
HP Microserver G8 и диски 4 Тб
Напишу несколько слов о сервере HP Microserver, раз уж он стал героем повествования. Мне нравится эта серия бюджетных серверов от HP. Ранее я уже рассказывал о том, как я использую подобные сервера — установка synology на обычный компьютер.
Сейчас считаю наиболее удобным и функциональным именно серию G8, так как у нее есть интерфейс для удаленного управления ILO. И это в сервере за 18000 р. с самым слабым процессором, которого тем не менее за глаза хватает для обычного файлового сервера.
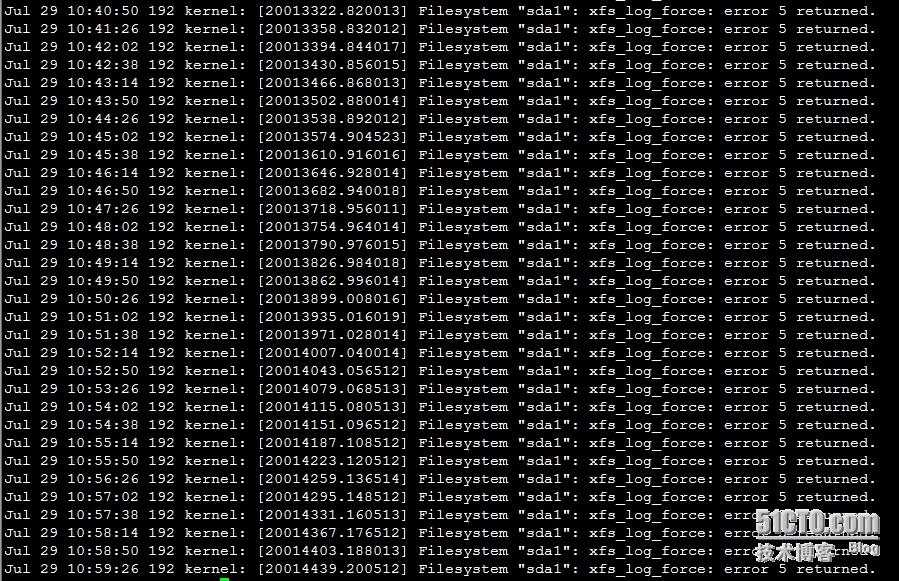
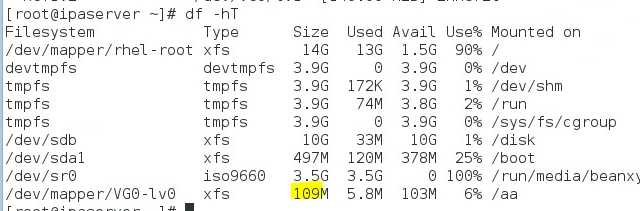
По документации данный сервер поддерживает максимум диски 3 Tb. Но по отзывам в интернете я увидел, что люди без проблем ставят диски большего объема и нормально ими пользуются. Решил тоже попробовать купить для начала 2 диска по 4 Tb и попробовать их в работе.
Во время установки и настройки CentOS 7 никаких проблем не возникло. Я спокойно настроил samba с интеграцией в AD, разместил все это на raid1 mdadm. Подергал диски, убедился, что сервер нормально запускается при выходе из строя любого из дисков. Перенес рабочие данные со старого сервера и запустил новый сервер в эксплуатацию.
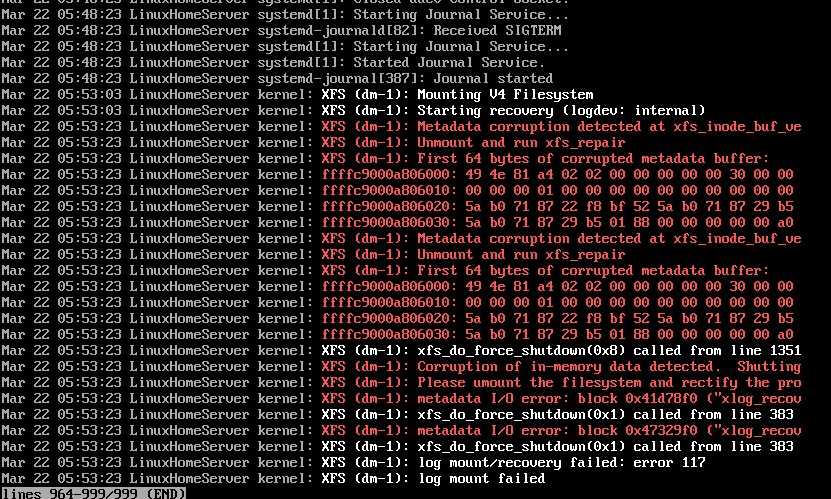
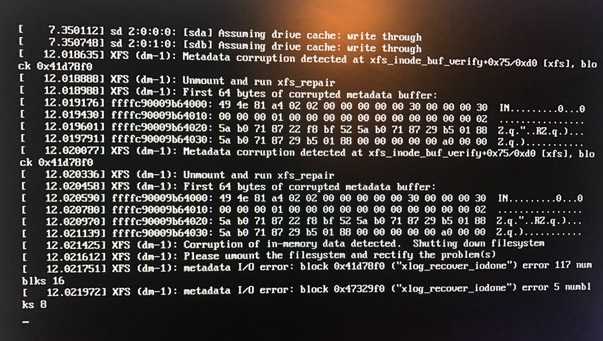
В процессе работы стал замечать в логах очень подозрительные и тревожные сообщения. Дальше об этих ошибках и пойдет речь.
Большая нагрузка от использования фильтра Layer 7
У меня есть статья про блокировку сайтов микротиком. В ней показана ошибочная настройка, которую как раз разбирает автор презентации.
