
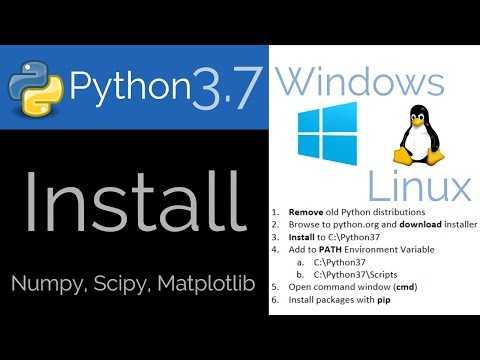
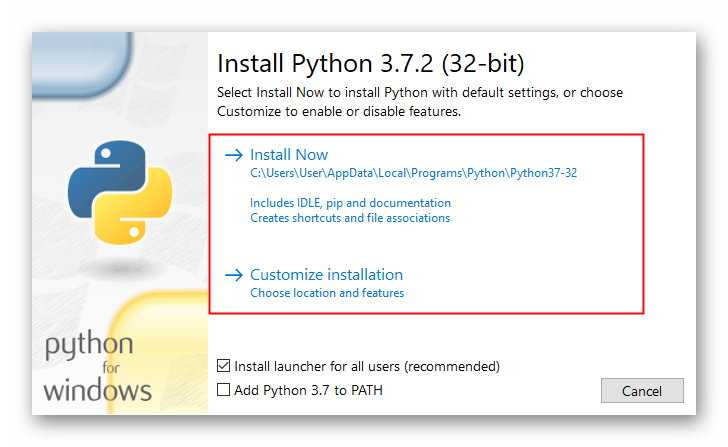
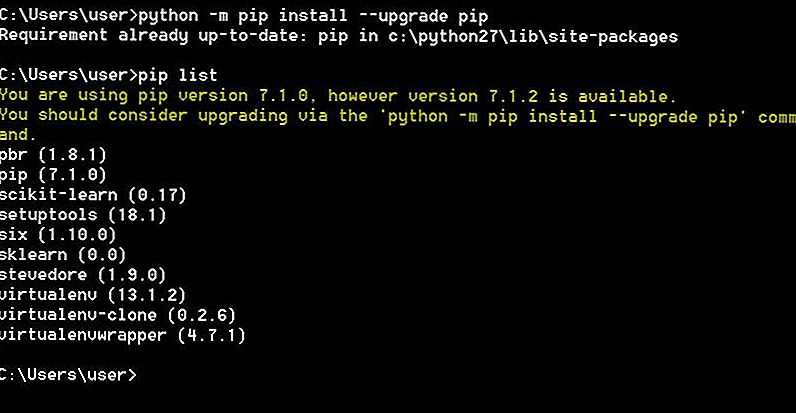
Создаём инстанс Ubuntu
1. Кликните по кнопке “Create Instance” (обведена на картинке выше).
2. Под изображением c выбором вашего инстанса выберите Linux/Unix.
3. Выберите “OS Only”.
4. Выберите Ubuntu 18.04.
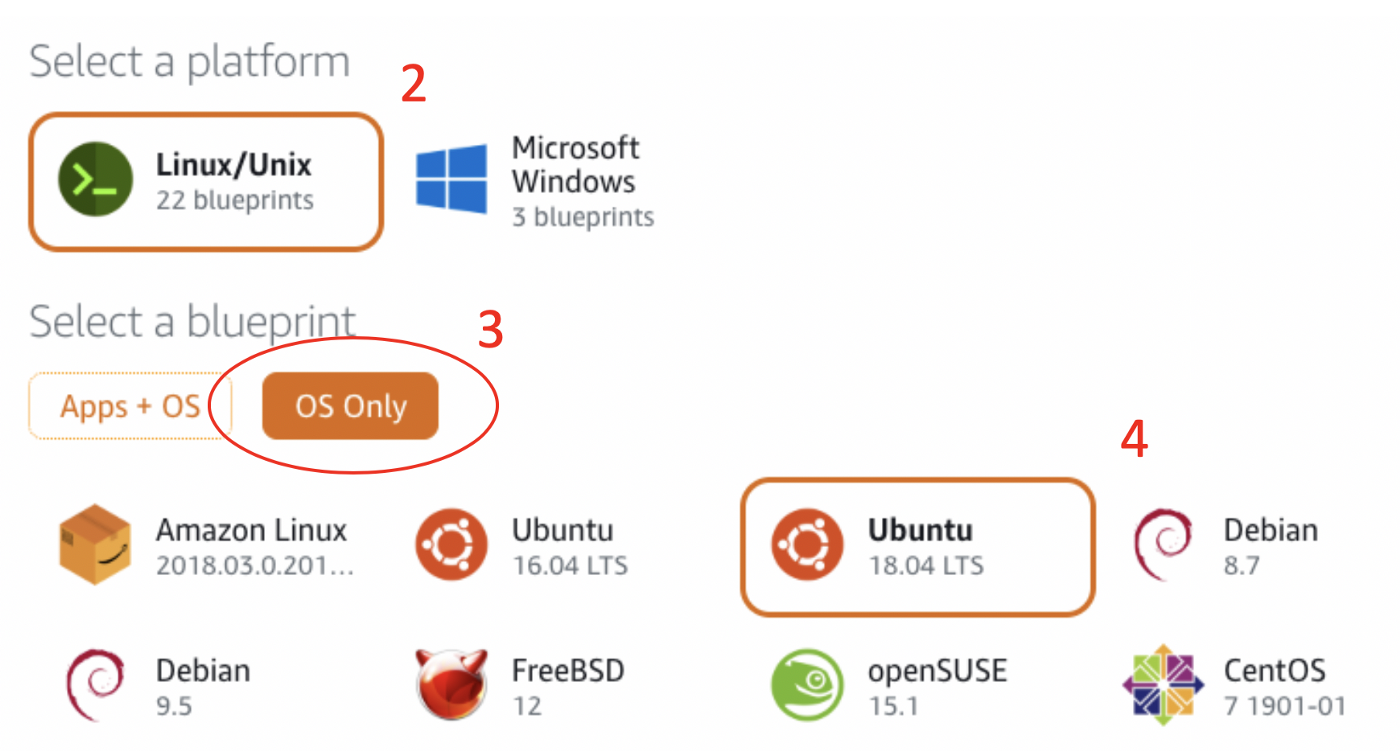
шаги создания инстанса ubuntu
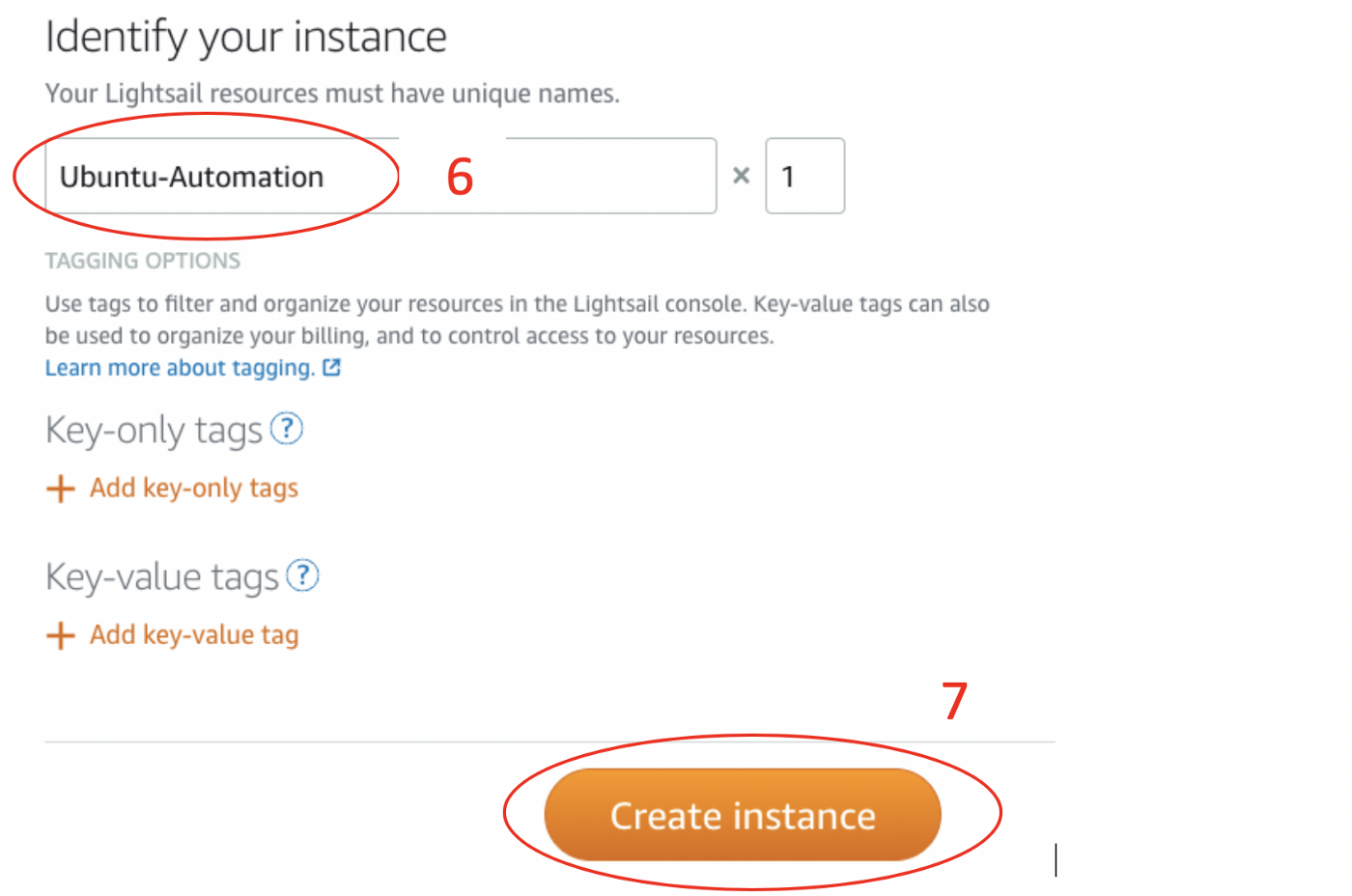
5. Выберите тариф для своего инстанса. Для этого проекта я беру самую недорогую опцию за $3.50. Она более чем подходит для запуска большинства скриптов на Python. Не забывайте, что платить за первый месяц не нужно.
6. Дайте название инстансу. Для своего проекта я придумал “Ubuntu-автоматизация”.
7. Выберите “Create Instance”.
После выбора “Create Instance” вы вернётесь на дашборд AWS LightSail. Чтобы новый Ubuntu-инстанс появился, должно пройти несколько минут. Пока это происходит, вы будете видеть статус “Pending”, как на скриншоте ниже:

В ожидании создания
Статус сменится на значение “Running” сразу после того, как новый инстанс будет создан. Также вы увидите IP-адрес, присвоенный инстансу. Например, у моего был 3.227.241.208. Этот адрес динамический и будет меняться каждый раз после перезагрузки инстанса. В зависимости от проекта, который вы будете хранить, может понадобиться и статический IP-адрес.
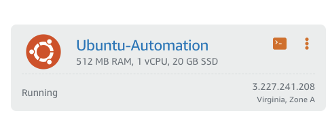
Ubuntu-инстанс создан и запущен
Создаём статический IP-адрес
Можно и не создавать статический IP, разве что он нужен по требованиям вашего проекта. Я буду создавать статический IP-шник потому, что собираюсь открывать свой SQL-сервер только на нём из соображений безопасности. После первой установки я предпочитаю подключаться по SSH в моем Ubuntu-инстансе со своей локальной машины, а благодаря статическому IP этот процесс упрощается.
1. Перейдите во вкладку “Networking” на вашем дашборде Lightsail.
2. Кликните на “Create static IP”.

дашборд Networking
3. Выберите ваш сервер для Ubuntu-инстанса в “Attach to an instance”.
4. Назовите статический IP.
5. Нажмите на “Create”.
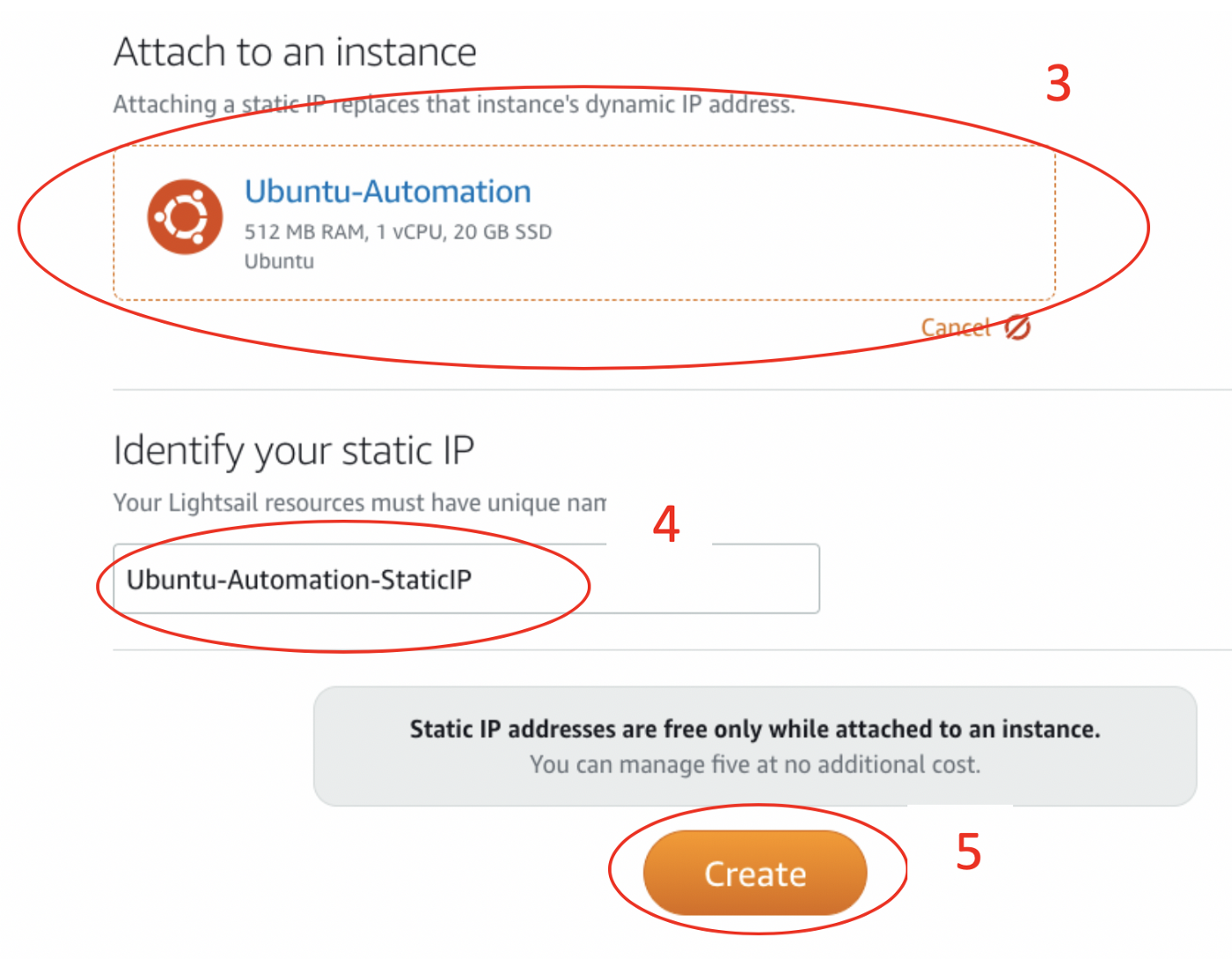
Затем вы должны увидеть ваш новый статический IP-адрес. И этот IP-адрес не будет изменяться.
