
1С:Предприятие Бухгалтерия переход с редакции 2.0 на 3.0. Практика перевода информационной базы для работы в управляемом приложении. Промо
Из информационного выпуска 1С № 16872 от 08.07.2013г. стало известно об относительно скором необходимом переходе на редакцию 1С:Бухгалтерия 3.0. В данной публикации будут разобраны некоторые особенности перевода нетиповой конфигурации 1С:Бухгалтерия 2.0 на редакцию 3.0, которая работает в режиме «Управляемое приложение».
Публикация будет дополняться по мере подготовки нового материала. Публикация не является «универсальной инструкцией».
Update 3. Права доступа. 14.08.2013
Update 4. Добавлен раздел 0. Дополнен раздел 4. Добавлен раздел 7. Внесены поправки, актуализирована информация. 23.11.2013.
1 стартмани
Статистика базы данных с отбором по подсистемам (кол-во и открытие списков: документов, справочников, регистров) и анализ наличия основных реквизитов: универсальная обработка (два файла — обычный и управляемый режим)
Универсальная обработка для статистики базы данных (документы, справочники, регистры, отчеты) с отбором по подсистемам и с анализом наличия основных реквизитов (организации, контрагенты, договора, номенклатура, сотрудники, физлица, валюта).
Возможность просмотра списка документов или справочников или регистров при активизации в колонке «Документы, справочники, регистры, отчеты» в текущей строке.
Полезная обработка для консультации пользователей, где искать метаданные в каком интерфейсе, т.к. подсистема указывает в каком интерфейсе находятся метаданные (документы, справочники, регистры, отчеты).
1 стартмани
Удаление помеченных объектов, замена ссылок. Обычное и управляемое приложение. Не монопольно, включая рекурсивные ссылки, с отбором по метаданным и произвольным запросом Промо
Обработка удаления помеченных объектов с расширенным функционалом. Работает в обычном и управляемом приложении. Монопольный и разделенный режим работы. Отображение и отбор по структуре метаданных. Отборы данных произвольными запросами. Копирование и сохранение отборов. Удаление циклических ссылок (рекурсия). Представление циклических в виде дерева с отображением ключевых ссылок, не позволяющих удалить текущий объект информационной базы. Удаление записей связанных независимых регистров сведений. Групповая замена ссылок. Индикатор прогресса при поиске и контроле ссылочности.
10 стартмани
31.10.2016
59985
730
m..adm
225
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
Параллельное выполнение запросов на нескольких ядрах в postgresql
Я использовал версию postgresql 9.6. Если верить новости — http://www.opennet.ru/opennews/art.shtml?num=43313 в ней добавлена поддержка распараллеливания запросов. Я стал пробовать на практике это распараллеливание. Информации в интернете, к моему сожалению, не так много. Вроде проблема популярная, много где видел вопросов на эту тему. Например, вот тут обсуждают тему использования нескольких ядер процессора для выполнения запроса — http://www.sql.ru/forum/1002408/zadeystvovanie-neskolkih-processorov.
Наиболее популярные рекомендации, это изменить запросы и логику работы приложения с БД, чтобы не попадать в ситуацию, когда возникает один большой запрос, который невозможно разбить и обработать параллельно на нескольких ядрах. Пример такого подхода есть на хабре — https://habrahabr.ru/post/76309/. У меня нет ни должных знаний sql, ни тем более 1С, чтобы на уровне приложения что-то менять. Стал разбираться с возможностями postgresql.
Есть несколько параметров, которые как раз отвечают за параллельную обработку запросов:
max_worker_processes = 16 max_parallel_workers_per_gather = 8 min_parallel_relation_size = 0 parallel_tuple_cost = 0.05 parallel_setup_cost = 1000
Их необходимо подбирать под свое количество ядер. В данном случае настройки представлены для 16-ти ядерной системы. Далее необходимо применить скрипт на базе 1С, который позволит оптимизатору постгреса использовать параллельную обработку тех запросов 1С где участвуют текстовые поля (большинство запросов), путём изменения определений функций. Текст скрипта очень длинный, поэтому не привожу его здесь, чтобы не нагружать статью. Качаем его с сайта — postgre.sql.
Запрос необходимо выполнить в базе, которую использует 1С. Для этого можно воспользоваться либо программой pgAdmin, либо напрямую подключиться к базе, через консоль сервера. Опишу второй вариант в подробностях.
Подключаемся к серверу с postgresql по ssh. Заходим под юзером postgres:
# su postgres
Переходим в домашний каталог пользователя:
# cd
Создаем файл с запросом, который будем выполнять. В данном случае можете сразу скопировать файл, который скачали ранее, либо создайте вручную и скопируйте в него текст запроса.
# touch postgre.sql
Если будете копировать готовый файл, убедитесь, что у пользователя postgres есть доступ к этому файлу.
Подключаемся к серверу бд:
# psql -U postgres
Подключаемся к нужной базе данных:
\connect base1c
Выполняем sql запрос из файла:
\i postgre.sql
Все, можно идти проверять. Мы должны были увеличить быстродействие 1С запросов в базе postgresql, разрешив использовать параллельную обработку некоторых запросов. В моем случае это не дало никакого прироста по проблемным запросам. Сама база в целом работала нормально, но спотыкалась на определенных запросах. Разбираемся дальше.
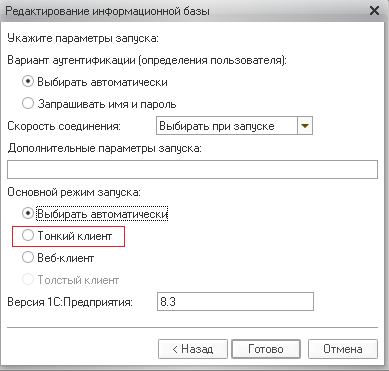
Запуск в тонком клиенте
Тонкий клиент – это особый режим запуска программы 1С, который позволяет минимизировать потребление программных ресурсов и каналов связи. Его можно запустить при помощи выполнения определенных манипуляций в настройках информационной базы.
Чтобы включить режим тонкого клиента, следует выполнить:
- Последовать в настройки. Чтобы в них попасть, необходимо при запуске 1С выбрать кнопку «Изменить».
- Появится новое окно, где следует найти раздел «Основной режим запуска».
- Данный раздел будет иметь несколько вариантов для выбора, среди которых находится тонкий клиент. Его необходимо выбрать.
- После выбора подходящего режима нажать кнопку «Готово», чтобы сохранить изменения.
Для просмотра режима работы программы необходимо перейти в меню «Справка», которое находится в основном перечне меню. В выбранной вкладке нажать «О программе», где будет отображаться режим программы, в котором она работает в данный момент.
Часто встречающиеся ошибки 1С и общие способы их решения Промо
Статья рассчитана в первую очередь на тех, кто недостаточно много работал с 1С и не успел набить шишек при встрече с часто встречающимися ошибками. Обычно можно определить для себя несколько действий благодаря которым можно определить решится ли проблема за несколько минут или же потребует дополнительного анализа. В первое время сталкиваясь с простыми ошибками тратил уйму времени на то, чтобы с ними разобраться. Конечно, интернет сильно помогает в таких вопросах, но не всегда есть возможность им воспользоваться. Поэтому надеюсь, что эта статья поможет кому-нибудь сэкономить время.
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
Установка RedHat Codeready Studio на ОС RedHat Enterprise Linux 8.4 (RHEL 8.4)
Red Hat CodeReady Studio — это бесплатная для участников программы RedHat Developer open source интегрированная среда (IDE), предоставляет широкий набор функционала разработки для нескольких платформ Red Hat, которые включают контейнеры CodeReady (развертывание через OpenShift4), Quarkus, JAX-RS, внедрение зависимостей контекстов (CDI) и инструменты Red Hat Fuse. Студия включает последние версии Eclipse и Web Tools Project (WTP), предоставляет инструменты для JEE и веб-разработки, такие как: инструменты Java EE, JSF и JSP; инструменты JPA; серверные инструменты; веб-сервисы и инструменты WSDL; инструменты HTML , CSS и JavaScript; инструменты XML , XML Schema и DTD. Студия Code Ready Studio также поддерживает популярные технологии, такие как Enterprise Application Platform (EAP 7.3) — платформа корпоративных приложений Red Hat, Hibernate и Wildfly 21, и обеспечивает встроенное усиление для Kubernetes, OpenShift (включая S2i), docker и клиента REST для микропрофайлов.
Результаты тестов
Этот тест показывает общее влияние различных размеров больших страниц. Первый набор тестов был создан с размером страницы по умолчанию в Linux 4 КБ без включения больших страниц
Обратите внимание, что прозрачные огромные страницы также были отключены и оставались отключенными на протяжении всех этих тестов.
Затем второй набор тестов был выполнен размером больших страниц в 2 MБ. Наконец, третий набор тестов выполняется с размером больших страниц 1 ГБ.
Все эти тесты были выполнены в PostgreSQL версии 11
Наборы включают в себя комбинацию разных размеров базы данных и клиентов. На приведенном ниже графике показаны сравнительные результаты производительности для этих тестов с TPS (транзакций в секунду) по оси Y, размером базы данных и количеством клиентов на размер базы данных по оси X.
Из приведенного выше графика видно, что прирост производительности с большими страницами увеличивается с увеличением количества клиентов и размера базы данных, если размер остается в предварительно выделенном буфере в разделяемой памяти (shared buffer).
Этот тест показывает TPS в сравнении с количеством клиентов. В этом случае размер базы данных составляет 48 ГБ. На оси Y у нас есть TPS, а на оси X у нас есть количество подключенных клиентов. Размер базы данных достаточно мал, чтобы поместиться в shared buffer, который установлен на 64 ГБ.
Если для больших страниц установлено значение 1 ГБ, то чем больше клиентов, тем выше сравнительный прирост производительности.
Следующий график такой же, как приведенный выше, за исключением размера базы данных 96 ГБ. Это превышает размер shared buffer, который установлен на 64 ГБ.
Ключевое наблюдение здесь заключается в том, что производительность с большими страницами, равными 1 ГБ, увеличивается по мере увеличения числа клиентов, и в конечном итоге она дает большую производительность, чем большие страницы в 2 МБ или стандартный размер страницы в 4 КБ.
Этот тест показывает TPS в зависимости от размера базы данных. В этом случае количество подключенных клиентов составляет 32. На оси Y у нас TPS, а на оси X — размеры базы данных.
Как и ожидалось, когда база данных выходит за пределы предварительно выделенных больших страниц, производительность значительно снижается.
Включить параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Для включения настройки:
-
В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc
-
В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows
-
Разверните узлы Настройки безопасности и Локальные политики
-
Выберите папку Назначение прав пользователя
-
Политики будут показаны на панели подробностей
-
На этой панели дважды кликните параметр Блокировка страниц в памяти
-
В диалоговом окне Параметр локальной безопасности — блокировка страниц в памяти выберите «Добавить» пользователя или группу
-
В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server
-
Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server
Копирование числовых ячеек из 1С в Excel Промо
Решение проблемы, когда значения скопированных ячеек из табличных документов 1С в Excel воспринимаются последним как текст, т.е. без дополнительного форматирования значений невозможно применить арифметические операции. Поводом для публикации послужило понимание того, что целое предприятие с более сотней активных пользователей уже на протяжении года мучилось с такой, казалось бы на первый взгляд, тривиальной проблемой. Варианты решения, предложенные специалистами helpdesk, обслуживающими данное предприятие, а так же многочисленные обсуждения на форумах, только подтвердили убеждение в необходимости описания способа, который позволил мне качественно и быстро справиться с ситуацией.
Послесловие.
Ко всему вышеперечисленному можно так же добавить:
- Необходимость использования управляемых блокировок при разработке прикладного решения. Если же у вас типовая конфигурация, то по возможности ее так же необходимо переводить на управляемые блокировки.
- Рекомендацию реализовать для PostgreSQL кэширование на SSD-накопитель. Сделать это можно с помощью Flashcache или Bcache. Подробнее вопрос организации системы кэширования я рассмотрю в другой статье.
- Довольно удобный веб-сервис для начальной настройки PostgreSQL. Его мне товарищ Vasiliy P. Melnik. Несмотря на то, что интерфейс на английском, он простой и интуитивно понятный. Думаю каждый желающий сможет с ним разобраться.
Статья обновлена 8 октября 2016 года. Добавлены сравнительные тесты
Опыт оптимизации и контроля производительности в БД с 3000 пользователей Промо
Данная статья написана по материалам доклада, прочитанного на Конференции Инфостарта IE 2014 29-31 октября 2014 года.
Меня зовут Сергей, являюсь руководителем отдела оптимизации и производительности систем в компании «Деловые линии».
Цель этого доклада – поделиться информацией о нашем опыте работы с большой базой на платформе 1С, с чем пришлось столкнуться, как удалось обеспечить работоспособность.
Уверен, что вам будет интересно, так как подобной информацией мало кто делится, да и про само существование таких систем их владельцы стараются не рассказывать, максимум про это «краем глаза» упоминают участвовавшие в проекте вендоры.
**update от 04.03.2016 по вопросам из комментариев
Ограничить максимальный объем памяти сервера MS SQL Server.
Необходимо ограничить максимальный объем памяти, потребляемый MS SQL Server, особенно это критично, если роли сервера 1С и сервера СУБД совмещены. Максимальный объем памяти, рекомендуемый для MS SQL Server, можно рассчитать по следующей формуле:
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
-
Запустить Management Studio и подключиться к нужному серверу
-
Открыть свойства сервера и выбрать закладку Память
-
Указать значение параметра Максимальный размер памяти сервера
Запуск Apache 2.4 с модулем 1С внутри Docker контейнера
Про Apache и про Linux слышали, наверное, все. А вот про Docker пока нет, но он сильно набирает популярность последнее время и не зря. Поделюсь своим опытом и дам пошаговую инструкцию настройки веб-сервера Apache с модулем 1С внутри Docker контейнера на Linux хосте. При этом сам сервер 1С может находиться совсем на другой машине и на другой операционной системе
Это не важно, главное чтобы Apache смог достучаться до сервера 1С по TCP. В статье дам подробное пояснение по каждой используемой команде со ссылками на документацию по Docker, чтобы не создавалось ощущение непонятной магии
Также прилагаю git репозиторий с описанием всей конфигурации, можете попробовать развернуть у себя буквально за 10 минут.
Режим совместимости конфигурации 1С
Приветствую, коллеги! В этой статье будет сделан обзор функции совместимости конфигурации 1С с другими версиями конфигураций 1С, а также рассмотрено, как выбрать и настроить режим совместимости конфигурации с версией 1С 8.3.
Во-первых, разберём главное понятие в этой статье: режим совместимости в конфигурации – это устройство, благодаря которому выводится номер версии системы, под которую станет открыто приложение 1С:Предприятие. Данный режим существует на платформе 1С начиная с версий 8.2 и 8.3 (платформа версии 1С:Предприятие 8.3 совместима с платформой версии 1С:Предприятие 8.2).
Новая версия Postgres для 1С
Вы сейчас работаете на Postgres 9.6, несмотря на то, что скоро выйдет Postgres 11. Но пока на него ни один серьезный человек не перейдет, нужно подождать, по крайней мере, несколько минорных релизов, потому что база данных – вещь серьезная. Поэтому наиболее актуальная для вас версия 10.
Что вас ожидает нового в этой версии, когда мы завершим тестирование? Вас ждут такие вещи, как:
параллельная обработка запросов — она уже была, но сейчас стала очень интересной;
многопараметрическая статистика добавлена
Это очень важно, потому что в Postgres выполнение запросов зависит от того, какую оценку стоимости база данных может дать для вашего запроса. И это зависит от статистики
До сих пор до версии 10 статистика была однопараметрическая, т.е. для какой-то определенной колонки. А сейчас стала многопараметрической, так что вы можете делать статистику для связанных колонок. Это важно для 1С, потому что в 1С бывают сложные запросы, когда колонки друг с другом связаны, и это надо учитывать;
логическая репликация и секционирование таблиц. Это очень важно, когда у вас база данных становится большой. Тогда ее начинают разбивать на секции. И в Postgres 10 добавлено надежное секционирование, которое позволяет масштабироваться. Не на уровне приложения, а на уровне баз данных.
Расскажу немного подробнее про параллельную обработку запросов. В версии 9.3 появились background workers – это «демоны», которые делают задачки в фоновом режиме. В версии 9.6 появились Parallel sequential scans, когда диск читается параллельно сразу несколькими запросами. Т.е. если у вас 1С генерит 10 запросов к одной и той же таблице, то раньше эти все 10 запросов «дрались» за диск, и тогда там очень много overhead. А с параллельной обработкой один процесс читает, а все остальные ждут и пользуются результатами этого «чтения». Это сильно облегчает работу базы данных.
Появились еще Hash joins и Nested Loops – все это обрабатывается в системе параллельно. Наверное, ни у кого не осталось ноутбука или сервера, у которого только 1 ядро. Сейчас нормально, когда сервера имеют 8-12 ядер, и Postgres их эффективно использует. В этом и заключается параллелизм. Все ядра используются для выполнения вашего запроса.
В версии 10 появилось еще больше поддержки параллелизма – Bitmap heap scans, Index scans, Merge joins…
Я хочу отметить одну вещь. Известно, что 1С-ники пишут запросы на “своем” языке. В первый раз, когда я столкнулся с запросами 1С в 2008 году, я был шокирован. Несколько дней мы занимались тем, что пытались сократить запрос размером в 100 кБ и сделать его удобоваримым. Сейчас к нам приходят запросы длиной даже в 1 мБ. Я всегда поражаюсь, когда прихожу к вам, смотрю, неужели вот этот человек может описать вот такой запрос? И я очень горд за Postgres, потому что он справляется с такими запросами и при этом не умирает. Перечисленные выше функции и помогают решать такие проблемы.
В версии 11 появятся еще более удивительные вещи: улучшилась параллельная обработка запросов, появилась JIT-компиляция — Just-in-time compilation, компиляция «на лету».
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
Опыт оптимизации и контроля производительности в БД с 3000 пользователей Промо
Данная статья написана по материалам доклада, прочитанного на Конференции Инфостарта IE 2014 29-31 октября 2014 года.
Меня зовут Сергей, являюсь руководителем отдела оптимизации и производительности систем в компании «Деловые линии».
Цель этого доклада – поделиться информацией о нашем опыте работы с большой базой на платформе 1С, с чем пришлось столкнуться, как удалось обеспечить работоспособность.
Уверен, что вам будет интересно, так как подобной информацией мало кто делится, да и про само существование таких систем их владельцы стараются не рассказывать, максимум про это «краем глаза» упоминают участвовавшие в проекте вендоры.
**update от 04.03.2016 по вопросам из комментариев
Копирование числовых ячеек из 1С в Excel Промо
Решение проблемы, когда значения скопированных ячеек из табличных документов 1С в Excel воспринимаются последним как текст, т.е. без дополнительного форматирования значений невозможно применить арифметические операции. Поводом для публикации послужило понимание того, что целое предприятие с более сотней активных пользователей уже на протяжении года мучилось с такой, казалось бы на первый взгляд, тривиальной проблемой. Варианты решения, предложенные специалистами helpdesk, обслуживающими данное предприятие, а так же многочисленные обсуждения на форумах, только подтвердили убеждение в необходимости описания способа, который позволил мне качественно и быстро справиться с ситуацией.
Сервер 1С:Предприятие на Ubuntu 16.04 и PostgreSQL 9.6, для тех, кто хочет узнать его вкус. Рецепт от Капитана
Если кратко описать мое отношение к Postgres: Использовал до того, как это стало мейнстримом.
Конкретнее: Собирал на нем сервера для компаний среднего размера (до 50 активных пользователей 1С).
На настоящий момент их набирается уже больше, чем пальцев рук пары человек (нормальных, а не фрезеровщиков).
Следуя этой статье вы сможете себе собрать такой же и начать спокойную легальную жизнь, максимально легко сделать первый шаг в мир Linux и Postgres.
А я побороться за 1. Лучший бизнес-кейс (лучший опыт автоматизации предприятия на базе PostgreSQL).
Если, конечно, статья придется вам по вкусу.
Настройка регламентных и фоновых заданий
Конфигурация программы 1С отличается обилием большого количества фоновых заданий. К ним можно отнести постоянное обновление курса валют, классификаторов банков, новостной ленты, задач бухгалтера и многое другое. Каждый выполняемый программой процесс отбирает ресурсы, как данного софта, так и компьютера. Некоторые из них можно отключить, так как они не особо нужны.
Одним из простых и эффективных решений, чтобы оптимизировать 1С и улучшить производительность, является настройка всех этих процессов, которые выполняются в фоновом режиме. Имеется в виду их полное отключение.
Для этого следует выполнить следующее:
- Поиск пункта «Администрирование» в главном разделе меню, которое перекинет в окно настройки программы. Появится перечень переходов, среди которых необходимо выбрать «Обслуживание».
- В появившемся новом окне необходимо перейти в раздел «Регламентные операции». Здесь будет располагаться ссылка «Регламентные и фоновые задания», по которой следует нажать.
- Будет предоставлен список всех доступных фоновых заданий для ознакомления, большинство которых будет находиться в рабочем состоянии. Об этом свидетельствует галочка, которая стоит слева.
- Выполнить полный просмотр данного списка, чтобы определить для себя ненужные процессы. Чтобы отключить ненужные задания, следует нажать на каждое из них. Появится отдельное окно, где следует снять галочку с пункта «Включено».
- Нажать «Записать и закрыть», чтобы выбранная задача больше не запускалась.
Данные простые, но достаточно эффективные, действия позволят повысить производительность и скорость программы 1С. Она будет шустрее работать и не будет терять драгоценные ресурсы. При необходимости выключенные задания можно повторно включить.
Опыт оптимизации и контроля производительности в БД с 3000 пользователей Промо
Данная статья написана по материалам доклада, прочитанного на Конференции Инфостарта IE 2014 29-31 октября 2014 года.
Меня зовут Сергей, являюсь руководителем отдела оптимизации и производительности систем в компании «Деловые линии».
Цель этого доклада – поделиться информацией о нашем опыте работы с большой базой на платформе 1С, с чем пришлось столкнуться, как удалось обеспечить работоспособность.
Уверен, что вам будет интересно, так как подобной информацией мало кто делится, да и про само существование таких систем их владельцы стараются не рассказывать, максимум про это «краем глаза» упоминают участвовавшие в проекте вендоры.
**update от 04.03.2016 по вопросам из комментариев
Методика оптимизации программного кода 1С: проведение документов
Описание простого метода анализа производительности программного кода 1С, способов его оптимизации и оценки результатов в виде числовых показателей прироста производительности. Не требует сторонних программных продуктов, используются только типовые возможности платформ 1С.
Методика проверена на линейке платформ начиная с 1С:Предприятие 8.2 (обычные формы, управляемые формы). Позволяет ускорить проведение проблемных документов в 3 и более раз, провести проверку корректности формирования проводок оптимизированным кодом и подтвердить результаты оптимизации реальными замерами производительности в режиме предприятия.
К публикации приложены демонстрационные базы для режимов обычного и управляемого приложения на платформе 1С:Предприятие 8.3 (8.3.9.2033).
1 стартмани



