
Введение
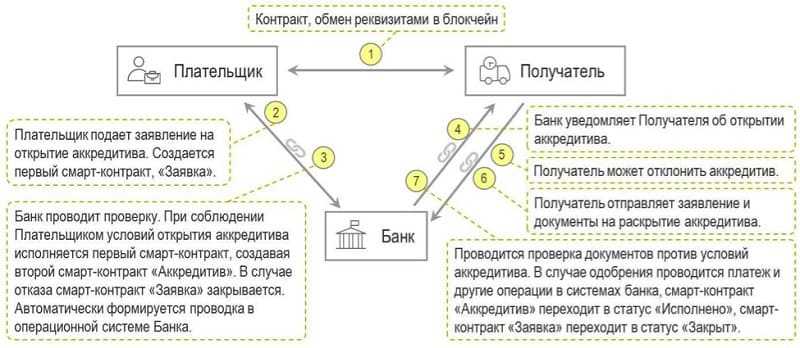
За последние годы современные компании, в том числе отечественные, сделали большой шаг вперед в части модернизации IT-инфраструктур и расширения используемых программных средств и компонентов, СЗИ, а также корпоративных систем. Вместе с повышением качества внутренних сервисов, защищенности инфраструктуры и других улучшений, неизбежно увеличивается и объем данных, генерируемых новыми системами. Разумеется, для сопровождения, развития и, что самое главное, получения ожидаемых прикладных результатов от соответствующих систем, необходимо эти данные как-то обрабатывать.
В сфере информационной безопасности особняком стоят SIEM системы, отвечающие за сбор, обработку, хранение и анализ данных . В то же время на сегодняшний день сложно кого-то удивить настроенной и корректно функционирующей SIEM системой. А вот стоимостью на лицензирование SIEM, особенно учитывая ежегодный рост объемов данных и существенно подскочивший курс иностранных валют, удивить можно практически каждого. Кроме этого, современные объемы данных часто нагружают SIEM системы настолько сильно, что они становятся неспособными переваривать такой поток информации, от чего страдает основной функционал SIEM – возможность корреляции событий и выявление инцидентов ИБ. В таких условиях многие компании присматриваются или уже внедрили в свою инфраструктуру, так называемые, CLM (Central Log Management) решения. Или, проще говоря, Logger – приложения, отвечающие за долгосрочное хранение данных больших объемов и фильтрацию событий, попадающих в SIEM.
В этой статье постараемся рассказать, как на базе всем доступного open-source можно построить эффективный Logger, поддерживающий интеграцию со всеми SIEM системами, а также как возможно модернизировать уже существующий Logger с помощью алгоритмов машинного обучения, сделав его умнее и эффективнее.
Введение
У меня есть целый цикл статей про настройку и эксплуатацию ELK Stack для сбора логов с различных приложений. Так же я подробно рассказал, как установить и настроить ELK Stack себе, если у вас есть под него мощности и компетенции. В целом, там нет чего-то сильно сложного, но тем не менее, все равно необходимо повозиться, чтобы все заработало.
Не обязательно все это разворачивать и настраивать у себя, если хочется просто попробовать продукт, чтобы понять, нужен он вам или нет. Есть сервис — https://cloud.elastic.co, где можно за 2 минуты зарегистрировать и развернуть свой стэк на базе Elasticsearch и Kibana. Отличие от описанного мной способа разворачивания стека в том, что тут не будет Logstash. Во многих случаях можно обойтись без него, так что это не критично. Особенно для того, чтобы просто попробовать.
Итак, прежде чем приступить к настройке, зарегистрируйтесь в облаке и активируйте учетную запись.
Введение
В своей статье я буду считать, что вы установили и настроили elk stack по моему материалу. Если это не так, то сами подредактируйте представленные конфиги под свои реалии. По большому счету, все самое основное по сбору логов windows серверов уже дано в указанной статье. Как минимум, там рассказано, как начать собирать логи с помощью winlogbeat. Дальше нам нужно их обработать и нарисовать функциональный дашборд для быстрого анализа поступающей информации.
Для того, чтобы оценить представленные мной графики и дашборды, рекомендую собирать логи сразу с нескольких серверов. Так можно будет оценить представленную информацию на практике. С одним сервером не так наглядно получится.
С визуализацией данных из windows журналов проблем нет никаких. Winlogbeat из коробки умеет парсить логи и добавлять все необходимые метаданные. Со стороны logstash не нужны никакие фильтры. Принимаем все данные как есть с winlogbeat.
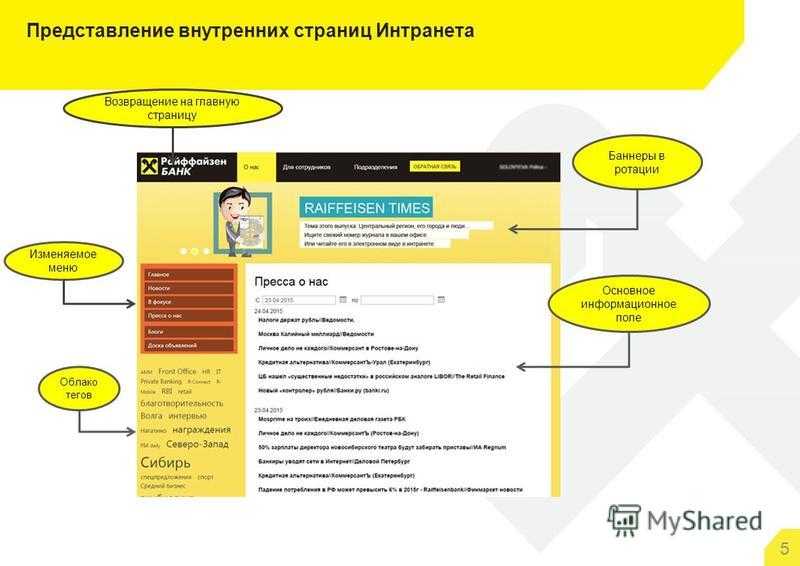
Почему Graylog?
Это не единственная и, возможно, далеко не самая лучшая платформа, но она широко распространена, прошла проверку временем и все еще поддерживается разработчиками.
Но, начать мы решили с анализа “конкурентов”.
Альтернативы
Splunk
Классный, модный, современный Splunk соответствует подавляющему большинству потребностей и скорее всего, может даже больше.
Но есть три момента, которые не понравились:
-
В нужной конфигурации решение платное.
-
Это закрытое решение.
-
Компания, без объяснений причин покинула рынок РФ.
Но, если вас это не смущает, немного полезной информации по платформе:
-
Обзорная статья на habr.
-
Сравнение платной и бесплатных версий.
С этим “претендентом” не получилось, идем дальше.
Например, тут и тут его часто сравнивают с ELK, который и рассмотрим.
ELK
Стек продуктов Elasticsearch, Logstash, Kibana, образующий аббревиатуру ELK — это очень популярное и еще более настраиваемое решение, по сравнению с предыдущим. Более того, это решение open source.






Что же пошло не так?
-
Некоторые фишки все же платные, например, уведомления и контроль доступа (однако, после некоторых событий часть данного функционала стала бесплатной).
-
Ресурсоемкость — требуется очень много ресурсов.
-
Систему сложно настроить, “из коробки” она работать не будет.
-
Еще нужно упомянуть Open Distro, которая развивается на базе ELK, но полностью бесплатная, что не отменяет ресурсоемкость и сложность в настройке.
Немного полезной информации:
-
Инструкция по установке и настройке (eng).
-
Цикл статей на habr: часть 1, часть 2, часть 3.
Остановились на Graylog
Двух претендентов отсеяли, остался виновник торжества — Graylog, выделяющийся по следующим причинам:
-
Это open source решение.
-
Бесплатная версия имеет все необходимое.
-
Функционал небольшой, что удобно, ничего лишнего (для наших задач).
-
“Из коробки” решение уже работает, нужны минимальные настройки.
-
По сравнению с ELK ресурсоемкость значительно ниже.
Далее, мы предлагаем лонгрид по настройке и установке Graylog.
Кратко™ про конфигурационные файлы
- Networks и volumes были взяты из исходного docker-compose.yml (тот где целиком стек запускается) и думаю, что сильно здесь на общую картинку не влияют.
- Мы создаём один сервис (services) logstash, из образа docker.elastic.co/logstash/logstash:6.3.2 и присваиваем ему имя logstash_one_channel.
