
Принцип работы GTID
GTID появился с MySQL 5.6 и представляет собой уникальный 128-битный глобальный идентификационный номер (SERVER_UUID), который увеличивается с каждой новой транзакцией. Выглядит GTID примерно так:
Классическая репликация MySQL без GTID использует позицию в бинарном логе. Но благодаря GTID больше не нужно разбираться с вычислениями позиции бинлога. Из преимуществ GTID является согласованность данных, т.е. на сервере (как на мастере, так и на слейве) будет подтверждена одна и только одна транзакция с одним GTID, а любые другие транзакции, имеющие такой же UUID, будут проигнорированы. Подробную теорию можно дополнительно изучить на официальном сайте MySQL.
Использование GTID – это хорошая практика, т.к. данные между мастером и слейвом более консистентные с GTID, настройка ещё быстрее и проще.
В MySQL при использовании GTID есть две глобальные переменные, о которых необходимо знать:
- gtid_executed – содержит набор всех транзакций из бинарного лога;
- gtid_purged – содержит набор транзакций, которые были зафиксированы на сервере, но не содержащиеся в бинарном логе. gtid_purged является подмножеством gtid_executed.
Вышеописанные переменные получают свои значения при каждом запуске MySQL. На мастер-сервере это выглядит так:
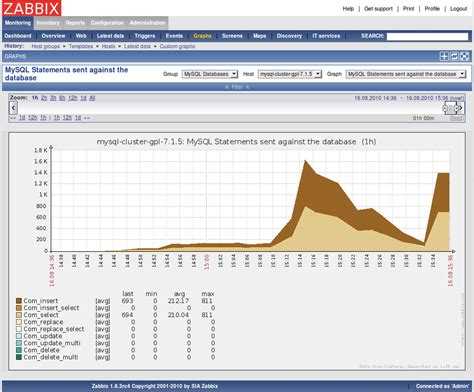
Как спланировать нагрузку на Zabbix
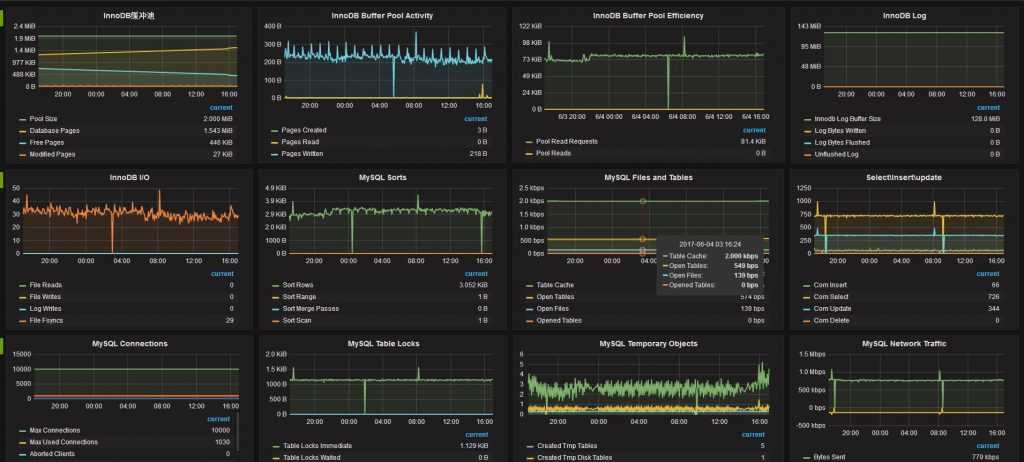
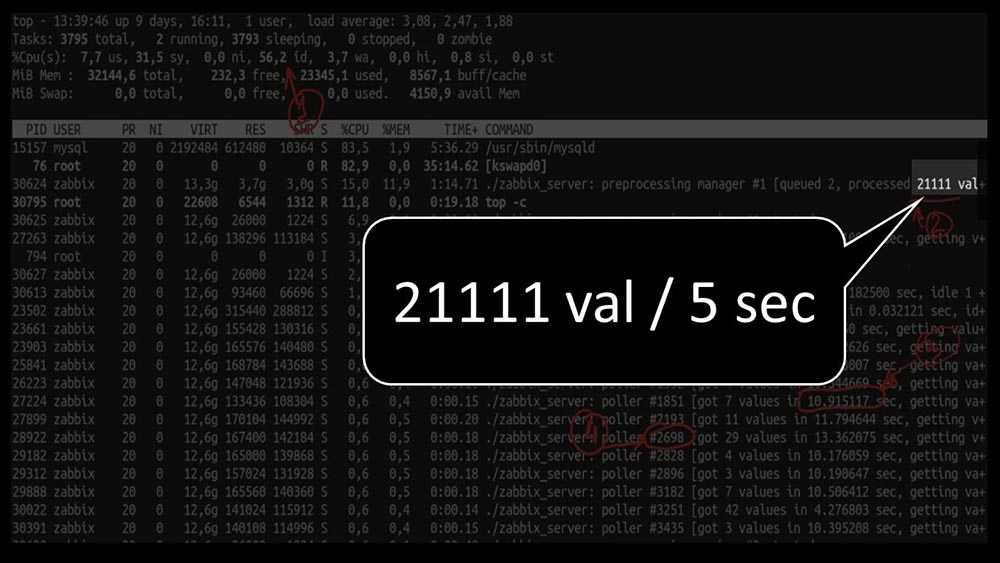
Под небольшой структурой, упомянутой в начале, я подразумеваю 50-100 узлов (не сетевое оборудование с десятками портов) сети на мониторинге и примерно 2000-4000 активных элементов данных, которые записывают 20-40 новых значений в секунду. Под такую сеть вам будет достаточно небольшой виртуальной машины с 2 ядрами и 4 гб памяти. База данных на преимущественно стандартных шаблонах будет расти примерно на 2-4 Гб в год. Дальше еще меньше, так как будет автоматически очищаться.
Для мониторинга такой сети можно вообще не выполнять никаких дополнительных настроек. Мониторинг будет вполне нормально работать. Если же нагрузка начнет расти, то первое, с чем вы столкнетесь — это с размером и производительностью базы данных. База zabbix будет расти пропорционально подключению к ней хостов. И с этим придется что-то делать.
Для решения вопроса производительности нужно будет двигаться в двух направлениях:
- Очистка базы от ненужных данных.
- Увеличение производительности сервера mysql.
Каждый из указанных вопросов многогранен. Далее мы частично их рассмотрим и выполним наиболее простые, очевидные и результативные изменения.
Решение:
Если данные на вашем сервере представляют некую ценность, то будет разумно обеспечить условия для возможности восстановления данных в случае их повреждения.
В этом случае резервное копирование нужно обязательно, но нередко и резервная копия может оказаться неработоспособной, неактуальной и т.п.
В MySQL предусмотрена возможность ведения бинарного журнала обновлений который содержит всю информацию об измененных данных с начала ведения журнала. Это может быть использовано для репликации данных между серверами или, в случае необходимости, для восстановления данных. Например, у вас периодичность резервного копирования один раз в неделю или в день, но если у вас есть бинарный журнал, то вы сможете восстановить состояние базы и на момент более поздний чем имеющаяся резервная копия.
Конфигурация
Активируем бинарные логи в секции файла /etc/my.cnf (/etc/mysql/my.cnf)
/etc/my.cnf
#включить журнал log-bin=mysql-bin # Хранить 7 дней. expire_logs_days = 7 # Кэш бинарного лога binlog-cache-size = 128K # Синхронная запись в файл журнала. Замедляет работу, но опция необходима если ваш сервер не имеет источник бесперебойного питания или возможно некорректное завершение работы сервера по другим причинам. sync-binlog = 1 # лимит размера лога "файла" max-binlog-size = 350M # максимальный размер кэша. max-binlog-cache-size = 90M
После перезагрузки mysql вы увидите в /var/lib/mysql файл mysqld-bin.00001
Восстановление базы
Для работы с бинарными логами понадобится утилита mysqlbinlog.
Утилита обрабатывает файлы журнала и выводит пригодный к использованию SQL код прямо в консоль.
Вывод можно перенаправить в файл
mysqlbinlog > файл.sql
или непосредственно в MySQL
mysqlbinlog | mysql
Не рекомендуется загружать данные из логов непосредственно в базу. В некоторых случаях это приводит к порче базы. Ниже сказано об этом.
Можно указать файл журнала для вывода в параметрах утилиты. Например:
mysqlbinlog -s -d db_name -r out.sql mysql-bin.000012
В данном случае будет обработан файл mysql-bin.000012 (из текущей директории), вывод оправится в out.sql, будут выведены только команды, относящиеся к изменению базы с именем db_name. Параметром -s мы запретили вывод дополнительной служебной информации.
Ещё пример:
mysqlbinlog -D -s -d NAME_BD -u USER_BD --start-datetime="2013-05-08 19:35:15" -t mysql-bin.000001 > my_new_bd.sql
- -s запрещаем вывод дополнительной служебной информации.
- -d база-данных имя.
- -u пользователь базы-данных.
- -D который запрещает ведение лога.
- -t говорим, что обрабатывать и логи нужно.
Здесь мы ограничиваем вывод запросов, которые выполнялись пользователем USER_BD начиная с указанной даты. Параметр -t сообщает утилите, что нужно обрабатывать и логи, которые идут после файла mysql-bin.000001.
Обратите внимание, что если вы будете перенаправлять вывод сразу в MySQL, то в журнал обновлений добавятся свежие записи и произойдет зацикливание.
Для предотвращения добавим еще и параметр -D, который запрещает ведение лога. Этот запрет будет доступен только если выполнять команду из под рута.
Теперь можно загрузить в базу восстановленные из журнала данные.
mysql -u root -p < my_new_bd.sql
Удаление файлов журнала
Если у вас проблемы с дисковым пространством и файлы логов надо будет срочно удалить…
Различные варианты удаления:
Удалить логи до mysql-bin.010
echo 'PURGE BINARY LOGS TO 'mysql-bin.010';' | mysql -u root -pPASSWORD
Удалить логи до 2008-04-02 22:46:26
echo 'PURGE BINARY LOGS BEFORE '2008-04-02 22:46:26';' | mysql -u root -pPASSWORD
Удалить логи старше 3-х дней
echo 'PURGE BINARY LOGS BEFORE NOW() - INTERVAL 3 DAY;' | mysql -u root -pPASSWORD
Удалить все логи
echo 'FLUSH LOGS;' | mysql -u root -pPASSWORD echo 'RESET MASTER;' | mysql -u root -pPASSWORD
Если нужно изменить параметр срока хранения логов без перезагрузки сервера:
echo 'SET GLOBAL expire_logs_days=7;' | mysql -u root -pPASSWORD echo 'RESET MASTER;' | mysql -u root -pPASSWORD
Пропустить первые N количество записей
Вместо чтения всего бинарного файла mysql, вы также можете прочитать только определенную его часть, указав смещение.
Для этого используйте опцию -o. -o означает смещение.
Ниже перечислены первые 10 записей в указанном журнале bin mysql.
mysqlbinlog -o 10 mysqld-bin.000001
Чтобы убедиться, что это работает должным образом, дайте номер события для смещения, и вы не увидите никаких записей. Следующий пример пропустит первые 10 000 записей (событий) из журнала.
В этом примере, поскольку этот конкретный файл журнала, нет 10 000 записей, он не указывает на какие-либо события базы данных на выходе.
# mysqlbinlog -o 10000 mysqld-bin.000001 /*!40019 SET @@session.max_insert_delayed_threads=0*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; .. .. # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
Проверка дампа mysql
То, что вы сделали дамп базы совсем не значит, что он завершился успешно. Он может быть прерван по какой-то причине. Причем, он год может выполняться успешно, а в какой-то момент начнет давать сбой в самом конце выгрузки. Если никак не отслеживаете ситуацию, можете это не заметить, а потом получить неконсистентную (битую) выгрузку.
Я делаю следующую проверку дампа сразу после его создания, чтобы не тащить на сервер бэкапов битый архив. Если дамп прошел успешно, то в первой строке дампа будет примерно такая строка:
-- MySQL dump 10.13 Distrib 5.7.33-36, for Linux (x86_64)
У вас может отличаться версия сервера, но начало будет одинаковое — двойное тире и слово Mysql. В конце дампа будет следующая строка:
-- Dump completed on 2021-07-11 20:21:06
Эти две строки я и буду проверять в скрипте, который будет делать дамп в автоматическом режиме. Результат проверки бэкапа я буду записывать в лог файл, а заодно и вывод утилиты mysqldump, чтобы в случае какой-то ошибки, я смог его проанализировать.
![Бинарный журнал обновлений mysql [colobridge wiki]](https://tehnikaarenda.ru/wp-content/uploads/f/3/8/f38445cfb92fc8eb632fe221f59ec215.jpeg)

#!/bin/bash
#ключи mysqldump
OPTS="-v --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob"
#файл дампа
FNAME="/mnt/backup/`date +%Y-%m-%d_%H-%M`_dbname.sql"
#лог результатов проверки дампа
LOG="/var/log/mysql/backup.log"
#лог вывода mysqldump
MLOG="/var/log/mysql"
#формат даты
DATA=`date +%Y-%m-%d_%H-%M`
#делаем дамп базы и записываем вывод в лог
/usr/bin/mysqldump ${OPTS} --databases dbname -u'root' -p'password' > ${FNAME} 2>> ${MLOG}/${DATA}-mysqldump.log
#сжимаем лог
/usr/bin/gzip ${MLOG}/${DATA}-mysqldump.log
#проверяем первую и последнюю строки дампа
BEGIN=`head -n 1 ${FNAME} | grep ^'-- MySQL dump' | wc -l`
END=`tail -n 1 ${FNAME} | grep ^'-- Dump completed' | wc -l`
#если обе строки верны, то пишем в лог ОК и сжимаем дамп
if ;then
if ;then
echo `date +%F_%H-%M` ${FNAME} is OK >> $LOG
/usr/bin/gzip ${FNAME}
else
echo `date +%F_%H-%M` ${FNAME} is corrupted >> $LOG
/usr/bin/rm ${FNAME}
fi
else
echo `date +%F_%H-%M` ${FNAME} is corrupted >> $LOG
/usr/bin/rm ${FNAME}
fi
#если дамп не проходит проверки, удаляем его и пишем в лог corrupted
#удаляем бэкапы и логи старше суток.
find /mnt/backup -type f -mmin +1440 -exec rm -rf {} \;
find /var/log/mysql/*mysqldump* -type f -mmin +1440 -exec rm -rf {} \;
Я скрипт прокомментировал, так что добавить особо нечего. Делаем дамп, проверяем первую и последнюю строки. Результат проверки пишем в лог файл, за которым далее будем наблюдать с помощью Zabbix.
Отключите двоичный журнал для восстановления.
Когда вы используете mysqlbinlog для восстановления базы данных из-за сбоя, вы не хотите, чтобы ваш процесс восстановления создавал двоичные журналы. Если да, то вы окажетесь в цикле, где вы продолжите восстановление, так как само восстановление будет генерировать новые двоичные файлы журналов.
Таким образом, чтобы отключить двоичный журнал, когда вы используете команду mysqlbinlog, используйте параметр -D, как показано ниже:
mysqlbinlog -D mysqld-bin.000001
Вы также можете использовать -disable-log-bin, как показано ниже. Следующее точно так же, как приведенная выше команда.
mysqlbinlog --disable-log-bin mysqld-bin.000001
Примечание
На выходе, когда вы указываете опцию -D, вы увидите дополнительную вторую строку на выходе, которая говорит SQL_LOG_BIN = 0.
/ *! 40019 SET @@ session.max_insert_delayed_threads = 0 * /; / *! 32316 SET @OLD_SQL_LOG_BIN = @@ SQL_LOG_BIN, SQL_LOG_BIN = 0 * /; / *! 50003 SET @OLD_COMPLETION_TYPE = @@ COMPLETION_TYPE, COMPLETION_TYPE = 0 * /;
Этот параметр также будет полезен, если вы используете опцию «–to-last-log». Кроме того, имейте в виду, что вам нужна привилегия root для выполнения этой команды.
Для резервного копирования и восстановления вы обычно используете команду mysqldump, но иногда в ситуации, когда вам приходится восстанавливаться после сбоя, полезно использовать mysqlbinlog.
Установка индексов
Для проверки использования индексов достаточно DELETE заменить на SELECT count(*):
## Выясним, используется ли здесь индекс
## Замена на SELECT позволит проверить использование индексов
Тогда сможем убедиться, что проблема в индексе:
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | ***key*** | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | users | ALL | NULL | ***NULL*** | NULL | NULL | 3224 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+
## Стоит установить индекс на колонку ts чтобы ускорить удаление
Настройка репликации с mysqldump
При создании дампа БД мастер-сервера с использованием mysqldump, необходимые значения GTID для слейва уже будут содержаться в дампе. Это параметр gtid_purged, который является gtid_executed с мастера. После восстановления дампа на слейве, переменная gtid_executed будет равна gtid_purged.
При запуске репликации слейв отправит мастеру диапазон GTID, которые он выполнил у себя, а мастер отправит в ответ все отсутствующие транзакции, которых нет на слейве. Таким образом можно настраивать репликацию на работающей базе (снимать копию), не останавливая запись с помощью переменной read_only=1, но очень не желательно!
При необходимости снять дамп с работающей базы, нужно использовать ключ –single-transaction, который позволяет не блокировать таблицы на момент создания дампа, но при выполнении операторов вида ALTER TABLE, DROP и т.п., которые выполняют изменения, данные в дампе могут оказаться поврежденными.
Как правило, на небольших базах допустимо использовать –single-transaction при снятии дампа. А вот на более объемных, где часто совершается запись или изменения, рекомендуется сначала выполнить блокировку таблиц на запись с помощью set global read_only=1, а потом уже выполнять снятие дампа. Но такой вариант будет очень долгий, поэтому в следующем разделе будет рассказано про Percona XtraBackup.
После получения дампа через mysqldump внутри него должно быть следующее:
У mysqldump есть важный параметр –set-gtid-purged, который позволяет управлять информацией глобальных идентификаторов транзакций (GTID), записанной в файл дампа, указывая, добавлять ли оператор SET @@ global.gtid_purged в вывод дампа. По умолчанию, значение этого флага auto, т.е. если GTID включен, то gtid_purged копируется, и наоборот.
Итого, чтобы правильно снять дамп через mysqldump с работающего мастера для настройки реплики необходимо:
- Перевести базу в read only – самый правильный вариант;
- Выполнить команду
После чего необходимо создать пользователя на мастере для выполнения репликация (лучше всего отдельного). С данным пользователем слейв будет подключаться к мастеру:
Важный момент! Необходимо убедиться, что слейв чистый, т.е. очищен от всех GTID. Для этого нужно на слейве выполнить следующее:
И запускать репликацию со слейва привычным способом, как и ранее с позицией бинлога, но позиция указывается автоматически:
Настройка mysqldump
Как я уже сказал, бэкап базы данных mysql я буду делать с помощью mysqldump. В общем случае выполнить его проще простого. Вот пример команды, которая сделает дамп базы данных:
# mysqldump --databases dbname -u'root' -p'password' > dbname.sql
Отдельно отмечу, что использовать выгрузку сырых данных из базы в виде текстового дампа имеет смысл для не очень больших баз. Думаю, что для баз размером до 10-15 Гб это можно делать. Сжатые дампы будут весить 500-1000 Мб. Если базы больше, лучше использовать другие способы. Например, бинарный бэкап с помощью Percona XtraBackup.
Мы выгрузили дамп базы dbname в отдельный файл. Дальше его можно сжать и отправить на сервер бэкапов. Но, как это обычно бывает, везде есть куча нюансов. Дефолтные настройки mysqldump очень часто не подходят. Например, наиболее распространенная проблема — блокировка таблиц во врем дампа с дефолтными настройками. Если в базу активно идёт запись, а тут вы запускаете mysqldump и блокируете таблицы, возникают проблемы с записью.
Все параметры mysqldump можно посмотреть в документации — https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html. Если вы не указываете никакие дополнительные ключи, то по умолчанию используется ключ —opt, который включает в себя следующие параметры:
- —add-drop-table — в дампе перед каждым созданием таблицы добавляется строка с её удалением. То есть при заливке дампа сначала удаляется таблица, потом создается пустая и в неё заливаются данные из дампа. И так для всех таблиц.
- —add-locks — в дампе в строке перед созданием таблицы ставится команда на ее блокировку, а после окончания заливки данных блокировка снимается. Это позволяет гарантировать успешную запись данных в таблицу при загрузке дампа.
- —create-options — в дамп добавляются команды на создание таблиц.
- —disable-keys — в дамп добавляются параметры, отключающие создание индексов рядом с каждой командой insert. Это позволяет ускорить загрузку дампа, а индексы создаются, когда все строки будут добавлены.
- —extended-insert — используется особый синтаксис multiple-row для команд insert.
- —lock-tables — блокировка таблиц перед созданием дампа. Этот параметр частенько мешает в движке innodb и его лучше не использовать (параметр, а не движок).
- —quick — ускоренный механизм получения строк таблицы.
- —set-charset — добавляет в дамп информацию о кодировках.
В целом, все дефолтные параметры можно считать полезными и удобными, кроме блокировки таблиц. Для дампа innodb баз, а это самый популярный движок хранения данных в mysql, рекомендуется не использовать lock-tables, а вместо этого включать механизм single-transaction. С этим параметром для обеспечения целостности данных в дампе используется не механизм блокировок, а учёт транзакций.
Я не буду сейчас подробно останавливаться на теории, так как все эти параметры очень хорошо описаны в документации. Можете сами зайти и почитать. Показываю свой набор ключей для создания дампов баз данных mysql с помощью mysqldump.
# mysqldump --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob --databases dbname -u'root' -p'password' > dbname.sql
Это мой универсальный набор параметров mysqldump, которые я обычно использую, когда делаю выгрузку базы данных mysql. В целом, тут почти дефолтные настройки, только убраны блокировки, добавлены транзакции и некоторые другие сущности mysql типа events, triggers и т.д.
Использование партиций
Индексы помогут при удалении сравнительно небольших объемов. Однако, если приходится постоянно удалять много (как в нашем случае), стоит посмотреть на [https://dev.mysql.com/doc/refman/5.7/en/partitioning.html партиционирование].
Это значит, что у нас будет возможность манипулировать отдельными партициями. И вместо удаления большого количества записей, мы сможем обьединить их в один блок (партицию) и удалить его одной операцией.
Чтобы проверить это на практике, создадим простую таблицу такой структуры:
**tmp**: id | title | datetime
## id, заголовок и дата создания заголовка
Наполним ее тестовыми данными (несколько десятков тысяч записей) и удалим данные:
## Удалим часть данных из таблицы
Запрос выполнился довольно медленно, удалив около 25 тыс. записей:
Query OK, 25750 rows affected (***0.27 sec***)
Убедимся, что проблема не в индексе (мы его создали, но на всякий случай проверим):
Увидим, что индекс используется – тут все хорошо:
+----+-------------+-------+------------+-------+---------------+----------+---------+------+-------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | **key** | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+----------+---------+------+-------+----------+--------------------------+ | 1 | SIMPLE | tmp | NULL | range | datetime | **datetime** | 5 | NULL | 28395 | 100.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+----------+---------+------+-------+----------+--------------------------+
Проверим также системную переменную, которая показывает количество удаленных записей из всех InnoDB таблиц:
Variable_name: Innodb_rows_deleted
Value: 25750
## Увидим количество удаленных строк
Мы проводим эксперимент в изолированной среде, поэтому других удалений тут не происходит.
Выбор схемы партиционирования
Поскольку мы решаем проблему удаления, нам необходимо иметь схему, в которой мы сможем удобно удалять (чистить) целые партиции. Нам необходимо удалять данные за час, поэтому мы создадим HASH партицию на основе часа из поля datetime:
## 24 партиции потому, что 24 часа в сутках
Проверим, как выглядит распределение наших данных по партициям:
FROM information_schema.PARTITIONS
WHERE TABLE_SCHEMA = ‘test’ AND TABLE_NAME = ‘tmp’;
+----------------------------+------------+------------------+ | PARTITION_ORDINAL_POSITION | TABLE_ROWS | PARTITION_METHOD | +----------------------------+------------+------------------+ | 1 | 0 | HASH | | 2 | 0 | HASH | | 3 | 0 | HASH | | 4 | 0 | HASH | | 5 | 0 | HASH | | 6 | 0 | HASH | | 7 | 0 | HASH | | 8 | 0 | HASH | | 9 | 0 | HASH | | 10 | 0 | HASH | | **11 | 25394** | HASH | | **12 | 31171** | HASH | | 13 | 0 | HASH | | 14 | 0 | HASH | | 15 | 0 | HASH | | 16 | 0 | HASH | | 17 | 0 | HASH | | 18 | 0 | HASH | | 19 | 0 | HASH | | 20 | 0 | HASH | | 21 | 0 | HASH | | 22 | 0 | HASH | | 23 | 0 | HASH | | 24 | 0 | HASH | +----------------------------+------------+------------------+
## номер партиции будет соответствовать часу колонки datetime
Как видим, данные в таблице помещены только в две партиции. Они соответствуют текущему и предыдущему часу. Что нам нужно – это очищать партицию за тот час, который нам уже не нужен. Для этого существует операция TRUNCATE :

## Эта операция выполнилась за (0.01 sec)
Если мы проверим счетчик удаленных InnoDB записей, увидим там:
Variable_name: Innodb_rows_deleted
Value: 25750
## Значение не изменилось
Это подтверждает тот факт, что TRUNCATE работает принципиально не так как DELETE. Вместо удаления каждой записи, таблица (или ее партиция) очищается на уровне структуры. Если очень грубо, то Mysql удаляет старый файл данных и создает новый. А эта операция выполняется значительно быстрее построчного удаления.
<h2>TL;DR
Если вам нужно удалять большие объемы данных из Mysql, следуйте двум советам:
- Стройте индексы для ускорения выборки при удалении, заменив DELETE FROM на EXPLAIN SELECT count(*) FROM.
- Используйте [https://dev.mysql.com/doc/refman/5.7/en/partitioning.html партиционирование] и TRUNCATE PARTITION для эффективного удаления большого количества строк.
Очистка и уменьшение mysql базы zabbix
Начнем с очистки базы данных zabbix от ненужных данных. Рассмотрим по пунктам в той последовательности, в которой это нужно делать.
- Первым делом надо внимательно просмотреть все используемые шаблоны и отключить там все, что вам не нужно. Например, если вам не нужен мониторинг сетевых соединений windows, обязательно отключите автообнаружение сетевых интерфейсов. Оно само по себе находит десятки виртуальных соединений, которые возвращают нули при опросе и не представляют никакой ценности. Тем не менее, все эти данные собираются и хранятся, создавая лишнюю нагрузку. Если же вам нужен мониторинг сети в windows, зайдите в каждый хост и отключите руками лишние адаптеры, которые будут найдены. Этим вы существенно уменьшите нагрузку. По моему опыту, в стандартных шаблонах windows мониторинг всех сетевых интерфейсов дает примерно 2/3 всей нагрузки этих шаблонов.
- Отредактируйте в используемых стандартных шаблонах время опроса и хранения данных. Возможно вам не нужна та частота опроса и время хранения, которые заданы. Там достаточно большие интервалы хранения. Чаще всего их можно уменьшить. В целом, не забывайте в своих шаблонах ставить адекватные реальной необходимости параметры. Не нужно хранить годами информацию, которая теряет актуальность уже через неделю.
- После отключения лишних элементов в шаблонах, нужно очистить базу данных от значений неактивных итемов. По-умолчанию, они там остаются. Можно их очистить через web интерфейс, но это плохая идея, так как неудобно и очень долго. Чаще всего попытки очистить 50-100 элементов за раз будут сопровождаться ошибками таймаута или зависанием web интерфейса. Далее расскажу, как это сделать эффективнее.
Для очистки базы данных zabbix от значений неактивных итемов, можно воспользоваться следующими запросами. Запускать их можно как в консоли mysql сервера (максимально быстрый вариант), так и в phpmyadmin, кому как удобнее.
Данными запросами можно прикинуть, сколько данных будет очищено:
SELECT count(itemid) AS history FROM history WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_uint FROM history_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_str FROM history_str WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_text FROM history_text WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS history_log FROM history_log WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS trends FROM trends WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); SELECT count(itemid) AS trends_uint FROM trends_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
Если запросы нормально отрабатывают и возвращают счетчик данных, которые будут удалены, дальше можете их удалять из базы следующими sql запросами.
DELETE FROM history WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_str WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_text WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM history_log WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM trends WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0'); DELETE FROM trends_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
Данными запросами вы очистите базу данных zabbix от значений неактивных элементов данных. Но реально размер базы данных у вас не уменьшится, потому что в дефолтной настройке базы данных используется формат innodb. Все данные хранятся в файле ibdata1, который автоматически не очищается после удаления данных из базы.
Администрировать такую базу неудобно. Нужно как минимум настроить хранение каждой таблицы в отдельном файле. Этим мы далее и займемся, а заодно обновим сервер базы данных до свежей версии mariadb и реально очистим базу, уменьшив ее размер.
Конфигурационные файлы
Для настройки репликации с использованием GTID в MYSQL в конфиге мастера достаточно прописать следующие значение:
Ниже описание используемых обязательных директив из конфига:
- gtid_mode=ON – собственно, включает GTID;
- log_bin=mysql-bin – ведение бинарного лога для мастера (с него читает слейв). Когда на сервере используются GTID, и если бинарный лог не включен, при перезапуске сервера после аварийного выключения, некоторые GTID могут быть потеряны, что приведет к сбою репликации. При обычном завершении работы набор идентификаторов GTID из бинарного лога сохраняется в таблице mysql.gtid_executed;
- enforce-gtid-consistency – обязательный параметр для GTID, который не даёт всё поломать;
- server_id=1 идентификатор мастер сервера, цифровое значение может быть отличным от единицы в данном примере;
Также присутствуют необязательные директивы, но пару слов можно сказать и про них:
log-slave-updates = 0 – необходим при использовании схемы А -> Б -> C, где А – гл. сервер для Б, а Б – гл. сервер для С, т.е. “гирляндная” или последовательная схема. Для случаев, когда данные от мастера пишутся в отдельный бинлог реплики для использования реплики в качестве мастера для другой реплики. Редкий случай;sync_binlog = 0 – используется для синхронизации всех транзакций с двоичным файлом. По факту повышает надёжность транзакций для слейва при отказе ОС в случае сбоя. А также сильно влияет на производительность I\O хранилища, поэтому можно либо его отключить и положиться на надёжность отказоустойчивости системы, или же включить при наличии скоростного хранилища. В общем, использовать или нет – зависит от требований. Например, при установке sync_binlog=1 для БД Битрикс24, попугаи в тестах производительности на чтение\запись в БД могут заметно уменьшиться.
Мониторинг бэкапов mysql
Для того, чтобы нам не тащить на бэкап сервер битые дампы, будем проверять их сразу же на месте. Сразу поясню, что это не отменяет дальнейшие проверки этих дампов на возможность реального восстановления из них. Эту процедуру надо делать на отдельном сервере. В рамках данной заметки я не буду это рассматривать. Сейчас мы просто будем следить за тем, что дамп базы данных mysql выполнен корректно.
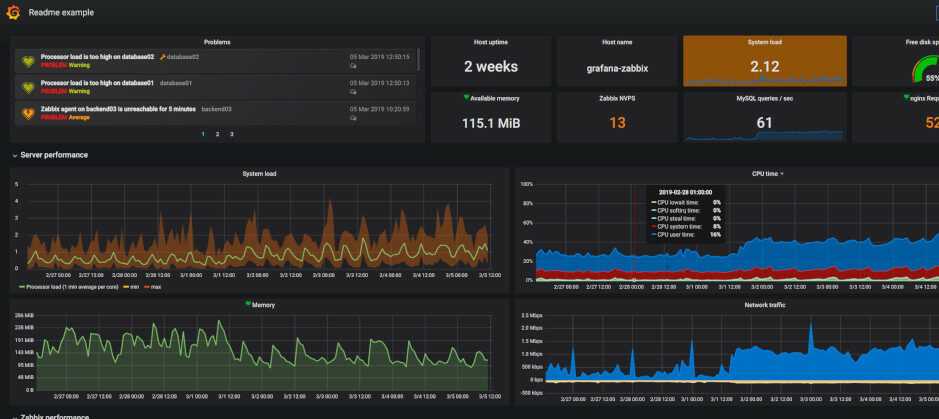
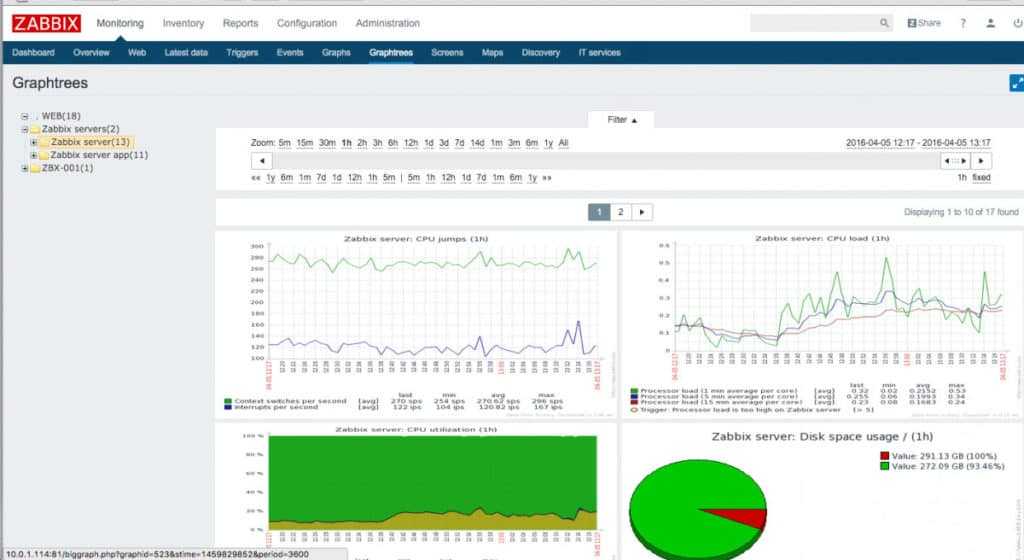
