Отказоустойчивый кластер
Настроим автоматический перезапуск виртуальных машин на рабочих нодах, если выйдет из строя сервер.
Для настройки отказоустойчивости (High Availability или HA) нам нужно:
- Минимум 3 ноды в кластере. Сам кластер может состоять из двух нод и более, но для точного определения живых/не живых узлов нужно большинство голосов (кворумов), то есть на стороне рабочих нод должно быть больше одного голоса. Это необходимо для того, чтобы избежать ситуации 2-я активными узлами, когда связь между серверами прерывается и каждый из них считает себя единственным рабочим и начинает запускать у себя все виртуальные машины. Именно по этой причине HA требует 3 узла и выше.
- Общее хранилище для виртуальных машин. Все ноды кластера должны быть подключены к общей системе хранения данных — это может быть СХД, подключенная по FC или iSCSI, NFS или распределенное хранилище Ceph или GlusterFS.
1. Подготовка кластера
Процесс добавления 3-о узла аналогичен процессу, — на одной из нод, уже работающей в кластере, мы копируем данные присоединения; в панели управления третьего сервера переходим к настройке кластера и присоединяем узел.
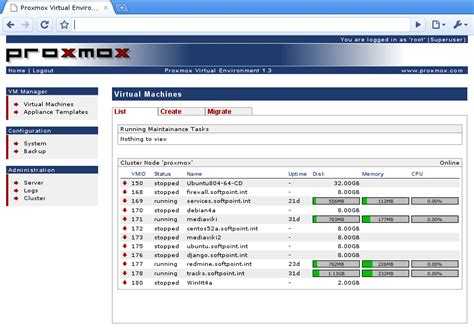
2. Добавление хранилища
Подробное описание процесса настройки самого хранилища выходит за рамки данной инструкции. В данном примере мы разберем пример и использованием СХД, подключенное по iSCSI.
Если наша СХД настроена на проверку инициаторов, на каждой ноде смотрим командой:
cat /etc/iscsi/initiatorname.iscsi
… IQN инициаторов. Пример ответа:
…
InitiatorName=iqn.1993-08.org.debian:01:4640b8a1c6f
* где iqn.1993-08.org.debian:01:4640b8a1c6f — IQN, который нужно добавить в настройках СХД.
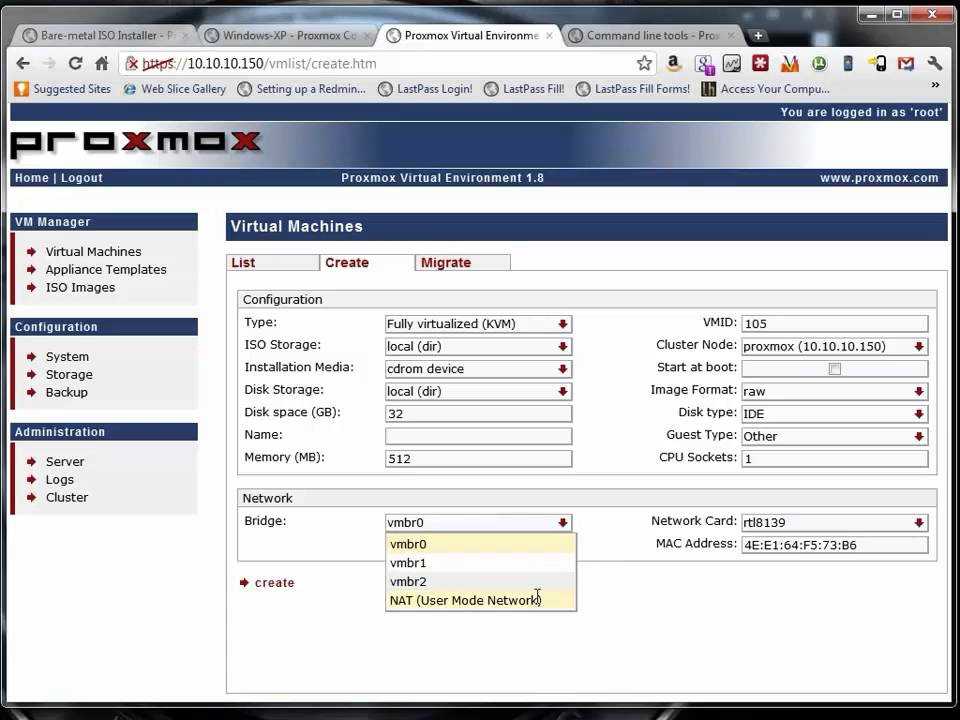
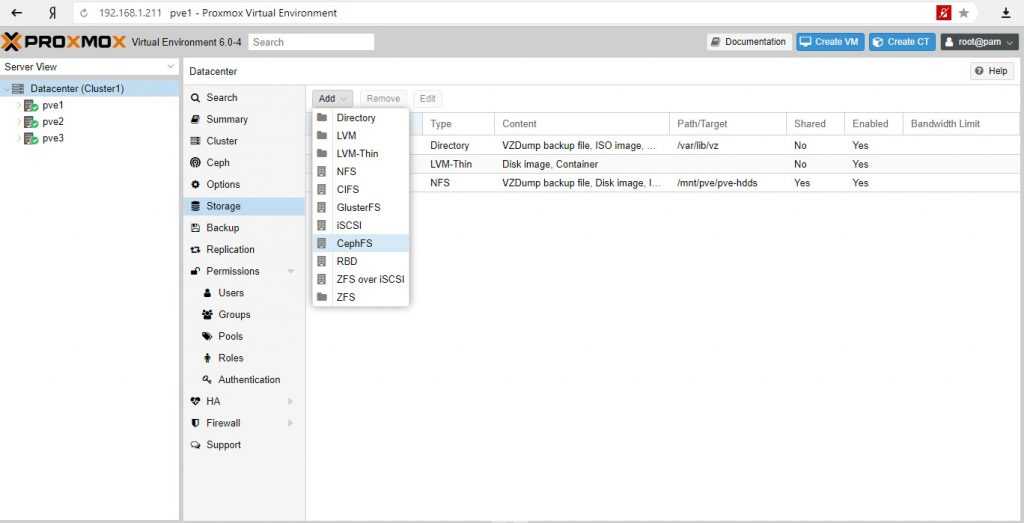
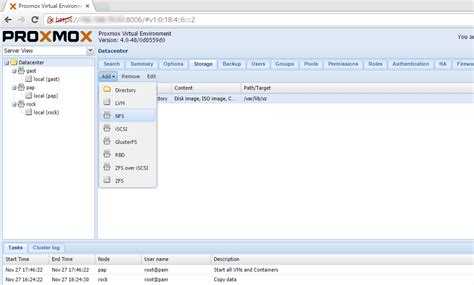
После настройки СХД, в панели управления Proxmox переходим в Датацентр — Хранилище. Кликаем Добавить и выбираем тип (в нашем случае, iSCSI):
В открывшемся окне указываем настройки для подключения к хранилке:
* где ID — произвольный идентификатор для удобства; Portal — адрес, по которому iSCSI отдает диски; Target — идентификатор таргета, по которому СХД отдает нужный нам LUN.
Нажимаем добавить, немного ждем — на всех хостах кластера должно появиться хранилище с указанным идентификатором. Чтобы использовать его для хранения виртуальных машин, еще раз добавляем хранилище, только выбираем LVM:
Задаем настройки для тома LVM:
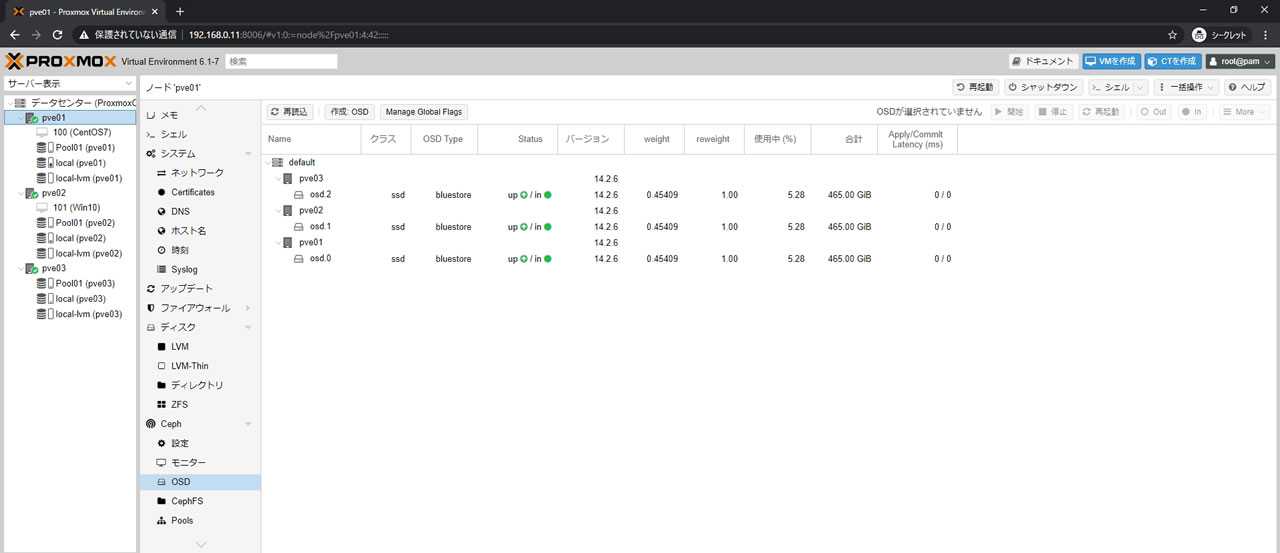
* где было настроено:
- ID — произвольный идентификатор. Будет служить как имя хранилища.
- Основное хранилище — выбираем добавленное устройство iSCSI.
- Основное том — выбираем LUN, который анонсируется таргетом.
- Группа томов — указываем название для группы томов. В данном примере указано таким же, как ID.
- Общедоступно — ставим галочку, чтобы устройство было доступно для всех нод нашего кластера.
Нажимаем Добавить — мы должны увидеть новое устройство для хранения виртуальных машин.
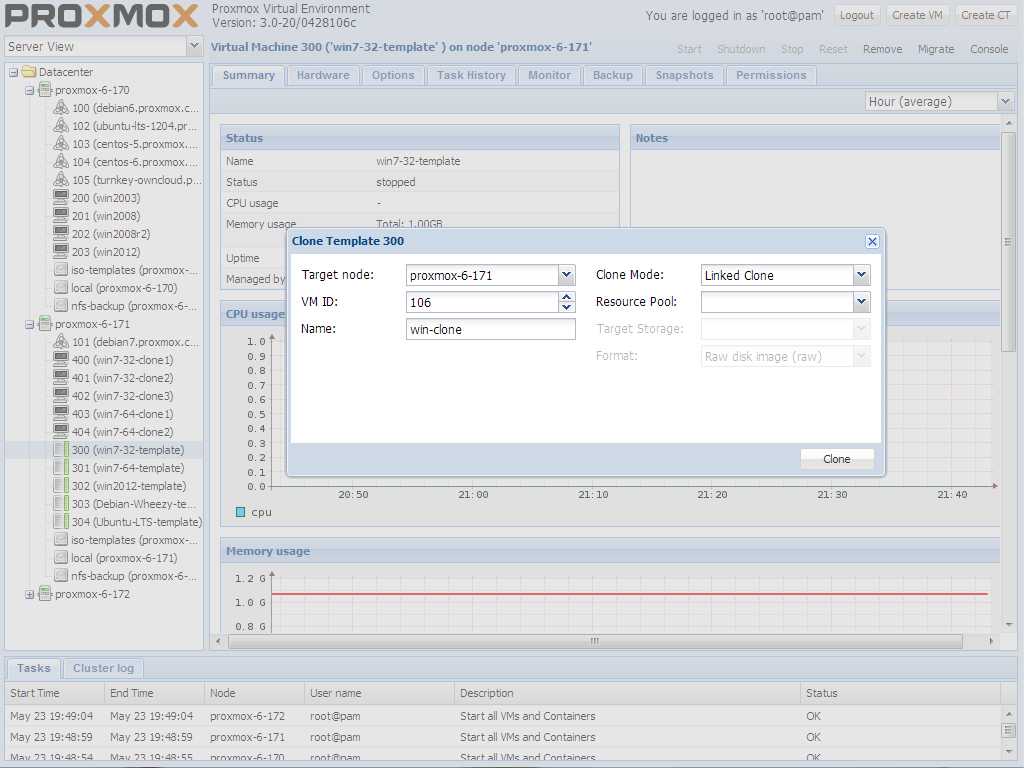
Для продолжения настройки отказоустойчивого кластера создаем виртуальную машину на общем хранилище.
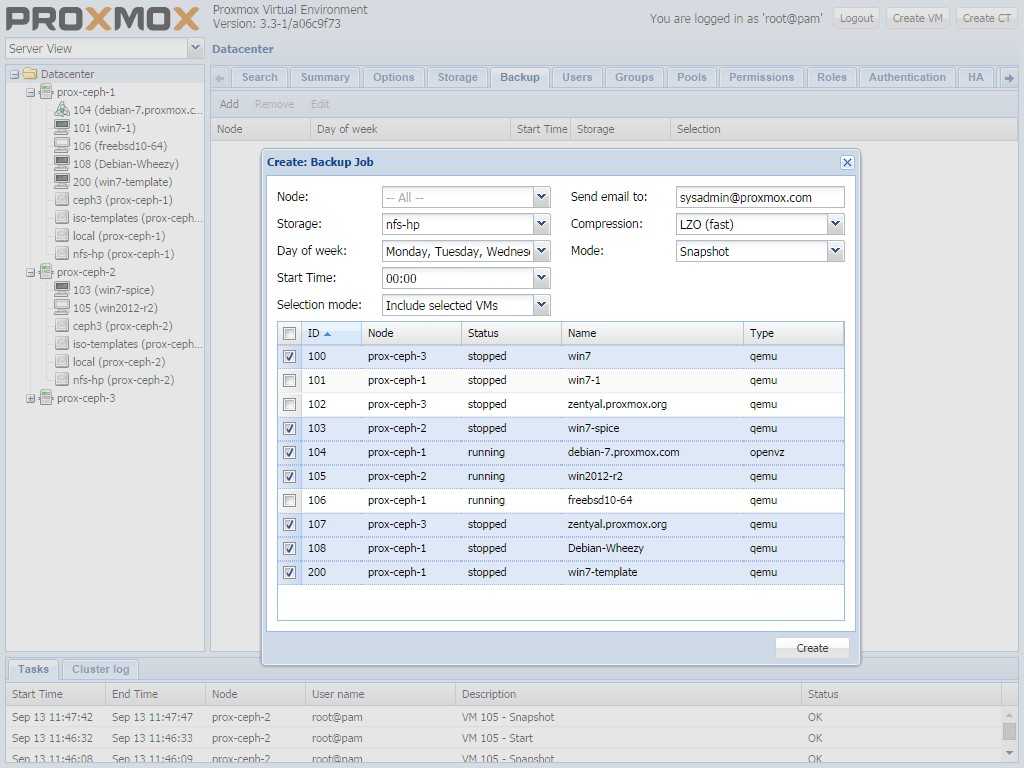
3. Настройка отказоустойчивости
Создание группы
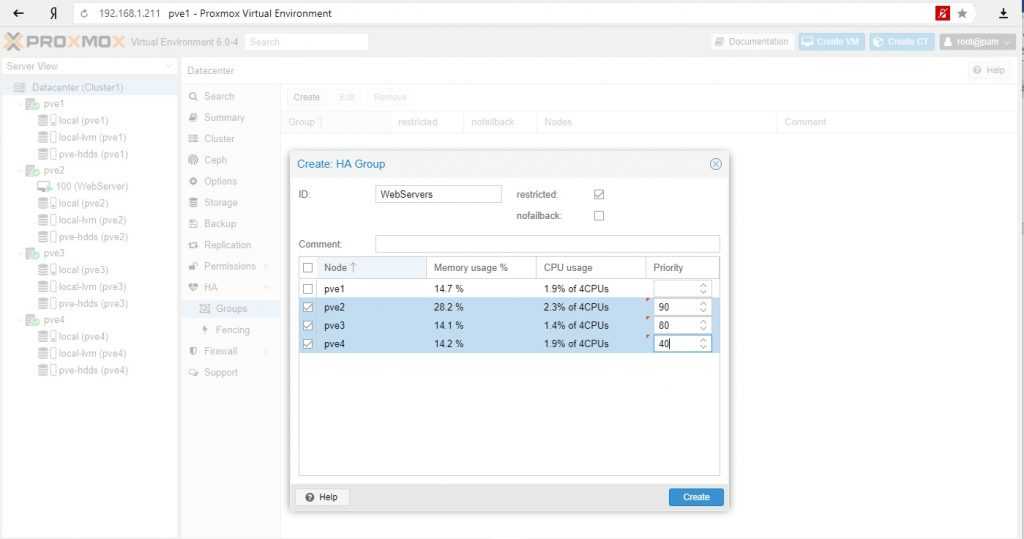
Для начала, определяется с необходимостью групп. Они нужны в случае, если у нас в кластере много серверов, но мы хотим перемещать виртуальную машину между определенными нодами. Если нам нужны группы, переходим в Датацентр — HA — Группы. Кликаем по кнопке Создать:

Вносим настройки для группы и выбираем галочками участников группы:
* где:
- ID — название для группы.
- restricted — определяет жесткое требование перемещения виртуальной машины внутри группы. Если в составе группы не окажется рабочих серверов, то виртуальная машина будет выключена.
- nofailback — в случае восстановления ноды, виртуальная машина не будет на нее возвращена, если галочка установлена.
Также мы можем задать приоритеты для серверов, если отдаем каким-то из них предпочтение.
Нажимаем OK — группа должна появиться в общем списке.
Настраиваем отказоустойчивость для виртуальной машины
Переходим в Датацентр — HA. Кликаем по кнопке Добавить:
В открывшемся окне выбираем виртуальную машину и группу:
… и нажимаем Добавить.
![Proxmox:как-убить-машину-которая-не-хочет-выключаться [wiki.autosys.tk]](https://tehnikaarenda.ru/wp-content/uploads/4/3/6/4361f64100e97096506e98eae8f5b45b.jpeg)
![Proxmox:как-убить-машину-которая-не-хочет-выключаться [wiki.autosys.tk]](https://tehnikaarenda.ru/wp-content/uploads/8/7/7/8771b6044336a37f9513a804c479336d.jpeg)
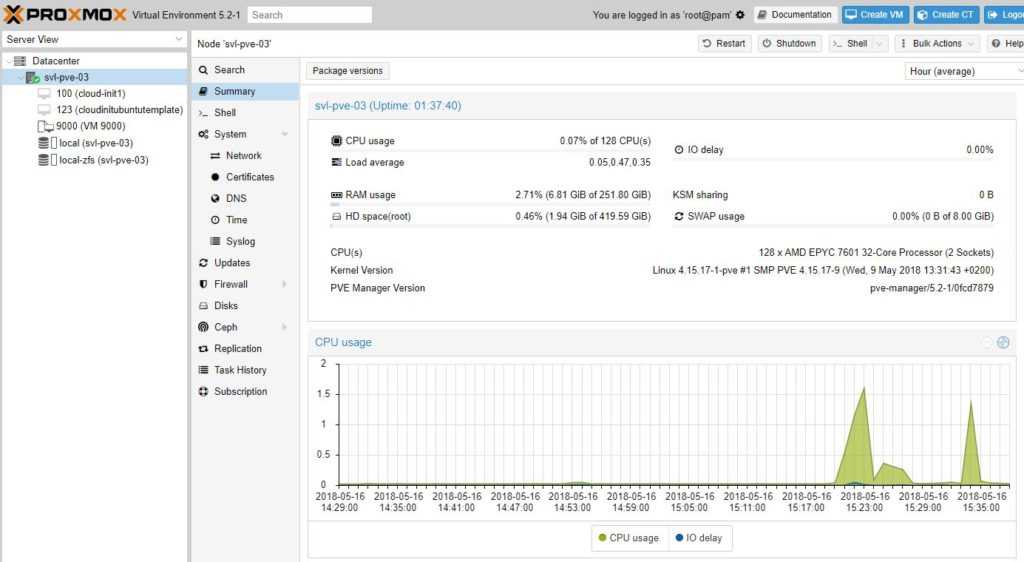
4. Проверка отказоустойчивости
После выполнения всех действий, необходимо проверить, что наша отказоустойчивость работает. Для чистоты эксперимента, можно выключиться сервер, на котором создана виртуальная машина, добавленная в HA.
Важно учесть, что перезагрузка ноды не приведет к перемещению виртуальной машины. В данном случае кластер отправляет сигнал, что он скоро будет доступен, а ресурсы, добавленные в HA останутся на своих местах
Для выключения ноды можно ввести команду:
systemctl poweroff
Виртуальная машина должна переместиться в течение 1 — 2 минут.
![Proxmox:как-убить-машину-которая-не-хочет-выключаться [wiki.autosys.tk]](https://tehnikaarenda.ru/wp-content/uploads/2/c/0/2c0c1b2bdb9654cf4720296489252d7e.jpeg)