Введение
Как я уже сказал, в статье все ссылки будут реферальные. Есть масса завистливых людей, которые непременно увидят рефф ссылку и напишут об этом. Назовут автора обманщиком и потребуют, чтобы он непременно либо говорил, что это реферальная ссылка, либо убирал ее.
Я искренне не понимаю, таких людей. Ведь для них стоимость услуги не изменится, а по реф ссылке иногда даже бывает дешевле и тем не менее, они все равно их не принимают. Природная зависть не позволяет им согласиться с тем, что кто-то получит дополнительные деньги. Перейдя по такой ссылке, завистник непременно удалит реф код, чтобы не дай бог кто-то получил доход, а он нет.
Это так, о наболевшем  Теперь о том, зачем все это. Скажу сразу завистникам, что доход с реферальных программ хостеров это сущие копейки. У меня нет ни одного оплаченного сервера или сервиса, который бы существовал на эти средства, кроме, пожалуй, айхора, которым я теперь не пользуюсь. Там рублей по 500-1000 капало каждый месяц за счет того, что я несколько лет собирал рефералов.
Теперь о том, зачем все это. Скажу сразу завистникам, что доход с реферальных программ хостеров это сущие копейки. У меня нет ни одного оплаченного сервера или сервиса, который бы существовал на эти средства, кроме, пожалуй, айхора, которым я теперь не пользуюсь. Там рублей по 500-1000 капало каждый месяц за счет того, что я несколько лет собирал рефералов.
Кстати, есть настолько жадные завистники, что они не поленились и добавили в популярные фильтры блокировщиков рекламы мой блок с рекламой Selectel справа в сайдбаре. Когда увидел это стало немного смешно. Из-под фильтра сразу вышел, но сам факт, что кто-то так заморачивается, чтобы не дай бог я не разбогател!

Если и другие именные фильтры специально под мой сайт.
Переходим теперь к сути статьи. Вот список хостеров, с которыми я сотрудничаю.
Кто дает рекомендацию
Рекомендательное письмо всегда пишется от имени предыдущего работодателя.
Причём непосредственно составлением документа обычно занимается бывший непосредственный руководитель, например, начальник структурного подразделения, отдела, цеха, участка.
Иногда формирование рекомендаций ложится на плечи специалиста по кадрам, секретаря организации или самого директора (в небольших фирмах). В любом случае это должен быть тот, кто хорошо знаком с человеком, нуждающимся в рекомендации, или, по крайней мере, настолько, чтобы дать максимально объективную, адекватную и справедливую характеристику.
Если рекомендацию пишет рядовой работник предприятия, подписана она должна быть сотрудником, стоящим на более высокой позиции – только при соблюдении этого условия рекомендация будет обладать достаточным весом и солидностью в глазах того, для кого она предназначена.
Ceph RBD
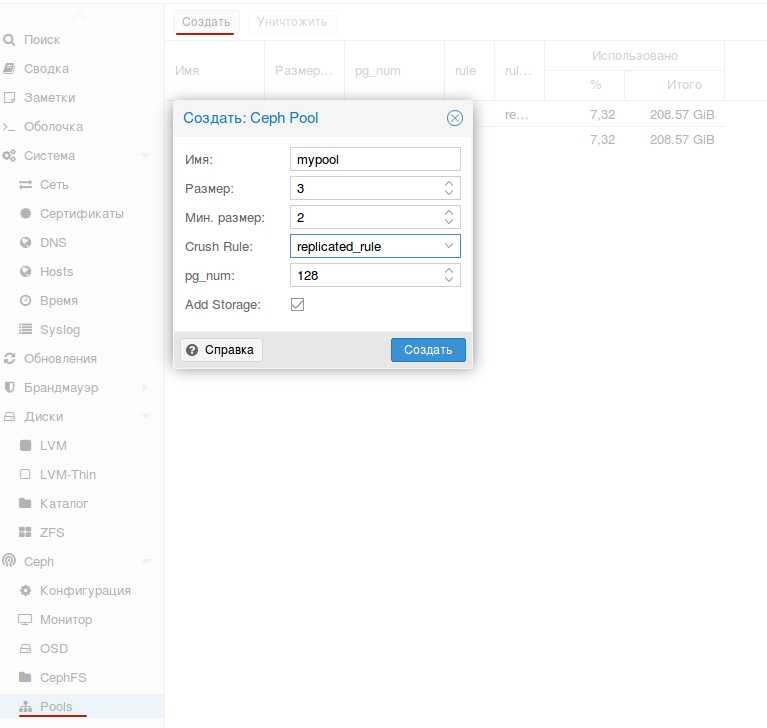
Теперь давайте создадим rbd диск в кластере ceph и подключим его к целевому серверу. Для этого идем в консоль на любую ноду кластера. Создаем pool для rbd дисков.
# ceph osd pool create rbdpool 32
| rbdpool | название пула, может быть любым |
| 32 | 32 — кол-во pg (placement groups) в пуле |
Проверим список пулов кластера.
# rados lspools
Создаем в этом пуле rbd диск на 10G.
# rbd create disk1 --size 10G --pool rbdpool
Добавим пользователя с разрешениями на использование этого пула. Делается точно так же, как в случае с cephfs, что мы проделали ранее.
# ceph auth get-or-create client.rbduser mon 'allow r, allow command "osd blacklist"' osd 'allow rwx pool=rbdpool'
В консоли увидите ключ пользователя rbduser для подключения пула rbdpool.
Перемещаемся на целевой сервер, куда мы будем подключать rbd диск кластера ceph. Для подключения blockdevice нам необходимо поставить программное обеспечение из репозитория ceph-luminous на сервер, где будет использоваться rbd.
# yum install centos-release-ceph-luminous # yum install ceph-common
Так же запишем на целевой сервер ключ клиента, который имеет доступ к пулу с дисками. Создаем файл /etc/ceph/ceph.client.rbduser.keyring следующего содержания.
key = AQCW5DFeXNy2JRAAWnCU/DpZhuNHmNcI5l1sEQ==
Там же создаем конфигурационный файл /etc/ceph/ceph.conf, где нам необходимо указать ip адреса мониторов ceph.
mon host = 10.1.4.32,10.1.4.33,10.1.4.39
В конце конфигурационного файла должен быть переход на новую строку. Если его не сделать, диск не смаппится, будет ошибка.
Пробуем подключить блочное устройство.
# rbd map disk1 --pool rbdpool --id rbduser rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbdpool/disk1 object-map fast-diff deep-flatten". In some cases useful info is found in syslog - try "dmesg | tail". rbd: map failed: (6) No such device or address
Скорее всего получите такую же или подобную ошибку. Суть ее в том, что текущее ядро поддерживает не все возможности образа RBD, поэтому их нужно отключить. Как это сделать показано в подсказке. Для отключения нужен администраторский доступ в кластер. Так что идем на любую ноду пула и выполняем там предложенную команду.
# rbd feature disable rbdpool/disk1 object-map fast-diff deep-flatten
Не должно быть никаких ошибок, как и любого вывода после работы команды. Возвращаемся на целевой сервер и пробуем подключить rbd диск еще раз.
# rbd map disk1 --pool rbdpool --id rbduser /dev/rbd0
Все в порядке. В системе появился новый диск — /dev/rbd0. Создадим на нем файловую систему и подмонтируем к серверу.
# mkfs.xfs -f /dev/rbd0 # mkdir /mnt/rbd # mount /dev/rbd0 /mnt/rbd # df -h | grep rbd
Можно попробовать туда что-то записать и посмотреть на скорость.
# dd if=/dev/zero of=/mnt/rbd/testfile bs=10240 count=100000 100000+0 records in 100000+0 records out 1024000000 bytes (1.0 GB) copied, 6.88704 s, 149 MB/s
Не знаю, что я измерил На самом деле это скорость одиночного sata диска, на котором установлена система сервера, которому я подключил диск. Так понимаю, запись вся ушла в буфер, а потом началась синхронизация по кластеру.
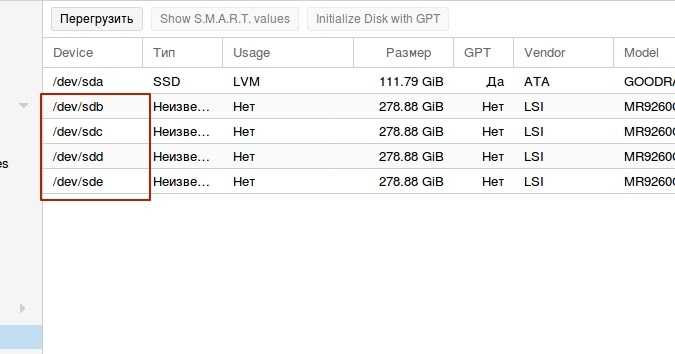
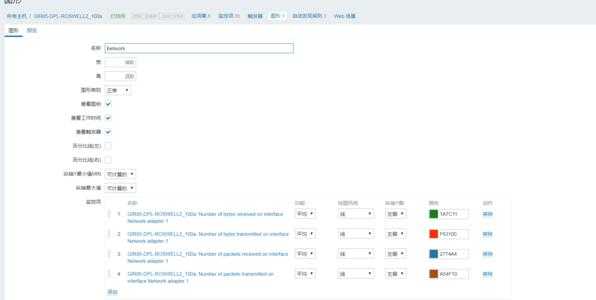
Настроим теперь автоматическое подключение rbd диска при старте системы. Для начала надо настроить mapping диска. Для этого создаем конфиг файл /etc/ceph/rbdmap следующего содержания.
rbdpool/disk1 id=rbduser,keyring=/etc/ceph/ceph.client.rbduser.keyring
Запускаем скрипт rbdmap и добавляем в автозапуск.
# systemctl enable --now rbdmap Created symlink from /etc/systemd/system/multi-user.target.wants/rbdmap.service to /usr/lib/systemd/system/rbdmap.service.
Проверяем статус.
# systemctl status rbdmap
Осталось добавить монтирование блочного устройства rbd в /etc/fstab.
/dev/rbd/rbdpool/disk1 /mnt/rbd xfs noauto,noatime 0 0
И не забудьте в конце сделать переход на новую строку. После этого перезагрузите сервер и проверьте, что rbd диск кластера ceph нормально подключается.
