
Введение
Хочу сразу обратить внимание на важный момент. У меня нет опыта промышленной эксплуатации кластера Kubernetes
Я нахожусь в состоянии обучения и исследования этого инструмента. Я прошел обучение Слёрм, это дало базовые знания и понимание принципов работы. Дальше стал разворачивать свои кластера и исследовать их. Изначально я не хотел писать статьи по этой теме до тех пор, пока не накопится достаточного опыта, но сейчас поменял свое мнение.
В рунете очень мало материалов по kubernetes с конкретикой и практикой, по которым можно было бы учиться. Думаю, что даже те знания, что есть сейчас у меня, будут многим полезны и интересны. Плюс, когда пишешь статьи, систематизируешь свои знания, запоминаешь и получаешь обратную связь. Ускоряется процесс обучения. Так что статьям по kubernetes и devops в целом быть. Думаю, что в ближайшее время я сфокусируюсь именно на этом.
Могу однозначно сказать, что если у вас есть необходимость в продакшене использовать Kubernetes, не тяните время и не откладывайте. Идите учиться на курсы. Самостоятельно вы не освоите в достаточном объеме материал, чтобы можно было переносить рабочую нагрузку в свой кластер. Очень много нюансов и подводных камней. Вы потратите больше времени, нервов и денег на самостоятельное освоение, если будете сами все с нуля изучать.
Лично у меня сейчас нет цели становиться администратором Kubernetes. Мой формат занятости не подразумевает обслуживание таких крупных систем и в планах этого тоже пока нет. Мне просто любопытно его исследовать, узнавать что-то новое, поэтому я этим занимаюсь. Знания карман не тянут, особенно современные и востребованные.
Если у вас нет возможности или желания настраивать кластер Kubernetes самостоятельно на своем железе, можете купить его в готовом виде как сервис в облаке Mail.ru Cloud Solutions.
Введение
Сразу поделюсь ссылкой на официальную документацию по kubernetes. Она хорошо структурирована и наполнена. Пользоваться ей удобно. С ее помощью настраивать кластер проще. Напоминаю, что мы будем работать с кластером, который установили по предыдущей статье — установка kubernetes. Перед тем, как начать работать с кластером, расскажу об одной полезной возможности. Есть команда:
# kubectl completion bash
Она формирует конфиг для настройки автодополнения команд в bash. Вывод этой команды нужно добавить в ваш ~/.bashrc Можно это сделать автоматически.
# kubectl completion bash >> ~/.bashrc
Чтобы автодополнение работало, нужен пакет bash-completion.
# yum install bash-completion
Публикация репозитория
Helm-репозиторий служит для хранения и распространения чартов. В качестве такого репозитория может выступать любой HTTP-сервер или же произвольное S3-хранилище. Мы для создания своего репозитория используем GitHub Pages.
Репозиторий должен содержать файл index.yaml со служебной информацией о чартах, а также ссылками на их архивы. Наиболее простой способ организации репозитория — хранить эти архивы на том же сервере.
Создадим в нашем GitHub репозитории папку docs и применим следующие команды:
Первая команда упакует наш чарт в архив и поместит его в папку docs. Вторая команда сгенерирует файл index.yaml в той же папке. В опции url надо указать будущий URL-адрес папки с архивами
Обращаю внимание, что при любом изменении чарта его необходимо переиндексировать. Далее все это пушим, заходим в настройки репозитория и активируем GitHub Pages, указав в графе ‘Source’ опцию ‘master branch /docs folder’
Jenkins
demo-values.yaml содержат версию Jenkins, набор предустановленых плагинов, доменное имя и прочую конфигурацию
Данная конфигурация использует admin/admin в качестве имени пользователя и пароля для входа, и может быть перенастроена в дальнейшем. Один из возможных вариантов — SSO от google (для этого необходим плагин google-login, его настройки находятся в Jenkins > Manage Jenkins > Configure Global Security > Access Control > Security Realm > Login with Google).
Jenkins будет сразу же настроен на автоматическое создание одноразовых slave для каждой сборки. Благодаря этому команда больше не будет ожидать свободный агент для сборки, а бизнес сможет сэкономить на количестве необходимых серверов.
Так же из коробки настроен PersistenceVolume для сохранения pipelines при перезапуске либо обновлении.
Для корректной работы скриптов автоматического деплоя понадобится дать разрешение cluster-admin для Jenkins для получения списка ресурсов в kubernetes и манипулирования с ними.
В дальнейшем можно обновить Jenkins используя helm, в случае выхода новых версий плагинов либо изменений конфигурации.
Это можно сделать и через интерфейс самого Jenkins, но с helm у вас появится возможность откатится к предыдущим ревизиям используя:
Виды миграции
- Компания не использовала оркестраторы и контейнеры ранее, приложения по большей части монолитные. Самый сложный старт для миграции. Требует частичного или полного рефакторинга приложений и добавления контейнеризации.
- Компания не использовала оркестраторы, но приложения построены на основе микросервисов и контейнеров. Чуть более простой вариант по сравнению с предыдущим. По сути, вся подготовительная часть уже выполнена, остается настроить и развернуть Kubernetes-кластер и написать Kubernetes-манифесты для деплоя приложения.
- Компания использовала оркестратор, отличный от Kubernetes: Docker Swarm, Mesos Marathon, Nomad и другие. Еще один непростой сценарий, который можно считать чуть легче двух предыдущих лишь потому, что у команды уже есть опыт работы и с контейнерами, и с оркестраторами. Однако нужно иметь в виду, что концепции и технологии, лежащие в основе других оркестраторов, могут сильно отличаться от используемых в K8s. Например, Kubernetes не поддерживает двухэтапное планирование (two-stage scheduling), реализованное в Mesos. Эти и другие отличия придется учитывать при переписывании yaml-файлов.
- Компания использовала один из дистрибутивов Kubernetes: Rancher, OpenShift и другие. Хотя этот вариант миграции легче перехода с другого оркестратора, он все еще не самый простой. Несмотря на то, что Rancher, OpenShift и другие подобные инструменты основаны на Kubernetes, между ними и «ванильным» K8s могут быть существенные различия. Например, Deployment config, используемый при развертывании сервисов в OpenShift, отличается от Deployment Kubernetes. Похожая ситуация будет и с другими дистрибутивами.
