
Введение
Я буду использовать очень простую проверку. В интернете находится много рецептов по мониторингу asterisk с помощью zabbix. Есть готовые наборы скриптов на питоне, есть шаблоны. Можно настроить мониторинг практически всего, что только пожелаешь.
Мне не хотелось во всем этом разбираться и нагромождать в систему, так как нужно только состояние транков — зарегистрирован или нет. Усложнять чем-то еще свои системы мониторинга не хотелось. Больше никакие данные мне не нужны. Я стараюсь настраивать мониторинг только тех параметров, которые реально необходимы. Это позволяет экономить время и ресурсы сервера.
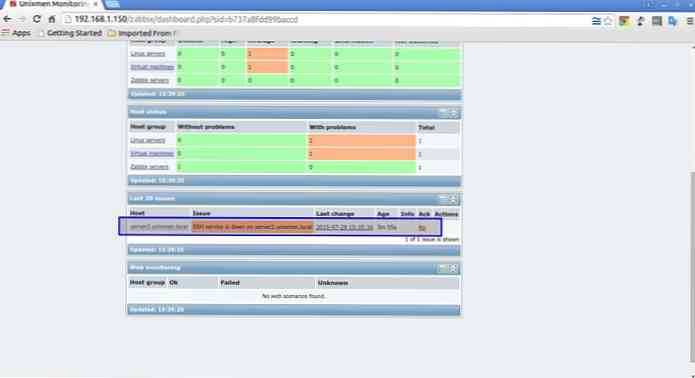
С помощью простого sh скрипта я буду проверять суммарное количество транков в системе и сравнивать это число с числом зарегистрированных транков. Если разница этих чисел будет отлична от нуля, значит как минимум одна регистрация отвалилась. Нужно на всякий случай проверить сервер и выяснить причину.
После этой проверки можно тем же скриптом и перезапустить регистрации, но я в статье ограничусь только мониторингом состояния. Лично мне перезапуск в данном случае не нужен, так как ситуации бывают редко и я хочу сам проверить, почему регистрации отвалились.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
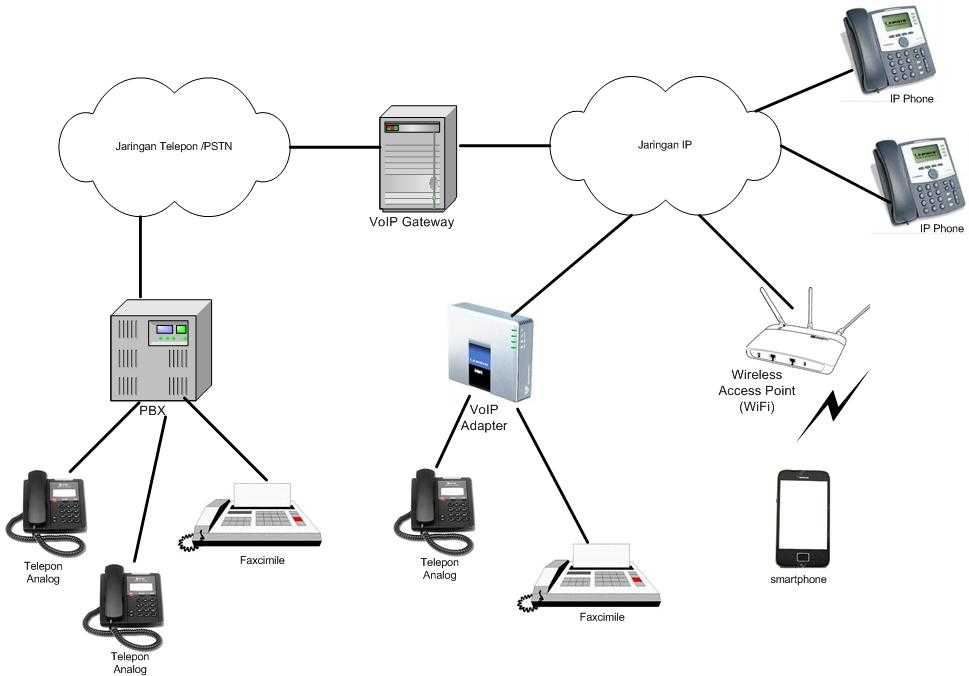
Если у вас есть вопросы по настройке Asterisk, рекомендую мою очень подробную статью на эту тему. Там разобран на примерах основаной функционал современной ip атс.
Для отладки и тестирования работы voip я рекомендую сервис Zadarma. Плюс его в том, что после регистрации вы получите настройки пира для внутренней сети оператора. И внутри этой сети вы можете бесплатно звонить. Например, я одного пира регистрирую на sip клиенте смартфона и с него звоню на второй аккаунт, пир от которого настроен в астериске. Таким образом эмулирую внешний звонок. Удобно отлаживать различные конфигурации звонков, не требуя платного подключения.
Настройка zabbix-agent

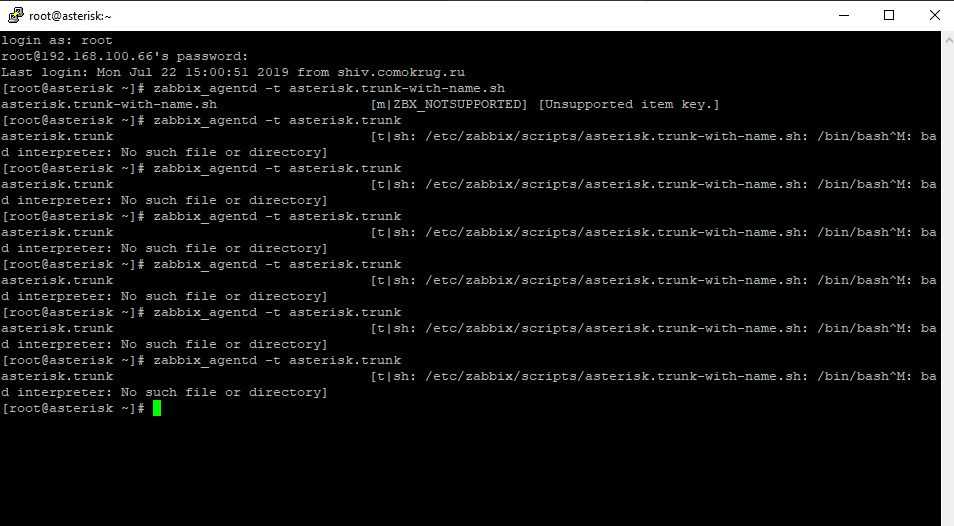
Для мониторинга за asterisk, я буду использовать один скрипт и несколько обработанных выводов из запросов к астериску. Начнем со скрипта. Он будет проверять статус транков и если какой-либо из них будет в offline, назовет его. Кладем этот скрипт в директорию /etc/zabbix/scripts.
# cat /etc/zabbix/scripts/asterisk.trunk-with-name.sh
#!/bin/bash
# Получаем количество всех транков в системе
total=`sudo asterisk -rx 'sip show registry' | sed -n '/registrations/p' | awk '{print $1}'`
# Получаем число активных транков
active=`sudo asterisk -rx 'sip show registry' | sed -n '/Registered/p' | wc -l`
# Получаем имена транков с проблемам
offline=`sudo asterisk -rx 'sip show registry' | sed -n '/Request|Rejected|Authentication|Auth/p' | awk '{print $3}'`
# Сравниваем общее число с числом активных транков и выводим сообщение об их состоянии
if
then
echo Trunks offline $offline
else
echo All trunks are online
fi
Я все прокомментировал. Добавлю только пояснение к регулярке, которая определяет проблемные транки. Я знаком со следующими состояниями транков, когда они не работают:
- Request Sent
- No Authentication
- Auth. Sent
- Rejected
Соответственно, эти состояния я и ищу. Если один из транков находится в одном из этих состояний, то он считается проблемным.
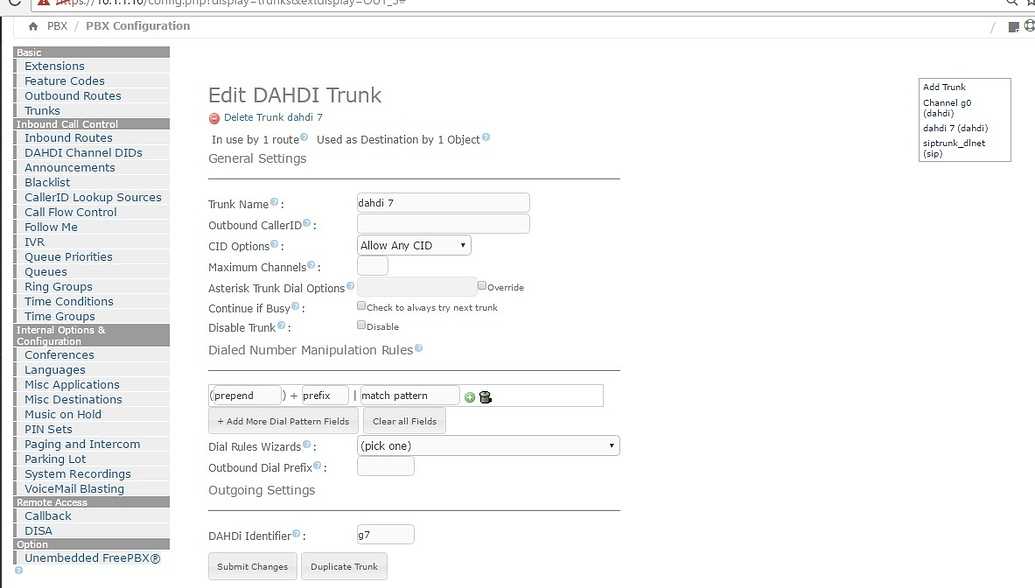
Далее создаем файл конфигурации zabbix с UserParameters в /etc/zabbix/zabbix_agentd.d.
# cat /etc/zabbix/zabbix_agentd.d/asterisk.conf
# Статус службы fail2ban
UserParameter=asterisk.fail2ban_status,ps cax | grep fail2ban | wc -l
# Количество цепочек fail2ban в iptables
UserParameter=asterisk.fail2ban_chain,iptables -nL | grep Chain | grep -E 'f2b|fail2ban' | wc -l
# Время работы службы asterisk
UserParameter=asterisk.uptime,asterisk -rx "core show uptime seconds" | grep --text -i "System uptime:" | gawk '{print $3}'
# Количество активных разговоров
UserParameter=asterisk.active_calls,asterisk -rvvvvvx 'core show channels'| grep --text -i 'active call'| cut -c1
# Статус транков
UserParameter=asterisk.trunk,/etc/zabbix/scripts/asterisk.trunk-with-name.sh
# Статус службы asterisk
UserParameter=asterisk.asterisk_status,ps cax | grep asterisk | wc -l
Некоторые из приведенных метрик требуют права root для своего исполнения. Скажу честно, мне было лениво разбираться с разрешениями и я просто запустил zabbix с правами root. Для этого в его конфиге /etc/zabbix/zabbix_agentd.conf раскомментировал следующую строку:
AllowRoot=1
После этого можно перезапустить zabbix-agent и проверить работу будущих итемов.
# systemctl restart zabbix-agent
Проверяем, насколько корректно агент возвращает указанные значения.
# zabbix_agentd -t asterisk.asterisk_status asterisk.asterisk_status
# zabbix_agentd -t asterisk.fail2ban_chain asterisk.fail2ban_chain
# zabbix_agentd -t asterisk.trunk asterisk.trunk
Все в порядке. В завершении настройки агента, поясню некоторые моменты для тех, кто не очень разбирается в bash скриптах. Для мониторинга статусов служб я просто вывожу список всех процессов, вычленяю из него нужный мне процесс, в данном случае asterisk или fail2ban и подсчитываю количество этих процессов. Далее в шаблоне я просто буду проверять число этих процессов. Если оно будет равно 0, значит процессы не работают.

Для анализа цепочки iptables я также обрабатываю ее вывод, ищу строки со словами fail2ban и подсчитываю их количество. Если они равны 0, значит fail2ban не работает, либо работает, но не добавляет правила в iptables, что по большому счету и равно тому, что он не работает.
Для мониторинга активных разговоров, я обрабатываю соответствующий вывод asterisk, вырезаю лишние строки и оставляю только необходимое мне число.
Триггеры шаблона
Для полноты картины, поясню остальные триггеры шаблона, чтобы у вас было понимание, за чем они следят и как правильно реагировать на них. Ниже список триггеров шаблона для мониторинга mysql сервера.
- Buffer pool utilization is too low (less {$MYSQL.BUFF_UTIL.MIN.WARN}% for 5m) — под innodb пул выделено слишком много памяти и она не используется вся. Триггер чисто информационный, делать ничего не надо, если у вас нет дефицита памяти на сервере. Если нехватка оперативной памяти есть, то имеет смысл забрать немного памяти у mysql и передать другому приложению. Настраивается потребление памяти пулом параметром innodb_buffer_pool_size.
- Failed to get items (no data for 30m) — от mysql сервера не поступают новые данные мониторинга в течении 30 минут. Имеет смысл уменьшить этот интервал до 5-10 минут.
- Refused connections (max_connections limit reached) — срабатывает ограничение на максимальное количество подключений к mysql. Увеличить его можно параметром mysql сервера — max_connections. Его необходимо увеличить, если позволяют возможности сервера. Напомню, что увеличенное количество подключений требует увеличения потребления оперативной памяти. Если у вас ее уже не хватает, нет смысла увеличивать число подключений. Нужно решать вопрос с потреблением памяти.
- Server has aborted connections (over {$MYSQL.ABORTED_CONN.MAX.WARN} for 5m) — сервер отклонил подключений выше заданного порога в макросе. Надо идти в лог mysql сервера и разбираться в причинах этого события. Скорее всего там будут подсказки.
- Server has slow queries (over {$MYSQL.SLOW_QUERIES.MAX.WARN} for 5m) — количество медленных запросов выше установленного макросом предела. Надо идти и разбираться с медленными запросами. Тема не самая простая. Надо заниматься профилированием запросов и решать проблемы по факту — добавлением индексов, редактированием запросов, увеличения ресурсов mysql сервера и т.д.
- Service has been restarted (uptime < 10m) — информационный триггер, срабатывающий на перезапуск mysql сервера (не ребут самого сервера).
- Service is down — служба mysql не запущена.
- Version has changed (new version value received: {ITEM.VALUE}) — версия mysql сервера изменилась. Тоже информационный триггер, сработает, к примеру, после обновления mysql сервера.
