
Введение
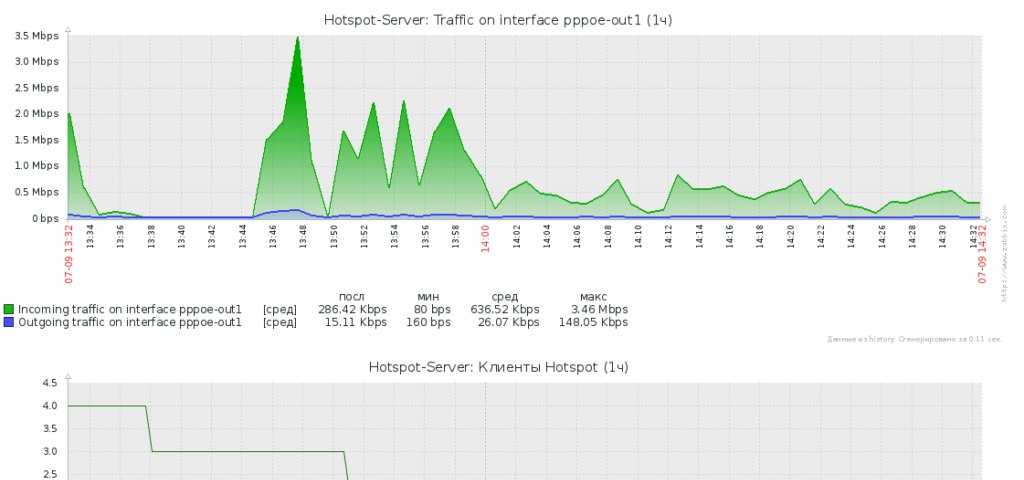
За основу мониторинга Mikrotik я возьму стандартный шаблон Zabbix от разработчиков. Он очень качественно сделан. Забирает информацию по snmp. Итемы и триггеры настраиваются через автообнаружение. Вот основные метрики, которые в нем реализованы:
- Состояние процессоров (загрузка, температура).
- Статус и характеристика интерфейсов (трафик, активность, ошибки, тип, скорость).
- Хранилища (общий объем и используемый).
- Использование оперативной памяти.
- Проверка доступности пингом.
- Версия прошивки, модель, система, серийный номер, расположение, описание устройства.
- Время работы (uptime).
Для всех основных метрик есть графики. На все значимые события настроены триггеры:
- Высокая температура процессора.
- Изменение серийного номера, прошивки.
- Сетевая недоступность по icmp.
- Высокая загрузка памяти или процессора.
- Окончание свободного места на хранилищах.
- Уменьшилась скорость на интерфейсе.
- Высокая утилизация интерфейса.
- Большое количество ошибок на интерфейсе.
- Интерфейс отключился.
Шаблон настолько хорош и полон, что я даже не придумал, чего в нем не хватает. По метрикам есть все. Для полного мониторинга Микротика мне не хватало только оповещений о том, что к нему кто-то подключился. Я реализовал это по своему, о чем расскажу далее подробно. В двух словах мониторинг подключений выглядит так:
- Mikrotik отправляет логи подключений на удаленный syslog сервер.
- На syslog сервере логи анализирует zabbix-agent.
- По определенному шаблону агент определяет имя и ip адрес подключившегося к микротику и отправляет эту информацию в уведомлении.
В целом, никаких сложностей в этой настройке нет. У меня уже есть статьи по сбору логов с микротиков — отправка в elk stack и на удаленный rsyslog сервер. Сегодня я актуализирую эту информацию и опишу еще раз.
Если вы не очень хорошо знакомы с описываемым роутером, рекомендую мою статью по базовой настройке микротика.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
- Установка CentOS 8.
- Настройка CentOS 8.
- Установка и настройка zabbix сервера.
То же самое на Debian 10, если предпочитаете его:
- Установка Debian 10.
- Базовая настройка Debian.
- Установка и настройка zabbix на debian.
Настройка мониторинга принтеров по snmp
На самом сервере мониторинга настраивать особо нечего. Вам достаточно будет взять мои готовые шаблоны, убедиться что MIB и OID совпадают с вашими принтерами и добавить сами принтеры в мониторинг, не забыв указать у них snmp интерфейс.
Printer_HP.xml Printer_Kyocera.xml Printer_Brother.xml
Все шаблоны экспортированы с версии сервера Zabbix 3.4. На других версиях я не проверял, но думаю, что работать будет, так как никаких специфичных вещей в шаблонах нет. Обычные snmp проверки.
Вот пример одного элемента для шаблона принтеров HP.
А вот пример вычисляемого значения уровня тонера для шаблона Kyocera.
Пример триггера, который присутствует во всех шаблонах.
Всю информацию о принтерах можно вывести на Dashboard примерно в таком виде:
Интервалы опроса итемов в шаблонах:
- Всего напечатано страниц – 1 час
- Напечатано на текущем тонере – 10 мин
- Объем тонера – 10 мин
- Уровень тонера – 10 мин
- Название картриджа – 1 день
- Серийный номер – 1 день
На момент отладки рекомендую поставить эти значения 1 минута.
Для элемента данных «Уровень тонера» указан тип данных «Числовой», чтобы работал триггер и сравнивал значение. Если у вас какие-то ошибки с тонером, например из-за того, что не новый использовали, а заправляли старый, то значение будет приходить -2 или -3 с типом «Строка». Итем станет неактивным с ошибкой:
Value "-2" of type "string" is not suitable for value type "Numeric (unsigned)"
С этим уже ничего не поделать. Можете сделать для таких принтеров отдельный шаблон и изменить тип итема с числового на строковый. Так вы хотя бы будете получать значение -2, а не ошибку итема.
На этом у меня все по данной теме. Добавляйте шаблоны, проверяйте и пользуйтесь.
Планируемые обновления
В будущем планируется создать новые триггеры и метрики. Триггеры будут реагировать на критические значения показателей, присылая уведомления.
Примеры триггеров:
- Число файлов в очереди выгрузки в БД SQL стало больше 10
- Число файлов в очереди на отправку на сервер уровнем выше стало больше 10
- Количество ошибок при выгрузке данных в БД SQL стало больше 0
Примеры метрик
- Метрики по сборку данных смен / онлайн данных
- Метрики по процессам синхронизации справочников
- Метрики по бизнес операциям (среднее время чека / работа систем лояльности и т. д.)
- Метрики по мониторингу доступности компонентов (основной / резервный принтеры)
Устраняйте найденные уязвимости
Но мало знать какие у нас уязвимости и определить как и какие из них можно устранить. Необходимо ещё и сделать это!
Для централизованного управления конфигурациями и обновления ПО широко используются такие системы как Puppet или Ansible. Вы можете использовать fix-команду, устраняющую уязвимость, и централизованно её выполнить с помощью таких систем.
Если же в вашей инфраструктуре не используются такие системы — Zabbix Threat Control позволяет устранять уязвимости прямо из веб-интерфейса Zabbix.
Для этого плагин использует стандартный функционал Zabbix: подтверждение событий и выполнение удаленных команд:
- Как только проблема будет подтверждена через веб-интерфейс авторизованным на это пользователем;
- Запустится удаленная команда, которая выполнит на целевом сервере, или списке серверов, fix-команду исправляющую уязвимость.
JavaScript и Duktape
Почему были выбраны именно JavaScript и Duktape? Рассматривались различные варианты языков и движков:
- Lua – Lua 5.1
- Lua – LuaJIT
- Javascript – Duktape
- Javascript – JerryScript
- Embedded Python
- Embedded Perl
Основными критериями выбора были распространенность, простота интеграции движка в продукт, низкое потребление ресурсов и общая производительность движка, и безопасность внедрения кода на этом языке в мониторинг. По совокупности показателей победил JavaScript на движке Duktape.

Критерии выбора и performance testing
Особенности Duktape:
— Стандарт ECMAScript E5/E5.1
— Модули Zabbix для Duktape:
- Zabbix.log() — позволяет вписать непосредственно в лог Zabbix Server сообщения с различным уровень детализации, что обеспечивает возможность сопоставлять ошибки, например, в Webhook с состоянием сервера.
- CurlHttpRequest() — позволяет делать HTTP-запросы в сеть, на чем основано применение Webhook.
- atob() и btoa() — позволяет кодировать и декодировать строки в формат Base64.
ПРИМЕЧАНИЕ. Duktape соответствует стандартам ACME. В Zabbix используется версия скрипта 2015 года. Последующие изменения незначительны, поэтому их можно игнорировать.
Магия JavaScript
Вся магия JavaScript заключена в динамической типизации и приведении типов: строковых, числовых и логических.
Это означает, что не нужно заранее объявлять какого типа переменная должна возвращать значение.
При математических операциях значения, которые возвращаются операторами-функциями, преобразуются в числа. Исключение из таких операций — сложение, поскольку, если хотя бы одно из слагаемых является строкой, ко всем слагаемым применяется строковое преобразование.
ПРИМЕЧАНИЕ. Методы, отвечающие за такие преобразования, как правило, реализованы в родительских прототипах объектов, valueOf и toString. valueOf вызывается при численном преобразовании и всегда перед методом toString. Метод valueOf обязан возвращать примитивные значения, иначе его результат игнорируется.
Для объекта вызывается метод valueOF. Если он не найден или не возвращает примитивное значение, вызывается метод toString. Если метод toString не найден, производится поиск valueOf в прототипе объекта, и все повторяется до завершения обработки значения и приведения всех значений в выражении к одному типу. Если для объекта реализован метод toString, который возвращает примитивное значение, то именно он используется для строкового преобразования. При этом результатом применения этого метода не обязательно является строка.
Например, если для для объекта ‘obj’ определяется метод toString,
метод toString возвращает именно строку, и при сложении строки с числом мы получаем склеенную строку:
Но если переписать toString, чтобы метод возвращал число, при сложении объекта будет выполняться математическая операция с числовым преобразованием и получается результат математического сложения.
При этом, если мы выполняем сложение со строкой, выполняется строковое преобразование, и мы получаем склеенную строку.
Именно в этом кроется причина большого количества ошибок начинающих пользователей JavaScript.
В метод toString можно вписать функцию, которая будет увеличивать текущее значения объекта на 1.
Выполнение скрипта при условии, что переменная равна 3, и она же равна 4.
При сравнении с приведением типов (==) каждый раз выполняется метод toString с функцией увеличения значения. Соответственно, при каждом последующем сравнении значение увеличивается. Этого можно избежать путем использования сравнения без приведения типов (===).
Сравнение без приведения типов
ПРИМЕЧАНИЕ. Не используйте сравнение с приведением типов без необходимости.
Для сложных скриптов, например, Webhook со сложной логикой, в которых необходимо сравнение с приведением типов, рекомендуется предварительно написать проверки для значений, которые возвращают переменные и обработать несоответствия и ошибки.
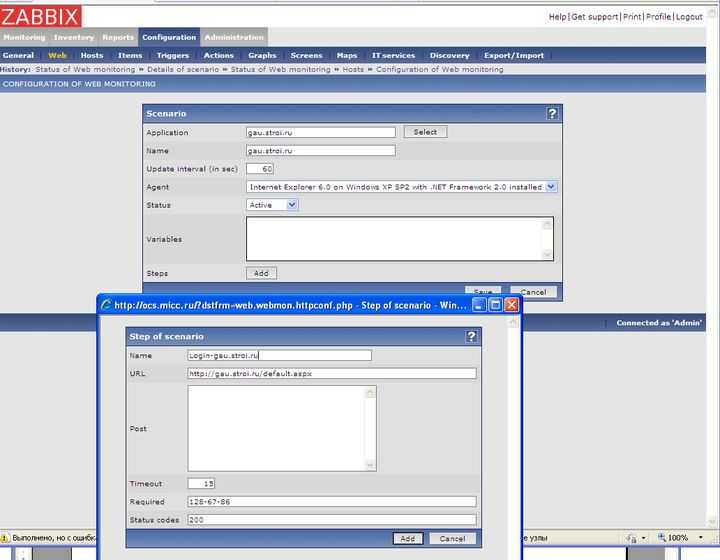
Оповещение о недоступности сайта
Давайте настроим уведомления о проблемах на сайте. Я предлагаю 2 типа оповещения:
- О низкой скорости доступа к сайту.
- О недоступности сайта вообще.
Идем, как обычно в исходный шаблон, на вкладку Triggers и добавляем новый.
Я предлагаю вот такое условие срабатывания для определения недоступности сайта. Если среднее значение 3-х последних проверок больше, либо равно единице, то срабатывает оповещение о недоступности сайта.
Когда идет 0 во всех проверках, все в порядке. Триггер сработает только если все 3 последних проверки не равны нулю. В моем примере Failed step может принимать значение либо 0, либо 1, где 1 это номер сбойного шага. Если у вас шагов несколько, то сбойным может оказаться второй шаг или третий шаг. То есть значение может быть больше 1. Но в любом случае, если последние 3 значения подряд строго не 0, то идет срабатывание триггера. Операция восстановления очень простая. Если последняя проверка без ошибки, то есть код равен 0, то считаем, что сайт уже работает.
Чтобы проверить работу триггера, достаточно на zabbix server в файл /etc/hosts добавить строку:
127.0.0.1 github.com
и подождать 3 минуты, чтобы получились 3 неудачных проверки. После этого вам должно было отправиться уведомление о недоступности сайта. Я получил вот такое:
Дальше делаем проверку времени ответа сервера. Тут каждый волен настраивать так, как ему кажется более правильным и удобным. Я использую такую схему. Беру среднее время отклика сайта и умножаю его на 3. Далее смотрю последние 7 проверок. Если в 5 проверках среди этих семи были значения выше, чем утроенное среднее время отклика, то считаю, что сайт тормозит и надо слать уведомление. Немного замороченно, но на практике такая схема у меня себя хорошо зарекомендовала без ложных срабатываний. При этом, если возникают реальные проблемы, я их вижу. Рисуем триггер.

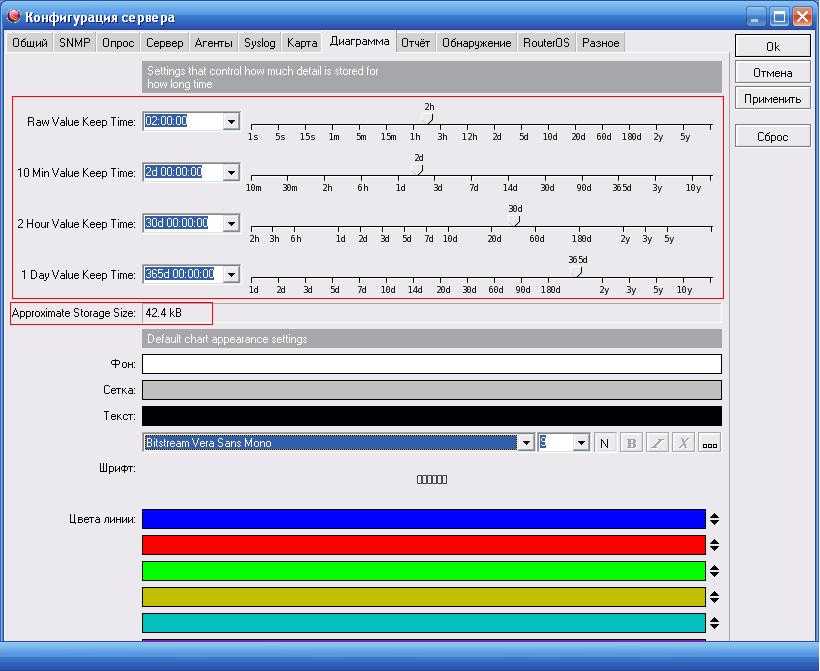
Условие восстановления — в последних трех запросах два и более были быстрее, чем утроенное среднее время доступа. Текст выражений для копирования:
{Sites Monitoring:web.test.time.count(#7,1.5,"ge")}>4
{Sites Monitoring:web.test.time.count(#3,1.5,"lt")}>1
В выражении 1.5 это время отклика в секундах. Именно в таком виде оно попадает в zabbix сервер. Проверить можно в Latest Data.
В завершении оставляю свой шаблон, который создал для написания статьи. Можете копированием и редактированием приспособить его для своих сайтов. Это быстрее, чем составлять с нуля. Шаблон экспортирован с версии zabbix 4.0 — sites_monitoring.xml
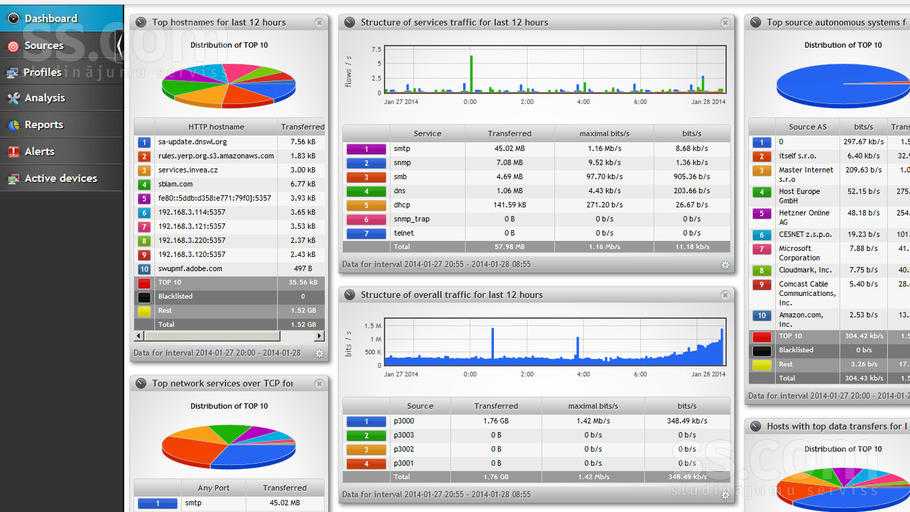
Вот и все, мониторинг веб сайта работает, авторизация проверяется, оповещение о недоступности сайта настроено. Для полноты картины можно создать Screen или Dashboard с выводом всех необходимых параметров на один экран. Его настройки уже будут зависеть от конкретной ситуации и тех данных, которыми вы располагаете. К примеру, если у вас настроен мониторинг веб сервера, то можно разместить рядом графики его загрузки и параметры доступа к сайту. Туда же можно добавить загрузку самого сервера по процессору и памяти и вывести график использования сетевого интерфейса.
В этом плане Zabbix очень гибок и позволяет настроить все на любой вкус и под любые требования.
Более подробно о мониторинге за временем отклика сайта читайте в отдельной статье на этот счет. Там описана теория процесса и практические рекомендации, вместе с готовым триггером.
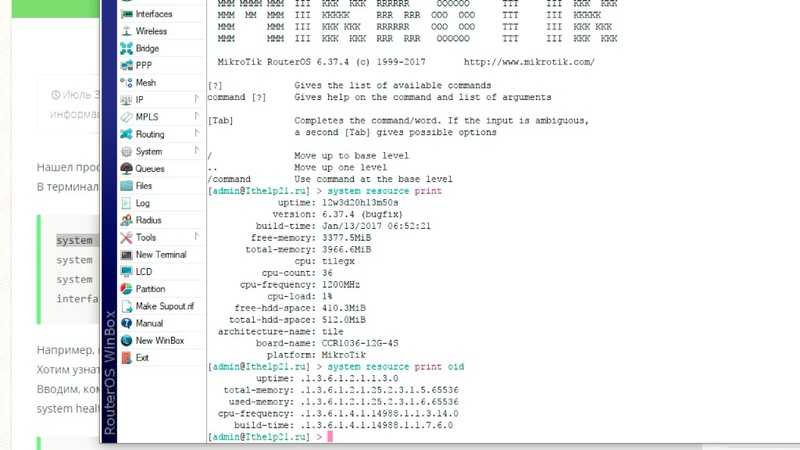
Поиск необходимых OID
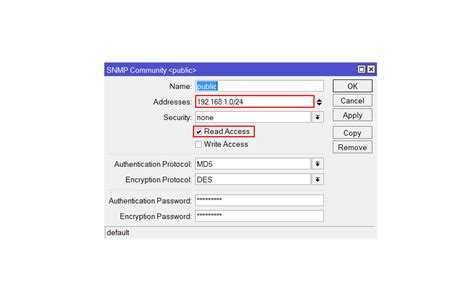
Для начала возьмем какой-нибудь принтер и посмотрим, что он нам будет отдавать по snmp. Я для примера возьму принтер HP LaserJet Pro MFP M426fdn (ip адрес 192.168.88.20). По-умолчанию у принтеров HP разрешен просмотр параметров по snmp.
Идем в консоль linux и посмотрим с помощью snmpwalk метрики принтера по snmp. Для этого установим необходимый пакет.
# yum install net-snmp-utils
Теперь посмотрим метрики принтера:
# snmpwalk -v 2c -c public 192.168.88.20
В консоль вылетит целая куча строк, которые неудобно просматривать. Направим вывод в текстовый файл и внимательно посмотрим на него.
# snmpwalk -v 2c -c public 192.168.88.20 > ~/snmp.txt
Я вас томить не буду, а сразу укажу на строки, которые нас интересуют:
| SNMPv2-SMI::mib-2.43.10.2.1.4.1.1 = Counter32: 8909 | Всего напечатано страниц |
| SNMPv2-SMI::mib-2.43.11.1.1.6.1.1 = STRING: «Black Cartridge HP CF226X» | Название картриджа |
| SNMPv2-SMI::mib-2.43.5.1.1.17.1 = STRING: «PHB8K3H0P1» | Серийный номер |
| SNMPv2-SMI::mib-2.43.11.1.1.9.1.1 = INTEGER: 85 | Уровень тонера |
Возможно, вас еще заинтересует параметр mib-2.43.5.1.1.16.1 — название принтера. Мне лично это не нужно, но если все выводить в сводную таблицу, то может пригодиться
Так же обращаю внимание на параметр mib-2.43.11.1.1.8.1.1. Обычно он показывает максимальное число страниц, которые можно напечатать с текущего картриджа
Мне приходилось сталкиваться с двумя различными ситуациями в показаниях уровня тонера:
- Уровень тонера выводится сразу в % в 2.43.11.1.1.9.1.1. Параметр максимального числа страниц с текущего картриджа указан как 100% в 2.43.11.1.1.8.1.1.
- Уровень тонера в 2.43.11.1.1.9.1.1 показывает количество напечатанных страниц с текущего картриджа. Второй параметр 2.43.11.1.1.8.1.1 показывает максимальное количество страниц, которое может быть напечатано текущим картриджем. Тогда уровень тонера в % нужно считать по формуле 100-100*(mib-2.43.11.1.1.9.1.1)/(mib-2.43.11.1.1.8.1.1).
Первая ситуация мне попалась в принтерах HP, вторая в Kyocera и Brother. Из-за этого пришлось сделать 3 разных шаблона под каждого производителя принтеров. Все остальные параметры у них совпали.
В принтерах Brother mib об уровне тонера были немного другие, такие же как у HP и Kyocera, но отличались на последнюю цифру — 2.43.11.1.1.8.1.2 и 2.43.11.1.1.9.1.2 соответственно. Я не знаю, с чем это связано, но видел подобную ситуацию у других людей. Кто-то из-за этого создавал правила автообнаружения, чтобы точно вычислить последнюю цифру. Мне не пришлось этого делать. Достаточно было создать разные шаблоны для каждого производителя. Все принтеры попали в эти шаблоны на 100%.
Отдельная история с цветными принтерами. Там несколько картриджей и надо внимательно смотреть на их номера. Но тоже не сложно, просто смещение будет на одну единицу, все картриджи будут идти по порядку.
JavaScript для Zabbix
В апреле 2019 года был представлен Zabbix 4.2 с функцией предобработки на JavaScript. Многие загорелись идеей отказаться от написания скриптов, которые где-то забирают данные, переваривают их и предоставляют уже в понятном для Zabbix формате, а выполнять простые проверки, которые будут получать неготовые для хранения и обработки Zabbix данные, а потом обрабатывать этот поток данных с использованием средств Zabbix и JavaScript. В связке с низкоуровневым обнаружением и зависимыми элементами данных, которые появились в Zabbix 3.4, получилось достаточно гибкая концепция для сортировки и управления полученными данными.
В Zabbix 4.4, как логическое продолжение предобработки на JavaScript, появился новый способ оповещения — Webhook, который можно использовать для простой интеграции оповещений Zabbix со сторонними приложениями.
Настройка Zabbix
Основная наша идея заключалась в том, чтобы сделать в 1С HTTP-сервис, через который Zabbix будет забирать информацию из базы данных и строить на ее основании метрики, триггеры и оповещения.
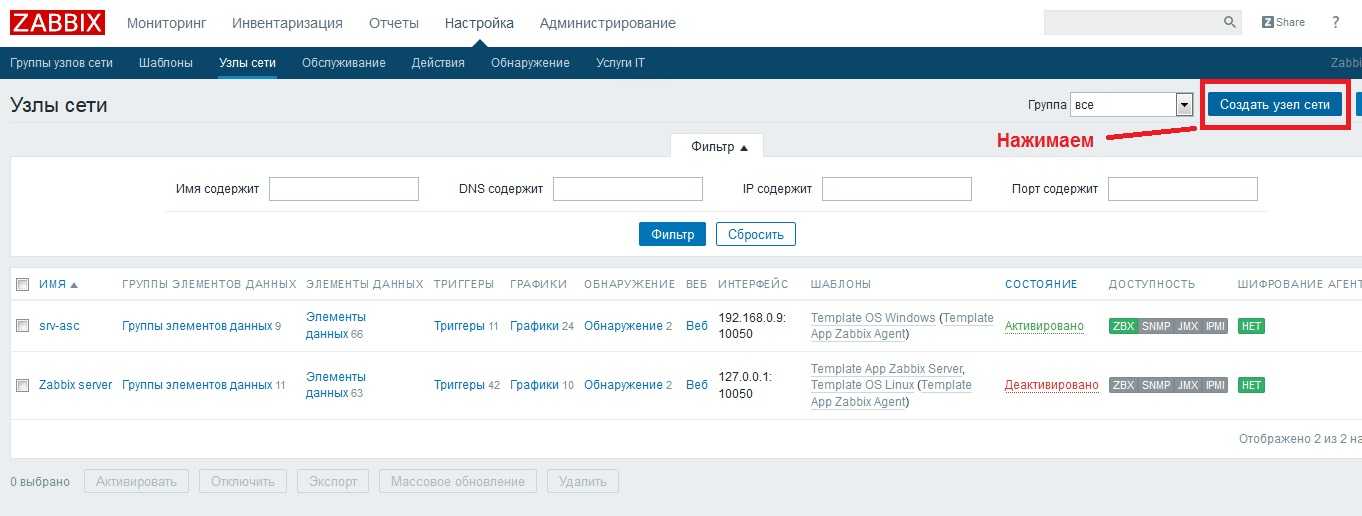
Для начала разберемся, что такое узлы сети.
В обычном понимании мониторинга Zabbix узлы сети – это элементы инфраструктуры (такие как сетевое оборудование, физические и виртуальные сервера, базы данных, источники бесперебойного питания и прочее), с которых Zabbix постоянно считывает информацию.
В нашем случае, узлы сети – это торговые точки, производства, города и даже базы 1С. Это то, по чему мы хотим получать информацию.
На слайде показан узел сети – торговая точка сети СушиВок Санкт-Петербурга:
-
она принадлежит к нескольким группам, чтобы в дальнейшем удобно настраивать права доступа.
-
узел имеет IP адрес – это адрес базы, где находится данная торговая точка.
В Zabbix узлам сети можно добавлять пользовательские макросы. По сути, это реквизиты, которые в дальнейшем можно использовать в элементах данных, в триггерах и оповещениях.

![Учебник zabbix - мониторинг коммутатора через snmp [шаг за шагом]](https://tehnikaarenda.ru/wp-content/uploads/a/a/f/aaf579967627ba0b7bac6e3c24427b56.jpeg)
На примере, показанном на слайде, макросы узла сети – это:
-
адрес URL базы, где находится торговая точка;
-
GUID данной точки.
Таким образом узлы сети — это элементы бизнеса, которые необходимо мониторить.
Переходим к элементам данных.
По сути, элемент данных – это и есть метрика. Даже в инструкции на сайте Zabbix написано, что элемент данных – это метрика, поэтому прошу не путаться, если я буду называть оба варианта.
Итак, метрика – это конкретный фрагмент данных, получаемый от узла сети.
Мы подразделяем метрики на «родительские» и зависимые.
«Родительские» метрики с некоторой периодичностью отправляют в 1С JSON с нужными ключами метрик, а в ответ получают из 1С JSON с такой же структурой, но уже с полученными данными.
В примере мы отсылаем ключи метрик:
-
MaxTimeKitchen – максимальное время отдачи кухни;
-
CountOrdersInKitchen – количество заказов на кухне и т.д.
И вместе с каждым ключом метрик отправляем $STOREGUID – это тот самый пользовательский макрос из узла сети.
На следующем слайде представлен пример JSON-структуры, полученной из базы 1С. Здесь мы видим результаты запрошенных метрик – например, максимальное время отдачи кухни равно 9 минутам, а активных заказов сейчас 2.
Получается, что родительская метрика хранит весь JSON с полученными данными из 1С, а зависимые метрики разбирают данный JSON и хранят уже конкретные значения.
В примере на слайде мы видим зависимую метрику «Совокупное время доставки», которая обновилась в 22:29 и получила информацию, что данный параметр равен 35 минутам.
Разбор JSON в Zabbix стал возможен с версии 4.0, которая вышла в 2018 году.
Smartctl и smartmontools
писалиподход
- избыточные запуски утилиты smartctl, а она в свою очередь каждый раз обращалась к контроллеру жесткого диска
- пришлось делать отдельный парсинг для Linux и Windows. Особенно больно с этим сейчас работать в Win: (for /F… так… экранируем двойные кавычки еще кавычками…. Аааа!!!!)
- smartctl нам JSON не возвращает
- дисков в сервере может быть различное количество, поэтому нам нужно использовать низкоуровневое обнаружение(LLD).
- uHDD.i
- uHDD.health
Тестируем, смотрим что получилось
- мы убрали весь парсинг из UserParameters
- нет внешних скриптов (кроме LLD), нет внешних зависимостей, весь парсинг происходит на Zabbix-сервере, там его легко посмотреть и подправить, если нужно
- когда утилита или API не возвращает XML/JSON – не беда, всегда можно попробовать использовать регулярные выражения
- жесткие диски больше не мучаем – сначала достаем весь список параметров S.M.A.R.T., а затем уже на Zabbix-сервере раскладываем его по метрикам.
здесь
Результат в Zabbix – метрики и триггеры
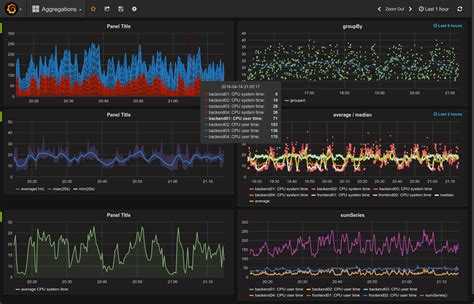
В итоге мы получаем метрики в Zabbix.
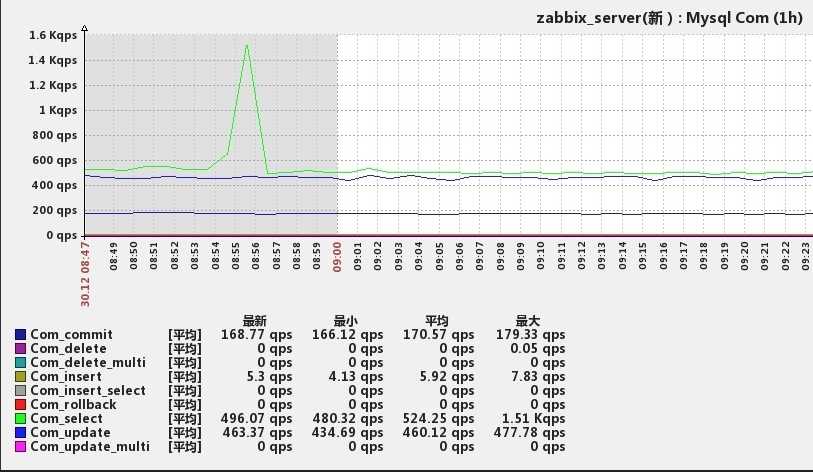
На представленном графике показаны значения метрик по одной Киевской точке. Мы видим, какими в период с 19 до 20 часов были значения показателей:
-
время кухни в инфо-табло – зеленая линия;
-
количество заказов – красные точки;
-
и максимальное время отдачи кухни – синяя линия.
На основании полученных метрик мы настроили триггеры.
Триггеры – это выражения, определяющие порог проблемы:
-
когда результаты всех неравенств в выражении триггера становятся истинными, открывается проблема;
-
как только хотя бы одно неравенство будет возвращать ложь, проблема закрывается.
На примере показан триггер, открывающий проблему, когда время отдачи кухни будет на 5 минут больше, чем регламентное. Это мы можем увидеть в последнем неравенстве, где MaxTimeKitchen.last() > TimeOfKitchenInInfo.last() + 5. Все остальные неравенства всегда истинны и указаны здесь, потому что в Zabbix в оповещениях о проблеме нельзя использовать метрики, если они не присутствуют в выражении триггера.




Настройка мониторинга за процессами
На Zabbix сервере идем в стандартный шаблон Linux и добавляем туда 2 новых айтема:
- Process List — список процессов, ограниченный десятью с самой высокой нагрузкой на cpu. Сюда будем записывать информацию о процессах на сервере при срабатывании триггеров на повышенную нагрузку CPU.
- Full Process List — полный список всех процессов. Сюда запишем полный список всех процессов, когда сработает триггер на превышение максимально допустимого количества запущенных процессов на сервере.
Так выглядит первый айтем. Второй сделайте по аналогии.
Теперь идем на сервер с агентом и пробуем отправку данных в данный айтем. Для этого нам нужен будет zabbix_sender. Если у вас его нет, то установите.
# yum install zabbix-sender
Отправку данных проверяем следующим образом:
/usr/bin/zabbix_sender -c /etc/zabbix/zabbix_agentd.conf -k process.list -o "`ps aux --sort=-pcpu,+pmem | awk 'NR<=10'`"
Я не буду подробно останавливаться на формате запросов с помощью zabbix_sender. Все это хорошо описано в документации. Теперь идем в веб интерфейс сервера и в разделе Последние данные смотрим на список процессов, который нам пришел с целевого сервера.
Ровно то, что нам было нужно. То же самое можно проверить с айтемом Full Process List, убрав в команде | awk ‘NR<=10’ в конце.
Далее нам нужно создать действие, которое будет запускать данную команду на сервере при срабатывании триггеров. Для этого идем в раздел Настройка -> Действия и добавляем новое.
Сохраняйте действие и можно проверять.
Настройка мониторинга логов
Для того, чтобы мониторить лог файл, на сервере должен быть установлен zabbix agent, а сам сервер добавлен в панель мониторинга. Я буду следить за логом программы apcupsd, который располагается по пути /var/log/apcupsd.events. Идем в веб интерфейс заббикса и добавляем новый итем к интересующему нас хосту. Если у вас таких будет несколько, то создавайте сразу шаблон. В моем случае у меня один сервер, поэтому я буду добавлять новый элемент сразу на него.
На всякий случай сообщаю, что вся настройка проходит на zabbix server версии 3.2. Но информация актуальна и для других версий, так как используется стандартный функционал, который поддерживают все версии заббикса.
Создаем новый итем со следующими параметрами:
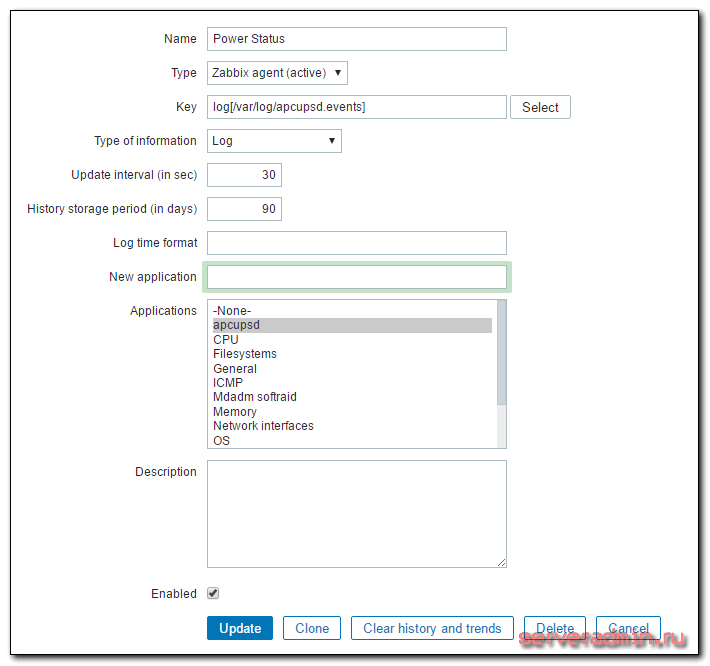
| Name | Имя нового итема. Можете указать любое название. |
| Type | Тип элемента. Обязательно выбираем Zabbix agent (active). По-умолчанию будет другой тип стоять. |
| Key | Ключ данных, log — тип, в квадратных скобках путь до лог файла. |
| Type of information | Указываем тип информации, поступающей в итем. |
Остальные параметры оставляете на свое усмотрение. Рекомендую время обновления итема ставить поменьше, чтобы оперативно получить информацию об инциденте. У меня стоит 30 секунд.
После того, как вы сохраните новый итем, через несколько минут начнут поступать данные. Проверять их как обычно в Latest data. В данной конфигурации будут сохраняться все строки из файла. В моем случае это не страшно, так как записей будет очень мало. Они создаются только по событиям в электро сети, а они случаются редко, поэтому я не стал делать фильтр по строкам или словам.
Но это только пол дела. Мы стали собирать логи, теперь нам нужно настроить отправку оповещения при пропадании электричества.
Оповещения в Telegram
Соответственно из этих метрик мы сделали оповещения через Telegram – в СушиВок для оперативной информации используется именно Telegram, а не почта. Причем, в Zabbix оповещения для Telegram настраиваются «из коробки».
В оповещениях операционный отдел просил указывать всю информацию о точке – количество поваров, сумма чеков, количество чеков в комплектации и т.д., чтобы можно было полностью понимать, какая ситуация на точке была во время сбоя. Из-за этого в выражении триггера и нужны были эти лишние всегда истинные неравенства. Но при большом объёме срабатывающих триггеров из-за всей этой информации сообщения стали не читаемы – получалось полотно из слов.
Поэтому я воспользовался советом Родислава Гандапаса из книги «К выступлению готов», где он при подготовке к выступлениям на карточках рекомендует использовать пиктограммы, т.к. они быстрее читаются при беглом взгляде.
Так в наших оповещениях появились:
-
ножи – это кухня;
-
черепашки – это доставка;
-
огоньки – если проблема не закрыта больше 10 мин.
Операционный отдел был очень доволен данными оповещениями.
Заключение
Теперь у нас zabbix работает современно, модно, молодежно  Использует telegram для отправки оповещений с графиками, ссылками и т.д. Функционал удобный и настраивается достаточно просто. У меня практически не было затруднений, когда разбирал тему. Беру себе на вооружение и использую по необходимости. Хотя сам не люблю оповещения в телеграме, и чаще всего их отключаю, как и от остальных программ. Не нравится, когда меня в каждую минуту могут отвлечь какие-то события. Проверка почты раз в 30 минут самая подходящая интенсивность для меня.
Использует telegram для отправки оповещений с графиками, ссылками и т.д. Функционал удобный и настраивается достаточно просто. У меня практически не было затруднений, когда разбирал тему. Беру себе на вооружение и использую по необходимости. Хотя сам не люблю оповещения в телеграме, и чаще всего их отключаю, как и от остальных программ. Не нравится, когда меня в каждую минуту могут отвлечь какие-то события. Проверка почты раз в 30 минут самая подходящая интенсивность для меня.

Тем не менее, при работе коллектива, оповещения в общую группу могут быть очень удобны. Особенно, если только на мониторинге сидят отдельные люди, в чью задачу входит оперативная реакция на события.
Прошлая версия статьи в pdf.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .
Заключение
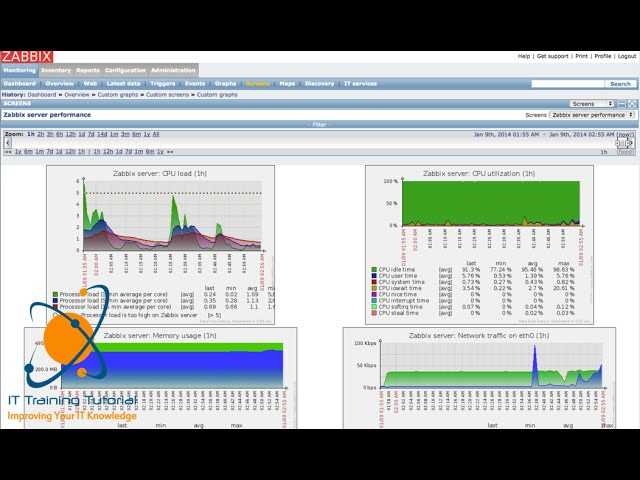
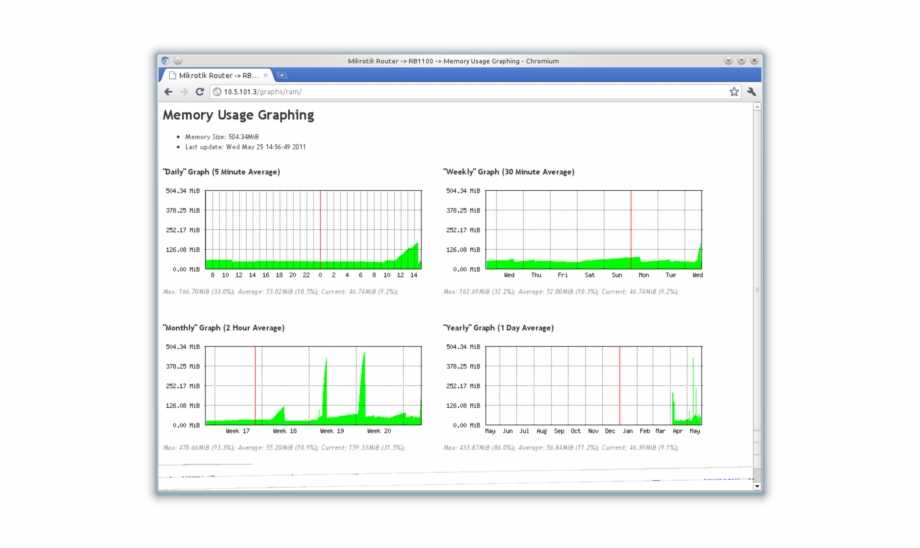
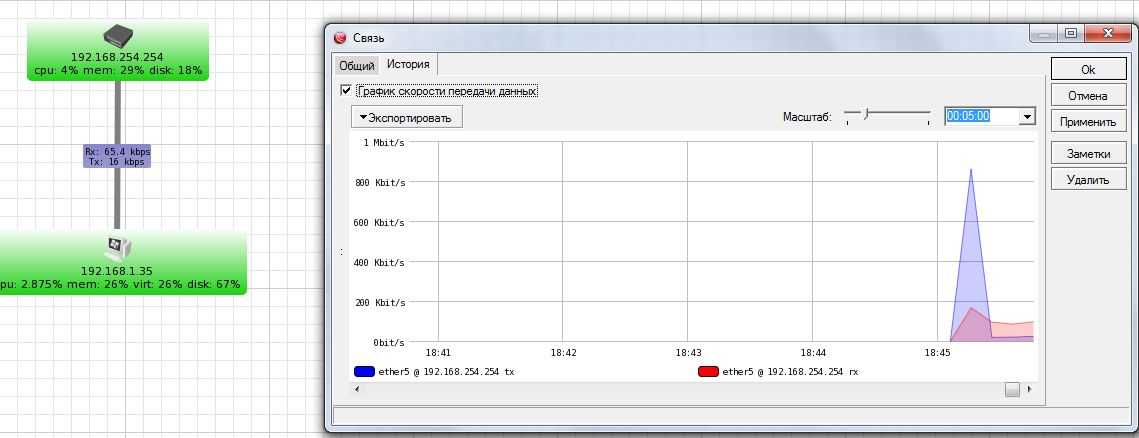
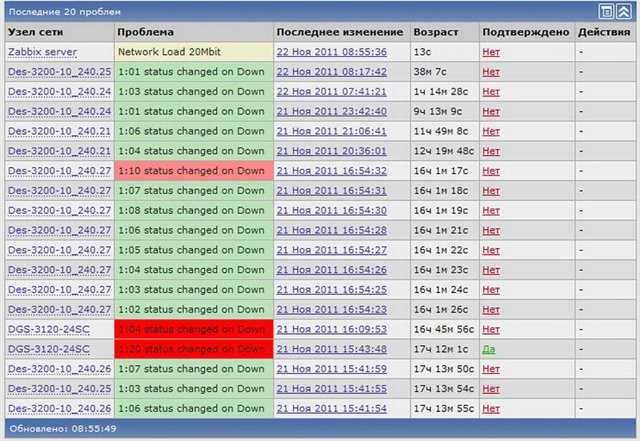
Вот такую реализацию я придумал, когда потребовалось решить задачу. Один сервер постоянно донимал оповещениями по ночам. Нужно было понять, что его дергает в это время. Жаль, что у Zabbix из коробки нет реализации подобного информирования. Помню лет 5 назад был бесплатный тариф у мониторинга NewRelic. Можно было поставить агент мониторинга на сервер и потом смотреть очень удобные отчеты в веб интерфейсе. Никаких настроек не нужно было, все работало из коробки. Там были отражены все запущенные процессы на сервере на временном ряду со всеми остальными метриками. Это было очень удобно. Я нигде в бесплатном софте не видел такой реализации. Это примерно вот так выглядело.
Кстати, в первоначальной версии действия я просто отправлял список процессов на почту. Мне показалось это удобным. Можно было сразу же в почте, в соседнем письме с триггером, посмотреть список процессов. Но потом решил, что удобнее все же хранить историю в одном месте на сервере и настроил сбор данных туда. Хотя можно делать и то, и другое. Например, в действии можно указать другую команду к исполнению:
# ps aux --sort=-pcpu,+pmem | awk 'NR<=10' | mail -s "Process List" zabbix@mail.ru
И вам на почту придет список запущенных процессов после активации триггера.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .





