proxy_connect_timeout);
- HAProxy: timeout connect;
- Envoy: connect-failure + refused-stream.
Request timeout:
- У nginx есть: timeout (prox_send_timeout* + proxy_read_timeout*);
- У HAProxy — OOPS
 — его в принципе нет. Многие не знают, что HAProxy, если успешно установил соединение, никогда не будет пробовать повторно послать запрос.
— его в принципе нет. Многие не знают, что HAProxy, если успешно установил соединение, никогда не будет пробовать повторно послать запрос. - Envoy все умеет: timeout || per_try_timeout.
 — его в принципе нет. Многие не знают, что HAProxy, если успешно установил соединение, никогда не будет пробовать повторно послать запрос.
— его в принципе нет. Многие не знают, что HAProxy, если успешно установил соединение, никогда не будет пробовать повторно послать запрос.HTTP status
- nginx: http_*
-
HAProxy: OOPS
- Envoy: 5xx, gateway-error (502, 503, 504), retriable-4xx (409)
Таймауты
Request timeout
характеристика группы запросовнет таймаута на весь запрос.
- proxy_send_timeout: время между двумя успешными операциями записи write();
- proxy_read_timeout: время между двумя успешными операциями чтения read().
Выбираем request timeout
- Если мы хотим обработать отказ одного единственного сервера, то таймаут должен быть меньше максимального допустимого времени ожидания: request_timeout < max.
- Если вы хотите иметь 2 гарантированные попытки отправки запроса на два разных бэкенда, то таймаут на одну попытку равен половине этого допустимого интервала: per_try_timeout = 0.5 * max.
- Есть также промежуточный вариант — 2 оптимистичные попытки на случай если первый бэкенд «притупил», но второй при этом ответит быстро: per_try_timeout = k * max (где k > 0.5).
выбрать таймаут — это сложно
- Появляется paging в тех местах, где невозможно за timeout отдать все данные целикомю.
- Админка/отчеты отделяются в отдельную группу урлов для того, чтобы поднять для них timeout, а да пользовательских запросов, наоборот понизить.
- Чиним/оптимизируем те запросы, которые не укладываются в наш таймаут.
.
- Если есть ошибки, все плохо, это нужно чинить.
- Если ошибок нет, мы укладываемся в нужное время ответа, значит все хорошо.
Retries: нужно ограничивать
в большинстве (99.9%) сервисов баз данных нет request cancellationNginx:
- proxy_next_upstream_timeout (global)
- proxt_read_timeout** в качестве per_try_timeout
- proxy_next_upstream_tries
Envoy:
- timeout (global)
- per_try_timeout
- num_retries
Envoy
Retries: применяем
два
Что произошло?
- proxy_next_upstream_tries = 2.
- В случае, когда вы первую попытку делаете на «мертвый» сервер, и вторую — на другой «мертвый», то получаете HTTP-503 в случае обеих попыток на «плохие» серверы.
- Ошибок мало, так как nginx «банит» плохой сервер. То есть если в nginx от бэкенда вернулось сколько-то ошибок, он перестает делать следующие попытки отправить на него запрос. Это регулируется переменной fail_timeout.
Что с этим делать?health checks.
Load Balancing of Microsoft Exchange Servers
In and later, NGINX Plus can proxy Microsoft Exchange traffic to a server or a group of servers and load balance it.
To set up load balancing of Microsoft Exchange servers:
-
In a block, configure proxying to the upstream group of Microsoft Exchange servers with the
directive: -
In order for Microsoft Exchange connections to pass to the upstream servers, in the block set the
directive value to , and the
directive to , just like for a keepalive connection: -
In the block, configure a upstream group of Microsoft Exchange servers with an
block named the same as the upstream group specified with the
directive in Step 1. Then specify the
directive to allow the servers in the group to accept requests with NTLM authentication: -
Add Microsoft Exchange servers to the upstream group and optionally specify a
:
Complete NTLM Example
For more information about configuring Microsoft Exchange and NGINX Plus, see the Load Balancing Microsoft Exchange Servers with NGINX Plus
deployment guide.
Тонкая настройка балансировки нагрузки +47
- 13.09.18 01:03
•
olegbunin
•
#423085
•
Хабрахабр
•
•
4600
Системное администрирование, Блог компании Конференции Олега Бунина (Онтико), Высокая производительность, Nginx, Блог компании okmeter.io

В этой статье речь пойдет о балансировке нагрузки в веб-проектах. Многие считают, что решение этой задачи в распределении нагрузки между серверами — чем точнее, тем лучше. Но мы же знаем, что это не совсем так. Стабильность работы системы куда важнее в сточки зрения бизнеса.
Маленький минутрый пик в 84 RPS «пятисоток» — это пять тысяч ошибок, которые получили реальные пользователи
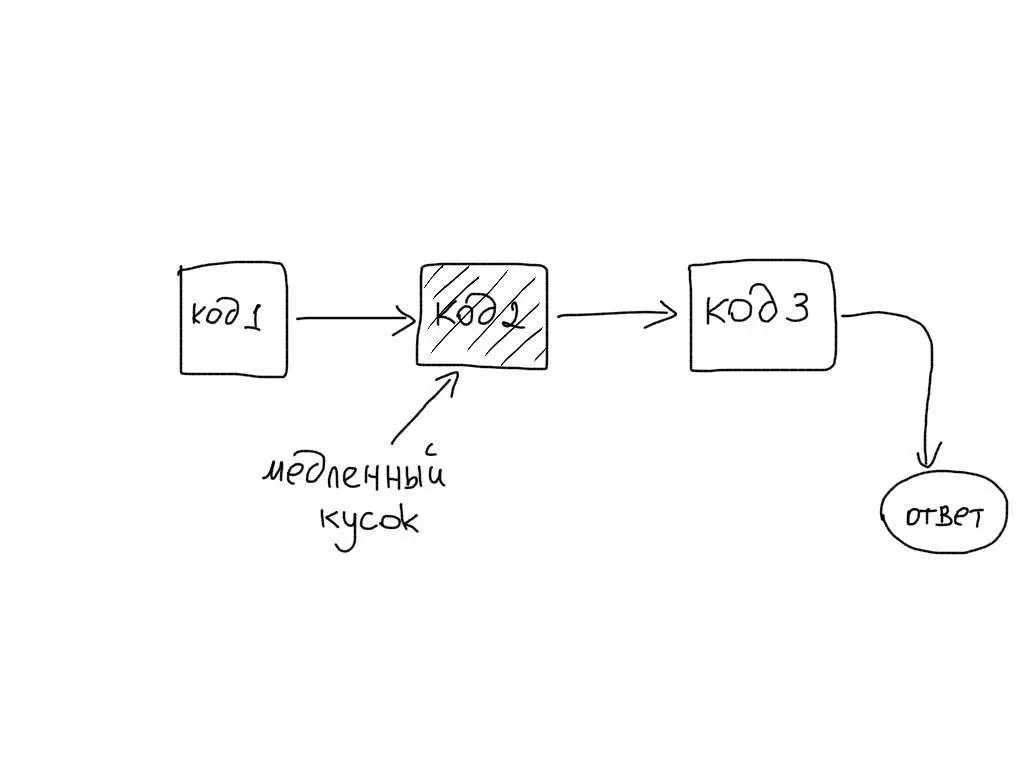

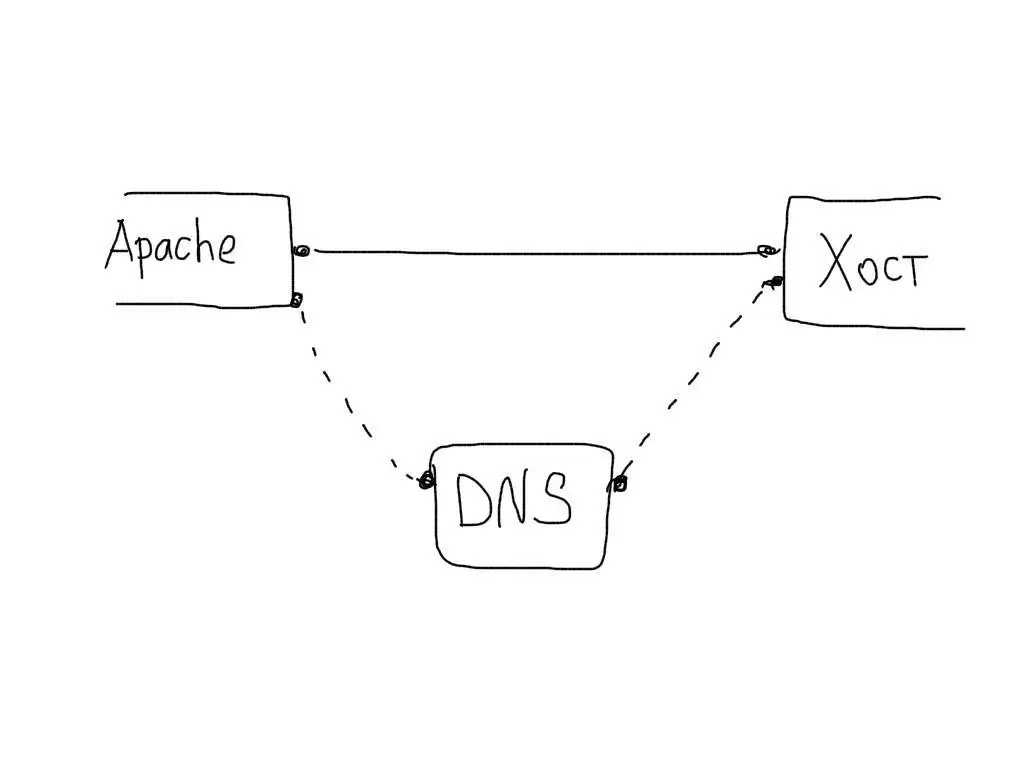
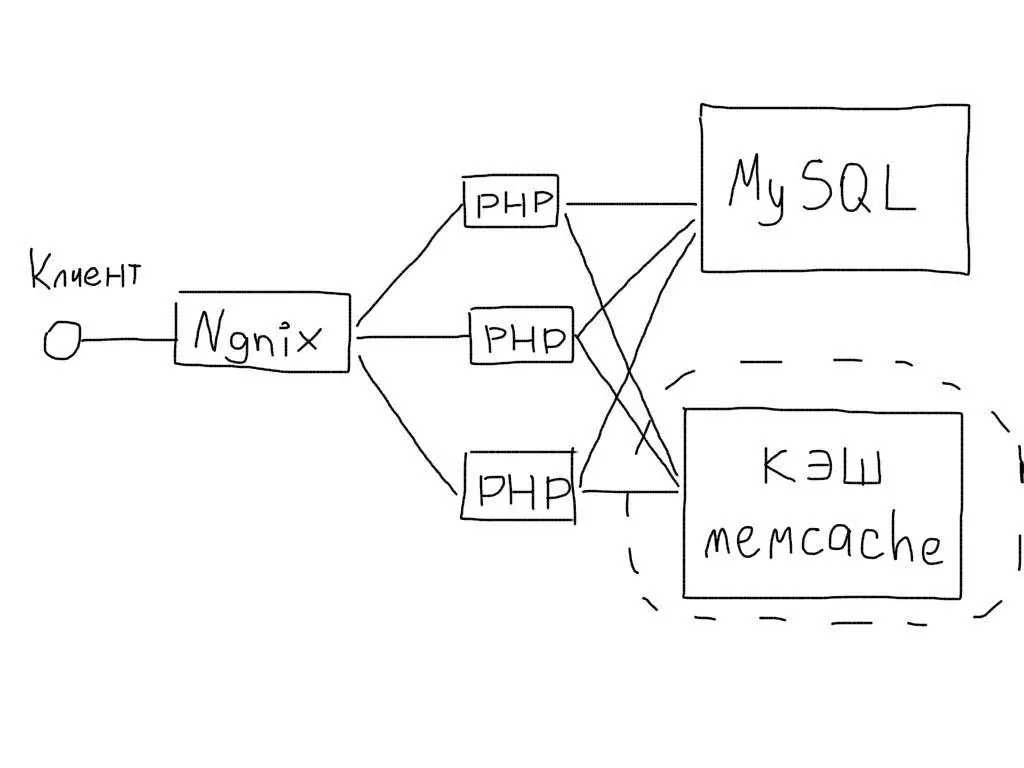
Это много и это очень важно. Необходимо искать причины, проводить работу над ошибками и стараться впредь не допускать подобных ситуаций.Николай Сивко (NikolaySivko) в своем докладе на RootConf 2018 рассказал о тонких и пока не очень популярных аспектах балансировки нагрузки:
- когда повторять запрос (retries);
- как выбрать значения для таймаутов;
- как не убить нижележащие серверы в момент аварии/перегрузки;
- нужны ли health checks;
- как обрабатывать «мерцающие» проблемы.
https://youtube.com/watch?v=2-j2ADWFkkE
О спикере:
Заключение
Мне не приходилось пробовать в деле никаких других балансировщиков, кроме Nginx. Знаю, что есть haproxy, но попробовать так и не дошли руки. Бесплатная версия nginx очень слабо подходит для полноценной балансировки крупного проекта, либо я просто не понимаю, как его правильно использовать. Реально не хватает тех фич, которые есть в Nginx Plus. До того момента, как не начал использовать балансировщик, не понимал толком, что там такого в платной версии. Теперь прекрасно понимаю 
Готовые примеры балансировки с использованием фич Nginx Plus приведены в этой статье
Так же обращаю внимание на формат логов, который для удобства стоит подправить под использование бэкендов. Этот вопрос я рассмотрел отдельно в статье про мониторинг производительности бэкендов с помощью elk stack
Буду рад любым комментариям, ссылкам, советам по существу затронутой темы. Я в ней новичок. Ни на что не претендую, поделился своим опытом.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .