
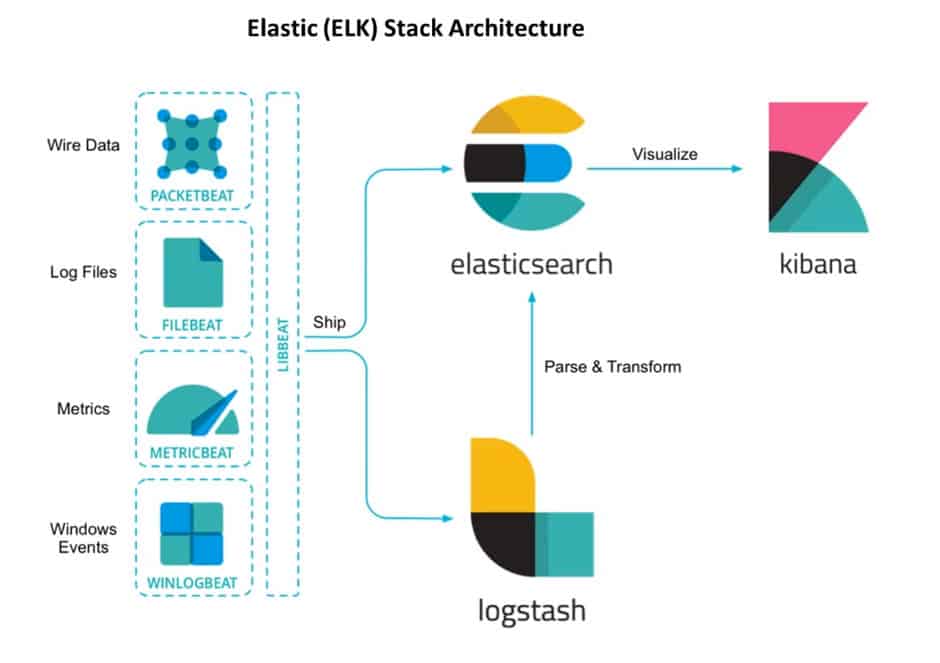
Введение
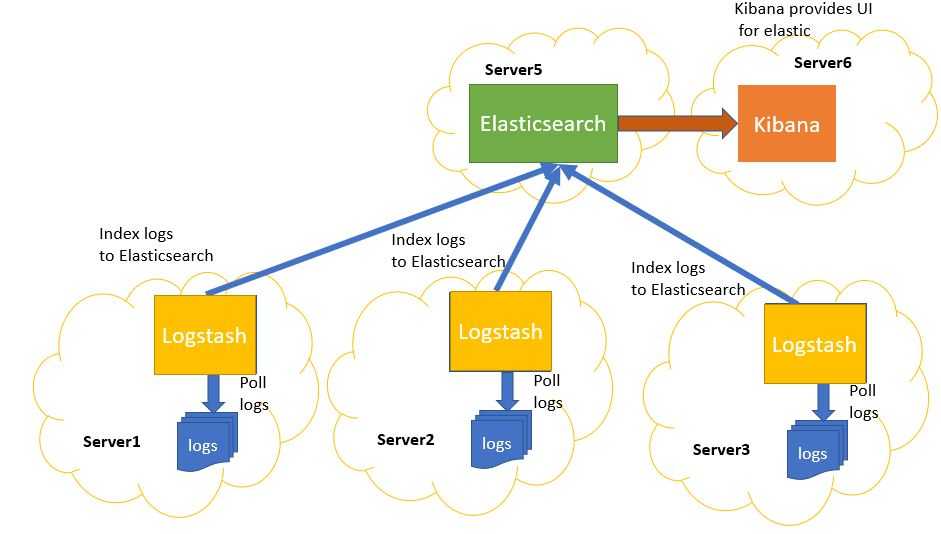
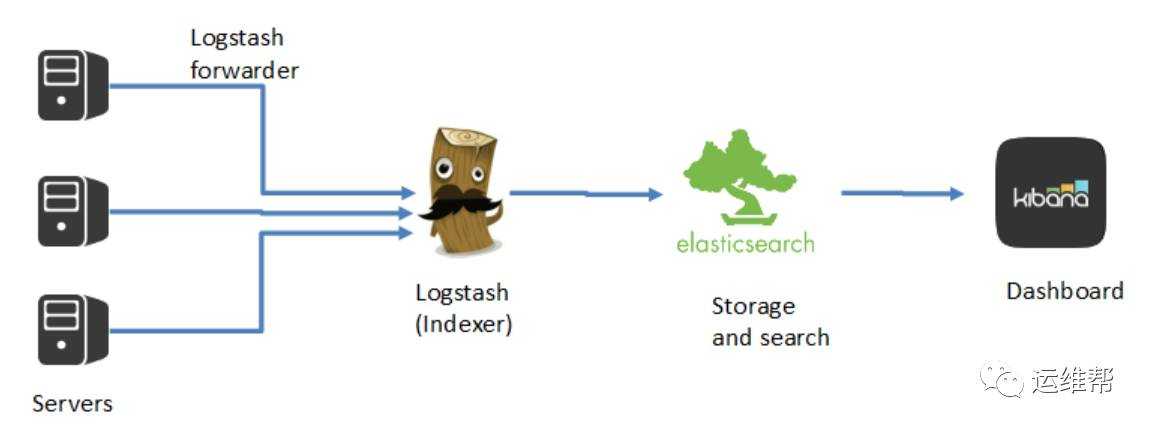
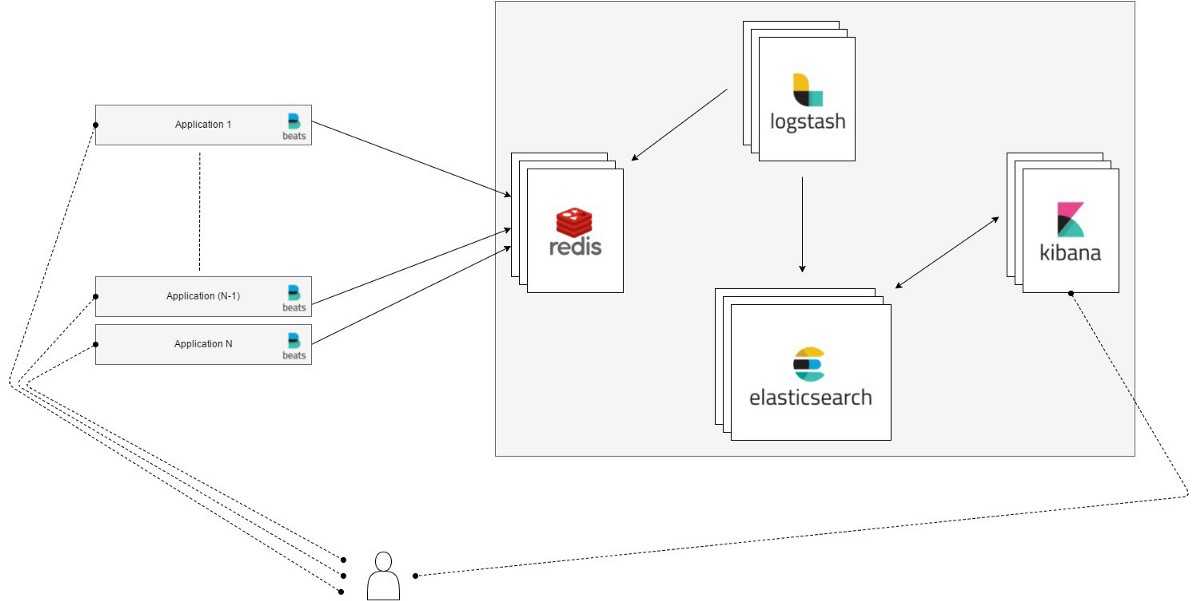
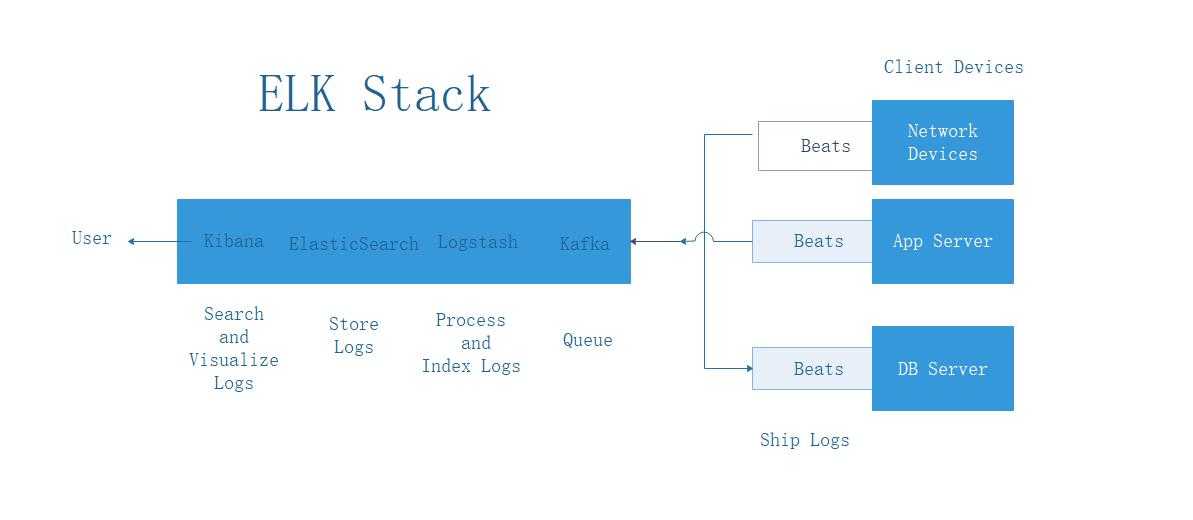
Ранее я рассказал, как установить и настроить elk stack, потом как загружать и анализировать логи nginx и samba. Теперь пришел черед логов Mikrotik. Я уже рассказывал, как отправлять логи микротика на удаленный syslog сервер, в качестве которого может выступать в том числе syslog-ng. В данном случае на самом микротике ничего особенного делать не надо. Будем точно так же отправлять данные на удаленный syslog сервер, в качестве которого будет трудиться logstash.
Я некоторое время рассуждал на тему парсинга и разбора логов. Но посмотрев на типичную картину стандартных логов mikrotik, понял, что ничего не выйдет. События очень разные и разобрать их одним правилом grok не получится. Если нужен парсинг и добавление метаданных к событиям, необходимо определенные события выделять и направлять отдельным потоком в logstash, где уже обрабатывать своим фильтром. Например, отдельный фильтр можно настроить на парсинг подключений к vpn или подключение по winbox с анализом имен пользователей.
Я же буду просто собирать все логи скопом и складывать в единый индекс. У записей не будет метаданных, по которым можно строить дашборды и анализировать данные. Но тем не менее, это все равно удобно, так как все логи в одном месте с удобным и быстрым поиском.
Подготовка сервера
Прежде чем начать, подготовим к установке и настройке наш сервер.
1. Установка wget
В процессе установки пакетов нам понадобиться скачивать установочные файлы. Для этого в системе должен быть установлен wget:
yum install wget
2. Настройка брандмауэра
Открываем порты для работы ELK:
firewall-cmd —permanent —add-port={5044,5601}/tcp
firewall-cmd —reload
где:
- 5044 — порт, на котором слушаем Logstash.
- 5601 — Kibana.
3. SELinux
Отключаем SELinux двумя командами:
setenforce 0
sed -i ‘s/^SELINUX=.*/SELINUX=disabled/g’ /etc/selinux/config
* первая команда выключит систему безопасности до перезагрузки сервера, вторая — навсегда.
Conclusion
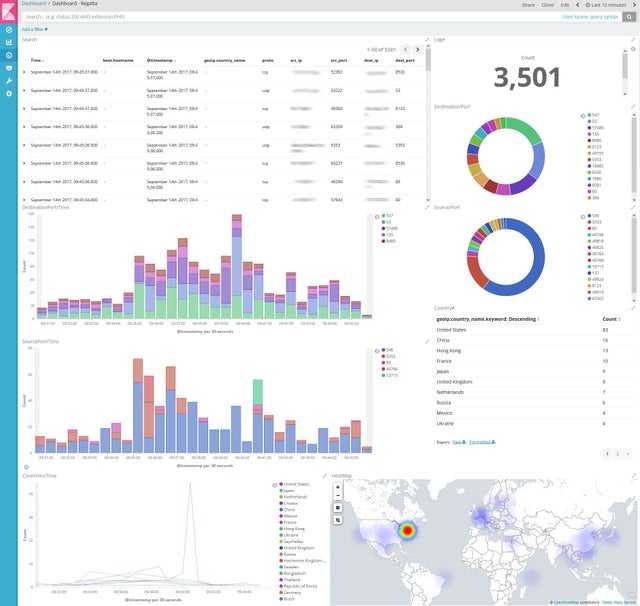
I have been thinking about dashboards for nginx logs for a long time. Draw graphics, select data. As a result, I stopped at this option. I couldn’t think of anything useful for output. By the way, the Geo card itself is more for beauty here. I don’t use it. I see no practical use in it. If you have advice on any other useful data that can be displayed – share. Of course, you can add information on user agents, systems and browsers. But it seems to me that it is more convenient to look at such things in third-party analytics. There will be more accurate data.
We should also add information on request_time, upstream_response_time, upstream_cache_status, etc. to the nginx logs. Then parse this information and make a separate dashboard for monitoring performance and upstream responses. But it will be a separate thing. And here I have provided general information for the primary analysis.
Генерирование SSL-сертификата
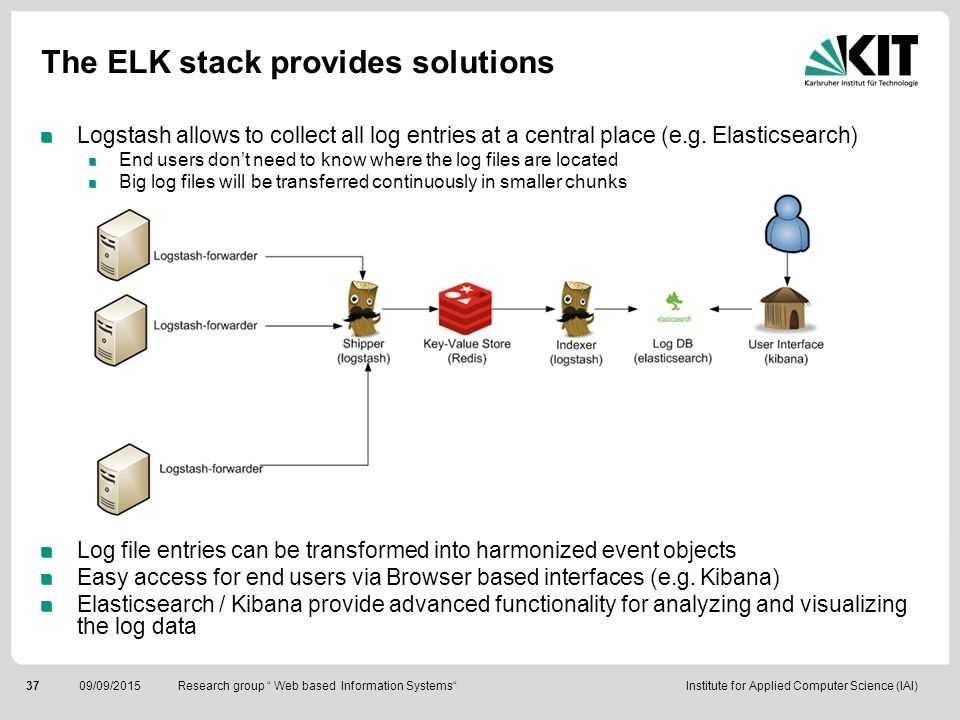
Чтобы сервис Logstash Forwarder передавал логи клиентов на сервер ELK, нужно создать SSL-сертификат и ключ. С помощью сертификата Logstash Forwarder сможет проверить подлинность сервера Logstash.
У вас есть два варианта: вы можете создать сертификат либо для IP-адреса, либо для доменного имени.
1: Сертификат для IP-адреса
Если у вас нет домена, вы можете указать в сертификате IP-адрес сертификата Logstash. Для этого укажите адрес в поле subjectAltName. Откройте конфигурационный файл OpenSSL.
Найдите в нём раздел и добавьте в него строку:
Примечание: Укажите IP своего сервера Logstash.
Сохраните и закройте файл.
Теперь вы можете сгенерировать SSL-сертификат и ключ в /etc/pki/tls/ с помощью команд:
Файл logstash-forwarder.crt будет скопирован на все серверы, которые отправляют логи в Logstash. После этого нужно завершить настройку Logstash.
2: Сертификат для домена
Если у вас есть доменное имя, направленное на сервер Logstash, вы можете указать это имя в сертификате SSL.
Чтобы сгенерировать сертификат, введите команду:
Примечание: Вместо logstash_server_fqdn укажите доменное имя сервера Logstash.
Файл logstash-forwarder.crt нужно скопировать на все серверы, которые отправляют логи в Logstash. После этого нужно завершить настройку Logstash.
Делаем важные настройки
Для нормальной работы кластера необходимо произвести еще некоторые настройки.
Heap size
Так как Elasticsearch написан на Java, то для работы необходимо настроить размер «кучи» (). В каталоге установки Elasticsearch имеется файл , в котором уже указаны размеры, по умолчанию — это 1 Гб. Однако, для настройки рекомендуется указать новые параметры в файле каталога , который находится там же.
Пример выше использует минимальный и максимальный размер , равный 16 Гб. Для настройки данных параметров следует использовать следующие рекомендации:
-
установите значения и не более 50% от имеющейся физической памяти узла. Оставшуюся память Elasticsearch будет использовать для других целей. Чем больше , тем меньше памяти используется под системные кеш;
-
устанавите значение не более того значения, которое использует для сжатия указателей, он же . Данное значение составляет около 32 Гб. Стоит также отметить, что рекомендуется ограничивать еще одним параметром , а именно (обычно размер около 26 Гб). Узнать подробнее об этих параметрах можно тут.
Отключаем подкачку
Подкачка негативно сказывается на производительности и стабильности работы Elasticsearch, ведь система может выгрузить страницы на диск. Есть несколько вариантов работы с подкачкой:
-
Полное отключение подкачки. Перезапуск Elasticseach при этом не требуется.
-
Ограничение подкачки через значение для .
-
Использование для блокировки адресного пространства в оперативной памяти.
Чтобы включить в конфигурации Elasticseach указываем для параметра значение .
Перезапускаем Elasticsearch и проверяем настройки через запрос к любому узлу:
Если перезапуск Elasticsearch завершился ошибкой вида:
или проверка показывает, что данная настройка не применилась, необходимо сделать следующее в зависимости от способа установки:
Установите перед запуском Elasticsearch или значению устанвоите в файле .
Установка из пакета RPM или Deb
Установите значение параметра как в для или для .
Если вы используете для запуска Elasticsearch, то лимиты должны быть указаны через настройку параметра . Для этого выполните команду:
и укажите следующее значение:
Настройка файловых дескрипторов
Elasticsearch работает с большим количеством файловых дескрипторов, и их нехватка может катастрофически сказаться на его работе. Согласно официальной документации необходимо указать значение файловых дескрипторов не ниже 65 536.
-
Если Elasticsearch установлен из или пакетов, то настройка не требуется.
-
Для установки из архива необходимо в файле установить параметр для пользователя, который осуществляет запуск Elasticsearch. В примере ниже таким пользователем является :
Проверить установленные значения можно следующим образом:
Настройка виртуальной памяти
Elasticsearch по умолчанию использует каталог для хранения индексов, и ограничение операционной системы по умолчанию для счетчиков может привести к нехватки памяти. Для настройки запустите из-под следующую команду:
Чтобы настройка сохранилась после перезапуска системы, необходимо указать параметр в файле .
Если Elasticsearch установлен из или пакетов, то настройка не требуется.
Настройка потоков
Необходимо убедиться, что количество потоков, которые Elasticsearch может создавать, было не менее 4096.
Это можно сделать, установив или установив значение равным 4096 в файле .
Если Elasticsearch работает под управлением , то настройка не требуется.
DNS кеширование
По умолчанию Elasticsearch кеширует результат DNS на 60 и 10 секунд для положительных и отрицательных запросов. В случае необходимости можно настроить эти параметры, а именно и , как опции в каталоге для и или в для установки из архива.
Предварительные требования
Для этого обучающего модуля вам потребуется следующее:
Сервер Ubuntu 20.04 с 4 ГБ оперативной памяти и 2 процессорами, а также настроенный пользователь без прав root с привилегиями sudo. Вы можете это сделать, воспользовавшись указаниями руководства Начальная настройка сервера Ubuntu 18.04. В этом обучающем руководстве мы будем использовать минимальное количество процессоров и оперативной памяти, необходимое для работы с Elasticsearch
Обратите внимание, что требования сервера Elasticsearch к количеству процессоров, оперативной памяти и хранению данных зависят от ожидаемого объема журналов.
Установленный пакет OpenJDK 11. Для настройки воспользуйтесь рекомендациями раздела in our guide в документе «Установка Java с помощью Apt в Ubuntu 20.04».
На сервере должен быть установлен Nginx, который мы позднее настроим как обратный прокси для Kibana
Для настройки следуйте указаниям нашего обучающего модуля «Установка Nginx в Ubuntu 20.04».
Кроме того, поскольку комплекс Elastic используется для доступа ценной информации о вашем сервере, которую вам нужно защищать, очень важно обеспечить защиту сервера сертификатом TLS/SSL. Это необязательно, но настоятельно рекомендуется
Однако поскольку вы будете вносить изменения в серверный блок Nginx в ходе выполнения этого обучающего модуля, разумнее всего будет пройти обучающий модуль «Let’s Encrypt в Ubuntu 18.04» после прохождения второго шага настоящего обучающего модуля. Если вы планируете настроить на сервере Let’s Encrypt, вам потребуется следующее:
- Полностью квалифицированное доменное имя (FQDN). В этом обучающем руководстве мы будем использовать your_domain. Вы можете купить доменное имя на Namecheap, получить его бесплатно на Freenom или воспользоваться услугами любого предпочитаемого регистратора доменных имен.
- На вашем сервере должны быть настроены обе нижеследующие записи DNS. В руководстве Введение в DigitalOcean DNS содержится подробная информация по их добавлению.
- Запись A, где your_domain указывает на публичный IP-адрес вашего сервера.
- Запись A, где www.your_domain указывает на публичный IP-адрес вашего сервера.
Создание API ключей
Для работы с Elasticsearch можно не только использовать учетные записи пользователей, но и генерировать API ключ. Для этого необходимо сделать запрос:
В качестве параметров указывают:
— имя ключа
— описание роли. Структура совпадает с на создание роли.
— Срок действия ключа. По умолчанию без срока действия.
Для примера заменим базовую аутентификацию в Logstash на API ключ.
Создаем API ключ в Kibana Dev Tool:
Получаем следующий результат:
Помещаем ключ в формате id:api_key в Keystore:
Указываем API ключ в конфигурационном файле конвейера:
Информацию по ключам можно получить в Kibana Menu > Management > API Keys или через API запрос:
Grok фильтр logstash для парсинга лога
Следующим шагом по настройке мониторинга ответа бэкенда является создание grok фильтра для logstash. Приведенный выше формат лога я парсю следующим grok фильтром. Привожу сразу весь конфиг logstash, который за него отвечает:
Привожу конфиг с рабочего сервера, который настраивал достаточно давно. Здесь выполняются следующие действия:
- grok фильтр парсит строки лога
- mutate конвертирует некоторые числовые поля в нужный формат, чтобы потом было удобнее работать
- ruby фильтр добавляет новое поле request_time_ms просто умножая значение из существующего request_time на 1000. Это делается для более удобной визуализации значений. Целые числа более наглядны для визуализации
- фильтр date берет время из поля access_time и использует его как время поступления лога в систему, заменяя @timestamp. Затем это поле удаляет, так как оно становится не нужно. Делается это для того, чтобы использовать только время из лога nginx, чтобы не было путаницы, когда порядок отправки логов по какой-то причине будет нарушен
- geoip фильтр используется для построения гео карты. Об этом я отдельно рассказывал в статье по настройке дашборда для nginx
Перезапускайте logstash и идите в Kibana проверять поступление логов в указанном формате. Если все сделали правильно, то должно получиться примерно следующее:
Возможности Fluent Bit
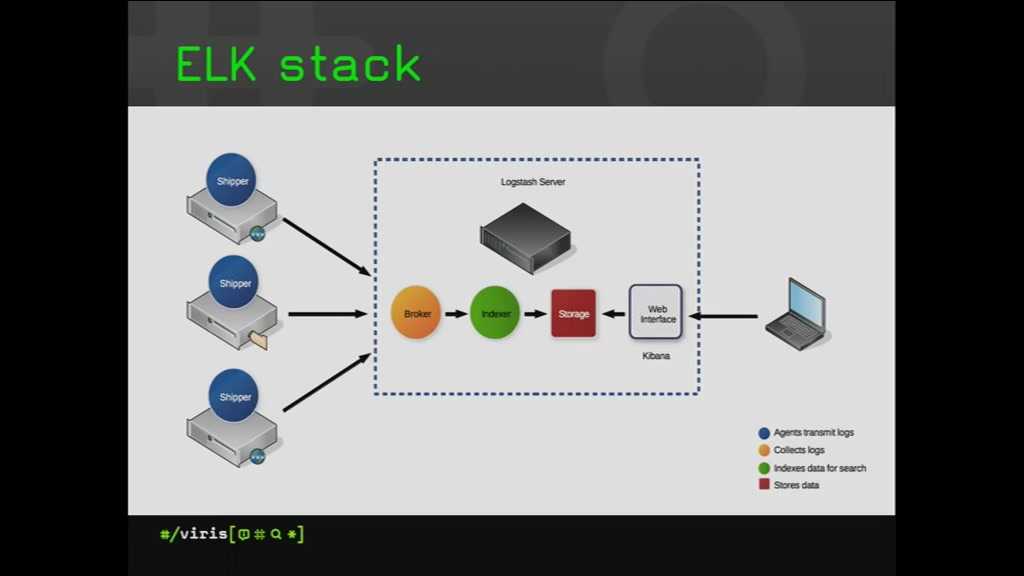
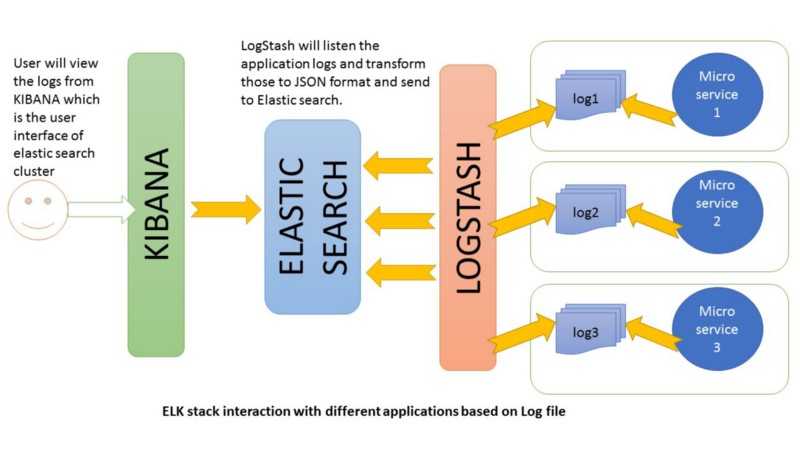
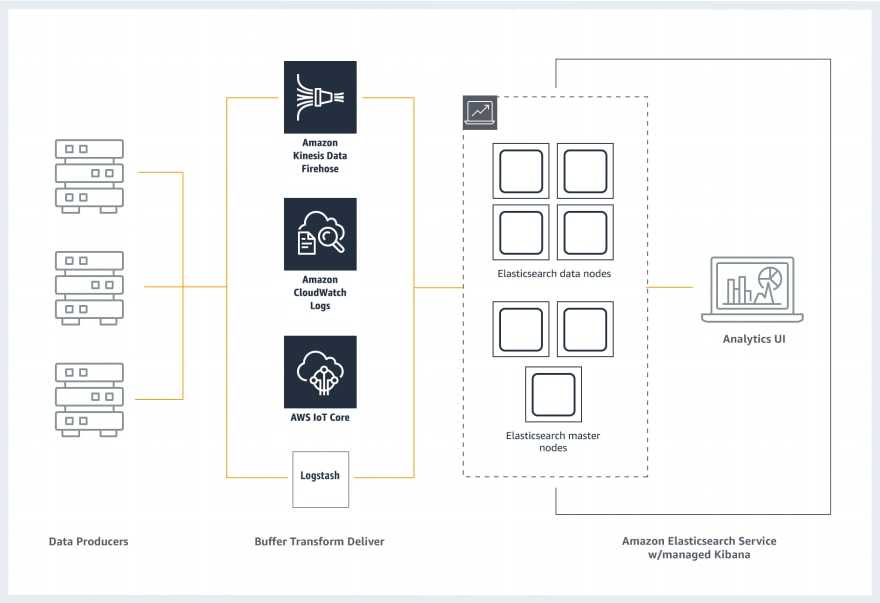
Так как о Fluent Bit, как правило, слышали меньше, чем о Logstash, рассмотрим его чуть подробнее. Fluent Bit логически можно поделить на 6 модулей, на часть модулей можно навесить плагины, которые расширяют возможности Fluent Bit.
Модуль Input собирает логи из файлов, служб systemd и даже из tcp-socket (надо только указать endpoint, и Fluent Bit начнёт туда ходить). Этих возможностей достаточно, чтобы собирать логи и с системы, и с контейнеров.
В продакшене мы чаще всего используем плагины tail (его можно натравить на папку с логами) и systemd (ему можно сказать, из каких служб собирать логи).
Модуль Parser приводит логи к общему виду. По умолчанию логи Nginx представляют собой строку. С помощью плагина эту строку можно преобразовать в JSON: задать поля и их значения. С JSON намного проще работать, чем со строковым логом, потому что есть более гибкие возможности сортировки.
Модуль Filter. На этом уровне отсеиваются ненужные логи. Например, на хранение отправляются логи только со значением “warning” или с определёнными лейблами. Отобранные логи попадают в буфер.
Модуль Buffer. У Fluent Bit есть два вида буфера: буфер памяти и буфер на диске. Буфер — это временное хранилище логов, нужное на случай ошибок или сбоев. Всем хочется сэкономить на ОЗУ, поэтому обычно выбирают дисковый буфер. Но нужно учитывать, что перед уходом на диск логи всё равно выгружаются в память.
Модуль Routing/Output содержит правила и адреса отправки логов. Как уже было сказано, логи можно отправлять в Elasticsearch, PostgreSQL или, например, Kafka.
Интересно, что из Fluent Bit логи можно отправлять во Fluentd. Так как первый более легковесный и менее функциональный, через него можно собирать логи и отправлять во Fluentd, и уже там, с помощью дополнительных плагинов, их дообрабатывать и отправлять в хранилища.
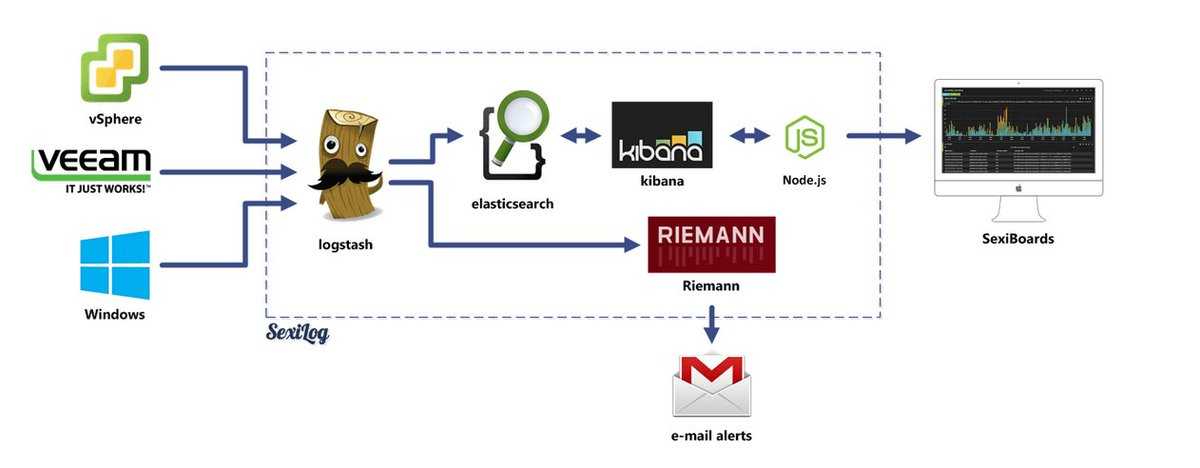
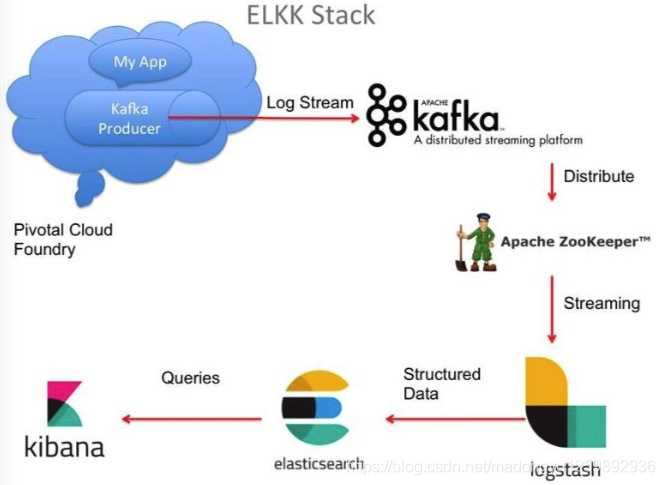
Продолжение следует…
Шаг 5 — Изучение информационных панелей Kibana
Вернемся в веб-интерфейс Kibana, который мы установили ранее.
Откройте в браузере FQDN или публичный IP-адрес вашего сервера с комплексом Elastic. Если сессия была прервана, вам нужно будет повторно ввести учетные данные, которые вы определили на шаге 2. После входа в систему вы получите домашнюю страницу Kibana:
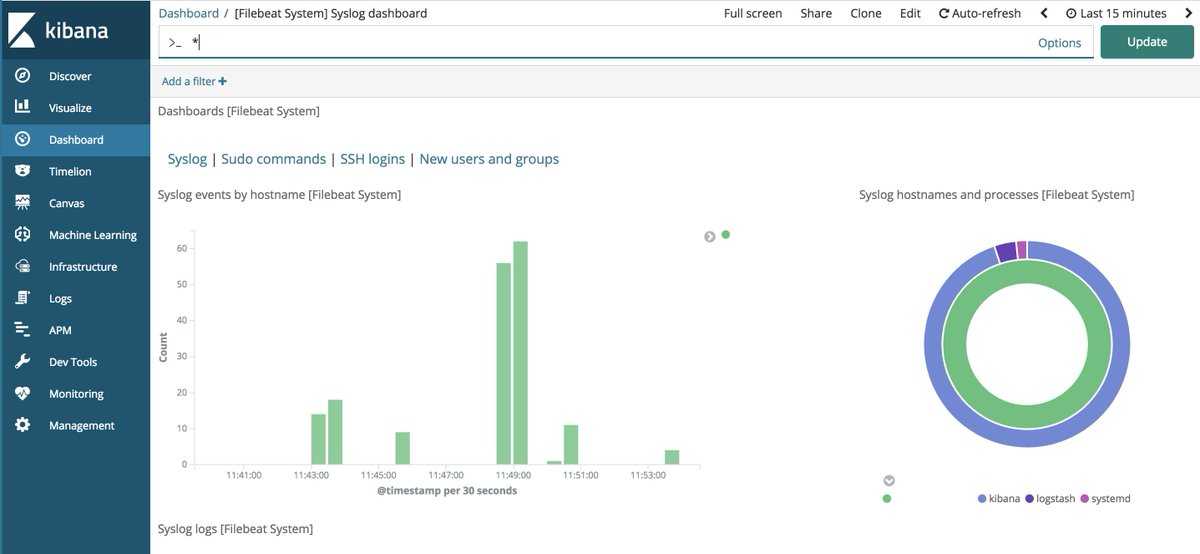
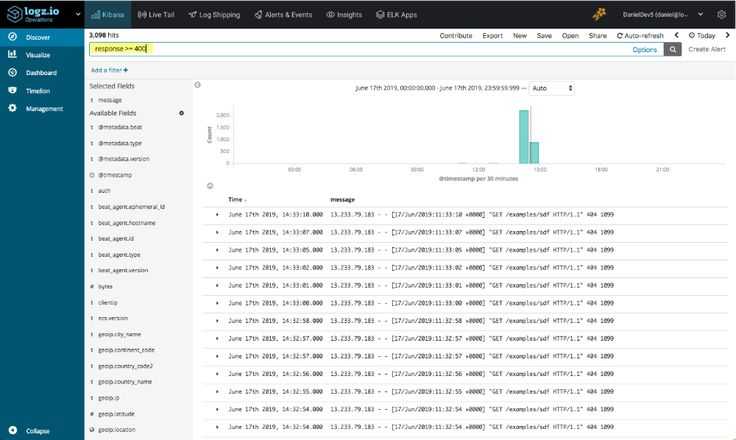
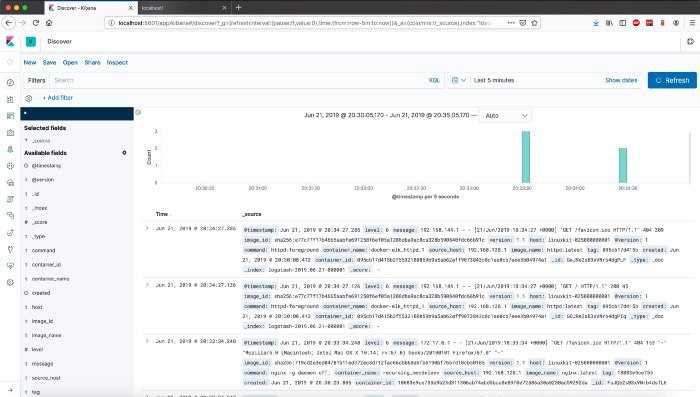
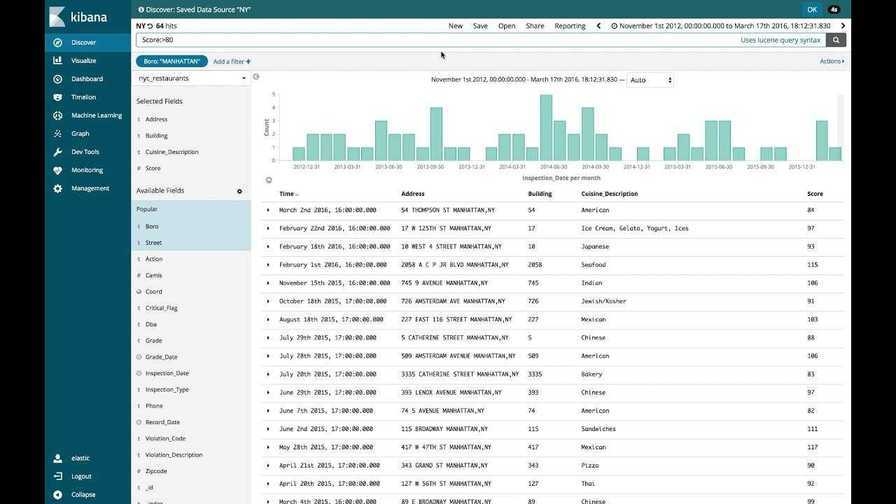
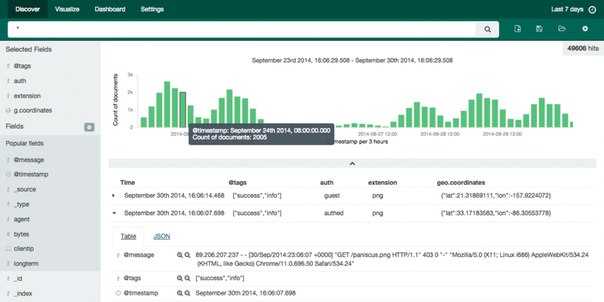
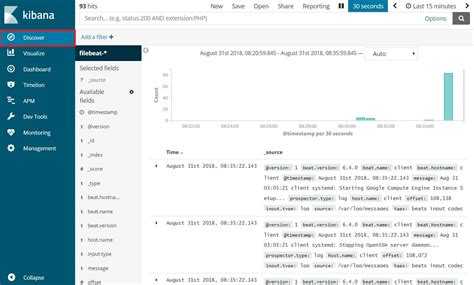
Нажмите ссылку Discover (Изучение) в левой панели навигации (возможно вам нужно будет нажать значок раскрытия в нижнем левом углу, чтобы увидеть все элементы меню навигации). Выберите на странице Discover (Изучение) заранее настроенный индекс filebeat-* для просмотра данных Filebeat. По умолчанию при этом будут выведены все данные журналов за последние 15 минут. Ниже вы увидите гистограмму с событиями журнала и некоторыми сообщениями журнала:
Здесь вы можете искать и просматривать журналы, а также настраивать информационные панели. Сейчас на этой странице будет немного данных, потому что вы собираете системные журналы только со своего сервера Elastic Stack.
Используйте левую панель навигации для перехода на страницу Dashboard и выполните на этой странице поиск информационных панелей Filebeat System. После этого вы можете выбрать образцы панелей управления, входящие в комплект модуля Filebeat system.
Например, вы можете просматривать подробную статистику по сообщениям системного журнала:
Также вы сможете видеть, какие пользователи использовали команду sudo и когда:
В Kibana имеется множество других функций, в том числе функции фильтрации и составления диаграмм, так что вы можете свободно их исследовать.
Раздел Visualize
На странице интерфейса Visualize вы можете создавать, редактировать и просматривать пользовательские визуализации. Kibana предлагает несколько видов визуализации: вертикальные и секторные диаграммы, отображение данных на карте, таблицы данных. Визуализацией можно поделиться с другими пользователями, которые имеют доступ к Kibana.
Если вы используете визуализацию Kibana впервые, перезапустите список полей.
Примечание: Об этом и других настройках можно прочитать в разделе о странице Settings данного руководства.
Создание вертикальной диаграммы
Чтобы создать визуализацию, откройте страницу Visualize.
Выберите тип визуализации. Например, чтобы создать вертикальную диаграмму, нужно выбрать Vertical bar chart.
Теперь нужно выбрать источник поиска. Вы можете создать новый или использовать сохраненный поиск. Если вы создали поиск type nginx access, как предлагалось ранее, используйте его.
Сначала появится график для предварительного просмотра. Если поисковой запрос обнаружил логи, вертикальная диаграмма будет состоять только из оси Y, которая отображает количество логов.
Вы можете расширить диаграмму с помощью меню слева, buckets. К примеру, вы можете добавить ось X, затем открыть выпадающее меню Aggregation, выбрать Date Histogram и нажать Apply. После этого в диаграмме появятся новые вертикали: количество логов распределится по оси Х, которая отображает время.
Попробуйте выполнить следующее:
- Кликните Add Sub Aggregation и выберите тип Split Bars.
- Откройте выпадающее меню Sub Aggregation и выберите Significant Term.
- Откройте выпадающее меню Field и выберите clientip.raw.
- В поле Size введите 10.
- Нажмите Apply, чтобы сгенерировать новый график.
Если отображаемые логи сгенерированы несколькими IP-адресами (т.е., ваш сайт посетил не один пользователь), вы увидите, что каждая вертикаль в графике разделена на несколько разноцветных сегментов. Каждый такой сегмент отображает количество логов, сгенерированных тем или иным IP-адресом. Максимальное количество сегментов – 10 (указано в Size).
Чтобы сохранить визуализацию, нажмите Save Visualization в верхнем меню, выберите название и нажмите Save.
Создание других визуализаций
Прежде чем приступить к работе над дашбордом, нужно создать хотя бы ещё одну диаграмму. Ознакомьтесь с остальными функциями страницы Visualize самостоятельно, выберите тип визуализации, создайте и сохраните график.
К примеру, вы можете создать круговую диаграмму из пяти самых распространённых типов логов. Для этого:
- Откройте Visualize и выберите Pie chart.
- В строку поиска введите запрос “” (чтобы вывести все логи).
- В меню buckets выберите *Split Slices**.
- В выпадающем меню Aggregation выберите Significant Terms.
- В выпадающем меню Field выберите type.raw.
- В поле Size введите 5.
- Чтобы отобразить диаграмму, нажмите Apply.
Примечание: Количество сегментов в круговой диаграмме может быть меньше, если запрашиваемых данных недостаточно для построения всех сегментов (например, если типов логов у вас всего 2).
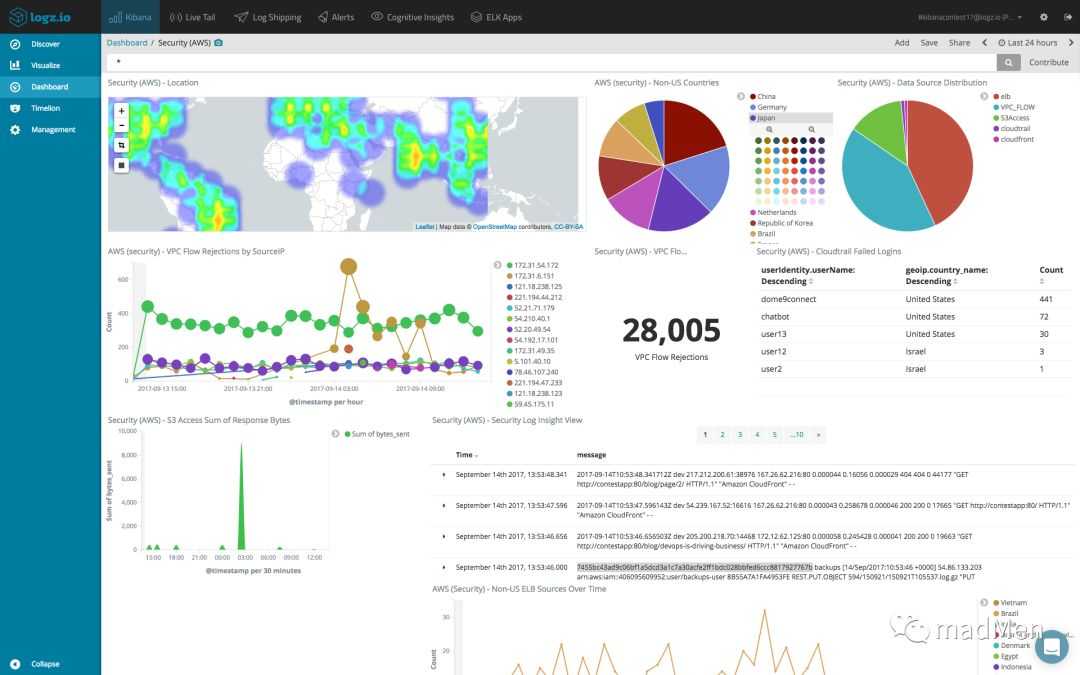
Смотрим полученные данные в Kibana
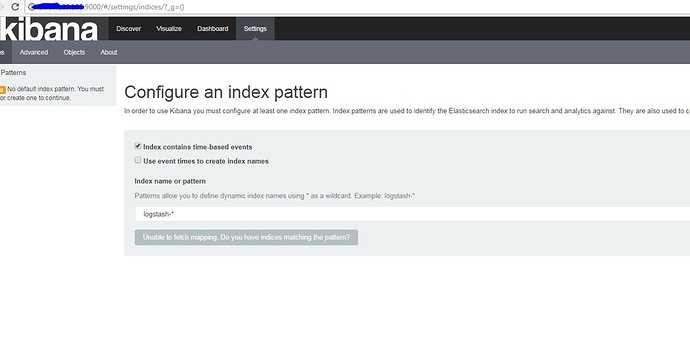
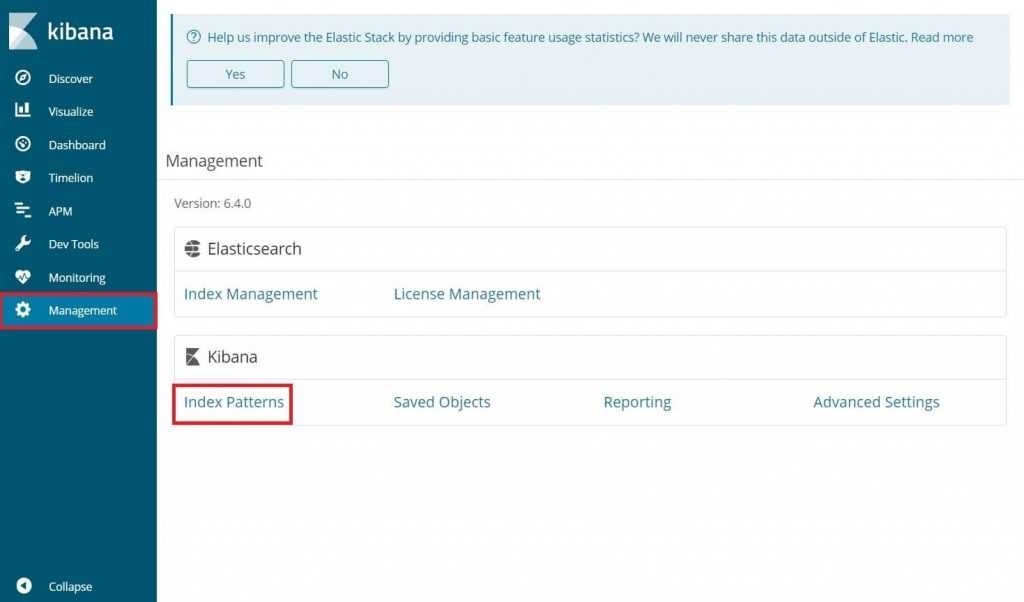
Открываем Kibana, в верхнем левом углу нажимаем меню и в секции выбираем . Далее слева выбираем и нажимаем кнопку . В поле описываем шаблон , в который попадут все индексы, начинающиеся с logstash.
Создание шаблона индекса
Жмем и выбираем поле , чтобы иметь возможность фильтровать данные по дате и времени. После жмем :
Выбор Time field
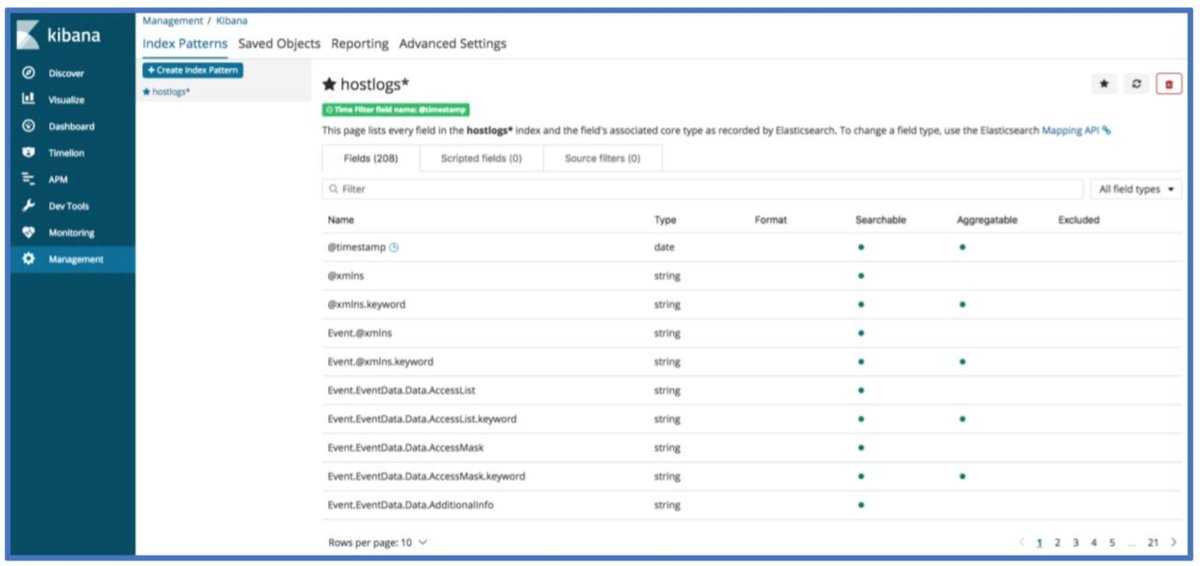
После создания шаблона индексов Kibana покажет информацию об имеющихся полях, типе данных и возможности делать агрегацию по этим полям.
Чтобы посмотреть полученные данные на основе созданного шаблона нажимаем меню и в секции выбираем .
Kibana Discover
В правой части экрана можно выбрать интервал в рамках которого отображать данные.
Выбор временного интервала
В левой часте экрана можно выбрать шаблон индекса или поля для отображения из списка . При нажатии на доступные поля можно получить топ-5 значений.
Шаблон индекса и доступные поля
Для фильтрации данных можно использовать . Запрос пишется в поле . Запросы можно сохранять, чтобы использовать их в будущем.
Фильтрация данных с помощью KQL
Для визуализации полученных данных нажимаем меню и в секции выбираем . Нажав , откроется окно с перечнем доступных типов визуализации.
Типы визуализации Kibana
Для примера выбираем , чтобы построить круговую диаграмму. В качестве источника данных выбираем шаблон индексов . В правой части в секции жмем , далее — . Тип агрегации выбираем , поле . Жмем в правом нижнем углу и получаем готовую диаграмму. В секции можно добавить отображение данных или изменить вид диаграммы.
Круговая диаграмма
Чтобы посмотреть данные в Elasticsearch необходимо сделать запрос к любому узлу кластера. Добавление параметра позволяет отобразить данные в читабельном виде. По умолчанию вывод состоит из 10 записей, чтобы увеличить это количество необходимо использовать параметр :
Заключение
В рамках этой статьи была рассмотрена процедура установки и настройки Kibana и Logstash, настройка балансировки трафика между Kibana и Elasticsearch и работа нескольких экземпляров Kibana. Собрали первые данные с помощью Logstash, посмотрели на данные с помощью и построили первую визуализацию.
Прежде чем углубляться в изучение плагинов Logstash, сбор данных с помощью Beats, визуализацию и анализ данных в Kibana, необходимо уделить внимание очень важному вопросу безопасности кластера. Об этом также постоянно намекает Kibana, выдавая сообщение
Теме безопасности будет посвящена следующая статья данного цикла.
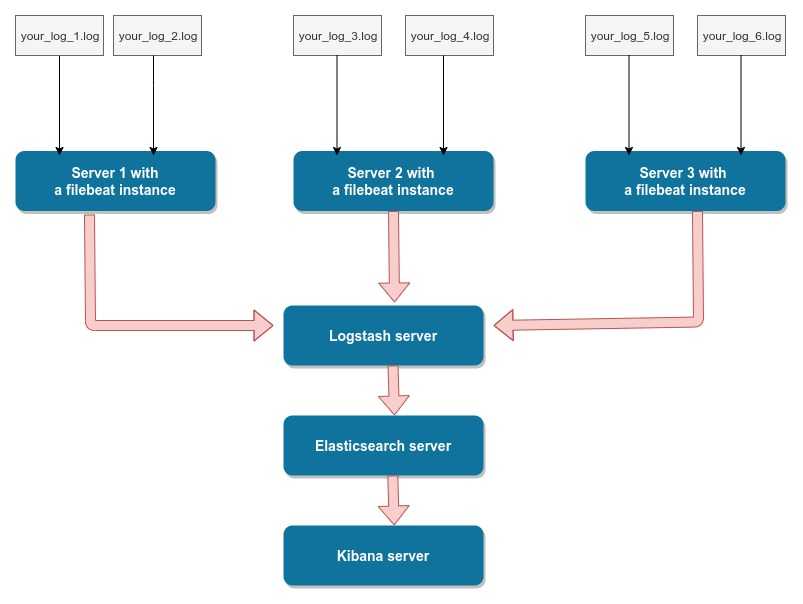
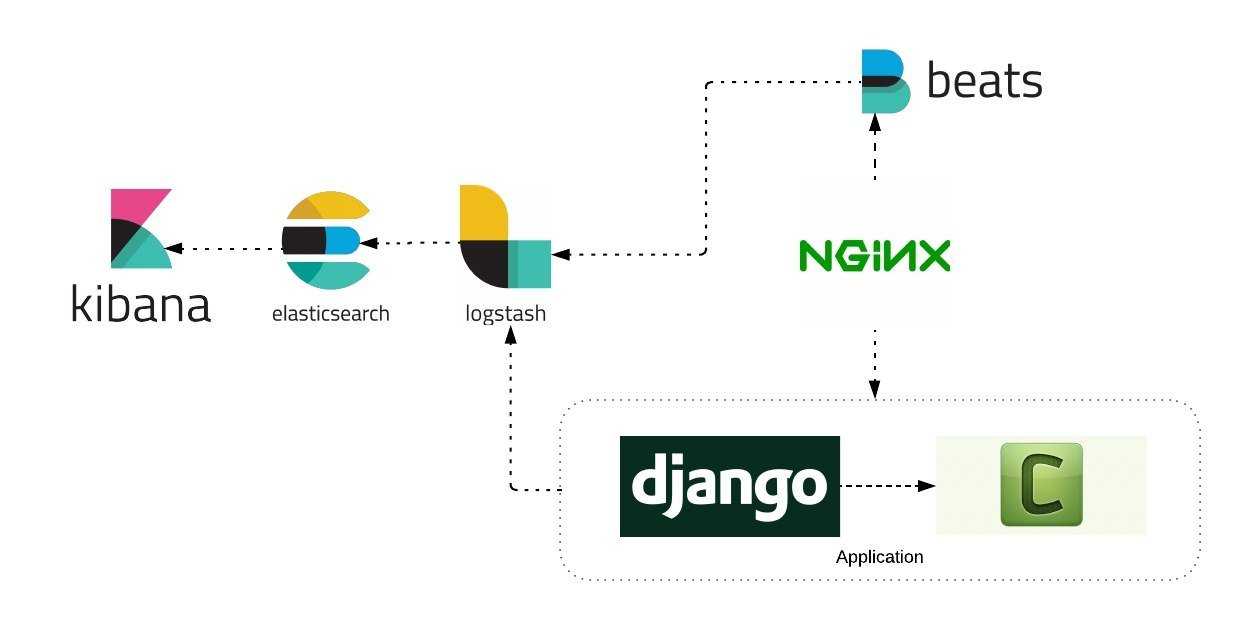
Установка Filebeat для отправки логов в Logstash
Установим первого агента Filebeat на сервер с nginx для отправки логов веб сервера на сервер с ELK. Ставить можно как из общего репозитория, который мы подключали ранее, так и по отдельности пакеты. Как ставить — решать вам. В первом случае придется на все хосты добавлять репозиторий, но зато потом удобно обновлять пакеты. Если подключать репозиторий не хочется, можно просто скачать пакет и установить его.
Ставим на Centos.