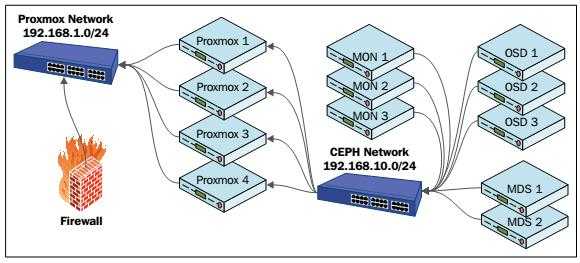
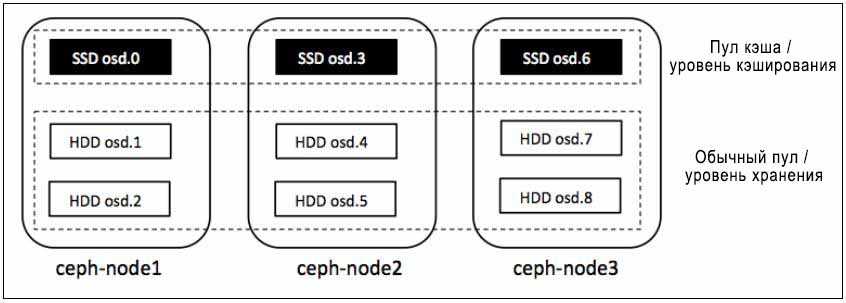
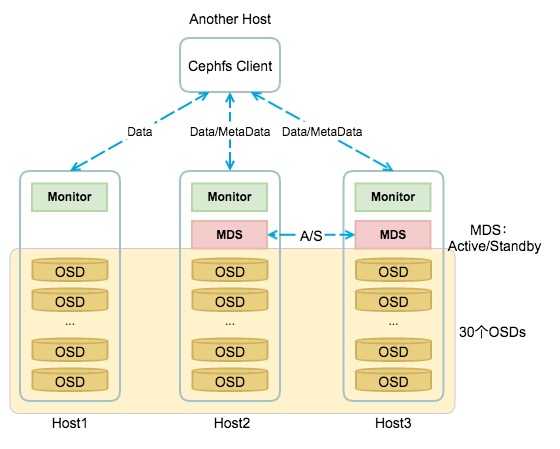
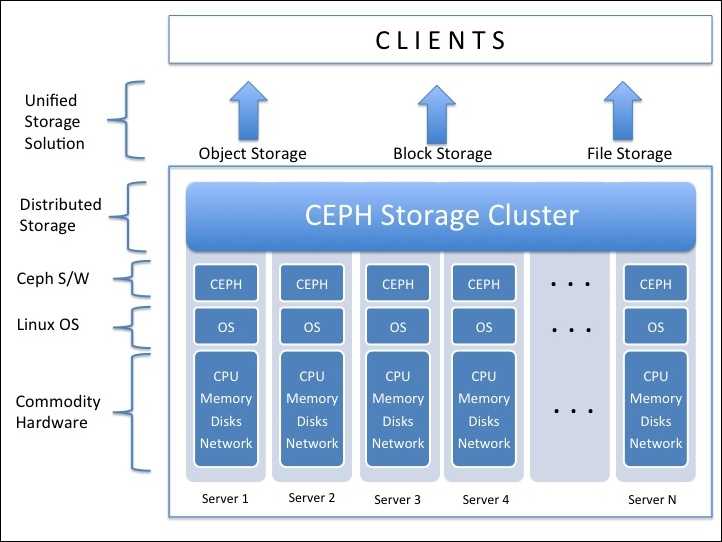
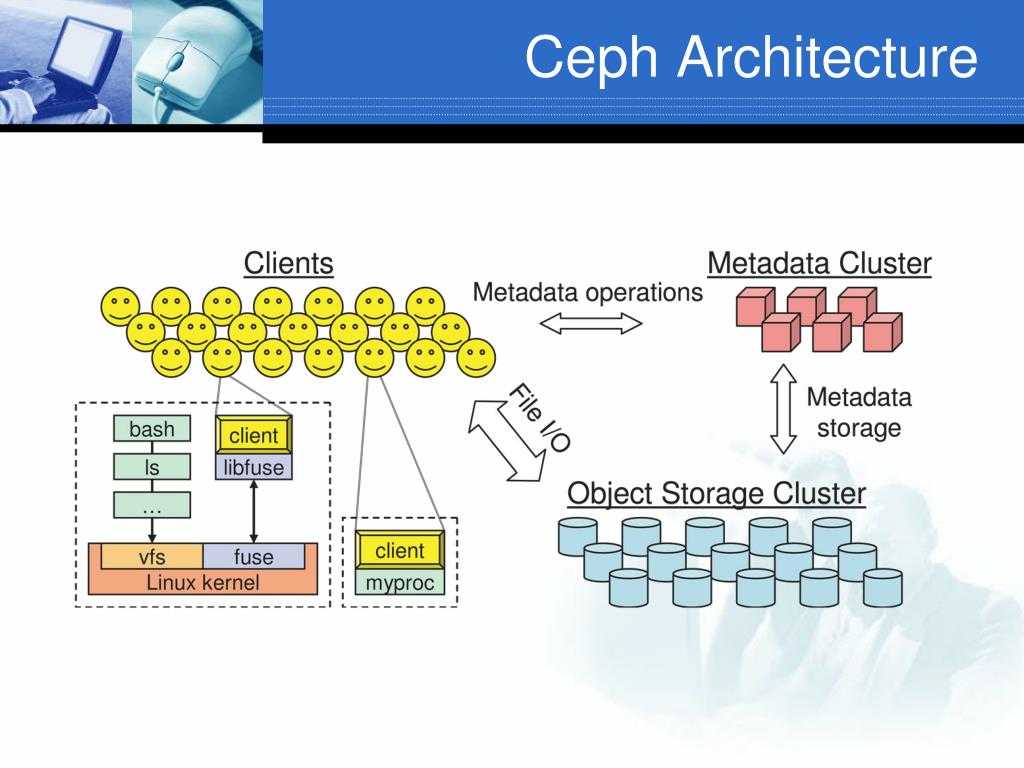
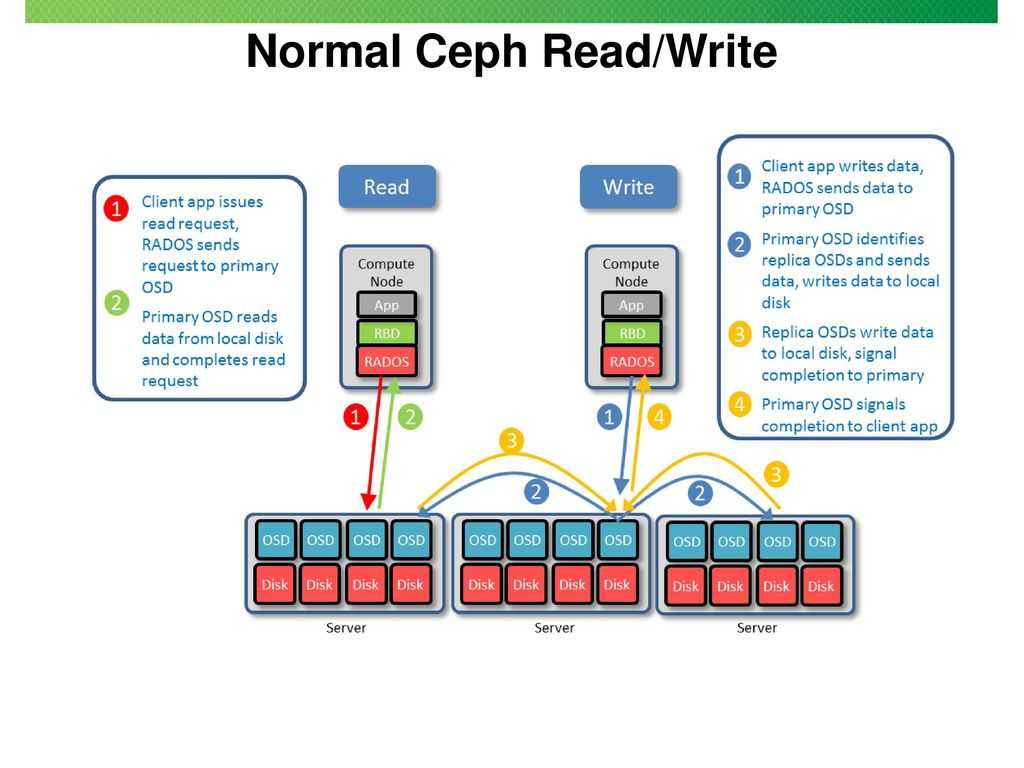
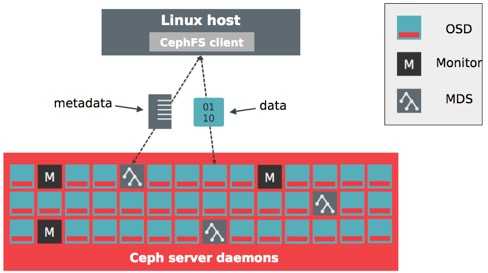
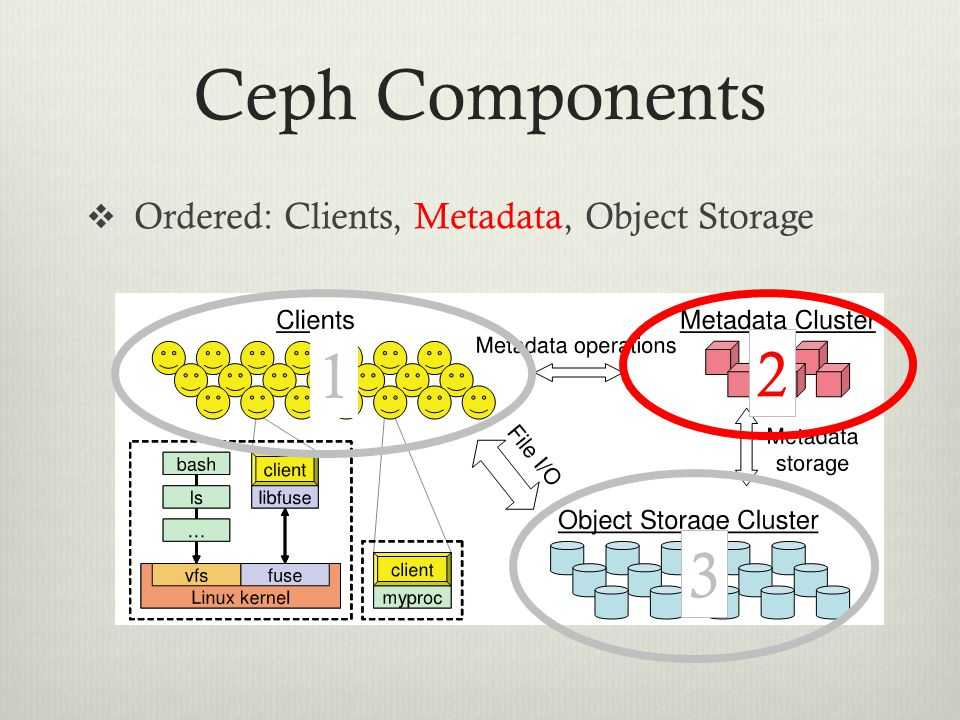
Архитектура Ceph
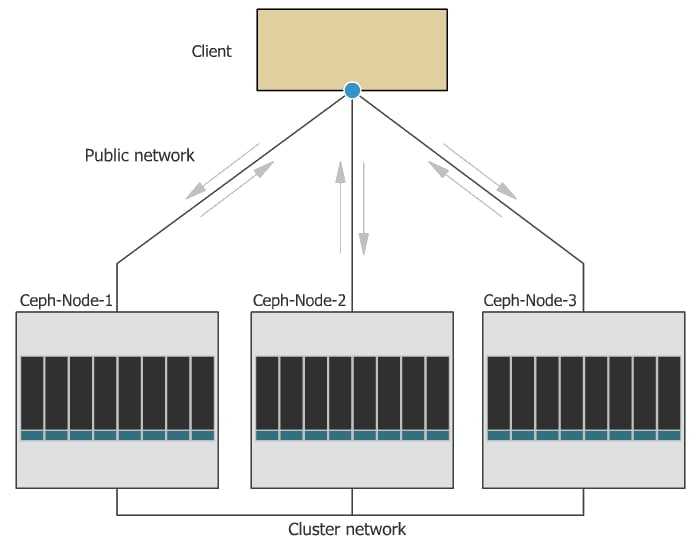
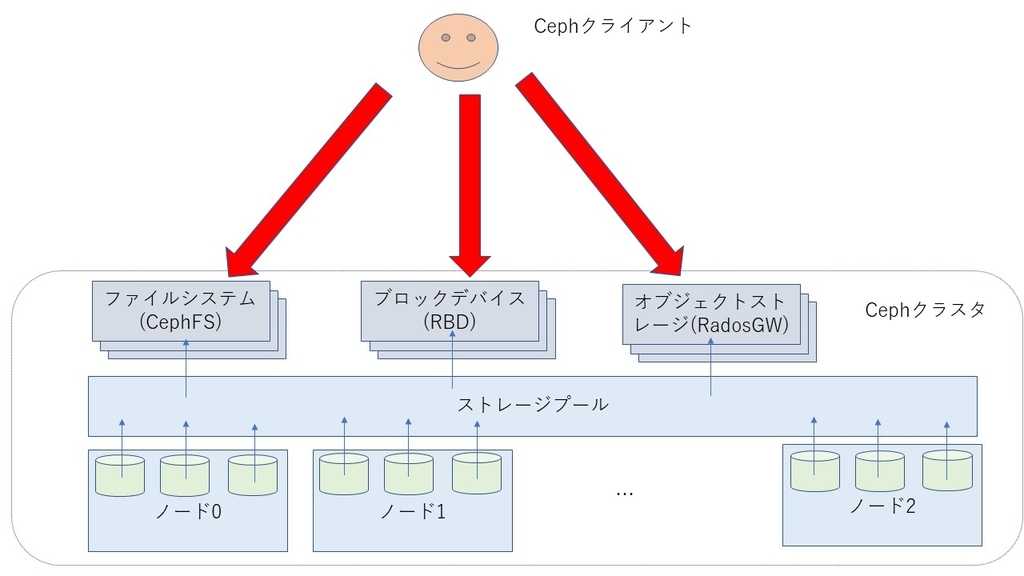
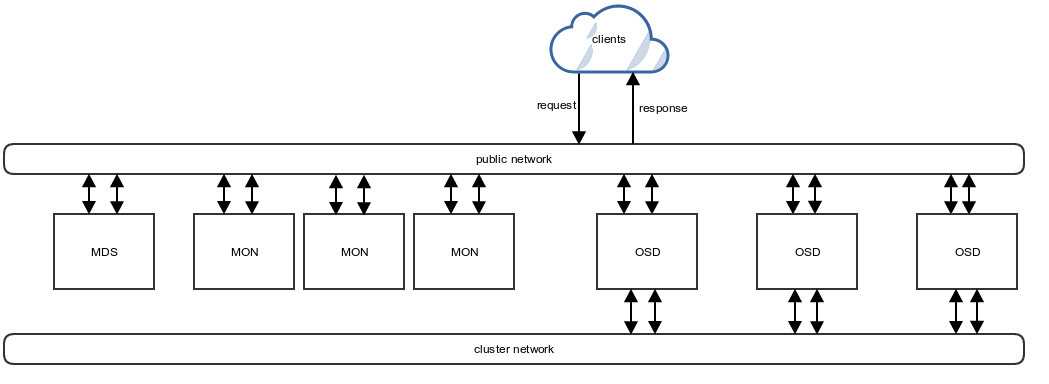
Кластерная система хранения данных ceph состоит из нескольких демонов, каждый из которых обладает своей уникальной функциональностью. Расскажу о них кратко своими словами.
- MON, Ceph monitor — монитор кластера, который отслеживает его состояние. Все узлы кластера сообщают мониторам информацию о своем состоянии. Когда вы монтируете хранилища кластера к целевым серверам, вы указываете адреса мониторов. Сами мониторы не хранят непосредственно данные.
- OSD, Object Storage Device — элемент хранилища, который хранит сами данные и обрабатывает запросы клиентов. OSD являются основными демонами кластера, на которые ложится большая часть нагрузки. Данные в OSD хранятся в виде блоков.
- MDS, Metadata Server Daemon — сервер метаданных. Он нужен для работы файловой системы CephFS. Если вы ее не используете, то MDS вам не нужен. К примеру, если кластер ceph предоставляет доступ к данным через блочное устройство RBD, сервер метаданных разворачивать нет необходимости. Разделение метаданных от данных значительно увеличивает производительность кластера. К примеру, для листинга директории нет необходимости дергать OSD. Данные берутся из MDS.
- MGR, Manager Daemon — сервис мониторинга. До релиза Luminous был не обязательным компонентом, теперь — неотъемлемая часть кластера. Демон обеспечивает различный мониторинг кластера — от собственного дашборда до выгрузки метрик через json. Очень удобно. Мониторинг кластера не представляет особых сложностей.
Кластер ceph состоит из пулов для хранения данных. Каждый pool может обладать своими настройками. Пулы состоят из Placement Groups (PG), в которых хранятся объекты с данными, к которым обращаются клиенты.
В каждом кластере ceph имеется понятие фактора репликации — это уровень избыточности данных, или по простому — сколько копий данных будет храниться на разных дисках. Фактор репликации можно задавать разным для каждого пула и менять на лету.
