
Введение
Косвенно данную тему я затрагивал в статье про повторяющиеся уведомления в zabbix. Основа для настроек одна и та же. Очень подробно этот вопрос освещен в официальной документации, в разделе Эскалации. Рекомендую ознакомиться, там все показано на примерах.
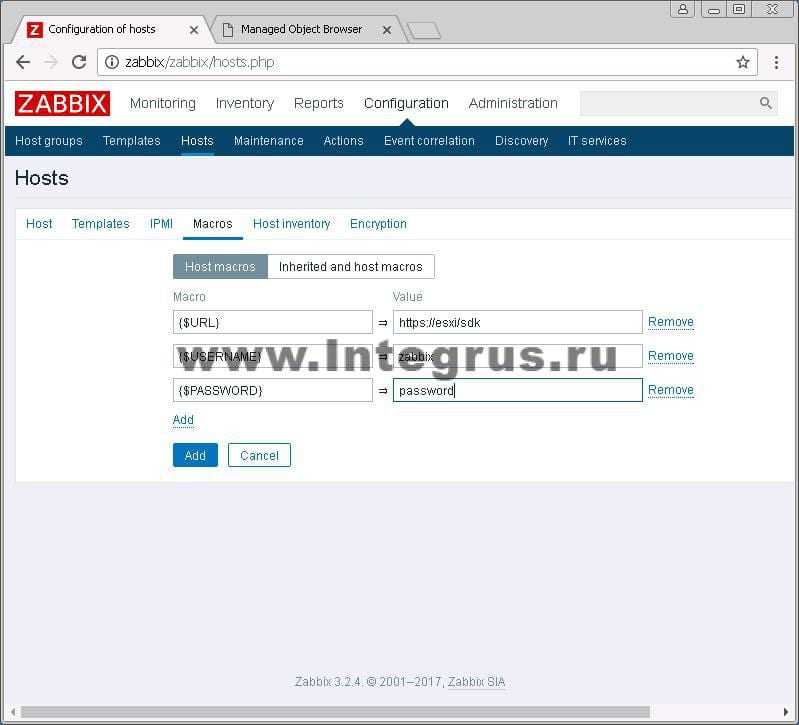
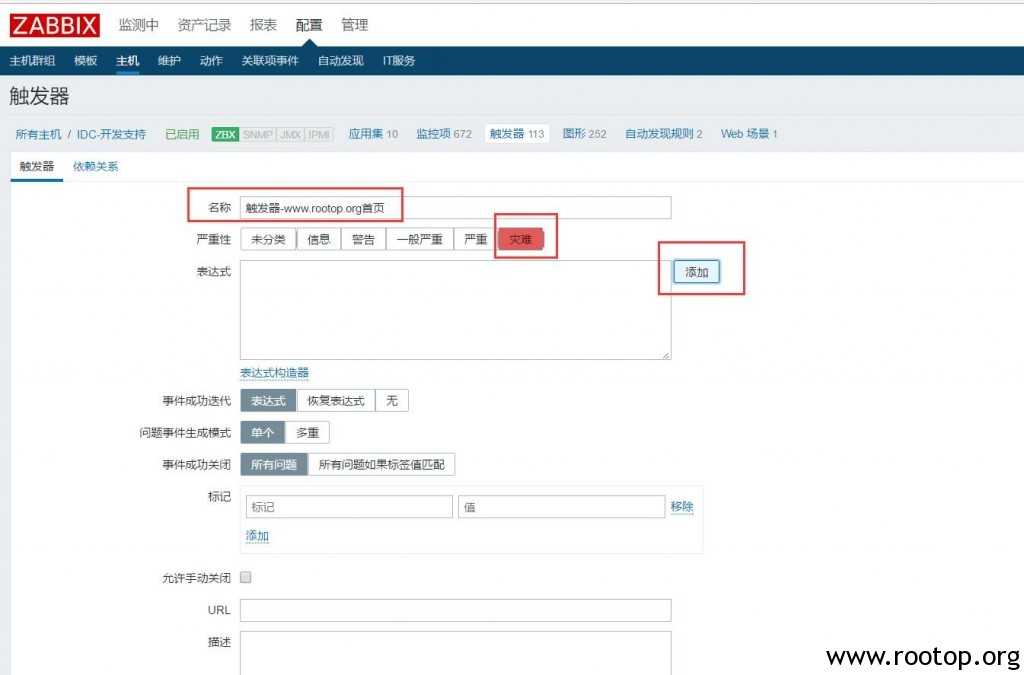
Я же кратко на своем примере покажу, как отложить отправку оповещения на 5 минут. Иногда надоедают какие-то триггеры, приходится их отключать, чтобы не спамили. Но если триггер отключить, то информации по нему не будет вообще никакой. Чаще всего хочется отключить именно уведомление, а не сам триггер. В таком случае, информация о его срабатывании сохранится в истории системы мониторинга.
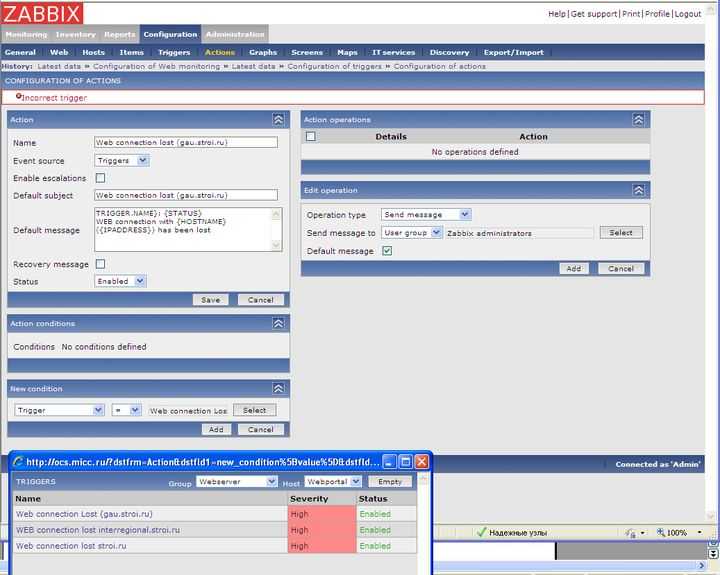
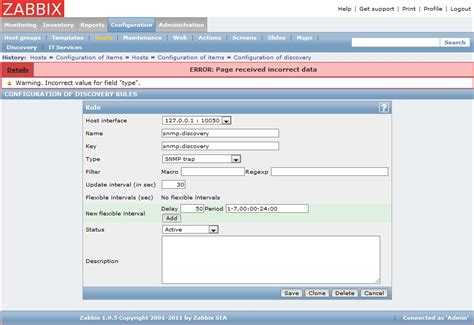
Одни из вариантов решения этой проблемы — добавление исключения в дефолтное правило оповещений, которое чаще всего остается после настройки. То есть можно сделать вот так:
Оповещения о триггерах с указанными названиями отправляться не будут. Я просто привел пример одного из подходов. Дальше расскажу, как сделать так, чтобы если триггер сработал и завершился в течении 5 минут, оповещение о нем не придет. Если же за 5 минут триггер не выключится, то оповещение будет отправлено.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Проверка отложенных уведомлений
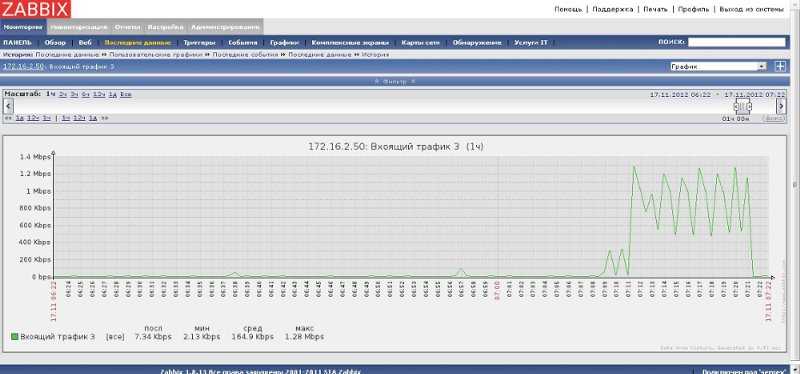
Для проверки отложенного уведомления, достаточно дождаться срабатывания какого-нибудь триггера. Вот мои примеры, когда оповещение не было отправлено вовсе, так как триггер работал менее 5 минут. И рядом же пример отправки уведомления только через 5 минут после срабатывания триггера.
Последнее событие длилось 1 минуту. Во время бэкапа сайта сработал триггер на нехватку места. После завершения бэкапа, скрипт подчистил за собой следы и места стало достаточно. Все случилось в течении 1 минуты, так что оповещения я вообще не получил.
Второе событие длилось 6 минут. Оповещение было отправлено только через 5 минут после срабатывания триггера.
Дополнительные материалы по Zabbix
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
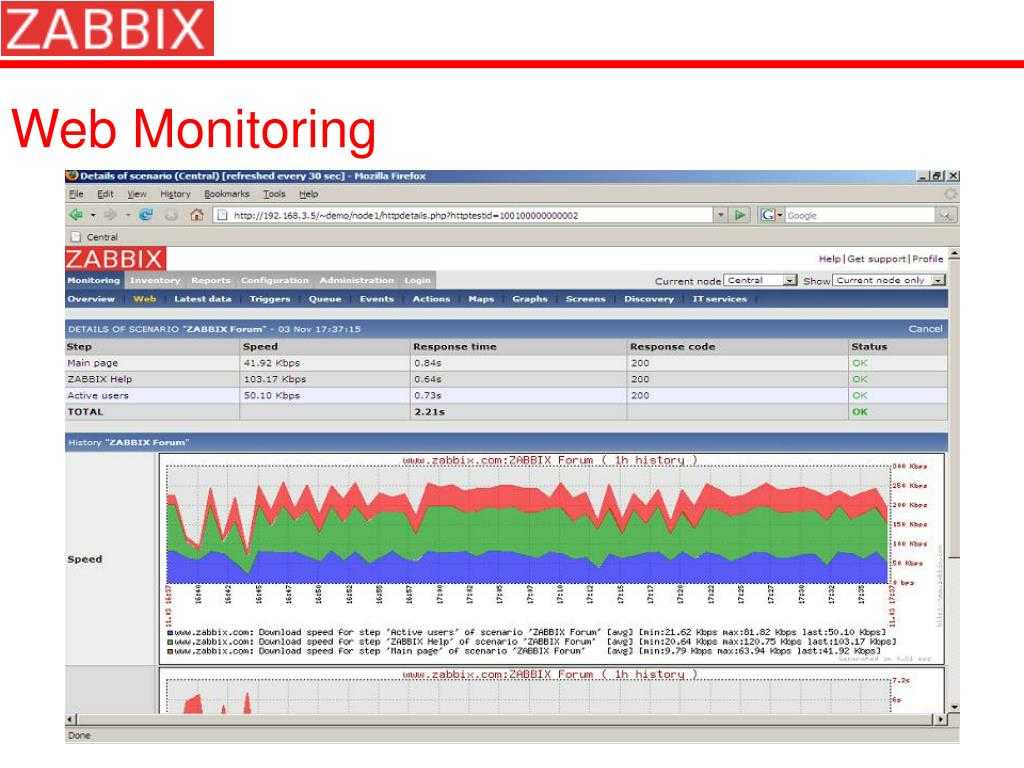
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Обзор
Систему создал Алексей Владышев на языке Perl. Впоследствии проект подвергся серьезным изменением, которые затронули и архитектуру. Zabbix переписали на C и PHP. Открытый исходный код появился в 2001 г., а уже через три года выпустили первую стабильную версию.
Веб-интерфейс Zabbix написан на PHP. Для хранения данных используются MySQL, Oracle, PostgreSQL, SQLite или IBM DB2.
На данный момент доступна система Zabbix 4.4. Скачать ее можно на официальном сайте. Там же можно найти официальные курсы и вебинары для начинающих пользователей системы.
Далее рассмотрим, из чего состоит и как работает технология Zabbix в доступном формате «для чайников».
Подготовка к мониторингу в Zabbix
Описанным мной способом можно мониторить температуру не только windows серверов, но и любых рабочих станций, если будет такая необходимость. Схема мониторинга следующая:
Существует бесплатная утилита Open Hardware Monitor, которая может показывать температуру некоторых датчиков сервера. Вообще говоря, она много чего может показывать (напряжение, скорость вентиляторов, загрузку процессора), но в данном случае нас интересует только температура. У этой утилиты есть версия, работающая в командной строке. Из командной строки показания датчиков можно записывать в файл. Этот файл можно анализировать и забирать из него необходимую для мониторинга информацию. Дальше эта информация передается в сервер Zabbix с помощью опции UserParameter. Все достаточно просто и в то же время эффективно.
Программа увидела несколько датчиков. С процессором все понятно, а вот три других датчика не ясно, чью температуру показывают. Я хотел мониторить температуру процессора и материнской платы. Узнать, какая температура относится к материнской плате можно несколькими способами. Конкретно в данной ситуации я просто запустил портированную версию AIDA64 и посмотрел, какие показания у датчика материнской платы:
Оказалось — 45 градусов. Я запомнил, что датчик Temperature #3 отображает температуру материнской платы.
Можно было пойти другим путем, зайти в IPMI панель, если она есть, и посмотреть там. Я работал с серверами SuperMicro, там она есть. Я на всякий случай зашел и проверил:
Почему-то в этой панели не оказалось информации с датчика температуры процессора
Но нам это не важно. Самое главное, что мы узнали параметры, за которыми будем следить — это CPU Packege и Temperature #3
Теперь запускаем консольную версию и смотрим вывод информации. Я для удобства положил OpenHardwareMonitorReport.exe в папку с основной программой и все это хозяйство скопировал в корень диска C:
Открываем файл 1.txt. Ищем там строки
| +- CPU Package : 52 51 52 (/intelcpu/0/temperature/4)
| | +- Temperature #3 : 45 45 45 (/lpc/nct6776f/temperature/3)
Нас интересует выделенный текст. По нему мы будем вычленять температуру для мониторинга и передавать ее на Zabbix сервер. Создаем в этой же папке 2 bat файла следующего содержания:
CPUTemperature.bat
@echo off for /F "usebackq tokens=7-10" %%a in (`C:\OpenHardwareMonitor\OpenHardwareMonitorReport.exe`) do echo %%b %%c %%d| find "/intelcpu/0/temperature/4">nul && set temper=%%a echo %temper%
MotherTemperature.bat
@echo off for /F "usebackq tokens=7-10" %%a in (`C:\OpenHardwareMonitor\OpenHardwareMonitorReport.exe`) do echo %%b %%c %%d| find "/lpc/nct6776f/temperature/3">nul && set temper=%%a echo %temper%
Запускаем эти батники в командной строке и проверяем вывод. Там должны быть только цифры температуры:
Отлично, на выходе готовые цифры, которые мы будем передавать в Zabbix. Займемся его настройкой.
item became not supported
Во время отладки работ я столкнулся с проблемами. Периодически Item отваливались и получали статус: Not Supported. При этом в логах сервера были следующие записи:
27614:20150702:065936.698 item "videoserver:Temperature.CPU" became not supported: Timeout while executing a shell script. 27625:20150702:070938.720 item "videoserver:Temperature.CPU" became supported
То есть данные то собирались, то переставали собираться. Иногда, чтобы данные снова пошли, приходилось удалять итем и создавать его заново. Некоторое время я повозился, пока не понял, в чем дело.
Я обратил внимание, что при запуске батника из командной строки, вывод данных происходит с приличной задержкой в 3-5 секунд. В Zabbix по-умолчанию стоит параметр, по которому агент ожидает ответа от скрипта 3 секунды и на сервере есть подобный параметр, по которому сервер ждет ответа от агента 3 секунды
Если за это время данные не поступают, то итем переходит в статус Not Supported и данные с него не собираются.
Чтобы избавиться от этой ошибки, необходимо увеличить таймаут до 15-ти секунд. Меняем параметр в конфиге на клиентах и на сервере. Он и там и там один и тот же:
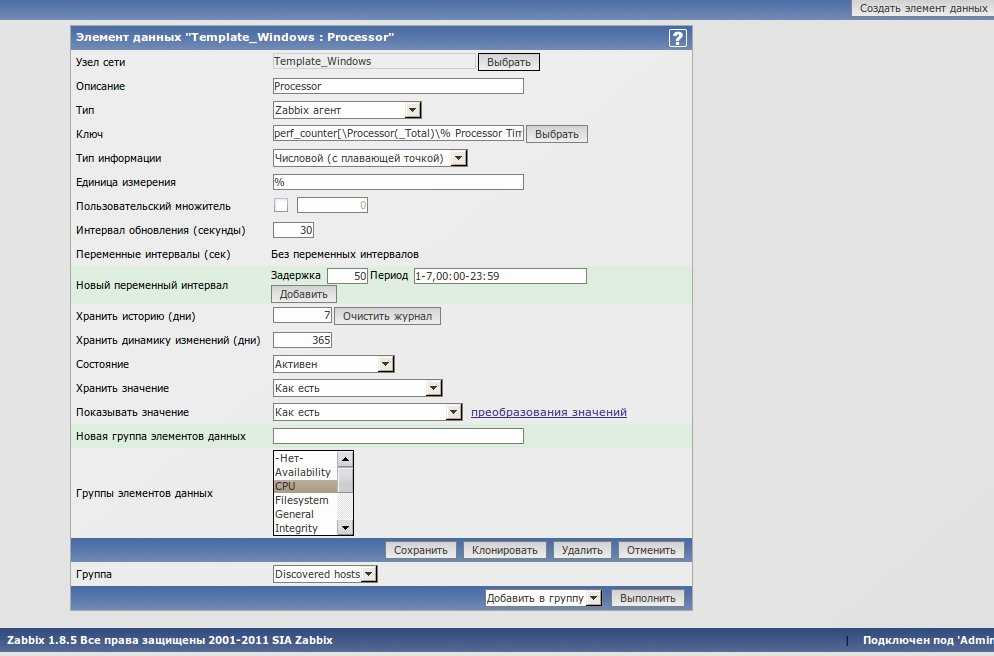
Timeout=15
Потом перезапускаем сервер и агентов и ждем результатов. Больше ошибок быть не должно.
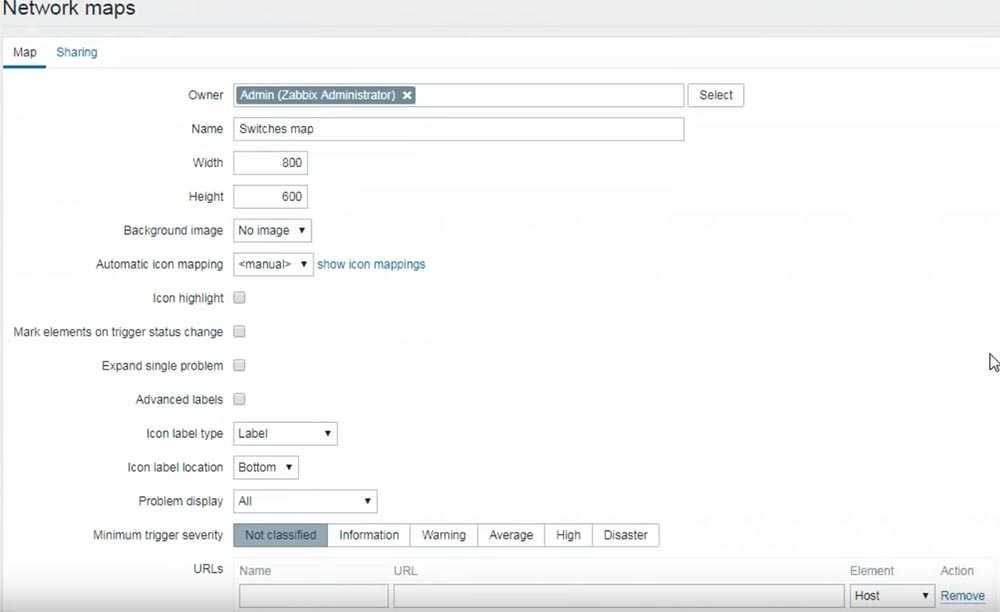
На этом, собственно настройка мониторинга температуры окончена. Можно дальше все оформить как полагается: настроить тригеры, оповещения, графики красивые нарисовать. Кому что нужно. Я себе вывел вот такую картинку для наглядности:
Особенности веб-интерфейса
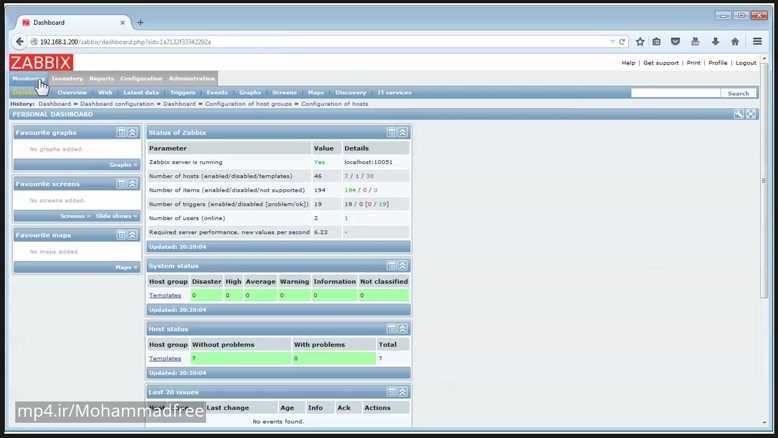
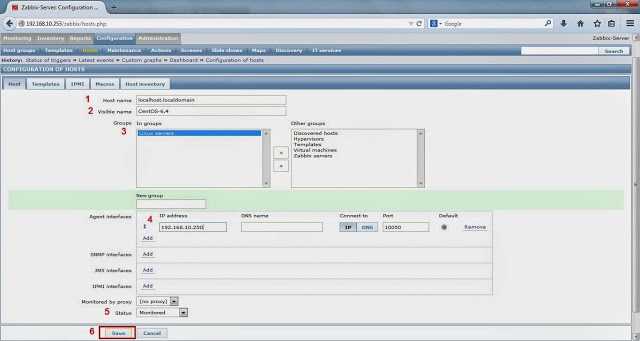
Система мониторинга Zabbix располагает удобным веб-интерфейсом, в котором сгруппированы элементы управления. Консоль предусматривает просмотр собранных данных, их настройку. Для безопасности входа и работы осуществляется автоматическое отсоединение через 30 минут пользовательского бездействия.
