
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
# zabbix_agent -t service_state service_state
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Мониторинг подключений (авторизаций) в Mikrotik
Логи с устройств мы собрали в одном месте. Теперь будем их анализировать и отправлять уведомления при каждом подключении к Mikrotik через Winbox. Я для этого сделал отдельный шаблон, где созданы элементы данных типа Журнал (лог) для анализа лог файла от каждого устройства.
Для каждого элемента данных есть триггер, который с помощью регулярного выражения анализирует лог файл и срабатывает тогда, когда видит строки с подключением к микротику через winbox. Имя триггера формируется таким образом, чтобы в нем была информация об имени пользователя и ip адрес, с которого он подключился.
Я не стал делать в шаблоне автообнаружение. Настраивал это в системах до 10-ти точек и мне банально было лень это делать, хотя и не сложно. Я просто копировал и исправлял итемы и триггеры, меняя ip адреса устройств. Для автообнаружения надо скрипт на сервер класть, который будет передавать список логов в мониторинг. А если руками делать, то можно все на сервере в шаблоне добавлять.
Итак, создаем простой итем.
К итему делаем триггер.
Вот и все. Прикрепляйте шаблон к хосту, на котором находится сам лог файл и проверяйте. В первую очередь смотрите, чтобы в Latest Data появилось содержимое лога.
Если триггеры настроены правильно, то при каждом подключении по Winbox вы будете получать уведомление на почту.
И еще одно после отключения.
Такой несложный механизм мониторинга за подключениями. Я отслеживаю именно подключения по winbox. Вы можете это изменить, добавив и другие типы подключения. Для этого надо изменить регулярное выражение в триггере.
Пример моего шаблона с двумя микротиками — zabbix-mikrotik-logs.xml. Если у вас много устройств, настройте автообнаружение лог файлов, чтобы автоматически создавать итемы и триггеры. Пример настройки автообнаружения в Zabbix можете посмотреть на примере мониторинга openvpn подключений. Там как раз показан очень похожий пример, когда анализируется список файлов в директории и передается в zabbix server.
На этом по мониторингу микротиков в Zabbix у меня все. По идее, рассмотрел все актуальные задачи по этой теме.
Отправка логов Mikrotik в syslog
Первым делом настроим сбор логов с микротиков на любой syslog сервер. В моем случае это будет сам сервер мониторинга на базе rsyslog и centos 7, но это не принципиально. Главное, чтобы на нем был zabbix-agent, который будет отправлять логи микротиков на заббикс сервер.
Для этого в rsyslog включим возможность слушать udp port 514. Открываем конфиг /etc/rsyslog.conf и раскомментируем там строки:
$ModLoad imudp
$UDPServerRun 514
|
1 2 |
$ModLoad imudp $UDPServerRun514 |
Дальше в этом же файле в самом начале перечисления правил, добавляем свое.
$template FILENAME,»/var/log/mikrotik/%fromhost-ip%.log»
if $fromhost-ip != ‘127.0.0.1’ then ?FILENAME
& stop
|
1 2 3 |
$template FILENAME,»/var/log/mikrotik/%fromhost-ip%.log» if$fromhost-ip!=’127.0.0.1’then?FILENAME &stop |
Данное правило будет автоматически раскладывать все логи с удаленных устройств по файлам в директории /var/log/mikrotik с именами в виде IP адресов. При этом не будет создан лог 127.0.0.1.log, куда бы складывались все локальные лог файлы. В своей предыдущей статье я не учитывал этот нюанс, что приводило к дублированию всех локальных логов. Сейчас я это исправляю.
Сразу же настроим ротацию лог файлов, чтобы они не забили нам весь диск. Для этого создаем конфиг для logrotate в файле /etc/logrotate.d/mikrotik примерно следующего содержания:
/var/log/mikrotik/*.log {
weekly
rotate 12
compress
olddir /var/log/mikrotik/old
missingok
notifempty
create 0640 root zabbix
}
|
1 2 3 4 5 6 7 8 9 |
varlogmikrotik*.log{ weekly rotate12 compress olddirvarlogmikrotikold missingok notifempty create0640root zabbix } |
Я ротирую файлы логов раз в неделю, сразу сжимаю и кладу их в директорию /var/log/mikrotik/old, где будут храниться 12 последних версий файла.
