
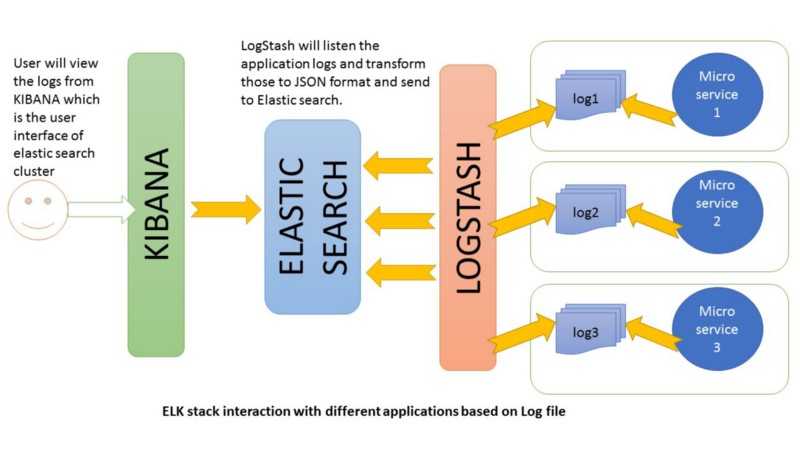
Введение
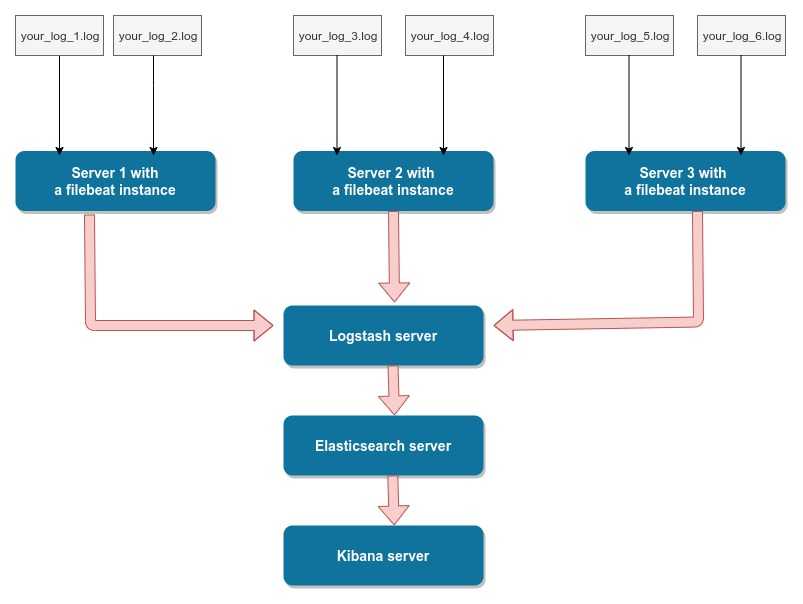
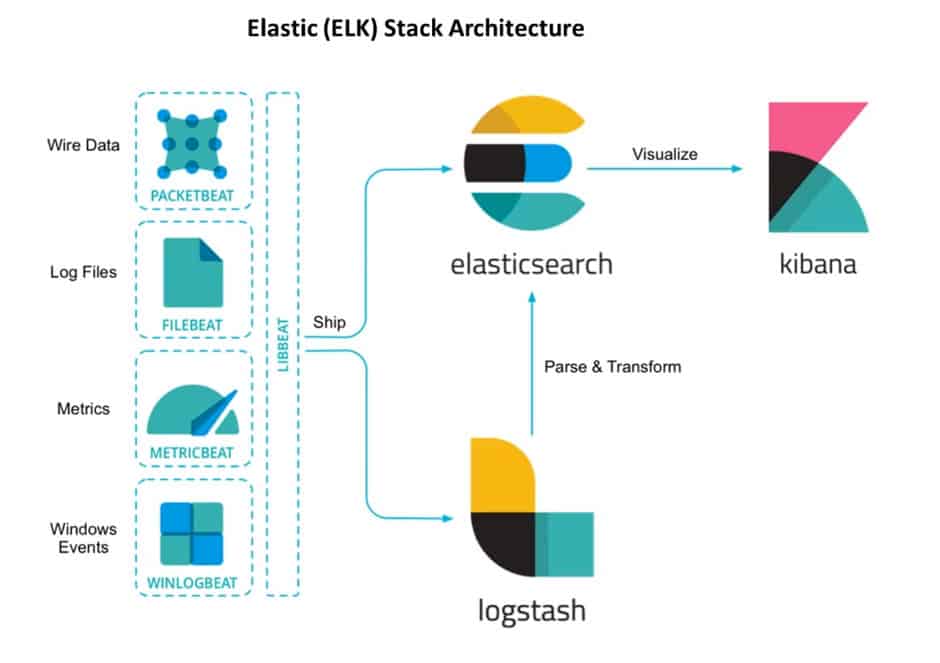
У меня есть целый цикл статей про настройку и эксплуатацию ELK Stack для сбора логов с различных приложений. Так же я подробно рассказал, как установить и настроить ELK Stack себе, если у вас есть под него мощности и компетенции. В целом, там нет чего-то сильно сложного, но тем не менее, все равно необходимо повозиться, чтобы все заработало.
Не обязательно все это разворачивать и настраивать у себя, если хочется просто попробовать продукт, чтобы понять, нужен он вам или нет. Есть сервис — https://cloud.elastic.co, где можно за 2 минуты зарегистрировать и развернуть свой стэк на базе Elasticsearch и Kibana. Отличие от описанного мной способа разворачивания стека в том, что тут не будет Logstash. Во многих случаях можно обойтись без него, так что это не критично. Особенно для того, чтобы просто попробовать.
Итак, прежде чем приступить к настройке, зарегистрируйтесь в облаке и активируйте учетную запись.
Запуск Elastic Stack в Elastic Cloud
При первом входе в личный кабинет у вас будет возможность создать Deployment с Elasticsearch.
Дальше нужно выбрать платформу, где вы хотите произвести установку сервиса, и регион. Я для теста выбрал Google Cloud Platform во Frankfurt. Все остальное оставил по дефолту. Дальше внизу жмете Create Deployment и ждете, когда он развернется. Обычно 2-3 минуты.
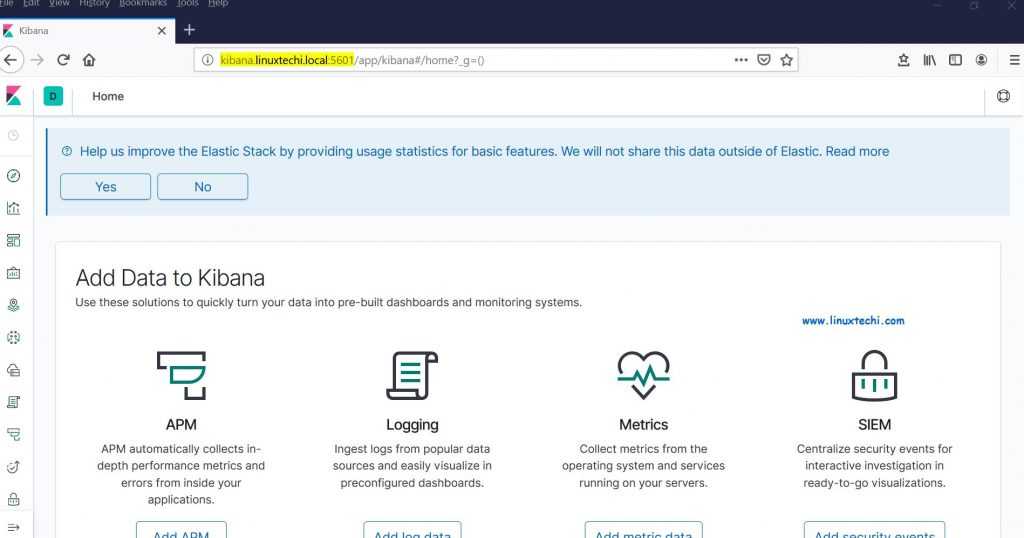
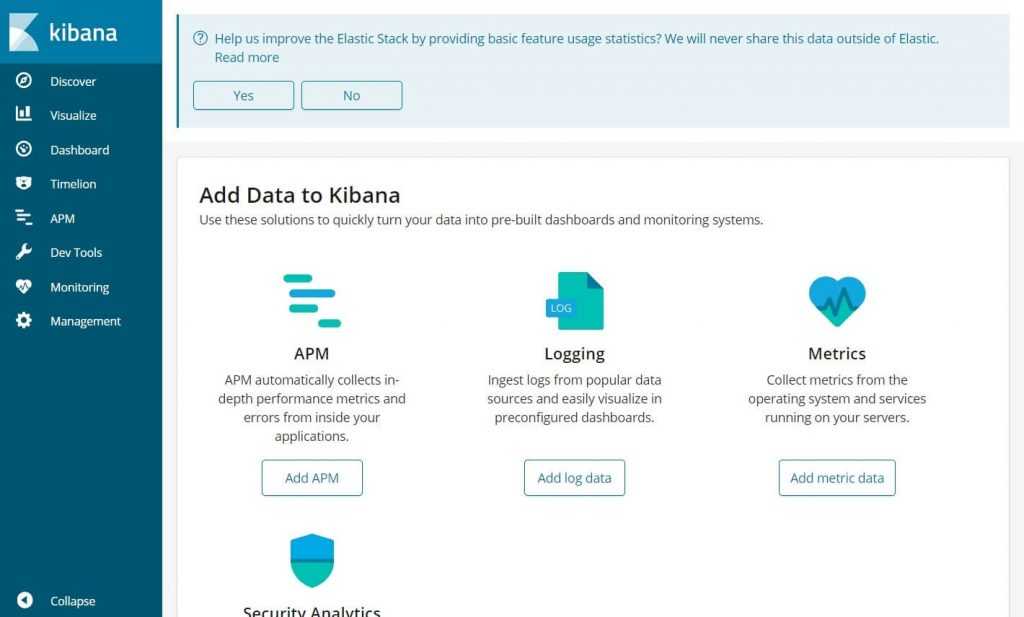
Дожидаемся окончание процесса установки и переходим в Kibana.
Логинимся в Kibana с учетными данными, которые указаны в личном кабинете, в Deployment. Username обычно elastic и какой-то пароль. При первом входе вам предложат залить набор демо данных, чтобы посмотреть функционал системы. Если хотите — посмотрите. Я там и так все видел, поэтому отказываюсь  Буду лить свои логи от apache.
Буду лить свои логи от apache.
После выбора оказываетесь на главной странице Kibana. По сути Elastic Stack вы уже развернули и он готов принимать данные. Вот так, быстро и просто все настроилось. И DevOps не нужен
Можете тут осмотреться и познакомиться с системой.
Настройка Kibana
Файл с настройками Кибана располагается по пути — /etc/kibana/kibana.yml. На начальном этапе можно вообще ничего не трогать и оставить все как есть. По-умолчанию kibana слушает только localhost и не позволяет подключаться удаленно. Это нормальная ситуация, если у вас будет на этом же сервере установлен nginx в качестве reverse proxy, который будет принимать подключения и проксировать их в кибана. Так и нужно делать в продакшене, когда системой будут пользоваться разные люди из разных мест. С помощью nginx можно будет разграничивать доступ, использовать сертификат, настраивать нормальное доменное имя и т.д. Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server.host, Если хотите, чтобы она слушала все интерфейсы, укажите в качестве адреса, например вот так:
server.host: "0.0.0.0"
После этого Kibana надо перезапустить:
systemctl restart kibana.service
Теперь можно зайти в веб интерфейс по адресу http://ubuntu:5601. Kibana В процессе настройки будем подключаться напрямую к Kibana.
Почему Graylog?
Это не единственная и, возможно, далеко не самая лучшая платформа, но она широко распространена, прошла проверку временем и все еще поддерживается разработчиками.
Но, начать мы решили с анализа “конкурентов”.
Альтернативы
Splunk
Классный, модный, современный Splunk соответствует подавляющему большинству потребностей и скорее всего, может даже больше.
Но есть три момента, которые не понравились:
-
В нужной конфигурации решение платное.
-
Это закрытое решение.
-
Компания, без объяснений причин покинула рынок РФ.
Но, если вас это не смущает, немного полезной информации по платформе:
-
Обзорная статья на habr.
-
Сравнение платной и бесплатных версий.
С этим “претендентом” не получилось, идем дальше.
Например, тут и тут его часто сравнивают с ELK, который и рассмотрим.
ELK
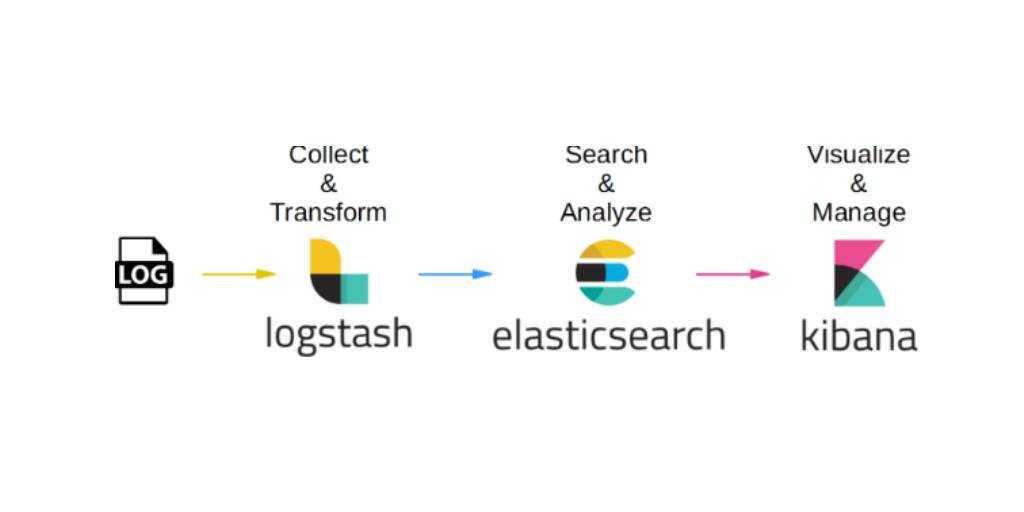
Стек продуктов Elasticsearch, Logstash, Kibana, образующий аббревиатуру ELK — это очень популярное и еще более настраиваемое решение, по сравнению с предыдущим. Более того, это решение open source.
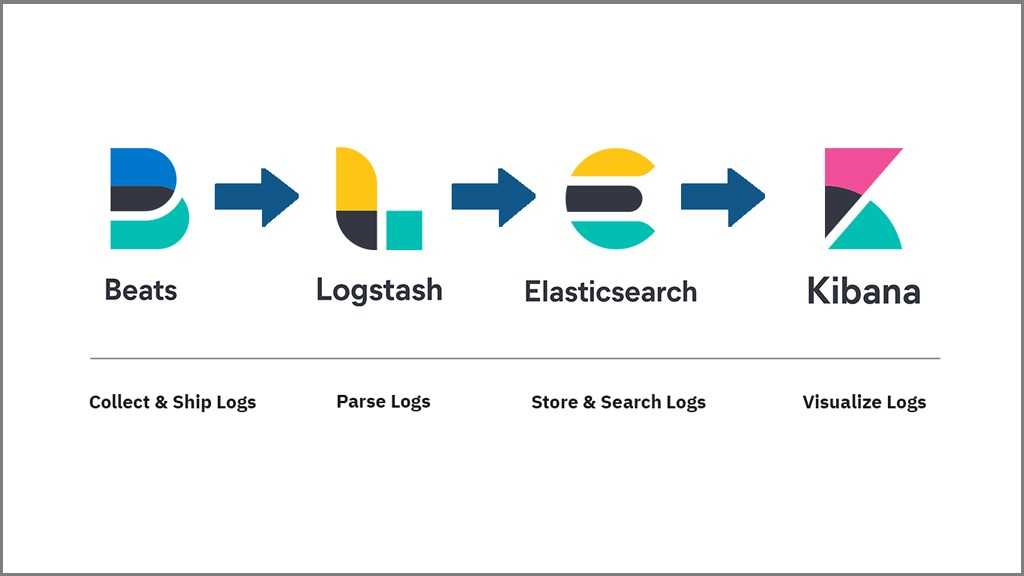
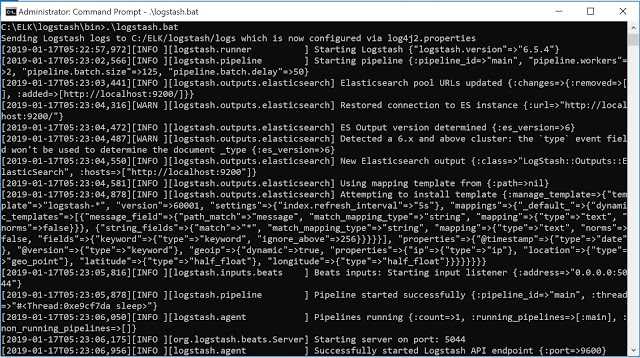
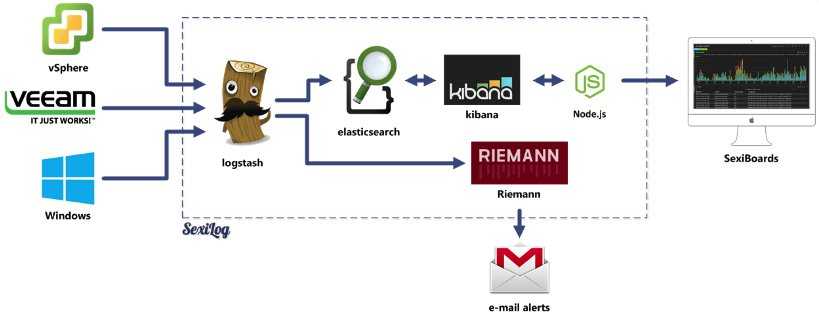
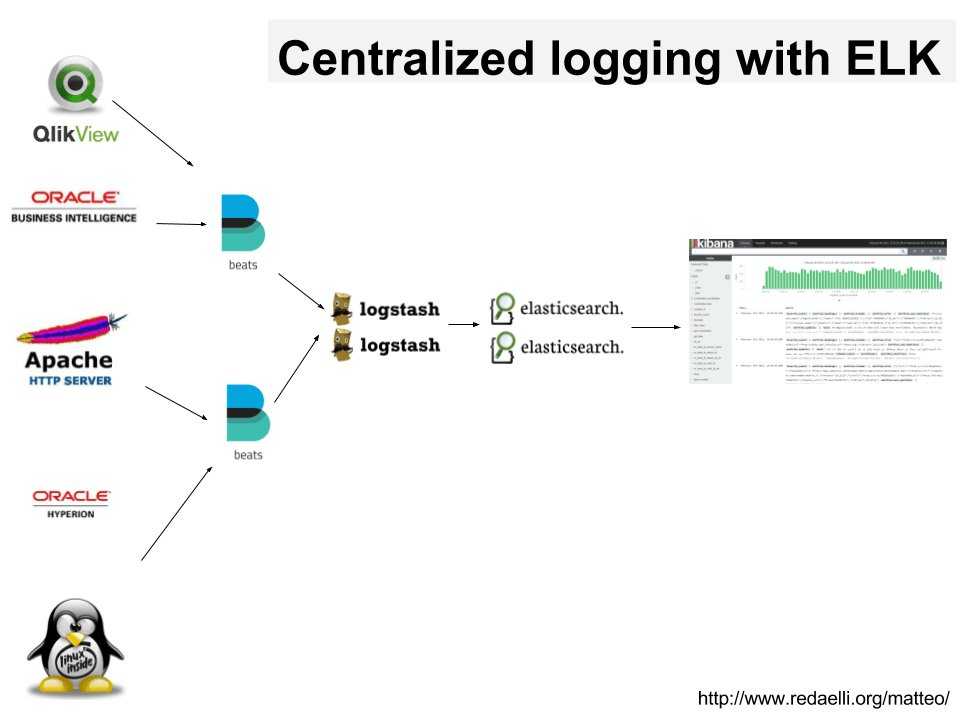
Что же пошло не так?
-
Некоторые фишки все же платные, например, уведомления и контроль доступа (однако, после некоторых событий часть данного функционала стала бесплатной).
-
Ресурсоемкость — требуется очень много ресурсов.
-
Систему сложно настроить, “из коробки” она работать не будет.
-
Еще нужно упомянуть Open Distro, которая развивается на базе ELK, но полностью бесплатная, что не отменяет ресурсоемкость и сложность в настройке.
Немного полезной информации:
-
Инструкция по установке и настройке (eng).
-
Цикл статей на habr: часть 1, часть 2, часть 3.
Остановились на Graylog
Двух претендентов отсеяли, остался виновник торжества — Graylog, выделяющийся по следующим причинам:
-
Это open source решение.
-
Бесплатная версия имеет все необходимое.
-
Функционал небольшой, что удобно, ничего лишнего (для наших задач).
-
“Из коробки” решение уже работает, нужны минимальные настройки.
-
По сравнению с ELK ресурсоемкость значительно ниже.
Далее, мы предлагаем лонгрид по настройке и установке Graylog.
Конфигурирование
- source — содержит информацию об источнике данных;
- match — содержит информацию о том, куда нужно передавать полученные данные;
- include — содержит информацию о типах файлов;
- system — содержит настройки системы.
Source: откуда брать данные
# Принимаем события с порта 24224/tcp
<source>
type forward
port 24224
</source>
# http://this.host:9880/myapp.access?json={"event":"data"}
<source>
type http
port 9880
</source>
# generated by http://this.host:9880/myapp.access?json={"event":"data"}
tag: myapp.access
time: (current time)
record: {"event":"data"}
Match: что делать с данными
# Получаем события с порта 24224
<source>
type forward
port 24224
</source>
# http://this.host:9880/myapp.access?json={"event":"data"}
<source>
type http
port 9880
</source>
#Берём события, помеченные тэгами "myapp.access"
#и сохраняем их в файле/var/log/fluent/access.%Y-%m-%d
#данные можно разбивать на порции с помощью опции time_slice_format.
<match myapp.access>
type file
path /var/log/fluent/access
</match>
- символ * означает соответствие любой части тэга (если указать <match a.*>, то a.b будет соответствовать заданному условию, а a.b.c — нет);
- ** означает соответствие любому тэгу (если указать <match **>, то заданному условию будут соответствовать и a, и a.b., и a.b.c);
- {x, y, z} означает соответствие по крайней мере одному из тэгов, указанных в фигурных скобках (если указать <match {a, b}>, то а и b будут соответствовать заданному условию, а с — нет);
- фигурные скобки можно использоовать в сочетании с символами * и **, например: <match {a, b}. c.*> или <match {a.*, b}.c>*;
- <match a b> означает соответствие тэгам a и b одновременно;
- <match a.** b.*> означает соответствие тэгам a, a.b и a.b.c (первая часть) и b.d (вторая часть).
