
Резервное копирование базы данных
Бэкап одной базы данных
В примере ниже, мы сделаем резервную копию базы данных под названием , принадлежащей пользователю и сохраним её в файл :
pg_dump -U bosha thebosharu -f thebosharu.sql
Если вы работаете с базой данных не под тем же пользователем, под которым работаете в системе, то pg_dump спросит пароль к базе данных и после его успешного ввода создаст указанный файл содержащий SQL команды для создания необходимой структуры и копирования данных.
Вот часть дампа моей базы данных, чтобы вы понимали что в нем находится:
--
-- Name: auth_user; Type: TABLE; Schema: public; Owner: bosha; Tablespace:
--
CREATE TABLE auth_user (
id integer NOT NULL,
username character varying(250) NOT NULL,
password character varying(250),
email character varying(250),
first_name character varying(250),
last_name character varying(250),
middle_name character varying(250),
authenticated boolean,
active boolean,
is_admin boolean
);
ALTER TABLE auth_user OWNER TO bosha;
--
-- Name: auth_user_id_seq; Type: SEQUENCE; Schema: public; Owner: bosha
--
CREATE SEQUENCE auth_user_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE auth_user_id_seq OWNER TO bosha;
--
-- Name: auth_user_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: bosha
--
ALTER SEQUENCE auth_user_id_seq OWNED BY auth_user.id;
--
-- Data for Name: auth_user; Type: TABLE DATA; Schema: public; Owner: bosha
--
COPY auth_user (id, username, password, email, first_name, last_name, middle_name, authenticated, active, is_admin) FROM stdin;
1 test pbkdf2sha1$sfadfadafda$sfadfadf10019sdfadfad0101010dsfadf0202022 \N f f f
\.
Так же можно передать ключ , чтобы pg_dump запаковал базу данных в tar:
pg_dump -U bosha thebosharu --format=t -f thebosharu.sql.tar
Бэкап всех баз данных
Для того, чтобы сделать резервную копию всех баз данных, нужно использовать другую утилиту — pg_dumpall.
Права доступа могут быть настроены у всех по разному, поэтому бэкап всех баз данных лучше делать из под пользователя .
Зайдем под ним:
su - postgres
И выполним:
pg_dumpall > all_databases.sql
Бэкап всех баз данных будет содержаться в файле .
Крайне желательно убедится, что все нужные базы данных были копированы. Для этого все из под того же пользователя postgres посмотрим список всех баз данных:
psql -l
В моем случае было три базы данных:
postgres~$ psql -l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
---------------+----------+----------+-------------+-------------+---------------------------
thebosharu | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tcpostgres +
| | | | | postgres=CTcpostgres +
| | | | | thebosharu=CTcpostgres
testdb1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tcpostgres +
| | | | | postgres=CTcpostgres +
| | | | | testdb1=CTcpostgres
testdb2 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tcpostgres +
| | | | | postgres=CTcpostgres +
| | | | | testdb2=CTcpostgres
(3 rows)
Теперь удостоверимся, что все перечисленные базы попали в дамп:
bash:~$ grep "^connect" all.sql \connect thebosharu \connect testdb1 \connect testdb2
Бэкап определенной таблицы
pg_dump --table auth_user -U bosha thebosharu -f auth_user_table.sql
Для бэкапа определенной таблицы используется параметр и следом за ним названием таблицы. Если в базе данных указанная таблица есть в разных схемах, то её можно указать используя параметр .
Распараллеливание
Когда я начинаю разбираться с какой-либо проблемой, первым делом читаю документацию и исходный код. У Postgres отличная документация, где в том числе ясно и подробно расписаны опции командной строки. Одна из опций команды pg_restore определяет количество параллельных потоков, которые запускаются во время выполнения наиболее затратных по времени задач, загрузки данных, создания индексов или ограничений.
Документация по pg_restore говорит, что лучше начинать с количества потоков, равного количеству ядер. У моей виртуальной машины 4 ядра, но я хотел поэкспериментировать с разными значениями этой опции.
Общее время 32 минуты 7 секунд (25,6 минут на восстановление в dev-окружении, что на 3% быстрее, чем однопоточный запуск pg_restore).
Хорошо, немного выиграли. Можем ли мы еще ускориться?
Общее время 28 минут 34 секунды (22,1 минуты на восстановление в dev-окружении, что на 14% быстрее, чем с двумя потоками).
Отлично! Четыре потока быстрее двух на 14%. Да данный момент в dev-окружении мы ускорились с 32,5 до 22,1 минуты: время улучшено на 32%!
Я решил выяснить, к чему приведет дальнейшее увеличение количества ядер.
Общее время 23 минуты 17 секунд (16,8 на восстановление в dev-окружении, что на 24% быстрее четырех потоков).
Итак, увеличив количество потоков до удвоенного количества ядер, нам удалось уменьшить время с 22,1 до 16,8 минут. Сейчас мы ускорились на 49%, что просто чудесно.
А еще можно что-нибудь выжать?
Общее время 22 минуты 35 секунд (16,1 минуты на восстановление в dev-окружении, что на 4%, чем 8 потоков).
Указав 12 потоков, мы еще немного ускорились, но CPU виртуальной машины во время восстановления был загружен настолько, что никакие другие действия в системе выполнить было невозможно. В этом вопросе я решил остановиться на 8 потоках (количество ядер * 2).
Автоматический бэкап PostgreSQL в Linux
О том как делать автоматические резервные копии в PostgreSQL рассказано в статье Automated Backup on Linux. Скрипты из этой статьи всем хороши, кроме того, что если их прописать в cron, то ничего бэкапиться не будет. А происходит так из-за того, что нигде не указывается пароль пользователя PostgreSQL от имени которого делается бэкап.
Для того чтобы эти скрипты заработали в автоматическом режиме нужно в самый конец pg_backup.config добавить: # Set PGUSER and PGPASSWORD PGUSER=”postgres” PGPASSWORD=”password” export PGUSER PGPASSWORD # End
Естественно, вместо пользователя postgres можно использовать любого нужного пользователя, а вместо password нужно указать пароль этого пользователя.
А в целях безопасности в самом конце pg_backup.sh нужно вставить: # Unset PGUSER and PGPASSWORD PGUSER=”” PGPASSWORD=”” export PGUSER PGPASSWORD # End
Теперь можно сделать файлы исполняемыми: chmod u+x pg_backup.sh pg_backup_rotated.sh
(для проверки работоспособности нужно выполнить bash pg_backup.sh)
Прописать их в cron пользователя postgres (на примере Ubuntu): sudo crontab -u postgres -e
В файл нужно добавить строки: SHELL=/bin/bash 15 3 * * * /path/to/script/pg_backup.sh > /dev/null 2>&1
Надо напоминать, что /path/to/script/ — это путь к директории с файлом?
Теперь ждём 03:15 утра и проверяем работоспособность.
Настраиваемый формат
Углубившись в документацию по pg_dump, я обнаружил, что pg_dump создает простой текстовый SQL-файл. Затем мы сжимаем его gzip-ом, чтобы сделать меньше. У Postgres есть настраиваемый (custom) формат, который по умолчанию использует zlib для сжатия. Я подумал, что можно будет добиться выигрыша в скорости создания бэкапа, сразу упаковывая данные в Postgres вместо направления простого текстового файл в gzip.
Поскольку psql не понимает настраиваемый формат, мне пришлось перейти на pg_restore.
Общее время 32 минуты 54 секунды (26,4 минуты на восстановление в dev-окружении).
Я оказался прав, считая, что создание бэкапа будет быстрее, если нам не придется направлять вывод в gzip. К сожалению, восстановление из настраиваемого формата на локальной машине не ускоряет процесс. Пришлось придумывать что-нибудь еще.
Просто и сердито. Архивирование (backup) типовых конфигураций 1С 8.2, 8.3
После эксплуатации различных «бесплатных» обработок и скриптов решил написать свой cmd-файл для ежедневного архивирования баз 1С.
Работает на конфигурациях, где есть процедуры «ЗавершитьРаботуПользователей» и «РазрешитьРаботуПользователей» (т.е. во всех типовых, в нетиповые данные модули можно скопировать из типовых).
Сохраняет файлы как локально так и на удаленном файловом сервере. Автоматически удаляет старые архивы и копирует на удалённый сервер отсутствующие.
Расписание задается установкой соответствующего задания (запуска cmd-файла по времени) в планировщике задач Windows.
Для борьбы с зависшими сеансами, рекомендуется настроить в режиме конфигуратора параметры информационной базы: «Время засыпания пассивного сеанса» и «Время завершения спящего сеанса».
Скрипт для резервирования БД
#!/bin/bash # Backup PostgreSQL DIR="/var/log/BACKUP/db_backup_mbill" TIMENAME=`date +%Y-%m-%d.%H.%M` PG_DUMP="/usr/bin/pg_dump" SUDO="/usr/bin/sudo" GZIP="/bin/gzip" ExcludeTable="-T cdr" DBNAME=mbillcz5054 BACKUP=$DIRpsql-$DBNAME-backup-$TIMENAME-db.sql.gz echo "$SUDO -u postgres $PG_DUMP $DBNAME $ExcludeTable | $GZIP > $BACKUP"; $SUDO -u postgres $PG_DUMP $DBNAME $ExcludeTable | $GZIP > $BACKUP; echo `/usrbindu -hsx $BACKUP`;
Запускаем еженедельно при помощи Anacron (если установлено) или Использование планировщика cron в Linux, для этого создаем символическую ссылку в директорию /etc/cron.weekly
# ln -s /scripts/psql_backup_zabbix /etc/cron.weekly/
Создание резервных копий
Пользователь и пароль
Если резервная копия выполняется не от учетной записи postgres, необходимо добавить опцию -U с указанием пользователя:
pg_dump -U dmosk -W users > /tmp/users.dump
* где dmosk — имя учетной записи; опция W потребует ввода пароля.
Сжатие данных
Для экономии дискового пространства или более быстрой передачи по сети можно сжать наш архив:
pg_dump users | gzip > users.dump.gz
Скрипт для автоматического резервного копирования
PGPASSWORD=password export PGPASSWORD pathB=/backup dbUser=dbuser database=db
find $pathB \( -name “*-1.*” -o -name “*-?.*” \) -ctime +61 -delete pg_dump -U $dbUser $database | gzip > $pathB/pgsql_$(date “+%Y-%m-%d”).sql.gz
* где password — пароль для подключения к postgresql; /backup — каталог, в котором будут храниться резервные копии; dbuser — имя учетной записи для подключения к БУБД. * данный скрипт сначала удалит все резервные копии, старше 61 дня, но оставит от 15-о числа как длительный архив. После при помощи утилиты pg_dump будет выполнено подключение и резервирование базы db. Пароль экспортируется в системную переменную на момент выполнения задачи.
Для запуска резервного копирования по расписанию, сохраняем скрипт в файл, например, /scripts/postgresql_dump.sh и создаем задание в планировщике:
3 0 * * * /scripts/postgresql_dump.sh
* наш скрипт будет запускаться каждый день в 03:00.
На удаленном сервере
Если сервер баз данных находится на другом сервере, просто добавляем опцию -h:
pg_dump -h 192.168.0.15 users > /tmp/users.dump
* необходимо убедиться, что сама СУБД разрешает удаленное подключение. Подробнее читайте инструкцию Как настроить удаленное подключение к PostgreSQL.
Дамп определенной таблицы
Запускается с опцией -t или –table= :
pg_dump -t students users > /tmp/students.dump
* где students — таблица; users — база данных.
Размещение каждой таблицы в отдельный файл
Также называется резервированием в каталог. Данный способ удобен при больших размерах базы или необходимости восстанавливать отдельные таблицы. Выполняется с ипользованием ключа -d:
pg_dump -d customers > /tmp/folder
* где /tmp/folder — путь до каталога, в котором разместяться файлы дампа для каждой таблицы.
Только схемы
Для резервного копирования без данных (только таблицы и их структуры):
pg_dump –schema-only users > /tmp/users.schema.dump
Использование pgAdmin
Данный метод хорошо подойдет для компьютеров с Windows и для быстрого создания резервных копий из графического интерфейса.
Запускаем pgAdmin – подключаемся к серверу – кликаем правой кнопкой мыши по базе, для которой хотим сделать дамп – выбираем Резервная копия:
В открывшемся окне выбираем путь для сохранения данных и настраиваемый формат:
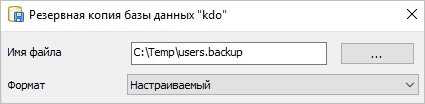
При желании, можно изучить дополнительные параметры для резервного копирования:

После нажимаем Резервная копия – ждем окончания процесса и кликаем по Завершено.
Возможные ошибки
Input file appears to be a text format dump. please use psql.
Причина: дамп сделан в текстовом формате, поэтому нельзя использовать утилиту pg_restore.
Решение: восстановить данные можно командой psql <имя базы> < <файл с дампом> или выполнив SQL, открыв файл, скопировав его содержимое и вставив в SQL-редактор.
No matching tables were found
Причина: Таблица, для которой создается дамп не существует. Утилита pg_dump чувствительна к лишним пробелам, порядку ключей и регистру.
Решение: проверьте, что правильно написано название таблицы и нет лишних пробелов.
Причина: Утилита pg_dump чувствительна к лишним пробелам.
Решение: проверьте, что нет лишних пробелов.
Aborting because of server version mismatch
Причина: несовместимая версия сервера и утилиты pg_dump. Может возникнуть после обновления или при выполнении резервного копирования с удаленной консоли.
Решение: нужная версия утилиты хранится в каталоге /usr/lib/postgresql/<version>/bin/. Необходимо найти нужный каталог, если их несколько и запускать нужную версию. При отсутствии последней, установить.
No password supplied
Причина: нет системной переменной PGPASSWORD или она пустая.
Решение: либо настройте сервер для предоставление доступа без пароля в файле pg_hba.conf либо экспортируйте переменную PGPASSWORD (export PGPASSWORD или set PGPASSWORD).
Неверная команда \
Причина: при выполнении восстановления возникла ошибка, которую СУБД не показывает при стандартных параметрах восстановления.
Решение: запускаем восстановление с опцией -v ON_ERROR_STOP=1, например:
psql -v ON_ERROR_STOP=1 users < /tmp/users.dump
Теперь, когда возникнет ошибка, система прекратит выполнять операцию и выведет сообщение на экран.
Дополнительная информация по изучению PostgreSQL
Обучение PostgreSQL. Полный курс по работе с базой данных PostgreSQL!
Курс включает в себя все инструменты: управление доступом, резервное копирование, репликация, журналирование, работа со статистикой, способы масштабирование, а также работа PostgreSQL в облаках AWS, GCP, Azure и в Kubernetes.
Проверь свои знания — пройди тестирование
- Резервное копирование и восстановление в PostgreSQL Предположим что у нас есть postgresql в режиме потоковой репликации. master-сервер и hot-standby готовый заменить погибшего товарища. При плохом развитии событий, нам остается только создать trigger-файл и переключить наши приложения на работу с новым мастером. Однако, возможны ситуации когда вполне законные изменения были сделаны криво написанной миграцией и попали как на мастер, так и на подчиненный сервер. Например, были удалены/изменены данные в части таблиц или же таблицы были вовсе удалены. С точки зрения базы данных все нормально, а с точки зрения бизнеса — катастрофа. В таком случае провозглашение горячего hot-standby в мастера, процедура явно бесполезная… Для предостережения такой ситуации есть, как минимум, два варианта… использовать периодическое резервное копирование средствами pg_dump;использовать резервное копирование на основе базовых копий и архивов WAL.
- Резервное копирование баз данных в СУБД PostgreSQL (On-line backup)
Как восстановить файл дампа PostgreSQL в базы данных Postgres?
Все админы делятся на 2 категории
— те которые уже делают бэкап
и те которые ещё не делают.
PostgreSQL является современной системой управления базами данных, часто используемая для хранения и обработки информации, связанной с веб-сайтами или сторонними приложениями
У любой базы данных, важно вовремя реализовать резервное копирование, чтобы избежать возможную потерю данных
В этом посте я постараюсь рассказать о некоторых способах, которыми вы можете сделать резервную копию PostgreSQL. Для тестов будем использовать Ubuntu 12,04 VPS с PostgreSQL 9.1. Для большинства современных дистрибутивов и последних версии PostgreSQL мои советы будут актуальны.
Создание резервной копии PostgreSQL при помощи pg_dump
PostgreSQL включает в себя утилиту под названием «pg_dump», которая позволяет сделать дамп базы данных в файл. Утилита консольная, синтаксис достаточно простой:
pg_dump name_of_database > name_of_backup_file
Команда должна быть запущена под пользователем с привилегиями на чтение базы данных.
Как вариант мы можем войти через sudo под пользователем «рostgres» и выполнить команду:
sudo su — postgres pg_dump postgres > postgres_db.bak
«pg_dump» — это «полноценный» клиент PostgreSQL, т.е. при необходимости её можно запустить с удаленной машины, если имеются соответствующие разрешения к базе данных.
Расширенный синтаксис выглядит следующим образом:
pg_dump -h remote_host -p remote_port name_of_database > name_of_backup_file pg_dump -U user_name -h remote_host -p remote_port name_of_database > name_of_backup_file
Как восстановить дампы pg_dump в PostgreSQL
Чтобы восстановить резервную копию, созданную pg_dump, необходимо перенаправить файл с дампом в стандартный ввод psql:
psql empty_database < backup_file
Эта операция не создает новую базу данных. Об этом необходимо позаботиться заранее.
Для примера, создадим новую базу данных под названием «restored_database», а затем развернем дамп под названием «database.bak»:
createdb -T template0 restored_database psql restored_database < database.bak
Пустая база данных должна быть создана при помощи шаблона «template0«. Так же нам необходимо убедиться в наличии пользователя с необходимыми правами на создаваемую базу, в противном случае нам придется создать нового:
createuser test_user psql restored_database < database.bak
По умолчанию, PostgreSQL будет пытаться продолжить восстановление базы данных, даже если он сталкнется с ошибками.
По многим причинам так делать не стоит. Мы можем явно указать PostgreSQL на остановку, в случае любой ошибки:
psql —set ON_ERROR_STOP=on restored_database < backup_file
С данной опцией мы получим частично восстановленную базу данных.
Можно попробовать восстановить весь дамп в одну транзацию, т.е. бекап будет или полностью восстановлен или не восстановлен совсем. Данный режим может быть задан, с помощью опций -1 или —single-transaction для psql.
psql -1 restored_database < backup_file
При этом любая ошибка приведет к откату процесса восстановления, что может потребовать достаточно продолжительного времени.
Резервное копирование и восстановление всех баз данных в PostgreSQL
Чтобы сэкономить время, можно сделать резервную копию всех баз данных в вашей системе, при помощи утилиты «pg_dumpall»:
pg_dumpall > backup_file
Похожим способом можно восстановить базы данных:
psql -f backup_file postgres
Резервные копии являются важным аспектом при любой работе с данными
К счастью, PostgreSQL включает утилиты, необходимые для эффективного резервного копирования важной информации. Как с любым видом резервного копирования, важно регулярно проверять свои резервные копии
В качестве дополнения скрипт, который создает резервную копию с меткой времени и сохраняет последние 14 резервных копий:
ls -t *.sql | sed -e ‘1,13d’ | xargs -d ‘\n’ rm echo Done at `date +\%Y-\%m-\%d_\%T` pg_dump dbname —username=dbuser > `date +\%Y-\%m-\%d_\%T`.sql
Вы можете оставить комментарий ниже.
Ярлыки
11.1
11.1.1 trial
11.10
12.04
14.04
16.04
17.04
17.10
18.04
1с
1С + postgresql под windows
1С:Отчетность
1С:Предприятие 7.7
1c
20.04
32 бит
3proxy
9.6.2
автономный сервер
админ
администрирование
анализ сервера
архивирование
безопсность
березка
веб доступ
время
второй кластер
выгнать пользователей
госзакупки
диагностика
диагностика postgresql
документация
Дорошкевич
журнал регистрации
Завершение работы пользователей
зависимости postgresql
запуск postgresql
зафиксировать postgresql
ибп
интересно
камин
книги
Конфигурация сервера
КриптоПро
лицензии
лицензия
логи
локальная сеть
минисервер 1с
Моё рабочее
мой сервер
настройка дампов
непрерывное архивирование
обновление 1с
обновление ядра
обновление postgresql
ограничение 1Гб
ОКБ
Олег Харин
ОПО
оптимизация
ошибка
пароли
переименовать хост
перенос win lin
печать
Поиск пакетов
Потоковая репликация
программная лицензия
размер базы
размер таблиц
РИБ
сборка postgresql
сервер хранилища
сессии
скачать дистрибутивы
скрипт
скрипт wal
справочник
спутник
спящие сеансы
сравнение cpu
ссылки
статический ip
тест
тестирование
Тестирование и исправление конфигурации
тестовый сервер
технологический журнал
тюнинг postgresql
удаление 1с
удаление postgresql
управление серверами
установка 1с
установка 2 сервера 1с
файловый режим
фиас
флешка
фрагментация памяти
холодный backup
Шпаргалка PostgreSQL
штрих-коды
энергосбережение
acme.sh
aksusbd
Aladdin Monitor
alt linux
alternative downloads
amcheck
ammyy admin
apache2
apc
apparmor
apport
Asterisk
astra
astra linux
astra lxc
astra lxd
atop
audio
autologon
autovacuum
B360M
B365M
backup
Bash-скрипты
bridge-utils
bug
cache_hit_ratio
cadaver
canon
centos
Certbot
Certificate
checkdb
chromium
chromium-gost
cloak
clonezilla
cpu
cpufreqd
cron
crontab
cryptcp
Crypto-Pro
cryptopro
CryptSync
cups-pdf
curl
cwRsync
Cygwin
cygwin-rsyncd
dante
db2
debian
debian 10
desktop
disk
Dns Leak Test
DO
docker
docker-compose
DokuWiki
dump
elastix
etersoft
excel
fail2ban
Failover
fedora
files
FileZilla
fio
firefox
fragster
freenx
ftp
ghostscript
GIMP
git
gitlab
gnome
gnome-tweak-tool
gost
governor
gpg
GPT to MBR
haproxy
hasp
hasp & lxc
hdd
hold
host
hostname
hostnamectl
Hyper-Threading
i7
i7-7700
icmp
intel
intel graphics 630
Intel Kaby Lake
ip
iperf
IPSec
iptables
journalctl
juju
Junction
kerberos
kvm
L2TP
Let’s Encrypt
linux
live-cd
LMNoIpServer
Load Average
log
LPD
LVM
lxc
lxc in lxd
lxd
lxd & virtualbox
lxd 1c
lxd backup
lxd haproxy
lxd nextcloud
lxd resource control
lxd vps
lxd-p2c
macvlan
Mandos
mariadb
mc
MediaWiki
mining
mint
MobaXterm
mp3
mssql
multipath
mysql
MZ1LB960HAJQ-00007
net.netfilter.nf_conntrack_max
nethasp
nethasp.ini
network
NetworkManager
nextcloud
Nginx
NoMachine
ntp
numactl
numlock
nut
NVMe
nvOC
ondemand
openconnect
OpenSSH
OpenSSL
openvpn
ops
orel. orel docer
performance
pg_basebackup
pg_catalog.pg_statistic
pg_controldata
pg_dump
pg_dump в каталог
pg_probackup
pg_probackup одна база
pg_probackup upgrade
pg_repack
pg_resetxlog
pgadmin4
pgBackRest
pgbench
PGConf
PgTune
phpvirtualbox
Playonlinux
plink
posfix
postfix
postgrespro
postgrespro-std-11
postgresql
PostgreSQL Configurator
postgresql port
postgresql ssl
postgresql win
postgresql.conf
proxmox
pulseaudio
pure-ftpd
python
QtdSyn
RAID
ramdisk
ramfs
rancher
ras
rclone
reverse-proxy
rphost
rsync
Rufus
samba
Samsung SSD
sandisk
Sar
screen
server
Shadowsocks
smartctl
smartmontools
smbclient
snap
snapshot
spice
squid
ssd
ssh
ssh к флешке
ssh по сертификату
ssl
stats_temp_directory
strongSwan
stubby
stunnel
Supermicro
swap
swappiness
sysctl
sysctl.conf
systemd
tap
TCmalloc
teamviewer
telegram
temp_tablespaces
terminal server
test
test Тестовый сервер
test ssd
test2
test3
timedatectl
timezona
tint2
tmpfs
TRIM
ubuntu
ubuntu 18.04
ubuntu 20.04
ufo
ufw
unity
UNIX sockets
ureadahead
usb
v2ray-plugin
vacuum
vacuumdb
vbox
vino
virsh
virt
virt-manager
virt-viewer
virtualbox
vnc
vsftpd
wal
wd my cloud
web
webdav
wget
windows
windows server
windows vs linux
wine
WinSetupFromUSB
WireGuard
wordpress
x11vnc
xming
xrdp
xubuntu
xubuntu-desktop
xvfb
yandex-disk
youtube
youtube-dl
zabbix
zfs
zram
Оффтоп: несколько слов по безопасности
- Ваша система имеет последние обновления
- Вы не работаете от пользователя ‘root’, вместо этого у вас создан персонифицированный (то есть, для каждого сотрудника, которому требуется доступ на сервер, свой) пользователь в группе sudo (в нашем случае, назовем его alex)
-
При подключении по SSH вы не используете авторизацию по логину/паролю, применяя вместо этого доступ по ключу
-
В конфиге ssh включена опция доступа по ключу, кроме этого порт доступа ssh изменен со стандартного на рандомный (макроподстановка в скрипте ниже) в диапазоне от 1024 до 57256 (т.к. часто сканеры портов для экономии ресурсов проверяют лишь стандартные порты)
- Доступ root-а по ssh — запрещен, доступ по паролю по ssh — запрещен
Восстановление и распаковка одной командой
Первое, что пришло в голову, — просто направить запакованный файл напрямую в с помощью zcat, которую можно считать аналогом cat для сжатых файлов. Эта команда распаковывает файл и выводит его в , который, в свою очередь, можно направить в .
Общее время: 33 минуты 31 секунда (26,3 минут на восстановление в dev-окружении, что на 20% быстрее).
Отлично, нам удалось ускорить процесс на 16%, выиграв 20% при восстановлении. Поскольку ввод/вывод был основным ограничивающим фактором, отказавшись от распаковки файла на диск, мы сэкономили более 6 минут. Но мне показалось, что этого недостаточно. Терять на восстановлении базы 26 минут — все равно плохо. Я должен был придумать что-то еще.
Восстановление бекапа
Проверка работоспособности бекапирования
Перед тем, как выводить нашу инсталляцию foo в продакшен, необходимо убедиться в работоспособности настроенной системы бекапов. Проверка, очевидно, должна состоять из двух частей:
- Базовый бекап отправлен на сервер бекапов
- WAL-файлы отправляются на сервер бекапов
П.1 проверяется так: на сервере бекапов заходим в папку /var/lib/postgresql/backups/foo/base и убеждаемся, что она содержит файлы base.tar.gz и pg_wal.tar.gz:
Чтобы быстро — без долгого времени наблюдения за системой — проверить п.2, вернемся в пункт настройки PostgreSQL и поменяем таймаут архивирования (archive_timeout) на 60 секунд, затем рестартуем PostgreSQL. Теперь при наличии изменений в базе WAL-файлы будут архивироваться не реже, чем раз в минуту. Далее в течение некоторого времени (3-5 минут) будем любым (безопасным) образом генерировать изменения в базе — например, мы делаем это просто через наш фронт, вручную создавая активность тестовыми пользователями.
Параллельно нужно наблюдать за папкой /var/lib/postgresql/backups/foo/wal сервера бекапов, где примерно раз в минуту будет появляться новый файл:
После проверки очень важно вернуть archive_timeout в продакшен значение (у нас в зависимости от клиента это минимум 1 час, т.е. 3600, максимум — сутки, т.е
86400).
Если видно, что файлы не отправляются на сервер бекапов, то исследование проблемы можно начать с анализа логов PostgreSQL, лежащих здесь /var/log/postgresql. Например, если пара приватный-публичный ключ была настроена неверно, то можно увидеть подобную запись в файле postgresql-10-main.log (название лог-файла зависит от устанавливаемой версии):
Восстановление из бекапа
Пусть у нас заранее подготовлен новый сервер, где установлен PostgreSQL той же мажорной версии, что и на целевом сервере. Также предположим, что с сервера бекапов мы предварительно скопировали папку бекапа /var/lib/postgresql/backups/foo на новый сервер по тому же пути.
Далее по шагам описана процедура развертывания этого бекапа на новом сервере.
Выясняем путь, по которому хранятся файлы данных:
В зависимости от версии PostgreSQL выдастся что-то подобное: /var/lib/postgresql/10/main
Удаляем все содержимое папки с данными:
Останавливаем инстанс PostgreSQL на ЦЕЛЕВОМ сервере:
Если после сбоя доступ к целевом серверу сохранился, то останавливаем там инстанс PostgreSQL, чтобы потерять как можно меньшее количество новых данных, которые не войдут в бекап.
Распаковываем файлы из бекапа в папку данных PostgreSQL:
Здесь и далее снова работаем с новым сервером.
Ожидается, что команда tar, запущенная от sudo, сохранит group и ownership распакованных файлов за пользователем postgres — это важно, поскольку далее их будет использовать PostgreSQL, работающий именно от этого пользователя. В папке с данными создаем конфиг восстановления:
В папке с данными создаем конфиг восстановления:
Если сжатия на шаге архивирования WAL-файлов не было:
Если сжатие на шаге архивирования WAL-файлов было, то restore_command должен выглядеть следующим образом (все остальное не меняется):
Запускаем PostgreSQL:
Обнаружив в папке с данными конфиг восстановления, PostgreSQL входит в режим восстановления и начинает применять (replay) WAL-файлы из архива
После окончания восстановления recovery.conf будет переименован в recovery.done (поэтому очень важно на предыдущем шаге дать пользователю postgres права на изменение файла). После этого шага сервер PostgreSQL готов к работе
Если по внешним признакам видно, что база не восстановилась либо восстановилась только до уровня базового бекапа, то исследование проблемы можно начать с анализа логов PostgreSQL, лежащих здесь /var/log/postgresql. Например, если на предыдущем шаге не были даны права пользователю postgres на папку с бекапом WAL-файлов, то можно увидеть подобную запись в файле postgresql-10-main.log (название лог-файла зависит от устанавливаемой версии):
Настройка резервного копирования файловой базы 1С
Зайдите в меню «Администрирование»-«Обслуживание»:
Раздел Обслуживание
Разверните раздел «Резервное копирование и восстановление»
Резервное копирование и администрирование
Здесь нас интересует поле «Способ резервного копирования».
Есть 2 варианта: «На локальном компьютере» и «1С:Облачный архив».
Рассмотрим каждый из вариантов.
1С:Облачный архив
Если у вас есть подписка ИТС:Проф и вы не собираетесь от нее отказываться, то я рекомендую использовать «1С:Облачный архив», т.к. для вас этот сервис бесплатный. Еще один плюс облачного хранения: вы сможете восстановить базу при физическом уничтожении компьютера или если у вас сломается жесткий диск. Если ИТС у вас нет, то переходите к следующему разделу «На локальном компьютере».
Выберите «1С: облачный сервис» и нажмите «Подключить»:
1С Облачный архив
В открывшейся форме введите свои логин и пароль от ИТС и нажмите «Подключиться»:
Мастер подключения 1С облачный архив
Дальше проблем быть не должно. Если будут — нажмите на «техническую поддержку»:
Техническая поддержка
Сформируется письмо в техподдержку, и она поможет вам зарегистрироваться.
На локальном компьютере
Если подписки ИТС:Проф нет, то облако обойдется вам почти в 1000р/месяц. Сейчас мы разберем как сделать тоже самое, но бесплатно.
Выберите вариант «На локальном компьютере» и нажмите «Настройка резервного копирования»:
На локальном компьютере
Поставьте флажок «Выполнять автоматическое резервное копирование»
Настройка резервного копирования файловой базы 1с
Укажите каталог для сохранения резервных копий. Лучше, чтобы это был отдельный жесткий диск. Если отдельного жесткого диска нет, то укажите каталог в том разделе диска, где НЕ установлен Windows. Т.е. любой, кроме диска «C»:
Каталог для сохранения резервных копий
«Хранить резервные копии» — укажите «Последние 10 шт», обычно этого достаточно, плюс будет не много места занимать на жестком диске:
Хранить только 10 последних копий
Теперь надо решить, как будет выполняться резервное копирование: «Регулярно по расписанию» или «При завершении работы».
При выборе надо учитывать, что и в том, и в другом случае всех пользователей базы 1С «выгонит», чтобы сделать резервную копию.
Вариант «Регулярно по расписанию»
Этот вариант можно выбрать, если все пользователи в одно и тоже время уходят, например, на обед или пить чай.
Тогда нажмите на «Один день; один раз в день» и выберите расписание. Например, через 15 минут после того, как все ушли на обед (на случай, если кто-то задержится)
Настройка расписания
В открывшемся меню поставьте «1» в поле «Повторять каждые», чтобы получилось «Каждый день; один раз в день»:
Каждый день. Один раз в день
Перейдите на закладку «Дневное» и укажите в поле «Время начала» время, когда надо делать резервную копию. Затем нажмите «Ок»:
Время резервного копирования
В результате должно получиться вот так:
Каждый день, с 13 15
Учтите, что ваш сеанс 1с должен быть запущен в это время, т.е. уходя на обед, вам надо оставлять 1с включенной, чтобы копия создалась
Вариант «При завершении работы»
Этот вариант подойдет вам, если вы последним уходите из офиса (или по крайней мере последним выходите из 1С).
При завершении работы
В этом варианте дополнительно ничего не нужно настраивать. Просто при закрытии 1С система будет предлагать вам сделать резервную копию.
Как происходит резервное копирование при завершении работы
При выходе из 1С будет появляться окно «Не выполнено резервное копирование при завершении работы»:
Если нажать «Завершить работу», то 1С закроется без резервной копии.
При нажатии «Продолжить работу» у правом нижнем углу 1С появится вот такое окно:
Окно, предлагающее сделать резервную копию
Нажмите на него, чтобы появилось вот такое окно:
Выполнить резервное копирование
Осталось только нажать «Завершить» не снимая флажок «Выполнить резервное копирование». После этого 1С сделает резервную копию и завершит работу:
Создание резервной копии информационной базы
Итак, самое главное сделали, резервные копии создаются, осталось сделать автоматическую выгрузку копий в облако, чтобы обезопасить данные от форс-мажоров.



