
Краткое введение
Что такое CI/CD и зачем нужно — можно легко нагуглить. Полноценную документацию по настройке пайплайнов в GitLab найти также несложно. Здесь я кратко и по возможности без огрехов опишу процесс работы системы с высоты птичьего полёта:
- разработчик отпраляет коммит в репозиторий, создаёт merge request через сайт, или ещё каким-либо образом явно или неявно запускает пайплайн,
- из конфигурации выбираются все задачи, условия которых позволяют их запустить в данном контексте,
- задачи организуются в соответствии со своими этапами,
- этапы по очереди выполняются — т.е. параллельно выполняются все задачи этого этапа,
- если этап завершается неудачей (т.е. завершается неудачей хотя бы одна из задач этапа) — пайплайн останавливается (почти всегда),
- если все этапы завершены успешно, пайплайн считается успешно прошедшим.
Таким образом, имеем:
- пайплайн — набор задач, организованных в этапы, в котором можно собрать, протестировать, упаковать код, развернуть готовую сборку в облачный сервис, и пр.,
- этап (stage) — единица организации пайплайна, содержит 1+ задачу,
- задача (job) — единица работы в пайплайне. Состоит из скрипта (обязательно), условий запуска, настроек публикации/кеширования артефактов и много другого.
Соответственно, задача при настройке CI/CD сводится к тому, чтобы создать набор задач, реализующих все необходимые действия для сборки, тестирования и публикации кода и артефактов.
Наш пайплайн
(здесь и далее в статье для термина stage использую перевод «стадия»)(здесь и далее в статье job — «задача»)(«конвейер» — один из вариантов дословного перевода)
- build — сборка приложения;
- testing — автотесты;
- staging — развёртывание приложения для разработчиков, DevOps, тестировщиков;
- pre-production — развёртывание в «предварительный production» для команды тестировщиков;
- approve — «предохранитель», благодаря которому релиз-инженер заказчика может отказать в развёртывании на production определённого тега;
- production — развёртывание на production.
Примечание: Нет ничего совершенно универсального, поэтому для вашего конкретного случая этот пайплайн скорее всего не подходит: он либо избыточен, либо прост. Однако цель статьи не описывать единственно верный вариант, подходящий каждому. Цель — рассказать на примере о том, как можно работать в GitLab CI нескольким командам и какие возможности есть, чтобы реализовать такой пайплайн. На основе этой информации можно разработать свою собственную конфигурацию GitLab CI.
Как это используется?
- Разработчики выкладывают код приложения в ветки с префиксом feature_, а DevOps-инженеры — код инфраструктуры в ветки с префиксом infra_. Каждый git push в эти ветки запускает процесс сборки приложения (стадия build) и автоматические тесты (стадия testing).
- Задачи на следующих стадиях не вызываются автоматически, а определены как задачи с ручным запуском (manual).
- На стадии staging можно запустить задание и выкатить собранное и протестированное приложение на упрощенное окружение. Это могут делать разработчики, DevOps-инженеры, тестировщики. При этом для выката на окружения тестировщиков должны быть пройдены все тесты.
- После успешного прохождения тестов и выката на одно из окружений staging можно выкатить приложение в pre-production — это делают только тестировщики, DevOps-инженеры или релиз-инженеры.
- По мере накопления успешно протестированных фич релиз-инженер готовит новую версию и создаёт в репозитории тег. Пайплайн для тега отличается от пайплайна для ветки двумя дополнительными стадиями.
- После успешной сборки, тестов и выката в pre-production проводятся дополнительные ручные тесты новой версии, показ заказчику и другие «издевательства» над приложением. Если всё прошло успешно, то релиз-инженер запускает задание approve. Если что-то пошло не так, то релиз-инженер запускает задание not approve.
- Выкат приложения на production возможен только после успешного выката на pre-production и выполнения задания approve. Выкат на production может запустить релиз-инженер или DevOps-инженер.
Роль релиз-инженера в пайплайне
Пайплайн и стадии в деталях
builddappfeature_infra_Обновлено 06 сентября 2019 г.:werfstagingfeature_infra_pre-productionproductionGitLab Flowавтоматическогоapproveapprovenot approveapprovedeploy to production
Git 101
Несмотря на то, что основная тема это CD, , а точнее ряд фундаментальных принципов лежащих в его основе оказали большое влияние на процессы разработки программного обеспечения, поэтому начнём с краткого описания основных терминов Git.
Git — система контроля и управления версиями, в основе которой такие идеи, как:
- Нелинейная разработка — несмотря на то, что версии приложения выходят последовательно, разработка каждой версии ведётся параллельно несколькими разработчиками, которые могут одновременно править одни и те же части приложения.
- Распределённая разработка — разработчик независим от центрального сервера и может разрабатывать в своём локальном окружении без каких-либо проблем.
- Слияние — реализация предыдущих двух пунктов приводит к тому, что существует несколько корректных версий проекта одновременно и часто нужно их объединять в единую версию правды.
Git не был первой системой контроля версий в которой данные идеи были реализованы, однако Git популяризовал данные идеи и существенно упростил их практическое применение.
Репозиторий (Repository)
Место, где хранятся и поддерживаются какие-либо данные.
- “Физически” — папка в ОС
- Хранит файлы и папки
- Хранит историю их изменения
Локальный репозиторий — репозиторий, расположенный на локальном компьютере
Удалённый репозиторий — репозиторий, находящийся на удалённом сервере
Коммит (Commit)
Зафиксированное состояние репозитория.
Хранит отличие (Diff) от какого-либо другого коммита который называется родительским.
Родителей бывает:
- 0 – у первого коммита.
- 1 – как правило бывает именно так.
- 2 – для слияния изменений.
- 3+ — для слияния изменений (но так делать не надо).
Ветка (Branch)
Указатель на коммит.
Всегда можно посмотреть на его историю до первого коммита. Например, ветка :
Дерево коммитов
Коммиты образуют деревья — графическое представление репозитория. Рассмотрим самый простой линейный вариант, когда к двум существующим коммитам с картинки выше добавили ещё три коммита:
Теперь пример дерева посложнее: два разработчика работают одновременно и, чтобы не мешать друг другу каждый из них работает в своей ветке. Это выглядит так:
Через некоторое время им надо объединить изменения, для этого существуют запросы на слияние — запросы на объединение двух состояний репозитория в одно новое состояние. В нашем случае запрос на слияние ветки в ветку . После того как запрос был рассмотрен и одобрен и слияние произошло репозиторий выглядит следующим образом:
После чего разработка продолжается:
- Git — система контроля и управления версиями.
- Репозиторий (Repository) — место, где хранятся и поддерживаются какие-либо данные.
- Коммит (Commit) — зафиксированное состояние репозитория.
- Ветка (Branch) — указатель на коммит.
- Запрос на слияние (Pull request или Merge request) – запрос на слияние двух состояний репозитория.
Работа в большой команде
Со временем ваш сайт стал очень популярным, а ваша команда выросла с двух до восьми человек. Разработка происходит параллельно, и людям все чаще приходится ждать в очереди для превью на Staging. Подход “Проводите развертывание каждой ветки на Staging” больше не работает.
Пришло время вновь модифицировать рабочий процесс. Вы и ваша команда пришли к соглашению, что для выкатывания изменений на staging-сервер нужно сначала сделать мерж этих изменений в ветку “staging”.
Для добавления этой функциональности нужно внести лишь небольшие изменения в файл :
становится
Разработчики проводят мерж своих feature-веток перед превью на Staging
Само собой, при таком подходе на мерж тратятся дополнительное время и силы, но все в команде согласны, что это лучше, чем ждать в очереди.
Непредвиденные обстоятельства
Невозможно все контролировать, и неприятности имеют свойство случаться. К примеру, кто-то неправильно смержил ветки и запушил результат прямо в production как раз когда ваш сайт находился в топе HackerNews. В результате тысячи человек увидели кривую версию сайта вместо вашей шикарной главной страницы.
К счастью, нашелся человек, который знал про кнопку Rollback, так что уже через минуту после обнаружения проблемы сайт принял прежний вид.
Rollback перезапускает более раннюю задачу, порожденную в прошлом каким-то другим коммитом
Чтобы избежать подобного в дальнейшем, вы решили отключить автоматическое развертывание в production и перейти на развертывание вручную. Для этого в задачу нужно добавить .
Для того, чтобы запустить развертывание вручную, перейдите на вкладку Pipelines > Builds и нажмите на вот эту кнопку:
И вот ваша компания превратилась в корпорацию. Над сайтом работают сотни человек, и некоторые из предыдущих рабочих практик уже не очень подходят к новым обстоятельствам.
Ревью приложений
Следующим логическим шагом является добавление возможности развертывания временного инстанса приложения каждой feature-ветки для ревью.
В нашем случае для этого надо настроить еще один бакет S3, с той лишь разницей, что в этом случае содержимое сайта копируется в “папку” с названием ветки. Поэтому URL выглядит следующим образом:
А так будет выглядеть код, замещающий задачу :
Стоит объяснить откуда у нас появилась переменная — из списка , которые вы можете использовать для любой своей задачи.
Обратите внимание на то, что переменная определена внутри задачи — таким образом можно переписывать определения более высокого уровня. Визуальная интерпретация такой конфигурации:
Визуальная интерпретация такой конфигурации:
Технические детали реализации такого подхода сильно разнятся в зависимости от используемых в вашем стеке технологий и от того, как устроен ваш процесс развертывания, что выходит за рамки этой статьи.
Реальные проекты, как правило, значительно сложнее, чем наш пример с сайтом на статическом HTML. К примеру, поскольку инстансы временные, это сильно усложняет их автоматическую загрузку со всеми требуемыми сервисами и софтом “на лету”. Однако это выполнимо, особенно, если вы используете Docker или хотя бы Chef или Ansible.
Про развертывание при помощи Docker будет рассказано в другой статье. Честно говоря, я чувствую себя немного виноватым за то, что упростил процесс развартывания до простого копирования HTML-файлов, совершенно упуская более хардкорные сценарии. Если вам это интересно, рекомендую почитать статью «Building an Elixir Release into a Docker image using GitLab CI».
А пока что давайте обсудим еще одну, последнюю проблему.
Развертывание на различные платформы
В реальности мы не ограничены S3 и GitLab Pages; приложения разворачиваются на различные сервисы.
Более того, в какой-то момент вы можете решить переехать на другую платформу, а для этого вам нужно будет переписать все скрипты развертывания. В такой ситуации использование gem’а сильно упрощает жизнь.
В приведенных в этой статье примерах мы использовали в качестве инструмента для доставки кода на сервис Amazon S3
На самом деле, неважно, какой инструмент вы используете и куда вы доставляете код — принцип остается тот же: запускается команда с определенными параметрами и в нее каким-то образом передается секретный ключ для идентификации
Инструмент для развертывания придерживается этого принципа и предоставляет унифицированный интерфейс для , предназначенных для развертывания вашего кода на разных хостинговых площадках.
Задача для развертывания в production с использованием dpl будет выглядеть вот так:
Так что если вы проводите развертывание на различные хостинговые площадки или часто меняете целевые платформы, подумайте над использованием в скриптах развертывания — это способствует их единообразию.
Шаг 2. Следим за тем, чтобы площадки для разработки не оказались в индексе поисковиков
Программисты, как правило, вообще не задумываются о поисковиках и последствиях индексации площадки для разработки. Нужно напоминать, что стенды разработки — это те же сайты в сети, а значит их видят роботы, Нам не нужно, чтобы служебная информация оказалась доступна в поиске. Сразу после установки не забываем изменить настройки на боевом сервере.
И в robots.txt прописать правило:
– запрещена индексация сайта;
Во время переноса сайта на боевой сервер, файл должен быть изменен (оставить запрет на индексацию только на системные папки, страницы, файлы, такие как bitrix, upload, auth и т.п.).
CI Test
Tag: CodeCov
Вот и пришло время тестирования. Вообще, принципы TDD мы уже нарушили, не написав тесты до написания кода. Так что пора все исправить.
Под проектом Bll создайте новый проект BllTest и добавьте туда BllTest.fs. В этот же проект установите xUnit
Напомню, что структура нашего проекта теперь должна выглядеть так:
— FSharpWebAppWithCIDemo
— — Bll
— — BllTest
— — WebServer
В проекте Bll, создайте новый bll.fs файл c модулем Say и функцией hello (мы опять нарушили TDD написав код до тестов)
И протестируйте ее, а именно то, что результат вызова этой функции будет всегда отличается от предыдущего. Что, кстати, не гарантировано, т.к. существует не нулевая вероятность того, что при генерации двух GUID нам могут выпасть два одинаковых. Правда, скорее всего, пока вы дождетесь этого события потухнет солнце, но все же шанс есть.
На самом деле ни сам код, ни сам тест нам не важны (ведь вы это уже когда-то слышали, не так ли?)
Важно только их наличие что бы правильно интегрироваться с Travis и CodeCov. Запустите тест вручную, убедитесь, что он проходит и давайте продолжать
После того как у нас появился первый тест, нам нужно, что бы Travis этот тест запустил. Для этого, в .travis.yml нужно добавить еще одну строку в секцию script
Здесь все очевидно — мы запускаем тесты без билда (т.к. билд артефакты уже получены на предыдущем шаге) чем экономим себе время.
Но этого мало. Нам нужна статистика покрытия кода. Для этого нам пригодится coverlet.msbuild прекрасный инструмент который встраивается в msbuild и создает отчеты в разных форматах, в том числе и в нужном нам opencover. Откройте вкладку Nuget (или запустите команду из консоли) и установите этот пакет для BllTest проекта. В других проектах он не нужен. После этого поменяйте предыдущую строку в .travis.yml на эту:
Напомню, что полную версию .travis.yml можно забрать тут
Можно запустить эту же команду и из-под консоли что бы убедиться что все работает. Заодно вы увидите текущий code coverage своего проекта.
Итак, тесты у нас есть, они запускаются и даже видно какой-то отчет о покрытии кода. Но и этого тоже недостаточно. Теперь нам нужен кто-то еще, кто сможет обработать этот отчет и сообщить о его результатах. Здесь нам пригодится Codecov который, тоже бесплатен для OpenSource проектов. Логинимся в Codecov с помощью аккаунта GitHub и добавляем нужный проект. Наконец, в последний раз обновляем .travis.yml — добавляем новую секцию after_script.
Когда я увидел этот пример я зарыдал. До этого я убил часа три на то что бы запустить отправку отчета в coverall, а здесь все оказалось настолько просто… Спасибо ребята, что сделали меня счастливым.
Теперь, когда все приготовления сделаны, можем делать комит и идти получать свой заслуженный бейдж со 100% покрытием.
Проблемы
- Не всегда понятно, сколько реально времени уходит на работу над задачами в срезе всего отдела. Были случаи, когда ревью по задаче суммарно занимало больше времени, чем сама задача, от них нужно было избавляться.
- Время, потраченное на ревью размазывалось по всему Битриксу и рабочему дню ревьюера. Для учёта времени что только не делали: кто-то создавал себе единую на все проекты задачу, кто-то по одной задаче в каждый проект, кто-то по одной задаче на каждый MR. Об едином именовании таких задач речи тоже не шло и визуально они почти ничем не отличались от нормальных.
- Как ревьюер, так и разработчик должны были постоянно мониторить Gitlab, чтобы видеть, за какие MR они в текущий момент являются ответственными. Также ревьюер не мог нормально спланировать завтрашний день при формировании ежедневного отчёта, так как задачи про ревью вроде как и не задачи, но время на них уходит.
- Нам нужно было определиться, сколько времени на ревью нам закладывать при оценке работы, но мы не могли посчитать этот коэффициент, потому что толкового отчёта при имеющихся на тот момент данных не построишь.
- После того, как задача отправлялась на ревью постановщик терял над ней всякий контроль и понимание происходящего, т.к. разработчики уходили на Gitlab, где кроме них никого нет, и могли общаться там несколько дней, ничего не отписывая в задаче.
- Нужно было раз и навсегда решить конфликты между ревьюером и разработчиком в вопросе соблюдения крайних сроков. Разработчик обязан закрывать задачи к тому крайнему сроку, который у них поставлен, но для этого ему нужно участие ревьюера, которого этот крайний срок будто и не касается. Разработчики тоже, конечно, любят открывать MR за 2 часа до крайнего срока и затем пытаться перекладывать ответственность на ревьюера, но это был уже вторичный вопрос.
- На ревьюере помимо задач по ревью стоят и обычные задачи, в которых он является разработчиком. Нужно было как-то научиться балансировать соотношение этих двух типов, чтобы ревьюер успевал в каждом из них.
Интеграция
- Каждому MR на Gitlab должна соответствовать задача на ревьюера на Битрикс24. Она должна быть подзадачей задачи, над которой работает разработчик и иметь тот же проект, теги, крайний срок, что и базовая задача. В описании задачи должна быть ссылка на MR, который нужно проверить.
- Каждое изменение статуса MR на Gitlab должно сопровождаться комментарием к базовой задаче от имени системного пользователя с пояснением, что именно сейчас произошло.
Расскажем, как мы её делали.
Настройки проектов
https://github.com/egnyte/gitlabform
gitlab:
url: "https://gitlab.magnifico.pro"
token: "auth_token_for_gitlabform"
api_version: 4
common_settings:
hooks:
"https://in.bizprofi.ru/bitrix/tools/bizprofi.gitlab/gitlab.php":
token: "secret_token_for_webhook"
push_events: false
merge_requests_events: true
$ gitlabform -c /etc/gitlab-form.yml ALL
*/10 * * * * gitlabform -c /etc/gitlab-form.yml ALL &>> /var/log/gitlabform.log
выглядит так
Доработка Битрикс24
настройках репозиториев на Gitlab’е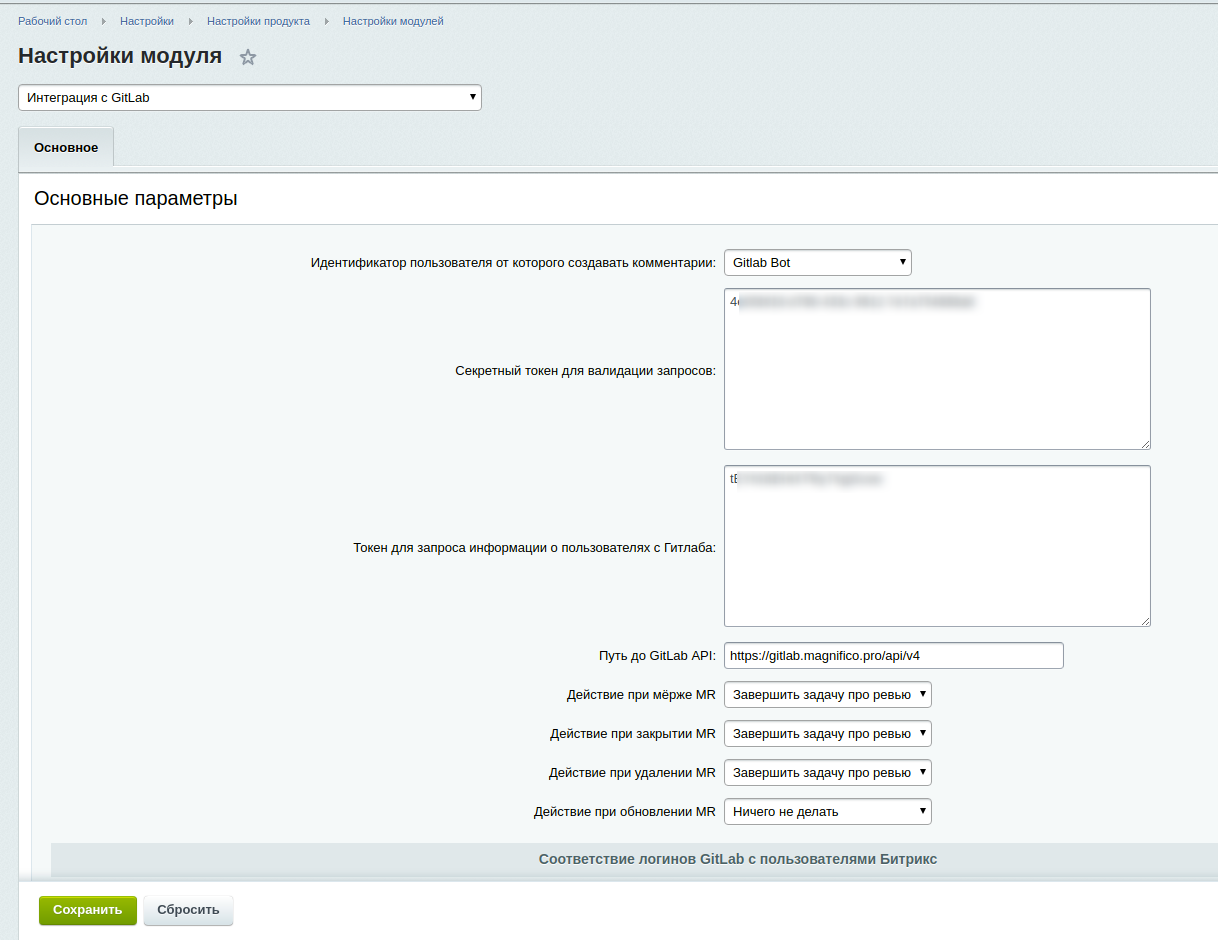
Что делать при открытии MR
Что делать при закрытии MR
Что делать при удалении MR
Что делать при мёрже MR
Что делать при переназначении MR
Что если не нашли задачу в Битрикс24
Что если не нашли пользователя в Битрикс24
Что если у пользователя нет прав на создание задач
Что если в настройках модуля задан некорректный токен
… и ещё несколько десятков “что если” в таком духе.
Подробнее
Задачи
- После смены версии werf на любом канале обновлений документация на сайте должна автоматически обновляться.
- Для разработки нужно иметь возможность иногда просматривать предварительные версии сайта.
- Поскольку список версий на каналах меняется, то пересобирать необходимо только документацию для каналов, где изменилась версия. Ведь пересобирать все заново не очень красиво.
- Сам набор каналов для релизов может меняться. В какой-то момент времени, например, может не быть версии на каналах стабильнее релиза early-access 1.1, но со временем они появятся — не менять же в этом случае сборку руками?
сборка зависит от меняющихся внешних данных
Usage
Git clone a repository
To download a repository using a deploy token:
- Create a deploy token with as a scope.
- Take note of your and .
-
the project using the deploy token:
Replace and with the proper values.
Read Container Registry images
To read the container registry images, you must:
- Create a deploy token with as a scope.
- Take note of your and .
- Sign in to the GitLab Container Registry using the deploy token:
Replace and with the proper values. You can now
pull images from your Container Registry.
Push Container Registry images
Introduced in GitLab 12.10.
To push the container registry images, you must:
- Create a deploy token with as a scope.
- Take note of your and .
-
Sign in to the GitLab Container Registry using the deploy token:
Replace and with the proper values. You can now
push images to your Container Registry.
Read or pull packages
Introduced in GitLab 13.0.
To pull packages in the GitLab package registry, you must:
- Create a deploy token with as a scope.
- Take note of your and .
- For the package type of your choice, follow the
authentication instructions for deploy tokens.
Example request publishing a NuGet package using a deploy token:
Push or upload packages
Introduced in GitLab 13.0.
To upload packages in the GitLab package registry, you must:
- Create a deploy token with as a scope.
- Take note of your and .
- For the package type of your choice, follow the
authentication instructions for deploy tokens.
Group deploy token
Introduced in GitLab 12.9.
A deploy token created at the group level can be used across all projects that
belong either to the specific group or to one of its subgroups.
For an overview, see Group Deploy Tokens.
The Group deploy tokens UI is now accessible under Settings > Repository,
not Settings > CI/CD as indicated in the video.
To use a group deploy token:
- a deploy token for a group.
- Use it the same way you use a project deploy token when
.
The scopes applied to a group deploy token (such as )
apply consistently when cloning the repository of related projects.
GitLab deploy token
Introduced in GitLab 10.8.
There’s a special case when it comes to deploy tokens. If a user creates one
named , the username and token of the deploy token is
automatically exposed to the CI/CD jobs as CI/CD variables:
and , respectively.
After you create the token, you can sign in to the Container Registry by using
those variables:
noteThe special handling for the deploy token is not
implemented for group deploy tokens. To make the group-level deploy token available for
CI/CD jobs, the and variables should be set under Settings to the name and token of the group deploy token respectively.
Установка GitLab
Будем устанавливать GitLab на нашем собственном сервере. Впрочем можно пользоваться GitLab.com. Существует много способов установки GitLab: из исходников, из пакета, в контейнере. Выберите тот способ который вам нравится и следуйте инструкции по установке.
Требования:
- Отдельный сервер — GitLab достаточно ресурсоёмкое веб-приложение, поэтому лучше держать его на отдельном сервере (4 Gb RAM, 2 CPU).
- ОС Linux.
- (Опционально но рекомендуется) Домен — необходим для обеспечения безопасности и запуска pages.
Конфигурация
Прежде всего настройте почтовые уведомления.
Далее, рекомендую установить Pages. Как было сказано выше, артефакты от выполнения скриптов могут быть загружены на GitLab. Пользователи могут загрузить их, но часто бывает полезно открыть их напрямую в браузере и для этого нужно установить pages.
Зачем нужны pages:
- Для вики или набора статичных страниц связанных с проектом.
- Для просмотра html артефактов.
- .
Так как в HTML может быть добавлено автоматическое перенаправление при загрузке страницы, то можно направлять пользователя на страницу с результатами юнит-тестов.
Кстати, я столкнулся с багом при использовании pages (Ошибка 502 при просмотре артефактов) — вот решение.
Подключение окружений к GitLab
Для запуска CD скриптов необходимы окружения — настроенные серверы для запуска вашего приложения. Для начала предположим, что у вас установлен Linux-сервер с платформой InterSystems (скажем, InterSystems IRIS, но всё будет работать с Caché или Ensemble). Для соединения окружения с GitLab нужно:
- Установить GitLab runner.
- Зарегистрировать GitLab runner в GitLab.
- Разрешить пользователю вызывать InterSystems IRIS.
Важное замечание по установке GitLab runner — НЕ клонируйте сервер после установки GitLab runner. Результаты непредсказуемы и нежелательны.
Расскажу поподробнее о шагах 2 и 3
Зарегистрировать GitLab runner в GitLab.
После запуска команды:
Будет предложено несколько опций на выбор, и хотя большинство шагов довольно просто, некоторые из них стоит прокомментировать:
Доступно несколько токенов: для всей системы (доступен в настройках администрирования) либо для одного проекта (доступен в настройках проекта).
Когда вы подключаете runner для CD конкретного проекта, нужно указать токен именно этого проекта.
В CD конфигурации можно фильтровать, какие скрипты выполняются окружениях с определёнными тегами. Поэтому в самом простом случае укажите один тег, который будет названием окружения.
Вне зависимости от того используете ли вы docker, выбирайте shell для запуска скриптов.
Разрешить пользователю вызывать InterSystems IRIS.
После подключения к GitLab нужно разрешить юзеру вызывать InterSystems IRIS. Для этого:
- Пользователь должен иметь права для вызова либо . Для этого его нужно добавить в группу либо командой:
- В InterSystems IRIS создайте пользователя и предоставьте ему права для выполнения скриптов CD (запись в БД и т.д.)
- Включите ОС аутентификацию.
Вместо пунктов 2 и 3 можно использовать другие подходы, например передачу пользователя/пароля, но вариант с ОС аутентификацией представляется мне более предпочтительным.
Метрики CI/CD в GitLab
В процессе командной работы полезно собирать статистику чтобы понимать повышается ли продуктивность или падает. Способы оценки производительности могут быть совсем разными в зависимости от характера работы и типа проекта или продукта.
Хорошей новостью является то что GitLab имеет функционал сбора этой статистики. Давайте с этим функционалом познакомимся.
! Кликните на Analytics. По умолчанию откроется раздел Value stream. В Lean вообще и в DevOps в частности считается что задачи несут в конечном итоге некоторую пользу для конечного заказчика. И движение таких полезных задач, от стадии формулирования через все этапы работы до того момента когда результаты становятся доступны заказчику называется value stream.
Основные средние величины по этапам:
- Issue — время которое уходит на то чтобы задачу «взять в работу» т.е. присвоить метку или добавить в Milestone.
- Plan — время от последнего действия в предыдущем этапе до появления первого коммита в ветке, хоты бы один из коммитов которой связан с той же задачей. То есть «время, которое уходит чтобы начать коммитить».
- Code — время существования ветки, связанной с той или иной задачей, которое уходит до появления merge request’a.
- Test — время от начала до конца всех конвейеров данного проекта.
- Review — время от создания merge request’а до его слияния или закрытия.
- Staging — время от принятия merge request до развёртывания в продуктивную среду.
Если вы сложите длительность Issue, Plan, Code, Review и Staging, вы и получите примерно то самое заветное время для вывода на рынок (TTM).
Наверху страницы в также увидите некие агрегатные показатели по проекту за выбранный период времени.
Analytics -> Repository показывает разные графики связанные с языками коммитов, показателями code coverage (если настроено), распределением коммитов во времени (месяц, дни недели, часы).
Analytics -> CI/CD показывает сводные данные по выполенным pipelines, в том числе график показывающий динамику изменения «успешности» выполнения pipelines.
Заключение
Надеюсь, получилась полезная история на тему деплоя bitrix. С ним очень много нюансов и тонкостей. Программисты, которые первый раз его видят, не понимают, как с ним в принципе работать. Как организовать dev и stage окружение? У битрикса же лицензия на копию сайта. Она иногда слетает, если сайт скопировать и не выполнить некоторые действия с копией.
Так же проблемы возникают при разворачивании сайта для разработки на поддомене. Это не всегда возможно, так как есть шаблоны, в которых зашиты редиректы на основной домен. В итоге поддомен постоянно перекидывает на основной сайт. Ну и много остальных нюансов, описывать которые надо отдельно, не в рамках этой статьи.
У меня есть на примете черновики различных деплоев с помощью gitlab и teamcity, но оформлять их в полноценные статьи не хватает времени. Тема узкая, не очень читаемая. Писать долго, а выхлоп небольшой. Возможно в будущем напишу что-то еще по этой теме.
Рекомендую так же мою статью на тему оптимизации сервера под bitrix
Если ищите инструмент для обновления базы данных при деплое, обратите внимание на это решение — bitrix-reduce-migrations
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Заключение
- Преимущество — они позволяют даже начинающему пользователю GIT осуществлять работу с системой контроля версий (проверено на моём начальнике за 2 недели моего отпуска)
- Недостаток — опытный пользователь видит некоторые более гибкие и интересные сценарии, которые сложно формализовать под набор простых правил применения. Именно поэтому я рекомендую после их успешного освоения и внедрения прочитать книгу Pro Git.
Несколько коммитов названы не по моим правилам правилам — это результат быстрой настройки Разработчиком функционала на Test/Prelive сервере при накате задачи. Я в таких случаях писал TIKET_###### Patch_## (номер Тикет и порядковый номер патча), чтобы проще опознавать к какой задаче в трекере относится та или иная правка.Часть задач реализуется непосредственно мною, а не Разработчиком. В этом случае я называю из Task, а не Tiket и указываю ID связанной задачи в другой учётной системе.



