r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
финансирование
Интернет-архив финансируется за счет пожертвований и грантов различных фондов, институтов и ассоциаций в области образования, исследований, науки и т. Д. В апреле 2019 года Интернет-архив указал следующих доноров: Фонд Эндрю У. Меллона , Совет по библиотеке и Информационные ресурсы , Фонд демократии Организации Объединенных Наций , Федеральная комиссия по связи универсального обслуживания программы для школ и библиотек (E-Rate) , институт музейных и библиотечных служб (IMLS) , Knight Foundation , Лаура и Джон Арнольд Фонд , Национальный гуманитарный фонд (Office цифровой гуманитарный) , Национальный научный фонд , Питер и Кармен Лусие Buck фонд , Филадельфия Фонд , Рита Аллен Фонд .
Which Sites Are Cataloged?
Many popular websites are automatically archived by the Wayback Machine. However, you can use the Wayback Machine to manually archive virtually any page. Websites are often abandoned or changed completely, so the Wayback machine acts as a way to preserve the culture of the Internet by keeping a digital “hard copy” of a website. Be aware that text and images are left intact; however, some outbound links and embedded items (e.g. videos) are not.
It is important to note that The Wayback Machine only scans and archives public sites. This means that password protected sites or ones located on private servers cannot be archived. In addition, if a website prohibits search engines from including it in search results, Wayback Machine will not be able to archive it.
Installation Method 1: The Easy Method
- 1. Register the domain with your hosting company. If you have registered the domain elsewhere, then create an add-on domain in the cPanel of your hosting company. Here is a tutorial from GoDaddy, that explains how to create an add-on domain.
- 2. Login to cPanel and go to «File Manager», as shown in the picture below:
- 3. Browse to the root folder of your domain. Normally this is /public_html/example.com, as shown below. For this tutorial, we used the domain buy-searchengine.com. Then click on «Upload»:
- 4. Then upload the ZIP file, as shown in the picture below. This assumes that you have already downloaded the ZIP file from waybackmachinedownloader.com.
- 5. Extract the ZIP file:
- 6. That’s it! If you purchased the domain and the hosting from different companies, then you still have to change the name servers at your domain registrar, and change them with the name servers from your hosting company.
- 7. If you want to edit the front page, then go to the File Manager and edit the index.html file, using a text editor. You might find it easier to copy part of that file and edit it with an online HTML editor.
WordPress installation instructions
If you also ordered the WordPress conversion, then wait until one of our developers sends you a ZIP file with WordPress files. This might take up to 48 hours after the scraping has finished.
It might sound strange, but you can not use a «Managed WordPress» hosting package. It doesn’t provide enough rights to edit the database. However, any cheap shared hosting package works, as long as it uses Apache. You can get this from providers such as Godaddy or Hostgator. We recommend Namecheap because it’s good enough and costs only $35/year.
- 8. Upload and extract this ZIP file as described above in step 2-6, in the same way as you would do with a zip file with HTML files. In the ZIP file there is also a folder called «database». If you want to save some time, you can remove this folder from the ZIP file, because you do not need to upload it. You will need the folder later though.
- 9. Go to your cPanel and open «MySQL Databases». Create a new database. You can name it anything, but in our example we use the name of our domain. You will need this name later, so pick something easy.
- 10. Create a new user and password. The name can be anything, but you’ll need it later.
- 11. Add this user to the database. Give your new user access to all privileges.
- 12. On your own computer, unzip the folder called «database». For example, unzip this to your desktop.
- 13. Go to your cPanel and open «phpMyAdmin».
- 14. First select your database on the left panel, by clicking on it. Then click «import» and import the database. This is the .sql file in the folder called «database».
- 15. Go to File Manager and find the file called «wp-config.php». Open this file in a text editor.
-
16. In wp-config.php, edit the database name, database user name and database password. Use the values that you created in step 9 and 10.
With some hosts you also have to change the hostname, but with 95%+ of hosting companies, you can leave this as «localhost». For example with iPage it is «UsernameOfYourAccount.ipagemysql.com» - 17. That’s it! Your WordPress website should now work.
How to Download Website from Wayback Machine (Linux Based OS)
For EL Capitan Or Later OS.

After Run Above Command, It will Install Wayback machine downloader in your System and then download websites via commands, same as described in windows pc section.
So This is the way which you can use for download entire website from Wayback machine with the help of simple ruby script. You can use it for recover your website from wayback machine or just to check how your website was looking in past. For more questions or suggestions regarding this blog, simply comment below, I will try to help you out. Enjoy this wayback downloader free in your PC. Thanks for visiting and stay tuned in this blog for more cool stuffs like this.
Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Я на этом деле конечно уже собаку съел, так что трудностей не возникло. Но прежде, чем закидывать вас инструкциями, давайте повторим сами себе, с чем имеем дело.
Это обычный рекламный вирус, коих стало пруд пруди. И имен у него много: может быть просто WAYBACK MACHINE, а может с дописанной строкой после имени домена WAYBACK MACHINE. В любом случае вирус закидывает вас рекламой, и про ваше любимое казино Вулкан не забывает. До кучи он заражает и свойства ярлыков браузеров.
Кроме того, вирус обожает создавать расписания для запуска самого себя, чтоб жизнь медом не казалась. В результате его деятельности вы вполне можете случайно кликнуть на нежелательную ссылку и скачать себе что-нибудь более серьезное.
Поэтому данный рекламный вирус следует удалять как можно быстрее. Ниже я приведу инструкции по избавлению от вируса WAYBACK MACHINE, но рекомендую использовать автоматизированный вариант.
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
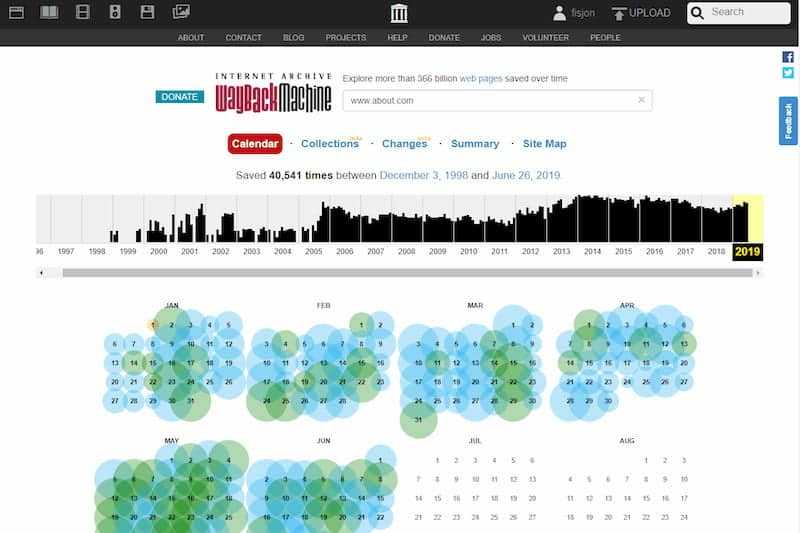
Поиск сайтов в Wayback Machine
Wayback Machine
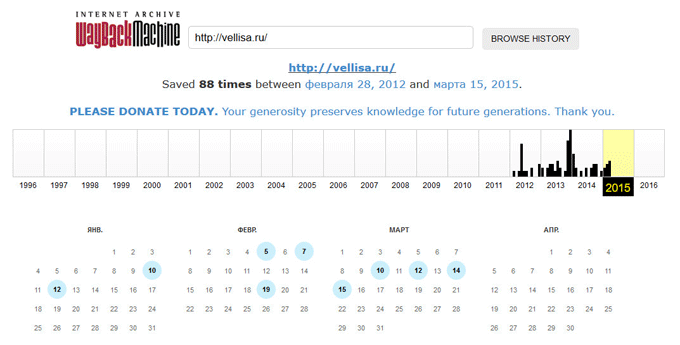
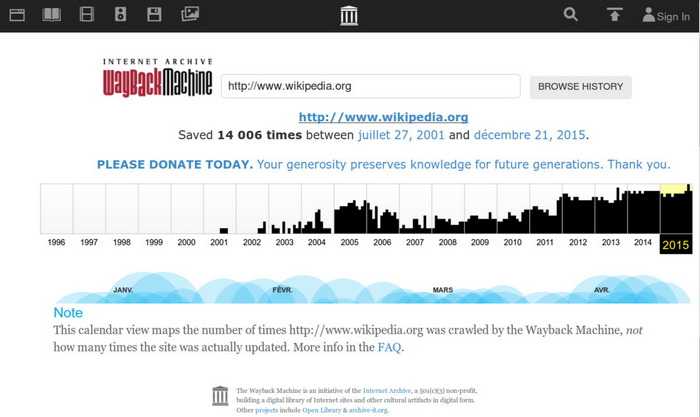
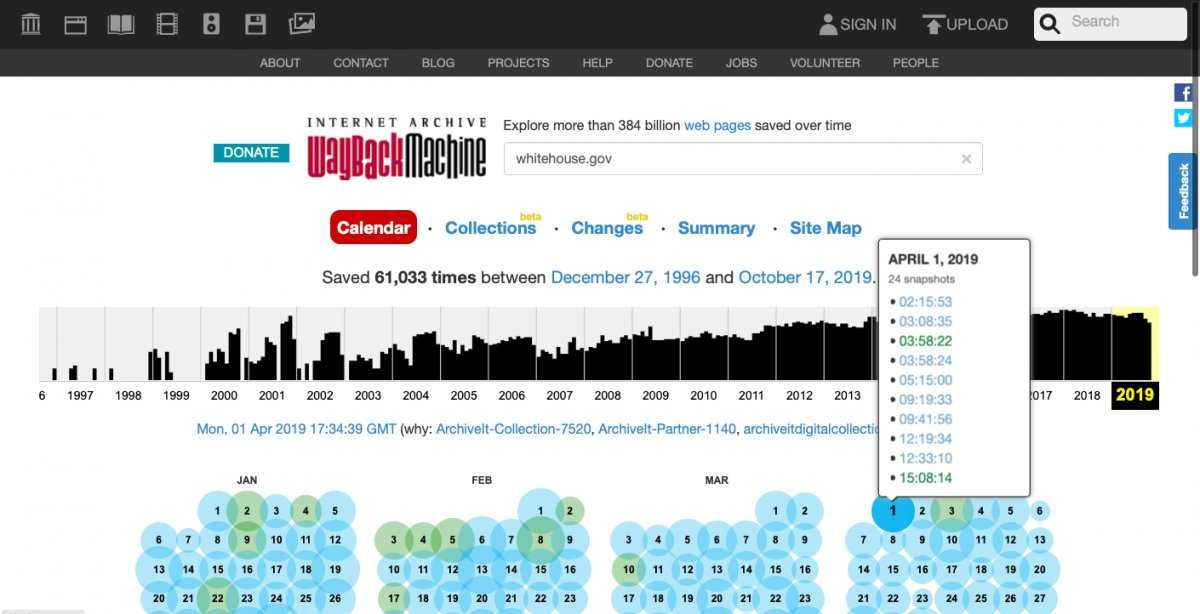
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
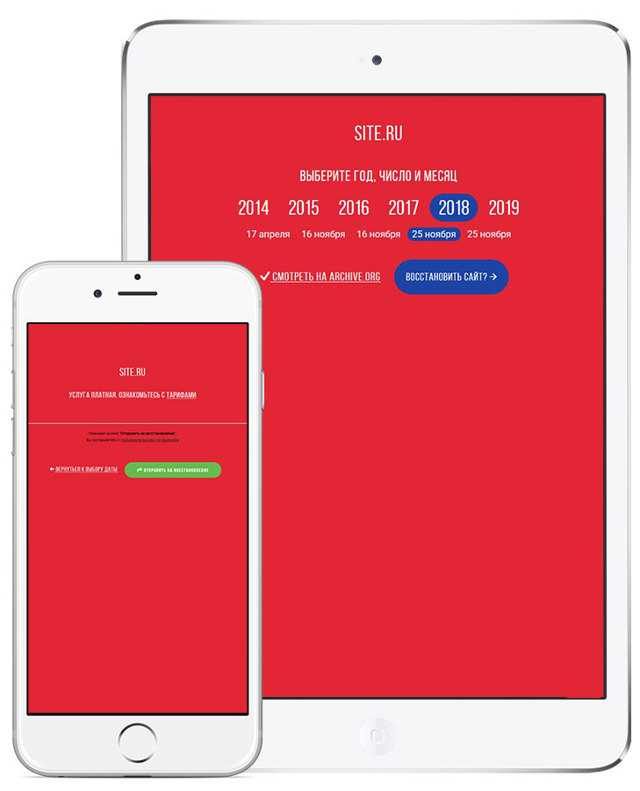
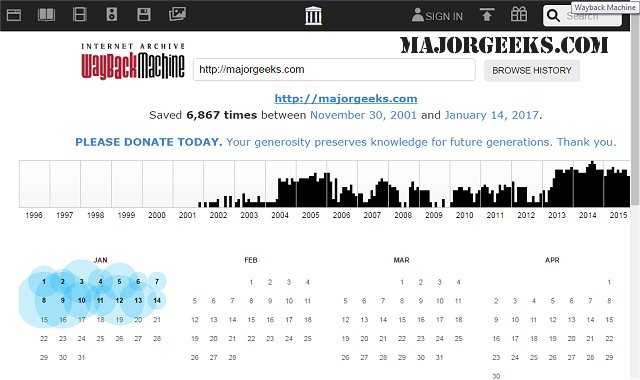
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).

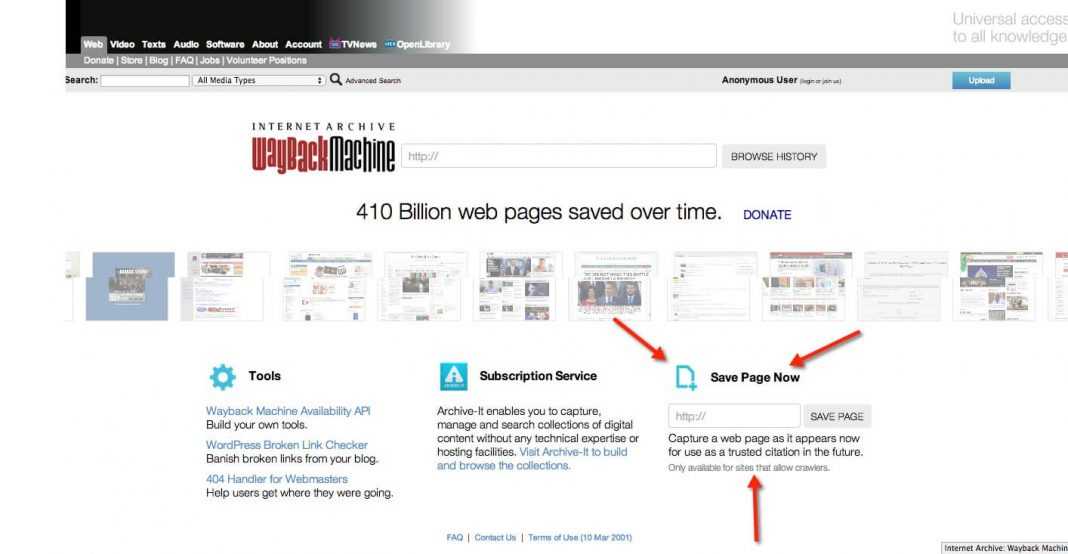
