Введение
Ранее я рассказал, как установить и настроить elk stack, потом как загружать и анализировать логи nginx и samba. Теперь пришел черед логов Mikrotik. Я уже рассказывал, как отправлять логи микротика на удаленный syslog сервер, в качестве которого может выступать в том числе syslog-ng. В данном случае на самом микротике ничего особенного делать не надо. Будем точно так же отправлять данные на удаленный syslog сервер, в качестве которого будет трудиться logstash.
Я некоторое время рассуждал на тему парсинга и разбора логов. Но посмотрев на типичную картину стандартных логов mikrotik, понял, что ничего не выйдет. События очень разные и разобрать их одним правилом grok не получится. Если нужен парсинг и добавление метаданных к событиям, необходимо определенные события выделять и направлять отдельным потоком в logstash, где уже обрабатывать своим фильтром. Например, отдельный фильтр можно настроить на парсинг подключений к vpn или подключение по winbox с анализом имен пользователей.
Я же буду просто собирать все логи скопом и складывать в единый индекс. У записей не будет метаданных, по которым можно строить дашборды и анализировать данные. Но тем не менее, это все равно удобно, так как все логи в одном месте с удобным и быстрым поиском.
Сбор windows логов
Приступим к настройке. последнюю версию winlogbeat на сервер, с которого мы будем отправлять логи в elk stack. Вот конфиг с тестового сервера, по которому пишу статью:
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: Security
- name: System
tags:
output.logstash:
hosts:
logging.level: info
logging.to_files: true
logging.files:
path: C:/Program Files/Winlogbeat/logs
name: winlogbeat
keepfiles: 7
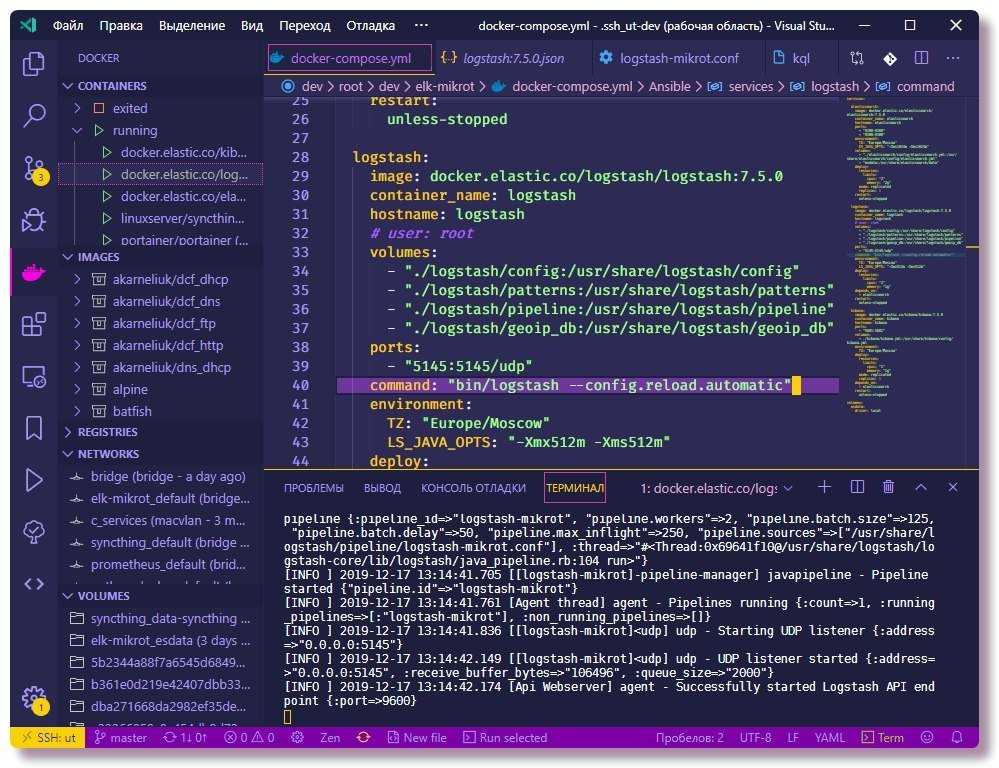
Теперь настраивает logstash на прием этих логов. Добавляем в конфиг:
else if "winsrv" in {
elasticsearch {
hosts => "localhost:9200"
index => "winsrv-%{+YYYY.MM}"
}
}
Я формирую месячные индексы с логами windows серверов. Если у вас очень много логов или хотите более гибкое управление занимаемым объемом, то делайте индексы дневные, указав winsrv-%{+YYYY.MM.dd}.
Перезапускайте службы на серверах и ждите поступления данных в elasticsearch.
Что такое ELK Stack
Расскажу своими словами о том, что мы будем настраивать. Ранее на своем сайте я уже рассказывал о централизованном сборе логов с помощью syslog-ng. Это вполне рабочее решение, хотя очевидно, что когда у тебя становится много логов, хранить их в текстовых файлах неудобно. Надо как-то обрабатывать и выводить в удобном виде для просмотра. Именно эти проблемы и решает представленный стек программ:
- Elasticsearch используется для хранения, анализа, поиска по логам.
- Kibana представляет удобную и красивую web панель для работы с логами.
- Logstash сервис для сбора логов и отправки их в Elasticsearch. В самой простой конфигурации можно обойтись без него и отправлять логи напрямую в еластик. Но с logstash это делать удобнее.
