
Удаление массива
При удалении массива внимателнее смотрите на имена массива и дисков и подставляйте свои значения.
Если нам нужно полностью разобрать RAID, сначала размонтируем и остановим его:
umount /mnt
* где /mnt — каталог монтирования нашего RAID.
mdadm -S /dev/md0
* где /dev/md0 — массив, который мы хотим разобрать.
* если мы получим ошибку mdadm: fail to stop array /dev/md0: Device or resource busy, с помощью команды lsof -f — /dev/md0 смотрим процессы, которые используют раздел и останавливаем их.
Затем очищаем суперблоки на всех дисках, из которых он был собран:
mdadm —zero-superblock /dev/sdb
mdadm —zero-superblock /dev/sdc
mdadm —zero-superblock /dev/sdd
* где диски /dev/sdb, /dev/sdc, /dev/sdd были частью массива md0.
А также удаляем метаданные и подпись:
wipefs —all —force /dev/sd{b,c,d}
Задание 3 (Добавление новых дисков и перенос раздела)
Это самое сложное и объемное задание из всех представленных. Очень внимательно проверяйте что вы делаете и с какими дисками и разделами. Рекомендуется снять копию перед его выполнением. Это задание независимо от задания №2, его можно выполнять после задания №1 с поправкой на имена дисков.
Вторая часть задания этой лабораторной должна привести в точно такое же состояние которое было после выполнения первой части.
Для того чтобы вам было проще работать могу рекомендовать не удалять физически диски с хостовой машины, а только лишь отсоединять их в свойствах машины. С точки зрения ОС в ВМ это будет выглядеть абсолютно одинаково, но вы сможете в случае чего подключить диск обратно и продолжить выполнение работы откатившись на пару пунктов назад, в случае если у вас возникли проблемы. Например вы могли выполнить неверно или забыть скопировать на новый диск раздел /boot. Я могу лишь посоветовать несколько раз перепроверять с какими дисками и разделами вы работаете, а еще лучше выписать на листочек соответствие дисков, разделов и «физическому» номеру диска. Красивое и понятное дерево рисует команда , пользуйтесь ей как можно чаще для анализа того что вы сделали и что нужно сделать.
К истории…
Представьте себе что ваш сервер работал долгое время на 2-х ssd дисках, как вдруг…
Восстановление RAID
Рассмотрим два варианта восстановлении массива.
Замена диска
В случае выхода из строя одного из дисков массива, команда cat /proc/mdstat покажет следующее:
cat /proc/mdstat
Personalities :
md0 : active raid1 sdb
1046528 blocks super 1.2 [2/1]
* о наличии проблемы нам говорит нижнее подчеркивание вместо U — вместо .
Или:
mdadm -D /dev/md0
…
Update Time : Thu Mar 7 20:20:40 2019
State : clean, degraded
…
* статус degraded говорит о проблемах с RAID.
Для восстановления, сначала удалим сбойный диск, например:
mdadm /dev/md0 —remove /dev/sdc
Теперь добавим новый:
mdadm /dev/md0 —add /dev/sde
Смотрим состояние массива:
mdadm -D /dev/md0
…
Update Time : Thu Mar 7 20:57:13 2019
State : clean, degraded, recovering
…
Rebuild Status : 40% complete
…
* recovering говорит, что RAID восстанавливается; Rebuild Status — текущее состояние восстановления массива (в данном примере он восстановлен на 40%).
Если синхронизация выполняется слишком медленно, можно увеличить ее скорость. Для изменения скорости синхронизации вводим:
echo ‘10000’ > /proc/sys/dev/raid/speed_limit_min
* по умолчанию скорость speed_limit_min = 1000 Кб, speed_limit_max — 200000 Кб. Для изменения скорости, можно поменять только минимальную.
Пересборка массива
Если нам нужно вернуть ранее разобранный или развалившийся массив из дисков, которые уже входили в состав RAID, вводим:
mdadm —assemble —scan
* данная команда сама найдет необходимую конфигурацию и восстановит RAID.
Также, мы можем указать, из каких дисков пересобрать массив:
mdadm —assemble /dev/md0 /dev/sdb /dev/sdc
Теория: Уровни RAID и принципы восстановления данных
Чаще всего сейчас используются массивы уровней 0, 1, 10, 5, 50. В последнее время наблюдается возрастающий интерес к шестому уровню.
Ниже приведена краткая информация о принципах работы массивов. Более подробно, об этом можно прочитать в соответствующей статье.
RAID 0 – использование чередующейся записи (страйп). Строится из двух и более накопителей. Информация записывается на все диски массива блоками определенного (8кб,16кб,32кб,64 кб, 128кб…) размера. Файлы, размер которых один блок, равномерно распределяются по двум или более дискам.
Из-за отсутствия избыточности или дублирования данных, при выходе из строя одного из дисков, восстановить информацию в полном объеме невозможно без использования данных с неисправного накопителя. Исключением будут лишь файлы, размер которых меньше размера блока. Для полноценного восстановления информации в таких случаях необходимо сначала снять данные с неисправного диска, после чего восстанавливать RAID.
В случаях, когда все диски исправны, а массив отказывается корректно работать, восстановление производится программными методами, которые описаны
RAID 1 – использование технологии зеркалирования (зеркало). Строится из двух дисков. Информация одновременно пишется на оба накопителя, каждый диск является полной копией своего собрата. В случае выхода из строя одного из дисков массив остается работоспособным.