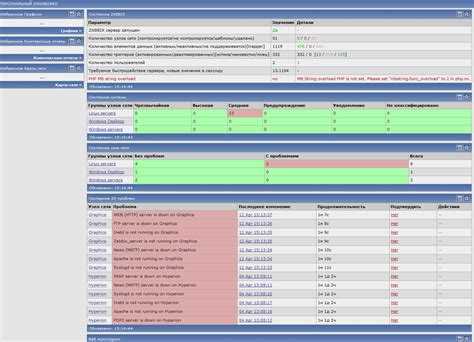
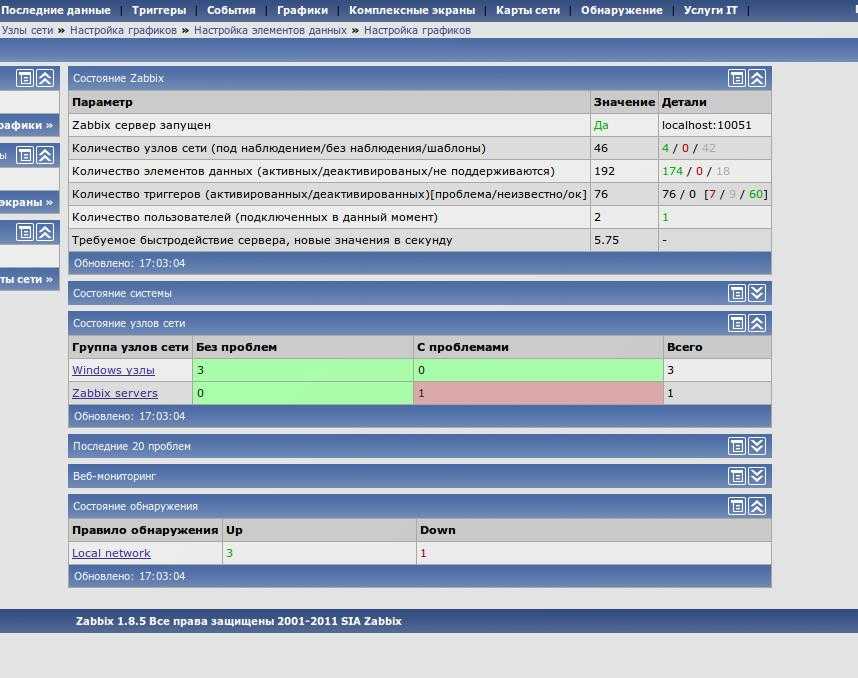
На главном экране всегда представлена информация о состоянии узлов сети и триггеров.
Пользователю доступны пять функциональных разделов, включая Monitoring («Мониторинг»), Inventory («Инвентарные данные»), Reports («Отчеты»), Configuration («Конфигурация») и Administration («Администрирование»).
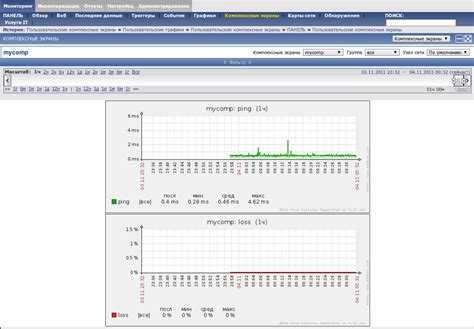
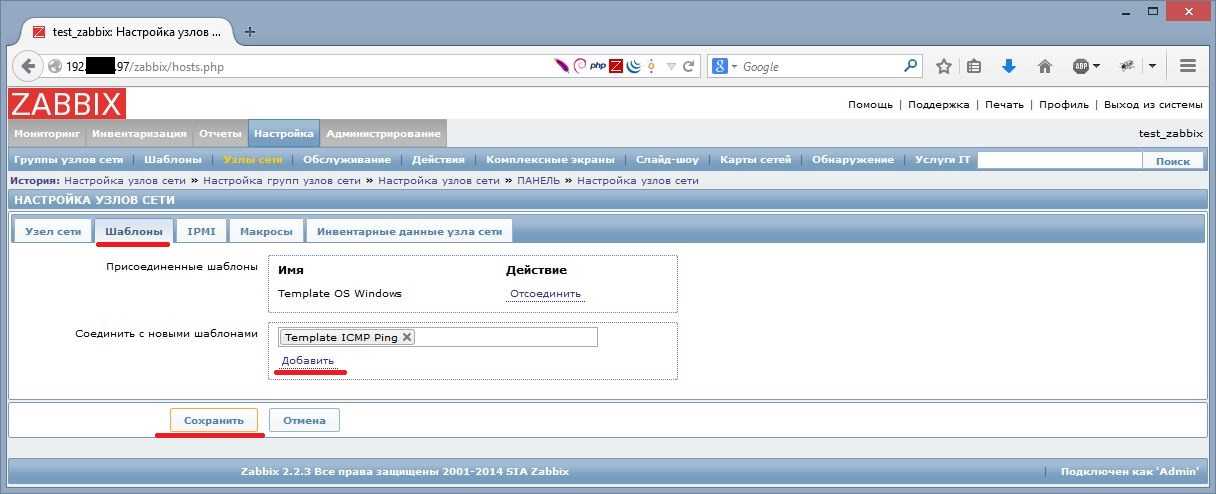
В разделе «Конфигурации» можно найти группы хостов. По каждому элементу списка можно посмотреть более подробную информацию, например, последние события и графики данных.
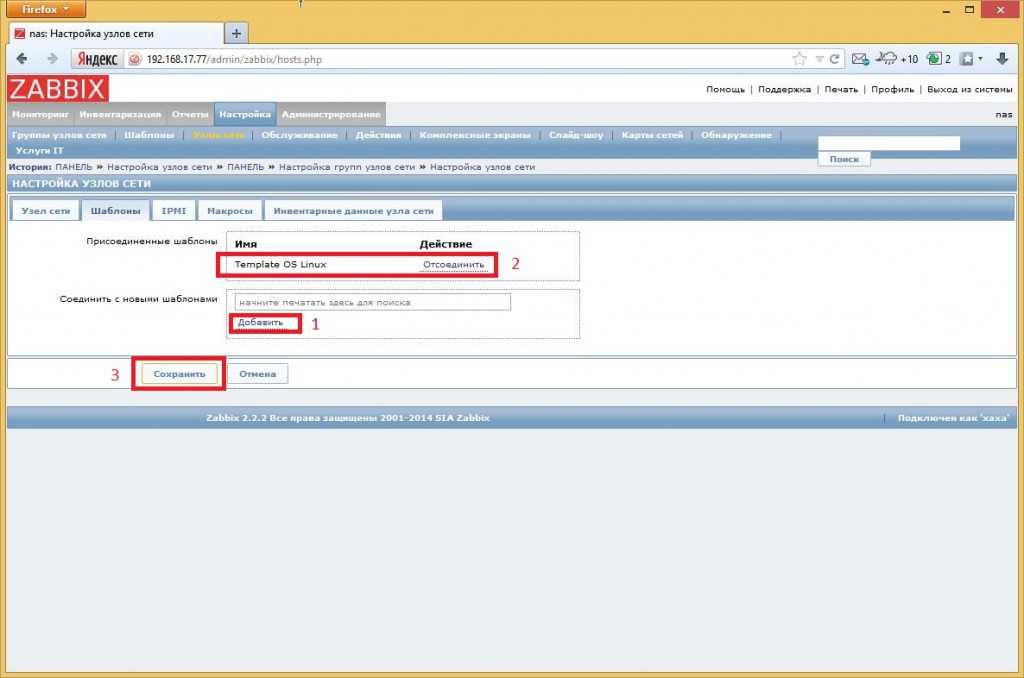
Управлять шаблонами, доступными администратору, можно в соответствующем подразделе — Templates («Шаблоны»).
Установка zabbix imap
- Необходимо скачать саму карту и положить ее в папку zabbix-морды. Какую именно скачивать зависит от вашей версии заббикс-сервера. Вот ссылки для 2.2-2.4 и 3.0-3.2 и 3.4
- Редактируем файл include/menu.inc.php добавляя туда
для версии 2.2-.2.4 — в самый конец вставить:require_once dirname(__FILE__).’ /../imap/menu.inc.php’ ;
для версии 3.x примерно на 314 строке находим «$denied_page_requested = false;» и перед этой строчкой вставляем:
require_once dirname(__FILE__).’ /../imap/menu3.inc.php’ ;
Сохраняем и выходим.
- Теперь у нас в мониторинге появилось меню «Интерактивная карта».
imapsettings.js.templatesettings.js
Так же можно устанавливать свои значки на устройства.
Чтобы работали связи между узлами, необходимо добавить пару таблиц в базу:
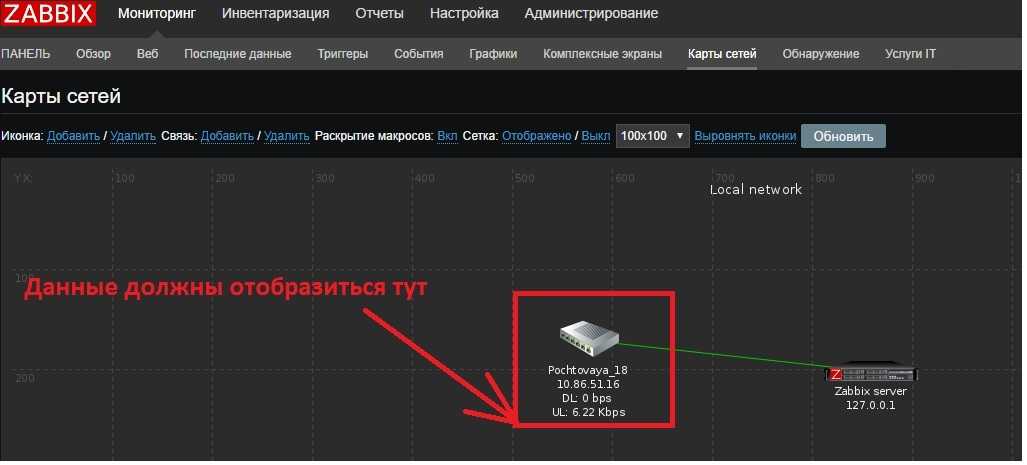
Размещение объектов на карте
Далее у нас есть 2 способа размещения объектов.
Первый способ — прописывание точных координат в самих инвентарных данных. Для этого листаем вниз и находим 2 поля «широта» и «долгота» и в них вписываем координаты.
Второй способ — размещение непосредственно на самой карте. Тут мы переходим на интерактивную карту и справа видим надпись «Узлы сети». При наведении на нее мышкой раскрывается список узлов. Те узлы, которые еще не нанесены на карту будут перед названием иметь значок «мишень», которые уже нанесены на карту — соответственно будут без этой иконки.
Чтобы разместить узел, нажимаете на эту «мишень» и далее просто тыкаете левой кнопкой мыши на то место, куда необходимо разместить данный узел.
Вот и все. На этом размещение узла закончено. Если вы не будите переставлять узел в другое место, то можно вернуть инвентарные данные опять в положение «Авто», если это Вам требуется.
Подготовка zabbix agent
Мониторинг значений SMART жесткого диска будет выполняться с помощью smartmontools. Установить их можно следующей командой для CentOS:
# yum install smartmontools
Либо аналогично в Debian/Ubuntu
# apt install smartmontools
Далее нам понадобится скрипт на perl для автообнаружения дисков и вывода информации о них в JSON формате, который понимает заббикс. Создадим такой скрипт.
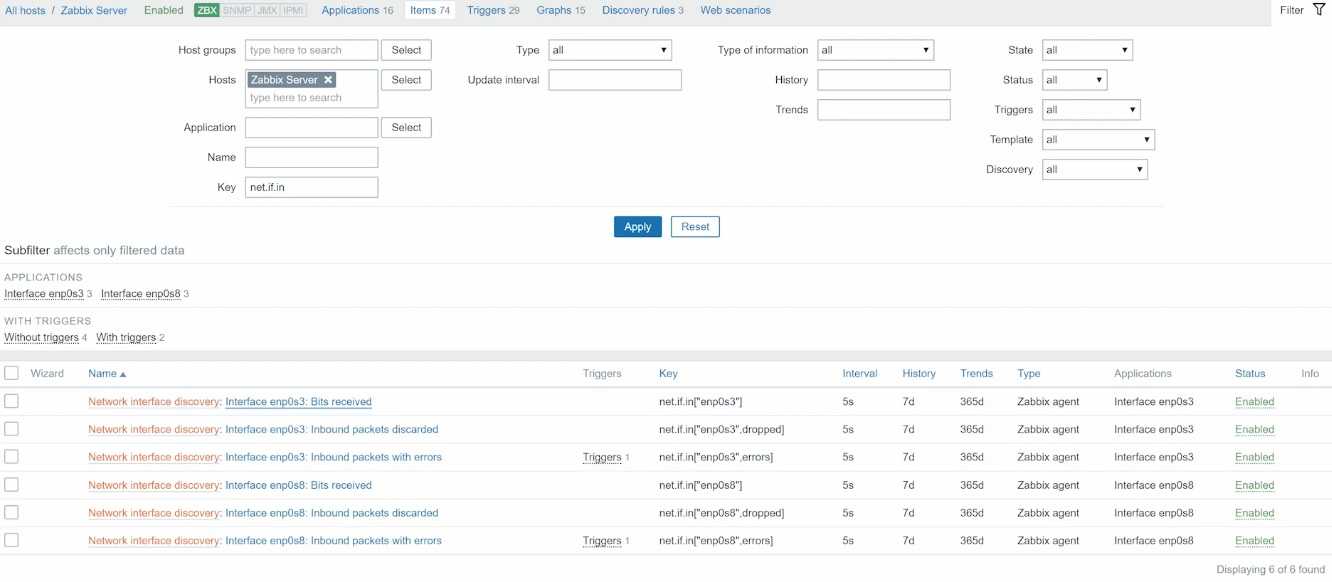
# mcedit /etc/zabbix/scripts/smartctl-disks-discovery.pl
#!/usr/bin/perl
#must be run as root
$first = 1;
print "{\n";
print "\t\"data\":[\n\n";
for (`ls -l /dev/disk/by-id/ | cut -d"/" -f3 | sort -n | uniq -w 3`)
{
#DISK LOOP
$smart_avail=0;
$smart_enabled=0;
$smart_enable_tried=0;
#next when total 0 at output
if ($_ eq "total 0\n")
{
next;
}
print "\t,\n" if not $first;
$first = 0;
$disk =$_;
chomp($disk);
#SMART STATUS LOOP
foreach(`smartctl -i /dev/$disk | grep SMART`)
{
$line=$_;
# if SMART available -> continue
if ($line = /Available/){
$smart_avail=1;
next;
}
#if SMART is disabled then try to enable it (also offline tests etc)
if ($line = /Disabled/ & $smart_enable_tried == 0){
foreach(`smartctl -i /dev/$disk -s on -o on -S on | grep SMART`) {
if (/SMART Enabled/){
$smart_enabled=1;
next;
}
}
$smart_enable_tried=1;
}
if ($line = /Enabled/){
$smart_enabled=1;
}
}
print "\t{\n";
print "\t\t\"{#DISKNAME}\":\"$disk\",\n";
print "\t\t\"{#SMART_ENABLED}\":\"$smart_enabled\"\n";
print "\t}\n";
}
print "\n\t]\n";
print "}\n";
Сохраняем скрипт и делаем исполняемым.
# chmod u+x smartctl-disks-discovery.pl
Выполняем скрипт и проверяем вывод. Должно быть примерно так с двумя дисками.
{
"data":
}
В данном случае у меня 2 физических диска — sda и sdb. Их мы и будем мониторить.
Настроим разрешение для пользователя zabbix на запуск этого скрипта, а заодно и smartctl, который нам понадобится дальше. Для этого запускаем утилиту для редактирования /etc/sudoers.
# visudo
Добавляем в самый конец еще одну строку:
zabbix ALL=(ALL) NOPASSWD:/usr/sbin/smartctl,/etc/zabbix/scripts/smartctl-disks-discovery.pl
Сохраняем, выходим  Это если вы умеете работать с vi. Если нет, то загуглите, как работать с этим редактором. Именно он запускается командой visudo.
Это если вы умеете работать с vi. Если нет, то загуглите, как работать с этим редактором. Именно он запускается командой visudo.
Проверим, что пользователь zabbix нормально исполняет скрипт.
# chown zabbix:zabbix /etc/zabbix/scripts/smartctl-disks-discovery.pl # sudo -u zabbix sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Вывод должен быть такой же, как от root. Если вам не хочется разбираться с этими разрешениями, либо что-то не получается, можете просто запустить zabbix-agent от пользователя root и проверить работу в таком режиме. Сделать это не трудно, данный параметр закомментирован в конфигурации агента. Вам достаточно просто снять комментарий и перезапустить агент.
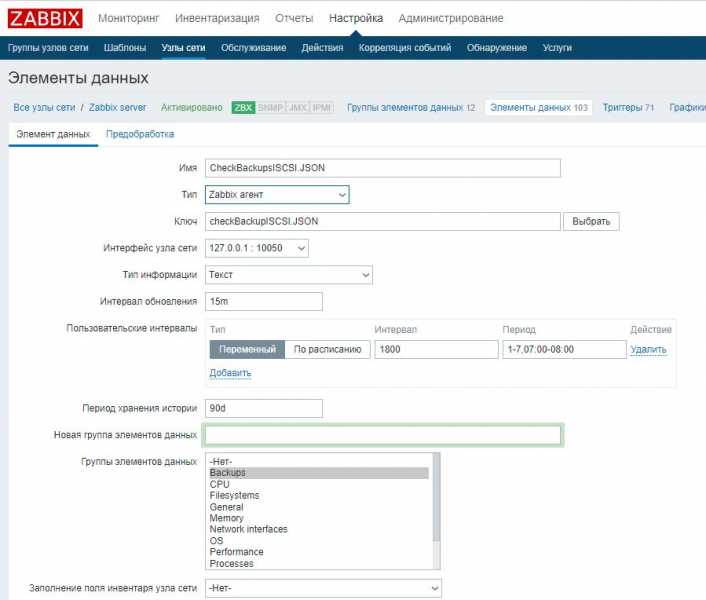
После настройки скрипта автообнаружения, добавим необходимые UserParameters для мониторинга SMART. Для этого создадим отдельный конфигурационный файл. Для версии 3.2 и ниже он будет выглядеть вот так.
# mcedit /etc/zabbix/zabbix_agentd.d/smart.conf
UserParameter=uHDD,sudo smartctl -A /dev/$1| grep -i "$2"| tail -1| cut -c 88-|cut -f1 -d' ' UserParameter=uHDD.model.,sudo smartctl -i /dev/$1 |grep -i "Device Model"| cut -f2 -d: |tr -d " " UserParameter=uHDD.sn.,sudo smartctl -i /dev/$1 |grep -i "Serial Number"| cut -f2 -d: |tr -d " " UserParameter=uHDD.health.,sudo smartctl -H /dev/$1 |grep -i "test"| cut -f2 -d: |tr -d " " UserParameter=uHDD.errorlog.,sudo smartctl -l error /dev/$1 |grep -i "ATA Error Count"| cut -f2 -d: |tr -d " " UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Версия настроек для агента 3.4
UserParameter=uHDD.A,sudo smartctl -A /dev/$1 UserParameter=uHDD.i,sudo smartctl -i /dev/$1 UserParameter=uHDD.health,sudo smartctl -H /dev/$1 || true UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Сохраняем файл и перезапускаем zabbix-agent.
# systemctl restart zabbix-agent
Проверяем, как наш агент будет отдавать данные. Ключ uHDD.discovery будет одинаковый для обоих версий агента.
# zabbix_agentd -t uHDD.discovery
Вы должны увидеть полный JSON вывод с информацией о ваших диска. Теперь посмотрим, как передаются информация о smart. Запросим температуру дисков для версии 3.2.
# zabbix_agentd -t uHDD uHDD
Все в порядке. Можете погонять еще какие-нибудь параметры из смарта, но скорее всего все будет работать, если хотя бы один параметр работает. На этом настройка на агенте закончена, переходим к настройке сервера мониторинга.
JavaScript и Duktape
Почему были выбраны именно JavaScript и Duktape? Рассматривались различные варианты языков и движков:
- Lua – Lua 5.1
- Lua – LuaJIT
- Javascript – Duktape
- Javascript – JerryScript
- Embedded Python
- Embedded Perl
Основными критериями выбора были распространенность, простота интеграции движка в продукт, низкое потребление ресурсов и общая производительность движка, и безопасность внедрения кода на этом языке в мониторинг. По совокупности показателей победил JavaScript на движке Duktape.
Критерии выбора и performance testing
Особенности Duktape:
— Стандарт ECMAScript E5/E5.1
— Модули Zabbix для Duktape:
- Zabbix.log() — позволяет вписать непосредственно в лог Zabbix Server сообщения с различным уровень детализации, что обеспечивает возможность сопоставлять ошибки, например, в Webhook с состоянием сервера.
- CurlHttpRequest() — позволяет делать HTTP-запросы в сеть, на чем основано применение Webhook.
- atob() и btoa() — позволяет кодировать и декодировать строки в формат Base64.
ПРИМЕЧАНИЕ. Duktape соответствует стандартам ACME. В Zabbix используется версия скрипта 2015 года. Последующие изменения незначительны, поэтому их можно игнорировать.
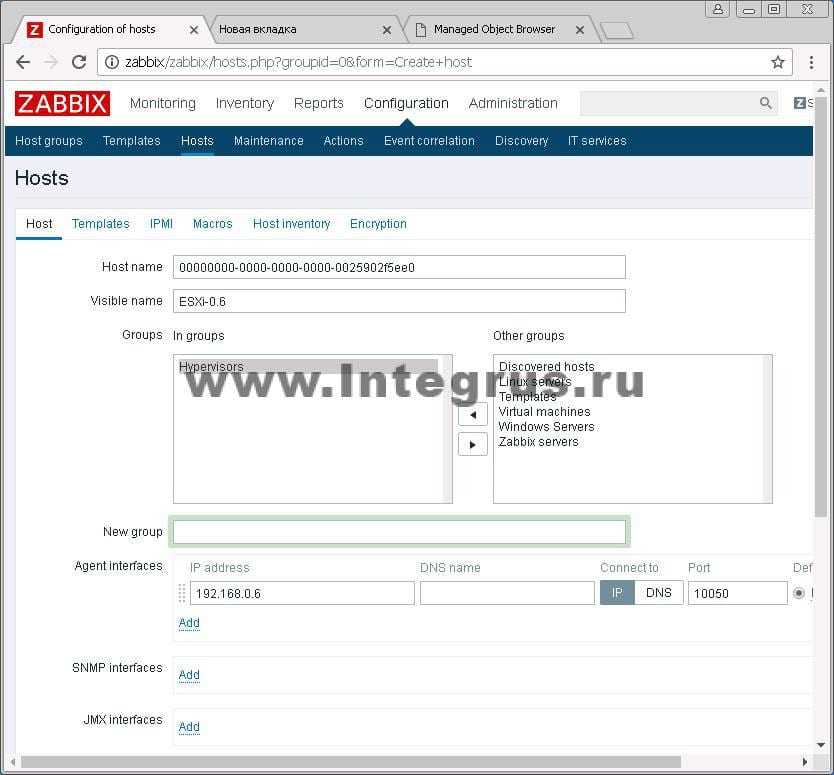
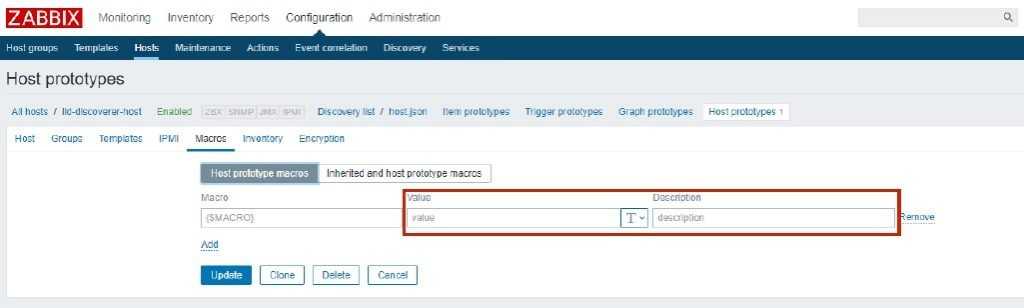
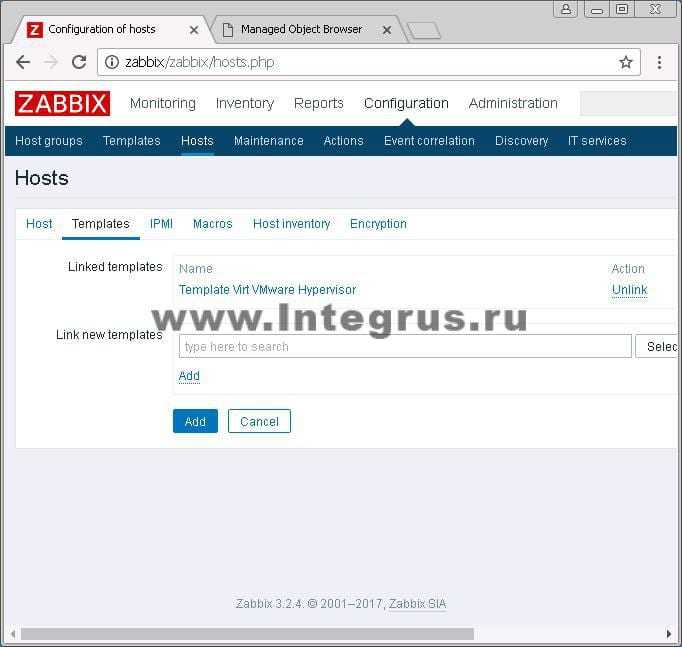
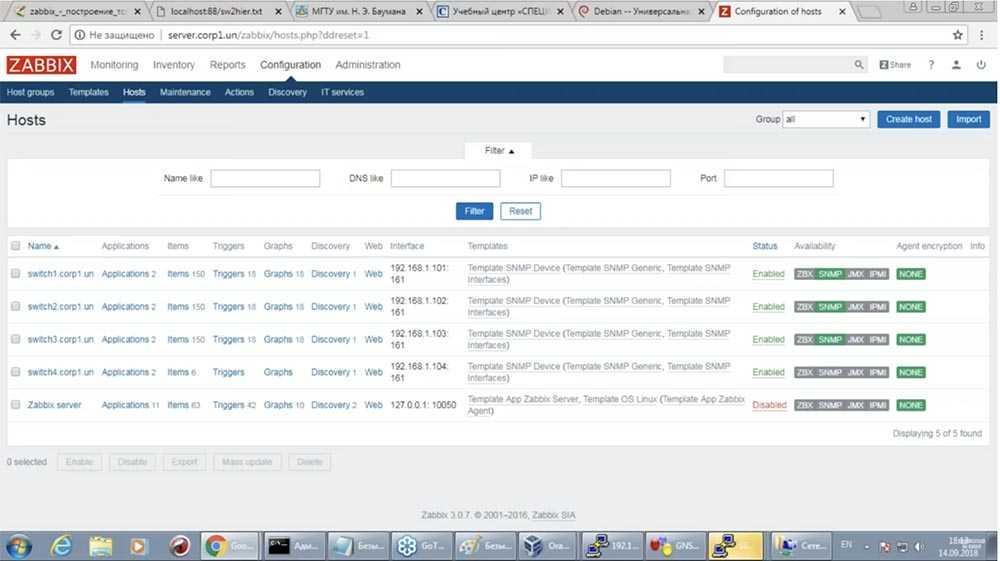
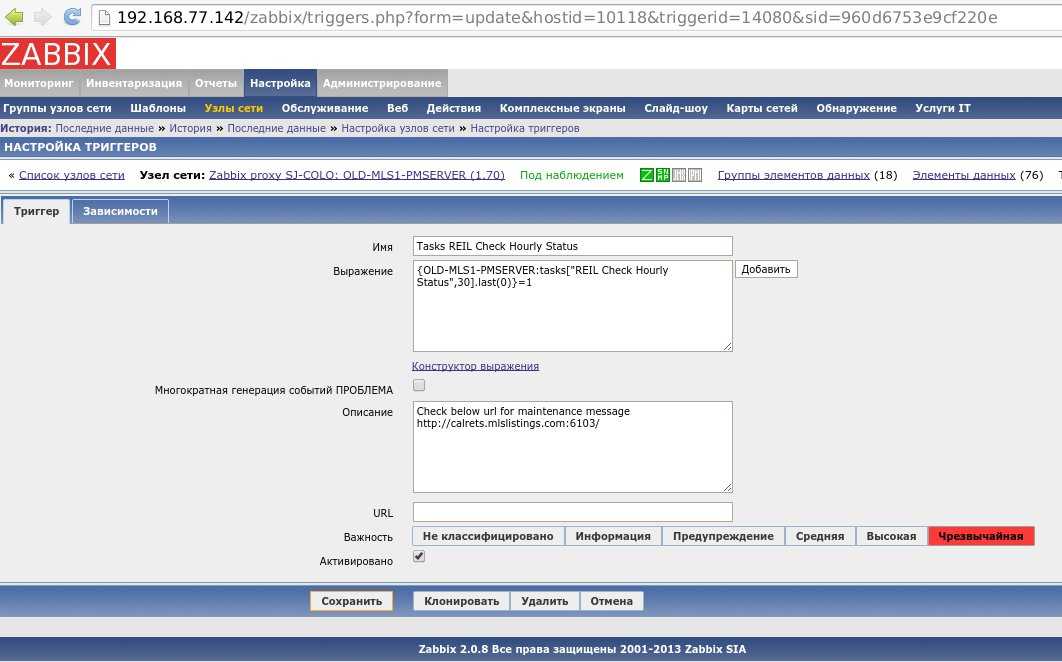
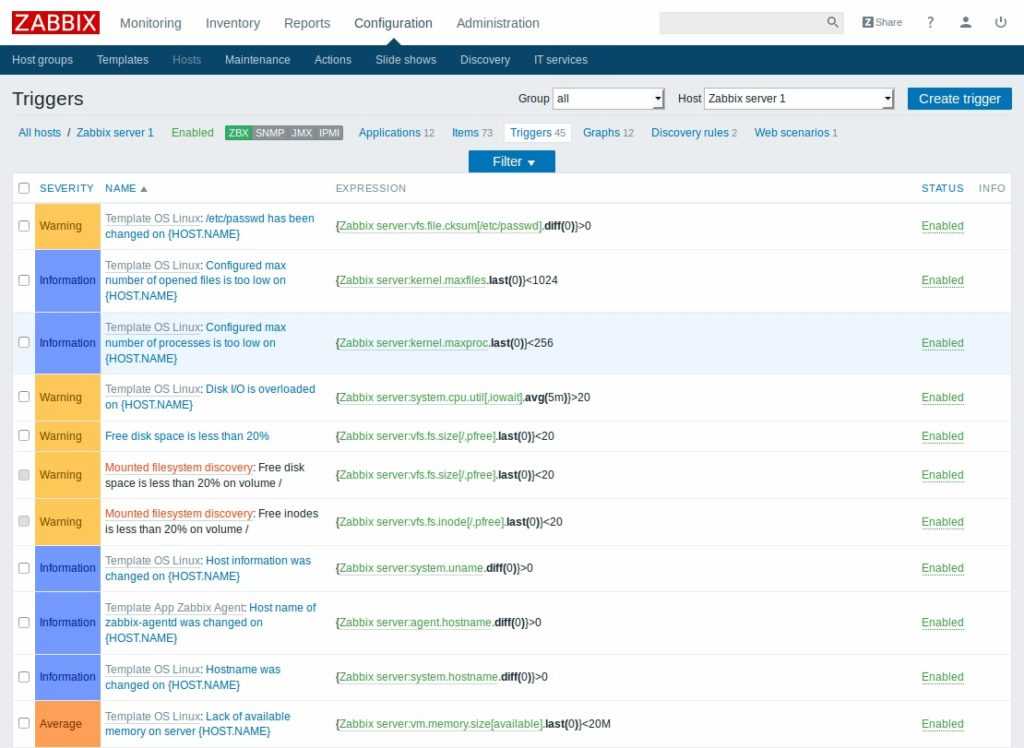
Триггеры
Это логические выражения со значениями FALSE, TRUE и UNKNOWN, которые используются для обработки данных. Их можно создать вручную. Перед использованием триггеры возможно протестировать на произвольных значениях.
У каждого триггера существует уровень серьезности угрозы, который маркируется цветом и передается звуковым оповещением в веб-интерфейсе.
- Не классифицировано (Not classified) — серый.
- Информация (Information) — светло-синий.
- Предупреждение (Warning) — жёлтый.
- Средняя (Average) — оранжевый.
- Высокая (High) — светло-красный.
- Чрезвычайная (Disaster) — красный.
Некоторые функции триггеров
- abschange — абсолютная разница между последним и предпоследним значением (0 — значения равны, 1 — не равны).
- avg — среднее значение за определенный интервал в секундах или количество отсчетов.
- delta — разность между максимумом и минимумом с определенным интервалом или количеством отсчетов.
- change — разница между последним и предпоследним значением.
- count — количество отсчетов, удовлетворяющих критерию.
- date — дата.
- dayofweek — день недели от 1 до 7.
- diff — у параметра есть значения, где 0 — последнее и предпоследнее значения равны, 1 — различаются.
- last — любое (с конца) значение элемента данных.
- max\min — максимум и минимум значений за указанные интервалы или отсчеты.
- now — время в формате UNIX.
- prev — предпоследнее значение.
- sum — сумма значений за указанный интервал или количество отсчетов.
- time — текущее время в формате HHMMSS.
Прогнозирование
Триггеры обладают еще одной важной функцией для мониторинга — прогнозированием. Она предугадывает возможные значения и время их возникновения
Прогноз составляется на основе ранее собранных данных.
Анализируя их, триггер выявляет будущие проблемы, предупреждает администратора о возникшей вероятности. Это дает возможность предотвратить пики нагрузки на оборудование или заканчивающееся место на жестком диске.
Функционал прогнозирования добавили с обновлением системы 3.0, вышедшим в феврале 2016 года.
Система HelpDesk (Служба поддержки)
Переходим к следующему нововведению, о котором я не рассказывал в прошлой статье, потому что его еще не было. Речь идет о встроенной системе HelpDesk. Специально ничего настраивать не надо, так как система уже установлена и готова работать. Она поддерживает интеграцию с Active Directory для авторизации пользователей. При этом работает и без нее. Подробнее про интеграцию с AD читайте в документации. Я же покажу, как начать работать с helpdesk без домена.
Для начала вам нужно будет создать пользователя для возможности открытия заявок. Это, как обычно, делается в клиенте, в разделе Панель администратора -> Служба поддержки -> Пользователи.
После создания, пользователю на почту придет письмо со ссылкой. С помощью этой ссылки он сможет сразу же авторизовываться в системе. При этом необходимости вводить логин с паролем не будет.
После входа в web интерфейс хелпдеска, пользователь увидит очень простой и лаконичный интерфейс, где не нужно долго разбираться. Создать заявку можно тут же. При этом не нужны никакие дополнительные инструкции и объяснения, так как все очень наглядно.
После создания, сотрудник поддержки увидит заявку у себя в клиенте в разделе Инциденты и заявки.
Если у поддержки установлен VNC клиент, а у сотрудника VNC сервер, то поддержка может сразу же подключиться к заявителю
При этом не важно, в какой сети они находятся, так как соединение будет установлено через облако. Достаточно просто нажать кнопку и сразу идет подключение к заявителю
Помимо этого заявку можно отложить, передать другому сотруднику, либо решить вопрос самому. Всю информацию по заявке пользователь будет получать на почту.
Если проблема решена, то пользователь сам закрывает заявку. Все оповещения работают автоматически через облачные службы Veliam. У себя ничего настраивать не надо.
Более подробно о настройке и работе helpdesk можно прочитать в документации. Она небольшая, понятная, отражена самая суть. Читать и разбираться легко.
На выходе вы имеете полностью настроенную систему поддержки пользователей. Ограничение бесплатной версии — 50 пользователей, что весьма неплохо. На своей стороне каких-то настроек, уведомлений, веб серверов для работы системы настраивать не надо. Все работает из коробки через облачные службы Veliam.
При всем при этом, система интуитивно понятна и наглядна. Не нужны подробные инструкции для описания работы с системой. Поэтому любой пользователь разберется самостоятельно.
Добавлю так же, что по инцидентам системы мониторинга так же создаются заявки в тех поддержку. С ними можно работать точно так же, как и с заявками пользователей — решать проблему, закрывать, комментировать, передавать заявку другому пользователю.
Здесь же из заявки можно подключиться к серверу и посмотреть, что на нем происходит. Это очень удобно. В традиционных системах мониторинга, с которыми мне приходится работать, таких возможностей нет. Понятно, что они решают более широкий спектр задач, чем Veliam. Если же у вас потребности в мониторинге не высокие и Велиам их закрывает, то пользовать им будет приятно и удобно.





