
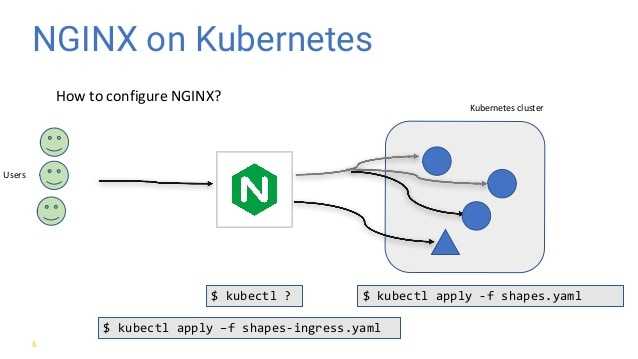
Create and Deploy Ingress Resource
Create the following ingress resource yaml file which will route the request to the respective service based url or path. In our example we be using url or fqdn.
~]# vim myweb-ingress.yaml apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: name-based-virtualhost-ingress spec: rules: - host: httpd.example.com http: paths: - backend: serviceName: httpd-service servicePort: 80 - host: nginx.example.com http: paths: - backend: serviceName: nginx-service servicePort: 80
save and close the file.
Execute beneath kubectl command to create above ingress resource,
~]# kubectl create -f myweb-ingress.yaml ingress.networking.k8s.io/name-based-virtualhost-ingress created ~]#
Run following to verify the status of above created ingress resource
~]# kubectl get ingress name-based-virtualhost-ingress ~]# kubectl describe ingress name-based-virtualhost-ingress
Perfect, above output confirms that ingress resources have been created successfully.
Before accessing these urls from outside of the cluster please make sure to add the following entries in hosts file of your system from where you intended to access these.
192.168.1.190 httpd.example.com 192.168.1.190 nginx.example.com
Now try to access these URLs from web browser, type
http://httpd.example.com
http://nginx.example.com
Создание кластера
По-отдельности, рассмотрим процесс настройки мастер ноды (control-plane) и присоединения к ней двух рабочих нод (worker).
Настройка control-plane (мастер ноды)
Выполняем команду на мастер ноде:
kubeadm init —pod-network-cidr=10.244.0.0/16
* данная команда выполнит начальную настройку и подготовку основного узла кластера. Ключ —pod-network-cidr задает адрес внутренней подсети для нашего кластера.
Выполнение займет несколько минут, после чего мы увидим что-то на подобие:
…
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.15:6443 —token f7sihu.wmgzwxkvbr8500al \
—discovery-token-ca-cert-hash sha256:6746f66b2197ef496192c9e240b31275747734cf74057e04409c33b1ad280321
* данную команду нужно вводить на worker нодах, чтобы присоединить их к нашему кластеру. Можно ее скопировать, но позже мы будем генерировать данную команду по новой.
В окружении пользователя создаем переменную KUBECONFIG, с помощью которой будет указан путь до файла конфигурации kubernetes:
export KUBECONFIG=/etc/kubernetes/admin.conf
Чтобы каждый раз при входе в систему не приходилось повторять данную команду, открываем файл:
vi /etc/environment
И добавляем в него строку:
export KUBECONFIG=/etc/kubernetes/admin.conf
Посмотреть список узлов кластера можно командой:
kubectl get nodes
На данном этапе мы должны увидеть только мастер ноду:
NAME STATUS ROLES AGE VERSION
k8s-master.dmosk.local NotReady <none> 10m v1.20.2
Чтобы завершить настройку, необходимо установить CNI (Container Networking Interface) — в моем примере это flannel:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
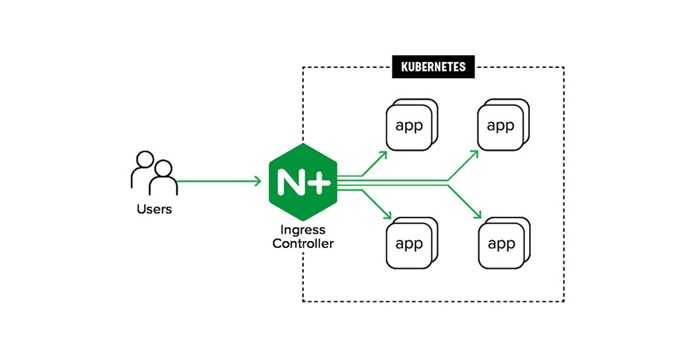
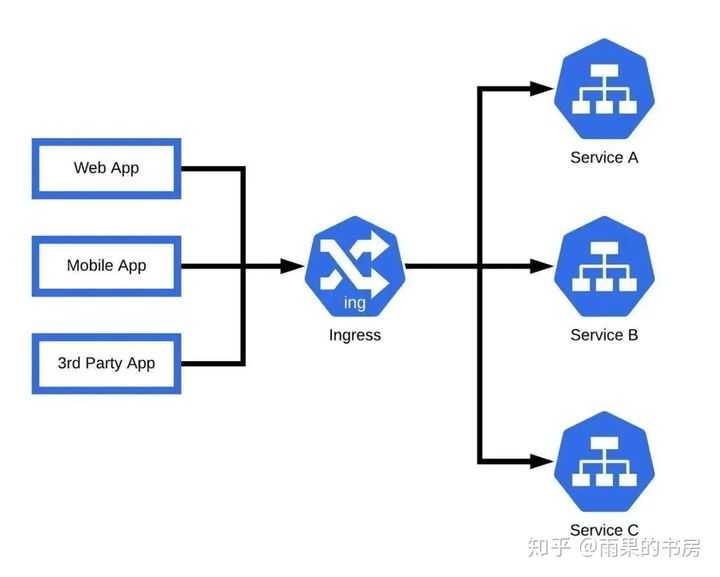
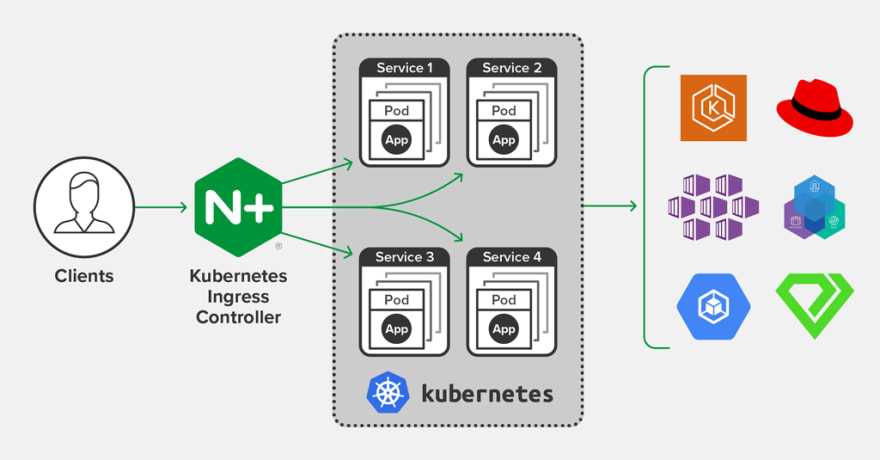
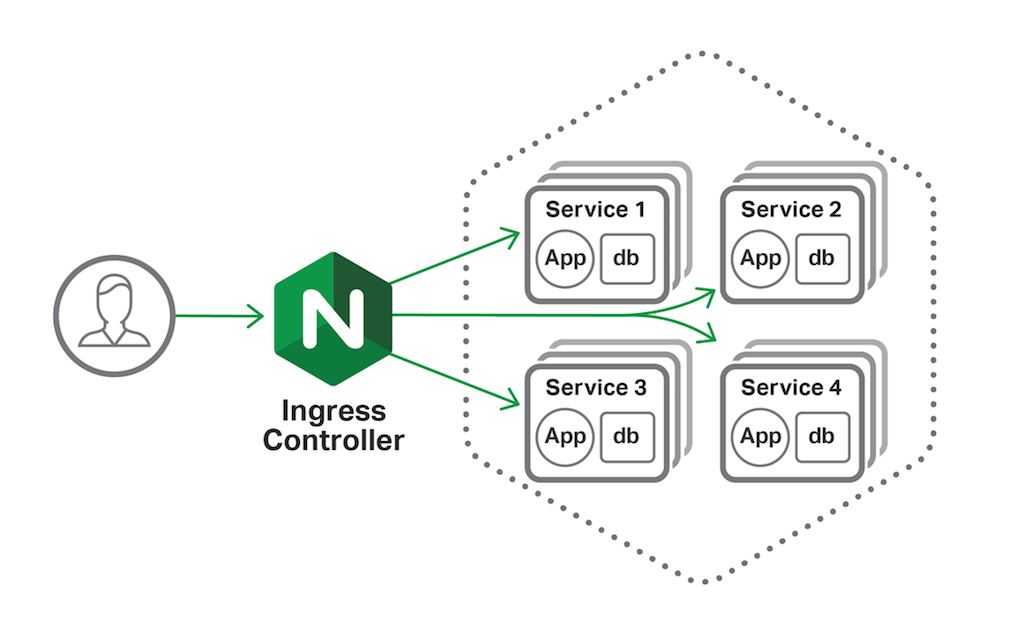
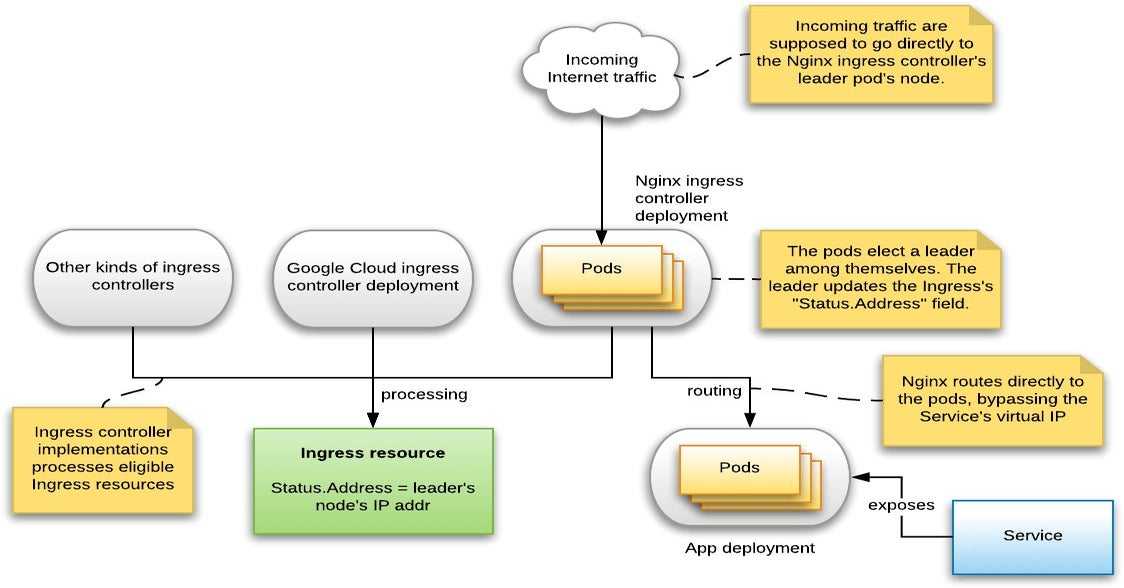
* краткий обзор и сравнение производительности CNI можно почитать в статье на хабре.
Узел управления кластером готов к работе.
Настройка worker (рабочей ноды)
Мы можем использовать команду для присоединения рабочего узла, которую мы получили после инициализации мастер ноды или вводим (на первом узле):
kubeadm token create —print-join-command
Данная команда покажет нам запрос на присоединения новой ноды к кластеру, например:
kubeadm join 192.168.0.15:6443 —token f7sihu.wmgzwxkvbr8500al \
—discovery-token-ca-cert-hash sha256:6746f66b2197ef496192c9e240b31275747734cf74057e04409c33b1ad280321
Копируем его и используем на двух наших узлах. После завершения работы команды, мы должны увидеть:
Run ‘kubectl get nodes’ on the control-plane to see this node join the cluster.
На мастер ноде вводим:
kubectl get nodes
Мы должны увидеть:
NAME STATUS ROLES AGE VERSION
k8s-master1.dmosk.local Ready control-plane,master 18m v1.20.2
k8s-worker1.dmosk.local Ready <none> 79s v1.20.2
k8s-worker2.dmosk.local Ready <none> 77s v1.20.2
Наш кластер готов к работе. Теперь можно создавать поды, развертывания и службы. Рассмотрим эти процессы подробнее.
Default SSL Certificate ¶
NGINX provides the option to configure a server as a catch-all with server_name for requests that do not match any of the configured server names. This configuration works out-of-the-box for HTTP traffic. For HTTPS, a certificate is naturally required.
For this reason the Ingress controller provides the flag . The secret referred to by this flag contains the default certificate to be used when accessing the catch-all server. If this flag is not provided NGINX will use a self-signed certificate.
For instance, if you have a TLS secret in the namespace, add in the deployment.
The default certificate will also be used for ingress sections that do not have a option.
Знай свой конфиг
Красота Ingress-контроллера том, что вы можете положиться на эту замечательную программу в вопросе генерации и перезагрузки конфигурации прокси-сервера и больше по этому поводу не беспокоиться. Вам даже не обязательно быть знакомым с нижележащей технологией (NGINX в данном случае). Правда? Нет!
Если вы этого еще не сделали, обязательно посмотрите на сгенерированную для вас конфигурацию. Для NGINX Ingress-контроллера можно получить содержимое с помощью .
Теперь попробуйте найти что-нибудь несовместимое с вашей установкой. Хотите пример? Давайте начнем с ;
Первая проблема: в настоящий момент (будет ли это когда-либо исправлено?) NGINX ничего не знает о cgroups, а значит, в случае будет использовано значение количества хоста, а не количества «виртуальных» процессоров, как определено в Kubernetes resource requests/limits.
Проведем эксперимент. Что будет, если мы попробуем загрузить следующий файл конфигурации NGINX на двухъядерном сервере в контейнере, ограниченном только одним CPU? Сколько рабочих процессов будет запущено?
Таким образом, если вы планируете ограничить ресурсы процессора, которые доступны NGINX Ingress, не стоит позволять nginx создавать большое количество рабочих процессов в одном контейнере. Лучше всего явно указать их необходимое количество с помощью директивы .
Теперь рассмотрим директиву . Значение параметра явно не указано и по умолчанию для Linux равно . Если параметр ядра равен, скажем, , то нужно присвоить соответствующее значение. Другими словами, убедитесь в том, что конфигурация nginx настроена с учетом параметров ядра.
Но на этом не останавливайтесь. Такое упражнение необходимо провести для каждой строчки сгенерированного файла конфигурации. Только посмотрите на все те параметры, которые позволяет поменять Ingress-контроллер. Исправляйте без колебаний все, что не подходит для вашего случая. Большинство параметров NGINX могут быть настроены с помощью записей и/или аннотаций .
Параметры ядра
С Ingress или без него, всегда проверяйте и настраивайте параметры нод в соответствии с ожидаемой нагрузкой.
Это достаточно сложная тема, поэтому я не планирую здесь подробно ее раскрывать. Дополнительные материалы по этом вопросу можно найти в разделе .
Kube-Proxy: Таблица Conntrack
Тем, кто использует Kubernetes, думаю, не нужно объяснять, что такое Сервисы и для чего они предназначены. Однако полезно будет рассмотреть некоторые особенности их работы.