Если происходит сбой в работе контроллера и массив перестает определяться, то восстановление данных можно выполнить, воспользовавшись советами из статьи «Простое восстановление данных». Для этого один из дисков следует подключить к компьютеру на прямую, минуя RAID контроллер. Если повезёт, после подключения Ваши данные могут оказаться доступными и без использования программ, описанных в вышеуказанной статье.
RAID 10 – это объединение уровня 0 с уровнем 1, т.е. два страйпа объединяются в зеркало. В массиве используются минимум 4 диска. Он может остаться работоспособным при выходе из строя одного из составляющих его RAID 0.
При возникновении проблемы, в первую очередь необходимо определить, с чем именно возникли неполадки – с контроллером или с дисками
Когда проблема на уровне контроллера, Вам следует определить, какие винчестеры являются парами, составляющими страйпы
Здесь важно не перепутать диски, т.к. это приведет к потерянному времени и отсутствию результата
После того, как это станет известно, берётся одна такая пара, и с неё снимается информация таким же образом, как и с самостоятельного RAID 0.
Во время эксплуатации RAID 10, случается и такое, что выходят из строя два диска. Здесь возможны следующие варианты:
1) Оба диска принадлежат к одному страйпу, контроллер корректно обрабатывает исключительную ситуацию, и массив продолжает функционировать нормально.
2) Оба диска принадлежат к одному страйпу, но массив разваливается. В этом случае просто берём исправный страйп, и программно собираем его (об этом ниже).
3) Диски принадлежат к разным страйпам, но в одном из них уцелел первый, а в другом второй накопитель. Попробуйте программно собрать из них RAID 0.
4) Вышли из строя одноимённые диски разных страйпов. Увы Один из сломанных дисков придётся отремонтировать, или каким-либо ещё образом снять с него данные. Затем программная сборка.
RAID 5 – массивы с контролем четности. Основным его достоинством является распределение блоков информации и контрольных блоков четности по всем дискам массива. Для создания такого массива требуется минимум три диска. Объём массива равен сумме объёмов составляющих его накопителей, минус один диск. Блоки контроля чётности используются для вычисления недостающей информации при выходе из строя одного из накопителей, составляющих массив. Таким образом, при утрате одного из дисков данные не теряются, и массив может продолжать работу.
Но, случается и такое, что после выхода из строя одного накопителя, контроллер неверно обрабатывает исключительную ситуацию и массив перестает корректно работать, либо полностью «падает». Подобный сбой может возникнуть также во время выполняемого после замены диска перестроения массива. Иногда в течение короткого времени после смерти первого диска, выходит из строя ещё один.
Если массив не работает, и количество неисправных дисков не более одного, то его можно собрать При выходе из строя двух накопителей, сначала потребуется восстановить работоспособность, или снять информацию на исправный диск с одного из них, и лишь затем можно заняться сборкой массива.
Информация о RAID
Посмотреть состояние всех RAID можно командой:
cat /proc/mdstat
В ответ мы получим что-то на подобие:
md0 : active raid1 sdc sdb
1046528 blocks super 1.2 [2/2]
* где md0 — имя RAID устройства; raid1 sdc sdb — уровень избыточности и из каких дисков собран; 1046528 blocks — размер массива; [2/2] — количество юнитов, которые на данный момент используются.
** мы можем увидеть строку md0 : active(auto-read-only) — это означает, что после монтирования массива, он не использовался для записи.
Подробную информацию о конкретном массиве можно посмотреть командой:
mdadm -D /dev/md0
* где /dev/md0 — имя RAID устройства.
Пример ответа:
Version : 1.2
Creation Time : Wed Mar 6 09:41:06 2019
Raid Level : raid1
Array Size : 1046528 (1022.00 MiB 1071.64 MB)
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Mar 6 09:41:26 2019
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : proxy.dmosk.local:0 (local to host proxy.dmosk.local)
UUID : 304ad447:a04cda4a:90457d04:d9a4e884
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
* где:
- Version — версия метаданных.
- Creation Time — дата в время создания массива.
- Raid Level — уровень RAID.
- Array Size — объем дискового пространства для RAID.
- Used Dev Size — используемый объем для устройств. Для каждого уровня будет индивидуальный расчет: RAID1 — равен половине общего размера дисков, RAID5 — равен размеру, используемому для контроля четности.
- Raid Devices — количество используемых устройств для RAID.
- Total Devices — количество добавленных в RAID устройств.
- Update Time — дата и время последнего изменения массива.
- State — текущее состояние. clean — все в порядке.
- Active Devices — количество работающих в массиве устройств.
- Working Devices — количество добавленных в массив устройств в рабочем состоянии.
- Failed Devices — количество сбойных устройств.
- Spare Devices — количество запасных устройств.
- Consistency Policy — политика согласованности активного массива (при неожиданном сбое). По умолчанию используется resync — полная ресинхронизация после восстановления. Также могут быть bitmap, journal, ppl.
- Name — имя компьютера.
- UUID — идентификатор для массива.
- Events — количество событий обновления.
- Chunk Size (для RAID5) — размер блока в килобайтах, который пишется на разные диски.