Nic.ua
Заходим в личный кабинет, и переходим в раздел настроек Name серверов.
Выбираем домен, для которого собираемся вносить изменения в DNS, и нажимаем на шестеренку справа.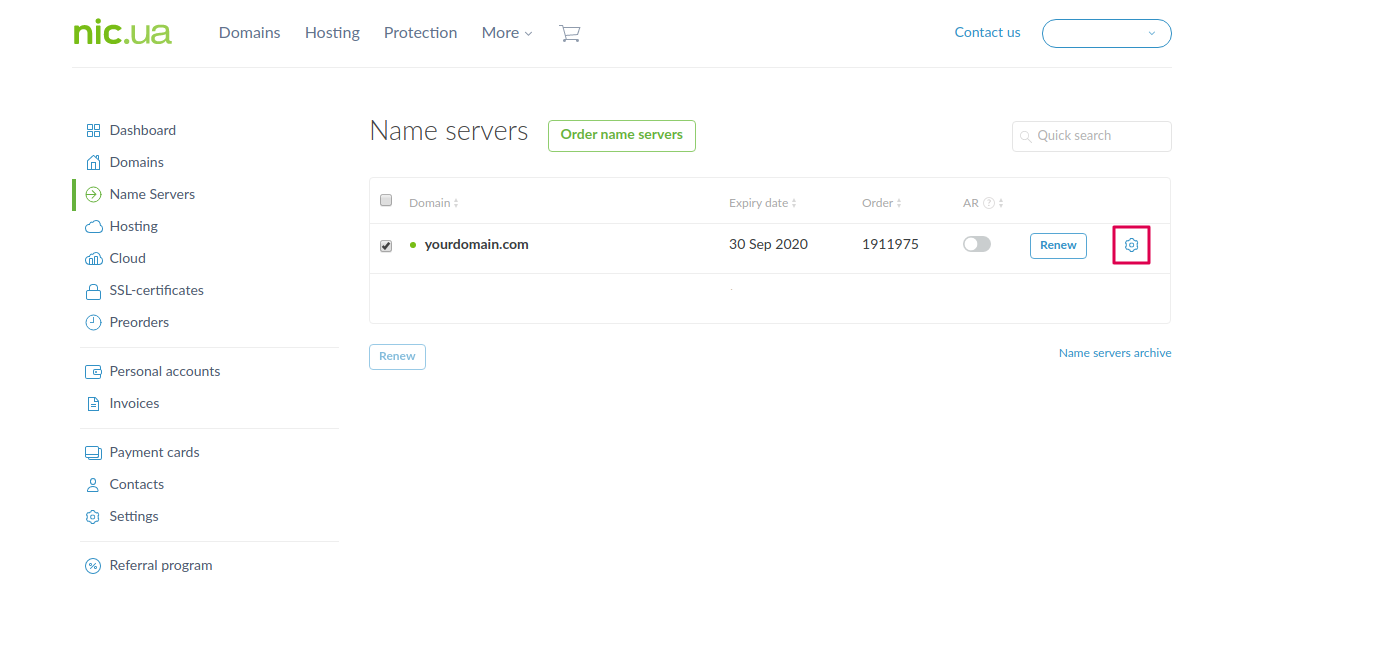
Здесь мы видим текущие DNS записи для нашего домена. Их мы оставляем без изменений, и приступаем к добавлению нужных нам записей в соответствии с выбранным типом верификации в системе eSputnik. Для этого нажимаем “Change”, а в появившемся редакторе записей нажимаем “Add record”.
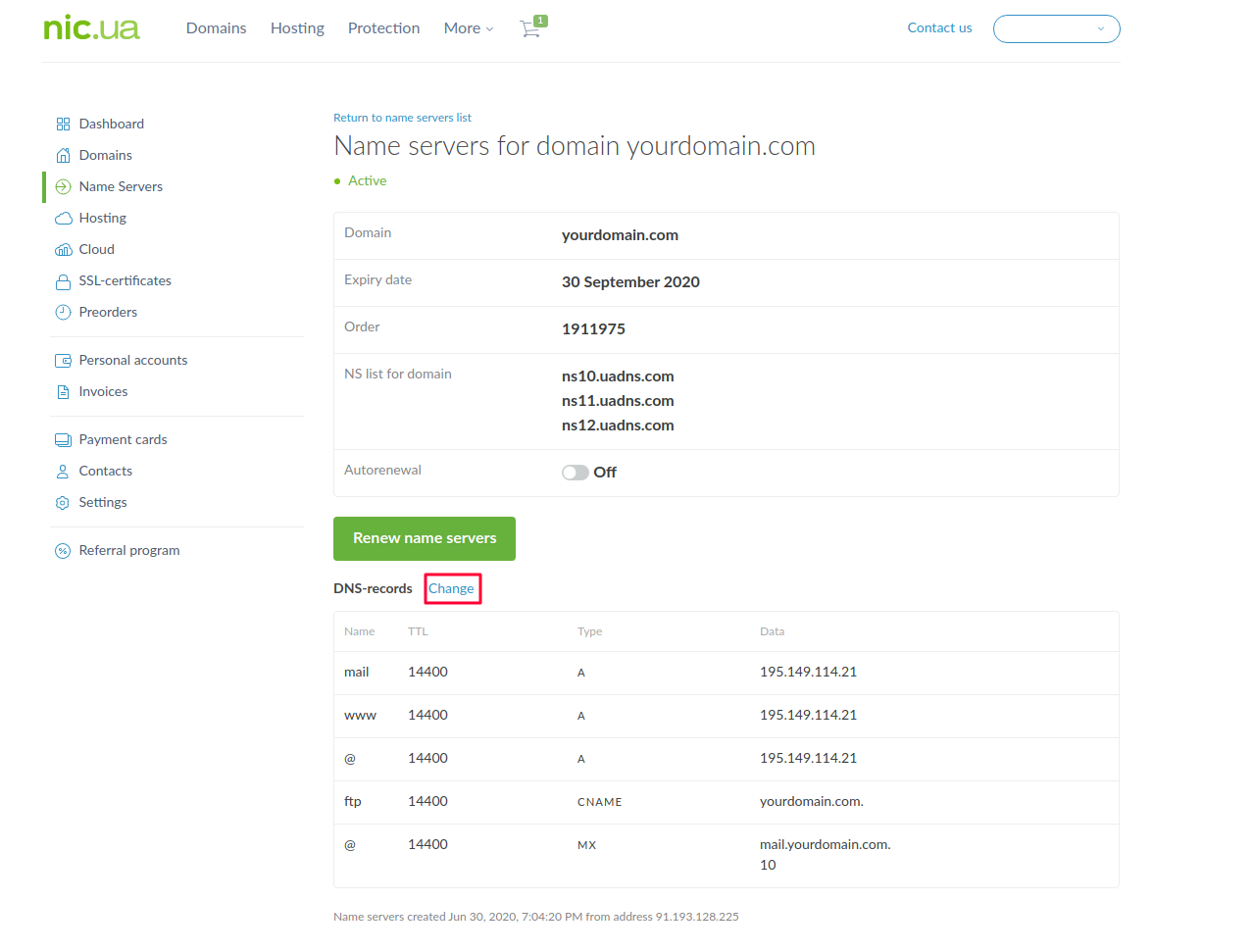
Для верификации по варианту “Полный” нам необходимо добавить две записи с типами CNAME и TXT.
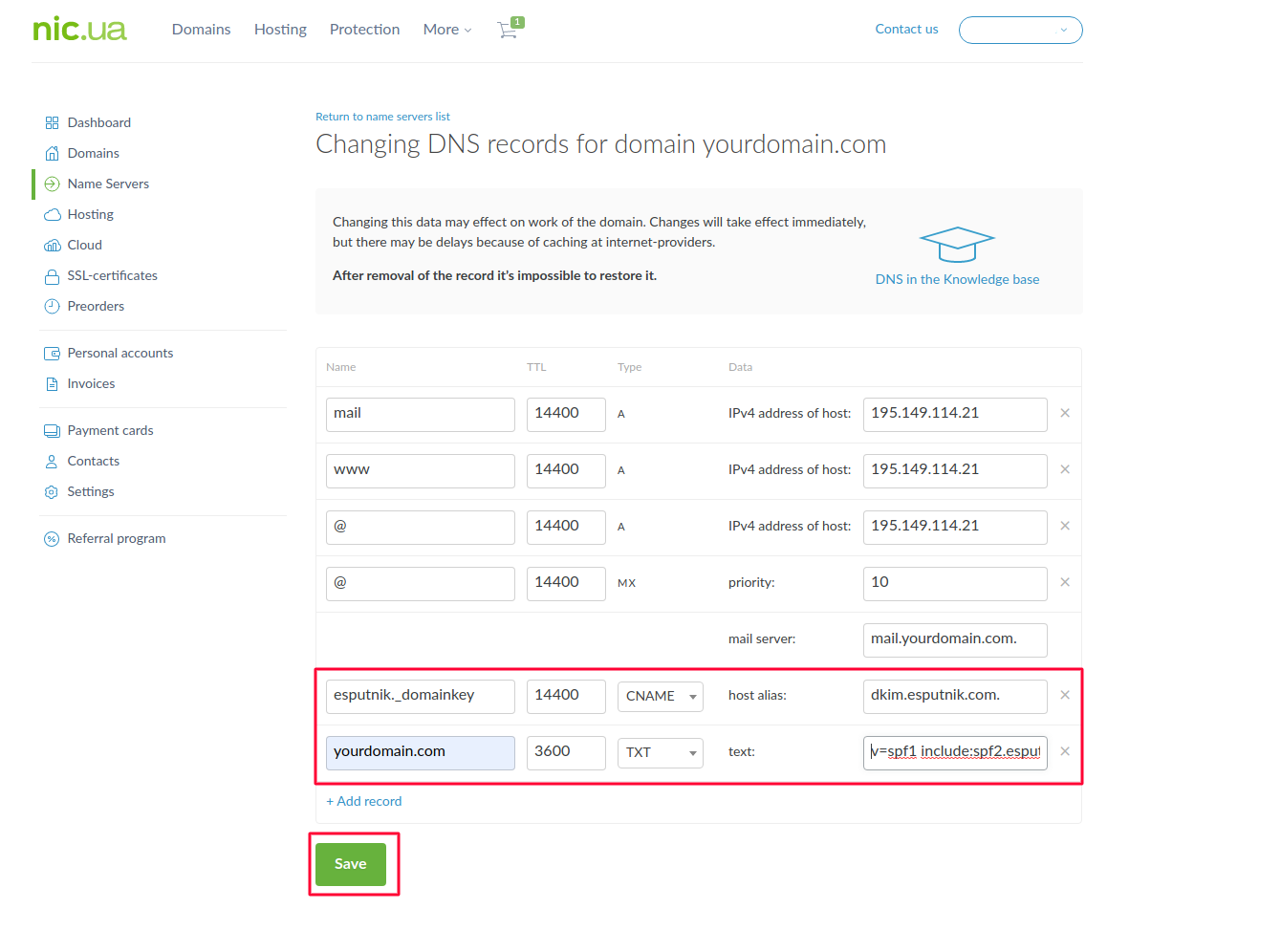
Вариант “Полный+”
Для данного варианта верификации к уже добавленным выше записям нам нужно внести MX и TXT записи для поддомена. Выглядеть это будет следующим образом:
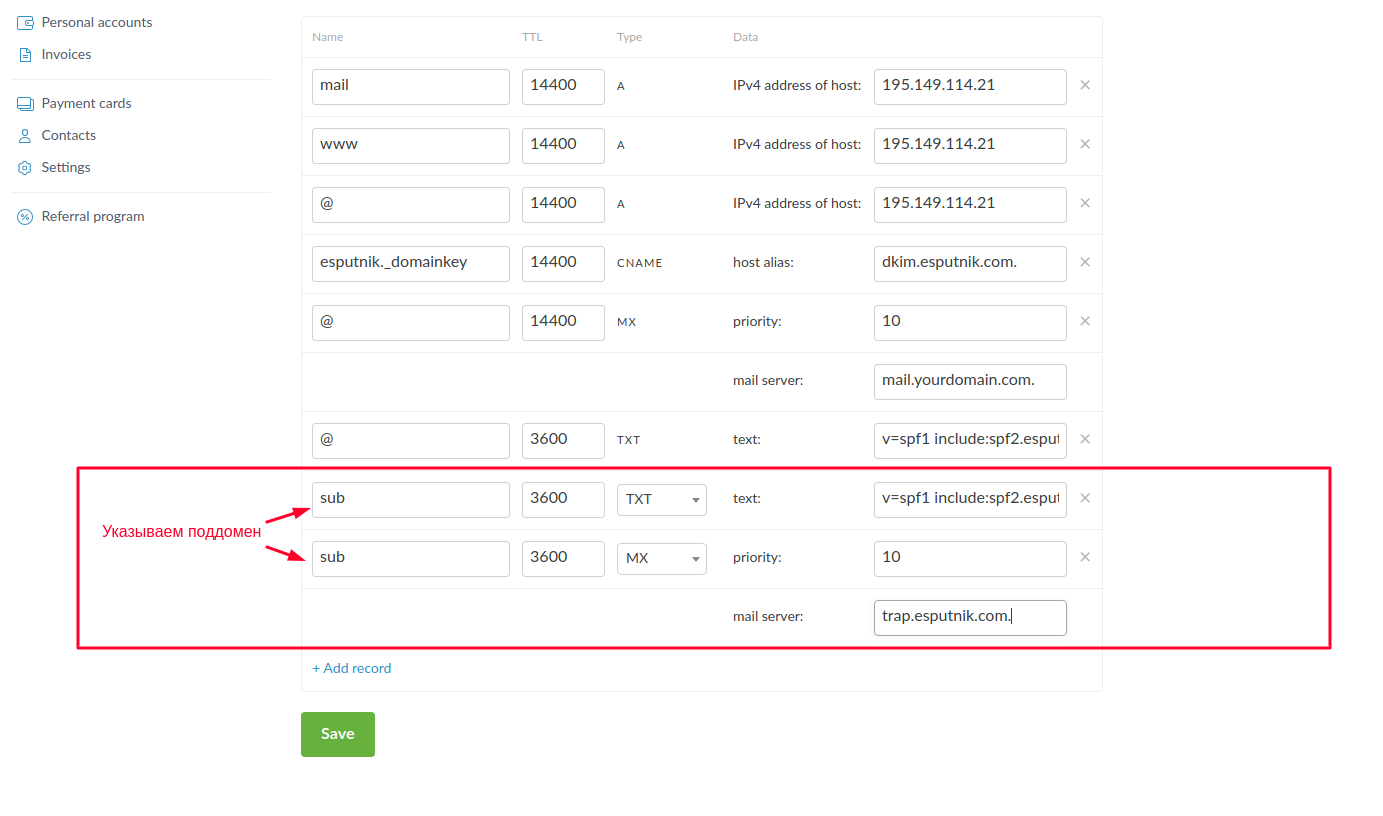
Сохраняем изменения, и в итоге конфигурация будет иметь такой вид (выделены записи, которые мы внесли. MX и A записи, которые были изначально остаются без изменений):
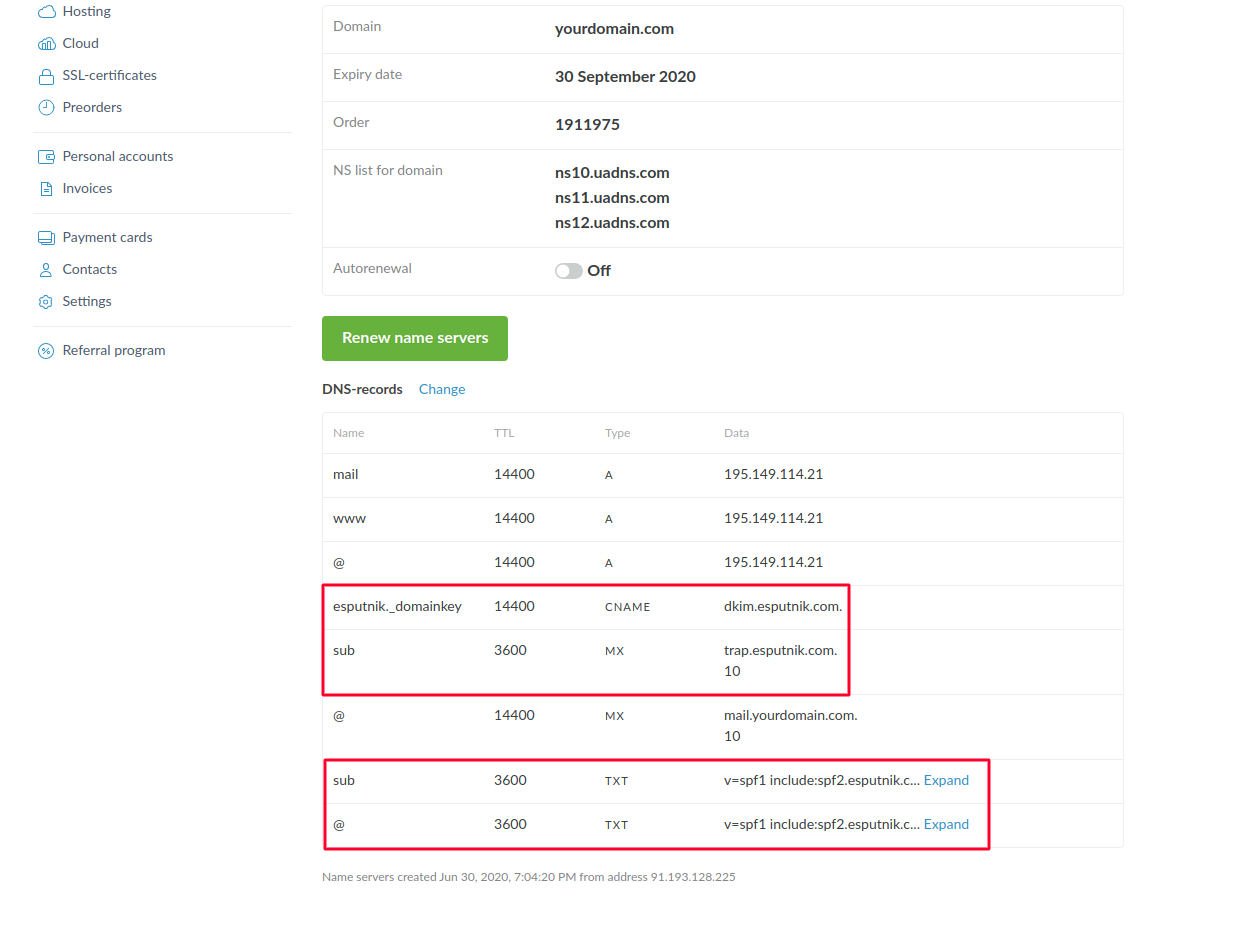
Вариант “Поддомен”
Для варианта “Поддомен” нам нужно внести только MX и TXT записи для выбранного вами поддомена, а также CNAME запись.
Данная конфигурация будет иметь следующий вид:
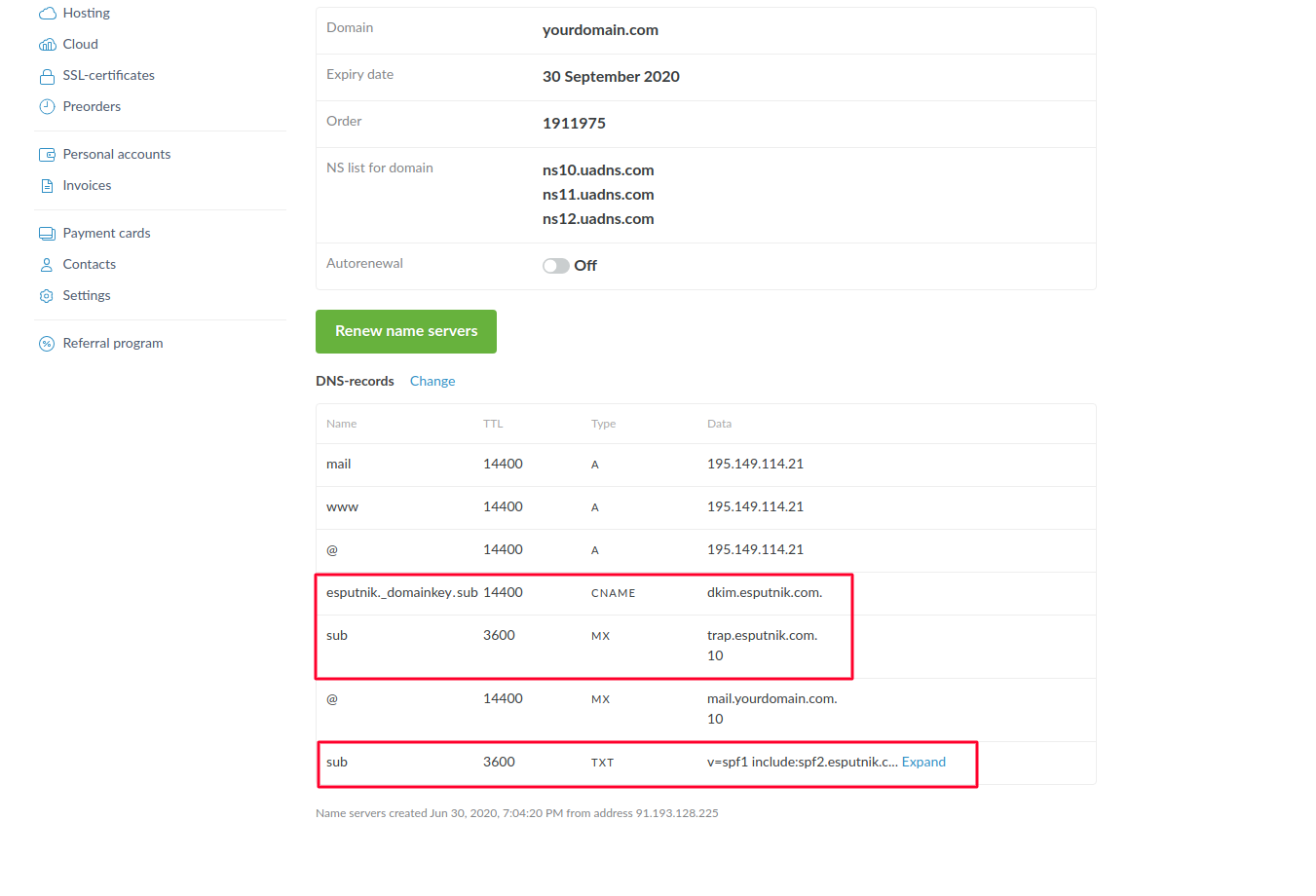
Аналоги
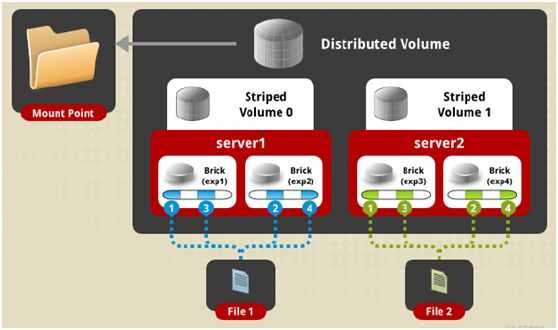
Вообще говоря, Ceph достаточно уникальное кластерное решение, прямых аналогов которого нет. Но есть некоторые системы, схожие по решаемым проблемам. Основным аналогом Ceph является GlusterFS, которую я рассмотрю ниже отдельно. Так же к аналогам можно отнести следующие кластерные системы хранения данных:
- Файловая система ocfs2.
- OpenStack Swift.
- Sheepdog.
- HDFS (Hadoop Distributed File System)
- LeoFS
Список не полный. Это только то, что вспомнил я из того, что слышал. Сразу оговорюсь, что перечисленные системы мне практически не знакомы. Список привожу только для того, что, чтобы вам было проще потом самим найти о них информацию и сравнить. Они не являются полными аналогами ceph, но в каких-то вариантах могут подойти больше, нежели он. К примеру, Sheepdog намного проще система и потребности только в хранилище для виртуальных машин может закрывать лучше, чем ceph.
Теперь рассмотрим отдельно GlusterFS.
Основные команды
Пройдемся по основным командам ceph, которые вам пригодятся при эксплуатации кластера. Основная — обзор состояния кластера:
# ceph -s
Традиционный ключ -w к команде для отслеживания изменений в реальном времени:
# ceph -w
Посмотреть список пулов в кластере:
# rados lspools
Статистика использования кластера:
# ceph df
Список всех ключей учетных записей кластера:
# ceph auth list
Состояние кворума:
# ceph quorum_status
Просмотр дерева OSD:
# ceph osd tree
Статистика OSD:
# ceph osd dump
Статистика PG:
# ceph pg stat
Список PG:
# ceph pg dump
Создание или удаление OSD:
# ceph osd create || ceph osd rm
Создание или удаление пула:
# ceph osd pool create || ceph osd pool delete
Тестирование производительности OSD:
# ceph tell osd.1 bench
Проверка надежности и отказоустойчивости
Расскажу, какие проверки отказоустойчивости ceph делал я. Напомню, что у меня кластер состоит всего из трех нод, да еще на sata дисках на двух разных гипервизорах. Многого тут не натестируешь Диски собраны в raid1, никакой нагрузки помимо ceph на серверах не было. Я просто выключал одну ноду. При этом в работе кластера не было никаких заметных изменений. С ним можно было нормально работать, писать и читать данные. Самое интересное начиналось, когда я запускал обратно выключенную ноду.


В этот момент запускался ребалансинг кластера и он начинал жутко тормозить. Настолько жутко, что в эти моменты я даже не мог зайти на ноды по ssh или напрямую с консоли, чтобы посмотреть, что именно там тормозит. Виртуальные машины вставали колом. Я пытался их отключать и включать по очереди, но ничего не помогало. В итоге я выключил все 3 ноды и стал включать их по одной. Очевидно, что и нагрузки никакой я не давал, так как кластер был не в состоянии обслуживать внешние запросы.
Включил сначала одну ноду, убедился, что она загрузилась и показывает свой статус. Запустил вторую. Дождался, когда полностью синхронизируются две ноды, потом включил третью. Только после этого все вернулось в нормальное состояние. При этом никаких действий с кластером я не производил. Только следил за статусом. Он сам вернулся в рабочее состояние. Данные все оказались на месте. Меня это приятно удивило, с учетом того, что я жестко выключал зависшие виртуалки несколько раз.
Как я понял, если у вас есть возможность снять с кластера нагрузку, то в момент деградации особых проблем у вас не будет. Это актуально для кластеров с холодными данными, например, под бэкапы или другое долгосрочное хранение. Там можно тормознуть задачи и дождаться ребаланса. Особых проблем с эксплуатацией ceph быть не должно. А вот если у вас идет постоянная работа с кластером, то вам нужно все внимательно проектировать, изучать, планировать, тестировать и т.д. Точно должен быть еще один тестовый кластер и доскональное понимание того, что вы делаете.
Что такое VPS и VDS
VPSVDS
▍Разница между VPS и VDS
VPS.FreeBSD JailParallels Virtuozzo ContainersiCore Virtual AccountsOpenVZVDS.LDomsKVMMicrosoft Hyper-V, XEN
▍Критерии выбора VPS/VDS
- Конфигурация сервера и мощность оборудования. От того, сколько процессорной мощности (CPU), процессорной и оперативной памяти (RAM) выделено зависит скорость работы хостируемого сайта. От того, насколько известен бренд предлагаемого в аренду физического оборудования зависит стабильность работы.
- Операционная система. От неё зависит широта спектра поддерживаемых приложений.
- Кто будет контролировать сервер? Если функции управления хостингом берёт на себя провайдер — это управляемый VPS (managed VPS), если вы сами занимаетесь поддержкой работоспособности и мониторингом производительности сервера — неуправляемый (unmanaged VPS). Логично, что неуправляемый вариант подходит опытным администраторам, а управляемый — владельцам бизнеса, жаждущим делегировать это занятие профессионалам. Степень управления влияет на тарифную сетку.
- Бесперебойность и надёжность работы. Бесперебойность характеризуется такими понятиями, как масштабируемость (возможность подключения резервных ресурсов при увеличении нагрузки) и избыточность (собственно резервирование ресурсов: как оно реализовано у хостера при возникновении проблем с электричеством, неполадками у интернет-провайдера, перегруживанием физического сервера). Проще говоря, поинтересуйтесь, какие меры по аварийному восстановлению применяет хостер? Надёжность, гарантируемая хостером, должна быть не ниже 99,95%. Помимо заявлений на сайте поставщика услуг, которые не всегда соответствуют действительности, хорошо бы почитать отзывы о нём на независимых площадках.
- Широта полосы пропускания. Для начала нужно понимать, какая полоса пропускания нужна для ваших проектов. А затем поинтересоваться у хостера, каковы его ограничения на этот параметр, какова плата за дополнительную широту и есть ли квоты.
- Дополнительные IP-адреса. Не все хостеры предоставляют такую услугу. Однако часто она необходима: чтобы у каждого сайта или сервиса на VPS был свой IP-адрес или чтобы у одного сайта с разными доменами были разные IP-адреса. Также разные IP-адреса нужны для установки защищённого соединения по .
- Месторасположение сервера. Чем меньше расстояние между VPS и локацией, в которой концентрируется аудитория вашего сайта, тем лучше: быстрее доступ пользователей к сайту (выше скорость отклика страницы на запрос), больше возможностей подняться в рейтингах поисковых систем.
- Отзывчивая техподдержка. От того, насколько быстро, бесперебойно и качественно хостер решает ваши проблемы, о которых вы сообщаете в техподдержку, зависит вся сторона вашего бизнеса, связанная с сайтом. Если поддержка клиента неудовлетворительная, то не стоит работать с этим хостером, даже при условии хорошей функциональности и цены хост-услуг.
- Гарантия возврата денег. У хостеров, хорошо заботящихся о клиентах, есть так называемая money back guarantee на тот случай, если вам не понравился хостинг. Также хорошо, если есть бесплатный тестовый период.
Hetzner
Речь в первую очередь идет об его облаке. Дедики у него не заказываю, нет необходимости. А вот облаком пользуюсь и часто рекомендую.
Особенно это облако подходит под хостинг криптонод. В первую очередь за то, что можно гибко увеличивать размер диска, который у криптонод постоянно растет.
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .
КАК САМОСТОЯТЕЛЬНО ЗАНЯТЬСЯ РАССЫЛКОЙ?
ВАРИАНТ ПЕРВЫЙ
Самый простой вариант – рассылка при помощи специальных программ. Для этого необходимо набрать большое количество подписок посетителей, найти специальную программу для рассылки, скачать её и установить, создать, собственно, текст сообщения и разослать подписчикам.
ВАРИАНТ ВТОРОЙ
Рассылка с личного сайта. Этот вариант так же является простым и материально выгодным. Итак, например, существует сайт с хостингом (компьютер, который дает возможность размещения вашего сайта), имеется язык программирования (PHP) – этого более чем достаточно. Остается создать страницу с .php расширением. К примеру, это может быть send.php, он будет производить рассылку писем хостинга с помощью PHP-скрипта. Пример содержания файла для письма:
Выкладываете этот файл на хостинг, переходите по адресу http://www.ваш_сайт.ru/send.php и первое сообщение отправлено. Посмотрите внимательно, сообщение отправлено только одному адресату. Пример содержания для массовой рассылки:
ВАРИАНТ ТРЕТИЙ
Третий способ рассылки имеет значительное отличие от предыдущих. Это рассылка с помощью веб-сервисов. У этого варианта множество достоинств и вариант попасть в спам список исключен. Рассмотрим достоинства:
-
Рассылка без ограничений;
-
Анонимная рассылка;
-
Любой контент сообщения;
-
Доставка сообщений не в виде спама;
-
Рассылка с разных IP;
-
Уникализация текста письма;
Что называется спам базой?
Спам баз в интернете достаточно много. Они имеют множество разных названий: «Dns blacklists», «Черные списки IP», «Ip blacklists». Они проверяют IP адрес адресанта или текста сообщения. Если они не соответствует их требованиям, ваш IP адрес будет занесен в спам базу.
Beget
Откройте настройки DNS в личном кабинете.
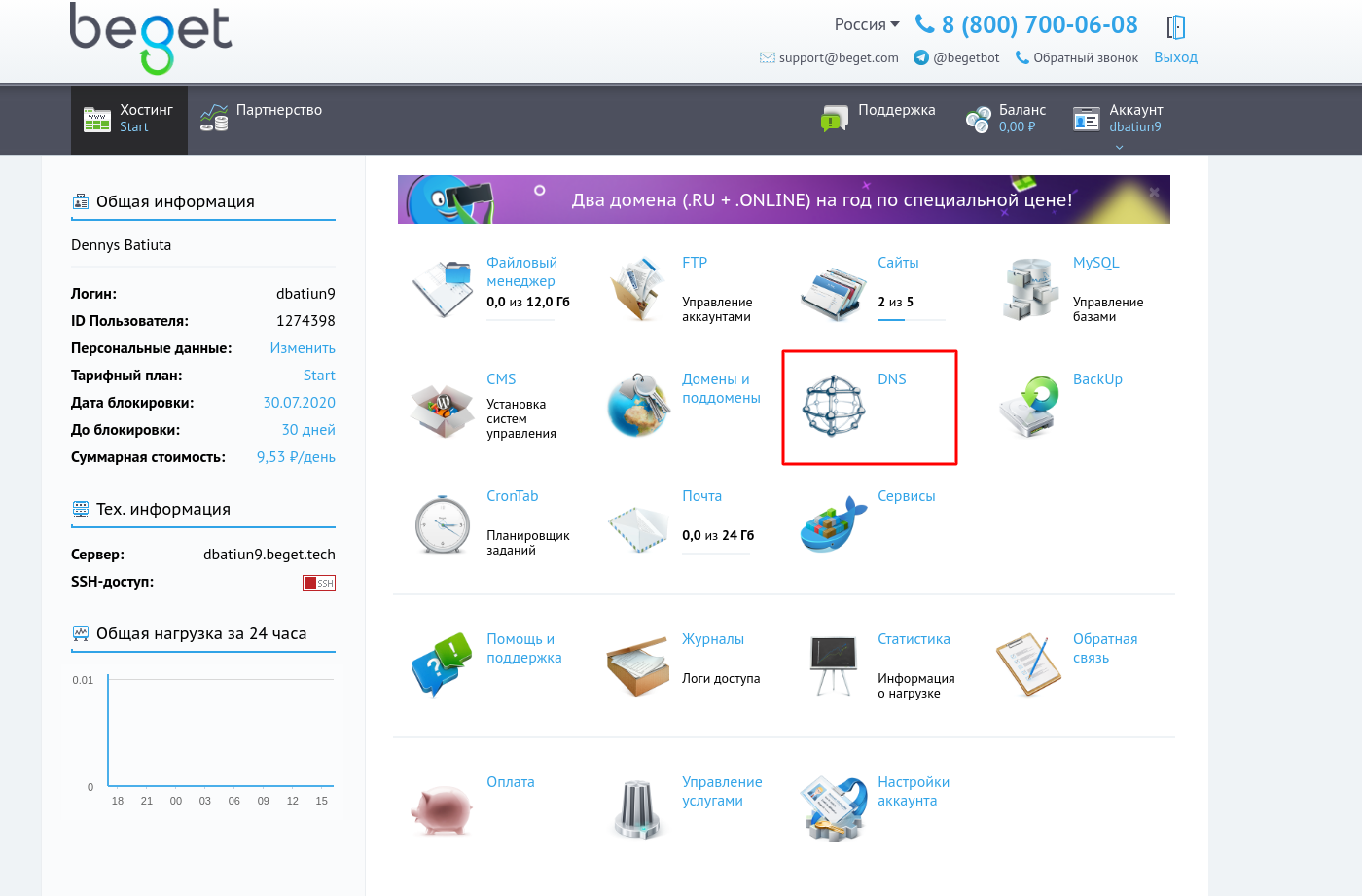
Вариант “Полный»
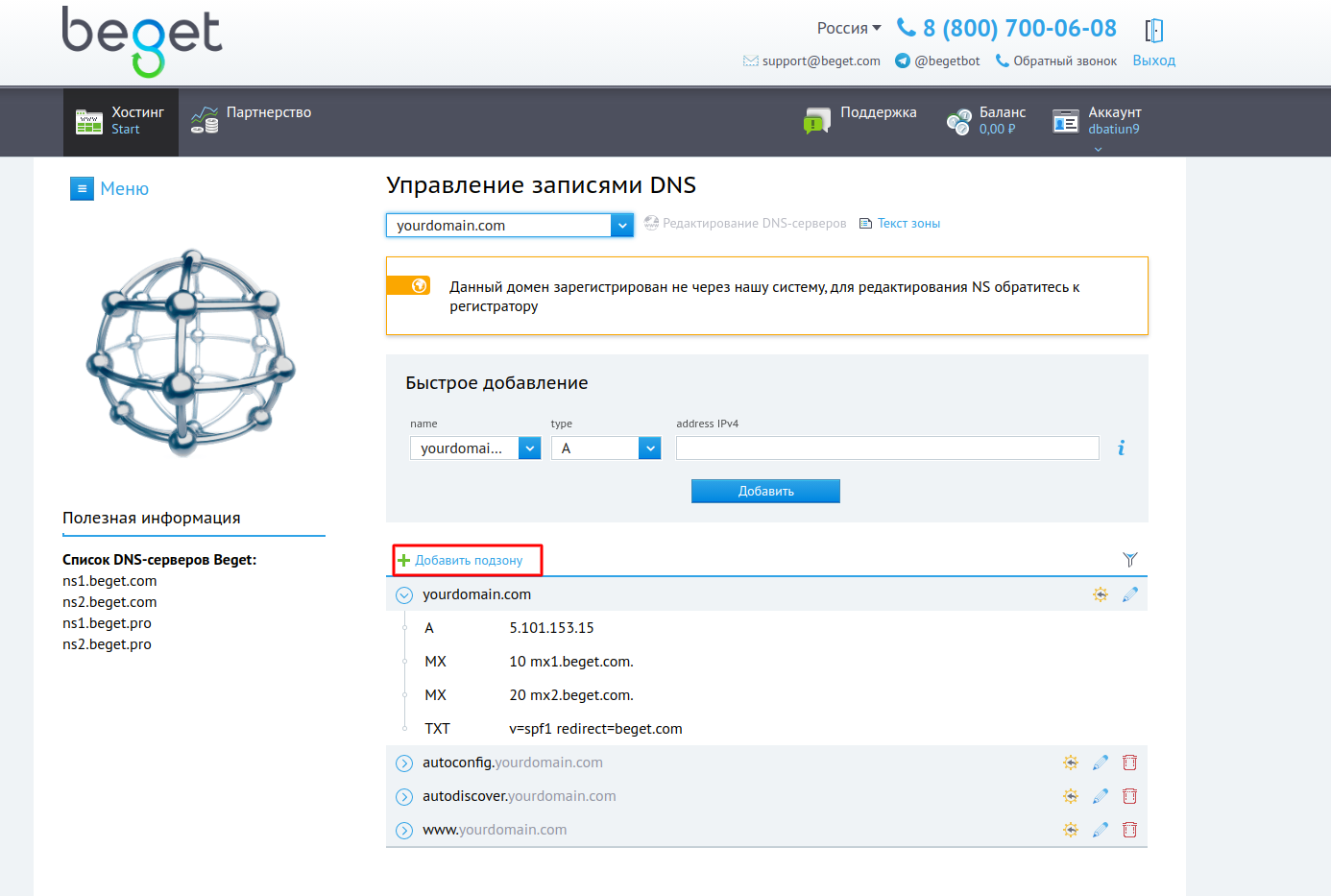
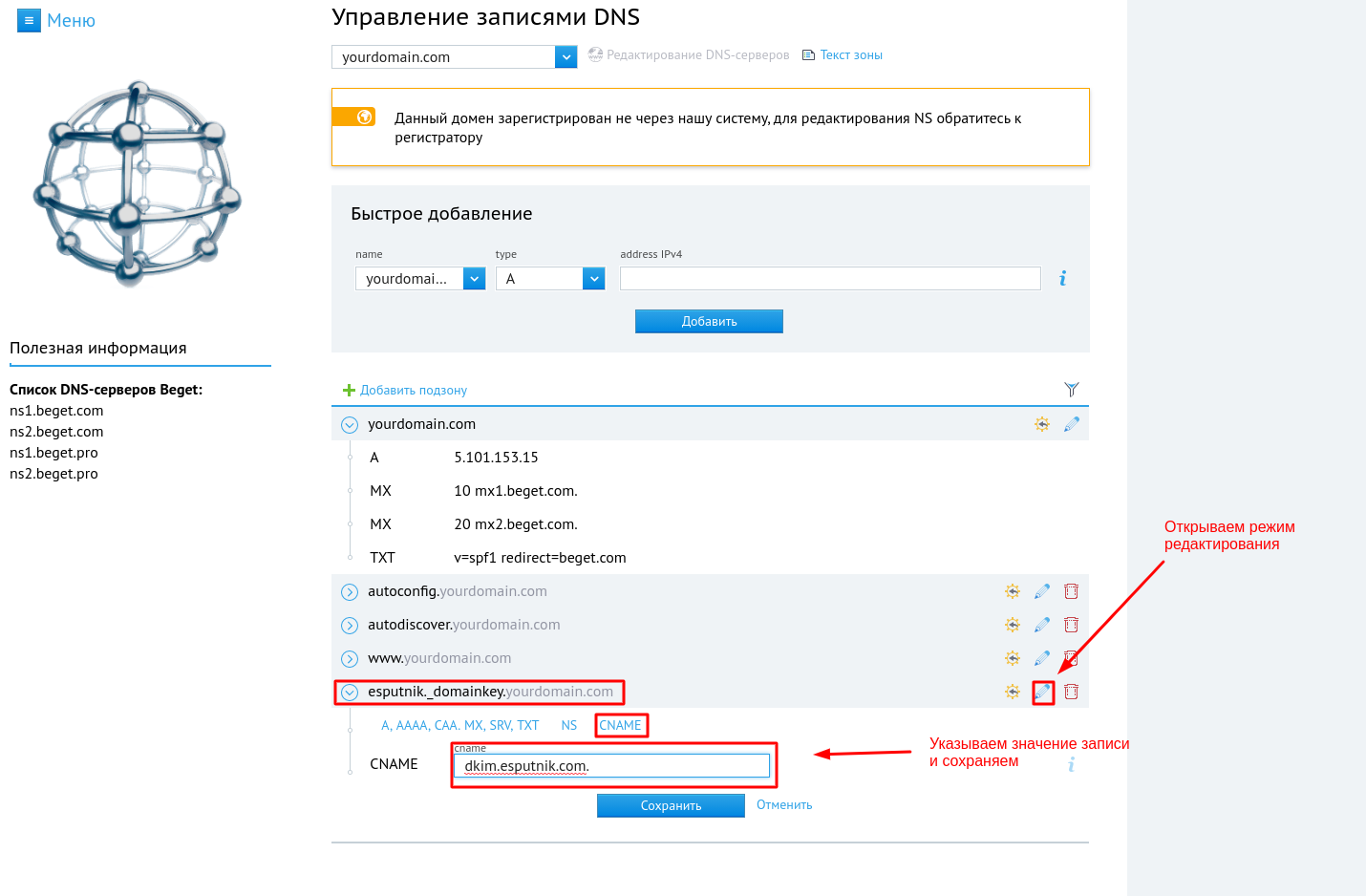
2. В открывшемся окне введите запись esputnik._domainkey и нажмите Добавить.