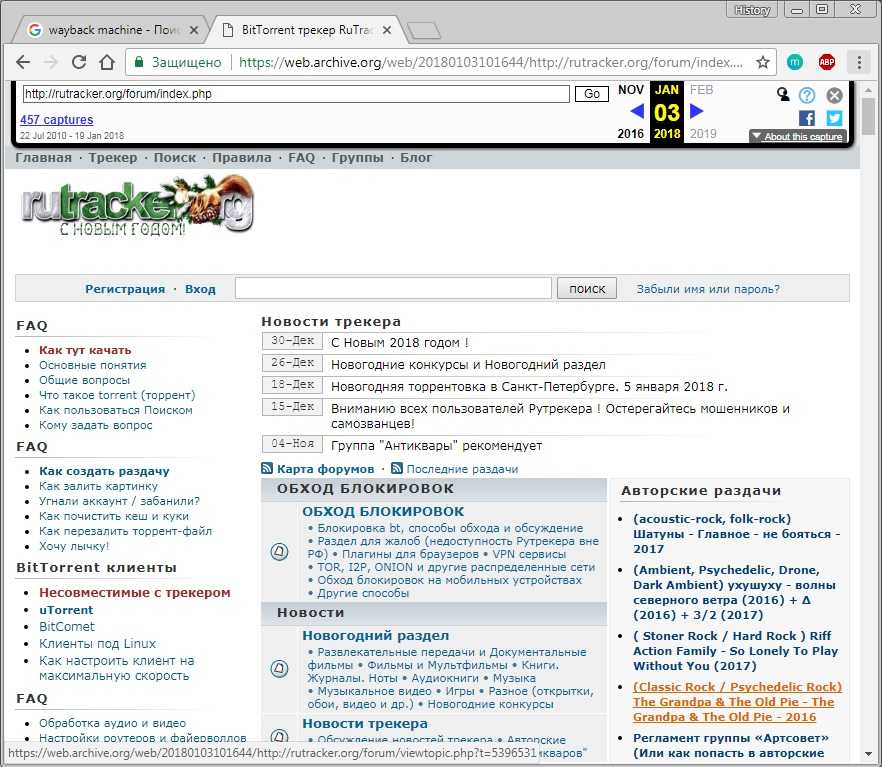
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов. Сайт будет открыт в том состоянии, которое у него было на момент создания архива
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
История
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к Интернет-сайтам: как и сервис кэшированных копий страниц от поисковых систем, архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам .
Open Library
Open Library
— общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта , включая изображения и документы в формате PDF . Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Как установить счётчик на все страницы статического сайта?
Последний штрих. Я ведь собираюсь отслеживать свои успехи. Поэтому мне нужно обязательно добавить какой-нибудь счётчик. Я ставлю на свои сайты обычно и Google аналитику и метрику яндекса. Но работаю больше с метрикой, analytics пользуюсь изредка для специфичных вещей. Здесь же мне счетчик гугла вообще не понадобится, по крайней мере первое время.
Итак, чтобы добавить во все страницы счётчик метрики, я воспользовался способом с выносом кода счётчика в отдельный js-файл. Просто потому, что так будет проще добавить потом код его вызова на все страницы. Создал счётчик, и записал его код в metrika.js
Теперь добавляю строку с его вызовом на все страницы перед закрывающим тегом body:
find site.ru/ -type f -iname ‘*.html’ -exec sed -i ‘/<\/body>/i \
<script type=»text\/javascript» src=»\/metrika.js»><\/script>’ {} \;
Теперь проверяю, везде ли установилось:
find site.ru/ -type f -iname ‘*.html’|xargs grep ‘metrika.js’|wc -l
173
И получаю неприятный сюрприз — установлено не везде. Около сотни страниц упущено. Это могло произойти только в том случае, если в каких то файлах нету тега </body>. Смотрим:
find site.ru/ -type f -iname ‘*.html’|xargs grep -L ‘</body>’|wc -l
119
Как раз в 119 файлах этого тега нету. Это совсем плохо, видимо на каком то из этапов по очистке что-то пошло не так, и был срублен этот тег. Можно конечно выяснить когда это случилось и откатиться до того момента, но это куча работы. Поэтому я просто добавлю в эти файлы недостающие теги, и потом таки добавлю счётчик.
Я делаю это одной строкой, чтобы указать паттерном именно теги в паре. Иначе, если я воспользуюсь для добавления счётчика той же командой, что я уже сделал — то я продублирую вызов счётчика там, где он уже есть. Чтобы этого избежать можно конечно удалить строку там где она есть и потом добавить её снова, но я просто укажу спаренный тег в виде паттерна и добавлю только в те файлы. Вот так:
Проверяю снова:
266
Ну вот, 266 из 290 это уже лучше  Там оказалось еще что 30 страниц не попали под какой-то из скриптов из-за кривых имен с вопросительными знаками. Я думаю мне достаточно и тех что есть
Там оказалось еще что 30 страниц не попали под какой-то из скриптов из-за кривых имен с вопросительными знаками. Я думаю мне достаточно и тех что есть
Что дальше?
Дальше мне пришла в голову мысль заточить имеющуюся на сайте страницу об услугах под предложение восстановления сайтов из веб архива.
Вот что получилось после очистки и правки страницы под свои нужды
Разобрались, не?
Если вы прониклись, во всём разобрались и собираетесь делать самостоятельно — низкий вам поклон и уважуха. Мне нравятся люди, которые хотят во всём разобраться и постичь.

![[guide] how to download full website from wayback machine](https://tehnikaarenda.ru/wp-content/uploads/e/6/5/e65b504ad4bbe42f86343b2d12096a7b.jpeg)
Если же вы кроме хаоса в мыслях ничего не испытываете после прочтения, а решить задачу надо, я отношусь со столь же большим уважением к тем, кто умеет находить профессионалов и просто делегировать свои задачи
Download Entire Website Wayback Machine
Hey Guys, In This Tutorial I will tell you about How can you download Full Website from Wayback Machine easily. Want to see how your website was looking in past? Want To download your website copy as it was looking in past? I have one simple Tutorial for you, Which you can follow for download your website from wayback machine. There are many tools available like Httrack for download website from current time, But downloading website from wayback, is also possible with the help of simple Ruby Script which is developed by .
For Download Website form Wayback machine, there are many online tools available which are paid and charge 10-15$ for download one single website from wayback machine. But I am here with the guide for provide you a Simple way to download full website from wayback for free without paying anything, isn’t it cool? One Day, I was searching for the way to download website from wayback and I Found best possible way is using ruby gem file. I was found this script on Github, special Thanks to that website. So If you also looking for the way to download website from wayback then simply follow below tutorial for this.
 download website from web archive
download website from web archive
What is Wayback Machine?
If you are a Blogger or Freelancer, then you maybe already know or heard about Wayback Machine. But if you are not, then let me tell you. You may have heard about Time Machine Right, Wayback Machine is the Time Machine of the web, Which Save the Entire website in their database (With CSS, Images, Files). Wayback Machine Bot Goto Different websites, and Saved the website so you can view your website in future that how your website was looking in past.
Requirements for Download Website from Wayback Machine
- Wayback Machine Downloader Gem File Install Via Command –
- For Mac or Linux Based System – Nothing Special Needed, Just Need to Run Command for Install Waybacm machine downloader Gem.
Проекты
Wayback Machine
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. По этой причине сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к сайтам: как и сервис кэшированных копий страниц от поисковых систем, Архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование Архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
mydrop.io
(реф. ссылка)
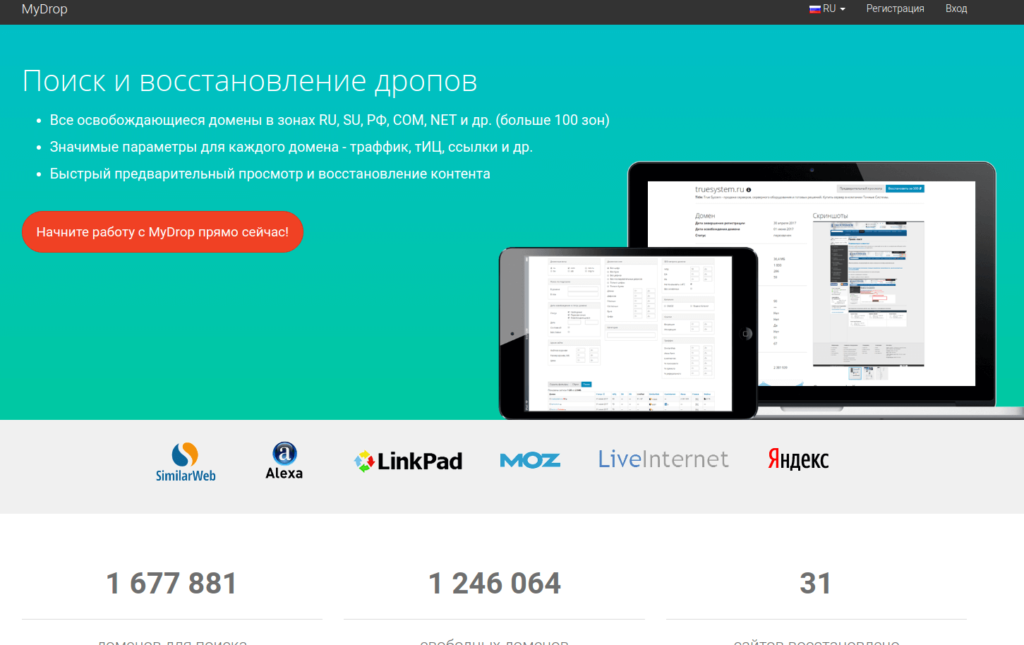
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления
Top 10 Best Internet Archive Wayback Machine Alternative 2020
There are plenty of interesting web archiving sites similar to Wayback Machine and today we are going to mention all of them in our list of best Internet Archive Wayback Machine alternatives. You can try out any Wayback Machine alternative which you would like to use in order to find out how a particular website looked a couple of days, months or even years ago.
Here we are going to list the top 10 best alternatives to Wayback Machine which you can use to see archived versions of web pages across time. All these Internet Archive Wayback Machine alternative sites function in the same matter. Let’s dive in:
Group 1: The Actual Wayback Machine Alternatives
Alternative 1: Archive.is
Archive.is is the closest thing you can find to the Wayback Machine. In terms of functionality, the website is in-between screenshots.com (see below) and Archive.org. Archive.is saves websites both as a screenshot and as HTML.
Based on a small experiment, their database is about 5% the size of archive.org’s database. It’s not much, but it’s still better than other the alternatives.




- Good for scraping pictures off a domain. Tip: browse an archive and then click “download .zip”
- It doesn’t crawl deep. Usually just the front page.
- Both web page and screenshot. Archive.org could learn from this feature, because many websites have broken stylesheets/css.
- You can download the original HTML, with some limitations.
Database size: 5/10
User friendliness: 7/10
Features: 9/10
NEW: We now also support archive.is. Simply go to our Wayback Downloader and use a link from archive.is, in the same way as you would with a link from archive.org.
Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
Для того, чтобы самостоятельно избавиться от рекламы WAYBACK MACHINE, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «WAYBACK MACHINE» в списке установленных программ и удалить ее.
Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «WAYBACK MACHINE». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
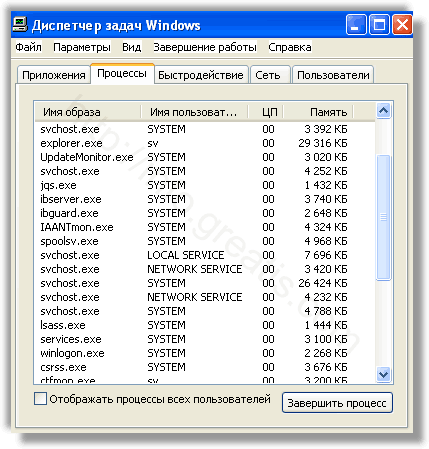
Запретить вредные службы с помощью консоли services.msc.
