
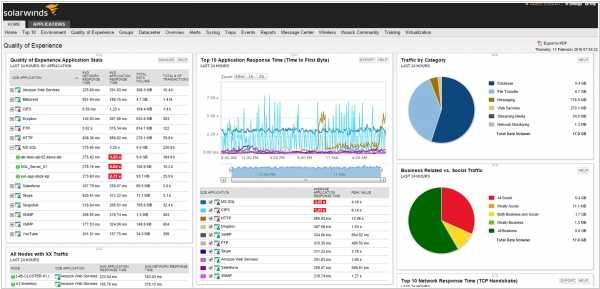
Общая информация
- Низкие требования к системным ресурсам. Для нормальной работы Fluentd вполне достаточно 30 — 40 Мб оперативной памяти; скорость обработки при этом составляет 13 000 событий в секунду.
- Использование унифицированного формата логгирования. Данные, полученные из разных источников, Fluentd переводит в формат JSON. Это помогает решить проблему сбора логов из различных систем и открывает широкие возможности для интеграции с другими программными решениями.
- Удобная архитектура. Архитектура Fluentd позволяет расширять имеющийся набор функций с помощью многочисленных плагинов (на сегодняшний день их создано более 300). С помощью плагинов можно подключать новые источники данных и выводить данные в различных форматах.
- Возможность интеграции с различными языками программирования. Fluentd может принимать логи из приложений на Python, Ruby, PHP, Perl, Node.JS, Java, Scala.
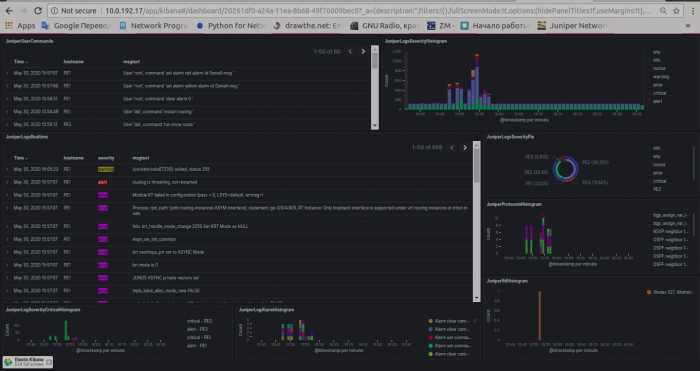
Смотрим полученные данные в Kibana
Открываем Kibana, в верхнем левом углу нажимаем меню и в секции выбираем . Далее слева выбираем и нажимаем кнопку . В поле описываем шаблон , в который попадут все индексы, начинающиеся с logstash.
Создание шаблона индекса
Жмем и выбираем поле , чтобы иметь возможность фильтровать данные по дате и времени. После жмем :
Выбор Time field
После создания шаблона индексов Kibana покажет информацию об имеющихся полях, типе данных и возможности делать агрегацию по этим полям.
Чтобы посмотреть полученные данные на основе созданного шаблона нажимаем меню и в секции выбираем .
Kibana Discover
В правой части экрана можно выбрать интервал в рамках которого отображать данные.
Выбор временного интервала
В левой часте экрана можно выбрать шаблон индекса или поля для отображения из списка . При нажатии на доступные поля можно получить топ-5 значений.
Шаблон индекса и доступные поля
Для фильтрации данных можно использовать . Запрос пишется в поле . Запросы можно сохранять, чтобы использовать их в будущем.
Фильтрация данных с помощью KQL
Для визуализации полученных данных нажимаем меню и в секции выбираем . Нажав , откроется окно с перечнем доступных типов визуализации.
Типы визуализации Kibana
Для примера выбираем , чтобы построить круговую диаграмму. В качестве источника данных выбираем шаблон индексов . В правой части в секции жмем , далее — . Тип агрегации выбираем , поле . Жмем в правом нижнем углу и получаем готовую диаграмму. В секции можно добавить отображение данных или изменить вид диаграммы.
Круговая диаграмма
Чтобы посмотреть данные в Elasticsearch необходимо сделать запрос к любому узлу кластера. Добавление параметра позволяет отобразить данные в читабельном виде. По умолчанию вывод состоит из 10 записей, чтобы увеличить это количество необходимо использовать параметр :
Заключение
В рамках этой статьи была рассмотрена процедура установки и настройки Kibana и Logstash, настройка балансировки трафика между Kibana и Elasticsearch и работа нескольких экземпляров Kibana. Собрали первые данные с помощью Logstash, посмотрели на данные с помощью и построили первую визуализацию.
Прежде чем углубляться в изучение плагинов Logstash, сбор данных с помощью Beats, визуализацию и анализ данных в Kibana, необходимо уделить внимание очень важному вопросу безопасности кластера. Об этом также постоянно намекает Kibana, выдавая сообщение
Теме безопасности будет посвящена следующая статья данного цикла.
Делаем важные настройки
Для нормальной работы кластера необходимо произвести еще некоторые настройки.
Heap size
Так как Elasticsearch написан на Java, то для работы необходимо настроить размер «кучи» (). В каталоге установки Elasticsearch имеется файл , в котором уже указаны размеры, по умолчанию — это 1 Гб. Однако, для настройки рекомендуется указать новые параметры в файле каталога , который находится там же.