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.11.0-x86_64.rpm # rpm -vi filebeat-7.11.0-x86_64.rpm
В Debian/Ubuntu ставим так:
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.11.0-amd64.deb# dpkg -i filebeat-7.11.0-amd64.deb
Или просто:
# yum install filebeat # apt install filebeat
После установки рисуем примерно такой конфиг /etc/filebeat/filebeat.yml для отправки логов в logstash.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*-access.log
fields:
type: nginx_access
fields_under_root: true
scan_frequency: 5s
- type: log
enabled: true
paths:
- /var/log/nginx/*-error.log
fields:
type: nginx_error
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts:
xpack.monitoring:
enabled: true
elasticsearch:
hosts: ["http://10.1.4.114:9200"]
Некоторые пояснения к конфигу, так как он не совсем дефолтный и минималистичный. Я его немного модифицировал для удобства. Во-первых, я разделил логи access и error с помощью отдельного поля type, куда записываю соответствующий тип лога: nginx_access или nginx_error. В зависимости от типа меняются правила обработки в logstash. Плюс, я включил мониторинг и для этого указал адрес elastichsearch, куда filebeat передает данные мониторинга напрямую. Показываю это для вас просто с целью продемонстрировать возможность. У меня везде отдельно работает мониторинг на zabbix, так что большого смысла в отдельном мониторинге нет. Но вы посмотрите на него, возможно вам он пригодится. Чтобы мониторинг работал, его надо активировать в соответствующем разделе в Management — Stack Monitoring. И не забудьте запустить elasticsearch на внешнем интерфейсе. В первоначальной настройке я указал слушать только локальный интерфейс.
Запускаем filebeat и добавляем в автозагрузку.
# systemctl start filebeat # systemctl enable filebeat
Проверяйте логи filebeat в дефолтном системном логе. По умолчанию, он все пишет туда. Лог весьма информативен. Если все в порядке, увидите список всех логов в директории /var/log/nginx, которые нашел filebeat и начал готовить к отправке. Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет индекса, нас перенаправит в раздел Managemet, где мы сможем его добавить.
Вы должны увидеть индекс, который начал заливать logstash в elasticsearch. В поле Index pattern введите nginx-* и нажмите Next Step.
На следующем этапе выберите имя поля для временного фильтра. У вас будет только один вариант — @timestamp, выбирайте его и жмите Create Index Pattern.
Новый индекс добавлен. Теперь при переходе в раздел Discover, он будет открываться по умолчанию со всеми данными, которые в него поступают.

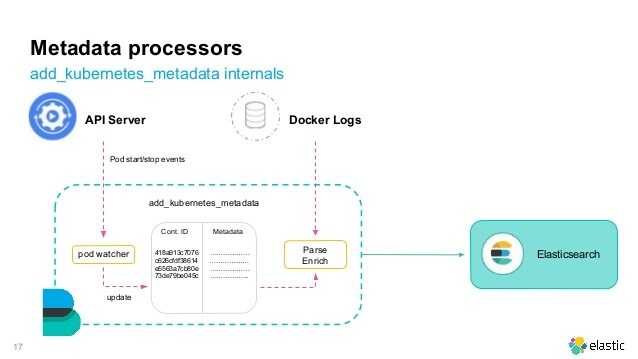
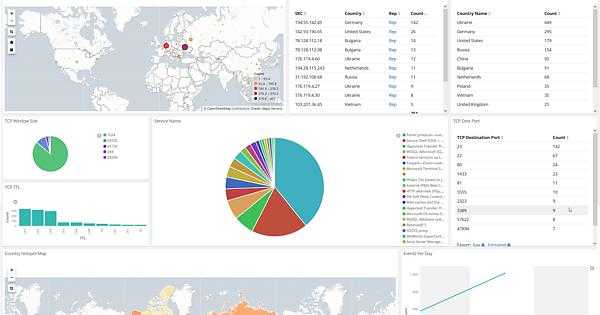
Получение логов с веб сервера nginx на linux настроили. Подобным образом настраивается сбор и анализ любых логов. Можно либо самим писать фильтры для парсинга с помощью grok, либо брать готовые. Вот несколько моих примеров по этой теме:
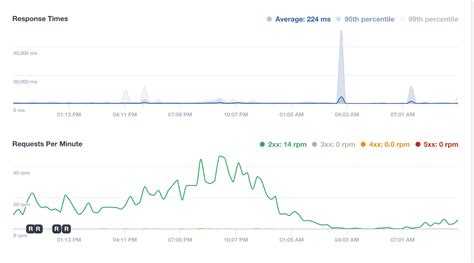
- Мониторинг производительности бэкенда с помощью ELK Stack
- Сбор и анализ логов samba в ELK Stack
- Дашборд для логов nginx
Теперь сделаем то же самое для журналов windows.
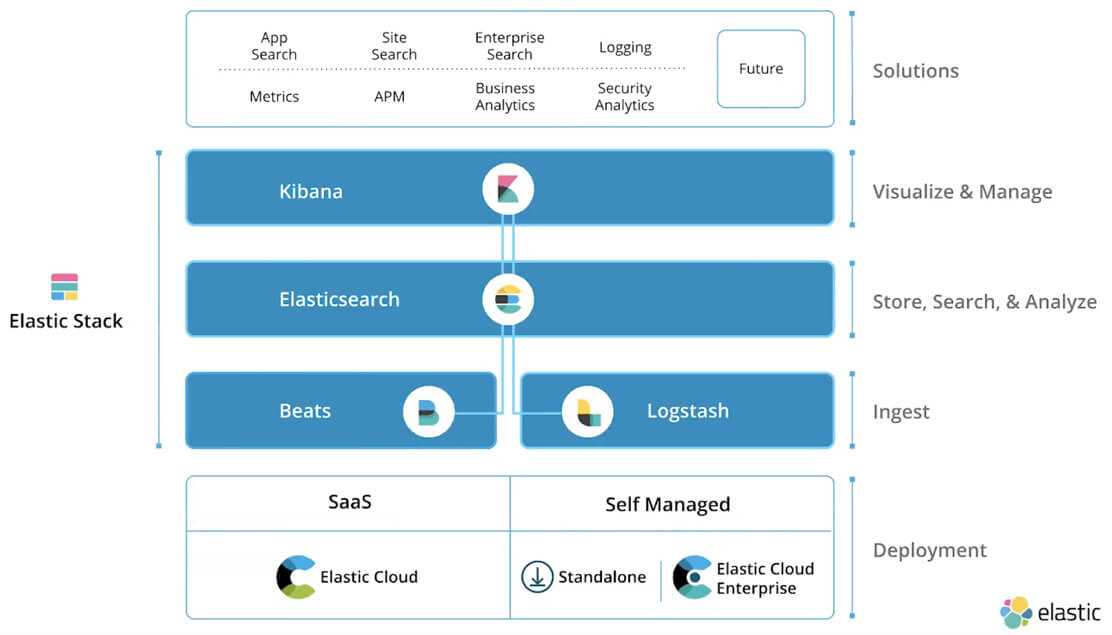
Шаг 1 — Установка и настройка Elasticsearch
Компоненты комплекса Elastic отсутствуют в репозиториях пакетов Ubuntu по умолчанию. Однако их можно установить с помощью APT после добавления списка источников пакетов Elastic.
Все пакеты комплекса Elastic подписаны ключом подписи Elasticsearch для защиты вашей системы от поддельных пакетов. Ваш диспетчер пакетов будет считать надежными пакеты, для которых проведена аутентификация с помощью ключа. На этом шаге вы импортируете открытый ключ Elasticsearch GPG и добавить список источников пакетов Elastic для установки Elasticsearch.
Для начала запустите следующую команду для импорта открытого ключа Elasticsearch GPG в APT:
Затем обновите списки пакетов, чтобы APT мог прочитать новый источник Elastic:
Установите Elasticsearch с помощью следующей команды:
После завершения установки Elasticsearch используйте предпочитаемый текстовый редактор для редактирования главного файла конфигурации Elasticsearch с именем . Мы будем использовать :
Примечание. Файл конфигурации Elasticsearch имеет формат YAML, и это значит, что отступы имеют большое значение! Не добавляйте никакие дополнительные пробелы при редактировании этого файла.
Elasticsearch прослушивает весь трафик порта . Вы можете захотеть ограничить внешний доступ к вашему экземпляру Elasticsearch, чтобы посторонние не могли читать ваши данные или отключать ваш кластер Elasticsearch через REST API. Найдите строку с указанием , уберите с нее значок комментария и замените значение на , чтобы она выглядела следующим образом:
/etc/elasticsearch/elasticsearch.yml
Сохраните и закройте файл , нажав , а затем и , если вы используете . Затем запустите службу Elasticsearch с помощью :
Затем запустите следующую команду, чтобы активировать Elasticsearch при каждой загрузке сервера:
Вы можете протестировать работу службы Elasticsearch, отправив запрос HTTP:
Вы получите ответ, содержащий базовую информацию о локальном узле:
Мы настроили и запустили Elasticsearch, и теперь можем перейти к установке Kibana, следующего компонента комплекса Elastic.





