
API-интерфейсы Яндекс.Метрики
У Яндекс.Метрики несколько API-интерфейсов:
- API управления. Предназначен для работы со счётчиками, фильтрами, сегментами, доступами и другими объектами аккаунта Яндекс.Метрики.
- API отчётов. Позволяет получать информацию о статистике посещений сайта и другие данные, не используя интерфейс Яндекс.Метрики.
- API, совместимый с Core API Google Analytics v3. По смыслу и функционалу схож с «API отчётов», но при формирования запроса вы можете использовать такое же название полей, как и при работе с COre API Google Analytics.
- Logs API. Интерфейс для загрузки сырых, не сгруппированных данных о посещениях сайта.
Сбор метрик на стороне 1С
Теперь обратимся к тому, что было сделано в 1С.
Мы добавили иерархический справочник «Метрики Zabbix», в котором у элемента есть ключ метрики, по которому 1С понимает, какую именно метрику в данный момент запрашивает Zabbix.
Для каждого элемента справочника «Метрики Zabbix» указывается текст запроса, который нужно выполнить, поэтому для добавления новых метрик не надо обновлять 1С. Это очень удобно.
Ну и какие запросы без параметров.
На слайде показан параметр Guid, значение которого мы передаем в JSON с помощью макроса узла сети. Значение этого параметра сразу же подхватывается в запрос и позволяет получить данные по нужной торговой точке.
Также параметры могут быть:
-
ссылками на элементы базы данных;
-
списком ссылок;
-
и даже исполняемым кодом, как ТекущаяДата на представленном примере.
Следующим этапом мы добавили в справочник «Метрики Zabbix» постобработку – это было необходимо для формирования более сложных JSON-ов с несколькими полученными запросом результатами.
Получение доступа к API Яндекс
Вам нужно будет заполнить несколько обязательных полей:
- Название приложения.
- В качестве платформы указать Веб-сервисы.
- Callback URI установить — https://oauth.yandex.ru/verification_code.
- В Доступах указать: Яндекс.Метрика, Получение статистики, чтение параметров своих и доверенных счетчиков.
Все остальное можно не указывать. Вы должны получить ID приложения и Пароль.
После разрешения, вы получите токен, с помощью которого можно подключаться к api.
Используя этот токен, можно получать данные из Метрики через API. Для примера зайдем на сервер мониторинга и через консоль запросим данные о посещаемости сайта. Для этого нам нужно узнать номер его id в метрике. Можно это сделать прямо в ней же.
Далее формируем запрос через curl с указанием токена в header.
# curl --header "Authorization: OAuth AgAAaaaaaaaaaaaDDDDDDDDDddd" --header "Content-Type: application/x-yametrika+json" -X GET "https://api-merika.yandex.ru/stat/v1/data?&ids=23506456&metrics=ym:s:users,ym:s:visits,ym:s:pageviews&dimensions=&date1=today&pretty=true"
В данном запросе я указал:
- AgAAAAAAGk3WAAaaYZaUSgzNyU7uvqAKCGwDSro — токен;
- ids=23506456 — id сайта в метрике;
- metrics=ym:s:users,ym:s:visits,ym:s:pageviews — запрошенные метрики — пользователи, визиты, просмотры страниц;
- date1=today — дата, сегодняшний день в данном случае;
- pretty=true — вывести в формате удобочитаемого json.
Получили ответ в виде подробного json. Он отлично подходит для zabbix, так как последний умеет из коробки парсить json. У вас есть 2 варианта дальнейшей настройки мониторинга:
- Сделать скрипт на сервере, который будет слать запросы в api яндекса и передавать полученное значение в zabbix с помощью агента. Плюс решения в том, что нагрузка на сервер мониторинга минимальная. Неудобство в том, что нужно куда-то добавлять скрипт.
- Слать запросы к api напрямую с zabbix сервера с помощью HTTP Агента. И сразу там же парсить полученный ответ. Плюс этого подхода в том, что все настройки хранятся в шаблоне и легко сохраняются или переносятся через экспорт шаблона. Минус в том, что все вычисления и запросы выполняются самим заббиксом.
Я обычно иду по второму пути, потому что так удобнее.
В таком виде это можно отправлять в Zabbix, чем мы далее и займемся.
Практическое применение логов
Цель данной статьи — в первую очередь дать инструмент, которым мог бы воспользоваться даже человек, далекий от технических разработок для выгрузки исходных логов Метрики
Работа непосредственно с «сырыми» данными выходит за границы этого материала, но все же важно обозначить задачи, которые можно решать с их помощью
Вот направления работы, которые рекомендует Яндекс для работы с логами:
- сложные воронки продаж;
- собственные модели атрибуции;
- объединение данных из разных источников;
- контроль над расхождениями в статистике.
Вы также сможете:
- проводить факторный анализ конверсий и прочих показателей;
- более глубоко исследовать метрики и зависимости;
- строить визуализации, недоступные в стандартных отчетах Яндекс.Метрики;
- использовать техники машинного обучения для построения моделей и проверки гипотез на «боевых» данных;
- автоматизировать рутинные типовые аналитические задач, что актуально для работы на потоке.
Если у вас есть что добавить в эти списки, обязательно напишите об этом в комментариях к статье.
Преимущества использования API
Самое важное преимущество, ради которого стоит изучать API – это программный доступ к данным. Т.е
мы можем написать программу, которая будет совершать нужные действия без необходимости использования веб-интерфейса.
Второе преимущество вытекает из первого. При использовании API мы можем автоматизировать процессы. Скажем, автоматическая генерация отчетности в необходимом виде. Мечта тысяч маркетологов и руководителей!
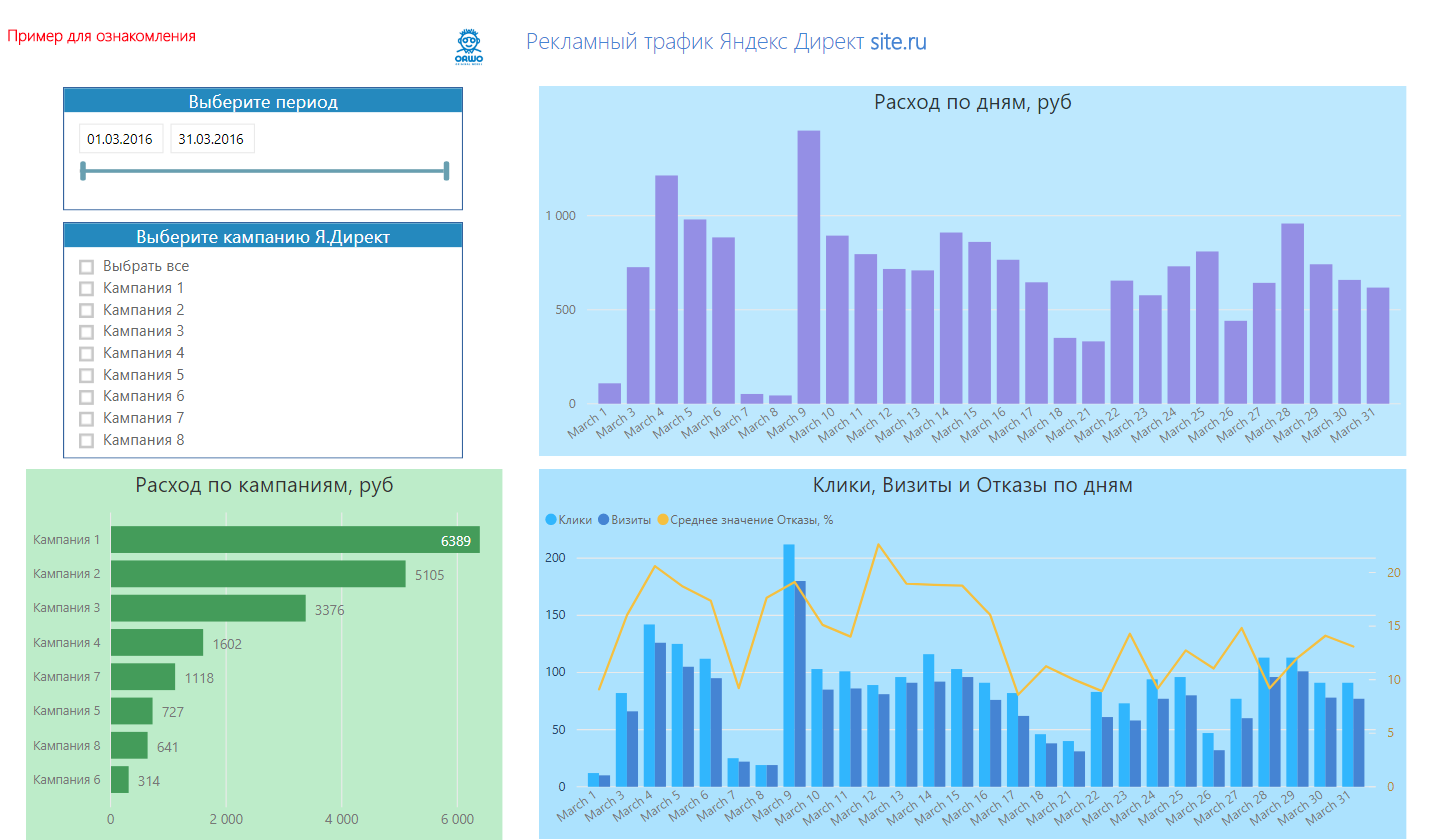
Пример отчета с использованием API Метрики и замечательного Power BI. Это одна из 5 страниц отчета для специалиста по рекламе.
Третье преимущество – частный случай второго. Автоматизировать можно не только отчетность, но и управление счетчиками. Например, мы агентство, и наш провайдер недавно сменил внешний IP. У всех клиентов отфильтрован наш трафик, чтобы не исказилась отчетность. Управлять счетчиками, когда их больше одного, становится неудобно, поэтому через API можно поменять фильтр сразу на всех счетчиках, к которым есть доступ на редактирование.
Об управлении счетчиком с помощью API также есть документация
По API мы можем «вытаскивать» данные по большему количеству группировок и метрик, чем через веб-интерфейс. 20 метрик и 10 группировок через API против 10 метрик и 7 группировок через веб-интерфейс Метрики.
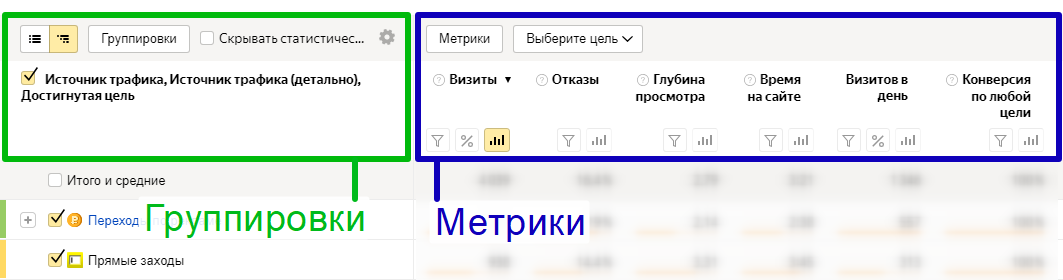
Полезное: список группировок и метрик API Яндекс.Метрики.
Если у вас есть штат программистов, и вы хотите автоматизировать отчетность (чтобы высвободить время аналитиков, маркетологов), то можете использовать API.
Результат в Zabbix – метрики и триггеры
В итоге мы получаем метрики в Zabbix.
На представленном графике показаны значения метрик по одной Киевской точке. Мы видим, какими в период с 19 до 20 часов были значения показателей:
-
время кухни в инфо-табло – зеленая линия;
-
количество заказов – красные точки;
-
и максимальное время отдачи кухни – синяя линия.
На основании полученных метрик мы настроили триггеры.
Триггеры – это выражения, определяющие порог проблемы:
-
когда результаты всех неравенств в выражении триггера становятся истинными, открывается проблема;
-
как только хотя бы одно неравенство будет возвращать ложь, проблема закрывается.
На примере показан триггер, открывающий проблему, когда время отдачи кухни будет на 5 минут больше, чем регламентное. Это мы можем увидеть в последнем неравенстве, где MaxTimeKitchen.last() > TimeOfKitchenInInfo.last() + 5. Все остальные неравенства всегда истинны и указаны здесь, потому что в Zabbix в оповещениях о проблеме нельзя использовать метрики, если они не присутствуют в выражении триггера.
Выполняем запрос
Теперь вставим запрос в адресную строку браузера и выполним его, перейдя по URL (ну или просто перейдите по ссылке выше).
Получили вот такой ответ:
Не стоит пугаться, это ответ в формате JSON. На самом деле, это крайне удобный формат данных, но пригоден он для использования в программировании, формировании post-запросов на веб-сервера, а вот человеку не очень просто быстро в нем разобраться. Чтобы облегчить эту задачу сделаем JSON более «красивым», добавив к запросу параметр pretty=true:
Теперь стало чуть более понятно:
Верхушка ответа от API — это параметры нашего запроса (выделена желтым)
Тут стоит обратить внимание на параметр dimensions. Это те группировки, что мы указали в своем запросе (выделены красной рамкой)
А ниже metrics (выделены синей рамкой):
После перечисления параметров идет ответ от API. Ответ содержится в параметре data, он представлен в виде массива данных, заключенных в квадратные скобки. Этот массив — множество строчек данных, каждая из которых заключена в фигурные скобки. Я обвел один элемент массива оранжевой обводкой — это одна строка данных:
Внутри каждой строки есть dimensions (обведены красным) и metrics (обведены синим). Это значения наших группировок, они указаны в том порядке, в котором идут в параметрах запроса. Значит для этой строки данных:
- ym:s:referer=«https://google.ru/»
- ym:s:startURLDomain=«help.yandex.ru»
- ym:s:visits=57136.0
- ym:s:pageviews=120931.0
В интерфейсе Метрики эта строчка выглядела бы так:
JSON, как я уже сказал, не самый человекопонятный вид данных, но только в JSON-формате API отдает важный параметр total_rows — общее количество строчек, доступных по заданному запросу. Чтобы найти этот параметр нужно перейти в самый конец страницы:
В нашем случае total_rows = 94629, а это значит, что нам пришлось бы сделать еще 9 запросов, итеративно увеличивая offset на 10000, чтобы выгрузить все данные.
Но оставим JSON разработчикам. Для «обывателей» (надеюсь никто не обидится) Метрика может отдавать данные в CSV. Всё, что для этого нужно — после data в запросе поставить параметр «.csv», тогда URL нашего запроса будет выглядеть так:
https://api-metrika.yandex.ru/stat/v1/data.csv?metrics=ym:s:visits,ym:s:pageviews&dimensions=ym:s:referer,ym:s:startURLDomain&date1=2015-01-01&date2=yesterday&limit=10000&offset=1&ids=2138128,2215573&oauth_token=05dd3dd84ff948fdae2bc4fb91f13e22bb1f289ceef0037 (обратите внимание, что я убрал pretty=true, т. к. для CSV-запроса он не нужен). После того как мы сделаем запрос по этому URL, загрузится файл data.csv:
После того как мы сделаем запрос по этому URL, загрузится файл data.csv:
Загруженный CSV (Comma-separated values) представляет собой обычный текстовый файл в кодировке UTF-8, где значения разделены запятыми:
Перед нами наши данные в значительно более привычном виде. Сначала идет заголовок таблицы, тут уже нет никаких ym:s:referer и названия группировок и метрик отображаются также как и в интерфейсе. Затем идет строчка с итоговыми данными (по всей выборке, а не только по выгруженным 10000 строкам), а после идут строки с данными. Их 10000. Если мы хотим выгрузить остальное — надо делать ещё запросы (изменяя offset).
Настройка Zabbix
Основная наша идея заключалась в том, чтобы сделать в 1С HTTP-сервис, через который Zabbix будет забирать информацию из базы данных и строить на ее основании метрики, триггеры и оповещения.
Для начала разберемся, что такое узлы сети.
В обычном понимании мониторинга Zabbix узлы сети – это элементы инфраструктуры (такие как сетевое оборудование, физические и виртуальные сервера, базы данных, источники бесперебойного питания и прочее), с которых Zabbix постоянно считывает информацию.
В нашем случае, узлы сети – это торговые точки, производства, города и даже базы 1С. Это то, по чему мы хотим получать информацию.
На слайде показан узел сети – торговая точка сети СушиВок Санкт-Петербурга:
-
она принадлежит к нескольким группам, чтобы в дальнейшем удобно настраивать права доступа.
-
узел имеет IP адрес – это адрес базы, где находится данная торговая точка.
В Zabbix узлам сети можно добавлять пользовательские макросы. По сути, это реквизиты, которые в дальнейшем можно использовать в элементах данных, в триггерах и оповещениях.
На примере, показанном на слайде, макросы узла сети – это:
-
адрес URL базы, где находится торговая точка;
-
GUID данной точки.
Таким образом узлы сети — это элементы бизнеса, которые необходимо мониторить.
Переходим к элементам данных.
По сути, элемент данных – это и есть метрика. Даже в инструкции на сайте Zabbix написано, что элемент данных – это метрика, поэтому прошу не путаться, если я буду называть оба варианта.
Итак, метрика – это конкретный фрагмент данных, получаемый от узла сети.
Мы подразделяем метрики на «родительские» и зависимые.
«Родительские» метрики с некоторой периодичностью отправляют в 1С JSON с нужными ключами метрик, а в ответ получают из 1С JSON с такой же структурой, но уже с полученными данными.
В примере мы отсылаем ключи метрик:
-
MaxTimeKitchen – максимальное время отдачи кухни;
-
CountOrdersInKitchen – количество заказов на кухне и т.д.
И вместе с каждым ключом метрик отправляем $STOREGUID – это тот самый пользовательский макрос из узла сети.
На следующем слайде представлен пример JSON-структуры, полученной из базы 1С. Здесь мы видим результаты запрошенных метрик – например, максимальное время отдачи кухни равно 9 минутам, а активных заказов сейчас 2.
Получается, что родительская метрика хранит весь JSON с полученными данными из 1С, а зависимые метрики разбирают данный JSON и хранят уже конкретные значения.
В примере на слайде мы видим зависимую метрику «Совокупное время доставки», которая обновилась в 22:29 и получила информацию, что данный параметр равен 35 минутам.
Разбор JSON в Zabbix стал возможен с версии 4.0, которая вышла в 2018 году.
Оповещения в telegram со ссылками на график и триггер
Расскажу про еще один интересный скрипт для отправки красивых и функциональных оповещений в telegram, в котором помимо всего прочего сразу же публикуются ссылки на триггер, график и некоторые другие полезности. Вот он на гитхабе — https://github.com/xxsokolov/Zabbix-Notification-Telegram. Инструкция от автора в некоторых местах не очень понятная, так что я немного повозился, прежде чем все получилось. В основном c xml были проблемы, но обо всем по порядку.
Клонируем к себе репозиторий.
# cd ~ # git clone https://github.com/xxsokolov/Zabbix-Notification-Telegram
Копируем в /usr/lib/zabbix/alertscripts папку zbxTelegram_files и файлы _config.yml, zbxTelegram.py, .requirements и zbxTelegram_config.example.py. Последний переименовываем в zbxTelegram_config.py.
Делаем пользователя zabbix владельцем этих файлов и разрешаем исполнение скрипта.
# chown -R zabbix. /usr/lib/zabbix/alertscripts # chmod +x zbxTelegram.py
Автор скрипта предлагает запускать его в виртуальном окружении, поэтому поставим пакет virtualenv.
# dnf install virtualenv
Переходим в /usr/lib/zabbix/alertscripts, создаем виртуальное окружение и активируем его.
# cd /usr/lib/zabbix/alertscripts # virtualenv venv --python=python3 # source venv/bin/activate
Ставим зависимости и деактивируем окружение.
# pip install -r .requirements # deactivate
Редактируем конфигурационный файл zbxTelegram_config.py. Список параметров, которые нужно поменять.
tg_proxy = False tg_token = '1393668911:AFGHTRDVdfJ28R-wxKfvH1RTR6-vdNw' zabbix_api_url = 'http://10.20.1.23/zabbix/' zabbix_api_login = 'Admin' zabbix_api_pass = 'zabbix'
В url на конце должен обязательно быть слеш. Дальше делаем все то же самое, что и ранее. Идем в Способы оповещений и добавляем новый тип, где в качестве скрипта указываем zbxTelegram.py.
Шаблоны тем сообщений можете настроить как вам больше нравится. Автор предлагает такие:
{Problem} {TRIGGER.SEVERITY} `TRIGGER`.`SEVERITY`: {EVENT.NAME}
{Resolved} {TRIGGER.SEVERITY} `TRIGGER`.`SEVERITY` {EVENT.NAME}
{Update} {TRIGGER.SEVERITY} `TRIGGER`.`SEVERITY` {EVENT.NAME}
- {Problem} — мапинг значений Problem\Resolved\Update в emoji (config: zabbix_status_emoji_map)
- `TRIGGER`.`SEVERITY` — мапинг значений Severity в emoji (config: zabbix_status_emoji_map)
В поле Сообщение копируется xml конфиг полностью, который приведен в файле actions.example. Копируйте его 1 в 1.
Во все шаблоны можете его вставить без изменений. Я немного попытался его править, но каждый раз потом получал ошибку парсинга xml. В итоге бросил. Автор перечисляет значение каждого парметра, так что можете попытаться настроишь шаблоны на свой вкус.
- <graphs></graphs> — прикреплять график (True\False)
- <graphlinks>True</graphlinks> — прикрепить ссылку url на History (True\False)
- <triggerlinks>True</triggerlinks> — прикрепить ссылку url из триггера (True\False)
- <tag>True</tag> — прикрепить теги (True\False)
- <graphs_period></graphs_period> — период графика в секундах
- <itemid></itemid> — передача itemid {ITEM.ID1}
- <triggerid></triggerid> — передача triggerid {TRIGGER.ID}
- <eventid></eventid>- передача eventid {EVENT.ID}
- <title></title> — заголовок графика {HOST.HOST} — {EVENT.NAME}
- <triggerurl></triggerurl> — передача url из триггера {TRIGGER.URL}
- <tags></tags> — передача списка тэгов из триггера {EVENT.TAGS}
Проверим работу уведомлений. Сначала через консоль.
# ./zbxTelegram.py @serveradmin_zabbix_group test test
В данном случае слова test менять нельзя. Именно они инициируют отправку тестового сообщения. Вот как оно выглядит.
То же самое можно сделать через web интерфейс.
Если все в порядке, подключайте данный тип уведомлений к пользователю, указывайте его в действиях и проверяйте. Уже не буду это подробоно описывать, так как устал. Материал и так очень объемный получился. В итоге уведомления в телеграме от этого скрипта будут выглядеть вот так:
Текст более информативен по дефолту и выглядит приятнее, графики в одном сообщении с текстом. В последней строке есть готовые ссылки на триггер, историю по итему. Только имейте ввиду, что url для ссылок берется из конфига и если у вас там указан localhost, то только с него и можно будет их посмотреть. Так что указывайте внешний, а не локальный url. Из минусов отмечу тоненькие графики без заливки. В скрипте от ableev они более наглядные.
Получение доступа к API
Метрика использует протокол OAuth. Этот протокол позволяет работать с данными Яндекса от лица пользователя Яндекса через приложение, зарегистрированное на Яндексе. Приложение получает доступ к данным пользователя с помощью специального ключа, называемого токеном. Итак, прежде чем начать использовать API Яндекс.Метрики нам нужно создать приложение и получить от имени пользователя OAuth-токен, с помощью которого мы будем делать свои запросы к API.
1: Заходим на страницу https://oauth.yandex.ru/
2: Нажимаем «Зарегистрировать новое приложение»
3: Запоняем поле «Название»
4: Выбираем в разделе права «Яндекс.Метрика» и ставим галочку напротив пункта «Получение статистики, чтение параметров своих и доверенных счетчиков»
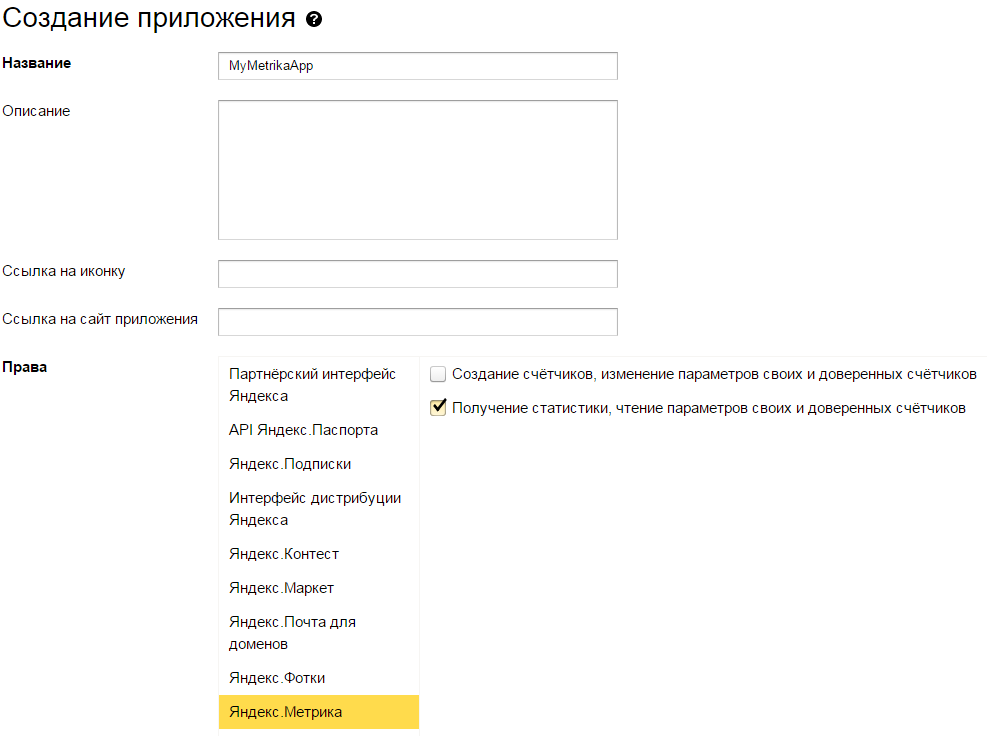
5: Нажимаем на ссылку «Подставить URL для разработки» под полем «Callback URL»
6: Нажимаем «Сохранить»
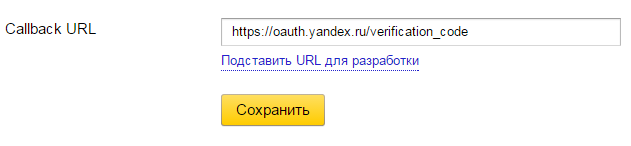
7: На открывшейся странице копируем ID приложения (его также можно скопировать увидеть в URL страницы)
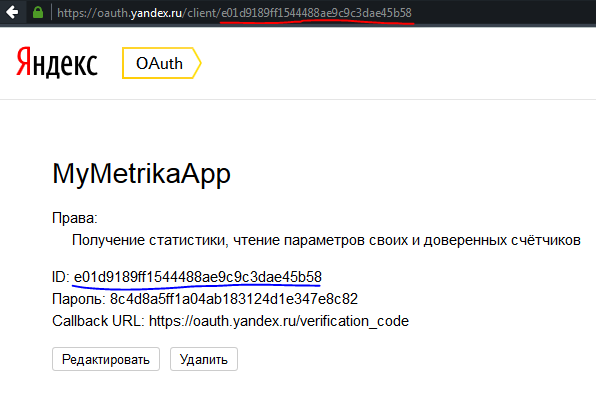
8: Авторизуемся на Яндексе под учеткой пользователя, от имени которого будет работать приложение. (Вы можете получать данные с разных логинов Яндекс.Метрики используя одно и то же приложение, только для этого нужно сначала выдать каждому логину свой токен доступа.)
9: Переходим по URL: https://oauth.yandex.ru/authorize?response_type=token&client_id= (В моем случае URL будет такой: https://oauth.yandex.ru/authorize?response_type=token&client_id=e01d9189ff1544488ae9c9c3dae45b58 и этот URL будет действителен и для вас, и токен вы получите, но лучше создайте свое приложение и укажите свой id)
10: Приложение запросит разрешение на доступ, которое нужно предоставить, нажав «Разрешить»:
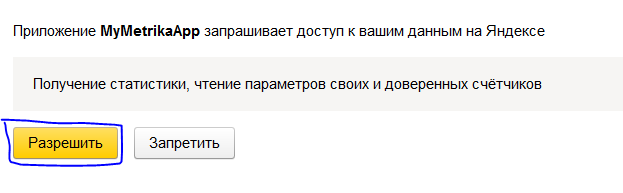
11: После чего мы получим токен:
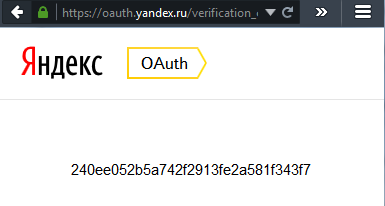
Скопируйте и сохраните его. Этот токен позволит получать данные Яндекс.Метрики для счетчиков того логина, которому вы выдали разрешение на доступ. Срок действия токена большой, если честно даже не знаю насколько большой. Для другого логина нужен будет другой токен, его легко получить перейдя по https://oauth.yandex.ru/authorize?response_type=token&client_id=. Если приложению уже предоставлен доступ, то повторно перейдя по адресу мы снова получим тот же токен, что был выдан ранее.
Открывать доступ к собственноручно созданному приложению — это безопасно, в случае с открытием доступов к стороннему приложению, рекомендую смотреть на уровень доступа к данным. Например, у сторонних приложений, которые строят отчеты по API на основе данных Яндекс.Метрики, не должно быть доступов к редактированию счетчиков. На странице «Управление доступом» в Яндекс.Паспорте можно увидеть каким приложением предоставлен доступ к данным Метрики.
Zabbix:
Отключение SQL-таблиц, хранящих значения метрик:
При первом запуске новая версия Zabbix’а произведёт автоматическое обновление базы.
Этому могут помешать старые проблемы, например, русские символы в таблицах с кодировкой latin1.
Чтобы обновление не закончилось с ошибкой, предварительно исправьте их вручную:
Чтобы ядро Zabbix’a начало использовать ElasticSearch и создавало посуточные индексы вместо монолитных, достаточно добавить две строки в /etc/zabbix/zabbix_server.conf:
Чтобы Веб-интерфейс начал читать значения из ElasticSearch, потребуется добавить в /etc/zabbix/web/zabbix.conf.php:
Настройка закончена, запускаем ядро и Веб-интерфейс Zabbix:
Проверяем, что индексы начали заполняться значениями:
Мониторинг работоспособности:
- Работоспособность ElasticSearch теперь является для Zabbix’a ключевой, поэтому о проблемах в работе ES надо узнавать максимально быстро.
- Zabbix является системой мониторинга, поэтому логично следить за состоянием ES прямо из него.
- В сети есть достаточное количество готовых полнофункциональных шаблонов, но если они представляются для вас слишком громоздкими, то можете воспользоваться предложенным ниже простым вариантом.
- Итак, создайте новый шаблон в Zabbix’e:
- имя: elasticsearch;
- создайте внутри него Application «ElasticSearch»;
- назначьте этот шаблон Zabbix-серверу.
- Создайте в шаблоне метрику, которая будет следить за сетевым портом, на котором ES принимает подключения:
- Name: ElasticSearch listening on port 9200;
- Key: ;
- Application: ElasticSearch.
- Триггер для неё:
- Name: ElasticSearch is not listening on port 9200 on {HOSTNAME}
- Severity: Disaster
- Expression:
- Метрика, показывающая состояние ES (green/yellow/red, для одиночного сервера без кластеризации нормальным будет yellow):
- Name: ElasticSearch cluster health;
- Type: Zabbix agent
- * Key: elasticsearch.cluster_health_status
- Type: Character;
- Application: ElasticSearch;
- Описание метрики в настройках агента:
создайте файл /etc/zabbix/zabbix_agentd.d/elasticsearch.conf;
скомандуйте агенту перечитать настройки:
Триггер на «жёлтый» уровень здоровья:
- Name = ElasticSearch cluster status is «yellow» on {HOSTNAME};
- Severity = Warning;
- Expression = .
Триггер на «красный» уровень здоровья:
- Name = ElasticSearch cluster status is «red» on {HOSTNAME}
- Severity = High
- Expression =
Убедитесь, что первый триггер срабатывает:
- остановите ES командой ;
- в течение минуты Zabbix должен отреагировать на это на странице Monitoring => Problems;
- снова запустите ES и убедитесь, что проблема в Zabbix’e ушла.
Уровень ноды
Метрики по памяти процесса elastic
- fs.total.total_in_bytes, fs.total.free_in_bytes, fs.total.available_in_bytes — метрики по дисковому пространству, доступному каждой ноде. Если значение приближается к watermark.low — аларм.
- http.current_open, http.total_opened — количество открытых http-подключений к нодам — на момент опроса и общее, накопительный счетчик с момента запуска ноды, из которого легко вычисляется rps.
http.total_rpsthrottle_time_in_millis
- indexing.throttle_time_in_millis — время, которое кластер потратил на ожидание при индексации новых данных. Имеет смысл только на нодах, принимающих данные.
- store.throttle_time_in_millis — время, затраченное кластером, на ожидание при записи новых данных на диск. Аналогично метрике выше — имеет смысл только на нодах куда поступают новые данные.
- recovery.throttle_time_in_millis — включает в себя не только время ожидания при восстановлении шард (например, после сбоев), но и время ожидания при перемещении шард с ноды на ноду (например, при ребалансе или миграции шард между зонами hot/warm). Метрика особо актуальна на нодах, где данные хранятся долго.
- merges.total_throttled_time_in_millis — общее время, затраченное кластером на ожидание объединения сегментов на данной ноде. Накопительный счётчик.
search
- search.query_total — всего запросов на поиск, выполненных на ноде с момента её перезагрузки. Из этой метрики вычисляем среднее количество запросов в секунду.
- search.query_time_in_millis — время в миллисекундах, затраченное на все операции поиска с момента перезагрузки ноды.
thread_poolдокументации
- thread_pool.bulk.completed — счётчик, хранящий количество выполненных операций пакетной (bulk) записи данных в кластер с момента перезагрузки ноды. Из него вычисляется rps по записи.
- thread_pool.bulk.active — количество задач в очереди на добавление данных на момент опроса, показывает загруженность кластера по записи на текущий момент времени. Если этот параметр выходит за установленный размер очереди, начинает расти следующий счётчик.
- thread_pool.bulk.rejected — счётчик количества отказов по запросам на добавление данных. Имеет смысл только на нодах осуществляющих приём данных. Суммируется накопительным итогом, раздельно по нодам, обнуляется в момент полной перезагрузки ноды.
Триггеры
Это логические выражения со значениями FALSE, TRUE и UNKNOWN, которые используются для обработки данных. Их можно создать вручную. Перед использованием триггеры возможно протестировать на произвольных значениях.
У каждого триггера существует уровень серьезности угрозы, который маркируется цветом и передается звуковым оповещением в веб-интерфейсе.
- Не классифицировано (Not classified) — серый.
- Информация (Information) — светло-синий.
- Предупреждение (Warning) — жёлтый.
- Средняя (Average) — оранжевый.
- Высокая (High) — светло-красный.
- Чрезвычайная (Disaster) — красный.
Некоторые функции триггеров
- abschange — абсолютная разница между последним и предпоследним значением (0 — значения равны, 1 — не равны).
- avg — среднее значение за определенный интервал в секундах или количество отсчетов.
- delta — разность между максимумом и минимумом с определенным интервалом или количеством отсчетов.
- change — разница между последним и предпоследним значением.
- count — количество отсчетов, удовлетворяющих критерию.
- date — дата.
- dayofweek — день недели от 1 до 7.
- diff — у параметра есть значения, где 0 — последнее и предпоследнее значения равны, 1 — различаются.
- last — любое (с конца) значение элемента данных.
- max\min — максимум и минимум значений за указанные интервалы или отсчеты.
- now — время в формате UNIX.
- prev — предпоследнее значение.
- sum — сумма значений за указанный интервал или количество отсчетов.
- time — текущее время в формате HHMMSS.
Прогнозирование
Триггеры обладают еще одной важной функцией для мониторинга — прогнозированием. Она предугадывает возможные значения и время их возникновения
Прогноз составляется на основе ранее собранных данных.
Анализируя их, триггер выявляет будущие проблемы, предупреждает администратора о возникшей вероятности. Это дает возможность предотвратить пики нагрузки на оборудование или заканчивающееся место на жестком диске.
Функционал прогнозирования добавили с обновлением системы 3.0, вышедшим в феврале 2016 года.
Заключение
Возможно, поначалу работа со скриптом покажется вам немного «громоздкой» и запутанной, но освоившись с интерфейсом, вы очень скоро будете создавать запросы не более чем за полминуты, а перспективы, которые откроет для вас работа с исходными данными Яндекс.Метрики, многократно окупит затраченное время. В следующих статьях мы разберем на практике решение задач, связанных с анализом и обработкой логов.
Если у вас есть желание разрабатывать подобные скрипты для автоматизации рабочих процессов, записывайтесь на базовый курс PPC-Scientist.
Ваши вопросы по работе скрипта, а также предложения и идеи новых скриптов оставляйте в комментариях к статье. Всем успехов в настройке.
Заключение
Онлайн курс Infrastructure as a code
Если у вас есть желание научиться автоматизировать свою работу, избавить себя и команду от рутины, рекомендую пройти онлайн курс Infrastructure as a code. в OTUS. Обучение длится 4 месяца.
Что даст вам этот курс:
- Познакомитесь с Terraform.
- Изучите систему управления конфигурацией Ansible.
- Познакомитесь с другими системами управления конфигурацией — Chef, Puppet, SaltStack.
- Узнаете, чем отличается изменяемая инфраструктура от неизменяемой, а также научитесь выбирать и управлять ей.
- В заключительном модуле изучите инструменты CI/CD: это GitLab и Jenkins
Смотрите подробнее программу по .