Действовать нужно по-другому. Layer 7 protocol задуман как способ поиска определенных шаблонов в подключениях для маркировки трафика на основе этих шаблонов. А дальше уже маркированный трафик обрабатывается фаерволом. Фильтр с Layer 7 protocol не должен проверять абсолютно весь трафик. Он должен брать первые 10 пакетов или 2KB данных подключения и анализировать только их.
Корректное использование Layer 7 protocol показано на следующем примере.
Очереди работают неправильно
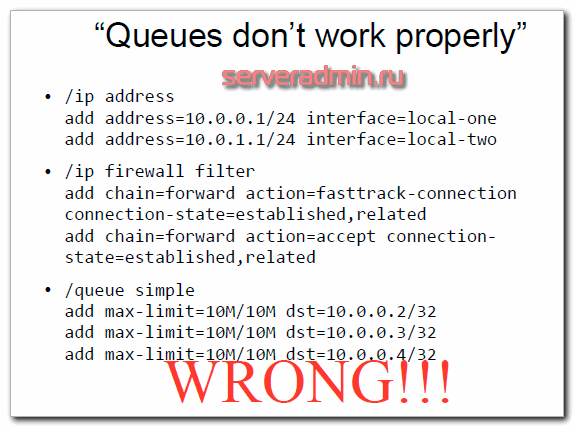
При такой настройке очереди будут работать, только когда запущена утилита Torch, или выключен fasttrack. При этом обрабатывается только download трафик. Между локальными сетями так же срабатывает ограничение. Обнаружить ошибку можно по счетчикам в очередях. Они покажут, когда правило работает, а когда нет.
Причина этой ошибки в том, что режим Fasttrack работает для всего трафика, а он работу с очередями не поддерживает. Ускорение обработки трафика в режиме fasttrack как раз и достигается за счет того, что трафик не проходит по всем цепочкам обработки трафика фаерволом и очередями. Так же в правилах очередей не установлен параметр target.
В данном случае правильно simple queue должны быть настроены следующим образом.
Мы включили fasttrack только для трафика между указанными локальными сетями. Остальной трафик идет в обычном режиме. Плюс, корректно настроили очереди, указав target.
IPSec туннель не работает

Суть проблемы в том, что не удается создать туннель, потому что пакеты ipsec дропаются. Причина тут в том, что правила NAT подменяют src-address в шифрованных пакетах. В итоге измененный адрес источника не принимается на второй стороне.
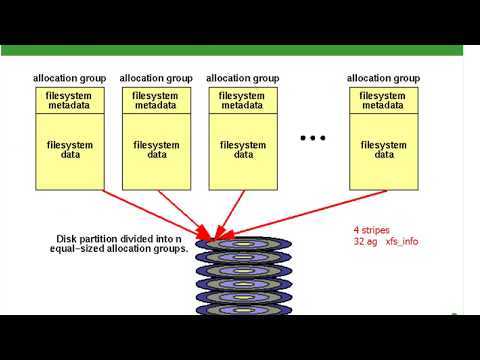

Решить эту проблему можно с помощью raw table. Смысл этой таблицы в том, что с ее помощью можно обходить механизм трекинга соединений (connection tracker), пропуская напрямую или дропая пакеты. Это в целом снижает нагрузку на CPU, если у вас сильно нагруженная железка.
В данном случае нужно добавить действие notrack для ipsec пакетов, для того, чтобы:
- не было дефрагментации пакетов
- они шли мимо NAT
- они шли мимо правил fasttrack, маркировки пакетов, и т.д.
Реализация следующая.
Установка CrowdSec
С установкой CrowdSec все просто. Есть несколько вариантов:
- Для deb дистрибутивов есть репозиторий.
- Для всех остальных бинарники с инсталлятором. Rpm пакета, к сожалению, нет.
- Сборка и установка из исходников.
- Установка в docker.
Я буду ставить на Centos 8, так что скачаю бинарники и установлю инсталлятором. Быстрее было бы запустить в докере, но мне не нравится, что туда надо мапить логи. Да и в целом не вижу смысла в установке подобного софта через докер. Это же не разработка, когда надо по 5 релизов в день с автотестами выкатывать. Один раз поставил и пользуешься, иногда обновляешь. Что бинарники, что контейнер обновить одно и то же время надо.
Для Debian / Ubuntu устанавливаем CrowdSec так:
# wget -qO - https://s3-eu-west-1.amazonaws.com/crowdsec.debian.pragmatic/crowdsec.asc |sudo apt-key add - && sudo apt-add-repository "https://s3-eu-west-1.amazonaws.com/crowdsec.debian.pragmatic/$(lsb_release -cs) $(lsb_release -cs) main" # apt update # apt install crowdsec
В Centos установка выглядит следующим образом. Идем в репозиторий https://github.com/crowdsecurity/crowdsec/releases и качаем последнюю версию.
# wget https://github.com/crowdsecurity/crowdsec/releases/download/v1.0.9/crowdsec-release.tgz # tar xvzf crowdsec-release.tgz # cd crowdsec-v1.0.9/
Запускаем инсталлятор:
# ./wizard.sh -i
Он сразу же определил основные сервисы, за логами которых будет следить. В моем случае это системные логи linux, лог авторизаций ssh и логи nginx. Далее он уточнит, какие именно лог файлы будет парсить. По умолчанию он проверяет дефолтные директории. Если что-то не нашел, то потом в конфигурационных файлах сможете вручную добавить нужные файлы с логами.
Далее нужно будет выбрать преднастроенные конфиги для различных служб. Они есть для наиболее популярных сервисов. Тут все по аналогии с Fail2ban сделано. В моем случае конфиги для веб сервера nginx, сайтов на wordpress, системных логов linux и sshd:
- crowdsecurity/nginx
- crowdsecurity/sshd
- crowdsecurity/wordpress
- crowdsecurity/linux
Далее установщик сообщит, что создал конфиг с белым списком адресов, включающим все серые подсети.
Я во время первого знакомства пропустил этот момент и потом долго не мог понять во время тестов в локалке, почему ничего не работает. Найти этот белых список так и не смог и забросил дело. Когда второй раз начал тесты, внимательнее все посмотрел и понял, в чем была проблема. Так что имейте ввиду этот момент.

Дальше вам будет сказано, что ни одного bouncer не установлено, так что ничего реально заблокировано не будет.
Как я уже говорил в начале, для выполнения каких-то действий, требуются отдельные компоненты системы в виде bouncers. Далее я расскажу, как их ставить и настраивать.
На этом установка CrowdSec закончена. В конце вы увидите список основных cli команд для взаимодействия с локальной службой.
Можете их позапускать и посмотреть, как все это работает. Сама установка CrowdSec выполнена. Переходим к настройке.
Видео обновления кластера proxmox
Помогла статья? Подписывайся на telegram канал автора
Watch this video on YouTube
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Bugs
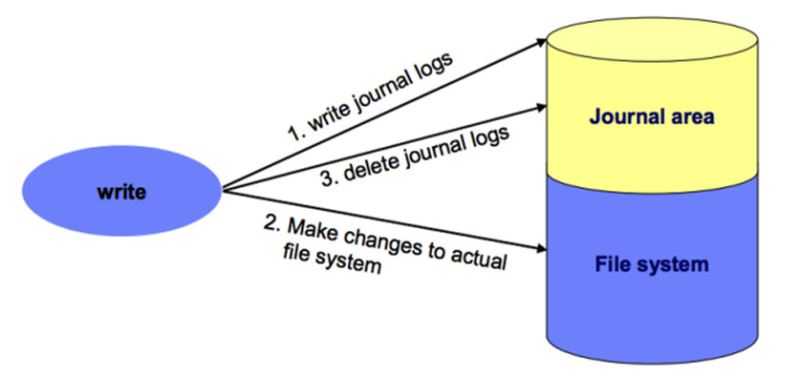
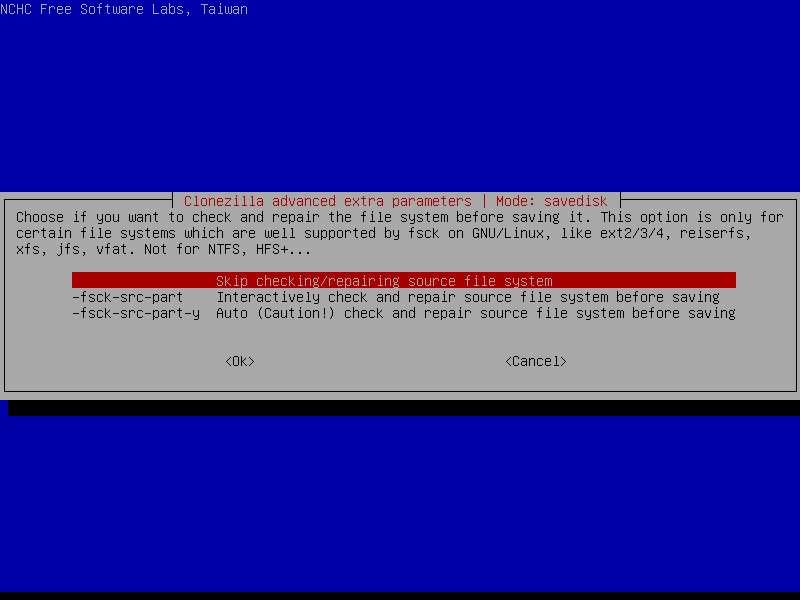
umount(8)xfs_repair
xfs_repair does not do a thorough job on XFS extended attributes. The structure of the attribute fork will be consistent, but only the contents of
attribute forks that will fit into an inode are checked. This limitation will be fixed in the future.
The no-modify mode (-n option) is not completely accurate. It does not catch inconsistencies in the freespace and inode maps, particularly lost
blocks or subtly corrupted maps (trees).
The no-modify mode can generate repeated warnings about the same problems because it cannot fix the problems as they are encountered.
If a filesystem fails to be repaired, a metadump image can be generated with xfs_metadump(8) and be sent to an XFS maintainer to be analysed
and xfs_repair fixed and/or improved.
