
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
В заббикс существуют различные способы получать данные для мониторинга. Наиболее распространенные источники информации:
- Zabbix агент. Устанавливается на наблюдаемую машину и отправляет данные на сервер мониторинга.
- SNMP агент. Чаще всего присутствует на устройстве, либо может быть установлен на сервер.
- Простые проверки — simple check. Выполняются непосредственно на сервере zabbix с помощью встроенных инструментов, не требуют дополнительных действий со стороны хоста.
- Внешние проверки — external checks. Как и простые проверки выполняются на сервере мониторинга, но не встроенными средствами, а внешними скриптами.
Есть и другие способы получения данных. Не буду их все перечислять, ознакомиться с ними можно в соответствующем разделе официальной документации. В нашем случае мы воспользуемся первыми двумя способами для мониторинга служб и сервисов в linux.
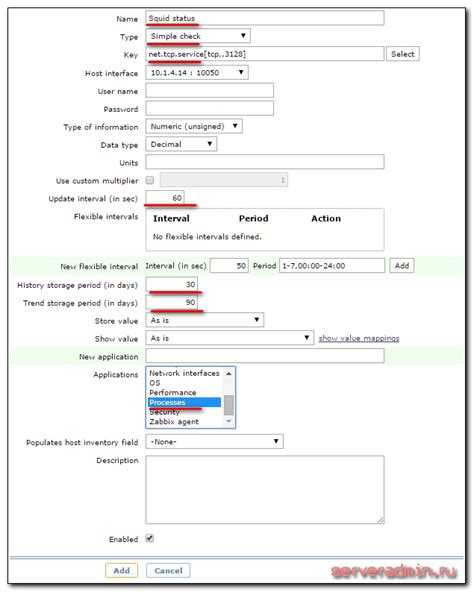
Тут можно пойти разными путями. Меня интересует мониторинг различных линукс служб, работающих как локально (samsdaemon, postgrey) в пределах конкретного сервера, так и для публичного доступа по сети, в частности squid, smtp, imap, http. Первое, что пришло в голову, это использовать итем с ключом service_state[]. Но как оказалось, этот тип данных снимает значения только с системных служб windows. Я не сразу это понял и некоторое время повозился в консоли, не понимая, почему при тестировании значения получаю сообщение, что данный item не поддерживается:
# zabbix_agent -t service_state service_state
Дальше придумал через UserParameter запускать какой-нибудь скрипт, который будет проверять запущен ли сервис в системе или нет. Например с помощью ps ax | grep squid. В принципе, рабочий вариант, но мне казалось, что такую простую задачу можно решить проще и быстрее, без создания на каждом хосте скрипта и изменения файла конфигурации. И я не ошибся. Есть 2 различных способа мониторинга служб (сервисов) в linux с помощью zabbix. Рассмотрим первый из них.
Grafana
Но на этом мы не остановились и подключили к Zabbix-у дашборды на основе Grafana. Это кроссплатформенное программное обеспечение с открытым исходным кодом для аналитики и интерактивной визуализации отчетов. Благо эти проекты (Grafana и Zabbix) очень хорошо дружат и настраиваются из коробки.
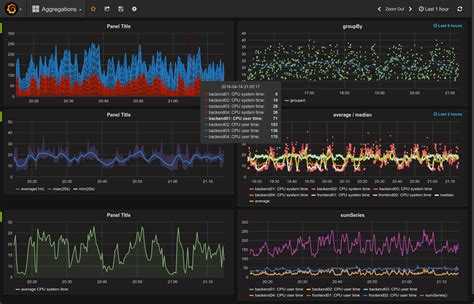
И после этого мы стали для всех штамповать удобные дашборды, т.к. в графане это делается очень просто и получается красиво.
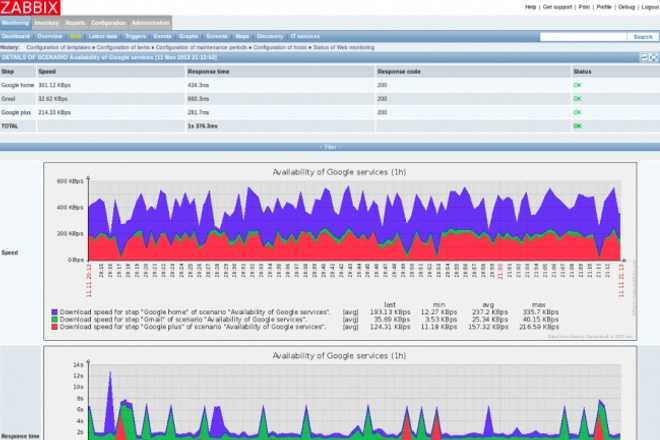
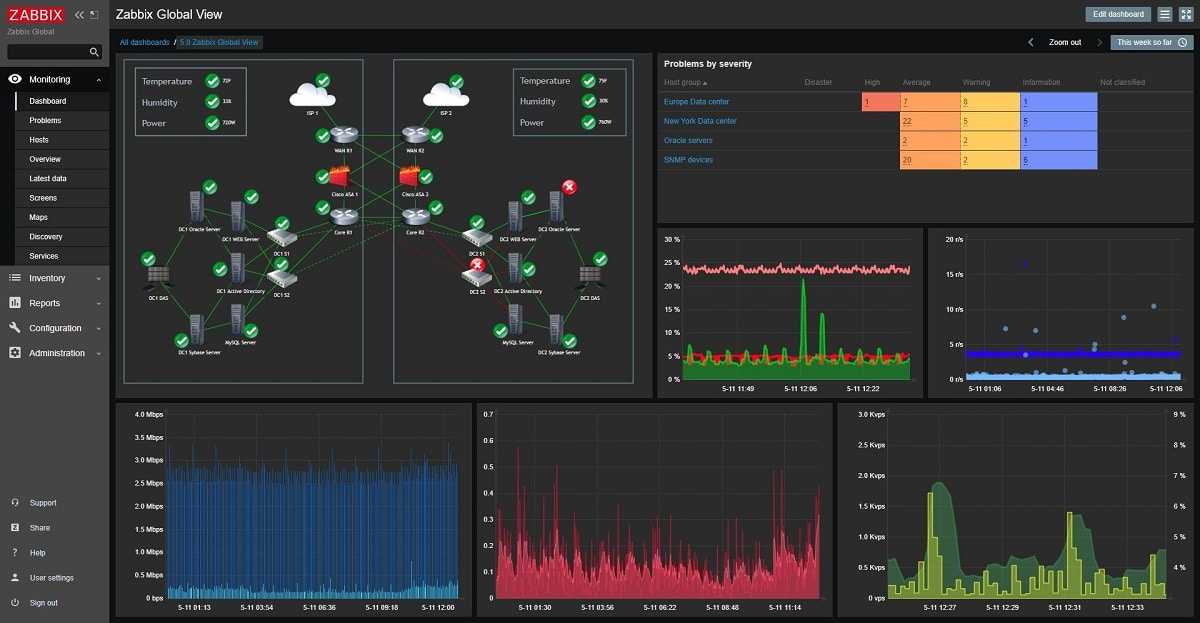
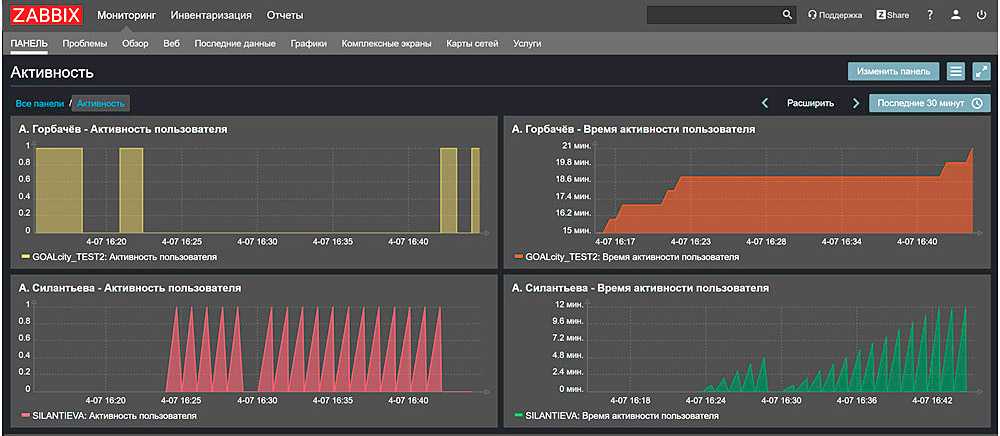
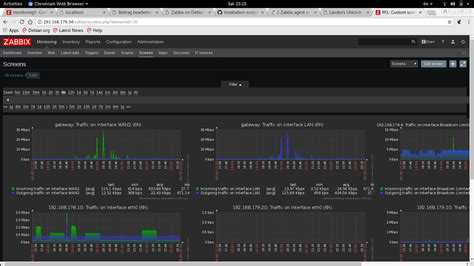
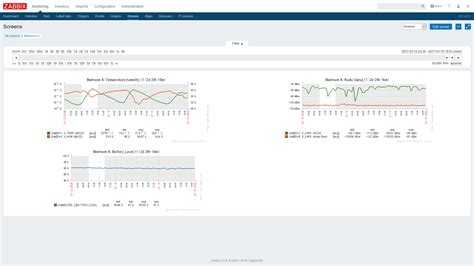
На слайде показан пример дашборда по сравнению производительности сотрудников 15 точек для территориального директора.
Далее показан дашборд для мониторинга состояния на торговой точке, показывающий ситуацию по персоналу, выполнению плана, производительность, претензии.
Если этот дашборд прокрутить вниз, можно увидеть графики по времени отдачи кухни и времени доставки.
Обратите внимание, что на графиках в графане можно оставлять комментарии, чтобы позже не вспоминать, что случилось на точке, и почему у них были такие показатели. Получив такие дашборды, операционный отдел уже хлопал стоя
Получив такие дашборды, операционный отдел уже хлопал стоя.
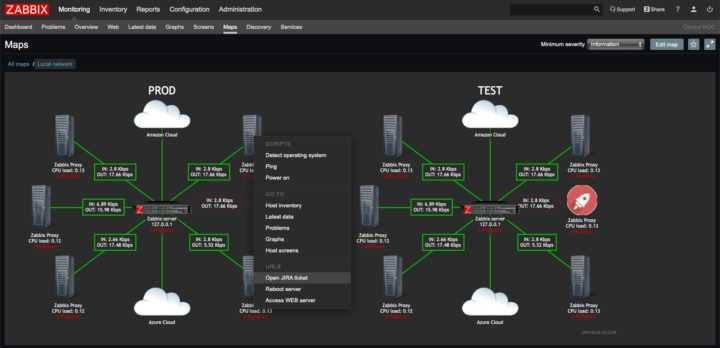
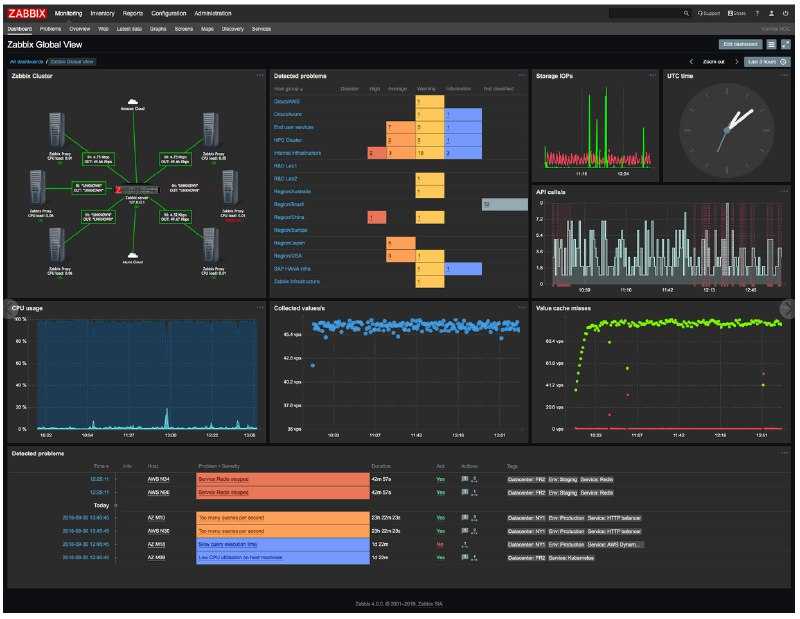
Архитектура Zabbix
У Zabbix есть 4 основных инструмента, с помощью которых можно мониторить определенную рабочую среду и собирать о ней полный пакет данных для оптимизации работы.
- Сервер — ядро, хранящее в себе все данные системы, включая статистические, оперативные и конфигурацию. Дистанционно управляет сетевыми сервисами, оповещает администратора о существующих проблемах с оборудованием, находящимся под наблюдением.
- Прокси — сервис, собирающий данные о доступности и производительности устройств, который работает от имени сервера. Все собранные данные сохраняются в буфер и загружаются на сервер. Нужен для распределения нагрузки на сервер. Благодаря этому процессу можно уменьшить нагрузку на процессор и жесткий диск. Для работы прокси Zabbix отдельно нужна база данных.
- Агент — программа (демон), которая активно мониторит и собирает статистику работы локальных ресурсов (накопители, оперативная память, процессор и др.) и приложений.
- Веб-интерфейс — является частью сервера системы и требует для работы веб-сервер. Часто запускается на том же физическом узле, что и Zabbix.
Конфигурация хоста
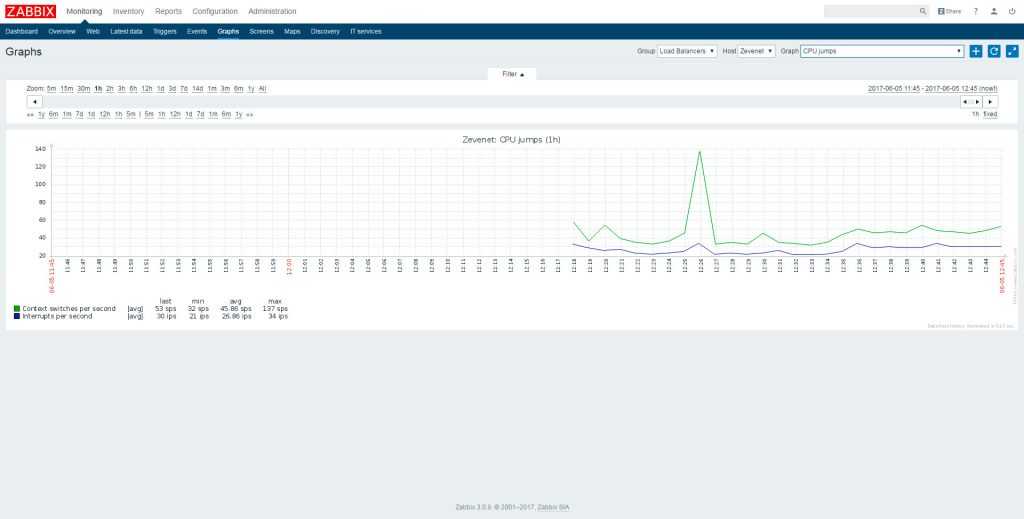
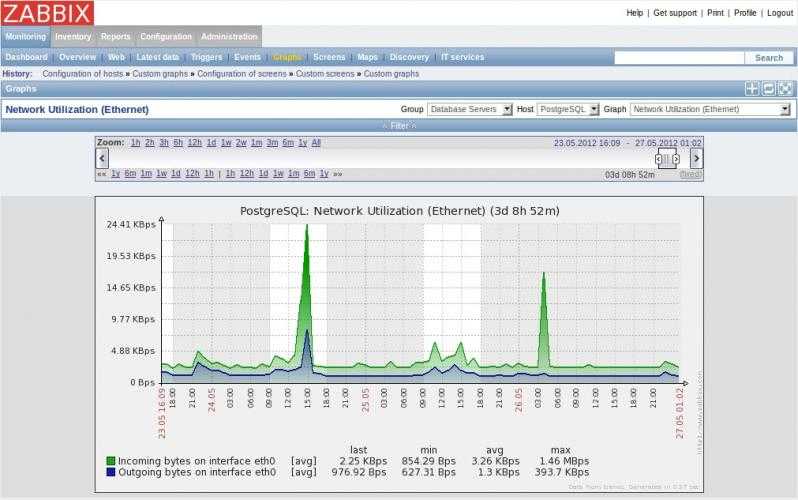
Для примера на нашем сервере необходимо мониторить процесс node (node.js). Давайте посмотрим один из моих графиков данного процесса:
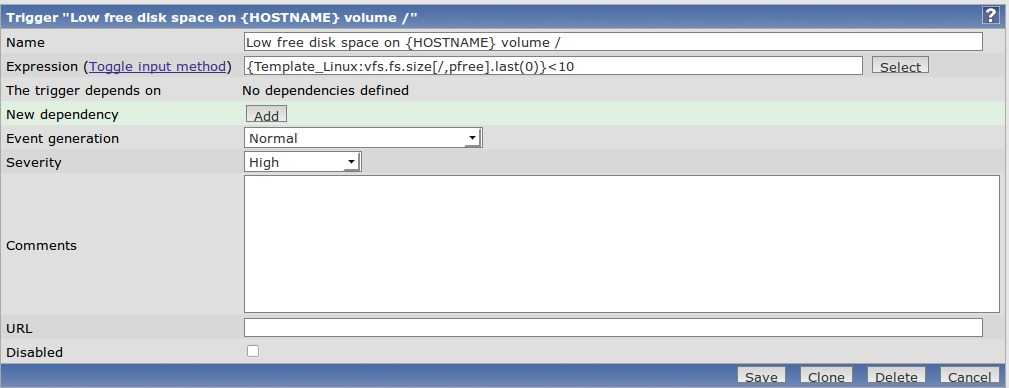
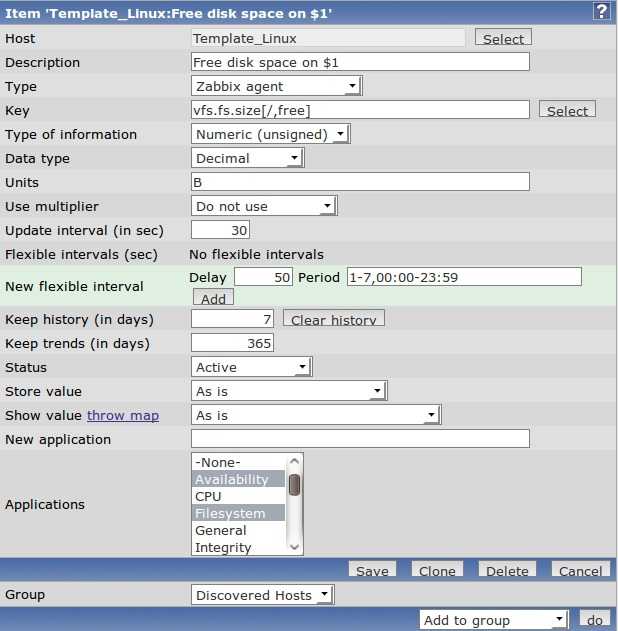
Вы видите, что у меня он потребляет порядка 4Gb RAM. Это нормальное состояние для моего сервиса. Так же вы видите колебание в районе красной линии. Без гистерезиса Zabbix нас просто заспамил бы сообщениями об изменении статуса в районе этой линии. В моем примере нормальное значение потребления памяти для указания в гистерезисе это 4G, а максимальное – больше чем 4.20G, пусть будет 4,5G. Добавим эти значения, а так же имя нашего процесса как макросы для данного хоста:
