
Введение
У меня есть целый цикл статей про настройку и эксплуатацию ELK Stack для сбора логов с различных приложений. Так же я подробно рассказал, как установить и настроить ELK Stack себе, если у вас есть под него мощности и компетенции. В целом, там нет чего-то сильно сложного, но тем не менее, все равно необходимо повозиться, чтобы все заработало.
Не обязательно все это разворачивать и настраивать у себя, если хочется просто попробовать продукт, чтобы понять, нужен он вам или нет. Есть сервис — https://cloud.elastic.co, где можно за 2 минуты зарегистрировать и развернуть свой стэк на базе Elasticsearch и Kibana. Отличие от описанного мной способа разворачивания стека в том, что тут не будет Logstash. Во многих случаях можно обойтись без него, так что это не критично. Особенно для того, чтобы просто попробовать.
Итак, прежде чем приступить к настройке, зарегистрируйтесь в облаке и активируйте учетную запись.
Запуск Elastic Stack в Elastic Cloud
При первом входе в личный кабинет у вас будет возможность создать Deployment с Elasticsearch.
Дальше нужно выбрать платформу, где вы хотите произвести установку сервиса, и регион. Я для теста выбрал Google Cloud Platform во Frankfurt. Все остальное оставил по дефолту. Дальше внизу жмете Create Deployment и ждете, когда он развернется. Обычно 2-3 минуты.
Дожидаемся окончание процесса установки и переходим в Kibana.
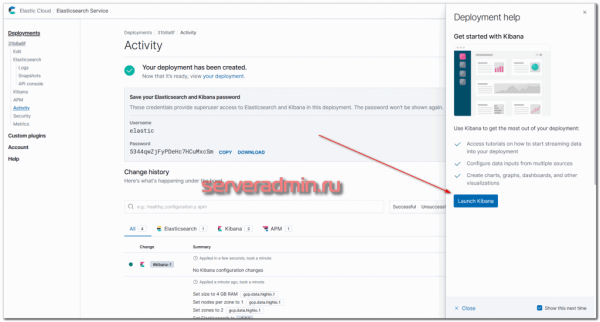
Логинимся в Kibana с учетными данными, которые указаны в личном кабинете, в Deployment. Username обычно elastic и какой-то пароль. При первом входе вам предложат залить набор демо данных, чтобы посмотреть функционал системы. Если хотите — посмотрите. Я там и так все видел, поэтому отказываюсь Буду лить свои логи от apache.

После выбора оказываетесь на главной странице Kibana. По сути Elastic Stack вы уже развернули и он готов принимать данные. Вот так, быстро и просто все настроилось. И DevOps не нужен
Можете тут осмотреться и познакомиться с системой.
Смотрим полученные данные в Kibana
Открываем Kibana, в верхнем левом углу нажимаем меню и в секции выбираем . Далее слева выбираем и нажимаем кнопку . В поле описываем шаблон , в который попадут все индексы, начинающиеся с logstash.
Создание шаблона индекса
Жмем и выбираем поле , чтобы иметь возможность фильтровать данные по дате и времени. После жмем :
Выбор Time field
После создания шаблона индексов Kibana покажет информацию об имеющихся полях, типе данных и возможности делать агрегацию по этим полям.
Чтобы посмотреть полученные данные на основе созданного шаблона нажимаем меню и в секции выбираем .
Kibana Discover
В правой части экрана можно выбрать интервал в рамках которого отображать данные.
Выбор временного интервала
В левой часте экрана можно выбрать шаблон индекса или поля для отображения из списка . При нажатии на доступные поля можно получить топ-5 значений.
Шаблон индекса и доступные поля
Для фильтрации данных можно использовать . Запрос пишется в поле . Запросы можно сохранять, чтобы использовать их в будущем.
Фильтрация данных с помощью KQL
Для визуализации полученных данных нажимаем меню и в секции выбираем . Нажав , откроется окно с перечнем доступных типов визуализации.
Типы визуализации Kibana
Для примера выбираем , чтобы построить круговую диаграмму. В качестве источника данных выбираем шаблон индексов . В правой части в секции жмем , далее — . Тип агрегации выбираем , поле . Жмем в правом нижнем углу и получаем готовую диаграмму. В секции можно добавить отображение данных или изменить вид диаграммы.
Круговая диаграмма
Чтобы посмотреть данные в Elasticsearch необходимо сделать запрос к любому узлу кластера. Добавление параметра позволяет отобразить данные в читабельном виде. По умолчанию вывод состоит из 10 записей, чтобы увеличить это количество необходимо использовать параметр :
Заключение
В рамках этой статьи была рассмотрена процедура установки и настройки Kibana и Logstash, настройка балансировки трафика между Kibana и Elasticsearch и работа нескольких экземпляров Kibana. Собрали первые данные с помощью Logstash, посмотрели на данные с помощью и построили первую визуализацию.
Прежде чем углубляться в изучение плагинов Logstash, сбор данных с помощью Beats, визуализацию и анализ данных в Kibana, необходимо уделить внимание очень важному вопросу безопасности кластера. Об этом также постоянно намекает Kibana, выдавая сообщение
Теме безопасности будет посвящена следующая статья данного цикла.
Elasticsearch Интерналс
Он работает даже если его не трогать. Пусть работает. Главное не забывать писать в отдельные индексы:
index => "uat-svc-%{+YYYY.MM.dd}"
Перформенс будет теряться на больших или размазанных выборках. Не нужно пытаться серчить все ерроры за миллион лет, ищите точное вхождение нужного ексепшена, который вызвал этот еррор.
С Еластиком интегрится очень много крутых штук. Например, для понимания того что происходит внутри еластика отлично подходит elasticsearch-kopf, с помощью его можно смотреть стату по всему кластеру: ноды/индексы/шарды/ресурсы/маппинги.
Очень интересно интегрироваться с Grafana, и потом рисовать, например, персентили скорости ответа нжинкса хомяка.
Реальный ip адрес посетителя bitrix в логах apache
Если вы используете преднастроенное окружение bitrixenv, то ничего особенного для вывода реального ip адреса в лог apache делать не надо. Напомню, для тех, кто не в курсе, о чем идет речь. Bitrixenv — набор рецептов ansible, которые автоматически разворачивают веб сервер на основе nginx и apache. На nginx приходят все запросы клиентов, а дальше проксируются на apache для исполнения php кода. Если ничего дополнительно не настраивать, то в логах apache все запросы будут с ip адреса 127.0.0.1.
При этом, в bitrixenv в настройках nginx для сайтов указано, что реальный ip адрес посетителя надо записывать в отдельный заголовок.
В apache можно взять информацию из этого заголовка и поместить сразу в лог файл.
Все, этого достаточно, чтобы в лог файле apache выводился реальный ip адрес посетителя. Теперь разберемся с session id.
4: Генерирование логов контейнера Docker
Docker может воспринимать логи как потоки данных через стандартный вывод (STDOUT) и поток ошибок (STDERR). Запуская приложение Docker, настройте Docker для использования встроенного драйвера Fluentd. Сервис Fluentd будет получать логи и передавать их в Elasticsearch.
Запустите в контейнере Docker такую команду:
Команда должна передать на стандартный вывод фразу Hello world, которая также будет перехвачена драйвером Fluentd и передана сервисом в указанное ранее место. Примерно через пять секунд записи будут сброшены в Elasticsearch. Этот интервал был настроен в разделе match конфигурационного файла Fluentd.
Теперь логи передаются в Elasticsearch.
Более подробную информацию можно найти в официальной документации Docker.
Осталось только убедиться, что Elasticsearch получает данные. Отправьте запрос с помощью curl:
Вывод будет содержать такие события:
Список событий может отличаться. Список начинается с {“took”: и заканчивается временной меткой. Здесь вы найдёте дополнительную информацию об исходном контейнере.
