
Введение
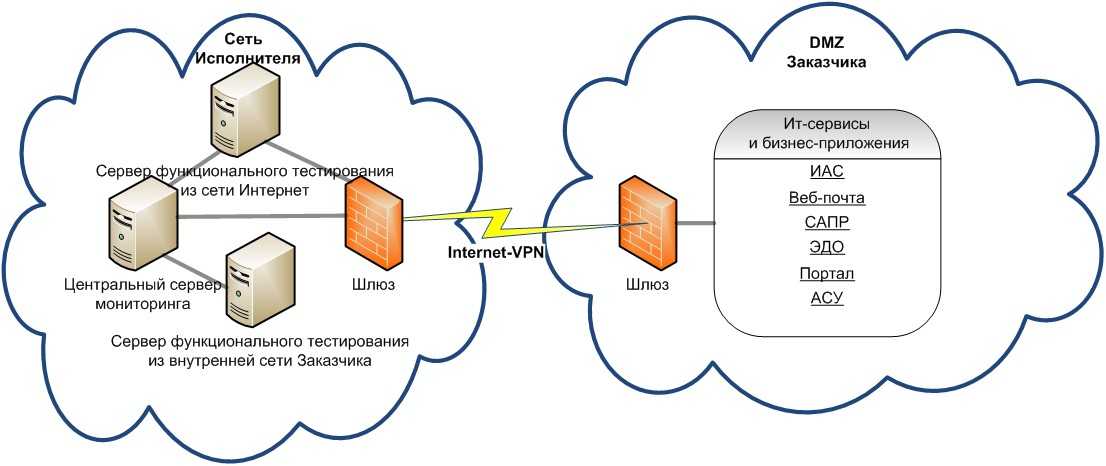
Разработанная программная система рано или поздно поступает в эксплуатацию
Пользователю важно, чтобы система работала без сбоев. Если внештатная ситуация все же произойдет, она должна устраняться с минимальными задержками
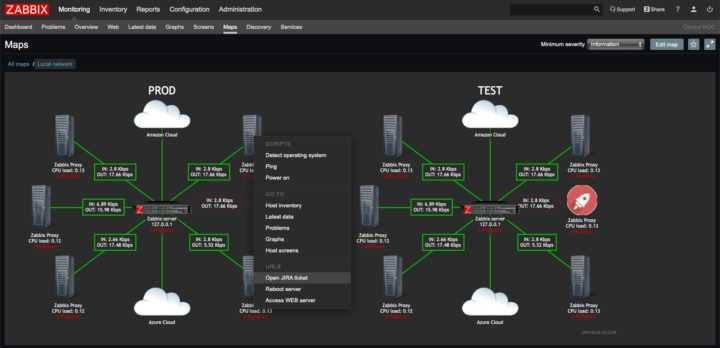
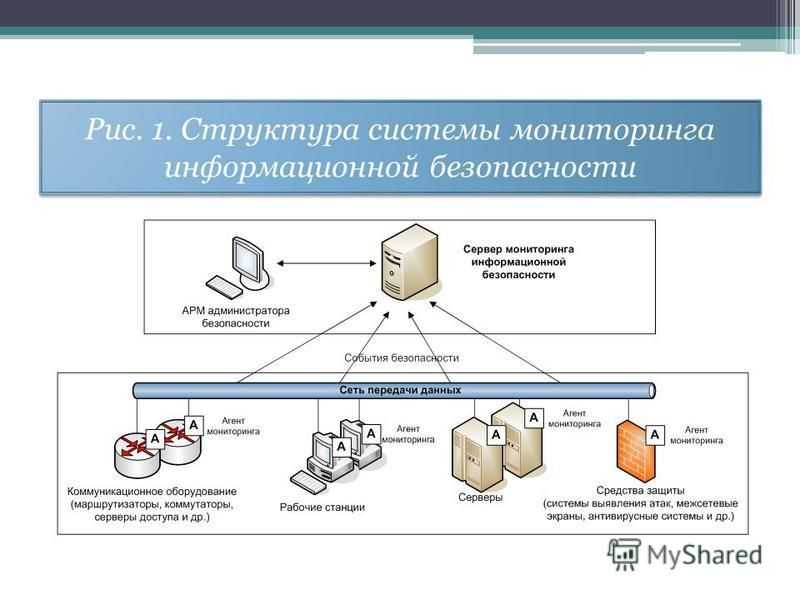
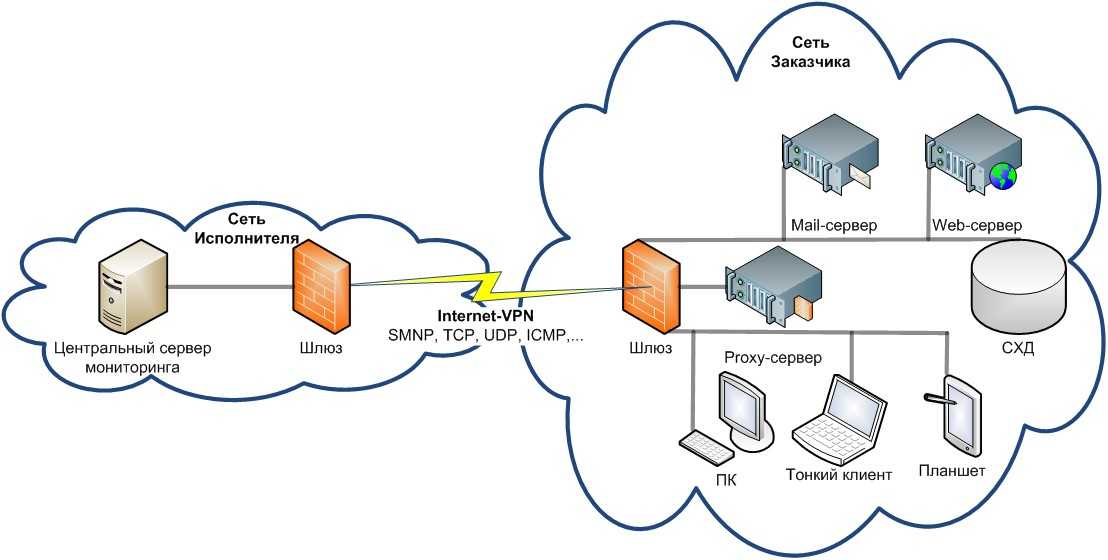
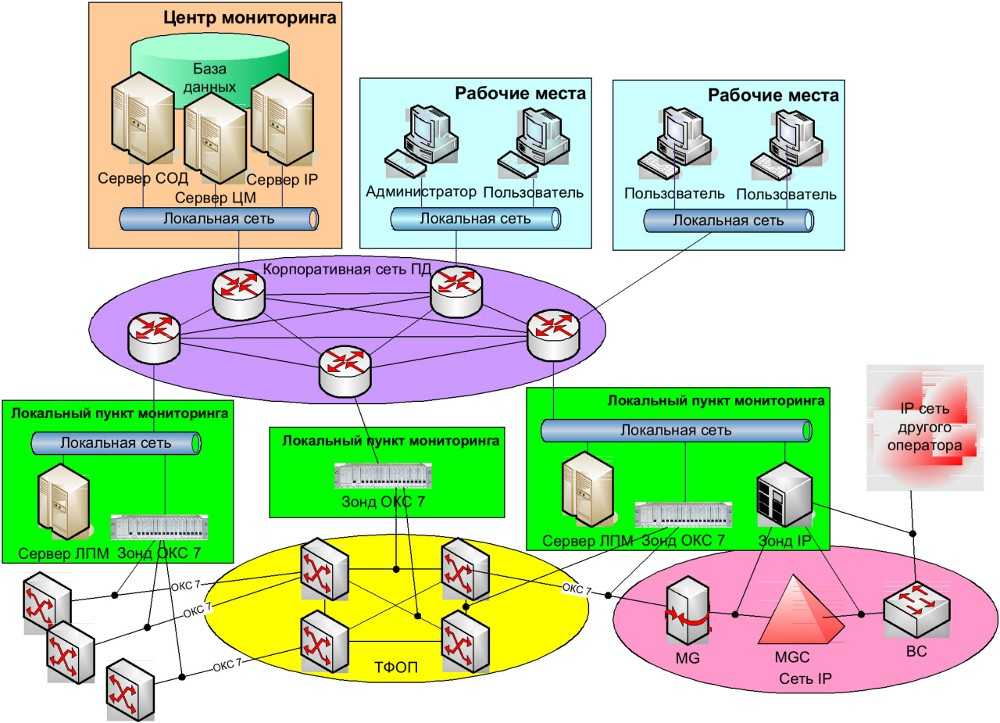
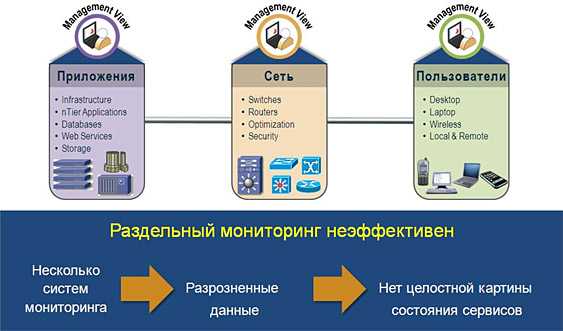
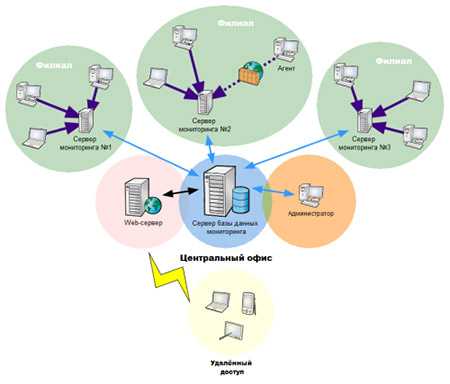
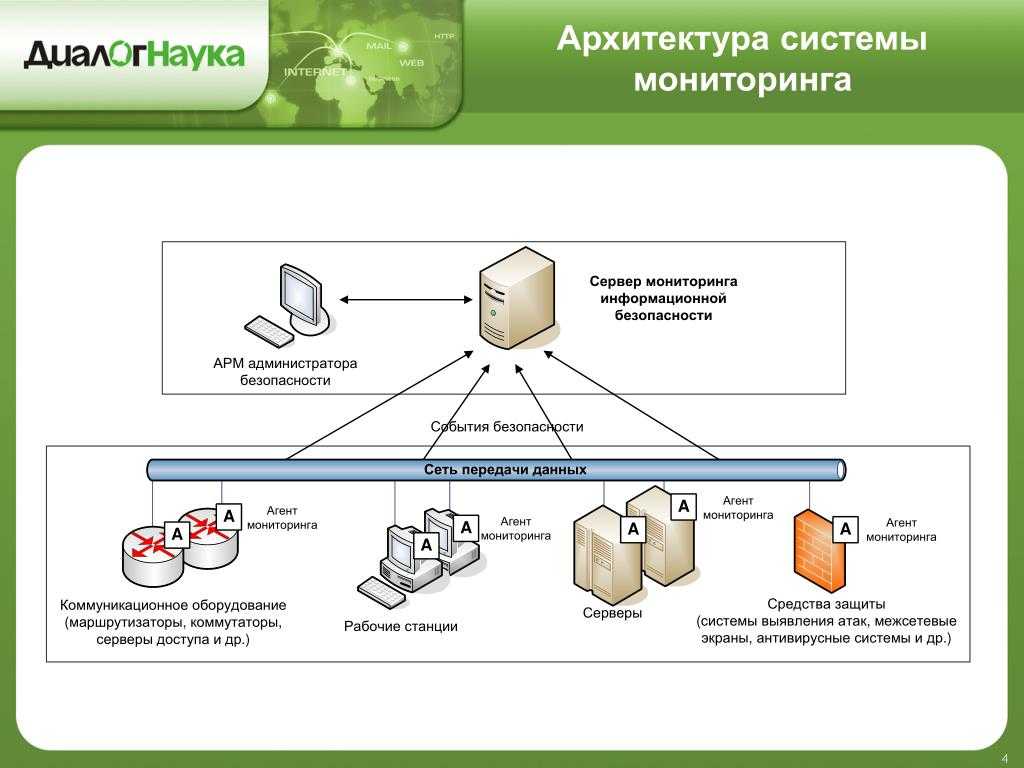
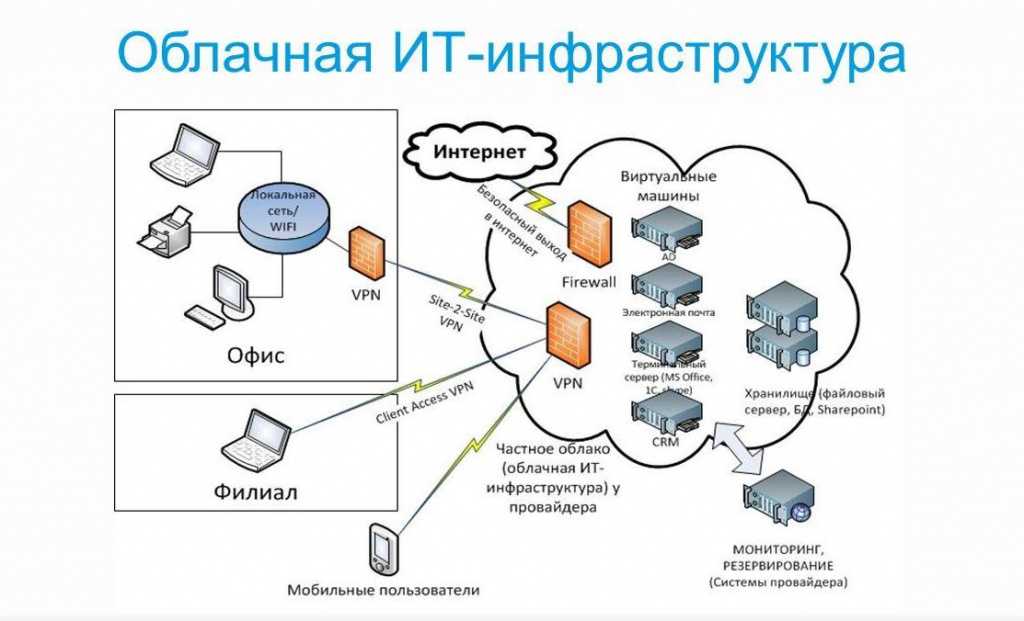
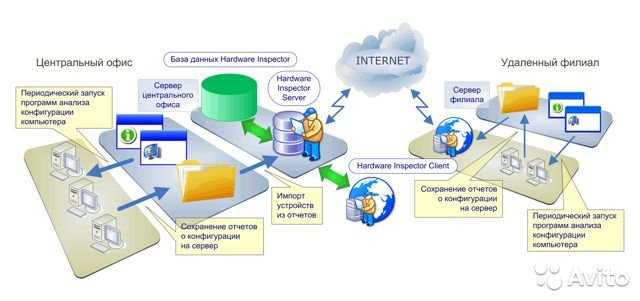
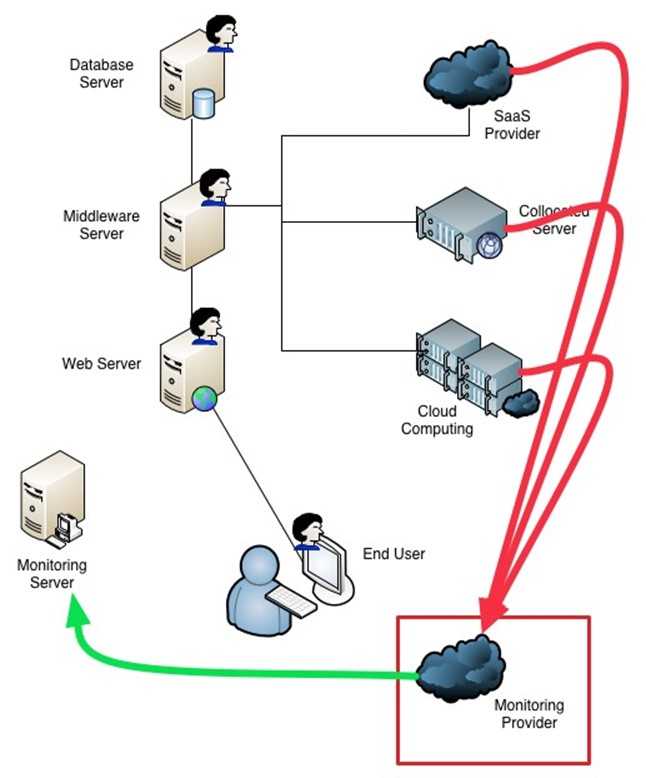
Для упрощения технической поддержки программной системы, особенно если серверов много, обычно используются программы мониторинга, которые снимают метрики с работающей программной системы, дают возможность диагностировать её состояние и помогают определить, что именно вызвало сбой. Этот процесс называется мониторингом программной системы.
Рисунок 1. Интерфейс для мониторинга grafana
Метрики – это различные показатели программной системы, среды её исполнения или физической вычислительной машины, под которой запущена система с меткой времени, того момента, когда метрики были получены. В статическом анализе данные метрик называются временными рядами. Для наблюдения за состоянием программной системы метрики отображают в виде графиков: по оси X – время, а по оси Y – значения (рисунок 1). С работающей программной системы может сниматься несколько тысяч метрик (с каждого узла). Они образуют пространство метрик (многомерных временных рядов).
Так как у сложных программных систем снимается большое количество метрик, ручной мониторинг становится сложной задачей. Для сокращения объема анализируемых администратором данных средства мониторинга содержат инструменты для автоматического выявления возможных проблем. Например, можно настроить триггер, срабатывающий в случае уменьшения свободного дискового пространства до указанного порога. Также можно автоматически диагностировать остановку сервера либо критическое замедление скорости обслуживания. На практике средства мониторинга неплохо справляются с обнаружением уже произошедших отказов либо выявлением простых симптомов будущих отказов, но в целом предсказание возможного сбоя остается для них крепким орешком. Предсказание же путем ручного анализа метрик требует привлечения квалифицированных специалистов. Оно низкопродуктивно. Большинство потенциальных отказов могут остаться незамеченными.
В последнее время среди крупных IT-компаний по разработке ПО всё большую популярность приобретает именно так называемое предиктивное обслуживание программных систем. Суть данного подхода заключается в нахождении неполадок, ведущих к деградации системы на ранних этапах, до её отказа с использованием искусственного интеллекта. Данный подход не исключает полностью ручной мониторинг системы. Он является вспомогательным для процесса мониторинга в целом.
Основным инструментом реализации предиктивного обслуживания является задача поиска аномалий во временных рядах, так как при возникновении аномалии в данных велика вероятность того, что через некоторое время возникнет сбой или отказ. Аномалия – это некоторое отклонение показателей программной системы, такое как выявление деградации скорости выполнения запроса одного вида или снижение среднего числа обслуживаемых обращений при постоянном уровне клиентских сессий.
Задача поиска аномалий для программных систем имеет свою специфику. По идее для каждой программной системы необходима разработка или доработка имеющихся методов, так как поиск аномалий очень зависит от данных, в которых он производится, а данные программных систем очень различаются в зависимости от инструментов реализации системы вплоть до того, под какой вычислительной машиной она запущена.
NTA и NBA
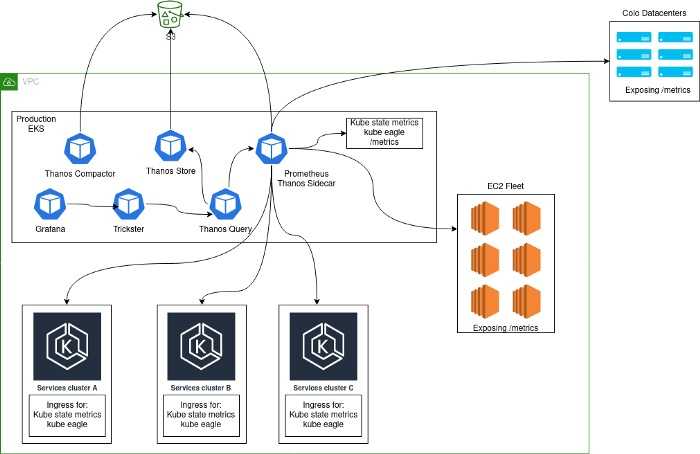
У вас уже скорее всего есть SIEM, который получает агрегированные данные трафика в форматах NetFlow, sFlow, jFlow, Packeteer или сам создаёт такие агрегаты из копии трафика. Их основные данные – информация L3 и L4 OSI. Также, у вас скорее всего внедрён IDS/IPS, который не записывает трафик, но анализирует его полную копию от L2 до L7, насколько позволяет шифрование.
Если эти средства не решили ваши задачи, можно дополнить систему мониторинга с помощью Network Traffic Analysis. Это решение производит запись трафика для его последующего исследования. При планировании стоит учесть гораздо больший по сравнению с LM/SIEM объем хранилища и необходимость предварительной расшифровки данных.
Трафик объединяет в себе и информацию, и факт её передачи. В отличие от событий, генерация которых избирательна, он полностью описывает, что произошло между двумя взаимодействующими системами, и его нельзя удалить или сфабриковать. События собираются в LM или SIEM с некоторой задержкой, если это не Syslog, в случае которого возможен спуфинг. А если успеть очистить журнал источника – действие, подозрительное само по себе – что точно случилось узнать будет трудно.
Также можно использовать решения класса Network Behavior Analysis – аналог U(E)BA для сети со всеми его преимуществами и недостатками, но с парой особенностей. Во-первых, эти решения гораздо чаще выпускаются в виде обособленных продуктов. Во-вторых, как мы уже говорили в части 6, основных сетевых протоколов несколько десятков, что делает решение «из коробки» довольно эффективным.

Результат использования NTA и NBA – у вас есть аналоги SIEM и U(E)BA, позволяющие использовать все особенности трафика.
Рекуррентная нейронная сеть
Для обнаружения аномалий во временных рядах можно применить рекуррентную нейронную сеть с памятью LSTM. Проблема есть лишь в том, что она может применяться только для прогнозируемых временных рядов. В нашем случае не все метрики являются прогнозируемыми. Попытка применить RNN LSTM для временного ряда представлена на рисунке 4.
Рисунок 4. Пример работы рекуррентной нейронной сети c ячейками памяти LSTM
Как видно из рисунка 4, RNN LSTM удалось справиться с поиском аномалии на данном участке времени. Там, где результат имеет высокую ошибку прогнозирования (mean error), действительно произошла аномалия по показателям. Использования одной RNN LSTM явно будет недостаточно, поскольку она применима к малому количеству метрик. Можно использовать как вспомогательный метод поиска аномалий.
Спектр (цветовая шкала) опасных явлений природного и техногенного характера
|
— о сейсмической и вулканической активности Данные о землетрясениях, активности вулканов и возникших цунами. — о температурных аномалиях Данные о пожарах, высоких и низких температурах, угрожающих жизни и здоровью людей. — о негативных медико-биологических факторах Данные об эпидемиях, отравлениях и о загрязнениях окружающей среды. — о климатических изменениях, авариях (не ДТП) Данные о чрезвычайных ситуациях, связанных с природными и техногенными катастрофами, а также с космической опасностью. — о ДТП и автокатастрофах — о гидрологических аномалиях Данные о наводнениях, лавинах, селях, оползнях и провалах грунта, об аномальных осадках, засухах и кораблекрушениях. — об атмосферных аномалиях Данные о циклонах, штормах, ураганах (тайфунах), смерчах (торнадо), Эль-Ниньо (Ла-Ниньо), сильных грозах), о солнечной активности и магнитных бурях Земли. |
Применение…Спектр (цветовая шкала) опасных явлений природного и техногенного характера является неотъемлемой частью Системы мониторинга за состоянием окружающей среды и применяется при:
- оповещении пользователей о прогнозируемых и фактических опасных явлениях погоды, ЧС и катастрофах природного и техногенного характера;
- суточной визуализации состояния субъектов РФ (история, факт, прогноз);
- визуализации состояния окружающей среды в месячных архивах и ежегодных итоговых аналитических заключениях.
Информер-индикатор оповещения:
<link href=»//idp-cs.net/css/info.css» rel=»stylesheet» type=»text/css» /><a class=»info» href=»//idp-cs.net/»><img class=»info» alt=»idp-cs.net» src=»https://idp-cs.net/pix/idpinfok_sm.gif» width=88 height=31 /></a>
Дата разработки: 2009 год.
Разработчик: Макаров О.В.
Copyright…Все права на материалы, находящиеся на сайте, охраняются в соответствии с законодательством РФ. Свидельство о госрегистрации № 2017662842.
Что нам стоит SOC построить
Чем выше бюджет проекта, чем больше проект политизирован, тем сложнее изменить его вводные. Но для решения вопросов безопасности тоже действует принцип Парето. Добивать самые трудоёмкие 1-5-10% договора, которые не будут заметны в общем результате, не выгодно ни одной из его сторон. Проект лучше разбивать на этапы, а не гнаться за постройкой условного SOC с нуля. Это позволит учесть опыт предыдущих стадий и минимизировать риски по реализации нереализуемого, а часто и не нужного.


Итоговые цели нужно как ставить, так и пересматривать. А когда они зафиксированы в договоре, это практически невозможно. Например, база данных, с которой по грандиозному плану будут собираться события аудита, упадёт под дополнительной нагрузкой, вызванной этим самым аудитом. Но в техническое задание уже заложено требование по написанию ранбука на основе данных источника и реализации его в IRP. Переходим к правкам по ходу пьесы?
Декомпозицию на этапы можно производить вплоть до подключения «вот этих 5 видов источников» или создания «вот этих 10 сценариев и ранбуков к ним». Главное – это не полнота внедрения, а полнота использования того, что внедрено. Обосновать модернизацию эффективного решения проще, чем того, которое всплывает два раза в год в негативном контексте и стоит в десять раз дороже.
Если не знаете, что точно хотите и можете получить от автоматизации – просите пилотный проект. Но если не понимаете, что вам надо «без автоматизации» – от кого будете защищаться, куда и как ему было бы интересно проникнуть, что вам с этим делать – преимуществ от пилота будет мало. В технической части вы, вероятно, совершите скачок. Но подходит ли вам конкретный продукт – сказать будет сложно. Тут нужен консалтинг, а не внедрение технических решений. Пока вы не определитесь, что хотите автоматизировать, выбор конкретной системы не будет обоснованным. То, что показалось достаточным в ходе сегодняшнего пилота, завтра придётся подпирать костылями.
Пилот должен проводиться в рамках разумного. Я знаю организацию, которая столкнулась с невозможностью масштабирования после закупки. Не первый раз просят пилот, в котором у SIEM 30 графических панелей, 40 видов источников, 50 правил корреляции и 60 отчётов. Сделайте, а мы подумаем, покупать или обойдёмся. Интересы сторон должны сходиться. В той же части масштабирования можно согласовать решение с производителем и, например, заручиться от него гарантийным письмом.
SIEM
Переход от LM к системам класса Security Information and Event Management требуется в двух случаях:
-
Необходимо оповещение операторов о подозрениях на инциденты (далее — инциденты) в режиме близком к реальному времени. К этой опции должны прилагаться сотрудники, работающие в том же режиме — 24х7.
-
Необходимо выявление последовательностей разнородных событий. Это уже не просто фильтрация и агрегация, как в LM или Sigma (на текущий момент).
Дополнительно вы получите:
-
Правила «из коробки», которые хороши в качестве примеров или отправной точки. Или после глубокой доработки и настройки.
-
Историческую корреляцию, совмещающую преимущества SIEM (структура корреляционного запроса) и LM (работа с данными на всю глубину). Быстрое тестирование нового правила на исторических данных, проверка только что пришедшего IOC, который обнаружен две недели назад, запуск правил с большими временными окнами в неурочное время – всё это применения данной функции. Она может быть частью базового решения, требовать отдельных лицензий или вовсе отсутствовать.
-
Второстепенные для одних, но критичные для других функции. Иное представление данных на дашбордах, отправка отчётов в мессенджер, гибкое управление хранением событий и т.д. Производитель стремится оправдать скачок цены от LM к SIEM.
Задачи на этом этапе следующие:
Создание логики детектирования всех интересных вам инцидентов. Без автоматизации вам приходилось выбирать только самые критичные
Сейчас можно учесть всё действительно важное. Главный вопрос – как на таком потоке выстроить реагирование.
Уменьшение ЛПС и ЛОС путём обогащения данных – добавления информации из внешних справочников, изменения пороговых значений, дробления правил по сегментам, группам пользователей и т.д
Возросший объём статистики по работе сценариев улучшает качество их анализа.
Обе задачи решаем итерационно. Хороший показатель – 15 инцидентов на смену аналитика. Достигли его – закручиваем гайки дальше.
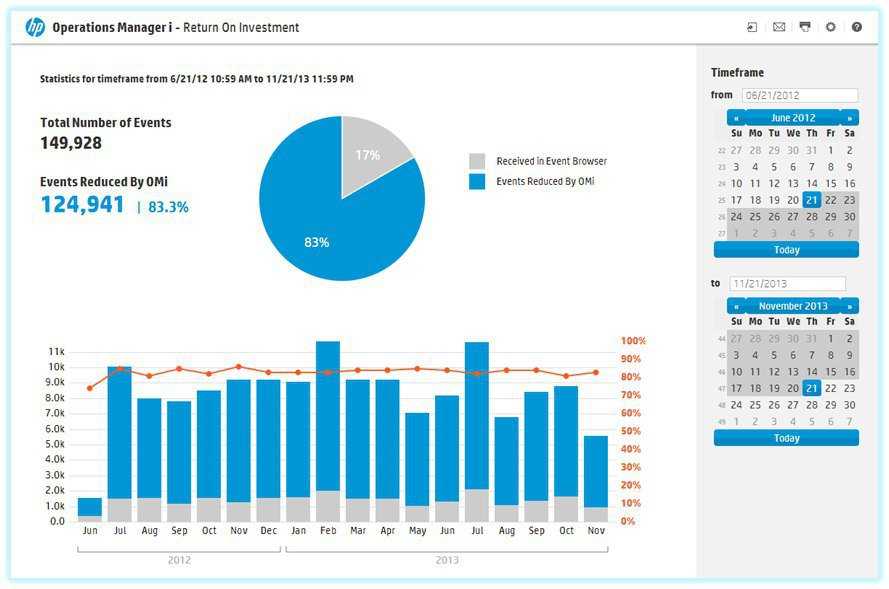
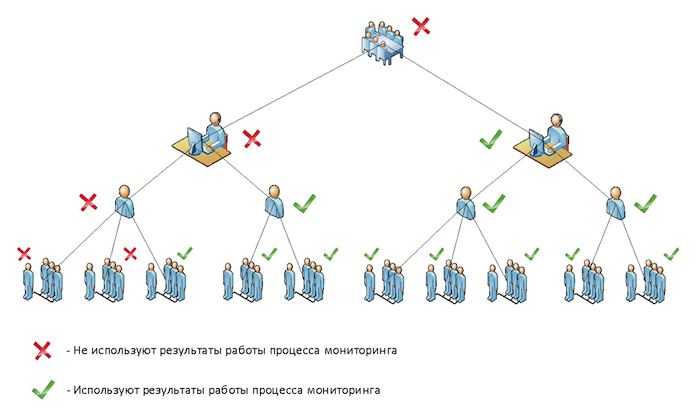
Начинаем оценивать эффективность расследования – время на приём в работу инцидента, время на реагирование, время на устранение последствий и т.д. И пытаться этой эффективностью управлять – что мешает работать быстрее, где основные задержки?
Результаты использования SIEM:
Выявление инцидентов происходит в автоматическом режиме, возможно обнаружение и корреляция цепочек разнородных событий.
Рост числа типов инцидентов
Аналитик переключает внимание с обнаружения на расследование и реагирование. При этом не стоит забывать про Threat Hunting – этот метод остаётся лучшим для определения новых для вас угроз.
Какой шаг сделать дальше? Тут лучших практик нет. Следующие этапы могут идти последовательно в любом порядке, параллельно или вовсе отсутствовать.
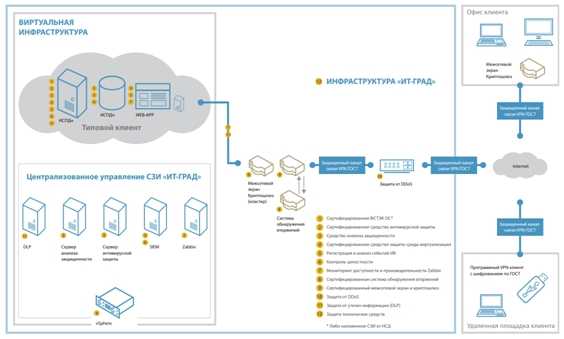
Автоматизированный мониторинг

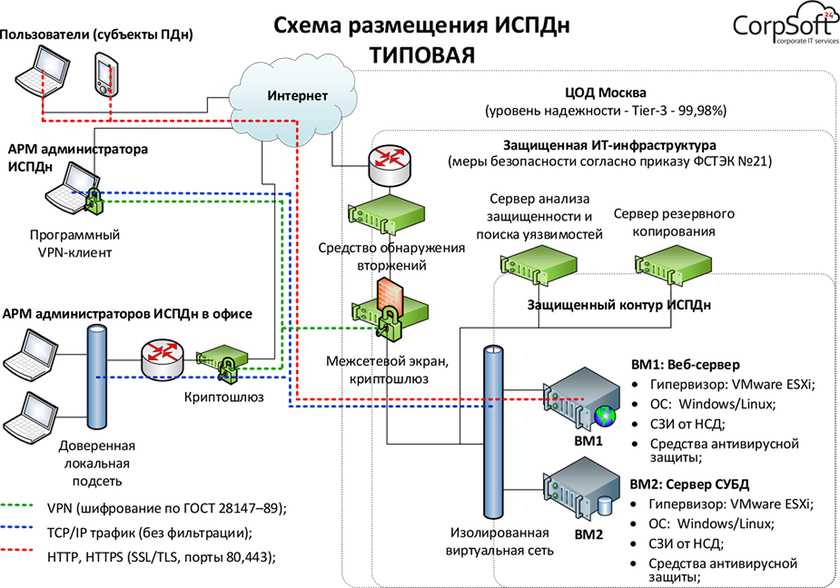
Автоматические мониторинговые системы для несущих конструкций разрабатывают на стадии проектирования объектов (зданий и сооружений), а их монтаж производится уже во время самого строительства.
Системы автоматизированного наблюдения используются с целью обнаружения отрицательных факторов, которые могут стать причиной негативного изменения состояния объекта, вплоть до его разрушения.
Наиболее эффективно, когда мониторинг начинают производить еще на ранних стадиях эксплуатации.
ООО НПО «ГЕОСМАРТ» предлагает следующий список услуг, связанных с разработкой и внедрением систем по мониторингу несущих конструкций:
- Проектирование СМИК и СМИС;
- Разработка программного обеспечения;
- Ввод в эксплуатацию систем мониторинга;
- Проведение мониторинга уже построенных зданий и сооружений.
Преимущества мониторинговых автоматических систем
Возможность производить отслеживание состояния объекта в режиме «24/7» из любой точки Земли, где есть доступ к интернету.
Следует понимать, что процесс изменений различных параметров непрерывен, и крайне важно своевременно отслеживать состояние объекта и момент, когда происходят эти изменения.
Анализ входящей информации, соответственно, тоже необходимо осуществлять в режиме реального времени и непрерывно.
Дистанционный круглосуточный мониторинг данных.
Необходимость в этом возникает довольно часто, в силу раздельного местонахождения объектов мониторинга и лиц, ответственных за контроль над ними.
Гибкость настроек временных интервалов у систем наблюдения.
Можно настроить дискретность отслеживания изменений практически в любом интервале – от секунд и до месяцев.
К тому же, система мониторинга будет в автоматическом режиме уведомлять установленных ответственных сотрудников о любых смещениях вне определенных в настройках диапазонов. Своевременность такой передачи информации позволит вовремя отреагировать на опасные изменения и избежать катастроф или других аварийных состояний.
Полученная в результате мониторинга со всех сенсоров информация синхронизируется с временной шкалой и будет доступна в графическом виде
Это позволяет использовать данные для последующей обработки и анализа.
Область применения систем автоматического мониторинга
- Анализ напряженно-деформированных состояний сооружений – гидротехнических объектов, мостов, многоэтажных зданий и т.д.;
- проектирование, прокладка и эксплуатация тоннелей;
- мониторинг сооружений в сейсмически активных зонах;
- мониторинг состояния котлованов, откосов и склонов.
Приборы и оборудование для измерений
В своей работе мы используем значительное количество самого разнообразного специализированного оборудования – дальномеры, акселерометры, геотехнические датчики (экстензометры, трещинометры, пьезометры), датчики наклона, тензометры, видеокамеры, метеорологические датчики, системы позиционирования TPS/GPS и т.д.
Благодаря обработке данных геодезических измерений, мы получаем точную информацию об объекте и его состоянии, в частности, о смещении и деформациях конструкций и отклонениях от предыдущего состояния либо состояния, зарегистрированного в проекте. Кроме того, использующееся оборудование дает возможность получать и другие параметры, анализ которых, совместно с геодезическими данными, позволяет выявить корреляцию и причины, по которым происходит изменение состояния сооружения.


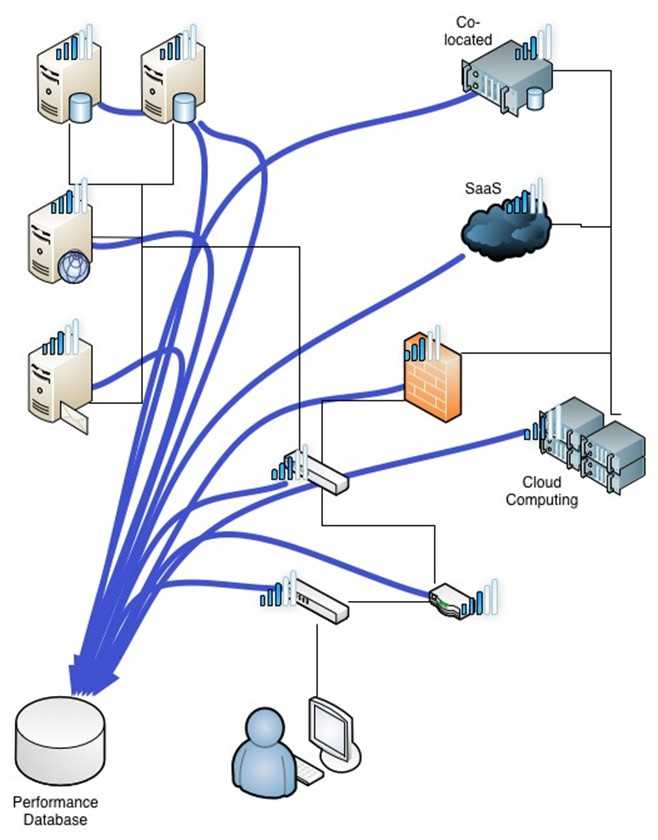
По результатам анализа и обработки сигналов, полученных с датчиков, определяется к какой категории можно отнести объект в соответствии с его состоянием.
Если контрольные показатели отличаются от нормативных/заданных, необходимо проводить срочный мониторинг, который поможет определить причины возникновения отклонения.
Анализ этих причин даст возможность сделать выводы о необходимости усиления строительных конструкций объекта либо ее отсутствии.
https://youtube.com/watch?v=rUccYdcbiaQ
Частота проведения периодического мониторинга конструкций – 1 раз в квартал. Как периодический, так и внеплановый мониторинг состояния объектов, проводятся в порядке, который установлен нормативной документацией.
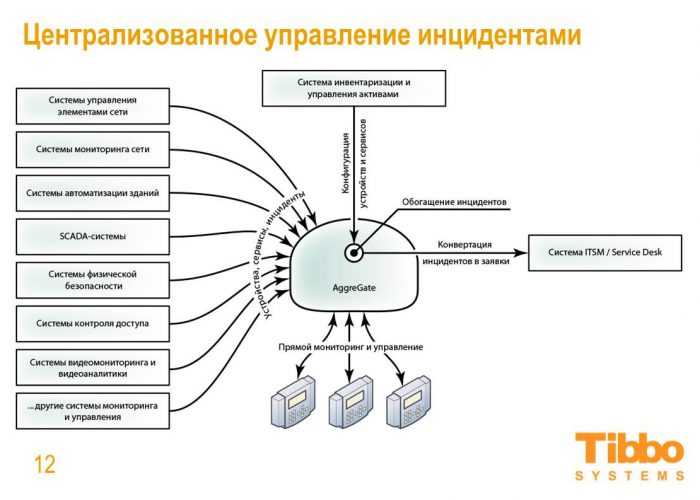
IRP или SOAR
Эти термины изначально говорили о разных системах: Incident Response Platform и Security Orchestration, Automation and Response (или Report). Но современные решения расположились по всей палитре между этими огнями и поэтому термины стали синонимами с широким диапазоном значений.
Основных функций у этих систем четыре:
-
Тикетница. В карточке инцидента аналитики получают задачи, комментируют их выполнение, передают активности между сменами и т.д.
-
Создание ранбуков. Варианты функционала различны: просто графическое представление алгоритма действий, оно же с функцией отображения хода расследования или расширенный вариант – каждый из шагов алгоритма может быть автоматизирован скриптом.
-
Автоматизированное реагирование на инциденты. Каждый шаг алгоритма может быть выполнен вручную, автоматизировано или автоматически. Зависит только от уровня контроля человеком, который вы хотите оставить. Блокировать ли в автоматическом режиме учётную запись для предотвращения развития инцидента? А если это ЛПС? А если это учётка главного бухгалтера в день выдачи заработной платы? А если это учётка администратора домена и через минуту будет поздно? Производитель даёт набор интеграций из коробки и инструменты создания практически любых пользовательских вариантов с использованием нескольких языков программирования.
-
Анализ метрик эффективности SOC, доступных системе.
Это специализированный сервис деск с функцией исполнения скриптов. Если у вас получится закрыть часть требований встроенным функционалом, вам необходимо получить более простые и стабильные способы работы со скриптами или дать службе мониторинга отдельный от ИТ инструмент со специализированным интерфейсом – это решения для вас.
Автоматизация способна ускорить реагирование на часть кейсов на 1-2 порядка. Но далеко не в каждом случае. Второй вариант использования – учёт действий аналитика. Если в инциденте участвует критичный актив, например, АСУ ТП, каждый шаг должен быть выполнен компетентным сотрудником, который ответственен за решение; ничего не должно быть пропущено, лог реагирования сохранён. Здесь будут преимущества от использования даже полностью «ручных» ранбуков. Таким образом систему можно применить к любому инциденту, сочетая оба варианта использования в разных пропорциях.
Результата использования IRP/SOAR:
-
Алгоритмы решения всех инцидентов собраны воедино, выстроен автоматизированный процесс расследования и реагирования.
-
Ведётся лог действий по реагированию, что позволяет как контролировать его в ручном режиме, так и собирать метрики для оценки эффективность процесса.
Ожидаемые результаты
- систематическое получение данных о фактических значениях параметров состояния контролируемых объектов и процессов;
- оперативный, плановый и опережающий контроль состояния сложных объектов и процессов на основании устанавливаемых или вычисляемых критериев;
- планирование мероприятий по восстановлению объектов контроля;
- прогнозирование изменений состояний контролируемых объектов и процессов;
- прогнозирование возможных критических ситуаций;
- визуализация изменения значений параметров контролируемых объектов и процессов;
- формирование и доведение до потребителей заключений о состоянии контролируемых объектов и процессов, а также оперативное оповещение потребителей об обнаруженных негативных тенденциях и критических ситуациях.
Виды и способы мониторинга
Наиболее простой системой мониторинга, или, правильнее сказать, командой для мониторинга, используемой практически во всех небольших организациях, в которых отсутствуют любые программные или аппаратные системы мониторинга, является команда «ping». Контроль осуществляется периодически, при пропадании сети или в постоянном режиме до определенных узлов сети. После того, как выявляется отсутствие связи с каким-либо из узлов сети, проводится уточняющая работа по выявлению конкретной неисправности сети (сети связи, каналообразующая аппаратура и т.п.). Однако использование команды «ping» не позволяет оперативно найти неисправность и требует постоянного операторского присутствия. При использовании больших вычислительных сетей или разнородных сетей данная команда может просто не работать.
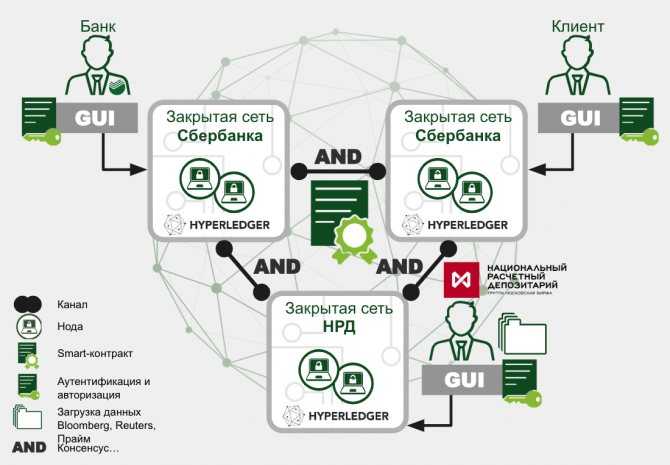

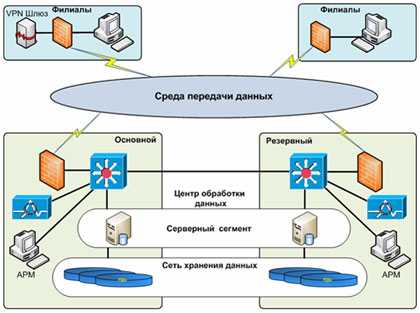
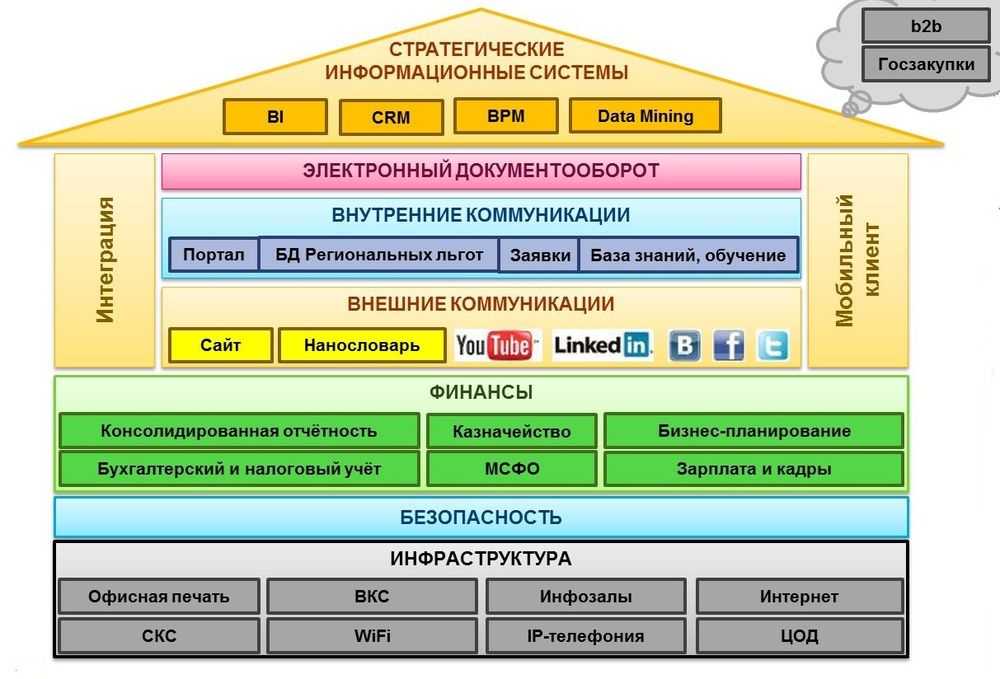




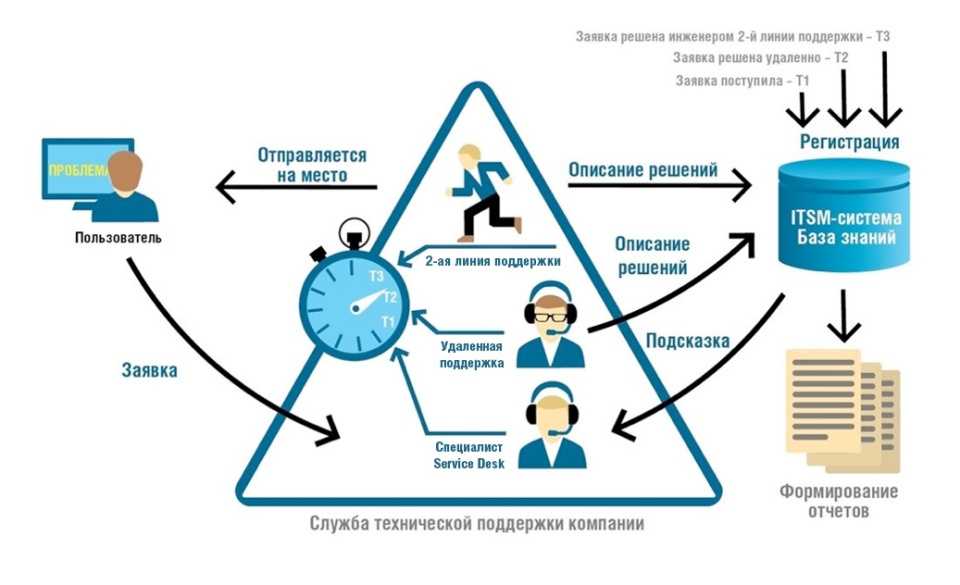
Современные требования к вычислительным сетям требуют более точного и гибкого подхода к мониторингу. От корректной работы Web-серверов и серверов баз данных может зависеть работоспособность внутрикорпоративных приложений и важных внешних сервисов для клиентов. Сбои и нарушения работы маршрутизаторов могут нарушать связь между различными частями корпорации и ее филиалами. Серверы внутренней почты и сетевых мессенджеров, автоматических обновлений и резервного копирования, принт-серверы – любые из этих элементов могут страдать от программных и аппаратных сбоев. Задача системы мониторинга – это предупреждение, так как перерывы в работе сети в целом влияют на авторитет организации, коммерческие организации теряют заработок при неработоспособности вычислительной сети, а государственные организации, такие как МВД или МЧС России, теряют управление подразделениями, а следовательно, неработоспособность вычислительной сети может быть прямой угрозой для жизни и здоровья людей.
Поэтому эти организации используют разнообразные средства и продукты для мониторинга. Рассмотрим несколько классов этих продуктов.
Вступление
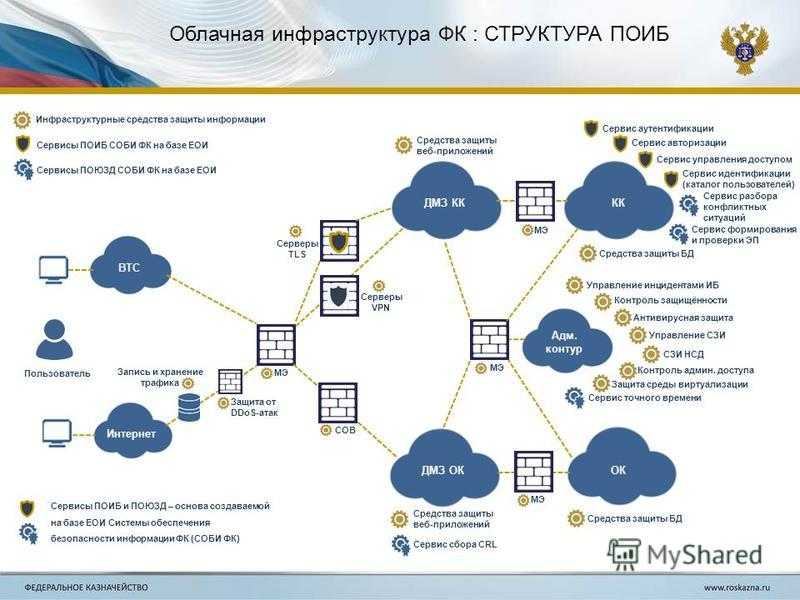
Мониторинг информационной безопасности автоматизируют с использованием различных средств защиты: LM/SIEM, UBA/UEBA, IRP/SOAR, TIP, IDS/IPS, NTA, EDR. Объединение решений по классам одновременно и удобно, и условно. Системы одного типа отличаются не только количеством функций, но и своей философией. Вернёмся к этой идее позже.
Эти решения давно есть на рынке, но при внедрении мне, как сотруднику интегратора ИБ с большим практическим опытом, приходится сталкиваться с проблемами. Непонимание принципов работы этих инструментов приводит к попыткам «приготовить» их неправильно. Даже успешный пилот – не гарантия успешного внедрения.
Все участники рынка со стороны исполнителя – интеграторы, дистрибьюторы, сервис провайдеры (далее просто «интеграторы») и производители – коммерческие компании. Но конкуренция растёт и для беспечной старости уже недостаточно, как в нулевых, «как-то» закрыть прибыльный проект и убежать в закат. Техническая поддержка, модернизация и развитие, смежные проекты – основной источник дохода в наши дни. И он не существует без нахождения в едином понятийном поле, обмена знаниями и принятия стратегий совместно с заказчиками.
Этой статьёй я хочу внести свои пять копеек в решение проблемы. Перед тем как перейти к технической составляющей, рассмотрим два связанных с ней вопроса.
Статья рассчитана на тех, кто уже задумался о мониторинге ИБ, но ещё не погрузился в тему глубоко. Поэтому в ней не раскрываются такие базовые термины, как «событие», «мониторинг», «аналитик», «пилот» («пилотный проект»). Смысловые компоненты, вкладываемые в них, различаются в зависимости от того, кто их применяет. А хорошее описание с обоснованием, почему именно так их определяем, может потянуть на отдельную статью.