Не забудьте создать указанные директории и дать пользователю zabbix права на чтение. Потом проследите, чтобы у самих логов тоже были права на чтение для zabbix
Это важно, так как агент должен их читать
После завершения настройки, надо перезапустить rsyslog.
# systemctl restart rsyslog
| 1 | # systemctl restart rsyslog |
Отправляемся на Mikrotik и настраиваем отправку логов на наш syslog сервер. Для этого переходите в раздел System -> Logging -> Actions и добавляйте новое действие.
Дальше открывайте вкладку Rules и добавляйте темы логов, которые вы будете отправлять в Zabbix. Для мониторинга за логинами достаточно темы System.
Чтобы проверить отправку логов, достаточно тут же в Mikrotik открыть новый терминал. Создастся событие в логе, который улетит на удаленный сервер. На сервере с rsyslog будет создан лог файл с содержимым.
Если у вас так же, можно двигаться дальше. Если же логи не поступают на syslog сервер, разбирайтесь в чем может быть причина. Первым делом проверьте настройки firewall. Убедитесь, что доступ к udp порту 514 есть. Дальше проверьте, что ваш rsyslog сервер реально слушает этот порт.
Проверки
Для описания системы мониторинга Zabbix существует два ключевых понятия:
- Узлы сети — рабочие устройства и их группы (сервера, рабочие станции, коммутаторы), которые необходимо проверять. С создания и настойки узлов сети обычно начинается практическая работа с Zabbix.
- Элементы данных — набор самостоятельных метрик, по которым происходит сбор данных с узлов сети. Настройка элементов данных производится на вкладке «Элемент данных» или в автоматическом режиме — через подключение шаблона.
Сам Zabbix-агент способен отражать текущее состояние физического сервера, собирая совокупность данных. У него достаточно много метрик. С их помощью можно проверить загруженность ядра (Processor load), время ожидания ресурсов (CPU iowait time), объем системы подкачки (Total swap space) и многое другое.
В Zabbix существует целых 17 способов, дающих возможность собирать информацию. Указанные ниже, входят в число наиболее часто применяемых.
- Zabbix agent (Zabbix-агент) — сервер собирает информацию у агента самостоятельно, подключаясь по определенному интервалу.
- Simple check (Простые проверки) — простые операции, в том числе пинг.
- Zabbix trapper (Zabbix-траппер) — сбор информации с трапперов, представляющих собой мосты между используемыми сервисами и самой системой.
- Zabbix aggregate (Zabbix-комплекс) — процесс, предусматривающий сбор совокупной информации из базы данных.
- SSH agent (SSH-агент) — система подключается по SSH, использует указанные команды.
- Calculate (Вычисление) — проверки, которые система производит, сопоставляя имеющиеся данные, в том числе после предыдущих сборов.
У проверок есть заданные шаблоны (Templates), которые упрощают создание новых. Кроме обычных операций существует возможность регулярно проверять доступность веб-сервера с помощью имитации запросов браузера.
Проверка через пользовательский параметр
Чтобы выполнить проверку через агент, нужно прописать соответствующую команду в конфигурационный файл Zabbix-агента в качестве пользовательского параметра (UserParameter). Сделать это можно с помощью выражения следующего вида:
UserParameter=<ключ>,<команда>
Помимо самой команды, приведенный синтаксис содержит уникальный (в пределах узла сети) ключ элемента данных, который надо придумать самостоятельно и сохранить. В дальнейшем, ключ можно использовать для ссылки на команду, внесенную в пользовательский параметр, при создании элемента данных.
Пример
UserParameter=ping,echo 1
С помощью данной команды можно настроить агент на постоянное возвращение значения «1» для элемента данных с ключем «ping».
Testing
zabbix_get -s 192.0.2.1 -k smartctl.discovery
Default operation mode. Displays json that server should get, detaches, then waits and sends data with zabbix-sender. is your field in zabbix.
zabbix_get -s 192.0.2.1 -k smartctl.discovery
Verbose mode. Does not detaches or prints LLD. Lists all items sent to zabbix-sender, also it is possible to see sender output in this mode.
Note: before scripts would work, zabbix server must first discover available items. It is done in 12 hour cycles by default. You can temporary decrease this parameter for testing in . In this monitoring solution update interval must not be less than 80 seconds.
These scripts were tested to work with following configurations:
- Centos 7 / Zabbix 3.0 / Python 3.6
- Debian 9 / Zabbix 3.0 / Python 3.5
- Ubuntu 17.10 / Zabbix 3.0 / Python 3.6
- FreeBSD 12.1 / Zabbix 4.2 / Python 3.7
- Windows XP / Zabbix 3.0 / Python 3.4
- Windows 7 / Zabbix 3.0 / Python (3.4, 3.7, 3.8)
- Windows Server 2012 / Zabbix 3.0 / Python 3.7
Дополнительные материалы по Zabbix
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
# zabbix_agentd -t proc.num proc.num
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных срабатываем.
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Installation
As prerequisites you need , , and packages. For testing, is also required.
Take a look at scripts first lines and provide paths if needed. If you have a RAID configuration, also provide that by hand. Choose or mode. Import in zabbix web interface.
Prerequisites
Debian
apt-get install zabbix-agent zabbix-sender smartmontools sudo python3-setuptools apt-get install zabbix-get # testing
Centos
yum install zabbix-agent zabbix-sender smartmontools sudo python3-setuptools yum install zabbix-get # testing
Placing the files
Linux
sudo python3 setup.py install sudo cp /usr/share/doc/examples/zabbix-smartmontools/sudoers.d/zabbix /etc/sudoers.d/zabbix sudo cp /usr/share/doc/examples/zabbix-smartmontools/zabbix-smartmontools.conf /etc sudo install -m 644 Linux/zabbix_agentd.d/userparameter_smartctl.conf /etc/zabbix/zabbix_agentd.conf.d/
FreeBSD
sudo python3 setup.py install sudo cp /usr/local/share/examples/zabbix-smartmontools/sudoers.d/zabbix /usr/local/etc/sudoers.d/zabbix sudo cp /usr/local/share/examples/zabbix-smartmontools/zabbix-smartmontools.conf /usr/local/etc sudo install -m 644 BSD/zabbix_agentd.conf.d/userparameter_smartctl.conf /usr/local/etc/zabbix42/zabbix_agentd.conf.d/
Windows
python setup.py install move zabbix-smartmontools.conf C:\zabbix-agent\ move Win\zabbix_agentd.conf.d\userparameter_smartctl.conf C:\zabbix-agent\zabbix_agentd.conf.d\
Finalizing
Then you need to include your zabbix conf folder in , like this:
That’s all for Windows. For others run the following to finish configuration:
sudo vim /etc/zabbix/zabbix-smartmontools.conf # Review settings sudo visudo # test sudoers configuration, type :q! to exit
Installation
Linux/BSD/Mac OSX
- Make sure that smartmontools package is installed
- (optional) Install if you need to monitor hardware RAIDs. See #29
- (optional) Install if you need to monitor NVMe devices.
- Copy the following contents of file to :
- Copy to
- Copy script to
- Test the discovery script by running it as sudo. You should receive JSON object in the script output.
- Restart zabbix-agent
You can create .deb package for Debian/Ubuntu distributions:
dpkg-buildpackage -tc -Zgzip
Ansible Role
There is an ansible role available in this repo, feel free to try it.
To build the role run create_ansible_role.sh script then copy ansible-role-zabbix-smartctl to your ansible/roles directory
- Copy script to folder
- Copy file to folder
- Restart Zabbix Agent service
- Test items
Настройка на сервере Zabbix
Теперь идем на сервер мониторинга и настраиваем на нем все, что необходимо для мониторинга mdadm. Нам нужно будет создать шаблон, в нем один item и один trigger. Создаем шаблон: Configuration -> Templates -> Create template.
Пишем название, добавляем в группу и сохраняем. Открываем созданный шаблон, переходим в Items и создаем новый.
Заполняем параметры как у меня и жмем add.
Я установил интервал обновления этого параметра в 3600 секунд, то есть раз в час. Не вижу смысла проверять его чаще. В этом нет практической пользы.
Теперь добавим триггер, который будет срабатывать, если с рейдом проблемы. Переходим на список триггеров, жмем Create trigger и заполняем значения.
Добавляем триггер. На этом настройка шаблона закончена. Можно назначить шаблон всем хостам, на которых мы добавили UserParameter и ждать, когда в Last Data появятся первые значения. Я на момент отладки на всякий случай поставил сбор данных каждые 60 секунд. Когда убедился, что все работает, изменил это значение обратно на 3600.
Создание триггера на событие из лога
Мы будем слать оповещение не только в момент отключения электричества, но и тогда, когда оно снова появится. Так что в триггере будут два условия:
- Условие активации события.
- И условие его прекращения.
Открываем вкладку с триггерами хоста и добавляем туда новый триггер со следующими параметрами:
| Name | Имя триггера. Может быть любым. |
| Problem expression | {xm-xen02:log[/var/log/apcupsd.events].str(Power failure.)}=1 |
| Recovery expression | {xm-xen02:log[/var/log/apcupsd.events].str(Power is back.)}=1 |
Рассказываю подробнее, что тут написано. xm-xen02 — имя сервера. Power failure. — строка в лог файле, которая появляется при отключении электричества. Когда оно возвращается, появляется запись Power is back. В общем виде лог выглядит примерно следующим образом:
2016-11-07 23:17:23 +0300 Power failure. 2016-11-07 23:17:29 +0300 Running on UPS batteries. 2016-11-07 23:21:20 +0300 Mains returned. No longer on UPS batteries. 2016-11-07 23:21:20 +0300 Power is back. UPS running on mains. 2016-11-16 14:20:42 +0300 Power failure. 2016-11-16 14:20:48 +0300 Running on UPS batteries. 2016-11-16 14:20:51 +0300 Mains returned. No longer on UPS batteries. 2016-11-16 14:20:51 +0300 Power is back. UPS running on mains.
Становится понятно, почему я взял именно эти строки. На этом все. После сохранения триггера он начнет работать и следить за итемом, который собирает строки из лога. Как только появятся строки, попадающие под условие, вы получите оповещение.
Шаблон для мониторинга за intel raid
Шаблон очень простой — один элемент и один триггер, поэтому экспорт шаблона делать не буду, лучше создать вручную, чтобы точно работало на всех версиях Zabbix. Вот элемент данных.
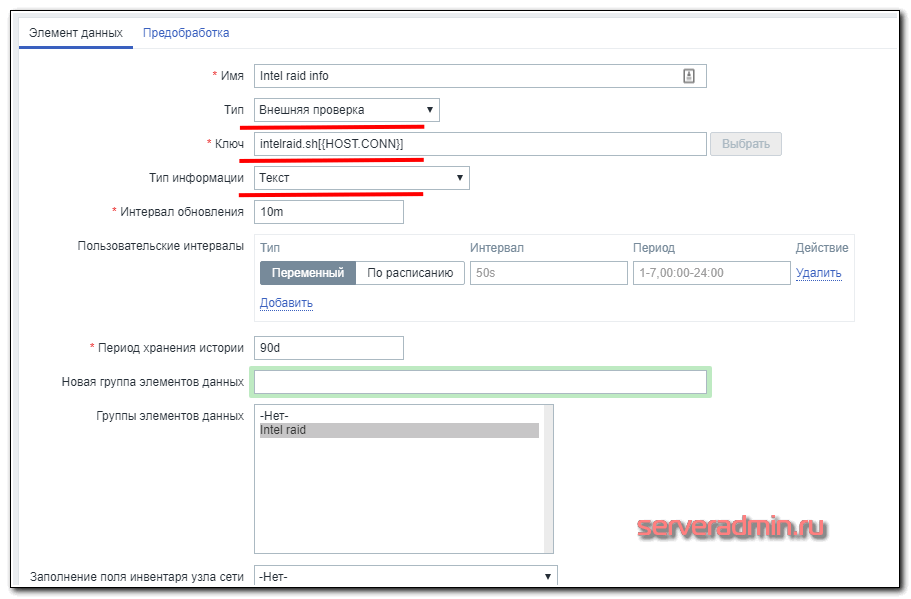
А вот триггер к нему.