- Beats — агенты для отправки логов в Logstash. Они бывают разные. Я буду использовать Filebeat для отправки данных из текстовых логов linux и Winlogbeat для отправки логов из журналов Windows систем.
К этой связке еще добавляется Nginx, который проксирует соединения на Kibana. В самом простом случае он не нужен, но с ним удобнее. Можно, к примеру, добавить авторизацию или ssl сертификат, в nginx удобно управлять именем домена. В случае большой нагрузки, разные службы разносятся по разным серверам или кластерам. В своем примере я все установлю на один сервер. Схематично работу данной системы можно изобразить вот так:
Начнем по этапам устанавливать и настраивать все компоненты нашей будущей системы хранения и обработки логов различных информационных систем.
Если у вас еще нет своего сервера с CentOS 8, то рекомендую мои материалы на эту тему:
- Установка CentOS 8.
- Настройка CentOS.
Если у вас еще не настроен сервер с Debian, рекомендую мои материалы на эту тему:
- Установка Debian на сервер
- Базовая настройка Debian после установки
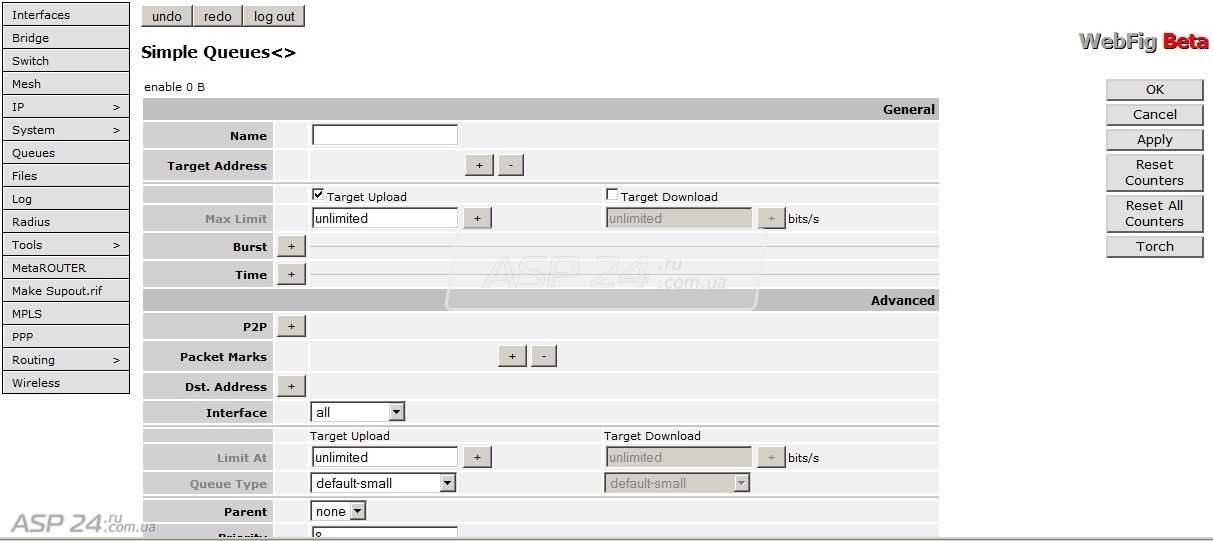
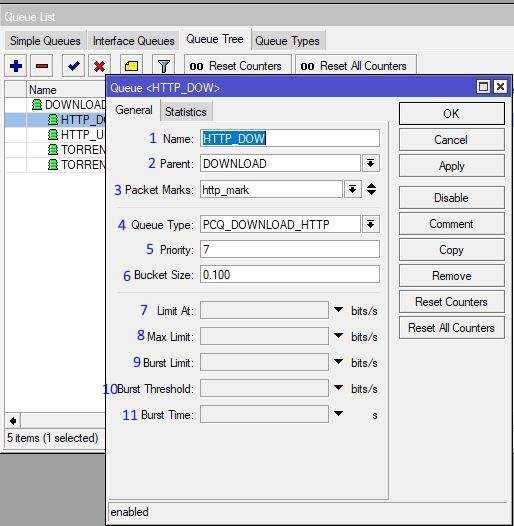
Режим Burst
В переводе с английского burst — вспышка, взрыв. В общем случае режим Burst используется для кратковременного увеличения полосы пропускания. С его помощью можно по определенным правилам превышать значение max-limit своего правила. При этом не могут быть превышены значения max-limit вышестоящего правила или pcq-rate типа очереди. С помощью настроек burst превышение скорости может быть как очень редким, так и частым.
