
Введение
Настройка Zabbix мониторинга, это самое главное что должен делать каждый нормальный системный администратор.
Главных причин по которым вам надо использовать мониторинг несколько:
- Не возможно качественно поддерживать работоспособность сети без постоянного анализа её параметров;
- Вы первый будете в курсе при возникновении проблемы на обслуживающем оборудовании.
Конечно, настройка системы мониторинга дело не простое и требует много времени при первоначальном внедрении. На практике я настраиваю систему мониторинга только клиентам которые заключают договор на абонентское обслуживание.
Иногда руководители просто не понимают в чем разница между приглашением специалиста по вызову и заключением договора на абонентское обслуживание.
Например, один клиент поймал шифровальщик файлов и восстановление данных ему обошлось в кругленькую сумму. Другой, который заключил договор на обслуживание (я успел на 80 % выполнить работы по защите баз данных и мониторинга сети) отделался легким испугом.
Главный принцип и подход разработчиков остается неизменным. В системе нет ничего лишнего и порой кажущееся усложнение на практике оказывается удобным механизмом упрощающим жизнь системному администратору контролирующему большой парк разнообразной техники.
Можно часами рассказывать о всех прелестях работы с этой системой, но не буду этого делать. Постараюсь внести понимание того из чего состоит и как работает эта система. Я посвятил много времени на изучение системы пока до меня не дошли элементарные вещи которые необходимо знать при работе с комплексом Zabbix.
Документация у разработчиков Zabbix есть, но написана она сухим техническим языком который вы сможете понять когда поймете основные принципы работы системы.
item became not supported
Во время отладки работ я столкнулся с проблемами. Периодически Item отваливались и получали статус: Not Supported. При этом в логах сервера были следующие записи:
27614:20150702:065936.698 item "videoserver:Temperature.CPU" became not supported: Timeout while executing a shell script. 27625:20150702:070938.720 item "videoserver:Temperature.CPU" became supported
То есть данные то собирались, то переставали собираться. Иногда, чтобы данные снова пошли, приходилось удалять итем и создавать его заново. Некоторое время я повозился, пока не понял, в чем дело.
Я обратил внимание, что при запуске батника из командной строки, вывод данных происходит с приличной задержкой в 3-5 секунд. В Zabbix по-умолчанию стоит параметр, по которому агент ожидает ответа от скрипта 3 секунды и на сервере есть подобный параметр, по которому сервер ждет ответа от агента 3 секунды
Если за это время данные не поступают, то итем переходит в статус Not Supported и данные с него не собираются.
Чтобы избавиться от этой ошибки, необходимо увеличить таймаут до 15-ти секунд. Меняем параметр в конфиге на клиентах и на сервере. Он и там и там один и тот же:
Timeout=15
Потом перезапускаем сервер и агентов и ждем результатов. Больше ошибок быть не должно.
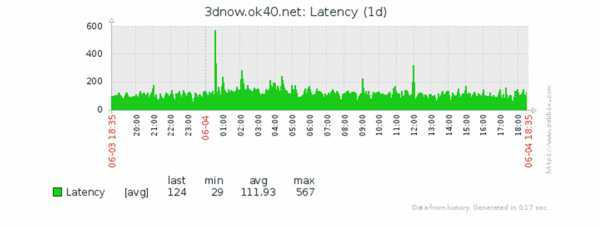
На этом, собственно настройка мониторинга температуры окончена. Можно дальше все оформить как полагается: настроить тригеры, оповещения, графики красивые нарисовать. Кому что нужно. Я себе вывел вот такую картинку для наглядности:
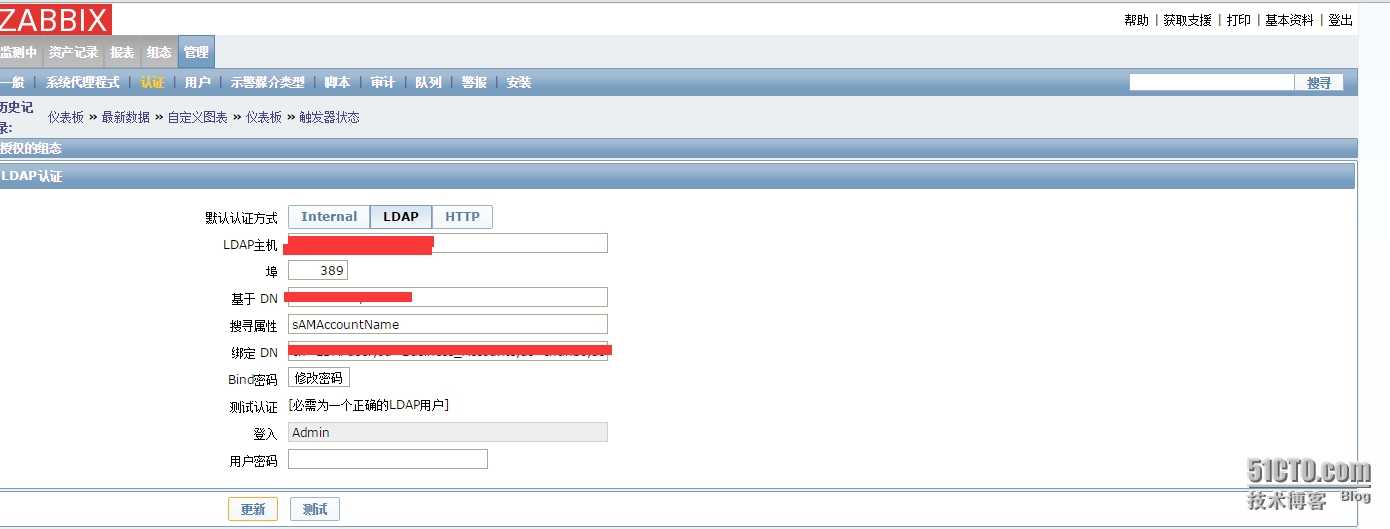
Получение доступа к API Яндекс
Вам нужно будет заполнить несколько обязательных полей:
- Название приложения.
- В качестве платформы указать Веб-сервисы.
- Callback URI установить — https://oauth.yandex.ru/verification_code.
- В Доступах указать: Яндекс.Метрика, Получение статистики, чтение параметров своих и доверенных счетчиков.
Все остальное можно не указывать. Вы должны получить ID приложения и Пароль.

После разрешения, вы получите токен, с помощью которого можно подключаться к api.
Используя этот токен, можно получать данные из Метрики через API. Для примера зайдем на сервер мониторинга и через консоль запросим данные о посещаемости сайта. Для этого нам нужно узнать номер его id в метрике. Можно это сделать прямо в ней же.
Далее формируем запрос через curl с указанием токена в header.
# curl --header "Authorization: OAuth AgAAaaaaaaaaaaaDDDDDDDDDddd" --header "Content-Type: application/x-yametrika+json" -X GET "https://api-merika.yandex.ru/stat/v1/data?&ids=23506456&metrics=ym:s:users,ym:s:visits,ym:s:pageviews&dimensions=&date1=today&pretty=true"
В данном запросе я указал:
- AgAAAAAAGk3WAAaaYZaUSgzNyU7uvqAKCGwDSro — токен;
- ids=23506456 — id сайта в метрике;
- metrics=ym:s:users,ym:s:visits,ym:s:pageviews — запрошенные метрики — пользователи, визиты, просмотры страниц;
- date1=today — дата, сегодняшний день в данном случае;
- pretty=true — вывести в формате удобочитаемого json.
Получили ответ в виде подробного json. Он отлично подходит для zabbix, так как последний умеет из коробки парсить json. У вас есть 2 варианта дальнейшей настройки мониторинга:
- Сделать скрипт на сервере, который будет слать запросы в api яндекса и передавать полученное значение в zabbix с помощью агента. Плюс решения в том, что нагрузка на сервер мониторинга минимальная. Неудобство в том, что нужно куда-то добавлять скрипт.
- Слать запросы к api напрямую с zabbix сервера с помощью HTTP Агента. И сразу там же парсить полученный ответ. Плюс этого подхода в том, что все настройки хранятся в шаблоне и легко сохраняются или переносятся через экспорт шаблона. Минус в том, что все вычисления и запросы выполняются самим заббиксом.
Я обычно иду по второму пути, потому что так удобнее.
В таком виде это можно отправлять в Zabbix, чем мы далее и займемся.
Подготовка к мониторингу в Zabbix
Описанным мной способом можно мониторить температуру не только windows серверов, но и любых рабочих станций, если будет такая необходимость. Схема мониторинга следующая:
Существует бесплатная утилита Open Hardware Monitor, которая может показывать температуру некоторых датчиков сервера. Вообще говоря, она много чего может показывать (напряжение, скорость вентиляторов, загрузку процессора), но в данном случае нас интересует только температура. У этой утилиты есть версия, работающая в командной строке. Из командной строки показания датчиков можно записывать в файл. Этот файл можно анализировать и забирать из него необходимую для мониторинга информацию. Дальше эта информация передается в сервер Zabbix с помощью опции UserParameter. Все достаточно просто и в то же время эффективно.
Программа увидела несколько датчиков. С процессором все понятно, а вот три других датчика не ясно, чью температуру показывают. Я хотел мониторить температуру процессора и материнской платы. Узнать, какая температура относится к материнской плате можно несколькими способами. Конкретно в данной ситуации я просто запустил портированную версию AIDA64 и посмотрел, какие показания у датчика материнской платы:
Оказалось — 45 градусов. Я запомнил, что датчик Temperature #3 отображает температуру материнской платы.
Можно было пойти другим путем, зайти в IPMI панель, если она есть, и посмотреть там. Я работал с серверами SuperMicro, там она есть. Я на всякий случай зашел и проверил:
Почему-то в этой панели не оказалось информации с датчика температуры процессора
Но нам это не важно. Самое главное, что мы узнали параметры, за которыми будем следить — это CPU Packege и Temperature #3
Теперь запускаем консольную версию и смотрим вывод информации. Я для удобства положил OpenHardwareMonitorReport.exe в папку с основной программой и все это хозяйство скопировал в корень диска C:








Открываем файл 1.txt. Ищем там строки
| +- CPU Package : 52 51 52 (/intelcpu/0/temperature/4)
| | +- Temperature #3 : 45 45 45 (/lpc/nct6776f/temperature/3)
Нас интересует выделенный текст. По нему мы будем вычленять температуру для мониторинга и передавать ее на Zabbix сервер. Создаем в этой же папке 2 bat файла следующего содержания:
CPUTemperature.bat
@echo off for /F "usebackq tokens=7-10" %%a in (`C:\OpenHardwareMonitor\OpenHardwareMonitorReport.exe`) do echo %%b %%c %%d| find "/intelcpu/0/temperature/4">nul && set temper=%%a echo %temper%
MotherTemperature.bat
@echo off for /F "usebackq tokens=7-10" %%a in (`C:\OpenHardwareMonitor\OpenHardwareMonitorReport.exe`) do echo %%b %%c %%d| find "/lpc/nct6776f/temperature/3">nul && set temper=%%a echo %temper%
Запускаем эти батники в командной строке и проверяем вывод. Там должны быть только цифры температуры:
Отлично, на выходе готовые цифры, которые мы будем передавать в Zabbix. Займемся его настройкой.
Проверки
Для описания системы мониторинга Zabbix существует два ключевых понятия:
- Узлы сети — рабочие устройства и их группы (сервера, рабочие станции, коммутаторы), которые необходимо проверять. С создания и настойки узлов сети обычно начинается практическая работа с Zabbix.
- Элементы данных — набор самостоятельных метрик, по которым происходит сбор данных с узлов сети. Настройка элементов данных производится на вкладке «Элемент данных» или в автоматическом режиме — через подключение шаблона.
Сам Zabbix-агент способен отражать текущее состояние физического сервера, собирая совокупность данных. У него достаточно много метрик. С их помощью можно проверить загруженность ядра (Processor load), время ожидания ресурсов (CPU iowait time), объем системы подкачки (Total swap space) и многое другое.
В Zabbix существует целых 17 способов, дающих возможность собирать информацию. Указанные ниже, входят в число наиболее часто применяемых.
- Zabbix agent (Zabbix-агент) — сервер собирает информацию у агента самостоятельно, подключаясь по определенному интервалу.
- Simple check (Простые проверки) — простые операции, в том числе пинг.
- Zabbix trapper (Zabbix-траппер) — сбор информации с трапперов, представляющих собой мосты между используемыми сервисами и самой системой.
- Zabbix aggregate (Zabbix-комплекс) — процесс, предусматривающий сбор совокупной информации из базы данных.
- SSH agent (SSH-агент) — система подключается по SSH, использует указанные команды.
- Calculate (Вычисление) — проверки, которые система производит, сопоставляя имеющиеся данные, в том числе после предыдущих сборов.
У проверок есть заданные шаблоны (Templates), которые упрощают создание новых. Кроме обычных операций существует возможность регулярно проверять доступность веб-сервера с помощью имитации запросов браузера.
Проверка через пользовательский параметр
Чтобы выполнить проверку через агент, нужно прописать соответствующую команду в конфигурационный файл Zabbix-агента в качестве пользовательского параметра (UserParameter). Сделать это можно с помощью выражения следующего вида:
UserParameter=<ключ>,<команда>
Помимо самой команды, приведенный синтаксис содержит уникальный (в пределах узла сети) ключ элемента данных, который надо придумать самостоятельно и сохранить. В дальнейшем, ключ можно использовать для ссылки на команду, внесенную в пользовательский параметр, при создании элемента данных.
Пример
UserParameter=ping,echo 1
С помощью данной команды можно настроить агент на постоянное возвращение значения «1» для элемента данных с ключем «ping».
Дополнительные материалы по Zabbix
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Обзор
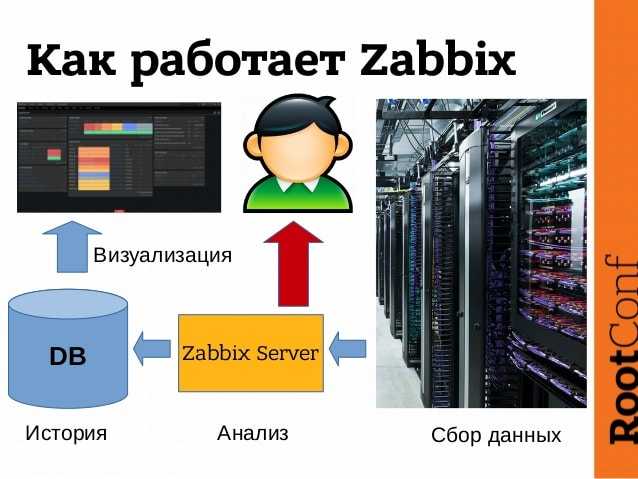
Систему создал Алексей Владышев на языке Perl. Впоследствии проект подвергся серьезным изменением, которые затронули и архитектуру. Zabbix переписали на C и PHP. Открытый исходный код появился в 2001 г., а уже через три года выпустили первую стабильную версию.
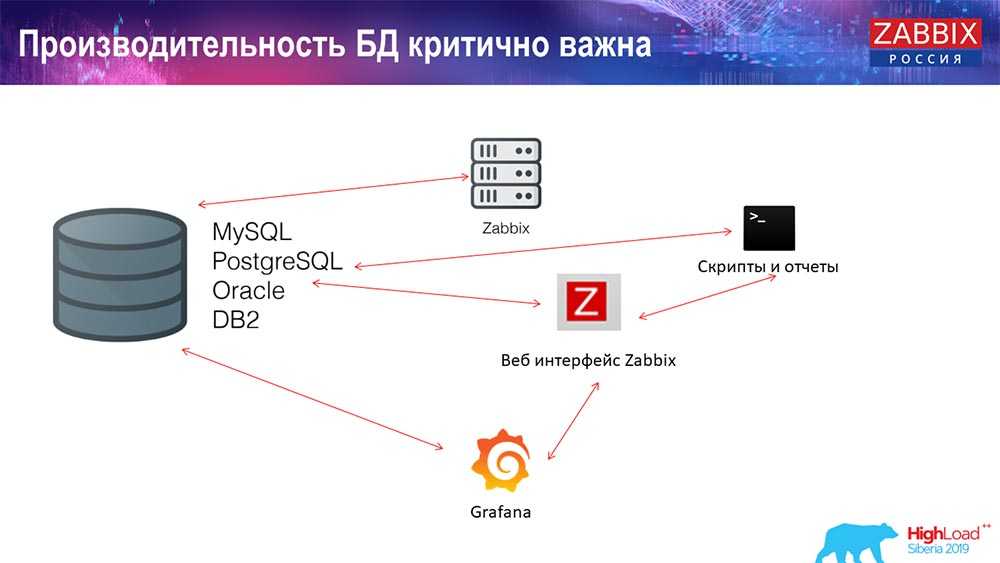
Веб-интерфейс Zabbix написан на PHP. Для хранения данных используются MySQL, Oracle, PostgreSQL, SQLite или IBM DB2.

На данный момент доступна система Zabbix 4.4. Скачать ее можно на официальном сайте. Там же можно найти официальные курсы и вебинары для начинающих пользователей системы.
Далее рассмотрим, из чего состоит и как работает технология Zabbix в доступном формате «для чайников».
Простое описание работы Zabbix
Система Zabbix это клиент-серверное решение. На всех контролируемых узлах должен быть установлен клиент (агент) который собирает данные для мониторинга узла.
Когда начнете изучать вы поймете что если описывать все доскональна, то статья получиться очень большая и нудная. Надеюсь из ниже сказанного основную суть вы поймёте.
Порты работы
Один из важных моментов который надо учитывать при настройке это знать на каких портах по умолчанию работает Zabbix.
Порта всего два:
- 10051 — по нему сервер получает данные от активных агентов. Порт должен быть открыть на сервере;
- 10050 — по нему сервер опрашивает клиентов и забирает данные. Порт должен быть открыть на клиенте.
Клиенты
Клиент может быть двух видов:
- Обычный агент — сервер получает доступ к узлу мониторинга и забирает данные;
- Активный агент — клиент сам отправляет данные серверу.
Далеко не сразу я смог разобраться в нюансах использования активного агента. Из статьи вы узнаете как правильно пользоваться мониторингом компьютеров которые не имеют статического IP адреса.
Шаблоны
Шаблоны это основа системы Zabbix. Разработчик добавил большое количество шаблонов для разных систем и настолько грамотно и взвешено подошел к их разработке, что они подходят под основные требования мониторинга. Кроме того, на просторах интернета вы можете встретить огромное количество шаблонов созданных пользователями. Для использования сторонних шаблонов вам достаточно загрузить их в свою систему и произвести минимальные настройки.
После добавления узла в систему мониторинга и зная операционную систему вам достаточно выбрать необходимый шаблон и узел подключен к мониторингу. Все параметры вы можете подкорректировать под свои требования.
В шаблоне основное понятие — элементы данных. В элементе данных указано какой параметр контролируется, по каким принципам и с указанием периода хранения данных в базе данных. Элементы данных можно группировать, что даёт удобство при выводе необходимых данных из огромной массы собираемых данных.
Для мониторинга кроме стандартных параметров существуют и те что невозможно указать в жестко. Например, количество и буквы разделов жестких дисков. Для этого в шаблоне присутствует раздел правила обнаружения в котором и указаны правила обнаружения жестких дисков, сетевых интерфейсов и служб (для Windows систем).
Триггеры
Триггеры это то на чем держится и в чем заключается вся прелесть мониторинга
В триггере указываются параметры при которых вы получите сообщение о изменении важного для вас контролируемого значения. Например, при большой нагрузке процессора, при маленьком количество свободной памяти на жестких дисках, и тд
и тп. В триггере указывается важность события. При добавлении нового триггера разработчик придумал конструктор выражения по которому можно составить необходимый вам вариант срабатывания триггера.
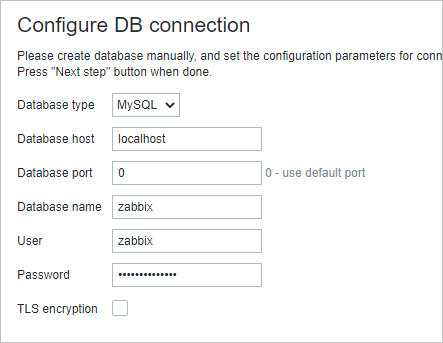
Настройка мониторинга на Zabbix сервере
Теперь идем на сервер. У меня Zabbix установлен на сервере CentOS, хотя это не принципиально. Добавляем новый Item. Пойти можно двумя путями:
- Создать template, в него добавить все items, создать триггеры, графики и назначить этот шаблон нужным серверам.
- К каждому серверу отдельно добавлять только необходимые итемы и вручную добавлять триггеры и графики.
Очевидно, что первым путем идти удобнее и разумнее. Я так и поступил, но в процессе реализации столкнулся с проблемой. Не все сервера имеют одинаковый набор датчиков. Где-то я не смог снять температуру с материнской платы, где-то вместо одного процессора, стояло два и хотелось снимать температуру с обоих камней. Как будет в вашем случае — не знаю. Если все серверы однотипные, то создавайте template, если все разные, то вручную добавляйте каждый итем на сервер. Я в итоге сделал и шаблон для одинотипных серверов, и вручную добавлял итемы туда, где имелись отличия от шаблона.
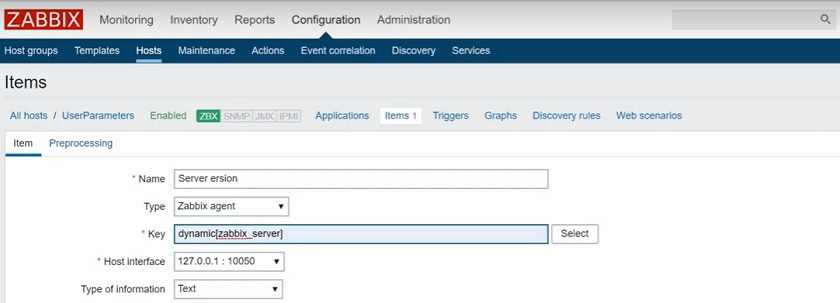
Итак, сначала создадим шаблон. Идем в Configurations — Templates — Create Template. Шаблон я назвал Temperature Windows. Добавил в него Application — Temperature, затем Item CPU Temperatue. Заполняем поля итема как у меня на картинке:
Параметр Temperature.CPU тот же самый, что и в файле конфигурации агента.




По аналогии создаем итем Mother Temperatue:
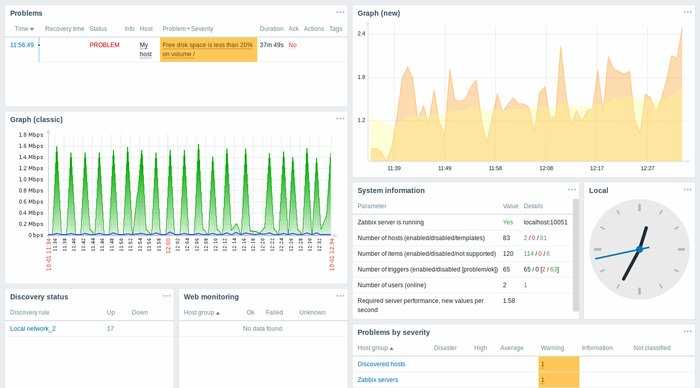
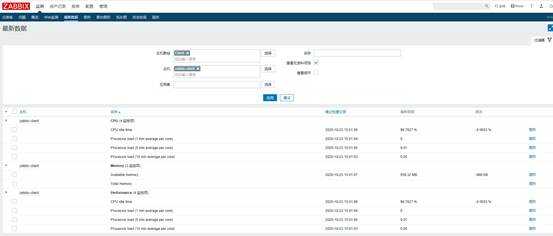
Сохраняем шаблон. По желанию создаем для него триггеры и графики. Можно и без них. Добавляем шаблон к серверу, который хотим мониторить. Ждем некоторое время и идем проверять входящие данные. Открываем Monitoring — Latest data:
Нажимаем graph и смотрим график:
Теперь добавим в Zabbix еще один сервер для мониторинга, который будет отличаться по конфигурации от предыдущего. На его примере я покажу, как менять настройки клиента и сервера. С этого сервера я не могу снять данные с датчика температуры материнской платы, по какой причине — не знаю, но не AIDA64 ни OpenHardwareMonitor мне температуру не показывают. Ее можно взять по SNTP с этого сервера, но это отдельная тема. В этом сервере 2 процессора и я хочу мониторить температуру обоих.
Запускаем GUI интерфейс и смотрим, какие датчики мы сможем мониторить:
Нас будет интересовать температура обоих ядер процессора. Теперь запускаем OpenHardwareMonitorReport.exe с выводом информации в текстовый файл. Смотрим, как выглядят строки с интересующей нас информацией:
| +- CPU Package : 59 59 59 (/intelcpu/0/temperature/6)
| +- CPU Package : 53 53 54 (/intelcpu/1/temperature/6)
Создаем два bat файла следующего содержания:
CPU1Temperature.bat
@echo off for /F "usebackq tokens=7-10" %%a in (`C:\OpenHardwareMonitor\OpenHardwareMonitorReport.exe`) do echo %%b %%c %%d| find "/intelcpu/0/temperature/6">nul && set temper=%%a echo %temper%
CPU2Temperature.bat
@echo off for /F "usebackq tokens=7-10" %%a in (`C:\OpenHardwareMonitor\OpenHardwareMonitorReport.exe`) do echo %%b %%c %%d| find "/intelcpu/1/temperature/6">nul && set temper=%%a echo %temper%
Редактируем конфигурационный файл zabbix_agentd.win.conf агента Zabbix на клиенте. Добавляем в конец две строки:
UserParameter=Temperature.CPU1, C:\OpenHardwareMonitor\CPU1Temperature.bat UserParameter=Temperature.CPU2, C:\OpenHardwareMonitor\CPU2Temperature.bat
Перезапускаем службу агента, чтобы изменения вступили в силу.
Дальше идем на сервер Zabbix и по аналогии с предыдущим сервером создаем там Итемы мониторинга. Причем итемы создаем не в шаблоне, а в конкретном сервере, который будем мониторить. Параметр key в этих итемах будет соответственно Temperature.CPU1 и Temperature.CPU2 Ждем некоторое время и проверяем результат.
Триггеры
Это логические выражения со значениями FALSE, TRUE и UNKNOWN, которые используются для обработки данных. Их можно создать вручную. Перед использованием триггеры возможно протестировать на произвольных значениях.
У каждого триггера существует уровень серьезности угрозы, который маркируется цветом и передается звуковым оповещением в веб-интерфейсе.
- Не классифицировано (Not classified) — серый.
- Информация (Information) — светло-синий.
- Предупреждение (Warning) — жёлтый.
- Средняя (Average) — оранжевый.
- Высокая (High) — светло-красный.
- Чрезвычайная (Disaster) — красный.
Некоторые функции триггеров
- abschange — абсолютная разница между последним и предпоследним значением (0 — значения равны, 1 — не равны).
- avg — среднее значение за определенный интервал в секундах или количество отсчетов.
- delta — разность между максимумом и минимумом с определенным интервалом или количеством отсчетов.
- change — разница между последним и предпоследним значением.
- count — количество отсчетов, удовлетворяющих критерию.
- date — дата.
- dayofweek — день недели от 1 до 7.
- diff — у параметра есть значения, где 0 — последнее и предпоследнее значения равны, 1 — различаются.
- last — любое (с конца) значение элемента данных.
- max\min — максимум и минимум значений за указанные интервалы или отсчеты.
- now — время в формате UNIX.
- prev — предпоследнее значение.
- sum — сумма значений за указанный интервал или количество отсчетов.
- time — текущее время в формате HHMMSS.
Прогнозирование
Триггеры обладают еще одной важной функцией для мониторинга — прогнозированием. Она предугадывает возможные значения и время их возникновения
Прогноз составляется на основе ранее собранных данных.
Анализируя их, триггер выявляет будущие проблемы, предупреждает администратора о возникшей вероятности. Это дает возможность предотвратить пики нагрузки на оборудование или заканчивающееся место на жестком диске.


Функционал прогнозирования добавили с обновлением системы 3.0, вышедшим в феврале 2016 года.
Алексей Владышев ( alexvl )
Zabbix
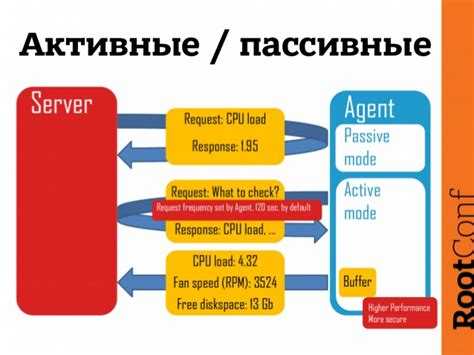
- это уровень железа – что-то произошло с какой-то железякой, мы тут же об этом узнаем,
- уровень операционной системы,
- сеть, в основном это мониторинг через SNMP,
- виртуальный уровень, т.е. «из коробки» мы предлагаем, например, мониторинг WMware инфраструктуры, vCenter и vSphere,
- дальше идет middleware,
- бизнес-приложения.
это работает быстро, по крайней мере, быстрее, т.к
сервер не должен заниматься постоянным опрашиванием устройств, сами устройства отправляют информацию,
более безопасно с точки зрения агента, потому что агент не должен слушать никакие TCP-соединения или сетевые соединения.
небольшое преимущество, то, что нам сегодня важно – в активном режиме есть буферизация. Если Zabbix-сервер недоступен по каким-то причинам, допустим, мы делаем апгрейд Zabbix-сервера, у нас downtime несколько минут, то данные будут накапливаться на стороне агента
Как только мы сервер запускаем, данные тут же отправятся на сторону сервера, и мы их сможем обрабатывать.
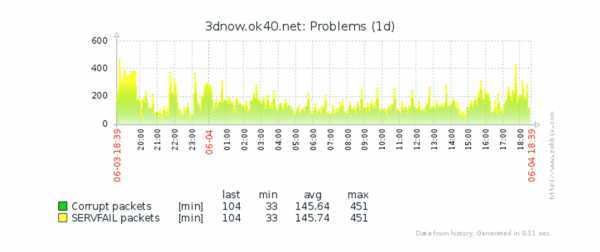
История. Мы основываем свое решение не только на real-time мониторинге, на оперативной информации, которую мы только-только получили, но и смотрим в историю. В историю нужно обязательно смотреть
Это важно.
Отсутствие проблемы – не есть ее решение. Я привел несколько примеров, но на самом деле, вы многие используете Zabbix, посмотрите критическим взглядом на те триггеры, которые у вас сейчас есть
Комбинация анализа истории с гистерезисом, с разными условиями для проблемы и для выхода из проблемы – она на самом деле творит чудеса. Получается такое очень-очень умное обнаружение проблем. Нужно обязательно использовать эту функциональность.
С аномалиями, опять же, мне трудно сказать, принесет ли это какую-то практическую пользу, но, по крайней мере, стоит попробовать. Что касается аномалии, в Zabbix 3.0, возможно, мы реализуем baseline monitoring. Что это означает? Baseline – это некая норма, т.е. этот baseline будет высчитываться из трендов. Если сейчас все триггеры работают с историей, то для baseline мониторинга мы будем брать информацию из трендов, из тенденций, и будет возможность, например, сравнивать поведение системы в рабочее время на прошлой неделе с поведением системы на этой неделе или сегодня. Т.е. мы что-то будем брать за основу, за нормальную ситуацию и сравнивать с тем, что есть сейчас. Это такой статистический анализ, основанный на тенденциях, на трендах.
Автоматическое решение проблем. Наверное, у каждого из вас, если вы используете систему мониторинга, есть такой класс проблем, про который вы знаете, что эта проблема произойдет рано или поздно, и с этим ничего нельзя сделать. Я привел примеры каких-то случайных падений операционной системы – мы знаем, что такая проблема есть, она может произойти в любое время, соответственно, автоматическое решение проблем – это хорошее решение.
И эскалируем проблемы. Отличный стимул для администраторов, если мы делаем эскалирование. Эскалирование не означает, что вот есть администратор, начальник, начальник начальника, начальник начальника начальника… Эскалирование – это означает, что мы сможем среагировать на проблему сразу одним способом, дальше попытаться, может быть, автоматически решить ее другим способом, и дальше, может быть, через 5 минут, если проблема все еще существует, попытаться решить ее следующим способом. Сначала мы перезапускаем сервис, проблема все еще существует, скажем, exchange не завелся с первого раза, что мы тогда можем сделать? Мы можем перезапустить сервер на физическом уровне и тогда уже смотреть, что произойдет.





