
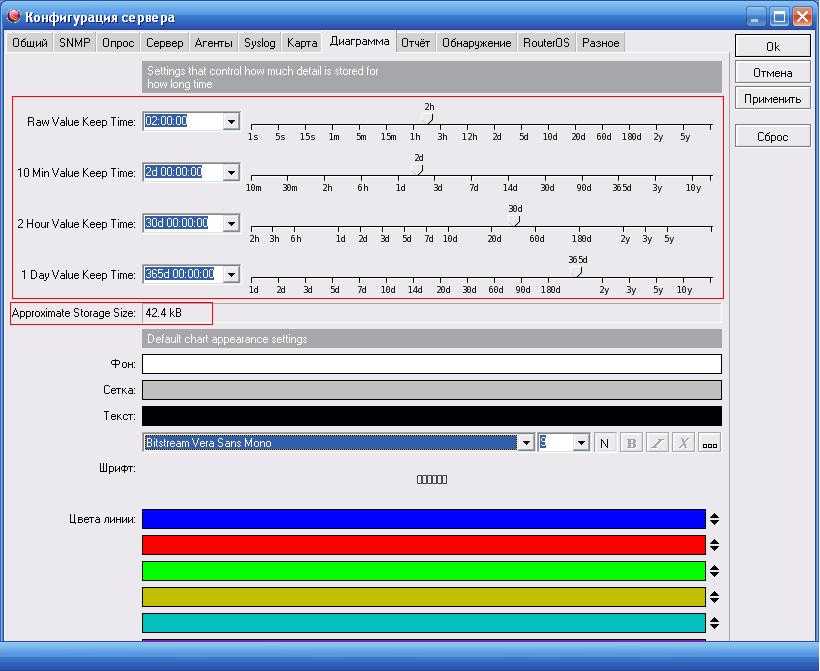
Введение
У нас имеется любой сервер Linux с настроенным рейдом mdadm. Я специально не останавливаюсь на каком-то конкретном дистрибутиве, потому что этот рецепт универсален и будет актуален в любом дистрибутиве. Узнать состояние рейда можно командой в консоли:
# cat /proc/mdstat Personalities : md0 : active raid6 sdg1 sde1 sdd1 sdf1 sdc1 sdb1 11720534016 blocks super 1.2 level 6, 512k chunk, algorithm 2 [6/6]
Заглавные буквы U означают, что все жесткие диски на месте, с рейдом все в порядке. Если какой-то из них выйдет из строя, то вместо буквы будет стоять знак _ . По этому значению мы и будем определять статус рейд массива mdadm — если знака _ нет, то все в порядке.
Воспользуемся простой командой для определения символа _ в выводе mdstat:
# egrep -c "\" /proc/mdstat
Если символа _ нет, то на выходе получаем значение 0. Если же это значение больше 1, то рейд считается поврежденным, zabbix отправляет уведомление. Отправлять полученные значения на сервер мониторинга будем с помощью UserParameter.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Введение
На серверах уже настроен мониторинг состояния SMART дисков. При использовании встроенного intel raid, состояние дисков с целевой системы нормально наблюдается. В принципе, мне этого хватало, но подумал, почему бы и состояние массивов не замониторить, ведь массив может развалиться и при нормальных показателях смарта дисков.
В первую очередь погуглил и не нашел практически ничего, что помогло бы настроить мониторинг интел рейдов в zabbix. На целевых системах установлена интеловская утилита raidcfg, с помощью которой можно посмотреть на состояние массивов и дисков. Например, с ключом /st получается вот такой вывод.
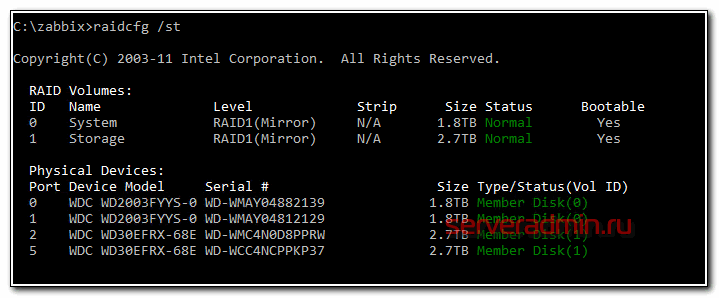
Красиво и наглядно, но для автоматизации не очень подходит. Лучше подойдет ключ /stv.

С такими данными уже можно работать. В целом, ничего сложного, нужно распарсить вывод любым удобным способом и передать на сервер мониторинга информацию о статуте рейд массива. Как можно с помощью батников парсить различные текстовые файлы я показывал на нескольких примерах в отдельной статье — Мониторинг значений из текстового файла в Zabbix.
В этот раз мне не захотелось такие костыли городить на каждом сервере. Я в итоге решил поступить по-другому. На zabbix сервере сделать скрипт для внешних проверок. Этот скрипт будет на целевом сервере с помощью zabbix_get забирать вывод команды raidcfg.exe /stv, запущенной через system.run. Дальше вывод команды в исходном виде поступает на zabbix сервер. Его можно парсить каким-то образом, но я решил этого не делать. Вывод и так короткий, много места не занимает. Проверка на наличие тревожных слов будет уже в триггере с помощью regexp.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Zabbix: LLD-мониторинг дисков без UserParameter и скриптов на агентах +8
- 14.12.17 11:32
•
AcidVenom
•
#344548
•
Хабрахабр
•
•
2600
Системное администрирование, Серверное администрирование
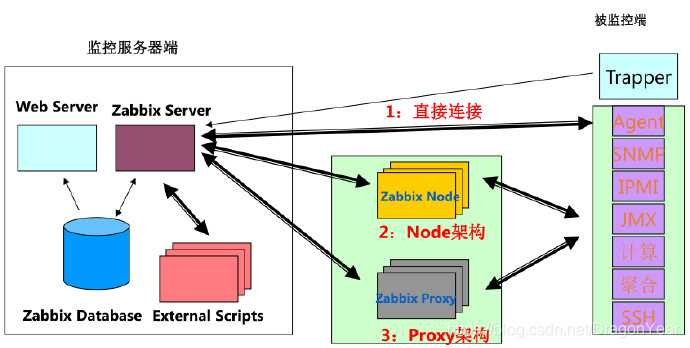
В предыдущей статье я описал низкоуровневый мониторинг дисков для Windows-машин. Считаю, что статья получилась достаточно успешная. Поэтому пришло время ее фактически уничтожить. Ниже будет описан универсальный прием для Windows- и Linux-машин, для которых вообще не нужны скрипты и UserParameter’ы.