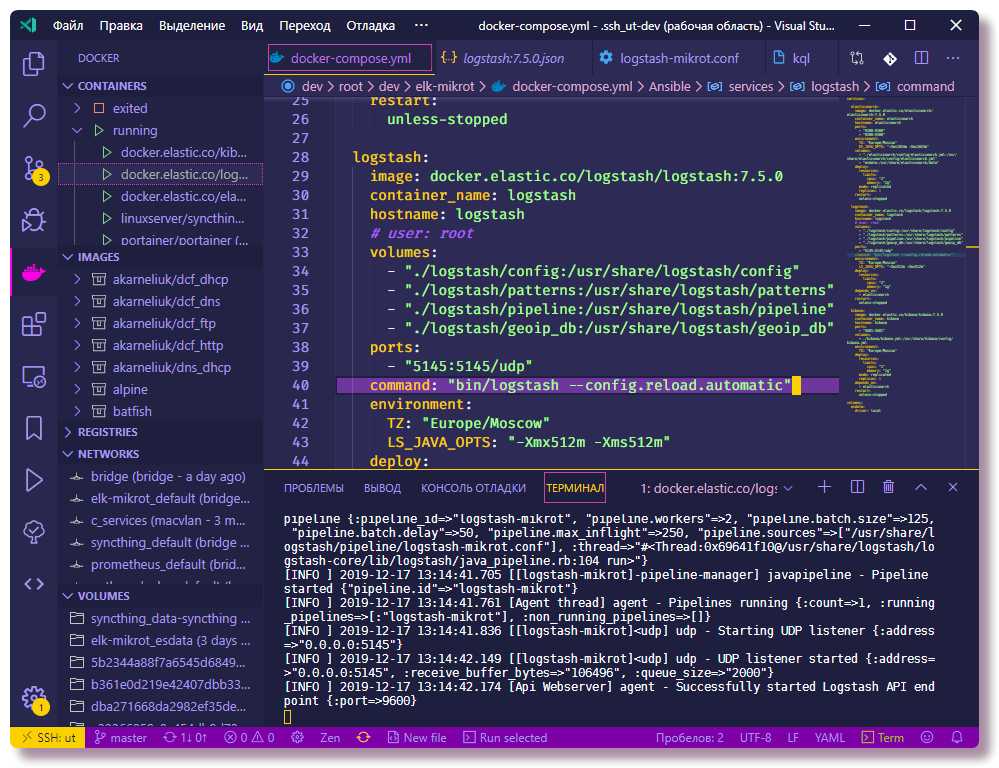
Пример выше использует минимальный и максимальный размер , равный 16 Гб. Для настройки данных параметров следует использовать следующие рекомендации:
-
установите значения и не более 50% от имеющейся физической памяти узла. Оставшуюся память Elasticsearch будет использовать для других целей. Чем больше , тем меньше памяти используется под системные кеш;
-
устанавите значение не более того значения, которое использует для сжатия указателей, он же . Данное значение составляет около 32 Гб. Стоит также отметить, что рекомендуется ограничивать еще одним параметром , а именно (обычно размер около 26 Гб). Узнать подробнее об этих параметрах можно тут.
Отключаем подкачку
Подкачка негативно сказывается на производительности и стабильности работы Elasticsearch, ведь система может выгрузить страницы на диск. Есть несколько вариантов работы с подкачкой:
-
Полное отключение подкачки. Перезапуск Elasticseach при этом не требуется.
-
Ограничение подкачки через значение для .
-
Использование для блокировки адресного пространства в оперативной памяти.
Чтобы включить в конфигурации Elasticseach указываем для параметра значение .
Перезапускаем Elasticsearch и проверяем настройки через запрос к любому узлу:
Если перезапуск Elasticsearch завершился ошибкой вида:
или проверка показывает, что данная настройка не применилась, необходимо сделать следующее в зависимости от способа установки:
Установка из архива
Установите перед запуском Elasticsearch или значению устанвоите в файле .
Установка из пакета RPM или Deb
Установите значение параметра как в для или для .
Если вы используете для запуска Elasticsearch, то лимиты должны быть указаны через настройку параметра . Для этого выполните команду:
и укажите следующее значение:
Настройка файловых дескрипторов
Elasticsearch работает с большим количеством файловых дескрипторов, и их нехватка может катастрофически сказаться на его работе. Согласно официальной документации необходимо указать значение файловых дескрипторов не ниже 65 536.
-
Если Elasticsearch установлен из или пакетов, то настройка не требуется.
-
Для установки из архива необходимо в файле установить параметр для пользователя, который осуществляет запуск Elasticsearch. В примере ниже таким пользователем является :
Проверить установленные значения можно следующим образом:
Настройка виртуальной памяти
Elasticsearch по умолчанию использует каталог для хранения индексов, и ограничение операционной системы по умолчанию для счетчиков может привести к нехватки памяти. Для настройки запустите из-под следующую команду:
Чтобы настройка сохранилась после перезапуска системы, необходимо указать параметр в файле .
Если Elasticsearch установлен из или пакетов, то настройка не требуется.
Настройка потоков
Необходимо убедиться, что количество потоков, которые Elasticsearch может создавать, было не менее 4096.
Это можно сделать, установив или установив значение равным 4096 в файле .
Если Elasticsearch работает под управлением , то настройка не требуется.
DNS кеширование
По умолчанию Elasticsearch кеширует результат DNS на 60 и 10 секунд для положительных и отрицательных запросов. В случае необходимости можно настроить эти параметры, а именно и , как опции в каталоге для и или в для установки из архива.