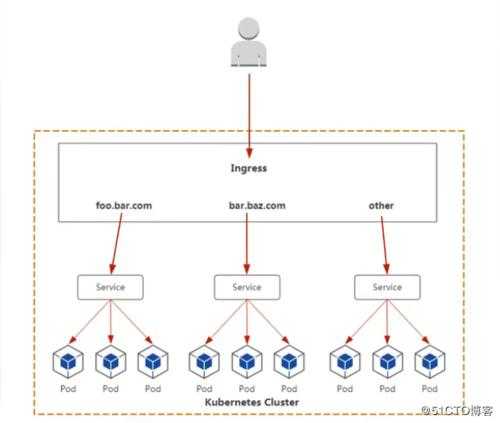
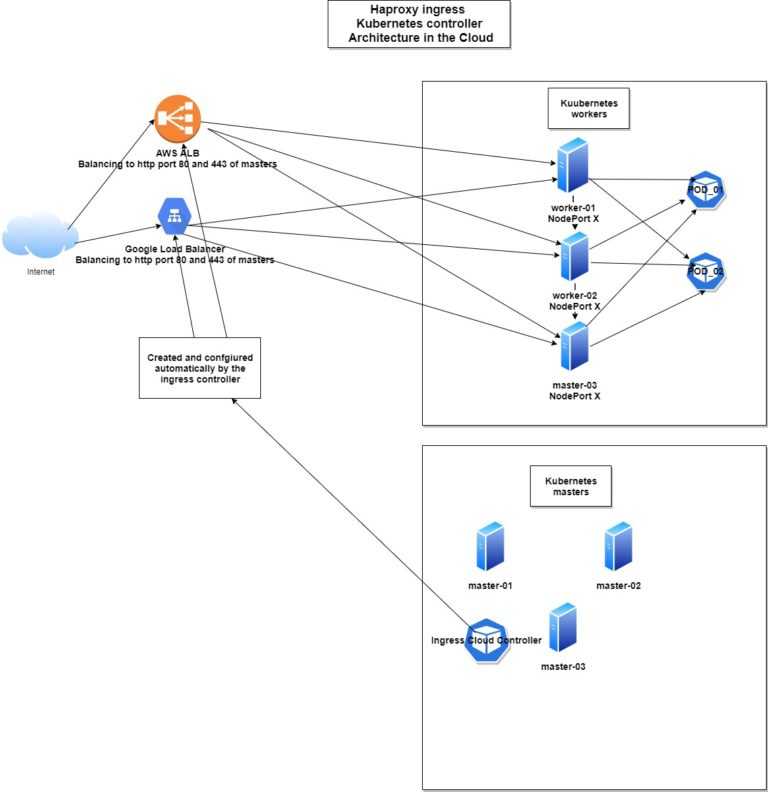
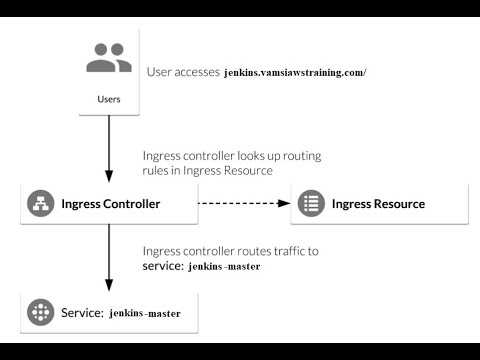
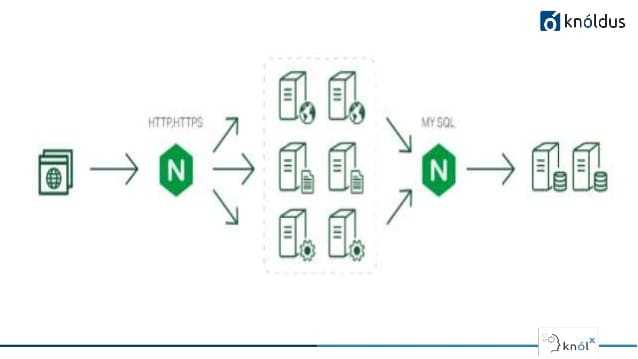
Другими словами, отправленные на IP сервиса пакеты направляются (напрямую или через балансировщик) на соответствующий (пары подов, которые соответствуют label selector сервиса) с помощью правил iptables, управляемых kube-proxy. Соединения с IP-адресами сервиса отслеживаются ядром с помощью модуля , и эта информация хранится в RAM.
Поскольку различные параметры conntrack должны быть согласованы друг с другом (например, и ), kube-proxy, начиная работу, устанавливает разумные значения по умолчанию.
Это неплохой вариант, но вам может потребоваться увеличить значения этих параметров, если мониторинг показывает, что у вас заканчивается место, выделенное для conntrack. Однако необходимо помнить, что увеличение значений этих параметров ведет к повышенному потреблению памяти, так что поаккуратнее там.
Мониторинг использования conntrack
Связь Deployment’а и Service’а
- Селектор () у Service’а должен соответствовать хотя бы одному лейблу Pod’а.
- должен совпадать с контейнера внутри Pod’а.
- Service’а может быть любым. Различные сервисы могут использовать один и тот же порт, поскольку у них разные IP-адреса.
Но через какой из них идет подключение к контейнеру?
А как насчет лейбла в верхней части раздела Deployment? Должен ли он совпадать? А что насчет селектора ?Он всегда должен совпадать с лейблами Pod’аПредположим, что вы внесли верные правки. Как их проверить?
Остались сложности?
- — имя сервиса; в нашем случае это ;
- 3000 — порт, который требуется открыть на компьютере;
- 80 — порт, прописанный в поле сервиса.
Подготовка к установке
Кластер Kubernetes я буду разворачивать на виртуальных машинах Centos 7. На них она установлена в минимальной конфигурации. Напоминаю, что установка будет проходить с помощью Kubespray. Я рекомендую склонировать к себе репозиторий, чтобы у вас сохранилась версия kubespray, с которой вы устанавливали кластер. Это позволит без проблем создавать копию кластера для тестов, дебага, обновления и т.д. Я для этого использую свой сервер Gitlab. Рекомендую озаботиться его наличием. Он нам очень пригодится и дальше в процессе знакомства и изучения кластера.
На виртуальных машинах нужно отключить следующие сущности:
- SELinux (привет любителям безопасности, считающим, что selinux отключают только дилетанты).
- Swap.
- FirewallD, либо любой другой firewall.
На все сервера должен быть разрешен доступ пользователя root по ssh с одним и тем же паролем.
Проброс порта в pod
А сейчас пробросим 80-й порт мастера в конкретный под и проверим, что nginx действительно работает в соответствии с установленным конфигом. Делается это следующим обарзом.
# kubectl port-forward deployment-nginx-848cc4c754-w7q9s 80:80 Forwarding from 127.0.0.1:80 -> 80 Forwarding from :80 -> 80
Перемещаемся в сосeднюю консоль мастера и там проверяем через curl.
# curl localhost:80 deployment-nginx-848cc4c754-w7q9s
Если сделать проброс в другой под и проверить подключение, вы получите в ответ на запрос curl на 80-й порт мастера имя второго пода. На практике, я не знаю, как можно использовать данную возможность. А вот для тестов в самый раз.
Проблема с сертификатами
Сразу обращаю внимание на очень важный момент. Необходимо тем или иным способом настроить мониторинг сертификатов, которые установил и настроил kubespray для обмена информацией мастеров
Сертификатов много и у них срок действия 1 год. Пока сертификаты не просрочились, их относительно легко обновлять. Если упустить этот момент, то все становится сложнее.
Я до конца не понял и не проработал вопрос обновления сертификатов, но это нужно будет сделать. Пока просто покажу, как за ними можно следить.
Сертификат api-server, порт 6443
# echo -n | openssl s_client -connect localhost:6443 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 19:32:42 2019 GMT
Not After : Sep 17 19:32:42 2020 GMT
Сертификат controller manager, порт 10257.
# echo -n | openssl s_client -connect localhost:10257 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 18:35:36 2019 GMT
Not After : Sep 17 18:35:36 2020 GMT
Сертификат scheduler, порт 10259.
# echo -n | openssl s_client -connect localhost:10259 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 18:35:35 2019 GMT
Not After : Sep 17 18:35:35 2020 GMT
Это все разные сертификаты и они выпущены на год. Их надо будет не забыть обновить. А вот сертификат для etcd. Он выпущен на 100 лет.
# echo -n | openssl s_client -connect localhost:2379 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 19:28:50 2019 GMT
Not After : Aug 25 19:28:50 2119 GMT
Я не понял, почему этого не сделали для всех сервисов, а оставили такой головняк на потом. Если у кого-то есть информация о том, как корректно и безпроблемно обновлять сертификаты, прошу поделиться. Я пока видел только вариант с полуручным обновлением и раскидыванием этих сертификатов по мастерам.
Устанавливаем haproxy на worknodes
Теперь мы имеем рабочий кластер с тремя master нодами и тремя worker нодами.
Проблема в том, что сейчас наши worker ноды не имеют HA режима.
Если посмотреть на конфиг файл kubelet, то мы увидим, что наши worker ноды обращаются только к одной master ноде из трех.
После того, как HAproxy, установлен нам нужно создать для него конфиг.
Если на worker нодах нет каталога с конфиг файлами, то клонируем его
И запускаем скрипт конфига с флагом haproxy
Скрипт сконфигурирует и перезапустит haproxy.
Проверим, что haproxy стал слушать порт 6443.




Теперь нам нужно сказать kubelet, чтобы он обращался на localhost вместо master ноды. Для этого нужно отредактировать значение server в файлах /etc/kubernetes/kubelet.conf и /etc/kubernetes/bootstrap-kubelet.conf на всех worker нодах.
Значение server должно принять вот такой вид:
После внесения изменений нужно перезапустить службы kubelet и docker
Проверим, что все ноды работают исправно
Пока что у нас нет приложений в кластере, чтобы проверить работу HA. Но мы можем остановить работу kubelet на первой master ноде и убедится, что наш кластер остался дееспособным.
Проверяем со второй master ноды
Все ноды функционируют нормально, кроме той, на которой мы остановили службы.
Не забываем включить обратно службы kubernetes на первой master ноде
Authentication to the Kubernetes API Server ¶
A number of components are involved in the authentication process and the first step is to narrow down the source of the problem, namely whether it is a problem with service authentication or with the kubeconfig file.
Both authentications must work:
Service authentication
The Ingress controller needs information from apiserver. Therefore, authentication is required, which can be achieved in two different ways:
-
Service Account: This is recommended, because nothing has to be configured. The Ingress controller will use information provided by the system to communicate with the API server. See ‘Service Account’ section for details.
-
Kubeconfig file: In some Kubernetes environments service accounts are not available. In this case a manual configuration is required. The Ingress controller binary can be started with the flag. The value of the flag is a path to a file specifying how to connect to the API server. Using the does not requires the flag . The format of the file is identical to which is used by kubectl to connect to the API server. See ‘kubeconfig’ section for details.
-
Using the flag : Using this flag it is possible to specify an unsecured API server or reach a remote kubernetes cluster using kubectl proxy. Please do not use this approach in production.
In the diagram below you can see the full authentication flow with all options, starting with the browser on the lower left hand side.
Service Account
If using a service account to connect to the API server, the ingress-controller expects the file to be present. It provides a secret token that is required to authenticate with the API server.
Verify with the following commands:
If it is not working, there are two possible reasons:
-
The contents of the tokens are invalid. Find the secret name with and delete it with . It will automatically be recreated.
-
You have a non-standard Kubernetes installation and the file containing the token may not be present. The API server will mount a volume containing this file, but only if the API server is configured to use the ServiceAccount admission controller. If you experience this error, verify that your API server is using the ServiceAccount admission controller. If you are configuring the API server by hand, you can set this with the parameter.
More information:
- User Guide: Service Accounts
- Cluster Administrator Guide: Managing Service Accounts
Предварительные требования
Прежде чем начать прохождение этого обучающего модуля, вам потребуется следующее:
- Кластер Kubernetes 1.10+ с включенным контролем доступа на основе ролей (RBAC)
- Инструмент командной строки , установленный на локальном компьютере и настроенный для подключения к вашему кластеру. Дополнительную информацию об установке можно найти в официальной документации.
- Доменное имя и записи DNS A, которые можно направить на балансировщик нагрузки DigitalOcean, используемый Ingress. Если вы используете DigitalOcean для управления записями DNS вашего домена, руководство Управление записями DNS поможет вам научиться создавать записи класса A.
- Инструмент командной строки , установленный на локальном компьютере. Вы можете установить с помощью диспетчера пакетов, встроенного в операционную систему.
Проверив наличие этих компонентов, вы можете начинать прохождение этого обучающего модуля.
Before You Begin ¶
-
The NGINX Ingress controller should already be deployed according to the deployment instructions here.
-
The controller should be configured for exporting metrics. This requires 3 configurations to the controller. These configurations are :
- controller.metrics.enabled=true
- controller.podAnnotations.»prometheus.io/scrape»=»true»
-
controller.podAnnotations.»prometheus.io/port»=»10254″
-
The easiest way to configure the controller for metrics is via helm upgrade. Assuming you have installed the ingress-nginx controller as a helm release named ingress-controller, then you can simply type the command show below :
- You can validate that the controller is configured for metrics by looking at the values of the installed release, like this ;
- You should be able to see the values shown below ;
-
If you are not using helm, you will have to edit your manifests like this:
-
Service manifest:
-
DaemonSet manifest:
-
Системные требования
Как таковых жестких системных требований у Kubernetes нет. Он с очень маленьких установок расширяется до огромных кластеров. Для того, чтобы его просто попробовать и посмотреть, достаточно следующих виртуальных машин:






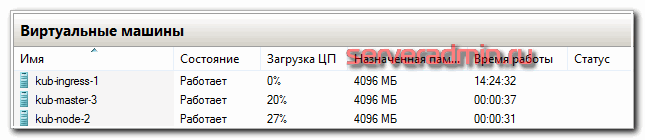
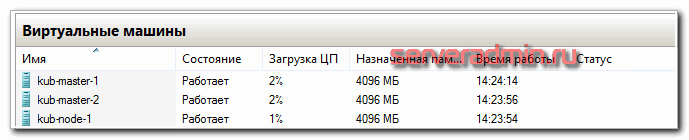
- 2-3 мастер ноды с 2 cpu и 4 gb ram
- ingress нода с 1 cpu и 2 gb ram
- рабочие ноды для контейнеров от 2 cpu и 4 gb ram
Для того, чтобы просто запустить кластер, достаточно буквально двух виртуальных машин, которые одновременно будут и мастер и рабочими нодами. Но я рекомендую сразу планировать более ли менее полную структуру, которую можно брать за основу для последующего превращения в рабочий кластер. Я буду разворачивать кластер на следующих виртуальных машинах.
| Название | IP | CPU | RAM | HDD |
| kub-master-1 | 10.1.4.36 | 2 | 4G | 50G |
| kub-master-2 | 10.1.4.37 | 2 | 4G | 50G |
| kub-master-3 | 10.1.4.38 | 2 | 4G | 50G |
| kub-ingress-1 | 10.1.4.39 | 2 | 4G | 50G |
| kub-node-1 | 10.1.4.32 | 2 | 4G | 50G |
| kub-node-2 | 10.1.4.33 | 2 | 4G | 50G |
В моем случае это виртуальные машины на двух гипервизорах Hyper-V. Как я уже сказал в системных требованиях, для теста ресурсов можно и чуть меньше дать, но у меня есть запас, поэтому я такие ресурсы выделил для кластера Kubernetes. Перед установкой кластера рекомендую сделать снепшоты чистых систем, чтобы можно было оперативно вернуться к исходному состоянию, если что-то пойдет не так. Вручную готовить и переустанавливать виртуалки хлопотно.
По гипервизорам виртуальные машины распределил следующим образом.
Упомяну про еще одну рекомендацию. Мастер ноды с etcd дают приличную нагрузку на диск. Их рекомендуется размещать на быстрых ssd дисках. Чем больше кластер — тем больше нагрузка. В наших тестах сойдет и hdd диск под мастер. Но если будете использовать в продакшене с учетом расширения и роста, лучше сразу планируйте быстрые диски под мастера.
Before You Begin
-
The NGINX Ingress controller should already be deployed according to the deployment instructions here.
-
The controller should be configured for exporting metrics. This requires 3 configurations to the controller. These configurations are :
- controller.metrics.enabled=true
- controller.podAnnotations.»prometheus.io/scrape»=»true»
- controller.podAnnotations.»prometheus.io/port»=»10254″
The easiest way to configure the controller for metrics is via helm upgrade. Assuming you have installed the ingress-nginx controller as a helm release named ingress-controller, then you can simply type the command show below :
You can validate that the controller is configured for metrics by looking at the values of the installed release, like this ;
You should be able to see the values shown below ;
- If you are not using helm, you will have to edit your manifests like this:
-
Service manifest:
-
DaemonSet manifest:
-
Terminology
For clarity, this guide defines the following terms:
- Node: A worker machine in Kubernetes, part of a cluster.
- Cluster: A set of Nodes that run containerized applications managed by Kubernetes. For this example, and in most common Kubernetes deployments, nodes in the cluster are not part of the public internet.
- Edge router: A router that enforces the firewall policy for your cluster. This could be a gateway managed by a cloud provider or a physical piece of hardware.
- Cluster network: A set of links, logical or physical, that facilitate communication within a cluster according to the Kubernetes networking model.
- Service: A Kubernetes Service that identifies a set of Pods using label selectors. Unless mentioned otherwise, Services are assumed to have virtual IPs only routable within the cluster network.
Step 6 — Issuing Staging and Production Let’s Encrypt Certificates
To issue a staging TLS certificate for our domains, we’ll annotate with the ClusterIssuer created in Step 4. This will use to automatically create and issue certificates for the domains specified in the Ingress manifest.
Open up in your favorite editor:
Add the following to the Ingress resource manifest:
echo_ingress.yaml
Here we add an annotation to set the cert-manager ClusterIssuer to , the test certificate ClusterIssuer created in Step 4.
We also add a block to specify the hosts for which we want to acquire certificates, and specify a . This secret will contain the TLS private key and issued certificate. Be sure to swap out with the domain for which you’ve created DNS records.
When you’re done making changes, save and close the file.
We’ll now push this update to the existing Ingress object using :
You should see the following output:
You can use to track the state of the Ingress changes you’ve just applied:
Once the certificate has been successfully created, you can run a on it to further confirm its successful creation:
You should see the following output in the section:
This confirms that the TLS certificate was successfully issued and HTTPS encryption is now active for the two domains configured.
We’re now ready to send a request to a backend server to test that HTTPS is functioning correctly.
Run the following command to send a request to and print the response headers to :
You should see the following output:
This indicates that HTTPS has successfully been enabled, but the certificate cannot be verified as it’s a fake temporary certificate issued by the Let’s Encrypt staging server.
Now that we’ve tested that everything works using this temporary fake certificate, we can roll out production certificates for the two hosts and . To do this, we’ll use the ClusterIssuer.





Update to use :
Make the following change to the file:
echo_ingress.yaml
Here, we update the ClusterIssuer name to .
Once you’re satisfied with your changes, save and close the file.
Roll out the changes using :
Wait a couple of minutes for the Let’s Encrypt production server to issue the certificate. You can track its progress using on the object:
Once you see the following output, the certificate has been issued successfully:
We’ll now perform a test using to verify that HTTPS is working correctly:
You should see the following:
This indicates that HTTP requests are being redirected to use HTTPS.
Run on :
You should now see the following output:
You can run the previous command with the verbose flag to dig deeper into the certificate handshake and to verify the certificate information.
At this point, you’ve successfully configured HTTPS using a Let’s Encrypt certificate for your Nginx Ingress.
