
Введение
Для установки и настройки файлового сервера samba можно воспользоваться одной из моих статей:
- Настройка файлового сервера Samba с интеграцией в Active Directory
- Быстрая и простая настройка samba
Дальнейшее описание подойдет для обоих случаев. И для интеграции с AD, и для одиночного сервера с авторизацией по IP или имени пользователя.
Для того, чтобы samba записывала в лог все операции с файлами, необходимо настроить логирование. Как это сделать я рассказал уже давно в отдельной статье — настройка логов доступа в samba. Дальше в статье я буду считать, что у вас настроено примерно так же. Формат логов очень важен, так как ниже я предложу свой вариант grok фильтра для парсинга.
Введение
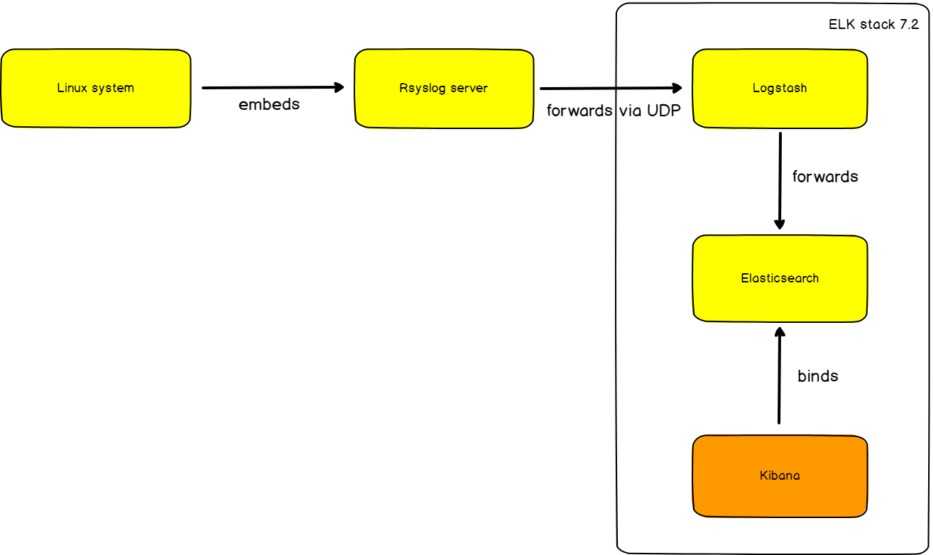
Ранее я рассказал, как установить и настроить elk stack, потом как загружать и анализировать логи nginx и samba. Теперь пришел черед логов Mikrotik. Я уже рассказывал, как отправлять логи микротика на удаленный syslog сервер, в качестве которого может выступать в том числе syslog-ng. В данном случае на самом микротике ничего особенного делать не надо. Будем точно так же отправлять данные на удаленный syslog сервер, в качестве которого будет трудиться logstash.