Обработка сообщений
- Все сообщения приходят из Input (их может быть много) и попадают на обработку в привязанный к нему RuleSet. Если это явно не задано, то сообщения попадут в RuleSet по-умолчанию. Все директивы обработки сообщений, не вынесенные в отдельные RuleSet-блоки, относятся именно к нему. В частности, к нему относятся все директивы из традиционного формата конфигов:
- к Input привязан список парсеров для разбора сообщения. Если явно не задано, будет использоваться список парсеров для разбора традиционного формата syslog
- Парсер выделяет из сообщения свойства. Самые используемые:
- — сообщение
- — сообщение целиком до обработки парсером
- , — DNS имя и IP адрес хоста-отправителя
- , — facility в числовой и текстовой форме
- , — то же для severity
- — время из сообщения
- — поле TAG
- — поле TAG с отрезанным id процесса: ->
- весь список можно посмотреть тут
- RuleSet содержит список правил, правило состоит из фильтра и привязанных к нему одного или нескольких Actions
- Фильтры — логические выражения, с использованием свойств сообщения. Подробнее про фильтры
- Правила применяются последовательно к сообщению, попавшему в RuleSet, на первом сработавшем правиле сообщение не останавливается
- Чтобы остановить обработку сообщения, можно использовать специальное discard action: или в легаси-формате.
- Внутри Action часто используются шаблоны. Шаблоны позволяют генерировать данные для передачи в Action из свойств сообщения, например, формат сообщения для передачи по сети или имя файла для записи. Подробнее про шаблоны
- Как правило, Action использует модуль вывода(«om…») или модуль изменения сообщения(«mm…»). Вот некоторые из них:
- omfile — вывод в файл
- omfwd — пересылка по сети, через udp или tcp
- omrelp — пересылка по сети по протоколу RELP
- onmysql, ompgsql, omoracle — запись в базу
- omelasticsearch — запись в ElasticSearch
- omamqp1 — пересылка по протоколу AMQP 1.0
- весь список модулей вывода
→
Установка Elasticsearch
Копируем себе публичный ключ репозитория:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | apt-key add -
Если у вас нет пакета apt-transport-https, то надо установить:
# apt install apt-transport-https
Добавляем репозиторий Elasticsearch в систему:
# echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-6.x.list
Устанавливаем Elasticsearch на Debian или Ubuntu:
apt update apt-get install elasticsearch
После установки добавляем elasticsearch в автозагрузку и запускаем.
systemctl daemon-reload systemctl enable elasticsearch.service systemctl start elasticsearch.service
Проверяем, состояние сервиса:
systemctl status elasticsearch.service
Если сервис запущен, тогда переходим к настройке Elasticsearch.
Установка Elasticsearch
Устанавливаем ядро системы по сбору логов — Elasticsearch. Его установка очень проста за счет готовых пакетов под все популярные платформы.
Centos 7 / 8
Копируем публичный ключ репозитория:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Подключаем репозиторий Elasticsearch:
# mcedit /etc/yum.repos.d/elasticsearch.repo
name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md
Приступаем к установке еластика:
# yum install --enablerepo=elasticsearch elasticsearch
В в завершении установки добавим elasticsearch в автозагрузку и запустим его с дефолтными настройками:
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустилась ли служба:
# systemctl status elasticsearch.service
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос о его статусе.
# curl 127.0.0.1:9200
{
"name" : "centos8",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "zsYgZQSeT6uvhTCkFJPiAA",
"version" : {
"number" : "7.11.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "8ced7813d6f16d2ef30792e2fcde3e755795ee04",
"build_date" : "2021-02-08T22:44:01.320463Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Все в порядке, сервис реально запущен и отвечает на запросы.
Ubuntu / Debian
Копируем себе публичный ключ репозитория:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Если у вас нет пакета apt-transport-https, то надо установить:
# apt install apt-transport-https
Добавляем репозиторий Elasticsearch в систему:
# echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
Устанавливаем Elasticsearch на Debian или Ubuntu:
# apt update && apt install elasticsearch
После установки добавляем elasticsearch в автозагрузку и запускаем.
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустился ли он:
# systemctl status elasticsearch.service
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос о его статусе.
# curl 127.0.0.1:9200
{
"name" : "debioan10",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "zsYgZQSeY6uvhWCkFJPiAA",
"version" : {
"number" : "7.11.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "8ced7813d6f16d2ef30792e2fcde3e755795ee04",
"build_date" : "2021-02-09T21:44:01.320413Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Если все в порядке, то переходим к настройке Elasticsearch.
Сlickhouse
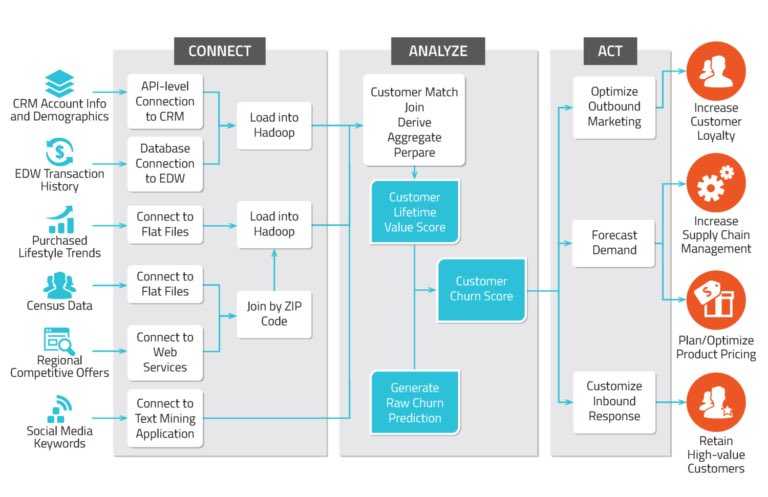
Изначально выбор пал на InfluxDB. Мы осознавали необходимость сбора логов Nginx, статистики из pg_stat_statements, хранения исторических данных Prometheus. Influx нам не понравился, так как он периодически начинал потреблять большое количество памяти и падал. Кроме того, хотелось группировать запросы по remote_addr, а группировка в этой СУБД только по тэгам. Тэги дороги (память), их количество условно ограничено.
