
Введение
Я не буду подробно останавливаться на том, зачем может понадобиться забирать данные из метрики в Zabbix, если в самой метрике есть отличный интерфейс с возможностью быстро создавать отчеты на любой вкус. Дублировать функционал метрики нет никакого смысла. Лично я использую самые простые данные о посещаемости сайтов на своем дашборде, чтобы не ходить за ними в метрику, так как там тяжелый интерфейс, который долго грузится. Раньше я для этих целей использовал виджеты на главной Яндекса, но они закрыли этот функционал, чтобы ты быстрее постиг помойку Дзена, который они всячески пихают на главной.
Введение
Сразу хочу предупредить, что моя информация это только мой личный опыт, результат моих мыслей и способностей по решению конкретных задач. Он не претендует на истину, а скорее всего нуждается в дополнении.
Как я уже сказал, статья с мониторингом web сайта актуальна и по сей день, хотя писалась для старой версии заббикса. Ни в одном из вышедших обновлений с тех пор модуль, отвечающий за мониторинг сайта, не менялся. Все осталось точно таким же, как и было. Сегодня я хочу дополнить статью некоторой информацией, плюс поделиться своими триггерами и советами по мониторингу времени отклика сайта.
Я обратил внимание на этот параметр не случайно. Последнее время поисковые системы стали внимательно относиться к времени отклика сервера с сайтом
Первым об этом заявил гугл еще несколько лет назад. В его инструменте PageSpeed Insights давно присутствует тест на время отклика сервера. Если он отвечает медленнее, чем 200 мс, то вы получаете предупреждение и рекомендации по устранению данного недостатка сервера. Некоторое время назад яндекс в вебмастере стал тоже указывать на высокое время отклика сайта, если таковое замечает.
Так что тема времени ответа сервера на сегодняшний день очень актуальна. Отдельно нужно рассматривать настройку веб сервера для уменьшения отклика. Возможно, я соберусь и напишу свои рекомендации на этот счет. А пока настроим мониторинг времени отклика сайта.
Введение
Рассказываю подробно, что я хочу получить в конце статьи. В стандартном шаблоне Zabbix для Linux есть несколько триггеров. Они могут немного отличаться в названиях, в зависимости от версии шаблона, но смысл один и тот же:
- High CPU utilization
- Load average is too high
- Too many processes on hostname
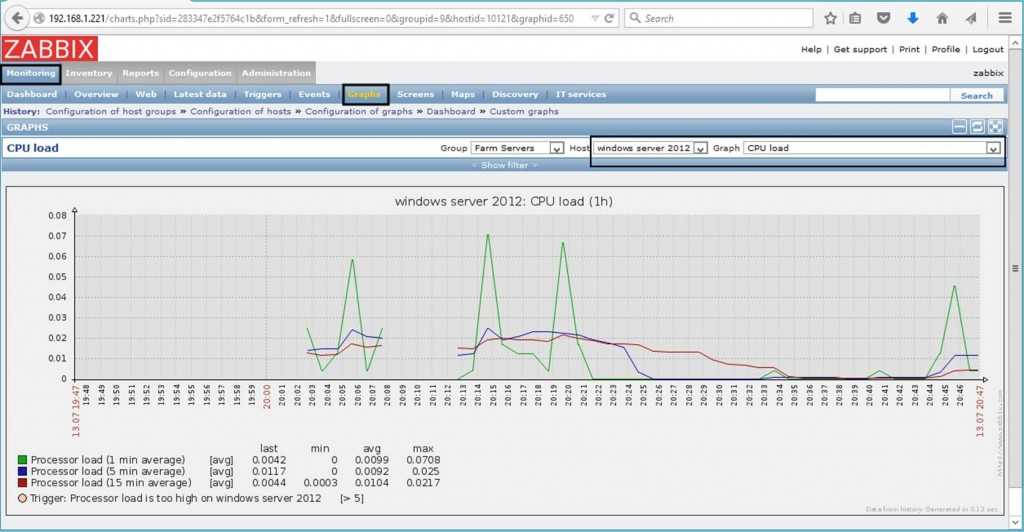
Я хочу получить информацию о запущенных процессах на хосте в момент срабатывания триггера. Это позволит мне спокойно посмотреть, что создает нагрузку, когда у меня будет возможность. Мне не придется идти руками в консоль хоста и пытаться ловить момент, когда опять появится нагрузка.
В дефолтной конфигурации у Zabbix нет готовых инструментов, чтобы реализовать желаемое. Вы можете настроить мониторинг процесса или группы процессов в Zabbix. Но это не то, что нужно. Можно настроить автообнаружение всех процессов и мониторить их. Чаще всего это тоже не нужно, а подобный мониторинг будет генерировать большую нагрузку и сохранять кучу данных в базу. Особенно если на сервере регулярно запущено несколько сотен процессов.
Моя задача посмотреть на список процессов именно в момент нагрузки. Более того, мне даже не нужны все процессы, достаточно первой десятки самых активных, нагружающих больше всего систему. Я буду реализовывать этот мониторинг следующим образом:
- Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
- Разрешаю на zabbix agent запуск внешних команд.
- Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
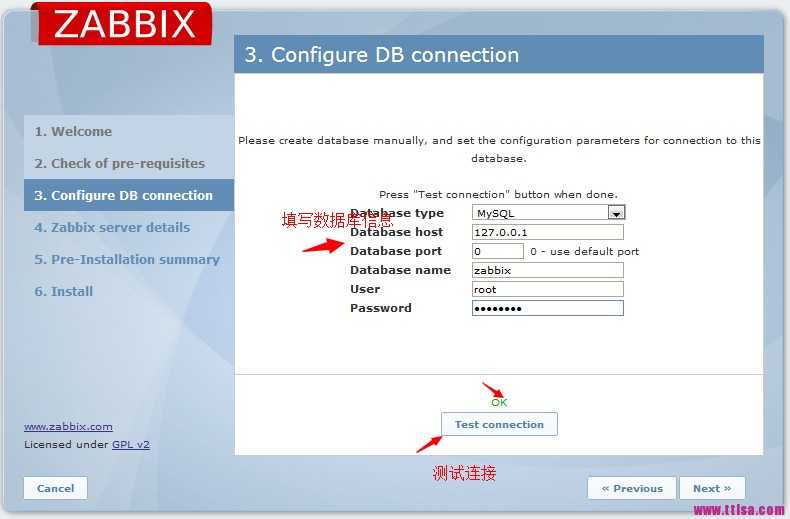
Приступаем к реализации задуманного. Я буду настраивать описанную схему на Zabbix Server версии 5.2. Если у вас его нет, читайте мою статью по установке и настройке zabbix. В качестве подопытной системы будет выступать Centos. Так же предлагаю мои статьи по ее установке и предварительной настройке.
Сразу же сделаю важное замечание. Все, что написано далее, полностью придумано и реализовано мной
Это не самый оптимальный вариант решения задачи, но лично я ничего лучше, удобнее, проще придумать не смог. Если вы знаете, как сделать то же самое лучше, поделитесь информацией. С удовольствием ознакомлюсь с ней.
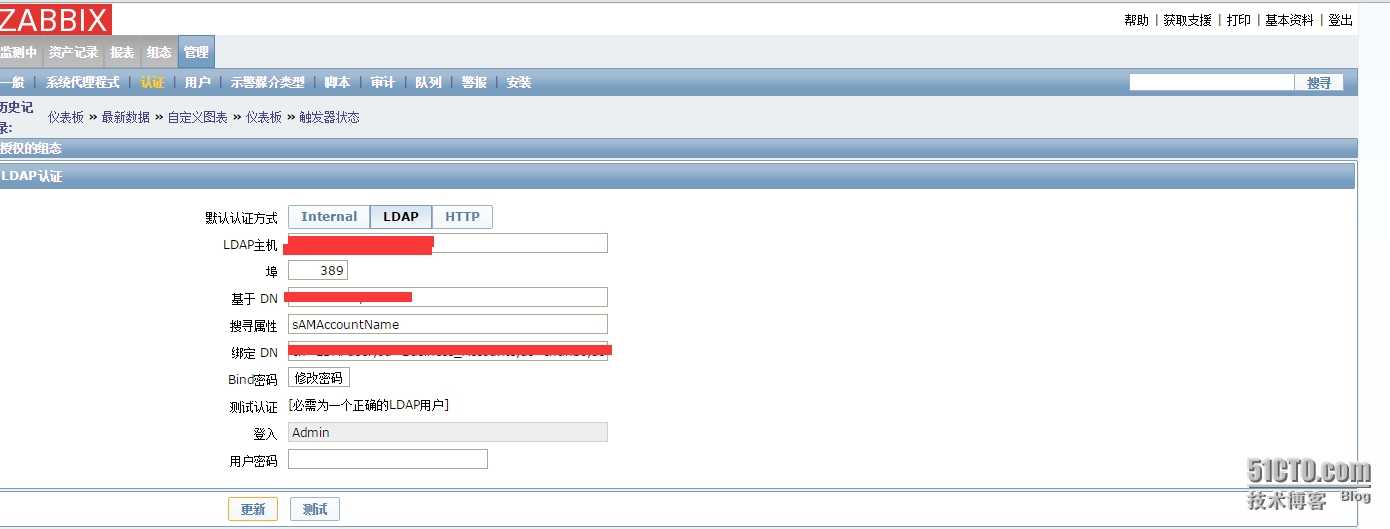
Настройка ssmtp для авторизации на почтовом сервере
Для отправки уведомлений на почту с помощью smtp авторизации нам понадобится почтовый клиент ssmtp. Установим его:
# yum install -y ssmtp
Если у вас еще не , сделайте это. Пакет устанавливается оттуда. Теперь нужно настроить почтовый клиент на отправку писем через указанную учетную запись. Для этого открываем файл /etc/ssmtp/ssmtp.conf и приводим его к следующему виду для отправки через почтовый сервер Яндекса:
cat ssmtp.conf
root=zabbix@zeroxzed.ru mailhub=smtp.yandex.ru:465 AuthUser=zabbix@zeroxzed.ru AuthPass=password AuthMethod=LOGIN FromLineOverride=YES UseTLS=YES RewriteDomain=zeroxzed.ru Hostname=zeroxzed.ru Debug=YES TLS_CA_File=/etc/pki/tls/certs/ca-bundle.crt
В данном примере я использую почтовый домен zeroxzed.ru, он у меня прикреплен к Яндексу и обслуживается им. Если у вас обычный почтовый ящик, используйте адрес вида mailbox@yandex.ru.
Если вы хотите использовать учетную запись gmail то настройки ssmtp должны быть следующие:
root=mailbox@gmail.com mailhub=smtp.gmail.com:587 RewriteDomain=gmail.com AuthUser=mailbox AuthPass=parolchik Hostname=gmail.com UseSTARTTLS=YES AuthMethod=LOGIN FromLineOverride=YES UseTLS=YES Debug=YES TLS_CA_File=/etc/pki/tls/certs/ca-bundle.crt
И редактируем там же файл revaliases, добавляя одну строку для яндекса:
root:zabbix@zeroxzed.ru:smtp.yandex.ru:465
И для gmail:
root:mailbox@gmail.com:smtp.gmail.com:587
Теперь проверим работу почтового клиента. Отправляем через консоль тестовое письмо:
# echo "test_message" | ssmtp -v zeroxzed@gmail.com 220 smtp3m.mail.yandex.net ESMTP EHLO zeroxzed.ru 250 ENHANCEDSTATUSCODES AUTH LOGIN 334 VXNlcb5hbDU6 emFiYml4QEplcm94tmVkLnJ1 334 UGFzR3dvc2Q6 235 2.7.0 Authentication successful. MAIL FROM:<zabbix@zeroxzed.ru> 250 2.1.0 <zabbix@zeroxzed.ru> ok RCPT TO:<zeroxzed@gmail.com> 250 2.1.5 <zeroxzed@gmail.com> recipient ok DATA 354 Enter mail, end with "." on a line by itself Received: by zeroxzed.ru (sSMTP sendmail emulation); Thu, 05 Nov 2015 18:32:18 +0300 From: "root" <zabbix@zeroxzed.ru> Date: Thu, 05 Nov 2015 18:32:18 +0300 test_message . 250 2.0.0 Ok: queued on smtp3m.mail.yandex.net as 1446737539-AXVW9QixF9-WJAWKNV9 QUIT 221 2.0.0 Closing connection.
Когда писал статью, не думал, что мне будут приходить на почту тестовые письма. Но долгое время не мог понять, что за сообщения с текстом test_message периодически прилетают в почту. Теперь понял, что это копипастом с этой статьи люди мне шлют тестовые письма. Не забывайте менять адрес получателя, мне ваши тестовые письма ни к чему 
Все в порядке, письмо улетело. Если что, логи работы почтового клиента можно посмотреть в файле /var/log/maillog.
Мониторинг локальной службы в linux
С мониторингом удаленного tcp сервиса разобрались, а что делать, если служба работает локально и к ней невозможно подключиться из вне. Тут уже не обойтись без установки zabbix агента. Если он установлен на хосте, то можно воспользоваться итемом с ключом proc.num. Этот ключ возвращает в качестве значения количество запущенных процессов. И если таких процессов больше одного, можно считать, что служба запущена.
Рассмотрим на примере мониторинга службы postgrey, реализующей greylist для борьбы со спамом. Она работает локально на почтовом сервере linux и является критическим сервисом, так как без него почтовый сервер postfix не будет принимать почту, выдавая временную ошибку почтовой системы. Проверим работу ключа proc.num:
# zabbix_agentd -t proc.num proc.num
Все в порядке, zabbix агент возвращает значение 1 при запущенном сервисе. Идем на сервер мониторинга, выбираем хост или шаблон и создаем новый item.
Показываю только основные параметры, остальные устанавливайте на свой вкус. Я лишь рекомендую не делать слишком частые проверки. В большинстве случаев в этом нет необходимости, а нагрузка на сервер постоянно растет при добавлении новых итемов.
Создаем триггер с оповещением о недоступности сервиса. При последних двух значениях равных срабатываем.
Я настраиваю триггер в шаблоне, поэтому сразу для удобства в названии триггера указываю маску для имени, чтобы было понятно в оповещении, на каком хосте сработал триггер. Как обычно, проверить поступаемые значения можно в Latest data.
Вот и все. Мы настроили мониторинг локальных служб linux в заббиксе.
Whois клиент для Node.js
Последнее рассмотренное мной консольное решение по получению данных whois основывается на клиенте для Node.js. Этот способ неудобен, как и с ruby, тем, что надо отдельно ставить node на сервер. Если python на centos сервере точно будет, то node придется ставить отдельно. Сделаем это.
# curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash - # yum install nodejs
Устанавливаем whois client:
# npm install whois
Под node.js я программировать вообще не умею и со скриптами не работал никогда. Так что готового скрипта для zabbix не сделал. Покажу на простом примере, как выполнять проверку. Делаем скрипт и в нем сразу указываем домен для проверки.
var whois = require('whois')
whois.lookup('serveradmin.ru', function(err, data) {
console.log(data)
})
Запускаем его:
# node domain-left.js
В выводе увидите привычную информацию whois в таком же виде, как и для остальных проверок. Если бы этот способ проверял все необходимые мне домены, я бы его доделал. Он понимает домены .pro и .io, но не понимает .fm. Так что я не стал на нем подробно останавливаться.
Настройка в zabbix мониторинга nginx
В прошлой редакции этой статьи дальше шло описание скрипта, который будет парсить вывод nginx-status и передавать данные в zabbix. Сейчас все можно сделать гораздо проще и удобнее. На агенте не надо ничего настраивать. Все выполняется исключительно в шаблоне. То есть вам достаточно загрузить готовый шаблон для мониторинга nginx на zabbix сервер, прикрепить его к хосту и все будет работать.
Это удобный подход, который избавляет от необходимости настраивать агентов. Теперь все выполняется с сервера. Минус этого подхода только в том, что возрастает нагрузка на сервер мониторинга. Это плата за удобство и централизацию. Имейте это ввиду. Если у вас большая инсталляция мониторинга и есть средства автоматизации типа ansible, возможно вам имеет смысл по старинке парсить данные скриптом. Но в общем случае я рекомендую делать так, как я расскажу далее.
Суть мониторинга Nginx будет сводиться к тому, что мы через агента станем забирать страницу http://localhost/nginx-status на сервер. Там с помощью регулярных выражений и зависимых элементов данных будем формировать нужные метрики.
Представляю вам готовый шаблон для мониторинга nginx. Скачиваем его zabbix-nginx-template.xml и открываем web интерфейс zabbix сервера. Идем в раздел Configuration -> Templates и жмем Import:
Выбираем файл и снова нажимаем Import:
Шаблон я подготовил сам на основе своих представлений о том, что нужно мониторить. Проверил и экспортировал его с версии 4.2 Регулярные выражения для парсинга html страницы статуса подсмотрел тут — https://github.com/AlexGluck/ZBX_NGINX. К представленному шаблону я добавил некоторые итемы и переделал все триггеры. Плюс убрал макросы. Не вижу в них в данном случае смысла.
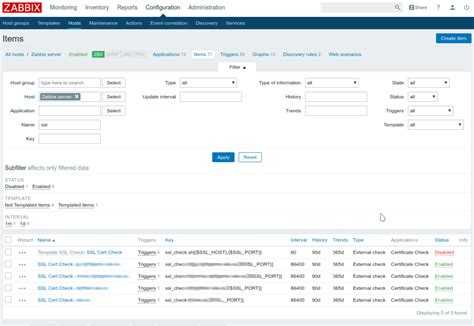
В шаблоне 11 итемов, описание которых я привел ранее.
Подробнее остановимся на триггерах. Их 5 штук.
- Many active connections — срабатывает если среднее количество соединений за последние 10 минут больше в 3 раза, чем среднее количество за интервал на 10 минут ранее.
- many requests и too many requests — срабатывают, когда среднее количество запросов за последние 10 минут больше в 3 и 6 раз соответственно, чем на 10 минут ранее.
- nginx is not running — тут все просто. Если не запущен ни один процесс nginx, шлем уведомление.
- nginx is slow to respond — срабатывает если время выполнения запроса на получение страницы со статусом за последние 10 минут больше предыдущих 10 минут в 2 раза.
С триггерами больше всего вопросов. Предложенная мной схема может работать независимо от проекта, не требует начальной калибровки, но могут быть ложные срабатывания из-за разовых очень сильных всплесков, которые быстро проходят, но сильно меняют средние параметры на интервале.
Более надежно могут сработать триггеры, где явно указаны лимиты в конкретных значениях. Но такой подход требует ручной калибровки на каждом проекте в отдельности. Надо смотреть средние значения метрик и выставлять лимиты в зависимости от них. Если проект будет расти, то лимиты постоянно придется менять. Это тоже не очень удобно и не универсально.
Я в итоге остановился на анализе средних значений, не используя конкретных лимитов. Как поступать вам, решайте отдельно, в зависимости от ситуации. Если у вас один проект, которому вы уделяете много внимания, то ставьте лимиты руками на основе анализа средних параметров. Если работаете на потоке с множеством проектов, то можно использовать мой вариант, он более универсален и не требует ручной правки.
Единственное, коэффициенты можно поправить, если будут ложные срабатывания. Но я обычно этот момент решаю через отложенные уведомления. Если чувствительность триггера очень высокая и есть кратковременные ложные срабатывания, меня они не беспокоят из-за 5-ти минутной задержки уведомлений. Зато при разборе инцидентов, эти кратковременные срабатывания помогают оценить ситуацию в целом.
С мониторингом nginx почти все готово. Теперь нам нужно прицепить добавленный шаблон к web серверу, который мы мониторим и дождаться поступления данных. Проверить их можно в Monitoring -> Latest Data:
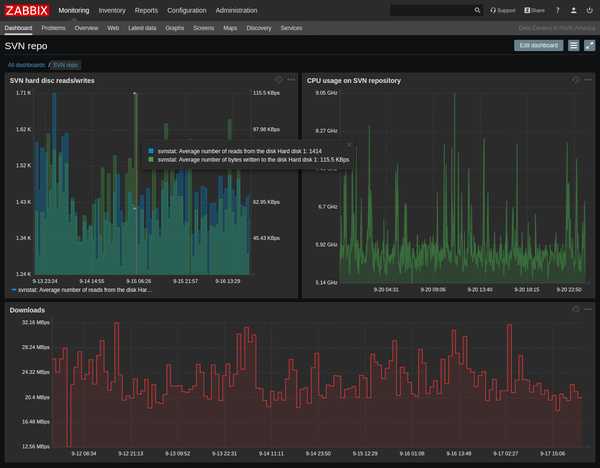
В шаблоне есть несколько графиков. Не буду о них рассказывать, так как последнее время практически не пользуюсь графиками. Вместо этого собираю дашборды. Это более удобно и информативно. Жаль, что дашборды нельзя к шаблонам прикреплять. Очень хлопотно каждый раз вручную их составлять и тратить время. В конце покажу пример дашборда, который я использую для мониторинга web сервера.
На этом настройка мониторинга nginx закончена, можно пользоваться.
1-й способ
Скрипт создания проверочного файла
Я использую описанную выше схему для бэкапа как windows так и linux серверов. Поэтому скрипта будет 2, для каждой системы. Вот пример такого скрипта для linux:
# mcedit create-timestamp.sh #!/bin/sh echo `date +"%Y-%m-%d_%H-%M"` > /shares/docs/timestamp
Скрипт просто создает файл и записывает в него текущую дату. Нам этого достаточно. Писать туда можно все, что угодно, так как проверять мы будем не содержимое, а дату последнего изменения.
Добавляем этот скрипт в cron:
# mcedit /etc/crontab #Create timestamp for backup monitoring 1 15 * * * root /root/bin/create-timestamp.sh
Раз в день в 15:01 скрипт будет создавать файл, перезаписывая предыдущий.
Делаем то же самое на windows. Создаем файл create-timestamp.bat следующего содержания:
echo %date:~-10% > D:\documents\timestamp
И добавляем его в планировщик windows. Не забудьте указать, чтобы скрипт запускался вне зависимости от регистрации пользователя, то есть чтобы он работал, даже если в системе никто не залогинен.
Запустите оба скрипта, чтобы проверить, что все в порядке, и необходимые файлы создаются.
Запустите стандартные скрипты бэкапа, чтобы созданные файлы переместились на резервные сервера. После этого можно приступать к настройке мониторинга за изменением файлов в zabbix.


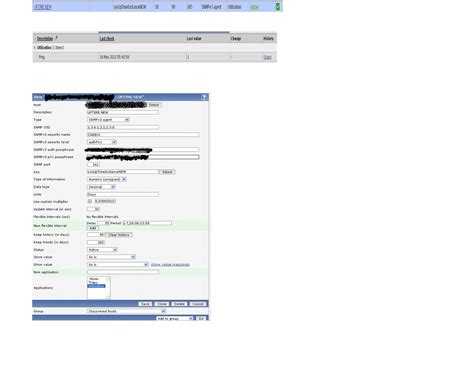

Настраиваем мониторинг бэкапов через проверку даты изменения файлов
Дальше привычное дело по созданию итемов и триггеров. Идем в панель управления zabbix, открываем раздел Configuration -> Hosts, выбираем сервер, на котором у нас хранятся бэкапы и создаем там итем со следующими параметрами:
На скриншот не влезла вся строка параметра Key, поэтому привожу ее здесь:
vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify]
| /mnt/data/BackUp/xb-share/documents/timestamp | Путь к проверяемому файлу на сервере бэкапов |
| modify | Время изменения файла. Параметр может принимать значения: access — время последнего доступа, change — время последнего изменения |
Не очень понимаю, чем отличается время изменения, от времени последнего изменения. Эта информация из документации zabbix. Для того, чтобы у вас корректно собирались данные, необходимо, чтобы у пользователя zabbix были права на чтение указанного файла. Обязательно проверьте это. Я не сделал это, через одну из папок агент не мог пройти из-за недостатка прав. В итоге получил ошибку:
17177:20160321:002008.008 item "xb-share-documents:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp]" became not supported: Not supported by Zabbix Agent
Из текста не понятно, в чем проблема. Про права я догадался. Обновление итема установил раз в 10 минут (параметр update interval), чаще не вижу смысла, можно вообще поставить пару раз в сутки, в зависимости от вашего плана архивации данных.
Теперь создадим триггер для этого элемента данных:
Разберем, что у нас в выражении написано:
{xm-backup:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify].now(0)}-{xm-backup:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify].last(0)}>172800
xm-backup — сервер, на котором хранятся бэкапы. Мы берем текущее время, вычитаем из него время последнего изменения файла. Если оно больше 172800 секунд (2 суток), то срабатывает триггер. Вы можете сами выбрать подходящий вам интервал времени сравнения в зависимости от плана бэкапа.
Для тестирования работы оповещений отключите в один из дней скрипты на источниках, создающие проверочный файл. Как только он просрочится, сработает триггер.
На этом все. Мы настроили простейший мониторинг бэкапов с помощью zabbix. Если по какой-то причине файлы перестанут синхронизироваться с сервером резервных копий, вы узнаете об этом и сможете вовремя обнаружить проблему.
Подготовка mysql к мониторингу
Для примера настроим мониторинг Mysql на самом сервере мониторинга Zabbix. Так как это часто узкое место производительности системы, мониторинг базы zabbix лишним не будет. Первым делом добавим новые параметры в агенте. Для этого создаем конфигурационный файл /etc/zabbix/zabbix_agentd.d/template_db_mysql.conf следующего содержания.
UserParameter=mysql.ping, mysqladmin -h"$1" -P"$2" ping UserParameter=mysql.get_status_variables, mysql -h"$1" -P"$2" -sNX -e "show global status" UserParameter=mysql.version, mysqladmin -s -h"$1" -P"$2" version UserParameter=mysql.db.discovery, mysql -h"$1" -P"$2" -sN -e "show databases" UserParameter=mysql.dbsize, mysql -h"$1" -P"$2" -sN -e "SELECT COALESCE(SUM(DATA_LENGTH + INDEX_LENGTH),0) FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='$3'" UserParameter=mysql.replication.discovery, mysql -h"$1" -P"$2" -sNX -e "show slave status" UserParameter=mysql.slave_status, mysql -h"$1" -P"$2" -sNX -e "show slave status"
После этого сразу перезапустим zabbix-agent.
# systemctl restart zabbix-agent
Дальше идем в консоль mysql и создаем пользователя, от которого будет работать мониторинг. Ему достаточно ограниченных прав на чтение.
# mysql -uroot -p > CREATE USER 'zbx_monitor'@'%' IDENTIFIED BY 'TTRy1bRRgLIB'; > GRANT USAGE,REPLICATION CLIENT,PROCESS,SHOW DATABASES,SHOW VIEW ON *.* TO 'zbx_monitor'@'%'; > quit
Теперь смотрим, где у нас домашняя директория пользователя zabbix.
# cat /etc/passwd | grep zabbix zabbix:x:990:986:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
У меня ее не было, так что создаем.
# mkdir /var/lib/zabbix
Кладем в эту директорию конфиг .my.cnf с реквизитами доступа к серверу mysql.
user='zbx_monitor' password='TTRy1bRRgLIB'
Назначаем пользователя zabbix владельцем своей домашней директории и файла в ней. Файлу ограничиваем доступ.
# chown -R zabbix. /var/lib/zabbix # chmod 400 /var/lib/zabbix/.my.cnf
Подготовка к мониторингу mysql сервера завершена. Идем теперь в web интерфейс системы мониторинга Zabbix.
Подготовка сервера к мониторингу процессов
Первым делом идем на целевой сервер и изменяем конфигурацию zabbix-agent. Нам надо активировать следующую опцию:
EnableRemoteCommands=1
Не забудьте после этого перезапустить агента.
# systemctl restart zabbix-agent
Предупреждаю, что подобная настройка — огромная дыра в безопасности сервера. Используйте на свой страх и риск. Чтобы у вас не было проблем с этим, настоятельно рекомендую ограничивать доступ к порту агента на сервере на уровне firewall только с сервера мониторинга. Так же в обязательном порядке использовать шифрованное соединение между сервером и агентом. Вообще, это универсальное правило при настройке мониторинга. В идеале, так надо делать всегда. Я стараюсь все это настраивать при работе мониторинга через интернет. Если проигнорировать данное предупреждение и оставить все в открытом доступе, то через разрешенные удаленные команды вам могут залить на сервер зловред.
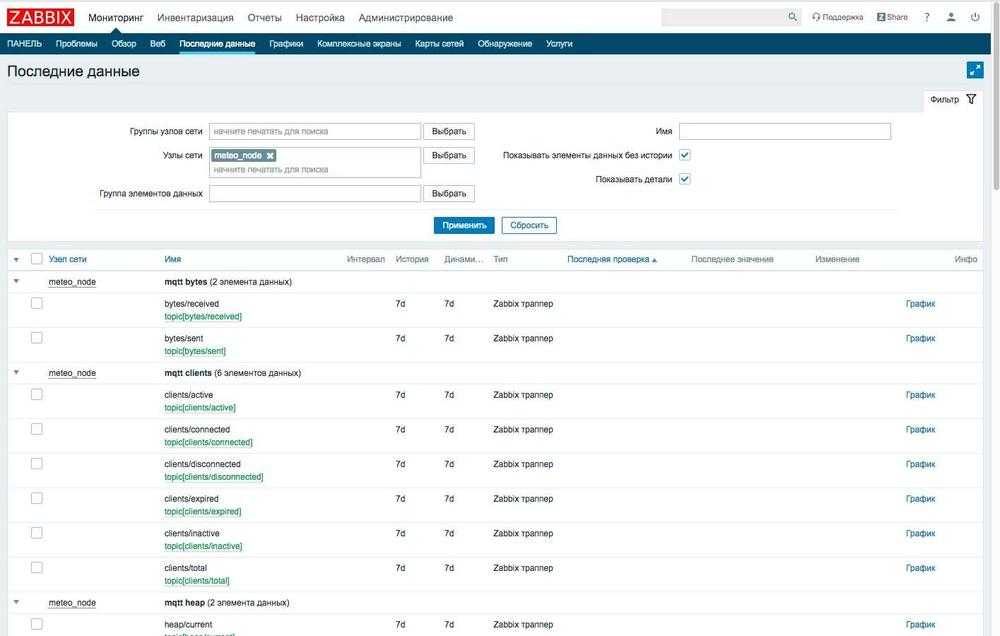
Далее проверим команду, которая будет формировать список процессов для отправки на сервер мониторинга. Я предлагаю использовать вот такую конструкцию, но вы можете придумать что-то свое.
# ps aux --sort=-pcpu,+pmem | awk 'NR<=10'
Получаем список запущенных процессов, отсортированный по потреблению cpu и ограниченный первыми десятью строками. В данный момент на сервере с агентом нам делать нечего. Перемещаемся в web интерфейс Zabbix Server.
Получение доступа к API Яндекс
Вам нужно будет заполнить несколько обязательных полей:
- Название приложения.
- В качестве платформы указать Веб-сервисы.
- Callback URI установить — https://oauth.yandex.ru/verification_code.
- В Доступах указать: Яндекс.Метрика, Получение статистики, чтение параметров своих и доверенных счетчиков.
Все остальное можно не указывать. Вы должны получить ID приложения и Пароль.
После разрешения, вы получите токен, с помощью которого можно подключаться к api.
Используя этот токен, можно получать данные из Метрики через API. Для примера зайдем на сервер мониторинга и через консоль запросим данные о посещаемости сайта. Для этого нам нужно узнать номер его id в метрике. Можно это сделать прямо в ней же.
Далее формируем запрос через curl с указанием токена в header.
# curl --header "Authorization: OAuth AgAAaaaaaaaaaaaDDDDDDDDDddd" --header "Content-Type: application/x-yametrika+json" -X GET "https://api-merika.yandex.ru/stat/v1/data?&ids=23506456&metrics=ym:s:users,ym:s:visits,ym:s:pageviews&dimensions=&date1=today&pretty=true"
В данном запросе я указал:
- AgAAAAAAGk3WAAaaYZaUSgzNyU7uvqAKCGwDSro — токен;
- ids=23506456 — id сайта в метрике;
- metrics=ym:s:users,ym:s:visits,ym:s:pageviews — запрошенные метрики — пользователи, визиты, просмотры страниц;
- date1=today — дата, сегодняшний день в данном случае;
- pretty=true — вывести в формате удобочитаемого json.
Получили ответ в виде подробного json. Он отлично подходит для zabbix, так как последний умеет из коробки парсить json. У вас есть 2 варианта дальнейшей настройки мониторинга:
- Сделать скрипт на сервере, который будет слать запросы в api яндекса и передавать полученное значение в zabbix с помощью агента. Плюс решения в том, что нагрузка на сервер мониторинга минимальная. Неудобство в том, что нужно куда-то добавлять скрипт.
- Слать запросы к api напрямую с zabbix сервера с помощью HTTP Агента. И сразу там же парсить полученный ответ. Плюс этого подхода в том, что все настройки хранятся в шаблоне и легко сохраняются или переносятся через экспорт шаблона. Минус в том, что все вычисления и запросы выполняются самим заббиксом.
Я обычно иду по второму пути, потому что так удобнее.
В таком виде это можно отправлять в Zabbix, чем мы далее и займемся.
Дополнительные материалы по Zabbix
Онлайн курс Основы сетевых технологий
Теоретический курс с самыми базовыми знаниями по сетям. Курс подходит и начинающим, и людям с опытом. Практикующим системным администраторам курс поможет упорядочить знания и восполнить пробелы. А те, кто только входит в профессию, получат на курсе базовые знания и навыки, без воды и избыточной теории. После обучения вы сможете ответить на вопросы:
- На каком уровне модели OSI могут работать коммутаторы;
- Как лучше организовать работу сети организации с множеством отделов;
- Для чего и как использовать технологию VLAN;
- Для чего сервера стоит выносить в DMZ;
- Как организовать объединение филиалов и удаленный доступ сотрудников по vpn;
- и многое другое.
Уже знаете ответы на вопросы выше? Или сомневаетесь? Попробуйте пройти тест по основам сетевых технологий. Всего 53 вопроса, в один цикл теста входит 10 вопросов в случайном порядке. Поэтому тест можно проходить несколько раз без потери интереса. Бесплатно и без регистрации. Все подробности на странице .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Проверка отложенных уведомлений
Для проверки отложенного уведомления, достаточно дождаться срабатывания какого-нибудь триггера. Вот мои примеры, когда оповещение не было отправлено вовсе, так как триггер работал менее 5 минут. И рядом же пример отправки уведомления только через 5 минут после срабатывания триггера.
