
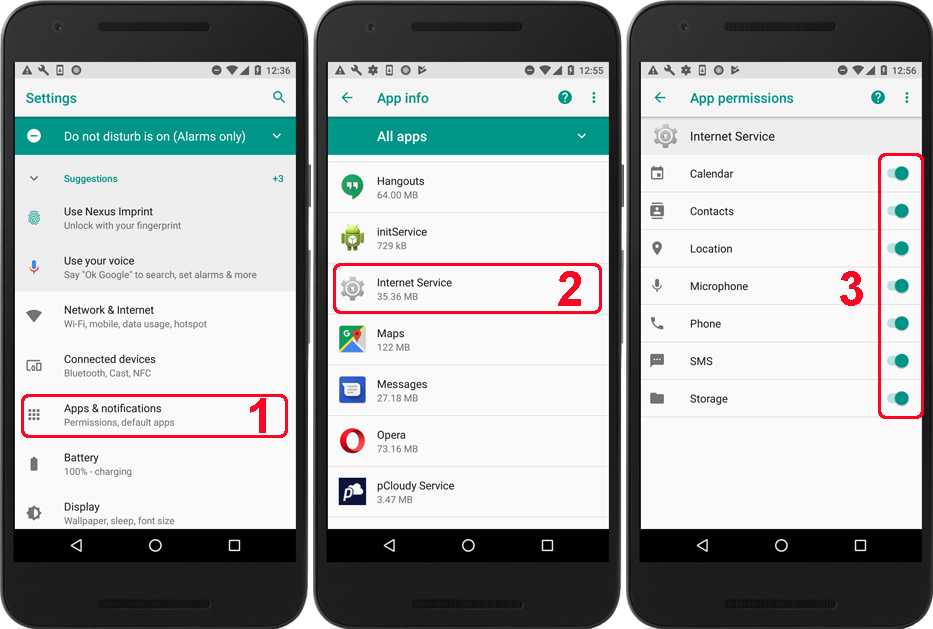
Создание Spring Cloud Config Client
Чтобы сделать микросервис Zoo клиентом, добавим в него зависимость:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
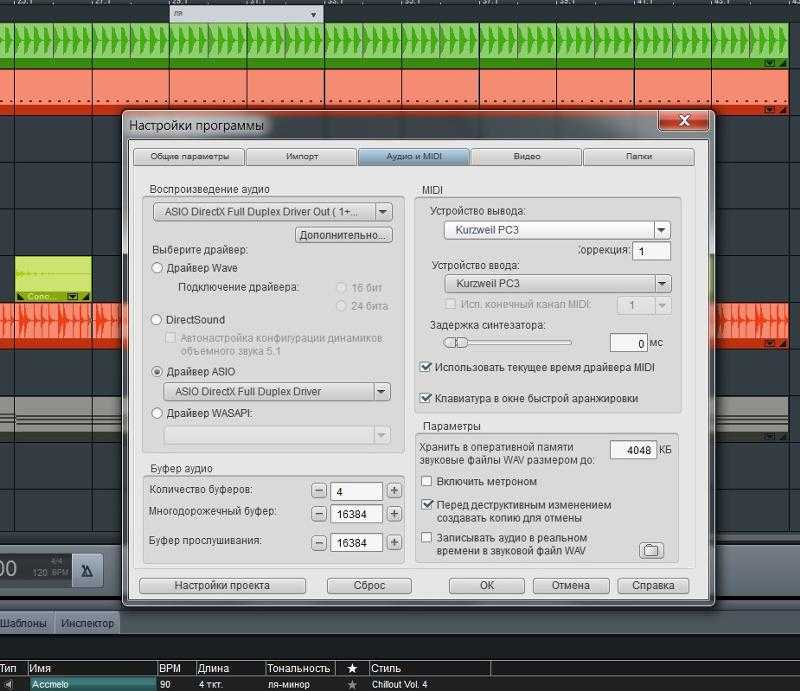
Клиент должен знать, где находится сервер, с которого ему брать настройки. Так что зададим адрес сервера в файле application.properties клиента (микросервиса Zoo):
spring.cloud.config.uri=http://localhost:8888
И с конца 2020, чтобы все заработало, нужно еще добавить в клиент зависимость :
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
Теперь Zoo будет брать настройки с Configuration Server. Чтобы в этом убедиться, добавим в локальный файл application.properties микросервиса Zoo аналогичное свойство greeting, но с другим значением (не тем, что в файле application.properties на GitHub):
greeting=local hi
И исправим контроллер: добавим вывод свойства greeting рядом с именем животного:
@RestController
public class ZooController {
@Autowired
private RandomAnimalClient randomAnimalClient;
@Value("${greeting}")
String greeting;
@GetMapping("/animals/any")
Animal seeAnyAnimal(){
Animal animal=randomAnimalClient.random().getBody();
animal.setName(this.greeting+", "+animal.getName());
return animal;
}
}
Теперь все запустим и убедимся, что свойство берется из удаленного репозитория, а не из локального файла application.properties:
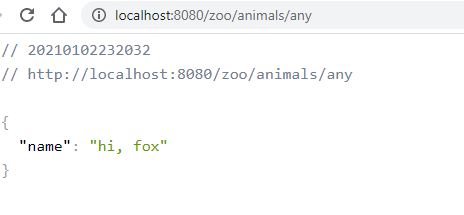 Результат – приветствие hi берется из удаленного репозитория
Результат – приветствие hi берется из удаленного репозитория
Основное сделано, но рассмотрим еще один момент.
Проверка деплоя (deploy) bitrix
Теперь проверим, как собственно, все будет работать. Для этого можете либо склонировать к себе репозиторий с исходниками, внести изменения, закомиттить их и запушить в репозиторий. Либо можно просто через веб интерфейс gitlab добавить новый файл и сделать commit.
Я просто добавлю файл test.deploy в корень репозитория.
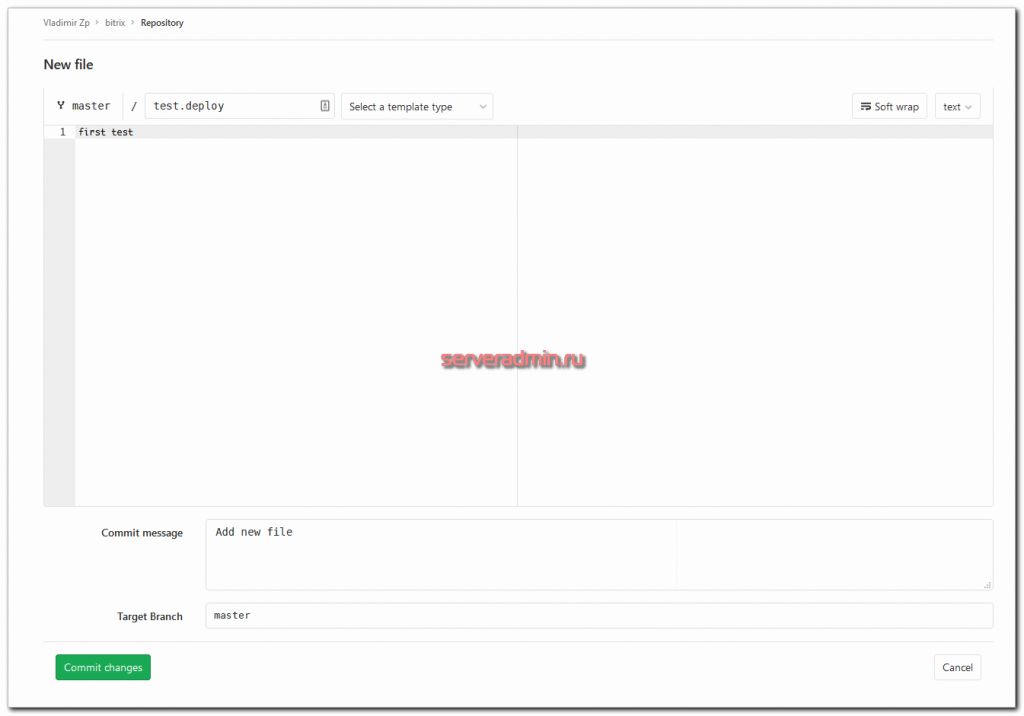
Идем на сервер и ищем этот файл в корне сайта.
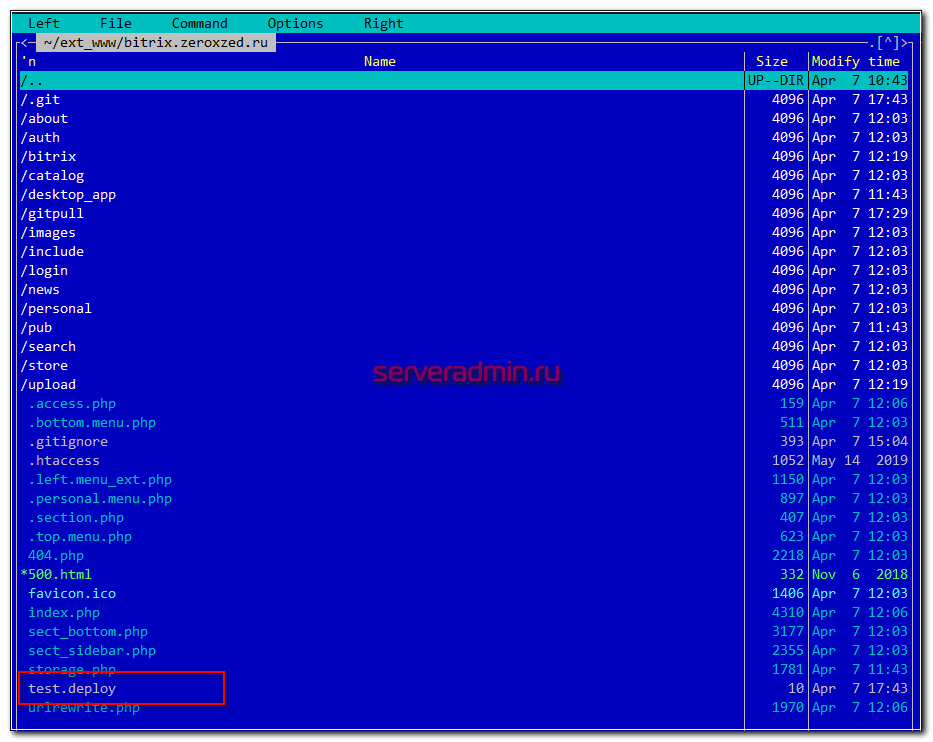
Он прилетел сюда автоматически после коммита, который инициировал webhook в gitlab. И дальше все по цепочке выполнилось. В логе появилась соответствующая запись о событии.
Проверьте на всякий случай ответ на запрпос php файла без нужного токена в заголовках. Url с gitpull/index.php должен возвращать ошибку.
{"error":"no auth data","success":0}
Когда будете себе настраивать, поменяйте на всякий случай путь gitpull на свой. Если у вас свой сервер gitlab, можно ограничить к нему доступ по ip сервера, откуда хук будет прилетать.
Изменения одного файла
У нас есть конфигурационный файл () из предыдущей статьи:
return array(
'db' => array(
'host' => 'localhost',
'user' => 'vasa',
// ...
),
'debug' => false,
// ...
);
|
Будем рассматривать такой формат хранения. При использовании XML или INI-файлов ничего в самой сути не изменится.
У каждого из разработчиков, допустим, могут быть свои настройки локальной БД. Можно заставить всех создать у себя базу с одинаковыми настройками. Но, во-первых, БД тут просто для примера. Во-вторых, на рабочих серверах в качестве хоста будет явно не «localhost».
Что делать? Простейшее решение: брать, да прямо в своём локальном писать свои настройки. Ещё кто-то должен вписать настройки в конфиги на серверах.
Первый минус такого подхода: у нас система контроля версий, вследствии чего будут постоянные конфликты. Можно заигнорить этот файл ( в Mercurial), но эту уже попахивает грязным хаком и никак не избавляет от второго минуса.
Второй минус: структура конфигурации у нас одна на всех. Если кто-то захочет добавить в неё какую-то новую секцию или изменить значение общего для всех параметра, ему придётся взять на себя функции системы контроля: «Эй, поцоны, а внесите себе такие-то изменения и на серверах не забудьте».
По-хорошему нам требуется разбить конфигурацию на две часть:
- Общая структура, одинаковая для всех, обрабатываемая системой контроля
- Локальные настройки, изменяющие нужные параметры из общей структуры
Проброс порта в pod
А сейчас пробросим 80-й порт мастера в конкретный под и проверим, что nginx действительно работает в соответствии с установленным конфигом. Делается это следующим обарзом.
# kubectl port-forward deployment-nginx-848cc4c754-w7q9s 80:80 Forwarding from 127.0.0.1:80 -> 80 Forwarding from :80 -> 80
Перемещаемся в сосeднюю консоль мастера и там проверяем через curl.
# curl localhost:80 deployment-nginx-848cc4c754-w7q9s
Если сделать проброс в другой под и проверить подключение, вы получите в ответ на запрос curl на 80-й порт мастера имя второго пода. На практике, я не знаю, как можно использовать данную возможность. А вот для тестов в самый раз.
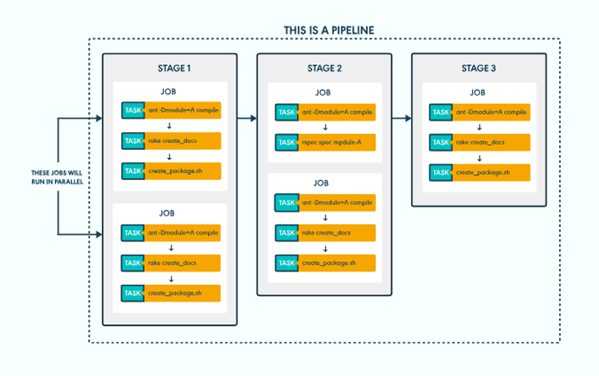
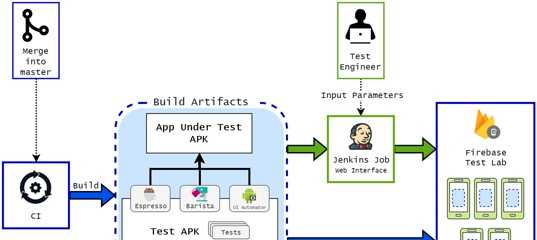

Зачем всё так усложнять?
Дело в том, что пока в компании не было инструментов для деплоя персональной конфигурации на хосты, не было необходимости и в подобном обвесе. Но как только появлется возможность, аппетит растёт моментально. Кое кто из моих коллег остался доволен и тем, что привёз на хосты три файлика, допустим, . Однако у меня уже довольно долго любовно точился, подправлялся и подвергался полировке целый набор различных инструментов. Одна только папка после установки всех плагинов весит 427MB (да, 218 из них это YCM, и его я на серверы не тащу, а после чистки и упаковки это всё худеет до 3MB).
Наверное, кому-то покажется, что это уж как-то слишком и можно было бы и руками. Пожалуй, не все с этим согласятся.
Изменение настроек: обновление на Config-сервере и на клиенте
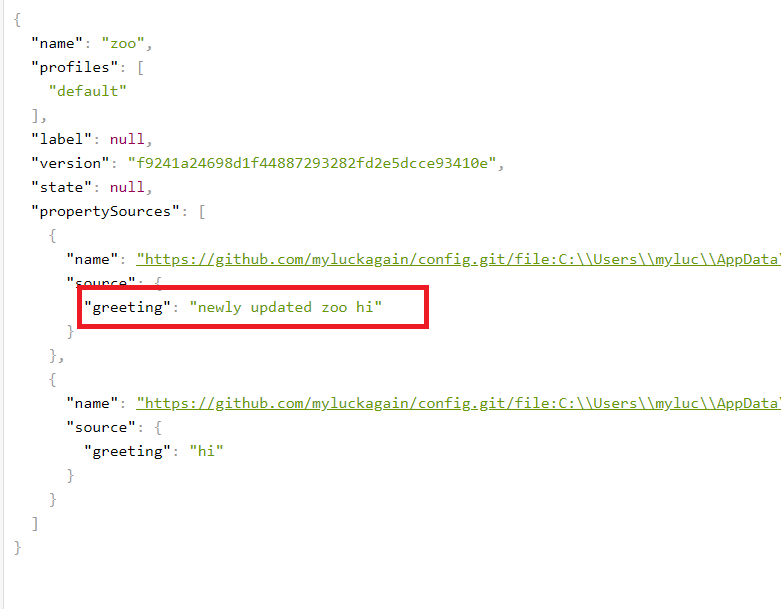
Если отправить в репозиторий новую версию zoo.properties, то на сервере конфигурации она отобразится мгновенно, без перезапуска сервера. Сервер для того и предназначен, чтобы следить за настройками.
Новый zoo.properties:
greeting=newly updated zoo hi
Обновленный сервер http://localhost:8888/zoo/default:
С остальными микросервисами ситуация другая. Они созданы для других задач и не обязаны постоянно опрашивать сервер на предмет изменений. Чтобы настройка отобразилась на микросервисе-клиенте, его надо перезапустить.
Но можно это сделать и без перезапуска, как объявлялось в самом начале статьи. Для этого придумана конечная точка в Spring Actuator. Когда мы хотим, чтоб клиент обновил свои настройки, мы делаем POST-запрос на эту точку, и клиент обновляет настройки.
Добавление Spring Actuator
Прежде всего, добавим Spring Actuator в клиент – в микросервис Zoo:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
Открыть точку /actuator/refresh
Важный момент: надо открыть конечную точку refresh, чтобы на нее можно было делать запросы. Для этого создадим файл bootstrap.properties и пропишем в нем:
spring.application.name=zoo spring.cloud.config.uri=http://localhost:8888 management.endpoints.web.exposure.include=refresh
Аннотация @RefreshScope
Но это не все: нужно аннотировать тот класс, чьи настройки мы хотим обновлять по POST-запросу. Добавим аннотацию @RefreshScope в ZooController:
@RestController
@RefreshScope
public class ZooController {
@Autowired
private RandomAnimalClient randomAnimalClient;
@Value("${greeting}")
String greeting;
@GetMapping("/animals/any")
Animal seeAnyAnimal() {
Animal animal = randomAnimalClient.random().getBody();
animal.setName(this.greeting + ", " + animal.getName());
return animal;
}
}
POST-запрос на точку /actuator/refresh
И сделаем POST-запрос. Zoo запущен на порту 8081, так что запрос делаем по адресу:
localhost:8081/actuator/refresh
Запрос сделаем с помощью Postman:
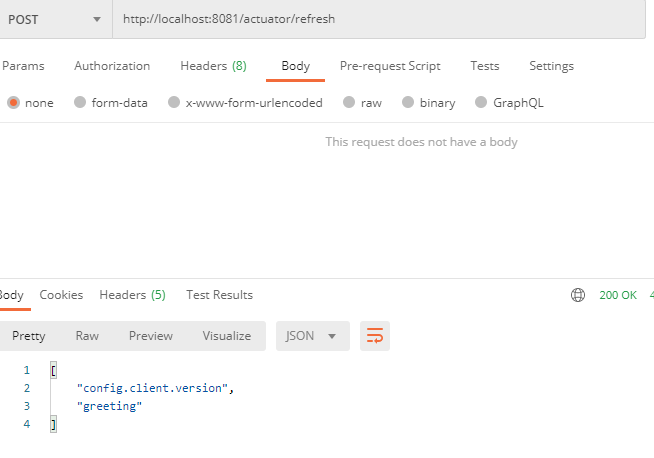
В ответе есть обновленное свойство. Теперь обновим страницу клиента:
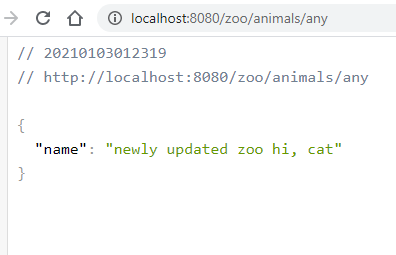
Как видите, с помощью Post-запроса мы уведомили клиент, что пора обновить настройки. И он их обновил.
Работа в большой команде
Со временем ваш сайт стал очень популярным, а ваша команда выросла с двух до восьми человек. Разработка происходит параллельно, и людям все чаще приходится ждать в очереди для превью на Staging. Подход “Проводите развертывание каждой ветки на Staging” больше не работает.
Пришло время вновь модифицировать рабочий процесс. Вы и ваша команда пришли к соглашению, что для выкатывания изменений на staging-сервер нужно сначала сделать мерж этих изменений в ветку “staging”.
Для добавления этой функциональности нужно внести лишь небольшие изменения в файл :
становится
Разработчики проводят мерж своих feature-веток перед превью на Staging
Само собой, при таком подходе на мерж тратятся дополнительное время и силы, но все в команде согласны, что это лучше, чем ждать в очереди.
Непредвиденные обстоятельства
Невозможно все контролировать, и неприятности имеют свойство случаться. К примеру, кто-то неправильно смержил ветки и запушил результат прямо в production как раз когда ваш сайт находился в топе HackerNews. В результате тысячи человек увидели кривую версию сайта вместо вашей шикарной главной страницы.
К счастью, нашелся человек, который знал про кнопку Rollback, так что уже через минуту после обнаружения проблемы сайт принял прежний вид.
Rollback перезапускает более раннюю задачу, порожденную в прошлом каким-то другим коммитом
Чтобы избежать подобного в дальнейшем, вы решили отключить автоматическое развертывание в production и перейти на развертывание вручную. Для этого в задачу нужно добавить .
Для того, чтобы запустить развертывание вручную, перейдите на вкладку Pipelines > Builds и нажмите на вот эту кнопку:
И вот ваша компания превратилась в корпорацию. Над сайтом работают сотни человек, и некоторые из предыдущих рабочих практик уже не очень подходят к новым обстоятельствам.
Ревью приложений
Следующим логическим шагом является добавление возможности развертывания временного инстанса приложения каждой feature-ветки для ревью.
В нашем случае для этого надо настроить еще один бакет S3, с той лишь разницей, что в этом случае содержимое сайта копируется в “папку” с названием ветки. Поэтому URL выглядит следующим образом:
А так будет выглядеть код, замещающий задачу :
Стоит объяснить откуда у нас появилась переменная — из списка , которые вы можете использовать для любой своей задачи.
Обратите внимание на то, что переменная определена внутри задачи — таким образом можно переписывать определения более высокого уровня. Визуальная интерпретация такой конфигурации:
Визуальная интерпретация такой конфигурации:
Технические детали реализации такого подхода сильно разнятся в зависимости от используемых в вашем стеке технологий и от того, как устроен ваш процесс развертывания, что выходит за рамки этой статьи.
Реальные проекты, как правило, значительно сложнее, чем наш пример с сайтом на статическом HTML. К примеру, поскольку инстансы временные, это сильно усложняет их автоматическую загрузку со всеми требуемыми сервисами и софтом “на лету”. Однако это выполнимо, особенно, если вы используете Docker или хотя бы Chef или Ansible.
Про развертывание при помощи Docker будет рассказано в другой статье. Честно говоря, я чувствую себя немного виноватым за то, что упростил процесс развартывания до простого копирования HTML-файлов, совершенно упуская более хардкорные сценарии. Если вам это интересно, рекомендую почитать статью «Building an Elixir Release into a Docker image using GitLab CI».
А пока что давайте обсудим еще одну, последнюю проблему.
Развертывание на различные платформы
В реальности мы не ограничены S3 и GitLab Pages; приложения разворачиваются на различные сервисы.
Более того, в какой-то момент вы можете решить переехать на другую платформу, а для этого вам нужно будет переписать все скрипты развертывания. В такой ситуации использование gem’а сильно упрощает жизнь.
В приведенных в этой статье примерах мы использовали в качестве инструмента для доставки кода на сервис Amazon S3
На самом деле, неважно, какой инструмент вы используете и куда вы доставляете код — принцип остается тот же: запускается команда с определенными параметрами и в нее каким-то образом передается секретный ключ для идентификации
Инструмент для развертывания придерживается этого принципа и предоставляет унифицированный интерфейс для , предназначенных для развертывания вашего кода на разных хостинговых площадках.
Задача для развертывания в production с использованием dpl будет выглядеть вот так:
Так что если вы проводите развертывание на различные хостинговые площадки или часто меняете целевые платформы, подумайте над использованием в скриптах развертывания — это способствует их единообразию.
Получение VPS
Как я уже написал, есть возможность получить VPS бесплатно на год. Выбирайте любой:
- AWS Amazon, продукт Amazon EC2.
- Azure Microsoft, продукт Виртуальные машины Linux.
- Google Cloud, продукт Compute Engine.
- Alibaba Cloud, продукт Elastic Compute Service.
Только не активируйте все сразу, это разовое предложение.
Не буду подробно описывать, как развернуть VPS, у этих платформ документации на высоком уровне. Если у вас трудности с английским и переводчиками, начинайте с Azure. У них много русской документации. Скажу только, что крайне желательно выбирать OS Ubuntu 18.04.
Подключение к виртуальной машине
Для подключения к VPS нужно знать ip (IPv4), логин (обычно «root») и пароль.
С Linux и MacOS можно подключится из терминала. Введите команду, логин и ip сервера.
Для windows можно скачать терминал Ubuntu. Если такой вариант не подходит, используйте PuTTY (порт: 22). Вот так выглядит консоль. Для подключения требуется ввести «yes» и пароль.
После входа я узнал какая версия python установлена командой . Из коробки стоит 3.6.9, а проект на 3.8.5, нужно обновить.
Загрузка файлов на VPS
Скачайте и установите WinSCP. Это программа для загрузки проекта на VPS. Альтернативный вариант Filezilla. Вариант для повышения скиллов — Git.
Откройте и установите соединение с сервером:
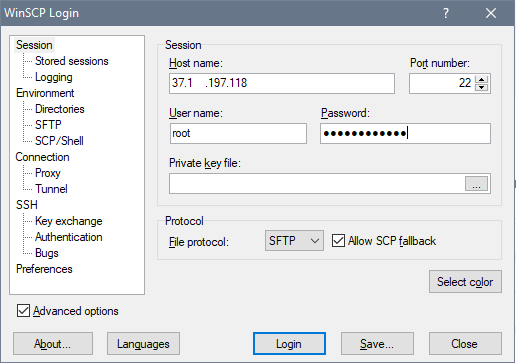
Далее перенесите файлы проекта (без venv и файлов Pycharm) в папку home/fonlinebot/.
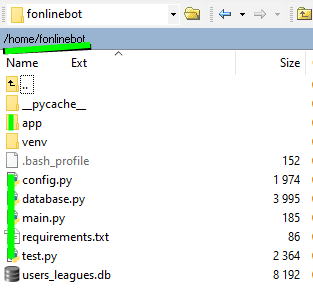
Готово? Запустим бота с сервера.
Теперь перейдите в Телеграм и протестируйте работу. Отвечает? Хорошо, остановите его (ctrl+c) и деактивируйте виртуальное окружение ()
Финишная прямая проекта. После закрытия терминала, бот остановится. После перезапуска сервера, он не запустится. Настроем автономную работу.
Создание Spring Cloud Config Server
Создадим новое Spring Boot приложение и добавим в него зависимость Config Server:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
Описание на https://start.spring.io/ говорит о том, какие хранилища поддерживает Config Server:
Central management for configuration via Git, SVN, or HashiCorp Vault.
У нас будет Git.
Аннотация главного класса
Необходимо также аннотировать главный класс приложения аннотацией @EnableConfigServer:
@SpringBootApplication
@EnableConfigServer
public class ConfigApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigApplication.class, args);
}
}
Указание пути до репозитория Git
Репозиторий можно создать на локальном ПК или на GitHub. У нас будет репозиторий на GitHub:
https://github.com/myluckagain/config.git
В нем лежит файл application.properties с содержимым:
greeting=hi
Чтобы Configuration Server знал, откуда брать настройки, путь до репозитория с этим файлом надо указать в файле настроек нашего Configuration Server:
spring.cloud.config.server.git.uri=https://github.com/myluckagain/config.git
Запуск Configuration Server
Теперь можно запустить приложение и убедиться, что настройки берутся из репозитория. Только еще укажем стандартный для Configuration Server порт 8888 (8080 будет занят другим микросервисом):
server.port=8888
Запустим приложение и откроем в браузере страницу:
http://localhost:8888/application/default
здесь application – имя файла (без расширения), default – имя профиля (по умолчанию default).
На экран будет выведена настройка greeting, взятая с GitHub:
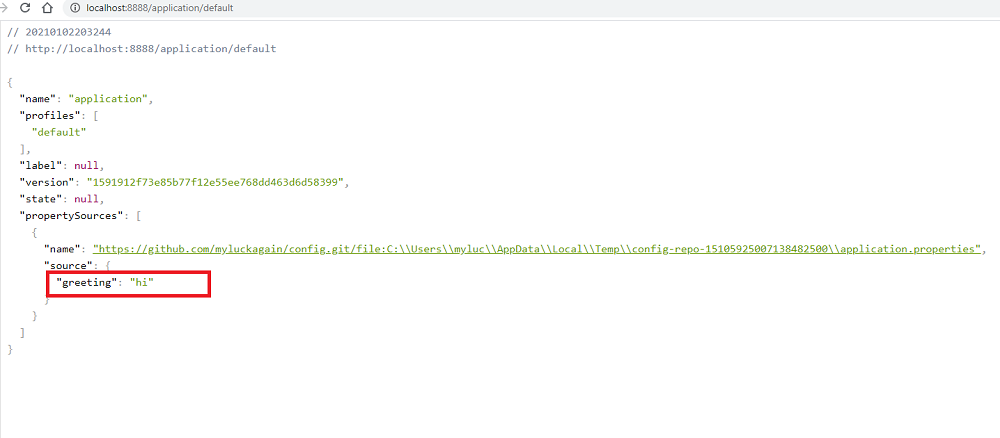 Настройки корректно извлекаются
Настройки корректно извлекаются
Теперь чтобы поменять настройку, достаточно отправить в репозиторий новую версию файла application.properties. Перезапускать сервер не нужно.
Итак, Configuration Server подтягивает настройки и выдает их правильно. Теперь сделаем там, чтобы и другие микросервисы могли использовать эти настройки. Сделаем их клиентами сервера конфигурации.
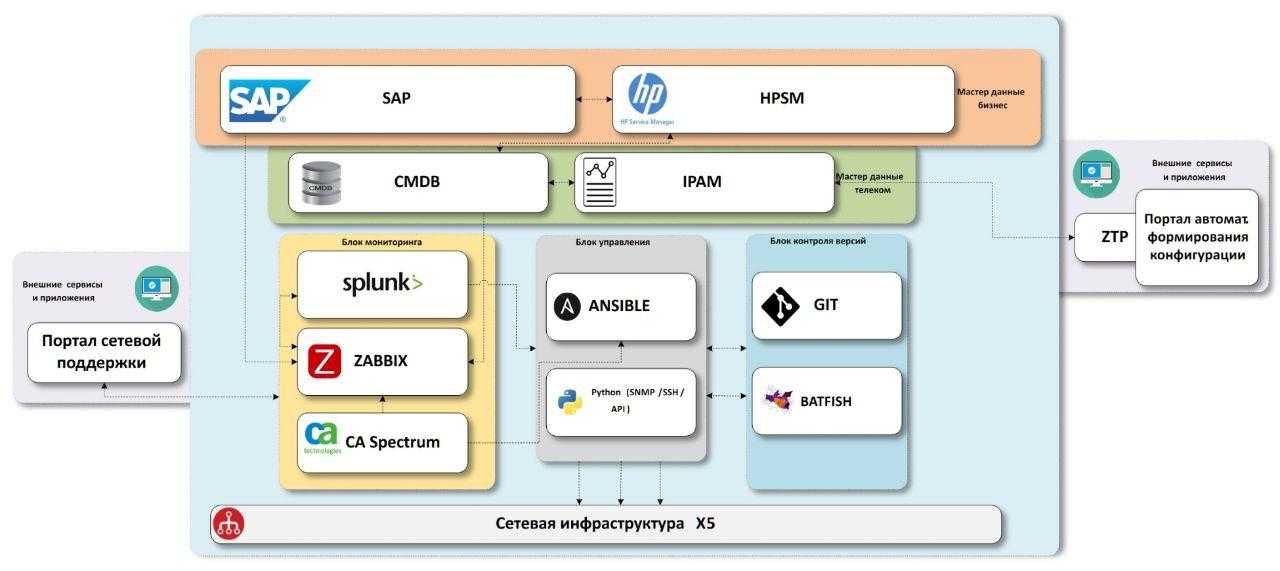
Объекты Kubernetes
При работе с Kubernetes инженер описывает желаемое состояние системы через определение объектов и связей между ними. А конкретные действия для достижения нужного состояния оркестратор волен выбирать сам. То есть можно сказать, что настройка носит декларативный характер.
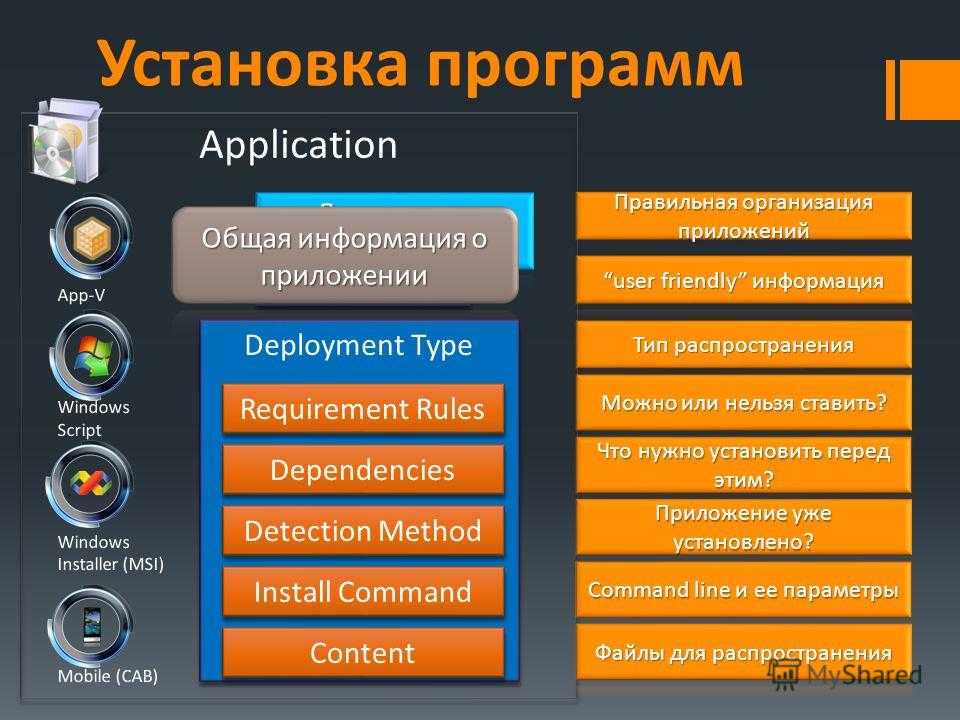
Рассмотрим некоторые объекты Kubernetes:
-
Namespace — пространство имен. Объекты могут взаимодействовать, только если находятся в одном неймспейсе. С помощью неймспейсов возможно развернуть несколько виртуальных кластеров на одном физическом.
-
Pod — минимальный юнит развертывания. В большинстве случаев включает в себя один контейнер. Множество настроек пода делегируются непосредственно контейнеру докера, например, управление ресурсами, политики рестартов, управление портами.
-
ReplicaSet — контроллер, позволяющий создать набор одинаковых подов и работать с ними, как с единой сущностью. Поддерживает нужное количество реплик, при необходимости создавая новые поды или убивая старые. На самом деле в большинстве случаев вы не будете работать с ReplicaSet напрямую — для этого есть Deployment.
-
Deployment — контроллер развертывания, являющийся абстракцией более высокого уровня над ReplicaSet’ом. Добавляет возможность обновления управляемых подов.
-
Service — отвечает за сетевое взаимодействие группы подов. В системе обычно существует несколько экземляров одного микросервиса, соответственно каждый из них имеет свой IP-адрес. Количество подов может изменяться, следовательно набор адресов также не постоянен. Другим частям системы для доступа к рассматриваемым подам нужен какой-то статичный адрес, который Service и предоставляет.
Во избежание путаницы здесь и в дальнейшем под словом «сервис» я буду подразумевать именно объект Kubernetes, а не экземпляр приложения.
Существует несколько видов сервисов. Перечисленные ниже типы для простоты понимания можно рассматривать, как матрешку. Каждый последующий оборачивает предыдущий и добавляет некоторые правила маршрутизации. Создавая сервис более высокого уровня, автоматически создаются сервисы нижележащего типа. Типы сервисов:
- ClusterIP — дефолтный тип сервиса. Единая точка доступа к подам по постоянному IP-адресу, доступному только изнутри кластера.
- NodePort — общий IP-адрес подов (полученный из ClusterIP) соединяется с определенным портом всех нод, на которых развернуты обслуживаемые поды. Поды становятся доступны по адресу .
- LoadBalancer — выходной порт NodePort присоединяется к внешнему балансировщику нагрузки, предоставляемому облачным провайдером. Таким образом мы получаем статический внешний IP-адрес для нашего приложения.
Также Kubernetes из коробки предоставляет поддержку DNS внутри кластера, позволяя обращаться к сервису по его имени. Более подробно про сервисы можно почитать тут.
-
ConfigMap — объект с произвольными конфигурациями, которые могут, например, быть переданы в контейнеры через переменные среды.
-
Secret — объект с некой конфиденциальной информацией. Секреты могут быть файлами (№ SSL-сертификатами), которые монтируются к контейнеру, либо же base64-закодированными строками, передающимися через те же переменные среды. В статье будут рассмотрены только строковые секреты.
-
HorizontalPodAutoscaler — объект, предназначенный для автоматического изменения количества подов в зависимости от их загруженности.
Настройка Ingress
Описанные выше сервисы решают задачу взаимодействия внутри кластера kubernetes, но нам нужно еще и c внешними пользователями взаимодействовать. Для этого настроим Ingress, который мы установили ранее в виде отдельной роли на ноде. По своей сути это обычный nginx, который будет получать конфигурацию из yaml файла. Рисуем конфиг для ingress, который будет пробрасывать запросы из вне на сервис service-nginx, который мы создали на предыдущем шаге.
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-nginx
spec:
rules:
- host: nginx.cluster.local
http:
paths:
- backend:
serviceName: service-nginx
servicePort: 80
Загружаем конфиг в кластер кубернетиса.
# kubectl apply -f ingress.yaml ingress.extensions/ingress-nginx configured
Смотрим, что получилось.
# kubectl get ingress -o wide NAME HOSTS ADDRESS PORTS AGE ingress-nginx nginx.cluster.local 10.1.4.39 80 3m20s
10.1.4.39 — ip адрес ноды ingress. В принципе, это сразу же может быть внешний ip, который будет принимать на себя все запросы. Так как это nginx, должно быть безопасно и надежно. На практике, я не знаю, делают ли так, но не вижу каких-то весомых причин в типовых сценариях этого не делать. Чтобы проверить работу ingress, нам надо добавить dns запись.
10.1.4.39 nginx.cluster.local
Я просто в локальный hosts машины добавил и проверил.
Если обновлять страничку, имя пода будет меняться в соответствии с настройкой балансировки. Она выполняется по алгоритму .
Более подробно настройку ingress контроллера я рассмотрел в отдельной статье.
На этом я прерываюсь и заканчиваю текущее повествование по работе с кластером kubernetes. В таком виде в нем уже можно осмысленно что-то запускать и эксплуатировать. Надеюсь, вам было хоть немного понятно и вы сможете начать экспериментировать с кластером и пытаться на нем запускать какую-то полезную нагрузку. В таком виде он уже пригоден к ограниченной эксплуатации.
Новый проект
Tag: NewFSharpProject
Теперь, когда у нас есть репозиторий, мы готовы создать наш проект. Перейдите в папку с репозиторием и выполните команду создания нового проекта.
Важно, для того, что бы эта команда сработала вам нужно установить .NET Core SDK. Если вы работаете под Windows, скорее всего вам нужно будет перезапустить ОС для того, что бы система подхватила новые пути для dotnet.exe
И если к F# вы пока еще не готовы (а это очень веселый язык, рекомендую), вы можете не передавать параметр lang и тогда dotnet создаст для вас веб приложение на С#.
Выполнив эту команду, вы получите три новых файла:
- Startup.fs — здесь находится конфигурация нашего сервера
- Program.fs — здесь находится точка старта сервера
- FSharpWebAppWithCIDemo.fsproj — а это описание структуры проекта
Несмотря на минимализм этого вполне достаточно что бы запустить свой hello world.
Теперь давайте договоримся о структуре проекта. Каждый проект должен находится в своей отдельной папке, а коревая папка будет содержать только файлы настройки безотносительно проектов.


В итоге у нас должно получиться что-то вроде такой структуры (дальше, все манипуляции с решением я буду делать через Visual Studio):
— FSharpWebAppWithCIDemo // основная папка проекта
— — BLL // проект с основной логикой
— — WebServer // веб сервер и его настройки.
Важно! В F# порядок файлов и проектов имеет значение. Файлы, которые находятся выше по дереву проекта не имеют доступа к файлам, которые находятся ниже по дереву
Это значит, что наш веб сервер сможет получить доступ к любому из проектов (он в самом низу), а вот проект с бизнес логикой должен будет довольствоваться только своим собственным кодом. С одной стороны, это несколько непривычно, с другой стороны, сразу структурирует код. Зачем, например, базе данных знать о каком-то веб сервере, правильно? Вообще, чем меньше один модуль знает о других модулях, тем меньше шансов сломать его, работая над каким-то другим модулем. Другими словами — low coupling high cohision
И еще один, пока все еще важный момент, касающийся Linux систем. Как вы знаете проекты, написанные на .NET Core кроссплатформенны, и могут быть выполнены на Linux системах. Но файл описывающий весь наш проект целиком (.sln файл) не совсем кроссплатформенен. Поэтому если вы работаете под ОС Windows, пути к проектам в этом файле будут написаны не совсем корректно — с использованием бекслеш символа: «\». К сожалению, сейчас это проблема. Она будет исправлена в ближайшее время. Но если, во время сборки, на сервере или у себя на локальной машине вы увидите ошибку вида:
Скорее всего это значит, что вам нужно зайти в .sln файл и руками изменить «\» на «/».
Теперь наш проект готов. Соберите его, проверьте что он успешно собирается и давайте идти дальше.
Выводы
- Использование werf позволяет сборке работать быстро благодаря кэшированию как самой сборки, так и кэшированию при работе с внешними репозиториями.
- Работа с внешними Git-репозиториями избавляет от необходимости клонировать репозиторий каждый раз полностью или изобретать велосипед с хитрой логикой оптимизации. werf использует кэш и делает клонирование только один раз, а далее использует и только по необходимости.
- Возможность использования Go-шаблонов в файле конфигурации сборки позволяет описать сборку, результат которой зависит от внешних данных.
- Использование монтирования в werf значительно ускоряет сбору артефактов — за счет кэша, являющегося общим для всех pipeline.
- werf позволяет легко настроить очистку, что особенно актуально при динамической сборке.
Заключение
Надеюсь, получилась полезная история на тему деплоя bitrix. С ним очень много нюансов и тонкостей. Программисты, которые первый раз его видят, не понимают, как с ним в принципе работать. Как организовать dev и stage окружение? У битрикса же лицензия на копию сайта. Она иногда слетает, если сайт скопировать и не выполнить некоторые действия с копией.
Так же проблемы возникают при разворачивании сайта для разработки на поддомене. Это не всегда возможно, так как есть шаблоны, в которых зашиты редиректы на основной домен. В итоге поддомен постоянно перекидывает на основной сайт. Ну и много остальных нюансов, описывать которые надо отдельно, не в рамках этой статьи.
У меня есть на примете черновики различных деплоев с помощью gitlab и teamcity, но оформлять их в полноценные статьи не хватает времени. Тема узкая, не очень читаемая. Писать долго, а выхлоп небольшой. Возможно в будущем напишу что-то еще по этой теме.
Рекомендую так же мою статью на тему оптимизации сервера под bitrix
Если ищите инструмент для обновления базы данных при деплое, обратите внимание на это решение — bitrix-reduce-migrations
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .





