
Введение
Сразу поделюсь ссылкой на официальную документацию по kubernetes. Она хорошо структурирована и наполнена. Пользоваться ей удобно. С ее помощью настраивать кластер проще. Напоминаю, что мы будем работать с кластером, который установили по предыдущей статье — установка kubernetes. Перед тем, как начать работать с кластером, расскажу об одной полезной возможности. Есть команда:
# kubectl completion bash
Она формирует конфиг для настройки автодополнения команд в bash. Вывод этой команды нужно добавить в ваш ~/.bashrc Можно это сделать автоматически.
# kubectl completion bash >> ~/.bashrc
Чтобы автодополнение работало, нужен пакет bash-completion.
# yum install bash-completion
Запрещение (DENY) всего не внесенного в белый список трафика в текущем пространстве имен
Сценарий использования
Это очень важная политика, которая блокирует весь трафик между подами, за исключением внесенного в белый список с помощью другой политики.
Всерьез подумайте о том, чтобы применить соответствующий манифест во всех пространствах имен, в которых развернута рабочая нагрузка (но не в ).
С помощью этой политики можно настроить доступ типа «отклонять все по умолчанию» (default «deny all»). Таким образом можно четко определить, какие компоненты зависят от других компонентов, и внедрить сетевые политики, по которым можно построить графы зависимостей между компонентами.
Манифест
Несколько замечаний:
- — по умолчанию применяйте эту политику в пространстве имен .
- — не заполнено, это означает соответствие всем подам. Таким образом, политика будет применена ко всем подам в указанном пространстве имен.
- -правила не определены, поэтому отклоняться будет трафик, идущий к выбранным (всем) подам.
Сохраните этот манифест в файл и примените политику:
Очистка
Что можно делать с сетевыми политиками
В кластере Kubernetes трафик между подами по умолчанию не ограничивается. Это означает, что поды могут беспрепятственно подключаться друг к другу, и внутри кластера нет брандмауэров, которые могли бы им помешать.
Сетевые политики позволяют декларативно определять, какие поды к кому могут подключаться. При настройке политик есть возможность детализировать их до пространств имен или более точно, обозначая порты, для которых будут действовать выбранные политики.
В настоящее время исходящий от подов трафик таким образом контролировать невозможно. Эта функциональность запланирована в Kubernetes 1.8.
При этом проект с открытым исходным кодом под названием Istio является хорошей альтернативой с поддержкой фильтрации исходящего трафика, а также многими другими возможностями, включая встроенную поддержку Kubernetes.
4. Обратитесь к поставщику (-ам) (или к вашему собственному отделу упаковки).
После того, как вы подтвердили, что проблема самовосстановления основана на MSI, и это не ваше собственное программное обеспечение, первое, что нужно попробовать, — это связаться с поставщиком приложений и посмотреть, у вас есть обновленный установщик, чтобы устранить проблему.
Важно попробовать эту опцию, так как все остальные опции — «обходные пути», а не реальные исправления. Проблема может быть только полностью разрешена постоянно с помощью изменений в установщике поставщика и, возможно, самого исполняемого приложения.
Исправление 1
Исправление может быть таким же простым, как отказ поставщика отфильтровать конфиденциально установленные, но глобально зарегистрированные COM файлы с соответствующим общим » слиянием модуля», чтобы установить время выполнения правильно для всех. Они должны правильно установить COM файлы в общие местоположения, где они могут быть зарегистрированы глобально без побочного эффекта. Готов для всех.
Исправить 2: Если поставщик утверждает, что это невозможно, то они должны быть в состоянии обеспечить надлежащую установку COM без регистрации с правильно изолированными COM файлами, установленными в основной папке приложения. Они также должны позаботиться о развертывании любых обновлений безопасности, когда они появятся.
Важно!. Если поставщик использует правильный, общий модуль слияния для развертывания файлов или, обеспечивает изолированную установку, используя без регистрации, тогда проблема должна решаться постоянно для всех.
Проблема также может быть вызвана другими проблемами, но очень часто COM является виновником. Иногда очистка их установщика MSI может разрешать другие, более неясные конфликты
Если вы знаете хорошего упаковщика приложений, он/она должен иметь возможность быстро выявлять конфликты (и предоставлять отзывы поставщику).
Обратите внимание, что также возможно, что саморемонт вызван ошибочной (внутренней) переупаковкой программного обеспечения поставщика. В этом случае вы можете исправить свои собственные пакеты через обновления, предоставленные вашим собственным отделом упаковки/развертывания (и в большинстве случаев они должны быть в состоянии добиться этого)
Это на самом деле очень распространенная проблема.
Данный цикл будет состоять минимум из четырех статей:
- В первой из них я расскажу, как на голое железо установить отказоустойчивый кластер kubernetes, как установить стандартный дашборд и настроить доступ к нему, как установить ingress контроллер.
- Во второй статье я расскажу, как развернуть отказоустойчивый кластер Ceph и как начать использовать RBD тома в нашем кластере Kubernetes. Также немного затрону остальные виды стораджей (storages) и более подробно рассмотрю local-storage. Дополнительно расскажу, как на базе созданного кластера CEPH организовать отказоустойчивое хранилище S3
- В третьей статье я расскажу, как в нашем кластере Kubernetes развернуть отказоустойчивый кластер MySql, а именно — Percona XtraDB Cluster on Kubernetes. И также опишу все проблемы с которыми мы столкнулись, когда решили перенести БД в kubernetes.
- В четвертой статье я постараюсь собрать все вместе и рассказать, как задеплоить и запустить приложение, которое будет использовать БД и тома ceph. Расскажу, как настроить ingress контроллер для доступа к нашему приложению извне и сервис автоматического заказа сертификатов от Let’s Encrypt. Еще — как автоматически поддерживать данные сертификаты в актуальном состоянии. Также немного затронем тему RBAC в контексте доступа до панели управления. Расскажу в двух словах про Helm и его установку.
Если Вам интересна информация данных публикаций, то — добро пожаловать !
Сообщество
Помощь, вопросы и комментарии приветствуются и поощряются! Разработчики Minikube проводят время на Slack в канале #minikube (получить приглашение можно здесь). У нас также есть . Если вы отправляете сообщение в список, пожалуйста, начните вашу тему с «minikube: «.
Обратная связь
Была ли эта страница полезной?
Да
Нет
Спасибо за отзыв! Если у вас есть конкретный вопрос об использовании Kubernetes, спрашивайте
Stack Overflow.
Сообщите о проблеме в репозитории GitHub, если вы хотите
сообщить о проблеме
или
предложить улучшение.
Изменено
October 15, 2020 at 1:46 AM PST
: fix typo (d3d574f28)
Resources — настройка ресурсов
Расскажу, как ограничиваются выделяемые для подов вычислительные ресурсы. Речь идет про CPU и Оперативную память. Задать верхнюю планку использования ресурсов можно с помощью Limits. А с помощью Requests мы можем зарезервировать необходимые ресурсы для пода на ноде. Если в Requests у пода параметры выше, чем есть свободных ресурсов у ноды, то под не сможет приехать на эту ноду.
Важно понимать, что реквесты никак не следят за реальным использованием ресурсов. То есть это просто пожелание к ресурсам ноды, где будет размещаться под
При этом после размещения он сможет занять ресурсов больше, чем указано в Requests. Кластер kubernetes за этим не следит. Если реквесты вообще не указать, то под может приехать на ноду, где свободно очень мало ресурсов, а ему для работы надо больше. В итоге он будет падать. Таким образом, requests используются для планирования ресурсов кластера.
Далее пример деплоймента с указанными параметрами ресурсов. Дополняем предыдущие примеры.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-nginx
spec:
replicas: 2
selector:
matchLabels:
app: my-nginx
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- image: nginx:1.16
name: nginx
ports:
- containerPort: 80
readinessProbe:
failureThreshold: 5
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 2
timeoutSeconds: 3
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
initialDelaySeconds: 10
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
Память выделяется в мегабайтах, а вот CPU в милли cpu, что равно 1/1000 от процессоронго ядра. То есть 1000 миллицпу это одно ядро процессора ноды. Запустим наш deployment и посмотрим на один из подов.
# kubectl describe pod deployment-nginx-79cd6dc79c-rlhtg
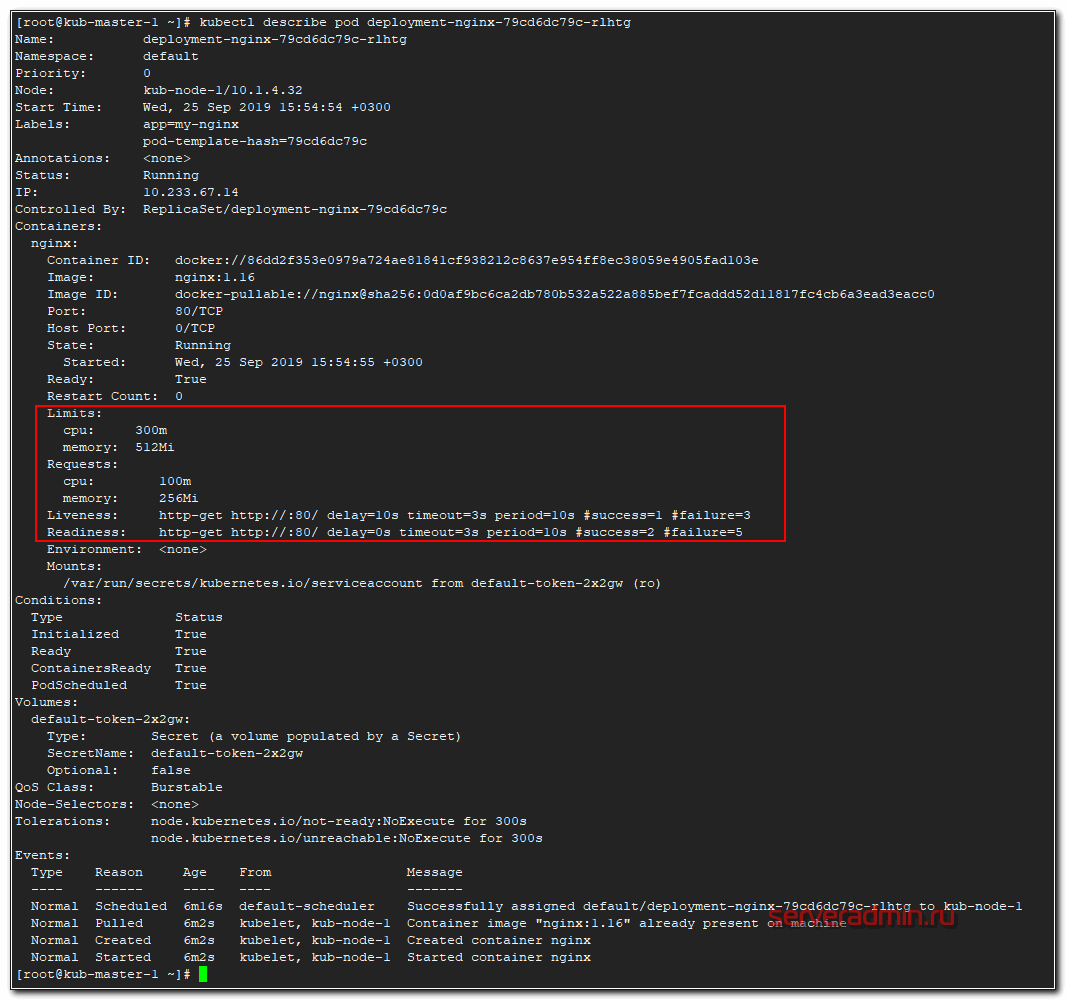
Вот они, наши проверки и лимиты с реквестами.
Подготовка к работе
Чтобы проверить, поддерживается ли виртуализация в Linux, выполните следующую команду и проверьте, что вывод не пустой:
Чтобы проверить, поддерживается ли виртуализация в macOS, выполните следующую команду в терминале:
Если вы видите в выводе (должен быть окрашенным), значит в вашем компьютере поддерживается виртуализация VT-x.
Чтобы проверить, поддерживается ли виртуализация в Windows 8 и выше, выполните следующую команду в Windows Terminal или в командной строке.
Если вы видите следующий вывод, значит виртуализация поддерживается в Windows.
Если вы видите следующий вывод, значит системе уже установлен гипервизор, значит вы можете пропустить следующий шаг установке гипервизора.
Контейнеры Docker
KubernetesдокументацииОбраз контейнера — это легковесный, автономный, исполняемый пакет, содержащий некое приложение, который включает в себя всё необходимое для его запуска: код приложения, среду исполнения, системные средства и библиотеки, настройки. Контейнеризированными программами можно пользоваться в средах Linux и Windows, при этом они всегда будут работать одинаково независимо от инфраструктуры.
▍Обслуживание статических файлов React-приложения средствами виртуальной машины
- Неэффективное использование ресурсов, так как каждая виртуальная машина представляет собой полноценную операционную систему.
- Зависимость от платформы. То, что работает на некоем локальном компьютере, вполне может не заработать на продакшн-сервере.
- Медленное и требовательное к ресурсам масштабирование решения, основанного на виртуальных машинах.
Веб-сервер Nginx, обслуживающий статические файлы, запущенный на виртуальной машине
- Эффективное использование ресурсов: работа с операционной системой с помощью Docker.
- Независимость от платформы. Контейнер, который разработчик сможет запустить на своём компьютере, будет работать где угодно.
- Легковесное развёртывание за счёт использования слоёв образов.
Веб-сервер Nginx, обслуживающий статические файлы, запущенный в контейнереЗдесь
▍Сборка образа контейнера для React-приложения
- Сборка пакета React-приложения ().
- Запуск Nginx-сервера.
- Копирование содержимого директории из папки проекта в папку сервера .
образ
- Основой образа нужно сделать образ Nginx.
- Содержимое папки нужно скопировать в папку образа .
описании
▍Сборка образа и загрузка его в репозиторий
- Установить Docker.
- Зарегистрироваться на сайте Docker Hub.
- Войти в учётную запись, выполнив в терминале команду следующего вида:
▍Запуск контейнера
- Первое число — это номер порта хоста (то есть — локального компьютера).
- Второе число — это порт контейнера, на который должен быть перенаправлен запрос.
Перенаправление портов
▍Тестирование контейнеризированных приложений
- Запустим контейнер приложения и настроим его на прослушивание порта :
- Запустим контейнер приложения и настроим его на прослушивание порта . Кроме того, нам нужно настроить порт, на котором Python-приложение будет ждать запросы от Java-приложения, переназначив переменную окружения :
README
Микросервисы выполняются в контейнерах
Разрешение (ALLOW) любого трафика из пространства имен
Эта политика похожа на разрешение трафика из всех пространств имен, при этом она позволяет выбрать определенное пространство имен.
Сценарии использования:
- Ограничение трафика к production-базе данных таким образом, чтобы он был разрешен только от пространств имен, в которых развернуты production-приложения.
- Развертывание средств мониторинга, которым разрешено собирать метрики текущего пространства имен в специально для этого созданном отдельном пространстве имен.
Пример
Запустите веб-сервер в пространстве имен по умолчанию:
Теперь предположим, что у вас есть вот такие пространства имен:
- — создано Kubernetes, здесь развернут ваш API;
- — здесь развернуты другие production-сервисы; на него установлена метка ;
- — это dev/test-окружение; на него установлена метка .
Создайте пространства имен и :
Следующий манифест разрешит трафик только от подов, находящихся в пространстве имен с меткой . Сохраните его в и примените к кластеру:
Проверка
Сделайте запрос к веб-серверу из пространства имен , убедитесь, что трафик заблокирован:
Теперь сделайте запрос из пространства имен , убедитесь, что запрос проходит:
Очистка
Persistent Volume Claim
PersistentVolumeClaim (PVC) есть не что иное как запрос к Persistent Volumes на хранение от пользователя. Это аналог создания Pod на ноде. Поды могут запрашивать определенные ресурсы ноды, то же самое делает и PVC. Основные параметры запроса:
- объем pvc
- тип доступа
Типы доступа у PVC могут быть следующие:
- ReadWriteOnce – том может быть смонтирован на чтение и запись к одному поду.
- ReadOnlyMany – том может быть смонтирован на много подов в режиме только чтения.
- ReadWriteMany – том может быть смонтирован к множеству подов в режиме чтения и записи.
Ограничение на тип доступа может налагаться типом самого хранилища. К примеру, хранилище RBD или iSCSI не поддерживают доступ в режиме ReadWriteMany.
Один PV может использоваться только одним PVС. К примеру, если у вас есть 3 PV по 50, 100 и 150 гб. Приходят 3 PVC каждый по 50 гб. Первому будет отдано PV на 50 гб, второму на 100 гб, третьему на 150 гб, несмотря на то, что второму и третьему было бы достаточно и 50 гб. Но если PV на 50 гб нет, то будет отдано на 100 или 150, так как они тоже удовлетворяют запросу. И больше никто с PV на 150 гб работать не сможет, несмотря на то, что там еще есть свободное место.
Из-за этого нюанса, нужно внимательно следить за доступными томами и запросами к ним. В основном это делается не вручную, а автоматически с помощью PV Provisioners. В момент запроса pvc через api кластера автоматически формируется запрос к storage provider. На основе этого запроса хранилище создает необходимый PV и он подключается к поду в соответствии с запросом.
Устанавливаем Ubuntu Server
Запускаем нашу шаблонную виртуальную машину. При первом старте VirtualBox предложит выбрать установочный диск. Выбираем iso файл для Ubuntu Server 20.04 и начинаем установку:
Когда установка запустится, начальные параметры, такие как язык и раскладку клавиатуры выбираем по умолчанию. Также отказываемся от обновления:
Но дойдя до настроек сетевых подключений останавливаемся:
Здесь мы видим, что у нашей виртуальной машины два сетевых адаптера, первый из которых уже получил свой IP адрес динамически, а вот второй — нет. Выбираем второй сетевой адаптер и вручную указываем его настройки:
Здесь мы указываем подсеть и статический IP адрес нашей виртуальной машины в этой подсети. Напомню, что IP адрес хоста у нас 192.168.10.1. Остальные параметры можно опустить.
После этого оба сетевых адаптера должны иметь свой собственный IP адрес:
Далее оставляем все настройки по умолчанию, пока не дойдём до настроек профиля. Я назвал машину kube-template, а в качестве username/password использовал test/test:
На следующем шаге нам будет предложено установить OpenSSH server. Я рекомендую воспользоваться этой возможностью, чтобы в будущем иметь возможность подключаться к виртуальным машинам по SSH с помощью PuTTY и Multi PuTTY Manager. Я не стал описывать это в статье, чтобы ещё больше не увеличивать объём:
(Следующий шаг с установкой дополнительных функций пропускаем.)
И наконец запускается сама установка. Теперь мы смело можем сходить пообедать или принять душ, т.к. процесс может занять некоторое время:
После того, как установка завершится, выбираем перезагрузку виртуальной машины (если при этом увидите ошибки об отсутствии cdrom, просто нажмите любую клавишу):
Разрешение (ALLOW) трафика от внешних клиентов
Эта сетевая политика позволяет внешним клиентам получать доступ к поду через балансировщик нагрузки или напрямую из Интернет.
Сценарии использования:
Пример
Запустите под и откройте его 80-й порт для доступа из Интернет через балансировщик нагрузки:
Дождитесь появления EXTERNAL-IP в выводе . Откройте в браузере и убедитесь в наличии доступа к ресурсу.
Следующий манифест разрешает трафик из любых источников (как внутри кластера, так и из внешних источников). Сохраните его в файл и примените к кластеру:
Снова откройте в браузере и убедитесь, что он по-прежнему работает.
Замечания
В этом манифесте определено одно ingress-правило для подов с меткой . Поскольку конкретные или не указаны, будет пропускаться трафик от любых источников, в том числе и внешних.
Чтобы разрешить доступ извне только к 80-му порту, воспользуйтесь следующим ingress-правилом:
Очистка
Цели
Кластер будет состоять из таких физических ресурсов:
Одна мастер-нода
Мастер-нода (главная, ведущая нода) отвечает за управление кластером и его состояние. На ней запускается Etcd, что позволяет хранить данные кластера в компонентах, которые планируют нагрузки для рабочих нод.
Две рабочие ноды
Рабочие ноды (ведомые) – это серверы, которые обрабатывают рабочие нагрузки (например, контейнеризованные приложения и сервисы). Рабочая нода выполняет задачи сразу, как только они ей назначаются, даже если после планирования мастер-нода перестанет работать. Производительность кластера можно увеличить путем добавления рабочих нод.
После выполнения этого мануала у вас будет кластер, готовый запускать контейнеризованные приложения (при условии, что серверы в кластере имеют достаточно CPU и RAM). Почти любое традиционное приложение Unix, включая веб-приложения, БД, демоны и инструменты командной строки, можно контейнеризовать и запустить в кластере. Сам кластер будет потреблять около 300-500 МБ памяти и 10% CPU от каждой ноды.
Настроив кластер, вы развернете веб-сервер Nginx, чтобы убедиться, что все работает правильно.
Требования
- Пара ключей SSH на локальной машине Linux/Mac OS/BSD (инструкции по настройке можно найти здесь).
- Три сервера Ubuntu 18.04, 1 Гб RAM минимум каждый. Также на каждом сервере должны быть SSH-ключи.
- Ansible на локальной машине. Если вы используете Ubuntu 18.04, читайте раздел 1 мануала Установка и настройка Ansible в Ubuntu 18.04. Если у вас Mac OS X или CentOS, обратитесь к .
- Навыки работы с плейбуками Ansible (читайте мануал Создание плейбука Ansible).
- Умение запускать Docker контейнеры из образов (за дополнительной информацией обратитесь к разделу 5 мануала Установка и использование Docker в Ubuntu 18.04).
Монтирование конфигов через ConfigMap
Абстракция kubernetes configmap придумана для того, чтобы отвязать конфиги контейнеров docker от deployment, чтобы не раздувать их размер. К примеру, нам нужно во все контейнеры с nginx положить конфиг default.conf. Мы для этого создаем configmap, в нем настраиваем желаемый конфиг и потом подключаем его в deployment. Показываю на примере. Создаем файл configmap.yaml.
---
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap-nginx
data:
default.conf: |
server {
listen 80 default_server;
server_name _;
default_type text/plain;
location / {
return 200 '$hostname\n';
}
}
В данном случае это простейший конфиг для nginx, который при обращении к серверу будет отдавать 200-й код ответа и имя сервера. Теперь подключаем его к нашему deployment из предыдущих примеров.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-nginx
spec:
replicas: 2
selector:
matchLabels:
app: my-nginx
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- image: nginx:1.16
name: nginx
ports:
- containerPort: 80
readinessProbe:
failureThreshold: 5
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 2
timeoutSeconds: 3
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
initialDelaySeconds: 10
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
volumeMounts:
- name: config
mountPath: /etc/nginx/conf.d/
volumes:
- name: config
configMap:
name: configmap-nginx
Мы создаем монтирование с именем config по пути /etc/nginx/conf.d/ и связываем это монтирование с configmap, который ранее создали. Теперь применяем сначала configmap, а затем deployment.
# kubectl apply -f configmap.yaml configmap/configmap-nginx created # kubectl apply -f deployment-nginx-confmap.yaml deployment.apps/deployment-nginx configured
Проверяем, что получилось. Я подключусь к одному из подов и прочитаю там конфигурацию nginx.
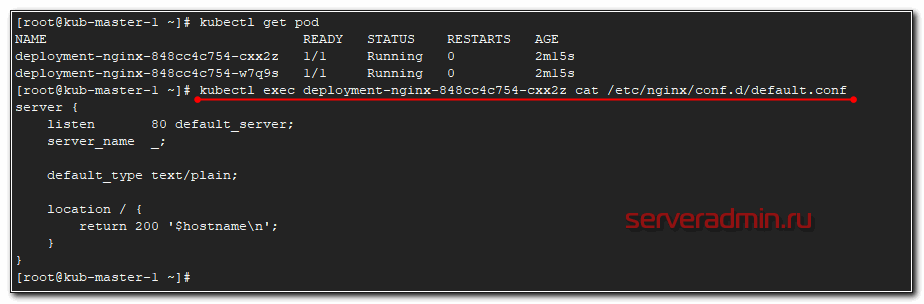
Видим, что применился наш configmap. На втором поде будет то же самое.
Компоненты узла
Компоненты узла работают на каждом узле, поддерживая работу подов и среды выполнения Kubernetes.
kubelet
Агент, работающий на каждом узле в кластере. Он следит за тем, чтобы контейнеры были запущены в поде.
Утилита kubelet принимает набор PodSpecs, и гарантирует работоспособность и исправность определённых в них контейнеров. Агент kubelet не отвечает за контейнеры, не созданные Kubernetes.
kube-proxy
kube-proxy — сетевой прокси, работающий на каждом узле в кластере, и реализующий часть концепции сервис.
kube-proxy конфигурирует правила сети на узлах. При помощи них разрешаются сетевые подключения к вашими подам изнутри и снаружи кластера.
kube-proxy использует уровень фильтрации пакетов в операционной системы, если он доступен. В противном случае, kube-proxy сам обрабатывает передачу сетевого трафика.
Среда выполнения контейнера
Среда выполнения контейнера — это программа, предназначенная для выполнения контейнеров.
Kubernetes поддерживает несколько сред для запуска контейнеров: Docker,
containerd, ,
и любая реализация Kubernetes CRI (Container Runtime
Interface).
Проверка конфигурации
Перед созданием отказоустойчивого кластера настоятельно рекомендуется проверить конфигурацию, чтобы убедиться в том, что оборудование и его настройки совместимы с отказоустойчивой кластеризацией. Корпорация Майкрософт поддерживает кластерное решение, только если конфигурация прошла все проверочные тесты и все оборудование сертифицировано для версии Windows Server, под управлением которой работают узлы кластера.
Примечание
Для выполнения всех тестов необходимы по крайней мере два узла. Если имеется только один узел, выполнение многих важных тестов хранилища невозможно.
Выполнение тестов проверки кластера
-
На компьютере, на котором установлены средства управления отказоустойчивыми кластерами из средств удаленного администрирования сервера, или на сервере, на котором установлено средство отказоустойчивости кластеров, запустите диспетчер отказоустойчивости кластеров. Чтобы сделать это на сервере, запустите диспетчер сервера, а затем в меню Сервис выберите Диспетчер отказоустойчивости кластеров.
-
В области Диспетчер отказоустойчивости кластеров в разделе Управление выберите проверить конфигурацию.
-
На странице Перед началом работы нажмите кнопку Далее.
-
На странице Выбор серверов или кластера в поле введите имя введите NetBIOS-имя или полное доменное имя сервера, который планируется добавить в качестве узла отказоустойчивого кластера, а затем нажмите кнопку добавить. Повторите этот шаг для каждого сервера, который нужно добавить. Чтобы добавить несколько серверов одновременно, разделяйте их имена запятой или точкой с запятой. Например, введите имена в формате . По завершении нажмите кнопку Далее.
-
На странице Параметры тестирования выберите выполнить все тесты (рекомендуется), а затем нажмите кнопку Далее.
-
На странице Подтверждение нажмите кнопку Далее.
На странице «Проверка» показано состояние выполняющихся тестов.
-
На странице Сводка выполните одно из указанных ниже действий.
-
Если результаты показывают, что тесты успешно завершены и конфигурация подходит для кластеризации, и вы хотите создать кластер немедленно, убедитесь, что установлен флажок создать кластер, использующий проверенные узлы , и нажмите кнопку Готово. Затем перейдите к шагу 4 процедуры .
-
Если результаты указывают на наличие предупреждений или сбоев, выберите Просмотреть отчет , чтобы просмотреть сведения и определить, какие проблемы необходимо исправить. Имейте в виду, что предупреждение в результатах определенного проверочного теста указывает на то, что данный аспект отказоустойчивого кластера поддерживается, но может не соответствовать рекомендациям.
Примечание
Если получено предупреждение для теста «Проверка постоянного резервирования дисковых пространств», дополнительную информацию см. в записи блога Предупреждение при проверке отказоустойчивого кластера Windows указывает на то, что диски не поддерживают постоянное резервирование дисковых пространств .
-
Подробнее о проверочных тестах оборудования см. в разделе Проверка оборудования для отказоустойчивого кластера.
Подведем итоги
Вы создали кластер Kubernetes и запустили свой первый микросервис. Теперь вы можете начать изучать компоненты кластера, используя в работе интерфейс командной строки .
Руководство Kubernetes by Example, созданное Michael Hausenblas, показалось мне детальным и доступным.
Состоящий из одной ноды кластер у нас теперь есть, можно начинать добавлять еще ноды , используя , полученный от .
Docker Swarm — это встроенный в Docker CE и EE инструмент оркестровки. Кластер Docker Swarm может быть поднят одной командой. Более подробную информацию можно почерпнуть из моих уроков по Docker Swarm.
Благодарности:
Спасибо @mhausenblas, @_errm и @kubernetesonarm за обратную связь и советы по настройке кластера Kubernetes.
Ссылки:



