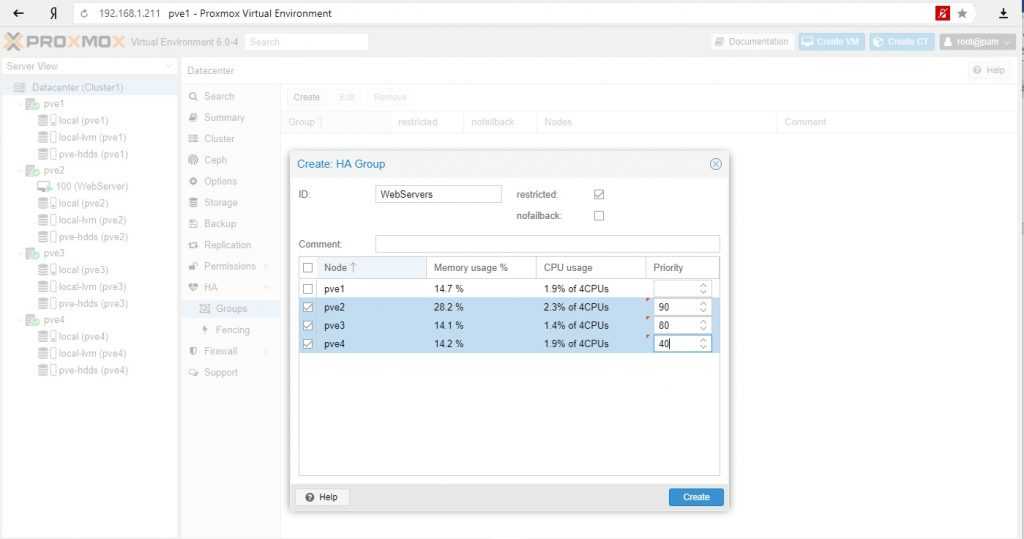
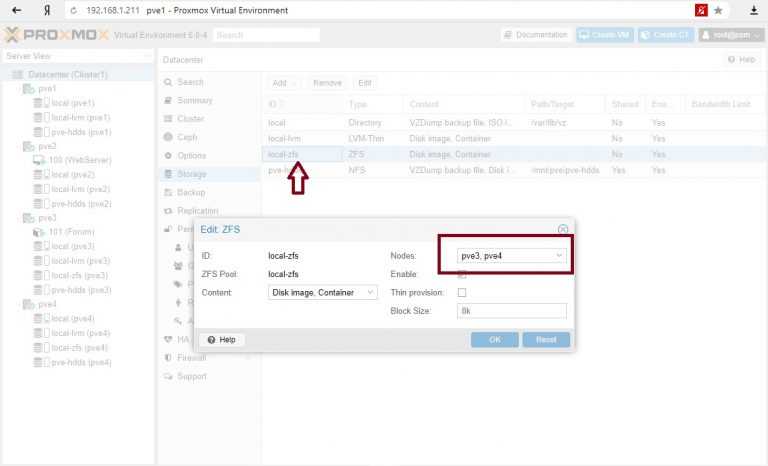
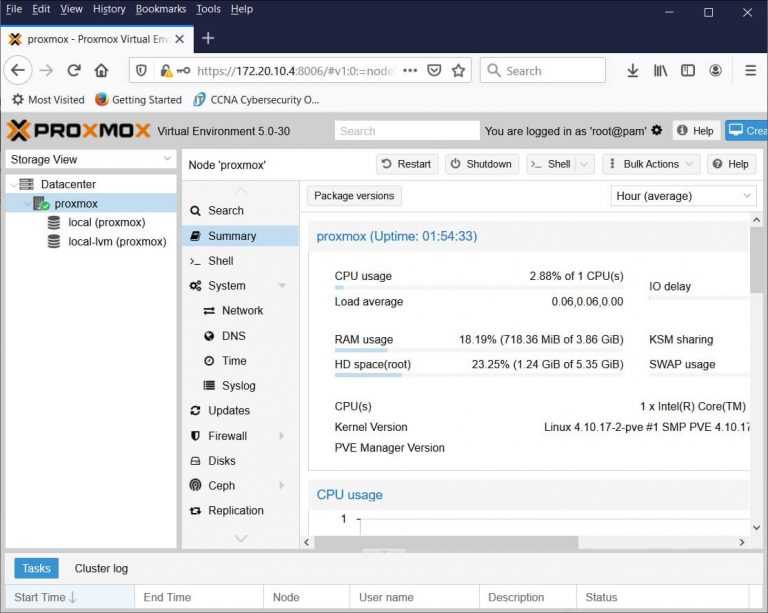
Восстановление конфигурации хранилища
После перезагрузки копируем из резервной копии файл storage.cfg:
cp -r /root/pve-backup/storage.cfg /etc/pve/
| 1 | cp-rrootpve-backupstorage.cfgetcpve |
Открываем файл при помощи консольного редактора:
nano -w /etc/pve/storage.cfg
| 1 | nano-wetcpvestorage.cfg |
Если эта нода не являлась мастером, тогда удаляем все хранилища которые не содержать nodes , после чего на каждом хранилище удаляем эту строку.
Если нода являлась мастером, тогда удаляем все хранилища которы содержать nodes .
Копируем файлы файлы виртуальных машин, если Вы не собираетесь добавлять ноду в кластер:
cp -r /root/pve-backup/nodes//qemu-server/* /etc/pve/qemu-server/
cp -r /root/pve-backup/nodes//lxc/* /etc/pve/lxc/
cp -r /root/pve-backup/nodes//openvz/* /etc/pve/openvz/
|
1 |
cp-rrootpve-backupnodesназваниенодыqemu-server*etcpveqemu-server cp-rrootpve-backupnodesназваниенодыlxc*etcpvelxc cp-rrootpve-backupnodesназваниенодыopenvz*etcpveopenvz |
Если вы собрались добавить ноду в кластер, тогда добавляем и в случае успешного добавления копируем виртуальные машины:
cp -r /root/pve-backup/nodes//qemu-server/* /etc/pve/nodes//qemu-server/
cp -r /root/pve-backup/nodes//lxc/* /etc/pve/nodes//lxc/
cp -r /root/pve-backup/nodes//openvz/* /etc/pve/nodes//openvz/
|
1 |
cp-rrootpve-backupnodesназваниенодыqemu-server*etcpvenodesназваниенодыqemu-server cp-rrootpve-backupnodesназваниенодыlxc*etcpvenodesназваниенодыlxc cp-rrootpve-backupnodesназваниенодыopenvz*etcpvenodesназваниенодыopenvz |
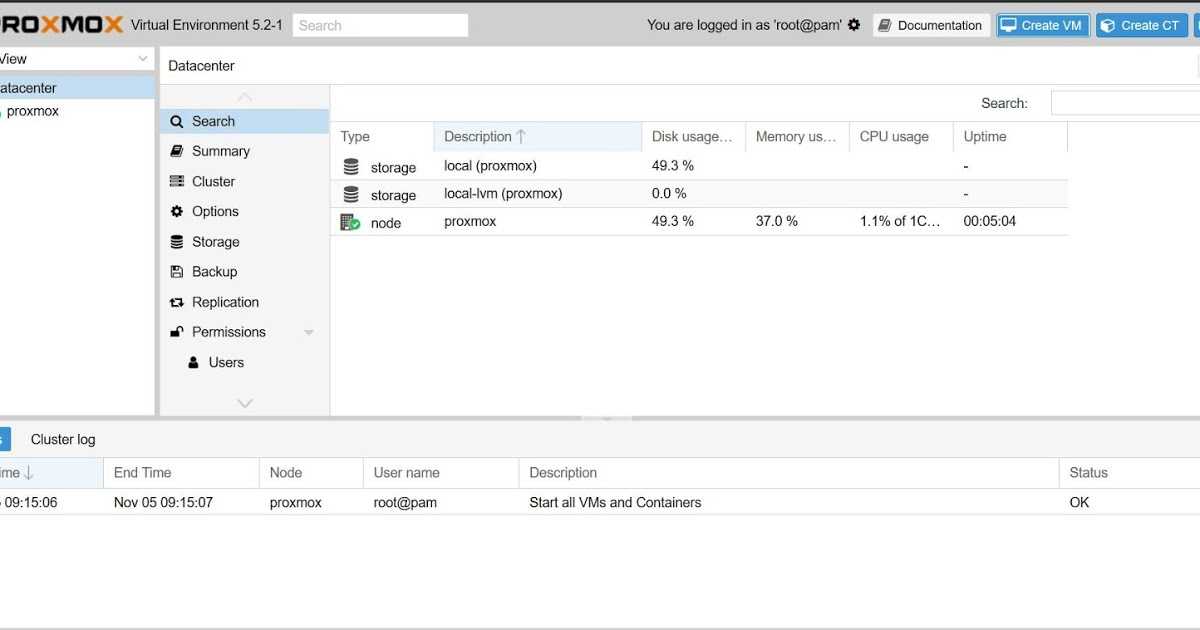
Открываем WEB-интерфейс, проверям наличие хранилища и виртуальных машин.
Виды сетевых соединений в Proxmox VE
- Linux Bridge — способ соединения двух сегментов Ethernet на канальном уровне, то есть без использования протоколов более высокого уровня, таких как IP. Поскольку передача выполняется на канальном уровне (уровень 2 модели OSI), все протоколы более высокого уровня прозрачно проходят через мост.
- Linux Bond — метод агрегации нескольких сетевых интерфейсов в единый логический bonded интерфейс. Таким образом, bond обеспечивает балансировку нагрузки либо горячий резерв по определённому сценарию.
- Linux VLAN – реализация на ядре Linux виртуальной локальной компьютерной сети.
- OVS Bridge – реализация моста на базе Open vSwitch.
- OVS Bond – реализация балансировки на базе Open vSwitch. Отличается от реализованной в ядре Linux балансировки режимами.
- OVS IntPort — реализация VLAN на базе Open vSwitch.
Обнуляем ноду PROXMOX
Смотрим текущий статус кластера:
pvecm status
| 1 | pvecm status |
Все машины которые кроме этой ноды — удаляем:
pvecm delnode
| 1 | pvecm delnodeИмянодыилиIPадрес |
Останавливаем все сервисы:
systemctl stop pvestatd.service
systemctl stop pvedaemon.service
systemctl stop pve-cluster.service
systemctl stop corosync
![Proxmox:как-убить-машину-которая-не-хочет-выключаться [wiki.autosys.tk]](https://tehnikaarenda.ru/wp-content/uploads/e/f/d/efd13be2d7837cdda355dfcce6e9917f.jpeg)
|
1 |
systemctl stop pvestatd.service systemctl stop pvedaemon.service systemctl stop pve-cluster.service systemctl stop corosync |
Заходим базу данных кластера:
sqlite3 /var/lib/pve-cluster/config.db
| 1 | sqlite3varlibpve-clusterconfig.db |
Удаляем конфигурацию:
SQLite version 3.27.2 2019-02-25 16:06:06
Enter «.help» for usage hints.
sqlite> delete from tree where name = ‘corosync.conf’;
sqlite> .quit
|
1 |
SQLite version3.27.22019-02-25160606 Enter».help»forusage hints. sqlite>delete from tree where name=’corosync.conf’; sqlite>.quit |
Сносим остальные файлы конфигурации:
pmxcfs -l
rm /etc/pve/corosync.conf
rm /etc/corosync/*
rm /var/lib/corosync/*
rm -rf /etc/pve/nodes/*
|
1 |
pmxcfs-l rmetcpvecorosync.conf rmetccorosync* rmvarlibcorosync* rm-rfetcpvenodes* |
Перезагружаем ноду т.к. поднять остановленные сервисы у Вас врятли получится без перезагрузки.
![Proxmox:как-убить-машину-которая-не-хочет-выключаться [wiki.autosys.tk]](https://tehnikaarenda.ru/wp-content/uploads/1/7/5/175f749fbc06daee9ecd79cf6c62671e.jpeg)

![Proxmox:как-убить-машину-которая-не-хочет-выключаться [wiki.autosys.tk]](https://tehnikaarenda.ru/wp-content/uploads/7/7/6/7769a3f7d6470545742b6582007ddefd.jpeg)
Резервная копия конфигурации ноды
Заходим на сервер по SSH, смотреть на pvecm status особого смысла нет т.к. все у нас лежит. На всякий случай делаем бэкап того, что мы имеем:
mkdir /root/pve-backup && cp -r /etc/pve/{storage.cfg,nodes}
| 1 | mkdirrootpve-backup&&cp-retcpve{storage.cfg,nodes} |
Бывает, что /etc/pve не доступен из-за падения служб или их зависанием. Настоятельно рекомендую добиться того, чтобы скопировать текущие файлы кластера перезапустив кластер systemctl restart pve-cluster.service. После перезапуска пытаемся сделать резервную копию. Если не получилось идем на другой сервер который в этом кластере и пытаемся сделать тоже самое т.к. если кластер работал то конфигурация машин и хранилища будут всех нод.