
Введение
В своей инструкции по установке и настройке zabbix я вообще не затрагиваю вопрос базы данных mysql или производительности сервера в целом. Я просто беру дефолтные настройки mariadb, которые идут с установкой и использую их. Когда у вас не очень большая инфраструктура на мониторинге этого вполне достаточно, чтобы нормально пользоваться системой.
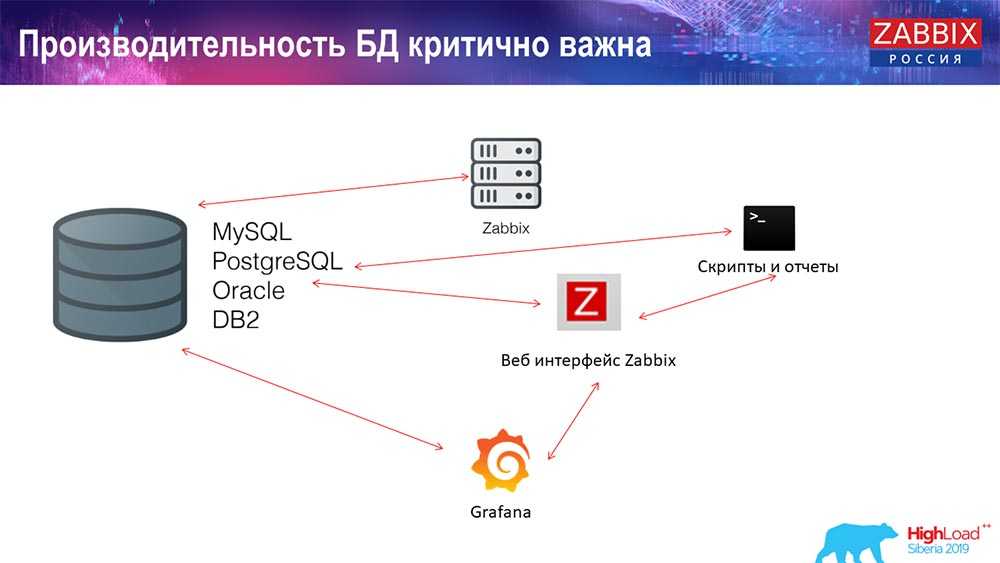
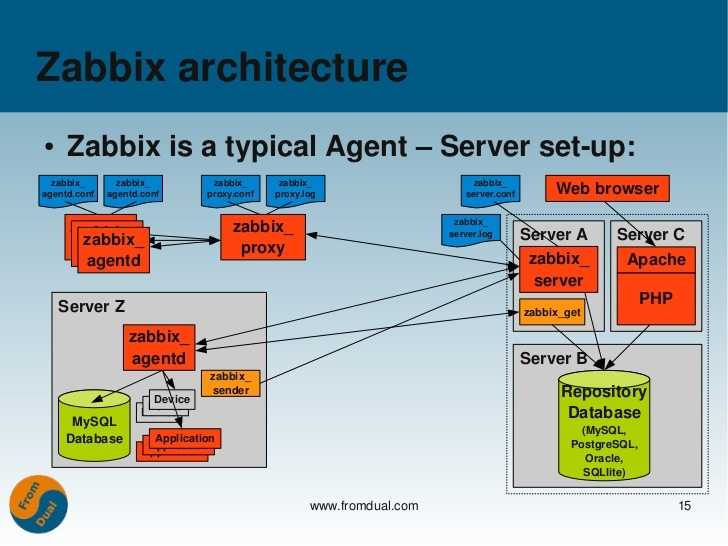
Если вы активно используете zabbix и внедряете его повсеместно во все используемые системы (а я рекомендую так делать), то вы рано или поздно столкнетесь с вопросом производительности системы мониторинга и размера базы данных zabbix.
Тема производительности zabbix очень индивидуальная. Она напрямую зависит от того, как вы его используете, а схемы мониторинга могут быть очень разные. Одно дело мониторить несколько серверов, а другое дело нагруженные свичи на 48 портов со съемом метрик с каждого порта раз в 30 секунд.
Чтобы помочь вам разобраться в этой теме и прикинуть, к чему готовиться, я поделюсь с вами своим опытом эксплуатации заббикса, его нагрузки, производительности и обслуживания базы данных mysql. Расскажу, как можно уменьшить размер базы.
Введение
Ранее я написал подробную статью по установке и настройке Zabbix 5, где в том числе рассказал своими словами обо всех основных нововведениях. Настоятельно рекомендую с ними ознакомиться, прежде чем обновляться. Обязательно сначала прочитайте всю статью, только потом начинайте обновление. По ходу дела будут важные замечания.
Второй момент. В этой версии очень много изменений, как в настройках, так и в интерфейсе. Обновлять без подготовки не рекомендую. Если у вас несколько серверов, начните с самого простого. Если же только один, то настоятельно рекомендую сделать его копию и проверить обновление на ней.
Еще один момент, который я упускал, когда обновлялся со старых версий Zabbix. В новых версиях часто обновляются стандартные шаблоны, но вы их не увидите при обновлении. У вас останутся работать старые версии. Новые нужно вручную переносить из свежих установок и подключать к хостам.
С одной стороны это плюс, так как шаблоны зачастую меняются очень сильно. Нужен ручной контроль. А с другой стороны неудобно вручную обновлять все шаблоны, которые еще и зависимости свои имеют. Рассмотрю все эти моменты по ходу дела. Приступаем к обновлению сервера мониторинг Zabbix версии 4.4 до 5.0.
Важный нюанс. Минимальные системные требования к версии php для Zabbix 5 — 7.2 Так что прежде чем обновлять сам сервер мониторинга, убедитесь, что у вас стоит подходящая версия php.
Установка сервера Zabbix
Перед тем как мы сможем установить zabbix ubuntu 17.04, 16.04 и в других версиях, потребуется кое-что настроить. Нужно установить веб-сервер, MySQL и PHP. Если эти сервисы у вас уже настроены, то просто можете пропустить этот шаг.
Установка Apache, PHP, MySQL
Для установки выполните такие команды:
Дальше необходимо настроить правильный часовой пояс в php.ini. Вам нужна секция Data и строка timezone:\
Добавление репозитория
Скачать установщик репозитория для вашего дистрибутива можно в папкеzabbix/5.2/ubuntu/pool/main/z/zabbix-release/. Там находятся установщики для разных версий Ubuntu:
Например, можно использовать wget для загрузки файла:
Если у вас другая операционная система, посмотрите список файлов на сервере через браузер и выберите нужный установщик. Затем установка zabbix 3.2 на Ubuntu:
После установки пакета репозитория, обновление списка пакетов обязательно:
Установка и настройка Zabbix
Когда репозиторий будет добавлен, можно перейти к настройке самого сервера Zabbix. Для установки программ выполните:
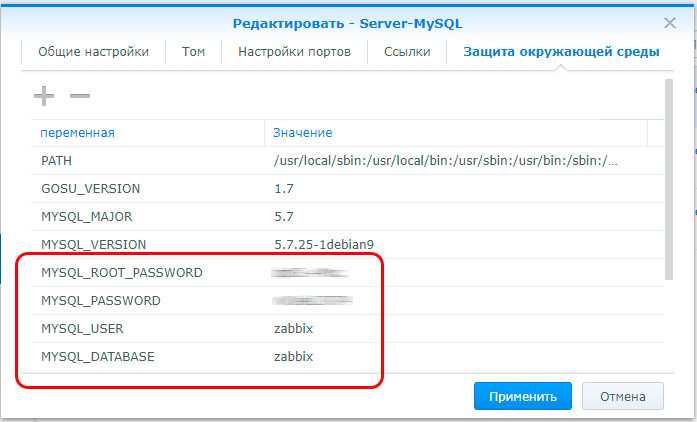
Как я уже говорил, для работы программы понадобится база данных. Сейчас нам предстоит создать ее и выдать все необходимые привилегии пользователю:
Для нормальной работы Zabbix нужна кодировка базы данных UTF-8, если вы создадите базу в кодировке utf8mb4, то получите ошибку: «Specified key was too long; max key length is 767 bytes». Дальше нужно загрузить все таблицы в базу данных, они находятся в папке /usr/share/doc/zabbix-server-mysql/ или /usr/share/zabbix-server-mysql/. Вместо zabbix и zabbixdb нужно указать своего пользователя и имя базы данных:
Чтобы Zabbix смог подключиться к базе данных нужно отредактировать конфигурационный файл /etc/zabbix/zabbix_server.conf и указать там данные аутентификации:
Далее, включаем конфигурационный файл zabbix для apache2:
Теперь нужно перезапустить Zabbix и Apache, чтобы применить изменения:
Установка и настройка Zabbix Ubuntu почти завершена, осталось настроить веб-интерфейс.
Настройка веб-интерфейса zabbix
Веб-интерфейс программы готов к работе, теперь вы можете его открыть, набрав в адресной строке http://адрес_сервера/zabbix/:
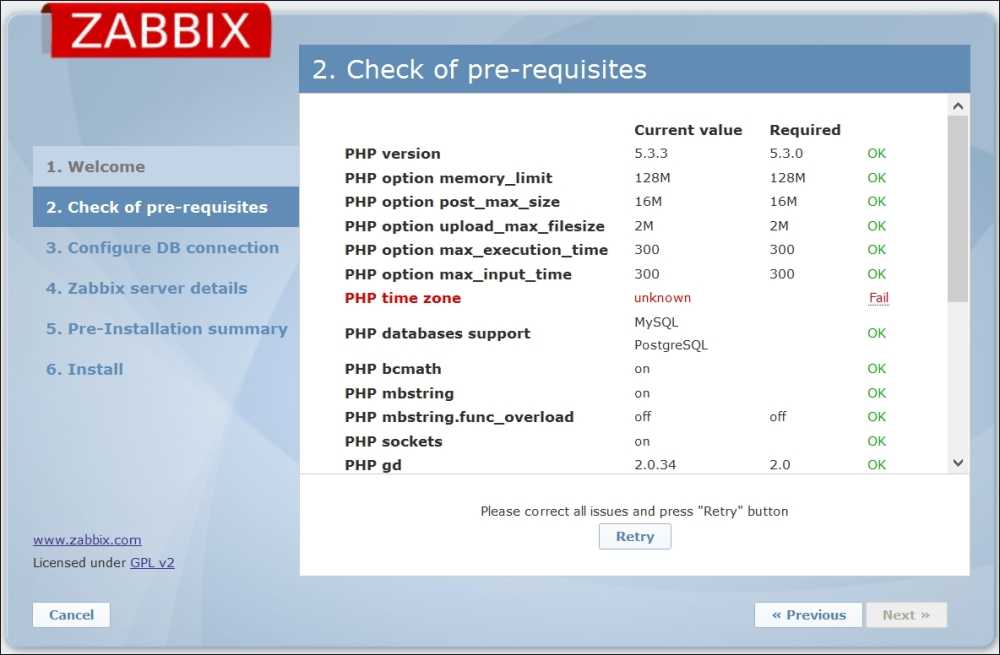
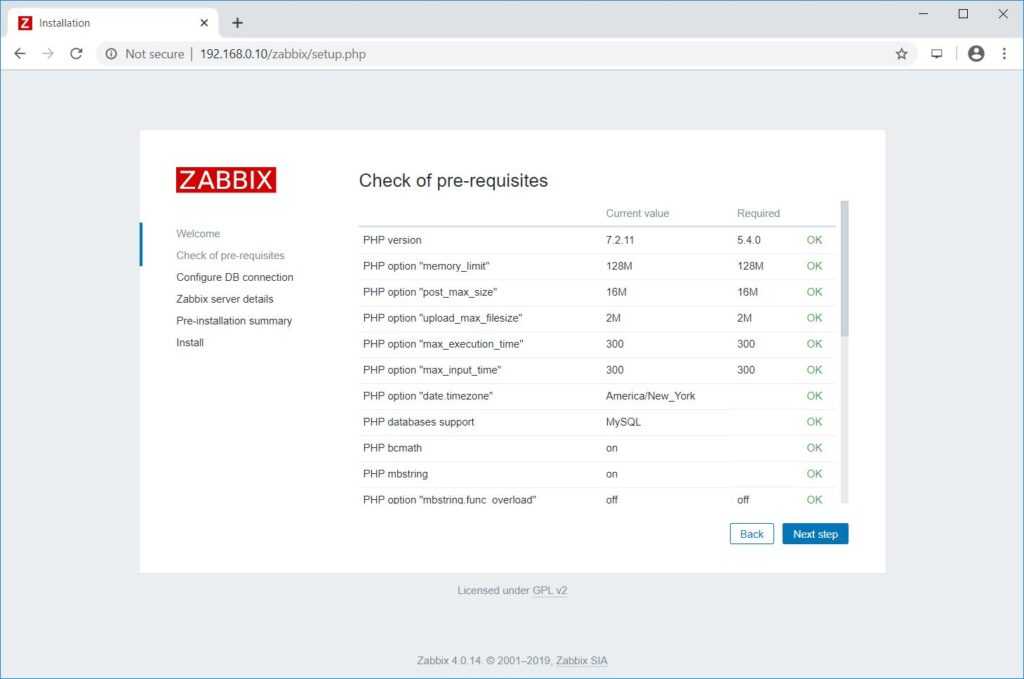
На первой странице нажмите Next. На следующем шаге программа проверит правильно ли настроен интерпретатор PHP:
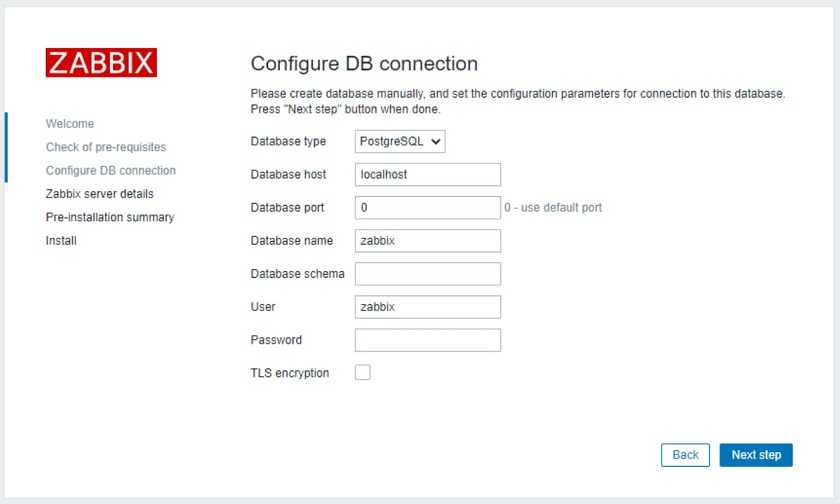
Дальше укажите параметры доступа к базе данных, они будут использоваться для работы веб-интерфейса:
На следующем шаге можно изменить ip и порт, на котором будет слушать Zabbix:
Далее можно выбрать тему оформления:
Последний шаг, проверьте все ли верно и не нужно ли чего менять:
Теперь вернитесь в браузер и нажмите Finish:
Перед вами откроется окно ввода логина и пароля. Используйте стандартные значения, логин Admin и пароль zabbix.
Вот и все, теперь установка Zabbix Ubuntu завершена и вы можете переходить к настройке.
Триггеры шаблона
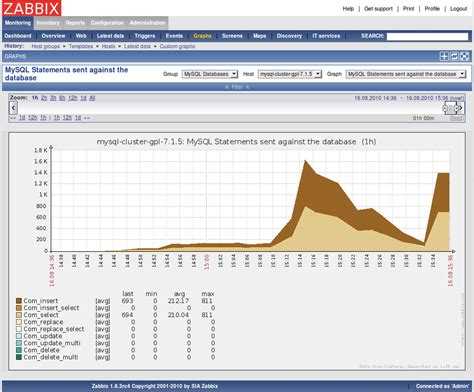
Для полноты картины, поясню остальные триггеры шаблона, чтобы у вас было понимание, за чем они следят и как правильно реагировать на них. Ниже список триггеров шаблона для мониторинга mysql сервера.

- Buffer pool utilization is too low (less {$MYSQL.BUFF_UTIL.MIN.WARN}% for 5m) — под innodb пул выделено слишком много памяти и она не используется вся. Триггер чисто информационный, делать ничего не надо, если у вас нет дефицита памяти на сервере. Если нехватка оперативной памяти есть, то имеет смысл забрать немного памяти у mysql и передать другому приложению. Настраивается потребление памяти пулом параметром innodb_buffer_pool_size.
- Failed to get items (no data for 30m) — от mysql сервера не поступают новые данные мониторинга в течении 30 минут. Имеет смысл уменьшить этот интервал до 5-10 минут.
- Refused connections (max_connections limit reached) — срабатывает ограничение на максимальное количество подключений к mysql. Увеличить его можно параметром mysql сервера — max_connections. Его необходимо увеличить, если позволяют возможности сервера. Напомню, что увеличенное количество подключений требует увеличения потребления оперативной памяти. Если у вас ее уже не хватает, нет смысла увеличивать число подключений. Нужно решать вопрос с потреблением памяти.
- Server has aborted connections (over {$MYSQL.ABORTED_CONN.MAX.WARN} for 5m) — сервер отклонил подключений выше заданного порога в макросе. Надо идти в лог mysql сервера и разбираться в причинах этого события. Скорее всего там будут подсказки.
- Server has slow queries (over {$MYSQL.SLOW_QUERIES.MAX.WARN} for 5m) — количество медленных запросов выше установленного макросом предела. Надо идти и разбираться с медленными запросами. Тема не самая простая. Надо заниматься профилированием запросов и решать проблемы по факту — добавлением индексов, редактированием запросов, увеличения ресурсов mysql сервера и т.д.
- Service has been restarted (uptime < 10m) — информационный триггер, срабатывающий на перезапуск mysql сервера (не ребут самого сервера).
- Service is down — служба mysql не запущена.
- Version has changed (new version value received: {ITEM.VALUE}) — версия mysql сервера изменилась. Тоже информационный триггер, сработает, к примеру, после обновления mysql сервера.
1) Запросы для чистки базы:
-- keep 1 week of history and 3 months of trends \SET history_interval 7 \SET trends_interval 90 DELETE FROM alerts WHERE age(to_timestamp(alerts.clock)) > (:history_interval * INTERVAL '1 day'); DELETE FROM acknowledges WHERE age(to_timestamp(acknowledges.clock)) > (:history_interval * INTERVAL '1 day'); DELETE FROM events WHERE age(to_timestamp(events.clock)) > (:history_interval * INTERVAL '1 day'); DELETE FROM history WHERE age(to_timestamp(history.clock)) > (:history_interval * INTERVAL '1 day'); DELETE FROM history_uint WHERE age(to_timestamp(history_uint.clock)) > (:history_interval * INTERVAL '1 day') ; DELETE FROM history_str WHERE age(to_timestamp(history_str.clock)) > (:history_interval * INTERVAL '1 day') ; DELETE FROM history_text WHERE age(to_timestamp(history_text.clock)) > (:history_interval * INTERVAL '1 day') ; DELETE FROM history_log WHERE age(to_timestamp(history_log.clock)) > (:history_interval * INTERVAL '1 day') ; DELETE FROM trends WHERE age(to_timestamp(trends.clock)) > (:trends_interval * INTERVAL '1 day'); DELETE FROM trends_uint WHERE age(to_timestamp(trends_uint.clock)) > (:trends_interval * INTERVAL '1 day') ; |
Непосредственно запуск:
time sudo -u postgres psql -A -R ' : ' -P 'footer=off' zabbix < delete-old-data.pg.sql |
Дополнительные материалы по Zabbix
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
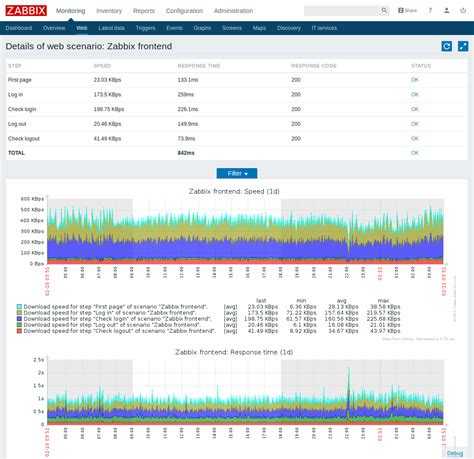
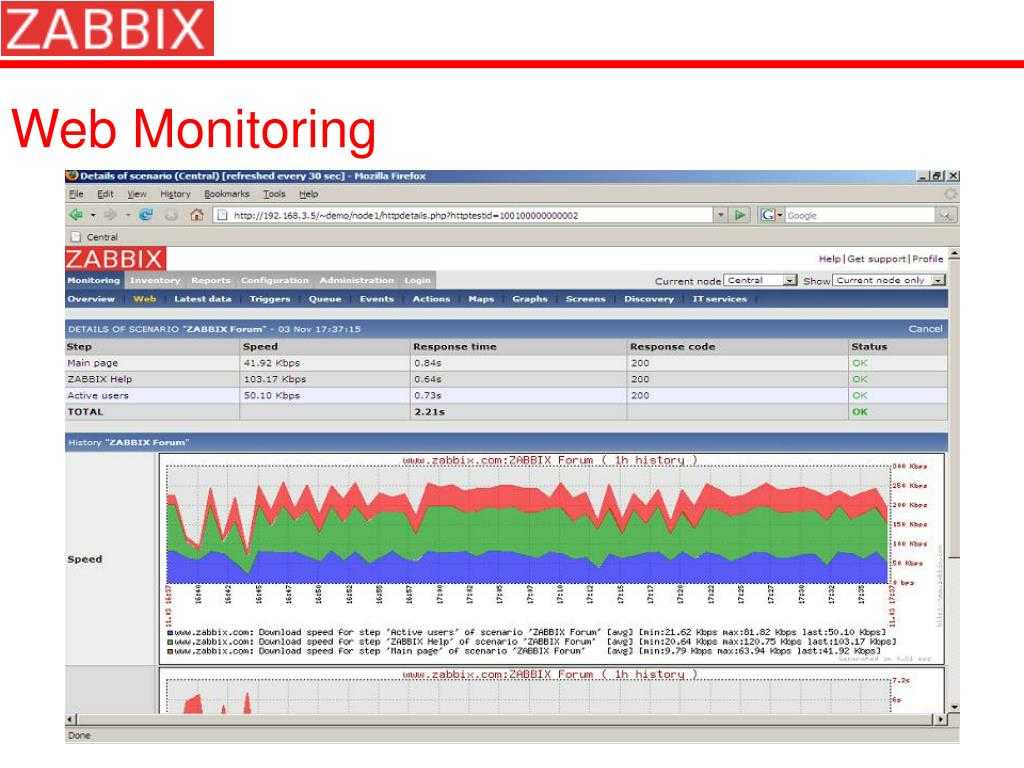
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
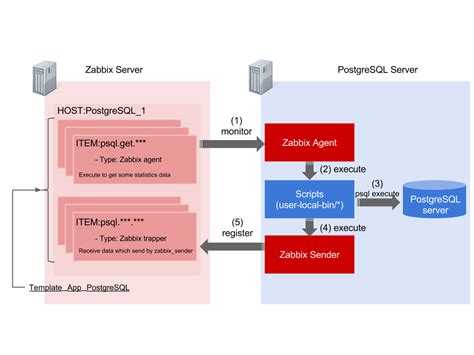
Создание скрипта для мониторинга mysql репликации
Теперь создадим скрипт для мониторинга. Скачиваем его отсюда mysql-slave.sh и вставляем содержимое в папку /etc/zabbix/scripts:
# mcedit /etc/zabbix/scripts/mysql-slave.sh # chown zabbix:zabbix /etc/zabbix/scripts/mysql-slave.sh # chmod 550 /etc/zabbix/scripts/mysql-slave.sh
Проверяем его работу:
/etc/zabbix/scripts/mysql-slave.sh Master_Host zabbix parol
Скрипт должен вернуть в консоль имя мастера.
Если вы будете проверять работу скрипта от пользователя root, обязательно удалите временный файл из папки /tmp, который создает скрипт. Если этого не сделать, то потом заббикс не сможет его прочитать, так как ему не хватит для этого прав.
Данный скрипт анализирует вывод show slave status\G и парсит 3 необходимых нам значения. Он передает агенту информацию о задержке репликации через параметр Seconds_Behind_Master и анализирует значения Slave_IO_Running и Slave_SQL_Running. Если их значения равны Yes, он передает агенту 1, если там что-то другое то 0.
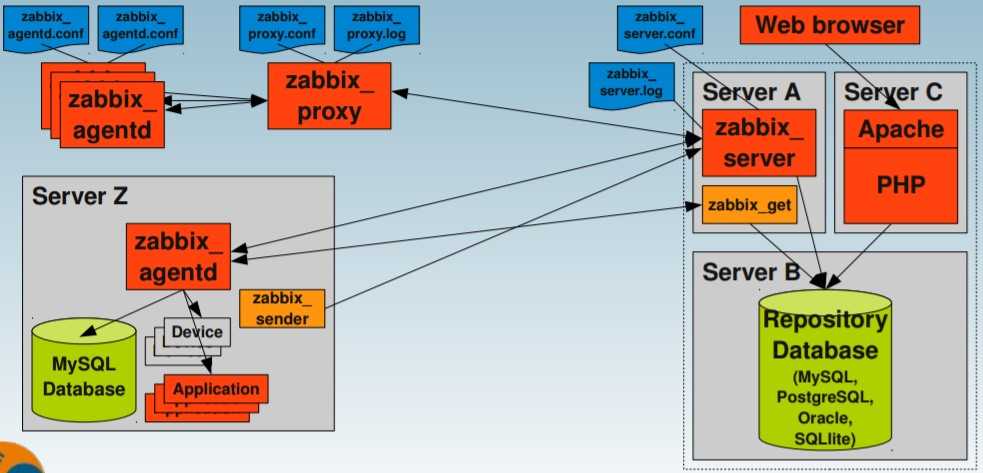
Установка Zabbix Agent на Linux
Если вы хотите установить zabbix-agent на сам сервер мониторинга, то ничего делать не надо, кроме самой установки. Для других систем необходимо подключить репозитории заббикса, которые мы использовали во время установки сервера. Можете посмотреть их в соответствующих разделах для своей системы.
Установка zabbix agent в Centos:
# yum install zabbix-agent
Тоже самое в Ubuntu/Debian:
# apt install zabbix-agent
Для работы с сервером, который установлен локально на этой же машине, больше никаких настроек не надо делать. Если же вы будете устанавливать zabbix agent на другую машину, то в файле конфигурации агента /etc/zabbix/zabbix_agentd.conf нужно будет задать следующие параметры:
# mcedit /etc/zabbix/zabbix_agentd.conf
Server=192.168.13.117 ServerActive=192.168.13.117 Hostname=srv10 # имя вашего узла мониторинга, которое будет указано на сервере zabbix, Zabbix server если это сам сервер заббикса
Запускаем агент и добавляем в автозагрузку:
# systemctl start zabbix-agent # systemctl enable zabbix-agent
Проверяем лог файл.
# cat /var/log/zabbix/zabbix_agentd.log 14154:20181004:201307.800 Starting Zabbix Agent . Zabbix 4.0.0 (revision 85308). 14154:20181004:201307.800 **** Enabled features **** 14154:20181004:201307.800 IPv6 support: YES 14154:20181004:201307.800 TLS support: YES 14154:20181004:201307.800 ************************** 14154:20181004:201307.800 using configuration file: /etc/zabbix/zabbix_agentd.conf 14154:20181004:201307.800 agent #0 started 14157:20181004:201307.801 agent #3 started 14159:20181004:201307.802 agent #5 started 14155:20181004:201307.804 agent #1 started 14158:20181004:201307.806 agent #4 started 14156:20181004:201307.810 agent #2 started
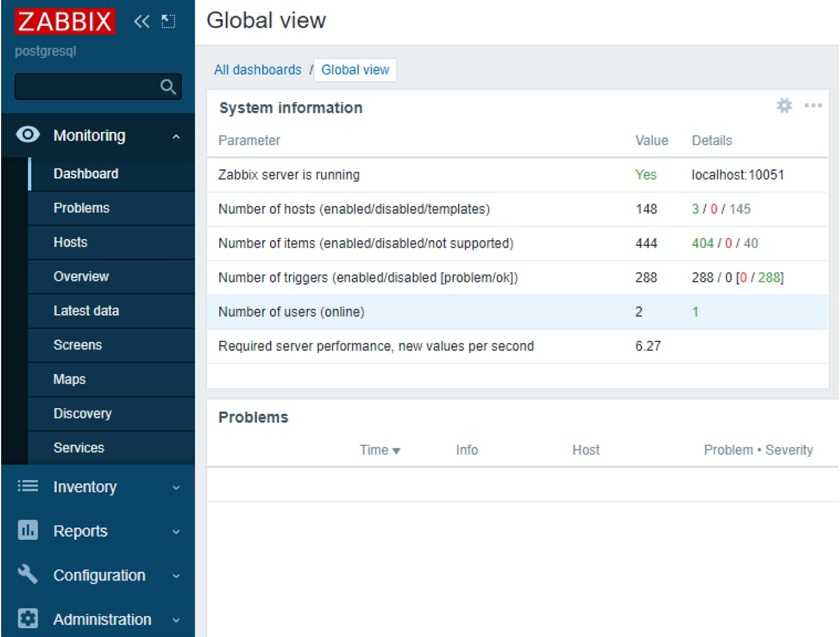
Все в порядке. Идем в веб интерфейс и проверяем поступление данных. Для этого идем в раздел Мониторинг -> Последние данные. Указываем в разделе Узлы сети Zabbix Server и ждем поступления первых данных. Они должны пойти через 2-3 минуты после запуска агента.
Теперь попробуем остановить агент и проверить, придет ли уведомление на почту. Идем в консоль и выключаем агента:
# systemctl stop zabbix-agent
Ждем минимум 5 минут. Именно такой интервал указан по-умолчанию для срабатывания триггера на недоступность агента. После этого проверяем главную панель, виджет Проблемы.
Проверка работы триггеров
Попробуем нарушить работу репликации mysql и проверим работу триггеров. Для этого я просто отключу vpn соединение, по которому доступны сервера. После разрыва связи на slave сервере следующая картинка статуса репликации:
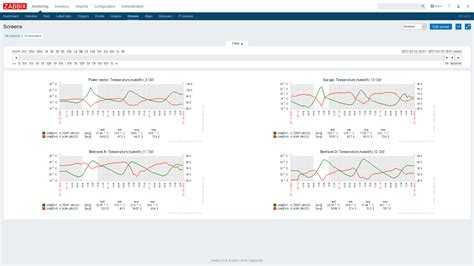
Проверяем данные мониторинга репликации:
Значение Slave_IO_Running сменилось с Yes на Connecting и скрипт проверки вернул значение 0 вместо 1. Этого достаточно, чтобы сработал триггер и пришло оповещение о том, что репликация mysql сервера нарушена:
На почту пришло оповещение:
Восстанавливаем связь между серверами и ждем новой работы триггера и уведомления:
Проверяем Latest Data:
Все в порядке, мониторинг нормально отработал нарушение mysql репликации. Больше тут настраивать нечего, графики и экраны не нужны, в них нет необходимости. На этом работа по настройке мониторинга окончена.
2) Обработка базы при помощи pgtoolkit:
pgtoolkit — инструмент для уменьшения раздувания таблиц и индексов без тяжелых блокировок и полной перестройки таблицы (https://github.com/grayhemp/pgtoolkit)
Непосредственно запуск:
time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -y 10 --reindex #Или по очереди: time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t alerts -y 10 --reindex time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t acknowledges -y 10 --reindex time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t events -y 10 --reindex time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t history -y 10 --reindex time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t history_uint -y 10 --reindex time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t history_str -y 10 --reindex time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t history_text -y 10 --reindex time sudo -u postgres /opt/pgtoolkit/bin/pgcompact -v info -d zabbix -t history_log -y 10 --reindex
Иногда может возникнуть необходимость проверить и удалить временные индексы, оставшиеся от работы pgcompact:
SELECT * FROM pg_indexes WHERE indexname LIKE '%pgcompact%'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------------+-----------------------+------------+----------------------------------------------------------------------------------------------- public | hostmacro | pgcompact_index_12057 | | CREATE UNIQUE INDEX pgcompact_index_12057 ON hostmacro USING btree (hostid, macro) public | graph_discovery | pgcompact_index_29490 | | CREATE UNIQUE INDEX pgcompact_index_29490 ON graph_discovery USING btree (graphid) public | hosts_templates | pgcompact_index_4305 | | CREATE UNIQUE INDEX pgcompact_index_4305 ON hosts_templates USING btree (hostid, templateid) public | hosts_templates | pgcompact_index_21016 | | CREATE UNIQUE INDEX pgcompact_index_21016 ON hosts_templates USING btree (hostid, templateid) DROP INDEX pgcompact_index_12057; DROP INDEX pgcompact_index_29490; DROP INDEX pgcompact_index_4305; DROP INDEX pgcompact_index_21016; |
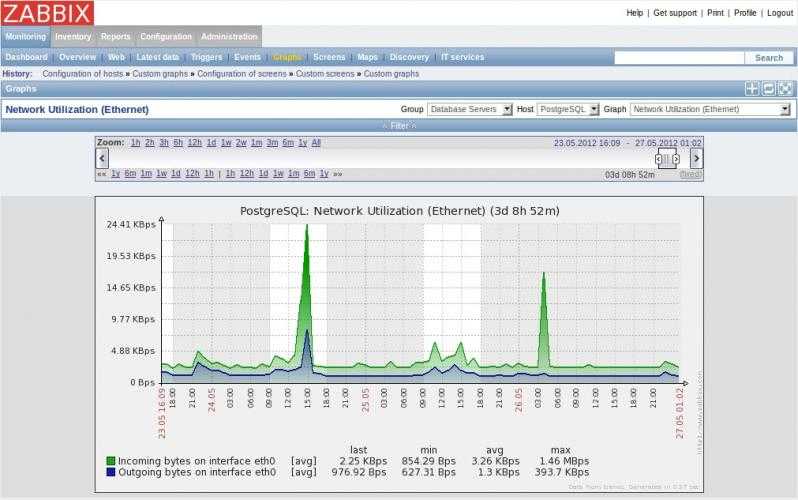
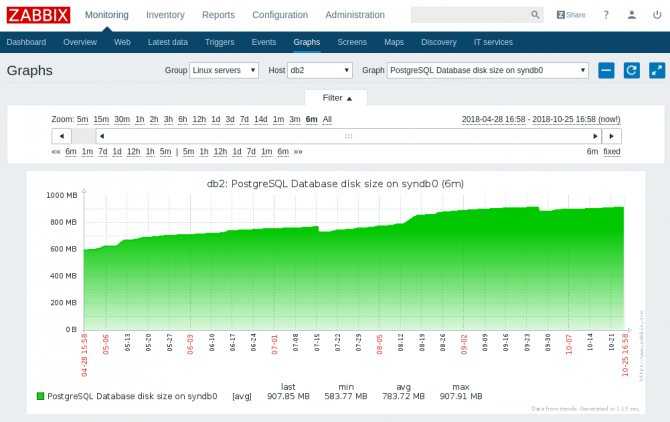
Результат работы можно увидеть на графиках.
В данном случае я пропустил момент распухания базы и на раздел пришлось экстренно добавлять место.
Чтобы не пропускать переполнение диска, рекомендуется добавить задание в cron:
sudo -u postgres /usr/bin/flock -w 0 /var/run/postgresql/backup_zabbix_psql.lock /usr/bin/psql -A -R ' : ' -P 'footer=off' zabbix
Если у вас mysql:
При использовании движка базы данных InnoDB, все таблицы и индексы хранятся в системном табличном пространстве (в одном файле /var/lib/mysql/ibdata).
Для того, чтобы хранить каждую таблицу InnoDB и связанные индексы в отдельных файлах — нужно активировать опцию innodb_file_per_table.
Второй шаг миграции
Теперь надо просто запустить миграцию истории, но чтобы этот процесс не сильно нагружал СУБД.
Так думал я, но все оказалось интереснее.
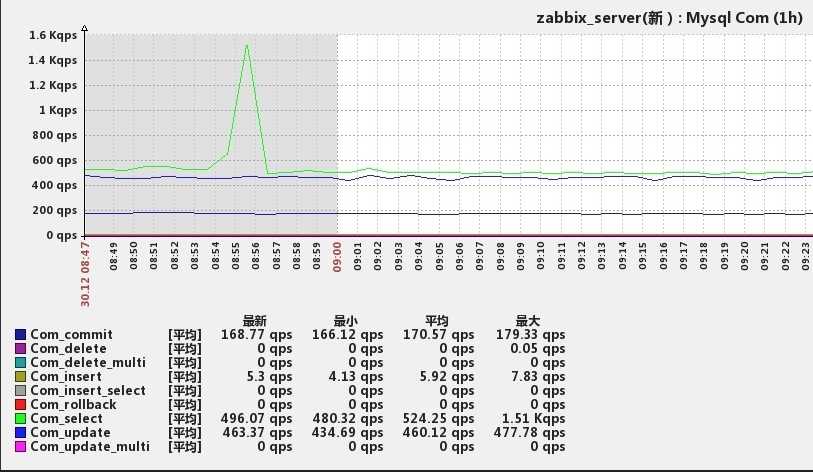
Перед вторым шагом миграции я решил создать в моем тестовом окружении нагрузку на Zabbix сервер. В тестовом окружении отсутствовали Zabbix прокси (это логично, так как мои основные прокси с тестовым сервером работать не намерены), так что нагрузку я решил создавать на самом сервере. Для этого с помощью API я создал около 200 хостов и попросил Zabbix сервер совершать проверки icmp и web checks к этим хостам каждую секунду. Получил около 1000 NVPS.
Очереди не росли, Zabbix server и PostgreSQL легко справлялись с такой нагрузкой.
Пора мигрировать историю.
Подготовим файл zabbix.load.data для pgloader:
Обратите внимание на строки:
говорит о том, что при начале миграции не будут очищены все мигрируемые таблицы. Ведь в истории уже появляются данные, так как мониторинг запущен.
говорит о том, что мигрировать в этот раз будут только таблицы истории.
Запускаем миграцию
Миграция истории началась, процесс этот может быть долгим. В моем случае при размере базы около 150 Гб и не самом сильном железе миграция истории занимает 4-5 часов.
Поначалу все шло хорошо. Потом я обнаружил, что загрузка CPU на PostgreSQL сервере растет линейно, и со временем ресурсов для нормальной работы уже не хватало (на графике load average на 1 ядро):
В логи Zabbix сервера сплошным полотном начали сыпаться медленные запросы SELECT. Как я понял, для того, чтобы совершить web check, нужно для начала сделать SELECT.
Я попробовал снизить интенсивность миграции. Для этого изменил следующие параметры в файле zabbix.load.data:
Но с такими настройками не поменялось ничего, кроме скорости миграции. Нагрузка росла также линейно со временем.
Ну не зря же я обвесил PostgreSQL мониторингом. Изучаю его показатели и вижу, что линейный рост нагрузки явно совпадал с продолжительностью транзакции, которую создал pgloader:
А также с количеством tuples, которые возвращала PostgreSQL клиентам в ответ на их запросы:
Идем в интернет, ищем информацию о том, как ведет себя PostgreSQL при длинных транзакциях. И находим вот такой замечательный доклад с конференции HighLoad:https://www.youtube.com/watch?v=3h48iowNbwo
Советую посмотреть доклад, но если вкратце, то при наличии длинной транзакции в PostgreSQL не срабатывает механизм внутристраничной очистки (single-page cleanup). И это приводит к росту тех самых возвращаемых tuple. СУБД приходится разбираться, какой tuple ей нужен, что ведет к росту загрузки CPU.
Я проверил мою ситуацию — действительно, достаточно открыть транзакцию, создать в ней таблицу, а затем НЕ закрыть транзакцию:
У спустя некоторое время видим рост загрузки CPU:
Падение загрузки в конце графика — это закрытая вручную транзакция.
Видимо, с этой особенностью придется мириться. Что можно сделать? Например, мигрировать историю отдельно, тренды отдельно, чтобы хоть немного уменьшить продолжительность транзакции.
Но это не всё. У меня все таки получилось сделать так, чтобы эта особенность PostgreSQL не мешала.
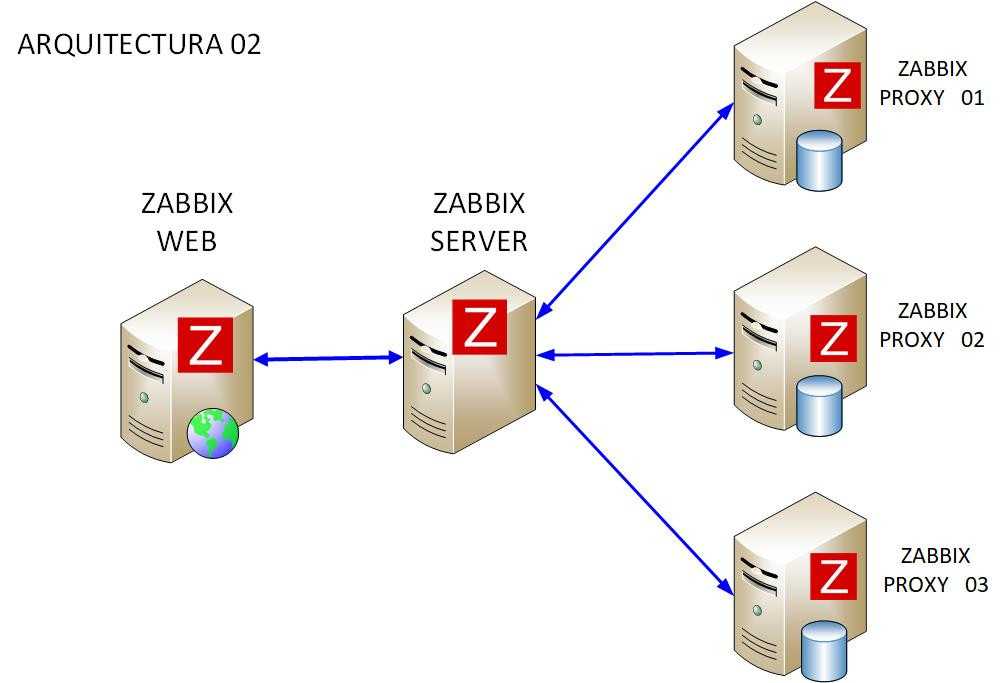
Немного о моей реальной инсталляции Zabbix. На ней почти все задачи сбора данных делегированы на Zabbix прокси. Сервер занимается лишь приемом данных и всякими триггерами/препроцессингом. Но как я написал выше, на тестовой инсталляции все проверки исполнял сам сервер.
Я вынес все задачи сбора данных на прокси в тестовой инсталляции, сильно снизив нагрузку на Zabbix Server и PostgreSQL. И оказалось, что это помогло! После этого никакая длинная транзакция не создавала сверхвысокой нагрузки на CPU, не мешала мониторингу нормально работать. Ну либо по какой-то причине внутристраничная очистка PostgreSQL при таком сценарии заработала. Может быть знатоки PostgreSQL подскажут?
Заключение
Здорово, что разработчики сами занялись написанием готовых шаблонов для мониторинга сетевых устройств, операционных систем и приложений. Поняли, что это будет способствовать развитию продукта. Многие шаблоны, которые разрабатывали сами пользователи, становятся неактуальными, так как разработчики их делают лучше. Собственно, это и логично. Кто лучше всех знает продукт, как не они. За последнее время появилось много обновления по этой теме. Надеюсь, будет еще больше.
Онлайн курсы по Mikrotik
Если у вас есть желание научиться работать с роутерами микротик и стать специалистом в этой области, рекомендую пройти курсы по программе, основанной на информации из официального курса MikroTik Certified Network Associate. Помимо официальной программы, в курсах будут лабораторные работы, в которых вы на практике сможете проверить и закрепить полученные знания. Все подробности на сайте .
Стоимость обучения весьма демократична, хорошая возможность получить новые знания в актуальной на сегодняшний день предметной области. Особенности курсов:
- Знания, ориентированные на практику;
- Реальные ситуации и задачи;
- Лучшее из международных программ.