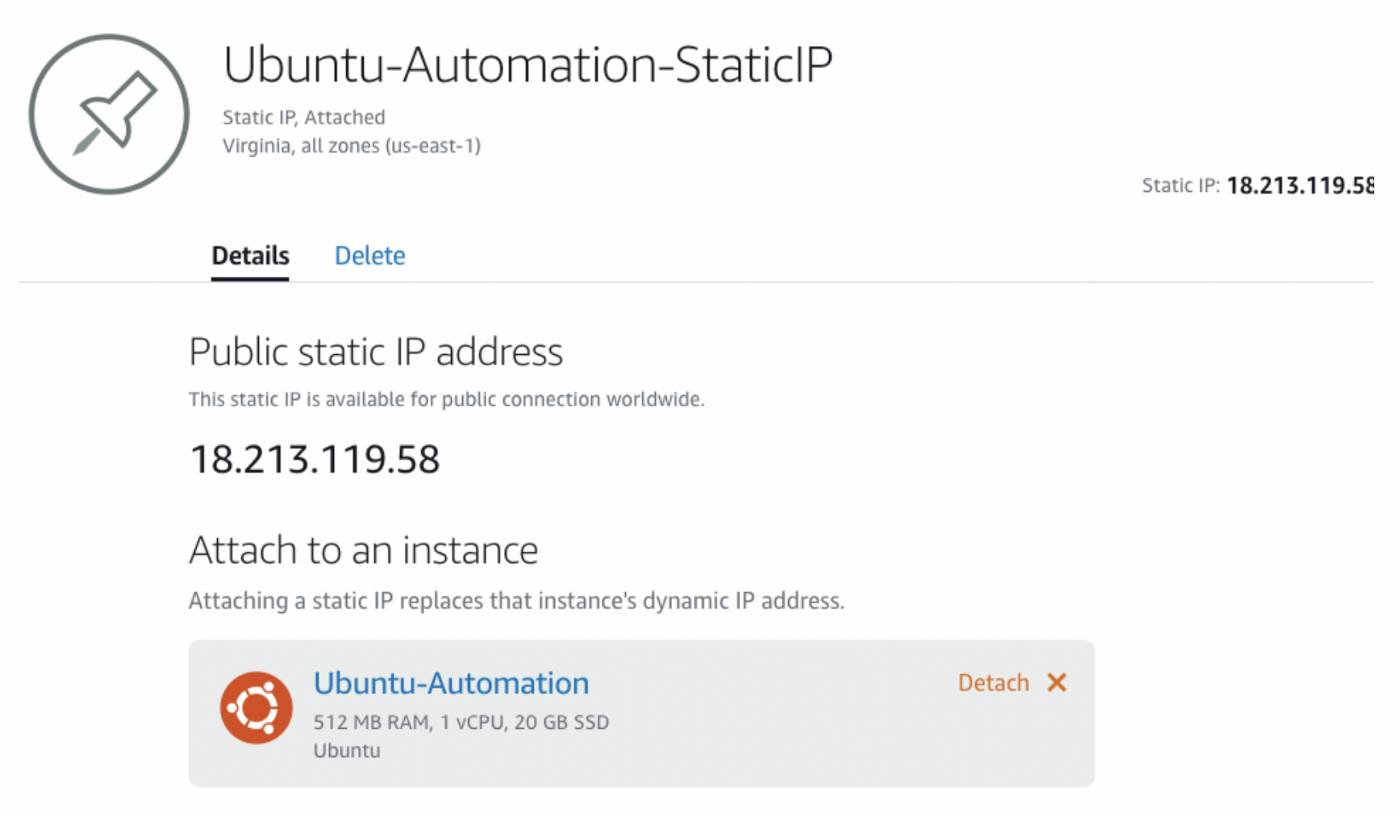
Поехали дальше: 18.213.119.58 — статический IP проекта.
Автоматизация Python
Для этого проекта я буду писать скрипт на Python. Он вызывает Reddit API и собирает все новые представления с reddit.com/r/learnpython. Чтобы не растягивать повествование, я не стану рассматривать работу этого отдельного скрипта, а вы можете увидеть весь код на GitHubLink.
Создание команд
Для создания команды helloworld изменим файл setup.py:
setup(
...
entry_points={
'console_scripts'
'helloworld = helloworld.core:print_message'
}
)
В параметре entry_points мы задаем словарь с «точками вызова» нашего приложения. Ключ console_scripts
задает список создаваемых исполняемых скриптов (в Windows это будут exe-файлы). В данном случае
мы указали создание исполняемого скрипта helloworld при вызове которого будет запускаться метод print_message
из модуля helloworld.core.
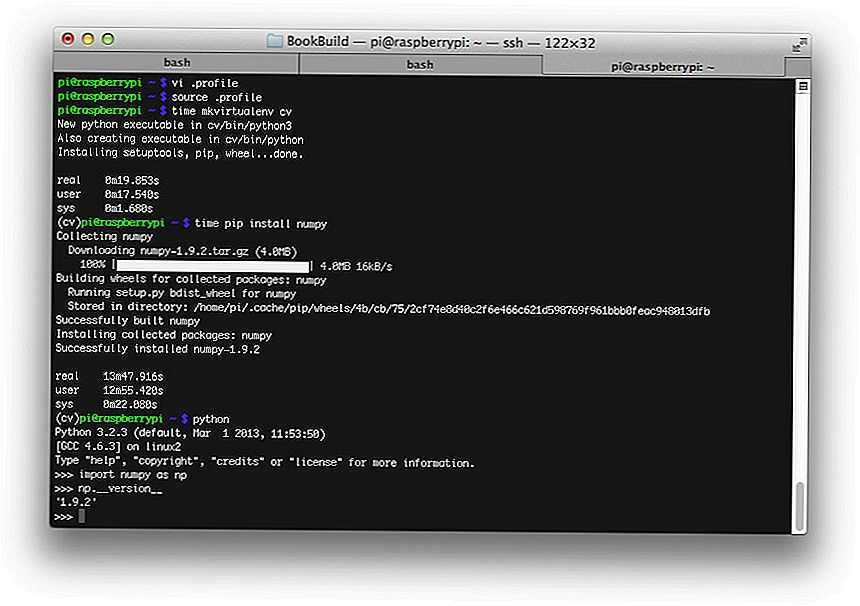
Переустановим модуль в наше окружение и проверим работу созданного скрипта (для этого прийдется активировать наше окружение):
$ ./env/bin/python setup.py install $ source ./env/bin/activate (env) $ helloworld Hello World! (env)
Как добавить пакет в системный путь
Невозможно всегда зависеть от иерархии каталогов для импорта модулей пакета. Мы можем добавить наш собственный пакет в переменную sys.path, а затем импортировать их в любой скрипт.
import sys
sys.path.append("/Users/pankaj/Desktop/python-packages")
print(sys.path)
import utilities.math as math
print(math.add(1, 2))
Вывод:
$ python3.7 my_script.py ['/Users/pankaj', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python37.zip', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages', '/Users/pankaj/Desktop/python-packages'] utilities package initialized 3 $
Пакеты в Python позволяют нам разделить наши прикладные модули и скрипты на логические модули. Это сохраняет нашу базу кода чистой и простой в обслуживании.
Файл spec
Файл spec — это первый файл, который PyInstaller создает, чтобы закодировать содержимое скрипта Python вместе с параметрами, переданными при запуске.
PyInstaller считывает содержимое файла для создания исполняемого файла, определяя все, что может понадобиться для него.
Файл с расширением .spec сохраняется по умолчанию в текущей директории.



Если у вас есть какое-либо из нижеперечисленных требований, то вы можете изменить файл спецификации:
- Собрать в один бандл с исполняемым файлы данных.
- Включить другие исполняемые файлы: .dll или .so.
- С помощью библиотек собрать в один бандл несколько программы.
Например, есть скрипт simpleModel.py, который использует TensorFlow и выводит номер версии этой библиотеки.
Копировать
Компилируем модель с помощью PyInstaller:
После успешной компиляции запускаем исполняемый файл, который возвращает следующую ошибку.
Исправим ее, обновив файл spec. Одно из решений — создать файл spec.
Команда pyi-makespec создает spec-файл по умолчанию, содержащий все параметры, которые можно указать в командной строке. Файл simpleModel.spec создается в текущей директории.
Поскольку был использован параметр , то внутри файла будет только раздел exe.
Если использовать параметр по умолчанию или onedir, то вместе с exe-разделом будет также и раздел collect.
Можно открыть simpleModel.spec и добавить следующий текст для создания хуков.
Создаем хуки и добавляем их в hidden imports и раздел данных.
Как скомпилировать Python код в .exe | немного теории
Python — высокоуровневый язык программирования общего назначения, ориентированный на повышение производительности разработчика и читаемости кода.
Хочется отметить, что для меня Python является одним из самых интересных, мощных языков программирования. С ним я познакомился примерно в 2016 году и только спустя год осознал всю его мощь и красоту.
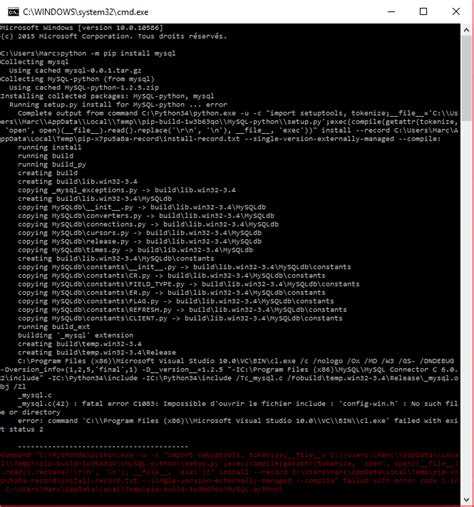
Многие задаются вопросом, когда написали программу на Python: “А как его скомпилировать в .exe файл?”. Вопрос довольно сложный, для того, кто только открыл для себя этот язык и ещё не сталкивался с pip.
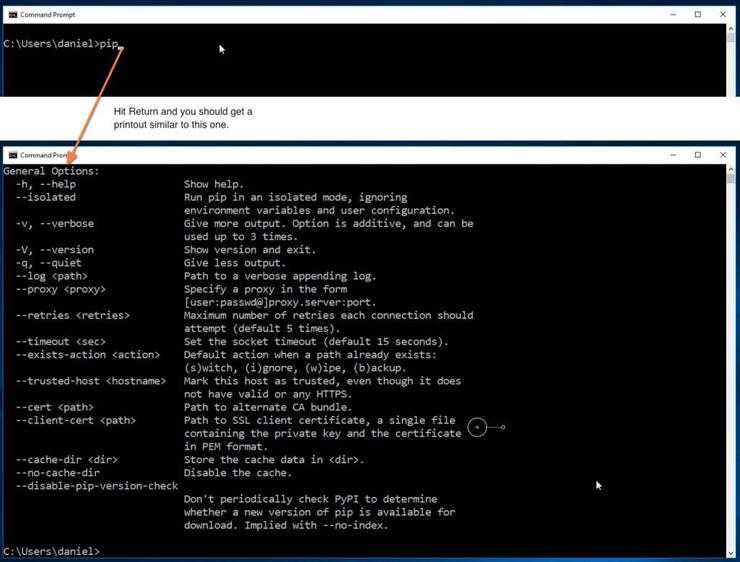
pip – система управления пакетами, которая используется для установки и управления программными пакетами, которые написаны на Python. Если кратко, то pip – это файловый менеджер языка Python.
pyinstaller – программа, которая собирает все зависимости и python-приложение в один пакет и превращает его в исполняемый файл для Windows, Linux, MacOS.
Абсолютный и относительный импорт
При абсолютном импорте используется полный путь (от начала корневой папки проекта) к желаемому модулю.
При относительном импорте используется относительный путь (начиная с пути текущего модуля) к желаемому модулю. Есть два типа относительных импортов:
- При явном импорте используется формат , где символы точки показывают, на сколько директорий «вверх» нужно подняться. Одна точка показывает текущую директорию, две точки — на одну директорию выше и т. д.
- Неявный относительный импорт пишется так, как если бы текущая директория была частью . Такой тип импортов поддерживается только в Python 2.
В документации Python об относительных импортах в Python 3 написано следующее:
В качестве примера допустим, что мы запускаем , который импортирует , который импортирует , и . Тогда импорты в будут выглядеть следующим образом:
Абсолютные импорты:
Явные относительные импорты:
Неявные относительные импорты (не поддерживаются в Python 3):
Учтите, что в относительных импортах с помощью точек можно дойти только до директории, содержащей запущенный из командной строки скрипт (не включительно). Таким образом, не сработает в . В результате мы получим ошибку .
Как правило, абсолютные импорты предпочтительнее относительных. Они позволяют избежать путаницы между явными и неявными импортами. Кроме того, любой скрипт с явными относительными импортами нельзя запустить напрямую:
Требования для хорошей среды разработки
Итак, что нам нужно от среды разработки? Набор функций разных сред может отличаться, но есть набор базовых вещей, упрощающих программирование:
- Сохранение файлов. Если IDE или редактор не дают вам возможности сохранить работу и позже всё открыть в том же состоянии, в котором оно было во время закрытия, то не такая уж это и IDE;
- Запуск кода из среды. То же самое, если вам нужно выйти из среды для запуска кода, то это не более, чем простой текстовый редактор;
- Поддержка отладки. Возможность пошагово выполнить код является базовой функцией всех IDE и большинства хороших редакторов кода;
- Подсветка синтаксиса. Возможность быстро найти ключевые слова, переменные и прочее делает чтение и понимание кода на порядок проще;
- Автоматическое форматирование кода. Любой редактор или IDE, который действительно таковым является, распознает двоеточие после while или for выражения и автоматически сделает отступ на следующей строке.
Разумеется, есть множество других функций, от которых вы бы не отказались, но приведённые выше — основные функции, которыми должна обладать хорошая среда разработки.
А теперь давайте взглянем на некоторые инструменты общего назначения, которые можно использовать для разработки на Python.
Примеры использования
Допустим, есть задача выполнить трудоемкие вычисления — например, для криптографического алгоритма, глубокого машинного обучения или обработки больших объемов данных. В этом случае расширения на Си могут снять нагрузку с интерпретатора Питона и ускорить работу приложения.
Что, если вам нужно создать низкоуровневый интерфейс или работать с памятью непосредственно из Питона? Здесь тоже стоит использовать расширения на Си — если вы знаете, как работать с «чистыми» указателями.
Еще один практический пример — оптимизация уже существующего «подтормаживающего» приложения на Питоне без переписывания его на другом языке.
А возможно, вы просто обожаете оптимизацию и хотите, чтобы код работал как можно быстрее, но не спешите расставаться с высокоуровневыми абстракциями для работы с сетью, графическим интерфейсом и т. д. — тогда вы определенно полюбите расширения на Си.
Как залить на pypi?
Как собрать пакет?
Снова пишу среду, которая поможет мне собрать необходимый пакет:
Зачем я удаляю папки с помощью python? Хочу соблюсти требование о кроссплатформенности разработки, удобного пути сделать это под Windows и Unix нет.
Запускаю тестовую среду:
В результате в папке получаю:
Заливаю!
Не совсем.
Изначально проект назывался , но при попытке заливки столкнулся с тем, что пакет с таким именем уже есть! И что самое обидное — он тоже умеет конвертировать в римские цифры:) Сильно не расстроился и переименовал в .
Теперь нужно установить пакет из тестового окружения. Проверку так же стоит автоматизировать:
Теперь нужно только запустить:
Вроде работает 
Да.
Создаю среду для заливки в production репозиторий.
И среду для production проверки.
Hydra — упрощаем разработку, динамически создавая иерархическую структуру конфигурации приложения
Рассмотрим последним, в этой статье, способ создания и поддержки конфигурации для вашего приложения, который по сути является гораздо большим, чем просто загрузчик и парсер файлов с настройками.
Hydra – это платформа, разработанная для гибкой и элегантной настройки самых сложных приложений. Которая помимо чтения, записи и валидации корректности файлов конфигурации, реализовывает свою достаточно рациональную стратегию упрощения управления несколькими конфигурационными файлами, переопределения (перезаписи) их с использованием интерфейса командной строки, создания snapshot снимка состояния приложения перед каждым его запуском (между перезапусками) и т.д.
Чтение
Рассмотрим основы использования hydra. Так в следующем примере команда , добавленная в командную строку при запуске скрипта, позволяет добавить новое поле (настройку) в конфигурацию приложения, а также осуществить перезапись значения существующего поля (значения настройки) .
import hydra
from omegaconf import DictConfig, OmegaConf
@hydra.main(config_name="config")
def my_app(cfg: DictConfig) -> None:
print(OmegaConf.to_yaml(cfg))
if __name__ == "__main__":
my_app()
# запускаем в командной строке скрипт с командами
# python3 source/hydra_basic.py +APP.NAME=hydra
#
# результат его выполнения
# APP:
# ENVIRONMENT: test
# DEBUG: true
# NAME: hydra1.1
Валидация
Hydra прекрасно интегрируется с декоратором для выполнения основных проверок корректности, таких как проверка типов или значения полей. Однако у нее нет поддержки метода расширенной проверки значений, как это описано в моей предыдущей статье.
from dataclasses import dataclass
from omegaconf import MISSING, OmegaConf
import hydra
from hydra.core.config_store import ConfigStore
@dataclass
# @dataclass(frozen=True) способ определения полей только для чтения
class MySQLConfig:
driver: str = "mysql"
host: str = "localhost"
port: int = 3306
user: str = MISSING
password: str = MISSING
@dataclass
class Config:
db: DBConfig = MISSING
cs = ConfigStore.instance()
cs.store(name="config", node=Config)
cs.store(group="db", name="mysql", node=MySQLConfig)
@hydra.main(config_path="conf", config_name="config")
def my_app(cfg: Config) -> None:
print(OmegaConf.to_yaml(cfg))
if __name__ == "__main__":
my_app()
Группа конфигураций
Hydra вводит концепцию под названием config group . Идея которой состоит в том, чтобы сгруппировать файлы конфигурации одного типа (или для выполнения одних задач) и затем выбирать один из них во время выполнения приложения. Например, у вас имеется группа настроек «Базы данных» с одной конфигурацией для Postgres, а другой для MySQL.
Когда конфигурация приложения станет более сложной, то в вашей программе она может иметь следующую структуру (пример из документации Hydra).
├── conf │ ├── config.yaml │ ├── db │ │ ├── mysql.yaml │ │ └── postgresql.yaml │ ├── schema │ ├── school.yaml │ ├── support.yaml │ └── warehouse.yaml └── my_app.py
Например, вы хотите протестировать свое приложение с различными комбинациями опций , и , это можно сделать следующим образом:
python my_app.py db=postgresql schema=school.yaml
Далее…
Hydra поддерживает использование нескольких наборов параметров конфигурации с опцией , при этом запускаются параллельно несколько задач с различными файлами конфигурации. Например, для предыдущего примера мы можем запустить скрипт следующим образом:
python my_app.py schema=warehouse,support,school db=mysql,postgresql -m
В этом случае в основном потоке запускаются 6 задач одновременно:
- Launching 6 jobs locally - Sweep output dir : multirun/2019-10-01/14-44-16 - #0 : schema=warehouse db=mysql - #1 : schema=warehouse db=postgresql - #2 : schema=support db=mysql - #3 : schema=support db=postgresql - #4 : schema=school db=mysql - #5 : schema=school db=postgresql
Вывод
В этой статье мы рассмотрели несколько способов управления конфигурацией приложений в Python. Независимо от того какой из них вы выберете, всегда необходимо думать о удобочитаемости файлов конфигурации, дальнейшей их поддержки, а также способах обнаружения ошибок для случаев их некорректного использования. Таким образом, конфигурационный файл – это по сути еще один тип кода.
Установка RPM пакетов в Linux
Давайте сначала рассмотрим синтаксис самой утилиты rpm:
$ rpm -режимопции пакет
Утилита может работать в одном из режимов:
- -q, —query — запрос, получение информации;
- -i, —install — установка;
- -V, —verify — проверка пакетов;
- -U, —upgrade — обновление;
- -e, —erase — удаление.
Рассмотрим только самые интересные опции программы, которые понадобятся нам в этой статье:
- -v — показать подробную информацию;
- —vv — выводить отладочную информацию;
- —quiet — выводить как можно меньше информации;
- -h — выводить статус-бар;
- —percent — выводить информацию в процентах о процессе распаковки;
- —force — выполнять действие принудительно;
- —nodeps — не проверять зависимости;
- —replacefiles — заменять все старые файлы на новые без предупреждений;
- -i — получить информацию о пакете;
- -l — список файлов пакета;
- -R — вывести пакеты, от которых зависит этот пакет;
Теперь, когда вы уже имеете представление как работать с этой утилитой, может быть рассмотрена установка rpm пакета в Linux. Самая простая команда установки будет выглядеть вот так:
Для работы с командной текущей директорией должна быть папка с пакетом. Здесь мы устанавливаем режим установки и передаем файл пакета. При успешной установке утилита не выведет ничего, если произойдет ошибка, вы об этом узнаете.
Для того чтобы посмотреть более подробную информацию в процессе установки используйте опцию -v:
Также вы можете включить отображение статус бара в процессе установки:
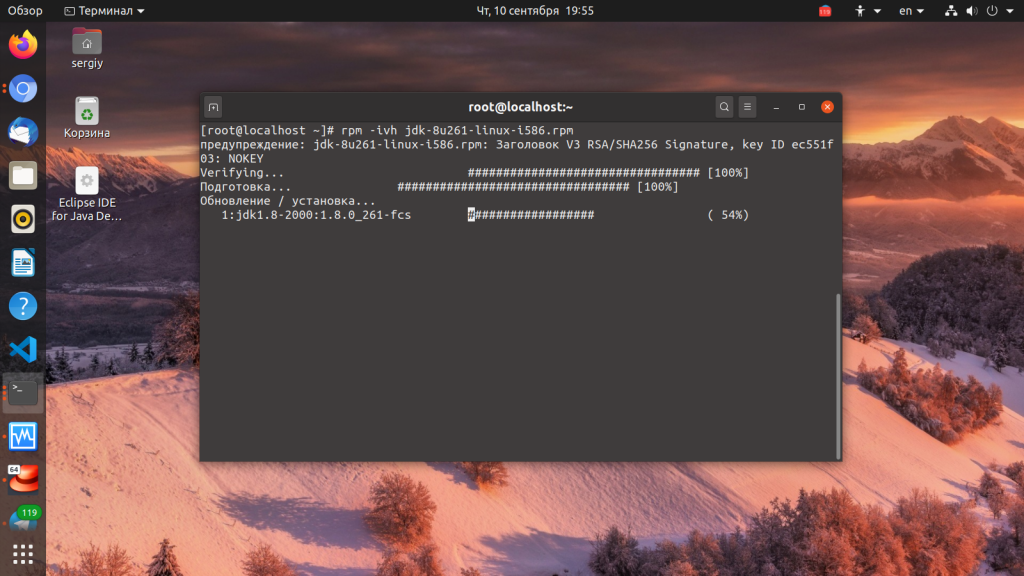
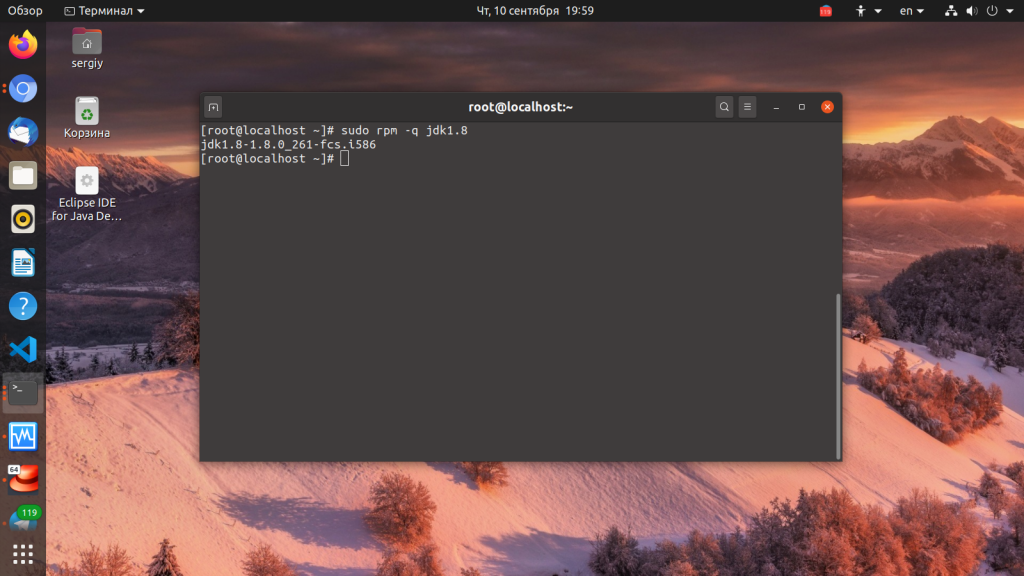
Чтобы проверить установлен ли пакет, нам уже нужно использовать режим запроса:
Также сразу можно удалить пакет, если он не нужен:
Но у rpm так же как и у dpkg, есть один существенный недостаток. Программа не может разрешать зависимости. В случае отсутствия нужного пакета в системе, вы просто получите сообщение об ошибке и пакет не установится.
Для автоматической загрузки зависимостей во время выполнения установки rpm linux нужно использовать пакетный менеджер дистрибутива. Рассмотрим несколько команд для самых популярных RPM дистрибутивов. В RedHat и других дистрибутивах, использующих Yum используйте такую команду:
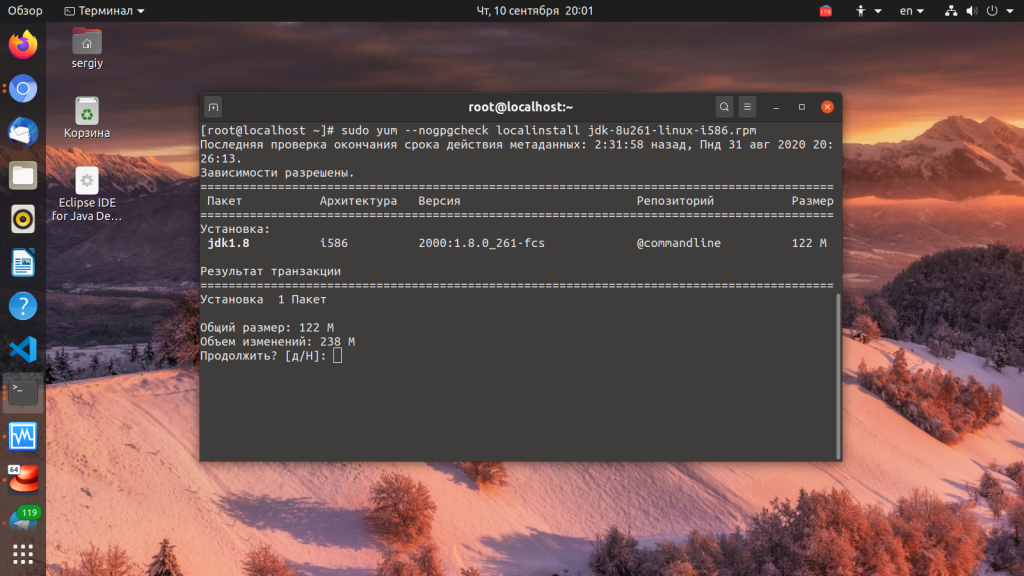
Первая опция отключает проверку GPG ключа, а вторая говорит, что мы будем выполнять установку локального пакета. В Fedora, с помощью dnf все делается еще проще:
Пакетный менеджер Zypper и OpenSUSE справляются не хуже:
Вот так очень просто выполняется установка rpm с зависимостями. Но не всем нравится работать в консоли, многие новые пользователи хотят использовать графический интерфейс для решения всех задач, в том числе и этой. Дальше мы рассмотрим несколько таких утилит.
Сравнение с версией на «чистом» Питоне
Теперь сравним функцию с ее аналогом на Питоне. Воспользуемся встроенным модулем :
Вывод:
Как и ожидалось, функция на Си работает быстрее.
А теперь попробуем на больших числах:
Версия Си явно превосходит версию на Питоне в случае больших чисел. Если нужно выполнить несколько простых вычислений, то использование Си вряд ли будет оправданно, поскольку разница в производительности будет минимальной. Но если у вас трудоемкая операция или функция, которую необходимо выполнять много раз, скорости Питона может быть недостаточно.
И здесь расширения на Си могут здорово выручить: так вы поручите всю тяжелую работу производительному языку, а в качестве основного продолжите использовать Питон.
Отладка исполняемых файлов PyInstaller ↑
Как вы видели выше, вы можете столкнуться с проблемами при запуске исполняемого файла. В зависимости от сложности вашего проекта исправления могут быть такими простыми, как включение файлов данных, таких как пример программы чтения каналов. Однако иногда требуется больше методов отладки.

Ниже приведены несколько распространенных стратегий, которые не указаны в определенном порядке.Часто одна из этих стратегий или их комбинация приводит к прорыву в сложных сеансах отладки.
Используйте терминал
Сначала попробуйте запустить исполняемый файл из терминала, чтобы увидеть весь вывод.
Не забудьте удалить флаг -w build, чтобы увидеть весь стандартный вывод в окне консоли. Часто вы увидите исключения ImportError, если зависимость отсутствует.
Файлы отладки
Проверьте файл build/cli/warn-cli.txt на наличие проблем. PyInstaller создает множество выходных данных, чтобы помочь вам понять, что именно он создает. Копание в папке build/ — отличное место для начала.
Используйте режим распространения —onedir для создания папки распространения вместо одного исполняемого файла. Опять же, это режим по умолчанию. Сборка с помощью —onedir дает вам возможность проверить все включенные зависимости вместо того, чтобы все было скрыто в одном исполняемом файле.
—onedir полезен для отладки, но —onefile обычно легче понять пользователям. После отладки вы можете переключиться в режим —onefile, чтобы упростить распространение.
Дополнительные параметры интерфейса командной строки
PyInstaller также имеет параметры для управления объемом информации, печатаемой в процессе сборки. Перестройте исполняемый файл с параметром —log-level=DEBUG в PyInstaller и просмотрите вывод.
PyInstaller создаст много вывода при увеличении детализации с помощью —log-level=DEBUG. Полезно сохранить этот вывод в файл, к которому вы можете обратиться позже, вместо того, чтобы прокручивать его в Терминале. Для этого вы можете использовать функцию перенаправления вашей оболочки. Вот пример:
$ pyinstaller --log-level=DEBUG cli.py 2> build.txt
Используя указанную выше команду, вы получите файл build.txt, содержащий множество дополнительных сообщений DEBUG.
Вот пример того, как может выглядеть ваш файл build.txt:
67 INFO: PyInstaller: 3.4 67 INFO: Python: 3.6.6 73 INFO: Platform: Darwin-18.2.0-x86_64-i386-64bit 74 INFO: wrote /Users/realpython/pyinstaller/reader/cli.spec 74 DEBUG: Testing for UPX ... 77 INFO: UPX is not available. 78 DEBUG: script: /Users/realptyhon/pyinstaller/reader/cli.py 78 INFO: Extending PYTHONPATH with paths ['/Users/realpython/pyinstaller/reader', '/Users/realpython/pyinstaller/reader']
В этом файле будет много подробной информации о том, что было включено в вашу сборку, почему что-то не было включено и как был упакован исполняемый файл.
Вы также можете перестроить свой исполняемый файл с помощью параметра —debug в дополнение к параметру —log-level для получения дополнительной информации.
Дополнительные документы PyInstaller
PyInstaller GitHub Wiki содержит множество полезных ссылок и советов по отладке. В первую очередь это разделы о том, , и что делать, если что-то пойдет не так.
Помощь в обнаружении зависимостей
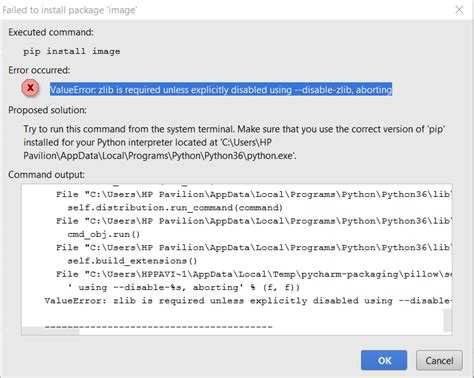
Наиболее частая проблема, с которой вы столкнетесь, — это исключения ImportError, если PyInstaller не может правильно определить все ваши зависимости. Как упоминалось ранее, это может произойти, если вы используете , импорт внутри функций или другие типы .
Многие из этих типов проблем можно решить с помощью —hidden-import параметр CLI PyInstaller. Это указывает PyInstaller включить модуль или пакет, даже если он не обнаруживает их автоматически. Это самый простой способ обойти множество магических действий динамического импорта в вашем приложении.
Другой способ обойти проблемы — файлы перехвата. Эти файлы содержат дополнительную информацию, которая поможет PyInstaller упаковать зависимость. Вы можете написать свои собственные хуки и указать PyInstaller использовать их с параметром CLI —additional-hooks-dir.
Файлы ловушек — это то, как сам PyInstaller работает внутри, поэтому вы можете найти множество примеров файлов ловушек в исходном коде PyInstaller.
Как создать пакет?
Предположим, вы хотите создать набор модулей для обработки музыкальных файлов. Взгляните на следующую структуру. Вот как вы организуете различные файлы в папке вашего пакета. В нашем случае папка пакета верхнего уровня – это «music»:
music/ Top-level package
__init__.py Initialize the music package
formats/ Subpackage for file conversions
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ Subpackage for sound effects
__init__.py
echo.py
surround.py
reverse.py
...
filters/ Subpackage for filters
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
Каждый пакет в Python должен иметь файл __init__.py, который гарантирует, что этот каталог будет рассматриваться как пакет.
Как правило, __init__.py может быть просто пустым файлом или исполняемым кодом инициализации для пакета или задавать переменную __all__, которая будет рассмотрена в последней части этого руководства.
Импортировать отдельный модуль из пакета можно любым из следующих способов.
import music.formats.wavwrite
Или:
from music.formats import wavwrite
Приведенные выше операторы загружают подмодуль music.formats.wavwrite.
Предположим, в модуле wavwrite.py есть функция с именем writeFile (aFileName), которая принимает имя файла в качестве аргумента, мы называем ее, как показано ниже:
import music.formats.wavwrite ... ... music.formats.wavwrite.writeFile(outputFileName)
Или, по-второму:
from music.formats import wavwrite ... ... wavwrite.writeFile(outputFileName)
Мы можем пойти еще глубже в операторе import, где мы импортируем только ту функцию, которая нам нужна. Вот пример того, как вы можете сделать то же самое:
from music.formats.wavwrite import writeFile ... ... writeFile(outputFileName)
Добавление файлов с данными, которые будут использоваться exe-файлом
Есть CSV-файл netflix_titles.csv, и Python-script, который считывает количество записей в нем. Теперь нужно добавить этот файл в бандл с исполняемым файлом. Файл Python-скрипта назовем просто simple1.py.
Копировать
Создадим исполняемый файл с данными в папке.
Параметр позволяет добавить файлы с данными, которые нужно сохранить в одном бандле с исполняемым файлом. Этот параметр можно применить много раз.
Синтаксис add-data:
- add-data <source;destination> — Windows.
- add-data <source:destination> — Linux.
Можно увидеть, что файл теперь добавляется в папку DIST вместе с исполняемым файлом.
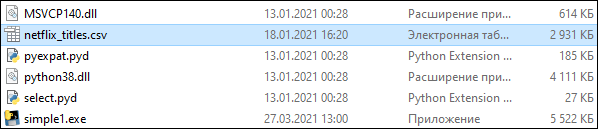
Также, открыв spec-файл, можно увидеть раздел datas, в котором указывается, что файл netflix_titles.csv копируется в текущую директорию.

Запустим файл simple1.exe, появится консоль с выводом: .
Как выполняются Python-скрипты?
Отличный способ представить, что происходит при выполнении Python-скрипта, — использовать диаграмму ниже. Этот блок представляет собой скрипт (или функцию) Python, а каждый внутренний блок — строка кода.
При запуске скрипта проходит сверху вниз, выполняя каждую из них. Именно таким образом происходит выполнение кода.
Но и это еще не все.
Блок-схема выполнения кода интерпретатором
- Шаг 1: скрипт или .py-файл компилируется, и из него генерируются бинарные данные. Готовый файл имеет расширение .pyc или .pyo.
- Шаг 2: генерируется бинарный файл. Он читается интерпретатором для выполнения инструкций.
Это набор инструкций, которые приводят к финальному результату.
Иногда полезно изучать байткод
Если вы планируете стать опытным Python-программистом, то важно уметь понимать его для написания качественного кода
Это также пригодится для принятия решений в процессе
Можно обратить внимание на отдельные факторы и понять, почему определенные функции/структуры данных работают быстрее остальных
Межсетевой экран
Важно ограничить доступ к нашему серверу. По этой причине настроим межсетевой экран:. Тут мы добавили наши службы http https ftp для доступности извне и ssh, но только для сети 192.168.0.0/28
Тут мы добавили наши службы http https ftp для доступности извне и ssh, но только для сети 192.168.0.0/28.
Подготовка площадки сборки
Подготовим саму площадку для сборки. Стоит отметить, что вернее всего сборку производить на отдельном виртуальном хосте, активно используя технологию snapshot’ов, но тут я опишу все в едином целом. Так же для сборки нужно выделить отдельного пользователя, не являющемся администратором (т.е. ему недоступно).
Второй пример: использование предварительно созданного виртуального окружения
Данный пример можно использовать во время изучения работы с библиотекой. Например, изучаем PySide2 и нам придется создать множество проектов. Создание для каждого проекта отдельного окружения довольно накладно. Это нужно каждый раз скачивать пакеты, также свободное место на локальных дисках ограничено.
Более практично заранее подготовить окружение с установленными нужными библиотеками. И во время создания проектов использовать это окружение.
В этом примере мы создадим виртуальное окружения PySide2, куда установим данную библиотеку. Затем создадим программу, использующую библиотеку PySide2 из предварительно созданного виртуального окружения. Программа будет показывать метку, отображающую версию установленной библиотеки PySide2.
Начнем с экран приветствия PyCharm. Для этого нужно выйти из текущего проекта. На экране приветствия в нижнем правом углу через Configure → Settings переходим в настройки. Затем переходим в раздел Project Interpreter. В верхнем правом углу есть кнопка с шестерёнкой, нажимаем на неё и выбираем Add…, создавая новое окружение. И указываем расположение для нового окружения. Имя конечной директории будет также именем самого окружения, в данном примере — . В Windows можно поменять в пути папку на , чтобы команда находила создаваемые в PyCharm окружения. Нажимаем на ОК.
Далее в созданном окружении устанавливаем пакет с библиотекой PySide2, также как мы устанавливали matplotlib. И выходим из настроек.
Теперь мы можем создавать новый проект использующий библиотеку PySide2. В окне приветствия выбираем Create New Project.
В мастере создания проекта, указываем имя расположения проекта в поле Location. Разворачиваем параметры окружения, щелкая по Project Interpreter, где выбираем Existing interpreter и указываем нужное нам окружение .
Для проверки работы библиотеки создаем файл со следующий кодом:
Далее создаем конфигурацию запуска программы, также как создавали для первого примера. После чего можно выполнить программу.