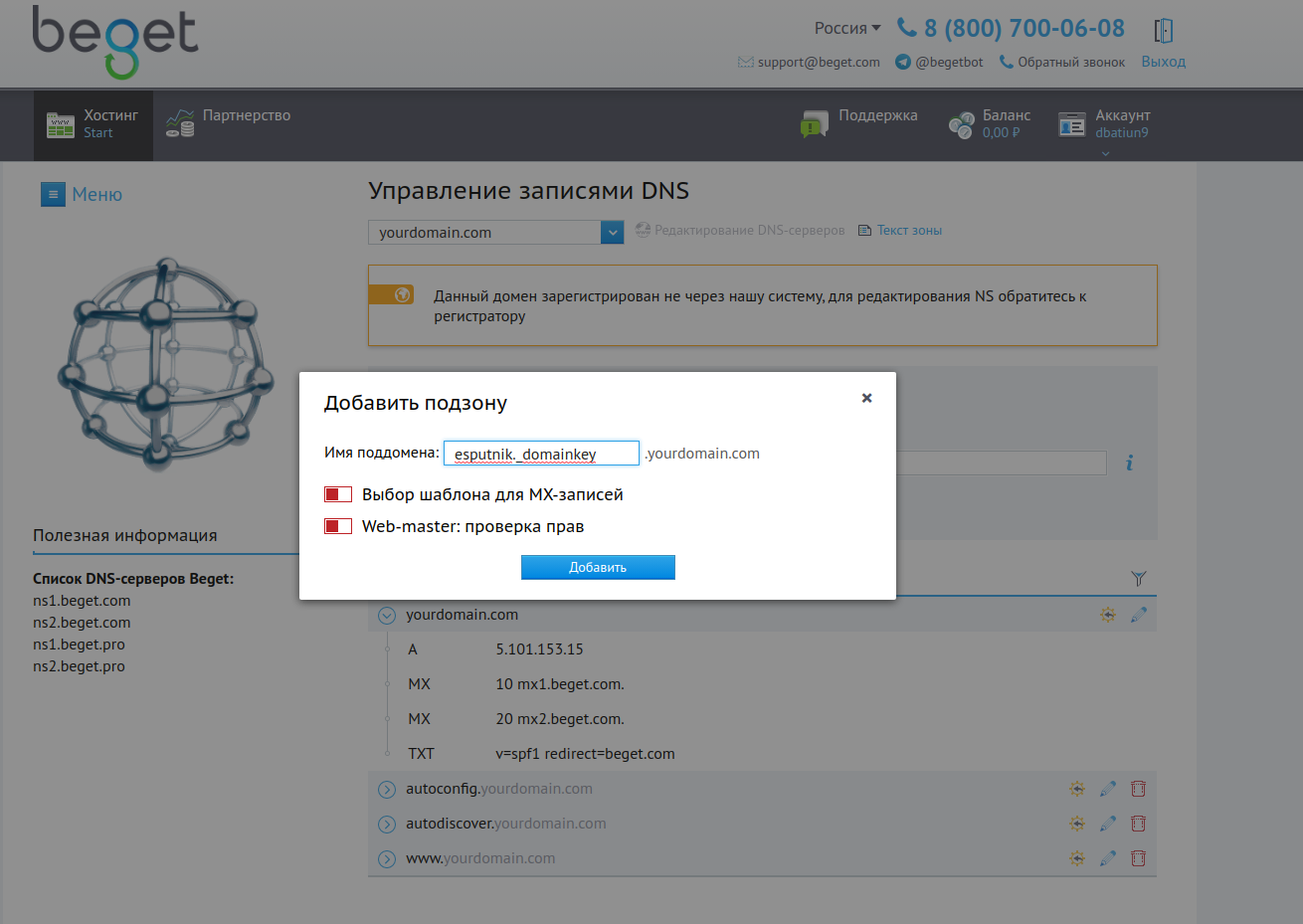
3. В новом окне “Управление записями DNS” откройте режим редактирования напротив записи esputnik._domainkey.
В окно CNAME введите запись dkim.esputnik.com.
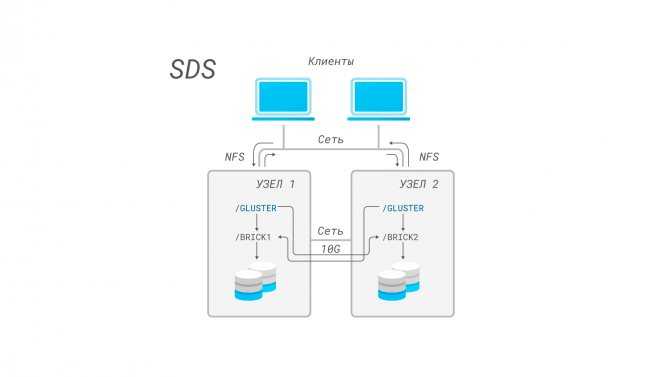


Сохраните изменения.
TXT-запись
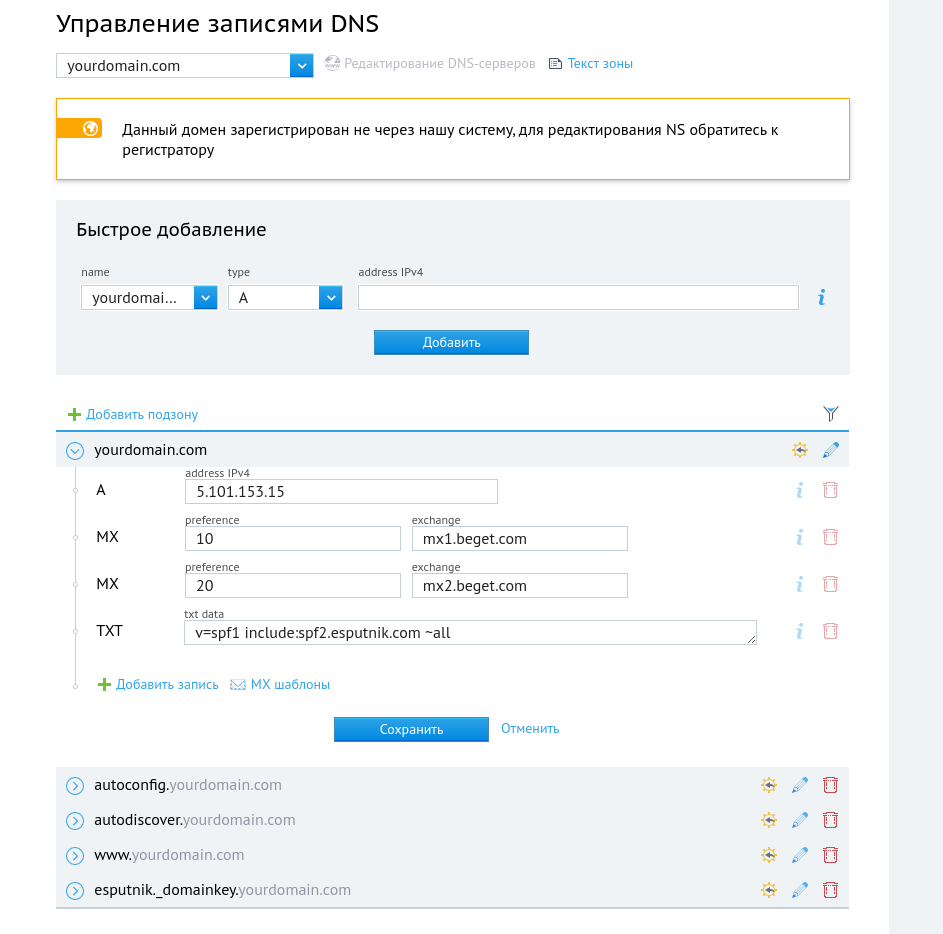
В поле Name введите название вашего домена, в поле Type выберите A, нажмите Добавить.
Окончательный вид записей для варианта “Полный” будет выглядеть так:
Вариант “Полный+”
1. Добавьте название поддомена для своего домена.
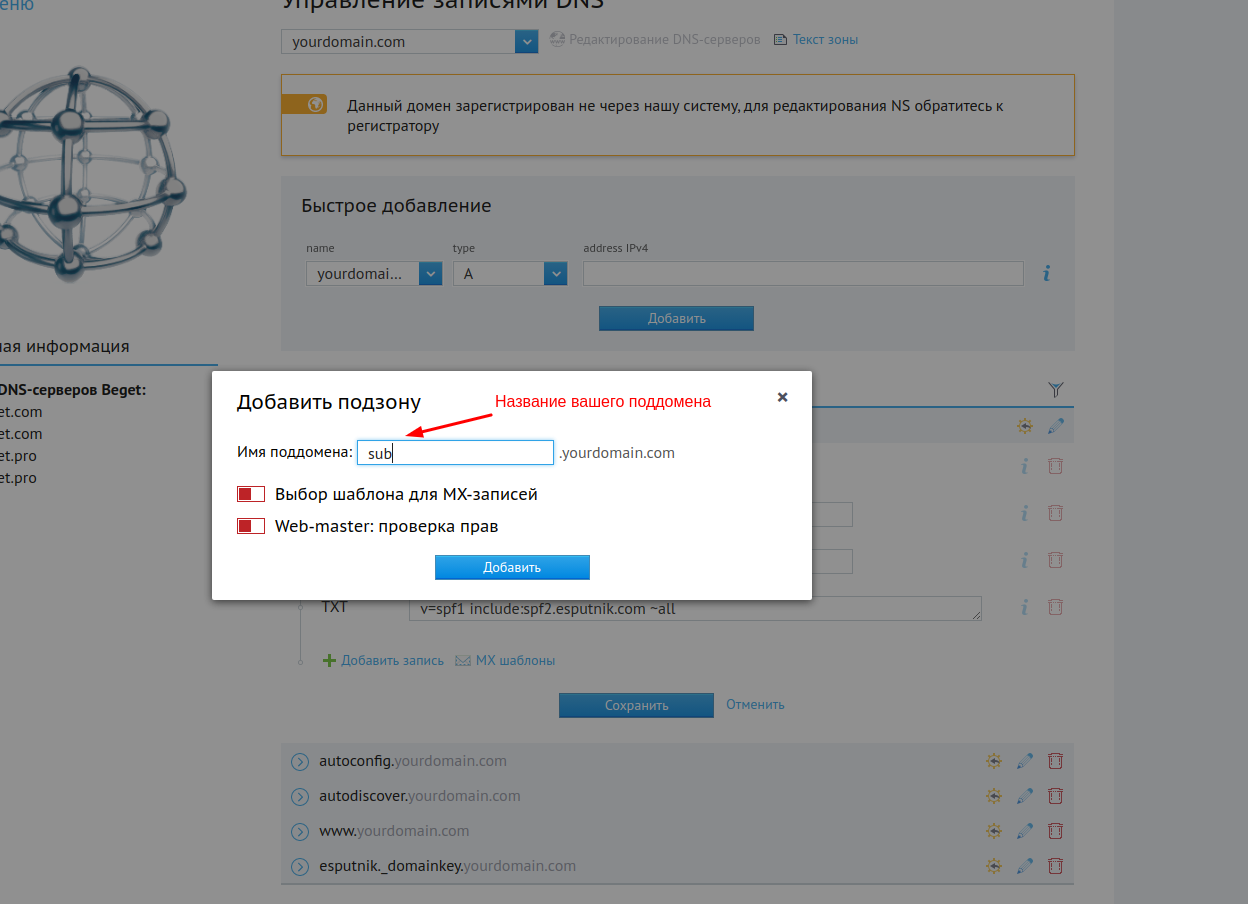
2. Введите запись ТХТ: v=spf1 include:spf2.esputnik.com ~all
3. Введите запись МХ: trap.esputnik.com. (приоритет = 10).