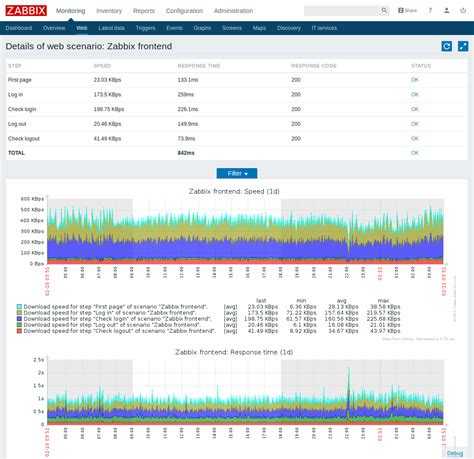
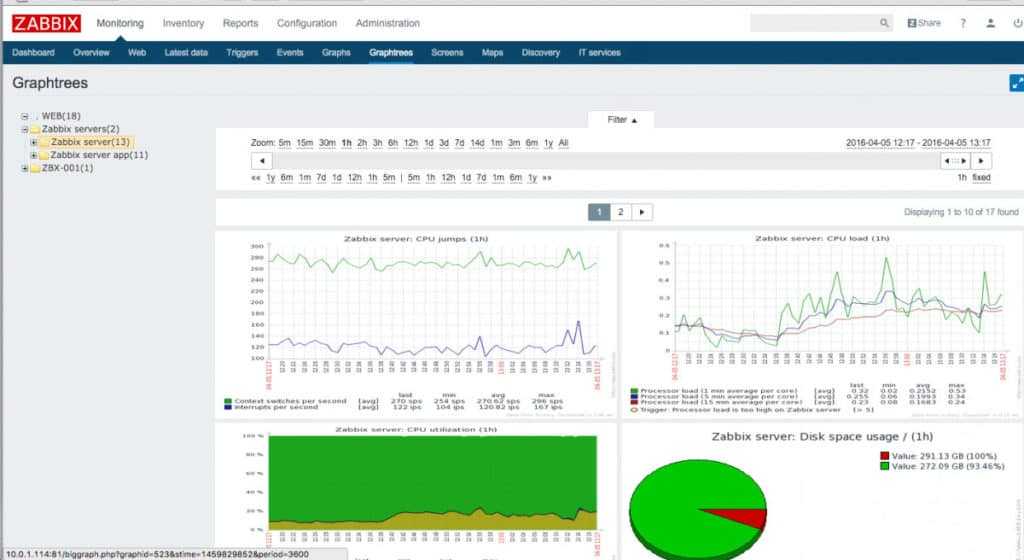
Итак, мой триггер перейдет в состоянии PROBLEM только когда значение потребляемой памяти будет больше чем 4,5Gb 3 раза подряд. А вернется он в нормальное состояние только тогда, когда потребление снизится ниже 4Г 3 раза подряд.
Модуль мониторинга PostgreSQL в составе Zabbix Agent 2
Для соединения с PostgreSQL используется быстрый и популярный драйвер pgx (PG driver and toolkit for Go).
Пока мы используем два интерфейса: Exporter, вызывающий обработчик по ключу, и Configurator Zabbix Agent 2, который считывает и проверяет параметры соединения с сервером, заданные в конфигурационном файле.
Мы постарались оптимизировать работу СУБД, группируя метрики и используя обработчик (handler) для метрик и групп метрик, а также используя группы метрик в JSON как зависимые переменные (dependency items), и низкоуровневое обнаружение (discovery rules).
Основные возможности
- сохранение постоянного соединения с PostgreSQL между проверками;
- поддержка гибких интервалов опроса;
- совместимость с версиями PostgreSQL, начиная с 10, и Zabbix Server, начиная с версии 4.4;
- возможность подключения и мониторинга нескольких инстансов PostgreSQL одновременно благодаря тому, что Zabbix Agent 2 позволяет создавать несколько сессий.
Уровни параметров подключения к PostgreSQL
Всего доступны три уровня параметров подключения к PostgreSQL, т. е. задач и настроек:
- Global,
- Sessions,
- Macros.
-
Параметры Global задаются на уровне агента, параметры Session и Macros определяют параметры подключения базе.
-
Параметры подключения к PostgreSQL — Sessions задаются в файле zabbix_agent2.conf.
Параметры подключения к PostgreSQL — Sessions
- После ключевого слова Sessions указывается уникальное имя сессии, которое должно быть указано в ключе (шаблоне).
- Параметры URI и UserName обязательны для каждой сессии.
- Если имя базы не задано, используется общее по умолчанию имя базы для всех сессий для PostgreSQL, которое также задается в конфигурационном файле.
- Параметры подключения к PostgreSQL — Macros задаются в ключе метрики в шаблоне (аналогично способу, использованному в Zabbix Agent 1), т. е. создаются в шаблоне и далее указываются как параметры в ключе. При этом последовательность макросов фиксирована, т. е., например, URI всегда указывается на первом месте.
Параметры подключения к PostgreSQL — Macros
Модуль мониторинга PostgreSQL включает уже более 95 метрик, которые позволяют охватить довольно широкий объем параметров PostgreSQL, включая:
- количество соединений,
- объем баз данных,
- архивация wal-файлов,
- контрольные точки,
- количество «раздувшихся» таблиц,
- статус репликации,
- отставание реплики.
Метрики PostgreSQL не информативны без параметров операционной системы. Но Zabbix Agent 2 уже умеет собирать параметры операционной системы, поэтому для получения полной картины просто подключаем к узлу сети необходимые шаблоны.
Обработчик (handler)
Обработчик (handler) — основная единица модуля, в которой выполняется сам запрос и которая позволяет получать метрики.
Чтобы получить простую метрику:
- Создаем файл для получения новой метрики:
zabbix/src/go/plugins/postgres/handler_uptime.go
- Подключаем пакет и указываем уникальный ключ (ключи) метрик:
- Создаем обработчик (handler) с запросом, т. е. инициируем переменную, в которой будет результат:
- Выполняем запрос:
Необходимо проверить запрос на предмет ошибок, после чего результат будет подхвачен процессом Zabbix Agent 2.
- Регистрируем ключ новой метрики:
После регистрации метрики можно пересобирать агент с новой метрикой.
Модуль доступен, начиная с Zabbix 5.0 на сайте https://www.zabbix.com/download. В этой версии Zabbix параметры задаются отдельно через host и port. В версии Zabbix 5.0.2, которая скоро выйдет, параметры подключения будут скомпонованы в один URI.
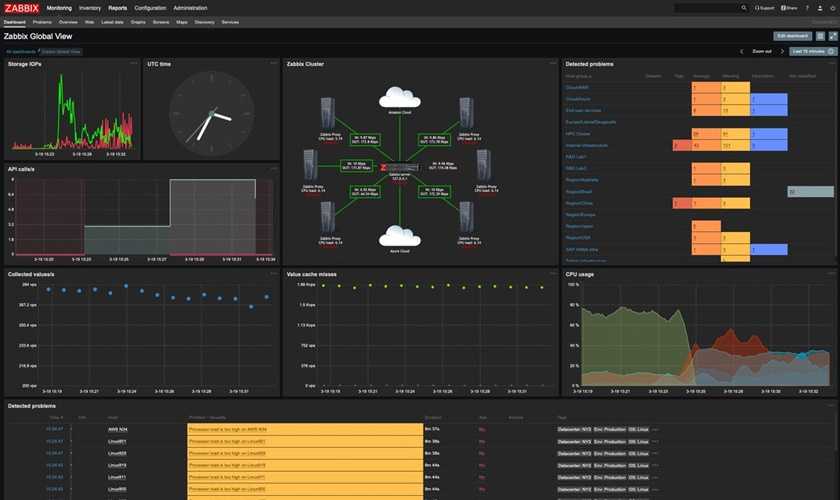
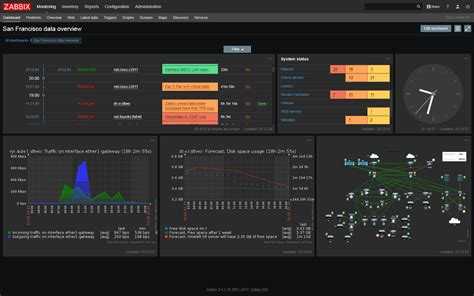
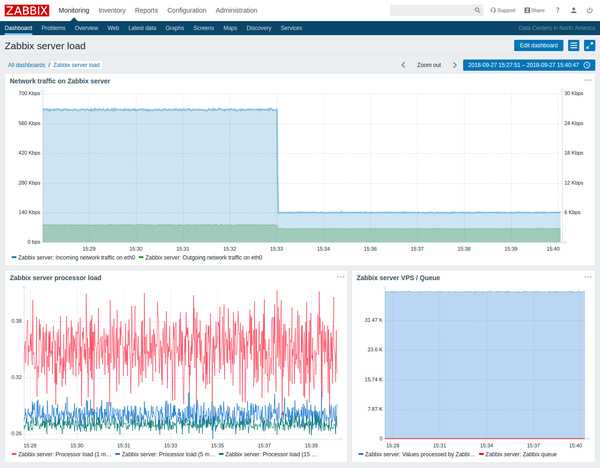
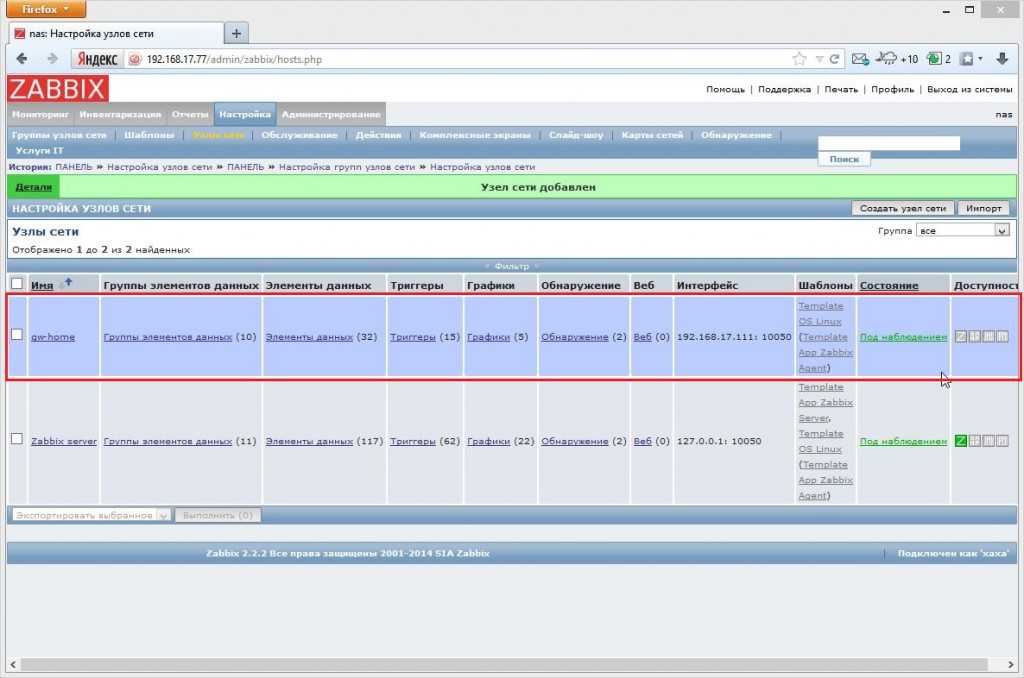
Спасибо за внимание!
Дополнительные материалы по Zabbix
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Настройка в zabbix мониторинга nginx
В прошлой редакции этой статьи дальше шло описание скрипта, который будет парсить вывод nginx-status и передавать данные в zabbix. Сейчас все можно сделать гораздо проще и удобнее. На агенте не надо ничего настраивать. Все выполняется исключительно в шаблоне. То есть вам достаточно загрузить готовый шаблон для мониторинга nginx на zabbix сервер, прикрепить его к хосту и все будет работать.
Это удобный подход, который избавляет от необходимости настраивать агентов. Теперь все выполняется с сервера. Минус этого подхода только в том, что возрастает нагрузка на сервер мониторинга. Это плата за удобство и централизацию. Имейте это ввиду. Если у вас большая инсталляция мониторинга и есть средства автоматизации типа ansible, возможно вам имеет смысл по старинке парсить данные скриптом. Но в общем случае я рекомендую делать так, как я расскажу далее.
Суть мониторинга Nginx будет сводиться к тому, что мы через агента станем забирать страницу http://localhost/nginx-status на сервер. Там с помощью регулярных выражений и зависимых элементов данных будем формировать нужные метрики.
Представляю вам готовый шаблон для мониторинга nginx. Скачиваем его zabbix-nginx-template.xml и открываем web интерфейс zabbix сервера. Идем в раздел Configuration -> Templates и жмем Import:
Выбираем файл и снова нажимаем Import:
Шаблон я подготовил сам на основе своих представлений о том, что нужно мониторить. Проверил и экспортировал его с версии 4.2 Регулярные выражения для парсинга html страницы статуса подсмотрел тут — https://github.com/AlexGluck/ZBX_NGINX. К представленному шаблону я добавил некоторые итемы и переделал все триггеры. Плюс убрал макросы. Не вижу в них в данном случае смысла.
В шаблоне 11 итемов, описание которых я привел ранее.
Подробнее остановимся на триггерах. Их 5 штук.
- Many active connections — срабатывает если среднее количество соединений за последние 10 минут больше в 3 раза, чем среднее количество за интервал на 10 минут ранее.
- many requests и too many requests — срабатывают, когда среднее количество запросов за последние 10 минут больше в 3 и 6 раз соответственно, чем на 10 минут ранее.
- nginx is not running — тут все просто. Если не запущен ни один процесс nginx, шлем уведомление.
- nginx is slow to respond — срабатывает если время выполнения запроса на получение страницы со статусом за последние 10 минут больше предыдущих 10 минут в 2 раза.
С триггерами больше всего вопросов. Предложенная мной схема может работать независимо от проекта, не требует начальной калибровки, но могут быть ложные срабатывания из-за разовых очень сильных всплесков, которые быстро проходят, но сильно меняют средние параметры на интервале.
Более надежно могут сработать триггеры, где явно указаны лимиты в конкретных значениях. Но такой подход требует ручной калибровки на каждом проекте в отдельности. Надо смотреть средние значения метрик и выставлять лимиты в зависимости от них. Если проект будет расти, то лимиты постоянно придется менять. Это тоже не очень удобно и не универсально.
Я в итоге остановился на анализе средних значений, не используя конкретных лимитов. Как поступать вам, решайте отдельно, в зависимости от ситуации. Если у вас один проект, которому вы уделяете много внимания, то ставьте лимиты руками на основе анализа средних параметров. Если работаете на потоке с множеством проектов, то можно использовать мой вариант, он более универсален и не требует ручной правки.
Единственное, коэффициенты можно поправить, если будут ложные срабатывания. Но я обычно этот момент решаю через отложенные уведомления. Если чувствительность триггера очень высокая и есть кратковременные ложные срабатывания, меня они не беспокоят из-за 5-ти минутной задержки уведомлений. Зато при разборе инцидентов, эти кратковременные срабатывания помогают оценить ситуацию в целом.
С мониторингом nginx почти все готово. Теперь нам нужно прицепить добавленный шаблон к web серверу, который мы мониторим и дождаться поступления данных. Проверить их можно в Monitoring -> Latest Data:
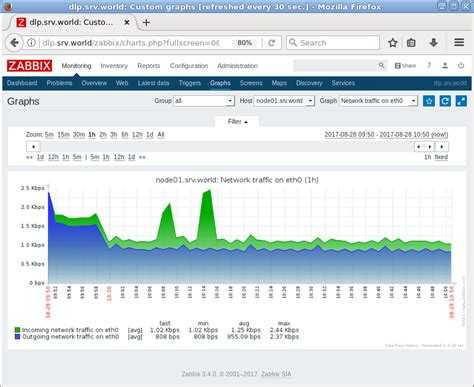
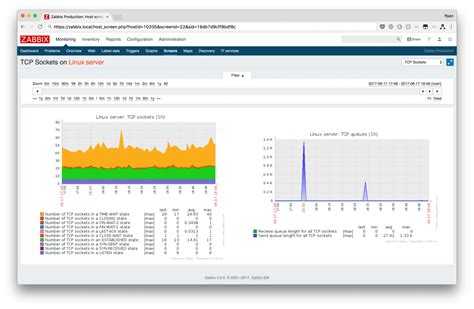
В шаблоне есть несколько графиков. Не буду о них рассказывать, так как последнее время практически не пользуюсь графиками. Вместо этого собираю дашборды. Это более удобно и информативно. Жаль, что дашборды нельзя к шаблонам прикреплять. Очень хлопотно каждый раз вручную их составлять и тратить время. В конце покажу пример дашборда, который я использую для мониторинга web сервера.
На этом настройка мониторинга nginx закончена, можно пользоваться.
Дополнительные материалы по Zabbix
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Консолидируйте информацию об уязвимостях
Результат работы плагина в Zabbix выглядит следующим образом:
Это дашборд в Zabbix. На котором, слева на право, отображается следующая информация:
- Распределение CVSS-балла по серверам. Круговая диаграмма показывает соотношение — как много у нас серверов с критическими уязвимостями, сколько имеют не критичные уязвимости или же вовсе не имеют известных уязвимостей.
- Медианное значение CVSS-балла всей инфраструктуры. Отображается в виде графика, что позволяет наблюдать динамику его изменения.
- Список уязвимых пакетов с индексом влияния уязвимости на инфраструктуру.
- Полный список уязвимых серверов с уровнем угрозы для каждого из них.
- Список бюллетеней безопасности, которые были «найдены» в инфраструктуре.
Ниже более подробно про самое интересное:
Информация об уязвимых серверах:
Панель отображает список всех серверов с уровнем уязвимости выше критического. Минимально допустимый уровень критичности, после которого сервер начинает отображаться как уязвимый, задается в настройках плагина.
По каждому серверу доступна следующая информация:
- Собственно имя уязвимого сервера.
- Максимальный CVSS-балл сервера. Отображается самый высокий балл из всех найденных уязвимостей для этого сервера.
- Команда для устранения всех обнаруженных уязвимостей на этом сервере. Выполнив которую, мы получим сервер, на котором отсутствуют известные версионные уязвимости.
Данные представлены с сортировкой по CVSS, от максимального к минимальному. Это позволяет держать сервера, требующие наибольшего внимания, всегда наверху списка, перед глазами.
Следующая панель показывает уязвимые пакеты:
Здесь для каждого уязвимого пакета в нашей инфраструктуре мы имеем краткую сводку:
- Имя уязвимого пакета.
- Уязвимая версия пакета.
- Количество серверов, на которых установлена уязвимая версия пакета.
- CVSS-балл данной версии пакета.
- Индекс влияния этой уязвимости на инфраструктуру.
- Список всех серверов, на которых обнаружена уязвимая версия пакета.
- Ссылка на бюллетень безопасности. Позволяет прочитать и понять насколько эта уязвимость критична именно в нашей ситуации.
- Команда исправляющая уязвимость в данном пакете.
Данные представлены с сортировкой по Индексу влияния, от максимального к минимальному.
Индекс влияния — это количество затронутых уязвимым пакетом серверов, умноженное на CVSS-балл уязвимости. Зачастую бывает что уязвимость с не самым выскоким балом имеет гораздо большее распространение в инфраструктуре, и поэтому потенциально более опасна.
Подготовка php-fpm к мониторингу
Переходим к мониторингу php-fpm. Он отдает побольше метрик, не буду описывать их все. Рассмотрю только самые основные. Мы будем наблюдать следующие параметры php-fpm:
| active processes count | Число активных процессов |
| connections per sec | Количество соединений в секунду |
| idle processes count | Количество idle процессов |
| slow requests | Количество медленных запросов |
| length of listen queue | Размер очереди ожидающих подключений |
| max children reached | Сколько раз был достигнут лимит по процессам |
| max length of listen queue | Максимальный размер очереди подключений |
Пару слов о том, зачем это нужно и как пользоваться полученными данными. Этот мониторинг актуален, если у вас динамическое создание процессов в php-fpm. К примеру, если у вас значение max children reached регулярно больше единицы, то вам рекомендуется увеличить лимит на максимальное количество процессов, если позволяют ресурсы сервера. То же самое относится и к параметру length of listen queue. Если он больше нуля, то создается очередь из запросов, которые не успевают обработать сервер. Необходимо увеличить количество процессов, которые смогут обработать ожидающие подключения.
Приступаем к настройке мониторинга php-fpm на web сервере. Установим fcgi:
# yum install fcgi
Теперь подготовим pfp-fpm для сбора статистики. Для этого мы снова воспользуемся nginx. Редактируем его конфиг, добавляя в ту же секцию server, что и на прошлом этапе, следующую конструкцию:
location /phpfpm-status {
include fastcgi_params;
fastcgi_pass unix:/var/run/php-fpm/php-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
Обращаю ваше внимание на то, что я в своей конфигурации использую подключение к php-fpm через unix сокет. За это отвечает параметр конфигурации fastcgi_pass
Если вы используете в работе tcp/ip порт, обычно 127.0.0.1:9000, то нужно указать его вместо сокета, вот так: fastcgi_pass 127.0.0.1:9000
Перезапускаем nginx:
# systemctl restart nginx
Внесем необходимые изменения в конфиг php-fpm — добавим одну строку:
# mcedit /etc/php-fpm.d/www.conf pm.status_path = /phpfpm-status
Перезапускаем php-fpm:
# systemctl restart php-fpm
Проверяем, что по указанному адресу мы получаем статистику php-fpm:
# curl http://localhost/phpfpm-status
И ее же в формате json.
# curl -s 'http://localhost/phpfpm-status?json'
{"pool":"www","process manager":"dynamic","start time":1566494413,"start since":2049,"accepted conn":3236,"listen queue":0,"max listen queue":0,"listen queue len":0,"idle processes":5,"active processes":1,"total processes":6,"max active processes":6,"max children reached":0,"slow requests":0}
Если у вас примерно то же самое, то все в порядке, php-fpm отдает информацию о своем состоянии.
Триггеры
Это логические выражения со значениями FALSE, TRUE и UNKNOWN, которые используются для обработки данных. Их можно создать вручную. Перед использованием триггеры возможно протестировать на произвольных значениях.
У каждого триггера существует уровень серьезности угрозы, который маркируется цветом и передается звуковым оповещением в веб-интерфейсе.
- Не классифицировано (Not classified) — серый.
- Информация (Information) — светло-синий.
- Предупреждение (Warning) — жёлтый.
- Средняя (Average) — оранжевый.
- Высокая (High) — светло-красный.
- Чрезвычайная (Disaster) — красный.
Некоторые функции триггеров
- abschange — абсолютная разница между последним и предпоследним значением (0 — значения равны, 1 — не равны).
- avg — среднее значение за определенный интервал в секундах или количество отсчетов.
- delta — разность между максимумом и минимумом с определенным интервалом или количеством отсчетов.
- change — разница между последним и предпоследним значением.
- count — количество отсчетов, удовлетворяющих критерию.
- date — дата.
- dayofweek — день недели от 1 до 7.
- diff — у параметра есть значения, где 0 — последнее и предпоследнее значения равны, 1 — различаются.
- last — любое (с конца) значение элемента данных.
- max\min — максимум и минимум значений за указанные интервалы или отсчеты.
- now — время в формате UNIX.
- prev — предпоследнее значение.
- sum — сумма значений за указанный интервал или количество отсчетов.
- time — текущее время в формате HHMMSS.
Прогнозирование
Триггеры обладают еще одной важной функцией для мониторинга — прогнозированием. Она предугадывает возможные значения и время их возникновения
Прогноз составляется на основе ранее собранных данных.
Анализируя их, триггер выявляет будущие проблемы, предупреждает администратора о возникшей вероятности. Это дает возможность предотвратить пики нагрузки на оборудование или заканчивающееся место на жестком диске.
Функционал прогнозирования добавили с обновлением системы 3.0, вышедшим в феврале 2016 года.
Zabbix и счетчики производительности (perf counters) : 8 комментариев
Добрый день! Мне этот способ не помог. Странно то, что у меня очень много Windows-серверов на мониторинге и небольшая часть из них не реагирует на это ключ, остальные работают нормально. Что я только уже не делал. Идеи у меня закончились. Может есть ещё какие-нибудь нюансы по данной проблеме?
Здравствуйте! Какой именно ключ не помог? Загрузка процессора? Если используется локализованная винда (русская или любая другая), то ключ в таком виде работать не будет, т.к. его нет в системе. Надо подбирать вместо этого цифровое значение ключа. Например, ключ для получения процента использования файла подкачки выглядит так: perf_counter
Да, Windows на русском. Использую вот этот ключ: perf_counter он не работает. Пробовал вот этот: perf_counter тоже не работает. Пробовал такой: perf_counter тоже не поддерживается. Во всех трёх случаях пишет: «Not supported». Причём, я непосредственно на сервере, где нужно мониторить нагрузку на CPU из командой строки вытянул счётчики с помощью команды: lodctr /s:perfcount.txt и ориентировался при построении ключа для Zabbix именно по ним. Даже не знаю что делать.
Для русской винды надо использовать только цифровое значение. Zabbix далеко не сразу пытается проверять «Not supported» счетчики после их изменения. Самый верный вариант — перезапустить сервис заббикса и агент. Опять же, можно попробовать включить дебаг-лог — он может сказать что именно ему не нравится. Я встречал такие случаи, когда заббикс писал «Not supported» на часть айтемов на разных серверах, а на следующий день уже все работало. Можно попробовать просто оставить правильное значение для счетчика (цифровое) и подождать.

Согласен, просто понять бы какое всё-таки правильное значение. Не подскажете правильное числовое значение для общей нагрузки процессора, аналог: perf_counter Заранее спасибо!
Найдено решение. Для локализованной русской версии Windows аналогом ключа: perf_counter является ключ: perf_counter
Надеюсь кому-то типа меня поможет не так долго мучаться с проблемой. Всем большое спасибо за помощь!
Оповещения в Telegram
Соответственно из этих метрик мы сделали оповещения через Telegram – в СушиВок для оперативной информации используется именно Telegram, а не почта. Причем, в Zabbix оповещения для Telegram настраиваются «из коробки».
В оповещениях операционный отдел просил указывать всю информацию о точке – количество поваров, сумма чеков, количество чеков в комплектации и т.д., чтобы можно было полностью понимать, какая ситуация на точке была во время сбоя. Из-за этого в выражении триггера и нужны были эти лишние всегда истинные неравенства. Но при большом объёме срабатывающих триггеров из-за всей этой информации сообщения стали не читаемы – получалось полотно из слов.
Поэтому я воспользовался советом Родислава Гандапаса из книги «К выступлению готов», где он при подготовке к выступлениям на карточках рекомендует использовать пиктограммы, т.к. они быстрее читаются при беглом взгляде.
Так в наших оповещениях появились:
-
ножи – это кухня;
-
черепашки – это доставка;
-
огоньки – если проблема не закрыта больше 10 мин.
Операционный отдел был очень доволен данными оповещениями.