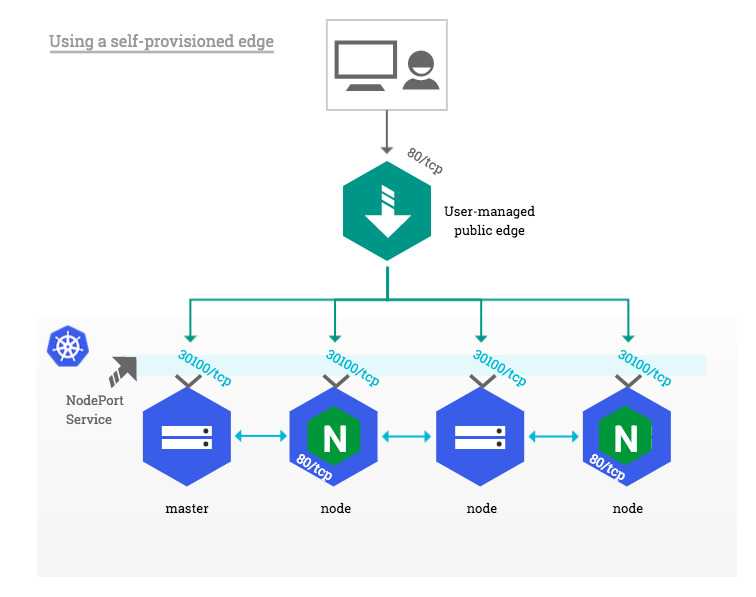
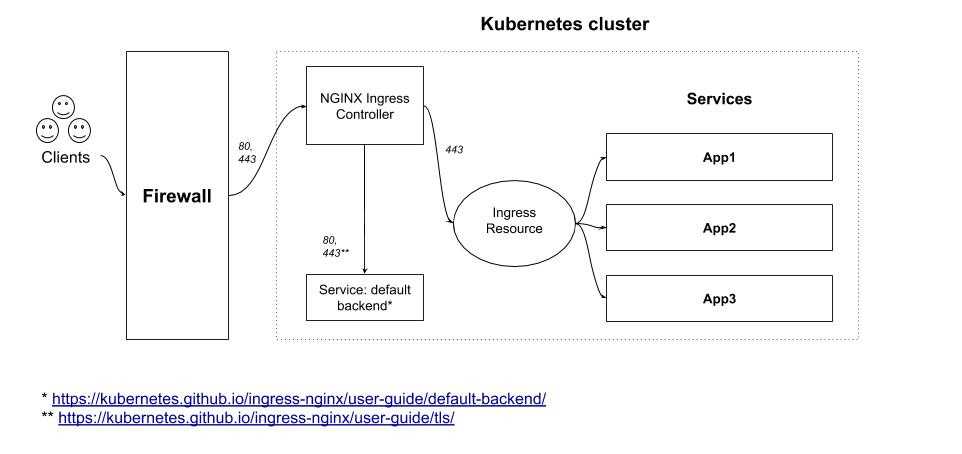
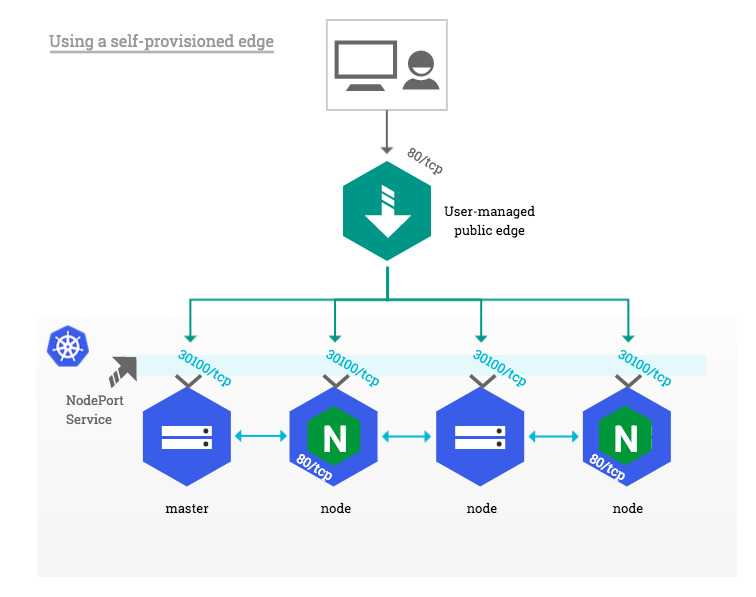
Using a self-provisioned edge ¶
Similarly to cloud environments, this deployment approach requires an edge network component providing a public entrypoint to the Kubernetes cluster. This edge component can be either hardware (e.g. vendor appliance) or software (e.g. HAproxy) and is usually managed outside of the Kubernetes landscape by operations teams.
Such deployment builds upon the NodePort Service described above in , with one significant difference: external clients do not access cluster nodes directly, only the edge component does. This is particularly suitable for private Kubernetes clusters where none of the nodes has a public IP address.
On the edge side, the only prerequisite is to dedicate a public IP address that forwards all HTTP traffic to Kubernetes nodes and/or masters. Incoming traffic on TCP ports 80 and 443 is forwarded to the corresponding HTTP and HTTPS NodePort on the target nodes as shown in the diagram below:
Заключение
Если у вас нет возможности или желания настраивать кластер Kubernetes самостоятельно на своем железе, можете купить его в готовом виде как сервис в облаке Mail.ru Cloud Solutions.
На этом начальную статью по Kubernetes заканчиваю. На выходе у нас получился рабочий кластер из трех мастер нод, двух рабочих нод и ingress контроллера. В последующих статьях я расскажу об основных сущностях kubernetes, как деплоить приложения в кластер с помощью Helm, как добавлять различные стореджи, как мониторить кластер и т.д. Да и в целом, хочу много о чем написать, но не знаю, как со временем будет.
В планах и git, и ansible, и prometeus, и teamcity, и кластер elasticsearch. К сожалению, доход с сайта не оправдывает временных затрат на написание статей, поэтому приходится писать их либо редко, либо поверхностно. Основное время уходит на текущие задачи по настройке и сопровождению.