<match **> type blackhole_plugin </match> <match myapp.access> type file path /var/log/fluent/access </match>
<match myapp.access> type file path /var/log/fluent/access </match> <match **> type blackhole_plugin </match>
Include: объединяем конфигурационные файлы
include config.d/*.conf
# абсолютный путь к файлу include /path/to/config.conf # можно указывать и относительный путь include extra.conf # маска include config.d/*.conf # http include http://example.com/fluent.conf
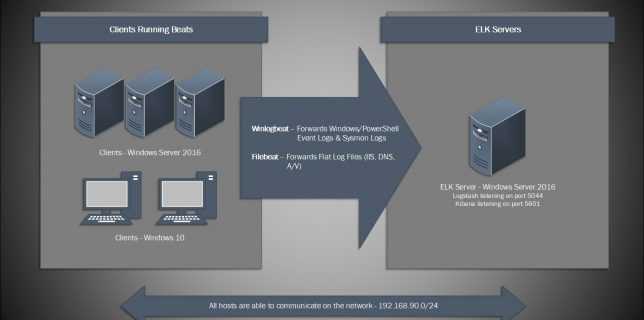
Сбор и анализ логов Windows Fileserver
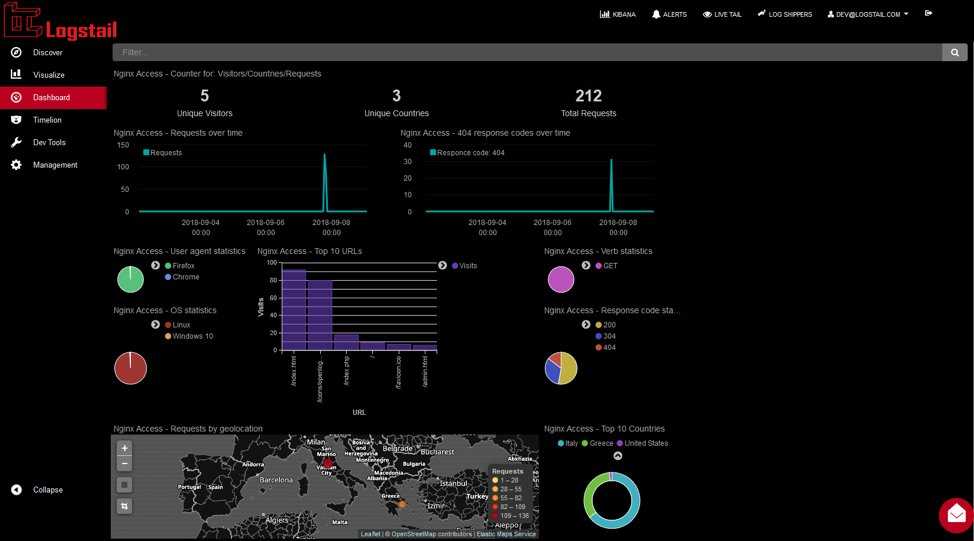
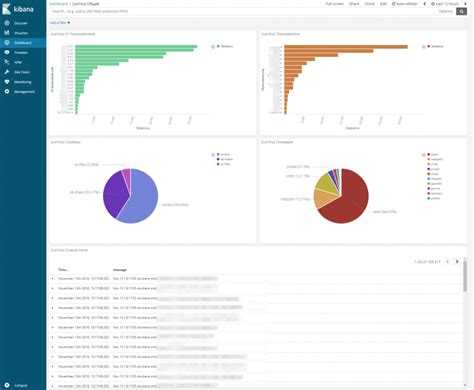
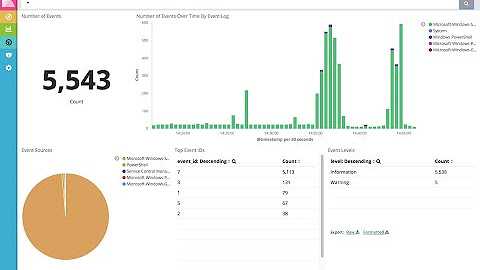
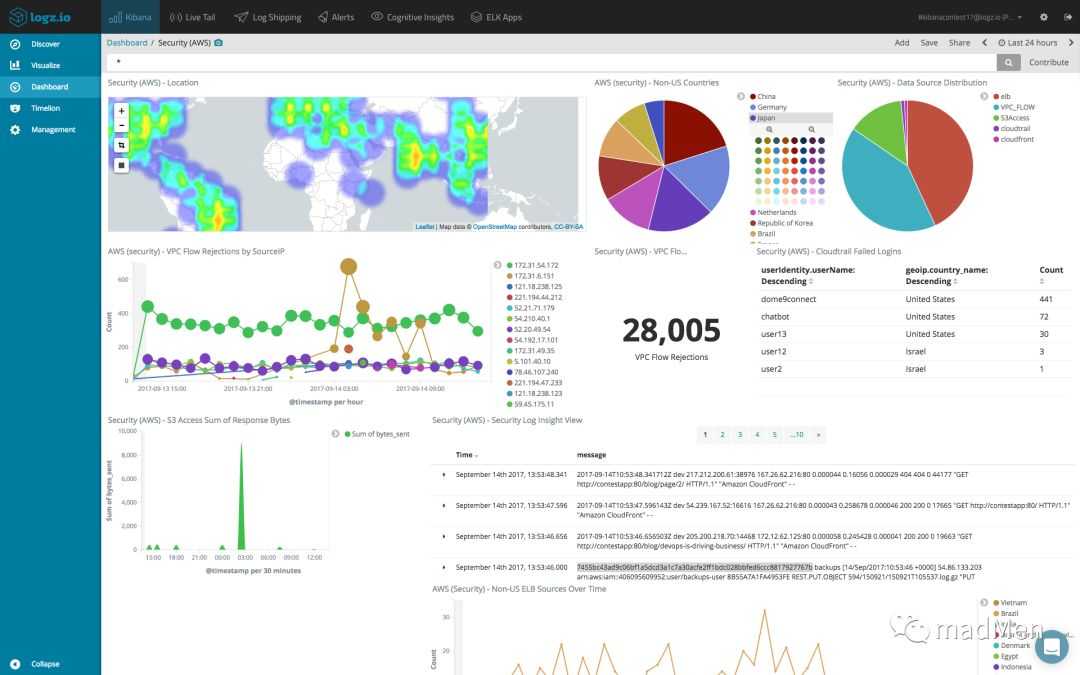
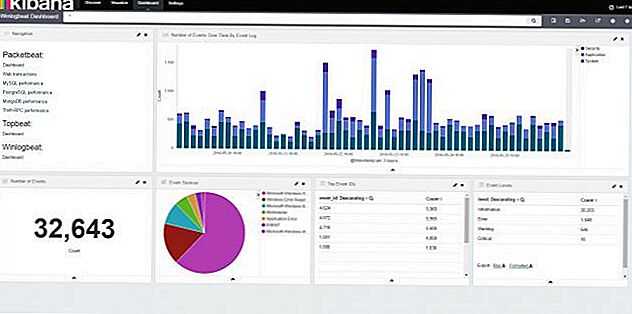
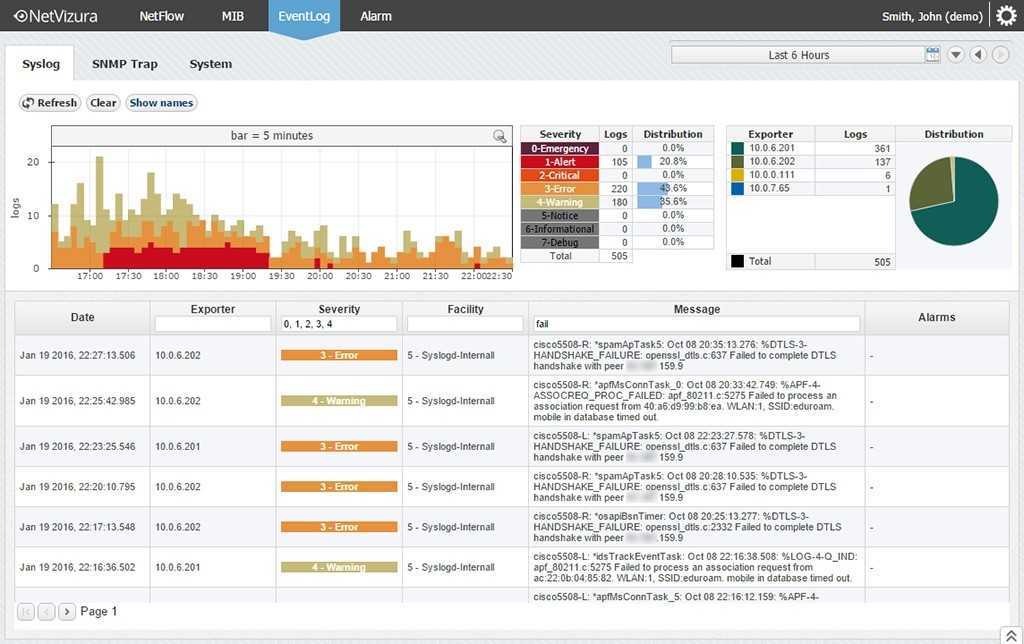
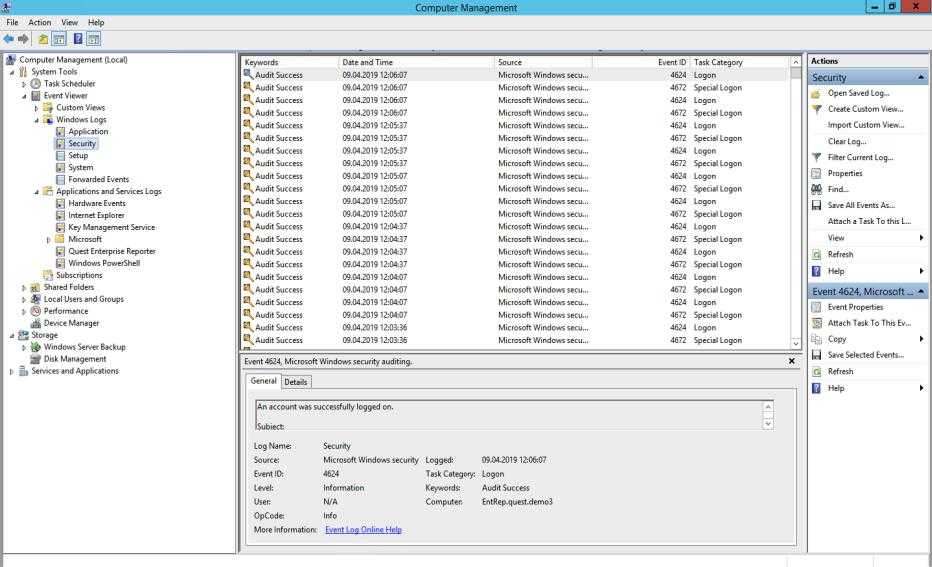
Для файлового сервера настраиваем сбор логов в ELK Stack точно так же, как я показал выше. Для визуализации данных я настроил отдельный дашборд в Kibana со следующей информацией:
- Имена пользователей, которые обращаются к файлам (поле event_data.SubjectUserName)
- Типы запросов, которые выполняются (поле file_action)
- Список доступа к файлам (формируется из сохраненного фильтра поиска)
Возможно, кому-то будет актуально выводить на дашборд еще и информацию об именах файлов, к которым идет доступ. Информация об этом хранится в поле event_data.ObjectName. Лично я не увидел в этом необходимости.
Подготовка
Скопируем логи 1с с Windows сервера на Ubuntu с помощью утилиты rsync, входящей в пакет cygwin.com На стороне сервера Ubuntu настраиваем сервис rsync
apt-get install rsync
Настраиваем параметры в /etc/rsyncd.conf
uid = user gid = root use chroot = yes max connections = 50 pid file = /var/run/rsyncd.pid log file = /var/log/rsync.log path = /home/files/ # каталог логов hosts allow = 192.168.0.1 # адрес сервера 1с hosts deny = * #list = true read only = false #auth users = s1 #secrets file = /etc/rsyncd.secrets
Создаем bat file на сервере 1с
set BACKUP_DIR=E:\1c\complex\syslog\ cd /d %BACKUP_DIR% C:\cygwin64\bin\rsync.exe -avz --inplace --append --chmod=u=rw --log-file=c:\bat\rsync.log ./*.mlg s1@192.168.100.2::share/1c/
Обязательно указываем параметр — копировать только изменения для уменьшения трафика. И чтобы не перезаписывать весь файл, иначе в ELK данные будут дублироваться. запускаем
C:\cygwin64\bin\rsync.exe -avz --inplace --append --chmod=u=rw --log-file=c:\bat\rsync.log ./*.mlg s1@192.168.100.2::share/1c/ sending incremental file list 1cv7.mlg sent 298 bytes received 35 bytes 666.00 bytes/sec total size is 68,683,437 speedup is 206,256.57
Проверяем файл в каталоге назначения на сервере Ubuntu Добавляем задание в планировщик заданий с периодом 5 минут.
Обработка сообщений
- Все сообщения приходят из Input (их может быть много) и попадают на обработку в привязанный к нему RuleSet. Если это явно не задано, то сообщения попадут в RuleSet по-умолчанию. Все директивы обработки сообщений, не вынесенные в отдельные RuleSet-блоки, относятся именно к нему. В частности, к нему относятся все директивы из традиционного формата конфигов:
- к Input привязан список парсеров для разбора сообщения. Если явно не задано, будет использоваться список парсеров для разбора традиционного формата syslog
- Парсер выделяет из сообщения свойства. Самые используемые:
- — сообщение
- — сообщение целиком до обработки парсером
- , — DNS имя и IP адрес хоста-отправителя
- , — facility в числовой и текстовой форме
- , — то же для severity
- — время из сообщения
- — поле TAG
- — поле TAG с отрезанным id процесса: ->
- весь список можно посмотреть тут
- RuleSet содержит список правил, правило состоит из фильтра и привязанных к нему одного или нескольких Actions
- Фильтры — логические выражения, с использованием свойств сообщения. Подробнее про фильтры
- Правила применяются последовательно к сообщению, попавшему в RuleSet, на первом сработавшем правиле сообщение не останавливается
- Чтобы остановить обработку сообщения, можно использовать специальное discard action: или в легаси-формате.
- Внутри Action часто используются шаблоны. Шаблоны позволяют генерировать данные для передачи в Action из свойств сообщения, например, формат сообщения для передачи по сети или имя файла для записи. Подробнее про шаблоны
- Как правило, Action использует модуль вывода(«om…») или модуль изменения сообщения(«mm…»). Вот некоторые из них:
- omfile — вывод в файл
- omfwd — пересылка по сети, через udp или tcp
- omrelp — пересылка по сети по протоколу RELP
- onmysql, ompgsql, omoracle — запись в базу
- omelasticsearch — запись в ElasticSearch
- omamqp1 — пересылка по протоколу AMQP 1.0
- весь список модулей вывода
→
5 Octopussy
Я даю ноль из десяти наименованию продукта, но Octopussy может быть хорошим выбором, если ваши потребности просты, и вы задаетесь вопросом о том, что же такое суета, связанная с конвейерами, приемом, агрегацией и т. д
По моему мнению, Octopussy покрывает потребности большинства продуктов (оценочная статистика бесполезна, но, если бы мне пришлось угадывать, я бы сказал, что в реальном мире она учитывает 80% случаев использования)
У Octopussy нет отличного пользовательского интерфейса:
но он компенсирует скорость и отсутствие раздувания.
Исходный код доступен на GitHub, как и ожидалось, и я думаю, что он заслуживает серьезного изучения.
Быстрый поиск в справочниках по наименованию, с использованием svcsvc.dll
По аналогии с http://infostart.ru/public/14286/, недавно узнал что в svcsvc.dll несколько обновился функционал, в частности был добавлен метод AddString().
В прилагаемом коде показан запрос, реализованный методами ВК 1SQlite, т.е. только для DBF.
Это только пример. Т.е. если например у справочника отсутствует поле «Наименование», то скорее всего будет ошибка.
Тем не менее критика приветствуется)))
Необходимые ВК: 1SQlite, FORMEX, svcsvc.dll (отсюда: http://www.1cpp.ru/forum/YaBB.pl?num=1373266553).
p.s.
Спасибо огромное уважаемому ADirks за все эти прекрасные плюшки, и помощь в их освоении)))
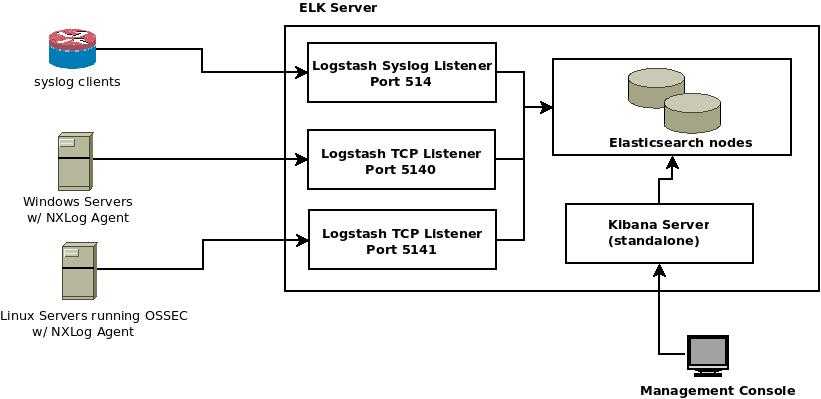
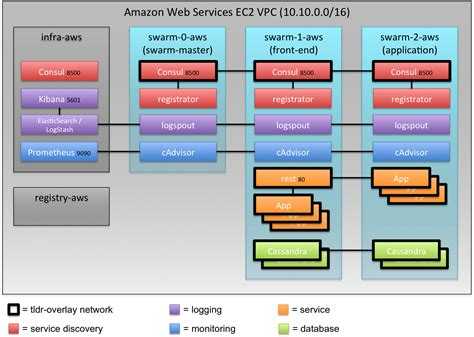
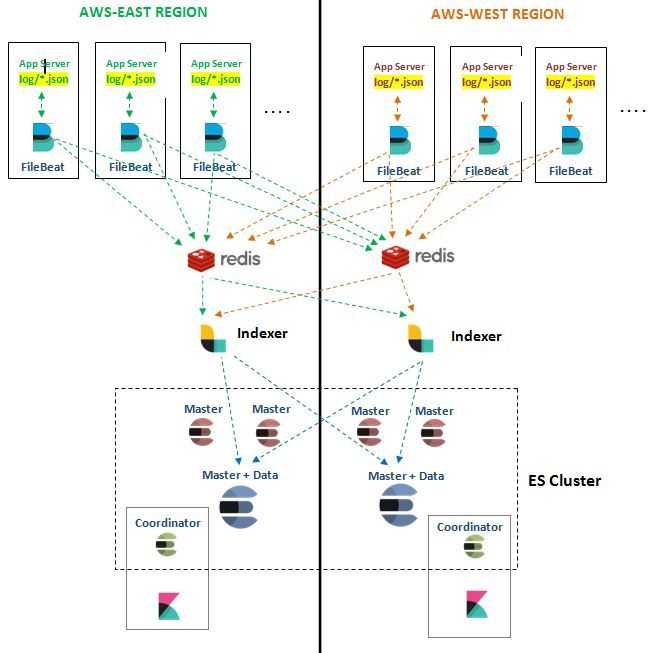
Архитектура
Надежность – одно из ключевых требований, предъявляемых к используемым системам
По этой причине ELK был установлен в отказоустойчивой конфигурации: нам важно быть уверенными, что логи продолжат собираться в случае недоступности части серверов
| Количество VM | Назначение | Используемое ПО |
|---|---|---|
| 2 | Балансировщики нагрузки | Keepalived + HAproxy + nginx |
| 4 | Получение и обработка входящих журналов | Logstash |
| 3 | Master-ноды кластера Elasticsearch | Elasticsearch |
| 6 | Data-ноды кластера Elasticsearch | Elasticsearch |
| 1 | Пользовательский интерфейс | Kibana |
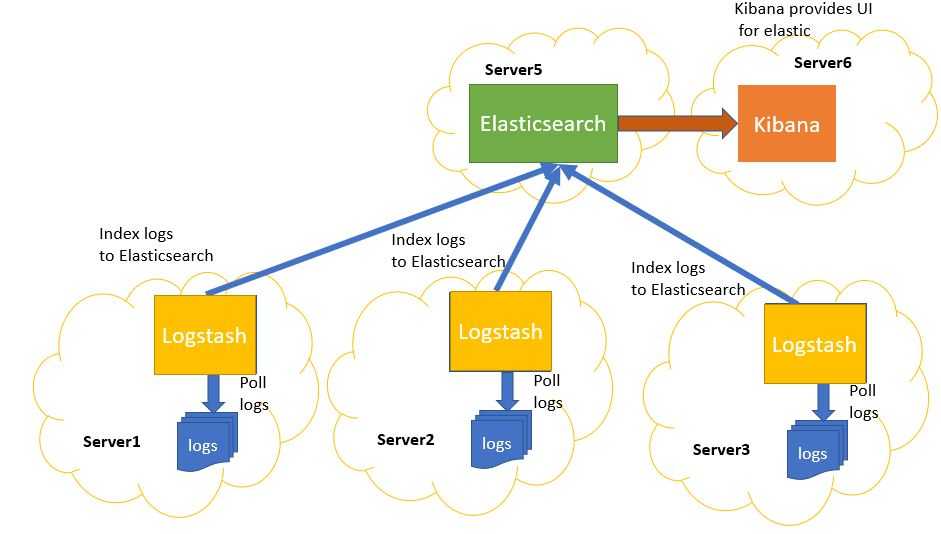
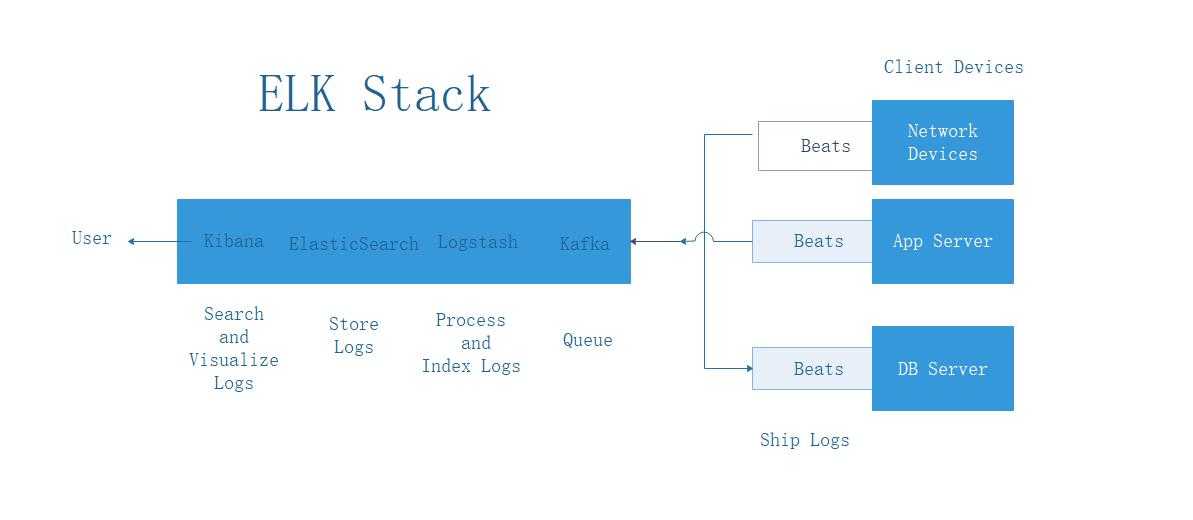
Так выглядит архитектура нашей инсталляции ELK:
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch.yml. На начальном этапе нас будут интересовать следующие параметры:
path.data: /var/lib/elasticsearch # директория для хранения данных network.host: 127.0.0.1 # слушаем только локальный интерфейс
По-умолчанию Elasticsearch слушает все сетевые интерфейсы. Нам это не нужно, так как данные в него будет передавать logstash, который будет установлен локально
Обратите внимание на параметр path.data для директории с данными. Чаще всего индексы будут занимать значительное место
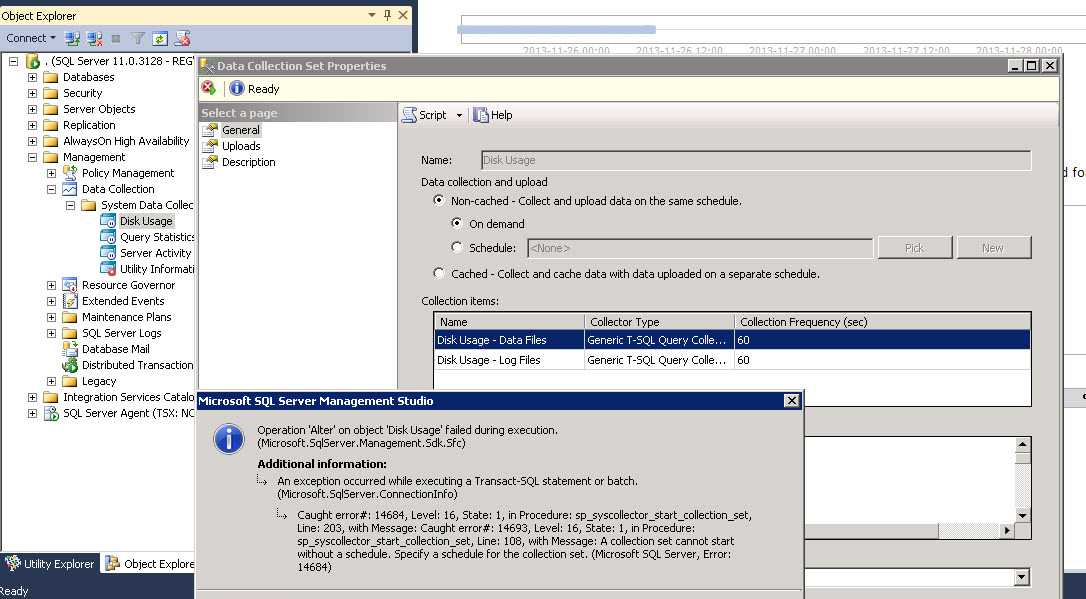
Если останется меньше 10% свободного места elasticsearch уходит в глухой read-only и вывести сервис из этого состояния – ещё та задача. Подумайте заранее, где вы будете хранить логи. Остальные настройки — дефолтные. После изменения настроек, перезапустите службу:
systemctl restart elasticsearch.service
Смотрим, что получилось:
netstat -tulnp | grep 9200 tcp6 0 0 127.0.0.1:9200 :::* LISTEN 14130/java
Elasticsearch работает на локальном интерфейсе — слушает ipv6, про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Переходим к установке kibana.