- Компания использовала «ванильный» Kubernetes On-premise или в облаке (и хочет сменить провайдера, например, из финансовых соображений). Самый простой сценарий миграции, когда планируется перенос существующего кластера, развернутого либо локально с использованием таких инструментов, как Kops и Kubeadm, либо в облачной инфраструктуре. Как правило, требует незначительной корректировки yaml-файлов и переключения трафика на новые адреса. Ситуация может усложниться, если были использованы некоторые проприетарные сервисы на стороне предыдущего облачного провайдера. Но к самому Kubernetes это, скорее всего, не будет иметь отношения, так как провайдеры стараются поддерживать переносимость своего Managed-решения и его совместимость с Open Source-версией K8s.
Зависимость уровня сложности миграции от текущего технологического стека и степени развития DevOps-культуры в компании
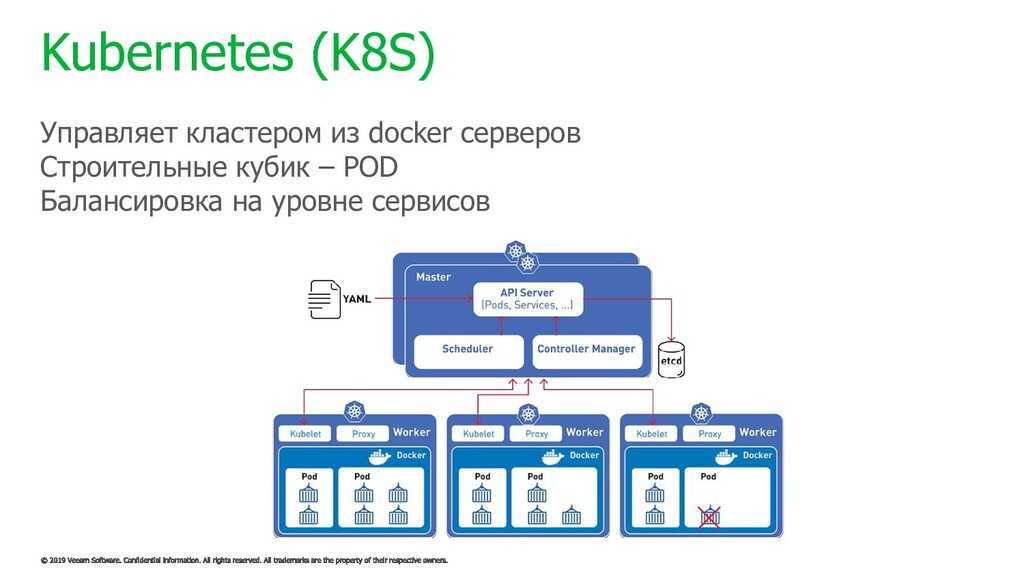
Kubernetes простыми словами
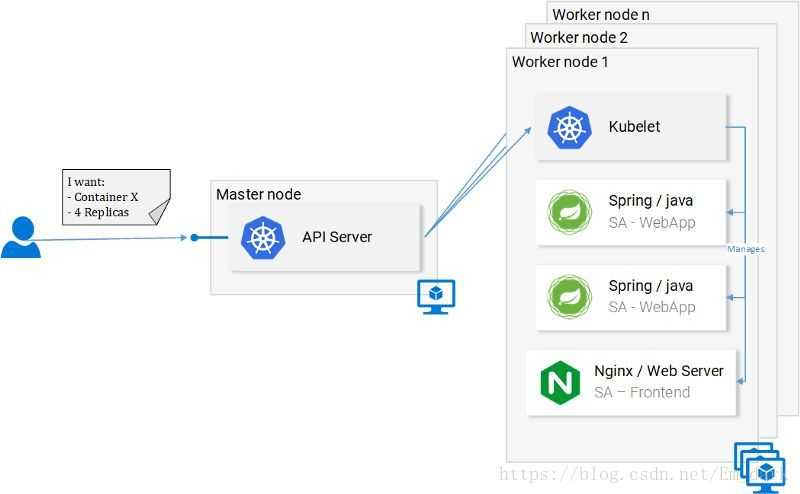
Попробую рассказать своими словами, что такое кластер Kubernetes для чайников, без отсылок к описаниям и документации. По своей сути это кластер для обслуживания docker контейнеров. Я слышал, что он может управлять не только докером, но практически ничего про это не знаю. Все в основном используют Kubernetes в связке с Docker.
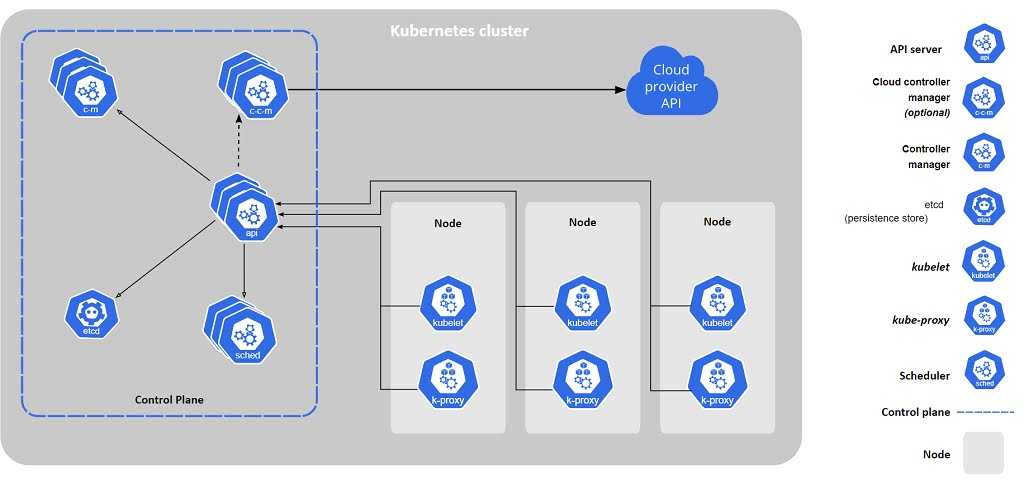
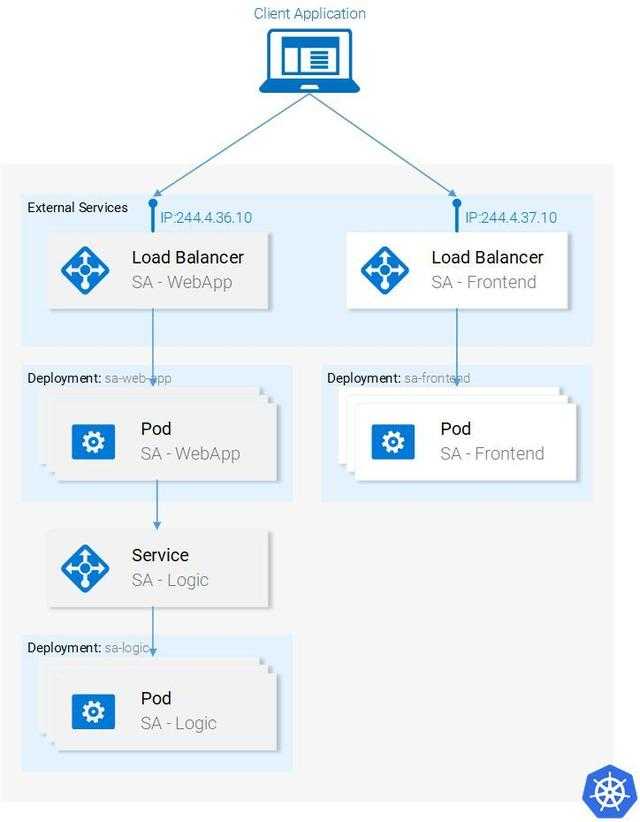
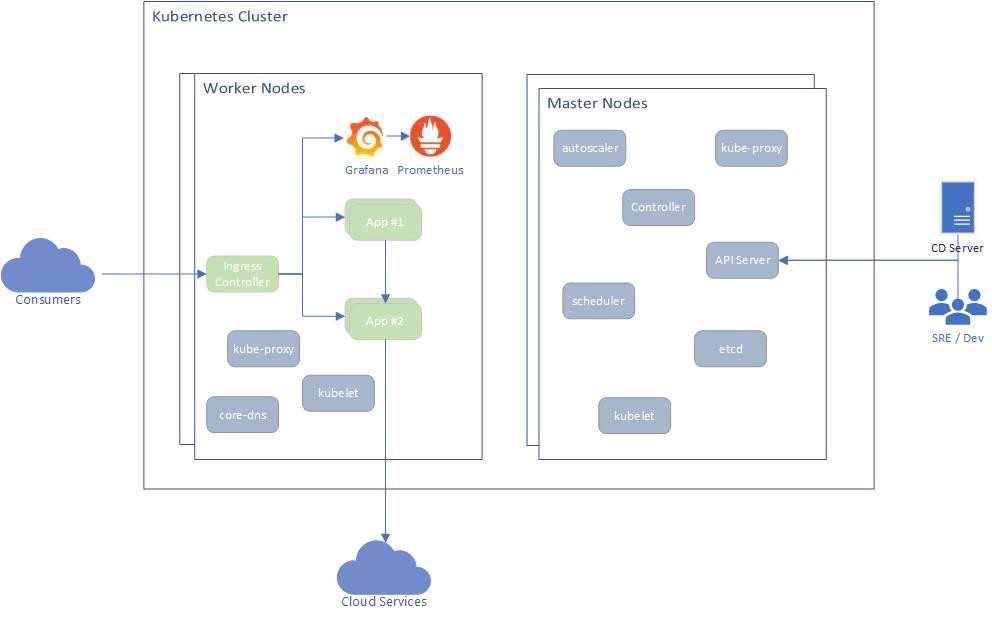
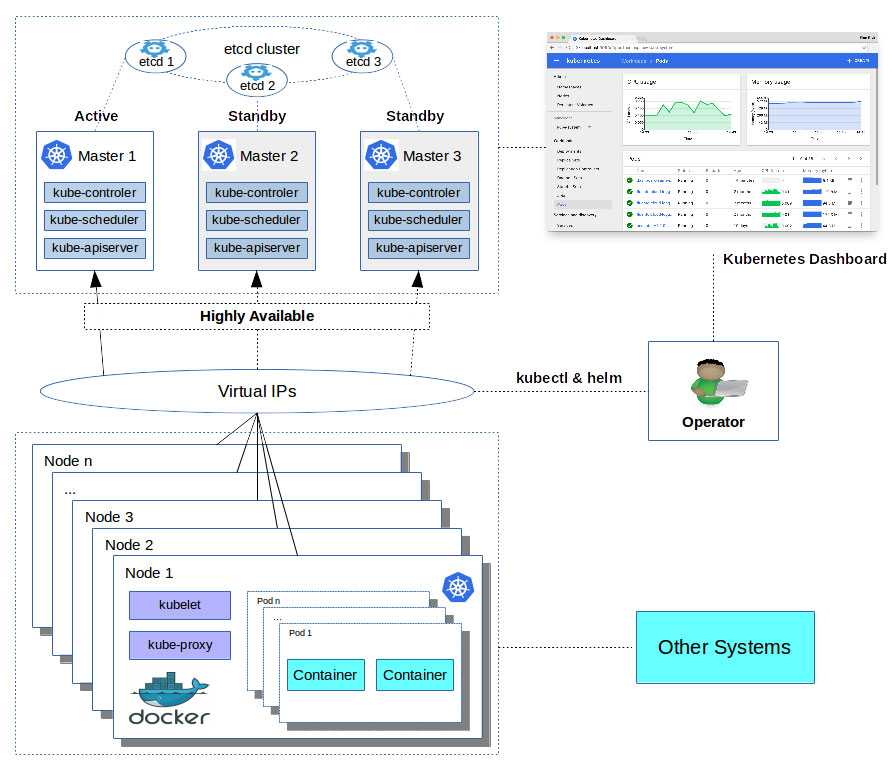
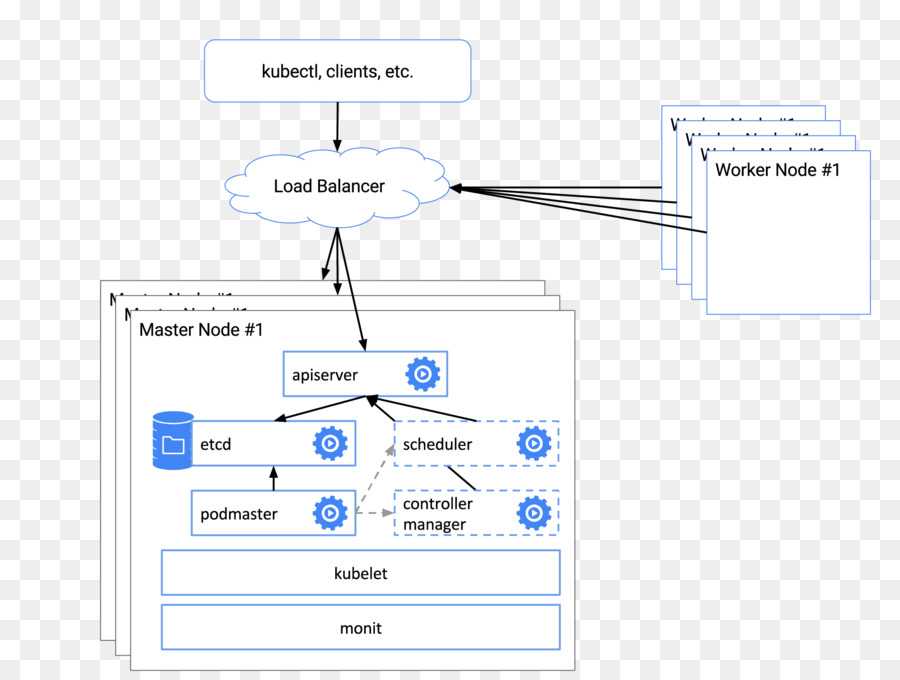
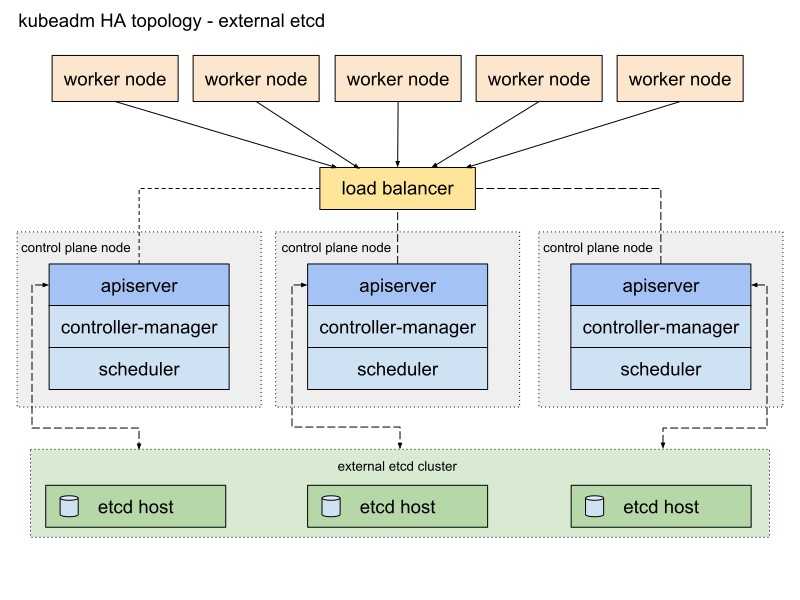
В Kubernetes все крутится вокруг докер контейнеров. Это инструмент для их запуска, поднятия в случае падения, распределения ресурсов и т.д. Под капотом никакой магии. Там обычный docker, iptables, etcd, nat, dns, ceph, nfs и т.д. Просто все собрано в одном месте для решения конкретных задач. Таким образом, для эффективного управления кластером кубера нужен хороший бэкграунд классического linux админа. Без этих знаний будет трудно.
Есть много способов разворачивания кластера, так как он модульный. Не всем и не всегда нужны все его компоненты. К примеру, есть ingress контроллер для распределения входящих запросов по сервисам. Под капотом там обычный nginx в режиме proxy_pass, интегрированный в инфраструктуру кластера. Реализация сети в кластере тоже может быть разной — на уровне l2 или l3 с помощью тех или иных технологий. То же самое с файловыми хранилищами — локальные хранилища серверов, nfs хранилища, ceph и т.д.
В зависимости от того, какой функционал вам нужен, выбирается способ установки кластера kubernetes. Мы можете его установить полностью вручную, добавляя один компонент за другим. А можно использовать готовое средство, к примеру Kubespray, где весь необходимый для установки функционал реализуется с помощью ролей ansible. На Слёрме нас учили ставить кластер, используя свой форк компании southbridge. Они там немного изменили функционал под свои потребности. Я ставил и по их форку, и по оригинальному Kubespray. Основное отличие от классического Kubespray в том, что не используется kubeadm и сертификаты для общения компонентов кластера сразу выпускаются то ли на 10, то ли на 100 лет, не помню точно. В Kubespray сертификаты выписываются только на год и надо отдельно следить за их актуальности и своевременно обновлять.
Подведу итог о том, что же такое Kubernetes. Кубернетис — средство оркестрации (управления) контейнерами Docker. Это удобный инструмент для их автоматического запуска, выделения ресурсов, контроля состояния, обновления.
Неправильное использование Health Probes
В прошлом антипаттерне мы рассказали о необходимости ограничивать ресурсы (limits), доступные приложениям, которые вы переносите в Kubernetes. Также следует настраивать проверки работоспособности (health probes).
По умолчанию приложения, развёрнутые в Kubernetes, не имеют health probes. По аналогии с лимитами вы должны рассматривать проверки работоспособности как неотъемлемую часть конфигурации ваших приложения в Kubernetes. Это означает, что все ваши приложения должны иметь лимиты и проверки работоспособности при развертывании в любом кластере Kubernetes.
Проверки работоспособности определяют, когда ваше приложение готово принимать трафик. Как разработчик, вы должны понимать, как работают health probes в Kubernetes (особенно, на что влияют тайм-ауты для каждой из них).
Типы проверок работоспособности:
-
Startup probe => Проверяет начальную загрузку вашего приложения. Запускается только один раз.
-
Readiness probe => Проверяет, способно ли ваше приложение принимать подключения. Работает постоянно. Если проверка вернёт ошибку, Kubernetes не будет больше направлять трафик в pod c этим приложением (и попробует выполнить повторную проверку позже).
-
Liveness probe => Проверяет работоспособность вашего приложения. Работает постоянно. Если проверка вернёт ошибку, Kubernetes перезапустит контейнер с приложением.
Стоит потратить время, чтобы разобраться, как работает каждый тип проверок доступности.
Несколько распространённых ошибок при использовании health probes:
-
Не учитывается состояние внешних сервисов в readiness probe (например, баз данных)
-
Используются одинаковые проверки для readiness и liveness probes
-
Не учитываете, что приложение запускается в контейнере, а не в виртуальной машине
-
Не используются средства проверки доступности вашего programming framework (если они есть)
-
Создание слишком сложных проверок работоспособности с неверными интервалами срабатывания (это может привести к отказу в обслуживании других приложений внутри кластера)
-
Проверки работоспособности приводят к каскадным сбоям при проверке внешних служб
Появление каскадных сбоев — очень распространенная проблема, которая разрушительна даже для виртуальных машин и балансировщиков нагрузки (т.е. не является специфической для Kubernetes)
Предположим, что у вас есть 3 службы, которые используют службу Auth в качестве зависимости. В идеале liveness probe для каждой службы должна проверять, может ли сама служба отвечать на запросы. Однако, если вы настроите liveness probe для проверки зависимостей, может произойти следующий сценарий:
-
Изначально все 4 сервиса работают корректно (включая Auth)
-
Служба аутентификации начинает работать некорректно
-
Все 3 сервиса определяют, что в работе службы аутентификации возникли проблемы
-
Несмотря на то, что все 3 сервиса работают корректно, результат проверки работоспособности зависит от состояния сервиса Auth
-
Kubernetes запускает liveness probe и решает, что все 4 сервиса не работают, и перезапускает их все (хотя на самом деле только у одного из них возникла проблема)
Запуск приложения, основанного на микросервисах, на локальном компьютере
1.2.
3.
Нам нужно Spring-приложение, способное принять POST-запрос
▍Анализ кода Java-приложения
- В S есть поле . Его значение задаётся свойством .
- Строка конкатенируется со значением . Вместе они формируют адрес для выполнения обращения к микросервису, выполняющему анализ текста.
▍Исследование кода
- Инициализация объекта .
- Задание адреса для выполнения к нему POST-запросов.
- Извлечение свойства из тела запроса.
- Инициализация анонимного объекта и получение значения для первого поступившего в теле запроса предложения (в нашем случае это — единственное предложение, передаваемое на анализ).
- Возврат ответа, в теле которого содержится текст предложения и вычисленный для него показатель .
- Запуск Flask-приложения, которое будет доступно по адресу (обратиться к нему можно и используя конструкцию вида ).
Все микросервисы, из которых состоит приложение, приведены в работоспособное состояние
Создание Собственных Chart-ов
Руководство по разработке Chart-ов объясняет, как
создавать свои собственные chart-ы. Но вы можете быстро начать работу с помощью команды :
Теперь у вас есть chart в . Вы можете редактировать его и создавать свои собственные
шаблоны.
У Helm есть линтер для проверки корректности chart-а, воспользоваться им можно с помощью .
Когда придет время упаковать chart в пакет для распространения вам поможет команда
Теперь вы можете с легкостью поставить этот chart в ваш Helm с помощью
Упакованные chart-ы могут быть загружены в репозиторий chart-ов. Смотрите документацию по
Helm chart репозитории для того, что бы узнать новые детали.
Что такое Helm и зачем нужен
Если вы уже работаете с Kubernetes или читали мои предыдущие статьи по этой теме (установка kubernetes, работа с кластером, дисковые тома, настройка ingress), то представляете себе, какие тонны yaml файлов приходится писать, чтобы запустить реальное приложение в кластере. Необходимо держать в голове и учитывать кучу абстракций, взаимосвязанных через метки, имена и т.д.
Helm призван упростить это. По своей сути он пытается работать как пакетный менеджер для запуска приложений в кластере. С его помощью можно создавать единые шаблоны для описания приложений, и helm будет дальше готовить и запускать все остальное сам.
Редактирование Helm чартов
Для примера возьмем еще одну панельку, но намного проще — kube-ops-view. Она показывает состояние кластера Kubernetes. Найдем ее в репозитории.
# helm search hub kube-ops-view URL CHART VERSION APP VERSION DESCRIPTION https://hub.helm.sh/charts/incubator/kube-ops-view 0.1.0 Kubernetes Operational View - read-only system ... https://hub.helm.sh/charts/stable/kube-ops-view 1.1.1 19.9.0 Kubernetes Operational View - read-only system ...
Выгрузим ее манифест в отдельный файл.
# helm inspect values stable/kube-ops-view > kube-ops-view.yaml
Открываем yaml файл и видим весь состав чарта. По сути это просто описание нескольких абстракций Kubernetes, которые нужны для работы панели. По-умолчанию панель устанавливается без поддержки ingress и не включен rbac. Без rbac состояние кластера она не сможет отображать. Давайте это исправим. Добавляем в секцию ingress и rbac параметры.
ingress: enabled: true path: / hostname: kou.cluster.local rbac: create: true
Устанавливаем чарт, используя измененный конфиг.
# helm install ops-view --namespace kube-system stable/kube-ops-view -f kube-ops-view.yaml
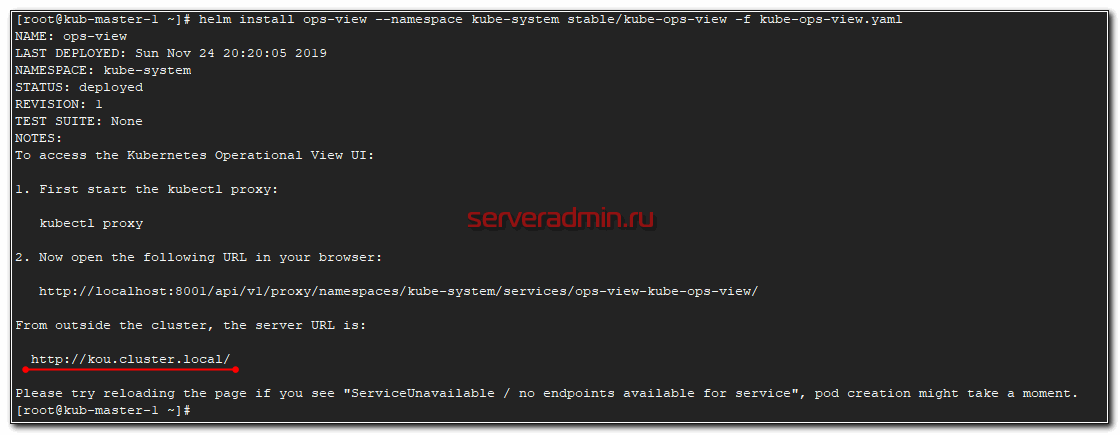
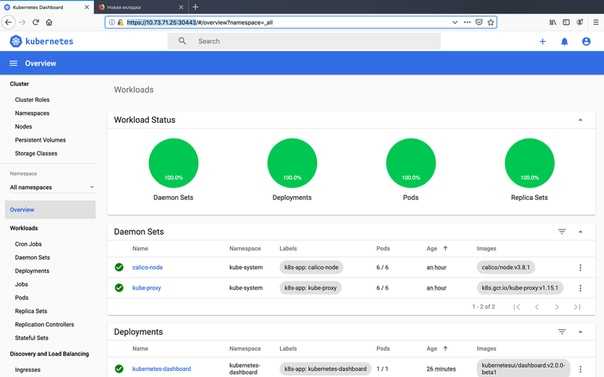
Переходим по адресу kou.cluster.local и наблюдаем визуально состояние кластера. Показаны ноды и запущенные в них поды.
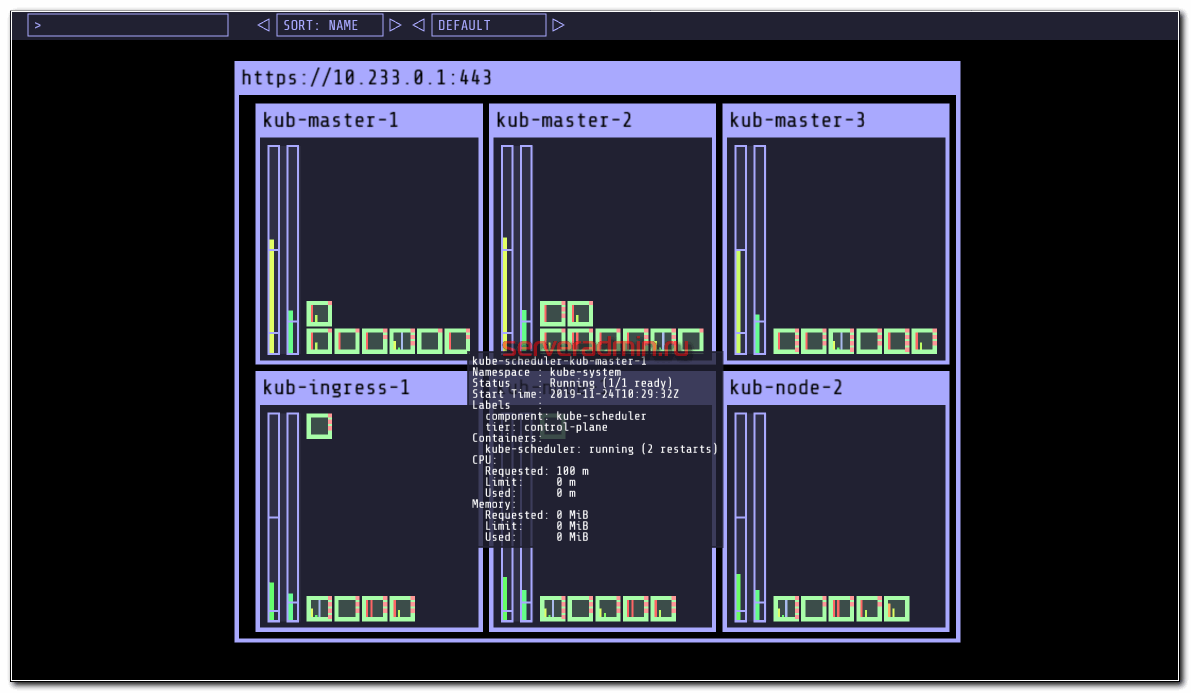
Панель неказистая и странная, но для учебных целей подходит. Зато очень маленькая и простая. Можно быстро визуально оценить весь кластер.
4: Откат и удаление релиза
Когда мы обновляли dashboard-demo в предыдущем разделе, мы создали вторую версию релиза. Helm сохраняет все сведения о предыдущих релизах на случай, если вам потребуется вернуться к предыдущей конфигурации или чарту.
Используйте эту команду, чтобы снова проверить релизы в кластере:
Вы увидите следующий вывод:
Столбец REVISION сообщает нам, что это уже вторая ревизия.
Чтобы вернуться к первой ревизии, используйте команду helm rollback:
Вы должны увидеть следующий вывод, если откат прошел успешно:
Если на этом этапе вы снова запустите команду kubectl get services, вы увидите, что сервис снова использует свое предыдущее имя. Helm повторно развернул приложение с конфигурацией первой версии.
Релизы Helm можно удалять с помощью команды helm delete. Например:
Вы получите такой результат:
Попробуйте запросить список релизов Helm:
Вы увидите, что в кластере их нет:
Теперь релиз удален, и вы можете использовать его название при создании нового релиза.
Данный цикл будет состоять минимум из четырех статей:
- В первой из них я расскажу, как на голое железо установить отказоустойчивый кластер kubernetes, как установить стандартный дашборд и настроить доступ к нему, как установить ingress контроллер.
- Во второй статье я расскажу, как развернуть отказоустойчивый кластер Ceph и как начать использовать RBD тома в нашем кластере Kubernetes. Также немного затрону остальные виды стораджей (storages) и более подробно рассмотрю local-storage. Дополнительно расскажу, как на базе созданного кластера CEPH организовать отказоустойчивое хранилище S3
- В третьей статье я расскажу, как в нашем кластере Kubernetes развернуть отказоустойчивый кластер MySql, а именно — Percona XtraDB Cluster on Kubernetes. И также опишу все проблемы с которыми мы столкнулись, когда решили перенести БД в kubernetes.
- В четвертой статье я постараюсь собрать все вместе и рассказать, как задеплоить и запустить приложение, которое будет использовать БД и тома ceph. Расскажу, как настроить ingress контроллер для доступа к нашему приложению извне и сервис автоматического заказа сертификатов от Let’s Encrypt. Еще — как автоматически поддерживать данные сертификаты в актуальном состоянии. Также немного затронем тему RBAC в контексте доступа до панели управления. Расскажу в двух словах про Helm и его установку.
Если Вам интересна информация данных публикаций, то — добро пожаловать !
Практика работы с Kubernetes: развёртывания
▍Использование развёртываний
Текущее состояние кластера
- Мы хотим иметь возможность создать два пода на основе одного контейнера .
- Нам нужна система развёртывания приложения, позволяющая ему, при его обновлении, работать без перерывов.
- Мы хотим, чтобы подам была бы назначена метка , что позволит обнаруживать эти поды сервису .
▍Описание развёртывания
- : тут указано, что мы описываем ресурс вида .
- : свойство объекта спецификаций развёртывания, которое задаёт то, сколько экземпляров (реплик) подов нужно запустить.
- : описывает стратегию, используемую в данном развёртывании при переходе с текущей версии на новую. Стратегия обеспечивает нулевое время простоя системы при обновлении.
- : это свойство объекта , которое задаёт максимальное число недоступных подов (в сравнении с желаемым количеством подов) при выполнении последовательного обновления системы. В нашем развёртывании, подразумевающем наличие 2 реплик, значение этого свойства указывает на то, что после завершения работы одного пода ещё один будет выполняться, что делает приложение доступным в ходе обновления.
- : это свойство объекта , которое описывает максимальное число подов, которое можно добавить в развёртывание (в сравнении с заданным числом подов). В нашем случае его значение, 1, означает, что, при переходе на новую версию программы, мы можем добавить в кластер ещё один под, что приведёт к тому, что у нас могут быть одновременно запущены до трёх подов.
- : этот объект задаёт шаблон пода, который описываемый ресурс будет использовать для создания новых подов. Вам эта настройка, наверняка, покажется знакомой.
- : метка для подов, создаваемых по заданному шаблону.
- : определяет порядок работы с образами. В нашем случае это свойство установлено в значение , то есть, в ходе каждого развёртывания соответствующий образ будет загружаться из репозитория.
▍Выполнение развёртываний с нулевым временем простоя системы
Замена подов в ходе обновления системы
Установка Helm 3
Установить Helm можно различными способами, но самый простой и быстрый — скачать и использовать готовый бинарник. Не так давно увидел свет свежий релиз Helm 3. Мы будем использовать именно его. В связи с этим многие приложения из репозиториев могут не устанавливаться или устанавливаться с ошибками, так как еще не поддерживают 3-ю версию. Проще было бы пока использовать 2-ю, но мне не хочется разбирать старую версию. Надо учиться работать с новой. Переход все равно неизбежен.
Идем на страницу загрузок и копируем ссылку на последнюю стабильную версию. Качаем, распаковываем и устанавливаем в систему. В моем случае я ставлю на master-1, так как все управление кластером веду с него.
# wget https://get.helm.sh/helm-v3.0.0-linux-amd64.tar.gz # tar xzvf helm-v3.0.0-linux-amd64.tar.gz # mv linux-amd64/helm /usr/local/bin/helm
Проверяем установленную версию.
# helm version
После установки самого helm, надо подключить репозиторий. По-умолчанию ни один из них не подключен. Поставим самый популярный дефолтный репозиторий.
# helm repo add stable https://kubernetes-charts.storage.googleapis.com/
Проверяем.
# helm search repo stable
Вы должны увидеть список всех чартов (charts), которые могут быть установлены из этого репозитория. По сути это набор приложений, которые может развернуть в kubernetes helm.
Обновить репозиторий можно командой.
# helm repo update
Все как в привычных пакетных менеджерах. Рекомендуется обновлять репозиторий перед установкой, чтобы забрать самую свежую версию приложения, которое будет развернуто в кластере с помощью Helm 3.
Искать в репозиториях helm можно ключом search (вот это да 
# helm search hub wordpress
Основной chart и единая конфигурация
Для начала создадим директории для основного чарта, сабчартов и типовых шаблонов.
Мы решили ,что для исключения путаницы имя директории основного чарта должно совпадать с его названием, именно под ним он будет помещен в репозиторий и будет использоваться в командах helm. У нас он называется exerica, здесь я буду использовать oursystem. Создадим для него следующую структуру:
Тут совсем мало файлов, поскольку в этом чарте определяются только:
-
зависимости в Chart.yaml
-
общие именованные шаблоны в _helpers.tpl
-
единый конфиг системы в configmap.yaml
-
сообщение, которое будет выведено после развертывания системы (NOTES.txt)
Параметры для всех приложений будут сгенерированы скриптом при сборке и записаны в values.yaml.
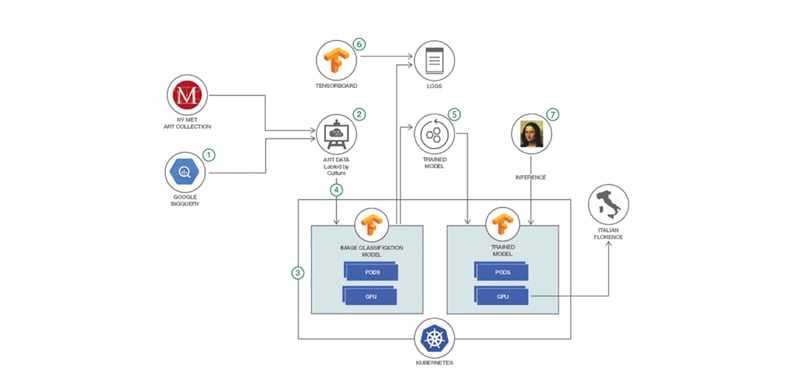

Определение единого конфига из configmap.yaml тоже совсем небольшое:
Шаблон toPropertiesYaml конвертирует произвольный (почти) yaml в массив пар «ключ-значение», где ключ формируется как последовательность ключей на пути от корня yaml-объекта:
Создадим файл versions.yaml, определяющий версии приложений, которые будем развертывать.
Все параметры конфигурации, которые будем выносить в единый конфиг системы, определим в одном файле templates/variables.yaml.
В дальнейшем в процессе сборки эти параметры дополняются «вычисляемыми» значениями, которые также нужны для конфигурирования приложений, например полный URL для ingress: ingressUrl. При сборке основного чарта эти параметры будут вставлены в секцию .Values.global.configuration и сформируют ConfigMap с единым конфигом системы. В частности, на них мы будем ссылаться в переменных окружения для контейнеров.
Таким образом можем передать параметры приложению webapi через переменные окружения, например такие:
-
DEPLOY_ENVIRONMENT — глобальное имя среды в которой функционирует приложение, берется из параметра common.envName
-
ProcessingRemoteConfiguration__RemoteAddress — адрес сервиса, с которым взаимодействует приложение webapi, берется из параметра processing.serviceUrl
Переменные среды считываются и передаются приложению при его запуске. Если при развертывании очередной версии системы какое-то приложение не поменялось, но поменялась конфигурация системы, то его под не будет перезапущен. Для решения этой проблемы удобно использовать контроллер Reloader, который отслеживает изменения объектов ConfigMap, Secret и производит плавающее обновление (rolling update) для подов, которые зависят от них. Мы включили его в состав системы, как внешнюю зависимость через helm chart. В нашем подходе это делается буквально в несколько строчек.
Проверки доступности Probes
С деплоем и перезапуском подов не все так просто. Есть тяжелые приложения, которые стартуют очень долго, либо зависят от других приложений. Прежде чем погасить старую версию, нужно убедиться, что новая уже запущена и готова к работе. Для этого существует liveness и readiness проверки. Покажу на примере. Берем предыдущий deployment и добавляем туда проверки.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-nginx
spec:
replicas: 2
selector:
matchLabels:
app: my-nginx
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- image: nginx:1.16
name: nginx
ports:
- containerPort: 80
readinessProbe:
failureThreshold: 5
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 2
timeoutSeconds: 3
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
initialDelaySeconds: 10
В данном примере используется проверка httpGet по корневому урлу на порт 80.
- readinessProbe проверяет способность приложения начать принимать трафик. Она делает 5 проверок (failureThreshold). Если хотя бы 2 (successThreshold) из них будут удачными, считается, что приложение готово. Метод httpGet проверяет код ответа веб сервера. Если он 200 или 3хх, то считается, что все в порядке. Эта проверка выполняется до тех пор, пока не будет выполнено заданное на успех условие — successThreshold. После этого прекращается.
- livenessProbe выполняется постоянно, следя за приложением во время его жизни. В моем примере проверка будет неудачной, если 3 (failureThreshold) проверки подряд провалились. При этом, если хотя бы одна (successThreshold) будет удачной, то счетчик неудачных сбрасывается. Параметр initialDelaySeconds задает задержку после старта пода для начала liveness проверок.
Вот еще один пример liveness проверки, но уже по наличию файла. Проверяется файл /tmp/healthy, если он существует, проверка удачна, если его нет, то ошибка.
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Создавать этот файл может само приложение во время работы.
3: Обновление релиза
Команда helm upgrade обновляет релизы при помощи свежего или отлаженного чарта, а также обновляет их параметры конфигурации (переменные).
Давайте предположим, что нам нужно внести простое изменение в релиз dashboard-demo. Чтобы продемонстрировать процесс обновления и отката релизов и конфигураций, мы изменим имя сервиса на kubernetes-dashboard (вместо dashboard-demo-kubernetes-dashboard).
Для управления именем сервиса чарт kubernetes-dashboard предоставляет опцию fullnameOverride. Чтобы переименовать релиз, запустите команду helm upgrade с этой опцией:
Передав аргумент –reuse-values, вы сохраняете ранее установленные вами переменные чарта в процессе обновления.
Вывод будет похож на тот, что вы получили во время установки Helm.
Проверьте, отражает ли ваш кластер Kubernetes новые значения:
Результат должен выглядеть так:
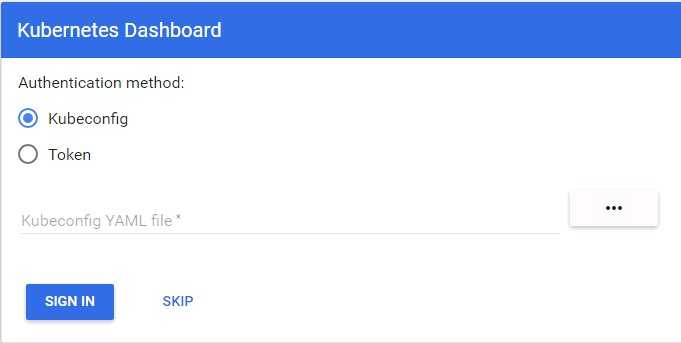
Обратите внимание: имя сервиса было обновлено. Примечание: На этом этапе вы можете загрузить приложение Kubernetes Dashboard в своем браузере и проверить, как оно работает
Для этого сначала запустите команду:
Примечание: На этом этапе вы можете загрузить приложение Kubernetes Dashboard в своем браузере и проверить, как оно работает. Для этого сначала запустите команду:
Эта команда создает прокси, который позволяет вам получать доступ к ресурсам удаленного кластера с локального компьютера. Согласно предыдущим инструкциям сервис этого приложения называется kubernetes-dashboard, он работает в пространстве имен default. Теперь вы можете получить доступ к дашборду по следующему URL-адресу:
Подробные инструкции по работе с этим приложением выходят за рамки нашего руководства, но вы можете почитать официальную документацию Kubernetes Dashboard.
Далее мы покажем вам, как с помощью Helm можно откатывать и удалять релизы.
‘helm search’: Поиск Charts
Helm поставляется с мощной поисковой командой.
Он может быть использован для поиска двух различных типов источников:
-
ищет в
the Artifact Hub, который агрегирует списки из различных хранилищ -
поиск в репозиториях, которые вы добавили в свой локальный каталог helm client (используя ).
Этот поиск выполняется по локальным данным, не используя подключение к публичной сети.
Вы можете найти общедоступные chart-ы, запустив :
Выше приведен поиск всех chart-ов на Artifact Hub.
Поиск показывает все доступные chart-ы с определенным именем .
Используя , вы можете найти названия chart-ов в
уже добавленных вами репозиториях:
Helm search использует приближённый поиск подстроки (fuzzy string matching), поэтому вы можете вводить части
слов или фраз:
Поиск – это хороший способ найти доступные пакеты. Как только вы нашли пакет
, который хотите установить, вы можете использовать для его установки.