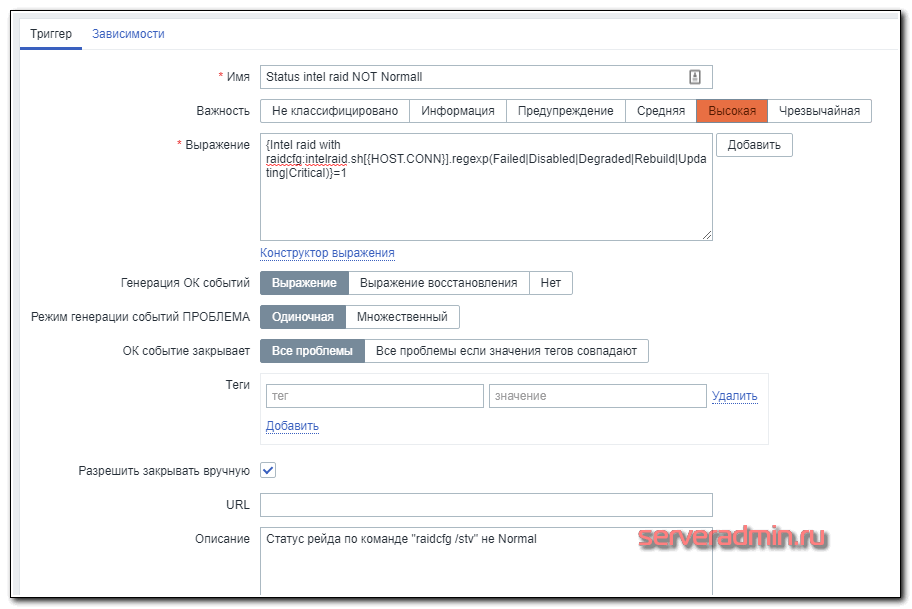
Выражение триггера:
{Intel raid with raidcfg:intelraid.sh.regexp(Failed|Disabled|Degraded|Rebuild|Updating|Critical)}=1
Если в строке будет найдено одно из слов Failed|Disabled|Degraded|Rebuild|Updating|Critical, то он сработает. Я на практике не проверял работу триггера, так как не хотелось рейд ломать. А потестил следующим образом. Добавил в проверочную строку название одного из массивов, к примеру, Storage, который встречается не на всех серверах. В итоге, триггер сработал только там, где было такое название. Так что в теории, проверка должна работать корректно.
Теперь можно добавлять шаблон к необходимым хостам и ждать поступление данных. В Latest Data должны увидеть следующее содержимое итема.
