Введение
Я не буду подробно останавливаться на том, зачем может понадобиться забирать данные из метрики в Zabbix, если в самой метрике есть отличный интерфейс с возможностью быстро создавать отчеты на любой вкус. Дублировать функционал метрики нет никакого смысла. Лично я использую самые простые данные о посещаемости сайтов на своем дашборде, чтобы не ходить за ними в метрику, так как там тяжелый интерфейс, который долго грузится. Раньше я для этих целей использовал виджеты на главной Яндекса, но они закрыли этот функционал, чтобы ты быстрее постиг помойку Дзена, который они всячески пихают на главной.
Введение
Задача по мониторингу времени на сервере на первый взгляд кажется тривиальной, но с ней не все так просто. Я несколько раз брался за эту задачу и не доводил ее до конца. Сейчас уже не помню всех подробностей, так как поделиться решил финальной версией, которая уже некоторое время у меня функционирует. Основная проблема там в том, что время с агента берется в один момент, а время заббикс сервера берется в другой момент. И когда они сравниваются, может быть большое расхождение именно потому, что бралось время для сравения в разные моменты, а не потому, что время реально расходится.
Сравнение времени идет между временем сервера zabbix и локальным временем на сервере, где установлен агент, с помощью встроенной функции fuzzytime. Я для себя решил, что мне достаточно проверять время раз в минуту. Если расхождение будет более 60 секунд в трех последних проверках, то срабатывает триггер.
Теоретически, к этому триггеру можно прицепить action, который будет что-то исполнять на сервере. К примеру, запуск утилиты ntpdate для синхронизации времени. Но я не стал это настраивать, так как на всех серверах у меня всегда работает служба ntpd или chrony. Так что если время неактуальное, то надо идти на сервер и проверять, что со службой синхронизации времени.
Приступаем к настройке.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Методика мониторинга времени ответа сервера
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Принципиальной разницы где у вас работает сервер мониторинга zabbix нет. Я не буду останавливаться на этом моменте. Далее я считаю, что вы уже настроили мониторинг сайта по приведенной ранее статье. Дам некоторые рекомендации по ее поводу на основе последнего опыта:
Лучше всего создавать шаблон web мониторинга, а не настраивать его на конкретном агенте. Совет этот универсальный для любых метрик, но именно для web мониторинга он более актуальный. Так вы сможете оперативно запускать проверки сайта с разных серверов, где установлены агенты забикса. Плюс, через экспорт шаблона вы легко сможете перенести мониторинг на другой сервер
Это очень важно, так как если у вас многоходовый мониторинга сайта, вручную его переносить на другой сервер очень хлопотно.
У заббикса есть свои внутренние таймауты. Иногда я вижу в полученных данных значения, которые сильно выбиваются из общей картины
Например, у вас среднее время отклика сайта 200-300 мс. Иногда вы будете видеть на графике всплески до 1500 мс, 2500 мс, 3500 мс. Значения будут кратны одной секунде. Я не нашел подробной информации, как именно заббикс делает мониторинг сайта. Я думаю, что свыше какой-то задержки, он ждет секунду, пробует снова и так далее
Эти данные не стоит брать в расчет.
Не стоит обращать внимание на абсолютные цифры. Все системы измеряют время отклика по-разному
В вебмастере яндекса вы увидите одно значение времени отклика сервера, в его же яндекс.метрике другое, гугл покажет третье, а заббикс четвертное. Отличаться эти значения могут существенно, в 2-3-4 раза. Я использую мониторинг времени отклика сайта в заббиксе для отслеживания динамики. К примеру, вы решили переехать на новый web сервер. Нужно как-то оценить его быстродействие. Вы сравниваете значения в мониторинге на старом сайта, потом на новом и делаете выводы.
По последнему пункту приведу простой пример из недавнего опыта. Я подготовил новый веб сервер. Нужно было оценить, насколько он быстрее работает на том же сайте, чем предыдущий. Я развернул сайт на новом сервере, поправил в файле hosts на сервере с заббикс агентом ip адрес сайта, направив запросы на новый web сервер. Получилась такая картинка.
Сначала идет мониторинг реального сайта на текущем сервере, потом я переключаю запросы zabbix на новый сервер. Убедившись, что сайт на новом веб сервере отвечает быстрее, переключаю мониторинг обратно на старый сервер.
Понятно, что тест очень условный. Новый сервер стоит без нагрузки, отвечает стабильно, без пилы на графике. И тем не менее, я понимаю, что на нем будет лучше. Зачастую время отклика сайта зависит от факторов, которые вы не можете оценить заранее:
- Сетевую систему хостера
- Отклик жестких дисков
- Загруженность ноды виртуальных машин, если переезжаете на VDS.
Вы можете заказать сервер с хорошими параметрами по железу, но не получить быстрого отклика сайта по независящим от вас причинам. С этим столкнулся не так давно, когда пробовал использовать веб сервер у облачного провайдера. На словах все красиво — гибкая настройка параметров, отказоустойчивость, удобный бэкап и т.д. В общем, все то, чем хвалят облака. А на деле время отклика сайта было 300-400 мс при типовых настройках веб сервера. Использовался самый дорогой и быстрый тип диска. На выделенном бюджетном сервере при тех же настройках отклик был 100 мс.
Несмотря на всю условность подобного теста, он отвечает на поставленный вопрос — будет ли сайт после переезда на новый сервер отвечать быстрее. Я несколько раз проверял данную методику, в том числе и на своем сайта, не так давно переехав на новое место, так как старый виртуальный сервер стал работать заметно медленнее.
Меркурий 236
добрые людирешениеммодуль
UserParameter
UserParameterZabbix trapperВнешние проверки
Настроим получение наших метрик счетчика
- Тип: Зависимый элемент данных
- Основной элемент данных: mercury-get
jsonpath.com
- Тип: Зависимый элемент данных
- Основной элемент данных: mercury-get
- будем использовать нотацию с квадратными скобками, так как в пути JSON есть дефис
- препроцессинг может быть многошаговым, например здесь результата первого шага умножим на 1000, чтобы получить Вт*ч из кВт*ч
Что получилось
здесь
- переиспользовали хорошую программку и не тратили время на написание своей реализации сбора данных по протоколу Меркурий
- UserParameter остался, но схлопнулся до простого вызова. По сути можно даже использовать
- cкрипты-обертки тоже не писали. Всё распарсили через JSON path в шаблоне
- cчетчик не мучали сильно, один запрос – все нужные нам данные разом.
А в чем была собственно проблема?
- медленные запуски утилит каждый раз, на каждый нужный элемент данных
- обращение к ресурсу (диск, порт, счетчик, API приложения) на каждый элемент данных
- парсинг результата нужно было делать внешними скриптами/утилитами
- а если потом нужно было поправить парсинг – приходилось опять обновлять UserParameters или скрипты
- кроме всего прочего, одновременные запросы от нескольких Zabbix pollers приводили к ошибке при обращении, например, к последовательному порту.
зависимых элементов данных
- В Zabbix 3.4 источником данных может выступать другой элемент данных, который называется родительским или мастер-элементом. Такой элемент может, например, содержать массив данных в формате JSON, XML или произвольном текстовом формате.
- В момент поступления новых данных в родительский элемент, остальные элементы данных, которые называются зависимыми, обращаются к родительскому элементу и при помощи таких как JSON path, XPath или Regex выделяют из текста нужную метрику.
шаблон для сервера
Может лучше на практике?
Нет ничего проще  Давайте для примера попробуем настроить мониторинг JBoss EAP 6.4.
Давайте для примера попробуем настроить мониторинг JBoss EAP 6.4.

Для начала сделаем несколько предположений:
- Вы уже установили Zabbix 3.4 и Zabbix Java Gateway. Если еще нет, то вы можете сделать это в соответствии с документацией Zabbix.
- Zabbix Server и Java Gateway с префиксом /usr/local/.
- JBoss уже установлен в /opt/jboss-eap-6.4/ и запускается в standalone режиме.
- Для простоты эксперимента будем считать, что все эти компоненты работают на одной и той же машине.
- Firewall и SELinux отключены (или настроены соответствующим образом, но это выходит за рамки статьи).
Сделаем несколько простых настроек в zabbix_server.conf:
И в конфиге zabbix_java/settings.sh (или zabbix_java_gateway.conf):
Проверьте, что JBoss слушает свой стандартный management port:
Теперь давайте создадим в Zabbix хост с JMX интерфейсом 127.0.0.1:9999.
Если мы сейчас просто возьмём стандартный шаблон «Template App Generic Java JMX» и прилинкуем его к хосту, то наверняка получим ошибку:
Java Gateway сообщает нам, что по указанному endpoint отвечает совсем не RMI. Хорошо, мы уже знаем, что эта версия JBoss использует протокол JBoss Remoting вместо RMI, и нам нужно лишь начать стучаться в правильный endpoint.
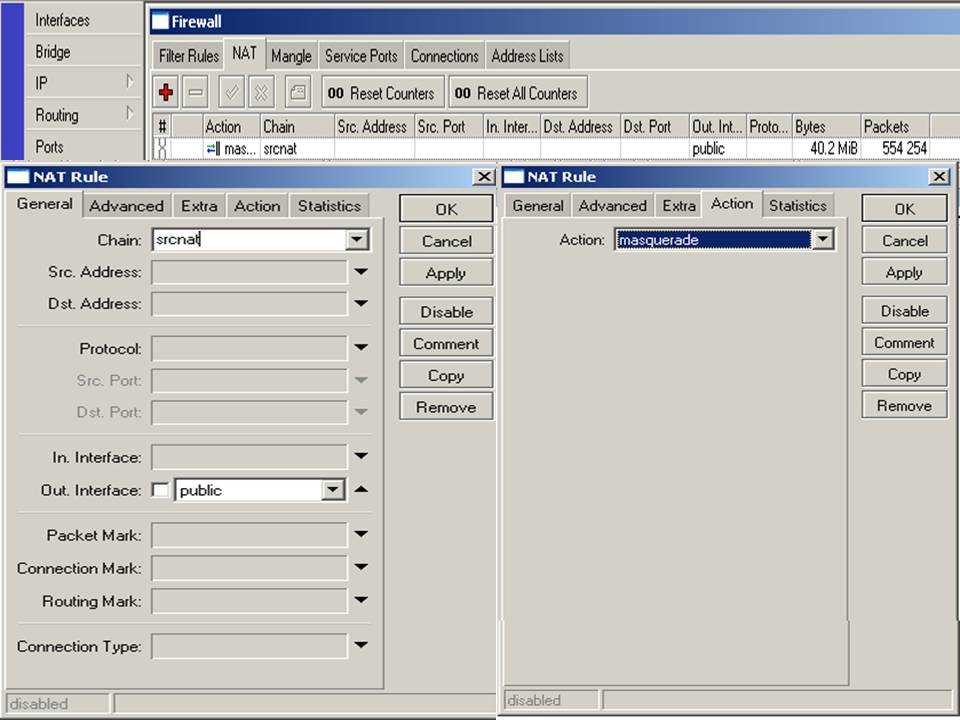
Давайте сделаем Full Clone шаблона «Template App Generic Java JMX» и назовём его «Template App Generic Java JMX-remoting». Выделим все элементы данных внутри этого шаблона и выполним операцию Mass update для параметра JMX endpoint. Пропишем такой URL:
Обновим конфигурационный кэш:
И снова ошибка.
Что на этот раз?
“Unsupported protocol: remoting-jmx” означает, что Java Gateway не умеет работать с указанным протоколом. Что ж, давайте его научим. В этом нам поможет совет из статьи «JBoss EAP 6 monitoring using remoting-jmx and Zabbix».
Создадим файл ~/needed_modules.txt со следующим содержимым:
Выполним команду:
Таким образом, Java Gateway будет иметь все необходимые модули для работы с jmx-remoting. Остаётся лишь перезапустить Java Gateway, немного подождать и, если вы всё сделали правильно, увидеть, что заветные данные начали поступать в Zabbix:
Онлайн курсы по Mikrotik
Если у вас есть желание научиться работать с роутерами микротик и стать специалистом в этой области, рекомендую пройти курсы по программе, основанной на информации из официального курса MikroTik Certified Network Associate. Помимо официальной программы, в курсах будут лабораторные работы, в которых вы на практике сможете проверить и закрепить полученные знания. Все подробности на сайте . Стоимость обучения весьма демократична, хорошая возможность получить новые знания в актуальной на сегодняшний день предметной области. Особенности курсов:
- Знания, ориентированные на практику;
- Реальные ситуации и задачи;
- Лучшее из международных программ.
Whois клиент для Node.js
Последнее рассмотренное мной консольное решение по получению данных whois основывается на клиенте для Node.js. Этот способ неудобен, как и с ruby, тем, что надо отдельно ставить node на сервер. Если python на centos сервере точно будет, то node придется ставить отдельно. Сделаем это.
# curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash - # yum install nodejs
Устанавливаем whois client:
# npm install whois
Под node.js я программировать вообще не умею и со скриптами не работал никогда. Так что готового скрипта для zabbix не сделал. Покажу на простом примере, как выполнять проверку. Делаем скрипт и в нем сразу указываем домен для проверки.
var whois = require('whois')
whois.lookup('serveradmin.ru', function(err, data) {
console.log(data)
})
Запускаем его:
# node domain-left.js
В выводе увидите привычную информацию whois в таком же виде, как и для остальных проверок. Если бы этот способ проверял все необходимые мне домены, я бы его доделал. Он понимает домены .pro и .io, но не понимает .fm. Так что я не стал на нем подробно останавливаться.
А в чем была собственно проблема?
- медленные запуски утилит каждый раз, на каждый нужный элемент данных
- обращение к ресурсу (диск, порт, счетчик, API приложения) на каждый элемент данных
- парсинг результата нужно было делать внешними скриптами/утилитами
- а если потом нужно было поправить парсинг – приходилось опять обновлять UserParameters или скрипты
- кроме всего прочего, одновременные запросы от нескольких Zabbix pollers приводили к ошибке при обращении, например, к последовательному порту.
зависимых элементов данных
- В Zabbix 3.4 источником данных может выступать другой элемент данных, который называется родительским или мастер-элементом. Такой элемент может, например, содержать массив данных в формате JSON, XML или произвольном текстовом формате.
- В момент поступления новых данных в родительский элемент, остальные элементы данных, которые называются зависимыми, обращаются к родительскому элементу и при помощи таких как JSON path, XPath или Regex выделяют из текста нужную метрику.
шаблон для сервера
Дополнительные материалы по Zabbix
Онлайн курс Основы сетевых технологий
Теоретический курс с самыми базовыми знаниями по сетям. Курс подходит и начинающим, и людям с опытом. Практикующим системным администраторам курс поможет упорядочить знания и восполнить пробелы. А те, кто только входит в профессию, получат на курсе базовые знания и навыки, без воды и избыточной теории. После обучения вы сможете ответить на вопросы:
![Сервис_zabbix [методические материалы лохтурова вячеслава]](https://tehnikaarenda.ru/wp-content/uploads/a/0/b/a0b88d133f37a7ada42bf2ff37da997c.jpeg)

- На каком уровне модели OSI могут работать коммутаторы;
- Как лучше организовать работу сети организации с множеством отделов;
- Для чего и как использовать технологию VLAN;
- Для чего сервера стоит выносить в DMZ;
- Как организовать объединение филиалов и удаленный доступ сотрудников по vpn;
- и многое другое.
Уже знаете ответы на вопросы выше? Или сомневаетесь? Попробуйте пройти тест по основам сетевых технологий. Всего 53 вопроса, в один цикл теста входит 10 вопросов в случайном порядке. Поэтому тест можно проходить несколько раз без потери интереса. Бесплатно и без регистрации. Все подробности на странице .
| Рекомендую полезные материалы по Zabbix: |
| Настройки системы |
|---|
Видео и подробное описание установки и настройки Zabbix 4.0, а также установка агентов на linux и windows и подключение их к мониторингу. Подробное описание обновления системы мониторинга zabbix версии 3.4 до новой версии 4.0. Пошаговая процедура обновления сервера мониторинга zabbix 2.4 до 3.0. Подробное описание каждого шага с пояснениями и рекомендациями. Подробное описание установки и настройки zabbix proxy для организации распределенной системы мониторинга. Все показано на примерах. Подробное описание установки системы мониторинга Zabbix на веб сервер на базе nginx + php-fpm. |
| Мониторинг служб и сервисов |
Мониторинг температуры процессора с помощью zabbix на Windows сервере с использованием пользовательских скриптов. Настройка полноценного мониторинга web сервера nginx и php-fpm в zabbix с помощью скриптов и пользовательских параметров. Мониторинг репликации mysql с помощью Zabbix. Подробный разбор методики и тестирование работы. Описание настройки мониторинга tcp служб с помощью zabbix и его инструмента простых проверок (simple checks) Настройка мониторинга рейда mdadm с помощью zabbix. Подробное пояснение принципа работы и пошаговая инструкция. Подробное описание мониторинга регистраций транков (trunk) в asterisk с помощью сервера мониторинга zabbix. Подробная инструкция со скриншотами по настройке мониторинга по snmp дискового хранилища synology с помощью сервера мониторинга zabbix. |
| Мониторинг различных значений |
Настройка мониторинга web сайта в zabbix. Параметры для наблюдения — доступность сайта, время отклика, скорость доступа к сайту. Один из способов мониторинга бэкапов с помощью zabbix через проверку даты последнего изменения файла из архивной копии с помощью vfs.file.time. Подробное описание настройки мониторинга размера бэкапов в Zabbix с помощью внешних скриптов. Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены. Пример распознавания и мониторинга за изменением значений в обычных текстовых файлах с помощью zabbix. Описание мониторинга лог файлов в zabbix на примере анализа лога программы apcupsd. Отправка оповещений по событиям из лога. |
Получение доступа к API Яндекс
Вам нужно будет заполнить несколько обязательных полей:
- Название приложения.
- В качестве платформы указать Веб-сервисы.
- Callback URI установить — https://oauth.yandex.ru/verification_code.
- В Доступах указать: Яндекс.Метрика, Получение статистики, чтение параметров своих и доверенных счетчиков.
Все остальное можно не указывать. Вы должны получить ID приложения и Пароль.
После разрешения, вы получите токен, с помощью которого можно подключаться к api.
Используя этот токен, можно получать данные из Метрики через API. Для примера зайдем на сервер мониторинга и через консоль запросим данные о посещаемости сайта. Для этого нам нужно узнать номер его id в метрике. Можно это сделать прямо в ней же.
Далее формируем запрос через curl с указанием токена в header.
# curl --header "Authorization: OAuth AgAAaaaaaaaaaaaDDDDDDDDDddd" --header "Content-Type: application/x-yametrika+json" -X GET "https://api-merika.yandex.ru/stat/v1/data?&ids=23506456&metrics=ym:s:users,ym:s:visits,ym:s:pageviews&dimensions=&date1=today&pretty=true"
В данном запросе я указал:
- AgAAAAAAGk3WAAaaYZaUSgzNyU7uvqAKCGwDSro — токен;
- ids=23506456 — id сайта в метрике;
- metrics=ym:s:users,ym:s:visits,ym:s:pageviews — запрошенные метрики — пользователи, визиты, просмотры страниц;
- date1=today — дата, сегодняшний день в данном случае;
- pretty=true — вывести в формате удобочитаемого json.
Получили ответ в виде подробного json. Он отлично подходит для zabbix, так как последний умеет из коробки парсить json. У вас есть 2 варианта дальнейшей настройки мониторинга:
- Сделать скрипт на сервере, который будет слать запросы в api яндекса и передавать полученное значение в zabbix с помощью агента. Плюс решения в том, что нагрузка на сервер мониторинга минимальная. Неудобство в том, что нужно куда-то добавлять скрипт.
- Слать запросы к api напрямую с zabbix сервера с помощью HTTP Агента. И сразу там же парсить полученный ответ. Плюс этого подхода в том, что все настройки хранятся в шаблоне и легко сохраняются или переносятся через экспорт шаблона. Минус в том, что все вычисления и запросы выполняются самим заббиксом.
Я обычно иду по второму пути, потому что так удобнее.
В таком виде это можно отправлять в Zabbix, чем мы далее и займемся.
Настройка в zabbix мониторинга nginx
В прошлой редакции этой статьи дальше шло описание скрипта, который будет парсить вывод nginx-status и передавать данные в zabbix. Сейчас все можно сделать гораздо проще и удобнее. На агенте не надо ничего настраивать. Все выполняется исключительно в шаблоне. То есть вам достаточно загрузить готовый шаблон для мониторинга nginx на zabbix сервер, прикрепить его к хосту и все будет работать.
Это удобный подход, который избавляет от необходимости настраивать агентов. Теперь все выполняется с сервера. Минус этого подхода только в том, что возрастает нагрузка на сервер мониторинга. Это плата за удобство и централизацию. Имейте это ввиду. Если у вас большая инсталляция мониторинга и есть средства автоматизации типа ansible, возможно вам имеет смысл по старинке парсить данные скриптом. Но в общем случае я рекомендую делать так, как я расскажу далее.
Суть мониторинга Nginx будет сводиться к тому, что мы через агента станем забирать страницу http://localhost/nginx-status на сервер. Там с помощью регулярных выражений и зависимых элементов данных будем формировать нужные метрики.
Представляю вам готовый шаблон для мониторинга nginx. Скачиваем его zabbix-nginx-template.xml и открываем web интерфейс zabbix сервера. Идем в раздел Configuration -> Templates и жмем Import:


Выбираем файл и снова нажимаем Import:
Шаблон я подготовил сам на основе своих представлений о том, что нужно мониторить. Проверил и экспортировал его с версии 4.2 Регулярные выражения для парсинга html страницы статуса подсмотрел тут — https://github.com/AlexGluck/ZBX_NGINX. К представленному шаблону я добавил некоторые итемы и переделал все триггеры. Плюс убрал макросы. Не вижу в них в данном случае смысла.
В шаблоне 11 итемов, описание которых я привел ранее.
Подробнее остановимся на триггерах. Их 5 штук.
- Many active connections — срабатывает если среднее количество соединений за последние 10 минут больше в 3 раза, чем среднее количество за интервал на 10 минут ранее.
- many requests и too many requests — срабатывают, когда среднее количество запросов за последние 10 минут больше в 3 и 6 раз соответственно, чем на 10 минут ранее.
- nginx is not running — тут все просто. Если не запущен ни один процесс nginx, шлем уведомление.
- nginx is slow to respond — срабатывает если время выполнения запроса на получение страницы со статусом за последние 10 минут больше предыдущих 10 минут в 2 раза.
С триггерами больше всего вопросов. Предложенная мной схема может работать независимо от проекта, не требует начальной калибровки, но могут быть ложные срабатывания из-за разовых очень сильных всплесков, которые быстро проходят, но сильно меняют средние параметры на интервале.
Более надежно могут сработать триггеры, где явно указаны лимиты в конкретных значениях. Но такой подход требует ручной калибровки на каждом проекте в отдельности. Надо смотреть средние значения метрик и выставлять лимиты в зависимости от них. Если проект будет расти, то лимиты постоянно придется менять. Это тоже не очень удобно и не универсально.
Я в итоге остановился на анализе средних значений, не используя конкретных лимитов. Как поступать вам, решайте отдельно, в зависимости от ситуации. Если у вас один проект, которому вы уделяете много внимания, то ставьте лимиты руками на основе анализа средних параметров. Если работаете на потоке с множеством проектов, то можно использовать мой вариант, он более универсален и не требует ручной правки.
Единственное, коэффициенты можно поправить, если будут ложные срабатывания. Но я обычно этот момент решаю через отложенные уведомления. Если чувствительность триггера очень высокая и есть кратковременные ложные срабатывания, меня они не беспокоят из-за 5-ти минутной задержки уведомлений. Зато при разборе инцидентов, эти кратковременные срабатывания помогают оценить ситуацию в целом.
С мониторингом nginx почти все готово. Теперь нам нужно прицепить добавленный шаблон к web серверу, который мы мониторим и дождаться поступления данных. Проверить их можно в Monitoring -> Latest Data:
В шаблоне есть несколько графиков. Не буду о них рассказывать, так как последнее время практически не пользуюсь графиками. Вместо этого собираю дашборды. Это более удобно и информативно. Жаль, что дашборды нельзя к шаблонам прикреплять. Очень хлопотно каждый раз вручную их составлять и тратить время. В конце покажу пример дашборда, который я использую для мониторинга web сервера.
На этом настройка мониторинга nginx закончена, можно пользоваться.
Заключение
Я показал простейший пример работы с json для тех, кто никогда не использовал его в zabbix. Благодаря тому, что в какой-то не очень давней версии появились зависимые элементы, работа с мониторингом сильно упростилась. Первое, что мне пришло в голову, когда нужно было выбрать отдельные значения из json вывода — написать баш скрипт. Это не сложно, я бы быстро распарсил и вытащил те данные, что мне нужны. Но вспомнив про зависимые элементы и возможность обработки данных в самом заббиксе, решил посмотреть в эту сторону и не ошибся. Так действительно проще и удобнее. За нас уже все сделали разработчики.
Скорее всего вам понадобится не просто парсинг json файла, но и автообнаружение на основе данных из него и автоматическое создание итемов. Но это уже тема отдельной статьи. А на сегодняшний момент это все, что я хотел рассказать, пока выдалась возможность поделиться информацией.
Итоги интеграции
На этом это пока все, что мы успели сделать за месяц активной работы с Zabbix.
Оценим трудозатраты…
-
Мы работаем по SCRUM’у, поэтому разработка интеграции у нас заняла четыре спринта – четыре недели (спринты у нас длятся одну неделю).
-
Оповещения в Telegram и дашборды в Grafana заработали уже после двух первых спринтов.
-
Работали над проектом два программиста 1С и затратили 16,5 ч/ч разработки.
С какими трудностями интеграции и настройки Zabbix мы столкнулись?
-
Как я уже упоминал, в оповещениях можно использовать только метрики присутствующие в выражении триггера, из-за этого выражения превращаются в нечитаемую простыню неравенств.
-
Второе – это то, что в оповещении можно использовать только 9 метрик, и уже были кейсы, когда из-за этого ограничения оповещение приходилось разбивать на несколько.
-
Третье – это назначение прав только группе пользователей на группу узлов, из-за этого человеку, который управляет одной точкой, нужно создавать отдельную группу узлов сети и отдельную группу пользователей.
-
Ну и последнее – в метрике может храниться только одно значение. Архитектурно мне понятно, почему так сделано в Zabbix, но из-за этого приходится создавать одну метрику, считающую количество, например, претензий, а второй метрикой запрашивать темы этих претензий, чтобы не просто оповещать что у вас новая претензия, а давать пользователю хотя бы часть информации – о чем эта претензия. И было бы намного проще, если бы в метрике хранилось значение + какой-то комментарий.
-




Но все это было не критично, поэтому перейдем к подведению итогов интеграции.
За счет справочника метрик в 1С можно получить абсолютно любую информацию из базы данных, при этом не надо обновлять конфигурацию.
Благодаря этому, меньше чем за месяц у нас появилось более ста метрик.
Удобное устройство шаблонов в Zabbix и макросы позволили подключать новые города с 50 точками за 20 минут.
За счёт этого мониторинг уже работает более чем на 300 точках.
Получившийся инструмент полезен не только для операционного отдела, но и для других. Например:
-
тех. поддержка использует для мониторинга времени обработки заказов с сайта;
-
программисты каждое утро после ночного обновления проверяют, не полезли ли ошибки в регламентных заданиях.
Это позволило выявлять проблемы раньше, чем это заметят пользователи, увеличивая уровень предоставляемых сервисов.
За счет автоматизации контроля состояния точек, получилось сократить количество сотрудников, занимающихся этим до появления Zabbix.
Раньше они следили за временем отдачи на точках, временем доставки, открывали и закрывали сбои в 1С, повышали время и останавливали работу точек в экстренных ситуациях и т.д. Теперь все это делает Zabbix.