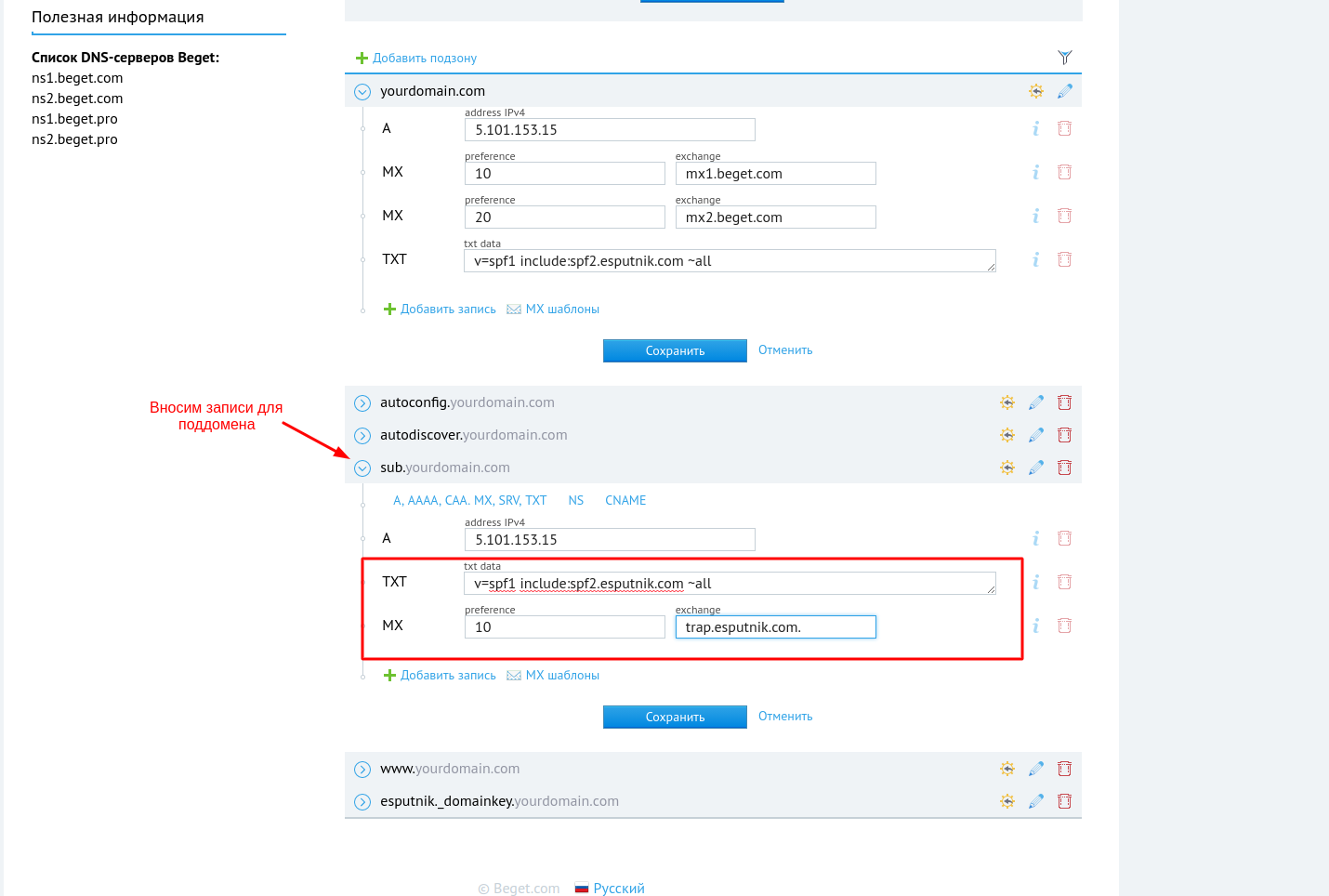
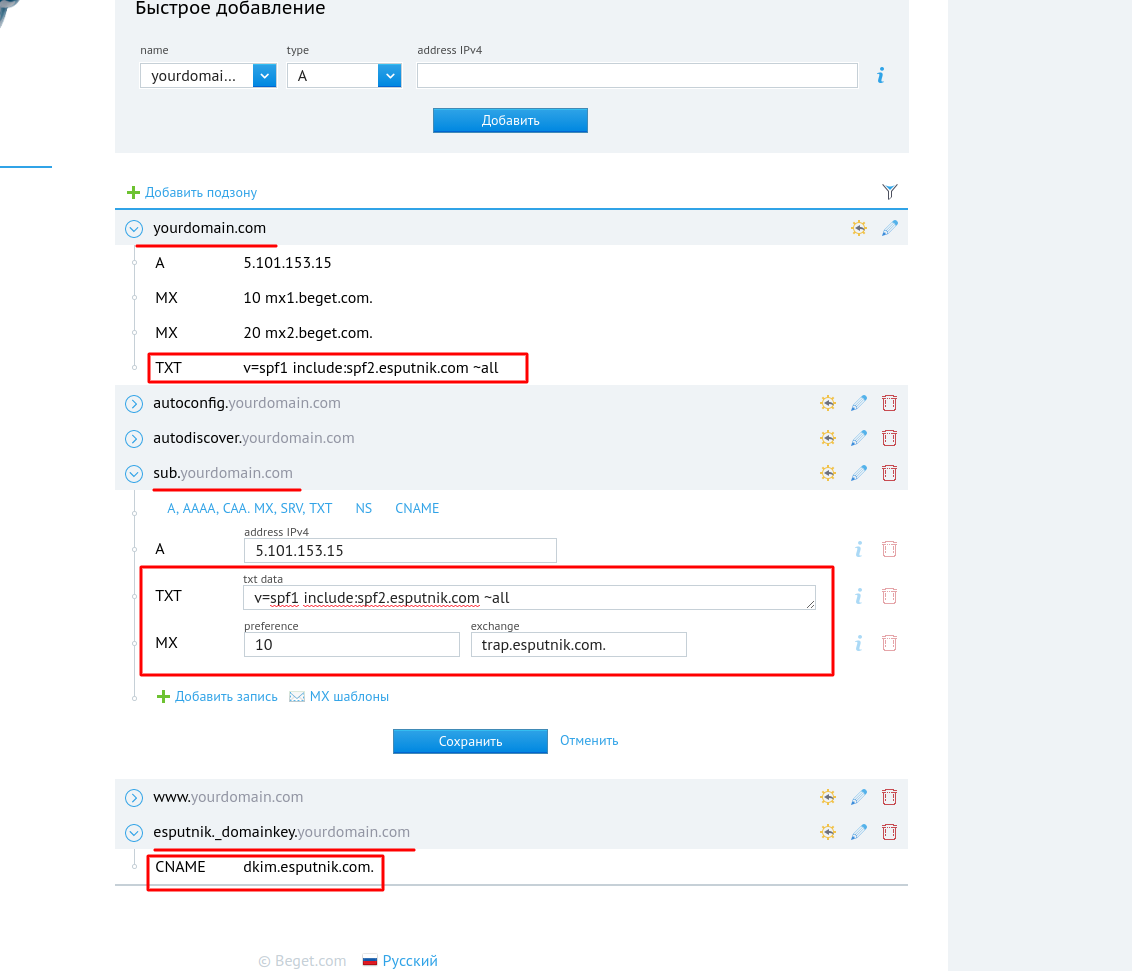
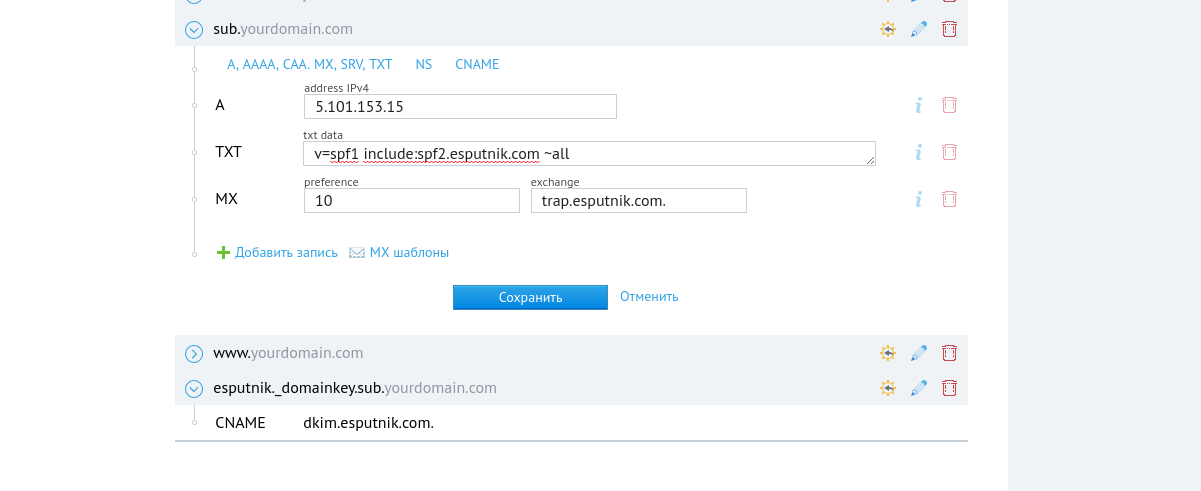
Окончательный вид записей для варианта “Полный+” будет выглядеть так:
Вычисление Placement Groups (PG)
Самая большая трудность в вычислении PG это необходимость соблюсти баланс между количеством групп на OSD и их размером. Чем больше PG на одной OSD, тем больше вам надо памяти для хранения информации об их расположении. А чем больше размер самой PG, тем больше данных будет перемещаться при балансировке.
Получается, что если у вас мало PG, они у вас большого размера, надо меньше памяти, но больше трафика уходит на репликацию. А если больше, то все наоборот. Теоретически считается, что для хранения 1 Тб данных в кластере надо 1 Гб оперативной памяти.
Как я уже кратко сказал выше, примерная формула расчета PG такая — Total PGs = (Number OSD * 100) / max_replication_count. Конкретно в моей установке по этой формуле получается цифра 100, которая округляется до 128. Но если задать такое количество pg, то роль ansible отработает с ошибкой:
Error ERANGE: pg_num 128 size 3 would mean 768 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Суть ошибки в том, что максимальное количество pg становится больше, чем возможно, исходя из параметра mon_max_pg_per_osd 250. То есть не более 250 на один OSD. Я не стал менять этот дефолтный параметр, а просто установил количество pg_num 64. Более подробная формула есть на официальном сайте — https://ceph.com/pgcalc/.
Существует проблема выделения pg и состоит она в том, что у нас в кластере обычно несколько пулов. Как распределить pg между ними? В общем случае поровну, но это не всегда эффективно, потому что в каждом пуле может храниться разное количество и типов данных. Поэтому для распределения pg по пулам стараются учитывать их размеры. Для этого тоже есть примерная формула — pg_num_pool = Total PGs * % of SizeofPool/TotalSize.
Количество PG можно изменять динамически. К примеру, если вы добавили новые OSD, то вы можете увеличить и количество PG в кластере. В последней версии ceph, которая еще не lts, появилась возможность уменьшения Placement Groups.
Нужно понимать одну важную вещь — изменение количества PG приводит к ребалансингу всего кластера. Нужно быть уверенным, что он к этому готов.
Selectel
У хостера Selectel я использую аренду выделенных серверов и облачное S3 хранилище. Этот сайт живет на дедике в Селектеле. Что мне у него нравится:
- Хорошая и быстрая тех. поддержка.
- Одни из самых низки цен на бюджетные дедики.
- Установка и передача дедиков клиенту автоматизирована и очень быстра.
- Бесплатный dns хостинг с API.
Облачное хранилище использую для хранения всевозможных бэкапов. Из более ли менее крупных хостеров у него наиболее низкие цены за хранение. Не скажу, что внимательно сравнивал, но дешевле мне не попадалось.
Нравится, что дедики очень быстро получаешь. Оплатил, заказал, через 10-30 минут можешь начинать с ним работать. Выбираешь шаблон системы, она автоматически раскатывается. Можешь оперативно заказать переустановку через админку.
В случае проблем можно загрузиться с rescue cd, просто выбрав его в панели управления. Пару раз у меня была необходимость подключить ip-kvm. Тех поддержка подключала его бесплатно по запросу. Можно оплачивать аренду по дням, что удобно для тестов чего-либо.
Timeweb
Хостер Timeweb я ставлю в тройку лидеров, т.к. являюсь его клиентом с 2016 года.
Виртуальный хостинг имеет 4 тарифа. Минимальный – Year+.
- объем дискового пространства под файлы: 5 Гб
- количество сайтов: 1 сайт
- количество баз данных: 1 база данных
- минимальный тариф на месяц: 119 рублей (при оплате за год)
- тестовый период: 10 дней.
При оплате тарифа за год вы получаете домен в подарок в зоне ru.
Здесь имеются ограничения по показателям. Для Optimo+ (это самый популярный тариф на Таймвеб) максимальная нагрузка на процессор не должна превышать 50 ср, а нагрузка на БД – 1000 единиц. Действует ограничение по посещаемости – до 3000 человек в сутки.
Так как я являюсь клиентом этого провайдера, смело могу порекомендовать Таймвеб для размещения сайта.
Mchost
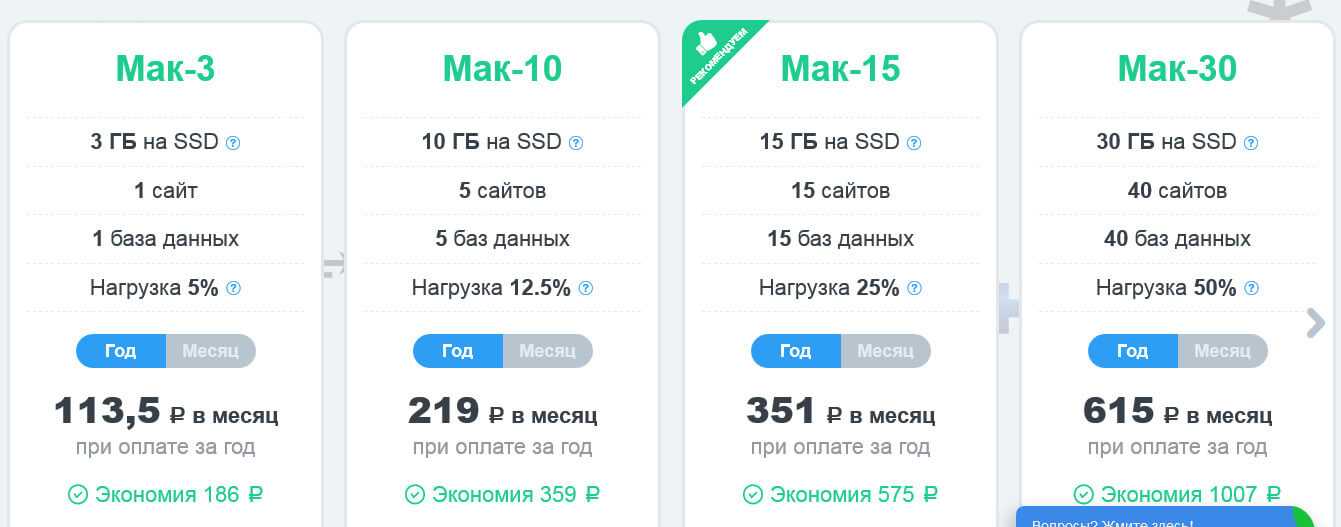
Еще один хороший хостинг сайтов – Макхост. Он работает с 2004 г.



Макхост имеет 5 тарифов для покупки виртуального хостинга. Базовый – Мак-3.
- объем дискового пространства под файлы: 3 Гб
- количество сайтов: 1 сайт
- количество баз данных: 1 база данных
- минимальный тариф на месяц: 113,5 рублей (при оплате за год)
- тестовый период: нет.
Друзья, когда я собирала информацию по Mchost, то задала вопрос в службу поддержки о возможности использования тестового периода. Официально бесплатного тестового периода для работы с Макхост нет. Но мне подсказали, что существует промокод на бесплатное использование хостинга в течение 3-х месяцев на тарифе Мак-10. Промокод вы можете найти на этой странице, если прокрутите ее до конца!
Установка ceph
Запускаем установку Ceph с помощью playbook ansible.
# cd ~/ceph-ansible/ # ansible-playbook -u root -k -i inventory/hosts site.yml -b --diff
Если вы используете авторизацию по паролю, то скорее всего получите ошибку подключения к ssh. Я с этим столкнулся. Когда вывел расширенный лог ошибок плейбука, увидел, что ansible подключается по ssh с использованием публичного ключа, который я не задаю. Изменить это можно в конфиге ansible.cfg, который лежит в корне репозитория. Находим там строку:
ssh_args = -o ControlMaster=auto -o ControlPersist=600s -o PreferredAuthentications=publickey
и удаляем параметр для publickey, чтобы получилось вот так:
ssh_args = -o ControlMaster=auto -o ControlPersist=600s
После этого заново запускайте развертывание ceph. Оно должно пойти без ошибок. В конце увидите примерно такое сообщение.
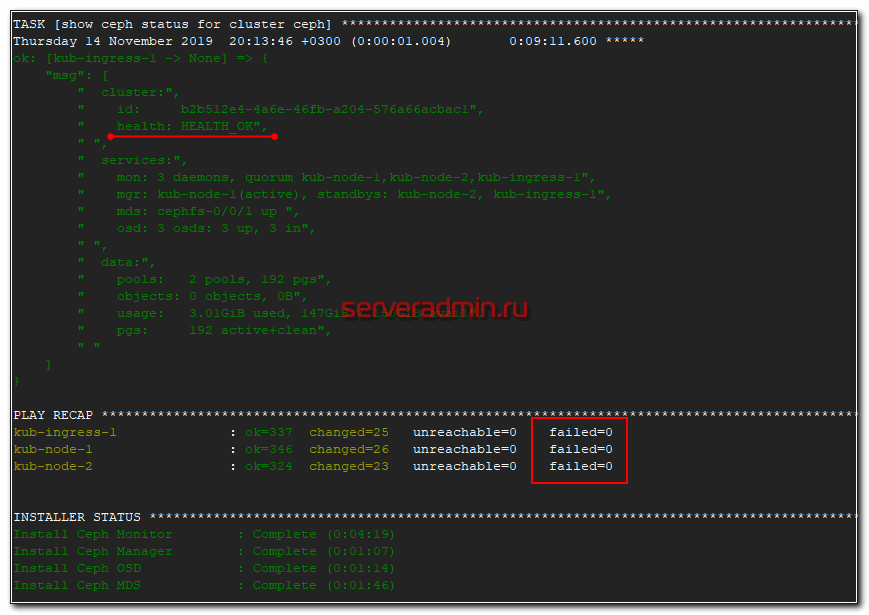
Если будут какие-то ошибки и счетчик failed не будет равен нулю, то разбирайте ошибки, исправляйте их и запускайте роль заново, пока она не закончится без ошибок.
После установки Ceph, можно проверить статус кластера командой, которую нужно выполнить на одной из нод кластера.
# ceph status

mon: 3 daemons, quorum kub-node-1,kub-node-2,kub-ingress-1
Вы должны увидеть примерно то же самое, что на скриншоте выше. 3 монитора работают в кворуме, друг друга видят, все хорошо.
mgr: kub-node-2(active), standbys: kub-node-1, kub-ingress-1
Менеджеры работают в режиме активный и ждущие — 1 активен, остальные ожидают.
usage: 3.03GiB used, 147GiB / 150GiB avail
3 Гб данный ceph занял под свои нужды. Так же нужно учитывать, что доступное пространство в 150 Гб это общее пространство кластера, которое будет расходоваться в зависимости от заданной репликации. Записать 150 Гб данных туда не получится. Если мы запишем 1 Гб данных, они реплицируются на все ноды и будут реально занимать 3 Гб в кластере.
Кластер ceph установлен. Дальше разберем, как с ним работать.
Чего не следует писать в рекомендациях
Несмотря на то, что составление рекомендации полностью отдано на откуп работодателя, при её написании следует придерживаться определенных правил и избегать некоторых вещей.
В частности, нужно стараться не давать негативных, ничем не подкрепленных отзывов (т.е. писать такие, конечно, не возбраняется, но только, если тому есть доказательства и подтверждения, например, письменные свидетельства о дисциплинарных взысканиях и т.п.), но тут же следует иметь ввиду, что такой документ вряд ли будет когда-либо применён по назначению.
В рекомендацию не следует вносить недостоверную, непроверенную или заведомо ложную информацию – при вскрытии таковых фактов пострадает репутация не только того, кому выдан документ, но и того, кто его выдал.
Eurobyte
И последняя компания, предоставляющая услуги хостинга, которая будет рассмотрена в рамках этой статьи – eurobyte.ru.
Этот хостер работает с 2010 года и зарекомендовал себя, как качественный хостинг.
Виртуальный хостинг для размещения сайта имеет 4 тарифа. Самый минимальный тариф предлагает следующие характеристики:
- объем дискового пространства под файлы: 3 Гб
- количество сайтов: не ограничено
- количество баз данных: не ограничено
- минимальный тариф на месяц: 159 рублей
- тестовый период: 30 дней.
Дополнительные бонусы: при оплате от 6 месяцев предоставляется скидка 10%, от 12 месяцев – 20%.

При регистрации виртуального хостинга на Евробайт появляется панель с информацией о месторасположениях data-центров: Россия или Амстердам. Выберите нужный вариант.
Simplecloud
Simplecloud — это лоу-костер по обычным VPS. Стоят дешево, заказываются быстро. Нравится удобная и простая панель управления виртуалками. Ничего лишнего нет. На обычном тарифе ограничение ширины канала 40 мегабит, поэтому для размещения реальных проектов не использую.
Заказываю здесь виртуалки с почасовой оплатой для тестов. Удобно, что можно сразу Bitrixenv развернуть, потестировать час-два, удалить виртуалку и заказать снова. Ставится она буквально за 5-10 минут.
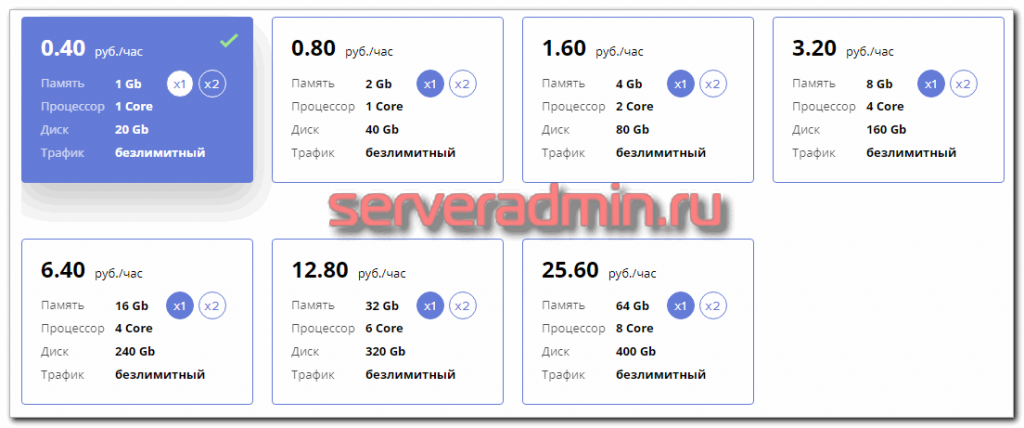
Можно заказать мощную виртуалку буквально за 6-12 р. в час. Если вас не смущает ограничение в 40 мегабит, можно использовать постоянно. Из-за простоты панели управления, хостера можно рекомендовать обычным юзерам.
Что такое рекомендательное письмо и когда составляется для сотрудника
Рекомендация (рекомендательное письмо) – это документ, который используется в качестве дополнительного веса при выборе лица из группы конкурентов.
Как правило, составляются незадолго до увольнением работника или спустя непродолжительное время. Запросить рекомендацию может как сам работник, так и его новый работодатель.






Чаще всего в письмо включаются следующие данные:
- Опыт работы, должность, непосредственная деятельность, которой занимался работник.
- Навыки и умения, которыми сотрудник обладает, а также дополнительные знания и умения, которые повышают продуктивность.
- Обучаемость, наличие дополнительного образования, сертификатов о прохождении курсов повышения квалификации.
- Профессиональные и личные качества, например ответственность, целеустремленность, умение работать в команде.
- Достижения на работе, наличие грамот, поощрений, патентов, грантов и прочее.
Рекомендации может составить только работодатель, который увольняет сотрудника или уже уволил. Работодатель и автор письма несут ответственность за полноту и достоверность указанных в документе сведений. Нельзя ни искусственно создавать хорошую рецензию, ни тем более принижать опыт и навыки сотрудника.
Логично, что писать рецензию должно то лицо, которое хорошо знало профессиональные стороны работника, поэтому непосредственный начальник является наиболее желательным автором рекомендации. В иных случаях составление рекомендации возлагается на начальника отдела кадров, секретаря, и даже руководителя предприятия (чаще подобная ситуация встречается в небольших организациях).
Чтобы получить рекомендацию, работник должен написать заявление на имя директора и передать его через секретаря.
Новый работодатель, если он не может самостоятельно через деловое письмо узнать о работнике на его бывшем месте работы, не вправе требовать рекомендацию постфактум.
Чаще всего компании сразу предупреждают соискателей о необходимости иметь рекомендательное письмо, поэтому его подготовкой потенциальный работник может заняться заблаговременно.
Основные правила оформления и реквизиты
Документ не предусматривает наличие унифицированного образца. Не требуется соблюдения даже локальных нормативов: любая организация может составлять рецензию в свободной форме.
Единственное правило – соблюдение общих правил делопроизводства и деловой этики. Язык текста должен быть грамотным, стилистически цельным, лаконичным. При этом формулировки следует использовать максимально четкие, чтобы не возникало недопонимания или двусмысленности.
Для того, чтобы письмо содержало минимум «вводных сведений», нужно перечислить следующее:
- наименование предприятия с его организационно-правовым статусом;
- должность и ФИО лица, непосредственно дающего рекомендацию, а также его подпись;
- подпись руководителя и печать, которые заверяют письмо.
В основной части обязательно прописывать причины увольнения работника (чаще всего это «по собственному желанию»).
В рекомендательных письмах не возбраняется давать пожелания будущему руководителю сотрудника, например, о наилучших условиях работы для максимального раскрытия потенциала работника.
Для подтверждения достижений к письму можно прикладывать копии сертификатов, наград и иных доказательств высокого профессионализма сотрудника.
Заключение
На российском рынке существует много компаний, предоставляющих услуги хостинга. Выбор хостинг-провайдера зависит от ваших задач. Ориентируйтесь на характеристики тарифов и условия хостеров. Если вам нужен хостинг на ssd дисках в России, соответственно выбирайте любой из перечисленных вариантов. Если вы ищете хостинг с большим объемом дискового пространства, однозначно, вы будущий клиент Hostiq.ua.
На что еще нужно обратить внимание при выборе тарифа: на ограничение по трафику, на бонусы, на службу заботы, на личный кабинет и т.д. Автор статьи Ольга Абрамова
Автор статьи Ольга Абрамова