- Мы пробрасываем внутрь контейнера порт 5046, на такой же внутренний порт.
- Мы отображаем наш файл настройки каналов ./config/pipelines.yml на файл /usr/share/logstash/config/pipelines.yml внутри контейнера, откуда его подхватит logstash и делаем его read-only, просто на всякий случай.
- Мы отображаем директорию ./config/pipelines, где у нас лежат файлы с настройками каналов, в директорию /usr/share/logstash/config/pipelines и тоже делаем её read-only.
logstash_one_channel | Unable to retrieve license information from license server {:message=>«Elasticsearch Unreachable: [http://elasticsearch:9200/]logstash_one_channel | Pipeline started successfully logstash_one_channel | logstash_one_channel | X-Pack is installed on Logstash but not on Elasticsearch. Please install X-Pack on Elasticsearch to use the monitoring feature. Other features may be available.logstash_one_channel | logstash_one_channel | ogstash_one_channel | Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/] elasticsearch»}logstash_one_channel | logstash_one_channel | Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/] elasticsearch»}elasticsearch
Grafana Loki
Grafana Loki появился недавно, но уже стал довольно известным. Его преимущества: лёгко устанавливается, потребляет мало ресурсов, не требует установки Elasticsearch, так как хранит данные в TSDB (time series database). В прошлой статье я писал, что в такой базе хранит данные Prometheus, и это одно из многочисленных сходств двух продуктов. Разработчики даже заявляют, что Loki — это «Prometheus для мира логирования».
Небольшое отступление про TSDB для тех, кто не читал предыдущую статью: TSDB отлично справляется с задачей хранения большого количества данных, временных рядов, но не предназначена для долгого хранения. Если по какой-то причине вам нужно хранить логи дольше двух недель, то лучше настроить их передачу в другую БД.
Ещё одно преимущество Loki — для визуализации данных используется Grafana. Очень удобно: в Grafana мы смотрим данные по мониторингу и там же, подключив Loki, смотрим логи. По логам можно строить графики.
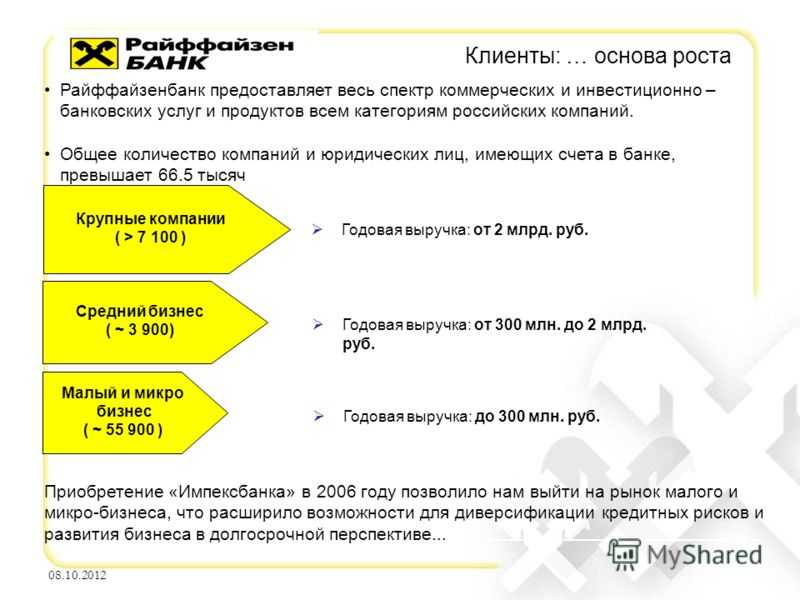






Архитектура Loki выглядит примерно так:
С помощью DaemonSet на всех серверах кластера разворачивается агент — Promtail или Fluent Bit. Агент собирает логи. Loki их забирает и хранит у себя в TSDB. К логам сразу добавляются метаданные, что удобно: можно фильтровать по Pods, namespaces, именам контейнеров и даже лейблам.
Loki работает в знакомом интерфейсе Grafana. У Loki даже есть собственный язык запросов, он называется LogQL — по названию и по синтаксису напоминает PromQL в Prometheus. В интерфейсе Loki есть подсказки с запросами, поэтому не обязательно их знать наизусть.