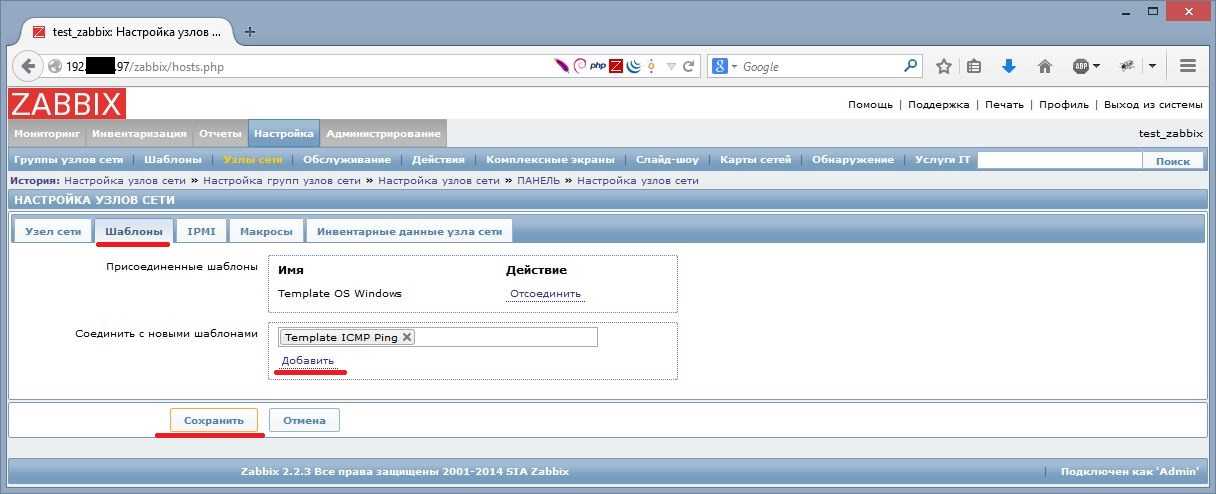

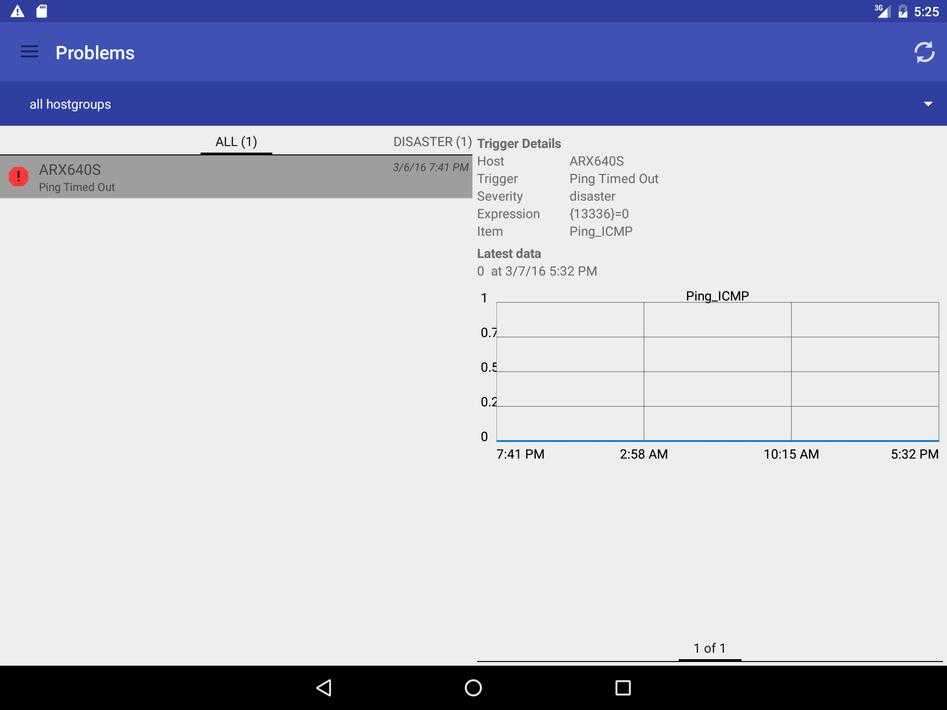
Последнее событие длилось 1 минуту. Во время бэкапа сайта сработал триггер на нехватку места. После завершения бэкапа, скрипт подчистил за собой следы и места стало достаточно. Все случилось в течении 1 минуты, так что оповещения я вообще не получил.
Второе событие длилось 6 минут. Оповещение было отправлено только через 5 минут после срабатывания триггера.
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.
Заключение
С помощью внешних скриптов настроили еще один тип мониторинга для бэкапов. Если у кого-то есть мысли на тему того, что нужно мониторить у резервных копий, высказывайте пожелания, попробую реализовать. Я очень внимательно отношусь к бэкапам и помимо автоматических проверок стараюсь время от времени заходить и глазами проверять все ли в порядке, на месте ли данные и можно ли их восстановить.
На своем опыте убедился в необходимости таких проверок. Приходилось сталкиваться с отказами различных систем, в том числе и коммерческих. Сервис может тупо зависнуть или выключиться, а ты надеешься на оповещения об ошибках, а раз не получаешь их, думаешь, что все в порядке, а на самом деле у тебя нет резервных копий. Еще вариант, с которым приходилось сталкиваться, это когда вроде все в порядке, никаких ошибок нет, а во время восстановления получаешь ошибку чтения данных.
Было бы неплохо автоматизировать восстановление данных и сравнение их с оригиналом для стопроцентной уверенности в том, что у тебя живые копии. Но для этого нужны дополнительные ресурсы.
Заключение
Теперь у нас zabbix работает современно, модно, молодежно Использует telegram для отправки оповещений с графиками, ссылками и т.д. Функционал удобный и настраивается достаточно просто. У меня практически не было затруднений, когда разбирал тему. Беру себе на вооружение и использую по необходимости. Хотя сам не люблю оповещения в телеграме, и чаще всего их отключаю, как и от остальных программ. Не нравится, когда меня в каждую минуту могут отвлечь какие-то события. Проверка почты раз в 30 минут самая подходящая интенсивность для меня.
Тем не менее, при работе коллектива, оповещения в общую группу могут быть очень удобны. Особенно, если только на мониторинге сидят отдельные люди, в чью задачу входит оперативная реакция на события.
Прошлая версия статьи в pdf.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .





