
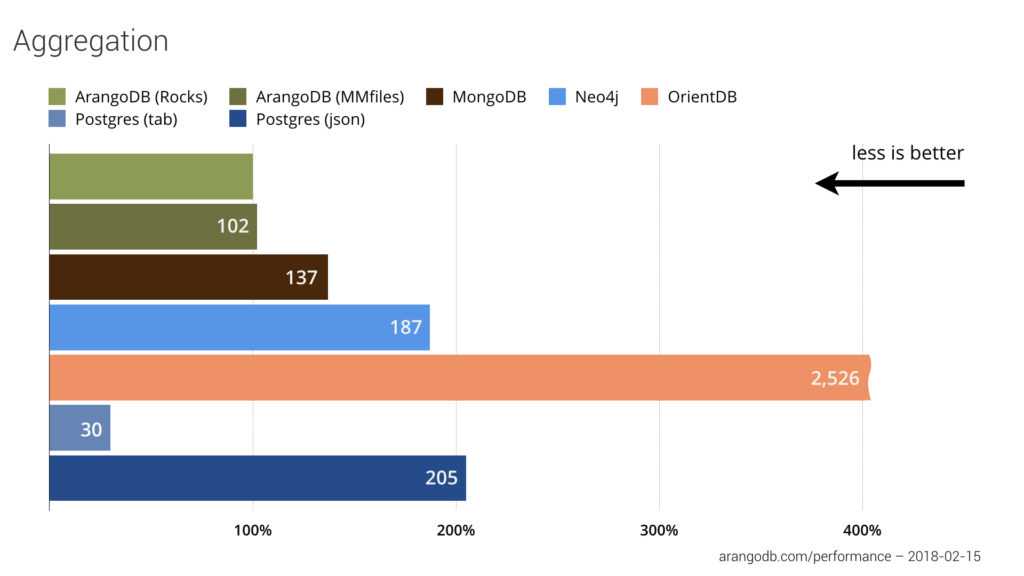
pgAdmin
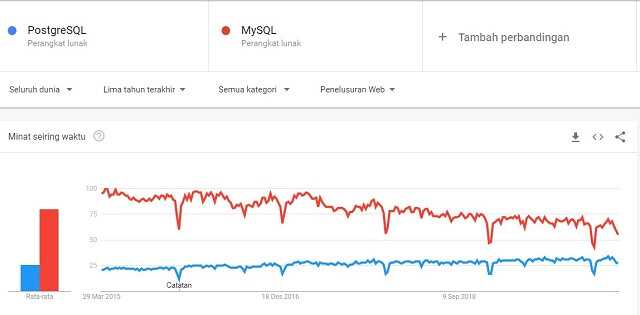
Им многие пользуются, но, скорее по привычке. Или потому что это бесплатно. pgAdmin4 — продукт странноватый, при этом в описании сказано, что это самый лучший опенсорс продукт для разработки и администрирования.
Как его использовать для администрирования — не очень понятно. pgAdmin’ом нельзя «заинитить» новый сервер, нельзя подправить pg_hba.conf или postgresql.conf. Видимо, имеются в виду скудные графики запросов в секунду, вывод подробностей конфигурации сервера и статистика в таблицах. Не уверен, в общем. Как вы испольуете pgAdmin для администрирования?
Как его использовать с точки зрения разработки — еще менее понятно. Субъективно, интерфейс в целом не удобен для разработки. Несмотря на то, что четвертую версию переписали на python + JS с jQuery, по сути, осталось всё то же самое.
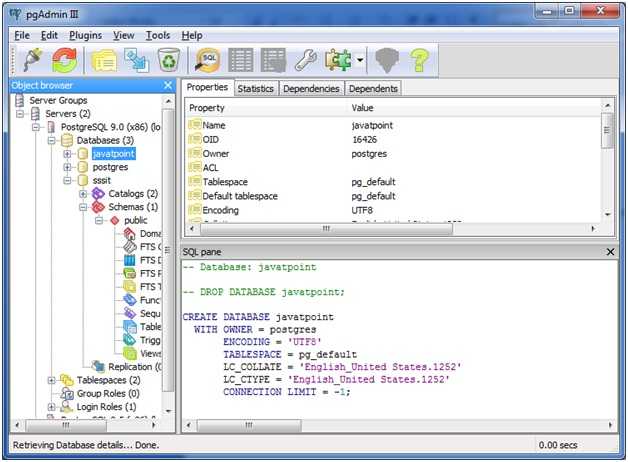
Чтобы немного пояснить ситуацию, в голове разработчика такая картина: есть база на каком-то серваке, в ней — схемы, в схемах — таблицы и вьюхи. Т.е. таблица — максимум, 3-й уровень. А если база одна, то вообще второй уровень. Ткнул по таблице — увидел несколько первых строк.
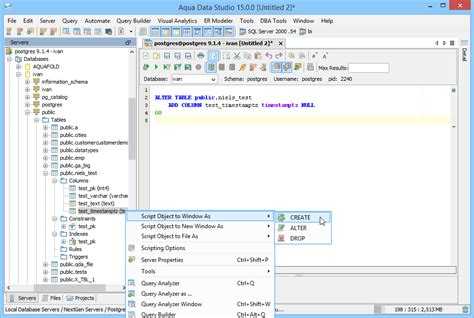
В голове разработчика pgAdmin как-то так: «Смерть Кощеева на конце иглы, та игла в яйце, то яйцо в утке, та утка в зайце, тот заяц в сундуке, а сундук стоит на высоком дубу, и то дерево Кощей как свой глаз бережёт», а именно (см. картинку):
Есть группа серверов, в ней есть сервер, на сервере существуют базы, роли и т.д., из баз можно выбрать конкретную базу, в ней видно схемы, языки, еще бог знает что. В схемах можно выбрать нужную схему, в схеме 100500 всего, и где-то в конце списка «таблицы». В таблицах можно выбрать нужную таблицу, по ней надо кликнуть правой кнопкой мыши, там в большом списке выбираешь «view data», в этой «view data» есть «view first 100 rows» и уже там наконец-то смерть кощеева несколько строк для ознакомления.
Киллер-фичей pgAdmin является возможность дебажить хранимые процедуры pl/pgsql. Других бесплатных программ с этой возможностью я не встречал.
Автокликер для 1С
Внешняя обработка, запускаемая в обычном (неуправляемом) режиме для автоматизации действий пользователя (кликер). ActiveX компонента, используемая в обработке, получает события от клавиатуры и мыши по всей области экрана в любом приложении и транслирует их в 1С, получает информацию о процессах, текущем активном приложении, выбранном языке в текущем приложении, умеет сохранять снимки произвольной области экрана, активных окон, буфера обмена, а также, в режиме воспроизведения умеет активировать описанные выше события. Все методы и свойства компоненты доступны при непосредственной интеграции в 1С. Примеры обращения к компоненте представлены в открытом коде обработки.
1 стартмани
Часто встречающиеся ошибки 1С и общие способы их решения Промо
Статья рассчитана в первую очередь на тех, кто недостаточно много работал с 1С и не успел набить шишек при встрече с часто встречающимися ошибками. Обычно можно определить для себя несколько действий благодаря которым можно определить решится ли проблема за несколько минут или же потребует дополнительного анализа. В первое время сталкиваясь с простыми ошибками тратил уйму времени на то, чтобы с ними разобраться. Конечно, интернет сильно помогает в таких вопросах, но не всегда есть возможность им воспользоваться. Поэтому надеюсь, что эта статья поможет кому-нибудь сэкономить время.
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
II. Создать пользователя PostgreSQL
Установленный PostgreSQL Server требует дополнительной настройки, прежде чем вы перейдете к развертыванию Creatio. После первичной установки PostgreSQL Server вам необходимо создать для него пользователя, который сможет подключаться к базе данных через логин и пароль и будет иметь права на создание и обновление баз данных. По умолчанию такого пользователя в PostgreSQL Server нет.
Рекомендуется создать следующих пользователей PostgreSQL:
-
Пользователь с ролью ”sysadmin” и неограниченными полномочиями на уровне сервера базы данных — нужен для восстановления базы данных и настройки доступа к ней. Далее для обозначения пользователя с ролью ”sysadmin” будет использован псевдоним pg_sysadmin.
-
Пользователь с ролью ”public” и ограниченными полномочиями — используется для настройки безопасного подключения Creatio к базе данных через аутентификацию средствами PostgreSQL. Далее для обозначения пользователя с ролью ”public” будет использован псевдоним pg_user.
Чтобы создать пользователей PostgreSQL:
-
Откройте командную строку.
-
Перейдите в папку с установочными файлами PostgreSQL:
\\path\to\PostgreSQL\folder — путь к папке с установочными файлами PostgreSQL.
-
Перейдите в папку с компонентом Command Line Tools:
-
Введите пароль подключения к серверу БД в переменную окружения:
pg_password — пароль пользователя postgres для подключения к серверу PostgreSQL.
-
Запустите оболочку PostgreSQL от имени пользователя postgres:
-
Создайте нового пользователя с правами администратора:
pg_sysadmin — пользователь, которому будут предоставлены права администратора. Нужен для восстановления базы данных и настройки доступа к ней.
-
Настройте для пользователя pg_sysadmin права администратора:
-
Разрешите pg_sysadmin авторизацию:
-
Настройте пароль для pg_sysadmin:
pg_password — пароль пользователя pg_sysadmin для подключения к серверу PostgreSQL.
-
Создайте нового пользователя с ограниченными правами:
pg_user — пользователь для подключения к серверу PostgreSQL. Используется для подключения Creatio к базе данных.
-
Разрешите pg_user авторизацию:
-
Настройте пароль для pg_user:
pg_password — пароль пользователя pg_user для подключения к серверу PostgreSQL.
-
Выйдите из оболочки PostgreSQL.
1С:Предприятие Бухгалтерия переход с редакции 2.0 на 3.0. Практика перевода информационной базы для работы в управляемом приложении. Промо
Из информационного выпуска 1С № 16872 от 08.07.2013г. стало известно об относительно скором необходимом переходе на редакцию 1С:Бухгалтерия 3.0. В данной публикации будут разобраны некоторые особенности перевода нетиповой конфигурации 1С:Бухгалтерия 2.0 на редакцию 3.0, которая работает в режиме «Управляемое приложение».
Публикация будет дополняться по мере подготовки нового материала. Публикация не является «универсальной инструкцией».
Update 3. Права доступа. 14.08.2013
Update 4. Добавлен раздел 0. Дополнен раздел 4. Добавлен раздел 7. Внесены поправки, актуализирована информация. 23.11.2013.
1 стартмани
Веб-публикации
Сервер 1С поддерживает возможность веб-публикаций баз 1С. Это дает возможность открывать программу в браузере или мобильном приложении. В Linux данные публикации осуществляются с помощью Apache.
Установка и запуск Apache
Первым делом, устанавливаем веб-сервер apache:
apt-get install apache2
Разрешаем автозапуск веб-сервера и стартуем сам сервис:
systemctl enable apache2
systemctl start apache2
Открываем браузер и переходим по адресу http://<IP-адрес сервера 1С> — мы должны увидеть стартовую страницу Apache:
Публикация 1С на веб-сервере
Публикация базы выполняется с помощью скрипта webinst, который устанавливается с сервером. Для простоты, мы опубликуем базу в корневую директорию /var/www/html, но при желании, можно настроить виртуальные домены.
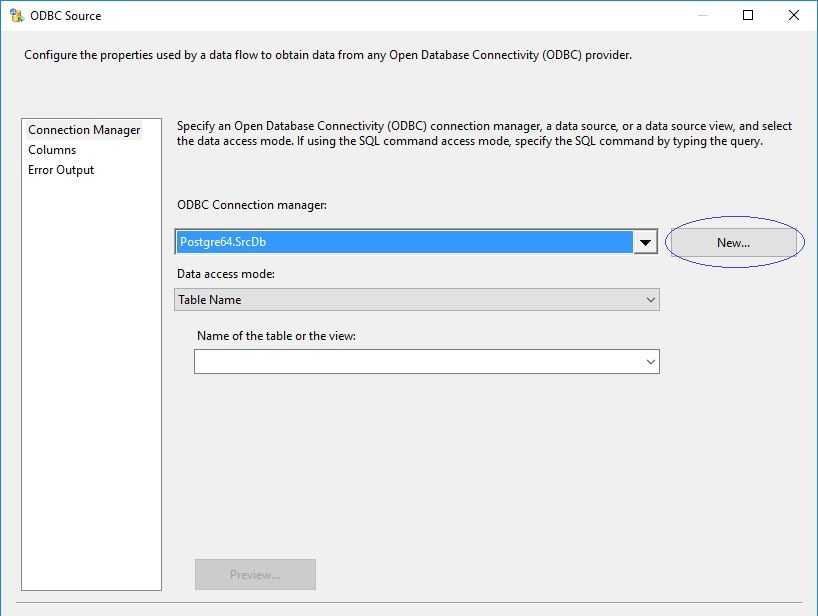
И так, создадим каталог, в который опубликуем нашу базу:
mkdir /var/www/html/test
Переходим в каталог с установленным 1С:
cd /opt/1C/v8.3/x86_64/
… или:
cd /opt/1cv8/x86_64/8.3.16.1148/
* где 8.3.16.1148 — версия установленной платформы.
Заускаем скрипт для публикации базы:
./webinst -apache24 -wsdir test -dir /var/www/html/test -connstr «Srvr=192.168.1.11;Ref=test;» -confPath /etc/apache2/apache2.conf
* где apache24 — версия установленного apache; test — имя нашей базы, которую мы создали ранее; /var/www/html/test — путь до каталога на сервере, в котором будет опубликована база; 192.168.1.11 — IP-адрес сервера 1С; Ref=test — имя базы в СУБД; /etc/apache2/apache2.conf — путь до конфигурационного файла apache.
Мы должны увидеть:
Publication successful
… или:
Публикация выполнена
Перезапускаем апач:
systemctl restart apache2
Открываем браузер и переходим по адресу http://<IP-адрес сервера 1С>/test/, где test — каталог в каталоге /var/www/html, куда мы опубликовали базу.
Установка PostgreSQL
1. Создадим каталог /opt/postgres_11_5
| 1 | mkdir /opt/postgres_11_5 |
2. Скачаем с сайта фирмы «1С» специальный пропатченный дистрибутив postgresql:
- postgresql11-1c-11.5-12.el7.x86_64.rpm;
- postgresql11-1c-contrib-11.5-12.el7.x86_64.rpm;
- postgresql11-1c-libs-11.5-12.el7.x86_64.rpm;
- postgresql11-1c-server-11.5-12.el7.x86_64.rpm.
Поместим установочные пакеты postgresql в каталог /opt/postgres_11_5:
Можно использовать для этого программу WinSCP. Как с ней работать тут.
3. Перейдем в каталог /opt/postgres_11_5
| 1 | cd /opt/postgres_11_5 |
4. Установим все пакеты из каталога:
| 1 | yum localinstallpostgresql11* |
5. Выполним смену пароля пользователю postgres:
| 1 | passwd postgres |
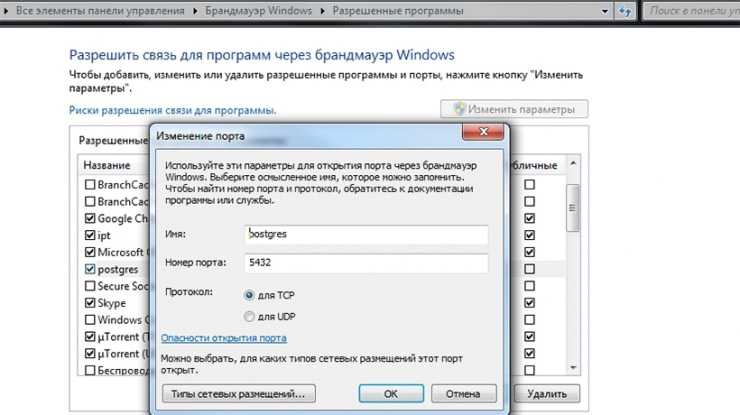
6. Если на сервере работает фаервол то настроим правила для сервера PostgreSQL . Нам надо открыть порт 5432 для входящих соединений. Если в системе используется утилита firewalld, то вводим команды:
|
1 |
firewall-cmd —permanent—zone=public—add-port=5432/tcp firewall-cmd -reload |
Если используется утилита iptables, то:
|
1 |
iptables -tfilter-IINPUT-ptcp—dport5432-jACCEPT service iptables save |
7. Отключим SELinux, позже при желании можно настроить политику доступа для PostgreSQL:
| 1 | setenforce0 |
Часто встречающиеся ошибки 1С и общие способы их решения Промо
Статья рассчитана в первую очередь на тех, кто недостаточно много работал с 1С и не успел набить шишек при встрече с часто встречающимися ошибками. Обычно можно определить для себя несколько действий благодаря которым можно определить решится ли проблема за несколько минут или же потребует дополнительного анализа. В первое время сталкиваясь с простыми ошибками тратил уйму времени на то, чтобы с ними разобраться. Конечно, интернет сильно помогает в таких вопросах, но не всегда есть возможность им воспользоваться. Поэтому надеюсь, что эта статья поможет кому-нибудь сэкономить время.
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
Установка сервера 1С
Для установки сервера 1С необходимо сначала установить вспомогательные пакеты, затем сам сервис. Дистрибутив необходимо скачать с сайта 1С — личного кабинета, доступного по подписке.
И так, выполним установку следующих пакетов:
apt-get install imagemagick unixodbc ttf-mscorefonts-installer
* где:
- imagemagick — набор программ для чтения и редактирования графических файлов.
- unixodbc — диспетчер драйверов для ODBC.
- ttf-mscorefonts-installer — набор шрифтов Microsoft.
В процессе установки система запросит принять лицензионное соглашение — выбираем Yes.
Копируем на сервер архив с дистрибутивом для 1С, который был загружен с сайта 1С или получен от поставщика. Распаковываем архив командой:
tar zxvf 8.3.16.1148_deb64.tar.gz
* где 8.3.16.1148_deb64.tar.gz — имя архива с 1С версии 8.3.16. В архиве пакеты deb (для Linux на основе Debian) для 64-х разрядной системы.
Устанавливаем все пакеты, которые находились в архиве командой:
dpkg -i 1c-enterprise*.deb
Разрешаем автозапуск сервиса 1С и стартуем его:
systemctl enable srv1cv83
systemctl start srv1cv83
Необходимо убедиться, что сервис запустился:
systemctl status srv1cv83
Если мы получим ошибку «srv1cv83.service not found», находим исполняемый файл srv1cv83:
find /opt -name srv1cv83
В моем случае он был по пути:
/opt/1cv8/x86_64/8.3.16.1148/srv1cv83


Делаем симлинк в каталоге /etc/init.d на найденный файл:
ln -s /opt/1cv8/x86_64/8.3.16.1148/srv1cv83 /etc/init.d/srv1cv83
Снова запускаем сервис:
systemctl start srv1cv83
Часто встречающиеся ошибки 1С и общие способы их решения Промо
Статья рассчитана в первую очередь на тех, кто недостаточно много работал с 1С и не успел набить шишек при встрече с часто встречающимися ошибками. Обычно можно определить для себя несколько действий благодаря которым можно определить решится ли проблема за несколько минут или же потребует дополнительного анализа. В первое время сталкиваясь с простыми ошибками тратил уйму времени на то, чтобы с ними разобраться. Конечно, интернет сильно помогает в таких вопросах, но не всегда есть возможность им воспользоваться. Поэтому надеюсь, что эта статья поможет кому-нибудь сэкономить время.
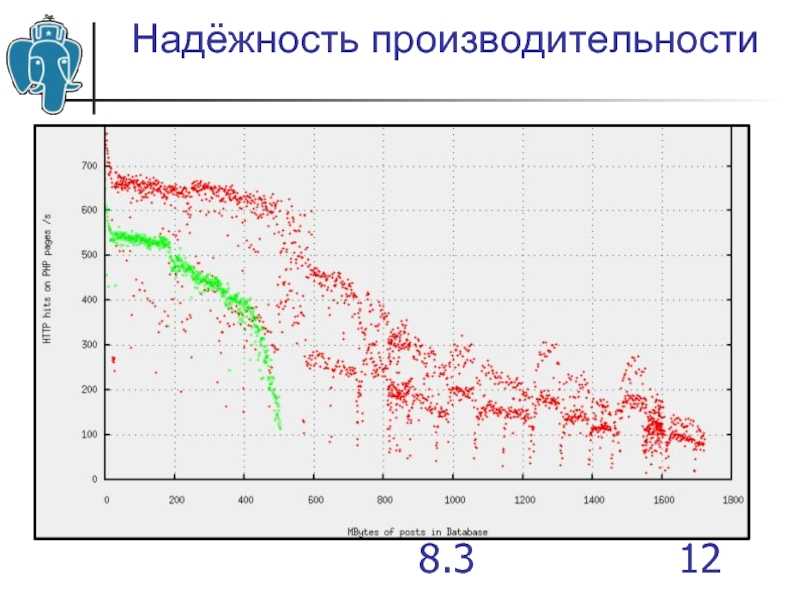
Новая версия Postgres для 1С
Вы сейчас работаете на Postgres 9.6, несмотря на то, что скоро выйдет Postgres 11. Но пока на него ни один серьезный человек не перейдет, нужно подождать, по крайней мере, несколько минорных релизов, потому что база данных – вещь серьезная. Поэтому наиболее актуальная для вас версия 10.
Что вас ожидает нового в этой версии, когда мы завершим тестирование? Вас ждут такие вещи, как:
параллельная обработка запросов — она уже была, но сейчас стала очень интересной;
многопараметрическая статистика добавлена
Это очень важно, потому что в Postgres выполнение запросов зависит от того, какую оценку стоимости база данных может дать для вашего запроса. И это зависит от статистики
До сих пор до версии 10 статистика была однопараметрическая, т.е. для какой-то определенной колонки. А сейчас стала многопараметрической, так что вы можете делать статистику для связанных колонок. Это важно для 1С, потому что в 1С бывают сложные запросы, когда колонки друг с другом связаны, и это надо учитывать;
логическая репликация и секционирование таблиц. Это очень важно, когда у вас база данных становится большой. Тогда ее начинают разбивать на секции. И в Postgres 10 добавлено надежное секционирование, которое позволяет масштабироваться. Не на уровне приложения, а на уровне баз данных.
Расскажу немного подробнее про параллельную обработку запросов. В версии 9.3 появились background workers – это «демоны», которые делают задачки в фоновом режиме. В версии 9.6 появились Parallel sequential scans, когда диск читается параллельно сразу несколькими запросами. Т.е. если у вас 1С генерит 10 запросов к одной и той же таблице, то раньше эти все 10 запросов «дрались» за диск, и тогда там очень много overhead. А с параллельной обработкой один процесс читает, а все остальные ждут и пользуются результатами этого «чтения». Это сильно облегчает работу базы данных.
Появились еще Hash joins и Nested Loops – все это обрабатывается в системе параллельно. Наверное, ни у кого не осталось ноутбука или сервера, у которого только 1 ядро. Сейчас нормально, когда сервера имеют 8-12 ядер, и Postgres их эффективно использует. В этом и заключается параллелизм. Все ядра используются для выполнения вашего запроса.
В версии 10 появилось еще больше поддержки параллелизма – Bitmap heap scans, Index scans, Merge joins…
Я хочу отметить одну вещь. Известно, что 1С-ники пишут запросы на “своем” языке. В первый раз, когда я столкнулся с запросами 1С в 2008 году, я был шокирован. Несколько дней мы занимались тем, что пытались сократить запрос размером в 100 кБ и сделать его удобоваримым. Сейчас к нам приходят запросы длиной даже в 1 мБ. Я всегда поражаюсь, когда прихожу к вам, смотрю, неужели вот этот человек может описать вот такой запрос? И я очень горд за Postgres, потому что он справляется с такими запросами и при этом не умирает. Перечисленные выше функции и помогают решать такие проблемы.
В версии 11 появятся еще более удивительные вещи: улучшилась параллельная обработка запросов, появилась JIT-компиляция — Just-in-time compilation, компиляция «на лету».
Настройки на Master
В данной статье мы будем настраивать серверы с IP-адресами 192.168.1.10 (первичный или master) и 192.168.1.11 (вторичный или slave).
Переходим на сервер, с которого будем реплицировать данные (мастер) и выполняем следующие действия.
Создаем пользователя в PostgreSQL
Входим в систему под пользователем postgres:
su — postgres
Создаем нового пользователя для репликации:
createuser —replication -P repluser
* система запросит пароль — его нужно придумать и ввести дважды. В данном примере мы создаем пользователя repluser.
Выходим из оболочки пользователя postgres:
exit
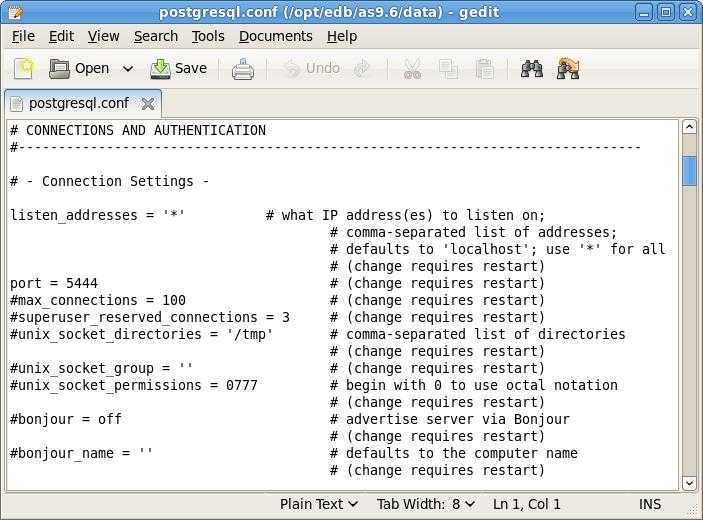
Настраиваем postgresql
Смотрим расположение конфигурационного файла postgresql.conf командой:
su — postgres -c «psql -c ‘SHOW config_file;'»
В моем случае система вернула строку:
/etc/postgresql/9.6/main/postgresql.conf
* конфигурационный файл находится по пути /etc/postgresql/9.6/main/postgresql.conf.
Открываем конфигурационный файл postgresql.conf.
vi /etc/postgresql/9.6/main/postgresql.conf
* мы открываем файл, который получили sql-командой SHOW config_file;.
Редактируем следующие параметры:
listen_addresses = ‘localhost, 192.168.1.10’
wal_level = replica
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
* где
- 192.168.1.10 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
- wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- max_replication_slots — максимальное число слотов репликации (данный параметр не нужен для postgresql 9.2 — с ним сервер не запустится);
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Открываем конфигурационный файл pg_hba.conf — он находитсяч в том же каталоге, что и файл postgresql.conf:
vi /etc/postgresql/9.6/main/pg_hba.conf
Добавляем следующие строки:
host replication repluser 127.0.0.1/32 md5
host replication repluser 192.168.1.10/32 md5
host replication repluser 192.168.1.11/32 md5
* данной настройкой мы разрешаем подключение к базе данных replication пользователю repluser с локального сервера (localhost и 192.168.1.10) и сервера 192.168.1.11.
Перезапускаем службу postgresql:
systemctl restart postgresql
* обратите внимание, что название для сервиса в системах Linux может различаться
Удаление помеченных объектов, замена ссылок. Обычное и управляемое приложение. Не монопольно, включая рекурсивные ссылки, с отбором по метаданным и произвольным запросом Промо
Обработка удаления помеченных объектов с расширенным функционалом. Работает в обычном и управляемом приложении. Монопольный и разделенный режим работы. Отображение и отбор по структуре метаданных. Отборы данных произвольными запросами. Копирование и сохранение отборов. Удаление циклических ссылок (рекурсия). Представление циклических в виде дерева с отображением ключевых ссылок, не позволяющих удалить текущий объект информационной базы. Удаление записей связанных независимых регистров сведений. Групповая замена ссылок. Индикатор прогресса при поиске и контроле ссылочности.


![Postgresql postgresql.conf [айти бубен]](https://tehnikaarenda.ru/wp-content/uploads/d/c/d/dcd3f804138a5d6b29241e47de42be9a.jpeg)





10 стартмани
31.10.2016
59985
730
m..adm
225
Дополнительные настройки
Все приведенные ниже действия не являются обязательными.
Установка Apache
Начиная с версии 8.3.8 платформа 1С поддерживает Apache 2.4, поэтому можно просто установить текущую версию:
Если по каким-то причинам Вам требуется Apache 2.2 то для начала нужно добавить репозитории с неактуальными версиями пакетов, как описано выше (если, конечно, Вы уже этого не сделали). Затем выполнить команду:
Команды выдаст список версий доступных к установке, затем, выбрав нужную версию сделать так:
Например:
Проверить версию Apache можно так:
Включение отладки на сервере
Останавливаем сервер:
В файле находим строку:
Приводим ее к виду:
Запускаем сервер:
В конфигураторе на клиентской машине идем в «Параметры» -> «Запуск 1С:Предприятия» -> «Дополнительные» и включаем два пункта:
- «Устанавливать режим разрешения отладки»
- «Начинать отладку при запуске»
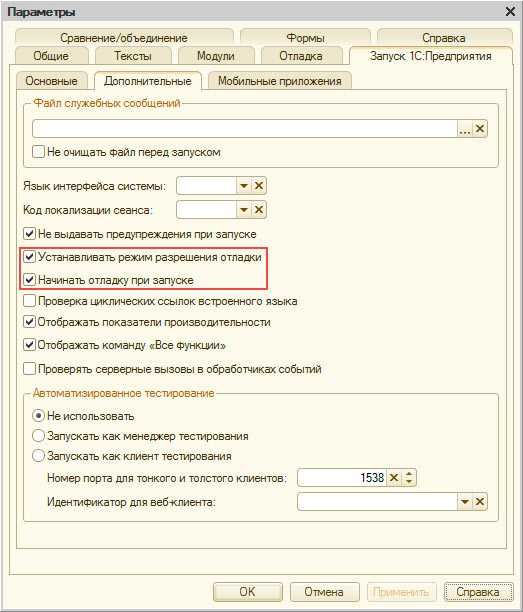 Включение режима отладки
Включение режима отладки
Настройка UFW
UFW — это простая утилита для конфигурирования файрвола Netfilter.
Разрешаем SSH:
Apache:
Порты для работы 1С (если используются стандартные порты):
Включаем UFW:
Нужна ли лицензия на сервер?
На момент написания статьи (версия технологической платформы 8.3.13.1472) лицензия на сервер не требуется, все прекрасно работает без нее.
На этом все, надеюсь, что данная статья была Вам полезна.
Подготовка системы
Задаем имя сервера
Чтобы сервер 1С мог запуститься без ошибки, необходимо ему задать корректное имя:
hostnamectl set-hostname server1C.dmosk.ru
Если данное имя не зарегистрировано в DNS, прописываем соответствие в файле hosts:
vi /etc/hosts
192.168.1.11 server1C.dmosk.ru
Настройка брандмауэра
Для корректной работы сервера, необходимо открыть порты:
- 1540 и 1541 для сервера 1С.
- 1560 — запросы к базе данных.
По умолчанию, в Ubuntu действует разрешающая политика и настройка брандмауэра не требуется. В противном случае, вводим команды:
iptables -I INPUT 1 -p tcp —dport 1540:1541 -j ACCEPT
iptables -I INPUT 1 -p tcp —dport 1560 -j ACCEPT
И сохраняем правила с помощью iptables-persistent:
apt-get install iptables-persistent
netfilter-persistent save
Сервер 1С:Предприятие на Ubuntu 16.04 и PostgreSQL 9.6, для тех, кто хочет узнать его вкус. Рецепт от Капитана
Если кратко описать мое отношение к Postgres: Использовал до того, как это стало мейнстримом.
Конкретнее: Собирал на нем сервера для компаний среднего размера (до 50 активных пользователей 1С).
На настоящий момент их набирается уже больше, чем пальцев рук пары человек (нормальных, а не фрезеровщиков).
Следуя этой статье вы сможете себе собрать такой же и начать спокойную легальную жизнь, максимально легко сделать первый шаг в мир Linux и Postgres.
А я побороться за 1. Лучший бизнес-кейс (лучший опыт автоматизации предприятия на базе PostgreSQL).
Если, конечно, статья придется вам по вкусу.
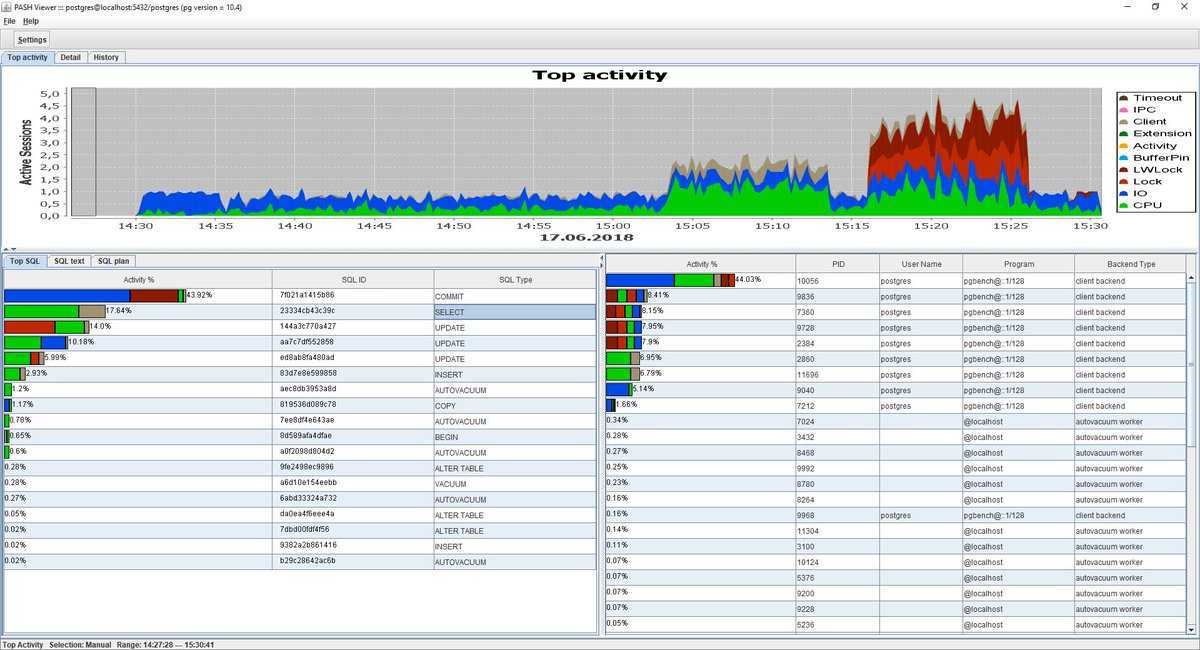
Настройка параметров PostgreSQL
1. Зайдем в командную оболочку psql сервера.
| 1 | psql |
2. Командой ALTER SYSTEM SET установить параметры сервера. Вам необходимо подобрать настройки исходя из параметров своего оборудования. Расчет необходимо осуществить на основании рекомендаций фирмы «1С» изложенных здесь https://its.1c.ru/db/metod8dev/content/5866/hdoc.
Пример установки настроек:
|
1 |
ALTERSYSTEMSETshared_buffers=’96GB’; ALTERSYSTEMSETeffective_cache_size=’288GB’; ALTERSYSTEMSETmaintenance_work_mem=’20GB’; ALTERSYSTEMSETwal_buffers=’16MB’; ALTERSYSTEMSETdefault_statistics_target=100; ALTERSYSTEMSETrandom_page_cost=1.1; ALTERSYSTEMSETeffective_io_concurrency=200; ALTERSYSTEMSETwork_mem=’10GB’; ALTERSYSTEMSETmax_worker_processes=44; ALTERSYSTEMSETmax_parallel_workers_per_gather=22; ALTERSYSTEMSETtemp_buffers=’265MB’; ALTERSYSTEMSETwal_level=’replica’; ALTERSYSTEMSETmax_replication_slots=’8′; ALTERSYSTEMSETmax_wal_senders=’32’; ALTERSYSTEMSETautovaccuum=’on’; ALTERSYSTEMSETautovaccuum_max_workers=16; ALTERSYSTEMSETautovacuum_naptime=’20s’; ALTERSYSTEMSETbgwriter_delay=’20ms’; ALTERSYSTEMSETbgwriter_lru_multiplier=4.0; ALTERSYSTEMSETbgwriter_lru_maxpages=400; ALTERSYSTEMSETsynchronous_commit=’off’; ALTERSYSTEMSETcheckpoint_segments=256; ALTERSYSTEMSETcheckpoint_completion_target=0.9; ALTERSYSTEMSETmin_wal_size=’4GB’; ALTERSYSTEMSETmax_wal_size=’8GB’; ALTERSYSTEMSETssl=’off’; ALTERSYSTEMSETmax_files_per_process=1000; ALTERSYSTEMSETstandard_conforming_strings=’off’; ALTERSYSTEMSETescape_string_warning=’off’; ALTERSYSTEMSETmax_locks_per_transaction=256; ALTERSYSTEMSETmax_connections=15000; |
Повторюсь, расчет необходимо выполнить обязательно, так как настройки подобранные для другого оборудования могут привести к значительному снижению производительности вашей СУБД.
Копирование числовых ячеек из 1С в Excel Промо
Решение проблемы, когда значения скопированных ячеек из табличных документов 1С в Excel воспринимаются последним как текст, т.е. без дополнительного форматирования значений невозможно применить арифметические операции. Поводом для публикации послужило понимание того, что целое предприятие с более сотней активных пользователей уже на протяжении года мучилось с такой, казалось бы на первый взгляд, тривиальной проблемой. Варианты решения, предложенные специалистами helpdesk, обслуживающими данное предприятие, а так же многочисленные обсуждения на форумах, только подтвердили убеждение в необходимости описания способа, который позволил мне качественно и быстро справиться с ситуацией.
Совместимость с 1С
Проверено, доказано и везде написано, что 1С может работать c:
- версией PostgreSQL 9.6*;
- PostgreSQL 10.3, начиная с платформы 8.3.13 – наиболее актуальной для всех версией;
- версией Postgres Pro Enterprise 9.6.3.1.
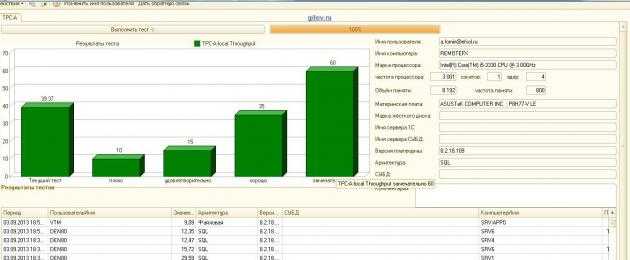
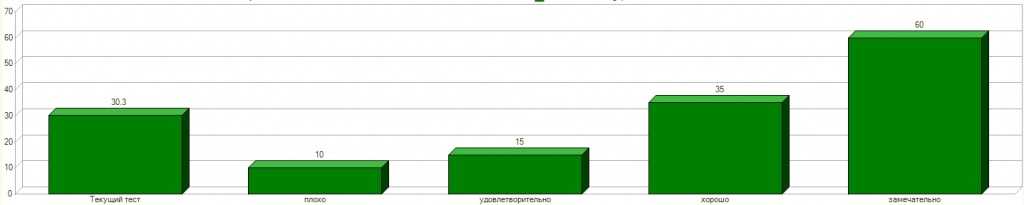
Мы запускаем автоматизированные тесты – функциональные и нагрузочные — после чего все согласовываем с 1С. Сейчас такие тесты проходят:
- Postgres Pro Enterprise 10.*;
- Postgres Pro Standard 10.*;
- PostgreSQL с патчами 10.*
Как видите, мы не отказываемся от поддержки 1С обычного ванильного PostgreSQL.

Обычно люди предпочитают брать ванильную версию на свой страх и риск, разбираться, пробовать. А потом если им чего-то не хватает или им нужна какая-то поддержка, они приходят к нам.
Хочу сказать, что процент внедрения Postgres в сообществе 1С еще небольшой. Но я всех убеждаю начать пользоваться Postgres уже завтра. Всем сомневающимся я отвечаю: «Не бойтесь!». Вы знаете, уже существуют достаточно крупные сервисы на Postgres, облачные бухгалтерии в Новосибирске, Екатеринбурге работают на Postgres, они обслуживают тысячи пользователей. Я лично знаю десятки клиентов, которые внедрили Postgres на заводах, работают на нем и просто счастливы. Вы почувствуете свободу с Postgres. Потому что вам не надо будет платить Microsoft, вы не будете зависеть от его патчей, от его поддержки и так далее.


Удаление помеченных объектов, замена ссылок. Обычное и управляемое приложение. Не монопольно, включая рекурсивные ссылки, с отбором по метаданным и произвольным запросом Промо
Обработка удаления помеченных объектов с расширенным функционалом. Работает в обычном и управляемом приложении. Монопольный и разделенный режим работы. Отображение и отбор по структуре метаданных. Отборы данных произвольными запросами. Копирование и сохранение отборов. Удаление циклических ссылок (рекурсия). Представление циклических в виде дерева с отображением ключевых ссылок, не позволяющих удалить текущий объект информационной базы. Удаление записей связанных независимых регистров сведений. Групповая замена ссылок. Индикатор прогресса при поиске и контроле ссылочности.
10 стартмани
Сервер 1С:Предприятие на Ubuntu 16.04 и PostgreSQL 9.6, для тех, кто хочет узнать его вкус. Рецепт от Капитана
Если кратко описать мое отношение к Postgres: Использовал до того, как это стало мейнстримом.
Конкретнее: Собирал на нем сервера для компаний среднего размера (до 50 активных пользователей 1С).
На настоящий момент их набирается уже больше, чем пальцев рук пары человек (нормальных, а не фрезеровщиков).
Следуя этой статье вы сможете себе собрать такой же и начать спокойную легальную жизнь, максимально легко сделать первый шаг в мир Linux и Postgres.
А я побороться за 1. Лучший бизнес-кейс (лучший опыт автоматизации предприятия на базе PostgreSQL).
Если, конечно, статья придется вам по вкусу.
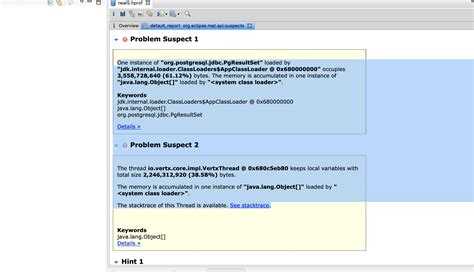
Опыт оптимизации и контроля производительности в БД с 3000 пользователей Промо
Данная статья написана по материалам доклада, прочитанного на Конференции Инфостарта IE 2014 29-31 октября 2014 года.
Меня зовут Сергей, являюсь руководителем отдела оптимизации и производительности систем в компании «Деловые линии».
Цель этого доклада – поделиться информацией о нашем опыте работы с большой базой на платформе 1С, с чем пришлось столкнуться, как удалось обеспечить работоспособность.
Уверен, что вам будет интересно, так как подобной информацией мало кто делится, да и про само существование таких систем их владельцы стараются не рассказывать, максимум про это «краем глаза» упоминают участвовавшие в проекте вендоры.
**update от 04.03.2016 по вопросам из комментариев
Настройка авторизации методом Peer
Метод Peer аутентификации работает путем получения имени пользователя операционной системы клиента от ядра, с использованием его в качестве разрешенного имени пользователя базы данных, с дополнительным сопоставлением имен пользователей. Этот метод поддерживается только для локальных соединений.
Настройка авторизации
Закомментируйте все виды подключений к базе данных, оставив только локальные, изменив метод аутентификации на :
/etc/postgresql-13/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all peer # IPv4 local connections: #host all all 127.0.0.1/32 trust # IPv6 local connections: #host all all ::1/128 trust # Allow replication connections from localhost, by a user with the # replication privilege. #local replication all trust #host replication all 127.0.0.1/32 trust #host replication all ::1/128 trust
Перезагрузите настройки PostgreSQL:
/etc/init.d/postgresql-13 reload
Создание пользователя и базы данных
Создайте системного пользователя test:
useradd test
Создайте пользователя PostgreSQL test:
su postgres -c «createuser test»
Заметка
По умолчанию пользователь создаётся без возможности самому создавать базы данных. Для разрешения пользователю создавать новые базы данных добавьте параметр
Создайте базу данных testdb для пользователя test:
su postgres -c «createdb -O test testdb»
Подключение к базе данных
Для подключения к базе данных dbtest пользователем test, выполните:
psql -d testdb
psql (13.2) Введите "help", чтобы получить справку. testdb=>
Для подключения к базе данных dbtest пользователем , выполните:
su postgres -c «psql -d testdb»
psql (13.2) Введите "help", чтобы получить справку. testing=#
StartManager 1.4 — Развитие альтернативного стартера Промо
Очередная редакция альтернативного стартера, являющегося продолжением StartManager 1.3. Спасибо всем, кто присылал свои замечания и пожелания, и тем, кто перечислял финансы на поддержку проекта. С учетом накопленного опыта, стартер был достаточно сильно переработан в плане архитектуры. В основном сделан упор на масштабируемость, для способности программы быстро адаптироваться к расширению предъявляемых требований (т.к. довольно часто просят добавить ту или иную хотелку). Было пересмотрено внешнее оформление, переработан существующий и добавлен новый функционал. В общем можно сказать, что стартер эволюционировал, по сравнению с предыдущей редакцией. Однако пока не всё реализовано, что планировалось, поэтому еще есть куда развиваться в плане функциональности.
1 стартмани
Настройка ежедневных ночных бэкапов баз на NAS
В папке 1c на NAS предварительно созданы папки:
base — там будут ночные бэкапы баз;
chpt — сюда сохраняются WAL-файлы в течение дня, которые ночью архивируются и кидаются в папку chp
chp — папка с архивированными WAL-файлами
Монтируем сетевую шару для бэкапов:
nano /etc/fstab
//10.10.10.22/backup/10.10.10.17/1c /mnt/backup cifs username=backup,password=password,iocharset=utf-8,file_mode=0777,dir_mode=0777,noperm 0 0
mkdir /mnt/backup
chmod 777 /mnt/backup
mount -a
(не монтировалась шара при загрузке если dhcp, статический ip -ок)
Включаем archive_mode в конфиге постгреса.
nano /var/lib/pgpro/1c-12/data/postgresql.conf
archive_mode = on
archive_command = ‘test ! -f /mnt/backup/chpt/%f.gz && gzip -c %p > /mnt/backup/chpt/%f.gz’
(Архивирование WAL-файлов на NAS в предварительно созданную папку chpt)
Перезапуск 1с и postgres:
/etc/init.d/monit stop
/etc/init.d/srv1cv83 stop
service postgrespro-1c-12 restart
/etc/init.d/srv1cv83 start
/etc/init.d/monit start
Создаем скрипт ночного бэкапа:
mkdir /home/scripts
touch /home/scripts/back_1s.sh
chmod +x /home/scripts/back_1s.sh
nano /home/scripts/back_1s.sh
#!/bin/bash
BS=»/mnt/backup»
DT=»$(date +%Y-%m-%d)»
CPDir=»$BS/chp/$DT»
BackFile=»$BS/base/$DT.backup»
SLink=»$BS/chpt»
host_ip=»127.0.0.1″
![Postgresql postgresql.conf [айти бубен]](https://tehnikaarenda.ru/wp-content/uploads/7/e/c/7ec9886982ca808ecf402527cd81c8ae.jpeg)

# Создаем новый каталог для заархивированных WAL-файлов
mkdir $CPDir
chown postgres $CPDir
#PGPASSWORD= пароль пользователя postgres, заданный выше
PGPASSWORD=password /opt/pgpro/1c-12/bin/psql -h 127.0.0.1 -U postgres -c «select pg_start_backup(‘$DT’);»
# архивируем WAL-файлы в каталог chp/дата/
tar -cvf $CPDir/chp.tar.gz $SLink
rm $SLink/*
# Функция бэкапа баз в папку base
backups () {
BackFile=»$BS/base/$DT$baza.backup»
PGPASSWORD=password /opt/pgpro/1c-12/bin/pg_dump -U postgres -h $host_ip -C -c -b -F c -f $BackFile $baza
}
baza=name_bd1
backups
baza=name_bd2
backups
PGPASSWORD=password /opt/pgpro/1c-12/bin/psql -h $host_ip -U postgres -c «select pg_stop_backup();»
exit
И добавляем скрипт бэкапа в планировщик (будет запускаться в 22:00 каждый день):
crontab -u root -e
0 22 * * * /home/scripts/back_1s.sh