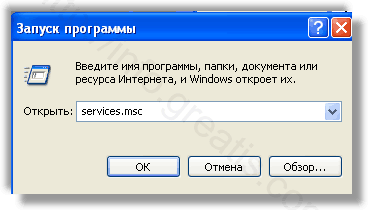
Удалить “Назначенные задания”, относящиеся к WAYBACK MACHINE, с помощью консоли taskschd.msc.
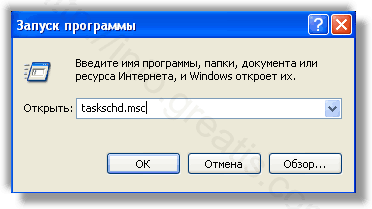
С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «WAYBACK MACHINE» в реестре.
Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
Очистить корзину, временные файлы, кэш браузеров.
Origins, growth and storage
Snapshots usually become available more than 6 months after they are archived, or in some cases, even later, 24 months or longer. The frequency of snapshots is variable, so not all tracked web site updates are recorded. Intervals of several weeks or years sometimes occur.
In 2011 a new, improved version of the Wayback Machine, with an updated interface and fresher index of archived content, was made available for public testing.
In March 2011 it was said on the Wayback Machine forum that «The Beta of the new Wayback Machine has a more complete and up-to-date index of all crawled materials into 2010, and will continue to be updated regularly. The index driving the classic Wayback Machine only has a little bit of material past 2008, and no further index updates are planned, as it will be phased out this year.»
Что нам понадобится
Задача перед нами стоит непростая, так что давайте сначала примемся за ее самую скучную и рутинную часть.
Установка Exiftool
Для дистрибутивов Linux, основанных на пакетной базе Ubuntu, можно сделать вот что:
# sudo apt-get install exiftool
Пользователи Mac OS X, скачайте программу-инсталлятор тут.
Если у вас стоит Windows, тогда:
- Скачайте двоичный фал ExifTool здесь. Сохраните его в папку C:\Python27 (у вас ведь уже стоит Python?)
- Переименуйте его в exiftool.exe
- Убедитесь, что в Path у вас указан путь к C:\Python27. Не знаете, как это сделать? . Или можете мне на электронную почту написать.
Установка необходимых библиотек Python
Теперь устанавливаем библиотеки Python, которые нам понадобятся:
pip install bs4 requests pandas pyexifinfo waybackpack
Ну что, поехали, ребята?
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:


- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
Для того, чтобы самостоятельно избавиться от рекламы WAYBACK MACHINE, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «WAYBACK MACHINE» в списке установленных программ и удалить ее.
Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «WAYBACK MACHINE». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
Запретить вредные службы с помощью консоли services.msc.
Удалить “Назначенные задания”, относящиеся к WAYBACK MACHINE, с помощью консоли taskschd.msc.
С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «WAYBACK MACHINE» в реестре.
Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
Очистить корзину, временные файлы, кэш браузеров.
Юридические проблемы с архивным контентом
Против Internet Archive было возбуждено несколько дел специально за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления, а владельцы сайта не хотели, чтобы их материалы были удалены.



![[guide] how to download full website from wayback machine](https://tehnikaarenda.ru/wp-content/uploads/1/4/7/147eb864d6ad593eb426c3a9f6bd241e.jpeg)

Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарном знаке с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать недействительность требований истца на основании содержания их веб-сайтов за несколько лет до этого. Истец, Healthcare Advocates, затем внес поправки в свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения того, что Internet Archive не нарушает авторские права Shell . Shell ответила и подала встречный иск против Internet Archive за архивирование ее сайта, что, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 года судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отказываться от претензий Shell о нарушении авторских прав, связанных с ее копировальной деятельностью, которая также будет продолжена.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив заявил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что г-жа Шелл имеет действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалеем. что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Shell заявила: «Я уважаю историческую ценность цели Internet Archive. Я никогда не собирался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 год порнографический актер по имени Даниэль Давыдюк пытался удалить свои заархивированные изображения из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем обратившись в Федеральный суд Канады .