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch.yml. На начальном этапе нас будут интересовать следующие параметры:
path.data: /var/lib/elasticsearch # директория для хранения данных network.host: 127.0.0.1 # слушаем только локальный интерфейс
По умолчанию Elasticsearch слушает localhost. Нам это и нужно, так как данные в него будет передавать logstash, который будет установлен локально
Обращаю отдельное внимание на параметр для директории с данными. Чаще всего они будут занимать значительное место, иначе зачем нам Elasticsearch  Подумайте заранее, где вы будете хранить логи
Подумайте заранее, где вы будете хранить логи
Все остальные настройки я оставляю дефолтными.
После изменения настроек, надо перезапустить службу:
# systemctl restart elasticsearch.service
Смотрим, что получилось:
# netstat -tulnp | grep 9200 tcp6 0 0 127.0.0.1:9200 :::* LISTEN 1479/java
Elasticsearch повис на локальном интерфейсе. Причем я вижу, что он слушает ipv6, а про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Переходим к установке kibana.
Если вы хотите, чтобы elasticsearch слушал все сетевые интерфейсы, настройте параметр:
network.host: 0.0.0.0
Только не спешите сразу же запускать службу. Если запустите, получите ошибку:
node validation exception bootstrap checks failed: the default discovery settings are unsuitable for production use; at least one of must be configured
Чтобы ее избежать, дополнительно надо добавить еще один параметр:
discovery.seed_hosts: "]
Эти мы указываем, что хосты кластера следует искать только локально.
Делаем важные настройки
Для нормальной работы кластера необходимо произвести еще некоторые настройки.
Heap size
Так как Elasticsearch написан на Java, то для работы необходимо настроить размер «кучи» (). В каталоге установки Elasticsearch имеется файл , в котором уже указаны размеры, по умолчанию — это 1 Гб. Однако, для настройки рекомендуется указать новые параметры в файле каталога , который находится там же.
Пример выше использует минимальный и максимальный размер , равный 16 Гб. Для настройки данных параметров следует использовать следующие рекомендации:
-
установите значения и не более 50% от имеющейся физической памяти узла. Оставшуюся память Elasticsearch будет использовать для других целей. Чем больше , тем меньше памяти используется под системные кеш;
-
устанавите значение не более того значения, которое использует для сжатия указателей, он же . Данное значение составляет около 32 Гб. Стоит также отметить, что рекомендуется ограничивать еще одним параметром , а именно (обычно размер около 26 Гб). Узнать подробнее об этих параметрах можно тут.
Отключаем подкачку
Подкачка негативно сказывается на производительности и стабильности работы Elasticsearch, ведь система может выгрузить страницы на диск. Есть несколько вариантов работы с подкачкой:
-
Полное отключение подкачки. Перезапуск Elasticseach при этом не требуется.
-
Ограничение подкачки через значение для .
-
Использование для блокировки адресного пространства в оперативной памяти.
Чтобы включить в конфигурации Elasticseach указываем для параметра значение .
Перезапускаем Elasticsearch и проверяем настройки через запрос к любому узлу:
Если перезапуск Elasticsearch завершился ошибкой вида:
или проверка показывает, что данная настройка не применилась, необходимо сделать следующее в зависимости от способа установки:
Установка из архива
Установите перед запуском Elasticsearch или значению устанвоите в файле .
Установка из пакета RPM или Deb
Установите значение параметра как в для или для .
Если вы используете для запуска Elasticsearch, то лимиты должны быть указаны через настройку параметра . Для этого выполните команду:
и укажите следующее значение:
Настройка файловых дескрипторов
Elasticsearch работает с большим количеством файловых дескрипторов, и их нехватка может катастрофически сказаться на его работе. Согласно официальной документации необходимо указать значение файловых дескрипторов не ниже 65 536.
-
Если Elasticsearch установлен из или пакетов, то настройка не требуется.
-
Для установки из архива необходимо в файле установить параметр для пользователя, который осуществляет запуск Elasticsearch. В примере ниже таким пользователем является :
Проверить установленные значения можно следующим образом:
Настройка виртуальной памяти
Elasticsearch по умолчанию использует каталог для хранения индексов, и ограничение операционной системы по умолчанию для счетчиков может привести к нехватки памяти. Для настройки запустите из-под следующую команду:
Чтобы настройка сохранилась после перезапуска системы, необходимо указать параметр в файле .
Если Elasticsearch установлен из или пакетов, то настройка не требуется.
Настройка потоков
Необходимо убедиться, что количество потоков, которые Elasticsearch может создавать, было не менее 4096.
Это можно сделать, установив или установив значение равным 4096 в файле .
Если Elasticsearch работает под управлением , то настройка не требуется.
DNS кеширование
По умолчанию Elasticsearch кеширует результат DNS на 60 и 10 секунд для положительных и отрицательных запросов. В случае необходимости можно настроить эти параметры, а именно и , как опции в каталоге для и или в для установки из архива.
1: Установка Fluentd
Обычно для развёртывания Fluentd используется пакет td-agent. Компания Treasure Data, автор Fluentd, упаковывает Fluentd с Ruby, так что пользователям не нужно устанавливать Ruby самостоятельно.
Чтобы установить td-agent, загрузите сценарий:
Вы можете просмотреть содержимое сценария, прежде чем запустить его.
Запустите установку td-agent:
После завершения установки запустите td-agent:
Чтобы убедиться, что пакет установлен успешно, проверьте логи:
Команда вернёт примерно такой вывод:
Теперь нужно установить плагин Elasticsearch для Fluentd с помощью команды td-agent-gem:
Примечание: Также программа Fluentd доступна в качестве gem-а Ruby. Если у вас уже есть среда Ruby, вы можете установить Fluentd и Elasticsearch с помощью команд:
Какую задачу мы решали?
Можно долго рассуждать о важности серверных логов и привести много примеров ситуаций, в которых они жизненно необходимы, но так как речь пойдет именно о сторонней системе и ее особенностях, то выделим ряд важных моментов:
-
Удобно, когда все логи хранятся в одном месте.
-
Круто, когда есть отчеты и возможность автоматически их проанализировать.
-
Полезно, когда логи можно посмотреть даже при “упавшем” сервере или после того как злоумышленник “прибрался” за собой.
-
Бесценно, когда о возникшей ошибке в логах будет оповещение.
Сформулировали задачу так:
“Подобрать бесплатное open source решение для сбора и анализа логов, не перегруженное функционалом, производительное, простое в установке и использовании.”
Клиентская часть (Агент)
Рассмотрим пример доставки лога от Docker контейнера.
Есть два варианта (на самом деле их больше ) как писать лог Docker контейнеров. В своем дефолтном состоянии, используется Logging Driver — “JSON file”, т.е. пишет классическим методом в файл. Второй способ — это переопределить Logging Driver и слать лог сразу в Fluentd.
Решили мы попробовать второй вариант.
Далее столкнулись с такой проблемой, что если просто сменить Logging Driver и, если вдруг, TCP сокет Fluentd, куда должны сыпаться логи, не доступен, то контейнер вообще не запустится. А если TCP сокет Fluentd пропадет, когда контейнер ранится, то логи начинают копиться в буфер.
Происходит это потому, что у Docker есть два режима доставки сообщений от контейнера к Logging Driver:
direct — является дефолтным. Приложение падает, когда не может записать лог в stdout и/или stderr.
non-blocking — позволяет записывать логи приложения в буфер при недоступности сокета коллектора. При этом, если буфер полон, новые логи начинают вытеснять старые.
Все эти вещи подтянули дополнительными опциями Logging Driver (—log-opt).
Но, так как нас не устроил ни первый, ни второй вариант, то мы решили не переопределять Logging Driver и оставить его дефолтным.
Вот тут и настал момент, когда мы задумались о том, что необходимо устанавливать агента, который бы старым, добрым способом вычитывал с помощью tail лог файл. Кстати, я думаю не все задумывались над тем, что происходит с tail, когда ротейтится лог-файл, а оказалось все достаточно просто, так как tail снабжен ключем -F (same as —follow=”name” —retry), который способен следить за файлом и переоткрывать его в случае необходимости.
Итак, первое на что было обращено внимание — это продукт FluentBit. Настройка FluentBit достаточна проста, но мы столкнулись с несколькими неприятными моментами
Настройка FluentBit достаточна проста, но мы столкнулись с несколькими неприятными моментами.
Проблема заключалась в том, что если TCP сокет коллектора не доступен, то FluentBit начинает активно писать в буфер, который находится в памяти и по мере его заполнения, начинает вытеснять (перезаписывать) лог, до тех пор, пока не восстановит соединение с коллектором, а следовательно, мы теряем логи. Это не критикал, но крайне неприятно.
Решили эту проблему следующим образом.
FluentBit в tail плагине имеет следующие параметры:
DB — определяет файл базы данных, в котором будет вестись учет файлов, которые мониторятся, а также позицию в этих файлах (offsets).
DB.Sync — устанавливает дефолтный метод синхронизации (I/O). Данная опция отвечает за то, как внутренний движок SQLite будет синхронизироваться на диск.
И стало все отлично, логи мы не теряли, но столкнулись со следующей проблемой — эта штука очень жутко начала потреблять IOPs
Обратили на это внимание когда заметили, что инстансы начали тупить и упираться в IO, которого раньше хватало за глаза и сейчас объясню почему
Мы используем EC2 инстансы (AWS) и тип EBS — gp2 (General Purpose SSD). У них есть такая штука, которая называется “Burst performance”. Это когда EBS способен выдерживать некоторые пики возрастающей нагрузки на файловую систему, например запуск какой-нибудь крон задачи, которая требует интенсивного IO и если ему недостаточно “baseline performance”, инстанс начинает потреблять накопленные кредиты на IO т.е. “Burst performance”.
Так вот, наша проблема заключалась в том, что были вычерпаны кредиты IO и EBS начал захлебываться от его недостатка.
Ок. Пройденный этап.
После этого мы решили, а почему бы не использовать тот же Fluentd в качестве агента.
2: Установка и настройка Kibana
Согласно официальной документации, устанавливать Kibana следует только после Elasticsearch. Такой порядок гарантирует, что все зависимые друг от друга программы будут установлены правильно.
Поскольку вы уже добавили исходный список Elastic, сейчас вы можете просто установить остальные компоненты стека с помощью apt:
Чтобы включить сервис Kibana, введите:
Поскольку Kibana прослушивает только локальный хост, нужно настроить обратный прокси-сервер, чтобы разрешить внешний доступ к сервису. Для этой цели мы будем использовать Nginx, который уже должен быть установлен на вашем сервере (согласно требованиям к мануалу).
Сначала используйте команду openssl, чтобы создать администратора Kibana, которого вы будете использовать для доступа к веб-интерфейсу. В качестве примера назовем эту учетную запись kibanaadmin, но для большей безопасности рекомендуется выбрать нестандартное имя, которое будет сложно угадать.
Следующая команда создаст администратора и пароль Kibana и сохранит их в файле htpasswd.users. Nginx будет запрашивать это имя и пароль в этом файле (скоро мы настроим это).
Введите и подтвердите пароль в командной строке. Запомните эти данные, так как они понадобятся вам для доступа к веб-интерфейсу Kibana.
Далее нужно создать файл блока server Nginx. Мы используем условный домен your_domain, но вы можете выбрать более описательное имя. Например, если у сервера есть FQDN и DNS-записи, вы можете назвать этот файл своим доменным именем:
Добавьте следующий блок кода в файл, обязательно заменив your_domain доменом или IP-адресом вашего сервера. Благодаря этому Nginx будет направлять HTTP-трафик сервера в приложение Kibana, которое прослушивает localhost:5601. Кроме того, Nginx теперь будет читать файл htpasswd.users и требовать базовой аутентификации.
Обратите внимание: если вы до конца выполнили мануал по Nginx (из требований), вероятно, вы уже создали такой файл и заполнили его некоторым кодом. В этом случае удалите все существующее содержимое в файле, а потом добавьте такой код
Сохраните и закройте файл.
Включите новую конфигурацию, добавив симлинк в каталог sites-enabled. Если вы создали файл блока server с таким же именем ранее, вам не нужно делать этого.
Проверьте ошибки в файле:
Если в выводе команда сообщает об ошибках, вернитесь в файл и проверьте код, который вы поместили в файл конфигурации. Исправив ошибки, снова запустите команду (в выводе должно быть syntax is ok ) и перезапустите Nginx:
Если вы следовали мануалу по начальной настройке сервера, у вас должен быть включен брандмауэр UFW. Чтобы разрешить подключения к Nginx, нужно настроить брандмауэр, набрав:
Примечание: Если вы следовали мануалу по установке Nginx, вероятно, ранее вы создали правило UFW, разрешающее профиль HTTP Nginx. Поскольку профиль Nginx Full поддерживает трафик HTTP и HTTPS, вы можете просто удалить это правило с помощью следующей команды:
Сервис Kibana теперь доступен по вашему домену или внешнему IP-адресу сервера Elastic Stack. Вы можете проверить страницу состояния сервера Kibana, перейдя по следующему адресу и введя свои учетные данные:
На странице вы увидите информацию об использовании ресурсов и установленных плагинах.
Примечание: В требованиях упоминалось, что сервер нужно защитить с помощью сертификата SSL/TLS. Сейчас самое время сделать это. Инструкции можно найти здесь.
5: Дашборды Kibana
Теперь давайте посмотрим, как работает Kibana.
В браузере откройте FQDN или внешний IP сервера Elastic. Введите свои учетные данные из раздела 2, и вы попадете на домашнюю страницу Kibana.
Нажмите Discover в левой панели навигации. На странице Discover выберите предопределенный шаблон индекса filebeat-*, чтобы увидеть данные Filebeat. По умолчанию будут показаны все данные лога за последние 15 минут. Вы увидите гистограмму с событиями и некоторыми сообщениями лога.
Здесь вы можете искать и просматривать логи, а также настраивать дашборды. На данный момент, однако, там не будет много данных, потому что сейчас отображаются только системные логи сервера Elastic Stack.
Используйте левую панель, чтобы перейти на страницу Dashboard и выполнить поиск по Filebeat System. Оказавшись там, вы можете искать примеры дашбордов, которые поставляются с модулем system.
Например, вы можете просмотреть подробную статистику на основе ваших сообщений системного лога или узнать, какие пользователи и когда использовали команду sudo.
У Kibana есть много других функций, таких как построение графиков и фильтров. Исследуйте их самостоятельно.
1: Установка и настройка Elasticsearch
Компоненты стека Elastic не доступны в стандартных репозиториях Ubuntu. Но их можно установить с помощью APT, если добавить исходный список Elastic.
Все пакеты Elastic Stack подписаны с помощью ключа Elasticsearch, чтобы защитить систему от подделки пакетов. Пакеты, прошедшие проверку подлинности с использованием ключа, будут считаться вашим менеджером пакетов доверенными. На этом этапе мы импортируем открытый ключ GPG Elasticsearch и добавим исходный список пакета Elastic для установки Elasticsearch.
Используйте инструмент командной строки cURL, чтобы импортировать открытый ключ GPG Elasticsearch в APT
Обратите внимание, что мы используем аргументы -fsSL, чтобы подавить вывод о прогрессе и потенциальных ошибках (кроме сбоя сервера) и позволить cURL перенаправить запрос. Мы направляем вывод команды cURL в apt-key, которая добавляет открытый ключ GPG в APT
Затем добавьте список Elastic в каталог sources.list.d, где менеджер apt будет искать новые пакеты.
Обновите индекс пакетов:
Теперь просто установите Elasticsearch.
После установки Elasticsearch откройте текстовый редактор, чтобы отредактировать главный конфигурационный файл Elasticsearch, elasticsearch.yml. Здесь мы будем использовать nano:
sudo nano /etc/elasticsearch/elasticsearch.yml
Примечание: Конфигурационный файл Elasticsearch пишется в формате YAML, а это означает, что отступы очень важны. Убедитесь, что при редактировании этого файла не появились лишние пробелы.
Файл elasticsearch.yml предоставляет параметры конфигурации для вашего кластера, нод, путей, памяти, сети, обнаружения и шлюзов. Большинство этих параметров имеет стандартное значение, но вы можете изменить их в соответствии с вашими потребностями. Для кластера, состоящего из одного сервера, мы изменим настройки только для сетевого хоста.
Elasticsearch прослушивает трафик через порт 9200. Нужно ограничить внешний доступ к экземпляру Elasticsearch, чтобы запретить посторонним пользователям читать ваши данные или не дать остановить работу кластера Elasticsearch через REST API. Найдите строку network.host, раскомментируйте ее и замените ее значение на localhost, чтобы она выглядела следующим образом:
Мы указали localhost, чтобы Elasticsearch прослушивал все интерфейсы и привязанные к ним IP-адреса. Если вы хотите, чтобы он прослушивал только определенный интерфейс, вы можете указать его IP вместо localhost. Сохраните и закройте файл.
Это минимальная настройка, необходимая для запуска Elasticsearch.
Теперь вы можете впервые запустить сервис Elasticsearch с помощью systemctl:
Затем добавьте сервис в автозагрузку, чтобы Elasticsearch запускался при каждой загрузке вашего сервера:
Убедитесь, что сервис Elasticsearch работает, отправив HTTP-запрос:
Вы увидите основную информацию о вашем локальном хосте:
Поисковая система Elasticsearch установлена и запущена.
Сбор windows логов
Приступим к настройке. последнюю версию winlogbeat на сервер, с которого мы будем отправлять логи в elk stack. Вот конфиг с тестового сервера, по которому пишу статью:
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: Security
- name: System
tags:
output.logstash:
hosts:
logging.level: info
logging.to_files: true
logging.files:
path: C:/Program Files/Winlogbeat/logs
name: winlogbeat
keepfiles: 7
Теперь настраивает logstash на прием этих логов. Добавляем в конфиг:
else if "winsrv" in {
elasticsearch {
hosts => "localhost:9200"
index => "winsrv-%{+YYYY.MM}"
}
}
Я формирую месячные индексы с логами windows серверов. Если у вас очень много логов или хотите более гибкое управление занимаемым объемом, то делайте индексы дневные, указав winsrv-%{+YYYY.MM.dd}.
Перезапускайте службы на серверах и ждите поступления данных в elasticsearch.
Установка Elasticsearch
Устанавливаем ядро системы по сбору логов — Elasticsearch. Его установка очень проста за счет готовых пакетов под все популярные платформы.
Centos 7 / 8
Копируем публичный ключ репозитория:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Подключаем репозиторий Elasticsearch:
# mcedit /etc/yum.repos.d/elasticsearch.repo
name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md
Приступаем к установке еластика:
# yum install --enablerepo=elasticsearch elasticsearch
В в завершении установки добавим elasticsearch в автозагрузку и запустим его с дефолтными настройками:
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустилась ли служба:
# systemctl status elasticsearch.service
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос о его статусе.
# curl 127.0.0.1:9200
{
"name" : "centos8",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "zsYgZQSeT6uvhTCkFJPiAA",
"version" : {
"number" : "7.11.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "8ced7813d6f16d2ef30792e2fcde3e755795ee04",
"build_date" : "2021-02-08T22:44:01.320463Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Все в порядке, сервис реально запущен и отвечает на запросы.
Ubuntu / Debian
Копируем себе публичный ключ репозитория:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Если у вас нет пакета apt-transport-https, то надо установить:
# apt install apt-transport-https
Добавляем репозиторий Elasticsearch в систему:
# echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
Устанавливаем Elasticsearch на Debian или Ubuntu:
# apt update && apt install elasticsearch
После установки добавляем elasticsearch в автозагрузку и запускаем.
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустился ли он:
# systemctl status elasticsearch.service
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос о его статусе.
# curl 127.0.0.1:9200
{
"name" : "debioan10",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "zsYgZQSeY6uvhWCkFJPiAA",
"version" : {
"number" : "7.11.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "8ced7813d6f16d2ef30792e2fcde3e755795ee04",
"build_date" : "2021-02-09T21:44:01.320413Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Если все в порядке, то переходим к настройке Elasticsearch.
Filebeat Интерналс
Он простой. Filebeat на гитхабе — написан на Go, легковесный, работает стабильнее чем старый Logstash forwarder.
Главное в директивах конфига:
filebeat
prospectors
-
paths
- /opt/tomcat/logs/catalina.out
input_type log
document_type java
tail_files true
scan_frequency 1s
backoff 1s
output
logstash
hosts "logstash:port"
tls
certificate_authorities "/etc/filebeat/filebeat.crt"
insecure false
logging
to_files true
files
path /var/log/filebeat
name filebeat.log
rotateeverybytes 1048576000
level info
В конфигах нужно указать путь к лог файлу, дать тип для этого типа логов, и настроить урлу логстеша, куда он будет отсылать. Все.
Настраиваем аутентификацию
Elasticsearch имеет несколько :
|
Пользователь |
Описание |
|
elastic |
Суперпользователь |
|
kibana_system |
Используется для коммуникации между Kibana и Elasticsearch |
|
logstash_system |
Пользователь, которого использует Logstash сервер, когда сохраняет информацию в Elasticsearch |
|
beats_system |
Пользователь, которого использует агент Beats, когда сохраняет информацию в Elasticsearch |
|
apm_system |
Пользователь, которого использует APM сервер, когда сохраняет информацию в Elasticsearch |
|
remote_monitoring_user |
Пользователь Metricbeat, который используется при сборе и хранении информации мониторинга в Elasticsearch |
Прежде чем воспользоваться перечисленными пользователями, необходимо установить для них пароль. Для этого используется утилита . В режиме для каждого пользователя необходимо ввести пароли самостоятельно, в режиме Elasticsearch создаст пароли автоматически:
Попробуем сделать API запрос к любому узлу Elasticsearch с использованием учетной записи и пароля к от неё:
Как видно из примера все работает, но мы обращались через , значит трафик между клиентом и кластером Elasticsearch не шифрованный.
Заключение
Вот и все. Мы очень быстро и просто настроил сбор логов в Elastic Stack, используя триальный период в 14 дней. Этого будет достаточно, чтобы протестировать продукт и понять, нужен ли он вам. Далее вы можете либо выбрать платный тарифный план в облаке, либо собрать все на своих мощностях.
В стандартном деплойменте, который вы развернули для теста, используется кластер. Данные хранятся в двух различных сегментах облака, в третьем расположен мастер. И еще по виртуалке под Kibana и APM (мониторинг приложений). Если вам нужны только логи и нет необходимости настраивать отказоустойчивость, достаточно будет только виртуалки с Kibana и Elasticsearch. Собрать свой Deployment под задачи можно в самом начале, там, где мы выбирали готовый. При своей сборке сразу же будет видна ее стоимость в час. В целом, все удоволствие начинается от 16$ в месяц.
В следующем материале расскажу, как вывести id сессии посетителя Битрикс в лог файл и затем с помощью Kibana следить за его перемещениями по сайту.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Вывод Session ID посетителя Битрикс в лог apache
Каждому посетителю сайта на Битриксе прописывается в Cookie PHPSESSID с уникальным идентификатором сеанса. Он остается постоянным в рамках одного посещения. По крайней мере на первый взгляд это так. Я не занимался подробно исследованием того, как это работает. Задачи не стояло.
Идентификатор PHPSESSID мы и будем выводить в лог файл apache. Сделать это очень просто, так как apache по умолчанию умеет анализировать куки и выводить информацию из них в лог. Делается это вот так.
Если хотите вывести в лог все содержимое куки, то используйте такую конструкцию — %{Cookie}i. В нашем случае это излишне. Хватит только PHPSESSID. Перезапускаем apache и смотрим, что у нас будет в логе.
IP адрес и ID сессии присутствуют в логе. В данном случае ip адрес серый, потому что тестовое окружение настроено в локальной сети. Теперь нам нужно настроить grok фильтр elastic на парсинг измененного лог файла. Затем добавить новое поле в индекс elasticsearch, чтобы с ним можно было работать.