Подробнее про каждый параметр можно прочитать в мануале для mdadm:
man mdadm
Также, информацию о разделах и дисковом пространстве массива можно посмотреть командой fdisk:
fdisk -l /dev/md0
Elastix 5
В Elastix 5, с недавнего времени доступной в бета-версии, пользователям предлагаются следующие улучшения:
- бесплатный ISO-образ Linux;
- сборка на основе новейшей версии Debian (Jessie);
- бесплатная версия АТС 3CX;
- бесплатный DNS-хостинг и SSL-сертификаты;
- встроенные средства организации видеоконференций WebRTC (бесплатные и безклиентные);
- автоматическая настройка популярных IP-телефонов для локального или удаленного пользования;
- автоматическая инициализация наиболее популярных SIP-магистралей;
- поддержка VoIP-шлюзов Patton, Beronet и Welltech;
- поддержка “родных” софтфонов для Android и iOS;
- средства унифицированных коммуникаций (голосовая почта, виртуальный факс, чат, индикация присутствия);
- клиенты для Mac и Windows;
- удобство установки, управления и обновления;
- встроенные функции отработки отказов, резервного копирования и восстановления;
- безопасная настройка как стандарт со встроенными механизмами защиты SIP от взломов.
Здесь можно загрузить бета-версию Elastix 5. Здесь можно получить бесплатный лицензионный ключ для неограниченного приема восьми одновременных вызовов.
ВНИМАНИЕ
Данная лабораторная работа связана с такой тонкой материей как сохранность данных — это такая область, которая позволяет из-за мельчайшей ошибки — одной лишней буквы или цифры потерять все ваши данные.
Поскольку вы выполняете лабораторную работу вам ничего не грозит, разве что придется начать делать ее заново.
В реальной жизни все гораздо серьезнее, поэтому следует очень внимательно вводить имена дисков, понимая что именно вы выполняете текущей командой и с какими дисками работаете.
Второй важный момент — именование дисков и разделов: в зависимости от ситуации номера дисков могут отличаться от тех значений, что представлены в командах в лабораторной работе.
Так, например, если удалить диск sda из массива, а затем добавить новый диск, то новый диск будет отображаться в системе с именем sda. Если же выполнить перезагрузку перед добавлением нового диска, то новый диск будет иметь имя sdb, а старый станет именоваться sda
Лабораторная работа должна выполняться под суперпользователем (root) поскольку большая часть команд требует повышенных привилегий и не имеет смысла постоянно повышать привилегии через sudo.
Эмулируем выход из строя жесткого диска
Для начала проверим, все ли в порядке после изменений загрузчика. Просто перезагружаем Elastix. Если все в порядке, то выключаем сервер и отключаем один из жестких дисков. Я буду выключать второй hd1, на котором раздел sdb.
Система благополучно загрузилась. Проверяем состояние рейда:
md1 : active raid1 sda1
18868224 blocks [2/1]
Видим, что одного диска нет в массиве, но при этом система нормально функционирует и не замечает отсутствие диска:
Выключим сервер и вернем отключенный диск. Снова включаемся, проверяем состояние RAID:
md1 : active raid1 sdb1
18868224 blocks [2/1]
Отключенный диск почему то автоматически обратно не подключился всеми разделами. Исправим это и вернем sda1 обратно в массив руками:
Снова проверяем:
md1 : active raid1 sda1 sdb1
18868224 blocks [2/1]
recovery = 0.8% (158272/18868224) finish=47.2min speed=6594K/sec
Раздел встал в рейд и началась синхронизация. После окончания синхронизации, массив вернется в обычное рабочее состояние.
На этом установка Elastix и тестирование отказоустойчивости закончены, можно смело начинать настройку.
Действия при выходе одного жёсткого диска из строя[править]
Если один жёсткий диск вышел из строя, то загрузите операционную систему (она будет работать и на одном диске), зайдите под пользователем root и проделайте следующее:
1. Посмотрите, что сломалось:
# cat /proc/mdstat
Personalities :
md1 : active raid1 sda2
4723008 blocks [2/1]
md0 : active (auto-read-only) raid1 sda1
513984 blocks [2/1]
Из вывода видно, что диск sdb недоступен: U_ показывает отсутствие второго раздела под RAID.
2. Подключаем диск и копируем таблицу разделов с диска sda на диск sdb. Также перечитаем скопированную таблицу разделов для ядра. Пример для таблицы разделов MBR:
# dd if=/dev/sda of=/dev/sdb bs=512 count=1 1+0 records in 1+0 records out 512 bytes (512 B) copied, 0.00682677 s, 75.0 kB/s # hdparm -z /dev/sdb /dev/sdb: re-reading partition table
Вместо hdparm можно использовать команду partprobe без параметров.
В случае GPT нужно копировать 2048 байт в начале диска (bs=2048), следом нужно запустить parted и подтвердить «починку» второй копии GPT, и уже тогда перечитывать ядром таблицу томов.
3. Добавляем разделы со второго диска к RAID-массиву:
# mdadm /dev/md0 -a /dev/sdb1 mdadm: added /dev/sdb1 # mdadm /dev/md1 -a /dev/sdb2 mdadm: added /dev/sdb2
4. Смотрим, что получилось:
# cat /proc/mdstat
Personalities :
md1 : active raid1 sdb2 sda2
4723008 blocks [2/1]
recovery = 0.6% (32064/4723008) finish=9.7min speed=8016K/sec
md0 : active raid1 sdb1 sda1
513984 blocks [2/2]
unused devices: <none>
Всё нормально: md0 уже засинхронизировался, md1 в процессе синхронизации.
5. Через некоторое время (точнее — 10 минут, смотрите значение finish на этапе 4) смотрим ещё раз:
# cat /proc/mdstat
Personalities :
md1 : active raid1 sdb2 sda2
4723008 blocks [2/2]
md0 : active raid1 sdb1 sda1
513984 blocks [2/2]
unused devices: <none>
Теперь RAID полностью восстановлен.
6. Обязательно восстанавливаем загрузчик, для lilo:
# lilo Added ALTLinux * Added failsafe The Master boot record of /dev/sda has been updated. Warning: /dev/sdb is not on the first disk The Master boot record of /dev/sdb has been updated. One warning was issued.
или для grub2:
# grub-autoupdate Updating grub on /dev/sdb Installation finished. No error reported. Updating grub on /dev/sda Installation finished. No error reported.
и или для grub2:
# grub-install /dev/sda Установка завершена. Ошибок нет. # grub-install /dev/sdb Установка завершена. Ошибок нет. # update-grub
Доступ к FreePBX
Войдите в web интерфейс Elastix.
Перейдите в раздел «Security»
Разрешите доступ к интерфейсу FreePBX:
После этого FreePBX интерфейс будет доступен по адресу
http:///admin
<IP_ADRESS> — IP адрес АТС
Загрузка дополнительных модулей
- Модуль pt1c предназначен для настройка интерфейса на стороне АТС для связи с 1С.
- Модуль pt1c_fax — дработанный модуль . Добавлен механизм заполнения информации об имени файла факса, в таблице истории звонков.
- Модуль pt1c_core — доработанный модуль . Добавлен механизм оповещения по AMI о входящем вызове. Механизм необходим для перехвата звонка на ответственного менеджера.
Панель телефонии 1.4.26.26+ и 1.2.24.18+
Установка дополнительных модулей
На примере модуля Asterisk AJAM Settings (PT1C).
Перед началом интеграции настоятельно рекомендуем делать РЕЗЕРВНУЮ КОПИЮ вашей конфигурации!!!
Войдите в веб-интерфейс FreePBX под учетной записью администратора.
Переходим на вкладку Module Admin (Администрирование модулей)
- Для загрузки модуля на сервер используйте действие Upload module (Закачать модули).
- Укажите расположение модуля.
- Используйте действие Upload (Загрузить).
Теперь в управлении модулями устанавливаем модуль Asterisk AJAM Settings (PT1C).
- Для этого в списке действий выбираем Install (Установить).
- Выполните действие Progress (Запустить процесс).
- Подтверждаем установку,и через пару секунд плагин будет установлен.
- Теперь необходимо нажать оранжевую кнопку Apply Configuration Changes (Применить изменения в конфигурации).
Необходимо внимательно отнестись к этому вопросу. Не следует разрешать AJAM на интерфейсе с реальным IP.
Учетная запись менеджера Asterisk (Elastix)
Теперь добавим менеджера, под которым будет работать панель телефонии.
Необходимо перейти в интерфейс модуля Manager API
Указать имя / пароль менеджера, указать разрешенные / запрещенные сети:
Обратите внимание на поля Запрещены и Разрешены. Запретить следует все адреса, а разрешить только адрес сервера, на котором будет работать панель телефонии
В примере параметр Разрешены установлен в значение 0.0.0.0/0.0.0.0 (разрешено подключаться под всеми сетевыми адресами)
Установить значения привилегий:
Не устанавливайте полные права для учетной записи! Больше — не всегда лучше!
Проверяем отказоустойчивость RAID1 на Elastix посте установки
Теперь давайте проверим, как на практике будут обстоять дела, если один из жестких дисков выйдет из строя. Для начала проверим, что мы в итоге получили:
Видим, что Elastix установлен на raid массив md1. Посмотрим информацию о массиве:
md1 : active raid1 sdb1 sda1
18868224 blocks [2/2]
Тут мы видим, что с рейдом все в порядке.
Теперь нужно проверить, какой диск прописан в качестве загрузочного в GRUB и где установлен сам загрузчик
Это очень важно, так как в случае выхода из строя диска с загрузчиком, мы не сможем загрузить систему
Здесь мы видим, что в качестве источника загрузки указан наш массив /dev/md1, это нам полностью подходит. Но при этом загрузчик, будет сначала пытаться загрузиться с первого диска. В случае его выхода из строя, загрузиться система не сможет. Это нужно обязательно исправить. Открываем и редактируем файл /boot/grub/grub.conf Приводим его к следующему виду:
Мы добавили в загрузчик информацию о втором диске и добавили опцию fallback=1, которая означает, что в случае выхода из строя первого диска загрузчик будет пытаться загрузить систему со второго.
Теперь наш загрузчик знает, что в случае выхода из строя одного диска, нужно загружаться со второго. Но сам загрузчик у нас установлен только на первый диск: splashimage=(hd0,0)/boot/grub/splash.xpm.gz Нужно это исправить и установить GRUB на оба жестких диска:
GNU GRUB version 0.97 (640K lower / 3072K upper memory)
root (hd0,0)setup (hd0)root (hd1,0)setup (hd1)
Жирным выделены мои команды, все остальное вывод.
Варианты установок[править]
Установка на несколько RAID-томовправить
При установке создаётся несколько разделов на каждом HDD, соответствующие разделы (одинаковые на разных дисках) объединяются в отдельные тома mdX.
Шаг 1. Готовим разделы для RAIDправить
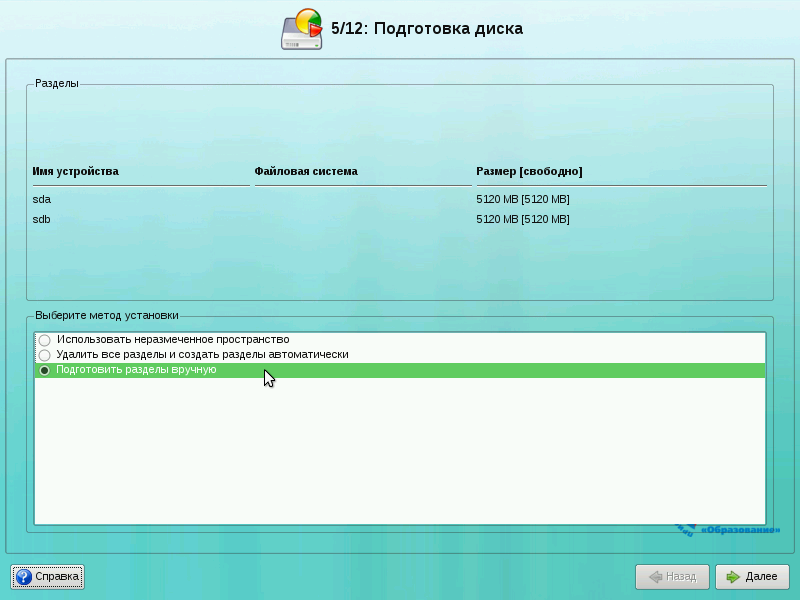
На этапе подготовка диска выберите пункт «Подготовить разделы вручную» и нажмите кнопку «Далее».
Это обязательное условие: если вы выберете другой вариант с опцией ручного изменения, скрипт установки наверняка не сможет правильно установить загрузчик.
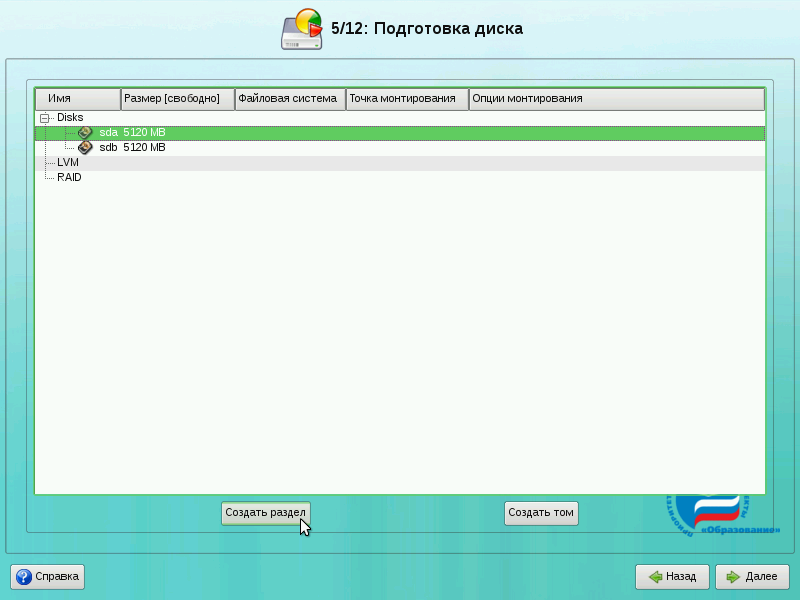
На следующем экране нам необходимо создать одинаковые разделы для RAID на обоих дисках. Для работы системы нам понадобиться два раздела на RAID: подкачка (swap) и корневая файловая система (/). Вы можете создать и другие разделы (например, для /var) способом, приведённым ниже.
Примечание: если у вас на каждом диске есть один общий раздел, выберите диск и нажмите кнопку «Удалить».
Выберите первый жёсткий диск и нажмите кнопку «Создать раздел». Появится следующий диалог:
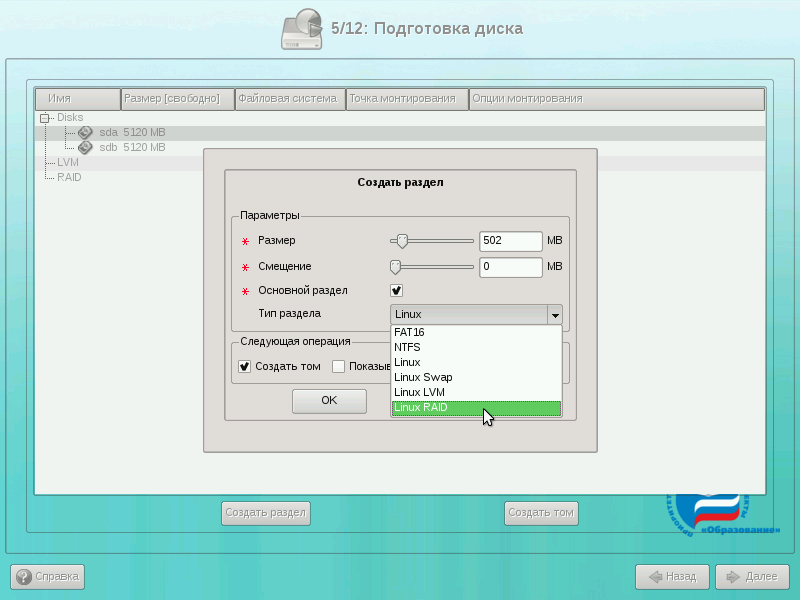
Укажите размер раздела (для начала создадим swap размером 502 Мб) и тип раздела укажем «Linux RAID»
Важно указать именно такой тип.

Аналогичным образом создадим ещё три раздела на дисках. При этом разделы на разных дисках должны совпадать по размеру.
Шаг 2. Создание массивов RAIDправить
Выберите в списке разделов пункт «RAID» и нажмите на кнопку «Создать RAID». Если такой кнопки нет, это означает, что вы ещё не создали разделы с типом «Linux RAID».
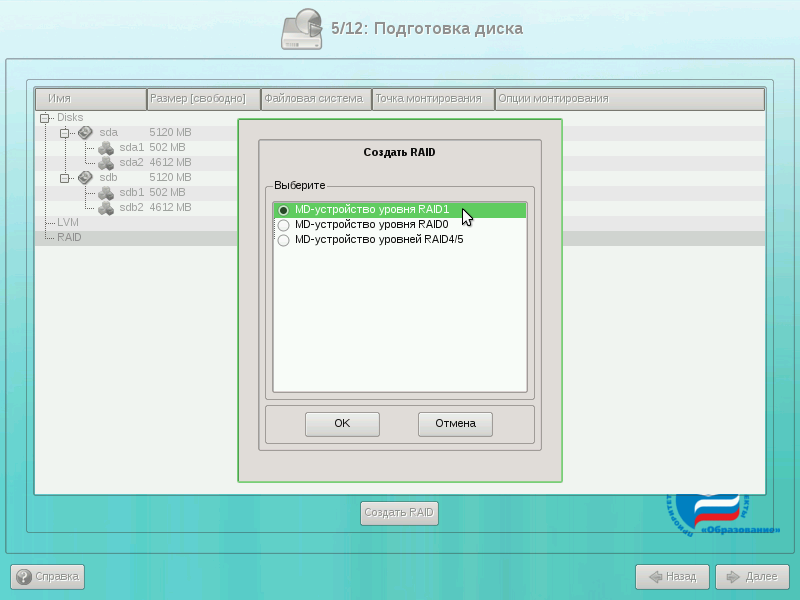
В диалоге создания RAID выберите «MD-устройство уровня RAID1» и нажмите на кнопку OK.
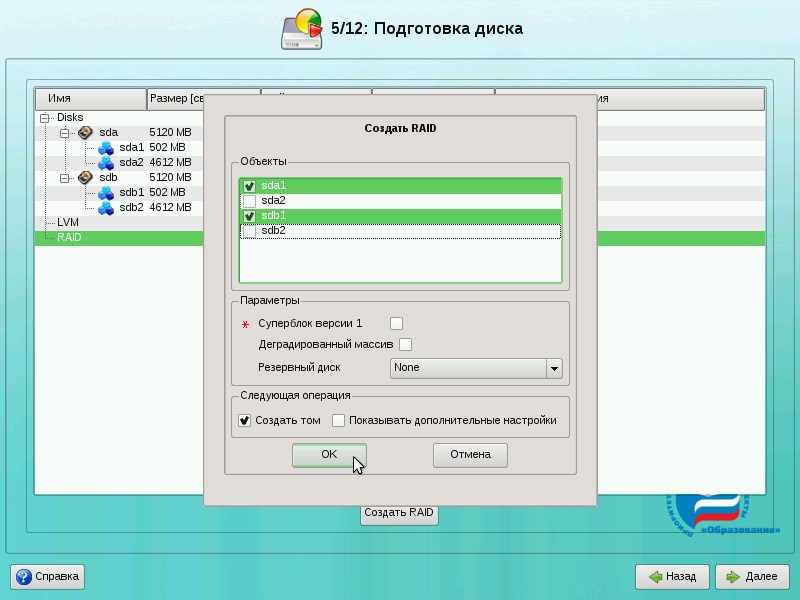
Появится диалог указания разделов жёстких дисков для RAID-раздела. По умолчанию выбираются все разделы, поэтому снимите флажки со всех разделов, кроме sda1 и sdb1. Нажмите на кнопку OK.

Затем будет запрошен тип создаваемой файловой системы. Для swap выберите «Файловая система подкачки (swap) и нажмите на кнопку OK.

У нас создан один раздел в массиве RAID (md0). Теперь аналогично создадим второй раздел под корневую файловую систему. Для этого снова выберите пункт «RAID» и нажмите на кнопку «Создать RAID». В появившемся диалоге укажите «MD-устройство уровня RAID1» и нажмите на кнопку OK.