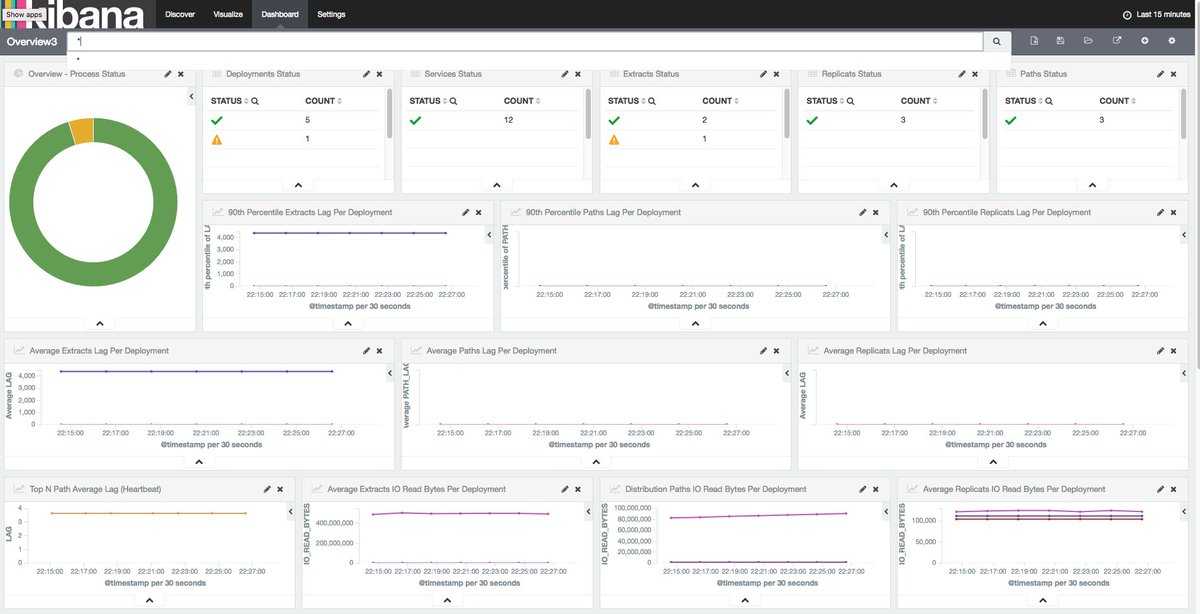
Loki в интерфейсе Grafana
Используя фильтры, в Loki можно найти коды (“400”, “404” и любой другой); посмотреть логи со всей ноды; отфильтровать все логи, где есть слово “error”. Если нажать на лог, раскроется карточка со всей информацией по событию.
В Loki достаточно инструментов, которые позволяют вытаскивать нужные логи, хотя честно говоря, технически их могло быть и больше. Сейчас Loki активно развивается и набирает популярность.
Возможности Fluent Bit
Так как о Fluent Bit, как правило, слышали меньше, чем о Logstash, рассмотрим его чуть подробнее. Fluent Bit логически можно поделить на 6 модулей, на часть модулей можно навесить плагины, которые расширяют возможности Fluent Bit.
Модуль Input собирает логи из файлов, служб systemd и даже из tcp-socket (надо только указать endpoint, и Fluent Bit начнёт туда ходить). Этих возможностей достаточно, чтобы собирать логи и с системы, и с контейнеров.
В продакшене мы чаще всего используем плагины tail (его можно натравить на папку с логами) и systemd (ему можно сказать, из каких служб собирать логи).
Модуль Parser приводит логи к общему виду. По умолчанию логи Nginx представляют собой строку. С помощью плагина эту строку можно преобразовать в JSON: задать поля и их значения. С JSON намного проще работать, чем со строковым логом, потому что есть более гибкие возможности сортировки.
Модуль Filter. На этом уровне отсеиваются ненужные логи. Например, на хранение отправляются логи только со значением “warning” или с определёнными лейблами. Отобранные логи попадают в буфер.
Модуль Buffer. У Fluent Bit есть два вида буфера: буфер памяти и буфер на диске. Буфер — это временное хранилище логов, нужное на случай ошибок или сбоев. Всем хочется сэкономить на ОЗУ, поэтому обычно выбирают дисковый буфер. Но нужно учитывать, что перед уходом на диск логи всё равно выгружаются в память.
Модуль Routing/Output содержит правила и адреса отправки логов. Как уже было сказано, логи можно отправлять в Elasticsearch, PostgreSQL или, например, Kafka.
Интересно, что из Fluent Bit логи можно отправлять во Fluentd. Так как первый более легковесный и менее функциональный, через него можно собирать логи и отправлять во Fluentd, и уже там, с помощью дополнительных плагинов, их дообрабатывать и отправлять в хранилища.
Продолжение следует…
6 LOGalyze
LOGalyze был коммерческим продуктом, который недавно стал инструментом с открытым исходным кодом.
Хотя я не смог реализовать проект на GitHub, они сделали установщик Windows и весь исходный код загружаемым.
Если вы намерены участвовать в сообществе, вы можете найти подробную информацию о списке рассылки здесь.
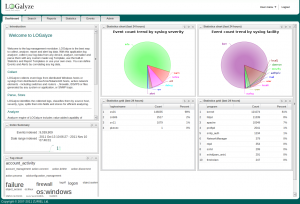
LOGalyze – это относительно гибкое и мощное предложение, которое отлично подойдет для развертываний в одной системе, которые стремятся объединить ведение журналов из известных источников, таких как Postfix, Apache и т. д. и выводить их в форматах CSV, PDF, HTML или аналогичных.




Да, он не делает все, но поскольку это был коммерческий продукт в свое время, он делает это довольно хорошо.
Logstash
Процесс установки Logstash аналогичен — переходим на страницу загрузки программного продукта, копируем ссылку на пакет RPM:
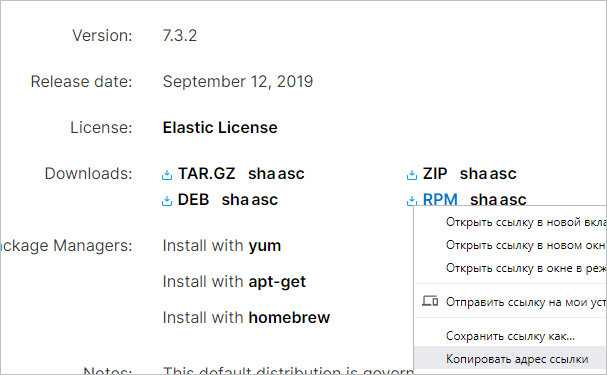
Скачиваем пакет на нашем сервере:
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.3.2.rpm
… и устанавливаем его:
rpm -ivh logstash-*
Разрешаем автозапуск и стартуем сервис:
systemctl enable logstash
systemctl start logstash
Настройка Logstash
Настройки для логстэша хранятся в каталоге /etc/logstash/conf.d в файлах формата JSON. Для конфигурации используются следующие секции:
- input (входные данные).
- filter (фильтры).
- output (выходные данные).
Для каждой из них мы создадим свой файл.
vi /etc/logstash/conf.d/input.conf
input {
beats {
port => 5044
}
}
* в данном примере мы настроили logstash для приема логов на порту 5044.
vi /etc/logstash/conf.d/filter.conf
filter {
if == «syslog» {
grok {
match => { «message» => «%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\)?: %{GREEDYDATA:syslog_message}» }
add_field =>
add_field =>
}
date {
match =>
}
}
}
vi /etc/logstash/conf.d/output.conf
output {
elasticsearch { hosts =>
hosts => «localhost:9200»
manage_template => false
index => «%{}-%{+YYYY.MM.dd}»
document_type => «%{}»
}
}
Перезапускаем сервис logstash:
systemctl restart logstash
Немного подождем — приложению нужно около 1 минуты, чтобы запуститься. После, введя команду:
ss -tunlp | grep 5044
… мы увидим что-то на подобие:





tcp LISTEN 0 128 :::5044 :::* users:((«java»,pid=11745,fd=114))
Сервис запустился и готов принимать логи.
Запуск Elastic Stack в Elastic Cloud
При первом входе в личный кабинет у вас будет возможность создать Deployment с Elasticsearch.
Дальше нужно выбрать платформу, где вы хотите произвести установку сервиса, и регион. Я для теста выбрал Google Cloud Platform во Frankfurt. Все остальное оставил по дефолту. Дальше внизу жмете Create Deployment и ждете, когда он развернется. Обычно 2-3 минуты.
Дожидаемся окончание процесса установки и переходим в Kibana.
Логинимся в Kibana с учетными данными, которые указаны в личном кабинете, в Deployment. Username обычно elastic и какой-то пароль. При первом входе вам предложат залить набор демо данных, чтобы посмотреть функционал системы. Если хотите — посмотрите. Я там и так все видел, поэтому отказываюсь  Буду лить свои логи от apache.
Буду лить свои логи от apache.
После выбора оказываетесь на главной странице Kibana. По сути Elastic Stack вы уже развернули и он готов принимать данные. Вот так, быстро и просто все настроилось. И DevOps не нужен
Можете тут осмотреться и познакомиться с системой.
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch.yml. На начальном этапе нас будут интересовать следующие параметры:
path.data: /var/lib/elasticsearch # директория для хранения данных network.host: 127.0.0.1 # слушаем только локальный интерфейс
По-умолчанию Elasticsearch слушает все сетевые интерфейсы. Нам это не нужно, так как данные в него будет передавать logstash, который будет установлен локально
Обратите внимание на параметр path.data для директории с данными. Чаще всего индексы будут занимать значительное место
Если останется меньше 10% свободного места elasticsearch уходит в глухой read-only и вывести сервис из этого состояния – ещё та задача. Подумайте заранее, где вы будете хранить логи. Остальные настройки — дефолтные. После изменения настроек, перезапустите службу:
systemctl restart elasticsearch.service
Смотрим, что получилось:
netstat -tulnp | grep 9200 tcp6 0 0 127.0.0.1:9200 :::* LISTEN 14130/java
Elasticsearch работает на локальном интерфейсе — слушает ipv6, про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Переходим к установке kibana.
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch.yml. На начальном этапе нас будут интересовать следующие параметры:
path.data: /var/lib/elasticsearch # директория для хранения данных network.host: 127.0.0.1 # слушаем только локальный интерфейс
По умолчанию Elasticsearch слушает localhost. Нам это и нужно, так как данные в него будет передавать logstash, который будет установлен локально
Обращаю отдельное внимание на параметр для директории с данными. Чаще всего они будут занимать значительное место, иначе зачем нам Elasticsearch Подумайте заранее, где вы будете хранить логи
Все остальные настройки я оставляю дефолтными.
После изменения настроек, надо перезапустить службу:
# systemctl restart elasticsearch.service
Смотрим, что получилось:
# netstat -tulnp | grep 9200 tcp6 0 0 127.0.0.1:9200 :::* LISTEN 1479/java
Elasticsearch повис на локальном интерфейсе. Причем я вижу, что он слушает ipv6, а про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Переходим к установке kibana.





Если вы хотите, чтобы elasticsearch слушал все сетевые интерфейсы, настройте параметр:
network.host: 0.0.0.0
Только не спешите сразу же запускать службу. Если запустите, получите ошибку:
node validation exception bootstrap checks failed: the default discovery settings are unsuitable for production use; at least one of must be configured
Чтобы ее избежать, дополнительно надо добавить еще один параметр:
discovery.seed_hosts: "]
Эти мы указываем, что хосты кластера следует искать только локально.
Сбор windows логов
Приступим к настройке. последнюю версию winlogbeat на сервер, с которого мы будем отправлять логи в elk stack. Вот конфиг с тестового сервера, по которому пишу статью:
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: Security
- name: System
tags:
output.logstash:
hosts:
logging.level: info
logging.to_files: true
logging.files:
path: C:/Program Files/Winlogbeat/logs
name: winlogbeat
keepfiles: 7
Теперь настраивает logstash на прием этих логов. Добавляем в конфиг:
else if "winsrv" in {
elasticsearch {
hosts => "localhost:9200"
index => "winsrv-%{+YYYY.MM}"
}
}
Я формирую месячные индексы с логами windows серверов. Если у вас очень много логов или хотите более гибкое управление занимаемым объемом, то делайте индексы дневные, указав winsrv-%{+YYYY.MM.dd}.
Перезапускайте службы на серверах и ждите поступления данных в elasticsearch.