Идея простая: все необходимое от smartmontools Zabbix-сервер будет получать через внешнюю обработку и zabbix_get, парсить и передавать далее в зависимые элементы (появились в Zabbix 3.4). Такие образом не только сокращается количество обращений к наблюдаемому серверу, но и не расходуются его ресурсы, так как парсинг происходит на стороне Zabbix-сервера.
Одно ограничение на данный момент: мониторинг дисков только формата /dev/sd*. Формат /dev/csmi*,* (Intel Matrix RAID) не поддерживается ввиду того, что zabbix_get считает запятую вторым аргументом. Поправьте меня, если я ошибаюсь.
Что понадобится для реализации:
- Шаблон
- Скрипт
- zabbix_get на сервере
- smartmontools на агентах
Шаблон
Hardware — HDD.xml
Более подробно о том, как все устроеноНиже я постараюсь подробно описать что же происходит на каждом этапе.
Первый этап: обнаружение доступных дисков sd* с помощью внешней проверки smartctl.sh с ключами {HOST.CONN} и discovery. В ответ сервер получает JSON с дисками, на которых активирована функция SMART. Диски без SMART’а или не sd* не выводятся.
Этап второй: получение для каждого из найденных дисков двух элементов — Info и Attr. Info — информация о диске, Attr — атрибуты SMART. «Почему не запросить smartctl -a /dev/sd* ?» — спросите вы. Такой вывод получается не полный для части дисков, теряются атрибуты и так далее. Пришлось изобретать на ходу.
Третий этап: Info и Attr разбираются на зависимые элементы с помощью предобработки регулярными выражениями. Это самая простая часть. Собственно, вам только останется подогнать под себя «регулярку».
Комментарии (14):
Nexon
14.12.17 11:51/#10566526
Если так важно не захламлять АРМ пользователя, то достаточно использовать system.run.
То есть, создаете один элемент с ключем system.run[«smartctl -A /dev/sda»] и несколько зависимых от него элементов с regex.
AcidVenom
14.12.17 12:03/#10566568
Это-то да, но как это вписывается в концепцию LLD? Как получить из system.run JSON?
Nexon
14.12.17 12:29/#10566660
А зачем Вам JSON? Есть же vfs.fs.discovery. Ключ в итоге будет иметь примерно такой вид:
system.run
AcidVenom
14.12.17 12:51/#10566726
Вы этот метод сами пробовали? Для Windows тоже?
Nexon
14.12.17 12:59/#10566756
Пробовал, но отказался в пользу openhardwaremonitor.
А так да, smartctl спокойно принимает буквы дисков как значение параметра:image.prntscr.com/image/3I0md9pOTkmpbUN9SN6b4A.jpeg
AcidVenom
14.12.17 01:03/#10566770
Ок, а как быть с разбитыми пополам дисками? Или с рейдами-стораджами?
Nexon
14.12.17 01:25/#10566852
Да, с дисками проблема, Zabbix пока-что не поддерживает LLD физических дисков.
Я RAID мониторю через IPMI\SNMP, т.к
ОС в случае ошибки может и не сообщить о ней.
AcidVenom
14.12.17 01:23/#10566844
Ок, я просто напишу почему это несостоятельно:
1) Если у диска более 1 раздела — задвоение
2) Рейд, сторадж спейсис, диск без поддержки СМАРТ — ошибочные элементы. Проверку-то вы не сделаете.
Nexon
14.12.17 01:32/#10566876
1) Не страшно, получите 2 срабатывания триггера в случае чего. Опять же, тут скорее зависит от админов, мы уже давно не разбиваем диски.
2) Для серверов я вообще не использую агент, там только IPMI\SNMP.
rt3879439
14.12.17 12:47/#10566716
Эх, как я не возился с этими /dev/csmi*,*, так нормального решения и не нашёл. Печально видеть, что воз и ныне там. Неужели так сложно сделать выбор сепаратора или реализовать экранирование?
Nexon
14.12.17 01:04/#10566772
Нормальное решение, мониторить через IPMI или SNMP.
Ведь достаточно мониторить статус RAID, а не состояние дисков в нём.
rt3879439
14.12.17 01:28/#10566862
А как же парк десктопов?
Nexon
14.12.17 01:33/#10566880
Выше ветка.
divanikus
14.12.17 04:52/#10567336
Немного не в тему, но может кому-нибудь будет интересно. Небольше «я сделаль»: github.com/divanikus/salus
Задумывалось как general purpose фреймворк, но для заббикса заточки тоже присутствуют.
Скрипт для внешних проверок raid массивов
В директорию на zabbix сервере /usr/lib/zabbix/externalscripts кладем скрипт intelraid.sh для внешних проверок.
Скрипт, как вы видите, очень простой. Для того, чтобы он работал, вам обязательно нужно на каждом агенте разрешить выполнение внешних команд. По-умолчанию они отключены. Добавляем в агенте параметр:
И перезапускаем агент. Это все, что надо делать на целевых серверах. Теперь можно проверить работу скрипта. Для этого выбираете любой сервер и передаем его ip адрес в качестве параметра скрипту.
Если получаете результат работы утилиты raidcfg, значит все в порядке. Можно переходить в web интерфейс сервера мониторинга.
Шаблон для мониторинга за intel raid
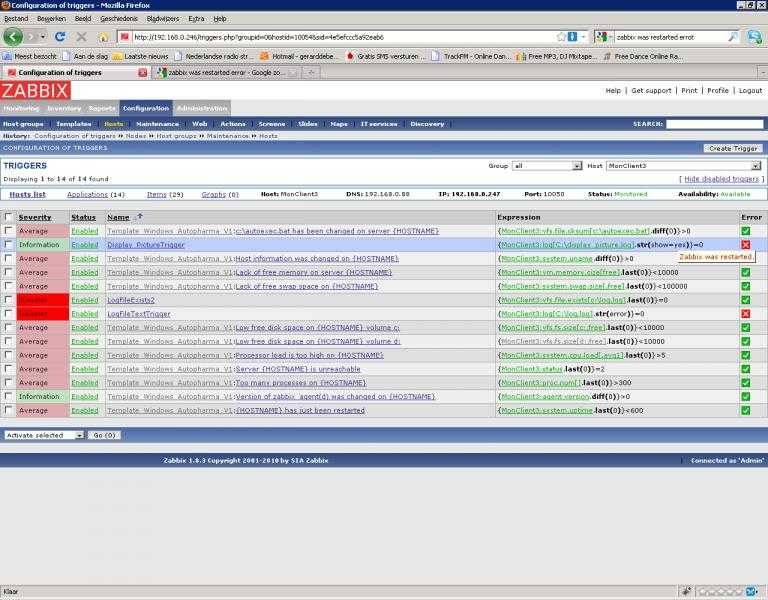
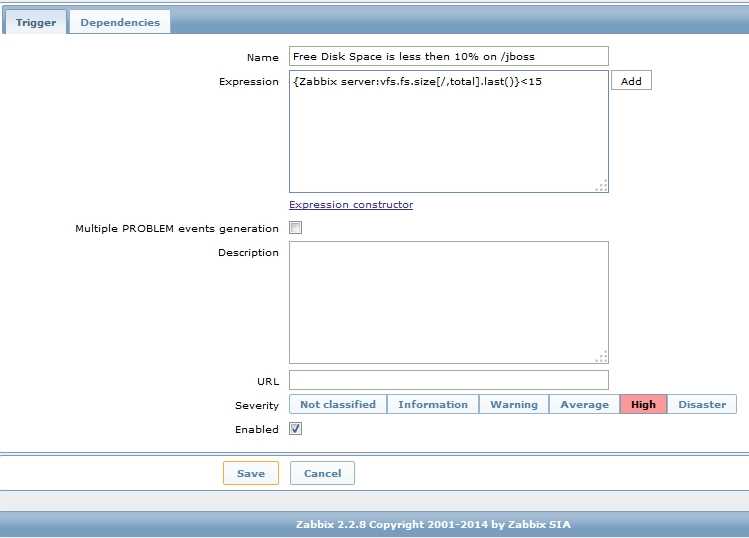
Шаблон очень простой — один элемент и один триггер, поэтому экспорт шаблона делать не буду, лучше создать вручную, чтобы точно работало на всех версиях Zabbix. Вот элемент данных.
А вот триггер к нему.
Выражение триггера:
{Intel raid with raidcfg:intelraid.sh.regexp(Failed|Disabled|Degraded|Rebuild|Updating|Critical)}=1
Если в строке будет найдено одно из слов Failed|Disabled|Degraded|Rebuild|Updating|Critical, то он сработает. Я на практике не проверял работу триггера, так как не хотелось рейд ломать. А потестил следующим образом. Добавил в проверочную строку название одного из массивов, к примеру, Storage, который встречается не на всех серверах. В итоге, триггер сработал только там, где было такое название. Так что в теории, проверка должна работать корректно.
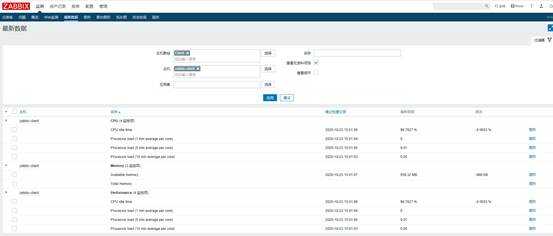
Теперь можно добавлять шаблон к необходимым хостам и ждать поступление данных. В Latest Data должны увидеть следующее содержимое итема.
![Мониторинг lsi megaraid в zabbix [enchanted technology]](https://tehnikaarenda.ru/wp-content/uploads/5/0/4/5042624846a7a12ef7c6f19fc11ffe3a.jpeg)
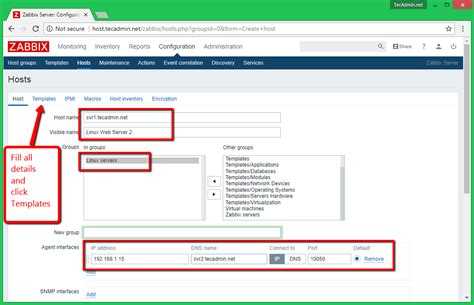
Вот и все. Теперь все intel raid массивы подключены к мониторингу.
Zabbix: LLD-мониторинг дисков без UserParameter и скриптов на агентах
В предыдущей статье я описал низкоуровневый мониторинг дисков для Windows-машин. Считаю, что статья получилась достаточно успешная. Поэтому пришло время ее фактически уничтожить. Ниже будет описан универсальный прием для Windows- и Linux-машин, для которых вообще не нужны скрипты и UserParameter’ы.
Идея простая: все необходимое от smartmontools Zabbix-сервер будет получать через внешнюю обработку и zabbix_get, парсить и передавать далее в зависимые элементы (появились в Zabbix 3.4). Такие образом не только сокращается количество обращений к наблюдаемому серверу, но и не расходуются его ресурсы, так как парсинг происходит на стороне Zabbix-сервера.
Одно ограничение на данный момент: мониторинг дисков только формата /dev/sd*. Формат /dev/csmi*,* (Intel Matrix RAID) не поддерживается ввиду того, что zabbix_get считает запятую вторым аргументом. Поправьте меня, если я ошибаюсь.
Что понадобится для реализации:
Настройка агента
Единственное, что заслуживает здесь внимания, это необходимость раскомментировать строку EnableRemoteCommands = 1, иначе агент не сможет принимать команды.
Smartmontools
Установка тривиальна и рассматриваться не будет, однако для Linux есть одна необходимость: для того, чтобы запуск проходил без sudo, необходимо установить бит SUID на файл smartctl. Для Ubuntu это — sudo chmod u+s /usr/sbin/smartctl.
Скрипт
В зависимости от вашего файла конфигурации zabbix_server.conf этот скрипт нужно положить в соответствующую директорию на Zabbix-сервер. По умолчанию для Ubuntu это — /usr/lib/zabbix/externalscripts. Не забывайте дать на файл права на выполнение — sudo chmod 775 /usr/lib/zabbix/externalscripts/smartctl.sh.
Шаблон
Ниже я постараюсь подробно описать что же происходит на каждом этапе. Первый этап: обнаружение доступных дисков sd* с помощью внешней проверки smartctl.sh с ключами и discovery. В ответ сервер получает JSON с дисками, на которых активирована функция SMART. Диски без SMART’а или не sd* не выводятся.
Третий этап: Info и Attr разбираются на зависимые элементы с помощью предобработки регулярными выражениями. Это самая простая часть. Собственно, вам только останется подогнать под себя «регулярку».
Вот и все. Не нужно держать в голове что и куда положить, отключить ли политику выполнения скриптов PS, отслеживать ту же версию PS. А в случае необходимости все изменения производятся на самом Zabbix’е в веб-интерфейсе.
В итоге хотелось бы просто сказать спасибо Алексею alexvl и его команде за качественный продукт, который не перестает радовать новым функционалом. Особенно за предобработку. Жизнь с ней администратору станет гораздо легче.
1-й способ
Скрипт создания проверочного файла
Я использую описанную выше схему для бэкапа как windows так и linux серверов. Поэтому скрипта будет 2, для каждой системы. Вот пример такого скрипта для linux:
# mcedit create-timestamp.sh #!/bin/sh echo `date +"%Y-%m-%d_%H-%M"` > /shares/docs/timestamp
Скрипт просто создает файл и записывает в него текущую дату. Нам этого достаточно. Писать туда можно все, что угодно, так как проверять мы будем не содержимое, а дату последнего изменения.
Добавляем этот скрипт в cron:
# mcedit /etc/crontab #Create timestamp for backup monitoring 1 15 * * * root /root/bin/create-timestamp.sh
Раз в день в 15:01 скрипт будет создавать файл, перезаписывая предыдущий.
Делаем то же самое на windows. Создаем файл create-timestamp.bat следующего содержания:
echo %date:~-10% > D:\documents\timestamp
И добавляем его в планировщик windows. Не забудьте указать, чтобы скрипт запускался вне зависимости от регистрации пользователя, то есть чтобы он работал, даже если в системе никто не залогинен.
Запустите оба скрипта, чтобы проверить, что все в порядке, и необходимые файлы создаются.
Запустите стандартные скрипты бэкапа, чтобы созданные файлы переместились на резервные сервера. После этого можно приступать к настройке мониторинга за изменением файлов в zabbix.
Настраиваем мониторинг бэкапов через проверку даты изменения файлов
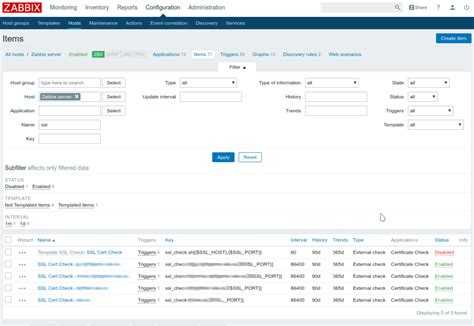
Дальше привычное дело по созданию итемов и триггеров. Идем в панель управления zabbix, открываем раздел Configuration -> Hosts, выбираем сервер, на котором у нас хранятся бэкапы и создаем там итем со следующими параметрами:
На скриншот не влезла вся строка параметра Key, поэтому привожу ее здесь:
vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify]
| /mnt/data/BackUp/xb-share/documents/timestamp | Путь к проверяемому файлу на сервере бэкапов |
| modify | Время изменения файла. Параметр может принимать значения: access — время последнего доступа, change — время последнего изменения |
Не очень понимаю, чем отличается время изменения, от времени последнего изменения. Эта информация из документации zabbix. Для того, чтобы у вас корректно собирались данные, необходимо, чтобы у пользователя zabbix были права на чтение указанного файла. Обязательно проверьте это. Я не сделал это, через одну из папок агент не мог пройти из-за недостатка прав. В итоге получил ошибку:
17177:20160321:002008.008 item "xb-share-documents:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp]" became not supported: Not supported by Zabbix Agent
Из текста не понятно, в чем проблема. Про права я догадался. Обновление итема установил раз в 10 минут (параметр update interval), чаще не вижу смысла, можно вообще поставить пару раз в сутки, в зависимости от вашего плана архивации данных.
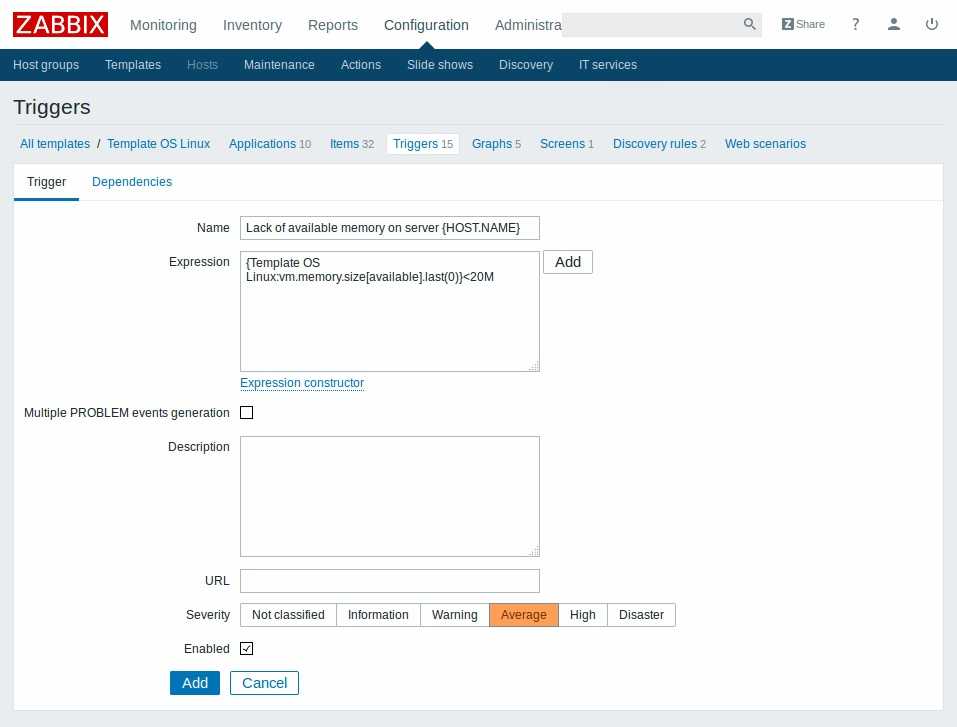
Теперь создадим триггер для этого элемента данных:
Разберем, что у нас в выражении написано:
{xm-backup:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify].now(0)}-{xm-backup:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify].last(0)}>172800
xm-backup — сервер, на котором хранятся бэкапы. Мы берем текущее время, вычитаем из него время последнего изменения файла. Если оно больше 172800 секунд (2 суток), то срабатывает триггер. Вы можете сами выбрать подходящий вам интервал времени сравнения в зависимости от плана бэкапа.
Для тестирования работы оповещений отключите в один из дней скрипты на источниках, создающие проверочный файл. Как только он просрочится, сработает триггер.

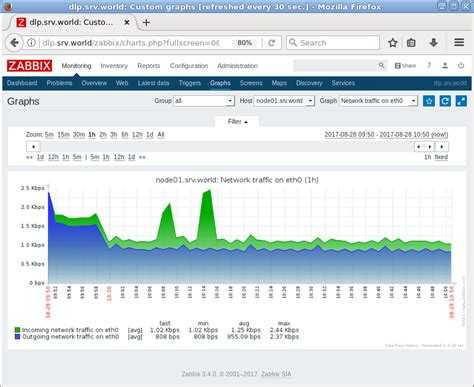
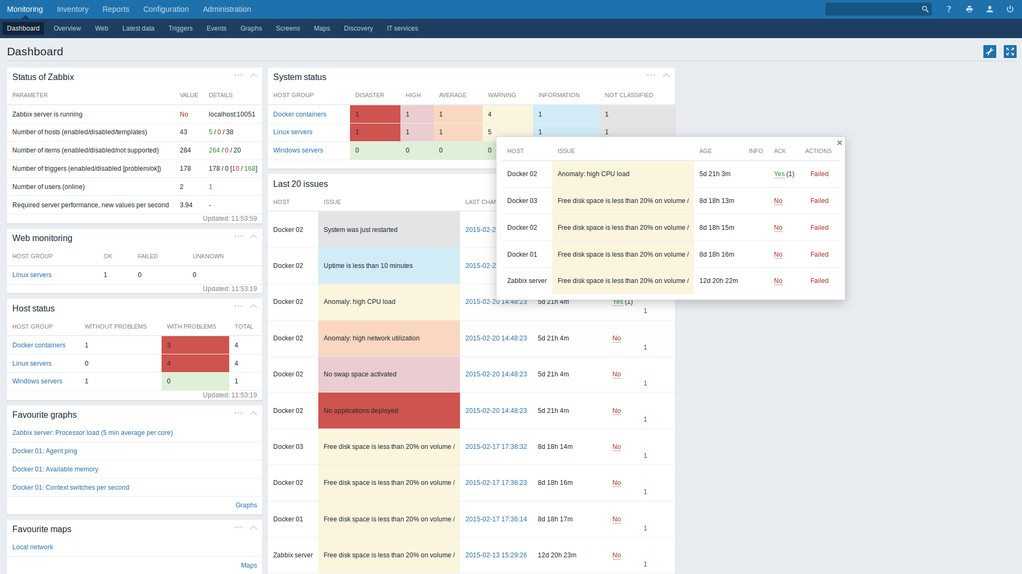
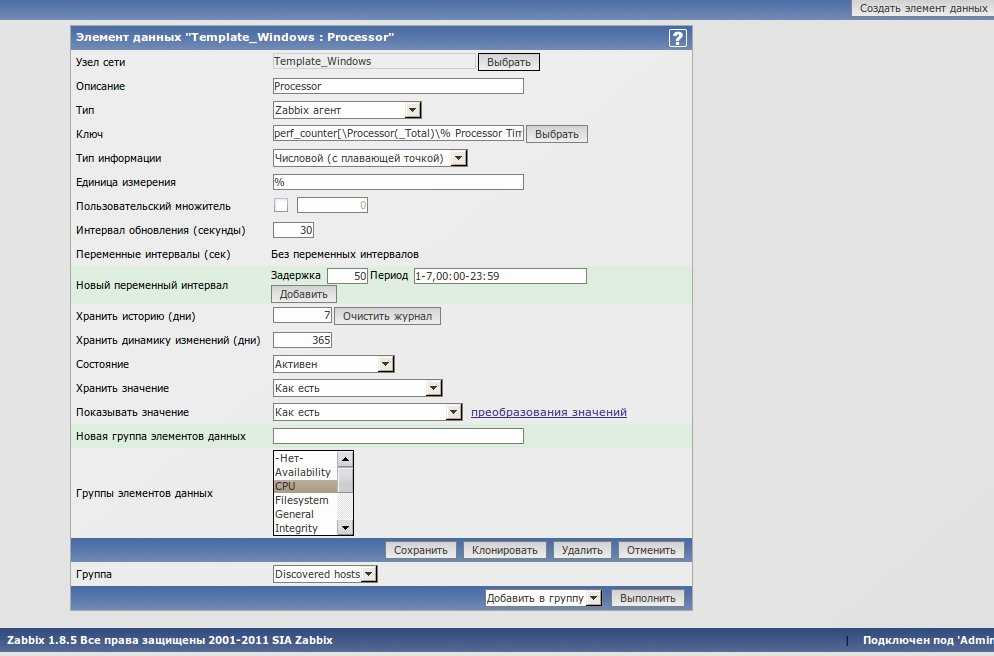
На этом все. Мы настроили простейший мониторинг бэкапов с помощью zabbix. Если по какой-то причине файлы перестанут синхронизироваться с сервером резервных копий, вы узнаете об этом и сможете вовремя обнаружить проблему.
Настройка мониторинга SMART параметров диска
На сервере нам никаких особенных настроек делать не придется. Достаточно будет загрузить готовый шаблон и применить его к интересующему нас хосту для мониторинга за диском.
Для сервера zabbix версии 3.4 используйте обновленный шаблон автора.
Интервал обновления правил автообнаружения в шаблоне 30 минут, поэтому придется подождать примерно пол часа, прежде чем какие-то новые данные по мониторингу смарта появятся на сервере. Во время отладки можете изменить этот параметр вручную в шаблоне.