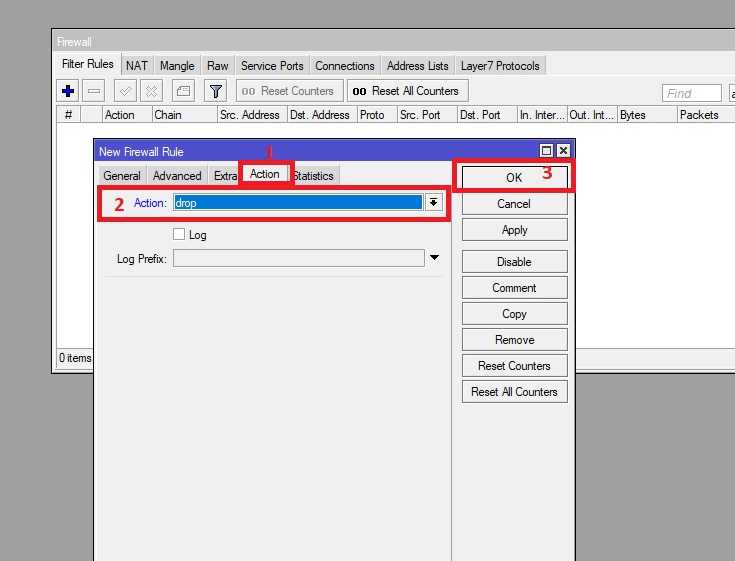
Ранее я уже упоминал параметры очереди, которые относятся к режиму burst:
- burst-limit
- burst-time
- burst-threshold
С их помощью происходит настройка активации этого режима. Я попробую своими словами рассказать, как работает Burst. Не обещаю, что получится понятно всем, но я постараюсь донести информацию. С помощью параметра burst-limit задается максимальный порог скорости при работе burst. Этот порог должен быть больше max-limit, иначе теряется его смысл. С помощью параметра burst-time задается время, в течении которого учитывается текущая средняя скорость (average-rate)
Важно!!! Это не время работы Burst, как я видел в некоторых описаниях в интернете. Значение average-rate рассчитывается каждую 1/16 интервала burst-time
Если у вас указано 10 секунд, средняя скорость будет рассчитываться каждую 0,625 секунды. Учтите, что на все это расходуются ресурсы процессора.
Дальше с помощью burst-threshold вы указываете порог average-rate, после превышения которого режим burst отключается. Таким образом, когда вы начинаете что-то качать, получаете максимальную скорость, указанную в burst-limit. Через некоторое время ваша средняя скорость возрастет до значения burst-threshold и режим burst будет отключен. Скорость будет равна значению max-limit. После того, как вы закончите закачку, режим burst не включится обратно сразу. Должно пройти немного времени, чтобы average-rate за интервал burst-time стал ниже burst-threshold и тогда burst включится обратно.
Рассмотрим условный пример. Это не точный расчет, я просто покажу принцип и примерные последствия, просчитанные на глазок по ходу написания статьи. Допустим, у вас указаны следующие параметры simple queue в вашем mikrotik:
- max-limit = 20M;
- burst-threshold = 15M;
- burst-time = 16s;
- burst-limit = 50M.
Вы начали качать большой файл. Первое время загрузка равна 50M (burst-limit), примерно на 5-й секунде средняя скорость за интервал в 16 (burst-time) секунд будет выше 15M (burst-threshold) (5 секунд на скорости 50M и 11 секунд 0M, пока вы еще ничего не качали, 50M*5сек + 0M*10сек)/16=15,625M, что больше 15M) и режим burst отключается. Вы продолжаете качать со скоростью 20M (max-limit), пока не загрузите весь файл. После окончания загрузки должно пройти примерно 4 секунды, чтобы у вас обратно включился burst ((20M*12сек + 0M*4сек)/16=15M). За это время у вас средняя скорость на интервале последних 16 секунд станет ниже 15M (burst-threshold). Это при условии, что вы не будете больше продолжать что-то скачивать.
Надеюсь, понятно объяснил  Я в свое время очень крепко надо всем этим корпел, пока пытался разобраться. Здесь по хорошему надо график и табличку значений сделать, но мне не хочется этим заниматься. Ниже будет еще один конкретный пример, так что если не поняли, как работает burst, посмотрите его.
Я в свое время очень крепко надо всем этим корпел, пока пытался разобраться. Здесь по хорошему надо график и табличку значений сделать, но мне не хочется этим заниматься. Ниже будет еще один конкретный пример, так что если не поняли, как работает burst, посмотрите его.
Настраиваем удаленный сервер rsyslog
У меня в хозяйстве имелся сервер Debian. Решил хранить логи с микротиков именно на нем. В составе Debian уже имеется сервис сбора логов с удаленных источников rsyslog. Необходимо только включить в нем необходимый функционал. Правим файл /etc/rsyslog.conf:
Раскомментируем строки
# provides UDP syslog reception $ModLoad imudp $UDPServerRun 514
чтобы получать логи по UDP, либо
# provides TCP syslog reception $ModLoad imtcp $InputTCPServerRun 514
чтобы получать логи по TCP
И в секцию RULES добавим несколько строк для удобного хранения файлов логов от разных удаленных источников:
# Зададим шаблон создания имен файлов (на основании IP адреса клиента) $template FILENAME,"/var/log/!remote/%fromhost-ip%/syslog.log"
# Укажем сохранять сообщения от любого источника (*) с любым приоритетом (*) в файл, заданный шаблоном # Например, клиенты (10.0.0.2,10.0.0.3...) будут раскладываться в соответствующие каталоги /var/log/10.0.0.2/syslog.log *.* ?FILENAME
Перезапускаем rsyslog для применения настроек:
/etc/init.d/rsyslog restart
Теперь наш сервер готов принимать логи с удаленных источников. Хранить он их будет в папке /var/log/!remote Для каждого источника будет создана папка с именем IP адреса этого источника.

Examples
Webproxy logging
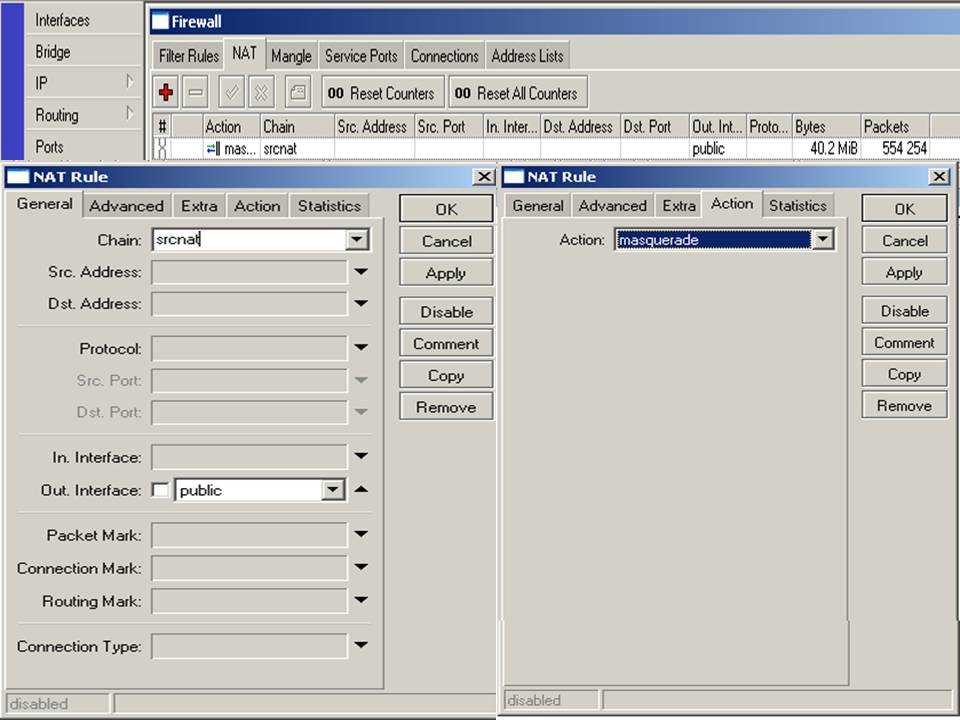
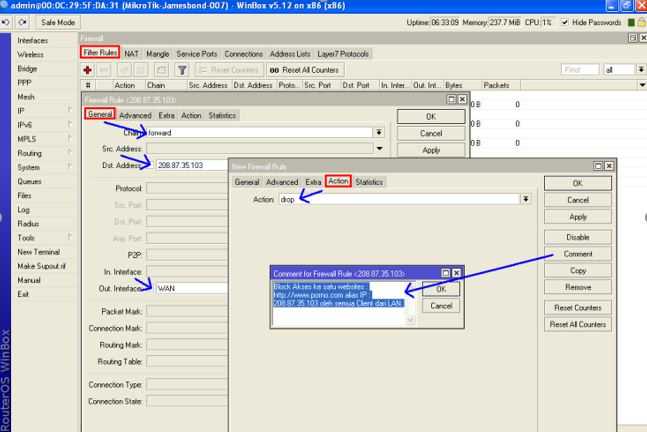
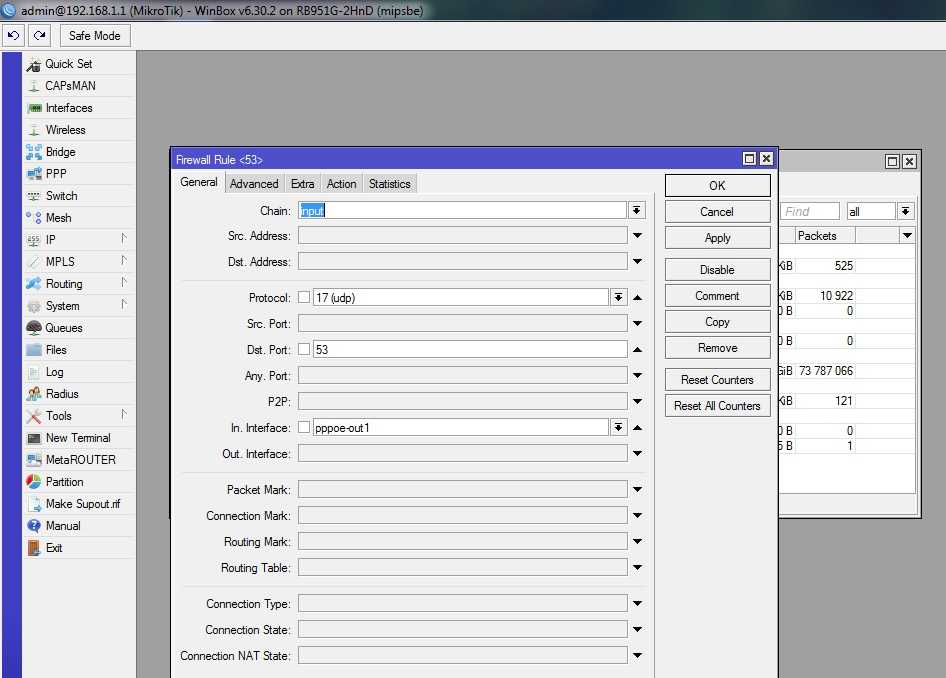
These two screenshots will show you how to configure the RouterOS logging facility to send Webrpoxy logs to a remote syslog server, in this example, located at 192.168.100.12. The syslog server can be any software that supports receiving syslogs, for example Kiwi syslog.
Add a new logging action, with «remote» and the IP of the remote server. Call it whatever you like
Then add a new logging rule with the topic «webproxy» and then newly created action. Note that you must have webproxy running on this router already, for this to work. To test, you can temporary change the action to «memory» and see the «log» window if the webproxy visited websites are logged. If it works, change it back to your new remote action
Note: it’s a good idea to add another topic in the same rule: !debug. This would be to ensure you don’t get any debug stuff, only the visited sites.
Rsyslog
It is possible to send all logs to a remote syslog server, one example of a syslog server is Rsyslog. Below you can find configuration example that is relevant to RouterOS:
With this configuration all logs will be present on the device and on the remote syslog server. Below you can find configuration lines that are relevant to a Rsyslog server (only lines that should be changed from the default values):
For security reasons you should only allow Rsyslog to listen to a certain address, this limits the instance to a single interface. You should also specify only certain IP addresses that are allowed to send their logs to the particular syslog server.
Note: Never rely on a single security measure, you should also implement proper Firewall on the machine running Rsyslog, to limit access to the server.
Источник
Grok фильтр logstash для парсинга лога
Следующим шагом по настройке мониторинга ответа бэкенда является создание grok фильтра для logstash. Приведенный выше формат лога я парсю следующим grok фильтром. Привожу сразу весь конфиг logstash, который за него отвечает:
Привожу конфиг с рабочего сервера, который настраивал достаточно давно. Здесь выполняются следующие действия:
- grok фильтр парсит строки лога
- mutate конвертирует некоторые числовые поля в нужный формат, чтобы потом было удобнее работать
- ruby фильтр добавляет новое поле request_time_ms просто умножая значение из существующего request_time на 1000. Это делается для более удобной визуализации значений. Целые числа более наглядны для визуализации
- фильтр date берет время из поля access_time и использует его как время поступления лога в систему, заменяя @timestamp. Затем это поле удаляет, так как оно становится не нужно. Делается это для того, чтобы использовать только время из лога nginx, чтобы не было путаницы, когда порядок отправки логов по какой-то причине будет нарушен
- geoip фильтр используется для построения гео карты. Об этом я отдельно рассказывал в статье по настройке дашборда для nginx
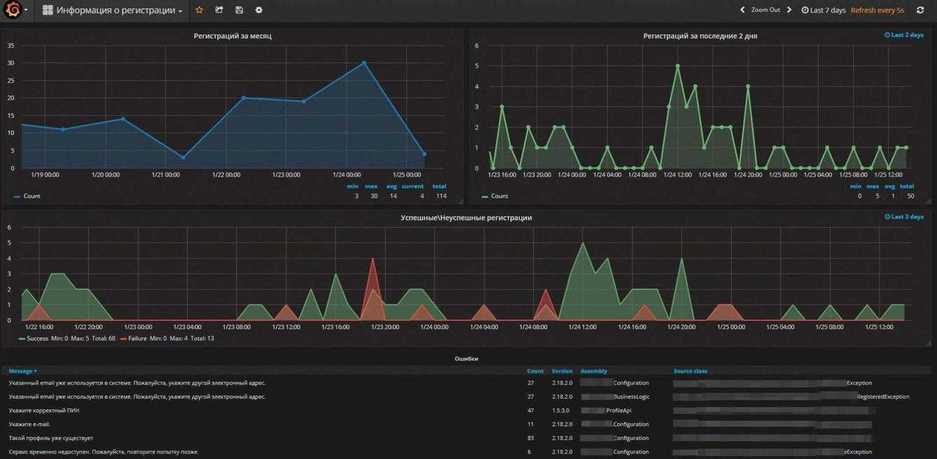
Перезапускайте logstash и идите в Kibana проверять поступление логов в указанном формате. Если все сделали правильно, то должно получиться примерно следующее:
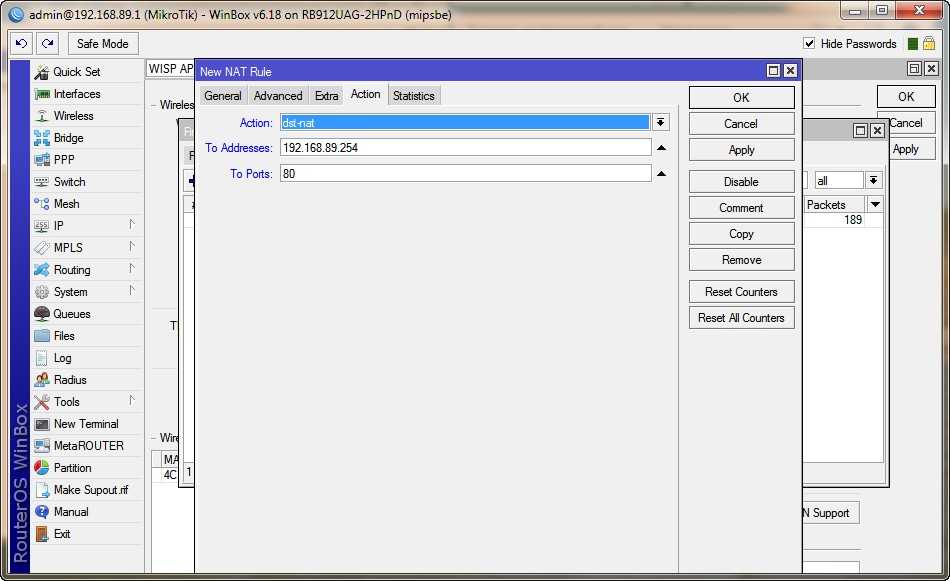
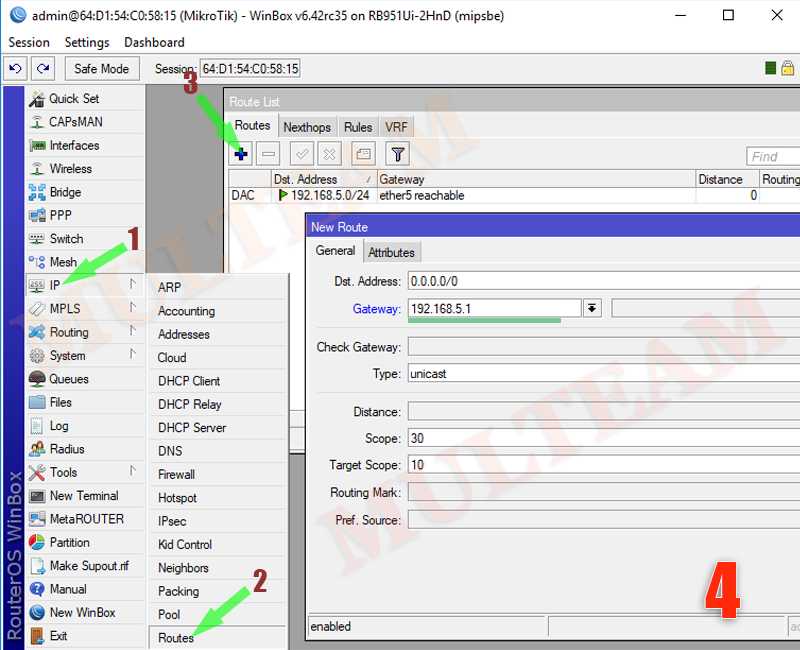
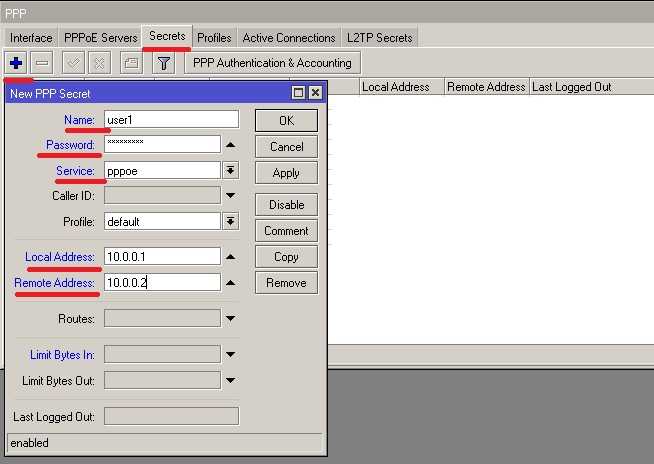
Настраиваем пересылку логов в Mikrotik
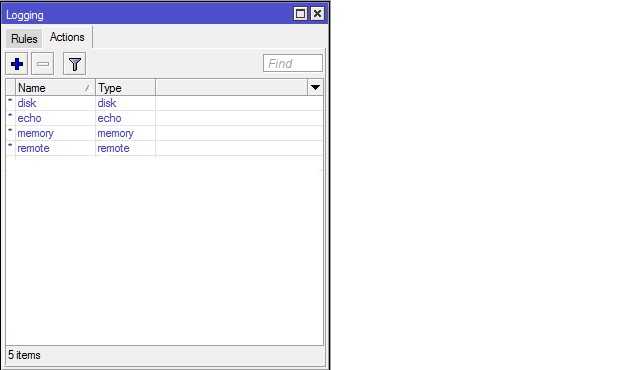
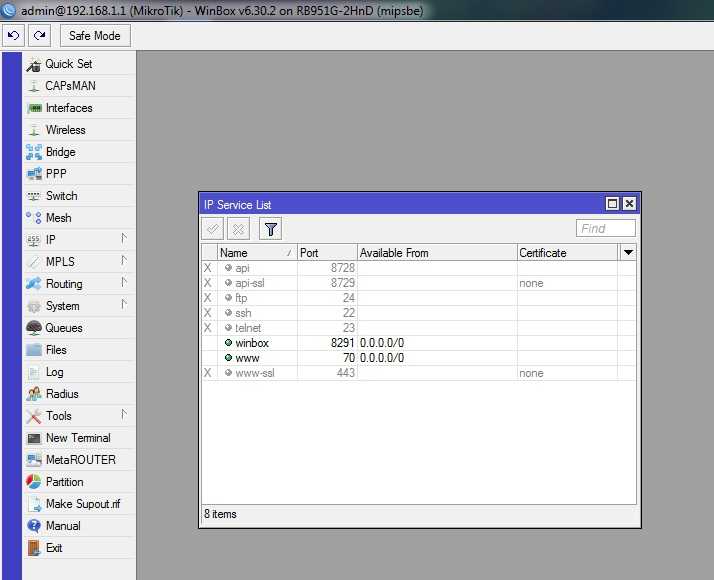
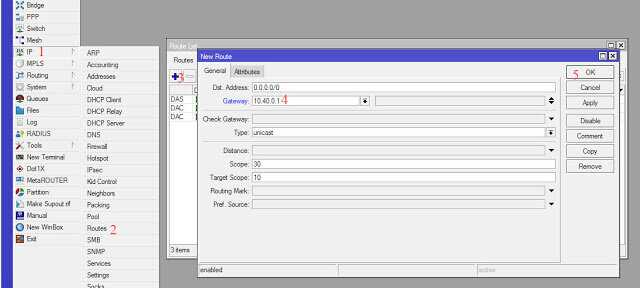
Теперь настраиваем в роутере хранение логов на удаленном сервере. Для этого заходим в раздел System -> Logging, выбираем закладку Actions, два раза щелкаем по строчке remote. Открывается окно настроек. В нем вводим адрес удаленного сервера сбора логов. Порт на свое усмотрение либо оставляем по-умолчанию, либо меняем на свой. Больше ничего добавлять не надо.