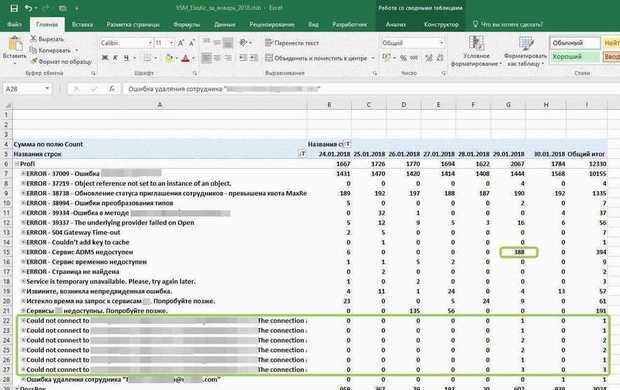
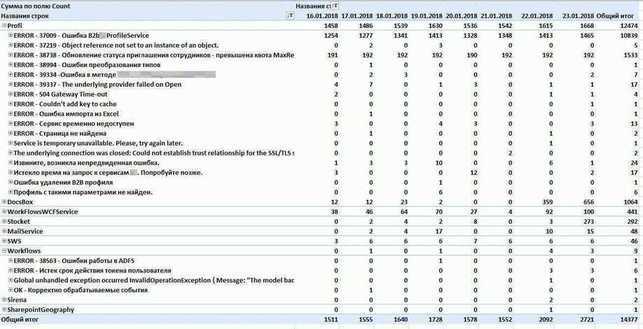

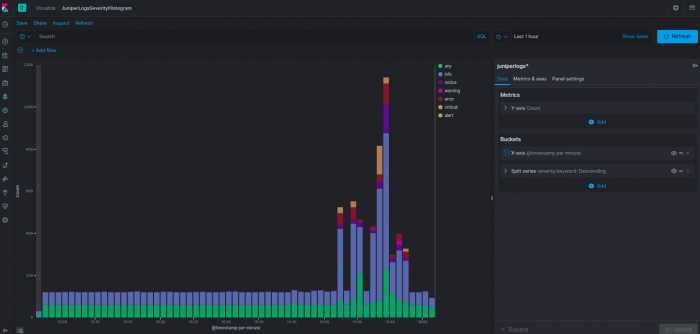
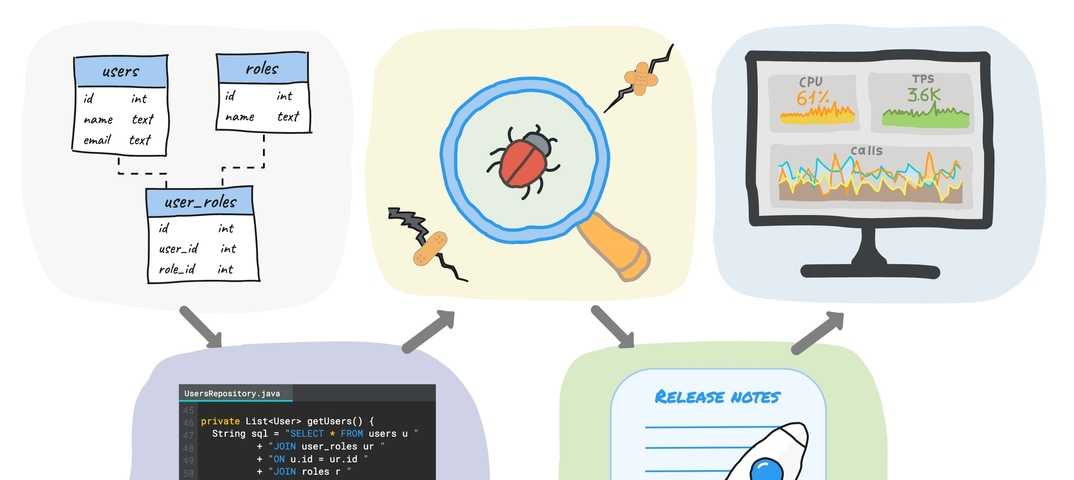
Мы начали поиски заново. Нужна была аналитическая база с минимальным потреблением ресурсов, желательно со сжатием данных на диске.
Clickhouse удовлетворяет всем этим критериям, и о выборе мы ни разу не пожалели. Мы не пишем в него каких-то выдающихся объёмов данных (количество вставок всего около пяти тысяч в минуту).
Процесс сбора журналов Docker
Основная идея состоит в том, чтобы получить журналы в Docker через logstash, а затем перенаправить журналы в elasticsearch для индексации, анализа кибаны и визуализации. Есть много способов получить файлы журнала в докере:
- Добавьте MQ или Redis в качестве среднего уровня контейнера докеров и logstash. Служба в докере передает журналы на средний уровень, а затем logstash получает их со среднего уровня.
- Используйте инструменты для получения журналов в докере, такие как: filebeat, logspout, log-pilot; но не рекомендуется устанавливать logstash на каждый сервер, потому что операция logstash займет много ресурсов сервера и увеличит нагрузку на сервер.
- Конфигурация filebeat кажется относительно сложной, и особого понимания нет;
- logspout может получить журнал stdout докера
- log-pilot — это инструмент журнала Ali с открытым исходным кодом, который может обрабатывать файлы stdout и log
В этой статье в основном используется Logspout.
Параметры сервера-источника логов
Разберем конфигурацию Heka на примере сервера-источника логов и файла service.toml.
Так как логи могут быть многострочными (те же stacktraces), не забываем про RegexSplitter, который даёт Heka понять, где заканчивается один блок текста и начинается другой.
В match_regex описываем строки лога регулярным выражением в стандарте языка Go. Регулярные выражения в Go практически совпадают со стандартным PCRE, но есть ряд нюансов, из-за которых Heka может отказаться стартовать. Например, некоторые реализации PCRE простят такой синтаксис:
А вот GOLANG — не простит.
С помощью параметра log_errors собираем все ошибки в отдельный лог — они понадобятся позже.
Буферизация выходящего потока — одна из отличных возможностей Heka. По умолчанию она хранит выходной буфер по следующему пути:
-
shutdown — при переполнении буфера Heka останавливается;
-
drop — при переполнении буфера он начинает работать как стек, удаляя старые сообщения в очереди;
- block — при заполнении буфера Heka приостанавливает все операции и ждёт, пока не появится возможность отправить данные.
С block вы гарантированно не потеряете ни одной строки лога. Единственный минус в том, что при обрыве соединения или деградации канала вы получите резкий скачок трафика при возобновлении связи. Это связано с тем, что Heka отправляет накопленный буфер, пытаясь вернуться к обработке в реальном времени. Приёмный пул нужно проектировать с запасом, обязательно учитывая возможность таких ситуаций, иначе можно с лёгкостью провернуть DDoS самих себя.
Кстати, по поводу использования двойных и одинарных кавычек в конфигурации Heka — подразумевается следующее:
-
Значения переменных в одинарных кавычках по умолчанию рассматриваются как raw string. Спецсимволы экранировать не нужно.
- Значения переменных в двойных кавычках рассматриваются как обычный текст и требуют двойного экранирования при использовании в них регулярных выражений.
Этот нюанс в свое время попортил мне немало крови.
Отказоустойчивость
Можно настроить Action для выполнения только в случае, если предыдущее Action было приостановлено: описание. Это позволяет настраивать failover конфигурации. Некоторые Actions используют транзакции для увеличения производительности. В таком случае, успех или неудача будут известны только после завершения транзакции, когда сообщения уже обработаны. Это может приводить к потере части сообщений без вызова failover Action. Чтобы такого не происходило, надо ставить параметр (по-умолчанию 16), что может снизить производительность.
Эту возможность я пока не пробовал в продакшене.
Настройка Kibana
Файл с настройками Кибана располагается по пути — /etc/kibana/kibana.yml. На начальном этапе можно вообще ничего не трогать и оставить все как есть. По-умолчанию kibana слушает только localhost и не позволяет подключаться удаленно. Это нормальная ситуация, если у вас будет на этом же сервере установлен nginx в качестве reverse proxy, который будет принимать подключения и проксировать их в кибана. Так и нужно делать в продакшене, когда системой будут пользоваться разные люди из разных мест. С помощью nginx можно будет разграничивать доступ, использовать сертификат, настраивать нормальное доменное имя и т.д. Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server.host, Если хотите, чтобы она слушала все интерфейсы, укажите в качестве адреса, например вот так:
server.host: "0.0.0.0"
После этого Kibana надо перезапустить:
systemctl restart kibana.service
Теперь можно зайти в веб интерфейс по адресу http://ubuntu:5601. Kibana В процессе настройки будем подключаться напрямую к Kibana.
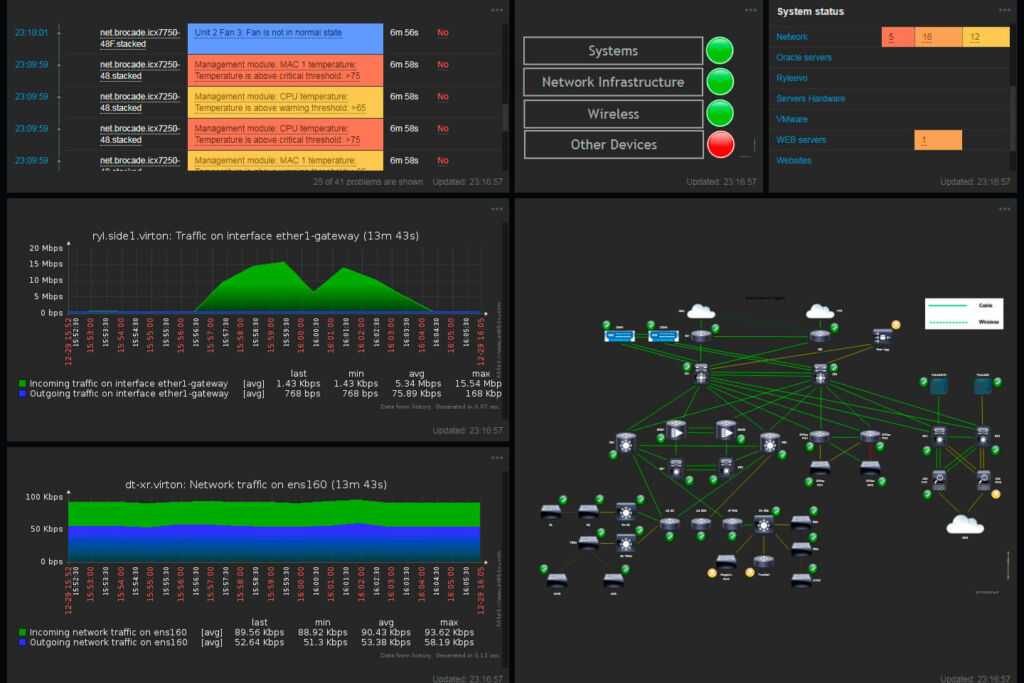
Архитектура
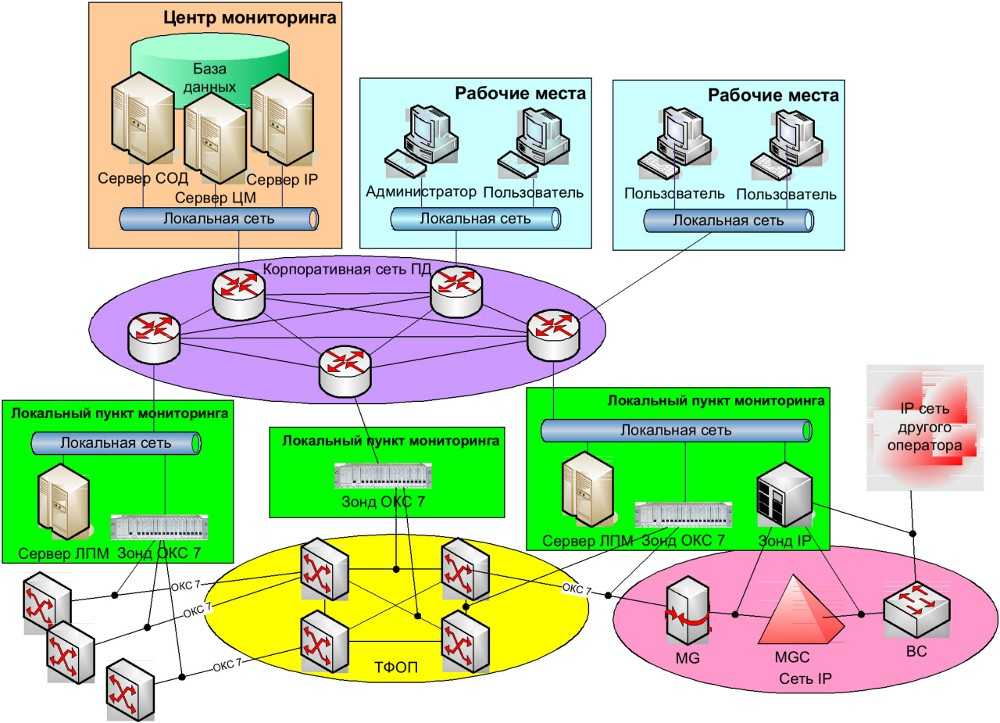
Надежность – одно из ключевых требований, предъявляемых к используемым системам
По этой причине ELK был установлен в отказоустойчивой конфигурации: нам важно быть уверенными, что логи продолжат собираться в случае недоступности части серверов
| Количество VM | Назначение | Используемое ПО |
|---|---|---|
| 2 | Балансировщики нагрузки | Keepalived + HAproxy + nginx |
| 4 | Получение и обработка входящих журналов | Logstash |
| 3 | Master-ноды кластера Elasticsearch | Elasticsearch |
| 6 | Data-ноды кластера Elasticsearch | Elasticsearch |
| 1 | Пользовательский интерфейс | Kibana |
Так выглядит архитектура нашей инсталляции ELK:
Хранилище логов для облачной платформы. Опыт внедрения ELK +10
- 29.08.17 11:25
•
TS_Cloud
•
#336154
•
Хабрахабр
•
•
3600
Информационная безопасность, Open source, Высокая производительность, Блог компании ТЕХНОСЕРВ

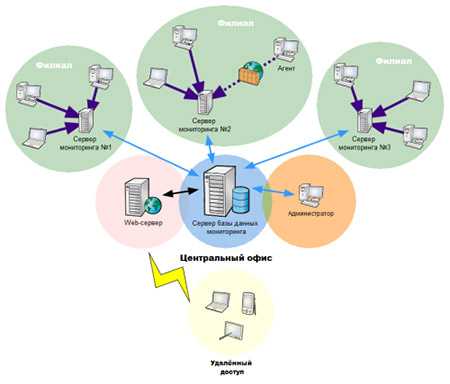
Всем привет! Сегодня мы продолжим рассказывать про облачное хранилище Техносерв Cloud, но уже с точки зрения эксплуатации. Ни одна ИТ-инфраструктура не обходится без инструментов мониторинга и управления, и наше облако не исключение. Для решения повседневных задач, связанных с мониторингом, мы используем продукты с открытым исходным кодом, одним из которых является стек ELK. В этой статье мы расскажем, как в нашем облаке устроен мониторинг журналов, и как ELK помог нам пройти аудит PCI DSS.
Задача централизованного сбора и анализа логов может возникнуть на любом этапе жизненного цикла продукта. В случае с облачным хранилищем Техносерв Cloud необходимость единой консоли для просмотра журналов стала очевидной еще до запуска решения в эксплуатацию, уже на старте проекта требовался инструмент, позволяющий быстро выявить проблемы в используемых системах. В качестве такого инструмента был выбран стек ELK – простой в настройке и эксплуатации продукт с открытым исходным кодом и возможностью масштабирования.
ELK – основной инструмент наших инженеров для просмотра логов платформы: в Elasticsearch собираются записи журналов со всех эксплуатируемых серверов и сетевого оборудования. Мы убеждены, что логов много не бывает, поэтому наши системы делают записи в журналы с максимальным уровнем отладки. Для получения событий используется Beats: filebeat и winlogbeat, syslog и SNMP трапы. С сетевых устройств также собирается информация о трафике по протоколу Netflow. На сегодняшний день наш стек ELK обрабатывает около 1000 входящих записей в секунду с пиками до 10000 записей, при этом выделенных ресурсов по предварительным прогнозам должно хватить на 2-/3-кратное увеличение потока логов.
Настройка logstash на прием логов микротик
В конфиге /etc/logstash/conf.d/input.conf добавляем секцию для приема syslog логов. Вместе с логами от beats конфиг будет выглядеть вот так:
input {
beats {
port => 5044
}
syslog {
port => 5045
type => syslog
}
}
В конфиге с фильтрами filter.conf я разделил с помощью тэгов логи обычных роутеров, свитчей и wifi точек доступа по ip адресам. Получилось примерно так:
else if == "10.1.4.19" or == "10.1.5.1" {
mutate {
add_tag =>
}
}
else if == "10.1.4.66" or == "10.1.3.110" or == "10.1.3.111" {
mutate {
add_tag =>
}
}
else if == "10.1.4.14" or == "10.1.5.33" {
mutate {
add_tag =>
}
}
Это простой случай, когда устройств мало. Если у вас много устройств, то лучше наверно придумать что-то другое, чтобы не нагружать logstash лишними правилами. Да и в ручную править конфиг неудобно. Как лучше поступать в таком случае — не знаю, не продумывал тему. Наверно имеет смысл разделить потоки по разным портам и на этом основании принимать решение о дальнейшей обработке.
Отправляем полученные логи в elasticsearch, настроив конфиг output.conf:
else if "mikrotik" in {
elasticsearch {
hosts => "localhost:9200"
index => "mikrotik-%{+YYYY.MM}"
}
}
Я просто складываю все логи с тэгом mikrotik в один индекс с разбивкой по месяцам. На типы gateway, switch и wifi не разделяю, хотя можно это сделать. Тэги я добавил просто для удобства просмотра логов. С помощью тэгов можно будет быстро группировать логи по типу устройств.
Перезапускаем logstash и идем настраивать микротики на отправку логов на удаленный сервер.
Установка и настройка syslog-ng
С установкой нет ничего сложного. Установить syslog-ng можно одной командой:
# yum install -y syslog-ng
Сразу переходим к настройке. Файл конфигурации располагается по адресу /etc/syslog-ng/syslog-ng.conf. Чтобы сервер начал принимать логи с удаленного устройства, его необходимо прописать в конфиг. Делается это просто. В самый конец конфигурационного файла добавляем информацию о новом устройстве:
destination d_xs-zabbix { file("/var/log/!remote/xs-zabbix.log"); };
filter f_xs-zabbix { netmask("10.1.3.29/255.255.255.255"); };
log { source(net); filter(f_xs-zabbix); destination(d_xs-zabbix); };
| d_xs-zabbix | Название назначения для записи лога по адресу /var/log/!remote/xs-zabbix.log |
| f_xs-zabbix | Название фильтра по адресу сервера источника. |
| 10.1.3.29 | Адрес сервера источника логов |
Соответственно для второго сервера нужно добавить еще 3 строки, например так:
destination d_xs-web { file("/var/log/!remote/xs-web.log"); };
filter f_xs-web { netmask("10.1.3.38/255.255.255.255"); };
log { source(net); filter(f_xs-web); destination(d_xs-web); };
И так далее. Добавляете столько серверов, сколько нужно. Не забудьте создать папку для логов. В моем примере это папка /var/log/!remote, сами файлы создавать не надо, служба автоматически их создаст, когда придет информация с удаленных серверов.
Запускаем syslog-ng и добавляем в автозагрузку:
# systemctl start syslog-ng # systemctl enable syslog-ng
Проверим, запустилась ли служба:
# netstat -tulnp | grep syslog udp 0 0 0.0.0.0:514 0.0.0.0:* 25960/syslog-ng
Все в порядке, слушает 514 udp порт. Не забудьте открыть этот порт в iptables, если у вас включен фаерволл. Сервер готов к приему логов.
Реализация
В качестве балансировщиков трафика используются HAproxy и nginx, их отказоустойчивость достигается при помощи keepalived – приложения, реализующего протокол маршрутизации VRRP (Virtual Router Redundancy Protocol). Keepalived настроен в простой конфигурации из master и backup нод, таким образом, входящий трафик приходит на ноду, которой в настоящий момент принадлежит виртуальный IP адрес. Дальнейшая балансировка трафика в Logstash и Elasticsearch осуществляется по алгоритму round-robin (все так же используем простые решения).
Для Logstash и Elasticseach отказоустойчивость достигается избыточностью: система продолжит корректно работать даже в случае выхода из строя нескольких серверов. Подобная схема проста в настройке и позволяет легко масштабировать каждый из установленных компонентов стека.
Сейчас мы используем четыре Logstash сервера, каждый из которых выполняет полный цикл обработки входных данных. В ближайшее время планируем разделить сервера Logstash по ролям Input и Filter, а также добавить кластер RabbitMQ для буферизации данных, отправляемых из Logstash. Использование брокера сообщений позволит исключить риски потери данных в случае разрыва соединения между Logstash и Elasticsearch.
Конфигурация Elasticsearch у нас также проста, мы используем три master ноды и шесть data нод.
Kibana – единственный компонент, который не резервируется, так как выход «кибаны» из строя не влияет на процессы сбора и обработки логов. Для ограничения доступа к консоли используется kibana-auth-plugin, а при помощи плагина Elastic HQ мы можем наблюдать за состоянием кластера Elasticsearch в веб-интерфейсе.
Установка Filebeat для отправки логов в Logstash
Установим первого агента Filebeat на сервер с nginx для отправки логов веб сервера на сервер с ELK. Ставить можно как из общего репозитория, который мы подключали ранее, так и по отдельности пакеты. Как ставить — решать вам. В первом случае придется на все хосты добавлять репозиторий, но зато потом удобно обновлять пакеты. Если подключать репозиторий не хочется, можно просто скачать пакет и установить его.
Ставим на Centos.
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.11.0-x86_64.rpm # rpm -vi filebeat-7.11.0-x86_64.rpm
В Debian/Ubuntu ставим так:
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.11.0-amd64.deb# dpkg -i filebeat-7.11.0-amd64.deb
Или просто:
# yum install filebeat # apt install filebeat
После установки рисуем примерно такой конфиг /etc/filebeat/filebeat.yml для отправки логов в logstash.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*-access.log
fields:
type: nginx_access
fields_under_root: true
scan_frequency: 5s
- type: log
enabled: true
paths:
- /var/log/nginx/*-error.log
fields:
type: nginx_error
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts:
xpack.monitoring:
enabled: true
elasticsearch:
hosts: ["http://10.1.4.114:9200"]
Некоторые пояснения к конфигу, так как он не совсем дефолтный и минималистичный. Я его немного модифицировал для удобства. Во-первых, я разделил логи access и error с помощью отдельного поля type, куда записываю соответствующий тип лога: nginx_access или nginx_error. В зависимости от типа меняются правила обработки в logstash. Плюс, я включил мониторинг и для этого указал адрес elastichsearch, куда filebeat передает данные мониторинга напрямую. Показываю это для вас просто с целью продемонстрировать возможность. У меня везде отдельно работает мониторинг на zabbix, так что большого смысла в отдельном мониторинге нет. Но вы посмотрите на него, возможно вам он пригодится. Чтобы мониторинг работал, его надо активировать в соответствующем разделе в Management — Stack Monitoring. И не забудьте запустить elasticsearch на внешнем интерфейсе. В первоначальной настройке я указал слушать только локальный интерфейс.

Запускаем filebeat и добавляем в автозагрузку.
# systemctl start filebeat # systemctl enable filebeat
Проверяйте логи filebeat в дефолтном системном логе. По умолчанию, он все пишет туда. Лог весьма информативен. Если все в порядке, увидите список всех логов в директории /var/log/nginx, которые нашел filebeat и начал готовить к отправке. Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет индекса, нас перенаправит в раздел Managemet, где мы сможем его добавить.
Вы должны увидеть индекс, который начал заливать logstash в elasticsearch. В поле Index pattern введите nginx-* и нажмите Next Step.
На следующем этапе выберите имя поля для временного фильтра. У вас будет только один вариант — @timestamp, выбирайте его и жмите Create Index Pattern.
Новый индекс добавлен. Теперь при переходе в раздел Discover, он будет открываться по умолчанию со всеми данными, которые в него поступают.
Получение логов с веб сервера nginx на linux настроили. Подобным образом настраивается сбор и анализ любых логов. Можно либо самим писать фильтры для парсинга с помощью grok, либо брать готовые. Вот несколько моих примеров по этой теме:
- Мониторинг производительности бэкенда с помощью ELK Stack
- Сбор и анализ логов samba в ELK Stack
- Дашборд для логов nginx
Теперь сделаем то же самое для журналов windows.
Плагины вывода
- плагины без буферизации — не сохраняют результаты в буфере и моментально пишут их в стандартный вывод;
- с буферизацией — делят события на группы и записывают поочередно; можно устанавливать лимиты на количество хранимых событий, а также на количество событий, помещаемых в очередь;
- с разделением по временным интервалам — эти плагины по сути являются разновидностью плагинов с буферизацией, только события делятся на группы по временным интервалам.
- out_copy — копирует события в указанное место (или несколько мест);
- out_null — этот плагин просто выбрасывает пакеты;
- out_roundrobin — записывает события в различные локации вывода, которые выбираются методом кругового перебора;
- out_stdout — моментально записывает события в стандартный вывод (или в файл лога, если он запущен в режиме демона).
- out_exec_filter — запускает внешнюю программу и считывает событие из её вывода;
- out_forward — передаёт события на другие узлы fluentd;
- out_mongo (или out_mongo_replset) — передаёт записи в БД MongoDB.
Плагины буферизации
- buf_memory — изменяет объём памяти, используемой для хранения буферизованных данных (подробнее см. в официальной документации);
- buf_file — даёт возможность хранить содержимое буфера в файле на жёстком диске.
Плагины форматирования
- out_file — позволяет кастомизировать данные, представленные в виде «время — тэг — запись в формате json»;
- json — убирает из записи в формате json поле «время» или «тэг»;
- ltsv — преобразует запись в формат LTSV;
- single_value — выводит значение одного поля вместо целой записи;
- csv — выводит запись в формате CSV/TSV.
Заключение
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .