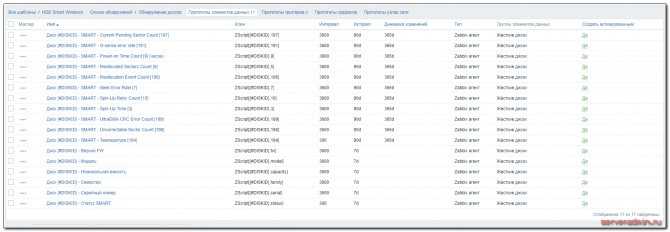
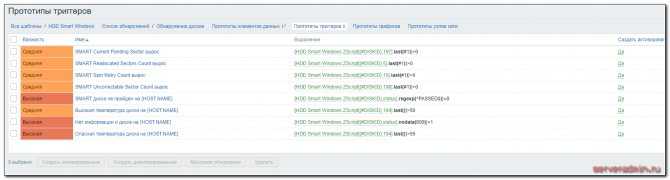
Тут же, в прототипах элементов данных, можете посмотреть остальные айтемы, их параметры и интервалы обновления. Возможно, что-то вам будет не нужно и вы отключите.
Может быть вам будет полезно чаще, чем раз в 10 минут мониторить температуру жесткого диска. В соседнем разделе посмотрите прототипы триггеров. Некоторые из них вычисляемые и начнут работать только после того, как накопится определенное количество данных. До этого они будут показывать ошибки, имейте это ввиду.
Важное замечание. Заметил уже во время написания статьи, что у меня триггер на температуру жесткого диска выставлен на значение, превышающее 52 градуса
Это достаточно много, но мне так было надо. Рекомендую снизить этот параметр до 50 или 45 градусов.
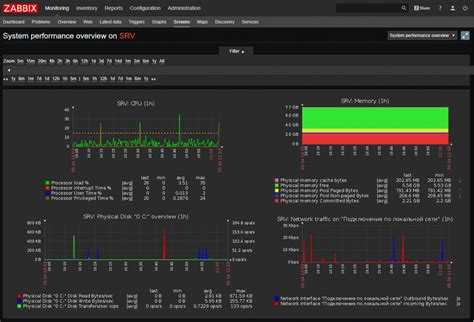
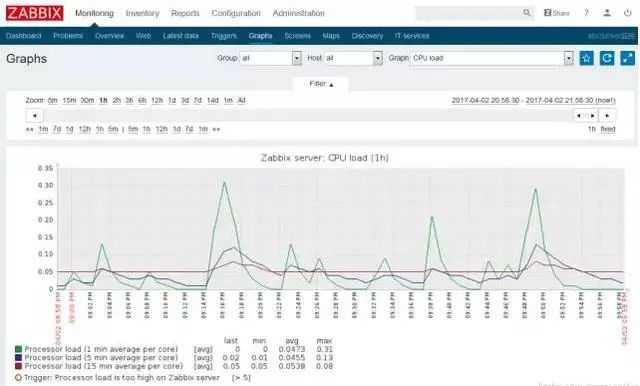
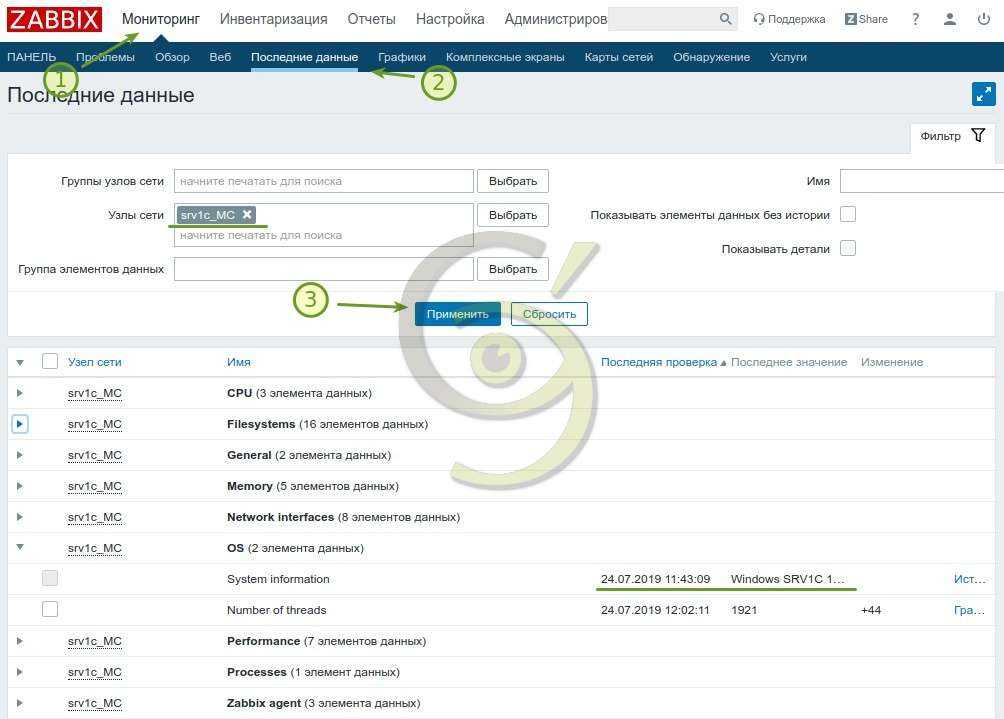
После того, как правило автообнаружения сработает и будут получены первые данные, можно их проверять в «Последние данные». Это будут значения температуры.
Скрипты для получения состояния дисков
В нашем примере мы напишем очень простой скрипт, который будет находить неправильное состояние диска. Если хотя бы один из носителей имеет тревоги по SMART или ошибки в состоянии, скрипт будет возвращать 1. Если проблем нет — 0. Сам скрипт будет написан на bash.
У меня не получилось сделать так, чтобы команда megacli нормально отрабатывала при запуске от zabbix агента, поэтому сам скрипт будет выполняться по крону и результат записывать в отдельный файл, который и будет читать агент заббикса.
Создаем каталог, в который поместим скрипт:
mkdir /scripts
Создаем файл скрипта:
vi /scripts/raid_mon_cron.sh
#!/bin/bash
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
count_errors=`megacli -PDList -Aall | grep -e «S.M.A.R.T alert : Yes» -e «Firmware state: Fail» | wc -l`
if
then
echo 1 > /scripts/scan_result
else
echo 0 > /scripts/scan_result
fi
exit 0
* это простой скрипт, который получает состояние всех дисков и проверяет, нет ли среди этих состояний тревог от SMART и состояния Failed — результат записывается в переменную count_errors в виде количества найденных проблем. Если значение данной переменной больше 0 (то есть, есть хотя бы одно состояние сбоя), скрипт записывает в файл /scripts/scan_result «1», иначе — «0».
Разрешаем запуск скрипта на выполнение:
chmod +x /scripts/raid_mon_cron.sh
Создадим задание в cron:
crontab -e
*/5 * * * * /scripts/raid_mon_cron.sh
* в данном примере мы будем запускать наш скрипт по проверке состояние дисков каждые 5 минут.
Теперь создадим скрипт, который будет запускать zabbix-agent:
vi /etc/zabbix/zabbix_agentd.d/raid_mon.sh
* обратите внимание, что скрипт создается в каталоге zabbix-агента. Если в нашей системе его нет, необходима установка — примеры установки для и
Содержимое скрипта:
#!/bin/bash
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
cat /scripts/scan_result
exit 0
* все, что делает скрипт — выводит содержимое файла /scripts/scan_result, в котором должно быть либо 0, либо 1.
Разрешаем запуск скрипта на выполнение и зададим владельца zabbix:
chmod 770 /etc/zabbix/zabbix_agentd.d/raid_mon.sh
chown zabbix:zabbix /etc/zabbix/zabbix_agentd.d/raid_mon.sh
Пробуем выполнить скрипты:
/scripts/raid_mon_cron.sh
/etc/zabbix/zabbix_agentd.d/raid_mon.sh
В зависимости от ситуации они вернут 0 или 1.
Мониторинг raid массивов в Windows Core
За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core
Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе»
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем основные инструменты:
Копируем raidcfg32.exe в c:\raidcfg32\
Проверяем корректно ли установлен драйвер: cmd.exe C:\raidcfg32\raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
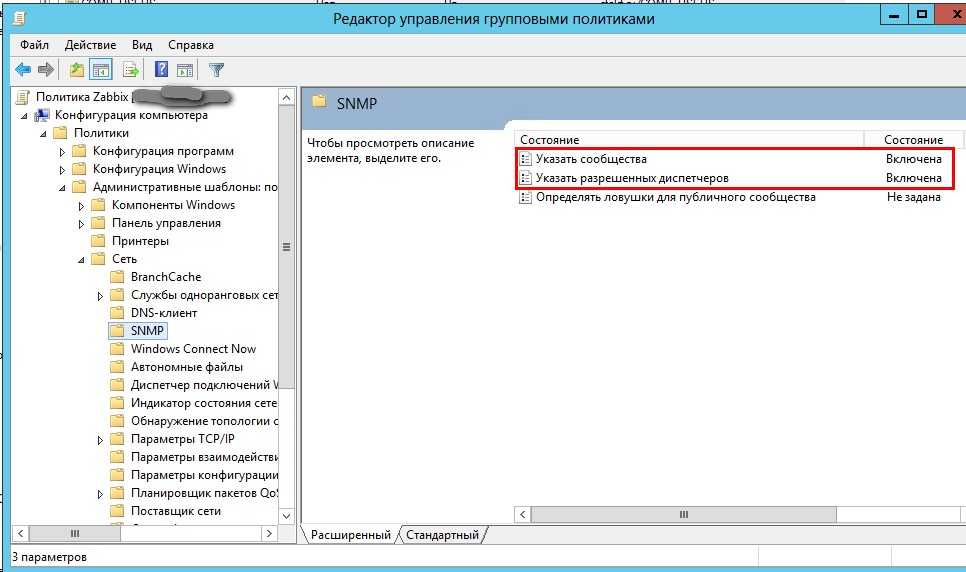
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:
UPD. По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
mdadm создание raid 1, raid 5
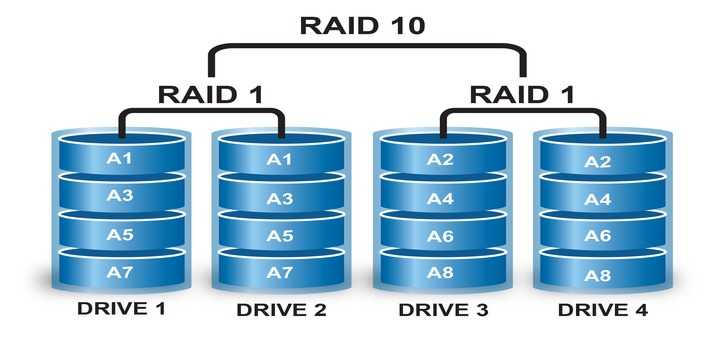
Рейд массив — RAID (redundunt array of inexpensive OR independant disks) — совокупность дисков сервера, работающих совместно и обеспечивающих избыточность по скорости записи/считывания информации или по надежности хранения данных. Для организации Raid mdadm является самым распространенным программным решением. Рассмотрим в mdadm создание массива raid 1, а также массива raid 5.
Рейды обычно реализованы аппаратно, однако часто встречаются и программные рейды. Применяются они, в частности, для хранения резервных копий данных.
Утилита позволит объединить несколько устройств в одно логическое, в процессе установки будет предложено ввести адрес электронной почты на который утилита будет отправлять сообщения в случае если программный рейд выйдет из строя.
Стандартный конфигурационный файл не имеет какой-либо настроенной конфигурации, чтобы получить функционирующий программный рейд необходимо вносить необходимые директивы самостоятельно.
Трудности при работе с mdadm могут случиться при восстановлении поврежденного элемента массива, на этапе создания рейда проблем обычно не возникает.
Изменяем таблицу разделов, прежде всего просматриваем существующие разделы
Отмонтируем устройство
Начинаем работу с ним
Выводим состояние девайса на экран
Удаляем его
Вновь смотрим, что устройства не стало. Удаление обязательным шагом не является, но лучше пересоздавать устройство каждый раз вновь
Добавляем девайс
Номер партиции
Сменим тип партиции
По умолчанию используется код 83 — Linux, сейчас выбираем fd-linux raid auto
Просматриваем внесенные изменения
Записываем их на диск
Добавляем новый диск и проделываем с ним аналогичные операции
Диск не форматируем
/dev/md0 — имя логического девайса, который мы создаем
raid-devices — количество устройств в рейде
level — тип рейд массива
Просматривая содержимое файла мы можем видеть прогресс в создании рейд массива
Данный цикл будет выводить данные о процессе создания нового устройства до тех под пока процесс не завершится.
Убедимся в том, что устройство было создано успешно
Теперь /dev/md0 выглядит для системы также как любое другое системное устройство, создадим на нем файловую систему
Проверяем, что все получилось
Добавляем созданное устройство в автозагрузку
Если в /etc/fstab (подробнее про fstab) были прописаны устройства, из которых создан программный рейд — отмонтируем их, в данном случае такое устройство одно
Используя mdadm создадим программный RAID-5
При использовании рейда 5 байты данных разделяются между дисками (первый байт пишется на диск А, второй на B, третий байт на C, вся информация записанная на первые три диска записывается на D). Таким образом реализуется защита от выхода из строя не более, чем одного жесткого диска.
Потребуется новое устройство, которое создается тем же способом, что рассматривался ранее
Вновь форматируем, монтируем устройство и размещаем данные
Читайте подробнее про утилиту fdisk, которая использовалась для работы с системными устройствами в процессе настройки
ZABBIX: мониторим состояние 3Ware RAID при помощи smartctl и tw_cli
Вступление
Имеется древний сервер на базе AMD Opteron, с hardware-raid 3Ware на борту.
Задача – мониторить состояние массива RAID (виртуальных дисков) и состояние физических дисков.
Для получения статуса будем использовать следующие утилиты командной строки:
- smartctl для определения состояния физических дисков
- tw_cli для определения состояния виртуальных дисков
Реализация
Установка драйверов 3dm2 и 3DM2_CLI остается за пределами статьи.
Настраиваем мониторинг через
Для начала нам нужно разобраться какие и сколько физических дисков установлено, какие raid массивы сконфигурированы
Смотрим контроллеры в системе:
# tw_cli info Ctl Model (V)Ports Drives Units NotOpt RRate VRate BBU ------------------------------------------------------------------------ c0 9550SX-8LP 8 8 2 0 1 1 OK Смотрим информацию по дискам для контроллера: # tw_cli info c0 Unit UnitType Status %RCmpl %V/I/M Stripe Size(GB) Cache AVrfy ------------------------------------------------------------------------------ u0 RAID-10 VERIFY-PAUSED - 31% 64K 596.025 ON ON u1 RAID-10 VERIFY-PAUSED - 11% 64K 1862.62 ON ON Port Status Unit Size Blocks Serial --------------------------------------------------------------- p0 OK u0 298.09 GB 625142448 WD-WCAPD3238373 p1 OK u0 298.09 GB 625142448 WD-WCAPD3238175 p2 OK u1 931.51 GB 1953525168 WD-WCAW36356801 p3 OK u0 298.09 GB 625142448 WD-WCAPD2763550 p4 OK u0 298.09 GB 625142448 WD-WCAPD3238222 p5 OK u1 931.51 GB 1953525168 WD-WCAW36356733 p6 OK u1 931.51 GB 1953525168 WD-WCAW36252351 p7 OK u1 931.51 GB 1953525168 WD-WCAW36329061 Name OnlineState BBUReady Status Volt Temp Hours LastCapTest --------------------------------------------------------------------------- bbu On Yes OK OK OK 255 25-Jan-2012
Нас будет интересовать колонка Status.
Для получения статуса raid, дисков или батареи используются следующие команды:
tw_cli /c0 show unitstatus tw_cli /c0 show bpustatus tw_cli /c0 show drivestatus
Пользовательский параметр назовем где в качестве параметра ключа будет передаваться , или .
Для вычисления значений будем использовать такую строчку:
/usr/local/bin/tw_cli /c0 show $1status | awk '(! /^]*$/) && (NR>3) {print $2 $3 $4}' | grep -v OK | grep -v VERIFY | wc -l
Эта команда отбрасывает пустые строки, отбрасывает первые три строки заголовка, и проверяет есть ли в полях 2, 3, 4 слово OK, если слова нет, то выдает количество таких строк.
Мониторинг через smartctl
Параметры дисков нужно смотреть вот примерно такой вот командой:
smartctl -a -d 3ware,0 /dev/twa0
Где – это физический диск, – это контроллер.
Эта команда выведет все показатели smart. Нас интересует по сути только информация об общем состоянии диска и количество сбойных секторов:
# smartctl -a -d 3ware,0 /dev/twa0 | grep overall-health | awk '{print $6}'
PASSED
# smartctl -a -d 3ware,0 /dev/twa0 | grep Reallocated_Sector_Ct | awk '{print $10}'
0
Пользовательские параметры назовем и , где “*” – номер диска.
А теперь самое интересное.. для доступа к и нужно обладать правами root. Поскольку мы не хотим, что бы zabbix имел доступ к этим жизненно важным файлам в системе, то будем использовать zabbix_trapper (запускать по cron скрипт, который будет передавать значения параметров в zabbix-сервер).
Итак, сделаем два скрипта:
/etc/zabbix/zabbix_raid_health.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#! /bin/bash
zabbix_sender='/usr/bin/zabbix_sender'
conf='/etc/zabbix/zabbix_agentd.conf'
tw_cli='/usr/local/bin/tw_cli'
controller='c0'
params="unit drive bbu"
for param in $params; do
status=`$tw_cli /$controller show $param"status"| awk '(! /^]*$/) && (NR>3) {print $2 $3 $4}' | grep -v OK | grep -v VERIFY | wc -l`
$zabbix_sender -c $conf -k raid_status$param -o $status
done
|
/etc/zabbix/zabbix_smartctl.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#! /bin/bash
zabbix_sender='/usr/bin/zabbix_sender'
conf='/etc/zabbix/zabbix_agentd.conf'
smartctl='/usr/sbin/smartctl'
controller='twa0'
disks="0 1 2 3 4 5 6 7"
for disk in $disks; do
status=`smartctl -a -d 3ware,$disk /dev/$controller | grep overall-health | awk '{print $6}'`
reallocated_sectors=`smartctl -a -d 3ware,$disk /dev/$controller | grep Reallocated_Sector_Ct | awk '{print $10}'`
$zabbix_sender -c $conf -k smart_health$disk -o $status
$zabbix_sender -c $conf -k smart_reallocated_sectors_count$disk -o $reallocated_sectors
done
|
запихиваем эти скрипты в cron (запускать каждый час):
echo "1 */1 * * * root /etc/zabbix/zabbix_raid_health.sh > /dev/null 2>&1" >> /etc/cron.d/zabbix echo "2 */1 * * * root /etc/zabbix/zabbix_smartctl.sh > /dev/null 2>&1" >> /etc/cron.d/zabbix
Далее импортируем шаблон Template_3ware_RAID.xml в zabbix и подключаем к хосту.





