
Свободное место на диске (df)
Для просмотра свободного и занятого места на разделах диска в Linux можно воспользоваться командой df.
Первым делом можно просто ввести команду df без каких-либо аргументов и получить занятое и свободное место на дисках. Но по умолчанию вывод команды не очень наглядный — например, размеры выводятся в КБайтах (1К-блоках).
df Файл.система 1K-блоков Использовано Доступно Использовано% Cмонтировано в udev 1969036 0 1969036 0% /dev tmpfs 404584 6372 398212 2% /run /dev/sda9 181668460 25176748 147240368 15% / … /dev/sda1 117194136 103725992 13468144 89% /media/yuriy/5EB893BEB893935F /dev/sda6 144050356 121905172 14804772 90% /media/yuriy/2f24…….d9075
Примечание: df не отображает информацию о не смонтированных дисках.
Размер конкретного диска
Команде df можно указать путь до точки монтирования диска, размер которого вы хотите вывести:
df -h /dev/sda9 Файл.система Размер Использовано Дост Использовано% Cмонтировано в /dev/sda9 174G 25G 141G 15% /
На что обращать внимание на работе
(1) Если существует большой разрыв между du и df, подумайте, не вызвано ли это неполным удалением файла. Метод — команда lsof, а затем остановите связанный процесс. (2) Вы можете использовать метод очистки файлов вместо удаления файлов, метод: echo> myfile.iso. (3) Для файлов журналов с частыми проблемами удаления используйте порядок переименования, очистки и удаления. (4) Помимо rm, некоторые команды удаляют файлы косвенно. Например, исходный файл будет удален после завершения команды gzip. Чтобы избежать проблем с удалением, убедитесь, что нет процесса для открытия файла перед сжатием. ,
Свободное место на диске (df)
Для просмотра свободного и занятого места на разделах диска в Linux можно воспользоваться командой df.
Первым делом можно просто ввести команду df без каких-либо аргументов и получить занятое и свободное место на дисках. Но по умолчанию вывод команды не очень наглядный — например, размеры выводятся в КБайтах (1К-блоках).
df Файл.система 1K-блоков Использовано Доступно Использовано% Cмонтировано в udev 1969036 0 1969036 0% /dev tmpfs 404584 6372 398212 2% /run /dev/sda9 181668460 25176748 147240368 15% / … /dev/sda1 117194136 103725992 13468144 89% /media/yuriy/5EB893BEB893935F /dev/sda6 144050356 121905172 14804772 90% /media/yuriy/2f24…….d9075
Опция -h (или —human-readable) позволяет сделать вывод более наглядным. Размеры выводятся теперь в ГБайтах.
df -h
Размер папок на диске (du)
Для просмотра размеров папок на диске используется команда du. Если просто ввести команду без каких либо аргументов, то она рекурсивно проскандирует вашу текущую директорию и выведет размеры всех файлов в ней. Обычно для du указывают путь до папки, которую вы хотите проанализировать. Если нужно просмотреть размеры без рекурсивного обхода всех папок, то используется опция -s (–summarize). Также как и с df, добавим опцию -h (–human-readable).
Размеры файлов и папок внутри конкретной папки:
du -sh ./Загрузки/* 140K ./Загрузки/antergos-17.1-x86_64.iso.torrent 79M ./Загрузки/ubuntu-amd64.deb 49M ./Загрузки/data.zip 3,2G ./Загрузки/Parrot-full-3.5_amd64.iso 7,1M ./Загрузки/secret.tgz Войдите, чтобы ставить лайкимне нравитсяЛайков: 0 войдите, чтобы ставить лайки
Причины и решения для расхождений между использованием дискового пространства, отображаемых df и du
y http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>le=»margin-bottom:5px;»>Теги: du df
Для проверки использования дискового пространства в Linux чаще всего используются du и df. Тем не менее, между ними все еще существует большая разница, и иногда выходные результаты даже сильно отличаются.
du-Disk Usage
df-Disk Free
Как дф и дю работают
1. Принцип работы du Команда du вызывает системный вызов fstat один за другим, чтобы получить размер файла. Его данные получаются на основе файлов, поэтому он обладает большой гибкостью. Он не обязательно должен быть нацелен на один раздел, и он может работать на нескольких разделах. Если в целевой директории много файлов, скорость будет очень медленной. 2. Как работает df Системный вызов statfs, используемый командой df, непосредственно считывает информацию о суперблоке раздела, чтобы получить информацию об использовании раздела. Его данные основаны на метаданных раздела, поэтому он может быть нацелен только на весь раздел. Поскольку df читает суперблок напрямую, на скорость работы не влияет количество файлов.
Моделирование несовместимости du и df
Общим несоответствием между df и du является проблема удаления файла. Когда файл удаляется, он больше не отображается в каталоге файловой системы, поэтому du больше не будет его считать. Однако, если все еще выполняется процесс, удерживающий дескриптор удаленного файла, файл не будет удален с диска, и информация в суперблоке раздела не будет изменена. Таким образом, df все равно будет считать удаленный файл.
1. Текущее использование раздела vda1
2. Создайте большой файл размером 5 ГБ.
3. Использование раздела vda1 в настоящее время
4. Смоделируйте процесс, чтобы открыть большой файл, а затем удалите большой файл.
5. Теперь сравните результаты du и df.
На данный момент результат df не изменился, и du больше не считает удаленный файл myfile.iso
6. Остановите процесс моделирования и сравните результаты du и df
Сначала убедитесь, что ни один процесс не имеет дескриптора myfile.iso
На этом этапе myfile.iso не имеет процесса, который мог бы его занять, поэтому он удаляется с диска, информация о суперблоке раздела была изменена, и df отображается как обычно.
На что обращать внимание на работе
(1) Если существует большой разрыв между du и df, подумайте, не вызвано ли это неполным удалением файла. Метод — команда lsof, а затем остановите связанный процесс. (2) Вы можете использовать метод очистки файлов вместо удаления файлов, метод: echo> myfile.iso. (3) Для файлов журналов с частыми проблемами удаления используйте порядок переименования, очистки и удаления. (4) Помимо rm, некоторые команды удаляют файлы косвенно. Например, исходный файл будет удален после завершения команды gzip. Чтобы избежать проблем с удалением, убедитесь, что нет процесса для открытия файла перед сжатием. ,
Интеллектуальная рекомендация
Глава первая: Причина В большинстве анекдотов в Интернете говорится, что программисты относительно тупые, плохие слова и в основном мужчины. Я один из тысяч программистов. Обычно я не знаю, как правил…
Всегда был спрос, надеясь увидеть в реальном времени рейтинг моего сайта в Baidu Я использовал некоторые инструменты, либо медленный ответ, либо результаты не точные или в режиме реального времени Поэ…
Алгоритм обнаружения характерных точек Обнаружение угла Харриса Обнаружение функции SIFT…
По просьбе пользователей сети напишите пример использования Selenium Grid для управления несколькими системами и несколькими браузерами для параллельного выполнения тестов. Поскольку у меня здесь две …
Эта проблема возникает, когда используется openrowset. Просто выполните следующий код: http://www.cnblogs.com/wayne-ivan/archive/2008/01/07/1028759.html…
Вам также может понравиться
В проекте .net я часто сталкиваюсь с необходимостью автоматически делать скриншот кадра после загрузки видео. Вот метод использования ffmpeg для автоматического создания скриншота Сначала загрузите фа…
Ленивая загрузка не удалась, потому что @Responsebobode JSON преобразует Getroles по умолчанию, которая заканчивается пользователем, поэтому ленивая загрузка недействительна. Если вы предоставляете TO…
virtualenv установка Основное использование Создайте виртуальную среду для проекта: virtualenv venv создаст папку в текущем каталоге, содержащую исполняемые файлы Python и копию библиотеки pip, чтобы …
Java.io.fileNotfoundException: файл: \ d: \ Code \ xml-load \ target \ xx.jar! \ Xxx (имя файла, имя каталога или синтаксис громкости неверно.) 1. При использовании Spring Boot для применения к JAR не…
4 ответа
Лучший ответ
просто сообщает вам общее свободное пространство в файловой системе. Файловая система может узнать это мгновенно, благодаря простой бухгалтерской отчетности.
, с другой стороны, фактически просматривает каталог и вычисляет общий размер его содержимого. Это медленнее, но и мощнее: например, он может вычислять размер отдельного каталога, а не всей файловой системы.
3
John Zwinck
13 Янв 2015 в 06:53
А также
Что делает , так это анализирует файл и с помощью сообщает об использовании диска. Тогда как проанализирует все файлы в каталоге, хранит размер каждого файла, а затем вычислит окончательную сумму, что утомительно по сравнению с тем, что делает .
Поскольку для синтаксического анализа файлов требуется доступ к памяти, что, в свою очередь, загружает процессор до завершения операции. Следовательно, df быстрее по сравнению с du
1
Santosh A
13 Янв 2015 в 06:58
2
Basile Starynkevitch
13 Янв 2015 в 06:58
Согласно руководствам,
И,
В то время как показывает использование файловой системы, показывает использование файлового пространства. работает с файлами, а работает на уровне файловой системы, сообщая о том, что ядро сообщает, что оно доступно. Вообще говоря, по своей конструкции заботится не о файлах, а о самой файловой системе.
С точки зрения работы, смотрит на используемые блоки диска непосредственно в метаданных файловой системы. Из-за этого он возвращается намного быстрее, чем , но может отображать информацию только обо всем диске / разделе. Где as, просматривает дерево каталогов и подсчитывает общий размер всех файлов в нем. Он может не выводить точную информацию из-за возможности нечитаемых файлов, жестких ссылок в дереве каталогов и т. Д.
ИЗМЕНИТЬ
Поскольку вы тоже спросили, как работает , очень интересно сказать, что если вы используете и , и , вы можете увидеть, что иногда есть разница в размере доступного свободного места. Теперь вы можете удивиться, подумав, как это возможно, что две похожие команды ( и ) возвращают разное свободное пространство для одного и того же жесткого диска ???
Ответ кроется в работе , Поскольку df напрямую связан с метаданными файловой системы, он также связан с дескриптором открытого файла . Предположим, что возникает ситуация, когда файл удаляется, возможно, что какой-то другой процесс удерживает файл открытым, в результате чего он не удаляется; (перезапуск или завершение этого процесса приведет к освобождению файла) Также, если вы создали жесткие ссылки, несколько имен файлов будут указывать на одни и те же данные, и данные (фактическое содержимое) будут помечены как свободные / пригодные для использования до тех пор, пока все ссылки на него не будут удалены . В этой ситуации будет учитывать размер этого файла / данных, в результате чего доступное пространство будет меньше.
5
RicoRicochet
13 Янв 2015 в 07:37
Проверка диска на ошибки и bad blocks
С выходом файловых систем ext4 и xfs я практически забыл, что такое проверка диска на ошибки. Сейчас прикинул и ни разу не вспомнил, чтобы у меня были проблемы с файловой системой. Раньше с ext3 или ufs на freebsd проверка диска на ошибки было обычным делом после аварийного выключения или еще каких бед с сервером. Ext4 и xfs в этом плане очень надежны.
В основном ошибки с диском вызваны проблемами с железом. Как посмотреть параметры smart я уже показал выше. Но если у вас все же появились какие-то проблемы с файловой системой, то решить их можно с помощью fsck (File System Check). Обычно она входит в базовый состав системы. Запустить проверку можно либо указав непосредственно раздел или диск, либо точку монтирования. Раздел при этом должен быть отмонтирован.
# umount /dev/sdb1 # fsck /dev/sdb1 fsck from util-linux 2.33.1 e2fsck 1.44.5 (15-Dec-2018) /dev/sdb1: clean, 11/1310720 files, 109927/5242619 blocks
Проверка завершена, ошибок у меня не обнаружено. Так же у fsck есть необычная опция, которая не указана в документации или man. Запустив fsck с ключем -c можно проверить диск на наличие бэд блоков.
# fsck -c /dev/sdb1
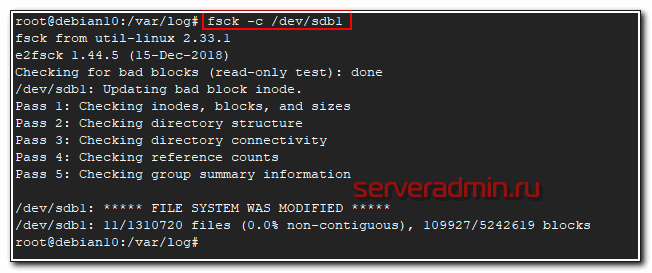
Насколько я понимаю, проверка выполняет посекторное чтение и просто сообщает о том, что найден бэд блок. Теоретически, можно собрать все эти блоки в отдельный файл и затем передать их утилите e2fsck, которая сможет запомнить эти бэды и исключить из использования.
# fsck -c /dev/sdb1 > badblocks.txt # e2fsck -l badblocks.txt /dev/sdb1
На практике я не проверял как это работает и имеет ли вообще смысл в таких действиях. Если с диском замечены хоть малейшие проблемы, я его сразу меняю.
Описание утилиты free
Linux утилита free показывает свободную и занятую память в системе. Данные получаются путем разбора /proc/meminfo.
При запуске без ключей Linux утилита free выведет на экран следующие данные:
$ free total used free shared buff/cache available Mem: 3871612 3444088 123092 4800 304432 199308 Swap: 3145724 977220 2168504
Вывод содержит данные о физической памяти Mem и файле подкачки Swap. В столбцах указаны следующие параметры:
total – всего установленной памятиused – использовано памяти (рассчитывается как total – free – buffers – cache)free – свободно памятиshared – разделенная память, используемая (в основном) tmpfsbuff/cache – память, используемая буферами ядра и кэшем страницavailable – доступно памяти для запуска новых приложений (без учета swap)По умолчанию все значения перечисленных параметров указываются в кибибайтах (2 в степени 10 = 1024).
Команда du – синтаксис и опции
Disk Usage – именно так интерпретируется название команды du. Она была написана ещё в самой первой версии UNIX (в определённом роде предшественницы Linux), еще в стенах одной из лабораторий компании AT&T
Этот факт даёт понять, насколько важно следить за дисковым пространством, а также анализировать его при наличии специализированных программных инструментов, ведь du – одна из самых первых утилит из стандартного комплекта UNIX/Linux
Итак давайте узнаем что у нас занимает место
du --max-depth=1 -h /
Более подробное описание команды du и ключей вы можете прочитать ниже. Вывод будет следующий
Отсюда мы видим что самый большой каталог у нас /var. Посмотрим что у на занимает место в каталоге /var
du --max-depth=1 -h /var
видим что это папка log
Теперь смотрим /var/log
du -ah /var/log
и вот здесь мы уже видим пять самых больших файлов с логами, именно они и заняли все место на диске. Давайте рассмотрим команду du подробнее.
Согласно описанию из официального man-руководства, утилита du суммирует использование дискового пространства набора элементов, рекурсивно с каталогами. Синтаксис команды не простой, а очень простой, поскольку представляет собой классический прототип команды Linux:
du … …
du code_text.txt 4 code_text.txt
Как видно, code_text.txt занимает 4 килобайта (т. к. 1024 байта = 1 килобайт) дискового пространства. То же самое и с папками, но по-умолчанию будет указан общий размер папки без детализации по файлам и подкаталогам. В следующей таблице приведены опции команды du:
| Опция | Назначение |
| -a | Выводит объём для всех элементов, а не только для каталогов |
| —apparent-size | Выводит действительные размеры, но не занимаемое место а диске |
| -B,
—block-size=РАЗМЕР |
Задаёт использование определённых единиц измерения объёма |
| -b,
—bytes |
То же самое, что и «—block-size —apparent-size=1» |
| -с,
—total |
Выводит общий результат |
| -D,
—dereference-args |
Указывает обрабатывать только те символьные ссылке, которые перечислены в командной строке |
| -d, —max-depth=N | Выводит общий размер только до N-го уровня (включительно) дерева каталогов |
| -h,
—human-readable |
Выводит размеры в удобном для человека виде |
| -k | Эквивалентно —block-size=1K |
| -L,
—dereference |
Разыменовывает символьные ссылки |
| -l,
—count-links |
Складывает размеры, если несколько жёстких ссылок |
| -m | Эквивалентно —block-size=1M |
| -t,
—threshold=РАЗМЕР |
Исключает элементы, которые меньше РАЗМЕРА, если это значение положительно или размер которых больше, если это значение отрицательно |
| —time | Выводит время последнего изменения в каталоге и во всех подкаталогах |
| —time=АТРИБУТ | Выводит указанный атрибут времени (atime, access, use, ctime, status), а не время последнего изменения |
| —time-style=СТИЛЬ | Выводит время в указанном в СТИЛЬ формате: full-iso, long-iso, iso |
|
-X, —exclude-from=ФАЙЛ |
Исключает все эдементы, которые совпадают с шаблоном из ФАЙЛа |
| —exclude=ШАБЛОН | Исключает элементы, совпадающие с шаблоном |
| -x,
—one-file-system |
Пропускать каталоги из других систем |
Используемые командой du единицы измерения размера (или объёма) задаются в формате «цифраБуква», где цифра — это коэффициент, а Буква — степень единицы измерения, например: 5K = 5 * 1024 = 5120 = 5 килобайт и по аналогии для M – мегабайт, G – гигабайт.
Примеры использования команды du
Узнать общий размер каталога (например с резервными копиями):
$ du -sh ~/home/backups 19G /home/john/backups
Вывод размеров всех подкаталогов (рекурсивно):
$ du -h ~/home/backups/ 3,2M /home/john/backups/vhosts/ssl 1,5M /home/john/backups/vhosts 5,0M /home/john/backups
С учётом файлов:
$ du -ha ~/home/backups/ 4,0K /home/john/backups/.directory 764K /home/john/backups/scheme.txt 3,2M /home/john/backups/vhosts/ssl 1,5M /home/john/backups/vhosts 5,0M /home/john/backups
С фильтрацией в зависимости от размера файла/каталога:
$ du -ha -t2M ~/home/backups/ 3,2M /home/john/backups/vhosts/ssl 5,0M /home/john/backups
Как видно, были отброшены файлы/каталоги размером меньше 2 мегабайт. Следующая команда, напротив — исключит из вывода только файлы/каталоги больше 2 мегабайт:
$ du -ha ~/home/backups/ 4,0K /home/john/backups/.directory 764K /home/john/backups/scheme.txt 1,5M /home/john/backups/vhosts
Основные различия между базовым и динамическим диском в Windows
При установке Windows на жесткий диск или твердотельный накопитель операционная система по умолчанию настраивает этот носитель как базовый диск. То же самое происходит при добавлении нового накопителя. Тем не менее, Windows предлагает возможность настроить диск как динамический. Но, каковы различия между базовым и динамическим диском и каковы преимущества одной и другой конфигурации?
Попробуйте нажать комбинацию клавиш Win + R , затем введите diskmgmt.msc и нажмите Enter .
Для каждого раздела, созданного в каждом блоке хранения, в столбце «Тип» появится индикация «Основной» или «Динамический», о чём это говорит?
Базовые диски существуют со времен MS-DOS: большинство пользователей могут без проблем работать с дисками этого типа и не испытывают необходимости конвертировать их в динамические диски. Например, с базовым диском можно создать один том, который будет использовать всю (или почти всю, потому что Windows по умолчанию создает зарезервированный раздел для системы) емкость устройства.
Что такое динамический диск и каковы его преимущества
Со времен Windows 2000 пользователи могли настраивать накопители как динамические диски. Тома, сконфигурированные таким образом (можно переключать с базовых на динамические и наоборот), позволяют вносить изменения, которые не допускаются при использовании базовых дисков, например, неограниченное изменение размера уже созданного тома.
Кроме того, динамические тома могут не быть смежными: поэтому изменение размера тома может касаться томов, которые не занимают последовательный блок в окне «Управление дисками».
Большая пластичность динамических дисков объясняется тем, что в этом случае мы работаем не напрямую над конфигурацией отдельных разделов, а над томами внутри них: поэтому можно сделать тома больше или меньше по своему вкусу, настроить тома с помощью схемы RAID, изменить пространство, назначенное каждому из них.
Главный недостаток , связанный с использованием динамических дисков, кроется в отсутствии поддержки мультизагрузочной конфигурации: вы не можете установить несколько операционных систем на одном диске. При попытке установить любую версию и редакцию Windows на динамический диск, вы получите следующее сообщение об ошибке: «Невозможно установить Windows (. ) Раздел содержит один или несколько динамических томов, которые не поддерживаются для установки».
Снова используя Управление дисками (diskmgmt.msc), проверьте, что диск, на котором вы хотите установить Windows в конфигурации мультизагрузки, настроен как базовый диск (с указанием «Базовый» в столбце «Тип»), а не как динамический диск.
Конвертировать базовый диск в динамический
Чтобы переключиться с базового на динамический диск, просто откройте окно «Управление дисками», которое вы видели ранее, затем щелкните правой кнопкой мыши на словах «Диск 0», «Диск 1» и т.д.
При выборе Преобразовать в динамический диск появится понятная процедура, которая поможет пользователю выполнить преобразование за несколько секунд и без потери каких-либо данных.
Прежде чем продолжить, необходимо принять во внимание важный аспект: динамический диск может быть преобразован обратно в базовый диск, но перед продолжением необходимо удалить ранее использованные тома (потеря данных, если не будет сделано их резервное копирование)
Преобразовать базовый диск в динамический из командной строки
Для преобразования базового диска в динамический с помощью командной строки или PowerShell необходимо сначала открыть окно с правами администратора и ввести следующие команды:
Вы получите список дисков , подключенных к системе. С помощью select disk N (заменив «N» на номер диска, подлежащего преобразованию в динамический диск), вы можете выбрать его.
Выполнив команду detail disk, вы получите техническую информацию о конфигурации ранее выбранного диска.
На этом этапе, используя команду convert dynamic, вы можете запустить процесс преобразования в динамический диск.
Чтобы перейти с динамического диска на базовый диск, сначала необходимо удалить имеющиеся динамические тома с последующей потерей данных (delete volume), а затем использовать команду базового преобразования convert basic.
Поэтому, прежде чем перейти с базового диска на динамический, желательно подумать о реальной необходимости выполнения этой операции: это очень полезно, например, когда структура томов должна часто изменяться. Если, с другой стороны, вы планировали установить несколько версий Windows на одну и ту же машину, было бы хорошо воздержаться от преобразования базового диска в динамический, поскольку возврат к базовому диску может занять некоторое время и быть довольно сложным.
Установка Дебиан 9 на raid
Рассмотрим вариант установки debian на софтовый рейд mdadm. Эта актуальная ситуация, когда вы разворачиваете систему на железе, а не виртуальной машине. К примеру, такая конфигурация будет полезна для установки proxmox. В этой статье я уже рассматривал установку debian на raid1. Но там версия 8-я, а у нас сейчас 9-я. Так что рассмотрю еще раз эту тему, но уже в варианте графического инсталлятора, а не консольного.
Итак, начинаем установку системы по приведенной ранее инструкции. Доходим до этапа разбивки диска и выбираем режим Manual.
Видим состояние наших дисков. В моем случае они полностью чистые, без разделов.
Выбираем режим Guided partitioning и настраиваем разделы на дисках, чтобы получилась такая картинка.
То есть мы на каждом диске создаем по одному пустому разделу, без точки монтирования и файловой системы. Эти пустые разделы мы объединим в raid и там уже сделаем корень системы — . Для swap я не создаю отдельный раздел, чтобы не делать потом отдельный raid для него. Swap сделаем в виде файла после установки системы. Итак, создаем рейд — Configure Software raid. Соглашаемся с предложением сохранить изменения.
Выбираем Create MD device, затем RAID1.
Указываем, что у нас будет 2 устройства в массиве и spare device не будет вовсе.
Далее выбираем 2 наших пустых раздела на каждом из дисков.
В конце соглашаемся на запись изменений. В разделе конфигурирования рейда нажимаем Finish и выходим из него.
Создаем на только что собранном массиве точку монтирования для нашей системы и указываем тип файловой системы. Должно получиться вот так.
На этом завершаем создание рейда и разметку диска и переходим дальше к установке debian, как было описано выше. Никаких принципиальных изменений больше не будет. Единственное, будет задан вопрос о том, что вы не создали раздел swap и будет предложено вернуться и исправить это.
Можно отказаться и продолжить установку.
После установки на raid нужно выполнить несколько важных действий.
- Зайти в систему и создать swap.
- Установить загрузчик на оба диска. Во время установки он был установлен только на один диск.
- Протестировать отказ одного из дисков.
# dpkg-reconfigure grub-pc
Выскочат пару запросов на указание дополнительных параметров. Можно ничего не указывать, оставлять все значения по-умолчанию.
А в конце выбрать оба жестких диска для установки загрузчика.
После установки загрузчика на оба диска, можно проработать вариант отказа одного из дисков. Для начала проверим статус нашего рейда:
# cat /proc/mdstat md0 : active raid1 sdb1 sda1 20953088 blocks super 1.2 [2/2]
Все в порядке, рейд на месте. Выключим сервер, отсоединим один диск и включим снова. Сервер замечательно загрузился с одним диском. Проверяем raid:
# cat /proc/mdstat md0 : active raid1 sda1 20953088 blocks super 1.2 [2/1]
Одного диска нет. Теперь снова выключим сервер и воткнем в него чистый диск такого же объема. То есть имитируем замену сломанного диска на новый. Запускаем сервер и проверяем список дисков в системе:
# fdisk -l | grep /dev Disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors /dev/sda1 * 2048 41940991 41938944 20G fd Linux raid autodetect Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors Disk /dev/md0: 20 GiB, 21455962112 bytes, 41906176 sectors
Старый диск sda c разделом sda1 и новый диск sdb без разделов. Нам нужно так же на нем создать один раздел на весь диск с типом Linux raid. Сделаем это с помощью cfdisk.
# cfdisk /dev/sdb
Записываем изменения и проверяем, что получилось:
# fdisk -l | grep /dev Disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors /dev/sda1 * 2048 41940991 41938944 20G fd Linux raid autodetect Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors /dev/sdb1 * 2048 41943039 41940992 20G fd Linux raid autodetect Disk /dev/md0: 20 GiB, 21455962112 bytes, 41906176 sectors
То, что надо. Второй раздел идентичный первому. Добавим его теперь в рейд.
# mdadm --add /dev/md0 /dev/sdb1 mdadm: added /dev/sdb1
Проверяем статус рейда:
# cat /proc/mdstat
md0 : active raid1 sdb1 sda1
20953088 blocks super 1.2 [2/1]
recovery = 4.5% (954304/20953088) finish=6.6min speed=50226K/sec
Идет ребилд массива. Надо дождаться его окончания, а пока поставим на новый диск загрузчик, как проделали это ранее. После пересборки массива замена сбойного диска завершена, можно продолжать эксплуатировать сервер в штатном режиме.
Моделирование несовместимости du и df
Общим несоответствием между df и du является проблема удаления файла. Когда файл удаляется, он больше не отображается в каталоге файловой системы, поэтому du больше не будет его считать. Однако, если все еще выполняется процесс, удерживающий дескриптор удаленного файла, файл не будет удален с диска, и информация в суперблоке раздела не будет изменена. Таким образом, df все равно будет считать удаленный файл.
1. Текущее использование раздела vda1
2. Создайте большой файл размером 5 ГБ.
3. Использование раздела vda1 в настоящее время
4. Смоделируйте процесс, чтобы открыть большой файл, а затем удалите большой файл.
5. Теперь сравните результаты du и df.
На данный момент результат df не изменился, и du больше не считает удаленный файл myfile.iso
6. Остановите процесс моделирования и сравните результаты du и df
Сначала убедитесь, что ни один процесс не имеет дескриптора myfile.iso
На этом этапе myfile.iso не имеет процесса, который мог бы его занять, поэтому он удаляется с диска, информация о суперблоке раздела была изменена, и df отображается как обычно.
Заключение
Команда df – очень простой в освоении, но эффективный инструмент, позволяющий всегда быть в курсе использования дискового пространства в ваших системах.
- https://losst.ru/komanda-df-linux
- https://www.vseprolinux.ru/komanda-df
- https://lumpics.ru/command-df-in-linux/
- https://ITProffi.ru/uznat-razmer-diskov-v-linux-komanda-df/
- https://pingvinus.ru/note/df-command
- http://website-lab.ru/article/linux-du-df/
- https://pocketadmin.tech/ru/linux-%D1%83%D1%82%D0%B8%D0%BB%D0%B8%D1%82%D1%8B/linux-%D1%83%D1%82%D0%B8%D0%BB%D0%B8%D1%82%D0%B0-free/
- https://andreyex.ru/operacionnaya-sistema-linux/komanda-free-v-linux-s-primerami/
- https://rtfm.co.ua/linux-utilita-free-i-ochistka-kesha-pamyati/