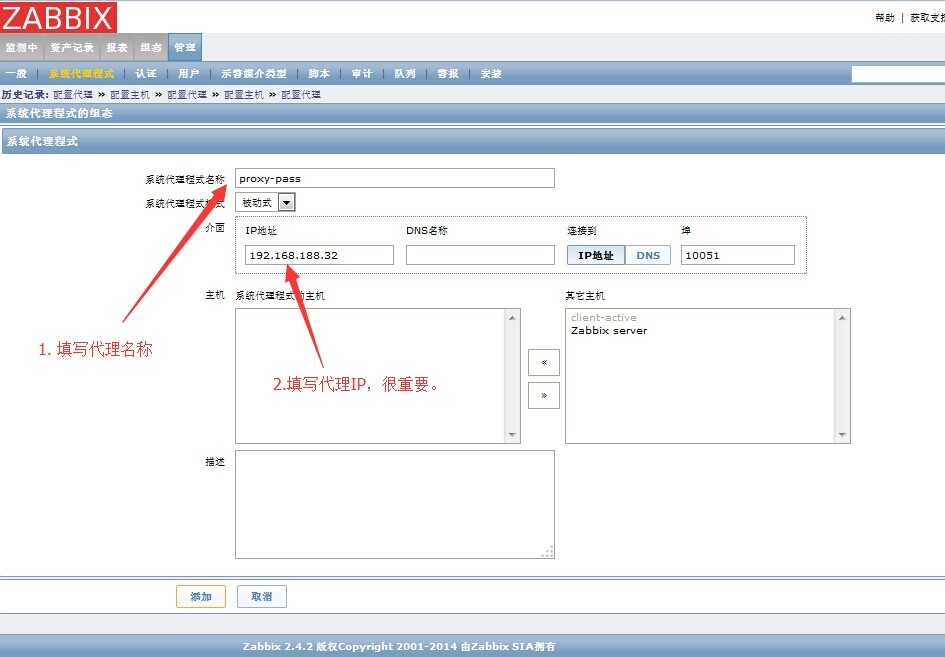
Установка и запуск proxy
Из репозитория Zabbix
# apt install zabbix-proxy-sqlite3 # mkdir /var/lib/zabbix # zcat /usr/share/doc/zabbix-proxy-sqlite3/schema.sql.gz | sqlite3 /var/lib/zabbix/zabbix.db # chown -R zabbix:zabbix /var/lib/zabbix # vim /etc/zabbix/zabbix_proxy.conf
... Hostname=gate ConfigFrequency=60 Server=server DBName=/var/lib/zabbix/zabbix.db
Debian 10
gate# apt install zabbix-proxy-mysql gate# cat zabbix_proxy.sql
#drop database zabbix_proxy; create database zabbix_proxy character set utf8 collate utf8_bin; grant all privileges on zabbix_proxy.* to zabbix@localhost identified by 'zabbix';
gate# mysql < zabbix_proxy.sql gate# zcat /usr/share/zabbix-proxy-mysql/schema.sql.gz | mysql -uzabbix -pzabbix zabbix_proxy gate# cat /etc/zabbix/zabbix_proxy.conf
... Hostname=gate ConfigFrequency=60 Server=server DBHost=localhost DBName=zabbix_proxy DBUser=zabbix DBPassword=zabbix
gate# systemctl enable zabbix-proxy gate# service zabbix-proxy start
Проверка работы триггеров
Попробуем нарушить работу репликации mysql и проверим работу триггеров. Для этого я просто отключу vpn соединение, по которому доступны сервера. После разрыва связи на slave сервере следующая картинка статуса репликации:
Проверяем данные мониторинга репликации:
Значение Slave_IO_Running сменилось с Yes на Connecting и скрипт проверки вернул значение 0 вместо 1. Этого достаточно, чтобы сработал триггер и пришло оповещение о том, что репликация mysql сервера нарушена:
На почту пришло оповещение:
Восстанавливаем связь между серверами и ждем новой работы триггера и уведомления:
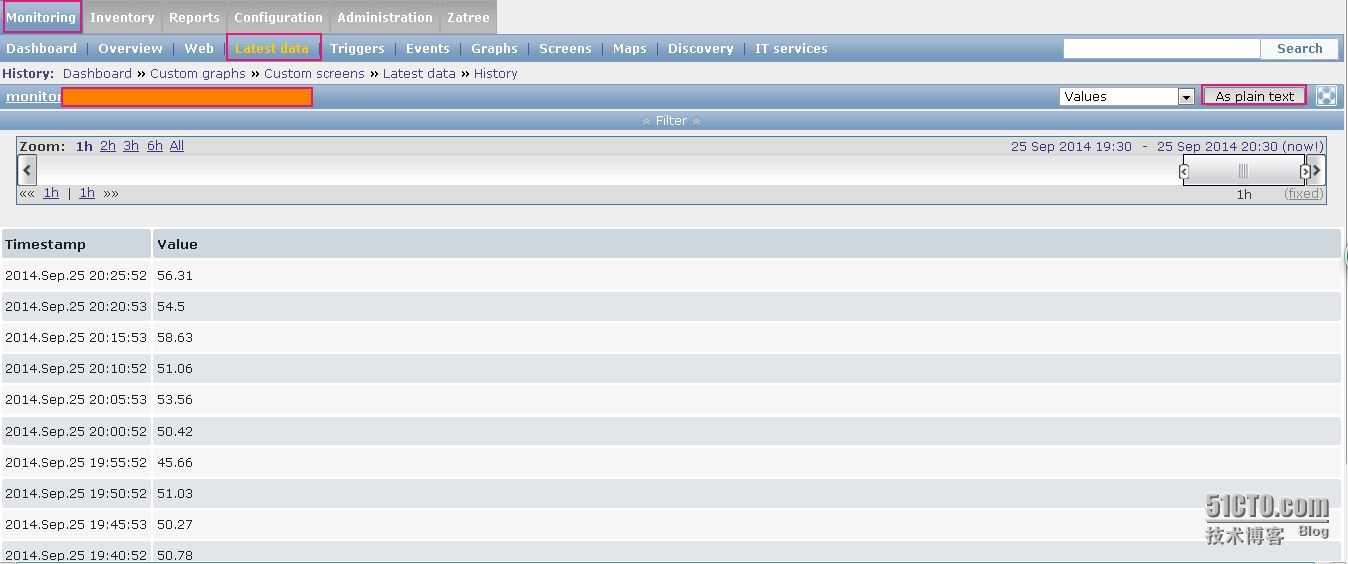
Проверяем Latest Data:
Все в порядке, мониторинг нормально отработал нарушение mysql репликации. Больше тут настраивать нечего, графики и экраны не нужны, в них нет необходимости. На этом работа по настройке мониторинга окончена.
![Учебное пособие - zabbix мониторинг сервера asterisk с использованием snmp [шаг за шагом]](https://tehnikaarenda.ru/wp-content/uploads/f/0/4/f0457fa5ed60186203767ed68c0463e9.jpeg)
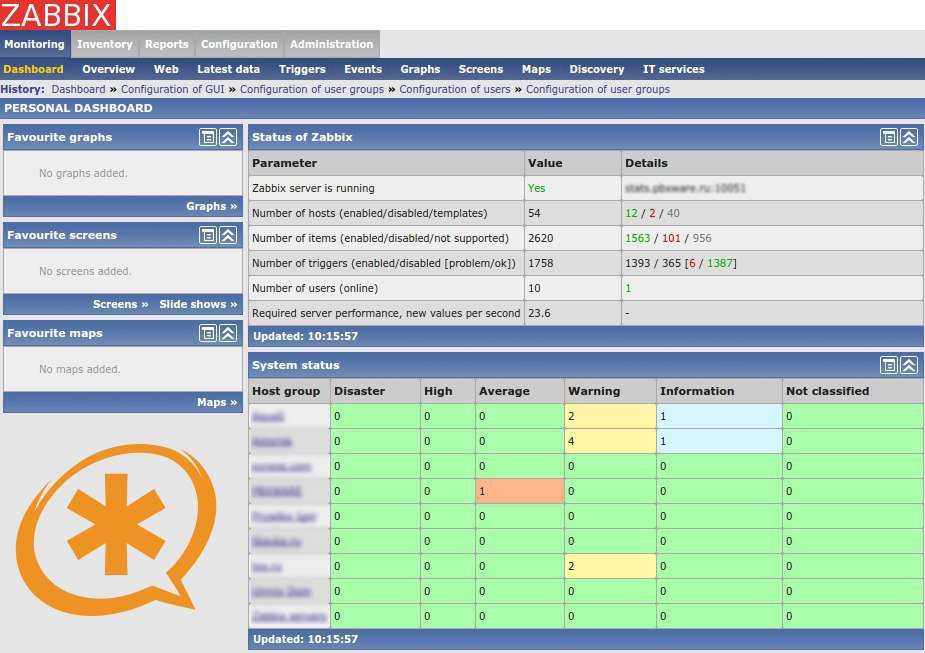
Настройка zabbix-agent
Для мониторинга за asterisk, я буду использовать один скрипт и несколько обработанных выводов из запросов к астериску. Начнем со скрипта. Он будет проверять статус транков и если какой-либо из них будет в offline, назовет его. Кладем этот скрипт в директорию /etc/zabbix/scripts.
Я все прокомментировал. Добавлю только пояснение к регулярке, которая определяет проблемные транки. Я знаком со следующими состояниями транков, когда они не работают:
- Request Sent
- No Authentication
- Auth. Sent
- Rejected
Соответственно, эти состояния я и ищу. Если один из транков находится в одном из этих состояний, то он считается проблемным.
Далее создаем файл конфигурации zabbix с UserParameters в /etc/zabbix/zabbix_agentd.d.
Некоторые из приведенных метрик требуют права root для своего исполнения. Скажу честно, мне было лениво разбираться с разрешениями и я просто запустил zabbix с правами root. Для этого в его конфиге /etc/zabbix/zabbix_agentd.conf раскомментировал следующую строку:
После этого можно перезапустить zabbix-agent и проверить работу будущих итемов.
Проверяем, насколько корректно агент возвращает указанные значения.
Все в порядке. В завершении настройки агента, поясню некоторые моменты для тех, кто не очень разбирается в bash скриптах. Для мониторинга статусов служб я просто вывожу список всех процессов, вычленяю из него нужный мне процесс, в данном случае asterisk или fail2ban и подсчитываю количество этих процессов. Далее в шаблоне я просто буду проверять число этих процессов. Если оно будет равно 0, значит процессы не работают.
Для анализа цепочки iptables я также обрабатываю ее вывод, ищу строки со словами fail2ban и подсчитываю их количество. Если они равны 0, значит fail2ban не работает, либо работает, но не добавляет правила в iptables, что по большому счету и равно тому, что он не работает.
Для мониторинга активных разговоров, я обрабатываю соответствующий вывод asterisk, вырезаю лишние строки и оставляю только необходимое мне число.
Методика мониторинга времени ответа сервера
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Принципиальной разницы где у вас работает сервер мониторинга zabbix нет. Я не буду останавливаться на этом моменте. Далее я считаю, что вы уже настроили мониторинг сайта по приведенной ранее статье. Дам некоторые рекомендации по ее поводу на основе последнего опыта:
Лучше всего создавать шаблон web мониторинга, а не настраивать его на конкретном агенте. Совет этот универсальный для любых метрик, но именно для web мониторинга он более актуальный. Так вы сможете оперативно запускать проверки сайта с разных серверов, где установлены агенты забикса. Плюс, через экспорт шаблона вы легко сможете перенести мониторинг на другой сервер
Это очень важно, так как если у вас многоходовый мониторинга сайта, вручную его переносить на другой сервер очень хлопотно.
У заббикса есть свои внутренние таймауты. Иногда я вижу в полученных данных значения, которые сильно выбиваются из общей картины
Например, у вас среднее время отклика сайта 200-300 мс. Иногда вы будете видеть на графике всплески до 1500 мс, 2500 мс, 3500 мс. Значения будут кратны одной секунде. Я не нашел подробной информации, как именно заббикс делает мониторинг сайта. Я думаю, что свыше какой-то задержки, он ждет секунду, пробует снова и так далее
Эти данные не стоит брать в расчет.
Не стоит обращать внимание на абсолютные цифры. Все системы измеряют время отклика по-разному
В вебмастере яндекса вы увидите одно значение времени отклика сервера, в его же яндекс.метрике другое, гугл покажет третье, а заббикс четвертное. Отличаться эти значения могут существенно, в 2-3-4 раза. Я использую мониторинг времени отклика сайта в заббиксе для отслеживания динамики. К примеру, вы решили переехать на новый web сервер. Нужно как-то оценить его быстродействие. Вы сравниваете значения в мониторинге на старом сайта, потом на новом и делаете выводы.
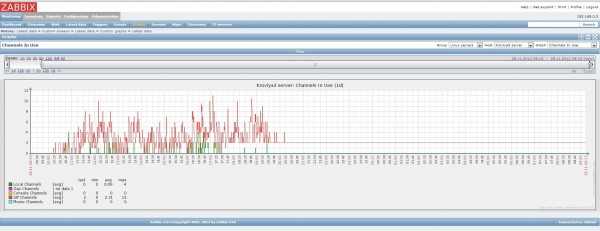
По последнему пункту приведу простой пример из недавнего опыта. Я подготовил новый веб сервер. Нужно было оценить, насколько он быстрее работает на том же сайте, чем предыдущий. Я развернул сайт на новом сервере, поправил в файле hosts на сервере с заббикс агентом ip адрес сайта, направив запросы на новый web сервер. Получилась такая картинка.
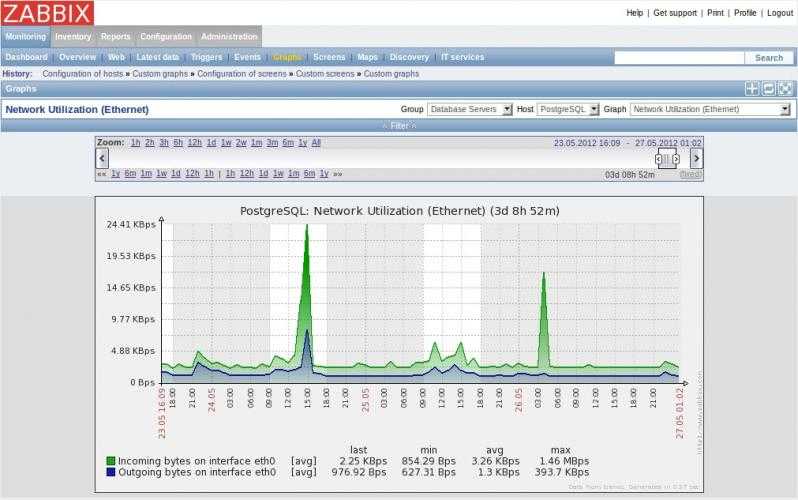
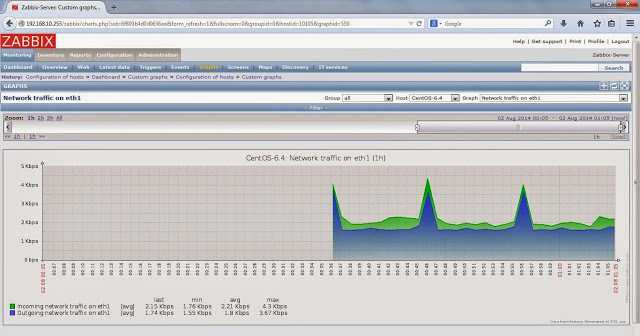
Сначала идет мониторинг реального сайта на текущем сервере, потом я переключаю запросы zabbix на новый сервер. Убедившись, что сайт на новом веб сервере отвечает быстрее, переключаю мониторинг обратно на старый сервер.
Понятно, что тест очень условный. Новый сервер стоит без нагрузки, отвечает стабильно, без пилы на графике. И тем не менее, я понимаю, что на нем будет лучше. Зачастую время отклика сайта зависит от факторов, которые вы не можете оценить заранее:
- Сетевую систему хостера
- Отклик жестких дисков
- Загруженность ноды виртуальных машин, если переезжаете на VDS.
Вы можете заказать сервер с хорошими параметрами по железу, но не получить быстрого отклика сайта по независящим от вас причинам. С этим столкнулся не так давно, когда пробовал использовать веб сервер у облачного провайдера. На словах все красиво — гибкая настройка параметров, отказоустойчивость, удобный бэкап и т.д. В общем, все то, чем хвалят облака. А на деле время отклика сайта было 300-400 мс при типовых настройках веб сервера. Использовался самый дорогой и быстрый тип диска. На выделенном бюджетном сервере при тех же настройках отклик был 100 мс.
Несмотря на всю условность подобного теста, он отвечает на поставленный вопрос — будет ли сайт после переезда на новый сервер отвечать быстрее. Я несколько раз проверял данную методику, в том числе и на своем сайта, не так давно переехав на новое место, так как старый виртуальный сервер стал работать заметно медленнее.
Отправка логов Mikrotik в syslog
Первым делом настроим сбор логов с микротиков на любой syslog сервер. В моем случае это будет сам сервер мониторинга на базе rsyslog и centos 7, но это не принципиально. Главное, чтобы на нем был zabbix-agent, который будет отправлять логи микротиков на заббикс сервер.
Для этого в rsyslog включим возможность слушать udp port 514. Открываем конфиг /etc/rsyslog.conf и раскомментируем там строки:
$ModLoad imudp
$UDPServerRun 514
|
1 2 |
$ModLoad imudp $UDPServerRun514 |
Дальше в этом же файле в самом начале перечисления правил, добавляем свое.
$template FILENAME,»/var/log/mikrotik/%fromhost-ip%.log»
if $fromhost-ip != ‘127.0.0.1’ then ?FILENAME
& stop
|
1 2 3 |
$template FILENAME,»/var/log/mikrotik/%fromhost-ip%.log» if$fromhost-ip!=’127.0.0.1’then?FILENAME &stop |
Данное правило будет автоматически раскладывать все логи с удаленных устройств по файлам в директории /var/log/mikrotik с именами в виде IP адресов. При этом не будет создан лог 127.0.0.1.log, куда бы складывались все локальные лог файлы. В своей предыдущей статье я не учитывал этот нюанс, что приводило к дублированию всех локальных логов. Сейчас я это исправляю.
Сразу же настроим ротацию лог файлов, чтобы они не забили нам весь диск. Для этого создаем конфиг для logrotate в файле /etc/logrotate.d/mikrotik примерно следующего содержания:
/var/log/mikrotik/*.log {
weekly
rotate 12
compress
olddir /var/log/mikrotik/old
missingok
notifempty
create 0640 root zabbix
}
|
1 2 3 4 5 6 7 8 9 |
varlogmikrotik*.log{ weekly rotate12 compress olddirvarlogmikrotikold missingok notifempty create0640root zabbix } |
Я ротирую файлы логов раз в неделю, сразу сжимаю и кладу их в директорию /var/log/mikrotik/old, где будут храниться 12 последних версий файла.
Не забудьте создать указанные директории и дать пользователю zabbix права на чтение. Потом проследите, чтобы у самих логов тоже были права на чтение для zabbix
Это важно, так как агент должен их читать
После завершения настройки, надо перезапустить rsyslog.
# systemctl restart rsyslog
| 1 | # systemctl restart rsyslog |
Отправляемся на Mikrotik и настраиваем отправку логов на наш syslog сервер. Для этого переходите в раздел System -> Logging -> Actions и добавляйте новое действие.
Дальше открывайте вкладку Rules и добавляйте темы логов, которые вы будете отправлять в Zabbix. Для мониторинга за логинами достаточно темы System.
Чтобы проверить отправку логов, достаточно тут же в Mikrotik открыть новый терминал. Создастся событие в логе, который улетит на удаленный сервер. На сервере с rsyslog будет создан лог файл с содержимым.
Если у вас так же, можно двигаться дальше. Если же логи не поступают на syslog сервер, разбирайтесь в чем может быть причина. Первым делом проверьте настройки firewall. Убедитесь, что доступ к udp порту 514 есть. Дальше проверьте, что ваш rsyslog сервер реально слушает этот порт.
Обзор
Систему создал Алексей Владышев на языке Perl. Впоследствии проект подвергся серьезным изменением, которые затронули и архитектуру. Zabbix переписали на C и PHP. Открытый исходный код появился в 2001 г., а уже через три года выпустили первую стабильную версию.
Веб-интерфейс Zabbix написан на PHP. Для хранения данных используются MySQL, Oracle, PostgreSQL, SQLite или IBM DB2.
На данный момент доступна система Zabbix 4.4. Скачать ее можно на официальном сайте. Там же можно найти официальные курсы и вебинары для начинающих пользователей системы.
Далее рассмотрим, из чего состоит и как работает технология Zabbix в доступном формате «для чайников».
Проверки
Для описания системы мониторинга Zabbix существует два ключевых понятия:
- Узлы сети — рабочие устройства и их группы (сервера, рабочие станции, коммутаторы), которые необходимо проверять. С создания и настойки узлов сети обычно начинается практическая работа с Zabbix.
- Элементы данных — набор самостоятельных метрик, по которым происходит сбор данных с узлов сети. Настройка элементов данных производится на вкладке «Элемент данных» или в автоматическом режиме — через подключение шаблона.
Сам Zabbix-агент способен отражать текущее состояние физического сервера, собирая совокупность данных. У него достаточно много метрик. С их помощью можно проверить загруженность ядра (Processor load), время ожидания ресурсов (CPU iowait time), объем системы подкачки (Total swap space) и многое другое.
В Zabbix существует целых 17 способов, дающих возможность собирать информацию. Указанные ниже, входят в число наиболее часто применяемых.
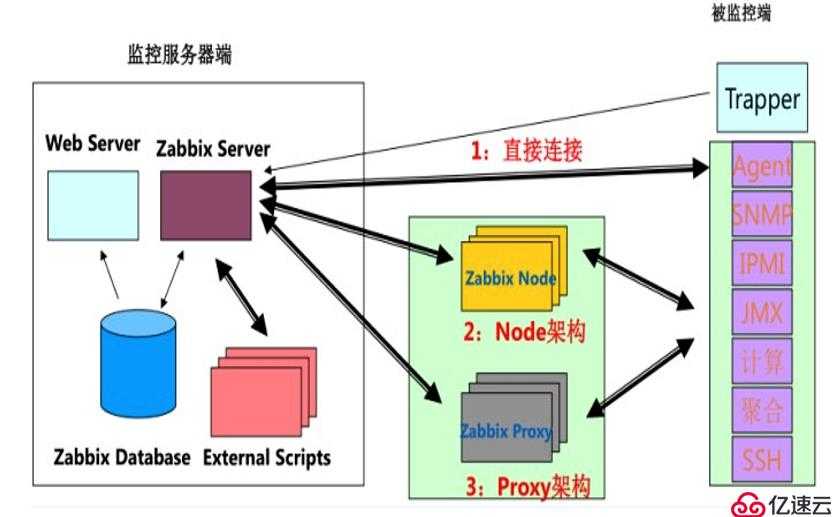
- Zabbix agent (Zabbix-агент) — сервер собирает информацию у агента самостоятельно, подключаясь по определенному интервалу.
- Simple check (Простые проверки) — простые операции, в том числе пинг.
- Zabbix trapper (Zabbix-траппер) — сбор информации с трапперов, представляющих собой мосты между используемыми сервисами и самой системой.
- Zabbix aggregate (Zabbix-комплекс) — процесс, предусматривающий сбор совокупной информации из базы данных.
- SSH agent (SSH-агент) — система подключается по SSH, использует указанные команды.
- Calculate (Вычисление) — проверки, которые система производит, сопоставляя имеющиеся данные, в том числе после предыдущих сборов.
У проверок есть заданные шаблоны (Templates), которые упрощают создание новых. Кроме обычных операций существует возможность регулярно проверять доступность веб-сервера с помощью имитации запросов браузера.

Проверка через пользовательский параметр
Чтобы выполнить проверку через агент, нужно прописать соответствующую команду в конфигурационный файл Zabbix-агента в качестве пользовательского параметра (UserParameter). Сделать это можно с помощью выражения следующего вида:
UserParameter=<ключ>,<команда>
Помимо самой команды, приведенный синтаксис содержит уникальный (в пределах узла сети) ключ элемента данных, который надо придумать самостоятельно и сохранить. В дальнейшем, ключ можно использовать для ссылки на команду, внесенную в пользовательский параметр, при создании элемента данных.
Пример
UserParameter=ping,echo 1
С помощью данной команды можно настроить агент на постоянное возвращение значения «1» для элемента данных с ключем «ping».
Заключение
Данный функционал можно использовать не только для мониторинга бэкапов, но и других актуальных данных. Например, какая-то программа должна выгружать данные с определенной периодичностью. Мы можем следить за тем, как она это делает. В данной статье мы рассмотрели несколько параметров, по которым заббикс может анализировать файлы и каталоги. Но таких возможностей много. Он может, к примеру, проверять конкретный размер файла и предупреждать, если он сильно меньше или больше предыдущей версии. Настраивается это примерно так же, как здесь.
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .