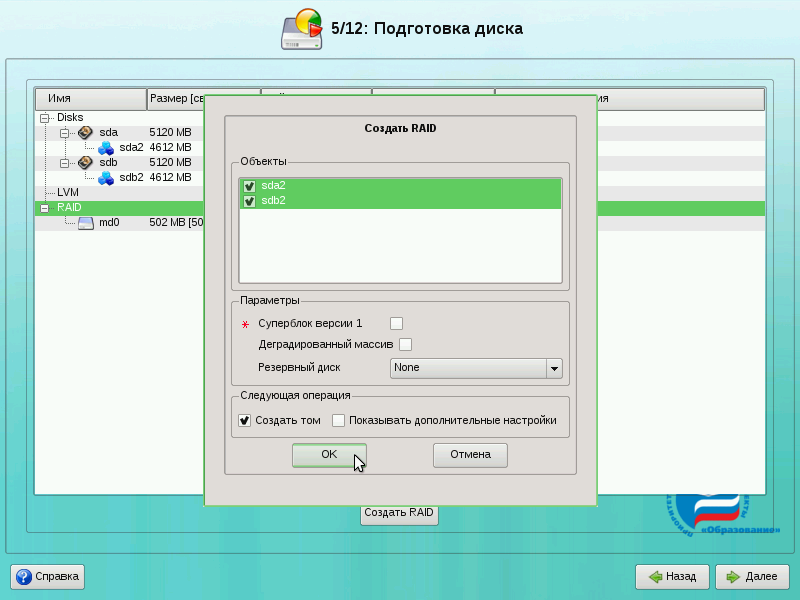
Так как у нас осталось два необъединённых раздела, просто нажмите на кнопку OK.
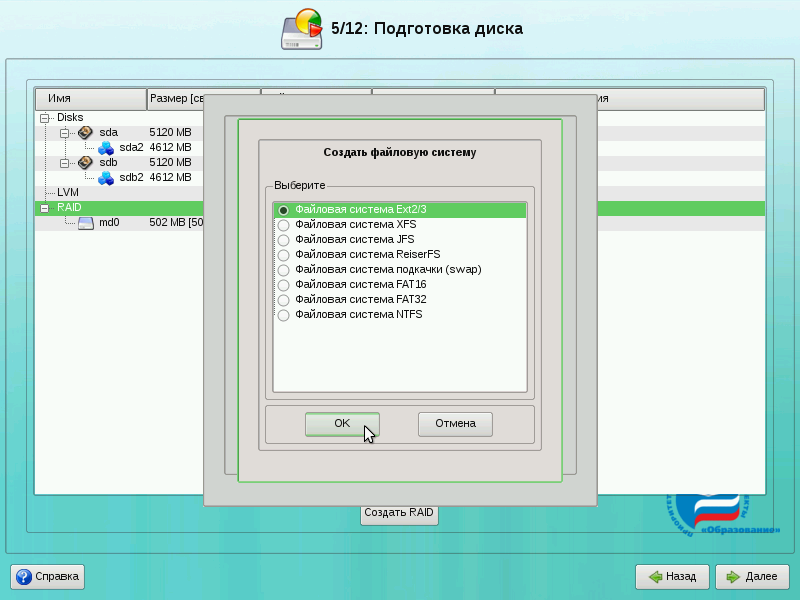
Для корневой файловой системы выберите тип «Файловая система Ext2/3» и нажмите на кнопку OK.
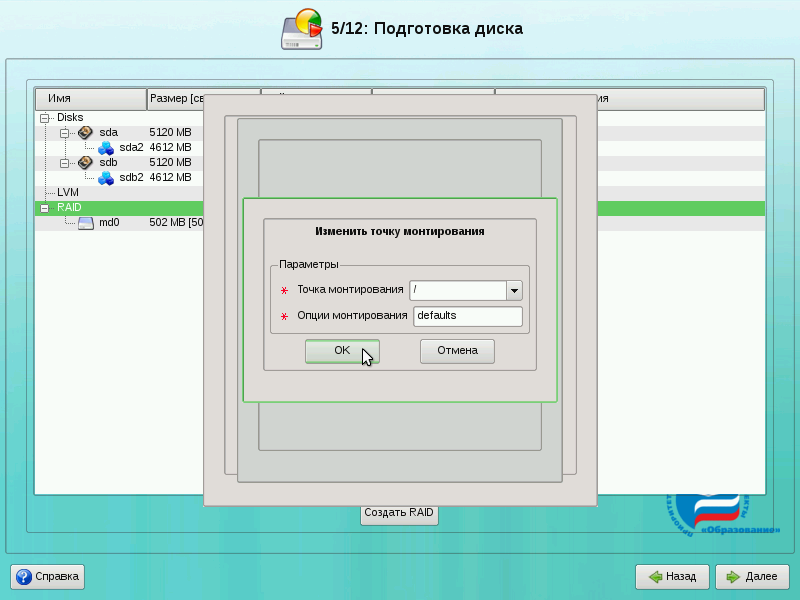
Для файловой системы Ext2/3 необходимо дополнительно указать точку монтирования. Для корневой файловой системы это «/» (предлагается по умолчанию). Нажмите на кнопку OK.
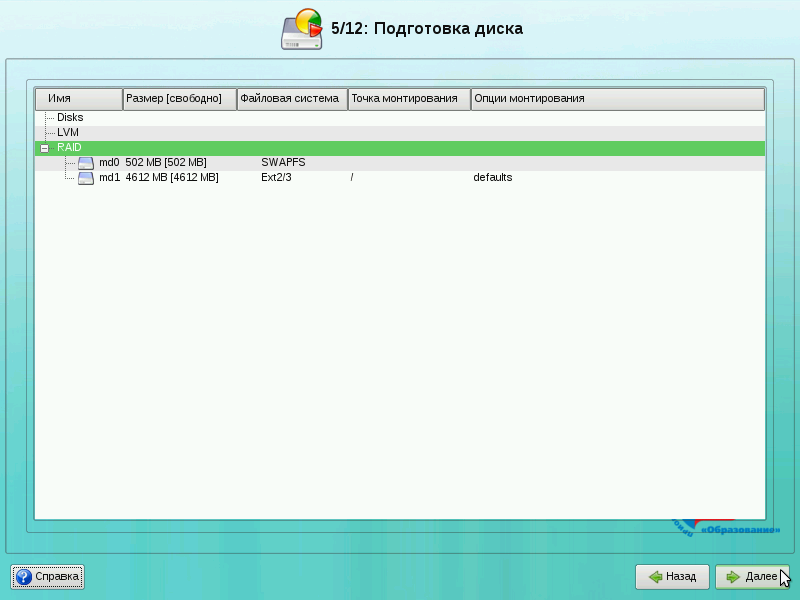
Поздравляем! Вы создали RAID! Теперь для продолжения установки нажмите кнопку «Далее». Будет запрошено подтверждение изменений. Нажмите на кнопку OK.
Шаг 3. Установка загрузчикаправить
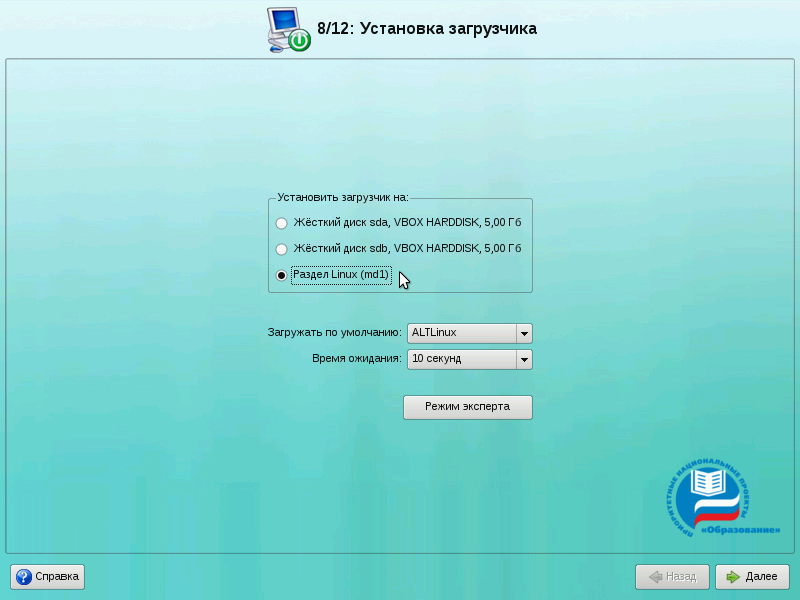
Далее при установке будет ещё один момент, который необходимо учесть. Речь идёт про установку загрузчика операционной системы. Выберите «Раздел Linux (md1)» (это созданный нами на RAID раздел корневой файловой системы). После этого нажмите кнопку «Далее» и продолжайте установку как обычно.
Установка на RAID+LVMправить
Как можно установить LVM поверх md? Я в инсталяторе создаю md, но нет возможности указать это md0 для создания группы томов.
- Создаёте разделы типа Linux RAID (и не забудьте /boot вынести на отдельный обычный или RAID-раздел, с LVM не грузилось).
- В разделе RAID создаёте RAID из этих разделов.
- В разделе LVM создаёте группу томов. Эта группа будет сделана на основе RAID-раздела (я проверял на единственном созданном, без разделов типа Linux LVM.
- В группе томов LVM создаёте раздел(ы), присваиваете точки монтирования.
- Дальше устанавливаете как обычно.
Что такое Elastix и зачем он нужен
Elastix представляет из себя готовую платформу на основе операционной системы CentOS. Эта платформа включает в себя панель веб администрирования всего функционала, который в ней присутствует: ip телефония, mail сервер, im сервер и прочие сопутствующие основным функции. Его удобно использовать, когда нужно быстро развернуть сервер IP телефонии. Остальные функции используются реже. Подробнее почитать о Elastix можно на Википедии.
Перед началом установки, скачиваем версию 2.5 нужной битности с сайта разработчика. Существует более новая версия 3.0, но на текущий момент в ней слишком много ошибок и недоработок, чтобы ее можно было использовать в реальной работе. Так что пока будем скачивать и устанавливать Elastix предыдущей версии 2.5.
Эмулируем выход из строя жесткого диска
Для начала проверим, все ли в порядке после изменений загрузчика. Просто перезагружаем Elastix. Если все в порядке, то выключаем сервер и отключаем один из жестких дисков. Я буду выключать второй hd1, на котором раздел sdb.
Система благополучно загрузилась. Проверяем состояние рейда:
md1 : active raid1 sda1
18868224 blocks [2/1]
Видим, что одного диска нет в массиве, но при этом система нормально функционирует и не замечает отсутствие диска:
Выключим сервер и вернем отключенный диск. Снова включаемся, проверяем состояние RAID:
md1 : active raid1 sdb1
18868224 blocks [2/1]
Отключенный диск почему то автоматически обратно не подключился всеми разделами. Исправим это и вернем sda1 обратно в массив руками:
Снова проверяем:
md1 : active raid1 sda1 sdb1
18868224 blocks [2/1]
recovery = 0.8% (158272/18868224) finish=47.2min speed=6594K/sec
Раздел встал в рейд и началась синхронизация. После окончания синхронизации, массив вернется в обычное рабочее состояние.
На этом установка Elastix и тестирование отказоустойчивости закончены, можно смело начинать настройку.
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .