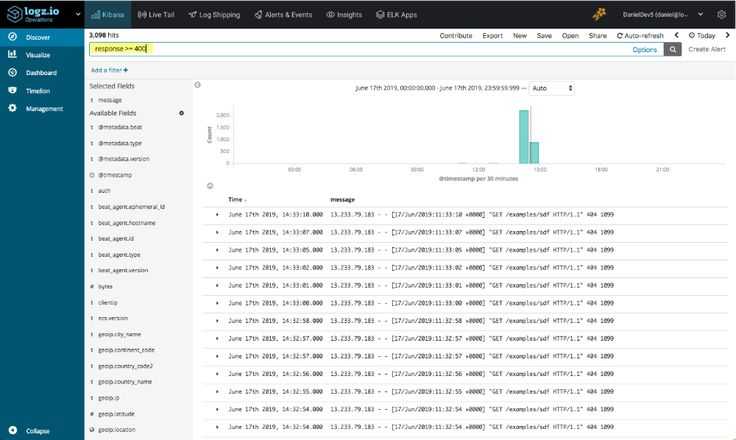
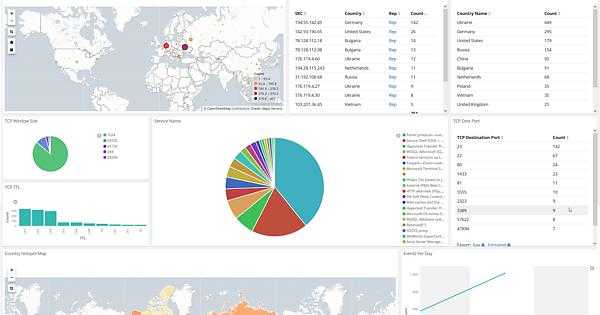
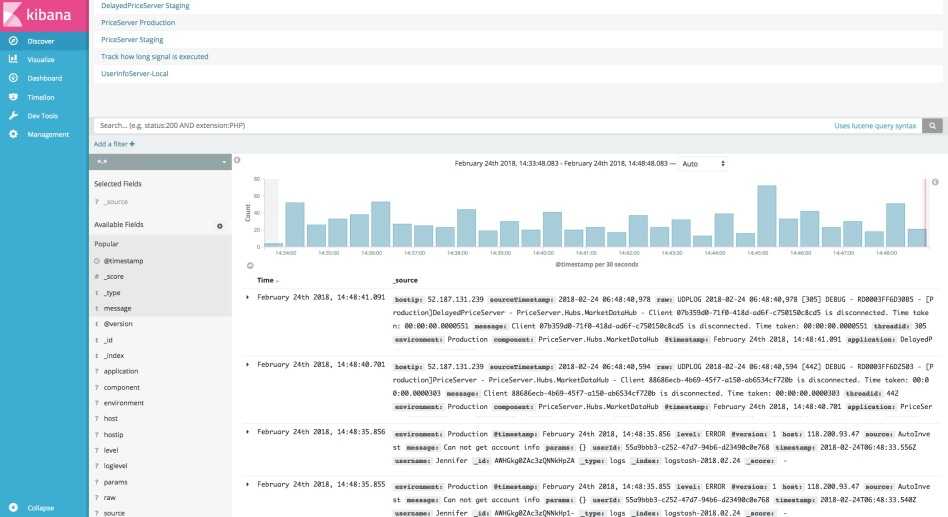
Работаем с журналами посредством запросов SQL
Утилита Log Parser появилась на свет в начале «нулевых» и с тех пор успела обзавестись официальной графической оболочкой. Тем не менее актуальности своей она не потеряла и до сих пор остается для меня одним из самых любимых инструментов для анализа логов. Загрузить утилиту можно в Центре Загрузок Microsoft, графический интерфейс к ней ― в галерее Technet. О графическом интерфейсе чуть позже, начнем с самой утилиты.
О возможностях Log Parser уже рассказывалось в материале «LogParser — привычный взгляд на непривычные вещи», поэтому я начну с конкретных примеров.
Для начала разберемся с текстовыми файлами ― например, получим список подключений по RDP, заблокированных нашим фаерволом. Для получения такой информации вполне подойдет следующий SQL-запрос:
Посмотрим на результат:
Смотрим журнал Windows Firewall.
Разумеется, с полученной таблицей можно делать все что угодно ― сортировать, группировать. Насколько хватит фантазии и знания SQL.
Log Parser также прекрасно работает с множеством других источников. Например, посмотрим откуда пользователи подключались к нашему серверу по RDP.
Работать будем с журналом TerminalServices-LocalSessionManager\Operational.
Данные будем получать таким запросом:
Смотрим, кто и когда подключался к нашему серверу терминалов.
Особенно удобно использовать Log Parser для работы с большим количеством файлов журналов ― например, в IIS или Exchange. Благодаря возможностям SQL можно получать самую разную аналитическую информацию, вплоть до статистики версий IOS и Android, которые подключаются к вашему серверу.
В качестве примера посмотрим статистику количества писем по дням таким запросом:
Если в системе установлены Office Web Components, загрузить которые можно в Центре загрузки Microsoft, то на выходе можно получить красивую диаграмму.
Выполняем запрос и открываем получившуюся картинку…
Любуемся результатом.
Следует отметить, что после установки Log Parser в системе регистрируется COM-компонент MSUtil.LogQuery. Он позволяет делать запросы к движку утилиты не только через вызов LogParser.exe, но и при помощи любого другого привычного языка. В качестве примера приведу простой скрипт PowerShell, который выведет 20 наиболее объемных файлов на диске С.
Ознакомиться с документацией о работе компонента можно в материале Log Parser COM API Overview на портале SystemManager.ru.
Благодаря этой возможности для облегчения работы существует несколько утилит, представляющих из себя графическую оболочку для Log Parser. Платные рассматривать не буду, а вот бесплатную Log Parser Studio покажу.
Интерфейс Log Parser Studio.
Основной особенностью здесь является библиотека, которая позволяет держать все запросы в одном месте, без россыпи по папкам. Также сходу представлено множество готовых примеров, которые помогут разобраться с запросами.
Вторая особенность ― возможность экспорта запроса в скрипт PowerShell.
В качестве примера посмотрим, как будет работать выборка ящиков, отправляющих больше всего писем:
Выборка наиболее активных ящиков.
При этом можно выбрать куда больше типов журналов. Например, в «чистом» Log Parser существуют ограничения по типам входных данных, и отдельного типа для Exchange нет ― нужно самостоятельно вводить описания полей и пропуск заголовков. В Log Parser Studio нужные форматы уже готовы к использованию.

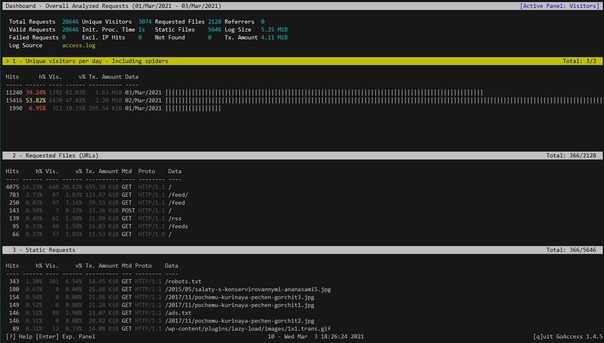
Помимо Log Parser, с логами можно работать и при помощи возможностей MS Excel, которые упоминались в материале «Excel вместо PowerShell». Но максимального удобства можно достичь, подготавливая первичный материал при помощи Log Parser с последующей обработкой его через Power Query в Excel.
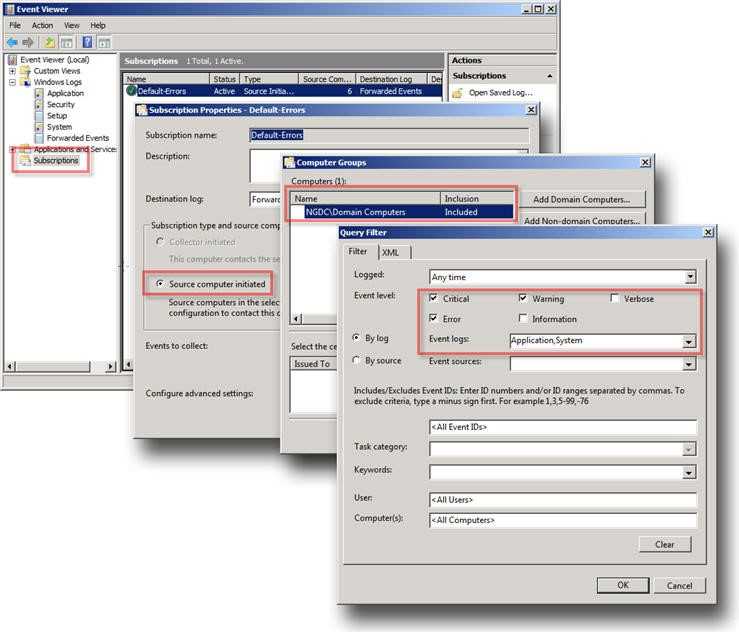
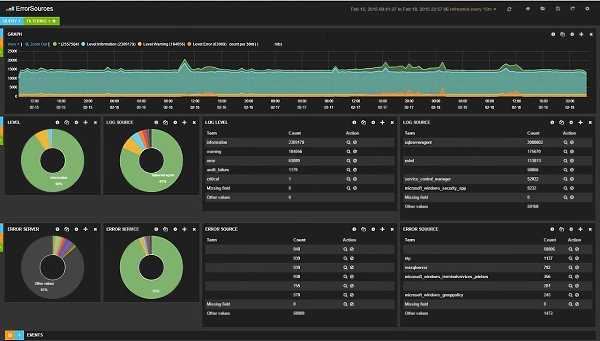
Контроль событий ИБ
В мае текущего года мы решали задачу прохождения сертификации PCI DSS — стандарту безопасности данных индустрии платежных карт. Одним из требований соответствия данному стандарту является наличие системы контроля событий информационной безопасности. На момент прохождения сертификации стек ELK уже работал и собирал данные с большей части эксплуатируемого оборудования, поэтому было принято решение использовать его в качестве системы контроля событий ИБ. В ходе подготовки к аудиту, для всех системных компонентов Техносерв Cloud была настроена отправка в ELK событий безопасности, в том числе следующих:
• любой доступ к данным заказчиков;
• все действия, совершенные с использованием административных полномочий, на серверах и сетевом оборудовании облачной платформы;
• любой доступ к журналам регистрации событий системных компонентов Техносерв Cloud;
• любой доступ пользователей к системным компонентам платформы;
• добавление, изменение и удаление учетных записей;
• запуск и остановка системных компонентов платформы;
• создание и удаление объектов системного уровня.
Для демонстрации наличия перечисленных выше событий в системе были подготовлены представления Kibana. На скриншотах ниже видны попытки доступа пользователей на наши сервера и записи о выполнении команд из-под sudo.
Зафиксированные неуспешные попытки доступа
Выполнение команд от имени суперпользователя
Кратко про конфигурационные файлы
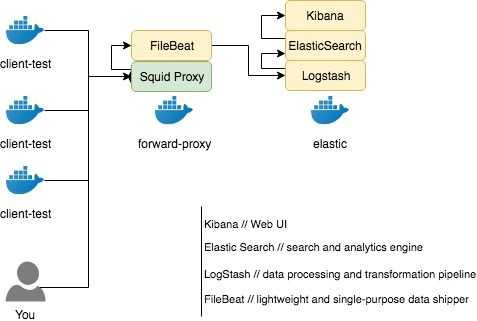
- Networks и volumes были взяты из исходного docker-compose.yml (тот где целиком стек запускается) и думаю, что сильно здесь на общую картинку не влияют.
- Мы создаём один сервис (services) logstash, из образа docker.elastic.co/logstash/logstash:6.3.2 и присваиваем ему имя logstash_one_channel.
- Мы пробрасываем внутрь контейнера порт 5046, на такой же внутренний порт.
- Мы отображаем наш файл настройки каналов ./config/pipelines.yml на файл /usr/share/logstash/config/pipelines.yml внутри контейнера, откуда его подхватит logstash и делаем его read-only, просто на всякий случай.
- Мы отображаем директорию ./config/pipelines, где у нас лежат файлы с настройками каналов, в директорию /usr/share/logstash/config/pipelines и тоже делаем её read-only.
logstash_one_channel | Unable to retrieve license information from license server {:message=>«Elasticsearch Unreachable: [http://elasticsearch:9200/]logstash_one_channel | Pipeline started successfully logstash_one_channel | logstash_one_channel | X-Pack is installed on Logstash but not on Elasticsearch. Please install X-Pack on Elasticsearch to use the monitoring feature. Other features may be available.logstash_one_channel | logstash_one_channel | ogstash_one_channel | Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/] elasticsearch»}logstash_one_channel | logstash_one_channel | Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/] elasticsearch»}elasticsearch
Настраиваем пересылку логов в Mikrotik
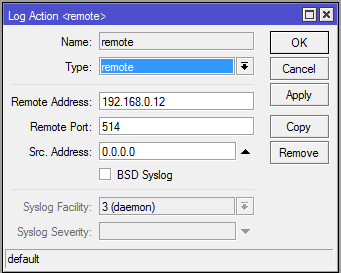
Теперь настраиваем в роутере хранение логов на удаленном сервере. Для этого заходим в раздел System -> Logging, выбираем закладку Actions, два раза щелкаем по строчке remote. Открывается окно настроек. В нем вводим адрес удаленного сервера сбора логов. Порт на свое усмотрение либо оставляем по-умолчанию, либо меняем на свой. Больше ничего добавлять не надо.
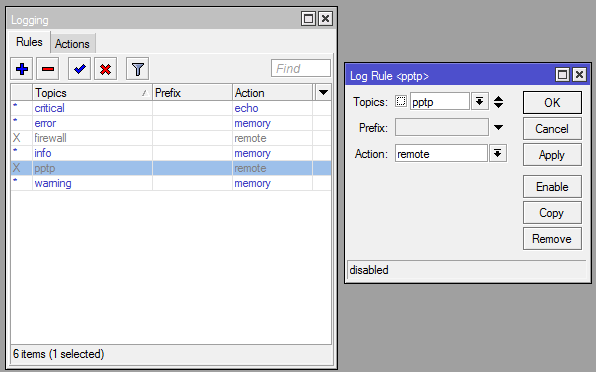
Дальше в разделе Rules создаем необходимое правило хранения:
Все готово. Теперь все наши логи будут храниться на удаленном сервере. Необходимо не забыть настроить ротацию логов, дабы в один прекрасный день они не заняли все свободное место.
Если вы используете ELK Stack для централизованного сбора логов, то у меня есть статья по отправке логов mikrotik в elk stack.
Напоминаю, что данная статья является частью единого цикла статьей про Mikrotik.
Помогла статья? Подписывайся на telegram канал автора
Рекомендую полезные материалы по схожей тематике:
Онлайн курсы по Mikrotik
Если у вас есть желание научиться работать с роутерами микротик и стать специалистом в этой области, рекомендую пройти курсы по программе, основанной на информации из официального курса MikroTik Certified Network Associate. Помимо официальной программы, в курсах будут лабораторные работы, в которых вы на практике сможете проверить и закрепить полученные знания. Все подробности на сайте .
Стоимость обучения весьма демократична, хорошая возможность получить новые знания в актуальной на сегодняшний день предметной области. Особенности курсов:
- Знания, ориентированные на практику;
- Реальные ситуации и задачи;
- Лучшее из международных программ.
- Инструкция о том, как быстро выполнить настройку mikrotik.
- Использование протокола Layer7 для блокировки сайтов средствами Микротик.
- Настройка простых правил фаервола для защиты локальной сети.
- Создание единой wifi сети из множества точек доступа mikrotik с помощью capsman.
- 2 провайдера и 2 wan интерфейса для создания отказоустойчивой связи с интернет.
Заключение
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.

Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Заключение
Я привел частный случай настройки хранения логов с удаленных устройств. Решение в лоб. В простых случаях этого достаточно. Лично мне удобно смотреть информацию в текстовых файлах. Это требуется редко, сделано на всякий случай для расследования инцидентов, если таковые возникают. Эту же задачу, к примеру, можно решить с помощью заббикс. Я уже показывал, как мониторить с помощью zabbix лог файлы. Приведенное решение легко переделать в хранение логов.
Для более удобного сбора и последующего просмотра информации существуют готовые решения с написанными веб панелями. Я посмотрел на некоторые из них. Что-то мне показалось слишком сложным в настройке, где-то веб интерфейс не понравился. Для себя остановился на приведенном варианте.
Онлайн курс Основы сетевых технологий
Теоретический курс с самыми базовыми знаниями по сетям. Курс подходит и начинающим, и людям с опытом. Практикующим системным администраторам курс поможет упорядочить знания и восполнить пробелы. А те, кто только входит в профессию, получат на курсе базовые знания и навыки, без воды и избыточной теории. После обучения вы сможете ответить на вопросы:
- На каком уровне модели OSI могут работать коммутаторы;
- Как лучше организовать работу сети организации с множеством отделов;
- Для чего и как использовать технологию VLAN;
- Для чего сервера стоит выносить в DMZ;
- Как организовать объединение филиалов и удаленный доступ сотрудников по vpn;
- и многое другое.
Уже знаете ответы на вопросы выше? Или сомневаетесь? Попробуйте пройти тест по основам сетевых технологий. Всего 53 вопроса, в один цикл теста входит 10 вопросов в случайном порядке. Поэтому тест можно проходить несколько раз без потери интереса. Бесплатно и без регистрации. Все подробности на странице .
Заключение
Вот таким относительно простым и эффективным способом можно облегчить управление файловыми серверами, особенно когда их много. Я раньше и представить не мог, что можно так удобно собрать всю информацию с логов и вывести в наглядном виде. А потом еще и фильтровать все это по нужным параметрам практически на лету.
В следующей статье расскажу, как сделать то же самое, только для файловых серверов на windows. Там примерно такой же dashboard будет, но сбор и анализ логов другие.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .





