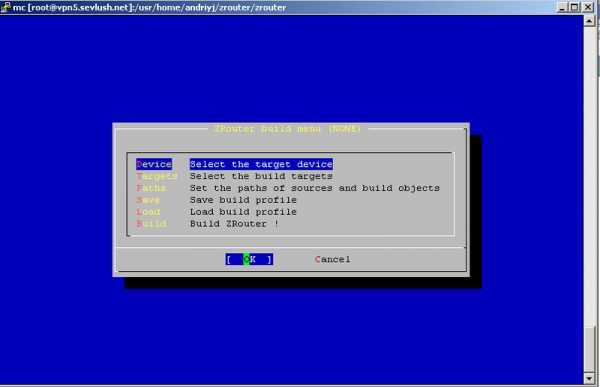
Введение
Ранее я уже неоднократно рассматривал вопрос резервного копирования данных или целых серверов linux. Конкретно в этих статьях:
- Бэкап сервера с помощью Duplicity.
- Создание резервной копии на Яндекс.Диске.
- Настройка Rsync для бэкапа данных.
Забэкапить сразу весь сервер можно, например, с помощью Duplicity. Но вот восстановить его на другом железе будет не так просто. Помимо данных нужно будет, как минимум, позаботиться о разметке диска, установке загрузчика. На это необходимо затратить некоторые усилия и немного разбираться в теме initramfs и grub. Сам я не очень разбираюсь в нюансах работы этих инструментов и очень не люблю с ними возиться.
Некоторое время назад появился отличный бесплатный продукт для бэкапа всего сервера целиком. Речь идет о Veeam Agent for Linux FREE. С его помощью можно сделать полный backup сервера, положить его куда-нибудь по smb или nfs, потом загрузиться с live cd и восстановить из бэкапа на другом железе.
Сразу расскажу о некоторых нюансах работы бесплатной версии, с которыми столкнулся в процессе эксплуатации замечательного продукта от veeam.
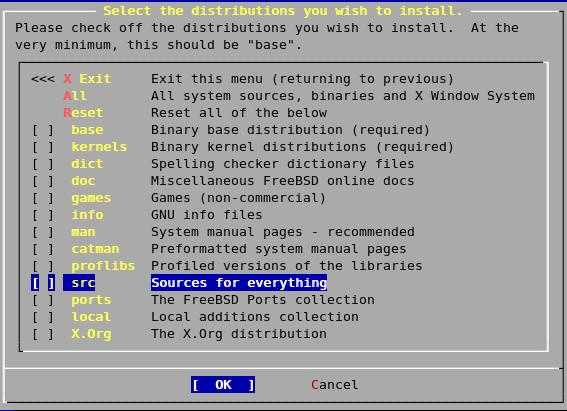
- Бэкап можно сделать либо всего сервера сразу, либо отдельного диска, либо отдельных папок и файлов. При выборе бэкапа всего диска или сервера, нельзя задать исключения для отдельных папок или файлов. Это очень неудобно, но увы и ах, таков функционал. Исключения можно сделать только если вы делаете бэкап на уровне папок.
- Бэкап можно положить локально на соседний раздел, если делаете резервную копию раздела, локально в папку — если делаете бэкап файлов и папок. Если бэкапите всю систему целиком, то удаленно по smb и nfs. К сожалению, по ftp или sftp программа не работает.
В качестве хранилища для архивов может выступать репозиторий Veeam Backup & Replication. Но я не рассматриваю этот вариант, так как в данном случае использую только бесплатное решение.
Мне очень хотелось настроить резервную копию всего сервера на Яндекс.Диск, но, к сожалению, у меня это не получилось из-за технических ограничений. Яндекс.Диск подключается к системе через webdav. Для того, чтобы сделать резервную копию всей системы, нужно бэкапить либо всю систему сразу, либо образ диска. Если у вас небольшой веб сервер, то скорее всего на нем только один раздел. На этом же разделе хранится кэш, который использует webdav для передачи файлов. Без кэша он работать не умеет.
Думаю вы уже поняли, в чем проблема сделать полный backup сервера с помощью Veeam Agent for Linux на Яндекс.Диск по webdav. Вы не сможете добавить в исключения папку с кэшом от webdav. В итоге, во время бэкапа с помощью veeam будет расти папка с кэшом webdav, которая, в свою очередь, будет бэкапиться. В итоге, свободное место на диске закончится, бэкап прервется.
Я подробно описал ситуацию с Яндекс.Диском, потому что пространство на нем не дорого стоит. Я часто его использую в повседневной жизни, настраиваю бэкапы, храню данные и т.д. В общем, мне он нравится по ряду причин. Для того, чтобы бэкапить весь сервер целиком, вам придется найти место для архивных копий с доступом по smb или nfs. Таких предложений не очень много на рынке. Практически не из чего выбирать, я специально искал.
Остановился вот на этом варианте — KeyDisk. После оплаты, вам дают адрес сервера, логин и пароль. Вы можете сразу же подключаться по smb к хранилищу. Можно прям в windows через два обратных слеша зайти или подмонтировать хранилище к linux серверу.
KeyDisk стоит примерно 350р. в месяц за 100 гигов. Не очень дешево, конечно, в сравнении с облачными сервисами, но все равно не дорого. Похожих предложений с доступом по smb я лично вообще не нашел в принципе. Этот объем позволит вам забэкапить небольшой веб сервер с глубиной архива в несколько недель или месяцев, в зависимости от того, сколько данных у вас на нем хранится.
Дальше я подробно на конкретном примере расскажу как все настроить и восстановить или перенести сервер целиком, если понадобится. Причем переносить буду вообще на другое железо. Но обо всем по порядку.
Пример бэкапа windows сервера с помощью rsync
Еще один пример из моей практики. Допустим, у нас есть windows сервер с некоторой информацией, которую мы хотим так же бэкапить. Никаких проблем, это делается достаточно просто.
Создаем на windows сервере сетевую шару с информацией. Создаем пользователя и добавляем его в доступ к этой папке. Этого пользователя мы будем использовать для подключения виндовой шары к linux серверу.
Монтируем шару с информацией, которую будем бэкапить:
# mount -t cifs //192.168.0.16/docs /mnt/docs -o user=backup,password=12345,iocharset=utf-8,codepage=cp866
192.168.0.16 — адрес виндовой шары
backup и 12345 — пользователь и пароль виндовой машины с доступом к шаре docs.
Все, теперь папку /mnt/docs можно использовать в качестве приемника в нашем скрипте бэкапа с rsync. Если папка примонтирована непосредственно к серверу с бэкапами, то нужно на нем самом настроить конфиг rsyncd на примере серверов источников, запустить на нем rsyncd и в скрипте в качестве ip адреса сервера указывать 127.0.0.1.
Я в таких случаях создаю несколько скриптов: на монтирование шары, бэкап и размонтирование, объединяю их в один и запускаю последовательно. В итоге получается, что подключаем диск, делаем бэкап и отключаем его.
Так же есть возможность установить на Windows Server rsync с помощью cygwin. Подобный функционал собран в готовом приложении — cwRsync server. Его настройка ничем принципиально не отличается от настройки linux версии. Нужно только внимательно следить за путями к директориям, примеры есть в конфигах.
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .
21.7. Отслеживание исходных текстов для нескольких машин
Если нужно отслеживать одно и то же дерево исходных текстов на множестве машин, то загрузка кода и полное перестроение системы на каждой из них выглядит как ненужная трата ресурсов: дискового пространства, пропускной способности сети и процессорного времени. Решением является выделение одной машины, которая выполняет основной объём работы, в то время как остальные используют результаты работы посредством NFS. В этом разделе описывается именно этот метод. Для получения информации об использовании NFS обращайтесь в .
Первым делом определите набор машин, на которых будет выполняться единый набор программ, который мы будем называть набором для построения. Каждая машина может иметь собственное уникальное ядро, но они будут работать с одними и теми же программами пользователя. Из этого набора выберите машину, которая будет являться машиной построения, на которой будут строиться ядро и всё окружение. В идеальном случае это быстрая машина с достаточно незагруженным CPU для выполнения команд и .
Выберите тестовую машину, которая будет выполнять проверку обновлений программного обеспечения, прежде чем они пойдут в работу. Это должна быть машина, которая может находиться в нерабочем состоянии достаточно долго. Это также может быть машина построения, но не обязательно.
Всем машинам в этом наборе для построения нужно смонтировать /usr/obj и /usr/src по NFS с машины построения. В случае нескольких наборов для построения каталог /usr/src должен находиться на одной машине построения и монтироваться на остальных по NFS.
Удостоверьтесь, что /etc/make.conf и /etc/src.conf на всех машинах в заданном наборе для построения согласуются с машиной построения. Это означает, что машина построения должна строить все те части базовой системы, которые будут устанавливаться на каждой машине из набора для построения. Кроме того, у каждой машины построения должно быть задано имя ядра в переменной в /etc/make.conf, и машина построения должна перечислить их все в переменной , причём первым должно идти имя её собственного ядра. Машина построения должна хранить конфигурационные файлы ядра каждой машины в каталоге /usr/src/sys/arch/conf.
Постройте ядро и всё окружение на машине построения так, как это описано в , но ничего не устанавливайте на самой машине. Вместо этого, установите собранное ядро на тестовой машине. Для этого смонтируйте /usr/src и /usr/obj по NFS. Затем выполните команду для перехода в однопользовательский режим, для того чтобы установить новое ядро и всё окружение, после чего выполните команду обычным образом. После этих действий перезагрузитесь для возврата к обычному режиму работы в многопользовательском режиме.
После того, как вы убедитесь в нормальной работе всего на тестовой машине, проведите эту процедуру для установки нового программного обеспечения на каждой из оставшихся машин в наборе для построения.
Такой же подход можно использовать и для дерева портов. Сперва нужно смонтировать /usr/ports по NFS на всех машинах в наборе для построения. Чтобы настроить /etc/make.conf для использования общего каталога с дистрибутивными файлами, задайте переменную так, чтобы она указывала на общедоступный каталог, доступный для записи тому пользователю, который отображается в пользователя для точек монтирования NFS. Каждая машина должна задавать так, чтобы она указывала на локальный каталог, если порты будут собираться локально. Если же пакеты будут распространяться, задайте на машине построения переменную , чтобы она указывала на каталог, соответствующий .
Обновление с предыдущих выпусков FreeBSD 12.2 до 13.0 бинарным методом
Протестировал следующие инструкции на моей виртуальной машине FreeBSD AMD64
Обратите внимание, что обновление систем powerpc64 из более ранних выпусков FreeBSD НЕ поддерживается. Пользователям необходимо переустановить из-за использования нового ABI
Двоичное обновление между версиями RELEASE рекомендуется с помощью утилиты командной строки freebsd-update. Следовательно, выполните следующую команду:
# freebsd-update -r 13.0-RELEASE upgrade
Freebsd-update оценит файлы конфигурации и может предложить вам следующее для слияния файлов конфигурации и других параметров в соответствии с вашими установленными приложениями и настройками. Прочтите их внимательно:
Процесс длительный и когда обновления загружены, объединены в каталог, фиксируем изменения на диске. Другими словами, введите следующую команду в командной строке, чтобы применить обновления:
# freebsd-update install
После установки обновлений перегрузим сервер:
# shutdown -r now
Снапшот на другой раздел
- Incremental_Backup
- btrfs-sxbackup
- btrfs-snapshot
Монтируем основной раздел.
Монтируем раздел/диск для сброса снапшота.
Нужно создавать снапшоты, только для чтения(readonly), требует . Для отправки на другие узлы.
Переносим снапшоты. Можно send в файл , receive из файла .
Инкрементальные readonly снимки.
Создаём разность между снимками.
Просмотрим листинг.
Отправка по ssh
Локально: генерируем ключи, создаём .
Пример скрипта — инкрементальный, взято с (ubuntu.ru/wiki).
Удаляем или переименовываем .
Переименовываем новые snapshot(ы).
Удаляем, если нужно.
Отмонтируем.
Исправление возможных ошибок UFS
Вполне вероятно, что последующие перезагрузки системы могут вызвать ошибку с таким предупреждением:
WARNING: / was not properly dismounted
и далее попросит ввести полный путь к шеллу:
Enter full pathname of shell or RETURN for /bin/sh:
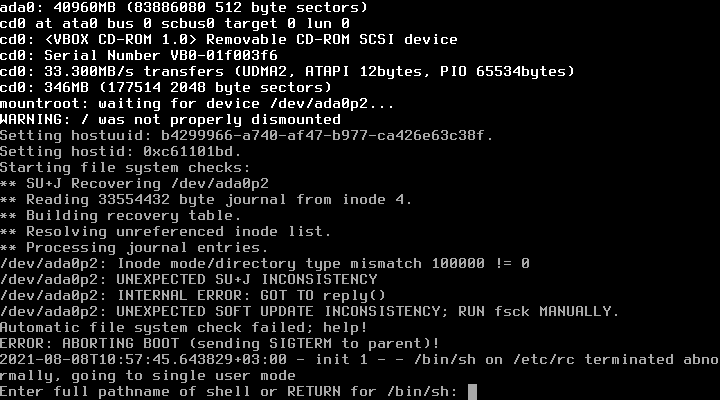
Исправим это.
Введём: /rescue/tcsh
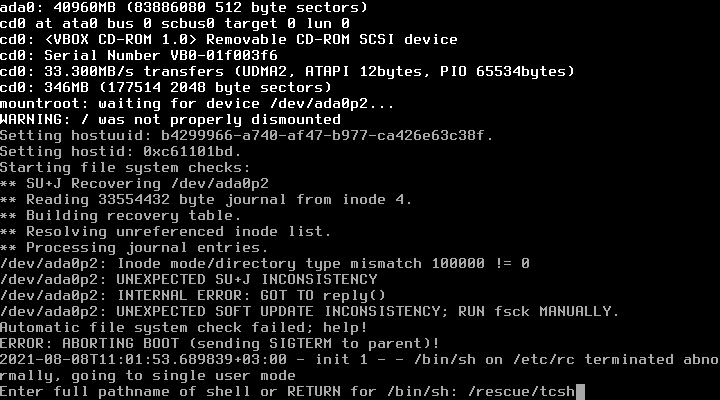
и вовзращаемся в стандартный шелл
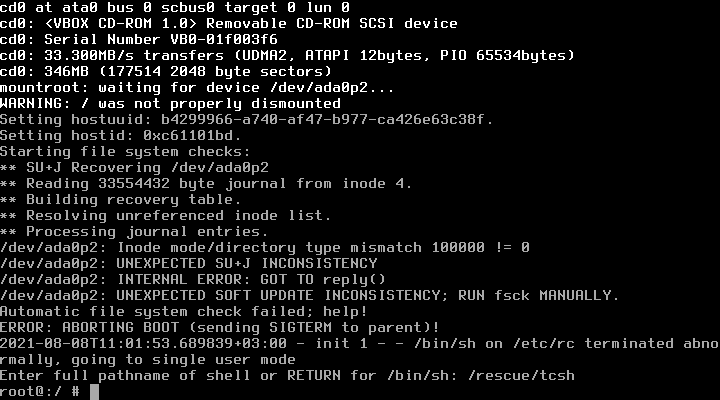
Чтобы исправить ошибку, необходимо воспользоваться утилитой fsck
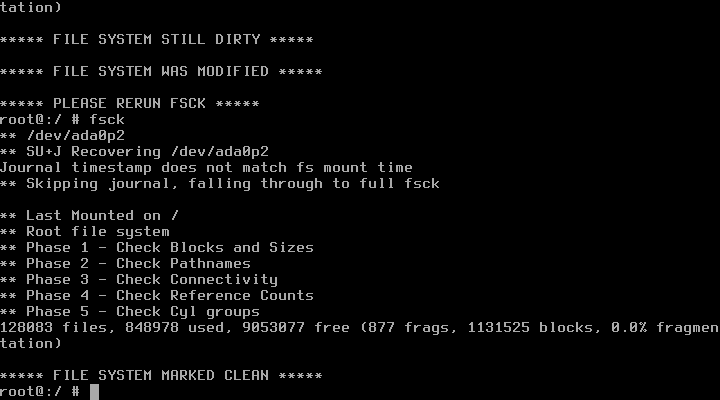
# fsck -f -y -t ufs
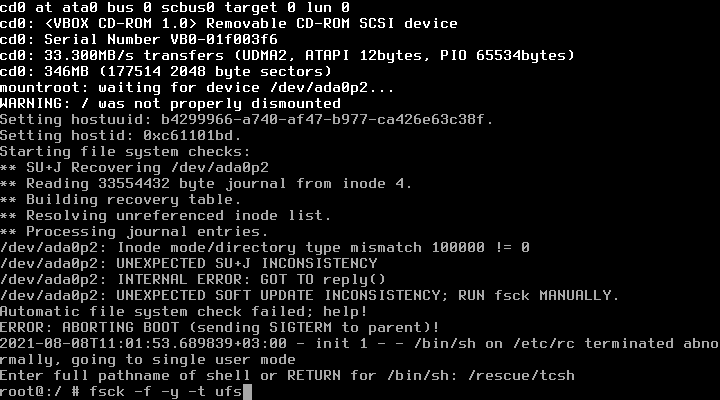
После проверки файловой системы появится сообщение, что она всё ещё DIRTY (то есть неисправна).
