
Синтаксис и опции docker run
Синтаксис команды docker run похож на синтаксис других команд Linux и выглядит следующим образом:
$ docker run опции образ команда
Утилите обязательно надо передать образ, на основе которого будет создан контейнер. Образ может быть локальным или указывать на образ, который надо загрузить из сети. Мы рассмотрим это в примерах ниже. Опции позволяют настроить контейнер и параметры его запуска более детально. Сама команда позволяет переопределить программу, которая выполняется после запуска контейнера. Например, выполнив /bin/bash, вы можете подключится к самому контейнеру.
Рассмотрим основные опции утилиты, которые мы будем использовать. Опций очень много, поэтому я не могу перечислить их все:
- -d — запускает контейнер в фоновом режиме;
- -t — прикрепляет к контейнеру псевдо-TTY-консоль;
- -i — выводит в терминал STDIN поток контейнера;
- —name — имя контейнера, по которому потом можно будет к нему обращаться;
- —dns — устанавливает DNS-серверы для контейнера;
- —network — тип сети для контейнера, может принимать такие значения: bridge (используется по умолчанию), none, host. Также можно передать идентификатор сети Docker, к которой надо подключится;
- —add-host — добавляет строчку в /etc/hosts;
- —restart — указывает, когда надо перезапускать контейнер. Возможные значения: no, on-failure, always, unless-stopped;
- —rm — удаляет контейнер после завершения его работы;
- -m, —memory — количество оперативной памяти, доступное Docker-контейнеру;
- —memory-swap — объём памяти раздела подкачки, доступный в контейнере;
- —cpus — количество ядер процессора, доступных в контейнере;
- —shm-size — размер файла /dev/shm;
- —device — позволяет монтировать устройства из папки /dev в контейнер;
- —entrypoint — позволяет переопределить скрипт, который выполняется при запуске контейнера, перед запуском основной команды;
- —expose — позволяет пробросить несколько портов из контейнера в хост-систему;
- -P — пробрасывает все порты контейнера в хост-систему;
- -p — переносит все порты контейнера в хост-систему без смены номера порта;
- —link — позволяет настроить связь контейнеров Docker;
- -e — добавляет переменную окружения в контейнер;
- -v, —volume — позволяет монтировать папки хоста в контейнер;
- -w — изменяет рабочую директорию контейнера.
Это основные опции, которые мы будем использовать в этой статье, а теперь давайте рассмотрим на примерах, как создать контейнер Docker в Linux.
Traefik
В первую очередь, я использую Traefik – что это такое, более подробно можно прочитать на сайте https://doc.traefik.io/traefik/.
Traefik – это реверс-прокси, который позволяет нам публиковать ресурсы в интернете. Это альтернатива Nginx, обладающая немного более богатыми возможностями. Основная преимущество Traefik – он может в автоматическом режиме публиковать уже развернутые контейнеры в интернете.
Traefik слушает два порта: 80 и 443. Все входящие запросы на эти порты он анализирует через свои правила и смотрит, относительно какого URL идет обращение. И в зависимости от URL запросы заворачиваются на контейнеры, которым установлен определенный лейбл.
Дополнительным плюсом является то, что Traefik с коробки может работать с сертификатами выписанными Letsencript, как для основного домена, так и поддоменов любого уровня.
Часть 0.2 Процессы в контейнерах
- Контейнер живет, пока живет процесс, вокруг которого рождается контейнер.
- Внутри контейнера этот процесс имеет pid=1
- Рядом с процессом с pid=1 можно порождать сколько угодно других процессов (в пределах возможностей ОС, естественно), но убив (рестартовав) именно процесс с pid=1, контейнер выходит. (см п.1)
- Внутри контейнера вы увидите привычное согласно стандартам FHS расположение директорий. Расположение это идентично исходному дистрибутиву (с которого взят контейнер).
- Данные, создаваемые внутри контейнера остаются в контейнере и нигде более не сохраняются (ну, еще к этому слою есть доступ из хостовой ОС). удалив контейнер — потеряете все ваши изменения. Поэтому данные в контейнерах не хранят, а выносят наружу, на хостовую ОС.
Установка WAMP сервера
И так, первое что нам нужно сделать это зайти на сайт http://www.wampserver.com/ru/ и скачать инсталлятор данного сервера.
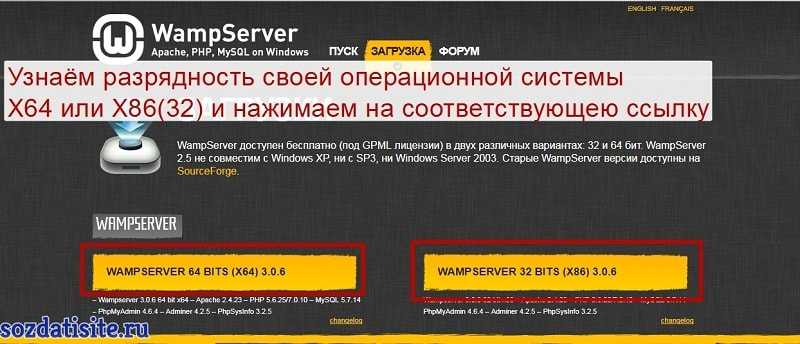
После нажатия на соответствующей ссылке, появится окно ( pop-up ) с несколькими предупреждениями. Где говориться, что, нельзя использовать предыдущие серверные расширения и для того чтобы сервер заработал, нужно перейти по предоставленной ссылке и скачать пакет Visual C++ Redistributable для Visual studio, и конечно установить его.
Если этого не сделать, то при запуске сервера появятся различные ошибки об отсутствии каких-то файлов с расширением dll. Пример ошибки: » Отсутствует файл MSVCR110.dll «.
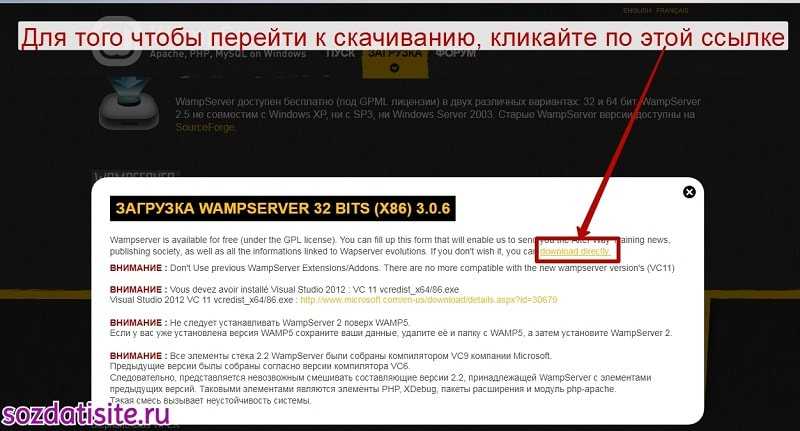
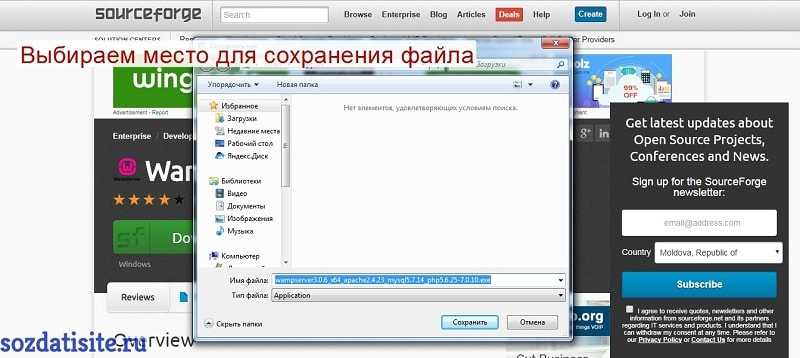
Выбираем место для сохранения файла и нажимаем на кнопку » сохранить «.
Дальше идёт обычная установка программы, с которой справится любой пользователь.
Открываем скаченный файл.
Выбираем язык установки.
Принимаем условия лицензии и нажимаем на Next.
Несколько Docker-инструкций
- — задаёт родительский (главный) образ;
- — добавляет метаданные для образа. Хорошее место для размещения информации об авторе;
- — создаёт переменную окружения;
- — запускает команды, создаёт слой образа. Используется для установки пакетов и библиотек внутри контейнера;
- — копирует файлы и директории в контейнер;
- — делает всё то же, что и инструкция . Но ещё может распаковывать локальные файлы;
- — указывает команду и аргументы для выполнения внутри контейнера. Параметры могут быть переопределены. Использоваться может только одна инструкция ;
- — устанавливает рабочую директорию для инструкции и ;
- — определяет переменную для передачи Docker’у во время сборки;
- — предоставляет команды и аргументы для выполняющегося контейнера. Суть его несколько отличается от , о чём мы поговорим ниже;
- — открывает порт;
- — создаёт точку подключения директории для добавления и хранения постоянных данных.
Куда отправляются данные, когда они записываются в контейнер?
Предположим, что мы заходим в оболочку внутри busybox контейнера:
Затем, давайте запишем некоторые данные, скажем, в /tmp:
Мы видим, что данные определенно записываются. Но куда же на самом деле идут эти данные? Как мы узнали ранее, образы Docker состоят из слоев, уложенных друг на друга, чтобы привести к окончательному образу. Каждый из этих слоев содержит данные, измененные в такой операции, как установка инструмента, добавление исходного кода и т.д. Каждый из этих слоев становится доступным только для чтения после его создания. Когда контейнер создается из образа, тонкий R/W слой добавляется поверх предыдущих слоев образа. Этот слой обрабатывает все вызовы записи из контейнера, которые, в противном случае, были бы направлены на слои ниже, доступные только для чтения. Помните, что контейнеры эфемерны по своей природе. Они предназначены для того, чтобы иметь определенную продолжительность жизни и умереть в какой-то момент, как и любой процесс. Тонкий слой чтения/записи также эфемерен — он исчезает вместе с контейнером. Таким образом, любые записи, которые мы выполняем в контейнере, ограничены временем жизни этого контейнера. Они исчезнут, когда контейнер будет уничтожен. Это очевидное ограничение, которое не способствует хранению статусной информации. Итак, как разработчики и администраторы работают с этим? Они используют Тома Docker.
Что общего между контейнерами и виртуальными машинами
Хотя контейнеры НЕ виртуальные машины, у них обоих есть три важные характеристики:
(Изображение Albund | Dreamstime.com)
Что общего между контейнерами и виртуальными машинами:
- Изолированное окружение: как и виртуальные машины, контейнеры гарантируют изоляцию файловой системы, переменных окружения, реестра и процессов между приложениями. Это значит, что, как и виртуальная машина, каждый контейнер создаёт изолированное окружение для всех приложений внутри себя. При миграции и контейнеры, и виртуальные машины сохраняют не только приложения внутри, но также и контекст этих приложений.
- Миграция между хостами: большое преимущество работы с виртуальными машинами в том, что можно перемещать слепки виртуальных машин между гипервизорами, при этом не нужно изменять их содержимое. Это справедливо и для контейнеров. Там, где виртуальные машины можно “перемещать” между разными гипервизорами, контейнеры можно “перемещать” между разными хостами контейнеров. При “перемещении” обоих видов артефактов между разными хостами содержимое виртуальной машины/контейнера остаётся точно таким же, как и на предыдущих хостах.
- Управление ресурсами: другая общая черта — это то, что доступные ресурсы (ЦП, ОЗУ, пропускная способность сети) как контейнеров, так и виртуальных машин могут быть ограничены до заданных значений. В обоих случаях это управление ресурсами может осуществляться только на стороне хоста контейнера или гипервизора. Управление ресурсами гарантирует, что контейнер получает ограниченные ресурсы, чтобы свести к минимуму риск того, что он повлияет на производительность других контейнеров, запущенных на том же самом хосте. К примеру, контейнеру можно задать ограничение, что он не может использовать больше 10% ЦП.
Исследуем Docker-образ с помощью Dive
Даже после сборки с соблюдением всех правил и советов нужно исследовать образ на возможность дополнительных улучшений.
Dive — прекрасный инструмент на основе командной строки для исследования образа, содержимого слоев и поиска способов уменьшить размер Docker/OCI-образа. У него на GitHub больше 24 тыс. звезд. К тому же он очень прост в использовании.
У Dive есть две очень полезные метрики:
- возможная трата места на диске,
- оценка эффективности образа.
Но его лучшая возможность — интеграция с любым CI-инструментом. Для обеих метрик можно указать , и если оно не выполняется, то и CI-задача тоже не выполняется. Поэтому мы всегда можем доверять Docker-образу, созданному с помощью CI-задачи.
Тома Docker
Тома Docker — это способ создания постоянного хранилища для контейнеров Docker. Тома Docker не привязаны к времени жизни контейнера, поэтому сделанные в них записи не исчезнут, как это произойдет с контейнером. Они также могут быть повторно подключены к одному или к нескольким контейнерам, чтобы можно было обмениваться данными и подключать новые контейнеры к существующему хранилищу. Тома Docker работают путем создания каталога на главной машине и последующего монтирования этого каталога в контейнер (или в несколько контейнеров). Этот каталог существует вне многослойного образа, который обычно содержит контейнер Docker, поэтому он не подчиняется тем же правилам (только для чтения и т. д.).
Давайте создадим том Docker и посмотрим его в действии:
Простой вызов docker volume create позволит создать новый том. Если мы проверим этот том, мы можем увидеть, где он живет на хост-файловой системе:
С вызовом inspect приходит много информации ,но все, что нас действительно беспокоит прямо сейчас, это Mountpoint
Обратите внимание, что здесь указан путь, начианющийся с /var/lib/docker…. Если вы откроете этот путь на своем компьютере, на котором работает Docker, вы можете просмотреть данные, хранящиеся внутри этого тома
Метод, который мы только что использовали для создания тома, не является единственным способом. При запуске контейнера вы можете указать -v, чтобы создать новый том на лету:
Как вы можете видеть, мы добавили новый аргумент к нашей docker run команде: -v. Существует специальный синтаксис для этого аргумента, с полями, разделенными двоеточиями. Первое поле — это название тома, в данном случае, testdata. Второе поле — это путь в контейнере, куда том будет примонтирован, в нашем случае, /data. Давайте запишем данные на том из контейнера:
Эти данные видны снаружи контейнера, в пути монтирования тома на хосте:
Вы должны были заметить, что в пути название тома больше не является случайной строкой — это теперь имя тома, которое мы указали при использовании -v аргумента. Тома Docker могут иметь либо рандомизированные имена, инициализированные Docker Engine, или имена, назначенные пользователем самостоятельно. Имена должны быть уникальными для каждого хоста. Созданный во время выполнения том Docker теперь становится доступным в команде docker volume ls :
Это означает, что мы можем использовать этот том снова с другим контейнером или даже несколькими контейнерами. Давайте проверим это прямо сейчас. Во-первых, подключите том к busybox контейнеру:
Внутри контейнера давайте напечатаем информацию о системе, а затем запишем на том:
Теперь запустите второй busybox контейнер, работающий одновременно с первым:
Нам доступны данные, которые были записаны в первом контейнере:
Это подчеркивает еще одно из преимуществ томов Docker: совместное использование данных между контейнерами.
Рекомендации по уменьшению размеров образов и ускорению процесса их сборки
- Используйте всегда, когда это возможно, официальные образы в качестве базовых образов. Официальные образы регулярно обновляются, они безопаснее неофициальных образов.
- Для того чтобы собирать как можно более компактные образы, пользуйтесь базовыми образами, основанными на Alpine Linux.
-
Если вы пользуетесь , комбинируйте в одной инструкции команды и . Кроме того, объединяйте в одну инструкцию команды установки пакетов. Перечисляйте пакеты в алфавитном порядке на нескольких строках, разделяя список символами . Например, это может выглядеть так:
Этот метод позволяет сократить число слоёв, которые должны быть добавлены в образ, и помогает поддерживать код файла в приличном виде.
- Включайте конструкцию вида в конец инструкции , используемой для установки пакетов. Это позволит очистить кэш и приведёт к тому, что он не будет сохраняться в слое, сформированном командой . Подробности об этом можно почитать в документации.
- Разумно пользуйтесь возможностями кэширования, размещая в Dockerfile команды, вероятность изменения которых высока, ближе к концу файла.
- Пользуйтесь файлом .
- Взгляните на — отличный инструмент для исследования образов Docker, который помогает в деле уменьшения их размеров.
- Не устанавливайте в образы пакеты, без которых можно обойтись.
Варианты Использования Тома Docker
Есть много допустимых вариантов использования для контейнеров Docker, но здесь мы рассмотрим два наиболее распространенных. Для каждого из этих примеров давайте представим, что у нас есть простое приложение, которое работает и собирает данные с некоторых датчиков погоды. Мы хотим собрать кучу метеорологических показателей, сохранить их, а затем использовать их снова в будущем. Давайте назовем наше тестовое приложение WeatherMon.
Сохранение данных за пределами срока службы контейнера
Если мы выполняем WeatherMon без использования томов Docker, все данные, которые мы собираем, будут уничтожены при исчезновении контейнера. Нам это не сильно поможет, если наша цель — собрать данные и сделать их доступными для дальнейшего использования. Тома Docker удобны тем, что мы можем сохранить наши данные в томе и оставить их за пределами срока службы контейнера. Допустим, мы создаем наш контейнер, вызывая docker run с аргументом -v weathermon:/opt/weathermon. Тогда наше приложение может хранить свои метрики погоды в каталоге /opt/weathermon непосредственно на эфемерном слое чтения/записи, предоставленном контейнером. Мы также могли бы настроить удаленную базу данных для хранения этой информации, но тома Docker предоставляют альтернативу для хранения локально используемых данных.
Совместное Использование Данных Между Контейнерами
Предположим, что мы уже используем контейнер WeatherMon некоторое время и собрали довольно много данных. Мы хотим проанализировать эти данные, чтобы определить информацию, такую как средняя температура за день, или какая неделя в месяце имела самую высокую среднюю влажность. Используя тома Docker, мы можем смонтировать существующий том в новый контейнер, WeatherMon-Analytics. Этот новый контейнер может считывать данные, не прерывая их сбор контейнером WeatherMon. Затем он может выполнять аналитику, которую мы хотим, и хранить эту информацию в том же томе или в другом томе, если это необходимо.
Разворачивание контейнера с GitLab
Теперь я хочу запустить контейнер с GitLab. Файл Docker-compose.yml для него скачан с репозитория https://github.com/sameersbn/docker-gitlab, найденного в Google. Я только настроил в нем параметры и добавил сюда лейблы для Traefik.
Также с помощью команды docker-compose up -d я могу могу этот контейнер поднять.
Здесь запускается сразу несколько сервисов: Redis, Postgre, GitLab. У них есть определенный набор переменных, с помощью которых они взаимодействуют.
И есть виртуальная сеть proxy, которая взаимодействует с ними и Traefik. Внутри этой сети как раз и проходит маршрутизация Traefik.
Если мы зайдем на сайт git.demoncat.ru, который прописан в переменной GITLAB_HOST_RULE, у нас откроется GitLab. Здесь тоже никакой магии нет.
Добавление узла в oVirt
Выполняется очень просто:
Compute → Hosts → New →…
В мастере обязательны поля Name (отображаемое имя, напр., kvm03), Hostname (FQDN, напр. kvm03.lab.example.com) и секция Authentication — пользователь root (неизменямо) — пароль или SSH Public Key.
После нажатия кнопки Ok Вы получите сообщение «You haven’t configured Power Management for this Host. Are you sure you want to continue?». Это нормально — управление питанием мы рассмотрим далее, после успешного подключения хоста. Однако, если машины, на которые установлены хосты, не поддерживает управление (IPMI, iLO, DRAC и т.п.), рекомендую его отключить: Compute → Clusters → Default → Edit → Fencing Ploicy → Enable fencing, убрать галку.
Если на хосте не был подключен репозиторий oVirt, установка закончится неудачей, но ничего страшного — надо его добавить, затем нажать Install -> Reinstall.
Подключение хоста занимает не более 5-10 минут.
Настройка сетевого интерфейса
Посколько мы строим отказоустойчивую систему, сетевое подключение также должно обеспечивать резервированное подключение, что и выполняется на вкладке Compute → Hosts → HOST → Network Interfaces — Setup Host Networks.
В зависимости от возможностей вашего сетевого оборудования и подходов к архитектуре, возможны варианты. Оптимальнее всего подключаться к стеку top-of-rack коммтуаторов, чтобы при отказе одного сетевая доступность не прервалась. Рассмотрим на примере агрегированного канала LACP. Для настройки агрегированного канала «взять» мышкой 2-й незадействованный адаптер и «отвезти» к 1-му. Откроется окно Create New Bond, где LACP (Mode 4, Dynamic link aggregation, 802.3ad) выбран по умолчанию. На стороне коммутаторов выполняется обычная настройка LACP группы. Если нет возможности построить стек коммутаторов, можно задействовать режим Active-Backup (Mode 1). Настройки VLAN рассмотрим в следующей статье, а подробнее с рекомендациями по настройке сети в документе .
Добавьте requirements.txt перед копированием кода
Перед копированием исходного кода всегда добавляйте в Dockerfile файл . Таким образом, каждый раз, когда вы будете менять код и пересобирать контейнер, Docker будет заново использовать кэшированный слой, пока пакеты не установятся, а не исполнять команду в каждой сборке, даже если нужные пакеты никогда не менялись. Никто не хочет ждать лишнюю минуту просто потому, что вы добавили пустую строку в код.
Если вам интересно узнать больше о , в Приложении есть короткий справочник по нескольким базовым командам. Переходим к Шагу 2 — создаем контейнер с только что созданным .
Создаем образ с Dockerfile
Команда создает образ согласно инструкциям, заданным в . Осталось дать образу имя.
docker build -t ${IMAGE_NAME}:${VERSION} .
Убедитесь, что образ существует локально:
docker images
Также можно поставить tag с более понятным именем, вместо использования hash ID.
docker tag ${IMAGE_ID} ${IMAGE_NAME}:${TAG}# ordocker tag ${IMAGE_NAME}:${VERSION} ${IMAGE_NAME}:${TAG}
Теперь нужно протестировать образ локально, чтобы убедиться, все ли работает хорошо.
docker run ${IMAGE_NAME}:${TAG}
Поздравляю! Вы упаковали модель в контейнер, который может быть запущен в любом месте, где установлен Docker.
Приложение. Команды Dockerfile
- начинается с — это необходимое условие. Образы создаются слоями, то есть можно использовать другой образ как основу для вашего. Команда определяет базовый слой и в качестве аргумента берет имя образа. Можно добавить имя пользователя в Docker Cloud и версию образа в формате.
- используется, чтобы собрать образ. Для каждой команды Docker запускает ее, затем создает новый слой образа. Таким образом, вы можете легко вернуться к предыдущей версии образа. Синтаксис инструкции заключается в размещении полного текста команды оболочки после (например, ). автоматически запускается в оболочке ; другую оболочку можно задать так .
- копирует локальные файлы в контейнер.
- определяет команды, которые запускаются в начале работы образа. В отличие от , он не создает новый слой, а просто запускает команды. В Dockerfile или образе может быть только один . Если вам нужно запустить несколько команд, лучше, чтобы запустил скрипт.
- создает подсказку для пользователей образа о том, какие порты предоставляют сервисы. Она включена в информацию, которую можно извлечь отсюда . Имейте в виду, что команда не делает порты доступными для хоста! Для этого требуется публикация портов с помощью флага -p при использовании docker run.
- загружает образ в частный или облачный реестр.
- 5 лучших библиотек машинного обучения
- Ускорение GPU в машинном обучении и больших данных
- Машинное обучение. С чего начать? Часть 1



