
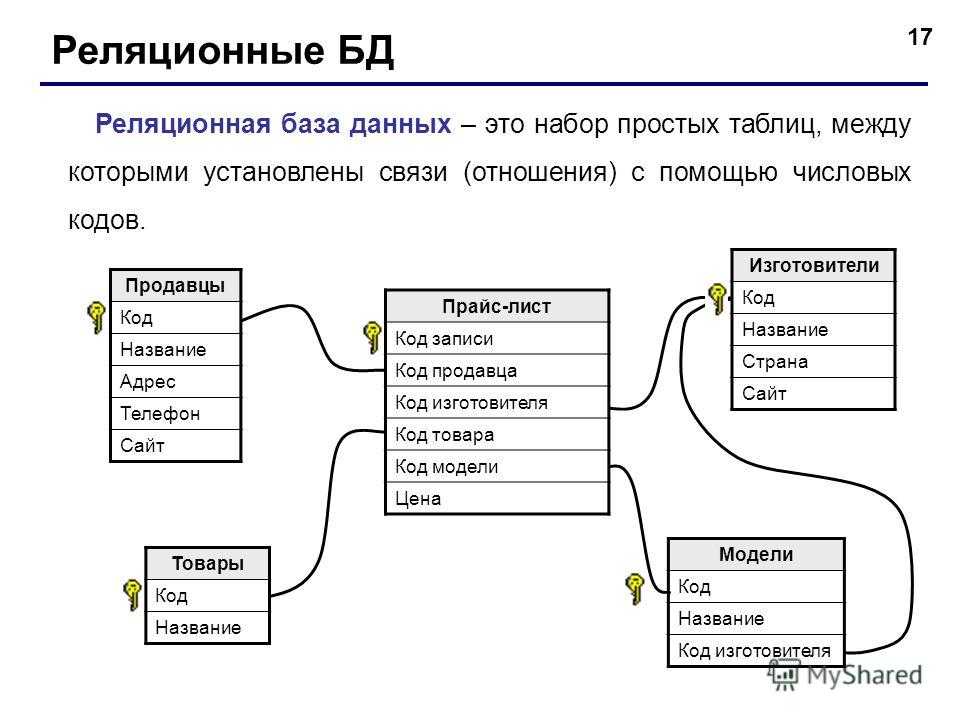
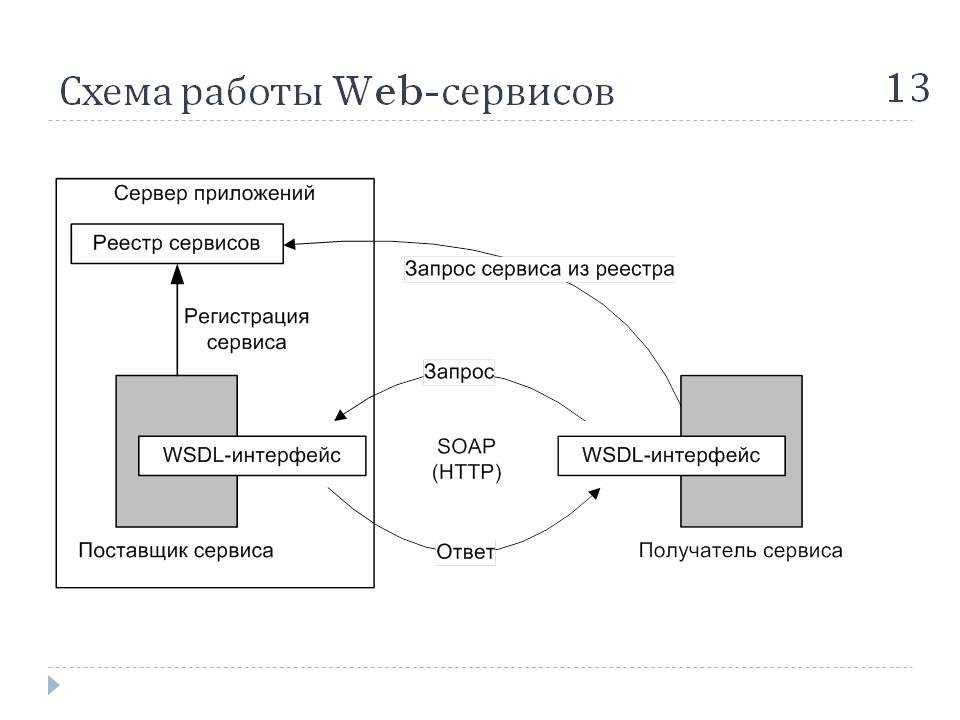
Структура HTTP-запроса
Каждый запрос имеет один и тот же формат:
протокол
Указывает, какая конкретная версия протокола HTTP будет использоваться. Чаще всего 1.0 и 1.1, но могут встречаться устаревшая 0.9 или новая 2.0. Однако, веб-сервер может не поддерживать указанную версию и вернуть ошибку. На практике подавляющее количество веб-серверов поддерживают 1.0 и 1.1.
/путь
Относительный путь (без доменного имени) до документа. В нашем примере указан корень /, но путь может быть любым: /index.php, /catalog/food/milk. Под документом понимаются не только файлы с расширением .html, но и любые другие файлы, например картинки, .css, .js.
метод
Определяет, что веб-сервер должен сделать с документом, найденным по указанному «/пути».
- GET — вернуть документ — GET /messages/1.
- HEAD — вернуть только заголовки без самой страницы. Это подходит для случая, когда мы хотим проверить, что ссылка на документ валидная. Пример: HEAD /messages/1
- POST — отправить данные для создания документа — POST /messages (и детали нового сообщения).
- PUT — заменить документ
- PATCH — частично обновить документ
- DELETE — удалить документ
- TRACE, CONNECT — технические методы, которые можно пропустить.
- OPTIONS — просьба к веб-серверу вернуть разрешённые настройки для запросов к указанному документу. Ответ включает в себя в том числе список разрешённых методов.
На практике примерно 80% запросов приходится на GET, 15% — на POST и 5% — на все остальные методы.
Заголовки
Они опциональны (в нашем примере их не было вовсе) и подсказывают веб-серверу, как именно нужно обработать запрос. Например, что клиент отправляет запрос в виде текста с кодировкой utf-8, а ожидает получить json в кодировке cp1251.
Наиболее частые на практике заголовки:
- Accept — в каком формате ожидаем ответ: обычный текст, html, xml, json, что угодно ещё.
- Accept-Charset — кодировка тела запроса: utf8, cp1251, koi8.
- Authorization — данные для авторизации между запросами. Здесь чаще всего передаются токены API. Авторизация между запросами будет рассмотрена ниже.
- Accept-Language — список языков, которые нас бы устроили. Например: «Accept-Language: ru».
- Cache-Control — настройки кэширования страниц
- Cookie — известные браузеру куки. В них сохраняются идентификаторы сессий и пользовательские предпочтения.
- Referrer — с какой страницы был сделан текущий запрос. Полезно для аналитики сайта и для возвращения юзера на первоначальную страницу после регистрации, например.
- User-Agent — тип клиента (чаще всего тип вашего браузера). Пример: «Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36». Это поле часто используется на сервере, чтобы отслеживать количество запросов с одного устройства и блокировать их при превышении лимита. Однако это не панацея, ведь после блокировки злоумышленник может поменять User-Agent на любой другой.
Тело
Для GET-запросов тело не имеет смысла, так как всё, что нужно — это путь в стартовой строке и заголовки. Но что происходит, когда мы хотим отправить информацию на сервер? Логин-пароль, форма обратной связи, форма создания поста? Для этого используется POST-запрос.
Каждый элемент формы имеет аттрибут name. В нашем примере страница http://http.maxkuznetsov.ru содержит форму с единственным тегом input, который имеет name=«name». Именно это имя и введённое пользователем в инпут значение будут отправлены на сервер. В консоли такой браузерный запрос будет выглядеть так:
Обратите внимание, что POST запрос очень похож на GET, мы даже обращаемся к тому же документу «/». Однако есть и отличия:
- вместо второй пустой строки в конце запроса содержатся данные: «name=Max»
- эти данные могут быть в разном формате, поэтому мы должны явно указать веб-серверу, что это данные из формы — application/x-www-form-urlencoded
- также мы сообщаем серверу, что в теле запроса содержится ровно 8 символов — «Content-Length: 8». Это техническое поле, которое браузер выполняет на лету, а нам приходится считать самим.
В ответ придёт знакомая страница, но с другим h1 заголовком — php-скрипт, обрабатывающий страницу, подставил вместо «http world» введённое нами имя.
Отправка данных методом POST с использованием CURL
Помимо сокетов, обеспечивающих низкоуровневое обращение к серверу, PHP располагает специальным расширением CURL (Client URL Library).
<?php
// Задаем адрес удаленного сервера
$curl = curl_init("http://localhost/handler/action.php");
// Передача данных осуществляется методом POST
curl_setopt($curl, CURLOPT_POST, 1);
// Задаем POST-данные
$data = 'name=Евгений&password=qwerty';
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
// Выполняем запрос и выводим ответ в браузер
curl_exec($curl);
// Закрываем CURL соединение
curl_close($curl);
С помощью функции задается адрес удаленного сервера и путь к файлу на нем. В отличие от функции , необходимо задавать адрес полностью, включая префикс , т.е. расширение CURL позволяет работать с несколькими видами протоколов (HTTP, HTTPS, FTP). Если соединение с указанным сервером происходит успешно, функция возвращает дескриптор соединения, который используется во всех остальных функциях библиотеки.
Для того, чтобы сообщить CURL о том, что данные будут передаваться методом POST, необходимо задать параметр . POST-данные устанавливаются при помощи параметра .
По умолчанию библиотека удаляет HTTP-заголовки, возвращаемые сервером. Однако CURL можно настроить на выдачу заголовков, если установить при помощи функции ненулевое значение параметра .
P.S. Из-за ошибки библиотеки сокетов протокол HTTP 1.1 под Windows работает медленно. При работе скрипта использующего сокеты под управлением этой ОС, лучше использовать версию HTTP 1.0.
Поиск:
CURL • HTTP • PHP • POST • Web-разработка • Форма
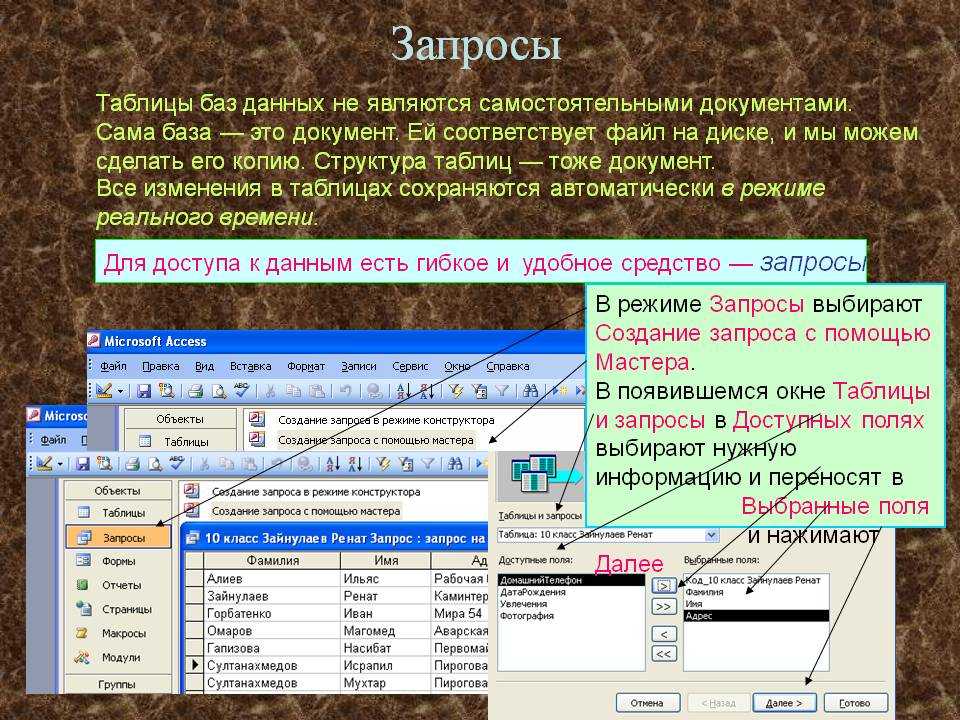
Публикация баз 1С на веб сервере
Идем на виртуалку с windows и работаем там с 1С. Кстати, если хотите обойтись вообще без windows, то есть возможность настроить публикацию баз 1С на linux на примере Centos.
Для начала устанавливаем технологическую платформу и не забываем выбрать Модули расширения веб-сервера.
Создаем там необходимую вам базу данных. Я покажу на примере публикации типовой базы Бухгалтерия 3.0. При первом запуске необходимо будет установить на этот компьютер софтовые лицензии. Они будут использоваться при доступе к базам через браузер.
Установка и настройка Apache 2.4 в Windows
Теперь устанавливаем apache 2.4. С ним опубликовать базы 1С проще и быстрее, чем с iis. Качаем apache отсюда — https://www.apachelounge.com/download/
Если у вас не установлен Visual C++ Redistributable for Visual Studio 2015-2019, то скачайте дистрибутивы там же. Бинарники apache скачали, теперь распакуем их в папку C:/apache24/. Затем идем в конфигурационный файл apache C:\Apache24\conf\httpd.conf, открываем его блокнотом и изменяем там несколько параметров:
ServerName localhost:80 ErrorLog "|C:/apache24/bin/rotatelogs.exe -l C:/apache24/logs/errorlog.%Y-%m-%d.log 2592000"
Последняя строка это автоматическая ротация логов. Рекомендую ее сразу настроить, а не откладывать на потом. Если у вас по какой-то причине нет возможности использовать стандартный порт 80, потому что он занят кем-то другим, то можно использовать любой другой, например 81. Я всегда так и делал раньше. Но с недавних пор это стало приводить к ошибке, так как после публикации баз 1c через reverse proxy с https, стали вылезать ссылки вида https://1c.server.ru:81. Подобные ссылки невозможно открыть. Это приводит к ошибкам в работе некоторых разделов базы, где эти ссылки вылезают. Подробнее этот момент я рассмотрю ниже, в разделе с возможными ошибками.
Если вы настраиваете apache на Windows Server, то скорее всего 80-й порт у вас будет занимать Служба веб-публикаций (World Wide Web Publushing Service) или W3SVC. Ее можно остановить и отключить.
Для того, чтобы точно узнать, кто занимает тот или иной порт в Windows, можно воспользоваться командой в консоли:
netstat -ao
Дальше через диспетчер задач смотрите, какой процесс имеет указанный pid. В моем случае это apache. Если это какой-то системный процесс, у него будет pid 4.
![Как вручную запускать запросы http post с помощью firefox или chrome? [закрытый]](https://tehnikaarenda.ru/wp-content/uploads/3/8/e/38e2964d04d8ebbdc6278ef979d8aa4b.jpeg)





Итак, конфиг apache отредактировали, порт 80 указали. Теперь установим apache 2.4 как службу windows
Для этого открываем командную строку от администратора (это важно), переходим в каталог C:\Apache24\bin и выполняем:
httpd.exe -k install
Вы можете увидеть ошибку, связанную с отсутствием fqdn имени у сервера. Но реально это не представляет проблемы, можно игнорировать.
Errors reported here must be corrected before the service can be started. AH00558: httpd.exe: Could not reliably determine the server's fully qualified domain name, using fe80::955f:6a46:c404:c1f7. Set the 'ServerName' directive globally to suppress this message.
Переходим в оснастку windows Службы и запускаем Apache2.4.
Убедимся, что веб сервер нормально работает. Для этого в браузере достаточно открыть страницу http://localhost.
Вы должны увидеть сообщение It works! Если видите, то все в порядке.
Дальше выполняем непосредственно публикацию базы 1С через web сервер apache. Открываем базу через Конфигуратор, выбираем Администрирование -> Публикация на веб-сервере. В качестве каталога можно указать тот же, где лежит сам файл с базой.
Все настройки можно оставлять дефолтными. Сохраняем изменения. После этого должен быть выполнен перезапуск службы apache автоматически. Но если платформа была запущена не от администратора, то у нее не хватит прав это сделать. Надо сходить в Службы и перезапустить вручную.
После этого можно зайти в браузере по адресу http://localhost/buh3 и увидеть локальную файловую базу, которую мы только что опубликовали.
Теперь с ней можно работать через браузер, но пока только с этого компьютера, либо по локальной сети. Далее сделаем так, чтобы доступ был и через интернет.
Postman
Основное предназначение приложения — создание коллекций с запросами к вашему API. Любой разработчик или тестировщик, открыв коллекцию, сможет с лёгкостью разобраться в работе вашего сервиса. Ко всему прочему, Postman позволяет проектировать дизайн API и создавать на его основе Mock-сервер. Вашим разработчикам больше нет необходимости тратить время на создание «заглушек». Реализацию сервера и клиента можно запустить одновременно. Тестировщики могут писать тесты и производить автоматизированное тестирование прямо из Postman. А инструменты для автоматического документирования по описаниям из ваших коллекций сэкономят время на ещё одну «полезную фичу». Есть кое-что и для администраторов — авторы предусмотрели возможность создания коллекций для мониторинга сервисов.
Работа с картами 1С 4 в 1: Яндекс, Google , 2ГИС, OpenStreetMap(OpenLayers) Промо
С каждым годом становится все очевидно, что использование онлайн-сервисов намного упрощает жизнь. К сожалению по картографическим сервисам условия пока жестковаты. Но, ориентируясь на будущее, я решил показать возможности API выше указанных сервисов:
Инициализация карты
Поиск адреса на карте с текстовым представлением
Геокодинг
Обратная поиск адреса по ее координатами
Взаимодействие с картами — прием координат установленного на карте метки
Построение маршрутов по указанным точками
Кластеризация меток на карте при увеличении масштаба
Теперь также поддержка тонкого и веб-клиента
1 стартмани
Что такое GET- и POST-запросы
Этот пост предназначен для объяснения принципов передачи данных в интернете с помощью двух основных методов: GET и POST. Написал я его в качестве дополнения к инструкции по генератору сменного графика работы для тех, кому вряд ли интересны подробности .
— это передача данных с помощью ссылки (в ссылке).
Перейдите по следующему адресу (это для наглядного объяснения): http://calendarin.net/calendar.php?year=2016 Обратите внимание на адресную строку браузера: calendarin.net/calendar.php?year=2016 Основной файл называется , за ним следует вопросительный знак (?) и параметр «year» со значением «2016». Так вот, всё, что следует за вопросительным знаком, это и есть GET-запрос
Всё просто. Чтобы передать не один параметр, а несколько, то их нужно разделить амперсандом (&). Пример: calendarin.net/calendar.php?year=2016&display=work-days-and-days-off
Основной файл всё также называется , за ним следует вопросительный знак (?), затем — параметр «year» со значением «2016», затем — амперсанд (&), затем — параметр «display» со значением «work-days-and-days-off».
GET-параметры могут изменяться прямо в адресной строке браузера. Например, изменив значение «2016» на «2017» и нажав клавишу , вы перейдёте к календарю на 2017 год.
— это передача данных скрытым способом (адрес страницы не изменяется); то есть увидеть, что было передано, можно только с помощью программы (скрипта). Например, в следующем инструменте для подсчёта символов в тексте исходные данные передаются методом POST: http://usefulonlinetools.com/free/character-counter.php
Что важно понимать про HTTP
- HTTP — это протокол общения клиент-серверных приложений в вебе. Набор правил, который помогает клиентам (прежде всего браузерам) и веб-серверам понимать друг друга.
- HTTP — это про формат общения, а не про управление сервером HTTP-командами. Клиент может отправить что угодно: удали страницу сайта, создай нового пользователя, выдай список всех пользователей — но сервер не обязан их выполнять, он лишь обязан ответить в формате HTTP, чтобы клиент его понял. То есть благодаря HTTP сервер поймёт, что клиент хочет, а потом уже решит, как это обработать и вернёт результат. Может быть удалит страницу, а может и нет.
- В HTTP общение всегда начинает клиент. А веб-сервер висит и ждёт. Сейчас есть способы инициировать запрос с сервера, но изначально протокол для этого не предназначен.
- HTTP-протокол не имеет шифрования, поэтому передавать персональные данные и прочие приватные данные через него не безопасно. В таком случае нужно использовать HTTPS.
- Простой способ изучить заголовки запроса и ответа — открыть консоль браузера на нужной странице и обновить её. В разделе Network/Сеть отобразятся все запросы с этой страницы, включая запросы на картинки и статические файлы.
Полезно знать
В завершении приведем основные команды, которые вам могут понадобиться во время написания скриптов. Для лучшего усвоения, попробуйте поиграться с ними самостоятельно.
Работа со встроенными библиотеками
Документация регламентирует наличие некоторого количества встроенных библиотек, среди которых — tv4 для валидации json, xml2js конвертер xml в json, crypto-js для работы с шифрованием, atob, btoa и др.
Некоторые из библиотек, например, как tv4 не требуют прямого подключения через require и доступны по имени сразу.
Управление последовательностью запросов из скрипта
Стоит отметить, что данный метод работает только в режиме запуска всех скриптов.
После перехода на следующий запрос Postman возвращается к линейному последовательному выполнению запросов.
Создание глобального хелпера
В некоторых случаях вам захочется создать функции, которые должны быть доступны во всех запросах. Для этого в первом запросе в секции “Pre-request Script” напишите следующий код:
А в последующих скриптах пользуемся им так:
Это лишь небольшой список полезных команд. Возможности скриптов гораздо шире, чем можно осветить в одной статье. В Postman есть хорошие «Templates», которые можно найти при создании новой коллекции. Не стесняйтесь подглядывать и изучать их реализацию. А официальная документация содержит ответы на большинство вопросов.







Более сложный пример
Чтобы завершить статью, мы рассмотрим несколько более сложный пример, который показывает более интересные применения Fetch. Мы создали образец сайта под названием The Can Store — это вымышленный супермаркет, который продаёт только консервы. Вы можете найти этот пример в прямом эфире на GitHub и посмотреть исходный код.
По умолчанию на сайте отображаются все продукты, но вы можете использовать элементы управления формы в столбце слева, чтобы отфильтровать их по категориям, поисковому запросу или и тому и другому.
Существует довольно много сложного кода, который включает фильтрацию продуктов по категориям и поисковым запросам, манипулирование строками, чтобы данные отображались правильно в пользовательском интерфейсе и т.д. Мы не будем обсуждать все это в статье, но вы можете найти обширные комментарии в коде (см. can-script.js).
Однако мы объясним код Fetch.
Первый блок, который использует Fetch, можно найти в начале JavaScript:
Это похоже на то, что мы видели раньше, за исключением того, что второй промис находится в условном выражении. В этом случае мы проверяем, был ли возвращённый ответ успешным — свойство (en-US) содержит логическое значение, которое , если ответ был в порядке (например, 200 meaning «OK») или , если он не увенчался успехом.
Если ответ был успешным, мы выполняем второй промис — на этот раз мы используем (en-US), а не (en-US), так как мы хотим вернуть наш ответ как структурированные данные JSON, а не обычный текст.
Если ответ не увенчался успехом, мы выводим сообщение об ошибке в консоль, в котором сообщается о сбое сетевого запроса, который сообщает о статусе сети и описательном сообщении ответа (содержащемся в (en-US) и (en-US), соответственно). Конечно, полный веб-сайт будет обрабатывать эту ошибку более грациозно, отображая сообщение на экране пользователя и, возможно, предлагая варианты для исправления ситуации.
Вы можете проверить сам случай отказа:
- Создание локальной копии файлов примеров (загрузка и распаковка the can-store ZIP file)
- Запустите код через веб-сервер (как описано выше, в )
- Измените путь к извлечённому файлу, например, «product.json» (т.е. убедитесь, что он написан неправильно)
- Теперь загрузите индексный файл в свой браузер (например, через ) и посмотрите в консоли разработчика браузера. Вы увидите сообщение в строке «Запрос сети для продуктов.json не удалось с ответом 404: Файл не найден»
Второй блок Fetch можно найти внутри функции :
Это работает во многом так же, как и предыдущий, за исключением того, что вместо использования (en-US) мы используем (en-US) — в этом случае мы хотим вернуть наш ответ в виде файла изображения, а формат данных, который мы используем для этого — Blob — этот термин является аббревиатурой от« Binary Large Object »и может в основном использоваться для представляют собой большие файловые объекты, такие как изображения или видеофайлы.
После того как мы успешно получили наш blob, мы создаём URL-адрес объекта, используя . Это возвращает временный внутренний URL-адрес, указывающий на объект, указанный в браузере. Они не очень читаемы, но вы можете видеть, как выглядит, открывая приложение Can Store, Ctrl-/щёлкнуть правой кнопкой мыши по изображению и выбрать опцию «Просмотр изображения» (которая может немного отличаться в зависимости от того, какой браузер вы ). URL-адрес объекта будет отображаться внутри адресной строки и должен выглядеть примерно так:
blob:http://localhost:7800/9b75250e-5279-e249-884f-d03eb1fd84f4
Мы хотели бы, чтобы вы решили преобразовать версию приложения Fetch для использования XHR в качестве полезной части практики. Возьмите копию ZIP файла и попробуйте изменить JavaScript, если это необходимо.
Некоторые полезные советы:
- Вы можете найти полезный справочный материал .
- Вам в основном нужно использовать тот же шаблон, что и раньше, в примере XHR-basic.html.
- Однако вам нужно будет добавить обработку ошибок, которые мы показали вам в версии Fetch Can Store:
- Ответ найден в после того, как событие запущено, а не в промисе .
- О наилучшем эквиваленте Fetch’s в XHR следует проверить, является ли равным 200 или если равно 4.
- Свойства для получения статуса и сообщения состояния одинаковы, но они находятся на объекте (XHR), а не в объекте .
Примечание: Если у вас есть проблемы с этим, не стесняйтесь сравнить свой код с готовой версией на GitHub (см. исходник здесь, а также см. это в действии).
Несколько слов о наступающем будущем — HTTP/2
Первая версия протокола HTTP была принята 20 лет назад. После этого 10 лет была тишина, пока Google не стал разрабатывать свой протокол SPDY поверх HTTP, что дало ускорение работе над HTTP/2. После серёзных подвижек Google отказался от разработки SPDY в пользу HTTP/2.
Вторая версия протокола отличается от первой чуть меньше, чем полностью.
- Протокол уже стал бинарен, а значит человеко нечитаемый.
- Несмотря на возможность работать без шифрования, все современные браузеры будут поддерживать именно вариант с шифрованием.
- В протоколе предусмотрена возможность push-сообщений, инициированных сервером.
- Протокол позволяет мультиплексирование — отправку нескольких запросов внутри одного соединения.
- Умеет сжимать данные заголовков.
Новый протокол безопаснее и в несколько раз быстрее. Самое приятное, что последние версии современных браузеров понимают http2, и половина наиболее крупных и популярных сайтов уже готовы к переходу на него. С приходом http2 веб станет ещё более интерактивным, а приложения приблизятся к десктопным.
Метод POST
Этот метод подразумевает передачу данных отдельным пакетным потоком в теле запроса, что надежно защищает отправляемые данные и позволяет передавать внушительные объемы информации, которые могут быть ограничены лишь настройками сервера. Поэтому такой тип запроса идеально подходит для отправки личных данных и любых типов файлов.
Измените ваш файл, заменив в PHP-коде имена переменных $_GET на $_POST, а в форме пропишите method=»POST». Обновите страницу и снова отправьте форму. Результат будет таким же, что и при методе GET, однако адресная строка осталась без изменений, а это значит, что данные были благополучно отправлены в защищенном виде в теле самого запроса.
Для закрепления материала создадим маленькое веб-приложение, которое будет запрашивать логин и пароль пользователя для входа на сайт
Код примера будет относительно сложным и от вас требуется внимание и желание разобраться в функционале PHP-программы
Итак,
Файл index.php:
Запустите пример и посмотрите, что происходит. Вначале запрашивается логин и пароль пользователя (в коде мы определили их как «admin» и «secret»), если все верно – мы попадаем на главную страницу сайта, если данные неверные – выводится соответствующее предупреждение.
Рассмотрим реализацию данной технологии.
Обратите внимание – весь код HTML-формы мы не выводим непосредственно, а запоминаем в переменной $form
Будьте внимательны с кавычками! Весь HMTL-код находится внутри одинарных кавычек, поэтому его внутренние кавычки должны быть двойными. Если бы вы написали
$form = " …ваш код… ",
то внутренний код будет содержать наоборот – одинарные кавычки.
Далее, в строке 27 проверяется, была ли отправлена форма (условие 1 на рис.), если нет – выводится HTML-форма, и сценарий прекращает свою работу – функция die(). Больше ничего, кроме формы в браузер не выводится.





Если данные были получены, то проверяются POST-переменные на соответствие заданным (условие 2 на рис.). Если они не совпадают, то выводится предупреждающее сообщение, HTML-форма для входа и сценарий снова прекращает работу (die()).
Если же второе условие выполняется, то скрипт пропускает все операторы else и переходит на отображение основной страницы. ( переход 3 на рис.).
Это простейший пример. Естественно, в реальных проектах таких прямых проверок не производится – логин и пароль в зашифрованном виде хранятся в файлах или базе данных. Поэтому в статье описана сама технология взаимодействия клиента и сервера на основе GET и POST запросов. Для создания полноценных приложений вам необходимо иметь твердые знания по базам данных и объектно-ориентированному программированию. Об этом – в следующих статьях.
Post и Get запросы, какая между ними разница и что лучше и для каких целей?
тело сообщения (Entity Body) – необязательный параметр
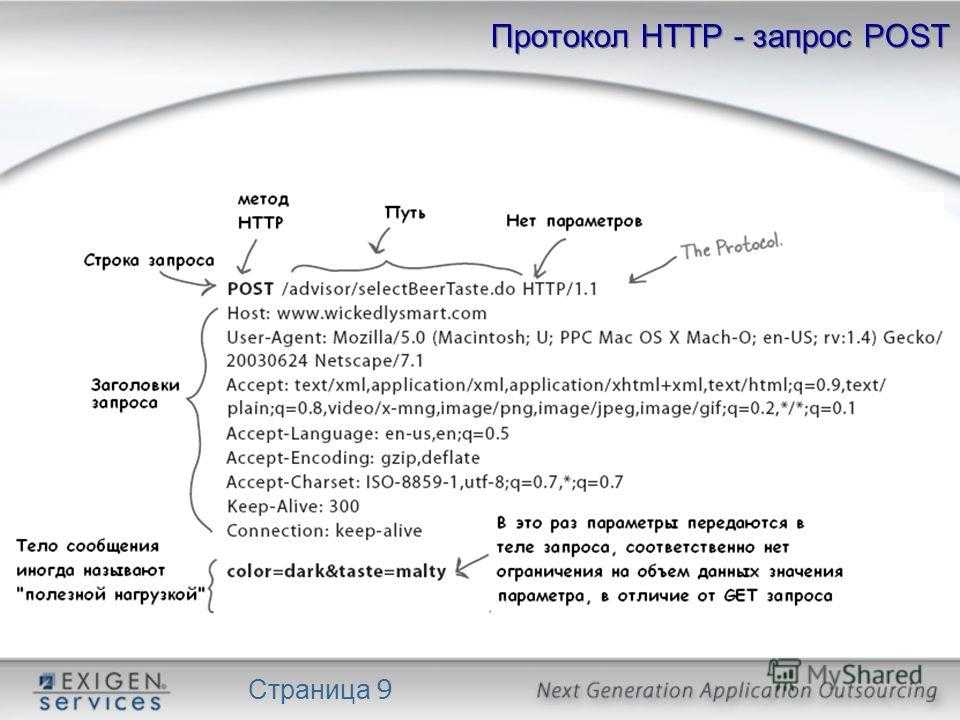
Строка запроса – указывает метод передачи, URL-адрес, к которому нужно обратиться и версию протокола HTTP.
Заголовки – описывают тело сообщений, передают различные параметры и др. сведения и информацию.
тело сообщения — это сами данные, которые передаются в запросе. Тело сообщения – это необязательный параметр и может отсутствовать.
Когда мы получаем ответный запрос от сервера, тело сообщения, чаще всего представляет собой содержимое веб-страницы. Но, при запросах к серверу, оно тоже может иногда присутствовать, например, когда мы передаем данные, которые заполнили в форме обратной связи на сервер.
Более подробно, каждый элемент запроса, мы рассмотрим в следующих заметках.
Давайте, для примера, рассмотрим один реальный запрос к серверу. Я выделил каждую часть запроса своим цветом: строка запроса — зеленый, заголовки — оранжевый, тело сообщения- голубой.
Запрос от браузера:
GET / HTTP/1.1
Host: webgyry.info
User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:18.0) Gecko/20100101 Firefox/18.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Cookie: wp-settings
Connection: keep-alive
В следующем примере уже присутствует тело сообщения.
Ответ сервера:
HTTP/1.1 200 OK
Date: Sun, 10 Feb 2013 03:51:41 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Keep-Alive: timeout=5
Server: Apache
X-Pingback: //webgyry.info/xmlrpc.php

![Как вручную запускать запросы http post с помощью firefox или chrome? [закрытый]](https://tehnikaarenda.ru/wp-content/uploads/1/c/3/1c3a21faa8a5543cbf41af321d7616be.jpeg)


<!DOCTYPE html PUBLIC «-//W3C//DTD XHTML 1.0 Transitional//EN» «http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd»>
<html xmlns=»http://www.w3.org/1999/xhtml»>
<head>
<meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″ />
<title>Документ без названия</title>
</head>
<body>
</body>
</html>
Вот такими сообщениями обмениваются клиент и сервер по протоколу HTTP.
Кстати, хотите узнать есть ли смысл в каком-то элементе на вашем сайте с помощью «целей» Яндекс Метрики и Google Analytics?
Уберите то, что НЕ работает, добавьте то, что работает и удвойте вашу выручку.
Курс по настройке целей Яндекс Метрики..
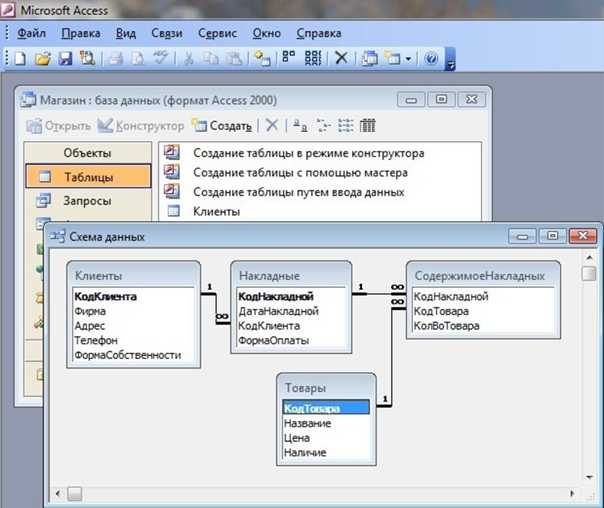
Схема установки
Я предлагаю следующую схему работы с базами 1С при их публикации. Доступ нужен будет отовсюду через интернет. Для этого арендуется выделенный сервер, например в selectel. Достаточно будет сервера примерно за 4000р. с 2 ssd дисками и 32g оперативной памяти. Туда ставится гипервизор proxmox. И настраиваются минимум 3 виртуальные машины:
- Любая windows система, где работает 1С. Если для подстраховки нужен терминальный доступ по rdp, то ставится windows server.
- Linux система, где будет работать nginx в качестве revers proxy. На ней будет настроен https с валидным сертификатом и при необходимости парольная защита.
- Любая система по вашему вкусу для бэкапов баз 1С. Они нужны будут для защиты основной виртуалки от шифровальщиков и прочей вирусни, которая может повредить базы данных. Смысл этой виртуалки в том, что тут бэкапы будут изолированы с ограниченным доступом. На этой же виртуалке настраивается передача этих бэкапов куда-то еще. Не должно быть так, что все архивные копии хранятся на одном физическом сервере у одного хостера.
Это минимальный набор виртуалок. Сюда же можно добавить мониторинг либо еще какой-то сервис, необходимый вашей компании. Например чат или ip телефония. Производительности дедика хватит для небольшой компании.
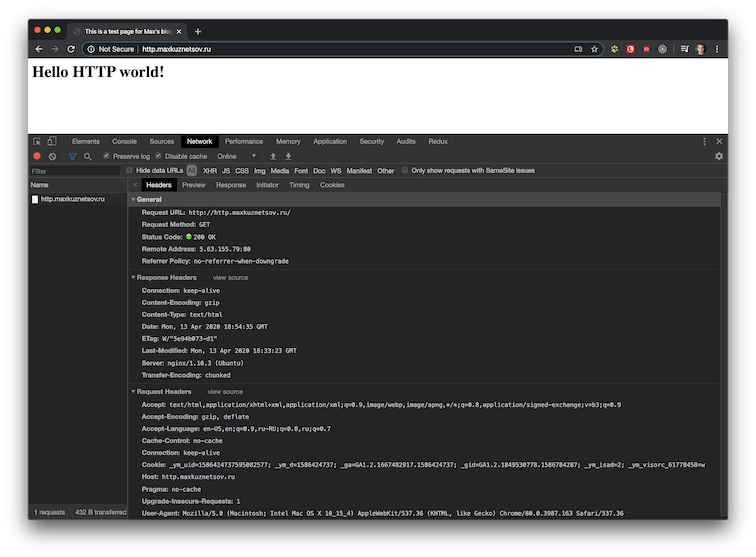
Прикидываемся браузером, или делаем HTTP-запрос из терминала
Чтобы понять, как браузер общается с сервером, нужно думать как браузер, нужно стать браузером.
Попробуем обратиться к веб-странице http://http.maxkuznetsov.ru так, как это делают браузеры под капотом. Для этого отправим запрос из терминала/командной строки с помощью утилиты netcat. Чаще всего она установлена по умолчанию: в Mac OS X — это «nc», в других ОС может быть «ncat» или «netcat». (Или воспользуйтесь онлайн-сервисом https://reqbin.com/u4178vu3, в котором слева и справа выберите табы Raw для отображения «голых» запросов и ответов. Но из терминала получится нагляднее.)
Дальше ничего не произойдёт, терминал подвиснет — это нормально. Команда netcat подключилась к серверу по адресу http.maxkuznetsov.ru к 80-му порту, и сервер ждёт от нас текст запроса.
Введём в терминале такие строки запроса.
После Host нужно ввести две пустые строки: одна строка отступа, вторая содержит тело запроса, но в данном примере оно пустое. Такие правила протокола HTTP. Получив вторую пустую строку, веб-сервер поймёт, что запрос завершён, обработает его и пришлёт ответ, включающий интересующую нас веб-страницу с html.
После этого браузер разбирает ответ, убирает техническую информацию и отображает html-страницу в кодировке UTF-8 — так ему сказал сервер в заголовке Content-Type. Если в HTML включены CSS, Javascript, картинки, то браузер запросит их отдельными запросами ровно таким же образом. Если он их уже запрашивал раньше, то возьмёт из локального кэша. Поэтому первый раз страницы грузятся визуально дольше.
Разберём структуру запроса и ответа более детально.
Метод GET
Во-первых, что вообще такое HTML-форма? Это интерфейс, позволяющий отправлять какие-либо данные с браузера клиента на сервер. Взгляните на атрибуты вашей формы:
<form action="index.php" method="GET" >
Атрибут action отвечает за адрес получателя отправляемых данных. В нашем случае форма отправляется на тот же адрес, т.е. на lessons/index.php.
Особое внимание заслуживает атрибут method, который определяет метод отправки запроса на сервер. Таких методов несколько, а наиболее распространенные (и практичные) это методы GET и POST
Сейчас нас будет интересовать метод GET.
GET-запрос означает, что данные будут передаваться на сервер непосредственно через адресную строку. Вы в этом уже убедились, отправив форму – к строке адреса добавились определенные данные
Откуда эти данные берутся? Обратите внимание на теги input в HTML-форме. У всех их присутствует атрибут name, который устанавливает имя данного поля
При методе GET к основному адресу добавляется символ «?» (знак вопроса), чтобы сервер понимал, что поступили какие-то данные. После символа «?» идут непосредственно сами данные в виде имя=значение. Если таких данных несколько, то они разделяются между собой символом объединения «&». Отправьте форму с другими значениями полей и убедитесь в этом.

![Как вручную запускать запросы http post с помощью firefox или chrome? [закрытый]](https://tehnikaarenda.ru/wp-content/uploads/1/2/0/12008654e93702b89b2cf087c8435f32.jpeg)

Ладно, данные отправились. Что дальше? Куда они ушли и что с ними делать? Вот тут и начинается самое интересное.
Пришло время научиться «ловить» и обрабатывать полученные данные. Ввиду того, что атрибут action указывает на текущий файл index.php, значит данные поступают именно сюда, поэтому в этом же файле мы и пропишем код обработки GET-запроса.
Итак, сразу же после тега <body> добавим такой PHP-код:
Сохраните файл, снова зайдите на http://lessons/, отправьте форму и – о, чудо! – что вы видите?
Только что, после отправки формы, сервер получил и обработал полученные данные и прислал в браузер свой ответ!
Рассмотрим PHP-код нашего проекта, который представляет собой условие:
if (isset($_GET)) {
}
Сервер проверяет, а получена ли переменная GET-запроса с именем submit_form? То есть, говоря проще, а была ли вообще отправлена форма? Если это так, то серверный php-код отправляет прямо в браузер пользователя новую HTML-разметку со своим ответом, используя для этого оператор echo. Если вы внимательно изучите написанный код-обработчик, то вам сразу все станет понятным!
Интересный же этот метод GET! Измените адресную строку, например, на такую:
http://lessons/index.php?user_name=Мое-имя&user_year=1900&submit_form=отправить
и нажмите кнопку «Ввод». Сервер снова вам ответит, приняв уже другие данные! Думаю, с этим все понятно.
Недостатки GET-метода в том, что, во-первых, есть ограничение на объем передаваемых данных, а во-вторых, этот метод является открытым и любую информацию можно перехватить. Поэтому личные данные пользователя (логин, имя, пароль и др.) никогда нельзя передавать через строку адреса.
Заключение
Основные плюсы, которые подтолкнули нас к использованию Postman в своём проекте:
- Наглядность – все запросы всегда под рукой, мануальное тестирование во время разработки становится легче
- Быстрый старт – вовлечение нового игрока в команду, будь то программист или тестировщик, проходит легко и быстро
- Тесты – возможность писать тесты для запросов, а потом быстро составлять из них, как из пазлов, различные варианты и пути жизни приложения
- Поддержка CI — возможность интегрировать тесты в CI с помощью newman (об этом будет отдельная статья)
Среди минусов можно выделить:
- Редактирование коллекции привязано к Postman, т. е. для изменений потребуется сделать импорт, отредактировать, а затем сделать экспорт в репозиторий проекта
- Так как коллекция лежит в одном большом json файле, Review изменений практически невозможно
У каждого проекта свои подходы и взгляды на тестирование и разработку. Мы увидели для себя больше плюсов, чем минусов, и поэтому решили использовать этот мощный инструмент, как для тестирования, так и для описания запросов к API нашего проекта. И по своему опыту можем сказать, даже, если вы не будете использовать средства тестирования, которые предоставляет Postman, то иметь описание запросов в виде коллекции будет весьма полезно. Коллекции Postman это живая, интерактивная документация к вашему API, которая сэкономит множество времени, и в разы ускорит разработку, отладку и тестирование!
P.S.:
Основной функционал Postman бесплатен и удовлетворяет ежедневным нуждам, но есть некоторые инструменты с рядом ограничений в бесплатной версии:






Бывает, что нужно сделать подсчет символов, для этого есть специальный сервис, который быстро и без заморочек это выполнит.