
Введение
В своей статье я буду считать, что вы установили и настроили elk stack по моему материалу. Если это не так, то сами подредактируйте представленные конфиги под свои реалии. По большому счету, все самое основное по сбору логов windows серверов уже дано в указанной статье. Как минимум, там рассказано, как начать собирать логи с помощью winlogbeat. Дальше нам нужно их обработать и нарисовать функциональный дашборд для быстрого анализа поступающей информации.
Для того, чтобы оценить представленные мной графики и дашборды, рекомендую собирать логи сразу с нескольких серверов. Так можно будет оценить представленную информацию на практике. С одним сервером не так наглядно получится.
С визуализацией данных из windows журналов проблем нет никаких. Winlogbeat из коробки умеет парсить логи и добавлять все необходимые метаданные. Со стороны logstash не нужны никакие фильтры. Принимаем все данные как есть с winlogbeat.
Elastic SIEM
Другой вариант – Elastic SIEM от Elastic, компании, которая стоит за стеком ELK.
Поскольку это только бета-версия, в решении по-прежнему отсутствуют основные функциональные возможности, ожидаемые от SIEM, но есть перспективы на будущее.
Подобно Logz.io, Elastic SIEM объединяет все существующие возможности управления и анализа журналов, предоставляемые ELK.
Кроме того, Elastic SIEM предлагает специальный пользовательский интерфейс для анализа событий.
Эти возможности предоставляются бесплатно, но под базовой лицензией Elastic, то есть они не являются полностью проектом с открытым исходным кодом.
Дополнительные функции, такие как оповещение, доступны по платной подписке.
На данный момент Elastic SIEM не предоставляет каких-либо расширенных возможностей обнаружения и корреляции угроз.
Определенно стоит следить за тем, как этот продукт будет развиваться в будущем.
Grafana Loki
Grafana Loki появился недавно, но уже стал довольно известным. Его преимущества: лёгко устанавливается, потребляет мало ресурсов, не требует установки Elasticsearch, так как хранит данные в TSDB (time series database). В прошлой статье я писал, что в такой базе хранит данные Prometheus, и это одно из многочисленных сходств двух продуктов. Разработчики даже заявляют, что Loki — это «Prometheus для мира логирования».
Небольшое отступление про TSDB для тех, кто не читал предыдущую статью: TSDB отлично справляется с задачей хранения большого количества данных, временных рядов, но не предназначена для долгого хранения. Если по какой-то причине вам нужно хранить логи дольше двух недель, то лучше настроить их передачу в другую БД.
Ещё одно преимущество Loki — для визуализации данных используется Grafana. Очень удобно: в Grafana мы смотрим данные по мониторингу и там же, подключив Loki, смотрим логи. По логам можно строить графики.
Архитектура Loki выглядит примерно так:
С помощью DaemonSet на всех серверах кластера разворачивается агент — Promtail или Fluent Bit. Агент собирает логи. Loki их забирает и хранит у себя в TSDB. К логам сразу добавляются метаданные, что удобно: можно фильтровать по Pods, namespaces, именам контейнеров и даже лейблам.
Loki работает в знакомом интерфейсе Grafana. У Loki даже есть собственный язык запросов, он называется LogQL — по названию и по синтаксису напоминает PromQL в Prometheus. В интерфейсе Loki есть подсказки с запросами, поэтому не обязательно их знать наизусть.
Loki в интерфейсе Grafana
Используя фильтры, в Loki можно найти коды (“400”, “404” и любой другой); посмотреть логи со всей ноды; отфильтровать все логи, где есть слово “error”. Если нажать на лог, раскроется карточка со всей информацией по событию.
В Loki достаточно инструментов, которые позволяют вытаскивать нужные логи, хотя честно говоря, технически их могло быть и больше. Сейчас Loki активно развивается и набирает популярность.
Настраиваем Logstash
На данный момент Logstash не отправляет данные в кластер Elasticsearch, и чтобы это исправить, сделаем несколько настроек.
Создаем роль для подключения к кластеру:
В Kibana открываем Menu > Management > Stack Management. Слева выбираем Roles и нажимаем Create role. Указываем имя роли и настраиваем привелегии:
|
Cluster privileges |
manage_index_templates |
Все операции над шаблонами индексов |
|
monitor |
Read-only права на получение информации о кластере |
|
|
Index privileges |
create_index |
Создание индексов |
|
write |
Индексирование, обновление и удаление индексов |
|
|
manage |
Мониторинг и управление индексом |
|
|
manage_ilm |
Управление жизненным циклом индексов (IML) |
Создаем пользователя для подключения к кластер:
Открываем Menu > Management > Stack Management, выбираем Users и нажимаем Create user. Заполняем требуемые данные, указав в качестве роли созданную выше роль.
Создание пользователя logstash_user
Создаем Logstash keystore, и добавляем туда пользователя и пароль от него:
Настраиваем аутентификацию в output плагине:
Настраиваем TLS в Logstash:
Для подключения по к Elasticsearch необходимо настроить использование и установить сертификат, который был получен для Kibana.
Перезагружаем Logstash и проверяем новые записи в индексе
Проверку можно сделать в Kibana через Discovery, как делали в , или через API:
Dev Tools — Console в Kibana
Архитектура
Архитектурно сервис собран на одном инстансе. Состоит из клиентской части и коллектора (коллектором будем называть весь EFK стэк). Клиент пересылает, а коллектор, в свою очередь, занимается обработкой логов.
Проект был полностью собран на Docker. Деплоится это все с помощью бережно написанных манифестов Puppet. Вообще он забавно деплоит контейнеры прописывая их в Systemd как сервис, поначалу было непривычно, а потом стало даже удобно, так как за состоянием контейнера начинает следить демон Systemd.
Сам сервис выглядит вот так:
# This file is managed by Puppet and local changes# may be overwrittenDescription=Daemon for fluentd_clientAfter=docker.serviceWants=Requires=docker.serviceRestart=on-failureStartLimitInterval=20StartLimitBurst=5TimeoutStartSec=0RestartSec=5Environment="HOME=/root"SyslogIdentifier=docker.fluentd_clientExecStartPre=-/usr/bin/docker kill fluentd_clientExecStartPre=-/usr/bin/docker rm fluentd_clientExecStartPre=-/usr/bin/docker pull fluent/fluentd:v1.2.5-debianExecStart=/usr/bin/docker run \ -h 'host1.example.com' --net bridge -m 0b \ -p 9122:9122 \ -v /opt/fluentd_client/fluent.conf:/fluentd/etc/fluent.conf \ -v /opt/fluentd_client/data:/data \ -v /var/lib/docker/containers:/logs/docker_logs:ro \ -v /var/log/nginx:/logs/nginx_logs:ro \ -v /var/log/auth.log:/logs/auth_logs:ro \ --name fluentd_client \ fluent/fluentd:v1.2.5-debian \ExecStop=-/usr/bin/docker stop --time=5 fluentd_clientWantedBy=multi-user.target
Итак, состав нашего стэка следующий:
- Elasticsearch — сердце всего проекта, именно на нем лежит задача приема, хранения, обработки и поиска всех сущностей.
- Fluentd — коллектор, который берет на себя роль приема всех логов, их последующего парсинга и бережного укладывания этого всего добра в индексы Elasticsearch.
- Kibana — визуализатор, т.е. умеет работать с API Elasticsearch, получать и отображать полученные данные.
- Cerebro — достаточно интересная штука, позволяющая смотреть состояние и управлять настройками ноды/кластера, управлять индексами (например создание, удаление, создание темплейтов для индексов, шардирование).
- Nginx — используется как прокси сервер для доступа к Kibana, а так же обеспечивает базовую HTTP аутентификацию (HTTP basic authentication).
- Curator — так как логи, в нашем случае, хранить более чем за 30 дней нету смысла, мы используем штуку, которая умеет ходить в Elasticsearch и подчищать индексы старше чем 30 дней.
- cAdvaser (Container Advisor) — контейнер, позволяющий получить информацию о производительности и потреблении ресурсов по запущенным контейнерам. А также используется для сбора метрик системой мониторинга Prometheus.
Наглядно весь EFK стэк (коллектор) изображен на схеме.
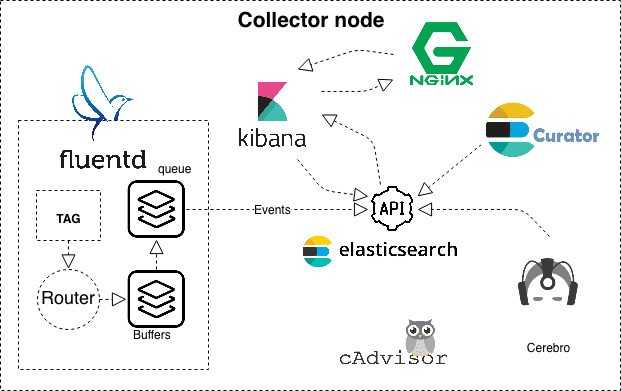
Система сбора логов EFK (коллектор)
Какие логи мы собираем:
- Логи Nginx (access и error).
- Логи с Docker контейнеров (stdout и stderr).
- Логи с Syslog, а именно ssh auth.log.
Тут рисуется вопрос: “А как это все работает под капотом?”.
Пакетный режим работы конфигуратора 1C 7.7
Многие ежедневно сталкиваются с рутинными процедурами администрирования баз данных 1С. К ним можно отнести выгрузку и сохранение данных, тестирование и исправление информационной базы, обмен данными между распределенными базами данных. Как раз в этом случае и можно воспользоваться пакетным режимом работы конфигуратора.
Работа в пакетном режиме подразумевает выполнение программой последовательных действий без участия пользователя. Причем сама последовательность действий должна быть описана пользователем по определенным правилам с использованием документированных ключевых параметров.
Плагины Fluentd: расширяем возможности
Плагины ввода
- in_forward — прослушивает TCP-сокет;
- in_http — принимает сообщения, передаваемые в POST-запросах;
- in_tail — считывает сообщения, записанные в последних строках текстовых файлов (работает так же, как команда tail -F);
- in_exec — с помощью этого плагина можно запускать стороннюю программу и получать её лог событий; поддерживаются форматы JSON, TSV и MessagePack;
- in_syslog — с помощью этого плагина можно принимать сообщения в формате syslog по протоколу UDP;
- in_scribe — позволяет получает сообщения в формате Scribe (Scribe — это тоже коллектор логов, разработанный Facebook).
Что внутри ELK-системы: архитектура и принципы работы
Инфраструктура ELK включает следующие компоненты :
- Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных. Как правило, ES используется в качестве NoSQL-базы данных для приложений со сложными функциями поиска. Elasticsearch основана на библиотеке Apache Lucene, предназначенной для индексирования и поиска информации в любом типе документов. В масштабных Big Data системах несколько копий Elasticsearch объединяются в кластер .
- Logstash — средство сбора, преобразования и сохранения в общем хранилище событий из файлов, баз данных, логов и других источников в реальном времени. Logsatsh позволяет модифицировать полученные данные с помощью фильтров: разбить строку на поля, обогатить или их, агрегировать несколько строк, преобразовать их в JSON-документы и пр. Обработанные данные Logsatsh отправляет в системы-потребители.
- Kibana – визуальный инструмент для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в индексах ES. Веб-интерфейс Kibana позволяет быстро создавать и обмениваться динамическими панелями мониторинга, включая таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени. Примечательно, что изначально Kibana была ориентирована на работу с Logstash, а не на Elasticsearch. Однако, с интеграцией 3-х систем в единую ELK-платформу, Kibana стала работать непосредственно с ES .
- FileBeat – агент на серверах для отправки различных типов оперативных данных в Elasticsearch.
В рамках единой ELK-платформы все вышеперечисленные компоненты взаимодействуют следующим образом :
- Logstash представляет собой конвейер обработки данных (data pipeline) на стороне сервера, который одновременно получает данные из нескольких источников, включая FileBeat. Здесь выполняется первичное преобразование, фильтрация, агрегация или парсинг логов, а затем обработанные данные отправляется в Elasticsearch.
- Elasticsearch играет роль ядра всей системы, сочетая функции базы данных, поискового и аналитического движков. Быстрый и гибкий поиск обеспечивается за счет анализаторов текста, нечеткого поиска, поддержки восточных языков (корейский, китайский, японский). Наличие REST API позволяет добавлять, просматривать, модифицировать и удалять данные .
- Kibana позволяет визуализировать данные ES, а также администрировать базу данных.
Принцип работы ELK-инфраструктуры: как взаимодействуют Elasticsearch, Logstash и Kibana
Завтра мы рассмотрим главные достоинства и недостатки ELK-инфраструктуры. А как эффективно использовать их для сбора и анализа больших данных в реальных проектах, вы узнаете на практических курсах по администрированию и эксплуатации Big Data систем в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков) в Москве.
Смотреть расписание
Записаться на курс
Источники
- https://www.softlab.ru/blog/technologies/5816/
- https://ru.bmstu.wiki/Elastic_Logstash
- https://system-admins.ru/elk-o-chem-i-zachem/
- http://samag.ru/archive/article/3575
Парсинг логов samba в logstash
Нам нужно принять логи с samba в logstash, обработать их и передать в elasticsearch. Для приема логов в конфиге logstash /etc/logstash/conf.d/input.conf (напомню, что у меня для удобства конфиг разделен на 3 части input.conf, filter.conf, output.conf) у меня уже есть строки:
input {
beats {
port => 5044
}
}
Так что ничего добавлять не надо. Дальше нам нужно настроить фильтрацию логов. Для этого в filter.conf добавляю строки:
else if == "smb-audit" {
mutate {
gsub => ",":"]
gsub =>
}
grok {
match =>
overwrite =>
}
}
В данном случае выше в конфиге у меня уже есть другие правила. Если же данное правило у вас будет единственным, то else не нужно указывать. Расскажу, что делают данные правила. Плагин mutate и операция gsub в первой строке заменяет в логе самбы все обратные слеши и | на : Это сделано для того, чтобы потом было проще использовать фильтр grok. Вторая операция gsub заменяет двойной пробел на единичный. Это сделано для того, чтобы убрать двойной пробел в логах самбы, когда в числе месяца используется одна цифра. Вот пример:
Nov 6 18:00:41 xmdoc smbd_audit: XSkobelev|10.1.4.49|documents|open|ok|r|Конструкторы/_Проекты/15667/проработка.dwg
Nov 13 12:04:47 xmdoc smbd_audit: XSignatev|10.1.4.81|documents|open|ok|r|Конструкторы/_Проекты/02649.обрамление.dwg
В первом случае после Nov стоят 2 пробела. Это усложняет настройку парсинга. Поэтому лишние пробелы и символы убираем. После работы фильтра mutate мы получим вот такую строку:
Nov 6 18:00:41 xmdoc smbd_audit: XS:kobelev:10.1.4.49:documents:open:ok:r:Конструкторы/_Проекты/15667/проработка.dwg
Дальше вступает в дело фильтр grok и его правило обработки:
%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: XS:%{GREEDYDATA:user_name}:%{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}
Оно не идеальное, но мои запросы удовлетворяет. Проверить работу фильтра можно в grok debugger. На выходе будет вот такой json:
{
"user_ip": "10.1.4.49",
"share_name": "documents",
"syslog_time": "18:00:41",
"srv_name": "xmdoc",
"user_name": "kobelev",
"syslog_month": "Nov",
"path": "r:Конструкторы/_Проекты/15667/проработка.dwg",
"syslog_day": "6",
"sucess": "ok",
"action": "open"
}
В моем случае не парсится значение домена XS из лога, так как все делается в рамках одного домена, и я просто опустил это действие. Вам нужно подработать правило под свои реалии. Если у вас много доменов, добавьте отдельное поле для имени домена. Если это не нужно, просто поменяйте на свой домен. Из названия полей думаю и так понятно, что я сделал. Я выделил ключевые для меня значения, которые дальше буду использовать в графиках и дашбордах. Я не смог отдельно выделить путь файла без лишних символов в начале. Не помню точно, с чем конкретно это связано, но в целом, проблема в том, что лог сильно изменяется в зависимости от проводимой операции. Единым фильтром было трудно все охватить, пришлось бы разделять разные события на разные потоки и анализировать отдельно. Я посчитал, что это не имеет смысла.
Если у вас samba не в домене, то лог будет немного другой. Вот пример строки лога и моего grok фильтра для обработки. Исходный лог:
Nov 13 11:40:54 xb-share smbd_audit: 10.1.5.20|scans|realpath|ok|Отсканированные счета/2018/счет.pdf
После работы фильтра mutate:
Nov 13 11:40:54 xb-share smbd_audit: 10.1.5.20:scans:realpath:ok:Отсканированные счета/2018/счет.pdf
Дальше вступает в дело grok фильтр
%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: %{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}
И на выходе получаем обработанные данные:
{
"user_ip": "10.1.5.20",
"share_name": "scans",
"syslog_time": "11:40:54",
"srv_name": "xb-share",
"syslog_month": "Nov",
"path": "Отсканированные счета/2018/счет.pdf",
"syslog_day": "13",
"sucess": "ok",
"action": "realpath"
}
Теперь эти данные надо передать в elasticsearch. Добавляем в конфиг output.conf строки:
else if == "smb-audit" {
elasticsearch {
hosts => "localhost:9200"
index => "smb-audit-%{+YYYY.MM}"
}
}
Обращаю внимание, что данными настройками я формирую месячные индексы, а не дневные. Если у вас большой объем данных за день и вы не планируете хранить данные за несколько месяцев, то разбивайте индексы на дни
Если других правил у вас нет, то else уберите. После этого нужно перезапустить logstash и проверять через kibana поступление обработанных логов.
Быстрый поиск в справочниках по наименованию, с использованием svcsvc.dll
По аналогии с http://infostart.ru/public/14286/, недавно узнал что в svcsvc.dll несколько обновился функционал, в частности был добавлен метод AddString().
В прилагаемом коде показан запрос, реализованный методами ВК 1SQlite, т.е. только для DBF.
Это только пример. Т.е. если например у справочника отсутствует поле «Наименование», то скорее всего будет ошибка.
Тем не менее критика приветствуется)))
Необходимые ВК: 1SQlite, FORMEX, svcsvc.dll (отсюда: http://www.1cpp.ru/forum/YaBB.pl?num=1373266553).
p.s.
Спасибо огромное уважаемому ADirks за все эти прекрасные плюшки, и помощь в их освоении)))
Сбор логов samba
Для сбора логов с samba сервера необходимо на него установить filebeat. Как это сделать рассказано в моей статье по установке и настройке elk stack. Создаем простой конфиг для filebeat — /etc/filebeat/filebeat.yml.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/samba/audit.log
fields:
type: smb-audit
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts:
Минимум опций. Просто отправляем все записи лога самбы audit.log в logstash по адресу 10.1.4.114 и устанавливаем тип — smb-audit. Это сделано для удобства в дальнейшей обработке и вычленении логов самбы из общего потока данных. Идентичные настройки будут на всех серверах samba.
Клиентская часть (Агент)
Рассмотрим пример доставки лога от Docker контейнера.
Есть два варианта (на самом деле их больше ) как писать лог Docker контейнеров. В своем дефолтном состоянии, используется Logging Driver — “JSON file”, т.е. пишет классическим методом в файл. Второй способ — это переопределить Logging Driver и слать лог сразу в Fluentd.
Решили мы попробовать второй вариант.
Далее столкнулись с такой проблемой, что если просто сменить Logging Driver и, если вдруг, TCP сокет Fluentd, куда должны сыпаться логи, не доступен, то контейнер вообще не запустится. А если TCP сокет Fluentd пропадет, когда контейнер ранится, то логи начинают копиться в буфер.
Происходит это потому, что у Docker есть два режима доставки сообщений от контейнера к Logging Driver:
direct — является дефолтным. Приложение падает, когда не может записать лог в stdout и/или stderr.
non-blocking — позволяет записывать логи приложения в буфер при недоступности сокета коллектора. При этом, если буфер полон, новые логи начинают вытеснять старые.
Все эти вещи подтянули дополнительными опциями Logging Driver (—log-opt).
Но, так как нас не устроил ни первый, ни второй вариант, то мы решили не переопределять Logging Driver и оставить его дефолтным.
Вот тут и настал момент, когда мы задумались о том, что необходимо устанавливать агента, который бы старым, добрым способом вычитывал с помощью tail лог файл. Кстати, я думаю не все задумывались над тем, что происходит с tail, когда ротейтится лог-файл, а оказалось все достаточно просто, так как tail снабжен ключем -F (same as —follow=”name” —retry), который способен следить за файлом и переоткрывать его в случае необходимости.
Итак, первое на что было обращено внимание — это продукт FluentBit. Настройка FluentBit достаточна проста, но мы столкнулись с несколькими неприятными моментами
Настройка FluentBit достаточна проста, но мы столкнулись с несколькими неприятными моментами.
Проблема заключалась в том, что если TCP сокет коллектора не доступен, то FluentBit начинает активно писать в буфер, который находится в памяти и по мере его заполнения, начинает вытеснять (перезаписывать) лог, до тех пор, пока не восстановит соединение с коллектором, а следовательно, мы теряем логи. Это не критикал, но крайне неприятно.
Решили эту проблему следующим образом.
FluentBit в tail плагине имеет следующие параметры:
DB — определяет файл базы данных, в котором будет вестись учет файлов, которые мониторятся, а также позицию в этих файлах (offsets).
DB.Sync — устанавливает дефолтный метод синхронизации (I/O). Данная опция отвечает за то, как внутренний движок SQLite будет синхронизироваться на диск.
И стало все отлично, логи мы не теряли, но столкнулись со следующей проблемой — эта штука очень жутко начала потреблять IOPs
Обратили на это внимание когда заметили, что инстансы начали тупить и упираться в IO, которого раньше хватало за глаза и сейчас объясню почему
Мы используем EC2 инстансы (AWS) и тип EBS — gp2 (General Purpose SSD). У них есть такая штука, которая называется “Burst performance”. Это когда EBS способен выдерживать некоторые пики возрастающей нагрузки на файловую систему, например запуск какой-нибудь крон задачи, которая требует интенсивного IO и если ему недостаточно “baseline performance”, инстанс начинает потреблять накопленные кредиты на IO т.е. “Burst performance”.
Так вот, наша проблема заключалась в том, что были вычерпаны кредиты IO и EBS начал захлебываться от его недостатка.
Ок. Пройденный этап.
После этого мы решили, а почему бы не использовать тот же Fluentd в качестве агента.
Плагины вывода
- плагины без буферизации — не сохраняют результаты в буфере и моментально пишут их в стандартный вывод;
- с буферизацией — делят события на группы и записывают поочередно; можно устанавливать лимиты на количество хранимых событий, а также на количество событий, помещаемых в очередь;
- с разделением по временным интервалам — эти плагины по сути являются разновидностью плагинов с буферизацией, только события делятся на группы по временным интервалам.
- out_copy — копирует события в указанное место (или несколько мест);
- out_null — этот плагин просто выбрасывает пакеты;
- out_roundrobin — записывает события в различные локации вывода, которые выбираются методом кругового перебора;
- out_stdout — моментально записывает события в стандартный вывод (или в файл лога, если он запущен в режиме демона).
- out_exec_filter — запускает внешнюю программу и считывает событие из её вывода;
- out_forward — передаёт события на другие узлы fluentd;
- out_mongo (или out_mongo_replset) — передаёт записи в БД MongoDB.
Плагины буферизации
- buf_memory — изменяет объём памяти, используемой для хранения буферизованных данных (подробнее см. в официальной документации);
- buf_file — даёт возможность хранить содержимое буфера в файле на жёстком диске.
Плагины форматирования
- out_file — позволяет кастомизировать данные, представленные в виде «время — тэг — запись в формате json»;
- json — убирает из записи в формате json поле «время» или «тэг»;
- ltsv — преобразует запись в формат LTSV;
- single_value — выводит значение одного поля вместо целой записи;
- csv — выводит запись в формате CSV/TSV.