Я некоторое время рассуждал на тему парсинга и разбора логов. Но посмотрев на типичную картину стандартных логов mikrotik, понял, что ничего не выйдет. События очень разные и разобрать их одним правилом grok не получится. Если нужен парсинг и добавление метаданных к событиям, необходимо определенные события выделять и направлять отдельным потоком в logstash, где уже обрабатывать своим фильтром. Например, отдельный фильтр можно настроить на парсинг подключений к vpn или подключение по winbox с анализом имен пользователей.
Я же буду просто собирать все логи скопом и складывать в единый индекс. У записей не будет метаданных, по которым можно строить дашборды и анализировать данные. Но тем не менее, это все равно удобно, так как все логи в одном месте с удобным и быстрым поиском.
Kibana
Переходим на страницу загрузки Kibana и скачиваем ссылку на последнюю вервию пакета RPM:
… и скачиваем по ней пакет для установки kibana:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.3.2-x86_64.rpm
Устанавливаем приложение:
rpm -ivh kibana-*
Открываем на редактирование конфигурационный файл:
vi /etc/kibana/kibana.yml
Редактируем параметр host:
server.host: 192.168.1.10
* в данном примере мы говорим, что сервер должен слушать на интерфейсе 192.168.1.10.
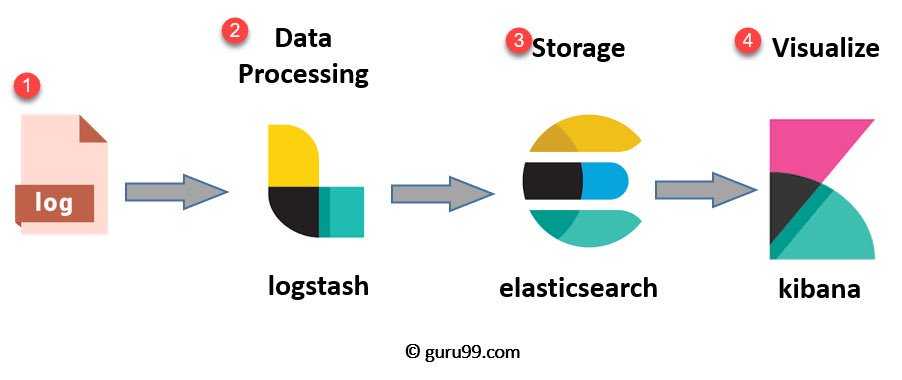
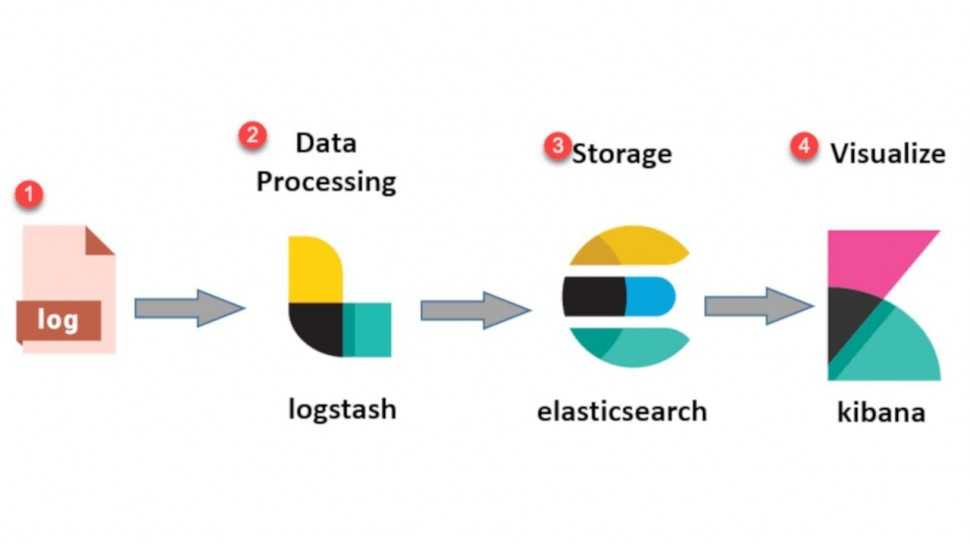

Разрешаем автозапуск Kibana и запускаем ее:
systemctl enable kibana
systemctl start kibana
Мы должны увидеть страницу приветствия с заголовком «Welcome to Kibana».
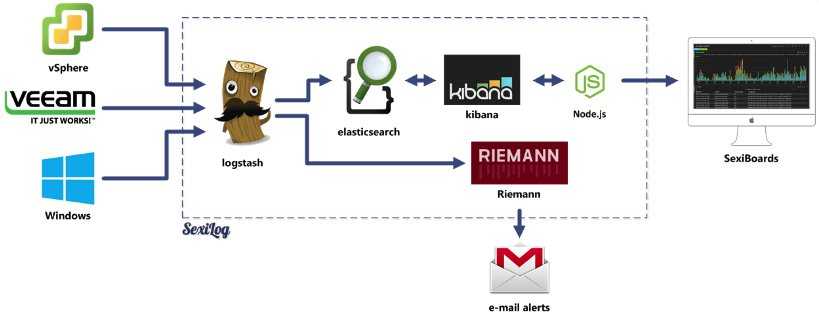
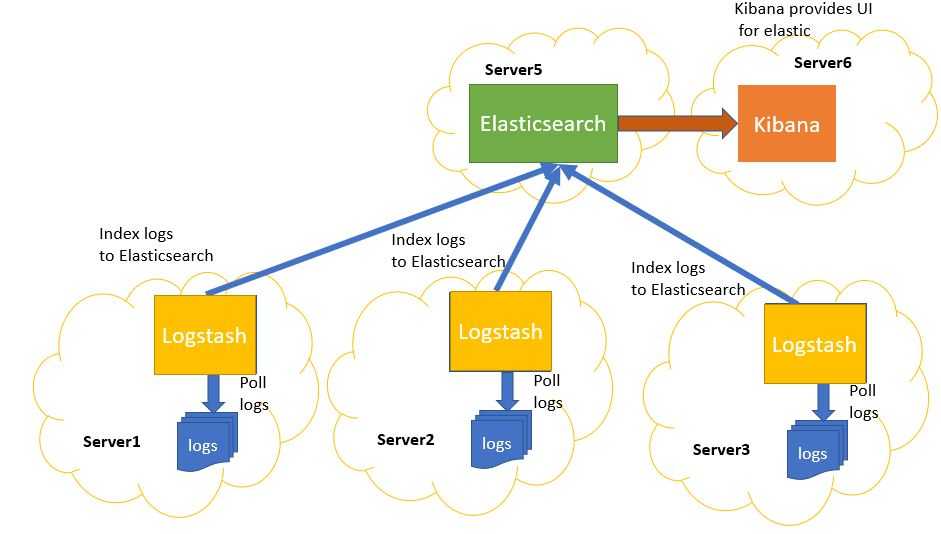
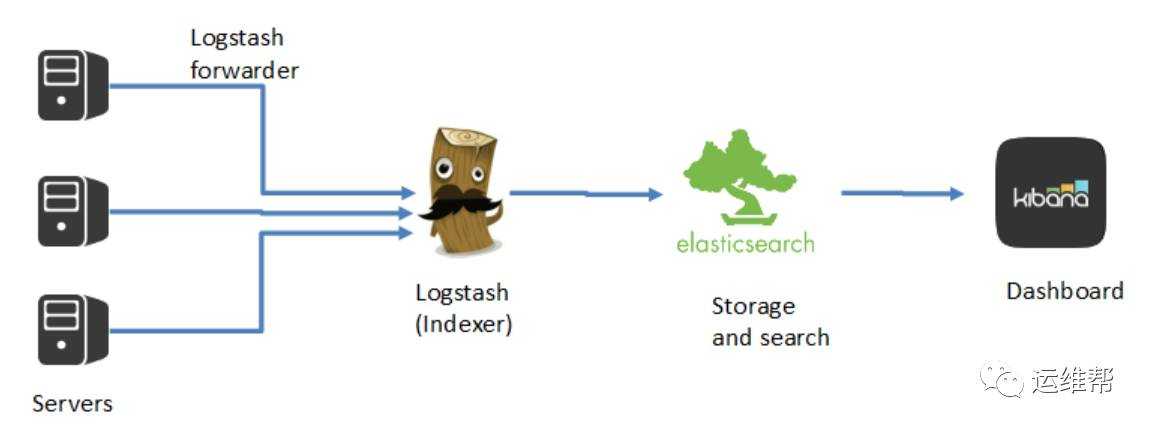
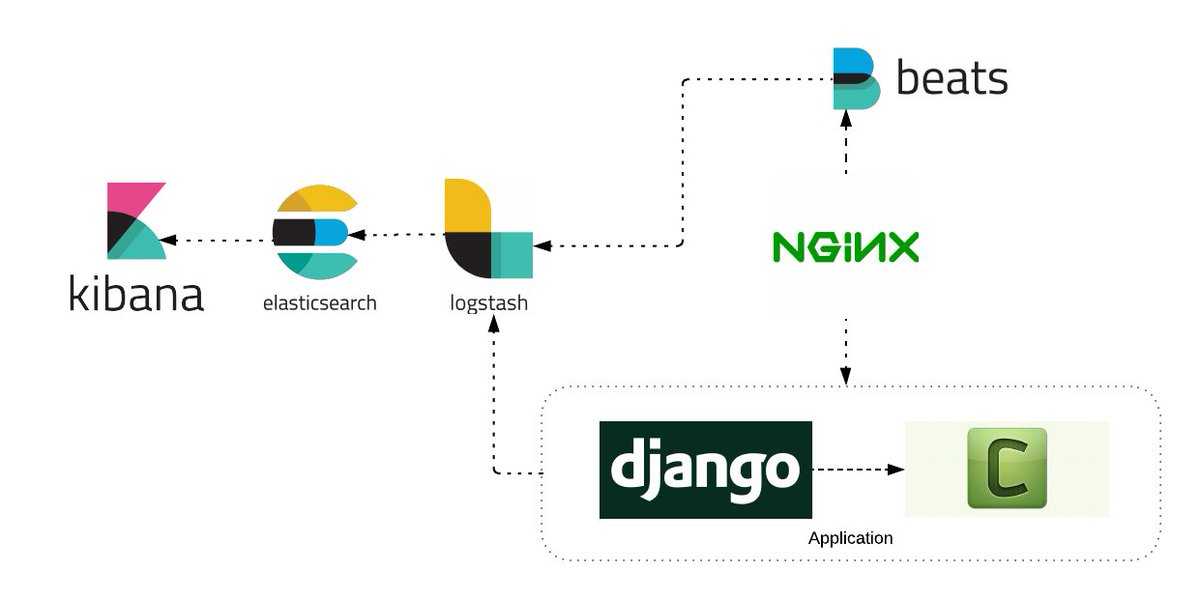
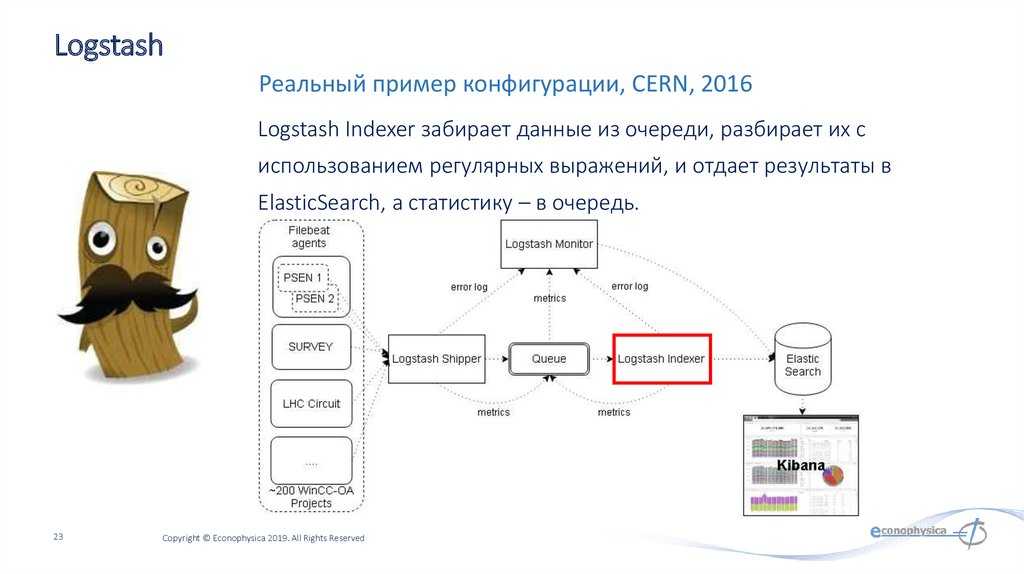
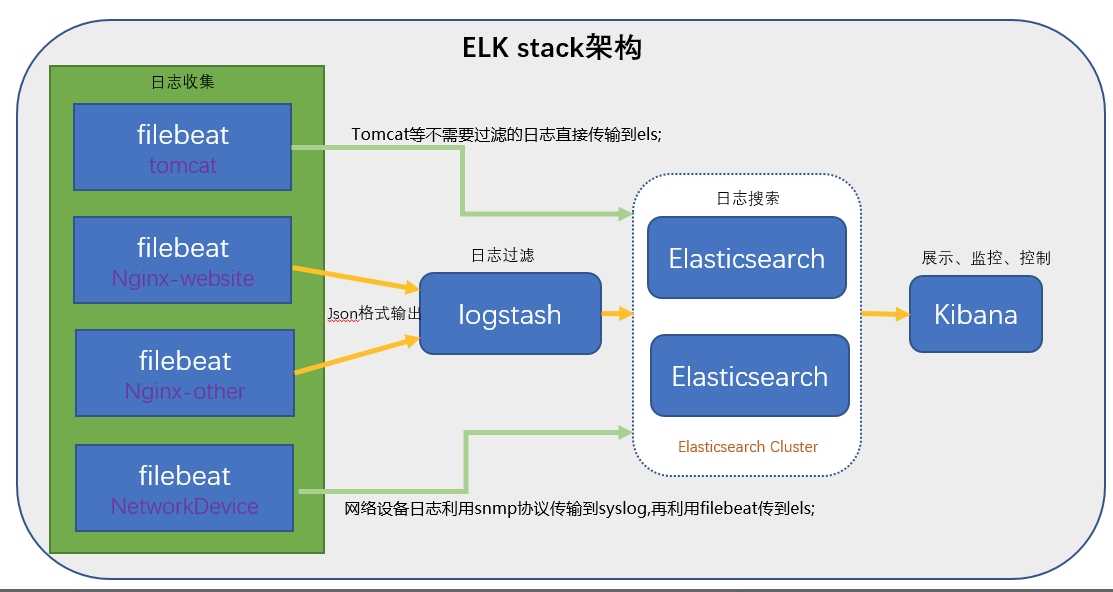
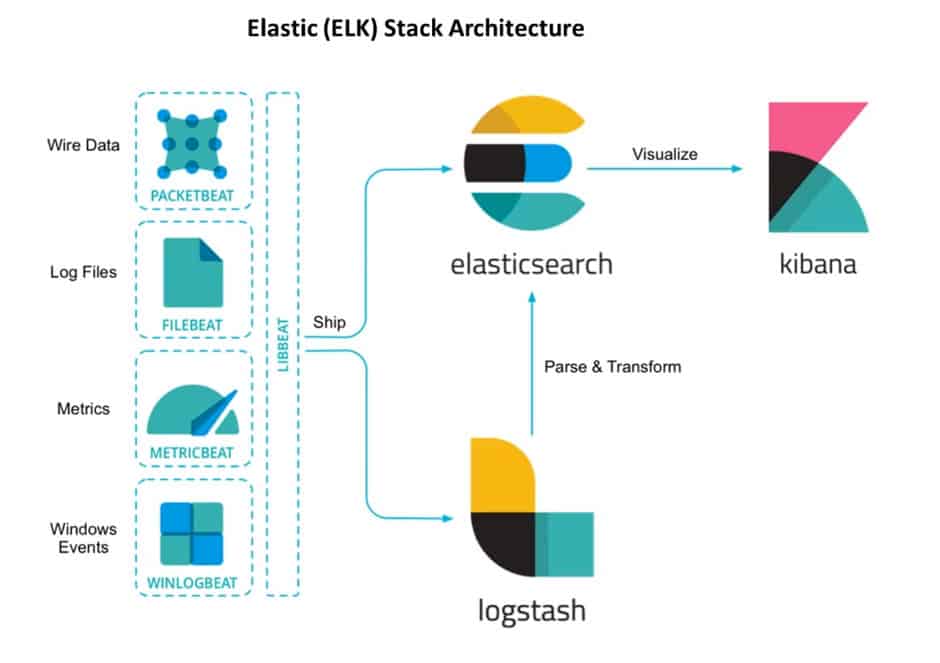
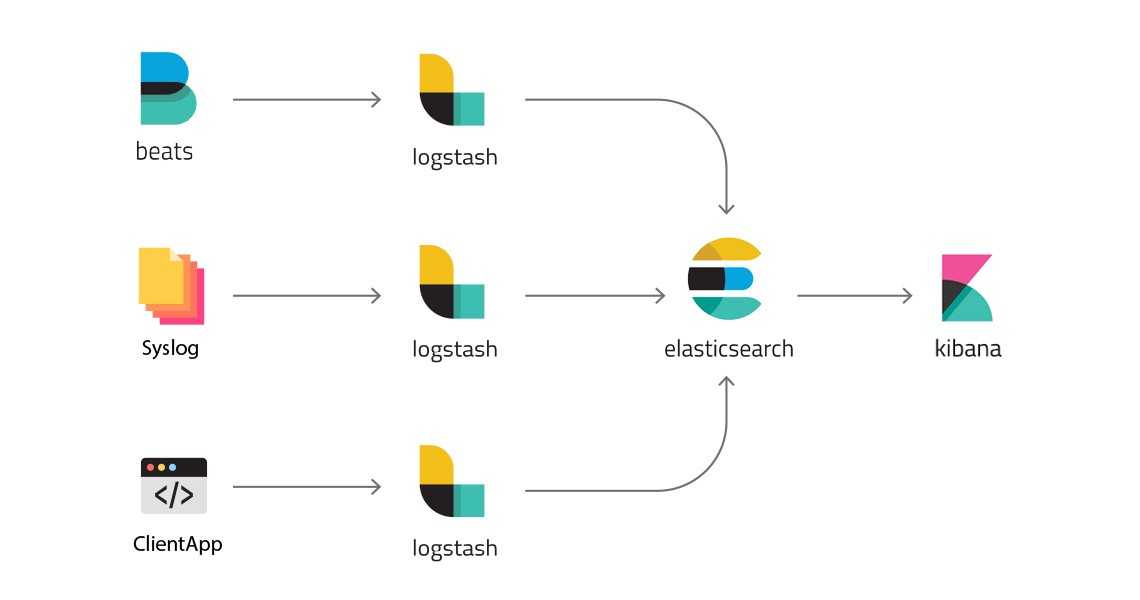
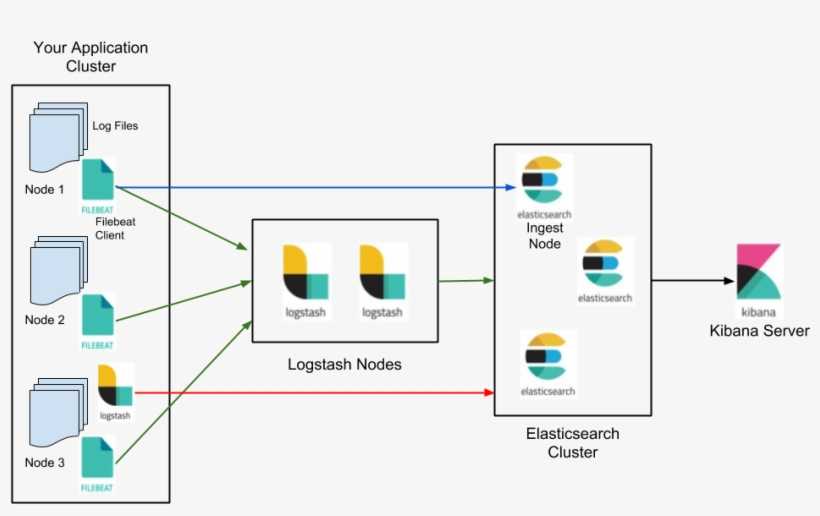
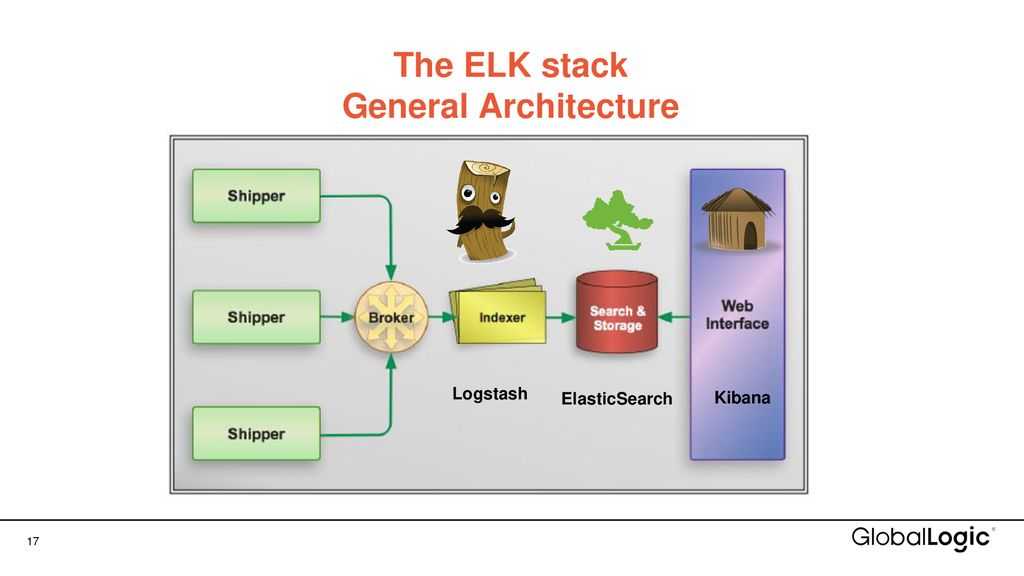
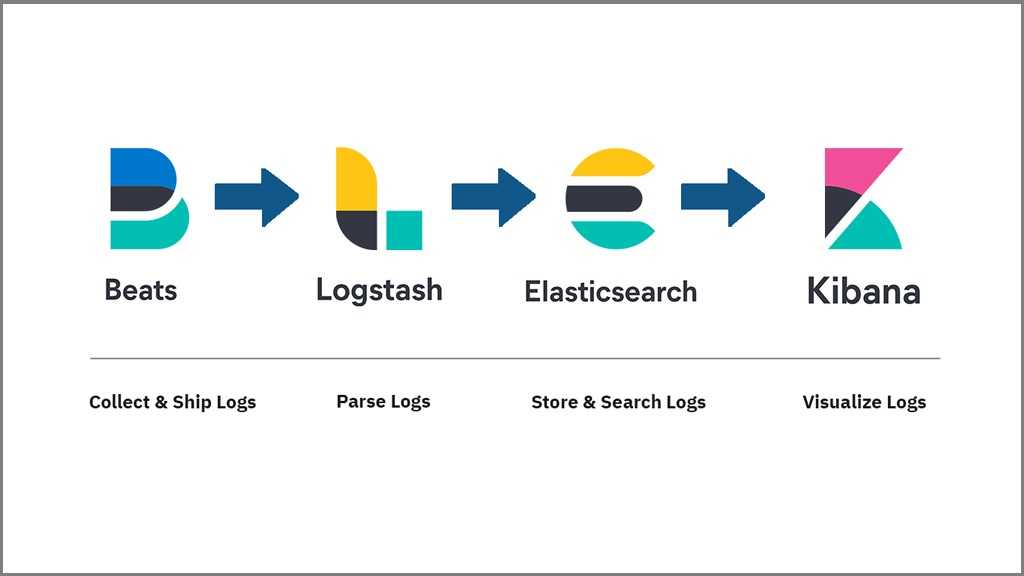
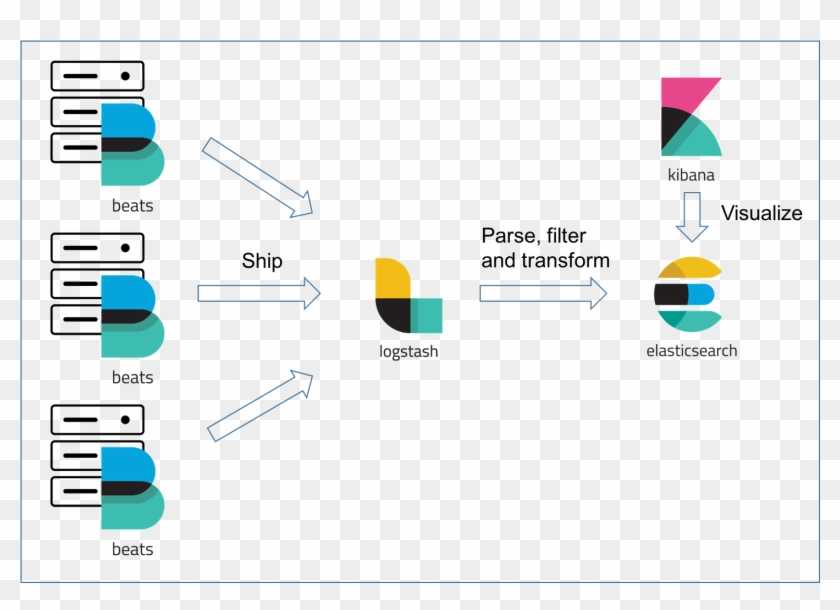
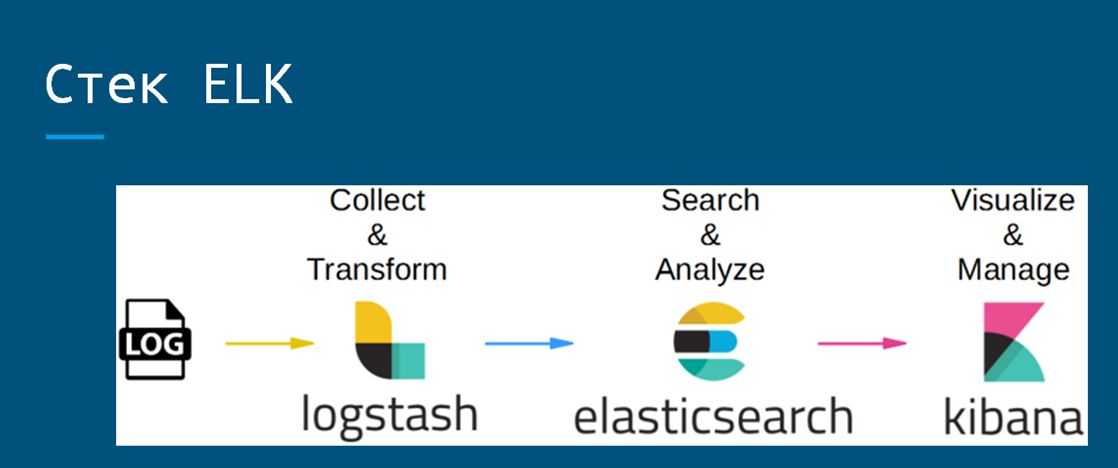
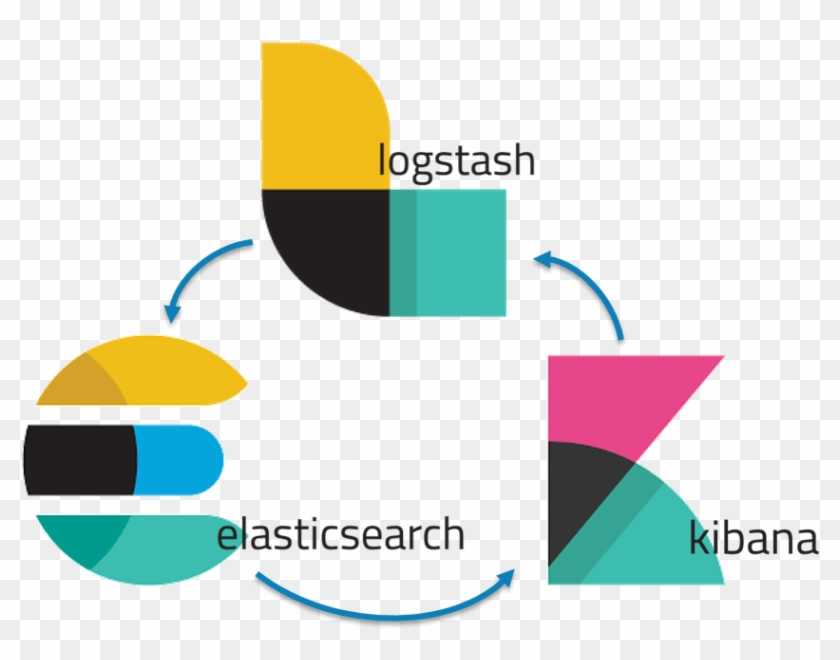
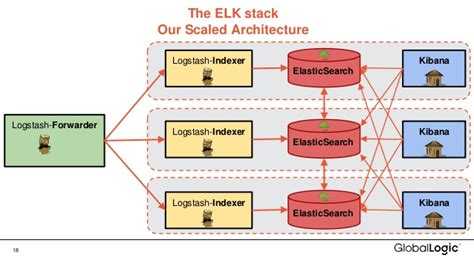
Что внутри ELK-системы: архитектура и принципы работы
Инфраструктура ELK включает следующие компоненты :
- Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных. Как правило, ES используется в качестве NoSQL-базы данных для приложений со сложными функциями поиска. Elasticsearch основана на библиотеке Apache Lucene, предназначенной для индексирования и поиска информации в любом типе документов. В масштабных Big Data системах несколько копий Elasticsearch объединяются в кластер .
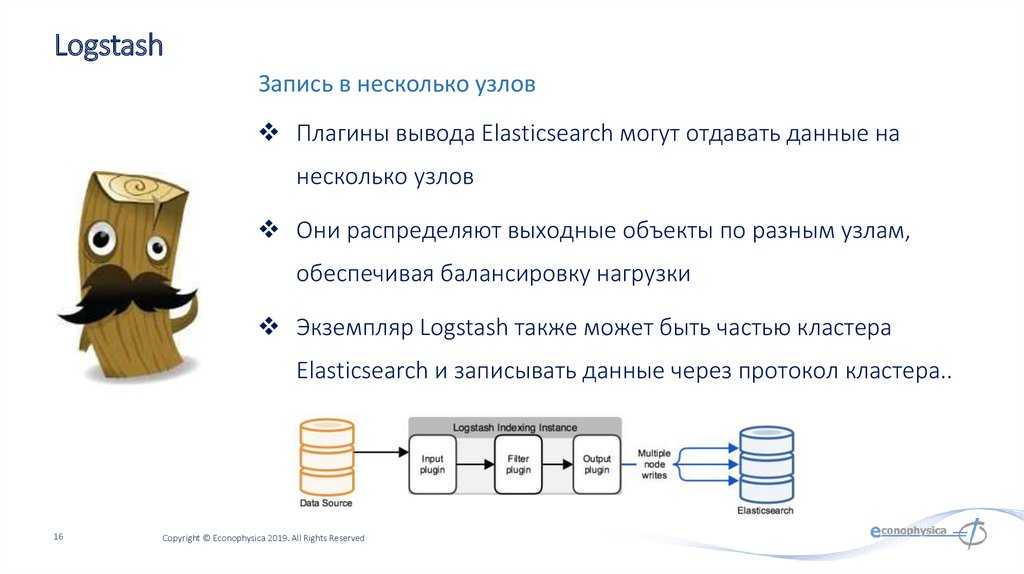
- Logstash — средство сбора, преобразования и сохранения в общем хранилище событий из файлов, баз данных, логов и других источников в реальном времени. Logsatsh позволяет модифицировать полученные данные с помощью фильтров: разбить строку на поля, обогатить или их, агрегировать несколько строк, преобразовать их в JSON-документы и пр. Обработанные данные Logsatsh отправляет в системы-потребители.
- Kibana – визуальный инструмент для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в индексах ES. Веб-интерфейс Kibana позволяет быстро создавать и обмениваться динамическими панелями мониторинга, включая таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени. Примечательно, что изначально Kibana была ориентирована на работу с Logstash, а не на Elasticsearch. Однако, с интеграцией 3-х систем в единую ELK-платформу, Kibana стала работать непосредственно с ES .
- FileBeat – агент на серверах для отправки различных типов оперативных данных в Elasticsearch.
В рамках единой ELK-платформы все вышеперечисленные компоненты взаимодействуют следующим образом :
- Logstash представляет собой конвейер обработки данных (data pipeline) на стороне сервера, который одновременно получает данные из нескольких источников, включая FileBeat. Здесь выполняется первичное преобразование, фильтрация, агрегация или парсинг логов, а затем обработанные данные отправляется в Elasticsearch.
- Elasticsearch играет роль ядра всей системы, сочетая функции базы данных, поискового и аналитического движков. Быстрый и гибкий поиск обеспечивается за счет анализаторов текста, нечеткого поиска, поддержки восточных языков (корейский, китайский, японский). Наличие REST API позволяет добавлять, просматривать, модифицировать и удалять данные .
- Kibana позволяет визуализировать данные ES, а также администрировать базу данных.
Принцип работы ELK-инфраструктуры: как взаимодействуют Elasticsearch, Logstash и Kibana
Завтра мы рассмотрим главные достоинства и недостатки ELK-инфраструктуры. А как эффективно использовать их для сбора и анализа больших данных в реальных проектах, вы узнаете на практических курсах по администрированию и эксплуатации Big Data систем в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков) в Москве.
Смотреть расписание
Записаться на курс
Источники
- https://www.softlab.ru/blog/technologies/5816/
- https://ru.bmstu.wiki/Elastic_Logstash
- https://system-admins.ru/elk-o-chem-i-zachem/
- http://samag.ru/archive/article/3575
What is an Elasticsearch cluster?
As the name implies, an Elasticsearch cluster is a group of one or more Elasticsearch nodes instances that are connected together. The power of an Elasticsearch cluster lies in the distribution of tasks, searching and indexing, across all the nodes in the cluster.
The nodes in the Elasticsearch cluster can be assigned different jobs or responsibilities:
- Data nodes — stores data and executes data-related operations such as search and aggregation
- Master nodes — in charge of cluster-wide management and configuration actions such as adding and removing nodes
- Client nodes — forwards cluster requests to the master node and data-related requests to data nodes
- Ingest nodes — for pre-processing documents before indexing
- *Note: Tribe nodes, which were similar to cross-cluster or federated nodes, were deprecated with Elasticsearch 5.4
By default, each node is automatically assigned a unique identifier, or name, that is used for management purposes and becomes even more important in a multi-node, or clustered, environment.
When installed, a single Elasticsearch node will form a new single-node cluster entitled “elasticsearch,” but as we shall see later on in this article it can also be configured to join an existing cluster using the cluster name. Needless to say, these nodes need to be able to identify each other to be able to connect.
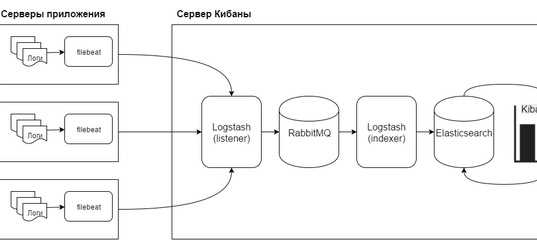
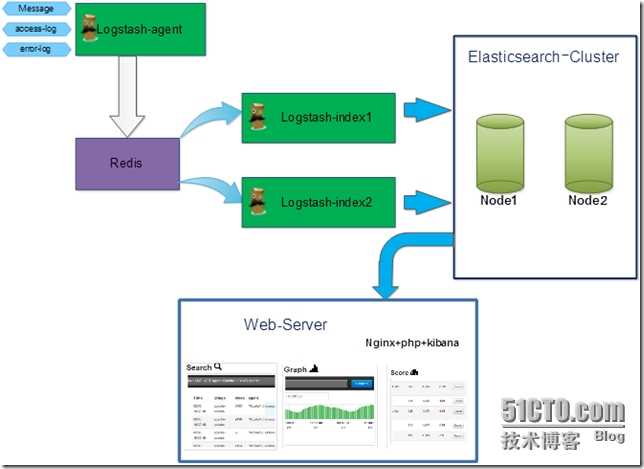
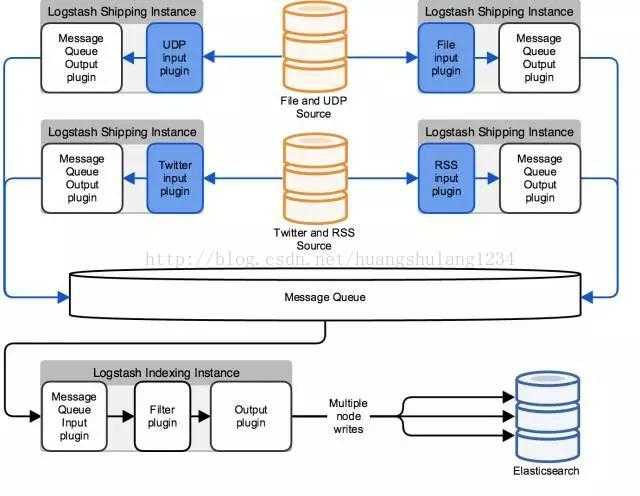
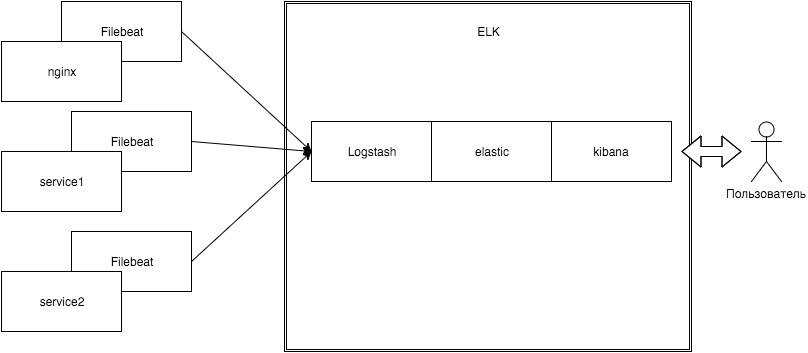
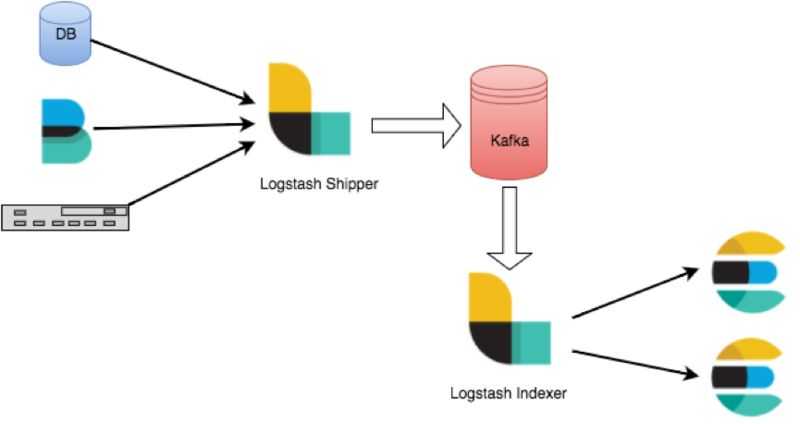
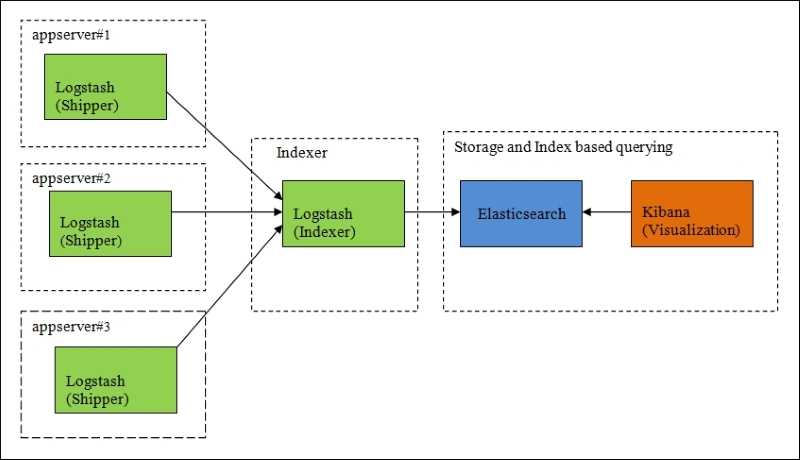
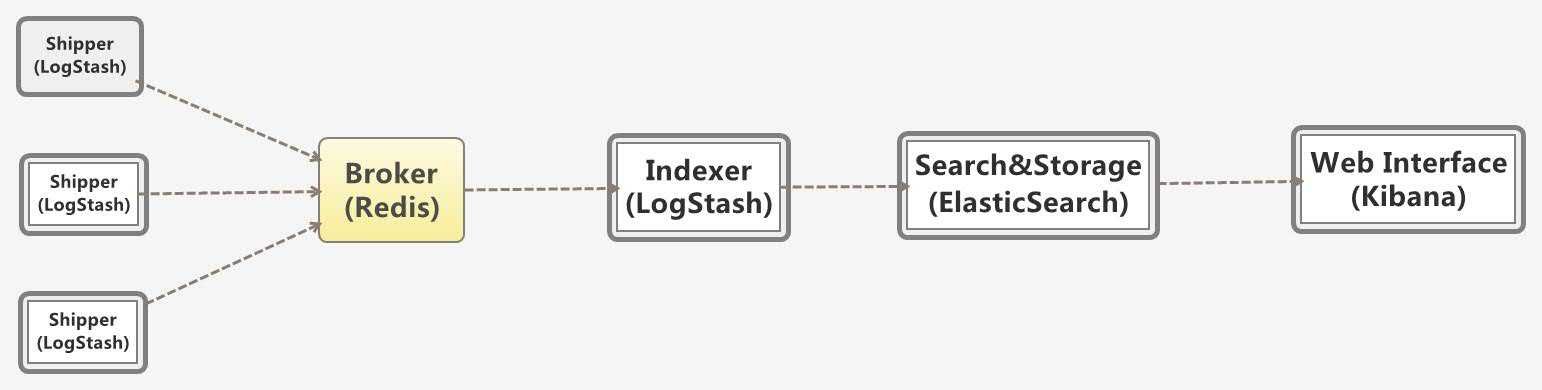
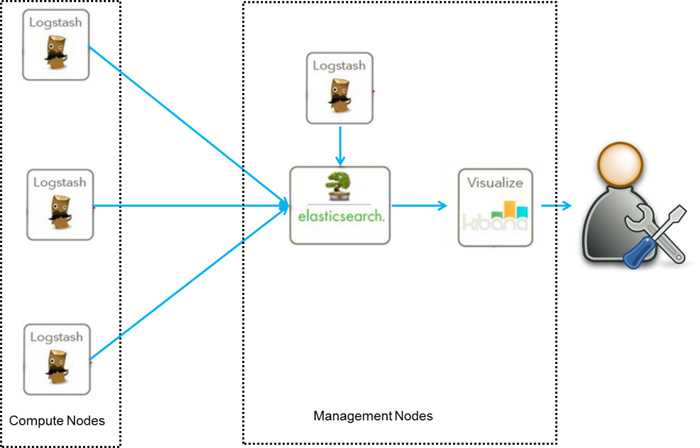
Logspout + ELK собирать логи
2.1 Установка Docker ELK
- файл конфигурации logstash
Объяснение конфигурации: конфигурация logstash разделена на три части:
- input: input, то есть поток ввода файла, который может быть передан через tcp, udp или может быть получен только из каталога. Конфигурация файла заключается в чтении содержимого указанного каталога (здесь не настраивается); конфигурация tcp зависит от разных машин logspout нужно проталкивать логи через tcp;
- filter: фильтрация; gork конвертирует нестандартные журналы в стандартизованные
- output: output, вы можете указать индекс вывода
- Настроить файл docker compose лося
- Установить образ ELK использоватьКоманда построить зеркало; Процесс сборки может завершиться неудачно, и его придется повторить несколько раз; Запустить и использовать
2.2 Установите logspout
- Установите logspout на другие машины
Среди них используйте syslog + tcp для отправки собранных файлов журнала в logstash;
- Вид интерфейса Посещение:http: // ip хоста kibana: 5601 / Вы можете увидеть интерфейс кибаны; Для первого посещения вам необходимо создать индекс: Если в elasticsearch есть индекс, он будет таким, как показано на рисунке ниже, введите logstash- * в поле ввода имени индекса и нажмитеКнопку, выберите, А затем щелкните Создать указатель, а затем щелкните в строке менюВы увидите информацию журнала: (ps: разные версии, интерфейс, который вы видите, может отличаться)
- Укажите контейнер для сбора logspout по умолчанию собирает журналы всех контейнеров на хосте. Однако иногда нам нужно собирать журналы только некоторых контейнеров. Есть два способа решить эту проблему:
Когда каждый контейнер запускается, добавьте переменные средыLOGSPOUT=ignore, Такие как настройки в ELK выше, официальный пример:
Чтобы указать, какие контейнеры включать при запуске logspout, вы можете обратиться к методу, представленному в официальном документе:https://github.com/gliderlabs/logspout
Я использовал второй метод, изменил файл docker-compose logspout выше и добавил его при отправке сообщения в конце
Контейнер, который должен собирать логи, суффикс нужно задать при запускеПсевдоним, вы можете отслеживать журнал контейнера;
Другие параметры фильтра:
Обратите внимание на формулировку запятой; Если существует несколько пунктов назначения маршрутизации, их можно разделить запятыми
What is Elasticsearch?
Elasticsearch is a NoSQL database. It is based on Lucene search engine, and it is built with RESTful APIS. It offers simple deployment, maximum reliability, and easy management. It also offers advanced queries to perform detail analysis and stores all the data centrally. It is helpful for executing a quick search of the documents.

Elasticsearch also allows you to store, search and analyze big volume of data. It is mostly used as the underlying engine to powers applications that completed search requirements. It has been adopted in search engine platforms for modern web and mobile applications. Apart from a quick search, the tool also offers complex analytics and many advanced features.
Features of Elastic search:
- Open source search server is written using Java
- Used to index any kind of heterogeneous data
- Has REST API web-interface with JSON output
- Full-Text Search
- Near Real Time (NRT) search
- Sharded, replicated searchable, JSON document store
- Schema-free, REST & JSON based distributed document store
- Multi-language & Geolocation support
Advantages of Elasticsearch
- Store schema-less data and also creates a schema for your data
- Manipulate your data record by record with the help of Multi-document APIs
- Perform filtering and querying your data for insights
- Based on Apache Lucene and provides RESTful API
- Provides horizontal scalability, reliability, and multitenant capability for real time use of indexing to make it faster search
- Helps you to scale vertically and horizontally
Important Terms used in Elastic Search
Now in this ELK tutorial, let’s learn about key terms used in ElasticSearch:
| Term | Usage |
|---|---|
| Cluster | A cluster is a collection of nodes which together holds data and provides joined indexing and search capabilities. |
| Node | A node is an elasticsearch Instance. It is created when an elasticsearch instance begins. |
| Index | An index is a collection of documents which has similar characteristics. e.g., customer data, product catalog. It is very useful while performing indexing, search, update, and delete operations. It allows you to define as many indexes in one single cluster. |
| Document | It is the basic unit of information which can be indexed. It is expressed in JSON (key: value) pair. ‘{«user»: «nullcon»}’. Every single Document is associated with a type and a unique id. |
| Shard | Every index can be split into several shards to be able to distribute data. The shard is the atomic part of an index, which can be distributed over the cluster if you want to add more nodes. |
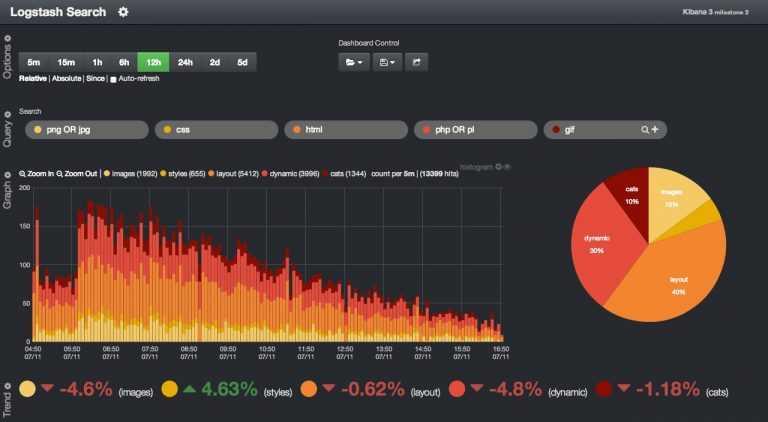
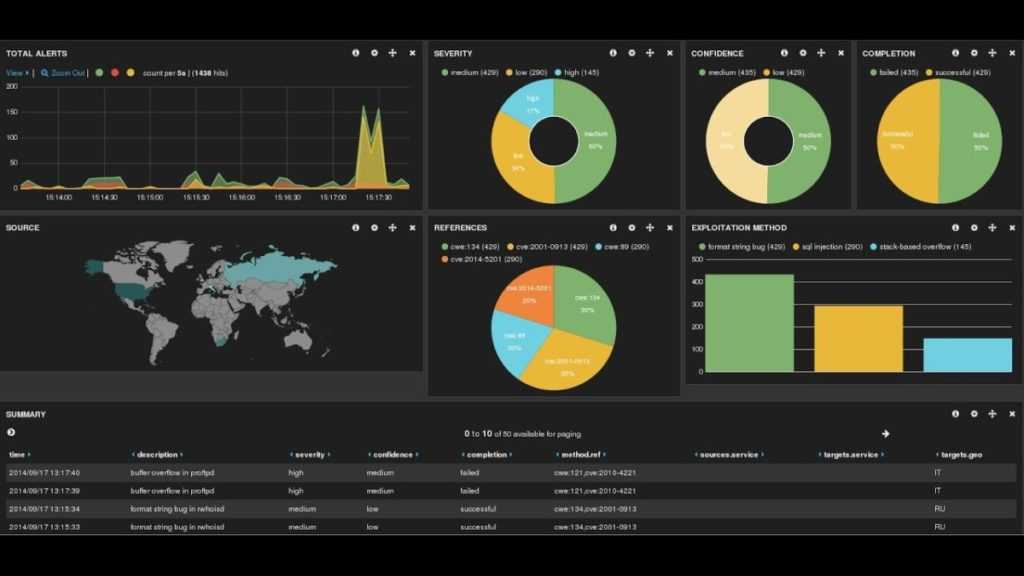
Шаг 5 — Изучение информационных панелей Kibana
Давайте получше познакомимся с веб-интерфейсом Kibana, который мы установили на одном из предыдущих шагов.
Откройте в браузере FQDN или публичный IP-адрес вашего сервера Elastic Stack. После ввода учетных данных, заданных на шаге 2, вы увидите главную страницу Kibana:
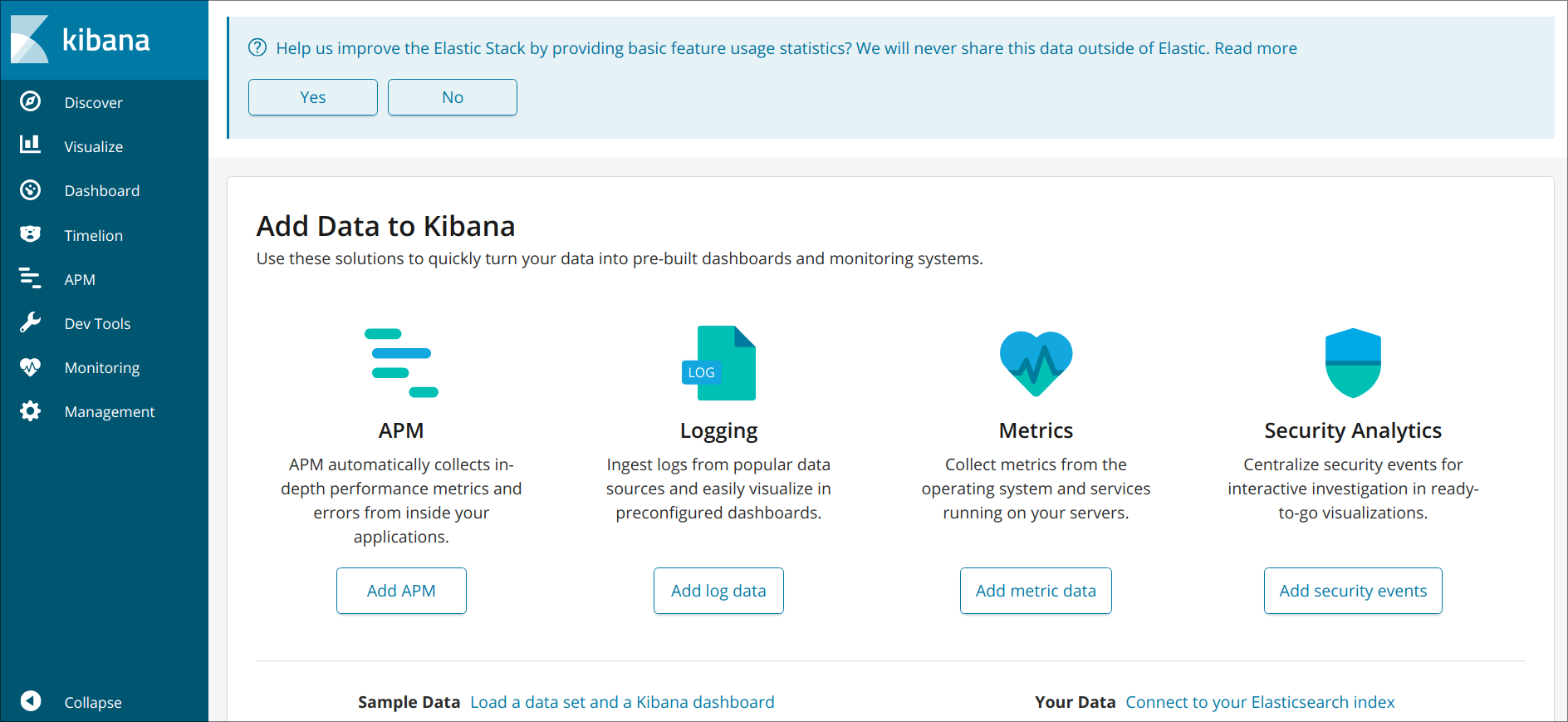
Нажмите ссылку Discover в левой панели навигации для обзора интерфейса. Выберите на странице Discover заранее настроенный индекс filebeat- для просмотра данных Filebeat. По умолчанию при этом будут выведены все данные журналов за последние 15 минут. Ниже вы увидите гистограмму с событиями журнала и некоторыми сообщениями журнала:
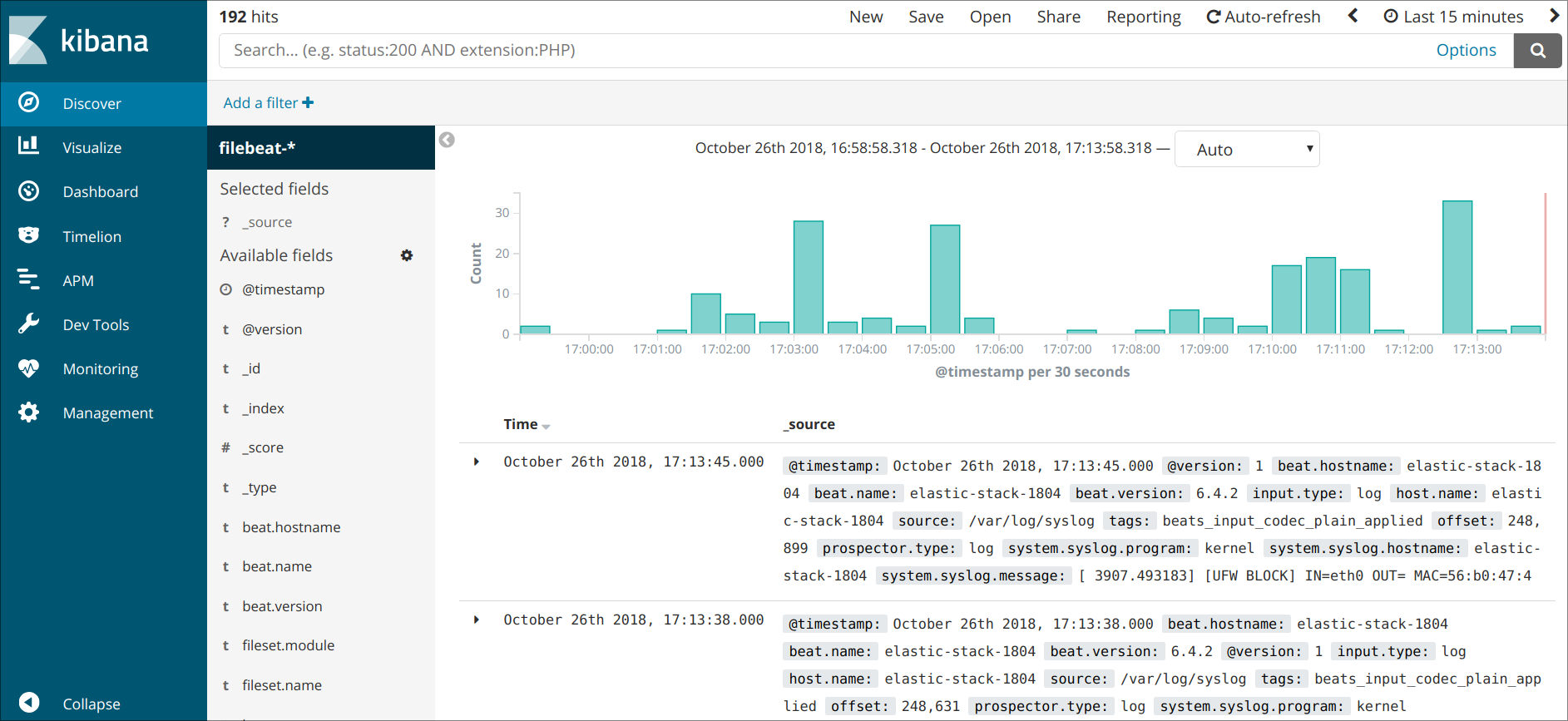
Здесь вы можете искать и просматривать журналы, а также настраивать информационные панели. Сейчас на этой странице будет немного данных, потому что вы собираете системные журналы только со своего сервера Elastic Stack.
Используйте левую панель навигации для перехода на страницу Dashboard и выполните на этой странице поиск информационных панелей Filebeat System. На этой странице вы можете искать образцы информационных панелей, входящих в комплектацию модуля в Filebeat.
Например, вы можете просматривать подробную статистику по сообщениям системного журнала:
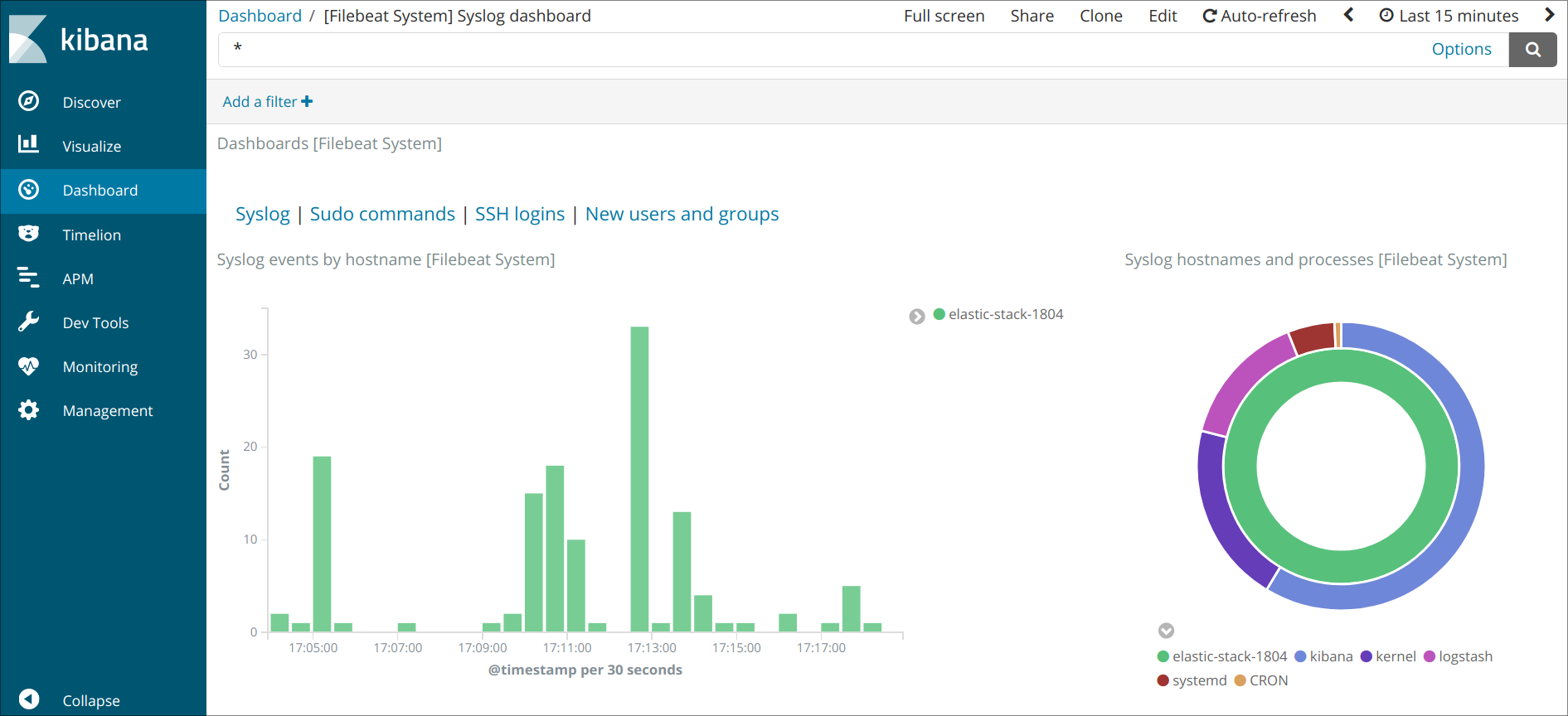
Также вы сможете видеть, какие пользователи использовали команду и когда:
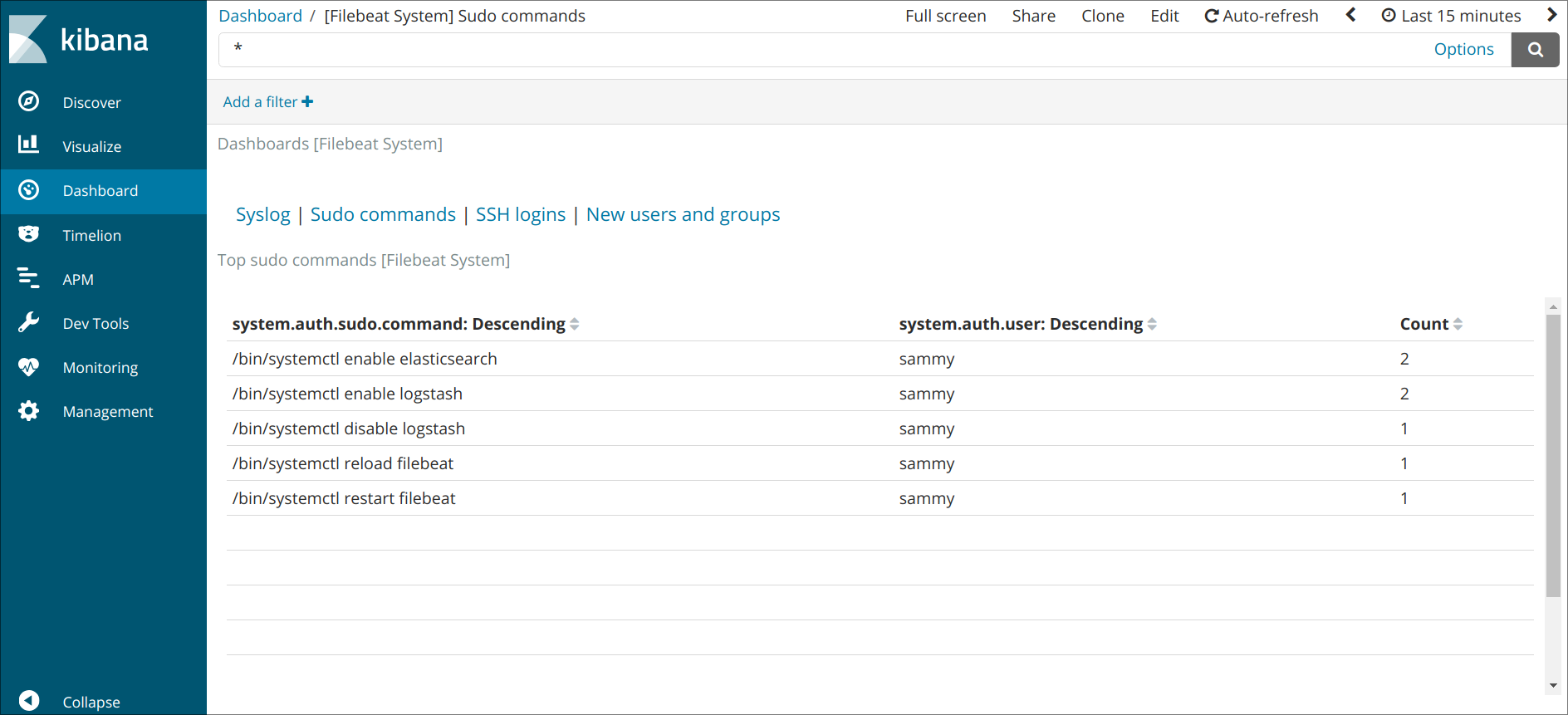
В Kibana имеется множество других функций, в том числе функции фильтрации и составления диаграмм, так что вы можете свободно их исследовать.
Восстановление etcd из снапшота
Здесь мы рассмотрим кейс когда всё пошло не так и нам потребовалось восстановить кластер из резервной копии.
У нас есть снапшот snap1.db сделанный на предыдущем этапе. Теперь давайте полностью удалим static-pod для etcd и данные со всех наших нод:
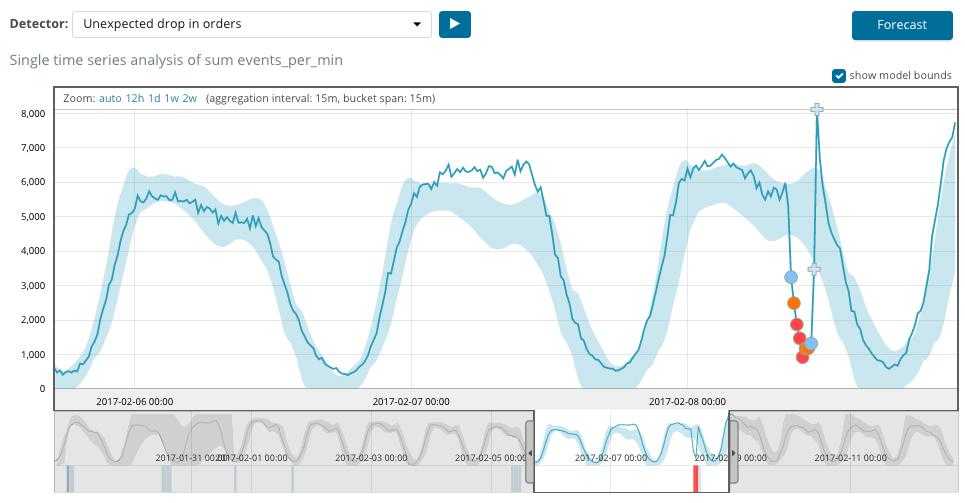
Теперь у нас снова есть два пути:
Вариант первый создать etcd-кластер из одной ноды и присоединить к нему остальные ноды, по описанной выше процедуре.
эта команда сгенерирует статик-манифест для etcd c опциями:
таким образом мы получим девственно чистый etcd на одной ноде.
Восстановим бэкап на первой ноде:
На остальных нодах выполним присоединение к кластеру:
Вариант второй: восстановить бэкап сразу на всех нодах кластера. Для этого копируем файл снапшота на остальные ноды, и выполняем восстановление вышеописанным образом. В данном случае в опциях к etcdctl нам потребуется указать сразу все ноды нашего кластера, к примеру
для node1:
для node2:
для node3:
Потеря кворума
Иногда случается так что мы потеряли большинство нод из кластера и etcd перешёл в неработоспособное состояние. Удалить или добавить новых мемберов у вас не получится, как и создать снапшот.
Выход из этой ситуации есть. Нужно отредактировать файл static-манифеста и добавить ключ к etcd:
после чего инстанс etcd перезапустится в кластере с единственным экземпляром:
Кратко про конфигурационные файлы
- Networks и volumes были взяты из исходного docker-compose.yml (тот где целиком стек запускается) и думаю, что сильно здесь на общую картинку не влияют.
- Мы создаём один сервис (services) logstash, из образа docker.elastic.co/logstash/logstash:6.3.2 и присваиваем ему имя logstash_one_channel.
- Мы пробрасываем внутрь контейнера порт 5046, на такой же внутренний порт.
- Мы отображаем наш файл настройки каналов ./config/pipelines.yml на файл /usr/share/logstash/config/pipelines.yml внутри контейнера, откуда его подхватит logstash и делаем его read-only, просто на всякий случай.
- Мы отображаем директорию ./config/pipelines, где у нас лежат файлы с настройками каналов, в директорию /usr/share/logstash/config/pipelines и тоже делаем её read-only.
logstash_one_channel | Unable to retrieve license information from license server {:message=>«Elasticsearch Unreachable: [http://elasticsearch:9200/]logstash_one_channel | Pipeline started successfully logstash_one_channel | logstash_one_channel | X-Pack is installed on Logstash but not on Elasticsearch. Please install X-Pack on Elasticsearch to use the monitoring feature. Other features may be available.logstash_one_channel | logstash_one_channel | ogstash_one_channel | Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/] elasticsearch»}logstash_one_channel | logstash_one_channel | Attempted to resurrect connection to dead ES instance, but got an error. {:url=>«elasticsearch:9200/», :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>«Elasticsearch Unreachable: [http://elasticsearch:9200/] elasticsearch»}elasticsearch
Шаг 2 — Установка и настройка информационной панели Kibana
Согласно официальной документации, Kibana следует устанавливать только после установки Elasticsearch. Установка в этом порядке обеспечивает правильность установки зависимостей компонентов.

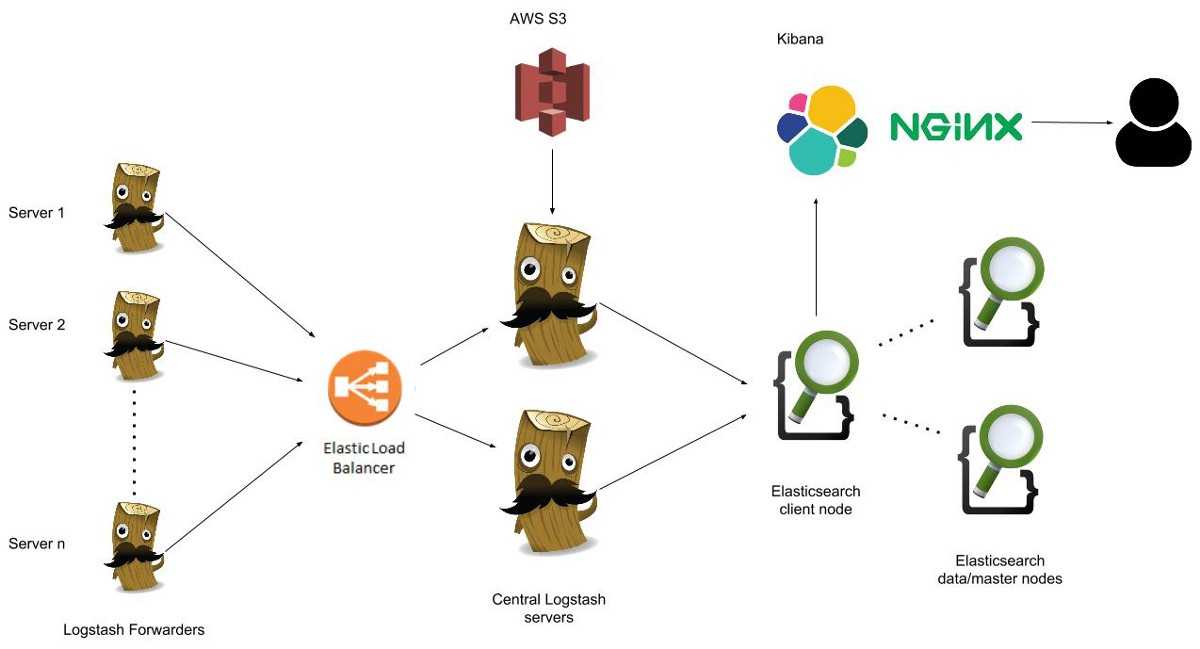
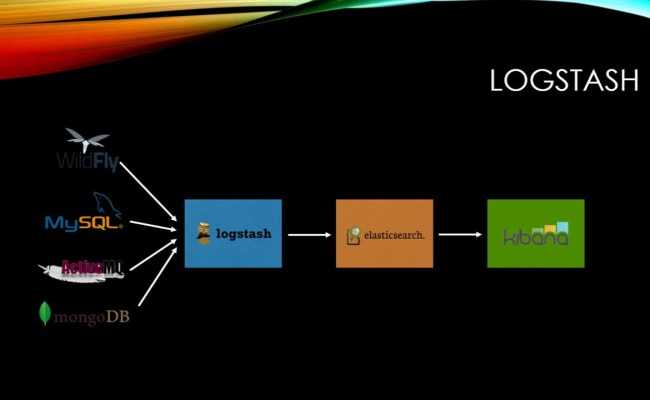
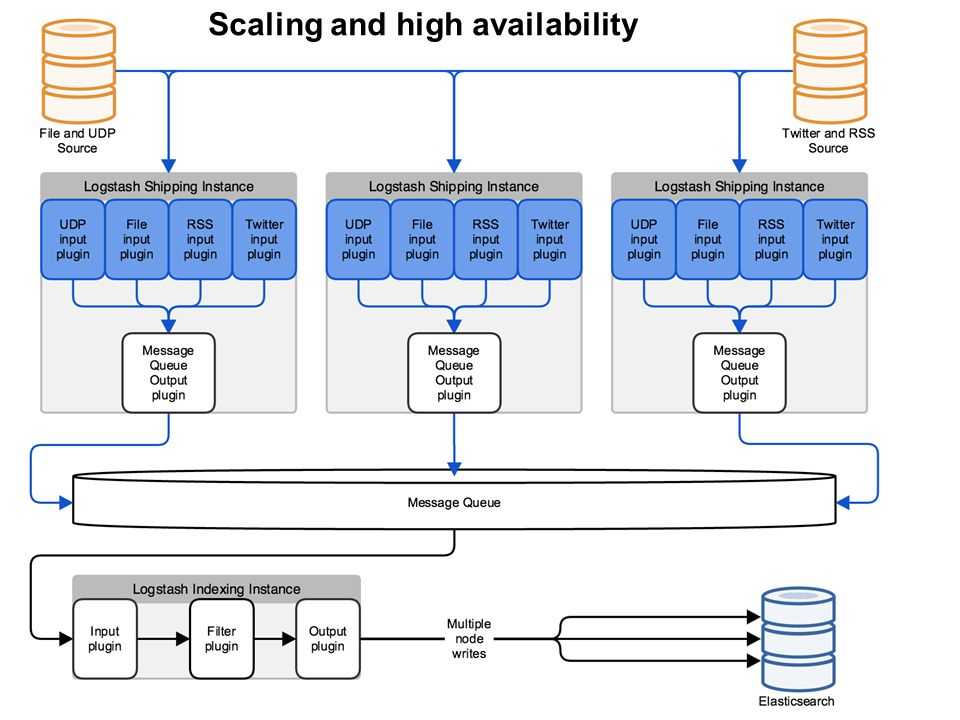
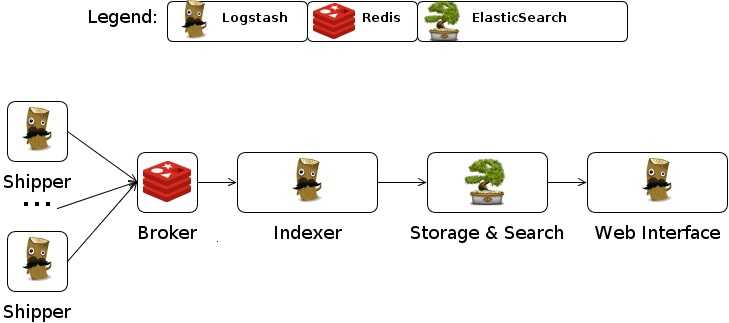
Поскольку вы уже добавили источник пакетов Elastic на предыдущем шаге, вы можете просто установить все остальные компоненты комплекса Elastic с помощью apt:
Затем активируйте и запустите службу Kibana:
Поскольку согласно настройкам Kibana прослушивает только localhost, мы должны задать , чтобы разрешить внешний доступ. Для этого мы используем Nginx, который должен быть уже установлен на вашем сервере.
Вначале нужно использовать команду openssl для создания административного пользователя Kibana, которого вы будете использовать для доступа к веб-интерфейсу Kibana. Для примера мы назовем эту учетную запись kibanaadmin, однако для большей безопасности мы рекомендуем выбрать нестандартное имя пользователя, которое будет сложно угадать.
Следующая команда создаст административного пользователя Kibana и пароль и сохранит их в файле htpasswd.users. Вы настроите Nginx для использования этого имени пользователя и пароля и моментально прочитаете этот файл:
Введите и подтвердить пароль в диалоговом окне. Запомните или запишите эти учетные данные, поскольку они вам потребуются для доступа к веб-интерфейсу Kibana.
Теперь мы создадим файл серверного блока Nginx. В качестве примера мы присвоим этому файлу имя your_domain, хотя вы можете дать ему более описательное имя. Например, если вы настроили записи FQDN и DNS для этого сервера, вы можете присвоить этому файлу имя своего FQDN:
Создайте файл серверного блока Nginx, используя nano или предпочитаемый текстовый редактор:
Добавьте в файл следующий блок кода и обязательно замените your_domain на FQDN или публичный IP-адрес вашего сервера. Этот код настраивает Nginx для перенаправления трафика HTTP вашего сервера в приложение Kibana, которое прослушивает порт localhost:5601. Также он настраивает Nginx для чтения файла htpasswd.users и требует использования базовой аутентификации.
Если вы выполнили предварительный обучающий модуль по Nginx до конца, возможно вы уже создали этот файл и заполнили его. В этом случае удалите из файла все содержание и добавьте следующее:
/etc/nginx/sites-available/your_domain
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file etcnginxhtpasswd.users;
location {
proxy_pass httplocalhost5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Завершив редактирование, сохраните и закройте файл.
Затем активируйте новую конфигурацию, создав символическую ссылку на каталог sites-enabled. Если вы уже создали файл серверного блока с тем же именем, что и в обучающем модуле по Nginx, вам не нужно выполнять эту команду:
Затем проверьте конфигурацию на синтаксические ошибки:
Если в результатах будут показаны какие-либо ошибки, вернитесь и еще раз проверьте правильность изменений в файле конфигурации. Когда вы увидите на экране результатов сообщение syntax is ok, перезапустите службу Nginx:
Если вы следовали указаниям модуля по начальной настройке сервера, у вас должен быть включен брандмауэр UFW. Чтобы разрешить соединения с Nginx, мы можем изменить правила с помощью следующей команды:
Примечание. Если вы выполнили предварительный обучающий модуль Nginx, вы могли уже создать правило UFW, разрешающее профилю Nginx HTTP доступ через брандмауэр. Поскольку профиль Nginx Full разрешает трафик HTTP и HTTPS на брандмауэре, вы можете безопасно удалить ранее созданное правило. Для этого нужно использовать следующую команду:

Теперь приложение Kibana доступно через FQDN или публичный IP-адрес вашего сервера комплекса Elastic. Вы можете посмотреть страницу состояния сервера Kibana, открыв следующий адрес и введя свои учетные данные в диалоге:
http://your_domain/status
На этой странице состояния отображается информация об использовании ресурсов сервера, а также выводится список установленных плагинов.
Примечание. Как указывалось в разделе предварительных требований, рекомендуется включить на сервере SSL/TLS. Теперь вы можете следовать указаниями обучающего модуля по Let’s Encrypt для получения бесплатного сертификата SSL для Nginx в Ubuntu 20.04. После получения сертификата SSL/TLS вы можете вернуться и завершить прохождение этого обучающего модуля.
Теперь информационная панель Kibana настроена и мы перейдем к установке следующего компонента: Logstash.