grub rescue
В grub rescue mode доступно всего четыре команды:
- ls
- set
- unset
- insmod
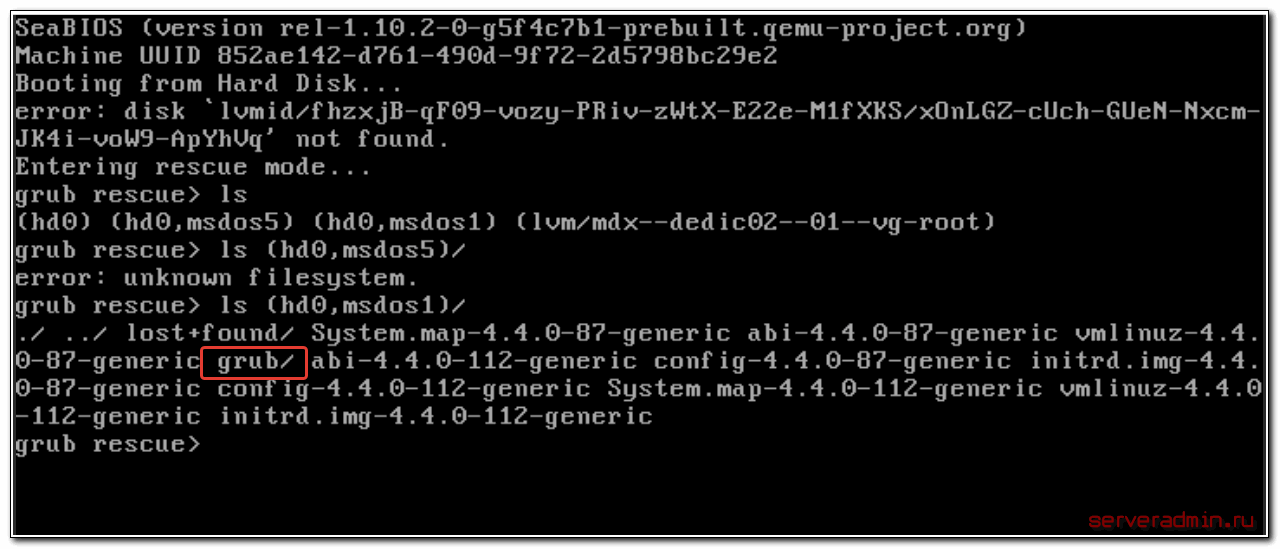
Для начала воспользуемся командой ls и посмотрим, какие разделы видит grub.
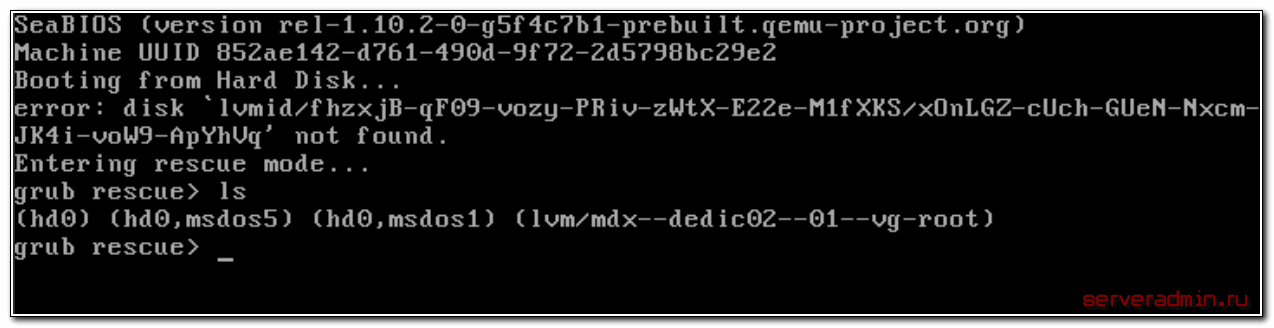
В моем случае несколько отдельных разделов диска и lvm том. К слову сказать, в моем случае раздел /boot расположен на lvm разделе, но по какой-то причине загрузчик не смог с него загрузиться. У вас может вообще не быть lvm, а проблема в чем-то другом. Например, если у вас в grub.cfg указан UUID раздела, с которого надо грузиться (это может быть массив mdadm), а раздел этот по какой-то причине исчез, или изменил свой uuid, вы как раз получите эту ошибку.
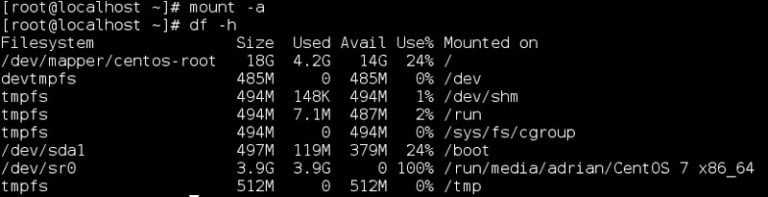
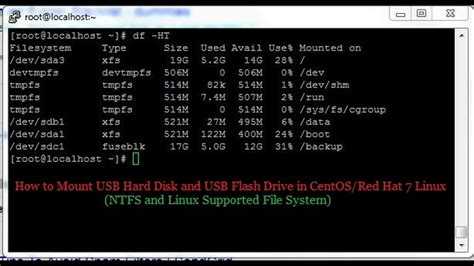
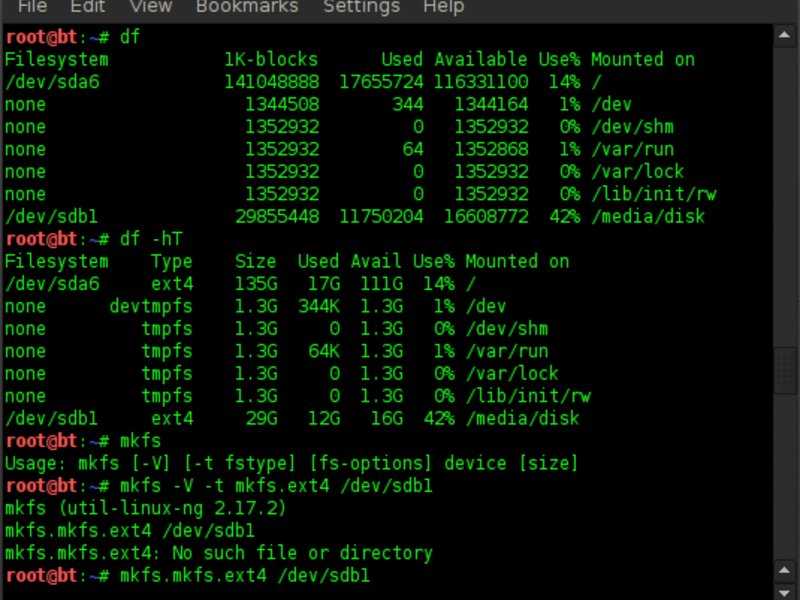
Сейчас нам нужно найти раздел, на котором расположен загрузчик. Первая часть загрузчика, которая записана в MBR диска очень примитивная и почти ничего не умеет. Она даже разделы диска толком не определила, решив почему-то, что там файловая система msdos, хотя это не она. Нам нужно проверить все разделы диска hd0 и найти реальный загрузчик. Проверяем это командами:
> ls (hd0,msdos5)/ > ls (hd0,msdos1)/
Я нашел на msdos1 искомый раздел /boot. Понял это по содержимому. В разделе есть директория /grub, где располагается вторая часть загрузчика. Искомая директория может называться /grub2 или /boot/grub. Указываем загрузчику использовать этот раздел при выполнении дальнейших команд.
> set prefix=(hd0,msdos1)/grub > set root=(hd0,msdos1)
Далее загружаем необходимые модули. Какие будут нужны, зависит от конкретной ситуации. На всякий случай показываю самые популярные:
> insmod ext2 > insmod lvm > insmod part_msdos
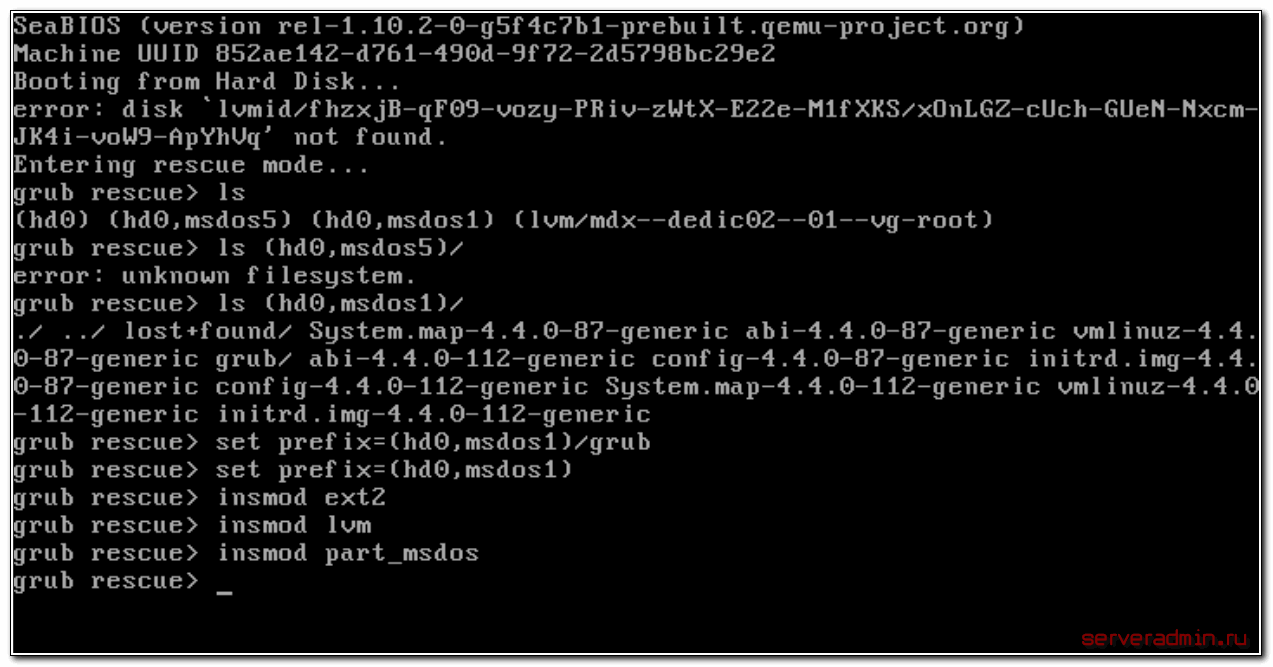
Начать стоит вообще без модулей, а потом добавлять, в зависимости от вашей ситуации. В завершении загружаем модуль normal и вводим одноименную команду:
> insmod normal > normal
После этого вы должны увидеть стандартное меню загрузчика grub. Дальше вы загрузитесь в операционную систему.
Что нового в Proxmox 7
Не хочется в рамках данной статьи подробно останавливаться на всех нововведениях 7-й версии, так как это всё можно посмотреть в официальном документе — https://forum.proxmox.com/threads/proxmox-ve-7-0-released.92007/. Плюс, было много переводов на популярных IT порталах. Скажу только, что каких-то кардинальных и революционных изменений в функционале не было. Обновление больше техническое. Вот краткий список основного, что поменялось:
- Proxmox 7 перешел на кодовую базу Debian 11. Немного странно, что сделано это раньше выхода релиза 11-й версии Дебиан.
- Обновилась версия Цеф — Ceph Pacific 16.2, обновилась QEMU до 6.0, LXC до 4.0.