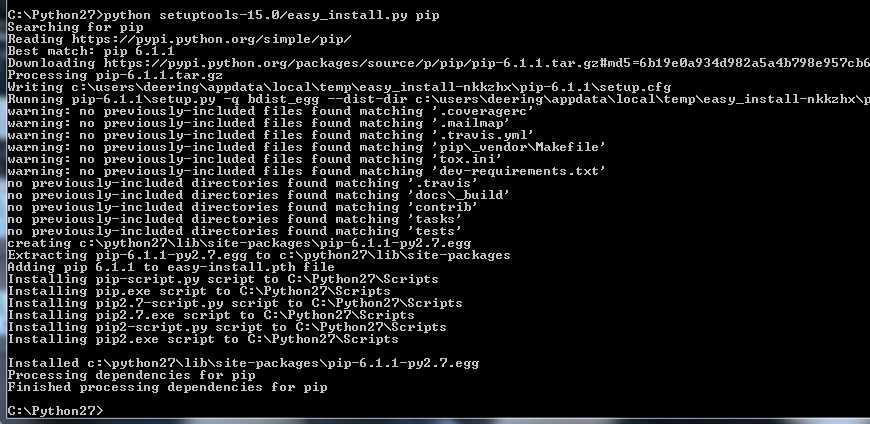
Применение easy_install
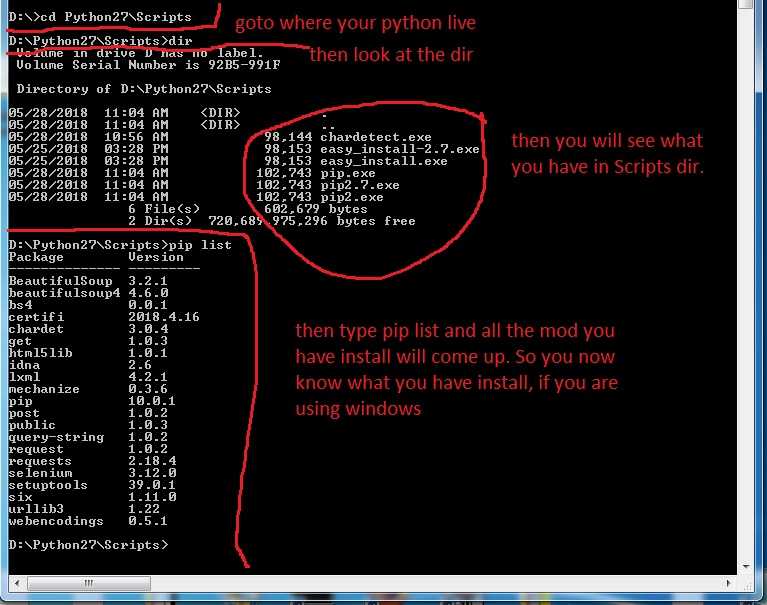
После установки setuptools, вы можете использовать easy_install. Вы можете найти его в папке с установочными скриптами Python. Не забудьте добавить папку со скриптами в путь вашей системы, чтобы вы в дальнейшем смогли вызывать easy_install в командной строке, без указания его полного пути. Попробуйте выполнить запустить следующую команду, чтобы узнать больше об опциях easy_install:
Python
easy_install -h
| 1 | easy_install -h |
Если вам нужно начать установку пакета при помощи easy_install, вам нужно сделать следующее:
Python
easy_install package_name
| 1 | easy_install package_name |
easy_install попытается скачать пакет с PyPI, скомпилировать его (если нужно) и установить его. Если вы зайдете в свою директорию site-packages, вы найдете файл под названием easy-install.pth, который содержит доступ ко всем пакетам, установленным через easy_install. Python использует этот файл, чтобы помочь в импорте модуля или пакета. Вы также можете указать easy_install на установку через URL или через путь на вашем компьютере. easy_install также может выполнить установку прямиком из файла tar. Вы можете использовать easy_install для обновления пакета, воспользовавшись функцией upgrade (или–U). И наконец, вы можете использовать easy_install для установки файла egg файлов. Вы можете найти эти файлы в PyPI, или в других источниках. Файлы egg – это особые zip файлы. На самом деле, если вы измените расширение на .zip, вы можете разархивировать файл egg.
Вот несколько примеров:
Python
easy_install -U SQLAlchemy
easy_install http://example.com/path/to/MyPackage-1.2.3.tgz
easy_install /path/to/downloaded/package



|
1 2 3 |
easy_install -U SQLAlchemy easy_install http://example.com/path/to/MyPackage-1.2.3.tgz easy_install /path/to/downloaded/package |
Существует несколько проблем с easy_install. Он может попробовать установить пакет, пока он еще загружается. При помощи easy_install нельзя деинсталлировать пакет. Вам придется удалить пакет вручную и обновить файл easy-install.pth, удалив доступ к пакету. По этой, и многим другим причинам, в сообществе Python создали pip.
Подключение к терминалу по SSH
В верхнем правом углу выберите Account -> Account. Так вы попадёте в дашборд аккаунта, где можно загрузить свой ключ SSH.
Тут же нажмите на “SSH keys” и после этого на “Download”.
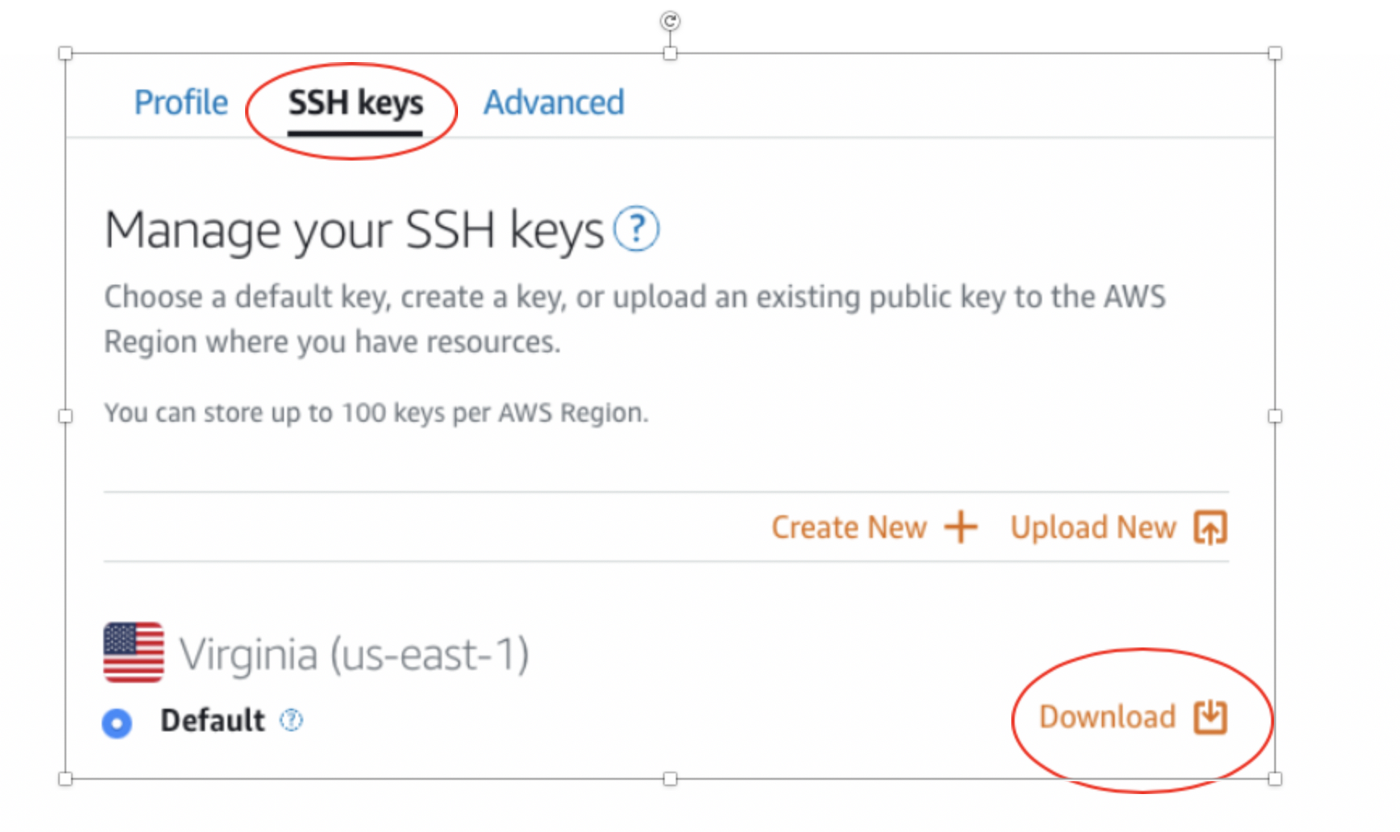
На вашем локальном компьютере пройдите в ~/.ssh при помощи команды cd ~/.ssh.
cd ~/.ssh
- Скопируйте загруженный ключ в это место.
- Чтобы проверить, был ли скопирован ключ в нужное место, выполните команду ls, она выводит все файлы списком. Такой способ сработает только в ОС семейства Unix.
ls

Чтобы подключиться по SSH, выполните следующую команду:
ssh -i ~/.ssh/lightsail.pem -T ubuntu@{your_lightsail_IP_address}
Адрес моего Ubuntu-сервера 18.213.119.58. Для подключения я воспользуюсь следующими командами

Во время первого подключения вы увидите вот такое сообщение:

Выберите “Yes”, чтобы подключиться к вашему Ubuntu-инстансу.
Как подключитесь, увидите следующее:
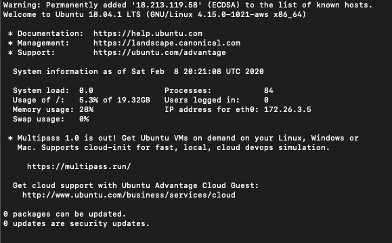
И веб-подключение по SSH, и локальное подключение к терминалу с SSH валидны и работают. Просто это я предпочитаю подключение через терминал.