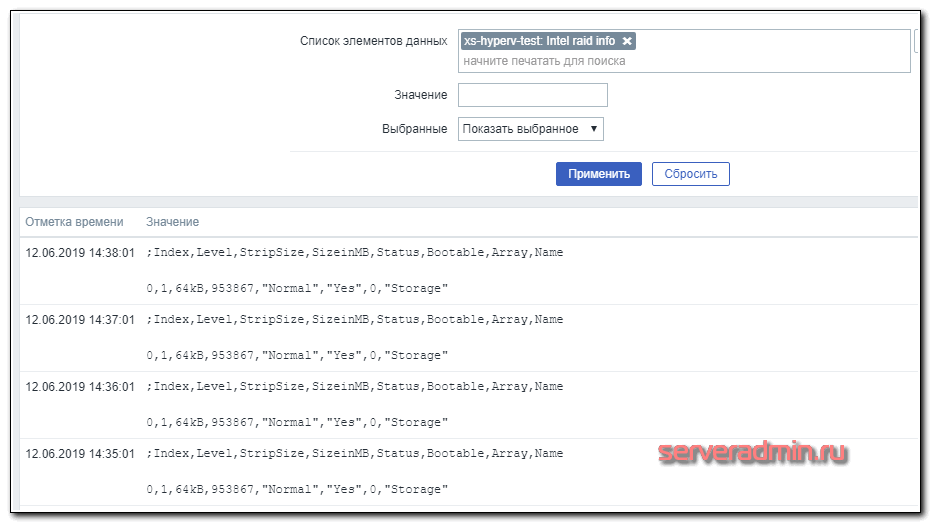
Вот и все. Теперь все intel raid массивы подключены к мониторингу.
Подготовка zabbix agent
Мониторинг значений SMART жесткого диска будет выполняться с помощью smartmontools. Установить их можно следующей командой для CentOS:
# yum install smartmontools
Либо аналогично в Debian/Ubuntu
# apt install smartmontools
Далее нам понадобится скрипт на perl для автообнаружения дисков и вывода информации о них в JSON формате, который понимает заббикс. Создадим такой скрипт.
# mcedit /etc/zabbix/scripts/smartctl-disks-discovery.pl
#!/usr/bin/perl
#must be run as root
$first = 1;
print "{\n";
print "\t\"data\":[\n\n";
for (`ls -l /dev/disk/by-id/ | cut -d"/" -f3 | sort -n | uniq -w 3`)
{
#DISK LOOP
$smart_avail=0;
$smart_enabled=0;
$smart_enable_tried=0;
#next when total 0 at output
if ($_ eq "total 0\n")
{
next;
}
print "\t,\n" if not $first;
$first = 0;
$disk =$_;
chomp($disk);
#SMART STATUS LOOP
foreach(`smartctl -i /dev/$disk | grep SMART`)
{
$line=$_;
# if SMART available -> continue
if ($line = /Available/){
$smart_avail=1;
next;
}
#if SMART is disabled then try to enable it (also offline tests etc)
if ($line = /Disabled/ & $smart_enable_tried == 0){
foreach(`smartctl -i /dev/$disk -s on -o on -S on | grep SMART`) {
if (/SMART Enabled/){
$smart_enabled=1;
next;
}
}
$smart_enable_tried=1;
}
if ($line = /Enabled/){
$smart_enabled=1;
}
}
print "\t{\n";
print "\t\t\"{#DISKNAME}\":\"$disk\",\n";
print "\t\t\"{#SMART_ENABLED}\":\"$smart_enabled\"\n";
print "\t}\n";
}
print "\n\t]\n";
print "}\n";
Сохраняем скрипт и делаем исполняемым.
# chmod u+x smartctl-disks-discovery.pl
Выполняем скрипт и проверяем вывод. Должно быть примерно так с двумя дисками.
{
"data":
}
В данном случае у меня 2 физических диска — sda и sdb. Их мы и будем мониторить.
Настроим разрешение для пользователя zabbix на запуск этого скрипта, а заодно и smartctl, который нам понадобится дальше. Для этого запускаем утилиту для редактирования /etc/sudoers.
# visudo
Добавляем в самый конец еще одну строку:
zabbix ALL=(ALL) NOPASSWD:/usr/sbin/smartctl,/etc/zabbix/scripts/smartctl-disks-discovery.pl
Сохраняем, выходим  Это если вы умеете работать с vi. Если нет, то загуглите, как работать с этим редактором. Именно он запускается командой visudo.
Это если вы умеете работать с vi. Если нет, то загуглите, как работать с этим редактором. Именно он запускается командой visudo.
Проверим, что пользователь zabbix нормально исполняет скрипт.
# chown zabbix:zabbix /etc/zabbix/scripts/smartctl-disks-discovery.pl # sudo -u zabbix sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Вывод должен быть такой же, как от root. Если вам не хочется разбираться с этими разрешениями, либо что-то не получается, можете просто запустить zabbix-agent от пользователя root и проверить работу в таком режиме. Сделать это не трудно, данный параметр закомментирован в конфигурации агента. Вам достаточно просто снять комментарий и перезапустить агент.
После настройки скрипта автообнаружения, добавим необходимые UserParameters для мониторинга SMART. Для этого создадим отдельный конфигурационный файл. Для версии 3.2 и ниже он будет выглядеть вот так.
# mcedit /etc/zabbix/zabbix_agentd.d/smart.conf
UserParameter=uHDD,sudo smartctl -A /dev/$1| grep -i "$2"| tail -1| cut -c 88-|cut -f1 -d' ' UserParameter=uHDD.model.,sudo smartctl -i /dev/$1 |grep -i "Device Model"| cut -f2 -d: |tr -d " " UserParameter=uHDD.sn.,sudo smartctl -i /dev/$1 |grep -i "Serial Number"| cut -f2 -d: |tr -d " " UserParameter=uHDD.health.,sudo smartctl -H /dev/$1 |grep -i "test"| cut -f2 -d: |tr -d " " UserParameter=uHDD.errorlog.,sudo smartctl -l error /dev/$1 |grep -i "ATA Error Count"| cut -f2 -d: |tr -d " " UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Версия настроек для агента 3.4
UserParameter=uHDD.A,sudo smartctl -A /dev/$1 UserParameter=uHDD.i,sudo smartctl -i /dev/$1 UserParameter=uHDD.health,sudo smartctl -H /dev/$1 || true UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
Сохраняем файл и перезапускаем zabbix-agent.
# systemctl restart zabbix-agent
Проверяем, как наш агент будет отдавать данные. Ключ uHDD.discovery будет одинаковый для обоих версий агента.
# zabbix_agentd -t uHDD.discovery
Вы должны увидеть полный JSON вывод с информацией о ваших диска. Теперь посмотрим, как передаются информация о smart. Запросим температуру дисков для версии 3.2.
# zabbix_agentd -t uHDD uHDD
Все в порядке. Можете погонять еще какие-нибудь параметры из смарта, но скорее всего все будет работать, если хотя бы один параметр работает. На этом настройка на агенте закончена, переходим к настройке сервера мониторинга.
Дополнительные материалы по Zabbix
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Заключение
Вот такую реализацию я придумал, когда потребовалось решить задачу. Один сервер постоянно донимал оповещениями по ночам. Нужно было понять, что его дергает в это время. Жаль, что у Zabbix из коробки нет реализации подобного информирования. Помню лет 5 назад был бесплатный тариф у мониторинга NewRelic. Можно было поставить агент мониторинга на сервер и потом смотреть очень удобные отчеты в веб интерфейсе. Никаких настроек не нужно было, все работало из коробки. Там были отражены все запущенные процессы на сервере на временном ряду со всеми остальными метриками. Это было очень удобно. Я нигде в бесплатном софте не видел такой реализации. Это примерно вот так выглядело.
Кстати, в первоначальной версии действия я просто отправлял список процессов на почту. Мне показалось это удобным. Можно было сразу же в почте, в соседнем письме с триггером, посмотреть список процессов. Но потом решил, что удобнее все же хранить историю в одном месте на сервере и настроил сбор данных туда. Хотя можно делать и то, и другое. Например, в действии можно указать другую команду к исполнению:
# ps aux --sort=-pcpu,+pmem | awk 'NR<=10' | mail -s "Process List" zabbix@mail.ru
И вам на почту придет список запущенных процессов после активации триггера.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .