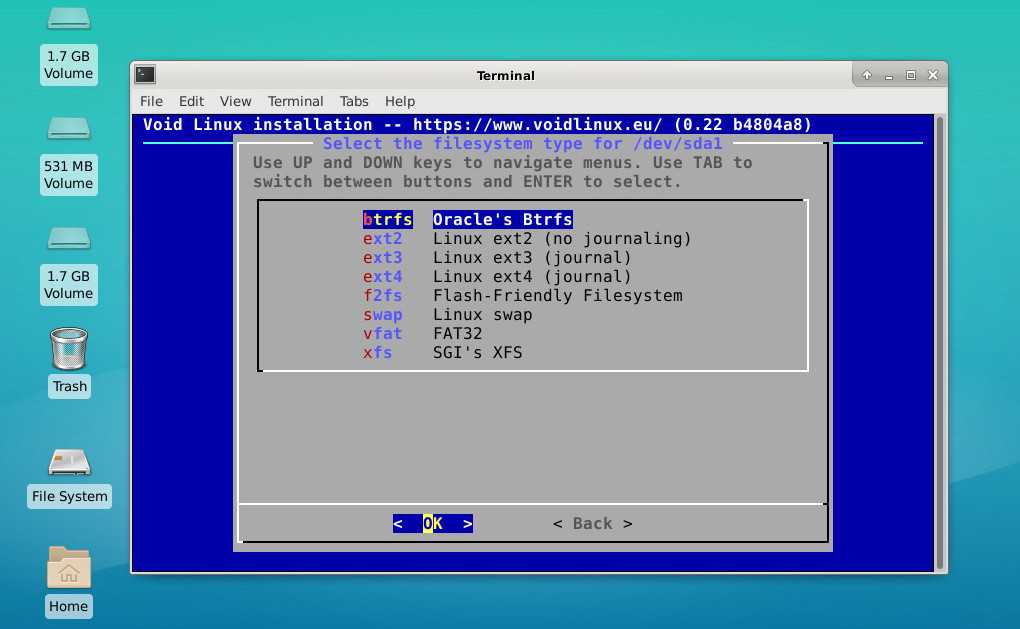
- Появилась встроенная поддержка файловой системы btrfs. По мне, это наиболее интересное изменение.
- Следом за добавлением btrfs изменился и установщик.
- Появилась новая панель в веб интерфейсе для управления репозиториями.
- Добавлена поддержка авторизации с помощью OpenID Connect.
Там еще много менее значительных обновлений. Не стану все перечислять. Переходим лучше к самому обновлению.
Изменения в Proxmox 6.0
Подробно об изменениях в Proxmox ve 6.0 можно посмотреть в официальном . На opennet сделан перевод основных нововведений. Я внимательно все прочитал, но особо не заметил кардинальных изменений, которые обычно ждешь от новой ветки. Из основных изменений там вот что:
- Перешли на кодовую базу Debian 10 Buster.
- Все компоненты (QEMU, LXC, ZFS, Ceph и т.д.) обновили до более свежих версий.
- Небольшие изменения в gui и некоторого функционала.
Тем не менее, я решил обновить proxmox, чтобы сильно не отставать по версиям. Обычно, если отстаешь по обновлениям, потом все труднее и ленивее наверстывать. Больше шанс, что будут проблемы, если прыгаешь в обновлениях с большей разницей в версиях. Лучше все делать своевременно.
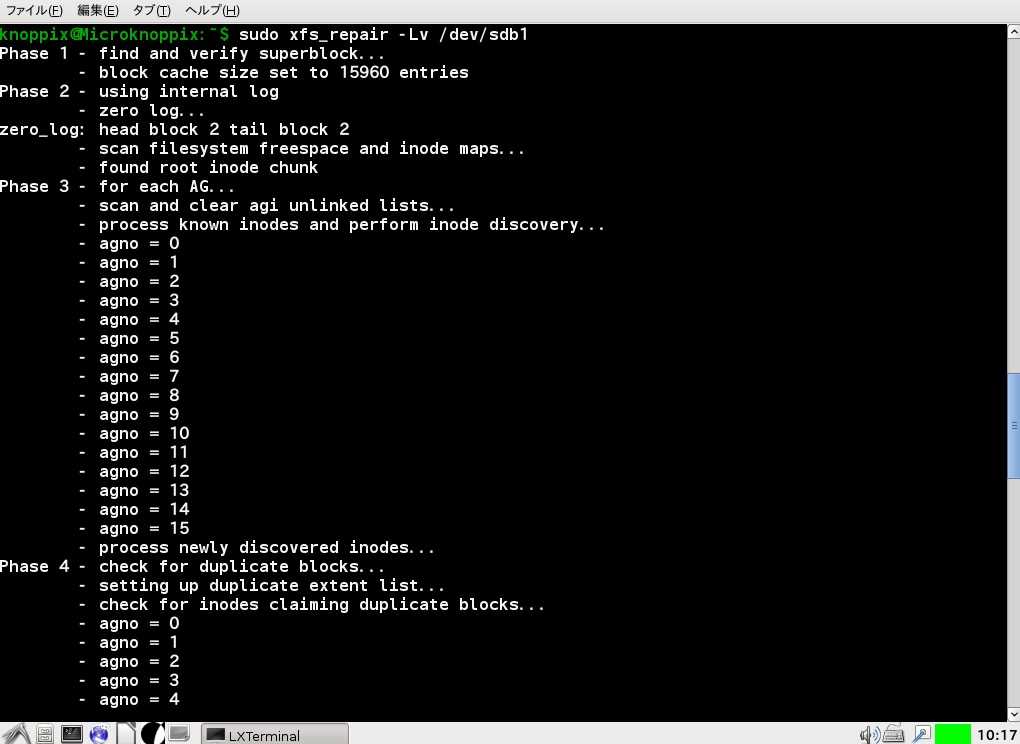
Diagnostics
xfs_repairxfs_repair
disconnected inode ino, moving to lost+found
- An inode numbered
-
ino was not connected to the filesystem directory tree and was reconnected to the lost+found directory. The inode is assigned the name of its
inode number (ino). If a lost+found directory does not exist, it is automatically created.
disconnected dir inode ino, moving to lost+found
- As above only the inode is a directory inode.
- If a directory inode is attached to lost+found, all of its children (if any) stay attached to the directory and therefore get automatically
reconnected when the directory is reconnected.
imap claims in-use inode ino is free, correcting imap
- The inode allocation map thinks that inode
-
ino is free whereas examination of the inode indicates that the inode may be in use (although it may be disconnected). The program updates the inode
allocation map.
imap claims free inode ino is in use, correcting imap
- The inode allocation map thinks that inode
-
ino is in use whereas examination of the inode indicates that the inode is not in use and therefore is free. The program updates the inode
allocation map.
resetting inode ino nlinks from x to y
- The program detected a mismatch between the
- number of valid directory entries referencing inode ino and the number of references recorded in the inode and corrected the the number in the
inode.
fork-type fork in ino ino claims used block bno
- Inode
-
ino claims a block bno that is used (claimed) by either another inode or the filesystem itself for metadata storage. The fork-type is
either data or attr indicating whether the problem lies in the portion of the inode that tracks regular data or the portion of the inode that
stores XFS attributes. If the inode is a real-time (rt) inode, the message says so. Any inode that claims blocks used by the filesystem is deleted. If two or
more inodes claim the same block, they are both deleted.
fork-type fork in ino ino claims dup extent …


- Inode
-
ino claims a block in an extent known to be claimed more than once. The offset in the inode, start and length of the extent is given. The message is
slightly different if the inode is a real-time (rt) inode and the extent is therefore a real-time (rt) extent.
inode ino — bad extent …
- An extent record in the blockmap of inode
-
ino claims blocks that are out of the legal range of the filesystem. The message supplies the start, end, and file offset of the extent. The message
is slightly different if the extent is a real-time (rt) extent.
bad fork-type fork in inode ino
- There was something structurally wrong or inconsistent with the
- data structures that map offsets to filesystem blocks.
cleared inode ino
- There was something wrong with the inode that
- was uncorrectable so the program freed the inode. This usually happens because the inode claims blocks that are used by something else or the inode itself
is badly corrupted. Typically, this message is preceded by one or more messages indicating why the inode needed to be cleared.
bad attribute fork in inode ino, clearing attr fork
- There was something wrong with the portion of the inode that
- stores XFS attributes (the attribute fork) so the program reset the attribute fork. As a result of this, all attributes on that inode are lost.
correcting nextents for inode ino, was x — counted y
- The program found that the number of extents used to store
- the data in the inode is wrong and corrected the number. The message refers to nextents if the count is wrong on the number of extents used to store
attribute information.
entry name in dir dir_ino not consistent with .. value (xxxx) in dir ino ino,
junking entry name in directory inode dir_ino
- The entry
-
name in directory inode dir_ino references a directory inode ino. However, the .. entry in directory ino does not point back to
directory dir_ino, so the program deletes the entry name in directory inode dir_ino. If the directory inode ino winds up becoming a
disconnected inode as a result of this, it is moved to lost+found later.
entry name in dir dir_ino references already connected dir ino ino, junking entry name in
directory inode dir_ino
- The entry
-
name in directory inode dir_ino points to a directory inode ino that is known to be a child of another directory. Therefore, the entry
is invalid and is deleted. This message refers to an entry in a small directory. If this were a large directory, the last phrase would read «will clear
entry».
entry references free inode ino in directory dir_ino, will clear entry
- An entry in directory inode
-
dir_ino references an inode ino that is known to be free. The entry is therefore invalid and is deleted. This message refers to a large
directory. If the directory were small, the message would read «junking entry …».
CrowdSec vs Fail2ban
Для начала рассмотрим основные отличия CrowdSec от Fail2ban:
- Crowdsec более производительный, так как написан на Go, в отличие от Fail2ban, который на Python.
- У crowdsec современный yaml формат конфигов.
- В качестве парсера лог файлов crowdsec использует фильтры grok, хорошо известные тем, кто активно использует elk stack. Мне лично этот фильтр нравится. Я научился на нем писать правила парсинга.
- У crowdsec есть готовая web панель, с помощью которой можно управлять защитой и просматривать статистику.
- Есть готовые контейнеры docker, которые призваны упростить установку и запуск. На практике особого упрощения нет, так как надо прокидывать в контейнеры все лог файлы для анализа. Тем не менее, кому актуален докер, не надо будет самому делать контейнеры.
- CrowdSec собирает глобальную статистику по заблокированным ip адресам и предоставляет возможность настроить у себя списки блокировки на основе этой статистики. Как по мне, инициатива сомнительная, так как получится то же самое, что и с подобными списками в почте. Потом употеешь себя из этих списков убирать или разбираться, почему кто-то из клиентов не может получить доступ к твоему сервису. Более того, через ботнет доверенных хостов crowdsec можно умышленно банить какие-то ip адреса.
- С локальной службой защиты можно взаимодействовать через встроенное API, что открывает безграничные возможности для интеграции.
- Из коробки работает экспорт всех основных метрик в формате Prometheus. То есть мониторинг вообще настраивать не надо, он сразу готов.
По сравнению видно, что авторы CrowdSec взяли тот же принцип анализа лог файлов, что и Fail2ban, но развили его и адаптировали под современные реалии. Я читал, что они работают над интеграцией своего продукта с Kubernetes и его Ingress Controller.
Заключение
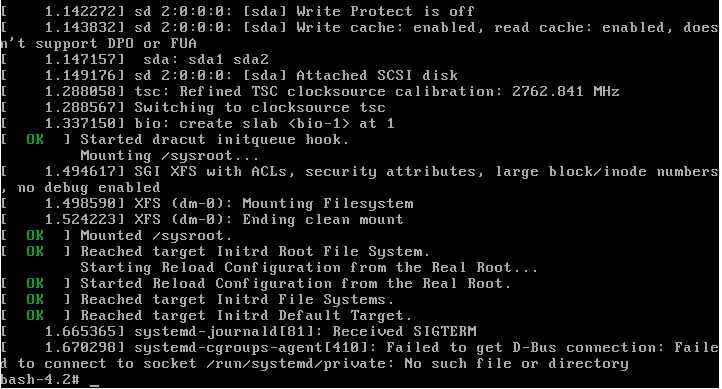
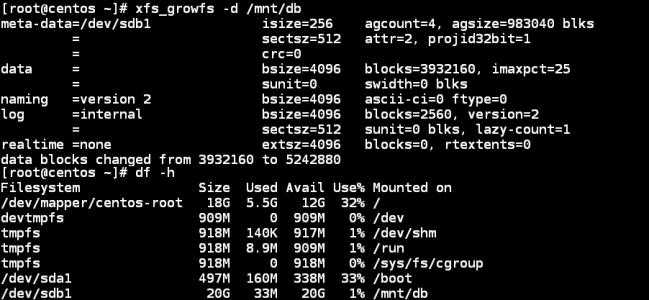
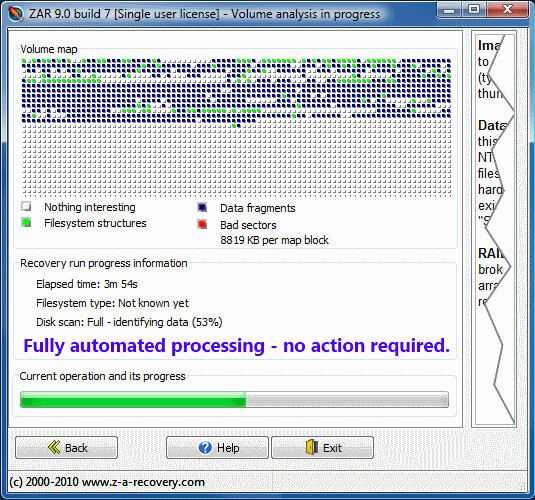
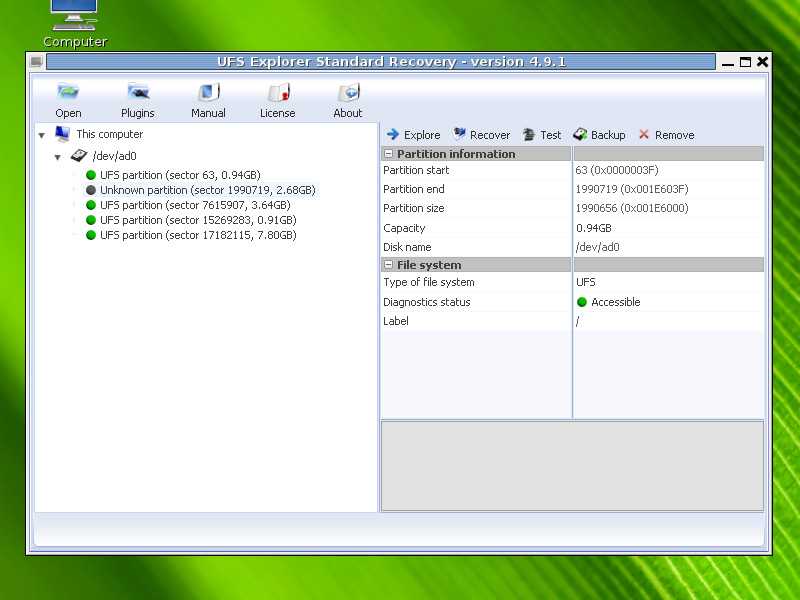
В итоге у меня все получилось, но считаю, что просто повезло, так как любое неверное действие в восстановлении таблицы разделов могло привести к фатальным последствиям. Если вы будете восстанавливать реально важные данные, то обязательно сделайте посекторную копию носителя и работайте с ней. И внимательно смотрите на восстановленные разделы перед их записью. Если что-то пойдет не так, то восстановить данные будет в разы сложнее. Наверняка таблицу разделов придется править уже вручную, а для этого нужны хорошие знания. У меня, к примеру, их нет.
Непонятной осталась причина сбоя, и это хуже всего. На вид все в порядке, но я теряю доступ к данным. Любой другой пользователь, не разбирающийся в linux, просто потерял бы данные, либо пришлось обращаться в специализированные фирмы по восстановлению информации, а это стоит дорого. И еще, как я понял, я точно так же мог потерять доступ и к массиву из нескольких дисков. К слову, потерпевший NAS это Synology, где под капотом обычный linux и mdadm, поэтому я понимал, как надо действовать. На этом же устройстве есть несколько массивов на много Tb и если бы кто-то из них сглючил, то было бы плохо.
Несколько моих статей по восстановлению загрузки linux после различных сбоев:
- Kernel panic not syncing: VFS: Unable to mount root fs
- Booting from Hard Disk error, Entering rescue mode
Надеюсь, вам они не пригодятся.
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .
Заключение
Я выполнил обновление Proxmox VE до 7-й версии на своем домашнем тестовом гипервизоре. Никаких проблем в процессе не возникло. Тем не менее, не рекомендую обновлять прод, пока не выйдет хотя бы версия 7.1. Торопиться в таких делах нет никакого смысла. Можно вообще не обновляться, если вам не нужны нововведения. Никаких проблем не будет, если вы останетесь на старой версии, пока она еще поддерживается.


Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Заключение
Данный функционал можно использовать не только для мониторинга бэкапов, но и других актуальных данных. Например, какая-то программа должна выгружать данные с определенной периодичностью. Мы можем следить за тем, как она это делает. В данной статье мы рассмотрели несколько параметров, по которым заббикс может анализировать файлы и каталоги. Но таких возможностей много. Он может, к примеру, проверять конкретный размер файла и предупреждать, если он сильно меньше или больше предыдущей версии. Настраивается это примерно так же, как здесь.
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .