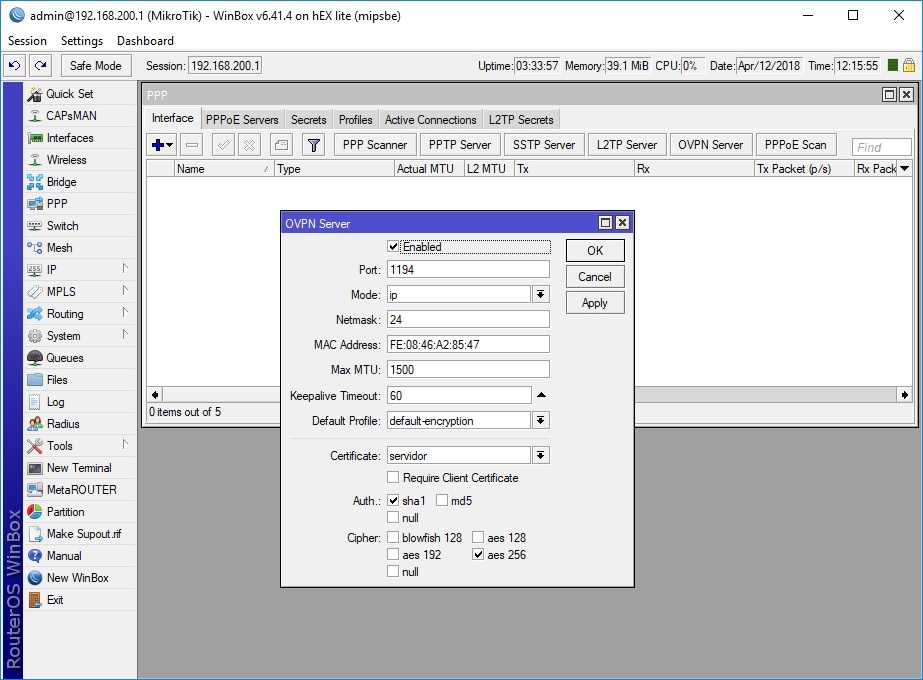
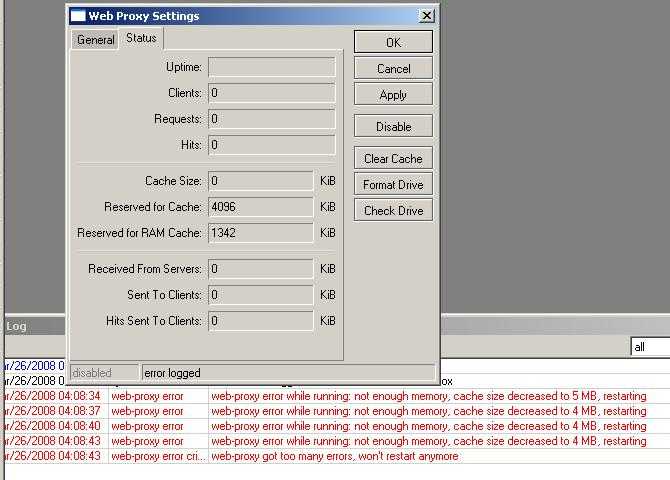
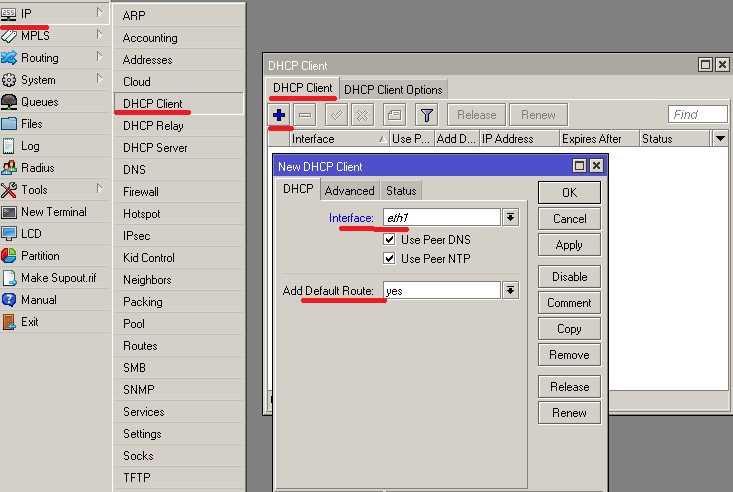
Дальше в разделе Rules создаем необходимое правило хранения:
Все готово. Теперь все наши логи будут храниться на удаленном сервере. Необходимо не забыть настроить ротацию логов, дабы в один прекрасный день они не заняли все свободное место.
Если вы используете ELK Stack для централизованного сбора логов, то у меня есть статья по отправке логов mikrotik в elk stack.
Напоминаю, что данная статья является частью единого цикла статьей про Mikrotik.
Рекомендую полезные материалы по схожей тематике:
Логика скрипта
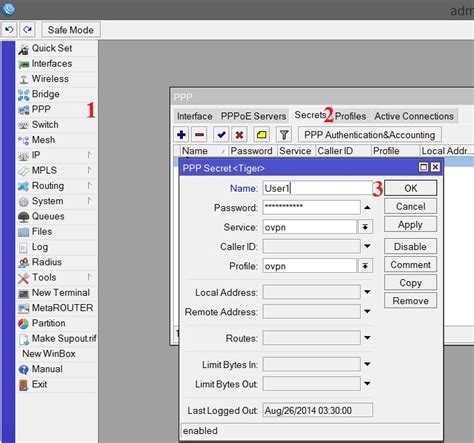
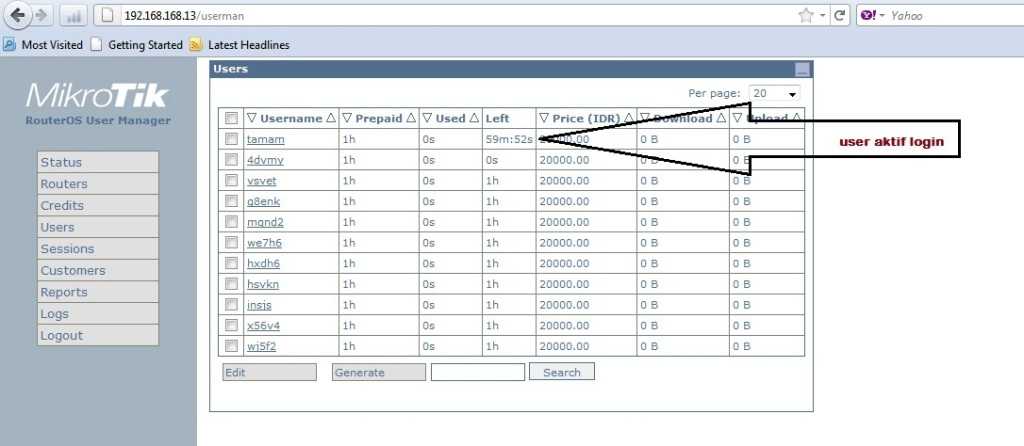
Помимо параметров время события, текст события, MikroTik использует уникальный параметр id события, который мы будем использовать (.id уникален до перезапуска устройства, потом отчет начинается заново, с 0).
-
Обозначаем глобальную переменную ParseLogAccountEndArrayID — хранит последний проверенный .id сообщения;
-
Собираем в массив IDsEventsAccount все .id сообщений, в теме которых встречается «account» — (события: успешный вход на устройство, завершение сессии пользователя). Стандартное ограничение журнала лога 1000 строк, это не вызовет значимой нагрузки на устройство;
-
Получаем LenArrayIDs — количество элементов массива, StartArrayID — номер элемента с которого начнем перебор (это как раз ID последнего запуска), и EndArrayID — номер последнего элемента массива минус 1(массив начинается с элемента с индексом 0).
-
Если последний элемент .id массива (IDsEventsAccount) не равен последнему проверенному .id (ParseLogAccountEndArrayID) (т.е. появились новые события «account») и последний элемент (ParseLogAccountEndArrayID) — не пустой (первый запуск/в журнале нет событий авторизации) начинаем формировать и отправлять сообщения;
-
-
Если в журнале присутствуют необработанные события «account», начинаем перебор ключей в массиве (IDsEventsAccount) по их номерам, начиная с «последнего +1» (чтобы не отправлять вновь предыдущее последнее событие) до «последнего -1» (т.к. индекс начинается с 0);
-
Получаем .id сообщения (IDMessage) по его номеру в массиве;
-
Формируем текст Telegram сообщения, используя %0D%0A для переноса строки;
-
Отправляем сформированное сообщение в Telegram;
-
Записываем в ParseLogAccountEndArrayID последний ID сообщения с темой «account» (EndArrayID).
Заключение
Я привел частный случай настройки хранения логов с удаленных устройств. Решение в лоб. В простых случаях этого достаточно. Лично мне удобно смотреть информацию в текстовых файлах. Это требуется редко, сделано на всякий случай для расследования инцидентов, если таковые возникают. Эту же задачу, к примеру, можно решить с помощью заббикс. Я уже показывал, как мониторить с помощью zabbix лог файлы. Приведенное решение легко переделать в хранение логов.
Для более удобного сбора и последующего просмотра информации существуют готовые решения с написанными веб панелями. Я посмотрел на некоторые из них. Что-то мне показалось слишком сложным в настройке, где-то веб интерфейс не понравился. Для себя остановился на приведенном варианте.
Онлайн курс Основы сетевых технологий
Теоретический курс с самыми базовыми знаниями по сетям. Курс подходит и начинающим, и людям с опытом. Практикующим системным администраторам курс поможет упорядочить знания и восполнить пробелы. А те, кто только входит в профессию, получат на курсе базовые знания и навыки, без воды и избыточной теории. После обучения вы сможете ответить на вопросы:
- На каком уровне модели OSI могут работать коммутаторы;
- Как лучше организовать работу сети организации с множеством отделов;
- Для чего и как использовать технологию VLAN;
- Для чего сервера стоит выносить в DMZ;
- Как организовать объединение филиалов и удаленный доступ сотрудников по vpn;
- и многое другое.
Уже знаете ответы на вопросы выше? Или сомневаетесь? Попробуйте пройти тест по основам сетевых технологий. Всего 53 вопроса, в один цикл теста входит 10 вопросов в случайном порядке. Поэтому тест можно проходить несколько раз без потери интереса. Бесплатно и без регистрации. Все подробности на странице .