
Админка для парсера сайтов на Laravel
При создании роута обязательно делайте параметр secret token, чтобы только вы могли запустить парсер с сайта (если вы не используете демон), например так:
// Start parser. Secret token need for start parser via cron.
Route::get('start-parser/{token}', 'ParserController@start')->name('parser.start');
В самом контроллере никакой бизнес логики быть не должно. Получили коллекцию парсера и передали его сразу в класс парсера. Другими словами, полная абстрация — отдали данные и получили обработанные данные. Если в будущем понадобится что-то допилить, то вы это будете делать только в одном независимом классе парсера, а не по всему коду проекта. Например, так:
// Get parsered links;
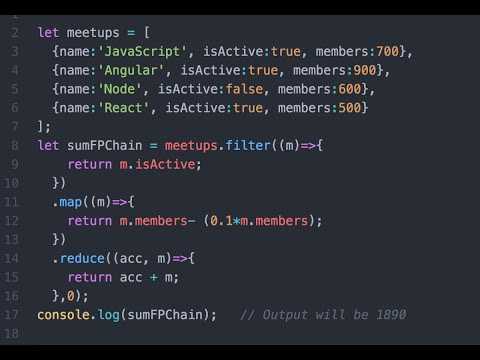
$parseredLinks = ParserLog::whereParserId($parser->id)->select('parsered_indexes')->get();
$parserClass = new ParserClass();
// Make parsing sites from DB. Get parsing data.
$parserData = $parserClass->parserData($parser, $parseredLinks);
В моём конкретном случае, получили для парсера все ссылки из лога, которые уже были распарсены, и передали вместе с парсером в метод parserData(). В переменную $parserData вы получите массив с «красивыми» данными, которые можете сохранять в базу. А уже в самом парсере делаете проверку на то, парсили ли вы по данной ссылке или нет.
Парсинг фото и картинок с сайтов
Теперь пару слов о том, что делать с изображениями в теле текста. Ведь все изображения хранятся на сайте донора. Здесь тоже поможет краулер и пакет UploadImage:
В этот метод мы передаем в краулер само тело и ссылку на донора, откуда был получен данный текст. И полностью проходимся по DOM с изображениями. Как только мы получили ссылку на изображение, то сразу его сохраняем к нам на сервер (если нужно, то прикрепляем водяной знак к изображению), и меняем пути у изображения, попутно удаляя весь возможный мусор из тэга.
В конце из текста вырезаем все html тэги, кроме разрешённых.
Публикация данных в фейсбук
В контролере, когда вы сохраняете в данные базу, можно навесить событие по отправке данных на страницу в фэйсбук. Делается это очень просто, например так:
// Add post to facebook page.
if($parser->facebook) {
$this->facebookAddPostToPage(route('post.show', $post->slug), $post->title);
}
Указанный метод проверяет ваши ключи и делает публикацию на странице фэйсбука. Лично я использую для этого вот этот пакет:
Подведение итогов
В принципе, если вначале не спеша сесть и подумать над реализацией парсера, нарисовать блок схемы и расписать концепцию, то сам код пишется за пол дня. Так что программист тоже не должен забывать о поговорке: «Семь раз отмерь и один раз отреж».
Как видите, ничего сложного нет. Сам файл парсера занял 300 строк кода, а контроллер — 200 строк. Для того, чтобы работать с категориями, вам придется сделать массив со словарём, по которому вы сможете получить идентификатор вашей категории (ключ массива), в зависимости от полученного из парсера названия категории (значения массива), например так:
/** * @var array Rubrics dictionary. */ public $rubrics = [ 1 => ['Авто', 'Авто/Мото'], 2 => , 3 => ];
Post Views:
6 448
Получение в cURL страниц со сжатием
Иногда при использовании cURL появляется предупреждение:
Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file.
Его можно увидеть, например при попытке получить страницу с kali.org,
curl https://www.kali.org/
Суть сообщения в том, что команда curl выведет бинарные данные, которые могут навести бардак в терминале
Нам предлагают использовать опцию «—output -» (обратите внимание на дефис после слова output – он означает стандартный вывод, т.е. показ бинарных данных в терминале), либо сохранить вывод в файл следующим образом: «—output «.
Причина в том, что веб-страница передаётся с использованием компрессии (сжатия), чтобы увидеть данные достаточно использовать опцию —compressed:
curl --compressed https://www.kali.org/
В результате будет выведен обычный HTML код запрашиваемой страницы.
Зачем нужен парсинг в среде 1С?
Наверное, любой сотрудник службы маркетинга, имеющий дело с интернет-бизнесом, или аналитик, желающий знать положение своей фирмы на рынке или среди конкурентов, сталкивался с задачей сбора информации на различных сайтах по специфике своего бизнеса.
Обычно цель таких работ – мониторинг цен конкурентов, отслеживание новинок в ассортименте, получение новостей, сбор и аналитическая обработка любой другой информации, не являющейся интеллектуальной собственностью.
Когда за эти задачи берется «не айтишник», это превращается в часы и дни монотонной работы по копированию-вставке однотипной информации с сайтов, что не только само по себе плохо и не эффективно, но еще и приводит к ошибкам – можно вставить повторно одно и то же, случайно затереть или переместить вставленные данные и так далее.
А если эти данные необходимо ввести в 1С и связать с какими-то объектами учета, это требует дополнительных доработок для организации работы пользователя – новые формы, проверки ввода, выполнение нескольких обновлений конфигурации, трата времени на обучение пользователей и т.д.
В современных условиях перехода к цифровизации бизнеса и «четвертой промышленной революции» такой подход, конечно же, является тупиковым, не масштабируемым и не эффективным по всем параметрам. Поэтому необходимо внедрять решения, исключающие человеческий труд, который должен использоваться только для анализа собранных данных и другой «интеллектуальной» работы.
В общемировой практике такие задачи автоматического сбора данных из общедоступных источников существуют со времен появления Интернета и первых поисковых систем. Они называются «парсинг» или «скрапинг», а программы-парсеры можно реализовать на всех популярных языках и платформах. Примеры самых популярных инструментов для парсинга:





- Python: BeautifulSoup, Scrapy
- PHP: Simple HTML DOM, phpQuery
- JavaScript: jQuery, Cheerio, Osmosis
- Java: JSOUP, TagSoup
- .NET: Html Agility Pack
- C++ : htmlcxx, libhtml++
Так же их можно реализовать и на 1С, ведь в нем есть объекты HTTPСоединение, HTTPЗапрос и возможности работы со структурой html-документа (DOM). В сочетании с регламентными заданиями можно реализовать периодический парсинг без участия человека, а совместно с http-сервисами можно организовать еще и публикацию собранных данных внутри сети предприятия – для обмена между разными базами 1С или другими информационными системами.
Требования к парсеру сайтов
Итак, поняв причины проблемы и саму проблему мы можем смело перейти к вопросу создания парсера. Давайте начнем формировать требования к парсеру, который будет нам упрощать жизнь, а не усложнять.
Давайте накидаем ряд пунктов (будем уже говорить о Laravel 5.6):
- Единый парсер для всех задач компании.
- Единая и понятная логика работы парсера.
- Добавление нового источника для парсинга должно занимать не более 10 минут.
- Парсер должен иметь админку с простым и понятным интерфейсом.
- Парсер должен уметь забирать не только текст, но и файлы.
- Перенастройка парсера должна занять не более 10 минут.
- Готовый парсер не должен требовать от программиста лазить в код.
- Вести лог того, что, когда и от куда. Успешно ли завершилась операция.
- Парсер не должен повторно обрабатывать уже обработанные данные.
- Система импорта/экспорта настроек.
Для начала 10 пунктов будет достаточно. Хотя, на самом деле, их будет определенно больше. Давайте перейдём к практике. Данный пост рассчитан на подготовленных и зрелых разработчиков, то я пройдусь по концепции и основным моментам реализации. Разжевывать код я не буду.
Главная задача — на тестовой машине отладить все настройки парсера, чтобы он правильно забирал данные без ошибок. И когда вы все настроите и убедитесь в том, что все работает как надо, вам эти настройки теперь нужно перенести на продакшн.
Шаг 2. Основы парсинга
Данную библиотеку очень просто использовать, но есть несколько основных моментов, которые следует изучить до того, как вы начнете приводить ее в действие.
Загрузка HTML
Вы можете создать исходный объект загрузив HTML либо из строки, либо из файла. Загрузка из файла может быть выполнена либо через указание URL, либо из вашей локальной файловой системы.
Примечания: Метод load_file() делегирует работу функции PHP file_get_contents. Если allow_url_fopen не установлен в значение true в вашем файле php.ini, то может отсутствовать возможность открывать удаленные файлы таким образом. В этом случае вы можете вернуться к использованию библиотеки CURL для загрузки удаленных страниц, а затем прочитать с помощью метода load().
Доступ к информации

Как только у вас будет объект DOM, вы сможете начать работать с ним, используя метод find() и создавая коллекции. Коллекция — это группа объектов, найденных по селектору. Синтаксис очень похож на jQuery.
В данном примере HTML мы собираемся разобраться, как получить доступ к информации во втором параграфе, изменить ее и затем вывести результат действий.
Строки 2-4: Загружаем HTML из строки, как объяснялось выше.
Строка 6: Находим все тэги <p> в HTML, и возвращаем их в массив. Первый параграф будет иметь индекс 0, а последующие параграфы индексируются соответственно.
Строка 8: Получаем доступ ко второму элементу в нашей коллекции параграфов (индекс 1), добавляем текст к его атрибуту innertext. Атрибут innertext представляет содержимое между тэгами, а атрибут outertext представляет содержимое включая тэги. Мы можем заменить тэг полностью, используя атрибут outertext.
Теперь добавим одну строку и модифицируем класс тэга нашего второго параграфа.
Окончательный вид HTML после команды save будет иметь вид:
Другие селекторы
Несколько других примеров селекторов. Если вы использовали jQuery, все покажется вам знакомым.
Первый пример требует пояснений. Все запросы по умолчанию возвращают коллекции, даже запрос с ID, который должен вернуть только один элемент. Однако, задавая второй параметр, мы говорим “вернуть только первый элемент из коллекции”.
Это означает, что $single — единичный элемент, а не не массив элементов с одним членом.
Остальные примеры достаточно очевидны.
Краулинг
Теперь нам нужно получить страницу каждой новости, проверить на ней имя автора, и при совпадении сохранить нужные данные. Так как у нас нет готового списка ссылок на страницы новостей, мы получим его рекурсивно пройдя по паджинированному списку. Как краулеры поисковиков, только более прицельно. Таким образом нам нужно, чтобы наш скрипт брал ссылку, отправлял её на обработку, полезные данные (если найдутся) где-нибудь сохранял, а новые ссылки (на новости или на следующие страницы списка) ставил в очередь на такую же обработку.
Поначалу может показаться, что краулинг проще осуществлять в несколько проходов. Например, сначала рекурсивно собрать все страницы паджинированного списка, затем получить с них все страницы новостей, а затем – обработать каждую новость. Такой подход помогает новичку удержать в голове процесс скрейпинга, но на практике единая одноуровневая очередь для запросов всех типов – это, как минимум, проще и быстрее в разработке.
Для создания такой очереди можно использовать функцию из знаменитого модуля async, однако я предпочитаю использовать модуль tress, который обратно совместим с , но намного меньше, так как не содержит остальных функций модуля . Маленький модуль хорош не тем, что занимает меньше места (это ерунда), а тем, что его проще быстренько допилить, если это понадобится для особо сложного краулинга.
Очередь из работает примерно так:
Стоит отметить, что наша функция каждый раз будет выполнять http-запрос, и пока он выполняется скрипт будет простаивать. Так скрипт будет работать довольно долго. Чтобы его ускорить можно передать вторым параметром количество ссылок, которые можно обрабатывать параллельно. При этом скрипт продолжит работать в одном процессе и в одном потоке, а параллельность будет обеспечиваться за счёт неблокирующих операций ввода/вывода в Node.js.




Извлечение информации из заголовков при использовании cURL
Иногда необходимо извлечь информацию из заголовка, либо просто узнать, куда делается перенаправление.
Заголовки – это некоторая техническая информация, которой обмениваются клиент (веб-браузер или программа curl) с веб-приложением (веб-сервером). Обычно нам не видна эта информация, она включает в себя такие данные как кукиз, перенаправления (редиректы), данные о User Agent, кодировка, наличие сжатия, информация о рукопожатии при использовании HTTPS, версия HTTP и т.д.
Пример команды:
curl -s -I -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' https://www.acrylicwifi.com/AcrylicWifi/UpdateCheckerFree.php?download | grep -i '^location'
Получаемый результат:
location: https://tarlogiccdn.s3.amazonaws.com/AcrylicWiFi/Home/Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe
В этой команде имеются уже знакомые нам опции -s (подавление вывода) и -A (для указания своего пользовательского агента).
Новой опцией является -I, которая означает показывать только заголовки. Т.е. не будет показываться HTML код, поскольку он нам не нужен.
На этом скриншоте видно, в какой именно момент отправляется информация о новой ссылке для перехода:
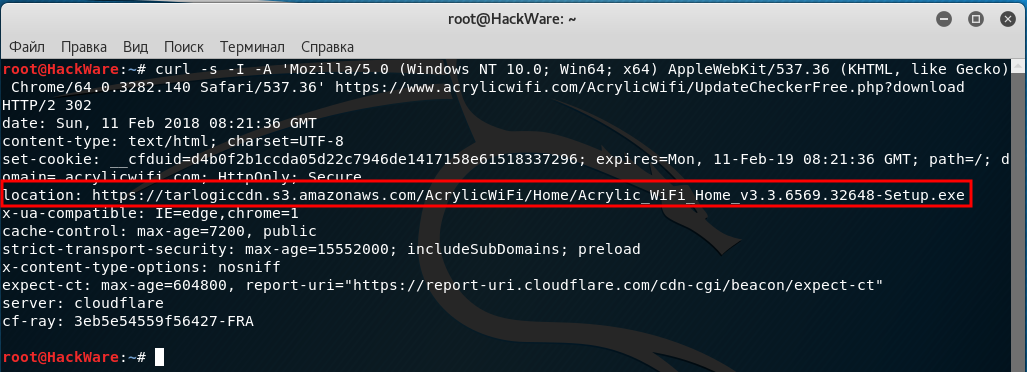
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' 2>&1 | grep -i 'Location:'
Обратите внимание, что в этой команде не использовалась опция -I, поскольку она вызывает ошибку:
Warning: You can only select one HTTP request method! You asked for both POST Warning: (-d, --data) and HEAD (-I, --head).
Суть ошибки в том, что можно выбрать только один метод запроса HTTP, а используются сразу два: POST и HEAD.
Кстати, опция -d (её псевдоним упоминался выше (—data), когда мы говорили про HTML аутентификацию через формы на веб-сайтах), передаёт данные методом POST, т.е. будто бы нажали на кнопку «Отправить» на веб-странице.
В последней команде используется новая для нас опция -v, которая увеличивает вербальность, т.е. количество показываемой информации. Но особенностью опции -v является то, что она дополнительные сведения (заголовки и прочее) выводит не в стандартный вывод (stdout), а в стандартный вывод ошибок (stderr). Хотя в консоли всё это выглядит одинаково, но команда grep перестаёт анализировать заголовки (как это происходит в случае с -I, которая выводит заголовки в стандартный вывод). В этом можно убедиться используя предыдущую команду без 2>&1:
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' | grep -i 'Location:'
Строка с Location никогда не будет найдена, хотя на экране она явно присутствует.
Конструкция 2>&1 перенаправляет стандартный вывод ошибок в стандартный вывод, в результате внешне ничего не меняется, но теперь grep может обрабатывать эти строки.
Более сложная команда для предыдущего обработчика форм (попробуйте в ней разобраться самостоятельно):
timeout 10 curl -s -L -v http://www.paterva.com/web7/downloadPaths.php -d 'fileType=exe&client=ce&os=Windows' -e 'www.paterva.com/web7/downloads.php' 2>&1 >/dev/null | grep -E 'Location:'
Логика парсера сайтов на PHP
Теперь пару слов о самой логике парсера. Предположим, что вам нужно забрать десять новостей с какого-то сайта. Как вы будете это делать? Самое простое и правильное — это заходить парсером на некую общую страницу, где содержится список новостей
Внимание! Не сама новость, а именно список новостей. Это может быть главная страница ил конкретный раздел новостей
В настройках парсера у вас указана логика поиска таких ссылок на странице донора. Итак, парсер заходит на страницу раздела и находит все ссылки, которые введут на новости (конкретная новость с текстом, изображениями и т.д.). Потом он начинает переходить по этим ссылкам и забирать контент, согласно настройкам парсера.
Если у вас в настройках указано, что нужно забрать только одну новость, то парсер перейдет только по одной ссылке. При этом нужно не забывать сверять ссылки с данными в логе. Вам нужно перейти по новой ссылке и забрать новый контент.
Шаг 2 – Основы HTML парсинга
Эта библиотека, очень проста в использовании, но все же,
необходимо разобрать некоторые основы, перед тем как ее использовать.
Загрузка HTML
$html = new simple_html_dom();
// Load from a string
$html->load('<html><body><p>Hello World!</p><p>We're here</p></body></html>');
// Load a file
$html->load_file('http://sitear.ru/');
Все просто, вы можете создать объект, загружая HTML из
строки. Или, загрузить HTML код из файла. Загрузить файл вы можете по URL адресу, или
с вашей локальной файловой системы (сервера).




Важно помнить: Метод
load_file(), работает на использовании PHP функции file_get_contents. Если в
вашем файле php.ini, параметр allow_url_fopen
не установлен как true,
вы не сможете получать HTML файлы по удаленному адресу
Но, вы сможете загрузить эти
файлы, используя библиотеку CURL. Далее, прочитать содержимое, используя метод load().
Получение доступа к HTML DOM объектам
Предположим у нас уже есть DOM объект,
структурой, как на картинке выше. Вы можете начать работать с ним, используя
метод find(), и создавая коллекции. Коллекции – это группы объектов, найденные
с помощью селекторов – синтаксис в чем-то схож с jQuery.
<html>
<body>
<p>Hello World!</p>
<p>We're Here.</p>
</body>
</html>
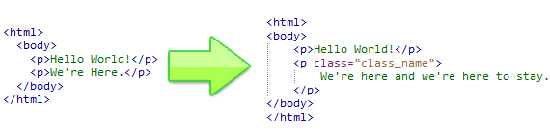
Используя этот пример HTML кода, мы узнаем, как получить доступ
к информации заключенной во втором параграфе (p). Также, мы изменим полученную
информацию и выведем результат на дисплей.
// создание объекта парсера и получение HTML
include('simple_html_dom.php');
$html = new simple_html_dom();
$html->load("<html><body><p>Hello World!</p><p>We're here</p></body></html>");
// получение массивов параграфов
$element = $html->find("p");
// изменение информации внутри параграфа
$element->innertext .= " and we're here to stay.";
// вывод
echo $html->save();
Как видите реализовать PHP парсинг документа HTML, очень даже просто, используя simple HTML DOM библиотеку.
В принципе, в этом куске PHP кода, все можно понять интуитивно, но если вы в чем-то
сомневаетесь, мы рассмотрим код.
Линия 2-4:
подключаем библиотеку, создаем объект класса и загружаем HTML код из
строки.
Линия 7: С
помощью данной строки, находим все <p> теги в HTML коде,
и сохраняем в переменной в виде массива. Первый параграф будет иметь индекс 0,
остальные параграфы будут индексированы соответственно 1,2,3…
Линия 10:
Получаем содержимое второго параграфа в нашей коллекции. Его индекс будет 1.
Также мы вносим изменения в текст с помощью атрибута innertext. Атрибут innertext, меняет все содержимое внутри
указанного тега. Также мы сможем
изменить сам тег с помощью атрибута outertext.
Давайте добавим еще одну строку PHP кода, с помощью которой мы назначим
класс стиля нашему параграфу.
$element->class = "class_name"; echo $html->save();
Результатом выполнения нашего кода будет следующий HTML документ:
<html>
<body>
<p>Hello World!</p>
<p class="class_name">We're here and we're here to stay.</p>
</body>
</html>
Другие селекторы
Ниже приведены другие примеры селекторов. Если вы
использовали jQuery, то
в библиотеке simple html dom синтаксис немножко схожий.
// получить первый элемент с id="foo"
$single = $html->find('#foo', 0);
// получает при парсинге все элементы с классом class="foo"
$collection = $html->find('.foo');
// получает все теги <a> при парсинге htmlдокумента
$collection = $html->find('a');
// получает все теги <a>, которые помещены в тег <h1>
$collection = $html->find('h1 a');
// получает все изображения с title='himom'
$collection = $html->find('img');
Использование первого селектора при php парсинге html документа,
очень простое и понятное. Его уникальность в том что он возвращает только один html элемент,
в отличии от других, которые возвращают массив (коллекцию). Вторым параметром (0),
мы указываем, что нам необходим только первый элемент нашей коллекции. Надеюсь,
вам понятны все варианты селекторов библиотеки simple HTML DOM, если вы чего-то не
поняли, попробуйте метод научного эксперимента. Если даже он не помог,
обратитесь в комментарии к статье.
Документация библиотеки
simple HTML DOM
Полнейшую документацию по использованию библиотеки simple HTML DOM вы
сможете найти по этому адресу:
http://simplehtmldom.sourceforge.net/manual.htm
Просто предоставлю вам иллюстрацию, которая показывает
возможные свойства выбранного HTML DOM элемента.

С ЧЕГО НАЧАТЬ?
Современный сайт — это не просто сгенерированная чем-то веб-страница — это веб-приложение с AJAX и прочими динамическими штучками. Для того, чтобы начать, нужно определиться, что перед нами за сайт и как он хранит данные.
Самое простое — это посмотреть код сайта, который пришел с сервера и отобразился у нас в виде веб-страницы. Если посмотреть на указанный сайт, то видно, что список интересующей нас информации не отдается весь целиком. Но давайте разберем все предельно подробно.
Итак, загрузив сайт ломбарды.рф мы видим следующую картину:

Здесь мы видим, что нам доступна только маленькая часть списка. За остальными нужно лезть через «Еще результаты».

Если мы посмотрим код, то по этой кнопке дергается сервис (data-url=»/lombards/load_more.php?category=&sort=&minloan=&maxloan=&region=»). Если мы откроем в браузере эту ссылку, то увидим вот такую интересную штуку:
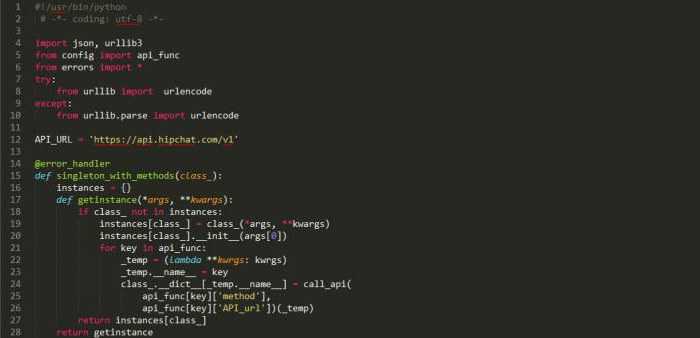



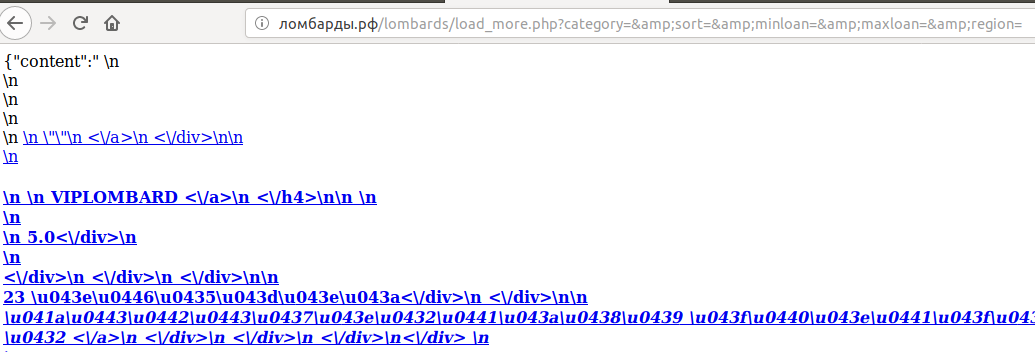
Как подсказывает нам ({«content»:» \n) в начале строки — это JSON. 1С умеет его читать, поэтому давайте начнем с простого — создадим HTTP-запрос и обработаем ответ.
Интеграция 1С 8 и HostCMS
Интеграции 1С с сайтами очень сложно оценивать, ибо на сайте разработчика CMS, а может, и на странице конкретного модуля, зачастую можно найти инструкцию подключения обмена, но в ходе работы постоянно появляются подводные камни: то одно не выгружается, то другое, порой, кажется, все данные передаются, но документы или элементы справочников не заполняются. А перерабатывать типовой механизм зачастую бывает себе дороже. Причем бывают и ситуации, когда нужно вносить изменения и в 1С, и на сайте. Стоимость таких работ возрастает и встает вопрос о том, нужно ли это вообще. Сейчас я расскажу о том, как мы подключали HostCMS, а в конце статьи приведу результаты обмена.
Библиотеки для парсинга html сайтов
Вот наконец мы подошли и к самому коду. Я более чем уверен, что вы без проблем можете создать все миграции и модели самостоятельно.
Для начала нам нужно создать отдельную и абстрактную бизнес логику самого парсера. Я привык создавать в App папочку Modules и хранить там отдельные классы для независимых решений.
В Laravel последних версий встроен отличнейший инструмент для парсинга — это компонент от Symfony DomCrawler. Именно благодаря этому компоненту ваша жизнь может очень сильно упроститься.
Его нужно импортировать в класс парсера:
use Symfony\Component\DomCrawler\Crawler;
Метод получения контента примерно следующий:
В этом методе не хватает ещё проверок на существование полей, изображений, на тип кодировки и так далее. Здесь только показан общий принцип того, на сколько просто можно получить данные благодаря Crawler. Инициализировать краулер можно и так:
// Create new instance for parser. $crawler = new Crawler($html);
Но если делать так, то вы получите ошибки путей при парсинге изображений. Поэтому, нужно обязательно передать в краулер линк (ссылка для парсинга), а потом и страницу:
// Create new instance for parser. $crawler = new Crawler(null, $link); $crawler->addHtmlContent($html, 'UTF-8');
Использование selenium
Вы можете установить модуль selenium через pip:
$ pip install selenium
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://quotes.toscrape.com/')
page = driver.page_source
Здесь мы сначала начнем с создания объекта webdriver, который представляет браузер. Это откроет браузер Chrome на компьютере, на котором запущен код. Затем, вызвав метод get объекта webdriver, мы можем открыть наш URL. И, наконец, мы получаем исходный код, обращаясь к свойству page_source объекта webdriver.
В обоих случаях HTML-источник URL-адреса сохраняется в переменной страницы в виде строки.
Пример задачи парсинга
Рассмотрим практический пример задачи извлечения данных. Допустим, мы хотим написать свою конфигурацию для учета инвестиций в акции и другие инструменты. Но вся необходимая информация хранится на разных сайтах или доступна только через REST API. Придется парсить разные источники, чтобы получать данные об инструментах, новостях, показателях компаний и т.д. Преимущество реализации на 1С в том, что мы можем написать несколько парсеров для разных источников и представить сводку в удобном виде, используя преимущества быстрой разработки на 1С – базу данных, конструктор форм и все другие средства.
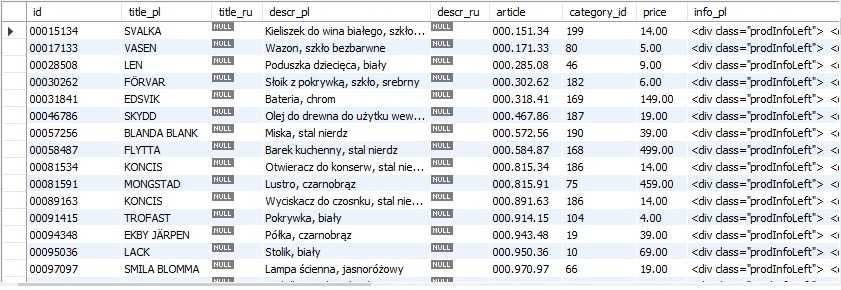
Возьмем за основу и начальную точку сайт «Тинькоф-инвестиции» и проанализируем структуру страницы с информацией о акциях – на примере Apple https://www.tinkoff.ru/invest/stocks/AAPL/. Выделим блоки с нужной информацией и их CSS-селекторы:
|
Блок информации |
Селектор |
|
Название акции |
Класс «SecurityHeaderPure__showName_1DvWf» |
|
О компании |
Класс «SecurityInfoPure__info_3Mgld», тег <p> внутри |
|
Сайт компании |
Класс «SecurityInfoPure__link_2lmEC», тег <SPAN> внутри него |
|
Логотип компании |
Класс «Avatar__image_3KvrS», ссылка в описании стиля: свойство background-image |
Здесь заметно, что имена классов имеют суффикс со случайным набором символов, но это мы легко обойдем.
Проверить корректность отбора можно в консоле разработчика любого браузера (кнопка F12), используя функции document.getElementsByClassName(), document.getElementById(), document.getElementsByTagName() или отбор через jQuery, который все еще часто применяется на многих сайтах: если вызов функции «$» не выдаст ошибки, можно проверять отборы по селекторам в виде $(“.classname”), $(“#element-id”) и т.д.




Создадим код для получения текста страницы:
Теперь подготовим объект документа для анализа и получения данных:
Дальше сформируем фильтр для передачи в функцию поиска по документу. Фильтр это конфигурация отбора в виде JSON-строки, и у нее есть два корневых элемента – type и value. Есть несколько типов и для каждого — несколько допустимых значений, полное описание вариантов есть в синтаксис-помощнике в разделе «Описание структуры JSON-конфигурации для отбора».
Такую структуру может быть неудобно каждый раз формировать вручную, если парсинг многоступенчатый и сложный, поэтому лучше сразу вынести это действие в отдельную функцию и пользоваться многократно.
В нашем случае – реализуем функцию для формирования фильтра поиска по тегу и классу элемента, для этого нужно выбрать тип «пересечение условий» («intersection») и добавить значение «value» как массив из трех условий – на равенство тега, наличие атрибута «class» и поиск по шаблону для значения атрибута:
Здесь в зависимости от флага «ТочноеСоответствие» используется два варианта отбора – точное равенство или проверка по регулярному выражению. Это позволяет задавать сложные шаблоны поиска селекторов. В нашем случае при неточном соответствии в переменной ИмяКласс помещаем переданное значение и добавляем символы «.+», что означает «1 или более любых символов» после указанного значения.
Теперь мы можем формировать любые фильтры для выбора элементов и извлекать из них информацию. Оформим парсинг в виде функции, возвращающей структуру с полученными данными страницы:
Здесь мы сочетали получение узла по селектору и получение дочерних узлов из DOM-структуры вместо нескольких выборок по селектору. В простых случаях это может быть удобнее.
Прохождение по структуре HTML
HTML — это HyperText Markup Language («язык гипертекстовой разметки»), который работает за счет распространения элементов документа со специальными тегами. В HTML есть много разнообразных тегов, но стандартный шаблон включает три основных: , и . Они организовывают весь документ. В случае со скрапингом интерес представляет только тег .
Написанный скрипт уже получает данные о разметке из указанного адреса. Дальше нужно сосредоточиться на конкретных интересующих данных.
Если в браузере воспользоваться инструментом «Inspect» (CTRL+SHIFT+I), то можно достаточно просто увидеть, какая из частей разметки отвечает за тот или иной элемент страницы. Достаточно навести мышью на определенный тег , как он подсветит соответствующую информацию на странице. Можно увидеть, что каждая цитата относится к тегу с классом .
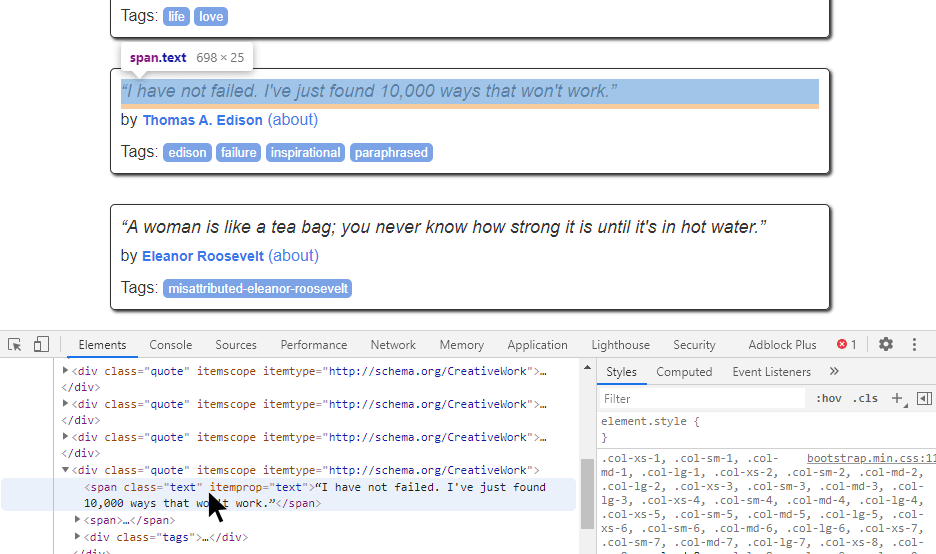
Таким образом и происходит дешифровка данных, которые требуется получить. Сперва нужно найти некий шаблон на странице, а после этого — создать код, который бы работал для него. Можете поводить мышью и увидеть, что это работает для всех элементов. Можно увидеть соотношение любой цитаты на странице с соответствующим тегом в коде.
Скрапинг же позволяет извлекать все похожие разделы HTML-документа. И это все, что нужно знать об HTML для скрапинга.
Большие ограничения
Данный материал не подойдет, если Вы решаете следующие задачи:
- Получение и обработка данных на сервере регламентным заданием или любым другим.
- Обработка очень большого массива данных.
- Пытаетесь парсингом заменить работу через API из-за его отсутствия или недоступности.
- Вам нужен надежный способ получения данных.
В случаях же, если нужен простой и быстрый в реализации способ извлечения данных с веб-страниц, и при этом работа с инструментом будет вестись интерактивно, то использование поля HTML-документа то что нужно.
Парсинг веб-ресурсов почти всегда «зло» как по отношению к владельцу ресурса, так и в части сопровождения таких решений. Ведь стоит разметке поменяться и алгоритмы извлечения данных нужно снова менять.
Однако, иногда выхода нет. Да и использование предлагаемого подхода можно считать этичным в каком-то плане, потому что создаем всего лишь помощника работы с браузером и автоматизируем действия пользователя на веб-странице. Хотя это вопрос «холиварный».