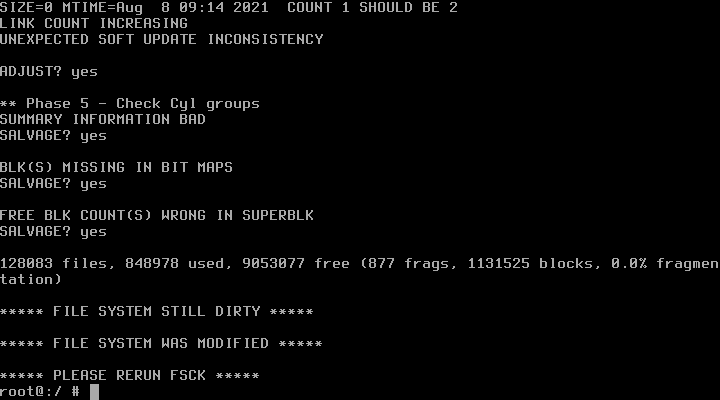
Вводим команду
# fsck
и после этого всё должно быть нормально:
Проверяем командами
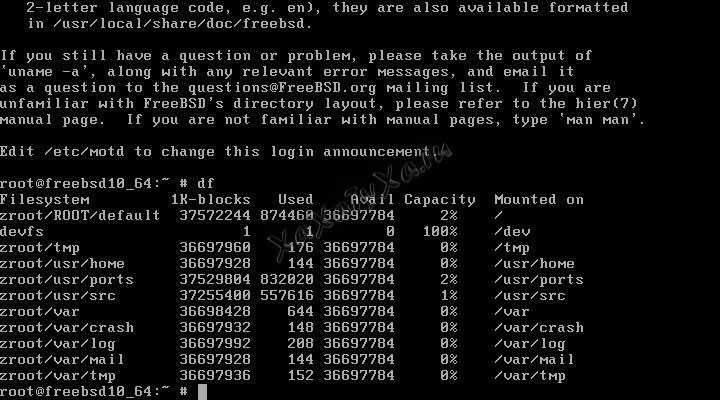
# df -h
и
# gpart show ada0
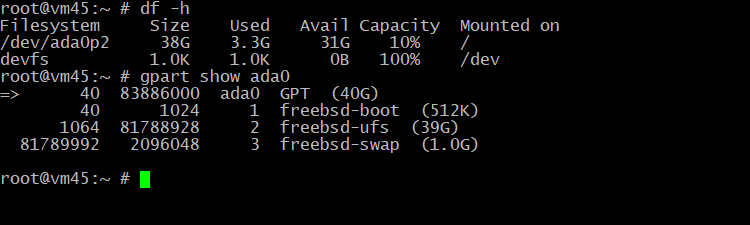
Теперь точно всё в порядке.
Бэкап во FreeBSD
Для выполнения backup будем пользоваться стандартными средствами FreeBSD. Самое главное из них – демон cron, служащий для запуска команд по расписанию. Чтобы не загромождать сам cron кучей строк, предлагаю создать отдельные исполняемые файлы, со списком необходимых нам команд. Для этого создадим в домашней директории пользователя root два файла backup_conf и backup_mysql. В первом файле мы напишем команды для сохранения всех конфигурационных файлов сервера, а во втором – необходимые для бэкапа базы данных mysql.

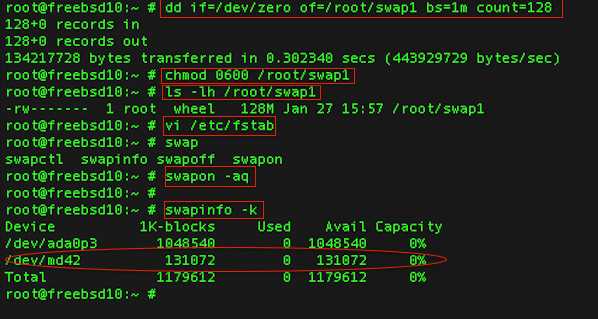
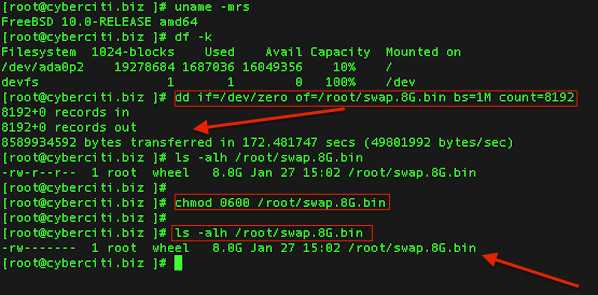
Небольшие пояснения для того, что мы сейчас проделали: 1. Мы создали в каталоге /root файл с именем backup_conf. 2. С помощью редактора nano мы занесли в этот файл команды, которые:
3. Сделали наш файл /root/backup_conf исполняемым.
Замечание: замените server на hostname вашего сервера. Это полезно, если вы будете хранить в одном месте бэкапы нескольких FreeBSD серверов.
Теперь создадим в каталоге /root файл backup_mysql, куда внесем команды для бэкапирования интересующих нас баз mysql-server.
Небольшие пояснения для того, что мы сейчас проделали: 1. Мы создали в каталоге /root файл с именем backup_mysql. 2. Сделали этот файл исполняемым и доступным только для root, так как он будет содержать пароль администратора в mysql (замените password на свой). 3. С помощью редактора nano мы занесли в этот файл команды, которые:
Нам осталось внести в cron созданные списки команд и настроить расписание их выполнения. Для этого:
Небольшие пояснения для того, что мы сейчас проделали: 1. Мы создали в каталоге /root файл с именем cron. 2. С помощью редактора nano мы занесли в этот файл строки, в которых:
Вы можете добавить в файл /root/cron свои команды или списки команд, которые необходимо выполнять по расписанию.
Нам осталось выполнить команды:
Первая команда заносит созданный нами список команд в cron. Вторая позволяет просмотреть этот список.
Статья не является универсальным лекарством, ее надо дополнять и перерабатывать “под себя”. Но если вы воспроизведете большинство из этих указаний для выполнения бэкапа, восстановление некоторой информации или всего (не дай Бог) сервера после его “падения”, пройдет гораздо быстрее и легче.
Веб сервер Nginx, обзор функциональных возможностей
Nginx — небольшой по размерам, очень быстрый, достаточно функциональный веб сервер и почтовый прокси-сервер, разработчик ]]>Игорь Сысоев]]> ( rambler.ru ). Из-за очень маленького потребления ресурсов системы и скорости работы, а так-же гибкости конфигурирования, веб сервер Nginx часто используется в качестве фронтэнда к более тяжеловесным серверам, такими как Apache, в проектах с высокой нагрузкой. Классическим вариантом является связка, Nginx — Apache — FastCGI. Работая в такой схеме, сервер Nginx, принимает все запросы приходящие по HTTP, и в зависимости от конфигурации и собственно самого запроса, решает, обработать-ли запрос самому и отдать клиенту готовый ответ или отправить запрос на обработку, одному из бакэндов ( Apache или FastCGI ).
Перенос на раздел
— подсветить все разделы что бы определиться что монтировать.
При необходимости разбить диск, флаг обнулить таблицу разделов.
Монтируем.
Создадим три подтома root, домашний каталог пользователя и подтом для хранения.
Для переноса смонтируйте резервную систему и перенесите ее.
И отмонтируем корень ФС.
Чтобы монтировать подтом подобно обычному разделу диска, команде mount нужно указывать опцию subvol=PATH. PATH — путь относительно корня ФС. Монтируем корень. Сжатие zstd, или lzo.
Какие рекомендуемые варианты для установки на SD-карту, или медленный SSD-накопитель? В См. https://wiki.debian.org/Btrfs.
Создаём директорию и монтируем в неё наш будущий каталог пользователей, если boot раздел отдеольно, нужно его тоже смонтироват в .
Если нужно .
Если нужно .
Начиная с ядра 5.0 можно создать swap-файл, swap-файл должен располагаться целиком на одном устройстве, создаваться с отключенным COW и сжатием.
Теперь нужно проинициализировать систему. Редактируем FSTAB, или запускаем genfstab.
Переходим в нашу новую систему.
Генерация initramfs с помощью mkinicpio.
Установить загрузчик GRUB2 и сконфигурировать его.
или “Ctrl + D” выйти из chroot.
Теперь нужно все размонтировать.
Восстановление
Монтируем файловую систему, для пересоздания fstab и инициализации.
Если boot раздел отдеольно, то нужно его тоже смонтироват в /mnt/boot и все другие subvolume.
Начиная с ядра 5.0 можно создать swap-файл, swap-файл должен располагаться целиком на одном устройстве, создаваться с отключенным COW и сжатием.
Редактируем FSTAB, или запускаем genfstab.
Переходим в нашу новую систему.
Или zsh.
Перегенерироваь.
Установить загрузчик GRUB2 и сконфигурировать его.
Инициализируем ключи и обновим, если требуется.
или “Ctrl + D” выйти из chroot.
Теперь нужно все размонтировать.
Please enable JavaScript to view the comments powered by Disqus.
Обновление всех приложений и пакетов
Теперь базовая система FreeBSD полностью пропатчена и обновлена. Пора обновить и все бинарные пакеты из-за изменений ABI. Мы просто запускаем следующую команду pkg:
# pkg-static install -f pkg # pkg bootstrap -f # pkg update # pkg upgrade
Установка всех сторонних приложений: Mysql, Nginx и так далее. Нам нужно запустить команду еще раз для удаления старых общих объектных файлов. В последний раз запускаем приведенную ниже команду и мы закончили обновление FreeBSD с 12 до 13 при помощи CLI:
# freebsd-update install
Также возможно обновить систему, используя исходный метод. Вам необходимо прочитать информацию, представленную в файле /usr/src/UPDATING.
# vim /usr/src/UPDATING
Как обновить JLS для FreeBSD с 12 до 13?
Мы тоже можем модернизировать Jail. Концепция та же, но вам нужно указать текущую версию следующим образом. Получить имя Jail и базовый каталог:
# jls
Запустим обновление:
# freebsd-update -b /jails/dnscrypt/ --currently-running 12.2-RELEASE -r 13.0-RELEASE upgrade
Работать в системе, смонтированной в jail на основе /jails/dnscrypt/Нам нужно сообщить об этом freebsd-update при использовании команды upgrade или fetch для обновлений Jail. Не обнаруживать текущий выпуск. Требуется только при обновлении.Укажите новую версию, до которой следует обновить:
-b /jails/dnscrypt/ --currently-running 12.2-RELEASE -r 13.0-RELEASE upgrade
Затем запуск последующих команд обновления и установки jails может быть выполнен обычным образом с помощью -b:
Установка обновления jail
# freebsd-update -b /jails/dnscrypt/ install
Перегрузка или рестарт jail
# /etc/rc.d/jail restart # freebsd-update -b /jails/dnscrypt/ install # jls
Запишите идентификатор jail и получите доступ в оболочку
# jexec 2 sh
Обновите весь пакет внутри jail
# pkg-static install -f pkg # pkg bootstrap -f # pkg update # pkg upgrade
Выход из jail
# exit
Настройка связки Nginx Apache FastCGI
В предыдущей статье «Установка и настройка веб сервера Nginx в качестве проксирующего фронтэнда к Apache», был рассмотрен простой вариант установки и использования Nginx, с настройками по-умолчанию, в качестве проксирующего сервера, с сервером Apache в качестве проксиркемого бакэнда.
В данном материале хотелось-бы рассказать о более сложном варианте установки и настройки Nginx, для построения связки Nginx Apache FastCGI. Для организации FastCGI сервера, будет использована утилиты, spawn-fcgi, ранее входившая в состав веб сервера lighttpd, а теперь выделенная в отдельный порт.
Часть 1. Подготовка и настройка FreeBSD.
Для того что-бы всё, что здесь написано корректно заработало, необходимо использовать FreeBSD версии 11.1, так-как начиная с данной версии в системе включена поддержка ограничения дискового ввода/вывода и т.п. Если в этом нет необходимости, тогда подойдёт версия 10.X. Добавим в rc.conf несколько параметров:
Первая строка указывает Jail автоматически запускаться с системой, вторая строка указывает включение ограничений для Jail, третья строка указывает на файл правил с ограничениями. В четвёртой строке активируется возможность использовать файловую систему ZFS(все Jail будут сохранены на разделах ZFS), этот параметр необходим если система использует родную файловую систему UFS. Запустить ZFS можно командой:
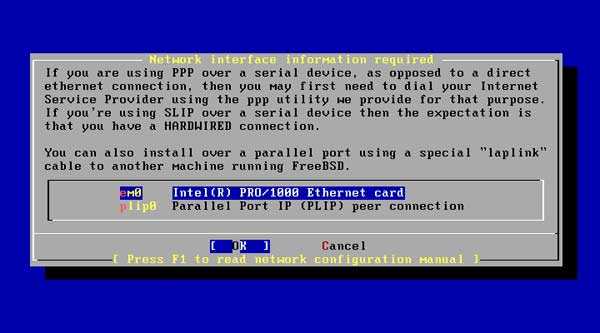
Пятая строка создаёт алиас для Jail, если необходимо несколько Jail, то в том случаи добавьте необходимое количество ip алиасов(так-как я использую VMware ESXI название сетевой карты у меня em0, Вам необходимо использовать название своей карты). В FreeBSD по умолчанию ядро собрано с отключённой возможность ограничивать ресурсы, но к счастью данное ограничение легко устранить, достаточно добавить одну строку в файл loader.conf, командой:
Изменения вступят в силу после перезагрузки системы. Так-же необходимо включить поддержку протокола iscsi, так-как резервное копирование будет осуществляться именно через этот протокол, добавить поддержку можно следующей командой:
Изменения вступят в силу после перезагрузки системы. Последнее, что необходимо настроить в системе(если не считать самого Jail) — firewall на ipfw. Следующая команда создаст файл с правилами ipfw:

В данный файл необходимо внести следующие строки:
Данные правила разрешат всем Jail осуществлять исходящие подключения через порты 443, 80, 21, 53, 3260(iscsi), а так-же будет возможность подключаться ко всем Jail через SSH. Строка:
отвечает зак подключение к будущему Jail, а в частности для вэб сервера, если необходимо добавить другие порты, то укажите их через запятую(80,21,443,68 и т.д). Если необходимо подключение udp, то необходимо скопировать строку и заменить tcp на udp, и изменить номер строки, а также убрать setup, так-как протокол udp не имеет флага SYN:
Выполните последовательно команды:
После выполнения данных команд, скорее всего, необходимо переподключиться по SSH. На этом начальная настройка закончена, перейдём к настройки сервера iscsi target.
Настройка iscsi target Для настройки необходим ещё один сервер в сети, или виртуальная машина(как в моём случае). Для настройки iscsi target будем использовать ctld(входит в состав FreeBSD), добавим запись в rc.conf:
На следующем шаге необходимо создать файл конфигурации для ctld:
В созданный файл добавьте строки:
В строке chap укажите необходимое имя и пароль(минимум 12-ть символов). Название в строке target обязательно должно начинаться на iqn. В строке listen укажите ip адрес текущего сервера. В строке path укажите путь к диску. Здесь указан виртуальный жёсткий диск, если используете физический, то укажите его, а если желаете использовать виртуальный, то читаем дальше. Перейдите в каталог в котором желаете создать файл для виртуально жёсткого диска и выполните команду:
Параметр count отвечает за количество гигабайт, в данном случаю создастся файл размером 10 гигабайт, если укажите другое число, то в этом случаи необходимо изменить параметр LUN 0 в ctl.conf. Данные процесс занимает относительно не много времени. После того как процесс завершиться, в текущей папке создастся фай disk, осталось только создать виртуальный жесткий диск командой:
После выполнение данной команды отобразиться название виртуально диска (в моём случаи — md0), если название отличается, то так-же необходимо изменить параметр LUN 0 в ctl.conf. Для того что-бы данный диск не пропал после перезагрузки, необходимо выполнить команду:
Либо укажите путь до файл:
Остался один штрих — firewall. Как и на основной системе создайте файл:
После того как сохраните изменения, введите:
На этом настройка сервера iscsi закончена, теперь приступим к настройки непосредственно Jail.
Резервное копирование и восстановление FreeBSD 8.2
По ходу работы с нашим сервером на FreeBSD частенько возникала мысль о резервном копировании и восстановлении системы. Мало ли что, экспериментов много разных ставим, снэпшоты в виртуальной среде – вещь хорошая, но в реальности этого не хватает, и тут уже придется самостоятельно позаботиться о резервном копировании данных и об оперативном восстановлении.
Кроме этого, такая задача может возникнуть в случае, если нужно перенести рабочую систему на другую аппаратную платформу (например, замена жесткого диска, переезд на другой сервер), да мало ли какие случаи бывают. Знать нужно. Уметь нужно. И сейчас мы вместе с Вами займемся этим.
Исходная система – FreeBSD 8.2, собрано своё ядро GATEWAY (на сайте я расписывал, как это делается), подняты базовые службы (SSH, APACHE, SQUID), в общем не скрою, сервер продакшн, т.е. боевой. Буду переносить из реальной среды в виртуальную машину с сохранением всего функционала.
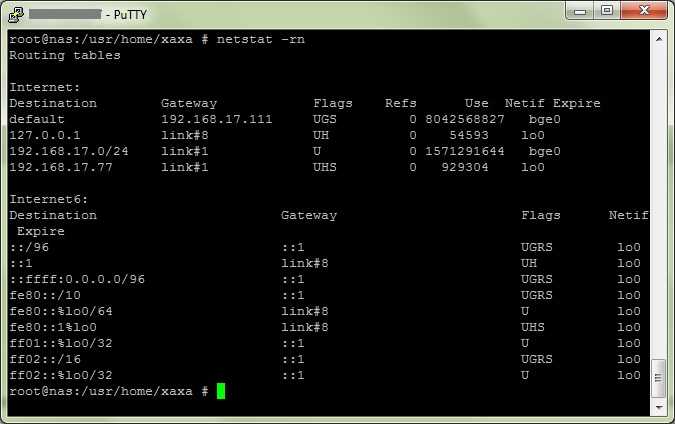
Шаг 1. Сохраняем (распечатываем) разметку диска, это может очень пригодиться.
Я рекомендую всегда при резервном копировании сохранять такую информацию. Во-первых, для создания точной копии файловой системы нам потребуются численные значения начала и конца точек монтирования, во-вторых, будет не лишним знать, какому символу соответствует та или иная точка монтирования, чтобы не запутаться.
Бэкапить мы будем корневой раздел / , раздел /var и раздел /usr . Итого – три архива. Запишите себе, что корневому разделу соответсвтует символ , usr – , var – . Если не очевидно, то это значение стоит после указания диска: /dev/ad0s1
Вот соответствие этих букв разделам очень для нас важно. Когда мы сохранили вывод команд, начинаем снимать архивы
Для архивирования воспользуемся утилитой dump. С помощью нее сделаем «снимок» состояния файловой системы на работающей системе, а потом этот снимок сожмем в один файл.
источник