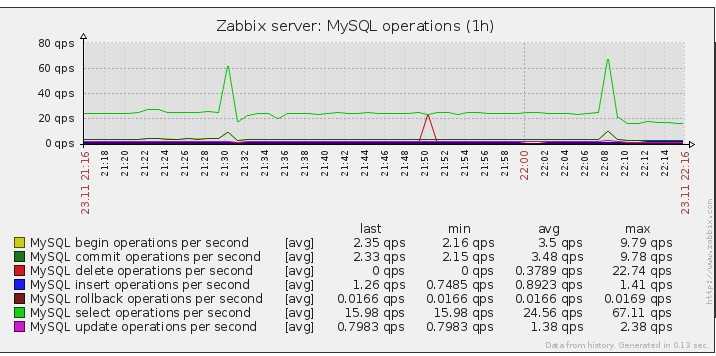
Мониторинг за валидацией бэкапов будем осуществлять с помощью Zabbix.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Мы настроили вывод результатов проверки архивов в лог файл /var/log/mysql/backup.log. Теперь сделаем так, чтобы Zabbix анализировал содержимое файла и слал оповещение, если там появится слово corrupted, что будет означать проблему с созданием дампа.
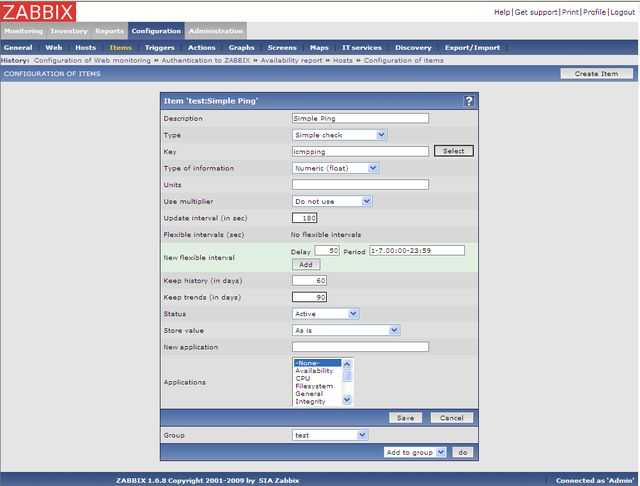
Для этого создаем новый шаблон и добавляем туда элемент данных.
Тут всё очень просто и стандартно. Далее делаем триггер.
Выражение проблемы:
{Backup mysql status:log[/var/log/mysql/backup.log].str(corrupted)}=1
Выражение восстановления:
{Backup mysql status:log[/var/log/mysql/backup.log].str(OK)}=1
Прикрепляем шаблон к хосту, где делаем бэкап. Не забудьте убедиться, что у zabbix-agent на хосте есть доступ на чтение этого лог файла. Таким образом, если проверка дампа не будет завершена успешно, сработает триггер. Он будет висеть активным до тех пор, пока не будет создан корректный бэкап базы mysql.
Вот так достаточно просто и быстро я решаю вопрос создания, проверки и оповещения о проблемах при создании дампов и бэкапов mysql баз.
Заключение
Решение задачи по бэкапу mysql баз, что я описал, не претендует на уникальность и 100% правильность. Это просто мой личный опыт. Никаких особых изысканий и поиска наилучшего решения не проводил. Просто сделал, как сделал, чем с вами и поделился. В моих задачах такой подход достаточен.
Еще раз напоминаю, что этот способ актуален для относительно небольших баз. Дампить объемные базы плохая идея, так как будет сильно проседать i/o дисков. Плюс тут нет возможности делать инкрементные бэкпы. Только полные, что, очевидно, не всегда удобно.
Для мониторинга бэкапов в целом, можете воспользоваться моей объемной статьей по теме — Мониторинг бэкапов с помощью zabbix.
Онлайн курсы по Mikrotik
Если у вас есть желание научиться работать с роутерами микротик и стать специалистом в этой области, рекомендую пройти курсы по программе, основанной на информации из официального курса MikroTik Certified Network Associate. Помимо официальной программы, в курсах будут лабораторные работы, в которых вы на практике сможете проверить и закрепить полученные знания. Все подробности на сайте .
Стоимость обучения весьма демократична, хорошая возможность получить новые знания в актуальной на сегодняшний день предметной области. Особенности курсов:
- Знания, ориентированные на практику;
- Реальные ситуации и задачи;
- Лучшее из международных программ.





